SFA-MDEN: Semantic-Feature-Aided Monocular Depth Estimation Network Using Dual Branches


Abstract
:1. Introduction
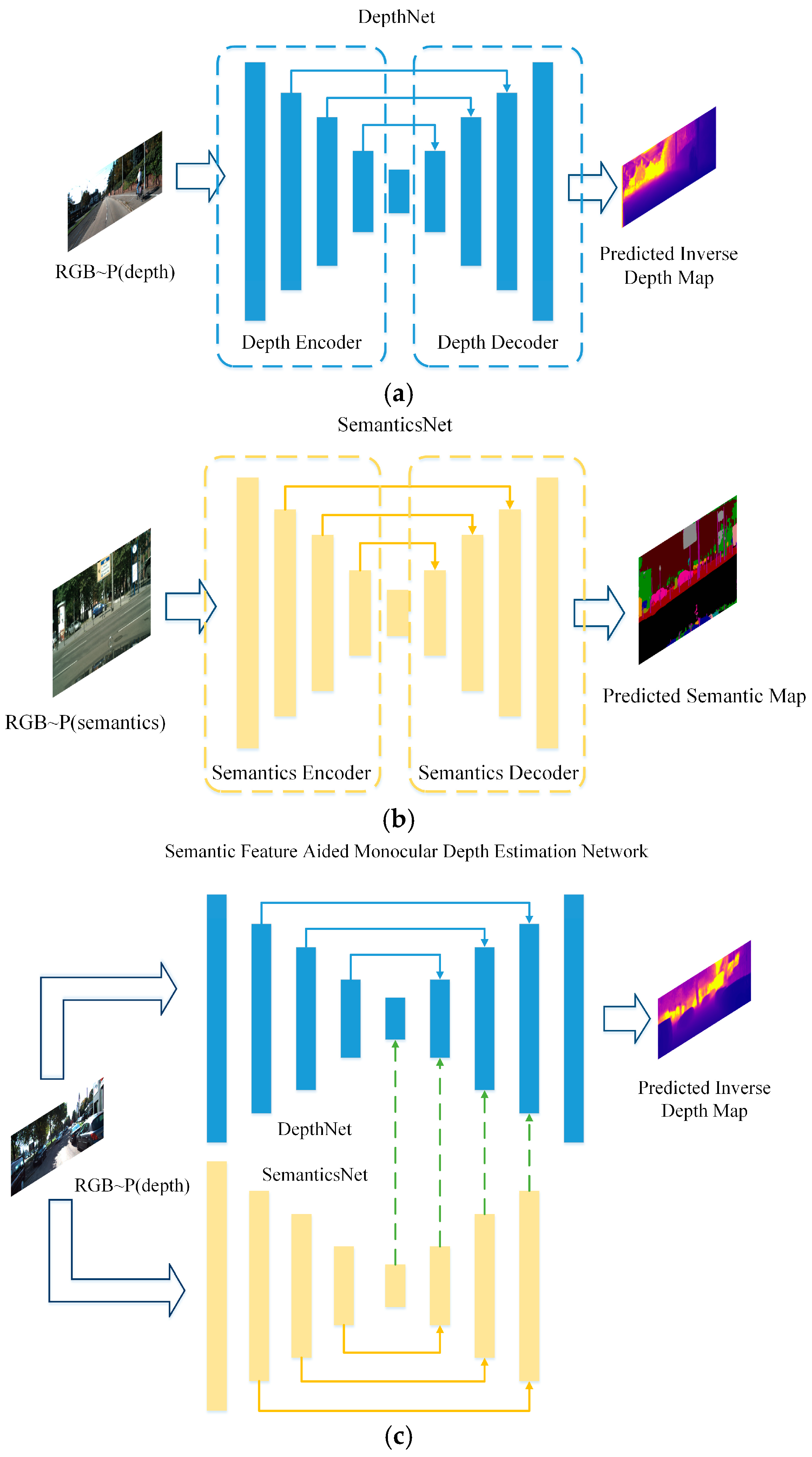
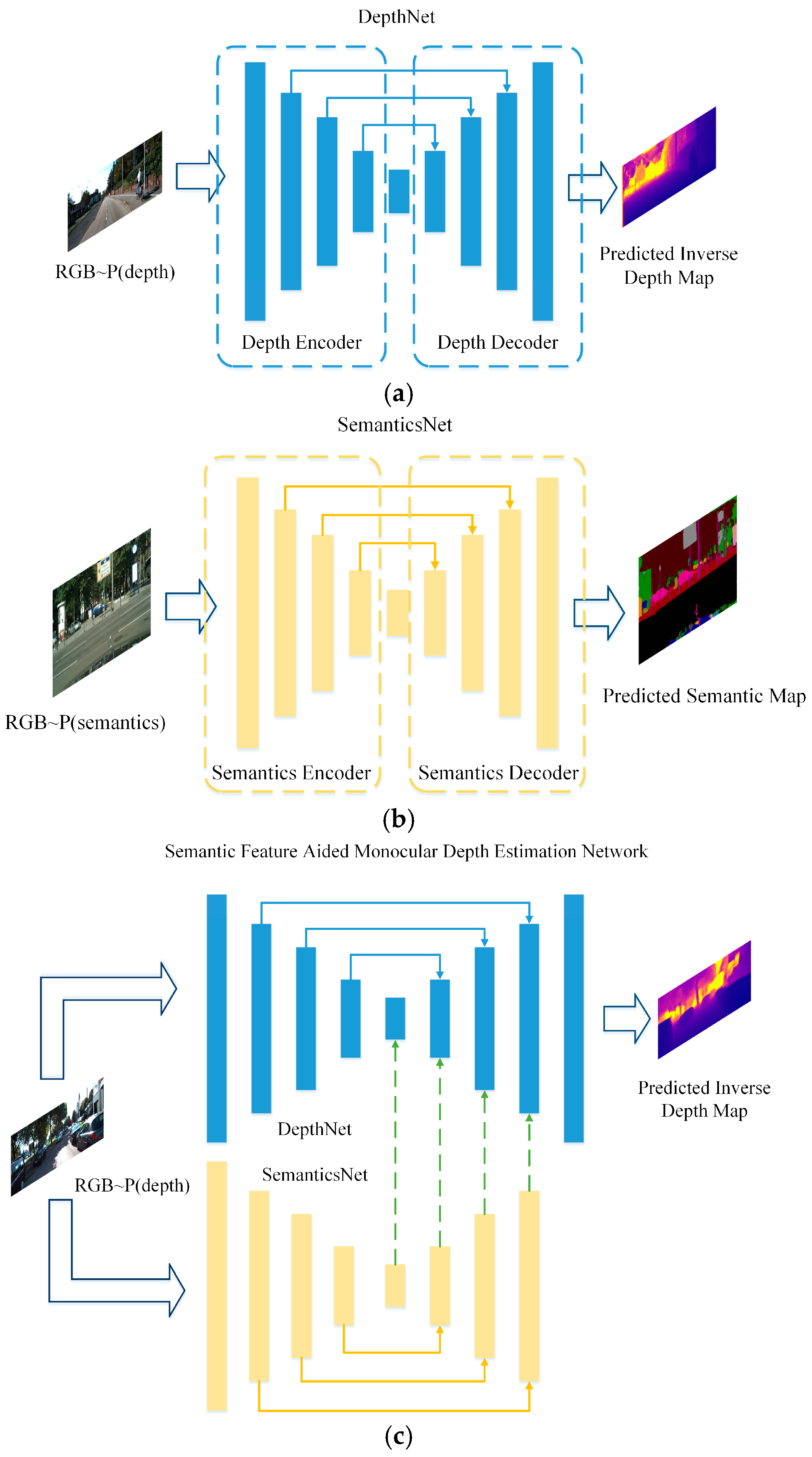
- We propose a Semantic-Feature-Aided Monocular Depth Estimation Network (SFA-MDEN), which fuses multi-resolution semantic feature maps into networks to achieve better precision and robustness for the monocular depth estimation task.
- A training strategy termed as Two-Stages for Two Branches (TSTB) is designed to train the SFA-MDEN. Instead of using the paired semantic label and stereo images for the input, a dataset for semantic segmentation and another dataset for monocular depth estimation with similar themes will satisfy the requirement. Therefore, larger datasets are guaranteed for better use of the semantic information to train our network.
2. Related Works
2.1. Monocular Depth Estimation
2.2. Monocular Depth Estimation with Semantics
3. Methodology
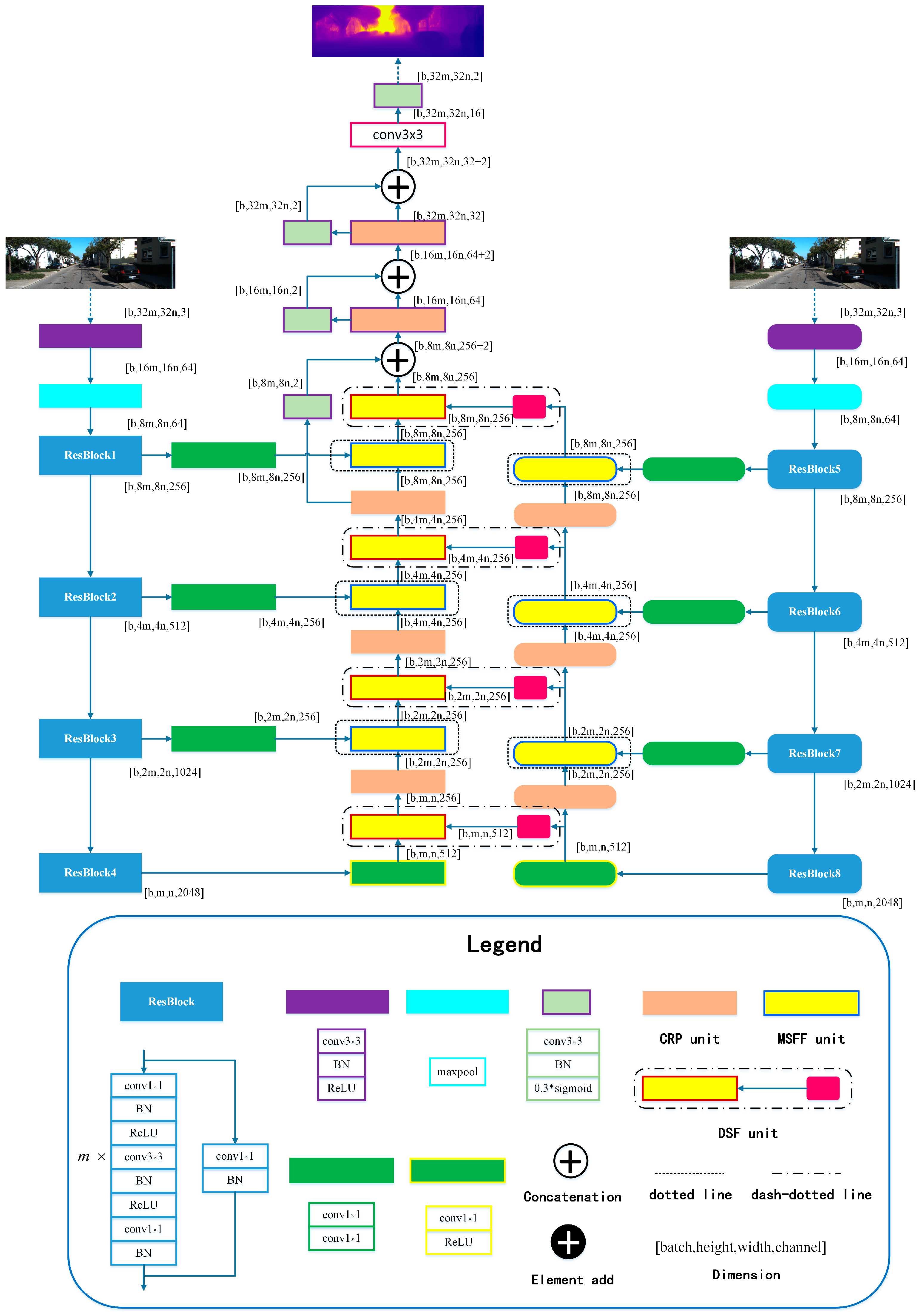
3.1. Framework and Training Strategy
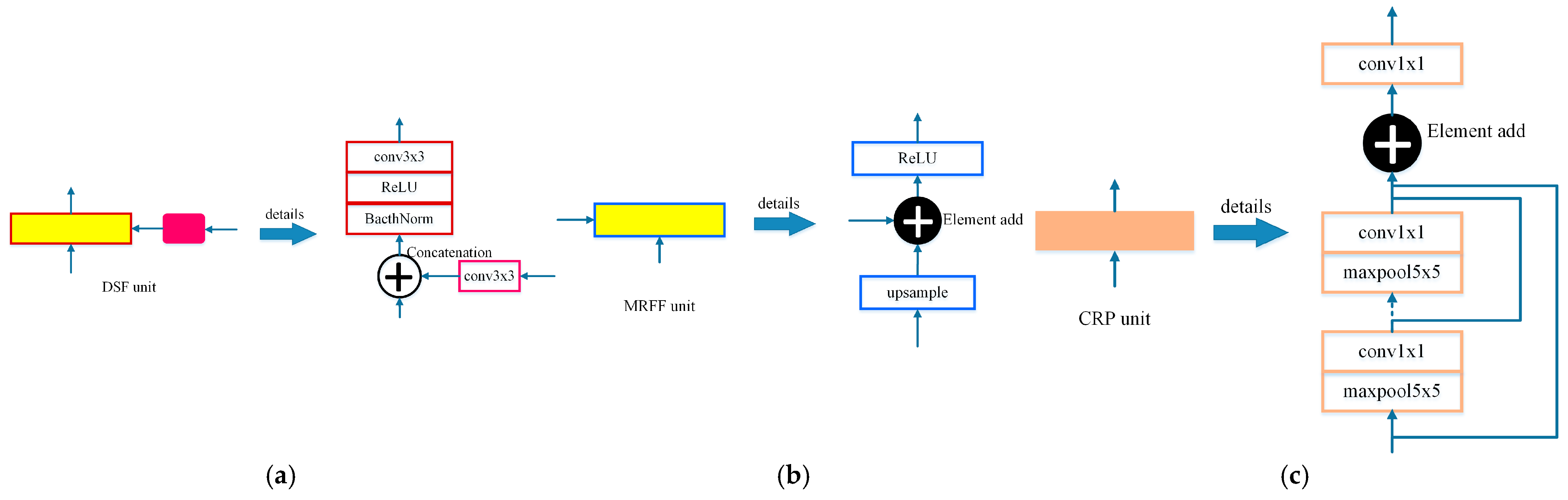
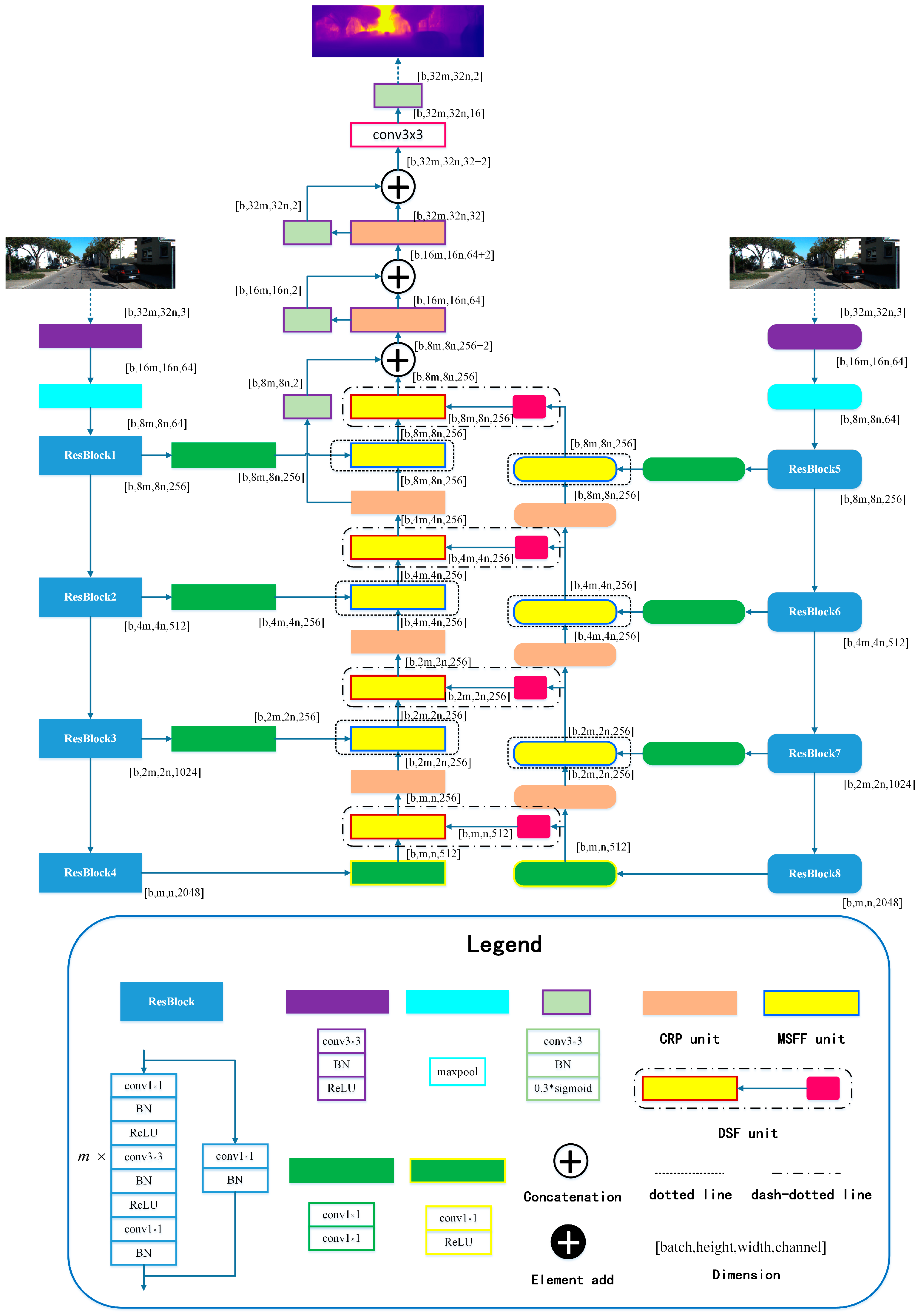
3.2. Network Architectures
3.3. Loss Function
4. Experiments and Analysis
4.1. Implementation Details and Metrics
- Absolute relative error:
- Square relative error:
- Linear root-mean-squared error:
- Logarithm root-mean-squared error:
- Threshold accuracy (%correct): (T is the threshold and can be assigned as 1.25, , )
4.2. Eigen Split of KITTI
4.3. Make3D
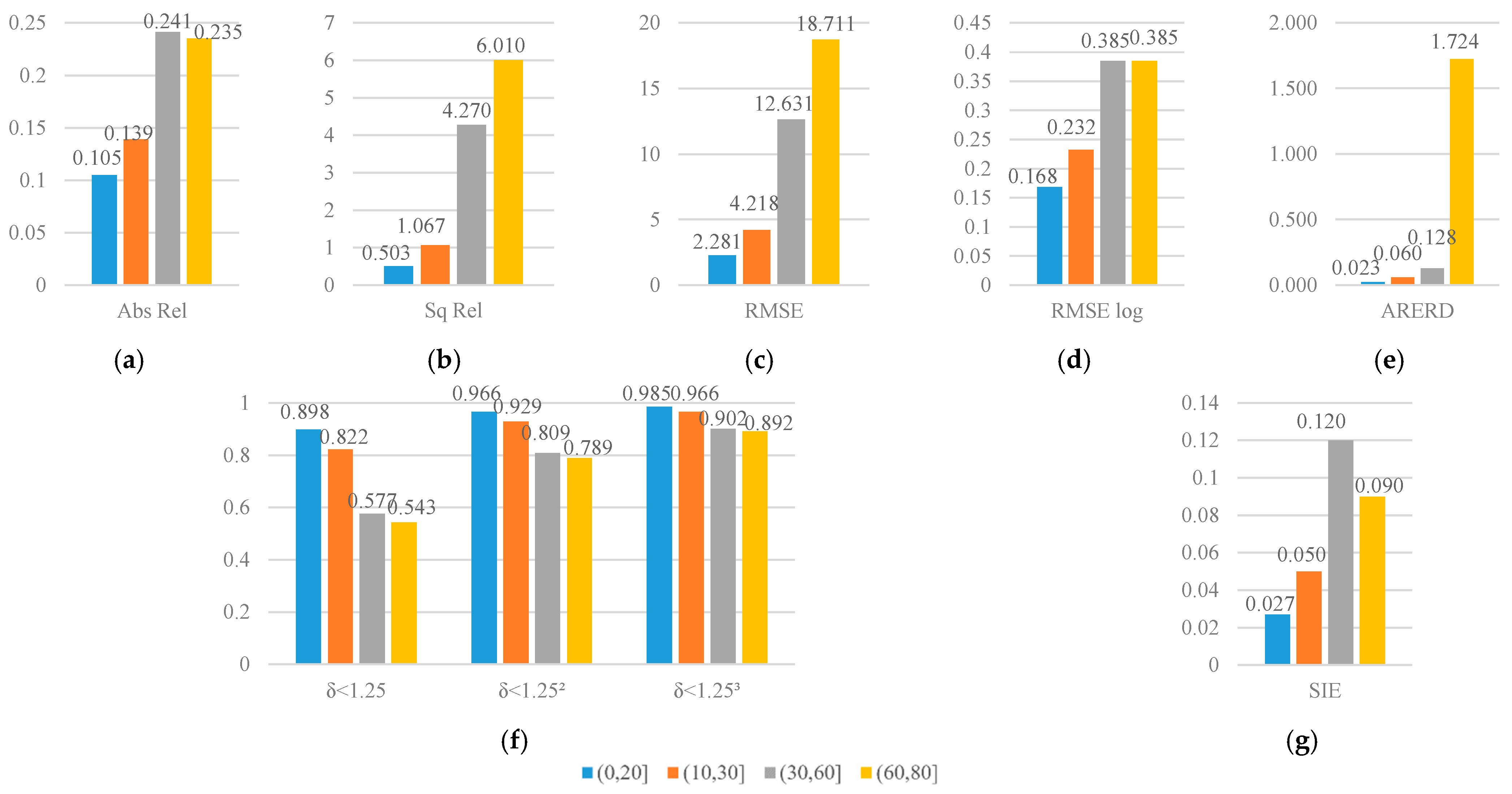
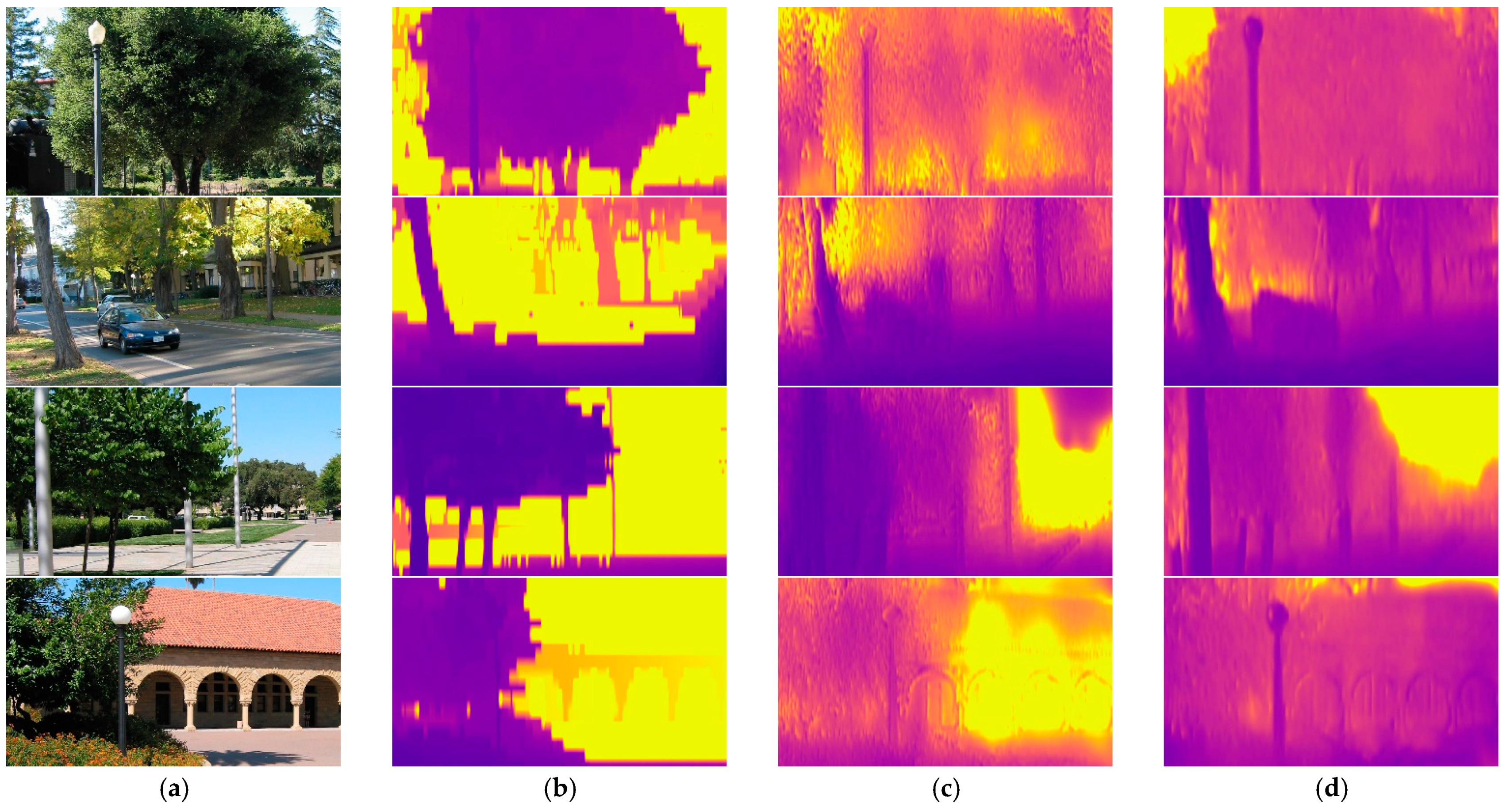
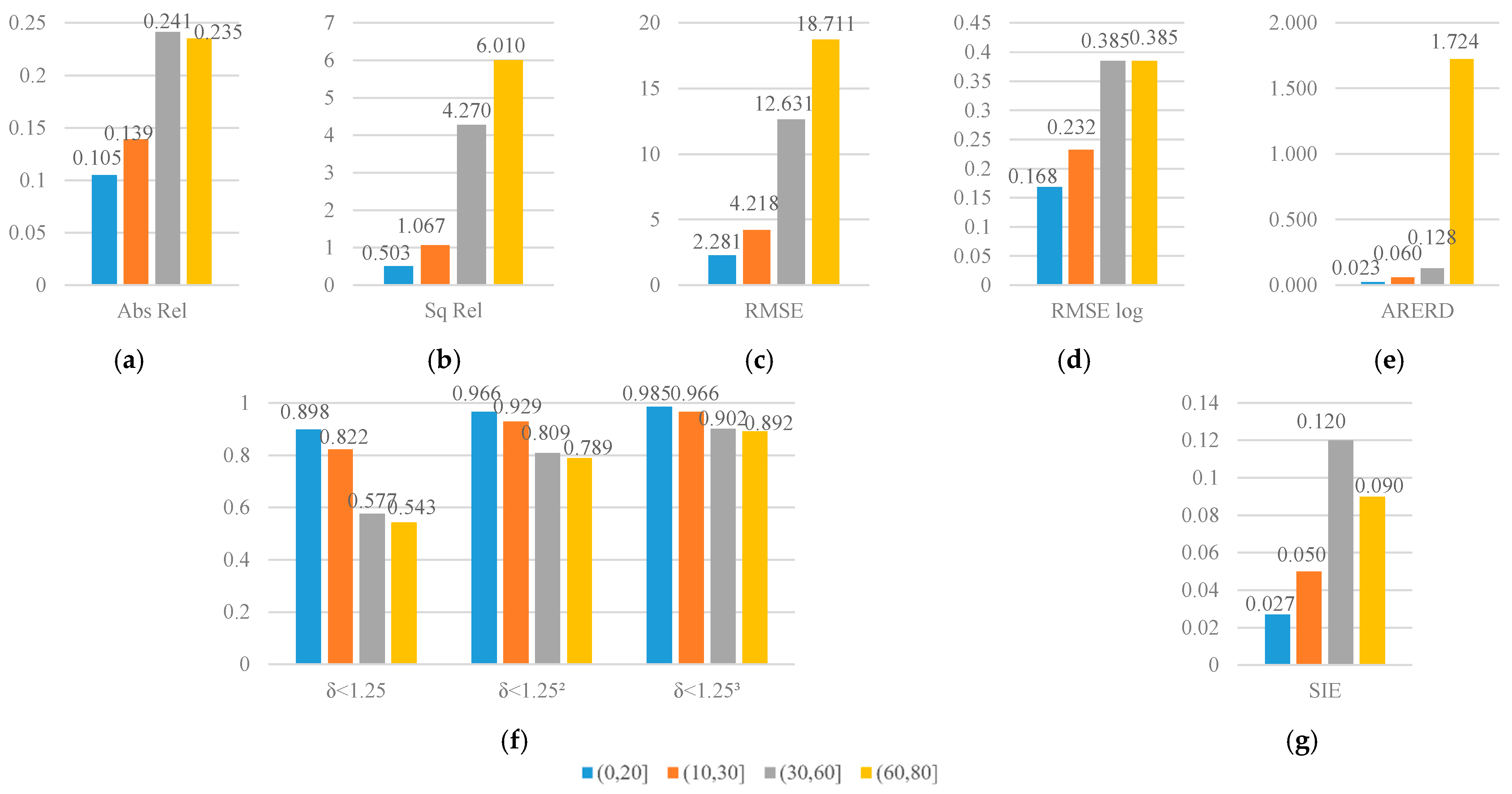
4.4. Self-Made Datasets: BHDE-v1
