
Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks †


Abstract
:1. Introduction
2. Related Works
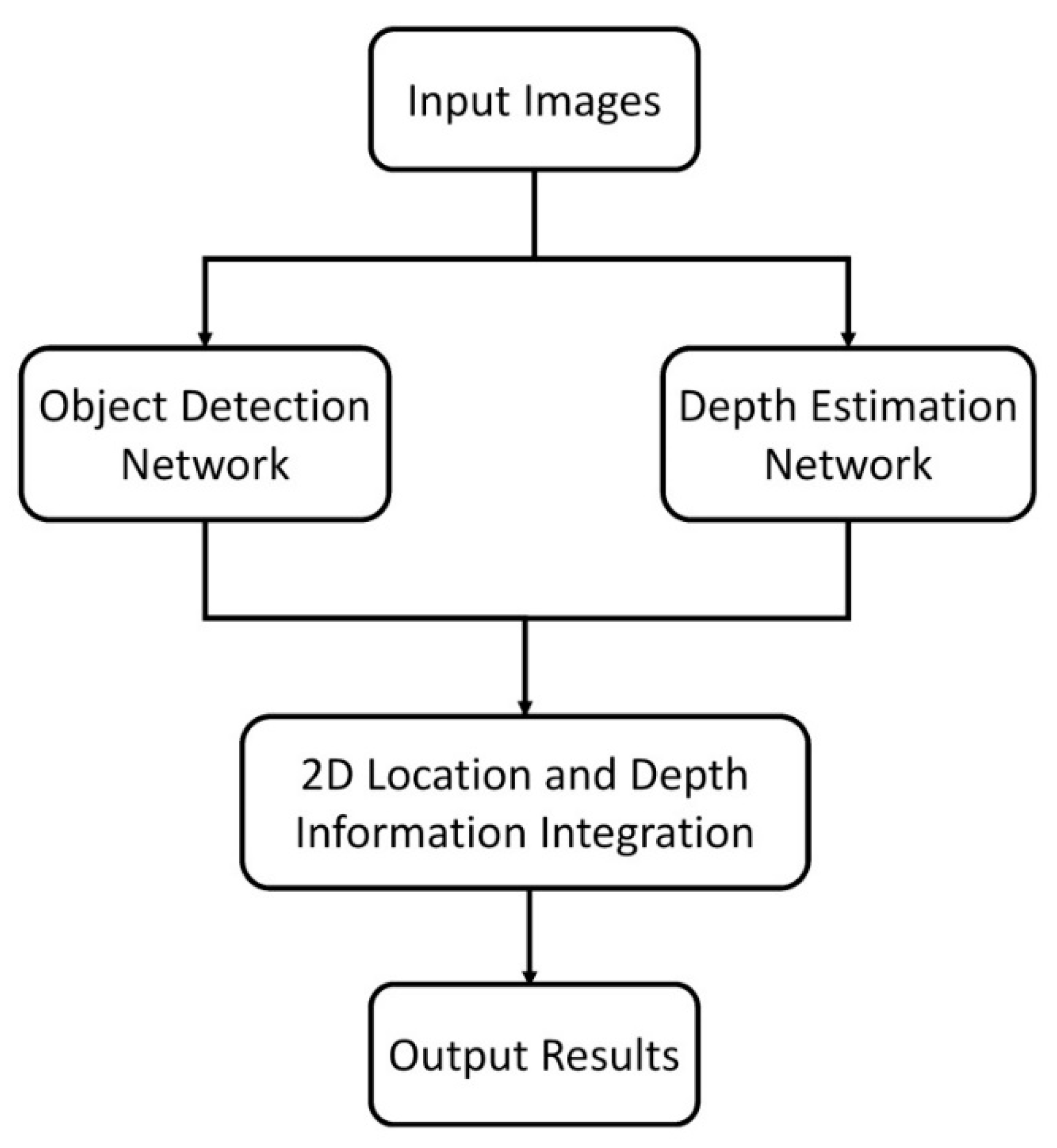
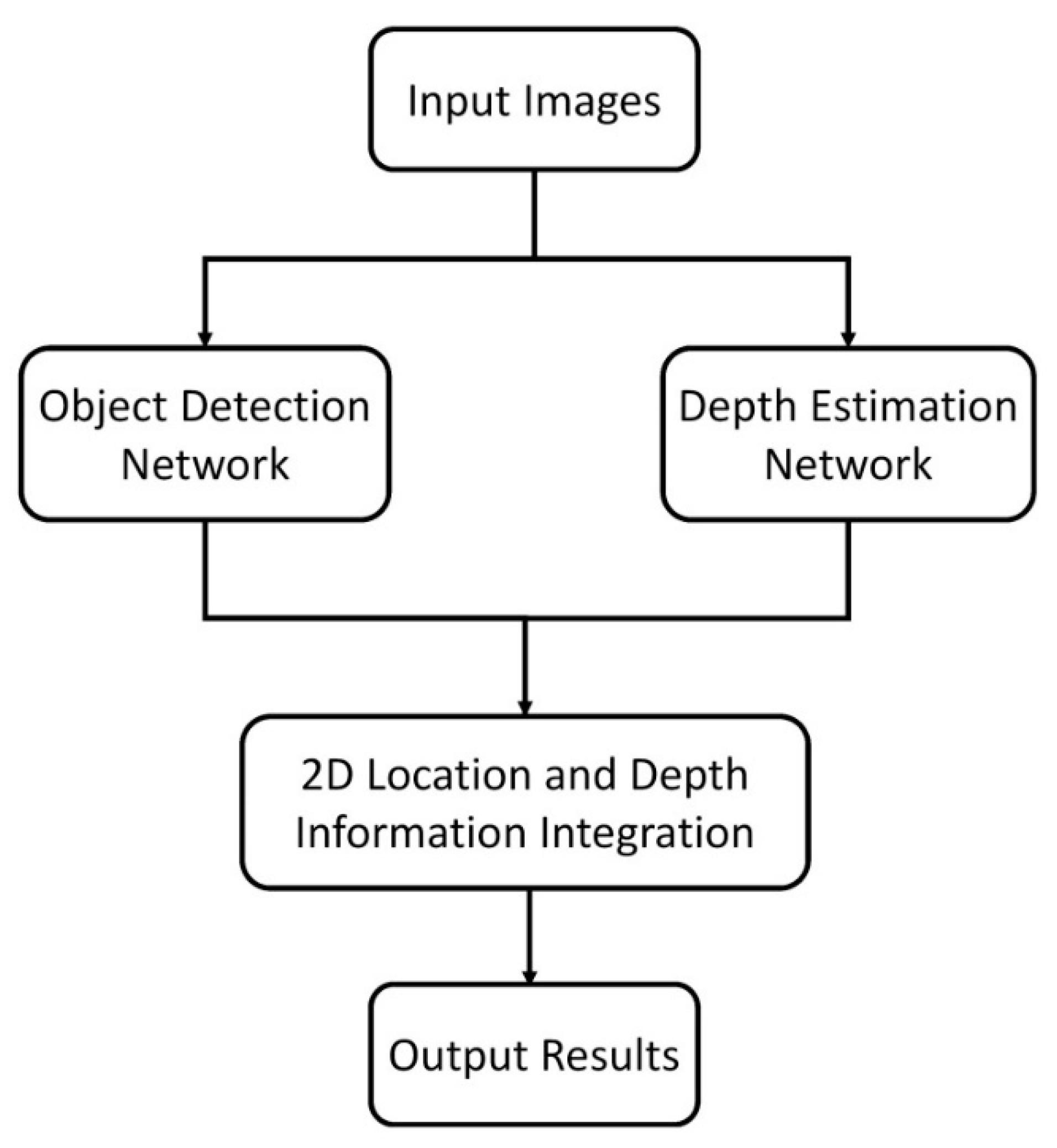
