
A Parametric Logarithmic Image Processing Framework Based on Fuzzy Graylevel Accumulation by the Hamacher T-Conorm



Abstract
1. Introduction
2. Logarithmic Image Processing Models
2.1. The Classical LIP Model
2.2. The Homomorphic LIP Model
2.3. The Pseudo-LIP Model
2.4. The Multiparametric LIP
2.5. The Gigavision-Camera LIP Model
2.6. The Spherical Color Coordinates Model
3. Fuzzy Aggregation of Graylevels
3.1. Fuzzy T-Conorms
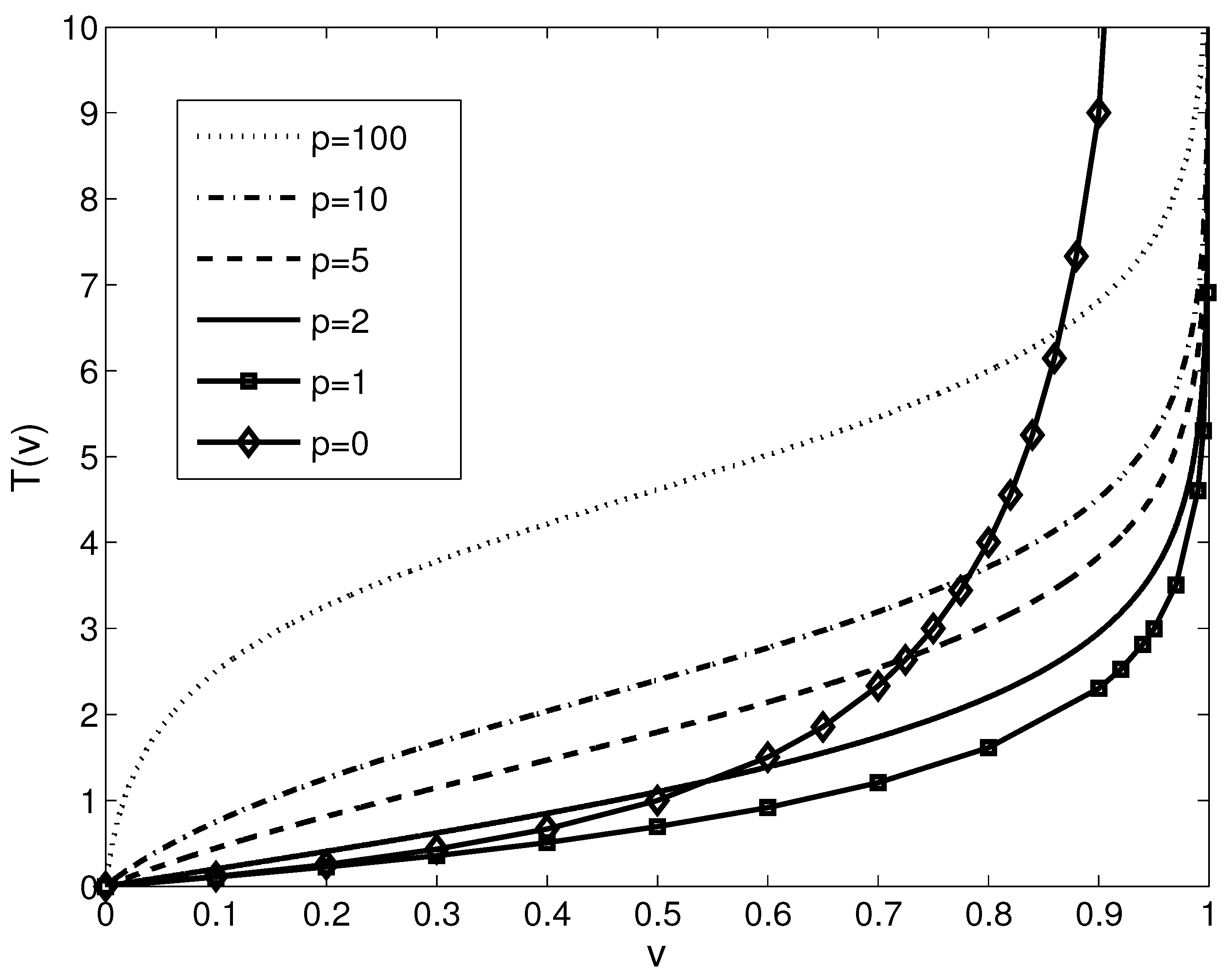
3.2. Hamacher T-Conorm Induced Parametric LIP
4. Applications
4.1. Dynamic Range Enhancement
4.2. Average-Based Noise Reduction
4.3. Gradient-Based Edge Detection
4.4. Image Blending
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Derivation of the FLIP Addition
Appendix B. Derivation of the FLIP Scalar Multiplication
Appendix C. Derivation of the Formula for the Dynamic Range
Appendix D. Typical Edge Extraction Results for Natural Images


References
- Stockham, T.G. Image processing in the context of visual models. Proc. IEEE 1972, 60, 828–842. [Google Scholar] [CrossRef]
- Oppenheim, A.V. Generalized Supperposition. Inf. Control 1967, 11, 528–536. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Shaffer, R.W.; Stockham, T.G., Jr. Nonlinear Filtering of Multiplied and Convolved Signals. IEEE Trans. Audio Electroaccoustics 1968, 16, 437–466. [Google Scholar] [CrossRef]
- Jourlin, M.; Pinoli, J.C. Image dynamic range enhancement and stabilization in the context of the logarithmic image processing model. Signal Process. 1995, 41, 225–237. [Google Scholar] [CrossRef]
- Jourlin, M.; Pinoli, J.C. A model for logarithmic image processing. J. Microsc. 1998, 149, 21–35. [Google Scholar] [CrossRef]
- Jourlin, M.; Breugnot, J.; Itthirad, F.; Bouabdellah, M.; Closs, B. Logarithmic image processing for color images. Adv. Imaging Electron Phys. 2011, 168, 65–107. [Google Scholar]
- Deng, G.; Cahill, L.W.; Tobin, G.R. The Study of Logarithmic Image Processing Model and Its Application to Image Enhancement. IEEE Trans. Image Process. 1995, 4, 506–512. [Google Scholar] [CrossRef] [PubMed]
- Florea, C.; Vertan, C.; Florea, L. Logarithmic Model-based Dynamic Range Enhancement of Hip Xray Images. In Lectures Notes in Computer Science LNCS; Springer: Berlin/Heidelberg, Germany, 2007; pp. 587–596. [Google Scholar]
- Jourlin, M. Logarithmic Image Processing: Theory and Applications. In Advances in Imaging and Electron Physics; Academic Press (Elsevier): Amsterdam, The Netherlands, 2016; Volume 195. [Google Scholar]
