A Password Meter without Password Exposure




Abstract
1. Introduction
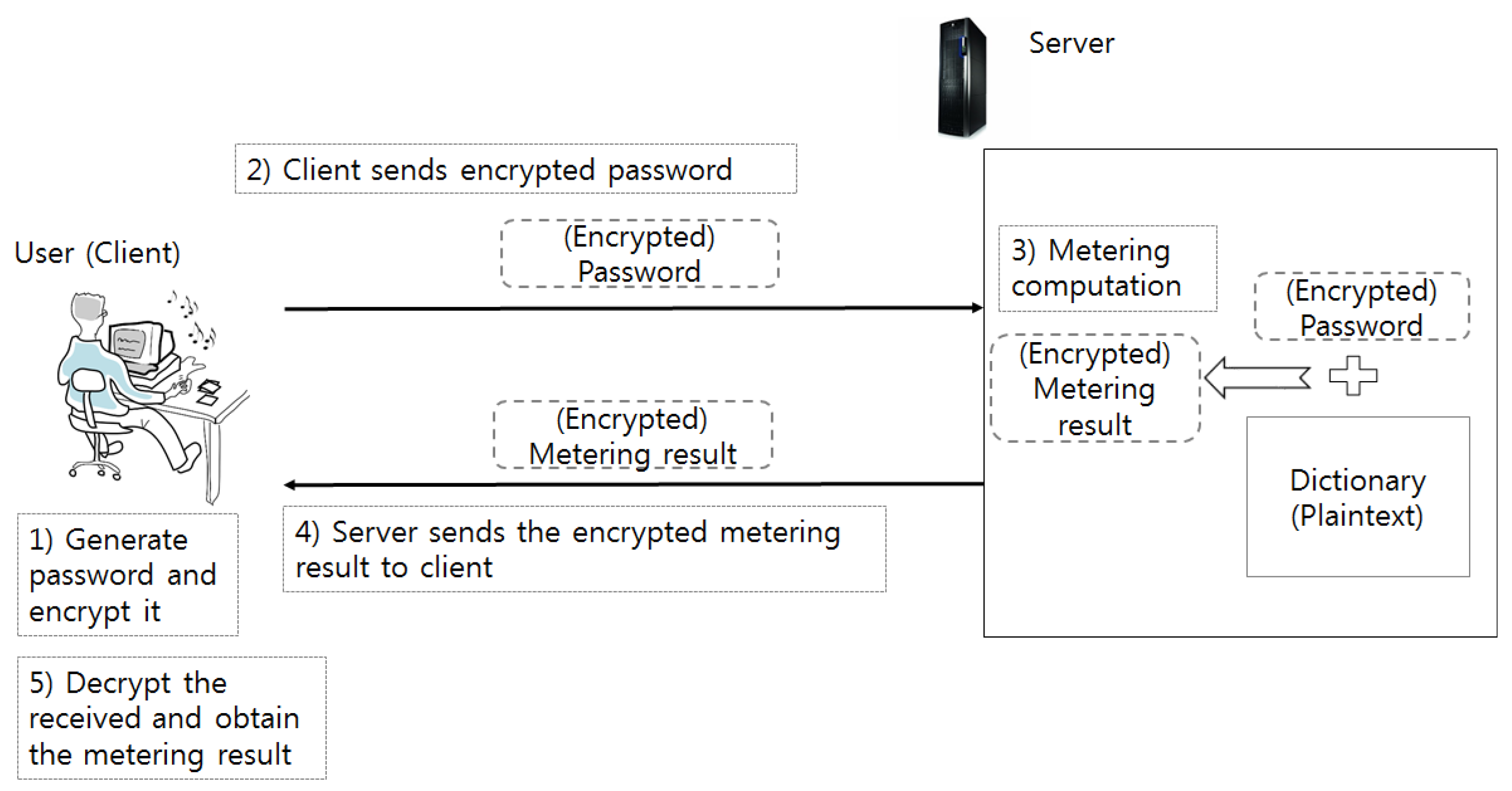
- We propose a new type of on-line password strength meter that can be secured during the password strength measurement process even if the client does not run the password meter directly. More specifically, the password meter’s input, strength measurement results, and any information such as dictionary used by the password meter are all protected. Therefore, since the proposed method can be run on the server, it can keep the password meter up-to-date and reduce the chances of an attacker to analyze how the password meter works.
- We have achieved an efficient implementation of the entropy-based NIST metering [5] which includes the dictionary membership operation with the encrypted password candidates from a number of different users that use different public keys to encrypt their (candidate) passwords. The experiment demonstrates that a single password metering operation can be completed only with 67 s without exposing the password candidate with a parameter supporting a reasonable level of security. We believe this is the first password meter preserving the password secrecy of the users. Even though there are more advanced metering techniques than the NIST metering, we also believe these can be implemented as our approach when the performance of FHE will be increased in the near future.
- Unfortunately, simply applying an FHE scheme just makes an impractical implementation because of the nature of FHE. Thus, we apply various performance enhancement techniques in order to minimize the required computation cost for metering. Specifically, the dictionary contains more than 50,000 words and the membership operation can be executed even without performing a single recryption operation.
