3D Hand Pose Estimation Based on Five-Layer Ensemble CNN

Abstract
:1. Introduction
- A 5LENet for 3D hand pose estimation from a single RGB image is proposed, in which hand pose estimation is decomposed into five single-finger pose estimations by using hierarchical thinking. More representative fingers are extracted for estimating a more accurate 3D finger pose, and then the features generated in the process of 3D finger pose estimation are fused to estimate a full 3D hand pose. It can not only extract more effective features but also enhance the association between fingers through the fusion of finger features.
- Five 3D finger pose constraints are newly added, which can not only promote 3D finger pose estimation but also can form soft constraints on 2D finger pose estimation to further indirectly optimize the accuracy of 3D hand pose estimation.
- According to the topology of the hand, a model of the hand with the Palm and middle finger connected is built. This is because the middle finger is located in the middle of five fingers, and its connection with the Palm is tighter. Therefore, we connect the Palm to middle finger, which can successfully solve the accuracy degradation problem caused by connecting the Palm with multiple fingers.
- We conduct experiments on the two public datasets, and results demonstrate that our approach achieves a new state-of-the-art in 3D hand pose prediction, which proves the effectiveness and advancement of 5LENet.
2. Related Works
3. Methodology
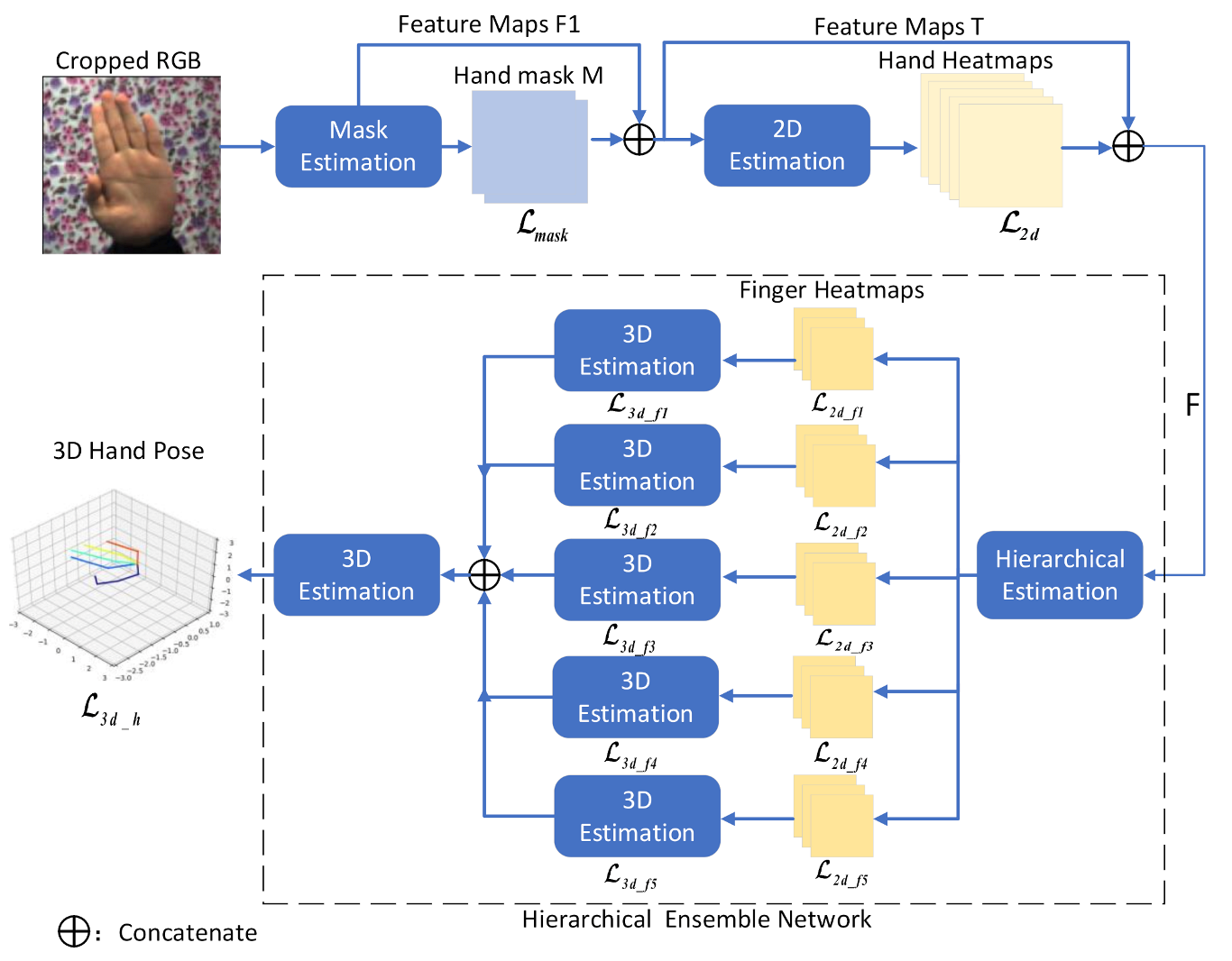
3.1. Overview
3.2. Localization and Segmentation Network
3.3. 2D Pose Estimation Network
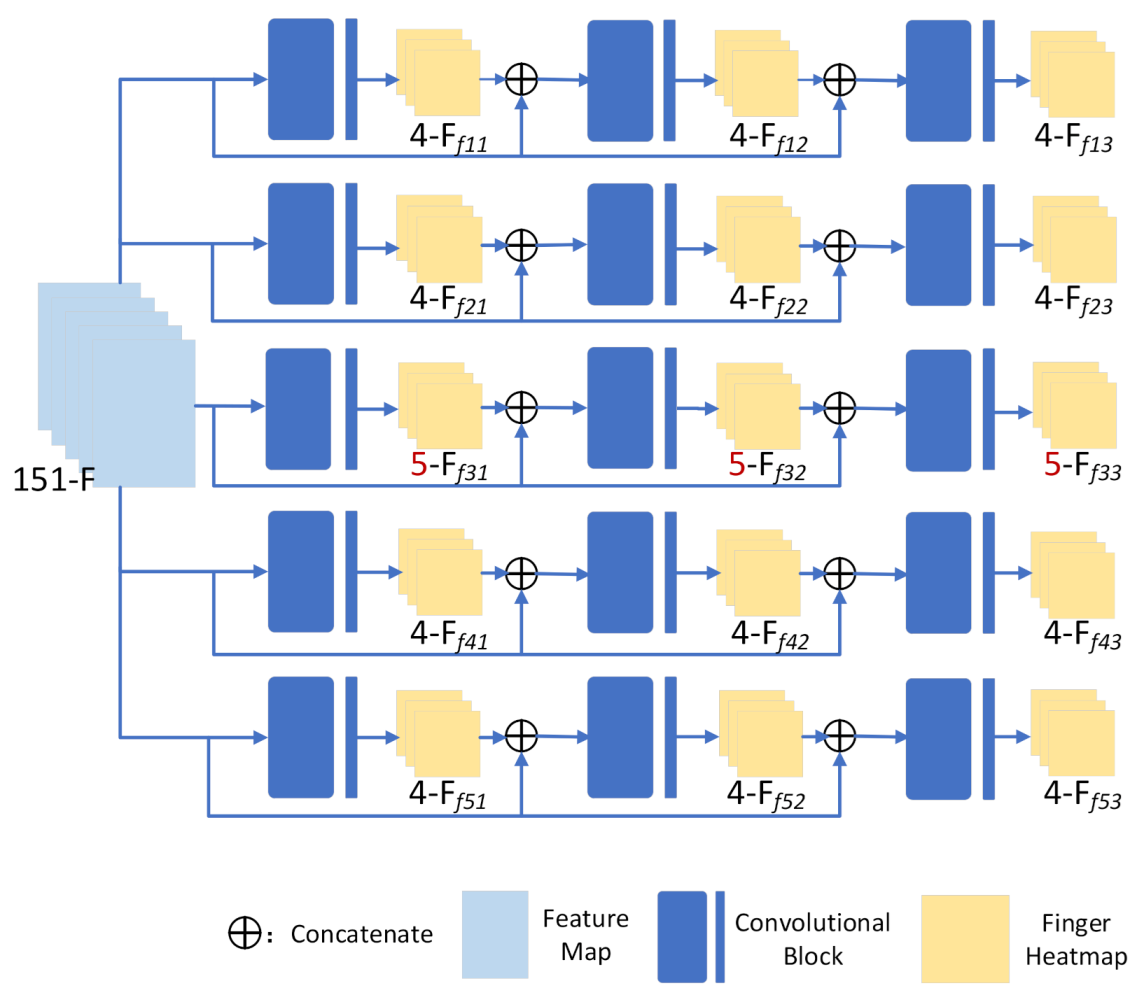
3.4. Hierarchical Ensemble Network
3.4.1. Hierarchical Estimation Network
3.4.2. 3D Pose Estimation Network
3.5. Loss Functions
3.5.1. Estimation Loss of 2D Pose
3.5.2. Loss of Hierarchical Estimation
3.5.3. Estimation Loss of 3D Pose
3.5.4. Total Loss of Network
4. Experiments
4.1. Datasets and Metrics
4.1.1. OneHand10K
4.1.2. RHD
4.1.3. STB
4.1.4. Evaluation Metrics
4.2. Experimental Details