- Jourlin, M.; Pinoli, J.C. Logarithmic image processing. The mathematical and physical framework fro the representation and processing of transmitted images. Adv. Imaging Electron Phys. 2001, 115, 129–196. [Google Scholar]
- Pătraşcu, V.; Buzuloiu, V.; Vertan, C. Fuzzy image enhancement in the framework of logarithmic models. In Fuzzy Filters in Image Processing; Series Studies in Fuzziness and Soft Computing; Physica Verlag: Heidelberg, Germany, 2003; Chapter 10; pp. 219–237. [Google Scholar]
- Vertan, C.; Oprea, A.; Florea, C.; Florea, L. A Pseudo-Logarithmic Framework for Edge Detection. In Lectures Notes in Computer Science LNCS; Springer: Berlin/Heidelberg, Germany, 2008; pp. 637–644. [Google Scholar]
- Palomares, J.; Gonzalez, J.; Ros, E.; Prieto, A. General Logarithmic Image Processing Convolution. IEEE Trans. Image Process. 2006, 15, 3602–3608. [Google Scholar] [CrossRef] [PubMed]
- Pinoli, J.C.; Debayle, J. Logarithmic adaptive neighborhood image processing (LANIP): Introduction, connections to human brightness perception, and application issues. EURASIP J. Appl. Signal Process. 2007, 2007, 114–135. [Google Scholar] [CrossRef][Green Version]
- Debayle, J.; Pinoli, J.C. Generalized Adaptive Neighborhood Image Processing: Part I: Introduction and Theoretical Aspects. J. Math. Imaging Vis. 2006, 25, 245–266. [Google Scholar] [CrossRef]
- Debayle, J.; Pinoli, J.C. Generalized Adaptive Neighborhood Image Processing: Part II: Practical Application Examples. J. Math. Imaging Vis. 2006, 25, 267–284. [Google Scholar] [CrossRef]
- Berehulyak, O.; Vorobel, R. The Algebraic Model with an Asymmetric Characteristic of Logarithmic Transformation. In Proceedings of the IEEE 15th International Conference on Computer Sciences and Information Technologies (CSIT), Zbarazh, Ukraine, 23–26 September 2020; Volume 2, pp. 119–122. [Google Scholar]
- Panetta, K.; Wharton, E.; Agaian, S. Human Visual System-Based Image Enhancement and Logarithmic Contrast Measure. IEEE Tran. Syst. Man Cybern. Part B Cybern. 2008, 38, 174–188. [Google Scholar] [CrossRef] [PubMed]
- Panetta, K.; Agaian, S.; Zhou, Y.; Wharton, E. Parameterized Logarithmic Framework for Image Enhancement. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2011, 41, 460–473. [Google Scholar] [CrossRef] [PubMed]
- Deng, G. A Generalized Logarithmic Image Processing Model Based on the Gigavision Sensor Model. IEEE Trans. Image Process. 2012, 21, 1406–1414. [Google Scholar] [CrossRef] [PubMed]
- Sbaiz, L.; Yang, F.; Charbon, E.; Susstrunk, S.; Vetterli, M. The Gigavision Camera. In Proceedings of the IEEE ICASSP, Taipei, Taiwan, 19–24 April 2009; pp. 1093–1096. [Google Scholar]
