1. Introduction
IP geolocation is a fundamental part of many Internet services and applications. It delivers the geographical location of any Internet device, independent of its use, installation, software, and hardware. Any of these locations may be needed retrospectively when the reason to locate the device was not known before, or when the locations were obtained but not archived. These usages include evaluation of longitudinal studies, observation of long-term location patterns, replication of past system states, study of long-term evolution of the global Internet, and investigation of crime incidents. In theory, there is an unlimited history of all IP address locations available. However, this is in reality not true as only pieces of historical data are available, which makes the retrospective location a challenge.
This work presents results of retrospective location. It also introduces an approach to handle missing historical data. The usage of the results is demonstrated by two longitudinal use cases. The first deals with the geotargeted online content in which some pages with dynamically generated content based on the viewers’ locations do not work for unknown reasons. The past viewers’ locations are used to investigate the reasons for the page loading errors. The second use case discusses the application in identity theft prevention. The history of address locations is used to estimate the confidence of the user travel between places of subsequent logins. In a secured system, such as an e-shop with stored credit card details for one-click payments, a confident suspicion of ID theft can prevent the payment to minimize fraud losses and chargebacks.
Historical IP geolocation databases are used to obtain past locations. Such databases are populated by various techniques, which include location self-reporting [
1,
2], network measurements [
3,
4], mining web content [
5], host and domain-name analyses [
6,
7], and custom submissions [
8]. The stored locations in a database are shared by a range of addresses to maximize the Internet space coverage.
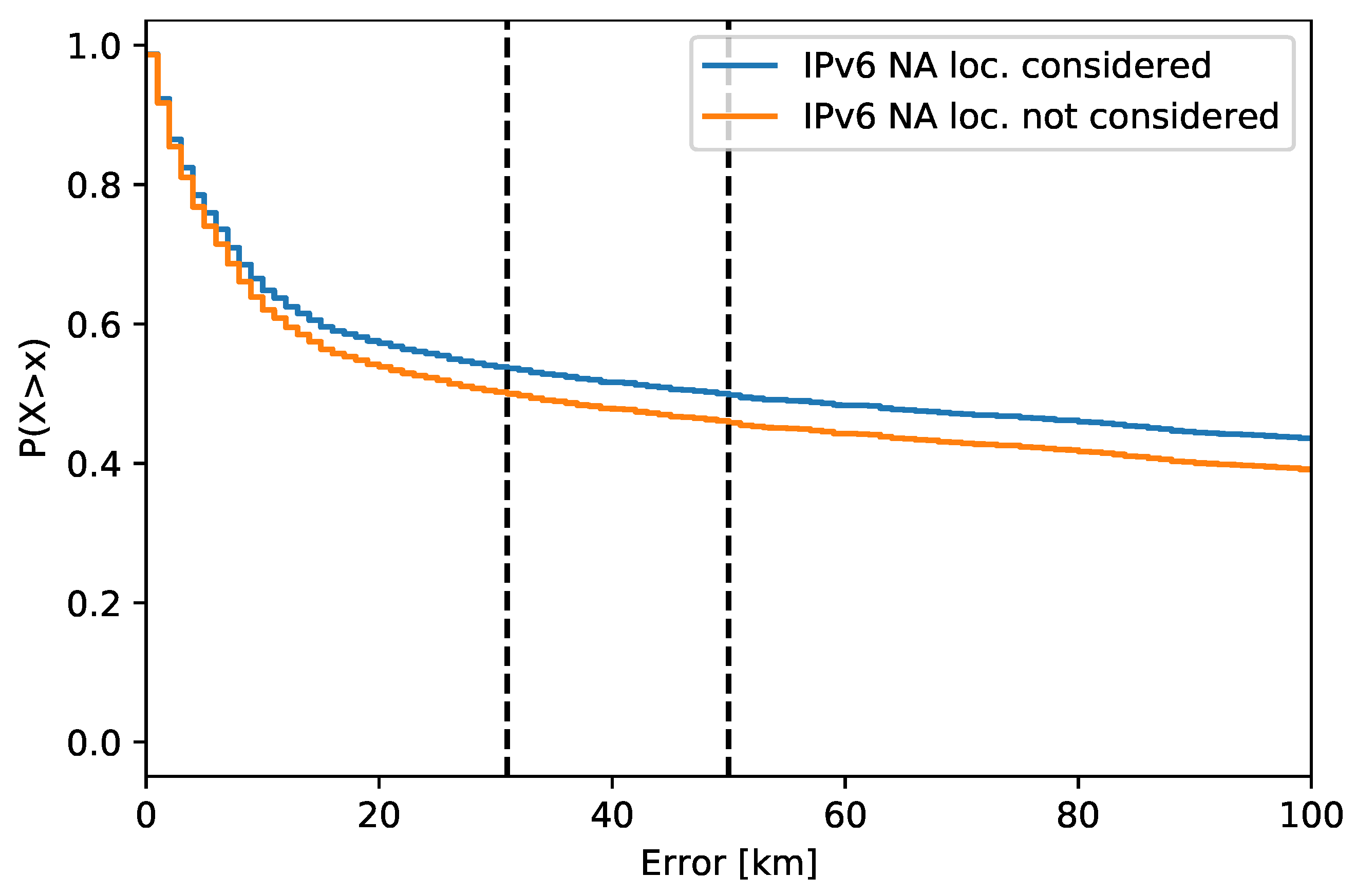
I work with the historical ground truth that includes past IPv4 and IPv6 addresses and their locations over five years. There are approx. 51 k IPv4 and 17 k IPv6 addresses in the ground truth. This ground truth was linked to historical geolocation databases to observe the past address locations. The NA (not available; not returned) locations are also considered in the analysis as their number significantly affects the accuracy, especially for IPv6 addresses. The results show how far into the past the system may locate an address without a noticeable accuracy loss. I also work with the location lifetime in a database. For this purpose, I evaluate the database-stored location history of one year of about 421 k IPv4 and 47 k IPv6 addresses. Due to missing data, survival analysis is applied to process the data. Specifically, interval censoring is used to cover the past dates where the historical geolocation databases are missing. The fitted lifetime model allows for a given address to estimate the time when its location was changed in the past.
The presented results have a defined scope. The results dealing with retrospective IP address locations (
Section 5) are limited to fixed devices. In addition, the historical ground truth is not evenly distributed across the world. Therefore, these results are mostly descriptive of Europe and North America. The results dealing with IP address location lifetime (
Section 6) are also valid for mobile devices.
The analyzed locations were observed via the past MaxMind GeoLite2 City databases. This database is commonly shipped with various software and operating systems. This makes their past versions available in data archives such as OS repositories and software development snapshots on GitHub and GitLab. To the best of my knowledge, it is the only universal solution for retrospective location.