4.3. Ablation Study
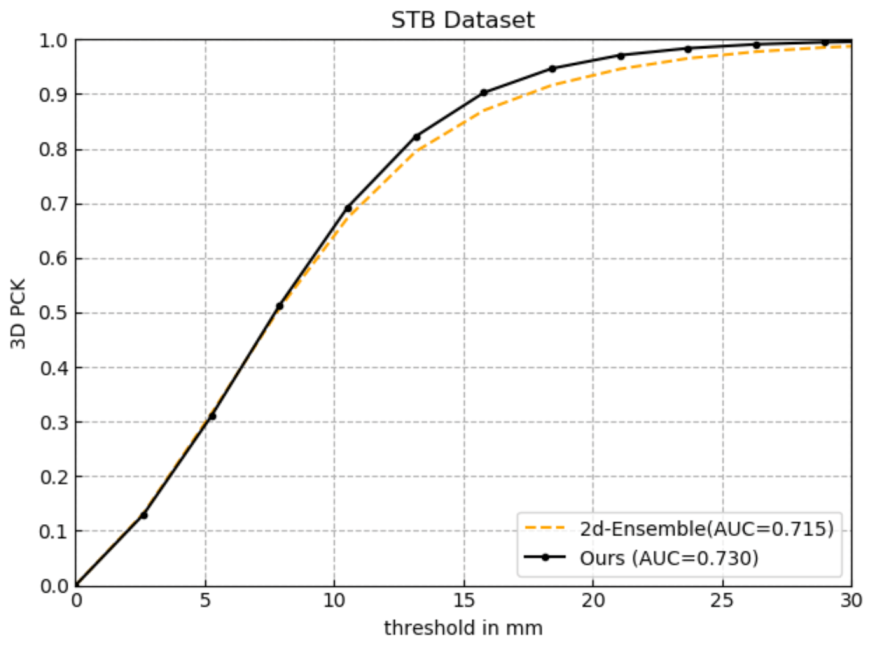
4.3.1. Effectiveness of Five-Layer Network
4.3.2. Effectiveness of Newly Added 3D Finger Pose Constraints
4.3.3. Effectiveness of Connecting Palm with a Single Finger
4.3.4. Effectiveness of Connecting Palm with Middle Finger
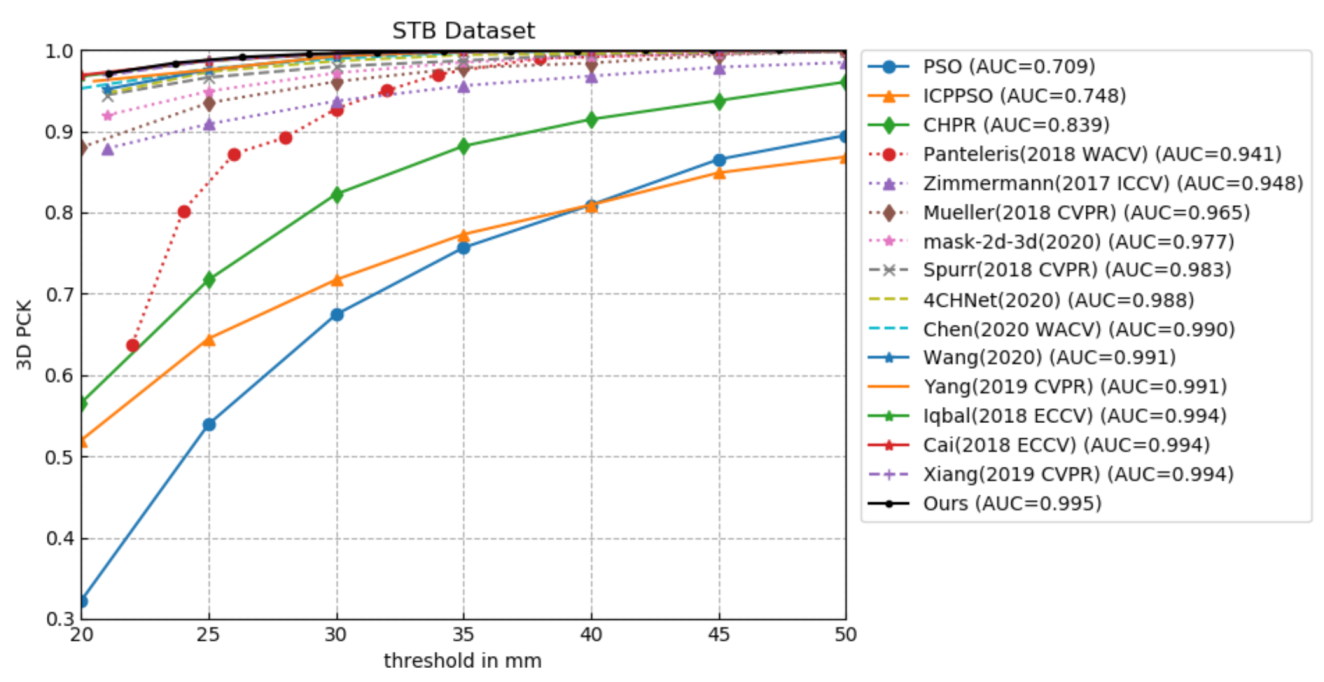
4.4. Comparison with the State-of-the-Art Methods
4.5. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, X.Y.; Tsai, M.S.; Huang, C.C. 3D Virtual-Reality Interaction System. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics-Taiwan, ICCE-TW 2019, Ilan, Taiwan, 20–22 May 2019; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2019. [Google Scholar]
- Hsieh, M.C.; Lee, J.J. Preliminary Study of VR and AR Applications in Medical and Healthcare Education. J. Nurs. Heal. Stud. 2018, 3. [Google Scholar] [CrossRef]
- Mahesh, M.M.; Jerry, M.S.; Wadala, D.S.B. FPGA based hand sign recognition system. In Proceedings of the RTEICT 2017–2nd IEEE International Conference on Recent Trends in Electronics, Information and Communication Technology, Bangalore, India, 19–20 May 2017; pp. 294–299. [Google Scholar] [CrossRef]
- Antoshchuk, S.; Kovalenko, M.; Sieck, J. Gesture recognition-based human-computer interaction interface for multimedia applications. In Digitisation of Culture: Namibian and International Perspectives; Springer: Singapore, 2018; pp. 269–286. ISBN 9789811076978. [Google Scholar]
- Yang, J.; Wang, C.; Jiang, B.; Song, H.; Meng, Q. Visual Perception Enabled Industry Intelligence: State of the Art, Challenges and Prospects. IEEE Trans. Ind. Inf. 2020, 17, 2204–2219. [Google Scholar] [CrossRef]
- Stenger, B.; Thayananthan, A.; Torr, P.H.S.; Cipolla, R. Model-based hand tracking using a hierarchical bayesian filter. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28. [Google Scholar] [CrossRef] [PubMed]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-time continuous pose recovery of human hands using convolutional networks. ACM Trans. Graph. 2014, 33. [Google Scholar] [CrossRef]
