
Lightweight Detection Network Based on Sub-Pixel Convolution and Objectness-Aware Structure for UAV Images

Abstract
:1. Introduction
- (1)
- The paper proposes a lightweight as well as anchor-free framework for UAV images, which efficiently reduces the time of computation and the memory consumption. The framework fits better for performing real-time detection in resource-constrained scenarios.
- (2)
- We introduce sub-pixel convolution to the small object detection and draw the support of a sub-pixel convolution structure to develop a simultaneous upsampling and detection module. The module implements upsampling and detection together using one convolutional layer that improves the efficiency and without reducing detection accuracy.
- (3)
- We add a novel objectness branch to the detection head. The additional supervision in the form of objectness makes the model develop more robust feature representations and perform better in detection.
2. Related Work
2.1. General Object Detection
2.2. Object Detection in UAV Images
3. Materials and Methods
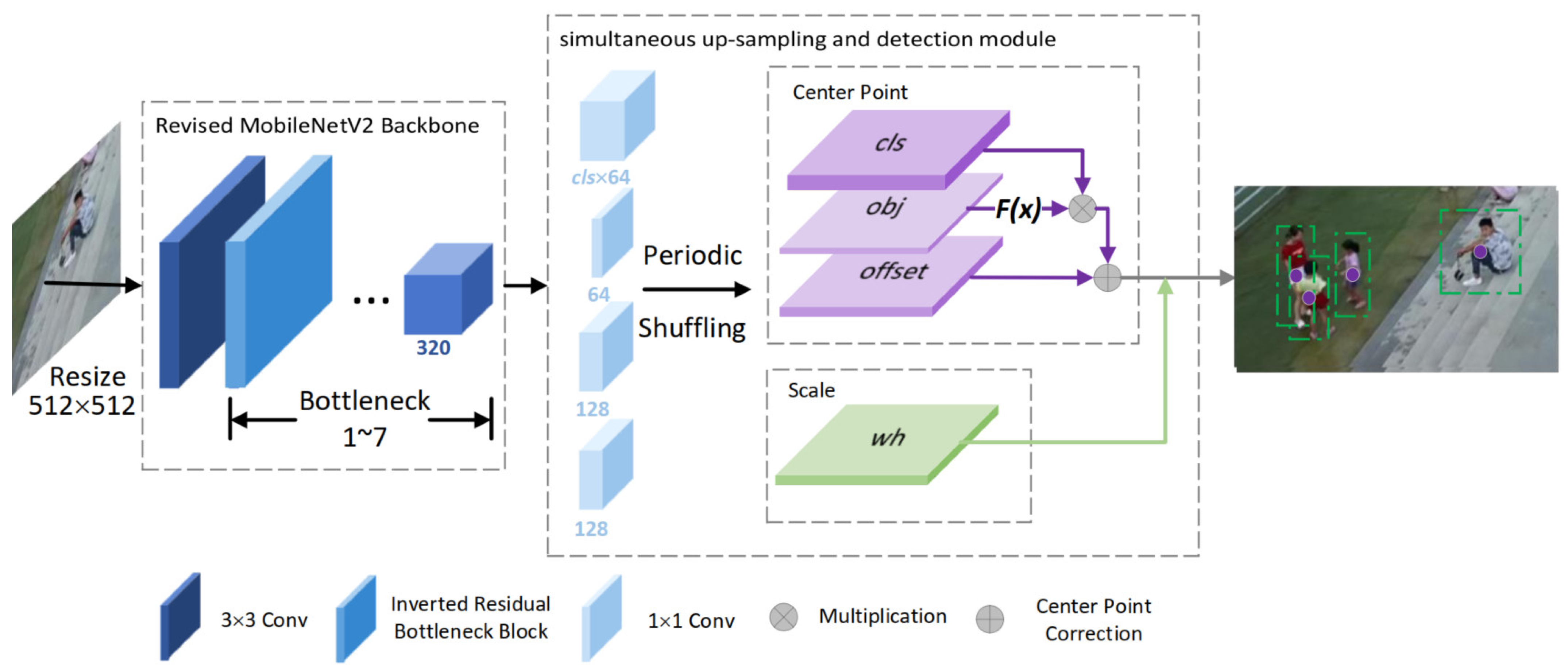
3.1. Overall Architecture
3.2. Lightweight Feature Extractor
3.3. Simultaneous Up-Sampling and Detection Module
3.4. Objectness Branch
3.5. Loss Function
3.6. Experiment
3.6.1. Datasets
- (1)
- Visdrone-2018-VIDThe Visdrone-2018-VID dataset [40] contains 96 video clips taken by the drone with resolutions varies from 1344 × 756 to 3840 × 2160. The training set contains 56 clips, with 24,201 pictures in total, the validation set contains seven clips, with 2819 pictures in total, and the test set contains 33 clips, 12,968 pictures in total. The videos were recorded at various places withf similar surroundings. The annotated boxes were divided into ten categories, namely pedestrian, person, car, van, bus, truck, motor, bicycle, awning-tricycle and tricycle. Specifically, pedestrians and people are treated as different categories: a standing or walking man will be classified as a pedestrian; a man in other positions will be sorted to be a person. In our experiment, the training set as well as the validation set were utilized to train and test the model, respectively.
