
Gated Skip-Connection Network with Adaptive Upsampling for Retinal Vessel Segmentation



Abstract
:1. Introduction
- We propose a gated skip-connection network with adaptive upsampling (GSAU-Net) to segment retinal vessels. A gating is introduced to the skip-connection between the encoder and decoder. A gated skip-connection was designed to facilitate the flow of information from the encoder to the decoder, which can effectively remove noise and help the decoder focus on processing the detailed information;
- A simple, yet effective upsampling module is used to recover feature maps from the decoder, which replaces the data-independent bilinear interpolation used extensively in previous methods. Compared to deconvolution, it improves the performance of the model with almost no additional computational cost;
2. Methods
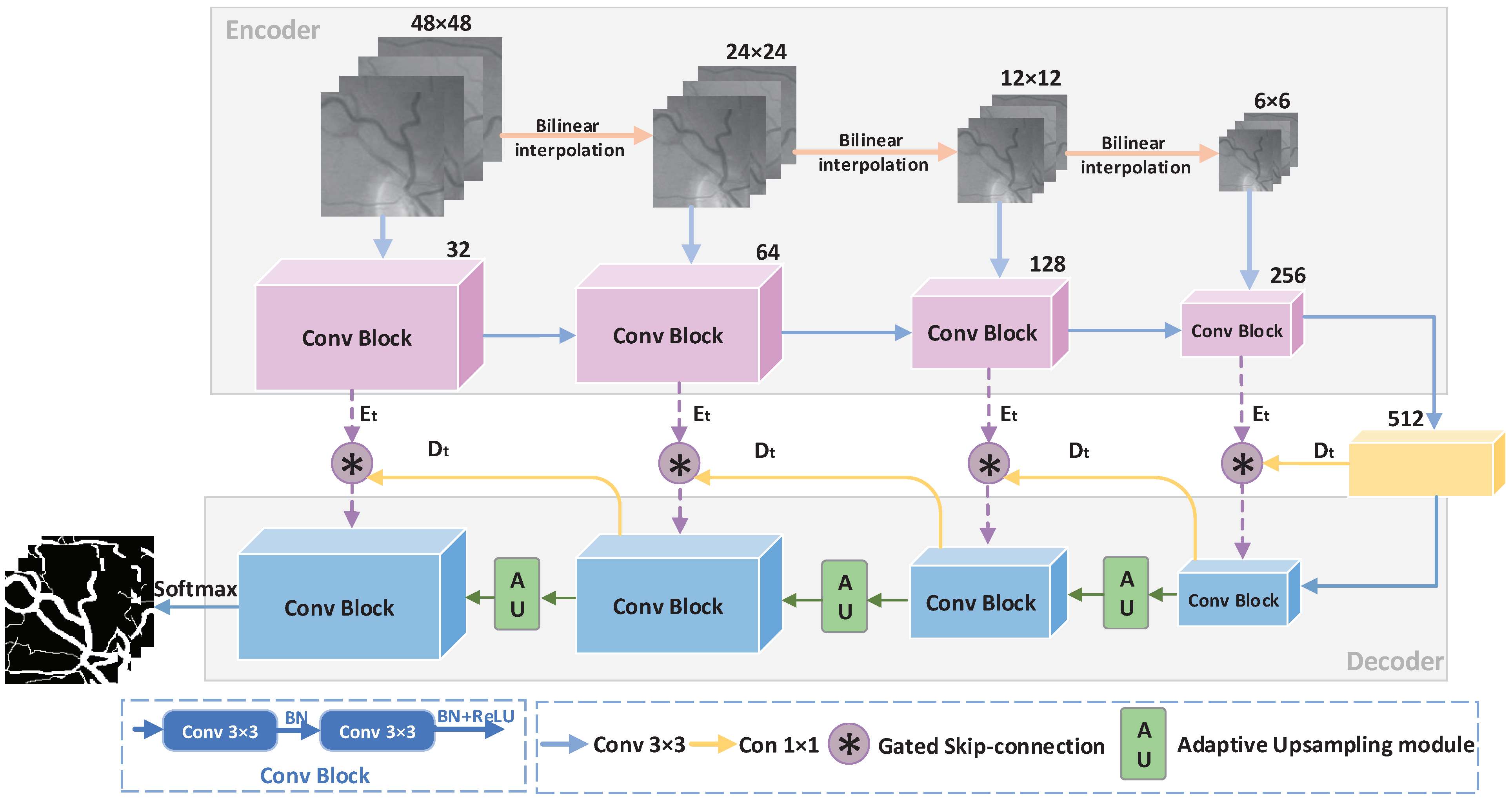
2.1. GSAU-Net Architecture
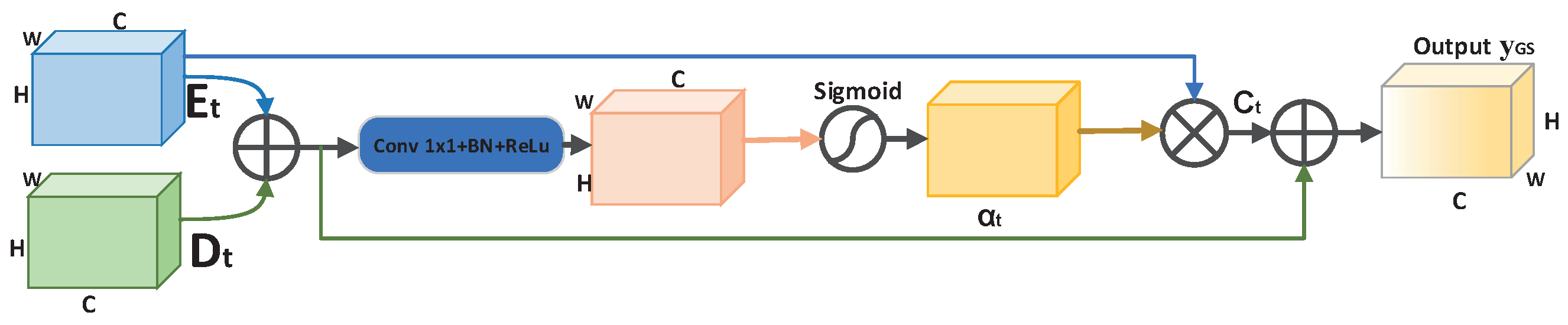
2.1.1. Gated Skip-Connection
2.1.2. Adaptive Upsampling
| Algorithm 1: Adaptive upsampling module. |
 |
3. Datasets and Evaluation
3.1. Datasets
3.2. Experimental Environment and Parameter Settings
3.3. Performance Evaluation Indicator
4. Experiment Results and Analysis
4.1. Comparison of the Results before and after Model Improvement
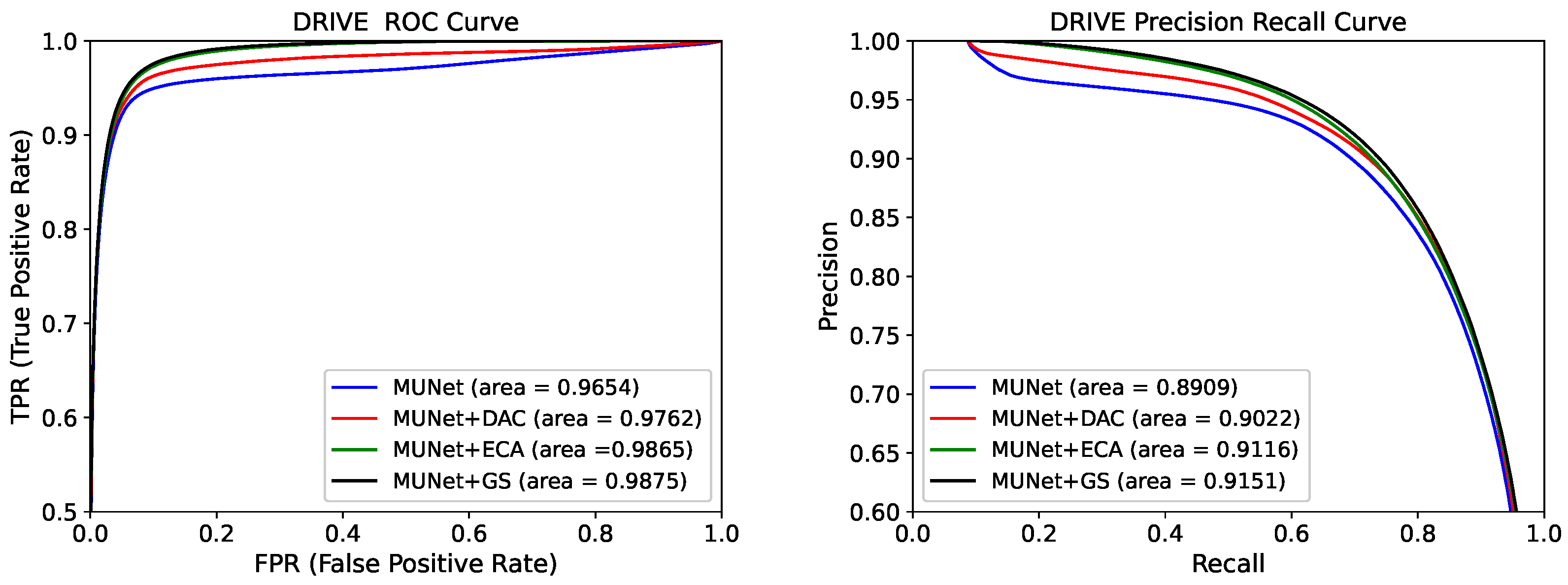
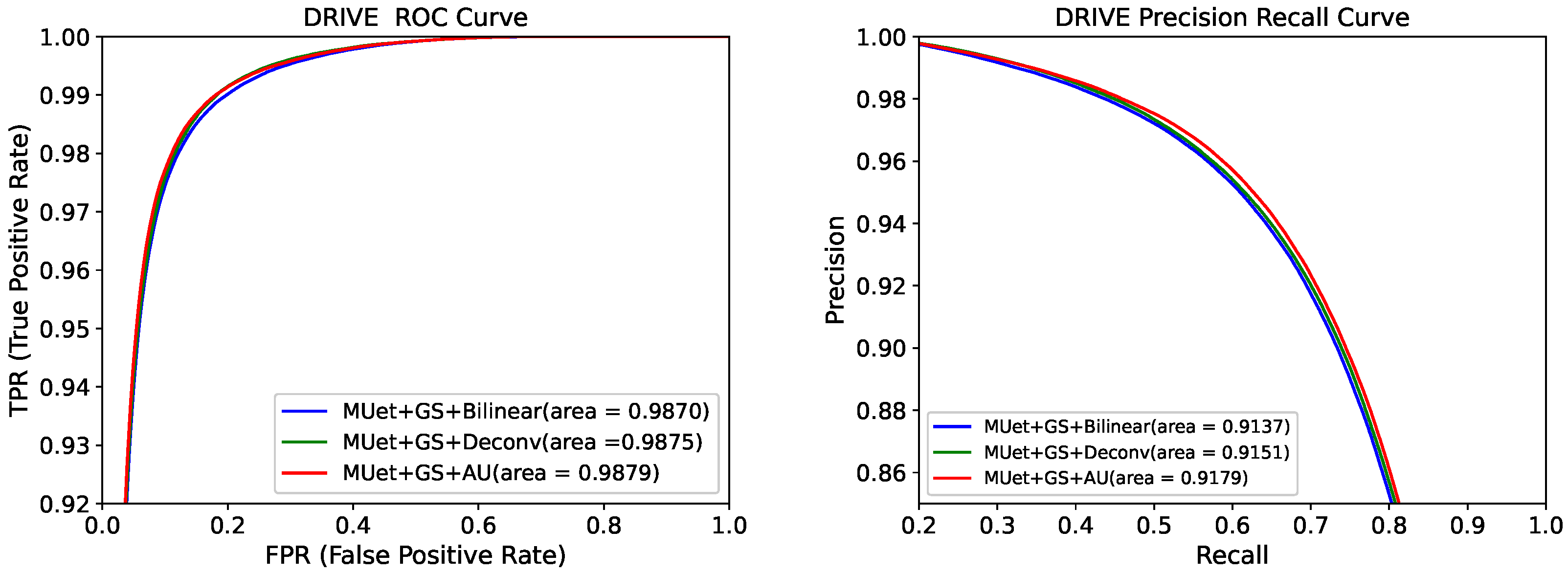
4.2. Evaluation of ROC and Precision Recall Curves before and after Model Improvement
4.3. Comparison of Segmentation Results with Different Methods
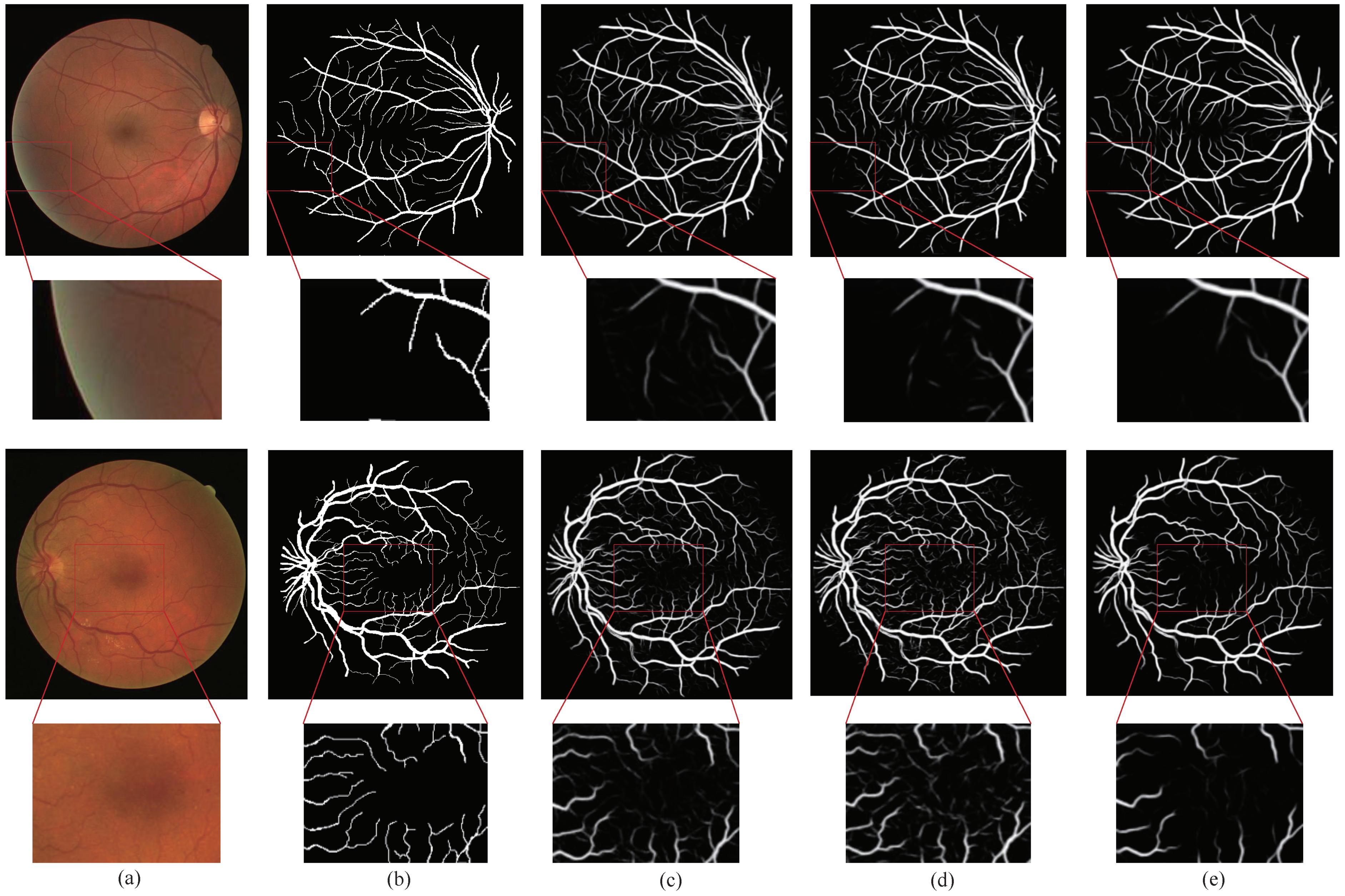
