
Boosting Intelligent Data Analysis in Smart Sensors by Integrating Knowledge and Machine Learning

 , , , ,
, , , ,  and
and 
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
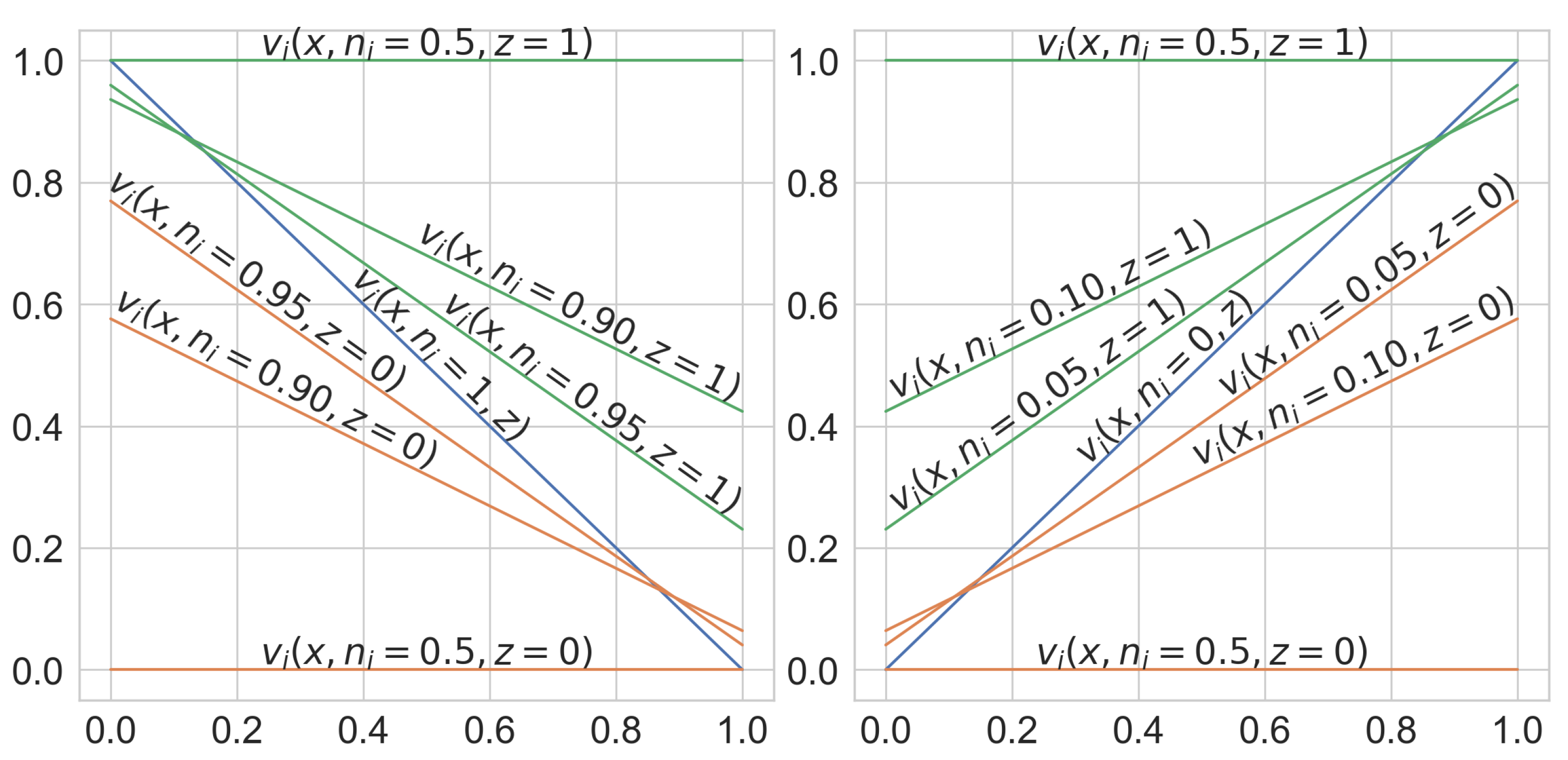
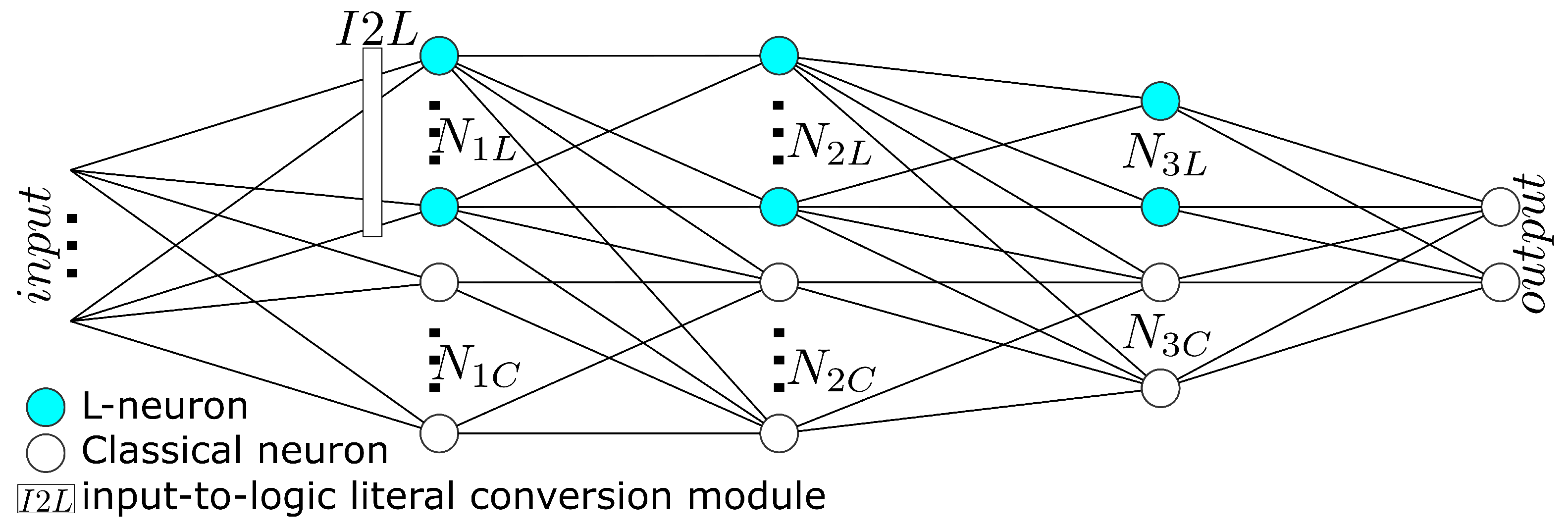
3.1. L-Neuron
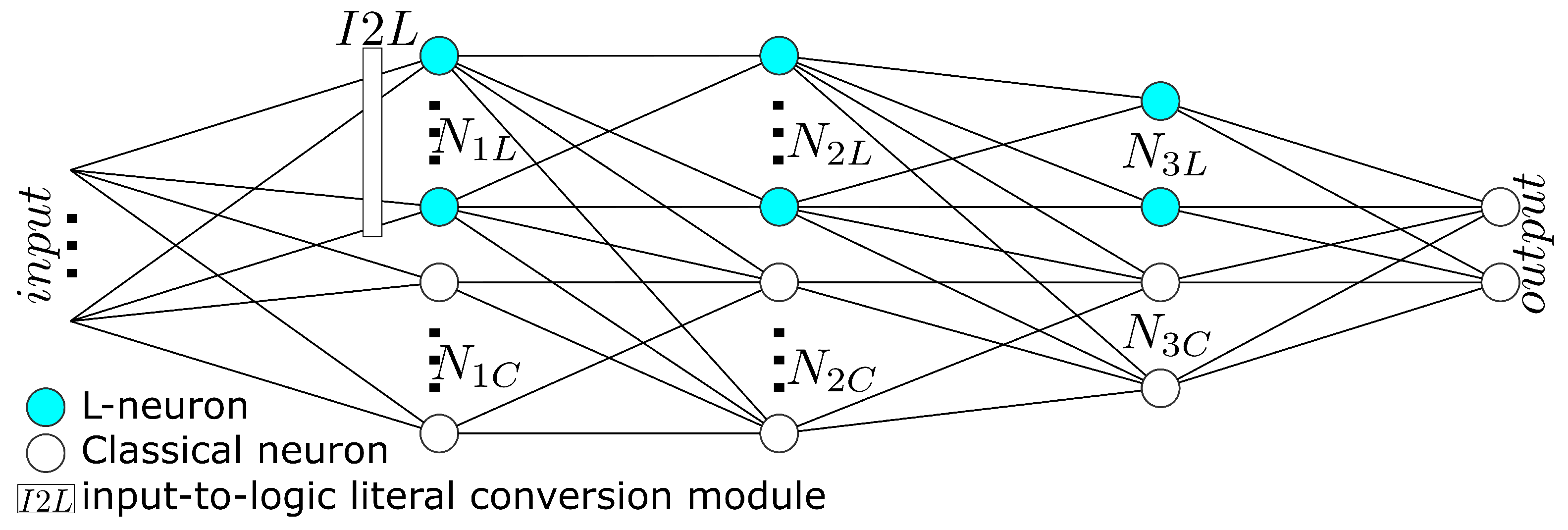
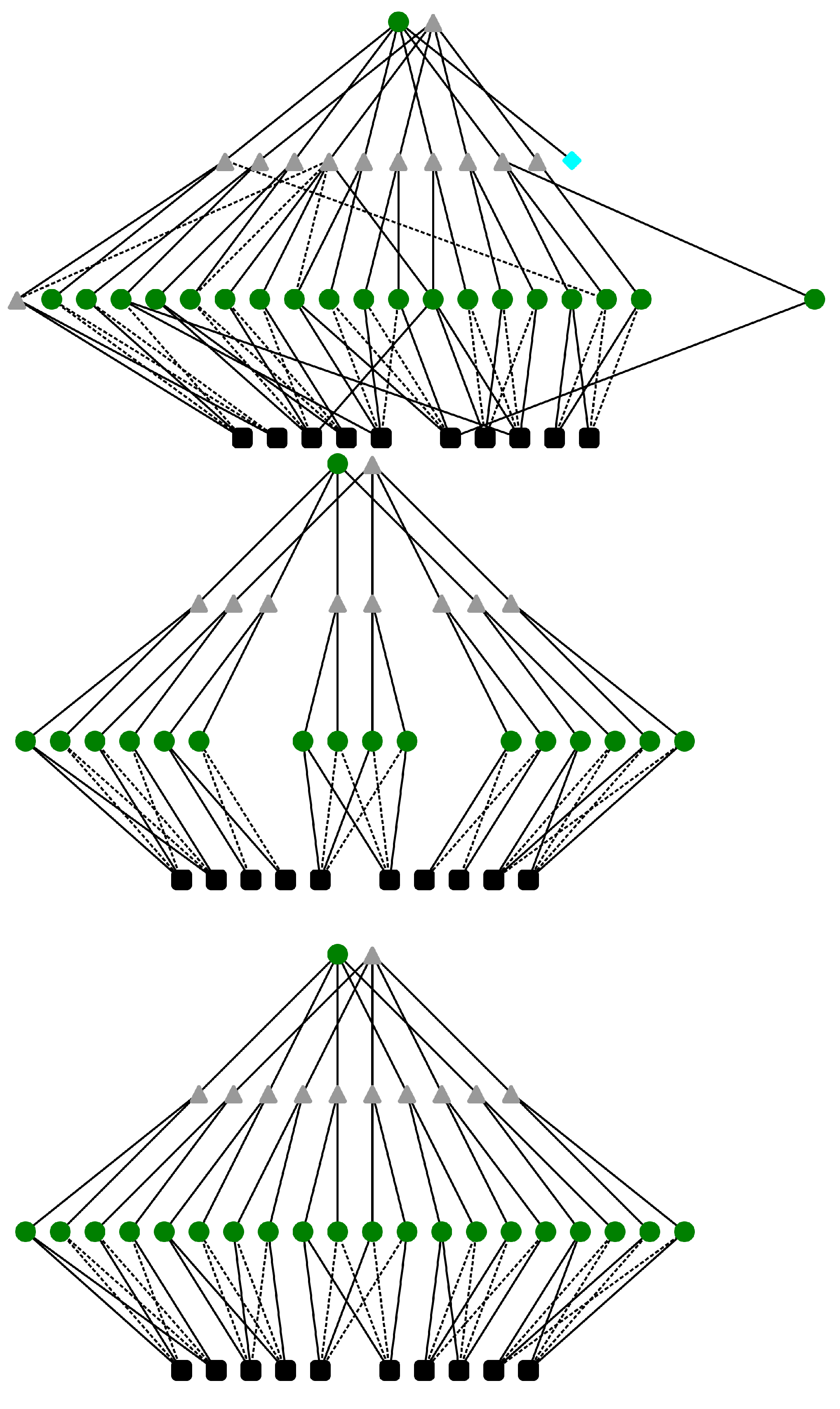
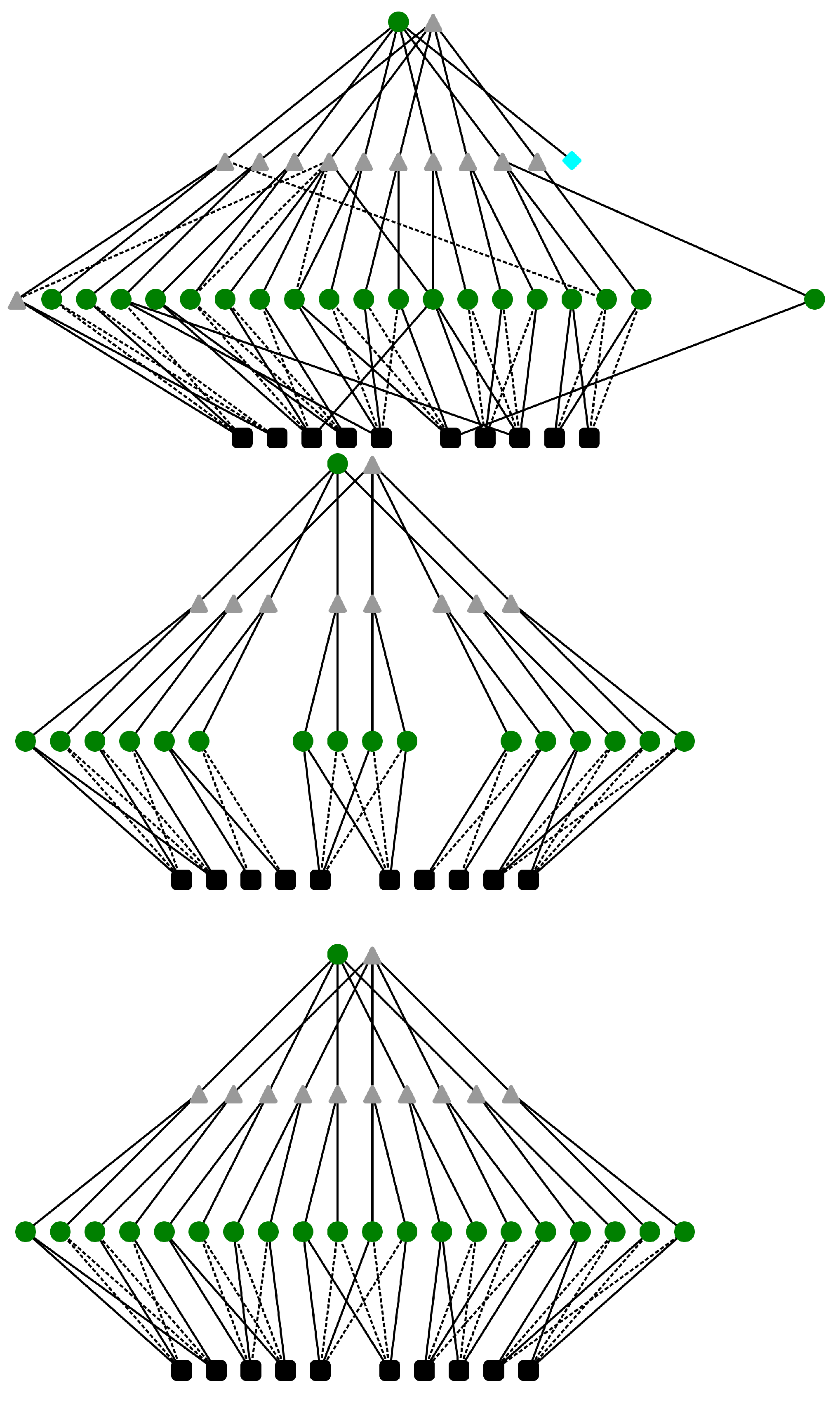
3.2. Proposed Network Architecture
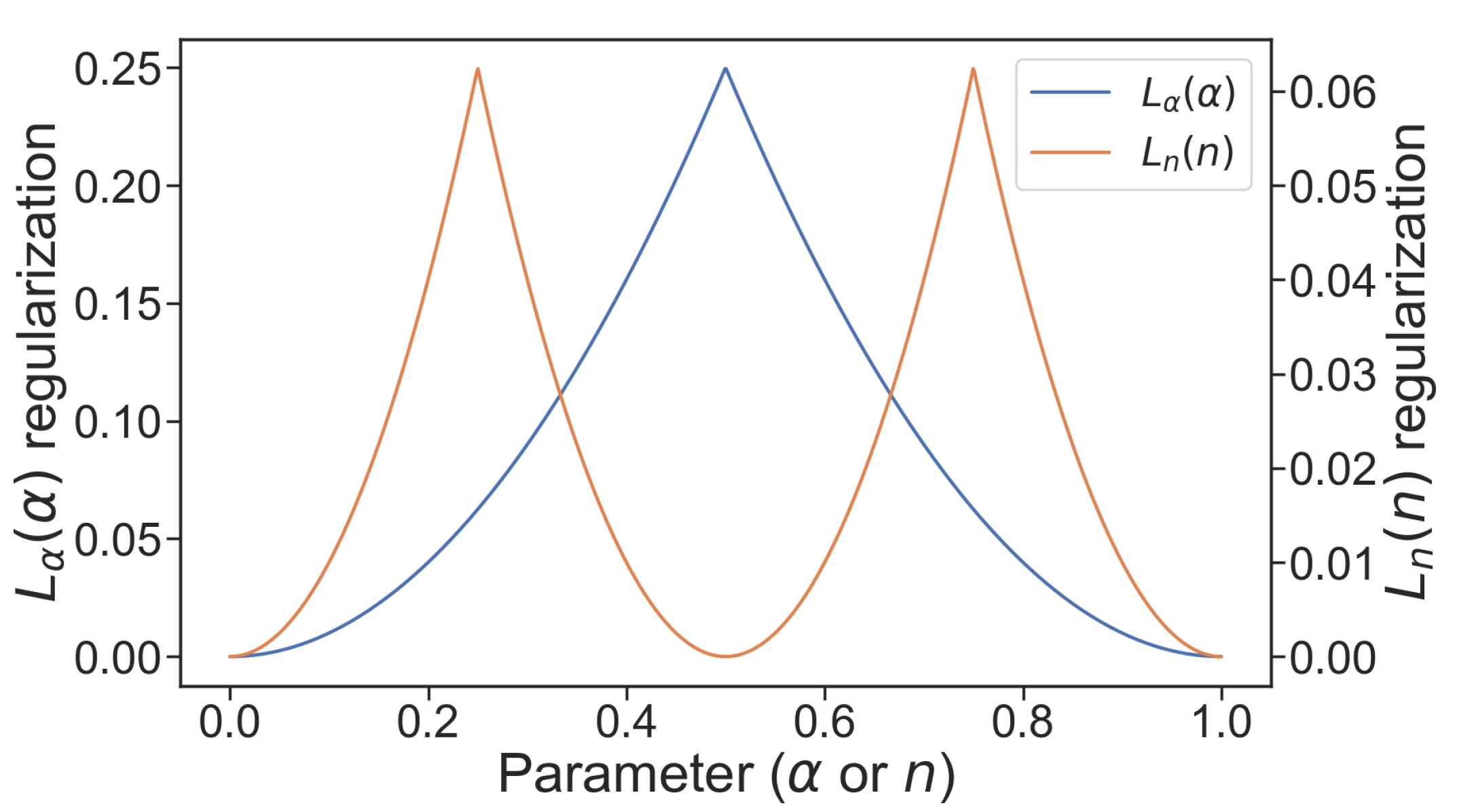
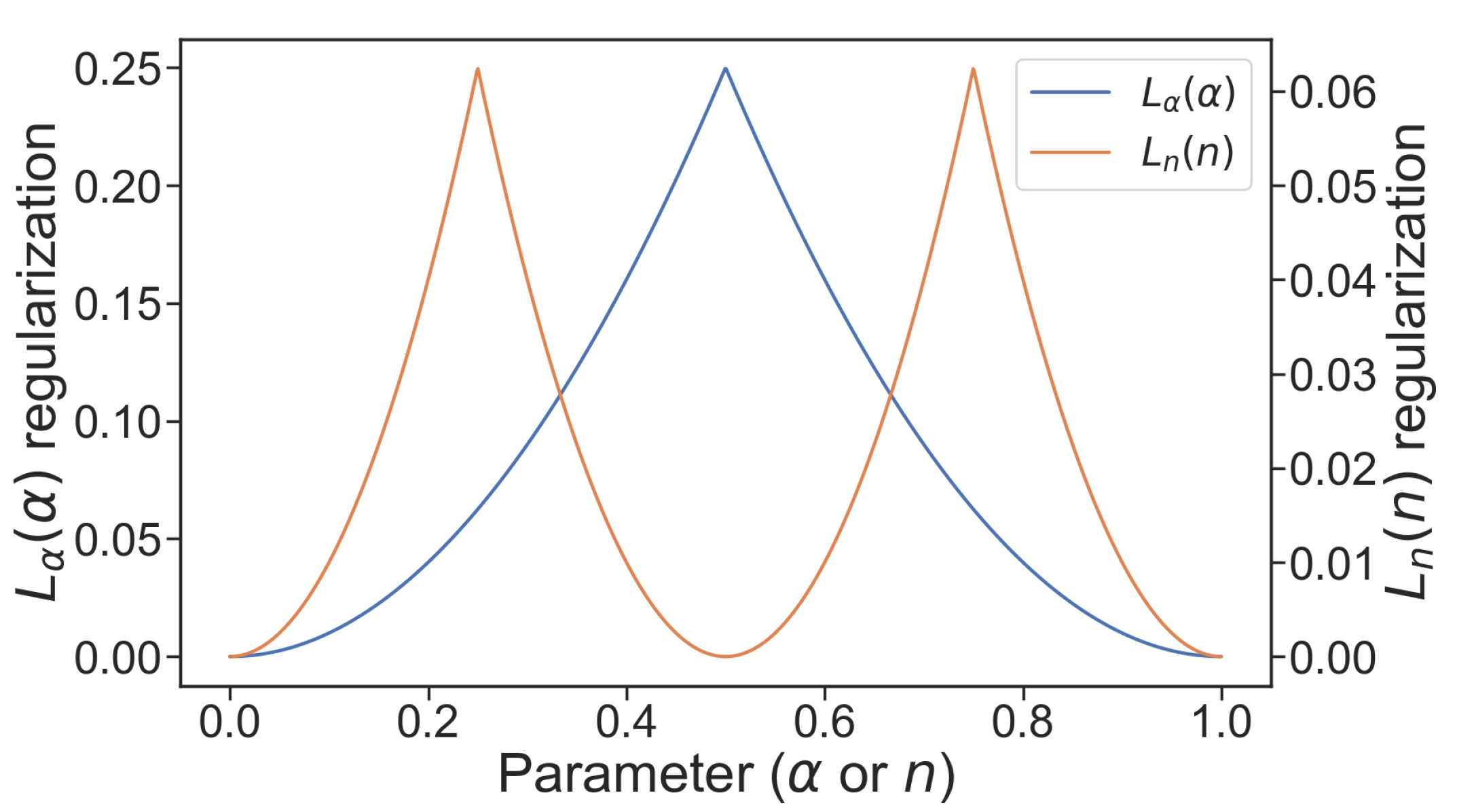
3.3. Loss
3.4. Experimental Evaluation
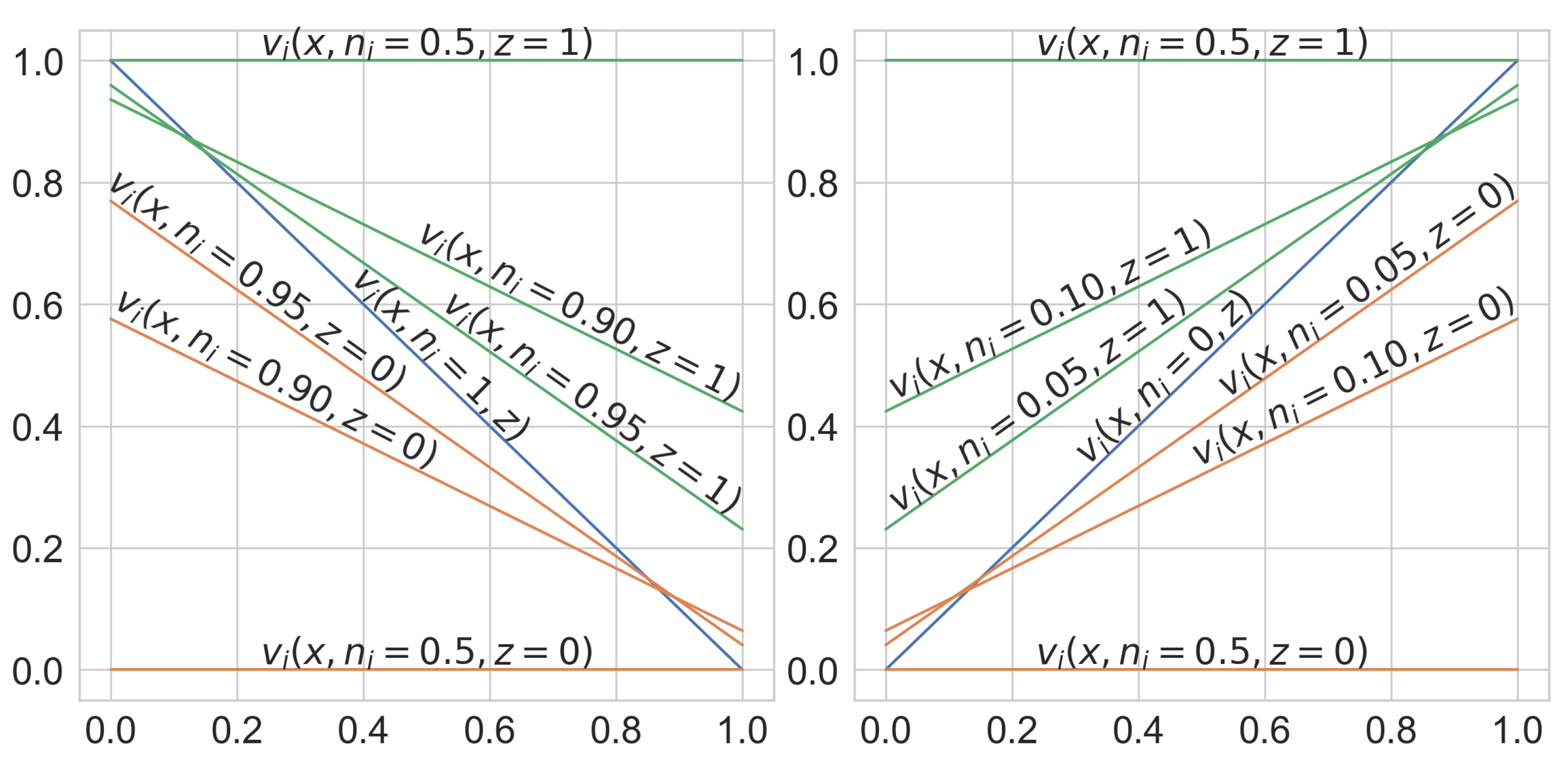
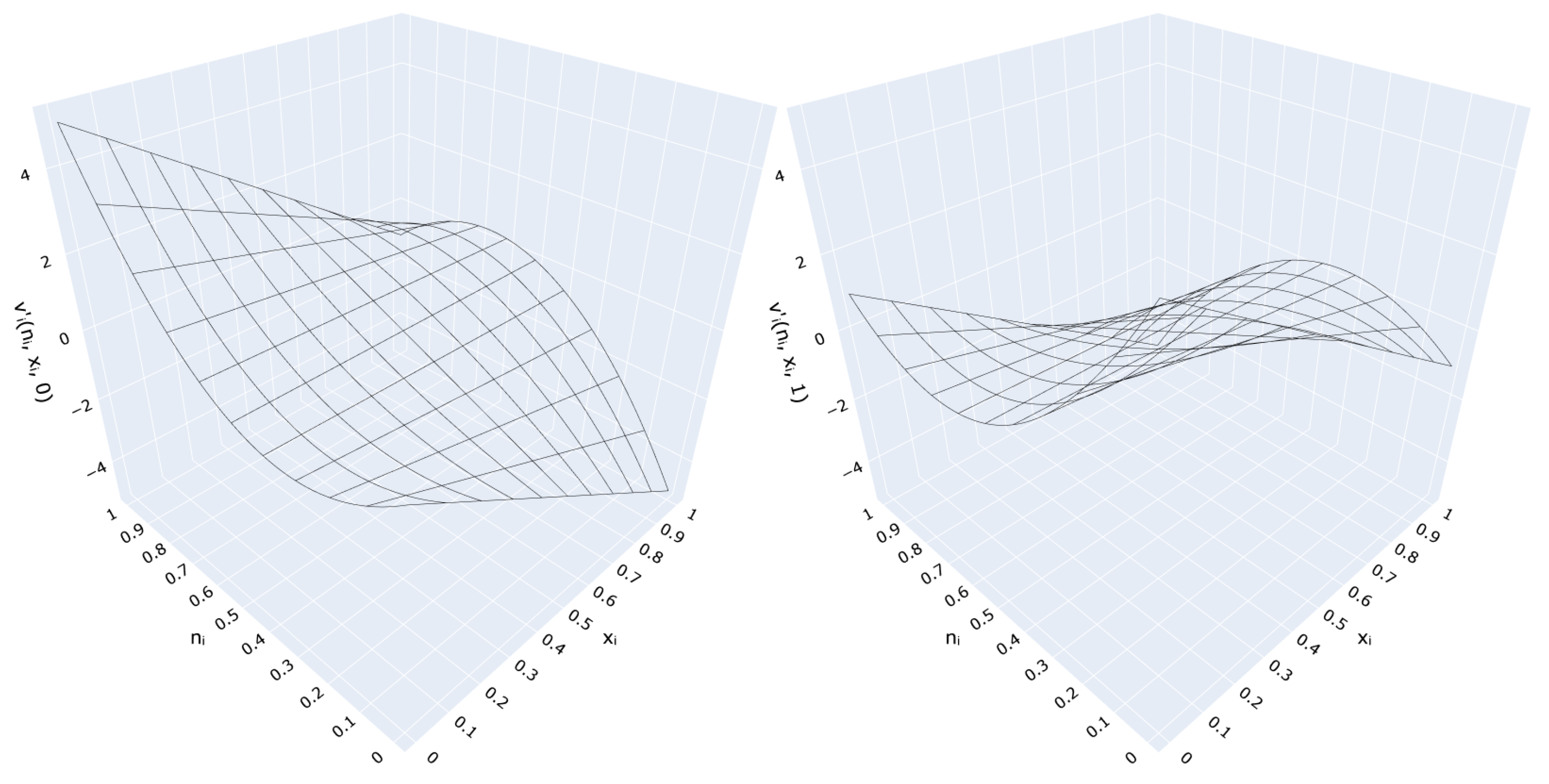
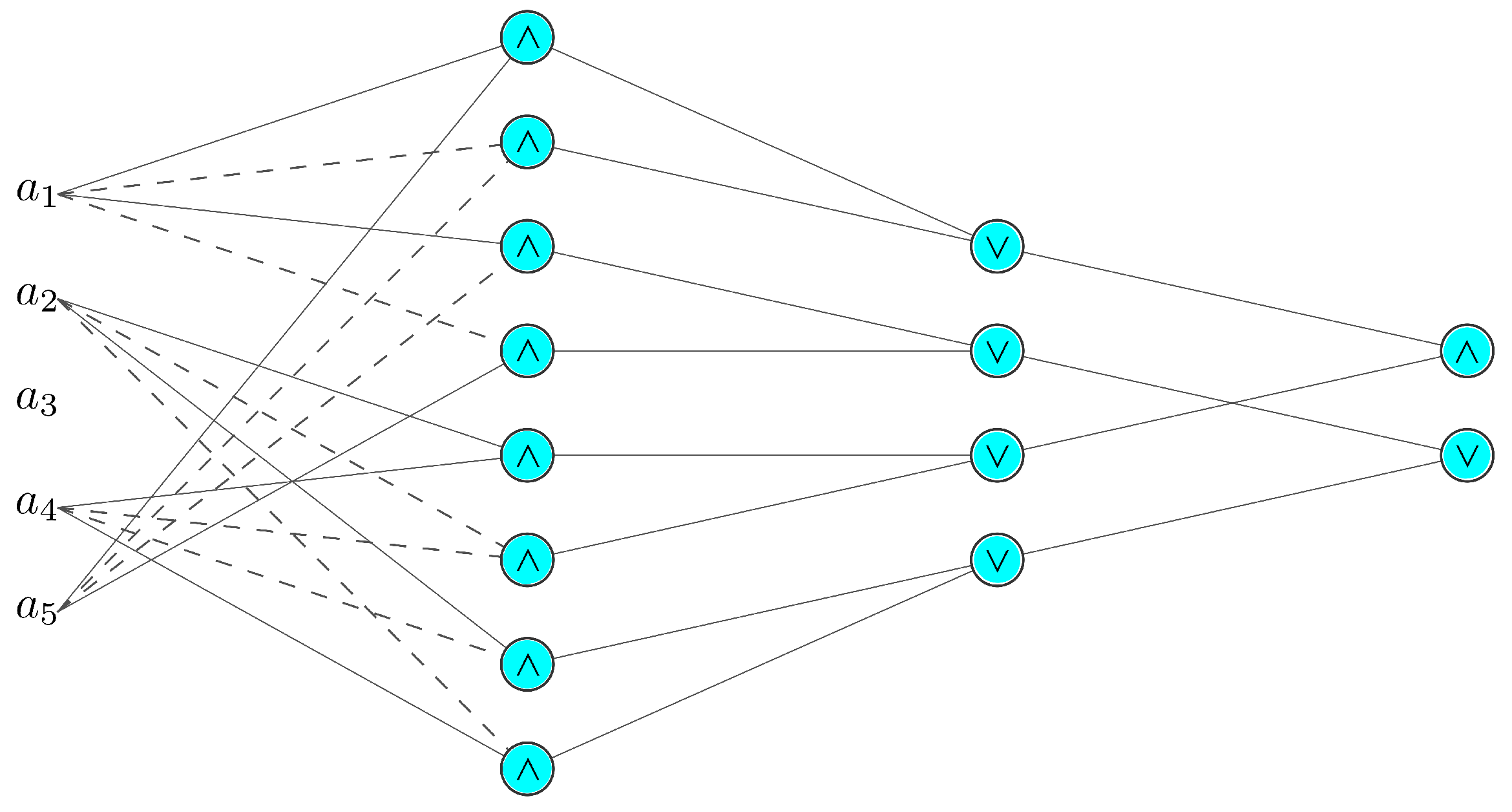
3.4.1. Mapping Knowledge Structure onto L-Neurons
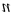 symbol is used to denote the symmetric bit in the string, that is
symbol is used to denote the symmetric bit in the string, that is 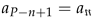 ):
): 

3.4.2. Metrics
3.4.3. Training Configurations
3.4.4. Model Structure
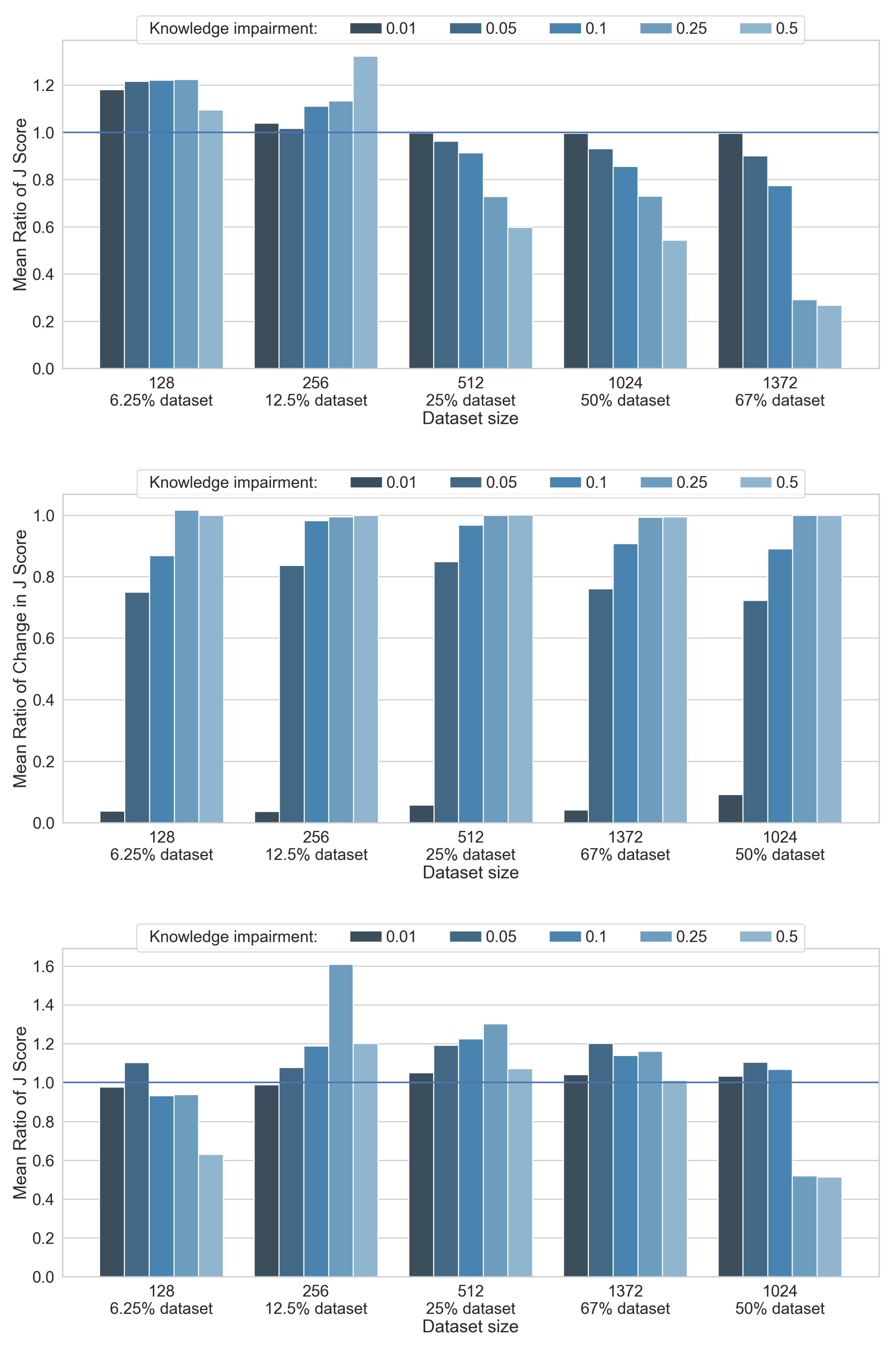
4. Results and Discussion
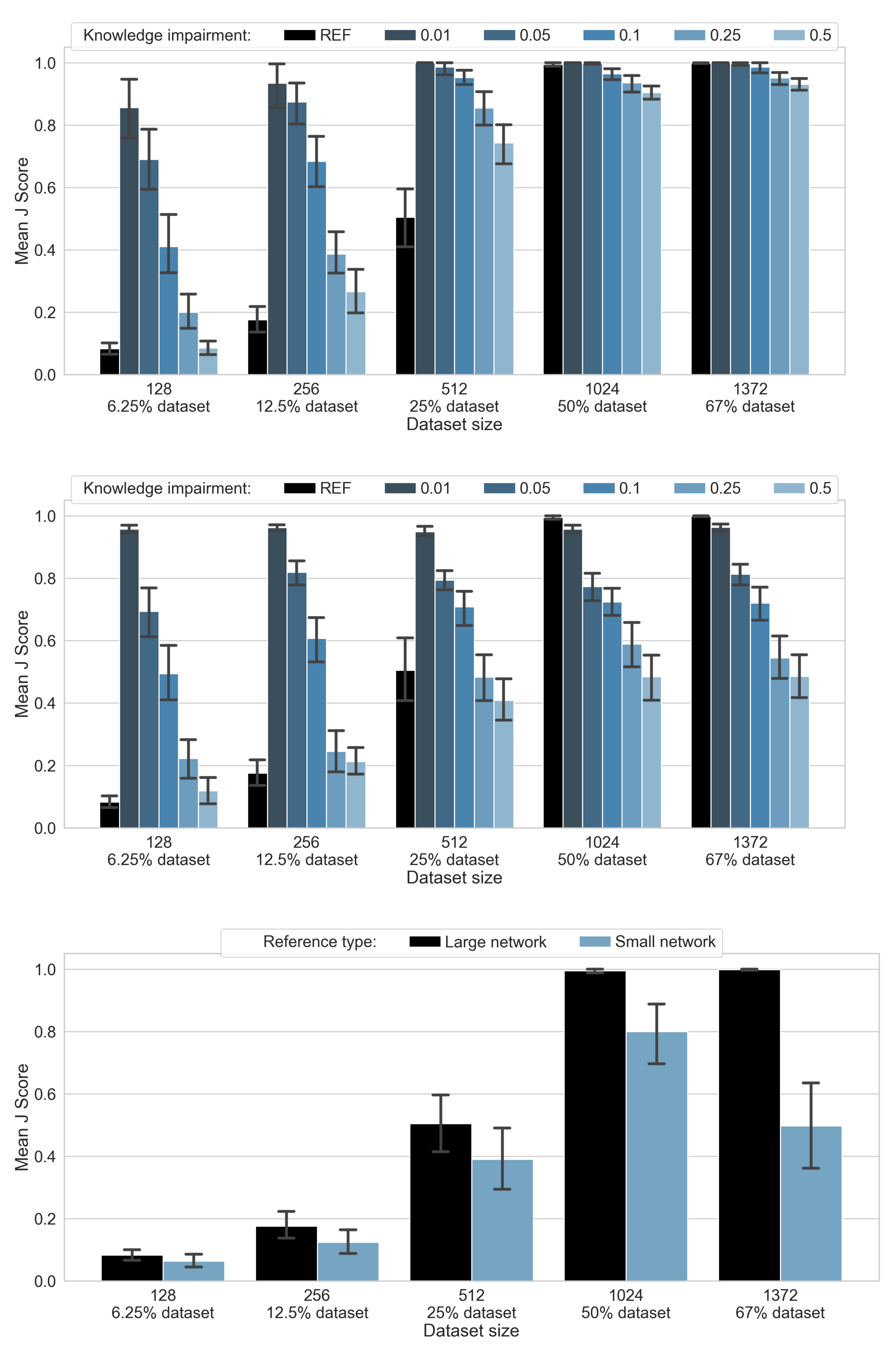
4.1. L-Neuron Network Evaluation