- Sun, X.; Wei, Y.; Liang, S.; Tang, X.; Sun, J. Cascaded hand pose regression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognitionm, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. 3D convolutional neural networks for efficient and robust hand pose estimation from single depth images. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5679–5688. [Google Scholar] [CrossRef]
- Wan, C.; Probst, T.; Van Gool, L.; Yao, A. Crossing nets: Combining gans and vaes with a shared latent space for hand pose estimation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1196–1205. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Ge, L.; Cai, J.; Magnenat-Thalmann, N.; Yuan, J. 3D Hand Pose Estimation Using Synthetic Data and Weakly Labeled RGB Images. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Zimmermann, C.; Brox, T. Learning to Estimate 3D Hand Pose from Single RGB Images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2017; pp. 4913–4921. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Jiang, J.; Guo, Y.; Kang, L.; Wei, Y.; Li, D. CFAM: Estimating 3D hand poses from a single RGB image with attention. Appl. Sci. 2020, 10, 618. [Google Scholar] [CrossRef] [Green Version]
- Spurr, A.; Song, J.; Park, S.; Hilliges, O. Cross-Modal Deep Variational Hand Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Ge, L.; Cai, J.; Yuan, J. Weakly-supervised 3D hand pose estimation from monocular RGB images. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Suzhou, China, 16–19 September 2018. [Google Scholar] [CrossRef]
- Baek, S.; Kim, K.I.; Kim, T.K. Pushing the envelope for rgb-based dense 3D hand pose estimation via neural rendering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1067–1076. [Google Scholar] [CrossRef] [Green Version]