The historical data used in this work are made available as a single collection for result replication and further work in [
9], with the list of files and their format described in
Appendix A. The processed data are also published, including the observed past locations and lifetime durations. The particular sources used for obtaining the past databases are described.
The work is structured as follows: The general problem of missing past IP geolocation databases is discussed in
Section 2.
Section 3 overviews the related work.
Section 4 describes the historical data used, including their sources. Locations of the addresses used in the past are analysed in
Section 5, including a discussion. Survival analysis of the location lifetime is described in
Section 6, including the discussion. Two use cases are described in
Section 7. The work limitations are given in
Section 8.
2. Problem of Retrospective IP Location
Retrospective IP geolocation is based on the availability of past IP location databases. Some past databases may be found by searching the historical content on the Internet. The success of the search highly depends on the targeted past dates (the range could be months to years) and how distant into the past it is. More databases can be found for recent dates and fewer for the distant past. The particular problems with the past databases availability are:
(i) Past databases are typically a part of other software, such as application installations or compressed files, such as software packages (e.g., Linux rpm). These data, which could be in all possible formats, need to be extracted and inspected in order to collect the past database. One needs to know or guess the application or software names that contain past geolocation databases.
(ii) Past databases are searched for a specific date of interest. However, the metadata of the files including the database do not correspond with the date the database was built. The reason is that the file date refers to the file-system storage time, which changes when the file is moved/copied (e.g., on an ftp repository). Thus, the file date is different from the database build date, with a possible difference of years. Dates incorporated into filenames are not also reliable, as they are not the date when the database was built. Therefore, it is not possible to search for the past databases by lower and upper date limits due to the file metadata and the database build date difference.
(iii) For some database formats, such as the common CSV, it is not possible to obtain the database build date as there is no such information stored in the database itself. Therefore, the database creation date is completely lost as time passes. The result is that many databases that may have been found cannot be used at all due to large date inaccuracies.
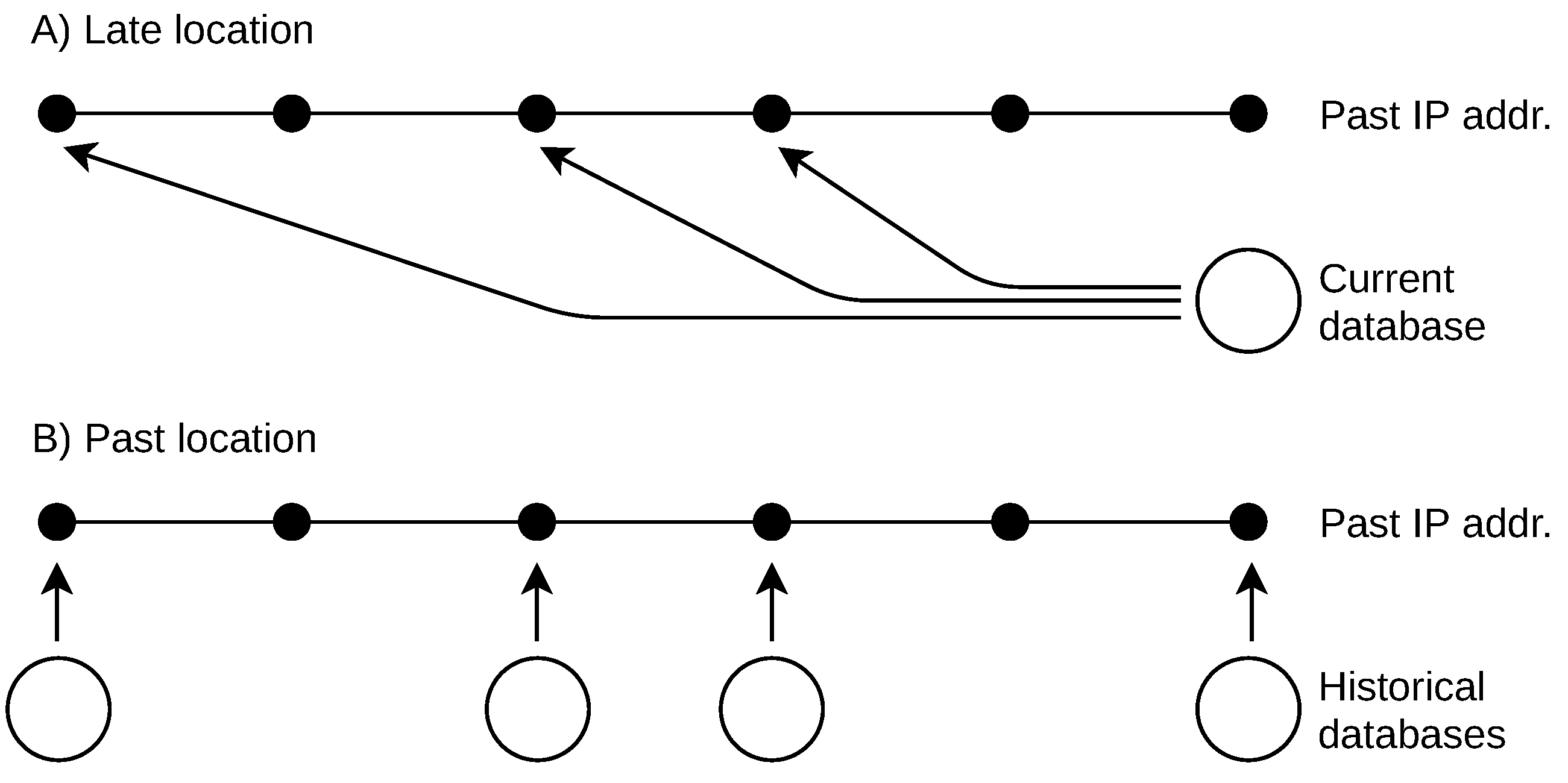
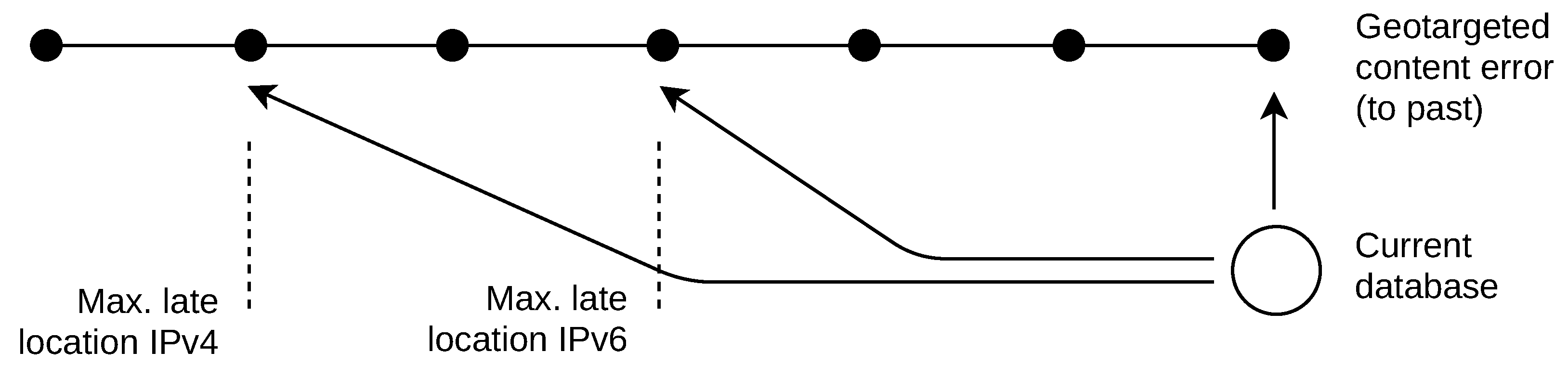
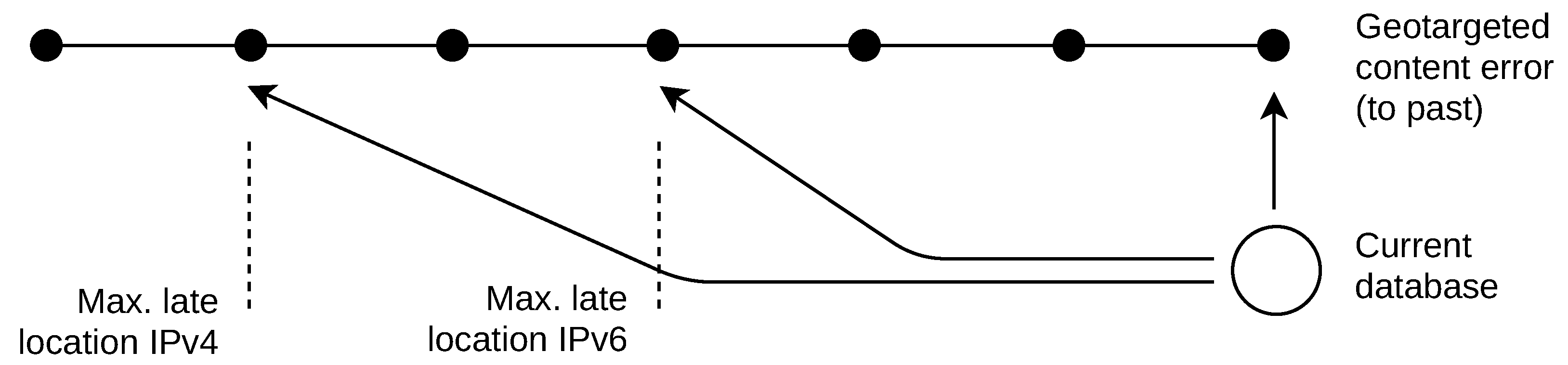
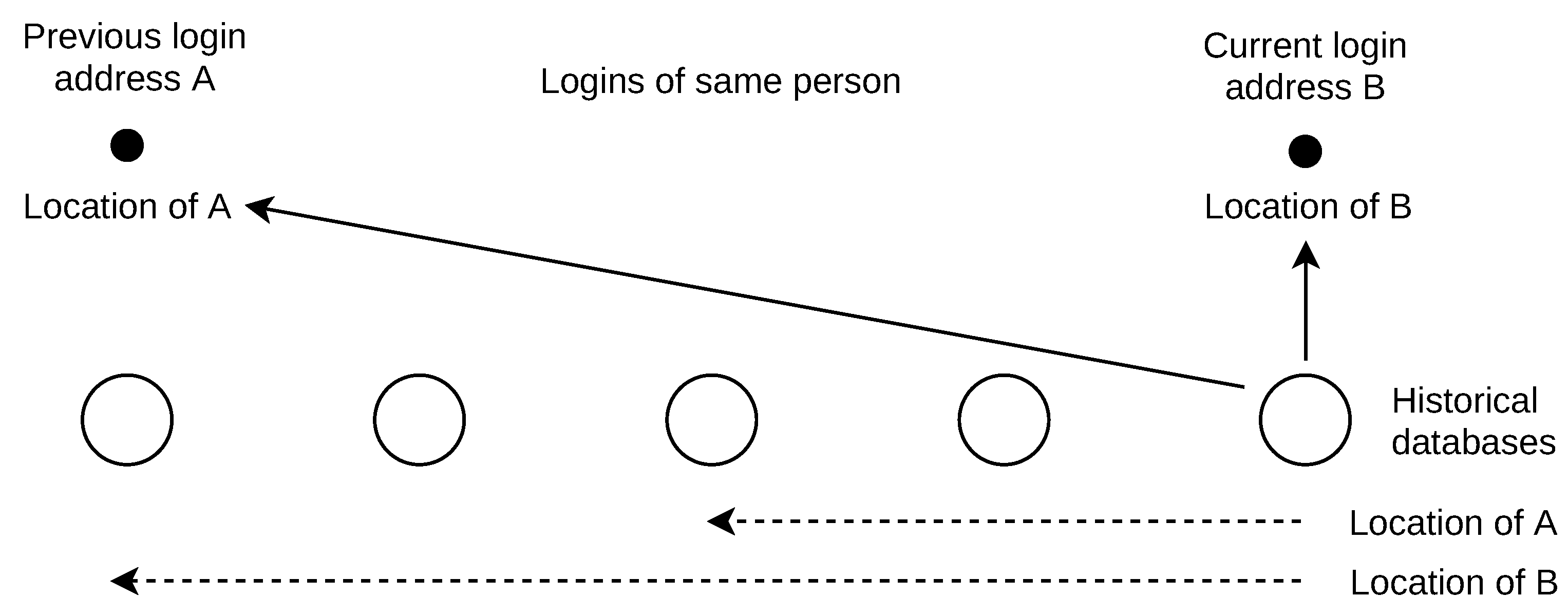
These historical data problems result in missing past databases. There are two basic approaches to retrospective IP location, as shown in
Figure 1. The first is a naive solution that the past IP addresses are located by a current geolocation database. In this work, I refer to this naive approach as “late location”. The second approach uses an incomplete list of past databases to locate addresses used in the past. I refer to this approach as “past location”.