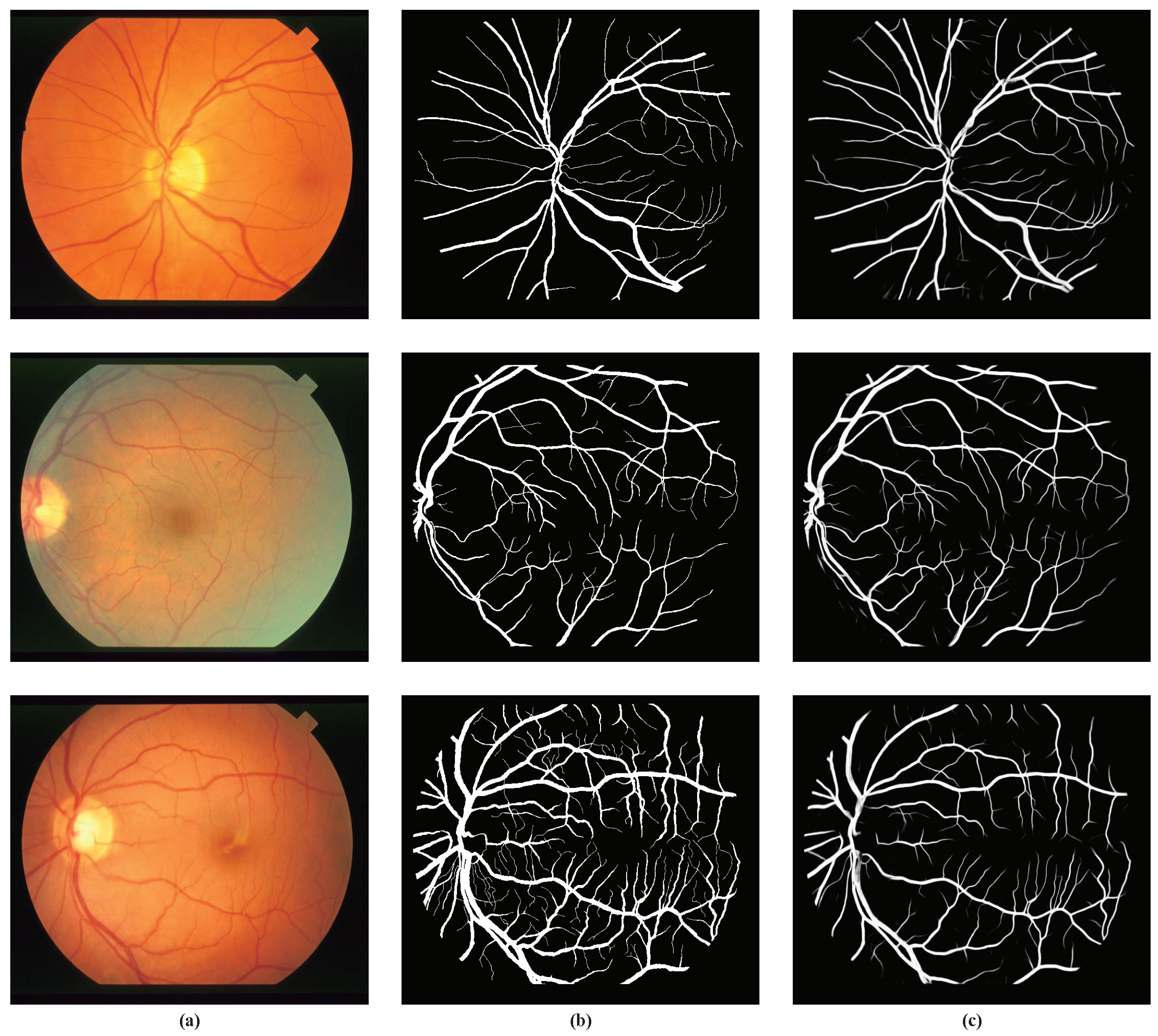
4.4. Visualization Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, H.; Wang, W.; Zhong, J.; Lei, B.; Wen, Z.; Qin, J. SCS-Net: A Scale and Context Sensitive Network for Retinal Vessel Segmentation. Med. Image Anal. 2021, 70, 102025. [Google Scholar] [CrossRef]
- Chaudhuri, S.; Chatterjee, S.; Katz, N.; Nelson, M.; Goldbaum, M. Detection of blood vessels in retinal images using two-dimensional matched filters. IEEE Trans. Med. Imaging 1989, 8, 263–269. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; You, J.; Zhang, D. Vessel segmentation and width estimation in retinal images using multiscale production of matched filter responses. Expert Syst. Appl. 2012, 39, 7600–7610. [Google Scholar] [CrossRef]
- Jaspreet, K.; Sinha, H.P. Automated Detection of Retinal Blood Vessels in Diabetic Retinopathy Using Gabor Filter. Int. J. Comput. Sci. Netw. Secur. 2012, 4, 109–116. [Google Scholar]
- Bao, X.R.; Ge, X.; She, L.H.; Zhang, S. Segmentation of retinal blood vessels based on cake filter. BioMed Res. Int. 2015, 2015, 137024. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salem, N.M.; Nandi, A.K. Segmentation of retinal blood vessels using scale-space features and K-nearest neighbour classifier. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, Toulouse, France, 14–19 May 2006. [Google Scholar]
- Carmen Alina, L.; Domenico, T.; Emanuele, T. FABC: Retinal vessel segmentation using AdaBoost. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1267–1274. [Google Scholar]