- Guo, S.; Rigall, E.; Qi, L.; Dong, X.; Li, H.; Dong, J. Graph-based CNNs with self-supervised module for 3D hand pose estimation from Monocular RGB. IEEE Trans. Circuits Syst. Video Technol. 2020. [Google Scholar] [CrossRef]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Robust 3D Hand Pose Estimation from Single Depth Images Using Multi-View CNNs. Proc. IEEE Trans. Image Process. 2018, 27. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Lin, S.Y.; Xie, Y.; Lin, Y.Y.; Fan, W.; Xie, X. DGGAN: Depth-image guided generative adversarial networks for disentangling RGB and depth images in 3D hand pose estimation. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, WACV 2020, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar] [CrossRef]
- Ge, L.; Ren, Z.; Li, Y.; Xue, Z.; Wang, Y.; Cai, J.; Yuan, J. 3D hand shape and pose estimation from a single RGB image. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.; Wang, G.; Chen, X.; Zhang, C.; Qiao, F.; Yang, H. Region ensemble network: Improving convolutional network for hand pose estimation. In Proceedings of the International Conference on Image Processing, ICIP, Beijing, China, 17–20 September 2017; pp. 4512–4516. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Lu, J.; Du, K.; Lin, X.; Sun, Y.; Ma, X. HBE: Hand branch ensemble network for real-time 3d hand pose estimation. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Hong Kong, China, 8–10 December 2011; Springer: Berlin/Heidelberg, Germany, 2018; pp. 521–536. [Google Scholar] [CrossRef]
- Madadi, M.; Escalera, S.; Baro, X.; Gonzalez, J. End-to-end Global to Local CNN Learning for Hand Pose Recovery in Depth Data. arXiv 2017, arXiv:1705.09606. [Google Scholar]
- Du, K.; Lin, X.; Sun, Y.; Ma, X. Crossinfonet: Multi-task information sharing based hand pose estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9888–9897. [Google Scholar] [CrossRef]
- Dai, S.; Liu, W.; Yang, W.; Fan, L.; Zhang, J. Cascaded Hierarchical CNN for RGB-Based 3D Hand Pose Estimation. Math. Probl. Eng. 2020, 2020, 1–13. [Google Scholar] [CrossRef]