3. Related Work
A recent major comparison of IP location databases was done by Gharaibeh et al. [
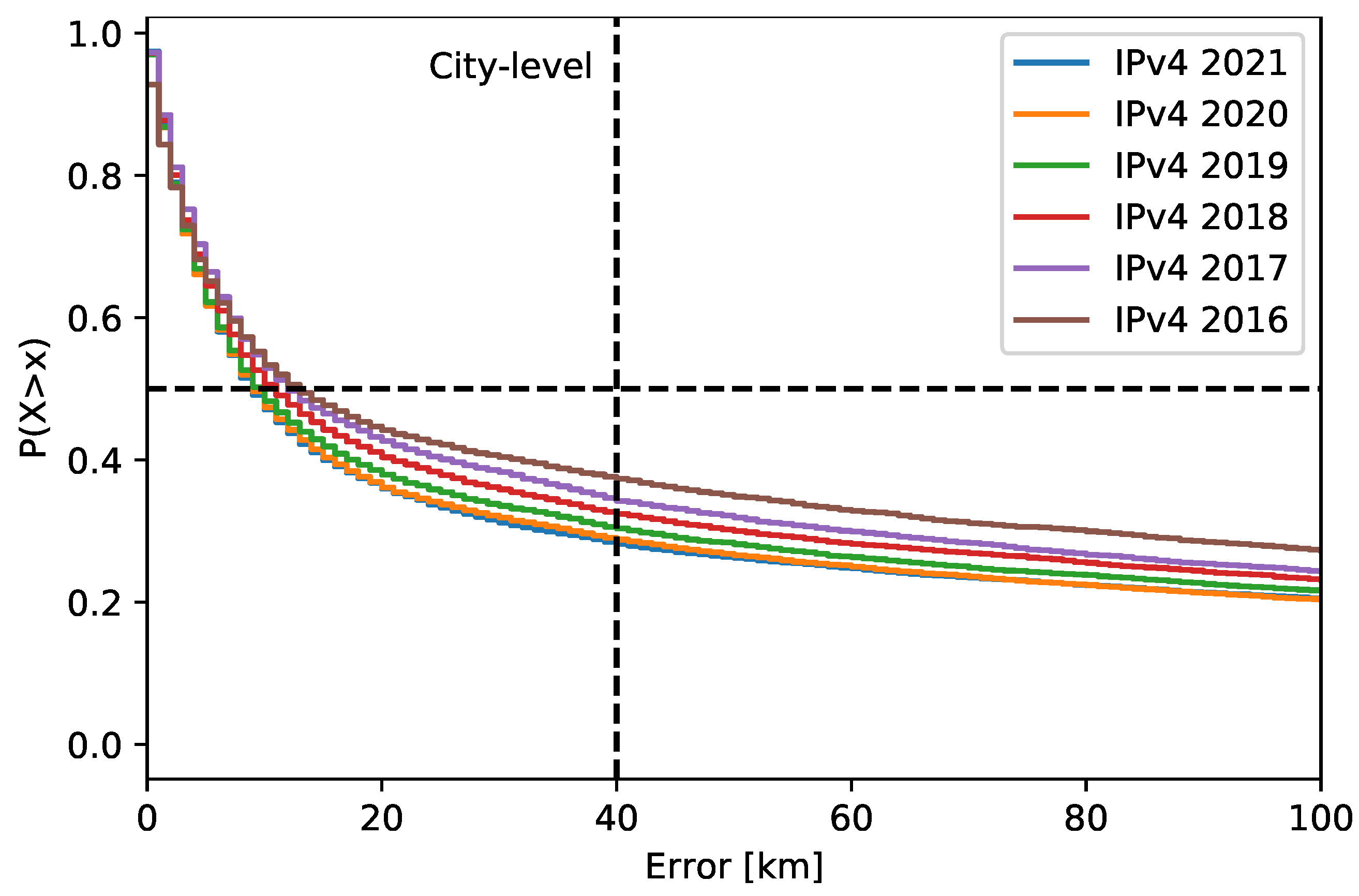
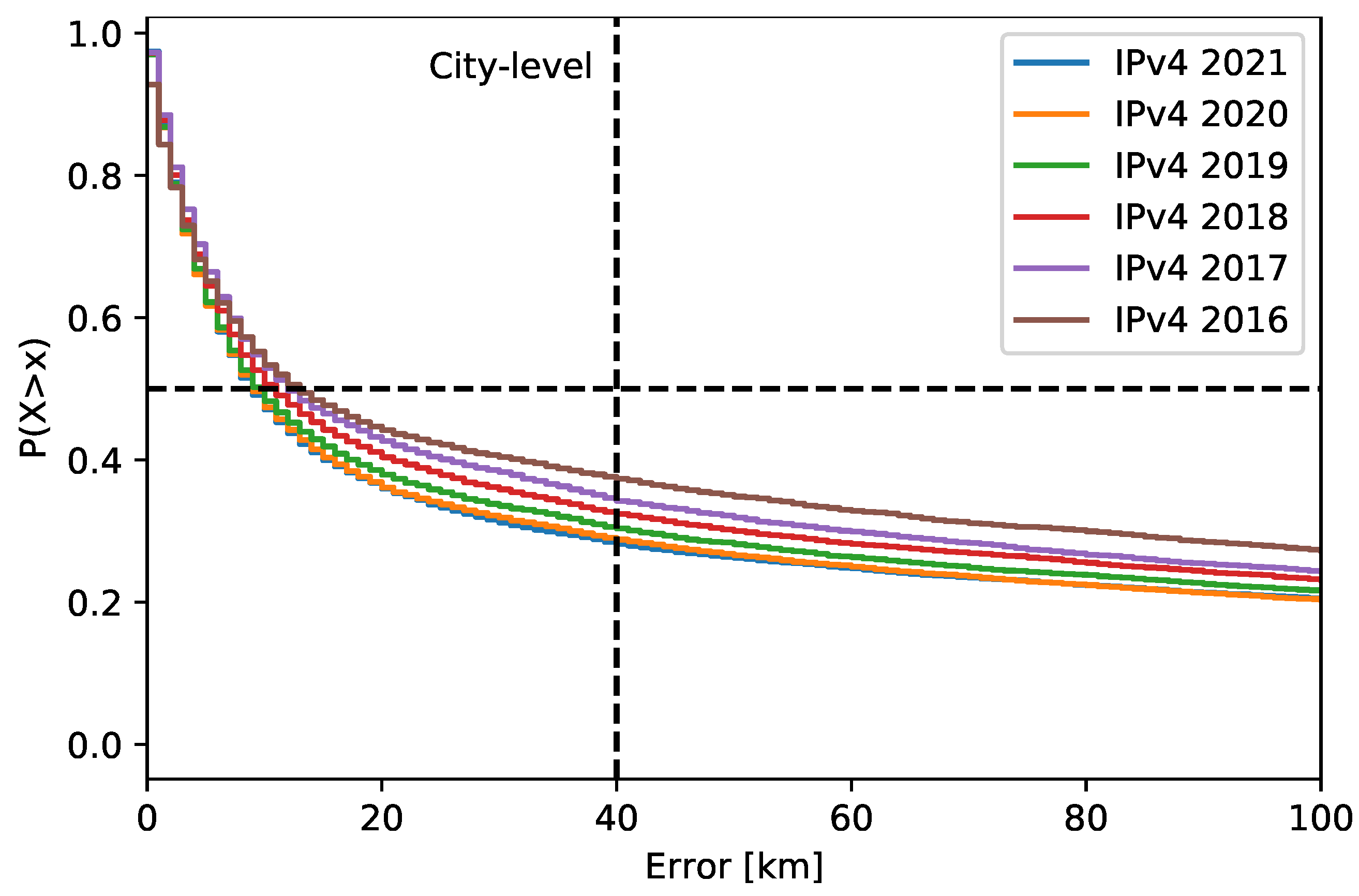
10]. They deal with the location accuracy of the addresses that belonged to router interfaces. Their ground truth included about 16,500 addresses. The evaluated geolocation databases were MaxMind GeoLite2 (free), IP2location DB11.Lite (free), MaxMind GeoIP2 (commercial), and Digital Envoy NetAcuity (commercial). The ground truth of router interface addresses was created by decoding the location hints from the router hostnames. The particular router addresses were collected from the RIPE Atlas built-in measurements. Specifically, the traceroute data were used to collect the addresses of the routers, which were within a distance of 50 km to the Atlas probes. The Atlas probe coordinates were used as reference locations. The work results were that the Digital Envoy NetAcuity had the best accuracy at the city level, followed by MaxMind GeoIP2 and GeoLite2. The latter databases performed similarly. The authors also used 692,000 addresses to study the inconsistency between the databases at the city level. The result was that at least 29% of the addresses across the databases had a city-level disagreement. A pairwise comparison of the MaxMind databases (free and commercial) showed that they were similar. There were 68% of the addresses with the same coordinates, and about 11% of the addresses had a distance difference of over 40 km. The authors also justified the usage of the 40 km limit for the city level, as this value is commonly used for location accuracy evaluation. In general, the databases may return different coordinates for the same city. These coordinates point, for example, to the organization headquarters with their own delegated address space or to the city cultural/geographical center. To justify this limit, the authors examined the distance between the coordinates from different databases. These coordinates were returned for the same cities. The result was that 99% of the same-city coordinates were within a distance of 40 km.
The active location is used to populate the databases, along with other methods, such as data mining and device self-reporting. The recent work of Du et al. [
11] has dealt with active location using the RIPE Atlas platform called IPmap. A single-radius engine was used to deliver the location of IP addresses. The latency measurements approximated the geographical distance between the located device and the Atlas probe, whose coordinates were taken as the ground truth. The cities around the geographically closest Atlas probe were ordered, and the most probable city was used as the location result for the IP address. The measurements were done only by a selected set of Atlas probes to reduce the Internet traffic and location delay. A possible triggering of a DoS attack alert was mitigated this way. The ground truth used covered 968 addresses of which 870 were located. Eighty percent of them were located within the city-level distance (40 km) to the correct location.
Other work combined different location approaches to improve the accuracy. Scheitle et al. [
7] used the hints in domain names and latency measurements to locate the routers. There was a location match in these two methods for 45,000 IPv4 addresses and 5000 IPv6 addresses. This way, they proposed an efficient way to establish a ground truth. Zhao et al. [
3] combined a location database and latency measurements to reduce the number of NA (not available) locations. The work was based on a set of classifiers. The result was a location accuracy of 99% at the the province level and 82% at the city level. The results were obtained for places in China. The authors also mentioned a non-standard application of IP location to broadcast important information, for example, issued by the government. The information is displayed similarly to online adverts. The broadcasting range may be limited to users from specific cities, thus introducing a new channel for message delivery.