- Grundland, M.; Vohra, R.; Williams, G.P.; Dodgson, N.A. Cross Dissolve Without Cross Fade: Preserving Contrast, Color and Salience in Image Compositing. Comput. Graph. Forum 2006, 25, 577–586. [Google Scholar] [CrossRef]
- Bezdeck, J.C.; Pal, S.K. Fuzzy Models for Pattern Recognition; IEEE Press: New York, NY, USA, 1992. [Google Scholar]
- Tizhoosh, M. Fuzzy Image Processing; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Nachtegael, M.; Van der Weken, D.; Van De Ville, D.; Kerre, E.E. (Eds.) Fuzzy Filters in Image Processing; Series Studies in Fuzziness and Soft Computing; Physica Verlag: Heidelberg, Germany, 2003. [Google Scholar]
- Vertan, C.; Boujemaa, N. Using Fuzzy Histograms and Distances for Color Image Retrieval. In Proceedings of the CIR, Brighton, UK, 3–5 May 2000. [Google Scholar]
- Vertan, C.; Boujemaa, N. Embedding Fuzzy Logic in Content Based Image Retrieval. In Proceedings of the NAFIPS, Atlanta, GA, USA, 13–15 July 2000; pp. 85–90. [Google Scholar]
- Zimmermann, H.J. Fuzzy Sets Theory and Its Applications; Kluwer Academic Publisher: Boston, MA, USA, 1996. [Google Scholar]
- Barnard, K.; Martin, L.; Funt, B.; Coath, A. A Data Set for Color Research. Color Res. Appl. 2002, 27, 148–152. [Google Scholar] [CrossRef]
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image database TID2013: Peculiarities, results and perspectives. Signal Process. Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Deng, G.; Pinoli, J.C. Differentiation-based Edge Detection Using the Logarithmic Image Processing Model. J. Math. Imaging Vis. 1998, 8, 161–180. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vertan, C.; Florea, C.; Florea, L. A Parametric Logarithmic Image Processing Framework Based on Fuzzy Graylevel Accumulation by the Hamacher T-Conorm. Sensors 2021, 21, 4857. https://doi.org/10.3390/s21144857
Vertan C, Florea C, Florea L. A Parametric Logarithmic Image Processing Framework Based on Fuzzy Graylevel Accumulation by the Hamacher T-Conorm. Sensors. 2021; 21(14):4857. https://doi.org/10.3390/s21144857
Chicago/Turabian StyleVertan, Constantin, Corneliu Florea, and Laura Florea. 2021. "A Parametric Logarithmic Image Processing Framework Based on Fuzzy Graylevel Accumulation by the Hamacher T-Conorm" Sensors 21, no. 14: 4857. https://doi.org/10.3390/s21144857
APA StyleVertan, C., Florea, C., & Florea, L. (2021). A Parametric Logarithmic Image Processing Framework Based on Fuzzy Graylevel Accumulation by the Hamacher T-Conorm. Sensors, 21(14), 4857. https://doi.org/10.3390/s21144857