- Liu, I.; Sun, Y. Recursive tracking of vascular networks in angiograms based on the detection-deletion scheme. IEEE Trans. Med. Imaging 1993, 12, 334–341. [Google Scholar] [CrossRef] [PubMed]
- Vlachos, M.; Dermatas, E. Multi-scale retinal vessel segmentation using line tracking. Comput. Med. Imaging Graph. 2010, 34, 213–227. [Google Scholar] [CrossRef] [PubMed]
- Nayebifar, B.; Moghaddam, H.A. A novel method for retinal vessel tracking using particle filters. Comput. Biol. Med. 2013, 43, 541–548. [Google Scholar] [CrossRef] [PubMed]
- Tolias, Y.A.; Panas, S.M. A fuzzy vessel tracking algorithm for retinal images based on fuzzy clustering. IEEE Trans. Med. Imaging 1998, 17, 263–273. [Google Scholar] [CrossRef] [PubMed]
- Chutatape, O.; Zheng, L.; Krishnan, S.M. Retinal blood vessel detection and tracking by atched Gaussian and Kalman filters. In Proceedings of the 20th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Vol.20 Biomedical Engineering Towards the Year 2000 and Beyond (Cat. No.98CH36286), Hong Kong, China, 1 November 1998. [Google Scholar]
- Khalaf, A.F.; Yassine, I.A.; Fahmy, A.S. Convolutional neural networks for deep feature learning in retinal vessel segmentation. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 385–388. [Google Scholar]
- Fu, H.; Xu, Y.; Lin, S.; Wong, D.W.K.; Liu, J. Deepvessel: Retinal vessel segmentation via deep learning and conditional random field. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Cham, Seitzerland, 2016; pp. 132–139. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Seitzerland, 2015; pp. 234–241. [Google Scholar]