IP location accuracy suffers from constant changes in the Internet space. Padmanabhan et al. [
12] studied the reasons behind the changes in the IP address space and consequently changes in their locations. The RIPE Atlas was used in this work as the ground truth. The ground truth IP addresses were obtained from the periodic connections of the Atlas probes to the controller. The authors worked with 3038 IPv4 probes over 12 months. The result was that ISPs assigned IP addresses to probes in a periodical manner, probably due to security reasons. Work by Almohri et al. [
13] focused on the IP address assignment. They attempted to predict the next assigned address, which may be used to improve the location accuracy. The previous address location could be immediately assigned to the new address. This way, the negative effect on the address reassignments could be mitigated. The work particularly dealt with the IPv4 addresses used by cloud service providers, which were the Amazon Web Services and Google Cloud Platform. There were around 4000 addresses used. The prediction success of the next assigned address was around 90% for the first three address bytes, which is sufficient for IP geolocation.
There are many applications of IP geolocation, such as where the device locations may be needed retrospectively. These include address reputation [
14], phishing mitigation [
15], credit card fraud [
16], and forensic investigation [
17].
4. Collection of Historical Data
The historical data used in this work consist of IP addresses used in the past, their past locations, and the previous versions of a geolocation database. The addresses used in the past and their locations were processed from the RIPE Atlas archive [
18]. This archive stores information about fixed devices, which are measurement probes. These probes are distributed around the world in different network environments. I use them as the historical ground truth since their past descriptive information is available, including IP address, operational status, and location. The archive starts in 2014 and is available up to 2021 as of the date of this work [
19].
I processed the archived ground truth to avoid bias caused by invalid data, including possible faulty addresses. The Atlas software automatically stores the probe addresses when they periodically connect to the Atlas controller. The probe operational status is also automatically set by the success of these connections as Connected, Abandoned, Disconnected, and Never Connected. I excluded probes that were not in the status Connected at a given past date. This way, only the IP addresses that were truly active in the past were considered. The probes without a location specified in the past were also excluded. For example, the original number of ground truth probes on 2 March 2021 was 33,655, and it was reduced by this processing to 11,523. There were also some missing or invalid networking data (e.g., duplicated addresses). This further reduced the number of usable probes on that date to 9781. The final reduction resulted in about one-third of the original data for each year covered.
The original and reduced ground truth data over the years are shown in
Table 1. The ground truth probes had IPv4, IPv6, or both addresses, as shown by the numbers. There were large differences in the number of usable probes between the years, mainly towards 2014, which was the start of the archive. The large difference in the number of probes could cause an inconsistency in the address space coverage. Therefore, I did not use the first two years (2014, 2015) of the ground truth for the IPv4 address historical analysis. For IPv6 addresses, I considered the years from 2018. In total, approx. 51 thousand IPv4 addresses and approx. 17 thousand IPv6 addresses were used.