4.2. Knowledge Repair
4.3. Hybrid Network Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hernandez, D.; Brown, T.B. Measuring the Algorithmic Efficiency of Neural Networks. arXiv 2020, arXiv:2005.04305. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go through Self-Play. Science 2018, 6419, 1140–1144. [Google Scholar] [CrossRef] [Green Version]
- Senior, A.W.; Evans, R.; Jumper, J.; Kirkpatrick, J.; Sifre, L.; Green, T.; Qin, C.; Žídek, A.; Nelson, A.W.R.; Bridgland, A.; et al. Improved Protein Structure Prediction Using Potentials from Deep Learning. Nature 2020, 577, 706–710. [Google Scholar] [CrossRef]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly Accurate Protein Structure Prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete Problems in AI Safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Lillicrap, T.P.; Kording, K.P. What Does It Mean to Understand a Neural Network? arXiv 2019, arXiv:1907.06374. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. Inf. Fusion 2019, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Gerke, S.; Babic, B.; Evgeniou, T.; Cohen, I.G. The Need for a System View to Regulate Artificial Intelligence/Machine Learning-Based Software as Medical Device. NPJ Digit. Med. 2020, 3, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Hu, S.; Alexandropoulos, G.C.; Zappone, A.; Yuen, C.; Zhang, R.; Renzo, M.D.; Debbah, M. Holographic MIMO Surfaces for 6G Wireless Networks: Opportunities, Challenges, and Trends. IEEE Wirel. Commun. 2020, 27, 118–125. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by Superpositions of a Sigmoidal Function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Kolmogorov, A. On the Representation of Continuous Functions of Several Variables by Superpositions of Continuous Functions of Lesser Variable Count. Dokl. Akad. Nauk SSSR 1956, 108, 2. [Google Scholar]
- Arnold, V.I. On Functions of Three Variables. In Doklady Akademii Nauk; Russian Academy of Sciences: Moscow, Russia, 1957; Volume 114, pp. 679–681. [Google Scholar]
- Gori, M. Machine Learning: A Constraint-Based Approach; Morgan Kaufmann: Burlington, MA, USA, 2017. [Google Scholar]
- Roychowdhury, S.; Diligenti, M.; Gori, M. Image Classification Using Deep Learning and Prior Knowledge. In Proceedings of the Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 336–342. [Google Scholar]