- Our last contribution is to defend against side-channel attacks by ensuring that the password meter always has the same execution time. Password meters that measure strength using password guessing are terminated as soon as the generated guess matches the input password, and the measured strength is correlated with the number of password guesses, that is, execution time. Therefore, if the server can infer at which step of the password meter the match was made by checking the execution time of the password meter, the range of the input password can be greatly reduced. The proposed method prevents such an attack by performing the operation provided by the FHE over the ciphertext according to the same prescribed procedure.
2. Preliminary and Related Work
2.1. Recent Literature on Password Cracking and Metering
2.2. Fully Homomorphic Encryption
- takes the security parameter and outputs a system parameter .
- () generates a secret key with that is an output of running .
- (,) takes and and outputs a public key that is associated with .
- (,,) performs encryption with , a public key , and a plaintext . can be one of various forms: from one-bit data to a vector of many bits depending on the way of implementation. It returns a ciphertext .
- (,,): it decrypts to the original plaintext if is a result of running (,,) where is the public key that corresponds to .
- (,,,): it performs an xor operation with the underlying plaintexts of and . If and have one-bit plaintexts, it performs a bit-wise xor operation with them. If the underlying plaintexts of and are represented as vectors, it performs a slot-wise xor operation on each component of and , respectively. One assumption to make this algorithm work is that both and are encrypted with the same public key. Otherwise it does not return a meaningful output. The result of this operations is a ciphertext c that can be decrypted with the secret key with which and can be decrypted.
- (,,,): It performs the multiplication operation on the underlying plaintexts of and . It could be a slot-wise multiplication if the ciphertexts have vector plaintexts as in the case of . This operation is the same as the encrypted ‘AND’ operation if the underlying plaintexts, or each of their slot values, are just either 0 or 1. If they are defined over a certain ring, this operation also follows the defined multiplication over the ring.
- (,,) can be explained after introducing the ‘noise’ of a ciphertext. In many of FHE schemes, a ciphertext contains a small amount of noise when it is created for security reasons. Whenever we perform some computation with ciphertexts, the resultant ciphertext has more amount of noise. If it is greater than certain amount, the ciphertext cannot be decrypted, so before it reaches the amount, we need to do this operation to reduce the amount of the noise it has. In fact, it creates a new ciphertext of the same plaintext that the parameter ciphertext has with less noise. However, the resultant ciphertext initially has more noise than a ciphertext that is created by .
- (,,,, ⋯, ): If the plaintext space is a vector space, we can define this operation. This returns an element in the plaintext space where the components are , ⋯, . The length l and the type of each s depend on the plaintext space.
- (,,) is a reverse of algorithm. The output is , ⋯, .
- (,,,t) shifts the position of the plaintext component in each slot to its left by t slots. This is defined only when the plaintext space is a vector space. t is an integer, and it can be negative. In this case, it means shifting right by slots. We assume that the first t slots are set to zero. If it is negative, the last slots are set to zero.
- (,,,t) returns a new ciphertext where t-th slot’s underlying plaintext value in is in the first slot of the resultant ciphertext. t is a multiple of u that is defined by the plaintext space. It does not consider what the other slots’ values of the resultant ciphertext are.
- (,,,t) produces a new ciphertext where the binary polynomial in each slot of is exponentiated by , respectively.
A Plaintext Can Be Regarded as a Correct (but Not Secure) Ciphertext That Is Encrypted by Any Public Key
- () returns =, where : ring description, d:degree, n: dimension, q: odd modulus, : noise distribution, and =.
- (): Sample from randomly. Let . Output .
- (,) generates a matrix uniformly at random. A column vector with ‘small’ coefficients is sampled from at random. Set . Set . Output . (Note that ).
- (,,): . Set a row vector . Sample a column vector with small coefficient from at random and output the ciphertext .
- (,,c): Calculate , where denotes the modular reduction function that reduces a real number x into an integer in the range if q is an odd modulus. If , over real numbers.