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alidoost, F.; Arefi, H.; Tombari, F. 2D image-to-3D model: Knowledge-based 3D building reconstruction (3DBR) using single aerial images and convolutional neural networks (CNNs). Remote Sens. 2019, 11, 2219. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Xu, J.; Han, T.X. Object instance detection with pruned alexnet and extended data. Signal Process Image Commun. 2019, 70, 145–156. [Google Scholar] [CrossRef]
- Stathopoulou, E.K.; Battisti, R.; Cernea, D.; Remondino, F.; Georgopoulos, A. Semantically derived geometric constraints for MVS reconstruction of textureless areas. Remote Sens. 2021, 13, 1053. [Google Scholar] [CrossRef]
- Jin, L.; Wang, X.; He, M.; Wang, J. DRNet: A depth-based regression network for 6D object pose estimation. Sensors 2021, 21, 1692. [Google Scholar] [CrossRef]
- Hwang, S.-J.; Park, S.-J.; Kim, G.-M.; Baek, J.-H. Unsupervised monocular depth estimation for colonoscope system using feedback network. Sensors 2021, 21, 2691. [Google Scholar] [CrossRef] [PubMed]
- Microsoft. Kinect for Windows. Available online: https://developer.microsoft.com/zh-cn/windows/kinect/ (accessed on 23 April 2021).
- Dhond, U.R.; Aggarwal, J.K. Structure from stereo—A review. IEEE Trans. Syst. Man Cybern. 1989, 19, 1489–1510. [Google Scholar] [CrossRef] [Green Version]
- Khan, F.; Salahuddin, S.; Javidnia, H. Deep learning-based monocular depth estimation methods—A state-of-the-art review. Sensors 2020, 20, 2272. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3D: Learning 3D scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 824–840. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saxena, A.; Chung, S.H.; Ng, A.Y. 3-D depth reconstruction from a single still image. Int. J. Comput. Vis. 2008, 76, 53–69. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [Green Version]