- Towell, G.G.; Shavlik, J.W. Knowledge-Based Artificial Neural Networks. Artif. Intell. 1994, 70, 119–165. [Google Scholar] [CrossRef]
- Gaier, A.; Ha, D. Weight Agnostic Neural Networks. In Proceedings of the NeurIPS 2019: Thirty-Third Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5364–5378. [Google Scholar]
- Shavlik, J.W.; Towell, G.G. An Approach to Combining Explanation-Based and Neural Learning Algorithms. Connect. Sci. 1989, 1, 231–253. [Google Scholar] [CrossRef]
- Towell, G.G.; Shavlik, J.W. Extracting Refined Rules from Knowledge-Based Neural Networks. Mach. Learn. 1993, 13, 71–101. [Google Scholar] [CrossRef] [Green Version]
- Riegel, R.; Gray, A.; Luus, F.; Khan, N.; Makondo, N.; Akhalwaya, I.Y.; Qian, H.; Fagin, R.; Barahona, F.; Sharma, U.; et al. Logical Neural Networks. arXiv 2020, arXiv:2006.13155. [Google Scholar]
- Marra, G.; Diligenti, M.; Giannini, F.; Gori, M.; Maggini, M. Relational Neural Machines. arXiv 2020, arXiv:2002.02193. [Google Scholar]
- Chen, D.; Bai, Y.; Zhao, W.; Ament, S.; Gregoire, J.; Gomes, C. Deep Reasoning Networks for Unsupervised Pattern De-Mixing with Constraint Reasoning. Proc. Mach. Learn. Res. 2020, 119, 1500–1509. [Google Scholar]