2.3. NIST Meter
3. Motivation
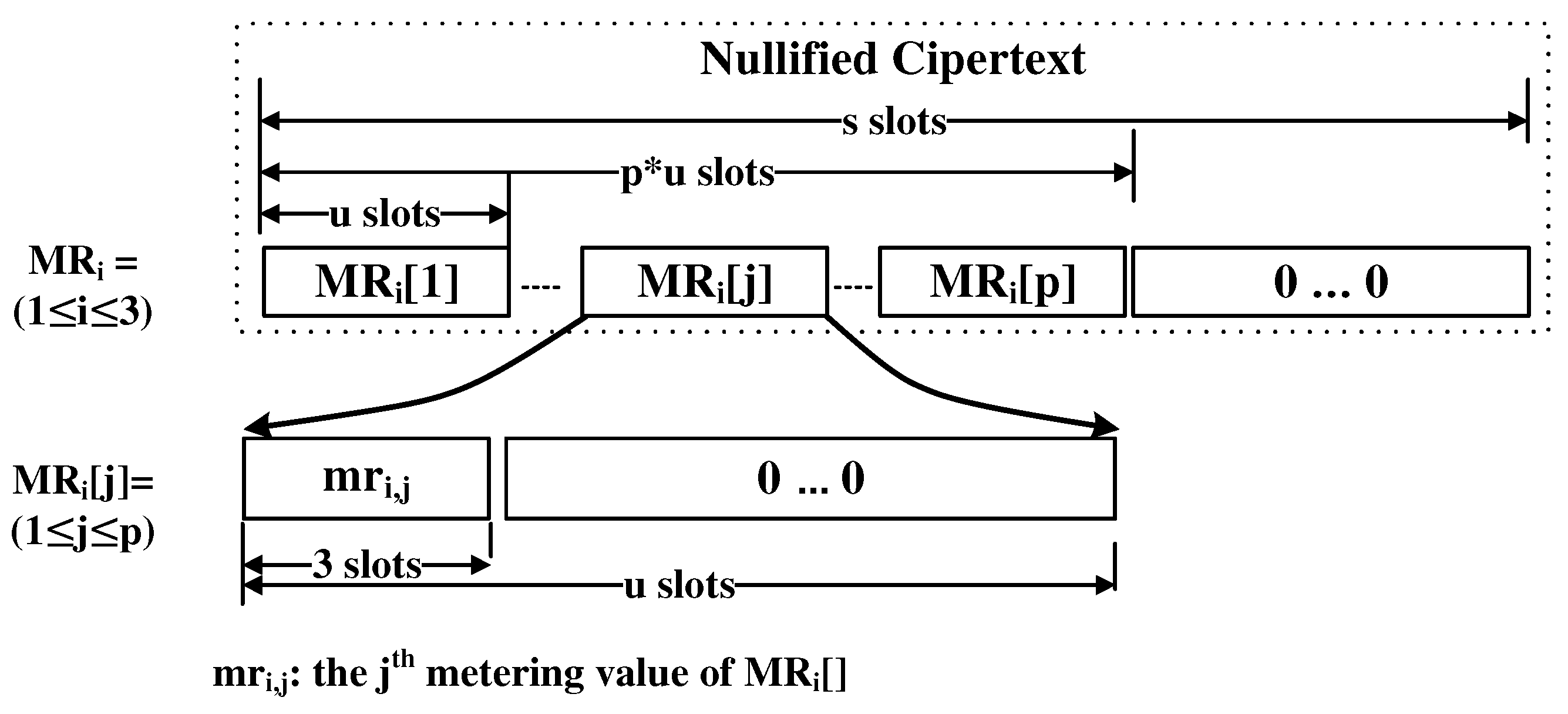
4. Proposed Method
4.1. Overview
| Algorithm 1: Pseudo-code of the proposed protocol |
 |
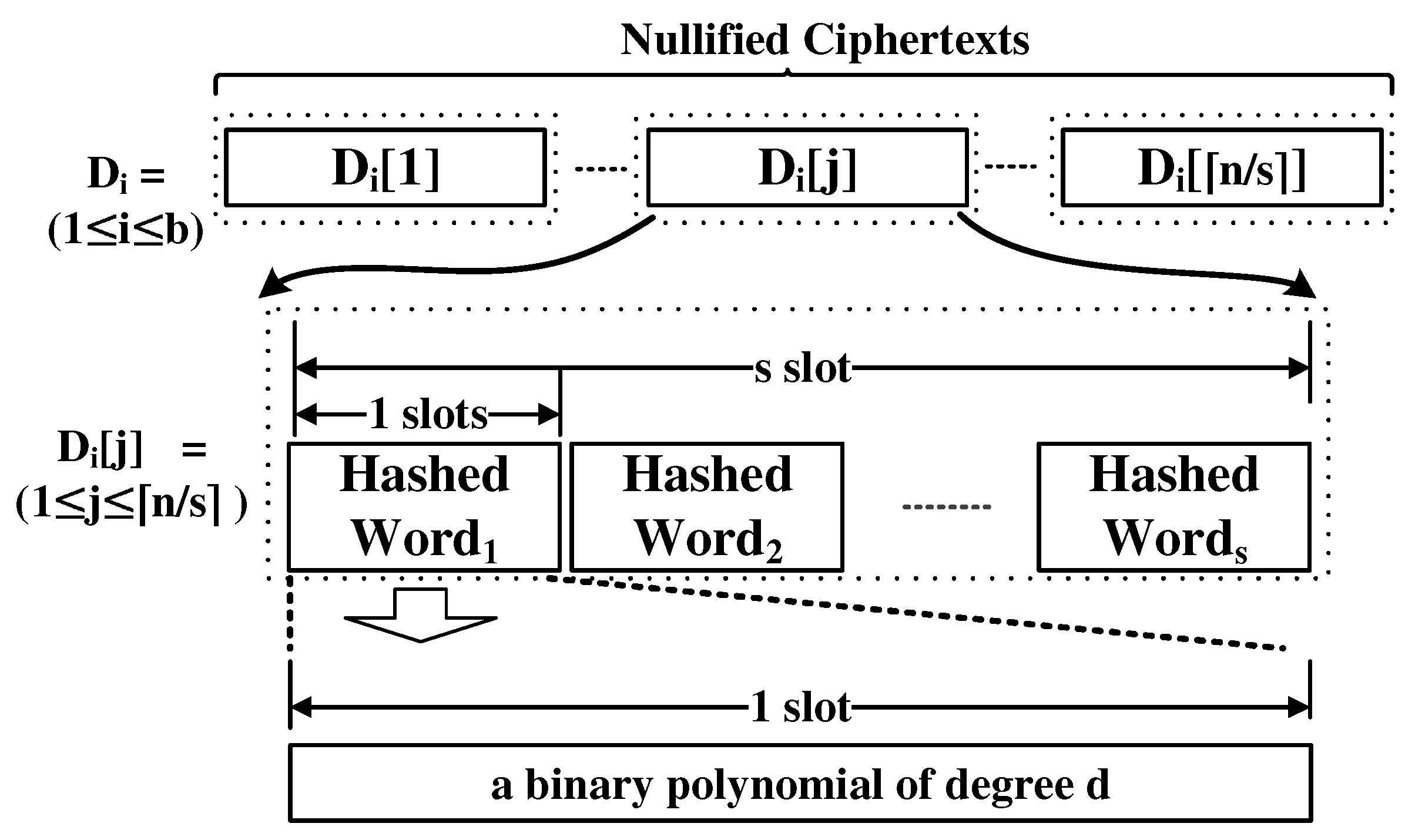
4.2. Dictionary Checker
| Algorithm 2: Pseudo-code of Dictionary Checker |
 |
| Algorithm 3: Pseudo-code of i-DRPart(), WordMatcher(), and Trace() function. |
 |
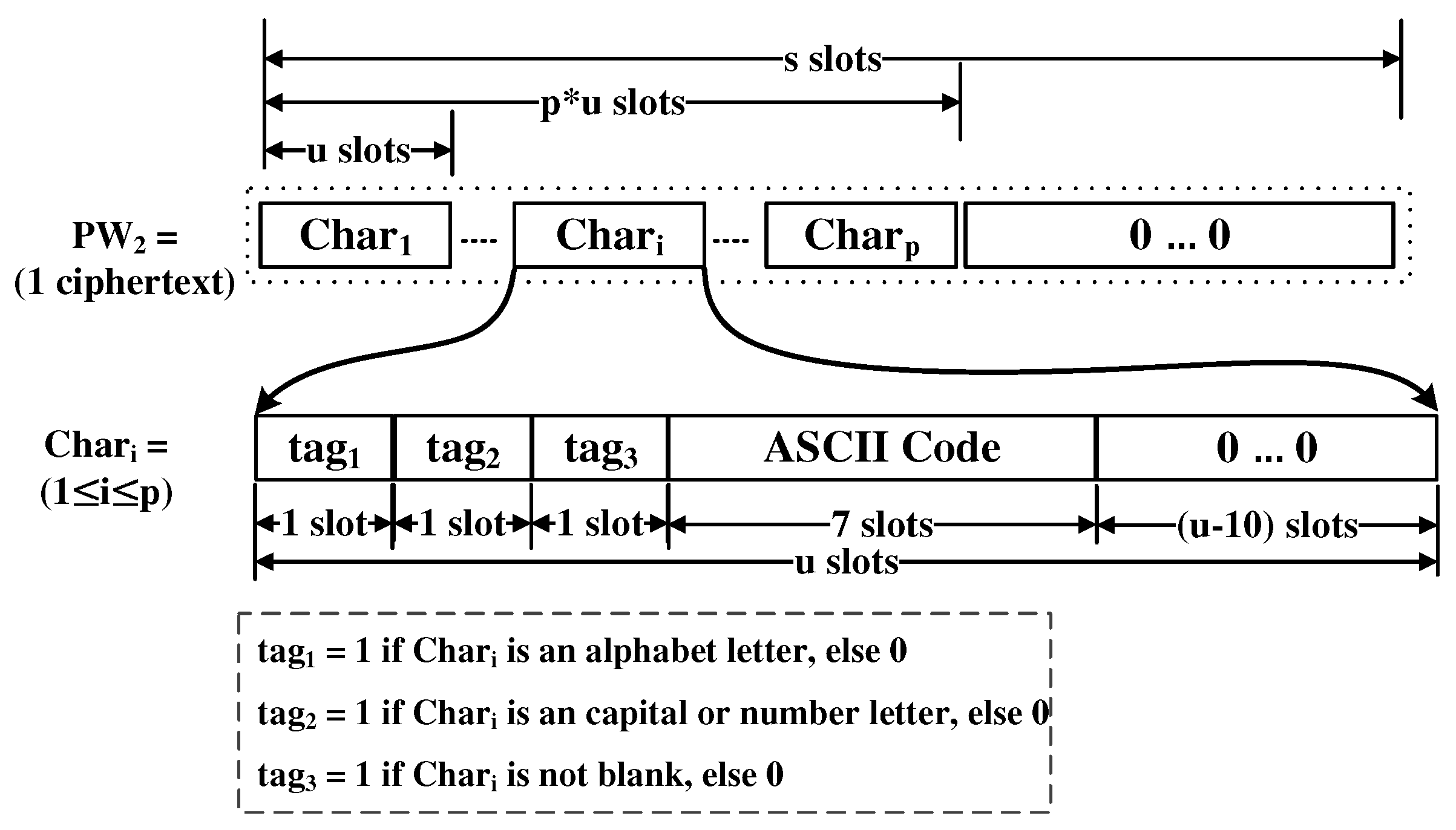
4.3. Composition Rule Checker
| Algorithm 4: Pseudo-code of CompositionRuleChecker(). |
 |
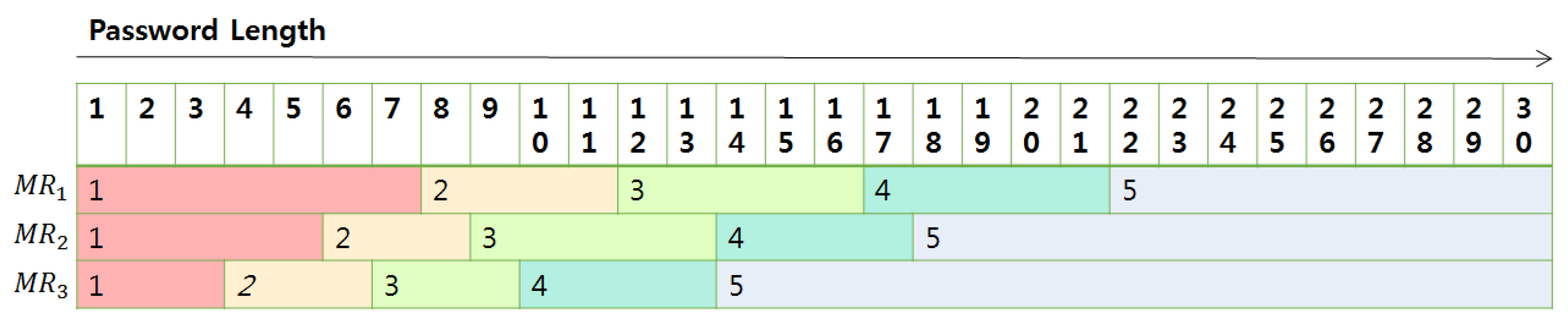
4.4. Length-Strength Matcher Table
| Algorithm 5: Pseudo-code of LengthStrengthMatcher() |
 |
4.5. Selector
| Algorithm 6: Pseudo-code of Selector() |
 |
5. Performance Evaluation
5.1. Theoretical Analysis
5.1.1. Number of Unit Operations in Components
5.1.2. Circuit Depth and Width Analysis
5.2. Experimental Analysis