- Karsch, K.; Liu, C.; Kang, S.B. Depth transfer: Depth extraction from video using non-parametric sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2144–2158. [Google Scholar] [CrossRef] [Green Version]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar] [CrossRef] [Green Version]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Wofk, D.; Ma, F.; Yang, T.-J.; Karaman, S.; Sze, V. Fast monocular depth estimation on embedded systems. In Proceedings of the 2019 International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 6101–6108. [Google Scholar] [CrossRef] [Green Version]
- Tu, X.; Xu, C.; Liu, S.; Xie, G.; Huang, J.; Li, R.; Yuan, J. Learning depth for scene reconstruction using an encoder-decoder model. IEEE Access 2020, 8, 89300–89317. [Google Scholar] [CrossRef]
- Lee, J.H.; Han, M.K.; Ko, D.W.; Suh, I.H. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv 2020, arXiv:1907.10326. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar] [CrossRef]
- Su, W.; Zhang, H. Soft regression of monocular depth using scale-semantic exchange network. IEEE Access 2020, 8, 114930–114939. [Google Scholar] [CrossRef]
- Kim, S.; Nam, J.; Ko, B. Fast depth estimation in a single image using lightweight efficient neural network. Sensors 2019, 19, 4434. [Google Scholar] [CrossRef] [Green Version]
- Kuznietsov, Y.; Stückler, J.; Leibe, B. Semi-supervised deep learning for monocular depth map prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2215–2223. [Google Scholar] [CrossRef] [Green Version]
- Atapour-Abarghouei, A.; Breckon, T.P. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2800–2810. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; Fu, H.; Gong, M.; Tao, D. Geometry-aware symmetric domain adaptation for monocular depth estimation. Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9780–9790. [Google Scholar] [CrossRef] [Green Version]
