Improving Real-Time Hand Gesture Recognition with Semantic Segmentation

 , ,
, , 
Abstract
1. Introduction
- We propose an alternative to the expensive dense optical flow estimation, and the extra sensor requirement of depth images, by using semantic segmentation images of the hand for real-time hand gesture recognition.
- By using a simple input modality combination, we demonstrate that our RGB-S proposal outperforms state-of-the-art methods of TSN and TSM. We also present a statistical analysis of both approaches’ results, which shows the type of gestures that gets more benefit from different input modalities.
- We extend our new IPN Hand dataset [20], including pixel-level annotations useful for training semantic segmentation models. Currently available at github.com/GibranBenitez/IPN-hand.
2. Related Work
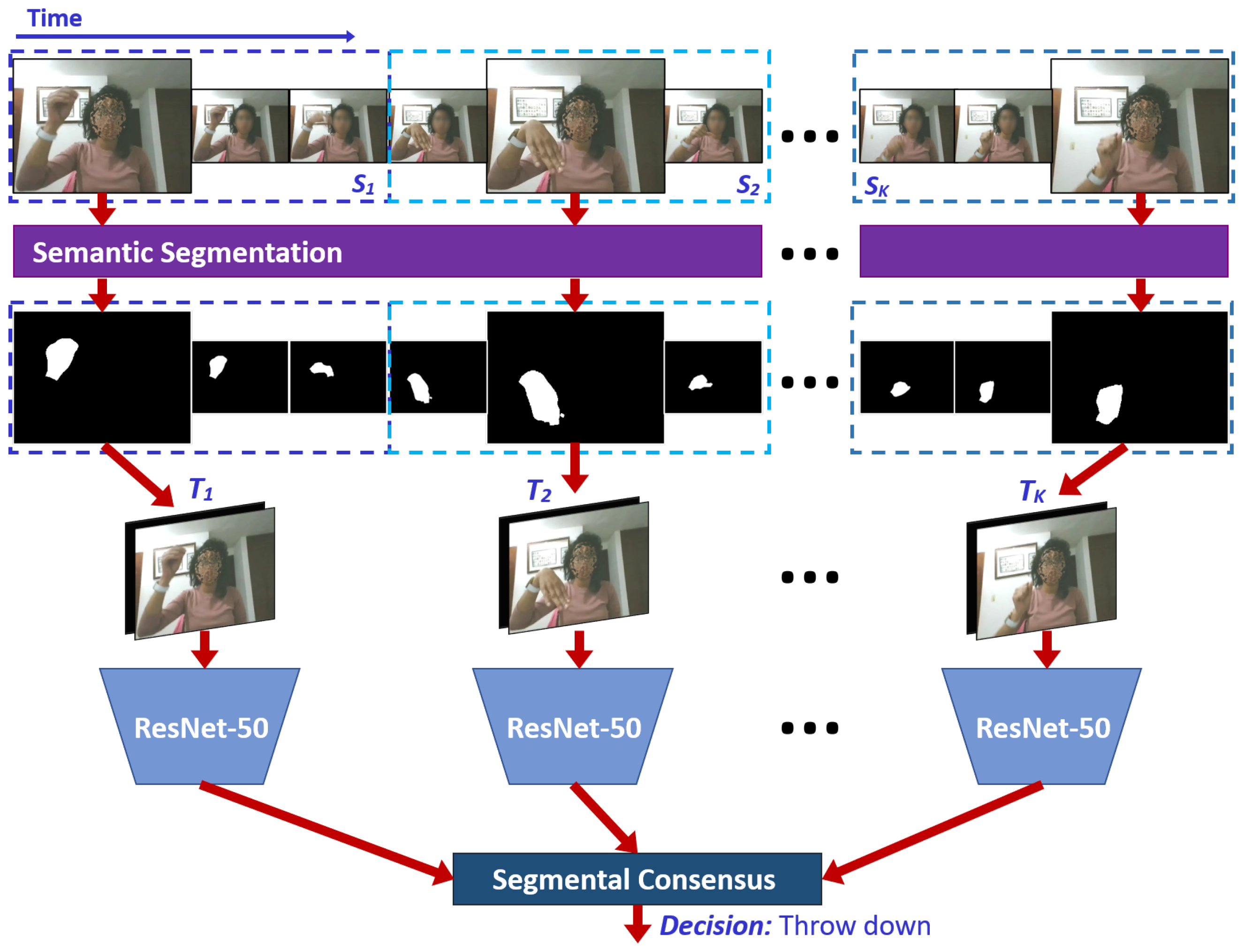
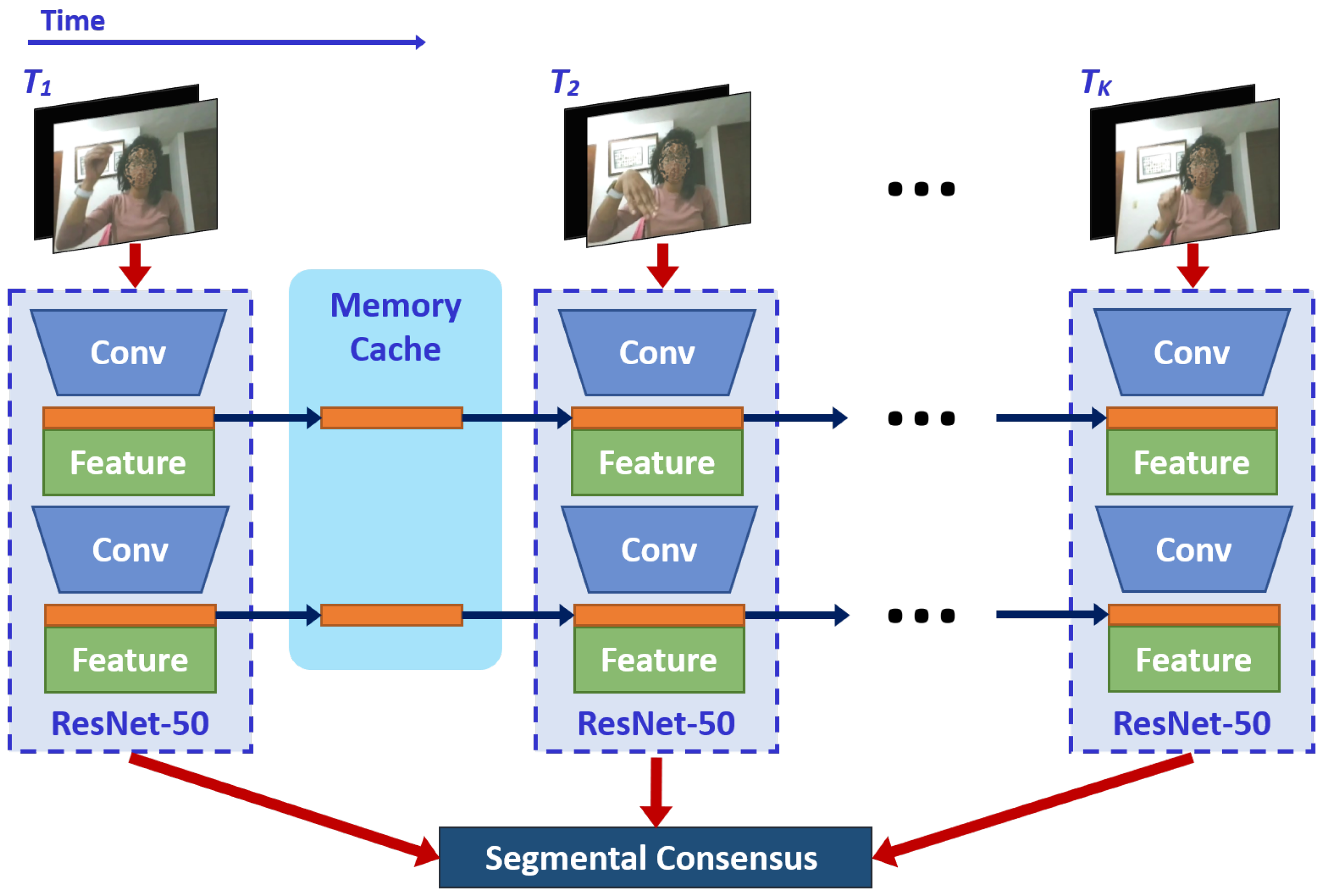
3. Proposed Method
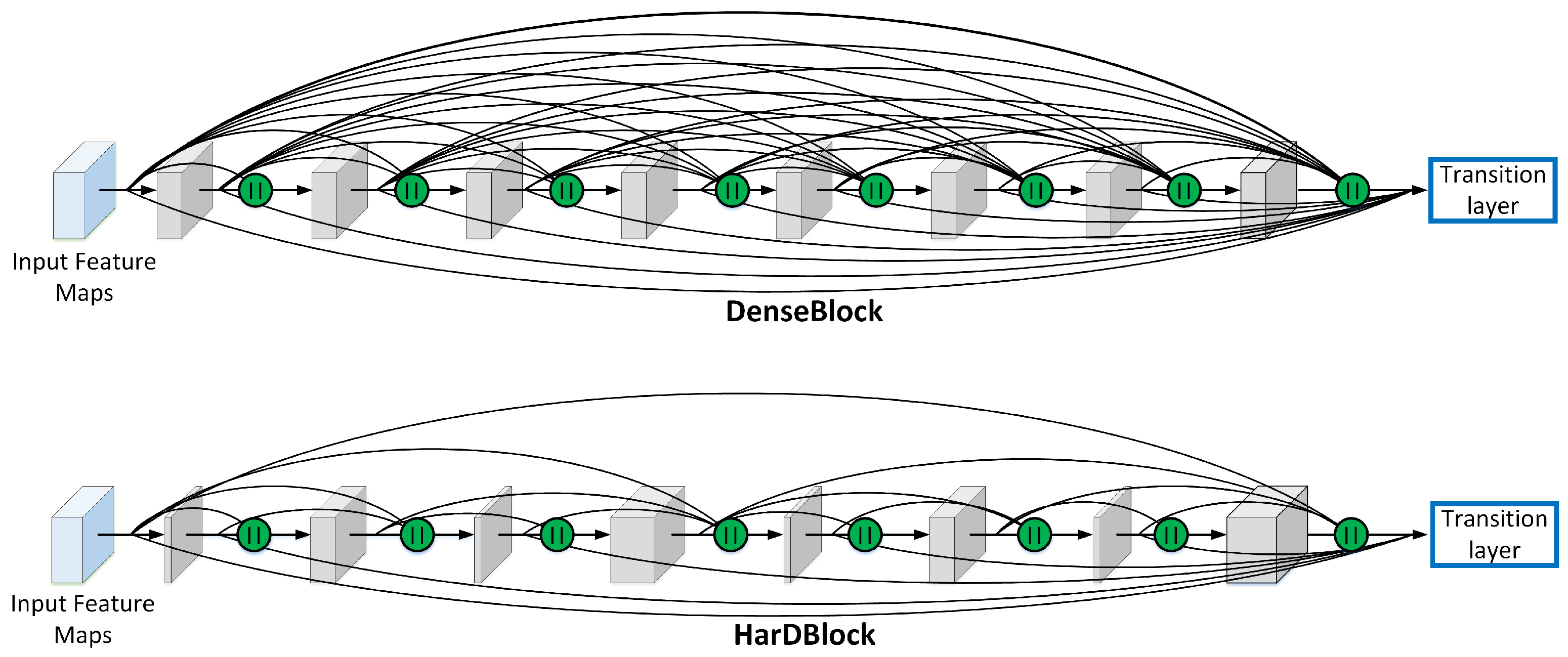
3.1. FASSD-Net for Real-Time Semantic Segmentation
3.2. Temporal Segment Networks (TSN)
3.3. Temporal Shift Module (TSM)
4. Experimental Results
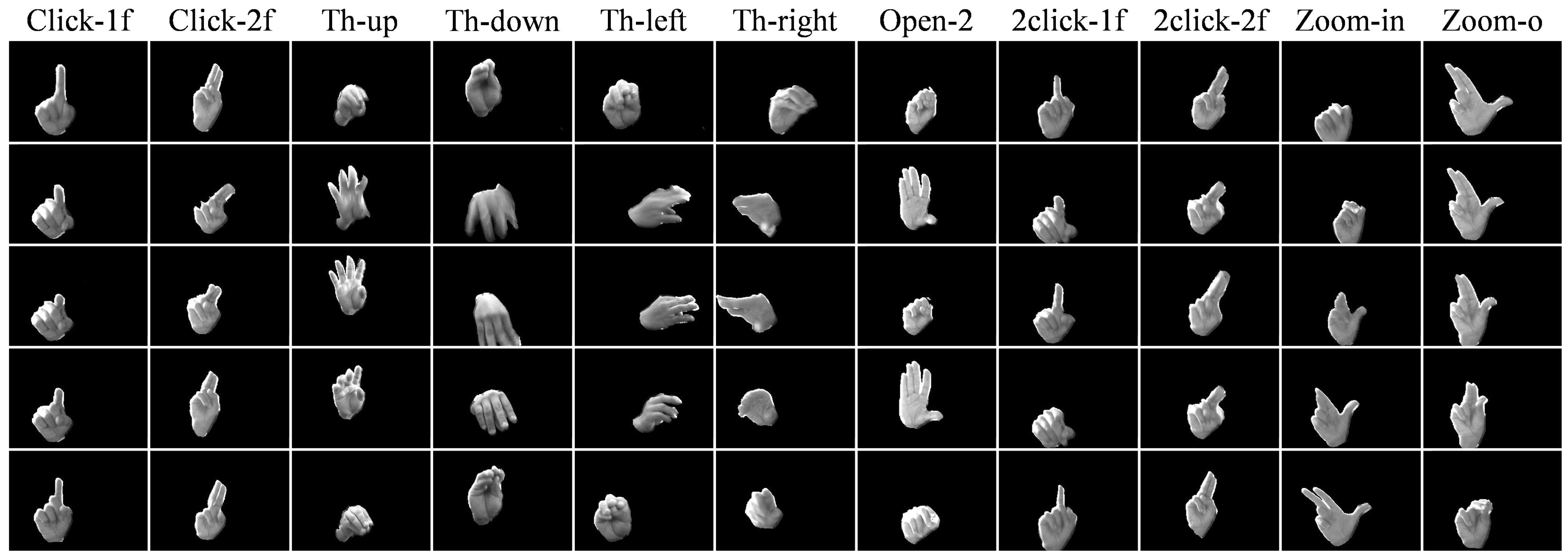
4.1. Dataset
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Results with Different Number of Segments