5.2.1. Unit Operation Time
5.2.2. False Positive Ratio in Dictionary Checking
5.2.3. Total Execution Time
5.2.4. Key Size for FHE
5.2.5. Ciphertext Size
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Narayanan, A.; Shmatikov, V. Fast dictionary attacks on passwords using time-space tradeoff. In Proceedings of the 12th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 7–11 November 2005; pp. 364–372. [Google Scholar] [CrossRef]
- Ur, B.; Kelley, P.G.; Komanduri, S.; Lee, J.; Maass, M.; Mazurek, M.L.; Christin, N. How does your password measure up? The effect of strength meters on password creation. In Proceedings of the 21st USENIX Security Symposium (USENIX Security), Bellevue, WA, USA, 8–10 August 2012; pp. 65–80. Available online: https://www.usenix.org/conference/usenixsecurity12/technical-sessions/presentation/ur (accessed on 6 January 2021).
- de Carné de Carnavalet, X.; Mannan, M. From very weak to very strong: Analyzing password-strength meters. In Proceedings of the Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 23–26 February 2014. [Google Scholar] [CrossRef]
- Ma, J.; Yang, W.; Luo, M.; Li, N. A study of probabilistic password models. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 689–704. [Google Scholar] [CrossRef]
- Burr, W.; Dodson, D.; Newton, E.; Perlner, R.; Polk, T.; Gupta, S.; Nabbus, E. NIST Special Publication 800-63-2 Electronic Authentication Guideline; Computer Security Division, Information Technology Laboratory, National Institute of Standards and Technology: Gaithersburg, MD, USA, August 2013.
- John the Ripper Password Cracker. 2013. Available online: http://www.openwall.com/john (accessed on 23 November 2020).