- Ji, R.; Li, K.; Wang, Y.; Sun, X.; Guo, F.; Guo, X.; Wu, Y.; Huang, F.; Luo, J. Semi-supervised adversarial monocular depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2410–2422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised CNN for single view depth estimation: Geometry to the rescue. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 740–756. [Google Scholar] [CrossRef] [Green Version]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar] [CrossRef] [Green Version]
- Goldman, M.; Hassner, T.; Avidan, S. Learn stereo, infer mono: Siamese networks for self-supervised, monocular, depth estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2886–2895. [Google Scholar] [CrossRef] [Green Version]
- Poggi, M.; Aleotti, F.; Tosi, F.; Mattoccia, S. Towards real-time unsupervised monocular depth estimation on CPU. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 5848–5854. [Google Scholar] [CrossRef] [Green Version]
- Ye, X.; Zhang, M.; Xu, R.; Zhong, W.; Fan, X.; Liu, Z.; Zhang, J. Unsupervised Monocular depth estimation based on dual attention mechanism and depth-aware loss. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 169–174. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, J.; Han, C. Unsupervised learning of depth estimation based on attention model from monocular images. In Proceedings of the 2020 International Conference on Virtual Reality and Visualization (ICVRV), Recife, Brazil, 13–14 November 2020; pp. 191–195. [Google Scholar] [CrossRef]
- Ling, C.; Zhang, X.; Chen, H. Unsupervised monocular depth estimation using attention and multi-warp reconstruction. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Wang, R.; Huang, R.; Yang, J. Facilitating PTZ camera auto-calibration to be noise resilient with two images. IEEE Access 2019, 7, 155612–155624. [Google Scholar] [CrossRef]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar] [CrossRef] [Green Version]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised learning of depth and ego-motion from monocular video using 3D geometric constraints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5667–5675. [Google Scholar] [CrossRef] [Green Version]