3. Proposed Approach
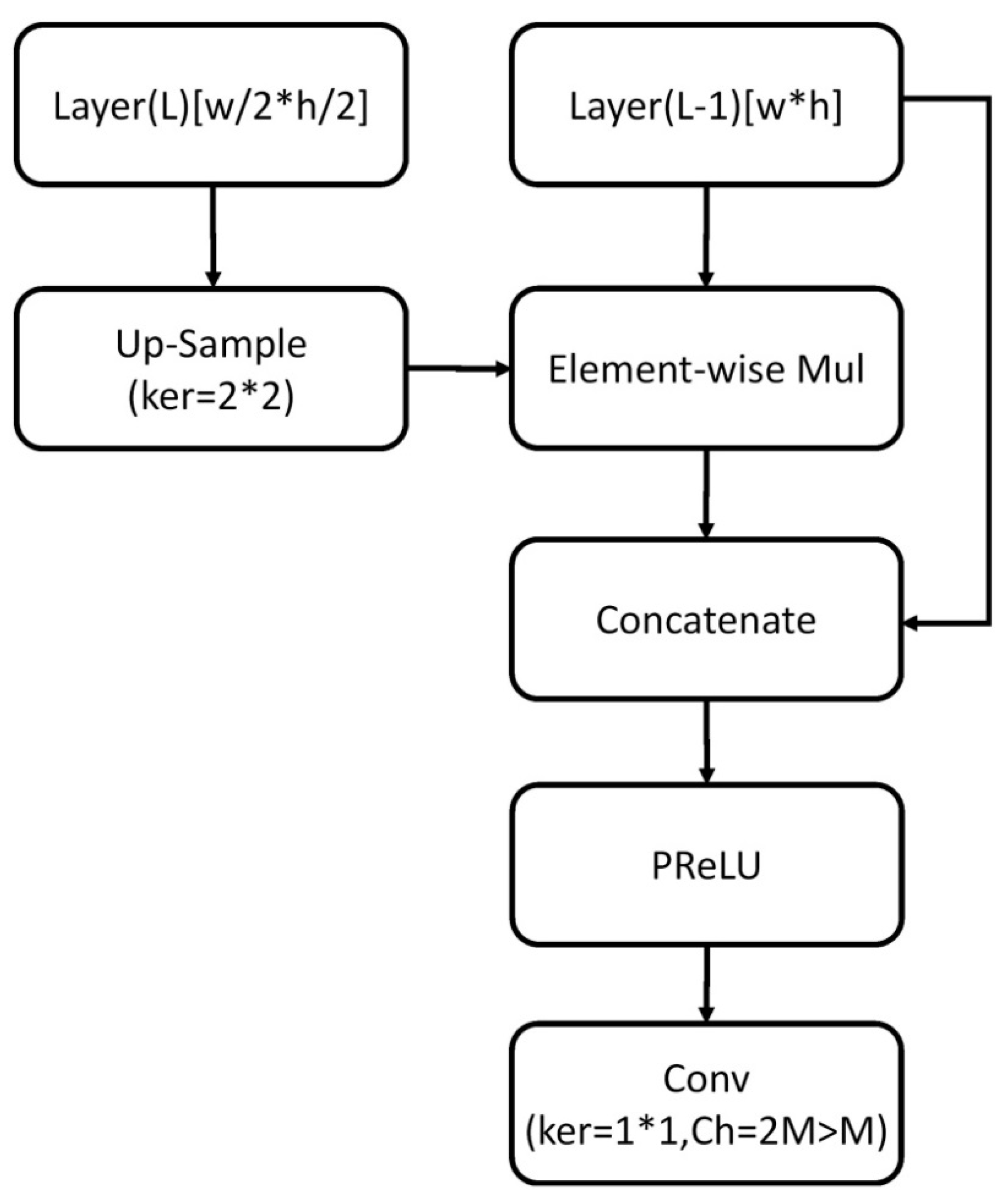
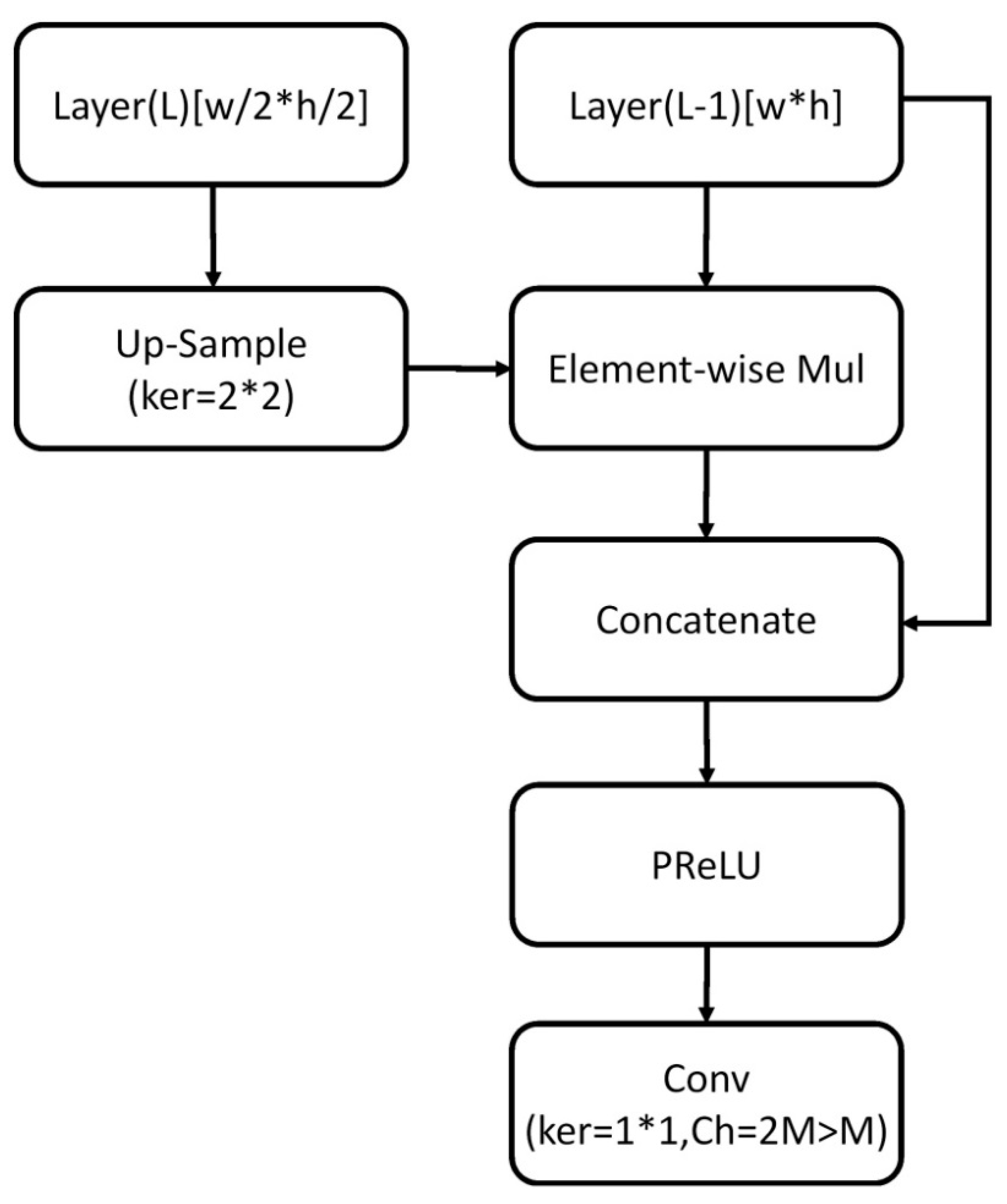
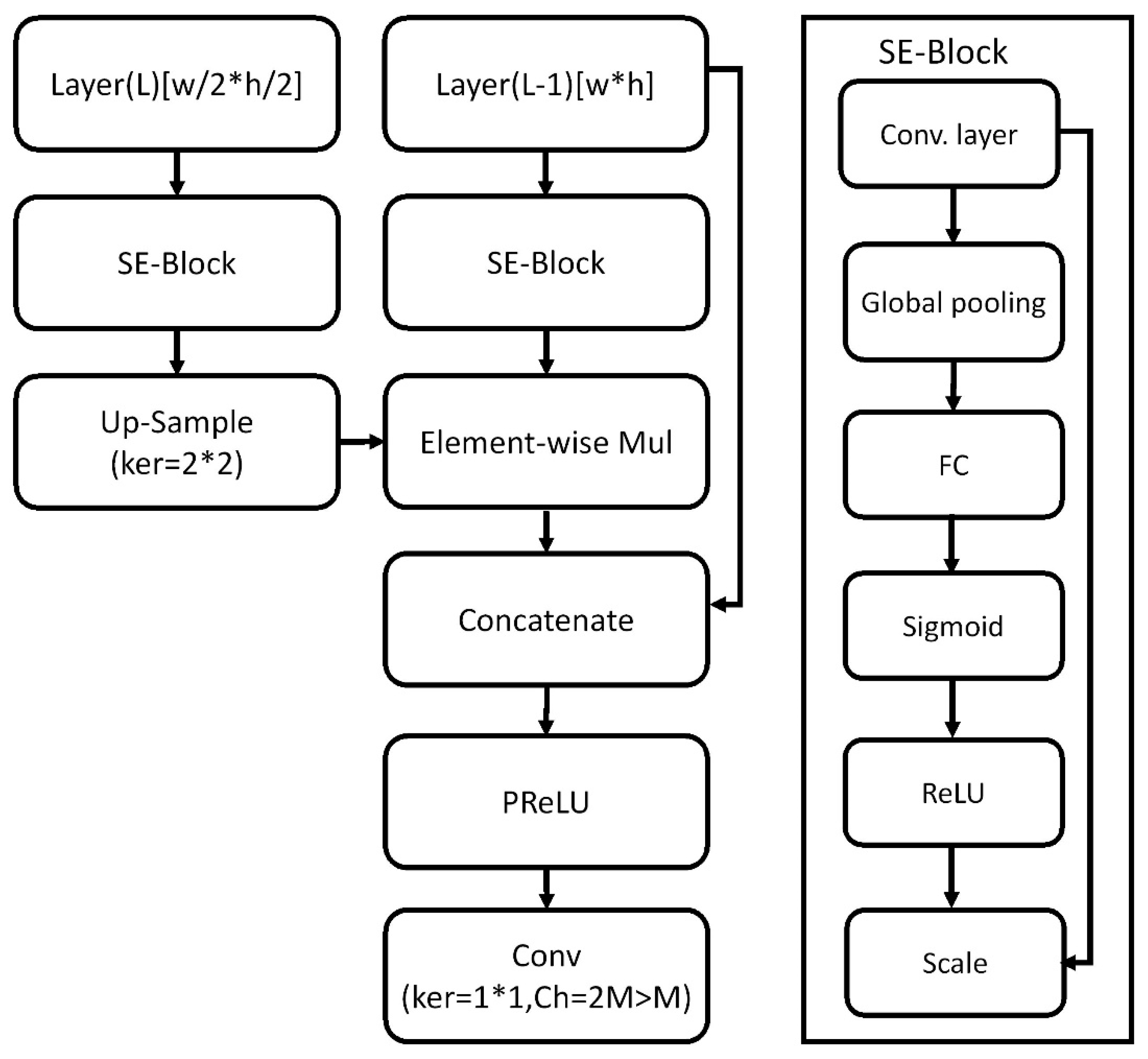
3.1. Object Detection
- (1)