- Weir, M.; Aggarwal, S.; De Medeiros, B.; Glodek, B. Password cracking using probabilistic context-free grammars. In Proceedings of the 2009 30th IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 17–20 May 2009; pp. 391–405. [Google Scholar] [CrossRef]
- Kelley, P.G.; Komanduri, S.; Mazurek, M.L.; Shay, R.; Vidas, T.; Bauer, L.; Lopez, J. Guess again (and again and again): Measuring password strength by simulating password-cracking algorithms. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 523–537. [Google Scholar] [CrossRef]
- Veras, R.; Collins, C.; Thorpe, J. On Semantic Patterns of Passwords and their Security Impact. In Proceedings of the 14th NDSS, San Diego, CA, USA, 23–26 February 2014. [Google Scholar] [CrossRef]
- Mazurek, M.L.; Komanduri, S.; Vidas, T.; Bauer, L.; Christin, N.; Cranor, L.F.; Ur, B. Measuring password guessability for an entire university. In Proceedings of the 2013 ACM SIGSAC Conference on Computer and Communications Security, Berlin, Germany, 4–8 November 2013; pp. 173–186. [Google Scholar] [CrossRef]
- Ur, B.; Segreti, S.M.; Bauer, L.; Christin, N.; Cranor, L.F.; Komanduri, S.; Shay, R. Measuring real-world accuracies and biases in modeling password guessability. In Proceedings of the 24th USENIX Security Symposium, Washington, DC, USA, 12–14 August 2015; pp. 463–481. Available online: https://www.usenix.org/conference/usenixsecurity15/technical-sessions/presentation/ur (accessed on 6 January 2021).
- Dell’Amico, M.; Michiardi, P.; Roudier, Y. Password Strength: An Empirical Analysis. In Proceedings of the 2010 IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; Volume 10, pp. 983–991. [Google Scholar] [CrossRef]
- Password Research Team at Carnegie Mellon University. Password Guessability Service. 2019. Available online: https://pgs.ece.cmu.edu (accessed on 23 November 2020).
- Steube, J. Hashcat. Available online: https://hashcat.net/ (accessed on 23 November 2020).
- Melicher, W.; Ur, B.; Segreti, S.M.; Komanduri, S.; Bauer, L.; Christin, N.; Cranor, L.F. Fast, Lean, and Accurate: Modeling Password Guessability Using Neural Networks. In Proceedings of the 25th USENIX Security Symposium, Austin, TX, USA, 10–12 August 2016; pp. 175–191. Available online: https://www.usenix.org/conference/usenixsecurity16/technical-sessions/presentation/melicher (accessed on 6 January 2021).
- Hitaj, B.; Gasti, P.; Ateniese, G.; Perez-Cruz, F. PassGAN: A Deep Learning Approach for Password Guessing. International Conference on Applied Cryptography and Network Security; Springer: Cham, Switzerland, 2019; pp. 217–237. [Google Scholar] [CrossRef]
- Nam, S.; Jeon, S.; Moon, J. A New Password Cracking Model with Generative Adversarial Networks. In Information Security Applications; You, I., Ed.; Springer: Cham, Switzerland, 2020; pp. 247–258. [Google Scholar] [CrossRef]
- Nam, S.; Jeon, S.; Kim, H.; Moon, J. Recurrent GANs Password Cracker For IoT Password Security Enhancement. Sensors 2020, 20, 3106. [Google Scholar] [CrossRef] [PubMed]
- Nam, S.; Jeon, S.; Moon, J. Generating Optimized Guessing Candidates toward Better Password Cracking from Multi-Dictionaries Using Relativistic GAN. Appl. Sci. 2020, 10, 7306. [Google Scholar] [CrossRef]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing (STOC’09), Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar] [CrossRef]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) Fully Homomorphic Encryption without Bootstrapping. ACM Trans. Comput. Theory (TOCT) 2014, 6, 1–36. [Google Scholar] [CrossRef]
- Halevi, S.; Shoup, V. Design and Implementation of a Homomorphic Encryption Library. 2013. Available online: https://github.com/shaih/HElib (accessed on 23 November 2020).
- Castelluccia, C.; Dürmuth, M.; Perito, D. Adaptive Password-Strength Meters from Markov Models. NDSS. 2012. Available online: https://www.ndss-symposium.org/ndss2012/ndss-2012-programme/adaptive-password-strength\-meters-markov-models/ (accessed on 6 January 2021).
- Dell’Amico, M.; Filippone, M. Monte Carlo strength evaluation: Fast and reliable password checking. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 158–169. [Google Scholar] [CrossRef]
- Habib, H.; Colnago, J.; Melicher, W.; Ur, B.; Segreti, S.; Bauer, L.; Chhristin, N.; Cranor, L. Password creation in the presence of blacklists. In Proceedings of the 2017 Workshop on Usable Security (USEC ’17), San Diego, CA, USA, 26 February 2017. [Google Scholar] [CrossRef]
- Ur, B.; Alfieri, F.; Aung, M.; Bauer, L.; Christin, N.; Colnago, J.; Dixon, H.; Naeini, P.E.; Habib, H.; Johnson, N.; et al. Design and evaluation of a data-driven password meter. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 3775–3786. [Google Scholar] [CrossRef]
- Weir, M.; Aggarwal, S.; Collins, M.; Stern, H. Testing metrics for password creation policies by attacking large sets of revealed passwords. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 162–175. [Google Scholar] [CrossRef]
- RockYou Hack: From Bad to Worse. Available online: http://techcrunch.com/2009/12/14/rockyou-hack-security-myspace-facebook-passwords (accessed on 23 November 2020).