- Luo, X.; Huang, J.B.; Szeliski, R.; Matzen, K.; Kopf, J. Consistent video depth estimation. ACM Trans. Graph. 2020, 39, 85–95. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G. Digging into self-supervised monocular depth estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3827–3837. [Google Scholar] [CrossRef] [Green Version]
- Ramamonjisoa, M.; Du, Y.; Lepetit, V. Predicting sharp and accurate occlusion boundaries in monocular depth estimation using displacement fields. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14636–14645. [Google Scholar] [CrossRef]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos. arXiv 2018, arXiv:1811.06152. [Google Scholar] [CrossRef] [Green Version]
- Bian, J.W.; Zhan, H.; Wang, N.; Li, Z.; Zhang, L.; Shen, C.; Cheng, M.; Reid, I. Unsupervised scale-consistent depth learning from video. Int. J. Comput. Vis. 2021, 129, 2548–2564. [Google Scholar] [CrossRef]
- Liu, J.; Li, Q.; Cao, R.; Tang, W.; Qiu, G. MiniNet: An extremely lightweight convolutional neural network for real-time unsupervised monocular depth estimation. ISPRS J. Photogramm. Remote Sens. 2020, 166, 255–267. [Google Scholar] [CrossRef]
- Wang, C.; Buenaposada, J.M.; Zhu, R.; Lucey, S. Learning depth from monocular videos using direct methods. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2022–2030. [Google Scholar] [CrossRef] [Green Version]
- Yin, Z.; Shi, J. GeoNet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar] [CrossRef] [Green Version]
- Cipolla, R.; Gal, Y.; Kendall, A. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7482–7491. [Google Scholar] [CrossRef] [Green Version]