- (2)
- UAVDT-DETThe UAVDT-DET dataset [41] consists of 50 video clips with a fixed resolution of 1024 × 540, which are shot with a UAV platform at different places in cities. Thirty of the video clips were set to be the training set with 24,143 pictures in total, and the testing set contained 20 clips, with 16,592 pictures in total. The annotated boxes were divided into three categories, namely car, truck and bus. The other two clips were set apart to test the results. In our experiment, we used the Visdrone-2018-VID dataset to perform an ablation study to examine the validity of each part in the model. Meanwhile, the model we proposed is compared with the baseline approaches on the Visdrone-2018-VID and UAVDT-DET datasets.
3.6.2. Metric
- (1)
- AccuracyWe apply mean average precision (mAP) to assess the accuracy of the object detection algorithm, which averages the average precisions (APs) in various categories and the APs are calculated by precision-recall curves. The following equations define precision and recall:TP, FP and FN refer to the number of true positives, false positives and false negatives, respectively. True positives and false positives are determined by the IOU between the predicted box and the ground truth box in the same category: If the IOU is greater than a certain threshold, the detection box is true positive, otherwise it is false positive. Meanwhile, a ground truth box without matching any predictions will produce a false negative. IOU is defined as:where and represent the predicted box as well as the ground truth box, respectively. This paper sets the IOU level to 0.5 according to the Pascal VOC guidelines. The possible values of Recall range from 0 to 1. We produced a coordinate system by setting recall and precision as the x and y axis, respectively, which altogether formed a precision-recall curve. The area between the curve and the coordinate axises of each category is the AP of the algorithm in that category.
- (2)
- Model ComplexityThe metrics for evaluating the complexity of the CNN-based algorithm are the amount of computation and the parameters. When the CNN model performs forward inference, the amount of computation determines the time complexity, that is, the time required for obtaining the detection results, and the number of parameters determines the space complexity, that is, the capacity of storage medium required. Generally, floating point operations (FLOPs) are used to evaluate computational cost, and the parameter size is obtained by counting the total weights of the network. In the experiment, we also adopted these metrics.
3.6.3. Training Details
- (1)
- Baseline MethodsWe chose CenterNet, Tiny YOLOv3, Pelee, and SSD for comparison. The specific training settings were as follows: For CenterNet, we trained the model using 16 as the lot size and 0.005 as the original learning rate for 180 epochs, with the learning rate decreasing by 10 each time at 90, 120 as well as 140 epochs. The weight decay was 0.0001, the momentum was 0.9, and the input size was 512 × 512. For Tiny YOLOv3, we trained the model using 32 as the lot size and 0.001 as the original learning rate for 150,000 steps, with the learning rate decreasing by 10 each time at 80,000 as well as 120,000 steps. The input size was 416 × 416. For Pelee, we trained the model using 32 as the lot size and 0.005 as the original learning rate for 150,000 steps, with the learning rate decreasing by 10 each time at 40,000, 80,000 as well as 120,000 steps. The input size was 304 × 304. For SSD, we trained the model using 32 as the lot size and 0.005 as the original learning rate for 120,000 steps, with the learning rate decreasing by 10 each time at 80,000 and 100,000 steps. The input size is 512 × 512.The weight decay was 0.0005 and momentum was 0.9 for Tiny YOLOv3, Pelee and SSD.
- (2)
- Our MethodThe model was trained using 16 as the lot size and 0.005 as the original learning rate for 180 epochs, with the learning rate decreasing by 10 each time at 90, 120 and as well as 140 epochs. The learning rate we propose, and the one in baseline approaches, both start from the level, and decrease by 10 each time when the loss curve stops dropping. Moreover, the training epochs of these methods are sufficient and similar in size to maintain a fairer comparison. Furthermore, other training hyperparameters keep their original setting of implementation.