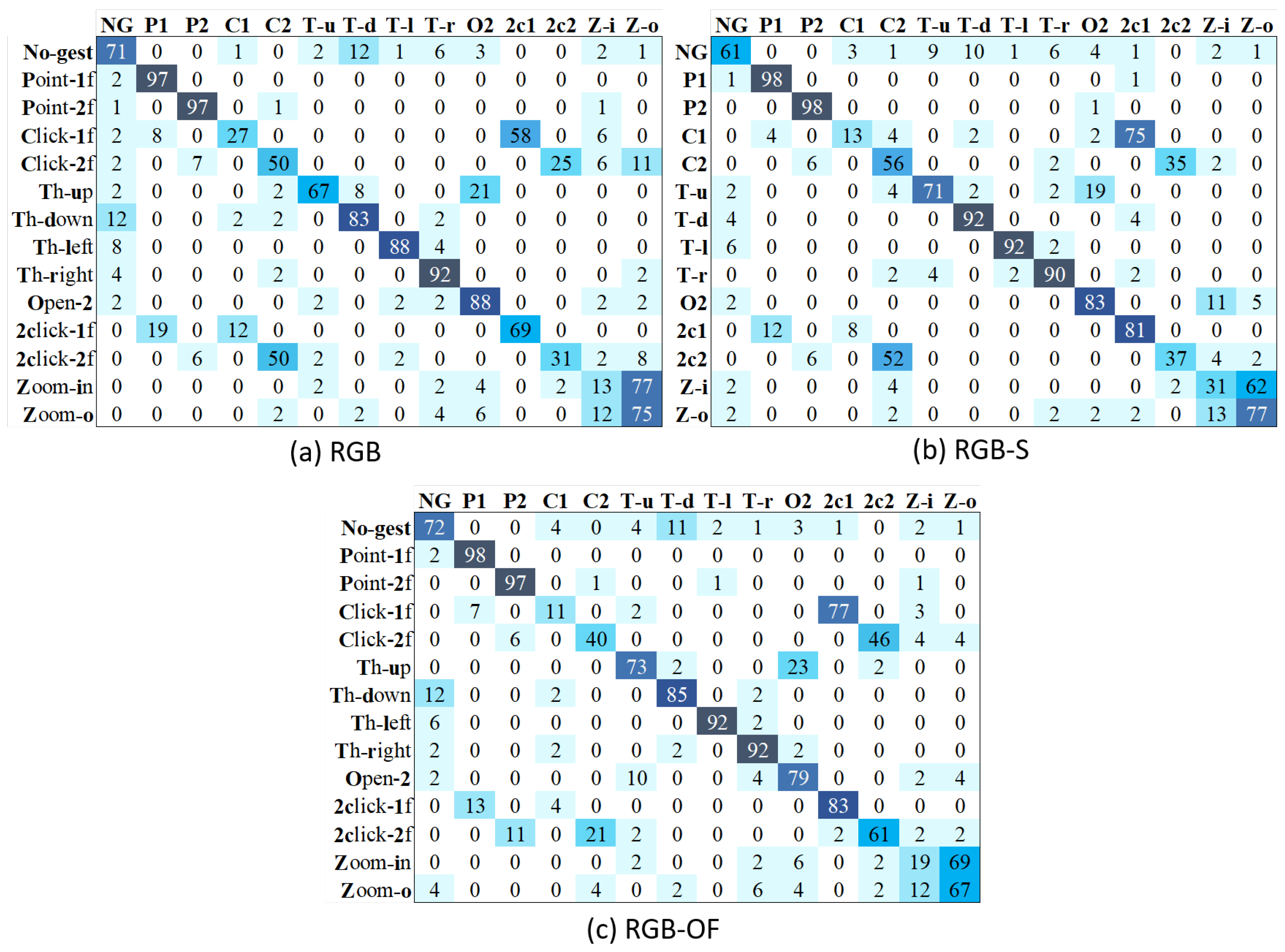
4.5. Results Using the Complete Dataset
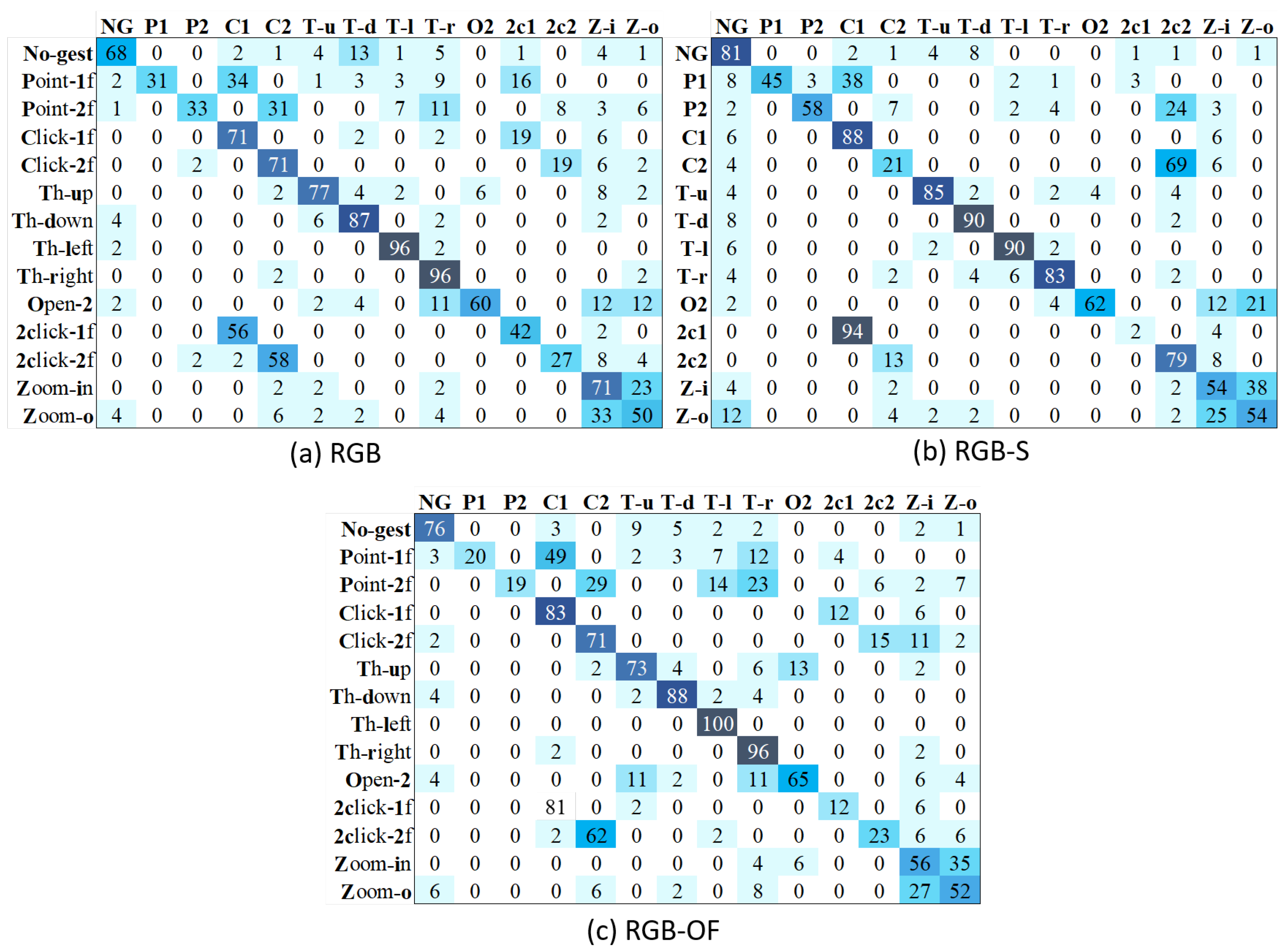
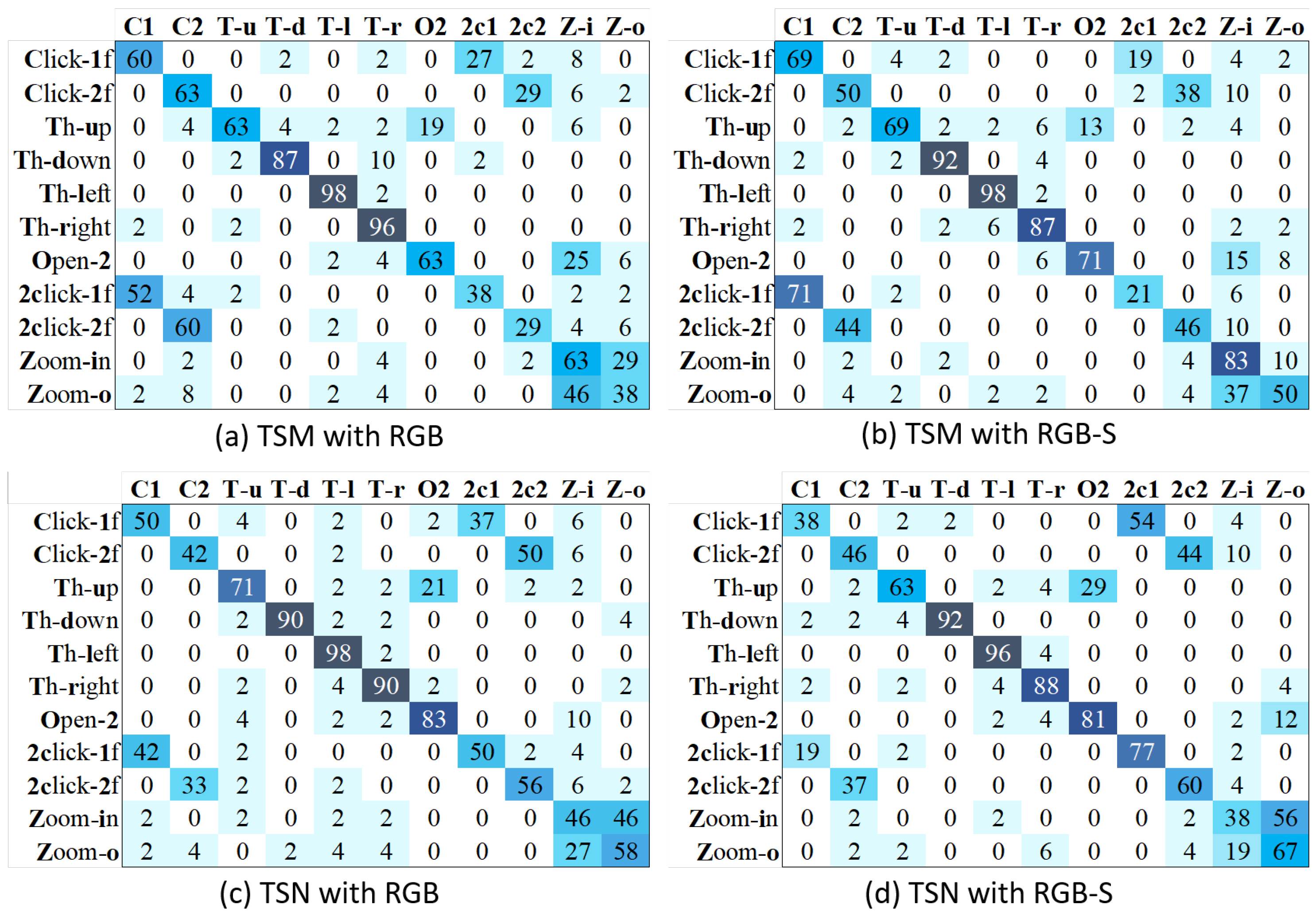
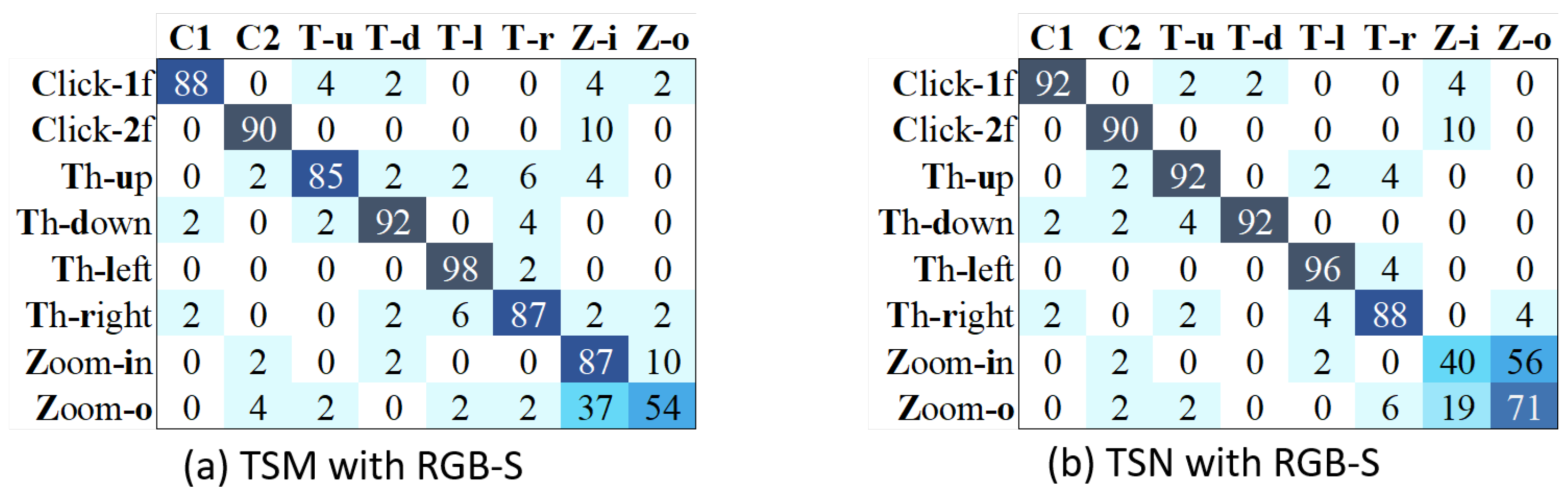
4.6. Results Using Action Classes of the Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Leo, M.; Medioni, G.; Trivedi, M.; Kanade, T.; Farinella, G.M. Computer vision for assistive technologies. Comput. Vis. Image Underst. 2017, 154, 1–15. [Google Scholar] [CrossRef]
- Berg, L.P.; Vance, J.M. Industry use of virtual reality in product design and manufacturing: A survey. Virtual Real. 2017, 21, 1–17. [Google Scholar] [CrossRef]
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Pickering, C.A.; Burnham, K.J.; Richardson, M.J. A research study of hand gesture recognition technologies and applications for human vehicle interaction. In Proceedings of the 2007 3rd Institution of Engineering and Technology Conference on Automotive Electronics, Warwick, UK, 28–29 June 2007; pp. 1–15. [Google Scholar]
- Parada-Loira, F.; González-Agulla, E.; Alba-Castro, J.L. Hand gestures to control infotainment equipment in cars. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 1–6. [Google Scholar]