- Ramirez, P.Z.; Poggi, M.; Tosi, F.; Mattoccia, S.; Di Stefano, L. Geometry meets semantics for semi-supervised monocular depth estimation. In Proceedings of the 2018 Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 298–313. [Google Scholar] [CrossRef] [Green Version]
- Mousavian, A.; Pirsiavash, H.; Košecká, J. Joint semantic segmentation and depth estimation with deep convolutional networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 611–619. [Google Scholar] [CrossRef] [Green Version]
- Nekrasov, V.; Dharmasiri, T.; Spek, A.; Drummond, T.; Shen, C.; Reid, I. Real-time joint semantic segmentation and depth estimation using asymmetric annotations. In Proceedings of the 2019 International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 7101–7107. [Google Scholar] [CrossRef] [Green Version]
- Yue, M.; Fu, G.; Wu, M.; Wang, H. Semi-supervised monocular depth estimation based on semantic supervision. J. Intell. Robot. Syst. 2020, 5, 455–463. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Nekrasov, V.; Shen, C.; Reid, I. Light-weight refinenet for real-time semantic segmentation. arxiv 2018, arXiv:1810.03272. [Google Scholar]
- PHANTOM 4 PRO/PRO+. Available online: https://dl.djicdn.com/downloads/phantom_4_pro/20200108/Phantom_4_Pro_Pro_Plus_Series_User_Manual_CHS.pdf (accessed on 22 April 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Supervision | Semantics | Datasets | Cap (m) | Error Metrics | Accuracy Metrics | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | RMSE log | ||||||||
| Eigen et al. [14] | Depth | No | K | 80 | 0.214 | 1.605 | 6.563 | 0.292 | 0.673 | 0.884 | 0.957 |
| Eigen et al. Fine [14] | Depth | No | K | 80 | 0.203 | 1.548 | 6.307 | 0.282 | 0.702 | 0.890 | 0.958 |
| Liu et al. [12] | Depth | No | K | 80 | 0.202 | 1.614 | 6.523 | 0.275 | 0.678 | 0.895 | 0.965 |
| Yin et al. [45] | Sequence | No | K | 80 | 0.155 | 1.296 | 5.857 | 0.233 | 0.793 | 0.931 | 0.973 |