- Wu, Y.; Xia, Y.; Song, Y.; Zhang, D.; Liu, D.; Zhang, C.; Cai, W. Vessel-Net: Retinal vessel segmentation under multi-path supervision. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Seitzerland, 2019; pp. 264–272. [Google Scholar]
- Feng, S.; Zhuo, Z.; Pan, D.; Tian, Q. CcNet: A cross-connected convolutional network for segmenting retinal vessels using multiscale features. Neurocomputing 2020, 392, 268–276. [Google Scholar] [CrossRef]
- Zhang, S.; Fu, H.; Yan, Y.; Zhang, Y.; Wu, Q.; Yang, M.; Tan, M.; Xu, Y. Attention guided network for retinal image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Seitzerland, 2019; pp. 797–805. [Google Scholar]
- Staal, J.; Abramoff, M.; Niemeijer, M.; A Viergever, M.; Van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Owen, C.G.; Rudnicka, A.R.; Mullen, R.; Barman, S.A.; Monekosso, D.; Whincup, P.H.; Ng, J.; Paterson, C. Measuring retinal vessel tortuosity in 10-year-old children: Validation of the computer-assisted image analysis of the retina (CAIAR) program. Investig. Ophthalmol. Visual Sci. 2009, 50, 2004–2010. [Google Scholar] [CrossRef] [Green Version]
- Hoover, A.D.; Kouznetsova, V.; Goldbaum, M. Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Trans. Med. Imaging 2000, 19, 203–210. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Zhuang, J. LadderNet: Multi-path networks based on U-Net for medical image segmentation. arXiv 2018, arXiv:1810.07810. [Google Scholar]