- Zengeler, N.; Kopinski, T.; Handmann, U. Hand gesture recognition in automotive human–machine interaction using depth cameras. Sensors 2019, 19, 59. [Google Scholar] [CrossRef] [PubMed]
- Asadi-Aghbolaghi, M.; Clapes, A.; Bellantonio, M.; Escalante, H.J.; Ponce-López, V.; Baró, X.; Guyon, I.; Kasaei, S.; Escalera, S. A survey on deep learning based approaches for action and gesture recognition in image sequences. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Washington, DC, USA, 30 May–3 June 2017; pp. 476–483. [Google Scholar]
- Asadi-Aghbolaghi, M.; Clapés, A.; Bellantonio, M.; Escalante, H.J.; Ponce-López, V.; Baró, X.; Guyon, I.; Kasaei, S.; Escalera, S. Deep learning for action and gesture recognition in image sequences: A survey. In Gesture Recognition; Springer: Cham, Switzerland, 2017; pp. 539–578. [Google Scholar]
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4207–4215. [Google Scholar]
- Miao, Q.; Li, Y.; Ouyang, W.; Ma, Z.; Xu, X.; Shi, W.; Cao, X. Multimodal gesture recognition based on the resc3d network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3047–3055. [Google Scholar]
- Hu, Z.; Hu, Y.; Liu, J.; Wu, B.; Han, D.; Kurfess, T. 3D separable convolutional neural network for dynamic hand gesture recognition. Neurocomputing 2018, 318, 151–161. [Google Scholar] [CrossRef]
- Narayana, P.; Beveridge, R.; Draper, B.A. Gesture recognition: Focus on the hands. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5235–5244. [Google Scholar]
- Köpüklü, O.; Gunduz, A.; Kose, N.; Rigoll, G. Online Dynamic Hand Gesture Recognition Including Efficiency Analysis. IEEE Trans. Biom. Behav. Identity Sci. 2020, 2, 85–97. [Google Scholar] [CrossRef]
- Molchanov, P.; Gupta, S.; Kim, K.; Pulli, K. Multi-sensor system for driver’s hand-gesture recognition. In Proceedings of the 11th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–8. [Google Scholar]
- Kopuklu, O.; Kose, N.; Rigoll, G. Motion Fused Frames: Data Level Fusion Strategy for Hand Gesture Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2184–21848. [Google Scholar]
- Rosas-Arias, L.; Benitez-Garcia, G.; Portillo-Portillo, J.; Sanchez-Perez, G.; Yanai, K. Fast and Accurate Real-Time Semantic Segmentation with Dilated Asymmetric Convolutions. In Proceedings of the 25th International Conference on Pattern Recognition, ICPR 2020, Milan, Italy, 10–15 January 2021; pp. 1–8. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal shift module for efficient video understanding. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Ranjan, A.; Black, M.J. Optical flow estimation using a spatial pyramid network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4161–4170. [Google Scholar]
- Benitez-Garcia, G.; Olivares-Mercado, J.; Sanchez-Perez, G.; Yanai, K. IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition. In Proceedings of the 25th International Conference on Pattern Recognition, ICPR 2020, Milan, Italy, 10–15 January 2021; pp. 1–8. [Google Scholar]
- Pisharady, P.K.; Saerbeck, M. Recent methods and databases in vision-based hand gesture recognition: A review. Comput. Vis. Image Underst. 2015, 141, 152–165. [Google Scholar] [CrossRef]
- Ohn-Bar, E.; Trivedi, M.M. Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2368–2377. [Google Scholar] [CrossRef]
- Joshi, A.; Monnier, C.; Betke, M.; Sclaroff, S. Comparing random forest approaches to segmenting and classifying gestures. Image Vis. Comput. 2017, 58, 86–95. [Google Scholar] [CrossRef]
- Borghi, G.; Frigieri, E.; Vezzani, R.; Cucchiara, R. Hands on the wheel: A Dataset for Driver Hand Detection and Tracking. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Xi’an, China, 15–19 May 2018; pp. 564–570. [Google Scholar]