4. Results
4.1. Evaluation of Lightweight Backbone
4.2. Evaluation of Simultaneous Upsampling and Detection Module
4.3. Evaluation of Objectness Branch
4.4. Comparisons with Other Detection Methods
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Menouar, H.; Guvenc, I.; Akkaya, K.; Uluagac, A.S.; Kadri, A.; Tuncer, A. UAV-enabled intelligent transportation systems for the smart city: Applications and challenges. IEEE Commun. Mag. 2017, 55, 22–28. [Google Scholar] [CrossRef]
- Ke, R.; Li, Z.; Tang, J.; Pan, Z.; Wang, Y. Real-Time Traffic Flow Parameter Estimation from UAV Video Based on Ensemble Classifier and Optical Flow. IEEE Trans. Intell. Transp. Syst. 2019, 20, 54–64. [Google Scholar] [CrossRef]
- Ke, R.; Li, Z.; Kim, S.; Ash, J.; Cui, Z.; Wang, Y. Real-Time Bidirectional Traffic Flow Parameter Estimation from Aerial Videos. IEEE Trans. Intell. Transp. Syst. 2017, 18, 890–901. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, G.; Wu, X.; Wang, Y.; Ma, Y. An Enhanced Viola-Jones Vehicle Detection Method from Unmanned Aerial Vehicles Imagery. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1845–1856. [Google Scholar] [CrossRef]
- Minaeian, S.; Liu, J.; Son, Y.J. Effective and Efficient Detection of Moving Targets from a UAV’s Camera. IEEE Trans. Intell. Transp. Syst. 2018, 19, 497–506. [Google Scholar] [CrossRef]
- Zhang, X.; Izquierdo, E.; Chandramouli, K. Dense and Small Object Detection in UAV Vision Based on Cascade Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 118–126. [Google Scholar]
- Chen, C.; Zhang, Y.; Lv, Q.; Wei, S.; Wang, X.; Sun, X.; Dong, J. RRNet: A Hybrid Detector for Object Detection in Drone-Captured Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Zhu, J.; Sun, K.; Jia, S.; Li, Q.; Hou, X.; Lin, W.; Liu, B.; Qiu, G. Urban traffic density estimation based on ultrahigh-resolution uav video and deep neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4968–4981. [Google Scholar] [CrossRef]
- Tang, Z.; Liu, X.; Shen, G.; Yang, B. PENet: Object Detection Using Points Estimation in Aerial Images. arXiv 2020, arXiv:2001.08247. [Google Scholar]
- Hong, S.; Kang, S.; Cho, D. Patch-Level Augmentation for Object Detection in Aerial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. Dsod: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 21–26 July 2017; pp. 1919–1927. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A real-time object detection system on mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1963–1972. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing Efficient Convnet Descriptor Pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Womg, A.; Shafiee, M.J.; Li, F.; Chwyl, B. Tiny SSD: A tiny single-shot detection deep convolutional neural network for real-time embedded object detection. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 95–101. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Luan, S.; Chen, C.; Zhang, B.; Han, J.; Liu, J. Gabor Convolutional Networks. IEEE Trans. Image Process. 2018, 27, 4357–4366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A real-time object detection algorithm optimized for non-GPU computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Li, Y.; Li, J.; Lin, W.; Li, J. Tiny-Dsod: Lightweight Object Detection for Resource-Restricted Usages. arXiv 2018, arXiv:1807.11013. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 9657–9666. [Google Scholar]