- Jiang, Y.; Zhang, H.; Tan, N.; Chen, L. Automatic retinal blood vessel segmentation based on fully convolutional neural networks. Symmetry 2019, 11, 1112. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, E.; Du, L.; Wu, Y.; Zhu, Y.J.; Megalooikonomou, V.; Ling, H. Discriminative vessel segmentation in retinal images by fusing context-aware hybrid features. Mach. Vis. Appl. 2014, 25, 1779–1792. [Google Scholar] [CrossRef]
- Mo, J.; Zhang, L. Multi-level deep supervised networks for retinal vessel segmentation. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 2181–2193. [Google Scholar] [CrossRef] [PubMed]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Jiang, Y.; Tan, N.; Peng, T.; Zhang, H. Retinal vessels segmentation based on dilated multiscale convolutional neural network. IEEE Access 2019, 7, 76342–76352. [Google Scholar] [CrossRef]
- Lv, Y.; Ma, H.; Li, J.; Liu, S. Attention Guided U-Net With Atrous Convolution for Accurate Retinal Vessels Segmentation. IEEE Access 2020, 8, 32826–32839. [Google Scholar] [CrossRef]
- Jiang, Y.; Yao, H.; Wu, C.; Liu, W. A multiscale residual attention network for retinal vessel segmentation. Symmetry 2021, 13, 24. [Google Scholar] [CrossRef]
- Hu, J.; Wang, H.; Wang, J.; Wang, Y.; He, F.; Zhang, J. SA-Net: A scale-attention network for medical image segmentation. PLoS ONE 2021, 16, e0247388. [Google Scholar]
- Jiang, Y.; Wu, C.; Wang, G.; Yao, H.X.; Liu, W.H. MFI-Net: A multi-resolution fusion input network for retinal vessel segmentation. PLoS ONE 2021, 16, e0253056. [Google Scholar] [CrossRef] [PubMed]