- Contreras Alejo, D.A.; Gallegos Funes, F.J. Recognition of a Single Dynamic Gesture with the Segmentation Technique HS-ab and Principle Components Analysis (PCA). Entropy 2019, 21, 1114. [Google Scholar] [CrossRef]
- D’Eusanio, A.; Simoni, A.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. Multimodal hand gesture classification for the human–car interaction. Informatics 2020, 7, 31. [Google Scholar] [CrossRef]
- Hakim, N.L.; Shih, T.K.; Kasthuri Arachchi, S.P.; Aditya, W.; Chen, Y.C.; Lin, C.Y. Dynamic Hand Gesture Recognition Using 3DCNN and LSTM with FSM Context-Aware Model. Sensors 2019, 19, 5429. [Google Scholar] [CrossRef] [PubMed]
- Jaramillo-Yánez, A.; Benalcázar, M.E.; Mena-Maldonado, E. Real-Time Hand Gesture Recognition Using Surface Electromyography and Machine Learning: A Systematic Literature Review. Sensors 2020, 20, 2467. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Fu, J.; Wu, Y.; Li, H.; Zheng, B. Hand gesture recognition using compact CNN via surface electromyography signals. Sensors 2020, 20, 672. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Wan, J.; Escalera, S.; Anbarjafari, G.; Escalante, H.J.; Baró, X.; Guyon, I.; Madadi, M.; Allik, J.; Gorbova, J.; Lin, C.; et al. Results and Analysis of ChaLearn LAP Multi-modal Isolated and Continuous Gesture Recognition, and Real Versus Fake Expressed Emotions Challenges. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 3189–3197. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4489–4497. [Google Scholar]
- Chao, P.; Kao, C.Y.; Ruan, Y.S.; Huang, C.H.; Lin, Y.L. HarDNet: A Low Memory Traffic Network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wan, J.; Zhao, Y.; Zhou, S.; Guyon, I.; Escalera, S.; Li, S.Z. Chalearn looking at people rgb-d isolated and continuous datasets for gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 761–769. [Google Scholar]
- Zhang, Y.; Cao, C.; Cheng, J.; Lu, H. Egogesture: A New Dataset and Benchmark for Egocentric Hand Gesture Recognition. IEEE Trans. Multimed. 2018, 20, 1038–1050. [Google Scholar] [CrossRef]
- Zimmermann, C.; Brox, T. Learning to estimate 3d hand pose from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4903–4911. [Google Scholar]
- Niklaus, S. A Reimplementation of SPyNet Using PyTorch. 2018. Available online: https://github.com/sniklaus/pytorch-spynet (accessed on 29 November 2020).