- Chen, X.; Wang, G.; Guo, H.; Zhang, C. Pose guided structured region ensemble network for cascaded hand pose estimation. Neurocomputing 2019, 395, 138–149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Dai, S.; Yang, W.; Yang, H.; Qian, W. Color image 3d gesture estimation based on cascade convolution neural network. J. Chin. Comput. Syst. 2020, 41, 558–563. [Google Scholar]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef] [Green Version]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition; IEEE Computer Society, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4724–4732. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015-Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Pfister, T.; Charles, J.; Zisserman, A. Flowing ConvNets for Human Pose Estimation in Videos. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway Township, NJ, USA, 2015; pp. 1913–1921. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Peng, C.; Liu, Y. Mask-Pose Cascaded CNN for 2D Hand Pose Estimation from Single Color Image. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3258–3268. [Google Scholar] [CrossRef]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. 3D Hand Pose Tracking and Estimation Using Stereo Matching. arXiv 2016, arXiv:1610.07214. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2016, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015-Conference Track Proceedings; International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Qian, C.; Sun, X.; Wei, Y.; Tang, X.; Sun, J. Realtime and robust hand tracking from depth. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Panteleris, P.; Oikonomidis, I.; Argyros, A. Using a Single RGB Frame for Real Time 3D Hand Pose Estimation in the Wild. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, WACV 2018, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 436–445. [Google Scholar] [CrossRef] [Green Version]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A. Efficient Model-Based 3D Tracking of Hand Articulations Using Kinect. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 101.1–101.11. [Google Scholar] [CrossRef]
- Yang, L.; Yao, A. Disentangling latent hands for image synthesis and pose estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9869–9878. [Google Scholar] [CrossRef] [Green Version]