- Azzopardi, G.; Strisciuglio, N.; Vento, M.; Petkov, N. Trainable COSFIRE filters for vessel delineation with application to retinal images. Med. Image Anal. 2015, 19, 46–57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miao, Y.-C.; Cheng, Y. Automatic extraction of retinal blood vessel based on matched filtering and local entropy thresholding. In Proceedings of the 2015 8th International Conference on Biomedical Engineering and Informatics (BMEI), Shenyang, China, 14–16 October 2015; pp. 62–67. [Google Scholar]
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3656–3665. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy | Sensitivity | Specificity | F-Measure | AUCROC | Params Size (MB) |
|---|---|---|---|---|---|---|
| MU-Net | 0.9686 | 0.7345 | 0.8040 | 0.9654 | ||
| MU-Net + DAC [28] | 0.9700 | 0.7770 | 0.9885 | 0.8195 | 0.9762 | 270.39 |
| MU-Net + ECA [26] | 0.9700 | 0.8116 | 0.9852 | 0.8258 | 0.9865 | 52.48 |
| MU-Net + GS (Ours) | 0.9836 | 47.98 |
| Method | Accuracy | Sensitivity | Specificity | F-Measure | AUCROC | Params Size (MB) |
|---|---|---|---|---|---|---|
| MU-Net + GS + Bilinear | 0.9706 | 0.8115 | 0.9859 | 0.8290 | 0.9870 | |
| MU-Net + GS + Deconv | 0.9701 | 0.9836 | 0.8294 | 0.9875 | 47.98 | |
| MU-Net + GS + AU (Ours) | 0.8264 | 47.97 |
| Methods | Year | Accuracy | Sensitivity | Specificity | F-Measure | AUCROC |
|---|---|---|---|---|---|---|
| FABC [7] | 2010 | 0.9597 | - | - | - | - |
| Cheng [29] | 2014 | 0.9474 | 0.7252 | 0.9798 | - | 0.9648 |
| Khalaf [13] | 2016 | 0.9456 | 0.9562 | - | - | |