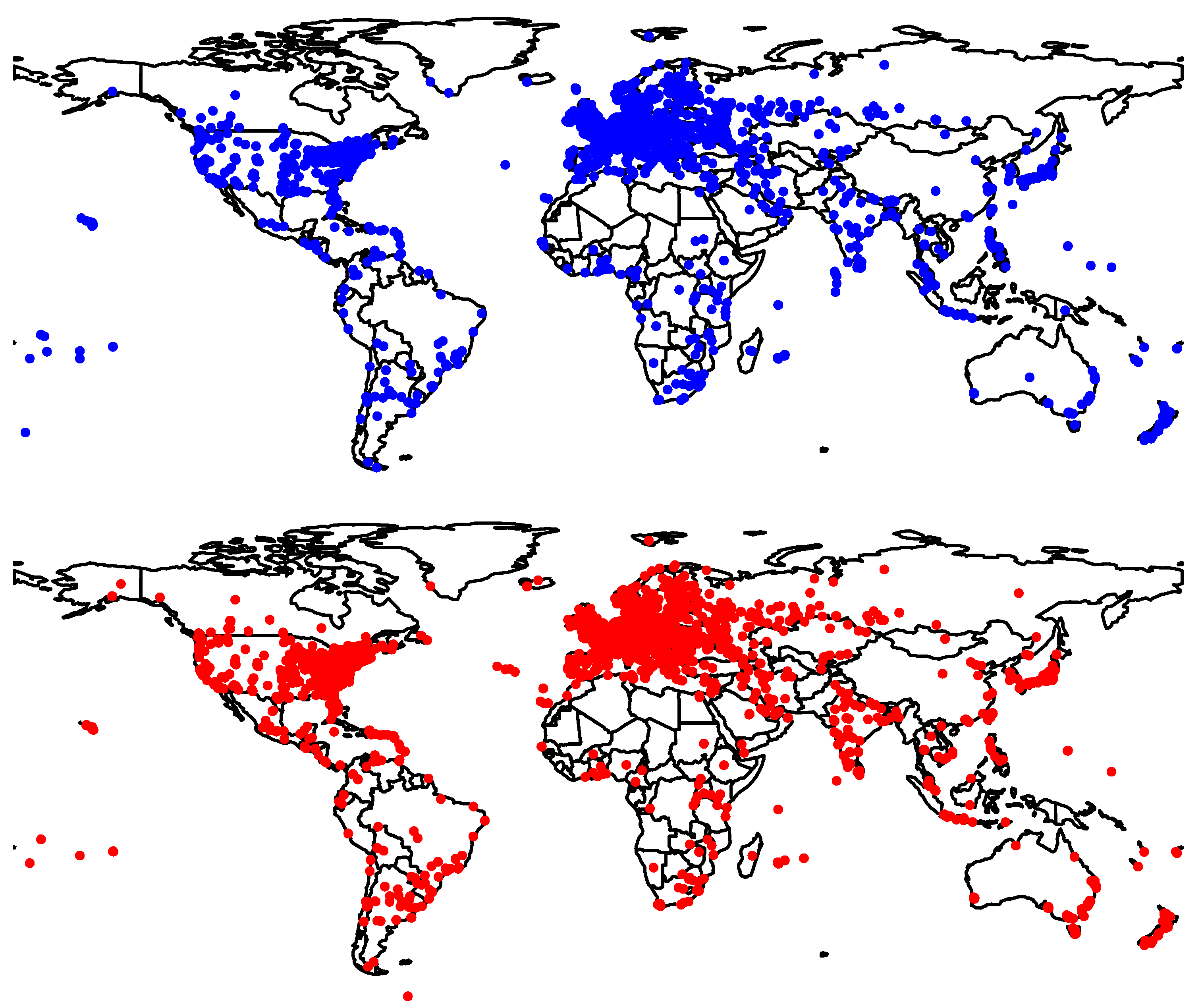
Figure 2 shows the global geographical distribution of the ground truth probes. The majority of the ground truth was in Europe and North America.
The historical data include past versions of a geolocation database. I used the past versions of the MaxMind GeoLite2 City database. This database is commonly shipped as a part of various software and operating systems. This makes some of their past versions reachable in the respective software archives compared to other databases, which are not archived. These particular sources were used:
Archives of UNIX and Linux OS updates [
20]. The historical data were obtained from the past versions of software packages (e.g., rpm, deb).
Web content archive provided by the Wayback Machine [
21]. The historical data were obtained from the snapshots of pages’ past content, mainly in the MaxMind domain.
Research datasets, such as Harvard Dataverse Repository [
22].
Installations of web servers that use IP geolocation, such as WordPress.
GitHub and GitLab and other general software repositories. The data were obtained from the archived software development versions.
As discussed in
Section 2, there is an issue with the database dates as the file metadata date is not the date when the database was built. Accurate dates of the past database are needed for past address locations and analysis. A single inaccurate date may give wrong results or wrong estimates of the location lifetime for many addresses. I also used the database date to link it to the correct day of the past ground truth. The MaxMind databases are stored in the MaxMind DB File Format (mmdb), which holds the “epoch” value [
23]. I used this epoch as the genuine database building date. For databases that are stored in other formats, such as the common CSV, obtaining the genuine date is not possible.
The past databases were linked to the past ground truth with a prerequisite of the same relative difference between the database dates. The best match was found to be in March and April of each of the covered years. The databases complying with this prerequisite were dated to 3 April 2014, 3 March 2015, 3 March 2016, 7 March 2017, 4 April 2018, 15 April 2019, 3 March 2020, and 2 March 2021. The past ground truth comes exactly from these same dates, starting from 2016. The used past databases and Atlas archives are listed in
Table A1.
The survival analysis is based on the duration of address locations over past databases. The databases store the locations for groups of addresses, delimited by a network range, for example, /24 for IPv4 addresses and /48 for IPv6 addresses. To extract the IP addresses, the CSV database version was used (the build date was obtained by direct download of the linked binary mmdb alternative of the same database). The database blocks are described as (simplified) network address/range, geoname_id, and coordinates. The geoname_id property refers to another CSV file storing the place textual descriptions. An example record for IPv4 is 71.195.26.0/23, 5037649, (45.0196, −93.2402), where the place geoname_id refers to Minneapolis, US. An example for IPv6 is 2a0f:9400:8008::/48, 3163392, (62.4684, 6.3427), where the place ID refers to Alesund, Norway. The CSV files used to derive the IPv4 and IPv6 addresses are listed in
Table A2 as ‘source files for lifetime end’. I selected the locations linked to the first IP address of each block in the database dated to 13 April 2021. These IP address locations were further checked for their change in the closest database dated to 5 April 2021. The changed address locations were used in the survival analysis only as their lifetime end date was known this way. There were 421 k IPv4 and 47 k IPv6 addresses with the known location end date. In total, 38 past databases were used in the survival analysis.