- Mao, M.; Tian, Y.; Zhang, B.; Ye, Q.; Liu, W.; Doermann, D. iffDetector: Inference-aware Feature Filtering for Object Detection. In IEEE TNNLS; IEEE: Piscataway Township, NJ, USA, 2021. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Ke, R.; Li, Z.; Tang, J.; Pan, Z.; Wang, Y. DAGN: A Real-Time UAV Remote Sensing Image Vehicle Detection Framework. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1884–1888. [Google Scholar]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A Global-Local Self-Adaptive Network for Drone-View Object Detection. IEEE Trans. Image Process. 2021, 30, 1556–1569. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. Learning rich features at high-speed for single-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 375–391. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Configuration | Output |
|---|---|---|
| Backbone | ||
| Input | — | 512 × 512 × 3 |
| Conv2d | 3 × 3 × 3 × 32 | 256 × 256 × 32 |
| Bottleneck | 256 × 256 × 16 | |
| Bottleneck | 128 × 128 × 24 | |
| Bottleneck | 64 × 64 × 32 | |
| Bottleneck | 32 × 32 × 64 | |
| Bottleneck | 32 × 32 × 96 | |
| Bottleneck | 16 × 16 × 160 | |
| Bottleneck | 16 × 16 × 320 | |
| Head | ||
| Conv2d | 1 × 1 × 320 × [( + 5) × 64] | 16 × 16 × [( + 5) × 64] |
| s = 1 | ||
| Periodic Shuffling | ratio = 8 | 128 × 128 × ( + 5) |
| Method | Model Complexity | Backbone | Head | |
|---|---|---|---|---|
| Feature Extractor | Up-Sampling | |||
| CenterNet (ResNet18) | FLOPs | 9.52 G | 5.92 G | 7.27 G |
| (41.91%) | (26.08%) | (32.01%) | ||
| Params | 11.18M | 41.20 M | 0.44 M | |
| (71.45%) | (26.53%) | (2.81%) | ||
| ours | FLOPs | 1.56 G | — | 0.08 G |
| (95.19%) | (4.81%) | |||
| Params | 1.81 M | — | 0.31 M | |
| (85.46%) | (14.54%) | |||
| Backbone | mAP | FLOPs | Params |
|---|---|---|---|
| ResNet18 | 11.5 | 22.71 G | 15.82 M |
| MobileNetV2 | 12.1 | 15.66 G | 10.01 M |
| MobileNetV3 | 10.8 | 15.08 G | 7.92 M |
| Structure | mAP | FLOPs | Params |
|---|---|---|---|
| MobileNetV2+SUAD w/o obj | 12.3 | 1.96 G | 3.37 M |
| MobileNetV2 w/o last 1 × 1 +SUAD w/o obj | 13.6 | 1.63 G | 2.10 M |
| MobileNetV2 w/o last 1 × 1 +SUAD w obj | 14.3 | 1.64 G | 2.12 M |
| 0.1 | 0.3 | 0.5 | 0.7 | 1.0 | |
| mAP | 12.3 | 13.0 | 14.3 | 12.9 | 13.2 |
| Method | Backbone | Input | mAP | FLOPs | Params | |
|---|---|---|---|---|---|---|
| VisDrone | UAVDT | |||||
| CenterNet | ResNet18 | 512 × 512 | 11.5 | 24.0 | 22.71 G | 15.82 M |
| MobileNetV2 | 512 × 512 | 12.1 | 24.6 | 15.66 G | 10.01 M | |
| Tiny YOLOv3 | Tiny DarkNet | 416 × 416 | 7.9 | 10.5 | 5.56 G | 12.30 M |
| Pelee | PeleeNet | 304 × 304 | 12.7 | 20.3 | 1.21 G | 5.43 M |
| SSD | MobileNetV2 | 512 × 512 | 11.4 | 18.1 | 1.82 G | 3.15 M |
| SqueezeNet | 512 × 512 | 10.5 | 20.7 | 1.76 G | 2.33 M | |
| Ours | MobileNetV2 | 512 × 512 | 14.3 | 26.6 | 1.64 G | 2.12 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Li, H.; Jiang, Y.; Wang, M. Lightweight Detection Network Based on Sub-Pixel Convolution and Objectness-Aware Structure for UAV Images. Sensors 2021, 21, 5656. https://doi.org/10.3390/s21165656
Li X, Li H, Jiang Y, Wang M. Lightweight Detection Network Based on Sub-Pixel Convolution and Objectness-Aware Structure for UAV Images. Sensors. 2021; 21(16):5656. https://doi.org/10.3390/s21165656
Chicago/Turabian StyleLi, Xuanye, Hongguang Li, Yalong Jiang, and Meng Wang. 2021. "Lightweight Detection Network Based on Sub-Pixel Convolution and Objectness-Aware Structure for UAV Images" Sensors 21, no. 16: 5656. https://doi.org/10.3390/s21165656
APA StyleLi, X., Li, H., Jiang, Y., & Wang, M. (2021). Lightweight Detection Network Based on Sub-Pixel Convolution and Objectness-Aware Structure for UAV Images. Sensors, 21(16), 5656. https://doi.org/10.3390/s21165656