- Malone, D.; Maher, K. Investigating the distribution of password choices. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 301–310. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Komanduri, S.; Shay, R.; Cranor, L.F.; Herley, C.; Schechter, S. Telepathwords: Preventing weak passwords by reading users’ minds. In Proceedings of the 23rd USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; pp. 591–606. Available online: https://www.usenix.org/conference/usenixsecurity14/technical-sessions/presentation/komanduri (accessed on 6 January 2021).
- Zhang, Y.; Monrose, F.; Reiter, M.K. The security of modern password expiration: An algorithmic framework and empirical analysis. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 176–186. [Google Scholar] [CrossRef]
- Wheeler, D.W. zxcvbn:Low-Budget Password Strength Estimation. In Proceedings of the 25th USENIX Security Symposium, Austin, TX, USA, 10–12 August 2016; pp. 157–173. Available online: https://www.usenix.org/conference/usenixsecurity16/technical-sessions/presentation/wheeler (accessed on 6 January 2021).
- Egelman, S.; Sotirakopoulos, A.; Muslukhov, I.; Beznosov, K.; Herley, C. Does my password go up to eleven? The impact of password meters on password selection. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 2379–2388. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. Available online: https://papers.nips.cc/paper/2017/hash/892c3b1c6dccd52936e27cbd0ff683d6-Abstract.html (accessed on 6 January 2021).
- Pasquini, D.; Gangwal, A.; Ateniese, G.; Bernaschi, M.; Conti, M. Improving Password Guessing via Representation Learning. arXiv 2019, arXiv:1910.04232. [Google Scholar]
- Pasquini, D.; Cianfriglia, M.; Ateniese, G.; Bernaschi, M. Reducing Bias in Modeling Real-world Password Strength via Deep Learning and Dynamic Dictionaries. arXiv 2020, arXiv:2010.12269. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. 2014. Available online: https://papers.nips.cc/paper/2014/hash/5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html (accessed on 6 January 2021).
- Halevi, S.; Shoup, V. Algorithms in HElib. In Proceedings of the 34th Annual Cryptology Conference (CRYPTO’14), Santa Barbara, CA, USA, 17–21 August 2014; pp. 554–571. [Google Scholar] [CrossRef]
- Halevi, S.; Shoup, V. Bootstrapping for HElib. In Proceedings of the 34th Annual International Conference (EUROCRYPT’15), Sofia, Bulgaria, 26–30 April 2015; pp. 641–670. [Google Scholar] [CrossRef]
- Gentry, W.; Halevi, S.; Smart, N.P. Homomorphic Evaluation of the AES Circuit. In CRYPTO 2012; Lecture Notes in Computer Science 7417; Springer: Berlin/Heidelberg, Germany, 2012; pp. 850–867. [Google Scholar] [CrossRef]
- Mitzenmacher, M.; Upfal, E. Probability and Computing: Randomization and Probabilistic Techniques in Algorithms and Data Analysis; Cambridge University Press: Cambridge, UK, 2017; pp. 1007–1112. [Google Scholar]
- Park, H.; Kim, P.; Kim, H.; Park, K.; Lee, Y. Efficient machine learning over encrypted data with non-interactive communication. Comput. Stand. Interfaces 2018, 58, 87–108. [Google Scholar] [CrossRef]
- Lee, J.; Kim, D.; Lee, H.; Lee, Y.; Cheon, J. RLizard: Post-Quantum Key Encapsulation Mechanism for IoT Devices. IEEE Access 2019, 7, 2080–2091. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | Entropy | |
|---|---|---|
| Length | 1 | Add 4 bits |
| 2∼8 | Add bits | |
| 9∼20 | Add bits | |
| 21∼ | Add bits | |
| Existence of Non-alphanumeric characters and capital letters | Add 6 bits | |
| A dictionary of more than 50,000 words does not contain the password | Add 6 bits | |
| Crack Time | Grade of Password Strength |
|---|---|
| ∼ | very-weak |
| ∼ | weak |
| ∼ | so-so |
| ∼ | good |
| > | great |
| Notation | Description |
|---|---|
| n | The number of words in the dictionary used |
| s | The number of plaintext slots that can be contained in a ciphertext |
| p | The maximum length of a word and a password in characters |
| L | The number of the characters in the password being checked |
| w | The number of the nullified ciphertexts of the dictionary used, |
| PW | i-th representation of a password of a plaintext form |
| d | The plaintext space in a slot is defined as . |
| t | The number of threads with which the password meter can run to execute the meter. |
| u | The minimum number of the slots that can be shifted without heavy noise increasing. |
| a rotation operation without heavy noise increasing | |
| a shift opertion that requires heavy noise increasing | |