Table A2 lists the dates of the past databases used.
6. IP Address Location Lifetime
Geolocation databases store locations for IP addresses. I apply survival analysis to these locations to investigate their lifetime. The location lifetime is the duration of the unchanged location over past geolocation databases. The survival function
gives the probability of a location surviving past time
t,
T is the random variable expressing the address location duration over past databases, and
is the cumulative distribution function for
,
.
T is known to be within the
ith interval
, where
is the left interval limit and
the right interval limit,
.
The location lifetime
T is expressed in days. The intervals of
T are open from the left,
, as the location change had to happen before the past database date, which was used to obtain
. The intervals are closed from the right,
, as the location change had to happen after or on the database date, which was used to obtain
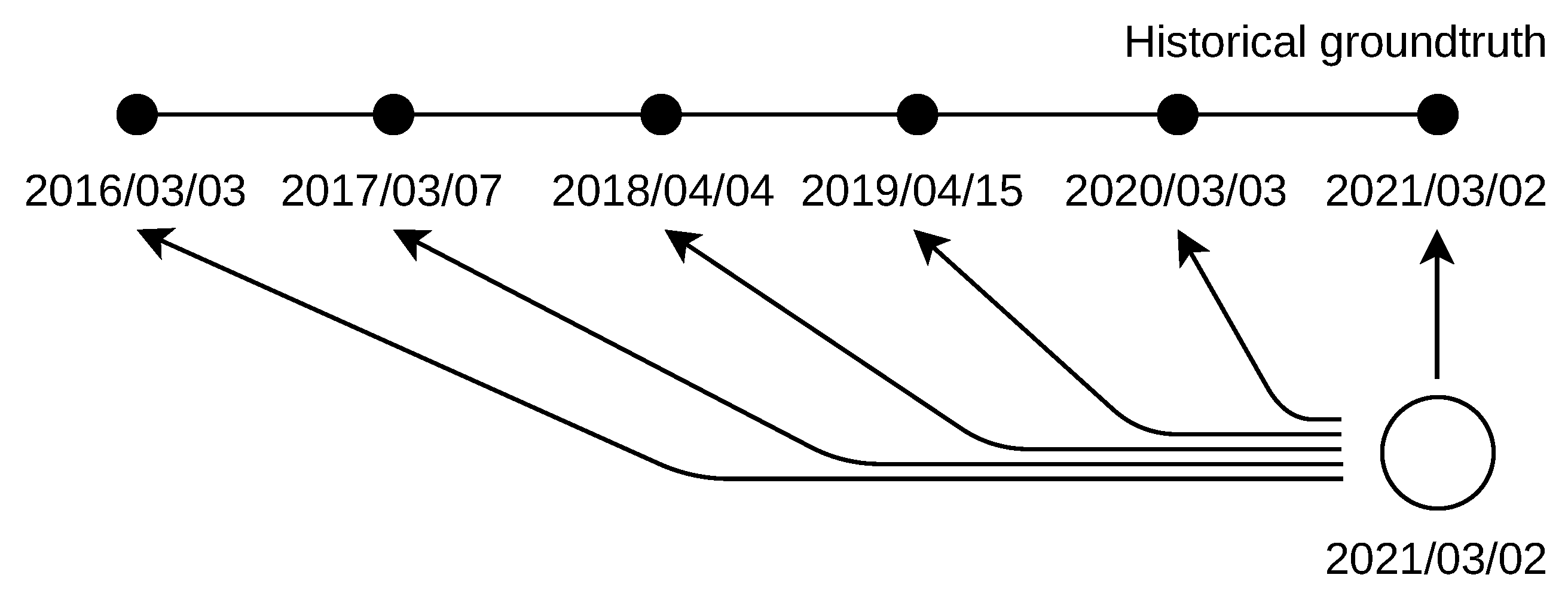
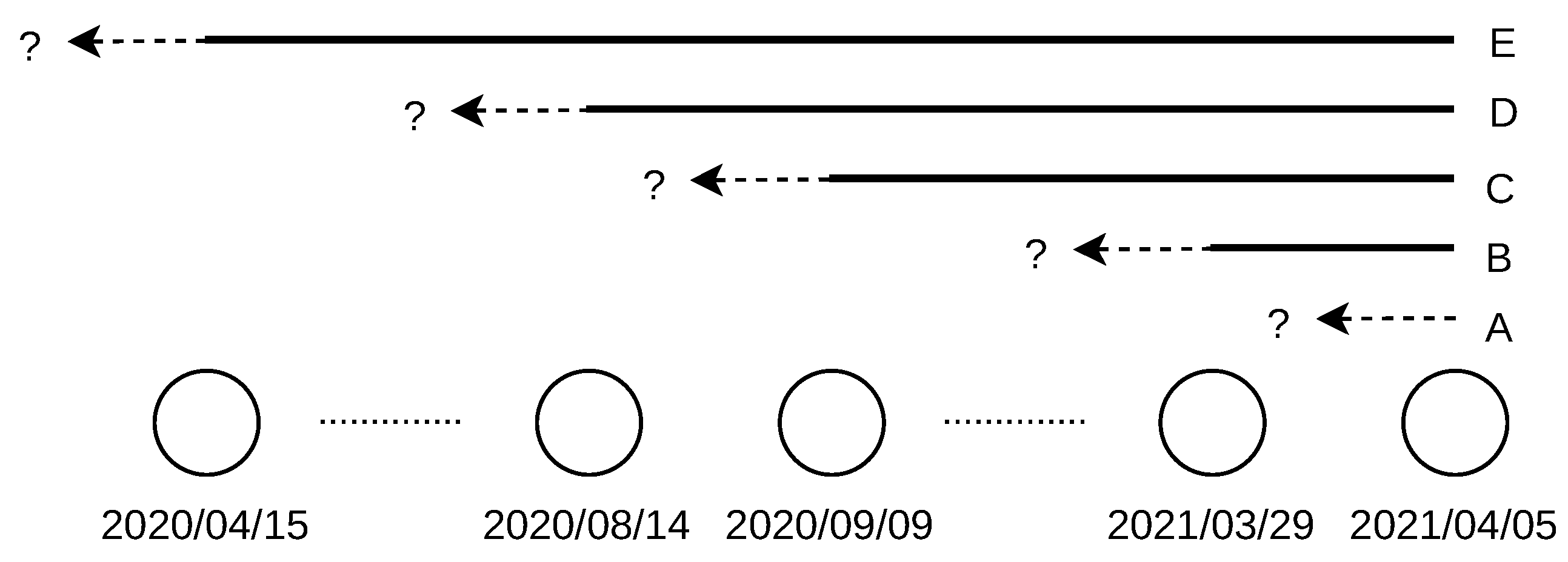
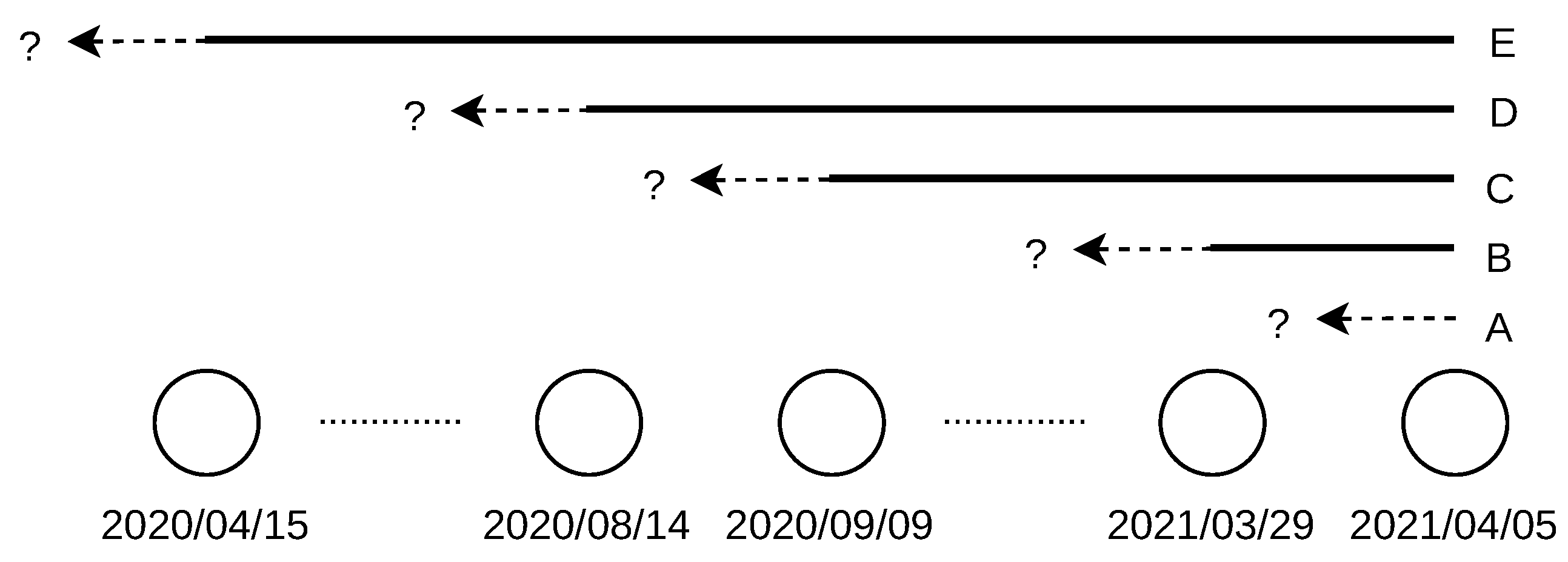
. For example, a location changed between 14 August 2020 and 9 September 2020, as the change was not observed in the database dated to 9 September 2020 (the location was “alive” on this day), but it was already observed in the database dated to 14 August 2020 (the location was “dead” on this day), as shown in
Figure 8.
The location change is right-censored for cases when it was not observed until the last (most distant) historical database date. There are no left-censored data, as all location durations ended at time
. The interval of
E and intervals of
set the doubly interval censored data. The problem of doubly censored data is approached by the reduced likelihood and use of the maximal intervals for
[
24]. Therefore,
where
is set to eight as all locations ended between 13 April 2021 and 5 April 2021.
is set to zero as 13 April 2021 is the database date used to derive the addresses. The last interval
indicates that the address location was alive (the same) before 15 April 2020; thus, the address location start was not observed. I assume that there cannot be two historical databases dated to the same date, and thus
, which states that any of the location changes cannot be observed on the exact day. I also assume that the interval censoring is non-informative, i.e., that it is independent of the likelihood of the location change. This means that the censored locations would have the same distribution of changes as if they were exactly observed.
Some locations changed with a low difference between the previous and new coordinates, such as (35.7298, 139.6347) to (35.69, 139.69), a distance of 7 km. There were also some changes that repeated periodically, thus alternating between a set of coordinates over time. To mitigate these false observations, I used a limit of 40 km distance between the coordinates to detect the true city-level change [
10]. It was also possible that a past database did not have a record for an IP address; therefore, its location was NA. The first observation of the NA data was considered as the location change, thus ending the address location lifetime.