- Enhanced fine-feature extraction:
- (2)
- Shared global information with features of each pixel:
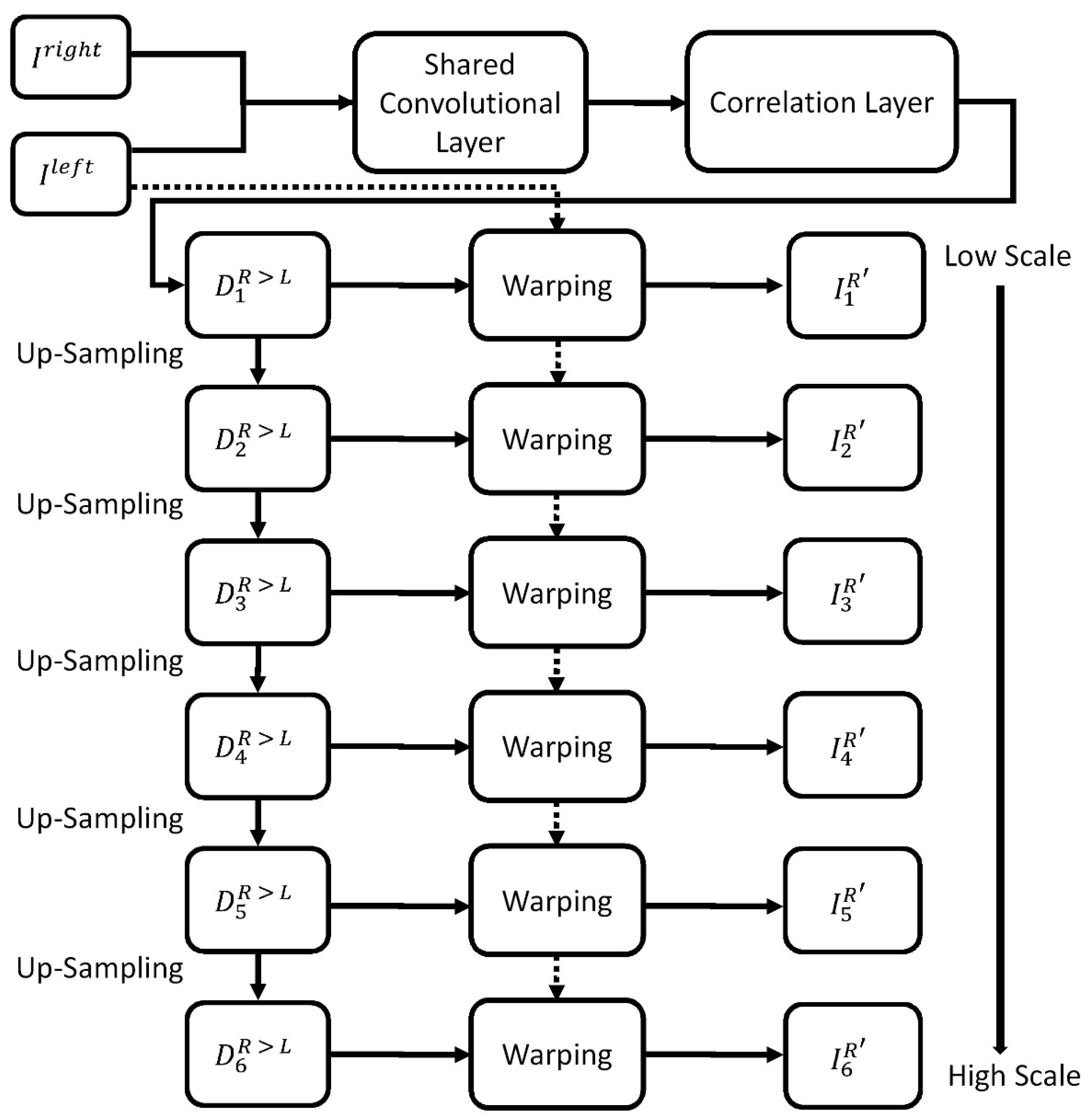
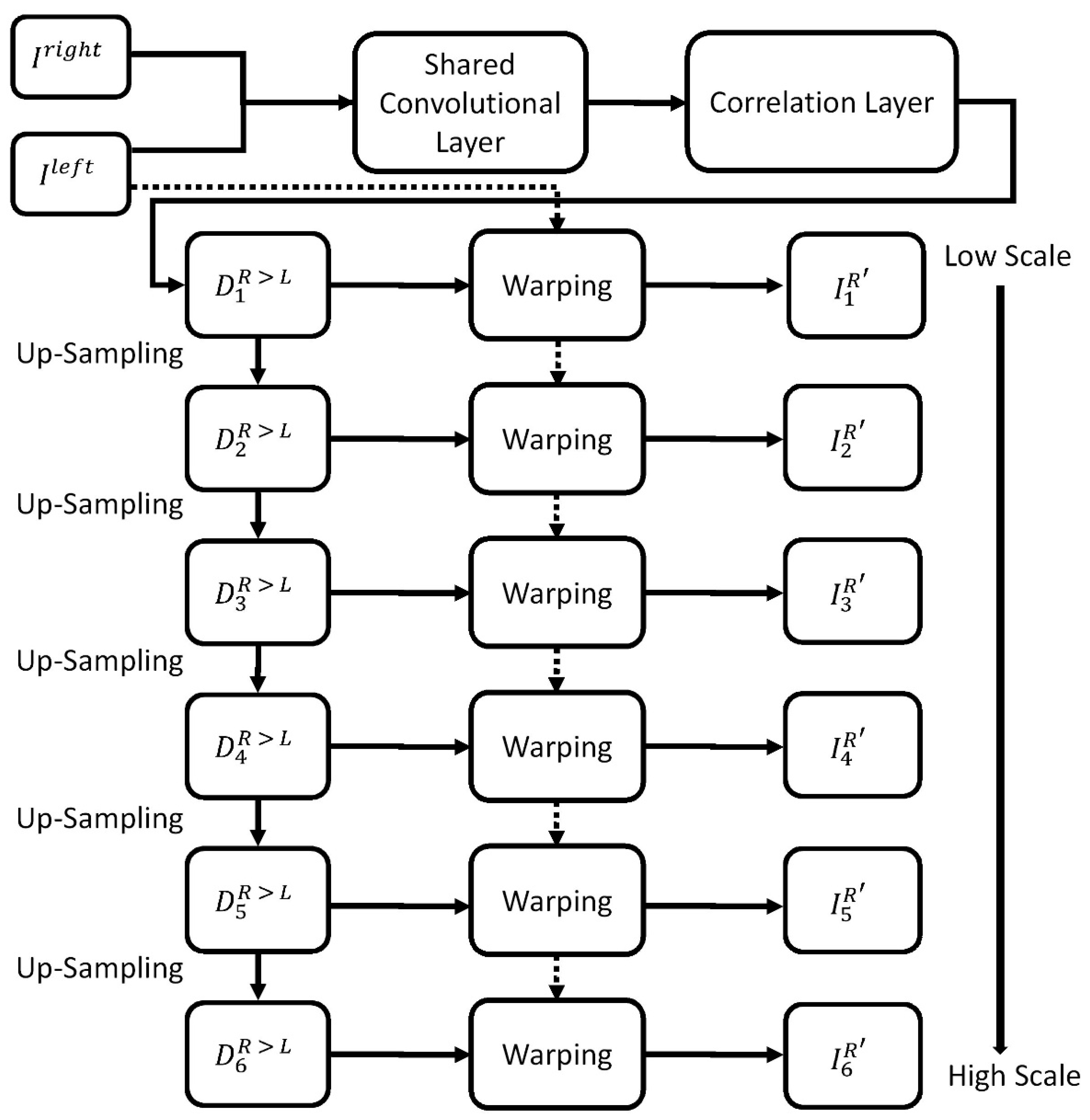