- Herrmann, C.; Thier, A. Backpropagation for Neural DNF- and CNF-Networks. Knowl. Represent. Neural Networks 1996, 63–72. [Google Scholar]
- Koh, P.W.; Nguyen, T.; Tang, Y.S.; Mussmann, S.; Pierson, E.; Kim, B.; Liang, P. Concept Bottleneck Models. Proc. Mach. Learn. Res. 2020, 119, 5338–5348. [Google Scholar]
- Stanley, K.O.; Miikkulainen, R. Evolving Neural Networks through Augmenting Topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.W.; Donti, P.L.; Wilder, B.; Kolter, Z. SATNet: Bridging Deep Learning and Logical Reasoning Using a Differentiable Satisfiability Solver. arXiv 2019, arXiv:1905.12149. [Google Scholar]
- Jang, J.S. ANFIS: Adaptive-Network-Based Fuzzy Inference System. IEEE Trans. Syst. Man. Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Czogala, E.; Leski, J. Fuzzy and Neuro-Fuzzy Intelligent Systems; Physica-Verlag HD: Heidelberg, Germany, 2000; Volume 47. [Google Scholar] [CrossRef]
- Yager, R.R.; Rybalov, A. Uninorm Aggregation Operators. Fuzzy Sets Syst. 1996, 80, 111–120. [Google Scholar] [CrossRef]