| DeepVessel [14] | 2016 | 0.9523 | 0.7603 | - | - | - |
| Mo [30] | 2017 | 0.9521 | 0.7779 | 0.9780 | - | 0.9782 |
| U-Net [31] | 2018 | 0.9531 | 0.7537 | 0.9820 | 0.8142 | 0.9755 |
| Residual U-Net [31] | 2018 | 0.9553 | 0.7726 | 0.9820 | 0.8149 | 0.9779 |
| AG-Net [18] | 2019 | 0.9692 | 0.8100 | 0.9848 | - | 0.9856 |
| D-Net [32] | 2019 | 0.7839 | 0.8246 | 0.9864 | ||
| Lv [33] | 2020 | 0.9558 | 0.7854 | 0.9810 | 0.8216 | 0.9682 |
| MRA-Net [34] | 2020 | 0.9698 | 0.8353 | 0.9828 | 0.8293 | 0.9873 |
| SA-Net [35] | 2021 | 0.9569 | 0.8252 | 0.9764 | 0.8289 | 0.9822 |
| MFI-Net [36] | 2021 | 0.9705 | 0.8325 | 0.9838 | - | |
| Ours | 2021 | 0.9706 | 0.8264 | 0.9845 | 0.8313 |
| Methods | Year | Accuracy | Sensitivity | Specificity | F-Measure | AUCROC |
|---|---|---|---|---|---|---|
| Azzopardi [37] | 2015 | 0.9563 | 0.7716 | 0.9701 | - | 0.9497 |
| Deepvessel [14] | 2016 | 0.9489 | 0.7412 | - | - | - |
| U-Net [31] | 2018 | 0.9578 | 0.8288 | 0.9701 | 0.7783 | 0.9772 |
| Recurrent U-Net [31] | 2018 | 0.9622 | 0.7459 | 0.9836 | 0.7810 | 0.9803 |
| R2U-Net [31] | 2018 | 0.9634 | 0.7756 | 0.9820 | 0.7928 | 0.9815 |
| AG-Net [18] | 2019 | 0.9743 | 0.8186 | 0.9848 | - | 0.9863 |
| D-Net [32] | 2019 | 0.9721 | 0.7839 | 0.8062 | 0.9866 | |
| Lv [33] | 2020 | 0.9608 | - | - | 0.7892 | 0.9865 |
| MRA-Net [34] | 2020 | 0.9758 | 0.9854 | 0.8127 | 0.9899 | |
| MFI-Net [36] | 2021 | 0.9762 | 0.8309 | 0.9860 | - | |
| Ours | 2021 | 0.8170 | 0.9872 | 0.8140 |
| Methods | Year | Accuracy | Sensitivity | Specificity | F-Measure | AUCROC |