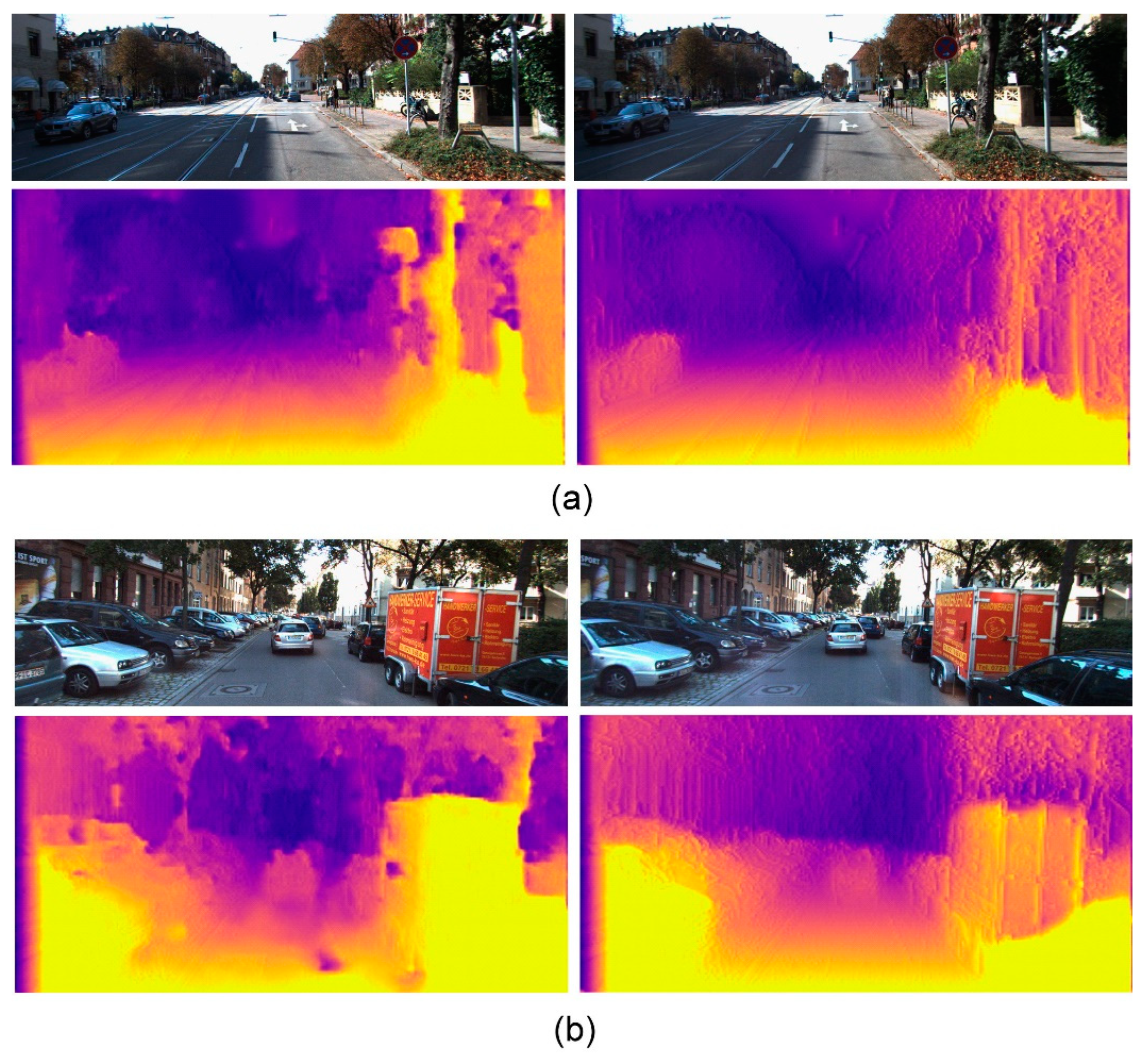
3.2. Depth Estimation
- (1)
- Input layer: We input left and right images;
- (2)
- Shared convolutional layer: With shared weights, we used the same convolution kernel to extract features of left and right images;
- (3)
- Correlation layer: We use mathematical inner product operations to match the common regions between left and right feature maps;
- (4)
- Disparity map prediction: We predicted all the possible disparity values for all matching points using a normal distribution method for six different scales; and
- (5)
- Grayscale image reconstruction: We reconstructed the left and right images on the basis of the predicted disparity maps and the internal camera parameters for the six scales.