| Zhou et al. [36] | Sequence | No | K | 80 | 0.208 | 1.768 | 6.856 | 0.283 | 0.678 | 0.885 | 0.957 |
| Zhou et al. [36] | Sequence | No | CS + K | 80 | 0.198 | 1.836 | 6.565 | 0.275 | 0.718 | 0.901 | 0.960 |
| Mahjourian et al. [37] | Sequence | No | CS + K | 80 | 0.159 | 1.231 | 5.912 | 0.243 | 0.784 | 0.923 | 0.970 |
| Godard et al. [29] | Stereo | No | K | 80 | 0.148 | 1.344 | 5.927 | 0.247 | 0.803 | 0.922 | 0.964 |
| Yue et al. [50] | Stereo | Yes (CS) | K | 80 | 0.143 | 1.034 | 5.505 | 0.219 | 0.809 | 0.937 | 0.977 |
| DepthNet only | Stereo | No | K | 80 | 0.144 | 1.168 | 5.808 | 0.249 | 0.828 | 0.930 | 0.963 |
| SFA-MDEN | Stereo | Yes (CS) | K | 80 | 0.120 | 1.095 | 5.370 | 0.226 | 0.838 | 0.939 | 0.972 |
| Zhou et al. [33] | Sequence | No | CS + K | 50 | 0.190 | 1.436 | 4.975 | 0.258 | 0.735 | 0.915 | 0.968 |
| Mahjourian et al. [37] | Sequence | No | CS + K | 50 | 0.151 | 0.949 | 4.383 | 0.227 | 0.802 | 0.945 | 0.974 |
| Yin et al. [45] | Sequence | No | K | 50 | 0.147 | 0.936 | 4.348 | 0.218 | 0.810 | 0.941 | 0.977 |
| Garg et al. [28] | Stereo | No | K | 50 | 0.169 | 1.080 | 5.104 | 0.273 | 0.740 | 0.904 | 0.962 |
| Godard et al. [29] | Stereo | No | K | 50 | 0.140 | 0.976 | 4.471 | 0.232 | 0.818 | 0.931 | 0.969 |
| Yue et al. [50] | Stereo | Yes (CS) | K | 50 | 0.137 | 0.792 | 4.158 | 0.205 | 0.826 | 0.947 | 0.981 |
| DepthNet only | Stereo | No | K | 50 | 0.140 | 1.010 | 4.724 | 0.239 | 0.812 | 0.925 | 0.966 |
| SFA-MDEN | Stereo | Yes (CS) | K | 50 | 0.116 | 0.956 | 4.361 | 0.217 | 0.848 | 0.948 | 0.974 |
| Method | Supervision | Datasets | Cap | Error Metrics | Accuracy Metrics | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | RMSE log | |||||||
| Nekrasov et al. [43] | Depth | K-6, K, CS | 80 m | - | - | 3.453 | 0.182 | - | - | - |
| Ramirez et al. [40] | Stereo | CS, K (200) | 80 m | 0.143 | 2.161 | 6.526 | 0.222 | 0.850 | 0.939 | 0.972 |
