Iterative Min Cut Clustering Based on Graph Cuts


Abstract
1. Introduction
1.1. Related Works
- (1)
- -neighborhood graph. It connects all vertexes (data points) whose pairwise distances are smaller than , and then obtains an undirected graph.
- (2)
- K-nearest neighbor graphs. It connects a vertex and a vertex if is among the K-nearest neighbors of or if is among the K-nearest neighbors of (or if both is among the K-nearest neighbors of and is among the K-nearest neighbors of ).
- (3)
- The fully connected graph. It connects all points, and then obtains a fully connected graph.
| Algorithm 1: Spectral clustering. |
| Input: |
| Do: |
| (1) Compute where is the similarity between and , |
| and is usually computed by |
| (2) Compute the Laplacian matrix where is the degree matrix, |
| and is computed by |
| (3) Compute the first k eigenvectors of , and these eigenvectors are seen as low |
| dimensiona embedding of the original dataset |
| (4) Using K-means to cluster the low dimensional embedding |
| Output: Clustering results of K-means |
2. Iterative Min Cut Clustering
| Algorithm 2: IMC algorithm. |
| Input: |
| compute by (3), Randomly initialize |
| Repeat |
| Compute via |
| Until is less than a prescribed tolerance or n is equal to the maximum |
| number of iterations |