- Baker, S.; Scharstein, D.; Lewis, J.P.; Roth, S.; Black, M.J.; Szeliski, R. A Database and Evaluation Methodology for Optical Flow. Int. J. Comput. Vis. 2011, 92, 1–31. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Name | Type | Output Size |
|---|---|---|---|
| Input | - | - | 512 × 1024 × 3 |
| Encoder | Stem Conv | Conv 3 × 3 () | 256 × 512 × 16 |
| Conv 3 × 3 | 256 × 512 × 24 | ||
| Conv 3 × 3 () | 128 × 256 × 32 | ||
| Conv 3 × 3 | 128 × 256 × 48 | ||
| Encoder B1 | HarDBlock () | 128 × 256 × 64 | |
| Encoder B2 | 2D Average Pooling | 64 × 128 × 96 | |
| HarDBlock () | |||
| Encoder B3 | 2D Average Pooling | 32 × 64 × 160 | |
| HarDBlock () | |||
| Encoder B4 | 2D Average Pooling | 16 × 32 × 224 | |
| HarDBlock () | |||
| DAPF | - | 16 × 32 × 224 | |
| Decoder | MDA | - | 32 × 64 × 192 |
| Decoder B1 | HarDBlock () | 32 × 64 × 160 | |
| MDA | - | 64 × 128 × 119 | |
| Decoder B2 | HarDBlock () | 64 × 128 × 78 | |
| MDA | - | 128 × 256 × 63 | |
| Decoder B3 | HarDBlock () | 128 × 256 × 48 | |
| Output Conv | Conv 1 × 1 | 128 × 256 × 4 | |
| Upsampling × 4 | 512 × 1024 × 4 |
| Modality | Segments | Accuracy |
|---|---|---|
| RGB | 8 | 54.0373 |
| RGB | 16 | 50.4969 |
| RGB | 24 | 55.0932 |
| RGB | 32 | 55.9627 |
| RGB-S | 8 | 55.5901 |
| RGB-S | 16 | 50.559 |
| RGB-S | 24 | 55.3478 |
| RGB-S | 32 | 65.2795 |
| Model | Segments | Modality | Extra Modality Time | Total Inference Time | Accuracy | Avg. Class Accuracy |
|---|---|---|---|---|---|---|
| TSM | 32 | RGB | - | 6.8 ms (147 fps) | 55.9627 | 62.7856 |
| TSM | 32 | RGB-seg | 8 ms | 15.2 ms (66 fps) | 65.2795 | 63.6383 |
| TSM | 32 | RGB-flo | 29 ms | 36.2 ms (27 fps) | 53.6646 | 59.5857 |
| TSN | 32 | RGB | - | 6.6 ms (152 fps) | 76.2733 | 67.7925 |
| TSN | 32 | RGB-seg | 8 ms | 15.1 ms (66 fps) | 74.8447 | 70.0014 |
| TSN | 32 | RGB-flo | 29 ms | 36.1 ms (28 fps) | 77.2671 | 69.1529 |
| Model | Segments | Modality | Accuracy | Avg. Class Accuracy |
|---|---|---|---|---|
| TSM | 32 | RGB | 63.6364 | 63.6364 |
| TSM | 32 | RGB-seg | 66.958 | 66.958 |
| TSM | 32 | RGB-flo | 65.035 | 65.035 |
| TSN | 32 | RGB | 66.7832 | 66.7832 |
| TSN | 32 | RGB-seg | 68.007 | 68.007 |
| TSN | 32 | RGB-flo | 65.9091 | 65.9091 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benitez-Garcia, G.; Prudente-Tixteco, L.; Castro-Madrid, L.C.; Toscano-Medina, R.; Olivares-Mercado, J.; Sanchez-Perez, G.; Villalba, L.J.G. Improving Real-Time Hand Gesture Recognition with Semantic Segmentation. Sensors 2021, 21, 356. https://doi.org/10.3390/s21020356
Benitez-Garcia G, Prudente-Tixteco L, Castro-Madrid LC, Toscano-Medina R, Olivares-Mercado J, Sanchez-Perez G, Villalba LJG. Improving Real-Time Hand Gesture Recognition with Semantic Segmentation. Sensors. 2021; 21(2):356. https://doi.org/10.3390/s21020356
Chicago/Turabian StyleBenitez-Garcia, Gibran, Lidia Prudente-Tixteco, Luis Carlos Castro-Madrid, Rocio Toscano-Medina, Jesus Olivares-Mercado, Gabriel Sanchez-Perez, and Luis Javier Garcia Villalba. 2021. "Improving Real-Time Hand Gesture Recognition with Semantic Segmentation" Sensors 21, no. 2: 356. https://doi.org/10.3390/s21020356
APA StyleBenitez-Garcia, G., Prudente-Tixteco, L., Castro-Madrid, L. C., Toscano-Medina, R., Olivares-Mercado, J., Sanchez-Perez, G., & Villalba, L. J. G. (2021). Improving Real-Time Hand Gesture Recognition with Semantic Segmentation. Sensors, 21(2), 356. https://doi.org/10.3390/s21020356