The definition of the address blocks in the past databases might have changed during the years. I worked with the addresses falling into different blocks the same way as with other addresses. This effectively means that if the address block was changed, the investigated address location was set to the new block location. Therefore, there were not any right-censored locations due to their dropping before the last observation time (note that there are right-censored data after the last observation time).
A sample of the interval-censored data for IPv6 addresses is shown in
Figure 9. The arrows on the red lines delimit the intervals of location change. The blue lines show the cases when the location change was not observed during the covered period, that is, over one year.
Table 4 shows the interval-censored survival data in days to pass for IPv4 and IPv6 addresses. The column “removed” gives the number of locations changed during the interval. All location changes are censored, which is shown in the next two columns as observed
and censored = removed. The column “at_risk” gives the number of unchanged locations. There are the same intervals for IPv4 and IPv6 addresses. The last interval is right-censored.
I used the iterative Turnbull Estimator to estimate the survival function
, which handles the interval of censored data via maximum likelihood computation. The estimator [
25] considers
times that include interval limits
and
,
. A weight
is defined for
ith observation and
as
which shows whether the location change during
could have happened at time
. The initial guess of
may be obtained by the Kaplan–Meier non-parametric estimator [
26] as
where
is the number of same locations at risk up to the right limit of interval
, and
is the number of locations that changed during
.
The mass within the interval
is
and the number of changed locations at
is estimated as
Finally, the number of locations at risk at
is computed as
The process of Equations (
5)–(
7) is repeated until the new survival function estimate is close to the previous
for all
. The software [
27] was used for this specific calculation.
Figure 10 shows the estimate of the survival function for the locations of IPv4 and IPv6 addresses. The upper and lower survival boundaries for each interval are shown. The last bounding box is not defined due to right censoring.
The non-parametric survival function was approximated by the parametric Log-logistic model
where
is the scale parameter and
is the shape parameter. The model was chosen based on the best AIC score among the common parametric models. The model fit for both IPv4 and IPv6 is shown in
Figure 10. The fitted parameters are listed in
Table 5.
The survival analysis shows that IPv4 address locations may be considered as stable in time with respect to IPv6. The median location lifetime duration for IPv4 addresses is about 46 days and 24 days for IPv6 addresses.
The raw data used in the analysis are available in the format listed in
Table A4.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}