| Yue et al. [44] | Sequence | K, CS | 80 m | 0.143 | 1.034 | 5.505 | 0.219 | 0.809 | 0.937 | 0.977 |
| SFA-MDEN | Stereo | K, CS | 80 m | 0.120 | 1.095 | 5.370 | 0.226 | 0.838 | 0.939 | 0.972 |
| Method | SIE | ARERD |
|---|---|---|
| Godard et al. | 0.051 | 0.0855 |
| DepthNet only | 0.059 | 0.0642 |
| SFA-MDEN | 0.048 | 0.0546 |
| Method | Supervision | Sq Rel | Abs Rel | RMSE | Log10 |
|---|---|---|---|---|---|
| Karsch et al. [13] | Depth | 4.894 | 0.417 | 8.172 | 0.144 |
| Liu et al. [12] | Depth | 6.625 | 0.462 | 9.972 | 0.161 |
| Laina et al. [16] | Depth | 1.840 | 0.204 | 5.683 | 0.084 |
| Zhou et al. [36] | Sequence | 5.321 | 0.383 | 10.470 | 0.478 |
| Godard et al. [29] | Stereo | 11.990 | 0.535 | 11.513 | 0.156 |
| Wang et al. [44] | Stereo | 4.720 | 0.387 | 8.090 | 0.204 |
| SFA-MDEN | Stereo | 4.181 | 0.402 | 6.497 | 0.158 |
| Method | Abs Rel | Sq Rel | RMSE | RMSE log | |||
|---|---|---|---|---|---|---|---|
| SFA-MDEN | 0.142 | 0.562 | 3.266 | 0.167 | 0.775 | 0.959 | 0.980 |
| Godard et al. | 0.240 | 1.822 | 5.738 | 0.310 | 0.489 | 0.791 | 0.917 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Zou, J.; Wen, J.Z. SFA-MDEN: Semantic-Feature-Aided Monocular Depth Estimation Network Using Dual Branches. Sensors 2021, 21, 5476. https://doi.org/10.3390/s21165476
Wang R, Zou J, Wen JZ. SFA-MDEN: Semantic-Feature-Aided Monocular Depth Estimation Network Using Dual Branches. Sensors. 2021; 21(16):5476. https://doi.org/10.3390/s21165476
Chicago/Turabian StyleWang, Rui, Jialing Zou, and James Zhiqing Wen. 2021. "SFA-MDEN: Semantic-Feature-Aided Monocular Depth Estimation Network Using Dual Branches" Sensors 21, no. 16: 5476. https://doi.org/10.3390/s21165476
APA StyleWang, R., Zou, J., & Wen, J. Z. (2021). SFA-MDEN: Semantic-Feature-Aided Monocular Depth Estimation Network Using Dual Branches. Sensors, 21(16), 5476. https://doi.org/10.3390/s21165476