|---|---|---|---|---|---|---|
| Azzopardi [37] | 2015 | 0.9497 | 0.7716 | 0.9701 | - | 0.9497 |
| Miao et al. [38] | 2015 | 0.9532 | 0.7298 | 0.9831 | - | - |
| DeepVessel [14] | 2016 | 0.9489 | 0.7130 | - | - | - |
| Mo et al. [30] | 2017 | 0.9674 | 0.8147 | 0.9844 | - | 0.9885 |
| U-Net [31] | 2018 | 0.9690 | 0.8270 | 0.9842 | 0.8373 | 0.9898 |
| IterNet [39] | 2019 | 0.9701 | 0.7715 | 0.9886 | 0.8146 | 0.9881 |
| D-Net [32] | 2019 | 0.8249 | ||||
| Lv [33] | 2020 | 0.9640 | - | - | 0.8142 | 0.9719 |
| MRA-Net [34] | 2020 | 0.9763 | 0.8422 | 0.9873 | 0.8422 | 0.9918 |
| MFI-Net [36] | 2021 | 0.9766 | 0.9859 | 0.8483 | - | |
| Ours | 2021 | 0.9771 | 0.8535 | 0.9872 | 0.8484 | 0.9923 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Yao, H.; Tao, S.; Liang, J. Gated Skip-Connection Network with Adaptive Upsampling for Retinal Vessel Segmentation. Sensors 2021, 21, 6177. https://doi.org/10.3390/s21186177
Jiang Y, Yao H, Tao S, Liang J. Gated Skip-Connection Network with Adaptive Upsampling for Retinal Vessel Segmentation. Sensors. 2021; 21(18):6177. https://doi.org/10.3390/s21186177
Chicago/Turabian StyleJiang, Yun, Huixia Yao, Shengxin Tao, and Jing Liang. 2021. "Gated Skip-Connection Network with Adaptive Upsampling for Retinal Vessel Segmentation" Sensors 21, no. 18: 6177. https://doi.org/10.3390/s21186177
APA StyleJiang, Y., Yao, H., Tao, S., & Liang, J. (2021). Gated Skip-Connection Network with Adaptive Upsampling for Retinal Vessel Segmentation. Sensors, 21(18), 6177. https://doi.org/10.3390/s21186177