- Mueller, F.; Bernard, F.; Sotnychenko, O.; Mehta, D.; Sridhar, S.; Casas, D.; Theobalt, C. GANerated Hands for Real-Time 3D Hand Tracking from Monocular RGB. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Xiang, D.; Joo, H.; Sheikh, Y. Monocular total capture: Posing face, body, and hands in the wild. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10957–10966. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, U.; Molchanov, P.; Breuel, T.; Gall, J.; Kautz, J. Hand Pose Estimation via Latent 2.5D Heatmap Regression. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Hong Kong, China, 14–16 March 2018. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | EPE Median (mm) | EPE Mean (mm) | AUC |
|---|---|---|---|
| 3L-M+Palm | 8.408 | 8.957 | 0.716 |
| 4L-M+Palm | 8.253 | 8.842 | 0.719 |
| Ours | 7.937 | 8.492 | 0.730 |
| Network | EPE Median (mm) | EPE Mean (mm) | AUC |
|---|---|---|---|
| 2d-Ensemble | 8.047 | 9.003 | 0.715 |
| Ours | 7.937 | 8.492 | 0.730 |
| Network | EPE Median (mm) | EPE Mean (mm) | AUC |
|---|---|---|---|
| TIMRP+Plam | 8.032 | 8.672 | 0.725 |
| IMR+Palm | 7.949 | 8.575 | 0.728 |
| Ours | 7.937 | 8.492 | 0.730 |
| Network | EPE Median (mm) | EPE Mean (mm) | AUC |
|---|---|---|---|
| t+palm | 8.258 | 8.858 | 0.718 |
| I+Palm | 8.195 | 8.852 | 0.719 |
| R+Palm | 8.351 | 8.940 | 0.716 |
| P+Palm | 8.375 | 8.989 | 0.715 |
| Ours (M+Palm) | 7.937 | 8.492 | 0.730 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, L.; Rao, H.; Yang, W. 3D Hand Pose Estimation Based on Five-Layer Ensemble CNN. Sensors 2021, 21, 649. https://doi.org/10.3390/s21020649
Fan L, Rao H, Yang W. 3D Hand Pose Estimation Based on Five-Layer Ensemble CNN. Sensors. 2021; 21(2):649. https://doi.org/10.3390/s21020649
Chicago/Turabian StyleFan, Lili, Hong Rao, and Wenji Yang. 2021. "3D Hand Pose Estimation Based on Five-Layer Ensemble CNN" Sensors 21, no. 2: 649. https://doi.org/10.3390/s21020649
APA StyleFan, L., Rao, H., & Yang, W. (2021). 3D Hand Pose Estimation Based on Five-Layer Ensemble CNN. Sensors, 21(2), 649. https://doi.org/10.3390/s21020649