- Cao, X.; Yang, B.; Huang, C.; Yuen, C.; Di Renzo, M.; Han, Z.; Niyato, D.; Poor, H.V.; Hanzo, L. AI-Assisted MAC for Reconfigurable Intelligent-Surface-Aided Wireless Networks: Challenges and Opportunities. IEEE Commun. Mag. 2021, 59, 21–27. [Google Scholar] [CrossRef]
- Ng, A.Y. Feature Selection, L1 vs. L2 Regularization, and Rotational Invariance. In Proceedings of the Twenty-First International Conference on Machine Learning; Association for Computing Machinery: New York, NY, USA, 2004; p. 78. [Google Scholar] [CrossRef] [Green Version]
- Halevy, A.; Norvig, P.; Pereira, F. The Unreasonable Effectiveness of Data. IEEE Intell. Syst. 2009, 24, 8–12. [Google Scholar] [CrossRef]
- Banko, M.; Brill, E. Scaling to Very Very Large Corpora for Natural Language Disambiguation. In Proceedings of the 39th Annual Meeting on Association for Computational Linguistics, ACL ’01, Toulouse, France, 6–11 July 2001; Association for Computational Linguistics: Stroudsburg, PA, USA, 2001; pp. 26–33. [Google Scholar] [CrossRef] [Green Version]
- Mosley, L. A Balanced Approach to the Multi-Class Imbalance Problem. Ph.D. Thesis, Iowa State University, Ames, IA, USA, 2013. [Google Scholar] [CrossRef]