| Output: |
3. Experiments
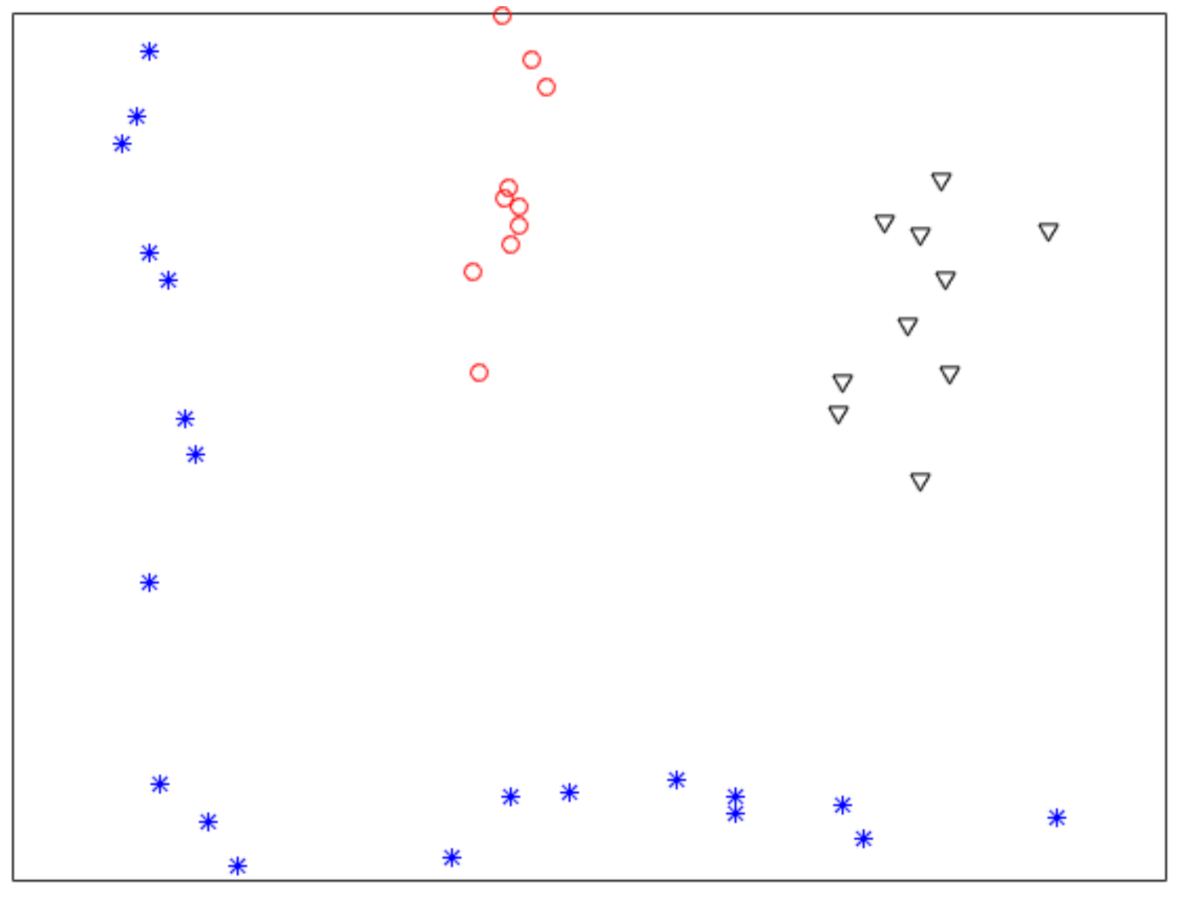
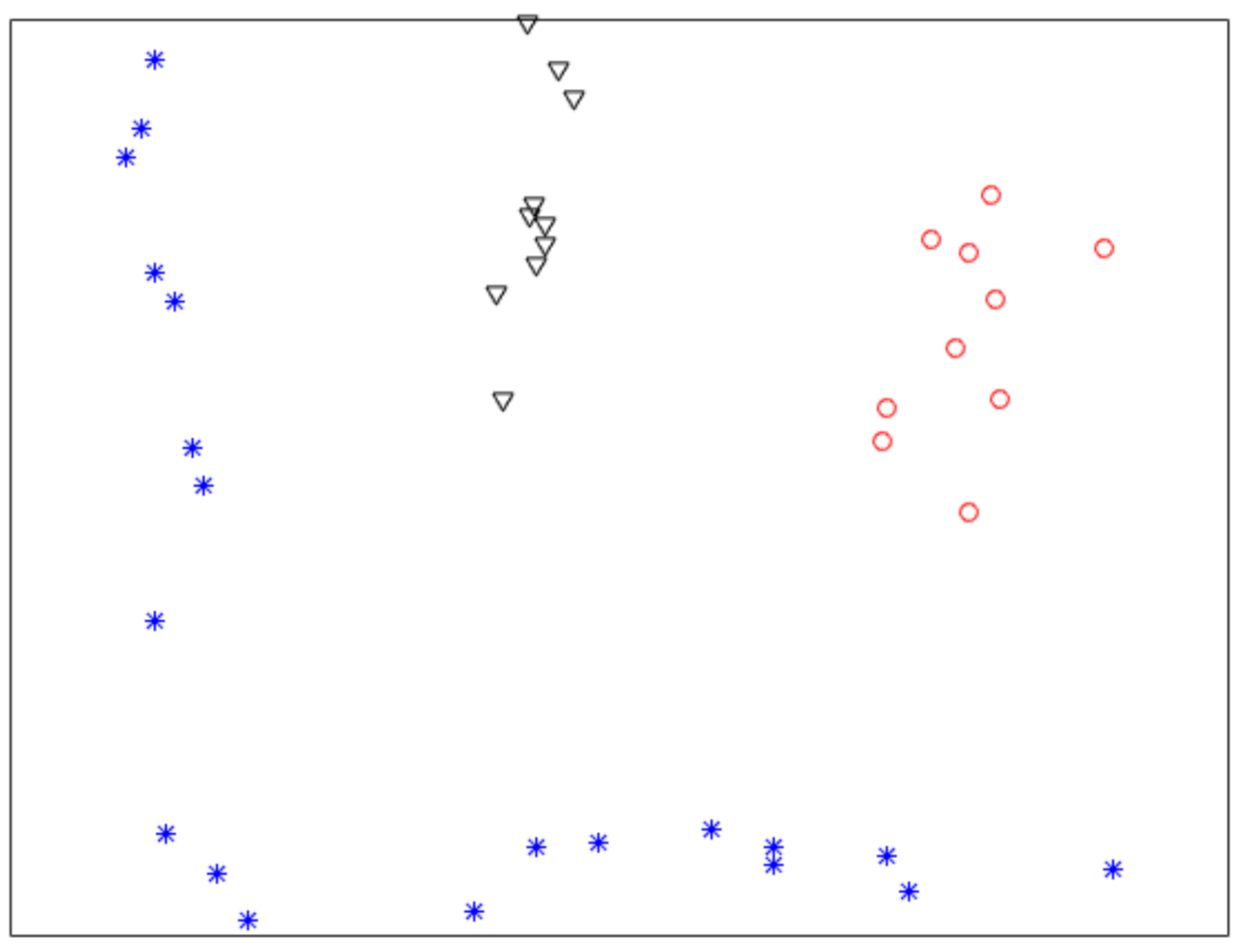
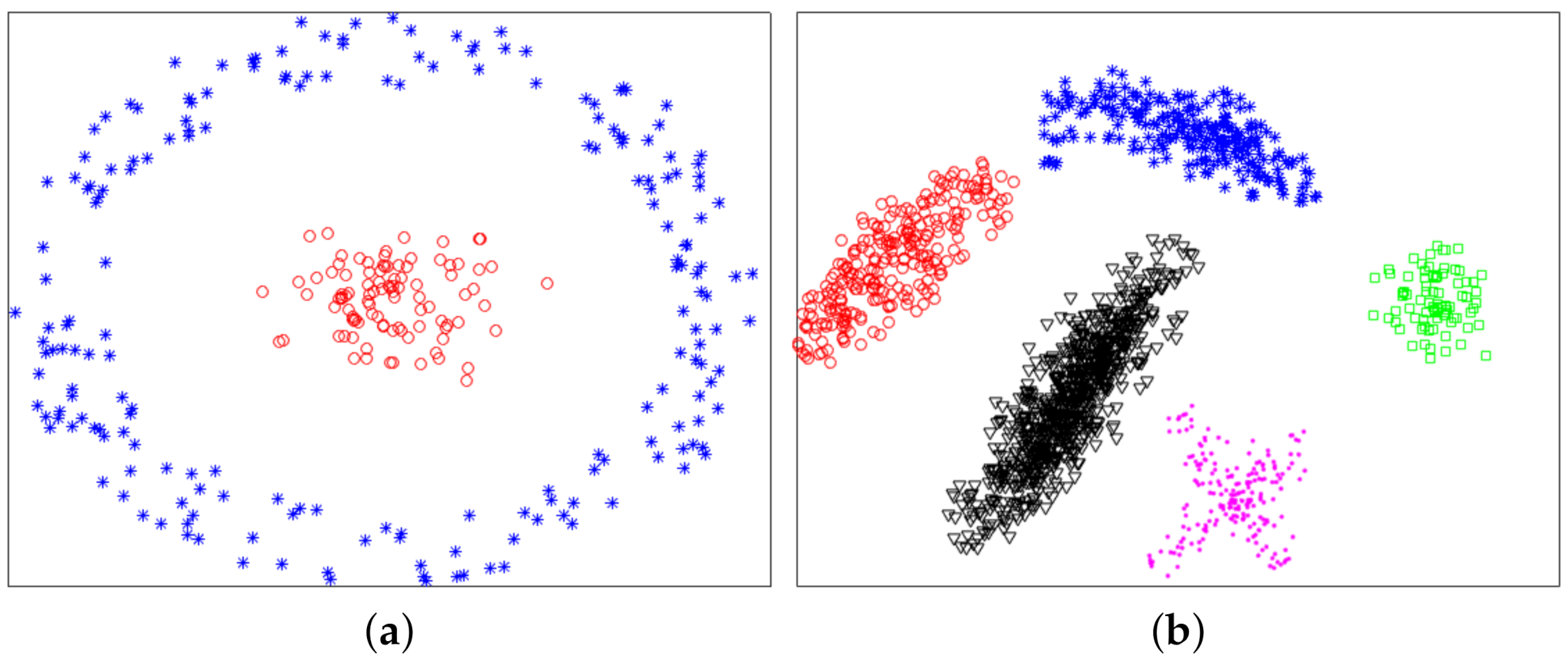
3.1. Experiments for Synthetic Datasets
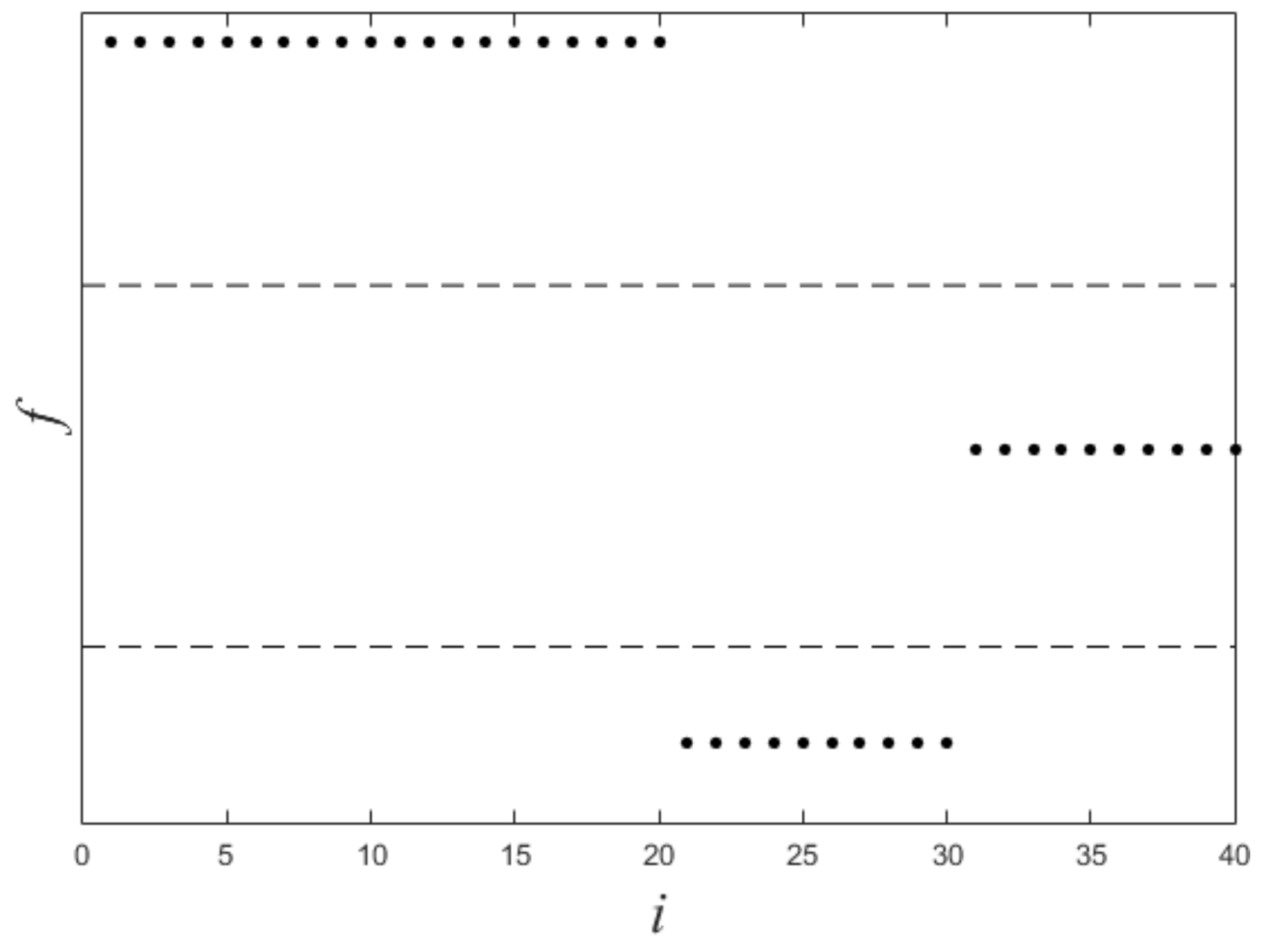
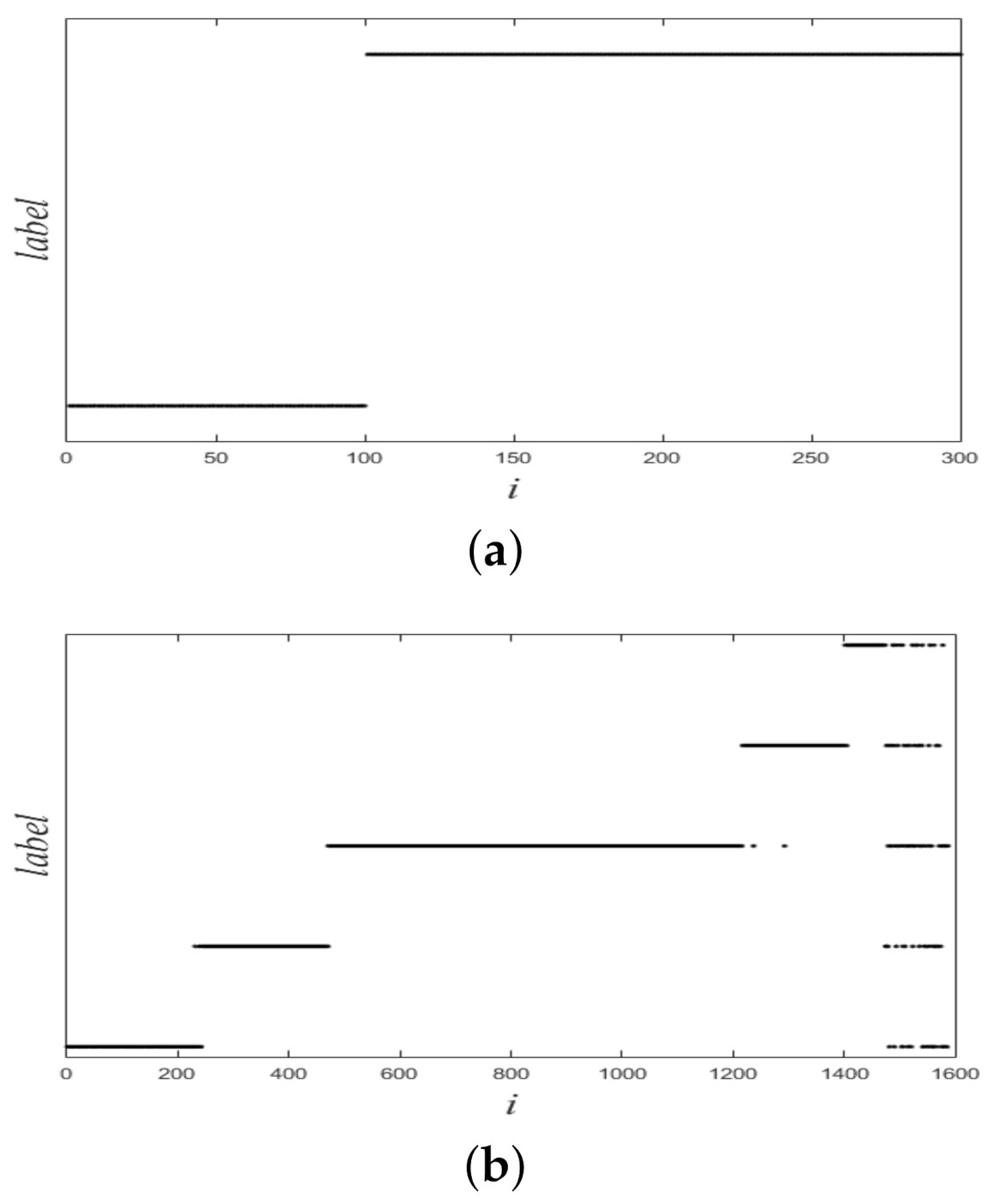
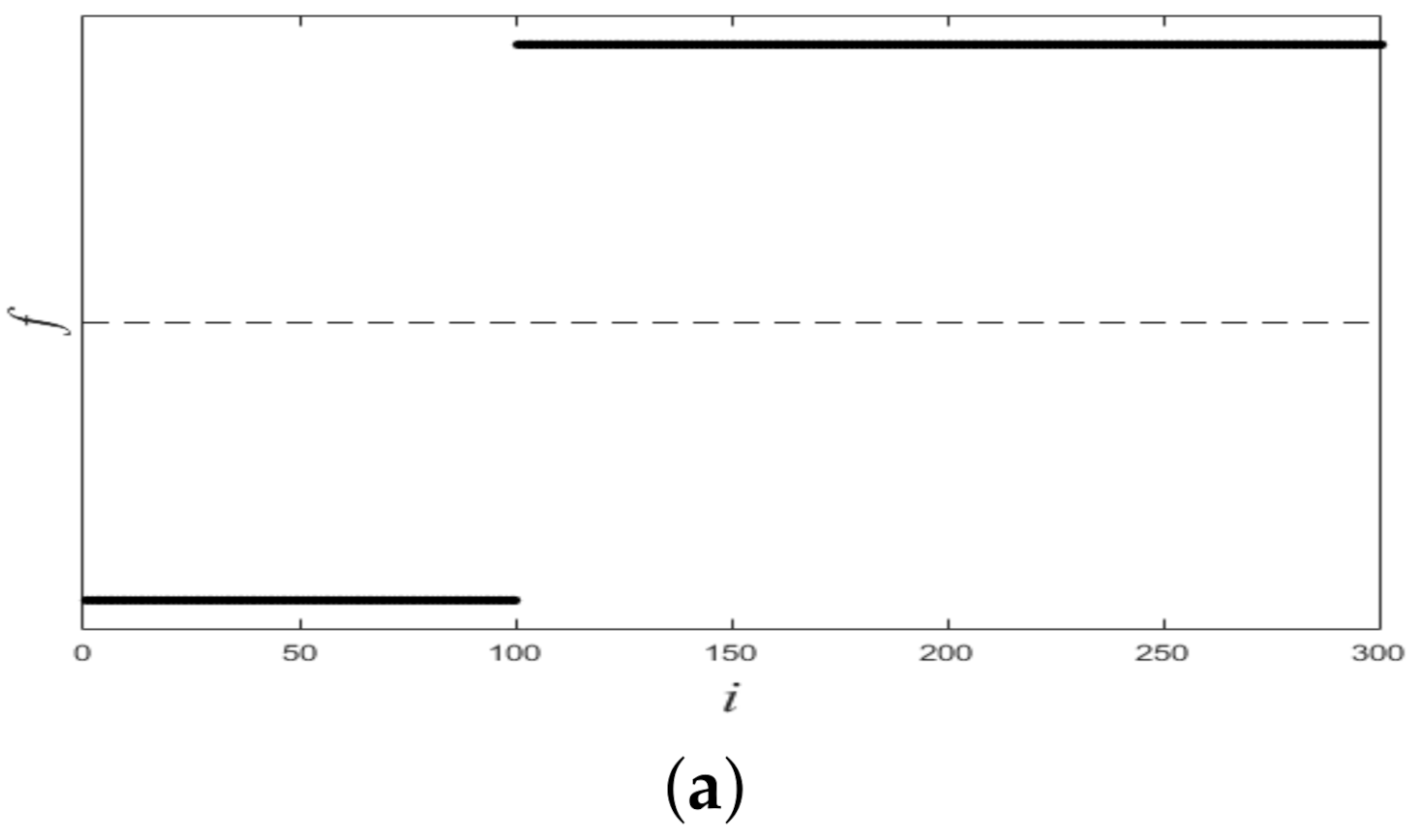
3.2. Experiment about Convergence
3.3. Experiments for Real Datasets
- (1)
- when the max iteration number was set to 1000 and 2000, IMC needed less running time than SC, but obtained higher NMI than SC;
- (2)
- for different max iteration numbers, IMC obtained different NMI, but all NMI of IMC were higher than those of SC.
4. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| dataset | |
| number of data points in a dataset | |
| H | dimension of data points |
| i-th data points in a dataset | |
| similarity matrix | |
| similarity between and | |
| degree matrix | |
| Laplace matrix | |
| the feature of | |
| i-th value of |
References
- Otto, C.; Wang, D.; Jain, A. Clustering Millions of Faces by Identity. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 289–303. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Yoo, C.D.; Nowozin, S.; Kohli, P. Image Segmentation Using Higher-Order Correlation Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1761–1774. [Google Scholar] [CrossRef] [PubMed]
- Taylor, M.J.; Husain, K.; Gartner, Z.J.; Mayor, S.; Vale, R.D. A DNA-Based T Cell Receptor Reveals a Role for Receptor Clustering in Ligand Discrimination. Cell 2017, 169, 108–119. [Google Scholar] [CrossRef] [PubMed]
- Liu, A.A.; Su, Y.T.; Nie, W.Z.; Kankanhalli, M. Hierarchical Clustering Multi-Task Learning for Joint Human Action Grouping and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 102–114. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Wu, Y.; Zheng, N.; Tu, L.; Luo, M. Improved Affinity Propagation Clustering for Business Districts Mining. In Proceedings of the IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), Volos, Greece, 5–7 November 2018; pp. 387–394. [Google Scholar]
- Macqueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965; pp. 281–297. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2007, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Bezdek, J.C. Pattern recognition with fuzzy objective function algorithms. Adv. Appl. Pattern Recognit. 1981, 22, 203–239. [Google Scholar]
- Tan, D.; Zhong, W.; Jiang, C.; Peng, X.; He, W. High-order fuzzy clustering algorithm based on multikernel mean shift. Neurocomputing 2020, 385, 63–79. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by Fast Search and Find of Density Peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.M.R.; Siddique, M.A.B.; Arif, R.B.; Oishe, M.R. ADBSCAN: Adaptive Density-Based Spatial Clustering of Applications with Noise for Identifying Clusters with Varying Densities. In Proceedings of the 4th International Conference on Electrical Engineering and Information & Communication Technology (iCEEiCT), Dhaka, Bangladesh, 13–15 September 2018; pp. 107–111. [Google Scholar]
- Luxburg, U.V. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Szlam, A.; Bresson, X. Total Variation and Cheeger Cuts. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–25 June 2010; pp. 1039–1046. [Google Scholar]
- Bresson, X.; Laurent, T.; Uminsky, D.; Von Brecht, J. Multiclass total variation clustering. Adv. Neural Inf. Process. Syst. 2013, 26, 1421–1429. [Google Scholar]
- Marin, D.; Tang, M.; Ayed, I.B.; Boykov, Y. Kernel Clustering: Density Biases and Solutions. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 136–147. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Tranchevent, L.; Liu, X.; Glanzel, W.; Suykens, J.A.; De Moor, B.; Moreau, Y. Optimized Data Fusion for Kernel k-Means Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1031–1039. [Google Scholar] [PubMed]
- Huang, H.; Chuang, Y.; Chen, C. Multiple Kernel Fuzzy Clustering. IEEE Trans. Fuzzy Syst. 2012, 20, 120–134. [Google Scholar] [CrossRef]