| · | the encrypted multiplication operation |
| ⊕ | the encrypted exclusive or operation |
| S | the multiplicative depth level of a shift operation |
| b | the number of the hash tables being used |
| i-th length-strength matcher table | |
| m | The degree of the cyclotomic polynomial of binary coefficiens. |
| The l-th ciphertext of thread #j which has the hashes of the s words of from the -th to the -th order in the dictionary. The i-th hash function is used. | |
| C | a constant with all slot set by 1. |
| C | a constant with the first of each k slot set by 1. |
| C | a constant with the first slot set by 1. |
| D | [], [], ⋯, : the set of hashed dictionaries. |
| Thread[j]:A() | the function A() is invoked by the thread j, which is an independent execution unit. |
| Dictionary Checker | ||||
| Non-multithreading part | Multithreading part | |||
| Operation | Number of operations | Thread no. | Operation | Number of operations |
| XOR | XOR | |||
| Multiply | i-DRPart | Multiply | ||
| Rotate | Rotate | 0 | ||
| Frobenius | 0 | Frobenius | ||
| Shift | Shift | 0 | ||
| Composition Rule Checker | ||||
| Non-multithreading part | Multithreading part | |||
| Operation | Number of operations | Thread no. | Operation | Number of operations |
| XOR | 0 | 1 | XOR | |
| Multiply | 1 | CapitalLetter | Multiply | |
| Rotate | 0 | Rotate | ||
| Frobenius | 0 | Frobenius | 0 | |
| Shift | 0 | Shift | 1 | |
| 2 | XOR | |||
| SpecialLetter | Multiply | |||
| Rotate | ||||
| Frobenius | 0 | |||
| Shift | 2 | |||
| Length Strength Matcher | ||||
| Non-multithreading part | Multithreading part | |||
| Operation | Number of operations | Thread no. | Operation | Number of operations |
| XOR | 0 | b | XOR | p |
| Multiply | 0 | Multiply | 2 | |
| Rotate | 0 | Rotate | p | |
| Frobenius | 0 | Frobenius | 0 | |
| Shift | 0 | Shift | 3 | |
| Selector | ||||
| Non-multithreading part | Multithreading part | |||
| Operation | Number of operations | Thread no. | Operation | Number of operations |
| XOR | 12 | − | XOR | 0 |
| Multiply | 6 | Multiply | 0 | |
| Rotate | 0 | Rotate | 0 | |
| Frobenius | 0 | Frobenius | 0 | |
| Shift | 6 | Shift | 0 | |
| Param1 | Param2 | Param3 | Param4 | |
|---|---|---|---|---|
| Cyclotomic ring (m) | 28,679 = | 31,775 = | 46,063 = | 49,981 = |
| Lattice dimension () | 23,040 | 24,000 | 45,360 | 49,500 |
| Plaintext space (=) | ||||
| Number of Slots (=s) | 980 | 1200 | 1008 | 1650 |
| Security Level | 93 | 93 | 86 | 94 |
| Maximum multiplicative depth to reach the first recryption | 22 | 24 | 24 | 24 |
| u | 10 | 30 | 14 | 11 |
| b | Parameter in HElib | Dictionary Checker | Working in Parallel | Selector | Execution Time | |
|---|---|---|---|---|---|---|
| Composition Rule Checker | Length Strength Meter | |||||
| 1 | Param1 | 53 | 7 | 11 | 3 | 67 |
| Param2 | 50 | 8 | 6 | 3 | 61 | |
| Param3 | 1154 | 25 | 19 | 10 | 1189 | |
| Param4 | 348 | 34 | 30 | 12 | 394 | |
| 2 | Param1 | 108 | 7 | 8 | 3 | 119 |
| Param2 | 101 | 8 | 6 | 3 | 112 | |
| Param3 | 2318 | 25 | 19 | 10 | 2353 | |
| Param4 | 705 | 34 | 30 | 9 | 748 | |
| 3 | Param1 | 162 | 7 | 9 | 3 | 175 |
| Param2 | 153 | 7 | 6 | 3 | 175 | |
| Param3 | 3450 | 25 | 18 | 9 | 3484 | |
| Param4 | 1055 | 34 | 30 | 9 | 1098 | |
| Param1 | Param2 | Param3 | Param4 | |
|---|---|---|---|---|
| 22.149 | 21.969 | 86.516 | 94.414 | |
| 27.422 | 27.102 | 106.593 | 116.320 |
| Param1 | Param2 | Param3 | Param4 | |
|---|---|---|---|---|
| size (in MB) | 3.9 | 4.3 | 17 | 19 |
| The Proposed Method | Current Meters | |
|---|---|---|
| Protection of password candidates to be entered | O | X |
| Protection of metering results | O | X |
| Protection of dictionary D, used in the meter | O | Only if meter uses hased dictionaries or nothing. |
| Maintaining up-to-date | O | Only the on-line meters. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, P.; Lee, Y.; Hong, Y.-S.; Kwon, T. A Password Meter without Password Exposure. Sensors 2021, 21, 345. https://doi.org/10.3390/s21020345
Kim P, Lee Y, Hong Y-S, Kwon T. A Password Meter without Password Exposure. Sensors. 2021; 21(2):345. https://doi.org/10.3390/s21020345
Chicago/Turabian StyleKim, Pyung, Younho Lee, Youn-Sik Hong, and Taekyoung Kwon. 2021. "A Password Meter without Password Exposure" Sensors 21, no. 2: 345. https://doi.org/10.3390/s21020345
APA StyleKim, P., Lee, Y., Hong, Y.-S., & Kwon, T. (2021). A Password Meter without Password Exposure. Sensors, 21(2), 345. https://doi.org/10.3390/s21020345