- Youden, W.J. Index for Rating Diagnostic Tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Farrar, Straus and Giroux: New York, NY, USA, 2011. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ki = 0.01 | ki = 0.05 | ki = 0.1 | ki = 0.25 | ki = 0.5 | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (1) | 128 | 256 | 512 | 1024 | 1372 | 128 | 256 | 512 | 1024 | 1372 | 128 | 256 | 512 | 1024 | 1372 | 128 | 256 | 512 | 1024 | 1372 | 128 | 256 | 512 | 1024 | 1372 |
| L-neuron-only | |||||||||||||||||||||||||
| (2) | 0.96 | 0.96 | 0.95 | 0.96 | 0.96 | 0.69 | 0.82 | 0.79 | 0.77 | 0.81 | 0.49 | 0.61 | 0.71 | 0.72 | 0.72 | 0.22 | 0.25 | 0.48 | 0.59 | 0.54 | 0.11 | 0.20 | 0.41 | 0.48 | 0.49 |
| (3) | 0.87 | 0.79 | 0.45 | −0.04 | −0.04 | 0.61 | 0.64 | 0.29 | −0.22 | −0.19 | 0.41 | 0.43 | 0.20 | −0.27 | −0.28 | 0.14 | 0.07 | −0.02 | −0.41 | −0.45 | 0.03 | 0.02 | −0.10 | −0.51 | −0.51 |
| Hybrid | |||||||||||||||||||||||||
| (2) | 0.83 | 0.94 | 1 | 1 | 1 | 0.69 | 0.87 | 0.99 | 1 | 1 | 0.41 | 0.68 | 0.95 | 0.97 | 0.99 | 0.19 | 0.39 | 0.86 | 0.94 | 0.95 | 0.08 | 0.24 | 0.74 | 0.91 | 0.93 |