- Thiagarajan, J.J.; Ramamurthy, K.N.; Spanias, A. Multiple Kernel Sparse Representations for Supervised and Unsupervised Learning. IEEE Trans. Image Process. 2014, 23, 2905–2915. [Google Scholar] [CrossRef] [PubMed]
- Jia, L.; Li, M.; Zhang, P.; Wu, Y.; Zhu, H. SAR Image Change Detection Based on Multiple Kernel K-Means Clustering With Local-Neighborhood Information. IEEE Geosci. Remote Sens. Lett. 2016, 13, 856–860. [Google Scholar] [CrossRef]
- Hofmeyr, D.P. Clustering by Minimum Cut Hyperplanes. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1547–1560. [Google Scholar] [CrossRef] [PubMed]
- Elhamifar, E.; Vidal, R. Sparse Subspace Clustering: Algorithm, Theory, and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.; Feng, J.; Lin, Z.; Mei, T.; Yan, S. Subspace Clustering by Block Diagonal Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 487–501. [Google Scholar] [CrossRef] [PubMed]
- Trenkler, G. Handbook of Matrices. Comput. Stats Data Anal. 1997, 25, 243. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, L.; Shen, F.; Shen, H.T.; Shao, L. Binary Multi-View Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1774–1782. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Codes | Instances | Classes | Dimensions |
|---|---|---|---|---|
| Iris | D3 | 150 | 3 | 4 |
| Dermatology | D4 | 358 | 6 | 34 |
| Glass | D5 | 214 | 6 | 10 |
| Parkinsons | D6 | 195 | 2 | 23 |
| DS | Mean | Min | Max |
|---|---|---|---|
| Dataset 1 | 1.0000 | 1.0000 | 1.0000 |
| Dataset 2 | 1.0000 | 1.0000 | 1.0000 |
| Method | Max | D3 | D4 | D5 | D6 | ||||
|---|---|---|---|---|---|---|---|---|---|
| Iteration | NMI | Time | NMI | Time | NMI | Time | NMI | Time | |
| SC | − | 0.7660 | 0.0570 | 0.1116 | 0.1599 | 0.331222 | 0.047160 | 0.014030 | 0.014457 |
| IMC | 1000 | 0.7777 | 0.0111 | 0.1362 | 0.0301 | 0.387883 | 0.014373 | 0.014030 | 0.011158 |
| 2000 | 0.7716 | 0.0257 | 0.1226 | 0.0653 | 0.359414 | 0.033953 | 0.014030 | 0.030275 | |
| 3000 | 0.7703 | 0.0432 | 0.1213 | 0.1061 | 0.340673 | 0.056648 | 0.014030 | 0.049958 | |
| 4000 | 0.7670 | 0.0633 | 0.1218 | 0.1426 | 0.322012 | 0.078662 | 0.014030 | 0.073234 | |
| 5000 | 0.7706 | 0.0981 | 0.1458 | 0.1697 | 0.348434 | 0.118252 | 0.014030 | 0.117675 | |
| 6000 | 0.7690 | 0.1172 | 0.1449 | 0.2462 | 0.349533 | 0.140191 | 0.014030 | 0.162995 | |
| 7000 | 0.7817 | 0.1502 | 0.1468 | 0.3033 | 0.327493 | 0.171360 | 0.014030 | 0.173535 | |
| 8000 | 0.7792 | 0.2191 | 0.1512 | 0.3710 | 0.386487 | 0.250267 | 0.014030 | 0.211110 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Liu, Z.; Li, Y.; Zhang, T.; Zhang, Z. Iterative Min Cut Clustering Based on Graph Cuts. Sensors 2021, 21, 474. https://doi.org/10.3390/s21020474
Liu B, Liu Z, Li Y, Zhang T, Zhang Z. Iterative Min Cut Clustering Based on Graph Cuts. Sensors. 2021; 21(2):474. https://doi.org/10.3390/s21020474
Chicago/Turabian StyleLiu, Bowen, Zhaoying Liu, Yujian Li, Ting Zhang, and Zhilin Zhang. 2021. "Iterative Min Cut Clustering Based on Graph Cuts" Sensors 21, no. 2: 474. https://doi.org/10.3390/s21020474
APA StyleLiu, B., Liu, Z., Li, Y., Zhang, T., & Zhang, Z. (2021). Iterative Min Cut Clustering Based on Graph Cuts. Sensors, 21(2), 474. https://doi.org/10.3390/s21020474