| (3) | 0.74 | 0.76 | 0.50 | 0.01 | 0 | 0.61 | 0.70 | 0.48 | 0 | 0 | 0.33 | 0.51 | 0.45 | −0.03 | −0.01 | 0.11 | 0.21 | 0.35 | −0.06 | −0.05 | −0.01 | 0.06 | 0.24 | −0.09 | −0.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Łuczak, P.; Kucharski, P.; Jaworski, T.; Perenc, I.; Ślot, K.; Kucharski, J. Boosting Intelligent Data Analysis in Smart Sensors by Integrating Knowledge and Machine Learning. Sensors 2021, 21, 6168. https://doi.org/10.3390/s21186168
Łuczak P, Kucharski P, Jaworski T, Perenc I, Ślot K, Kucharski J. Boosting Intelligent Data Analysis in Smart Sensors by Integrating Knowledge and Machine Learning. Sensors. 2021; 21(18):6168. https://doi.org/10.3390/s21186168
Chicago/Turabian StyleŁuczak, Piotr, Przemysław Kucharski, Tomasz Jaworski, Izabela Perenc, Krzysztof Ślot, and Jacek Kucharski. 2021. "Boosting Intelligent Data Analysis in Smart Sensors by Integrating Knowledge and Machine Learning" Sensors 21, no. 18: 6168. https://doi.org/10.3390/s21186168
APA StyleŁuczak, P., Kucharski, P., Jaworski, T., Perenc, I., Ślot, K., & Kucharski, J. (2021). Boosting Intelligent Data Analysis in Smart Sensors by Integrating Knowledge and Machine Learning. Sensors, 21(18), 6168. https://doi.org/10.3390/s21186168