4. Implementation and Results
4.1. Implementation
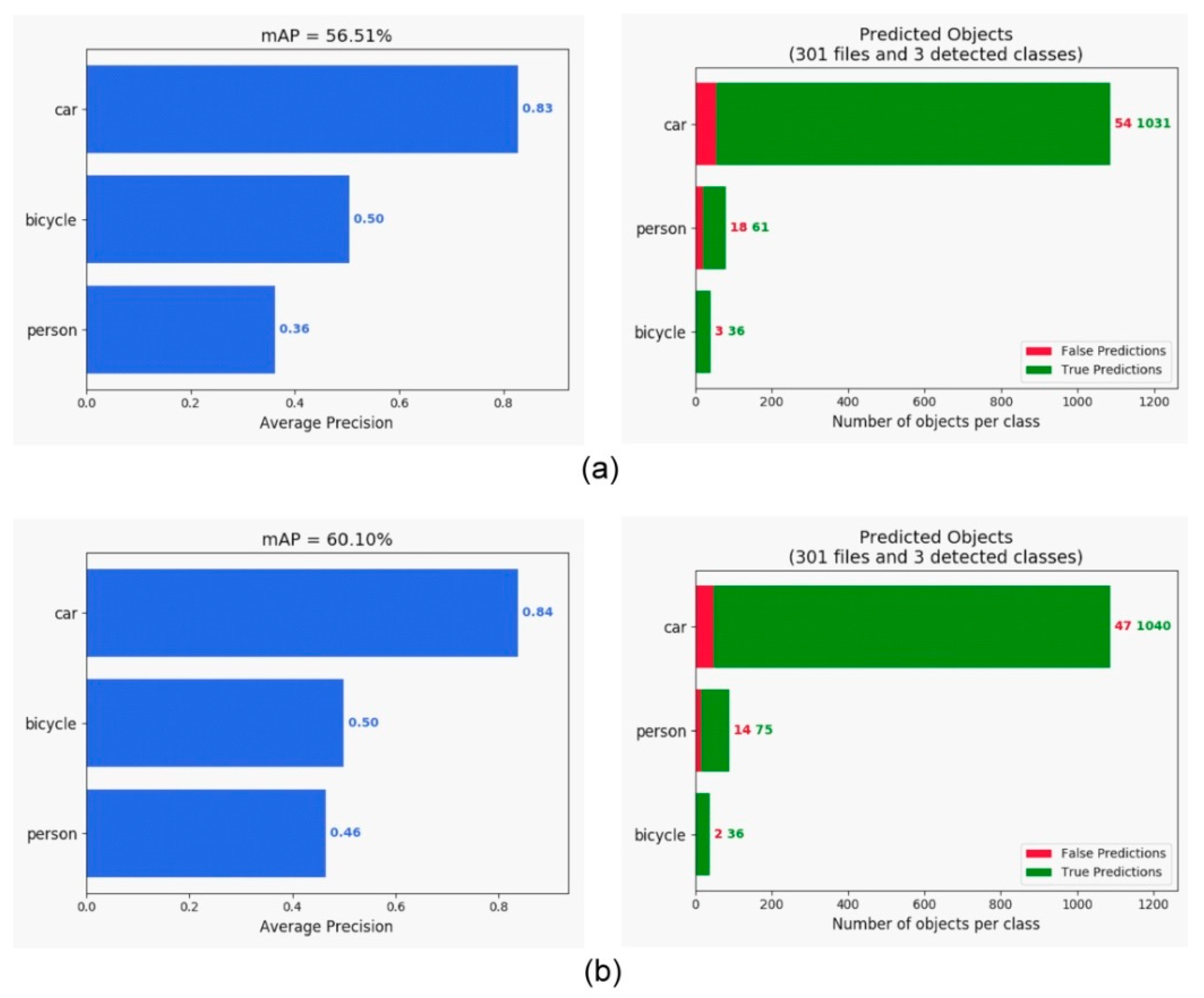
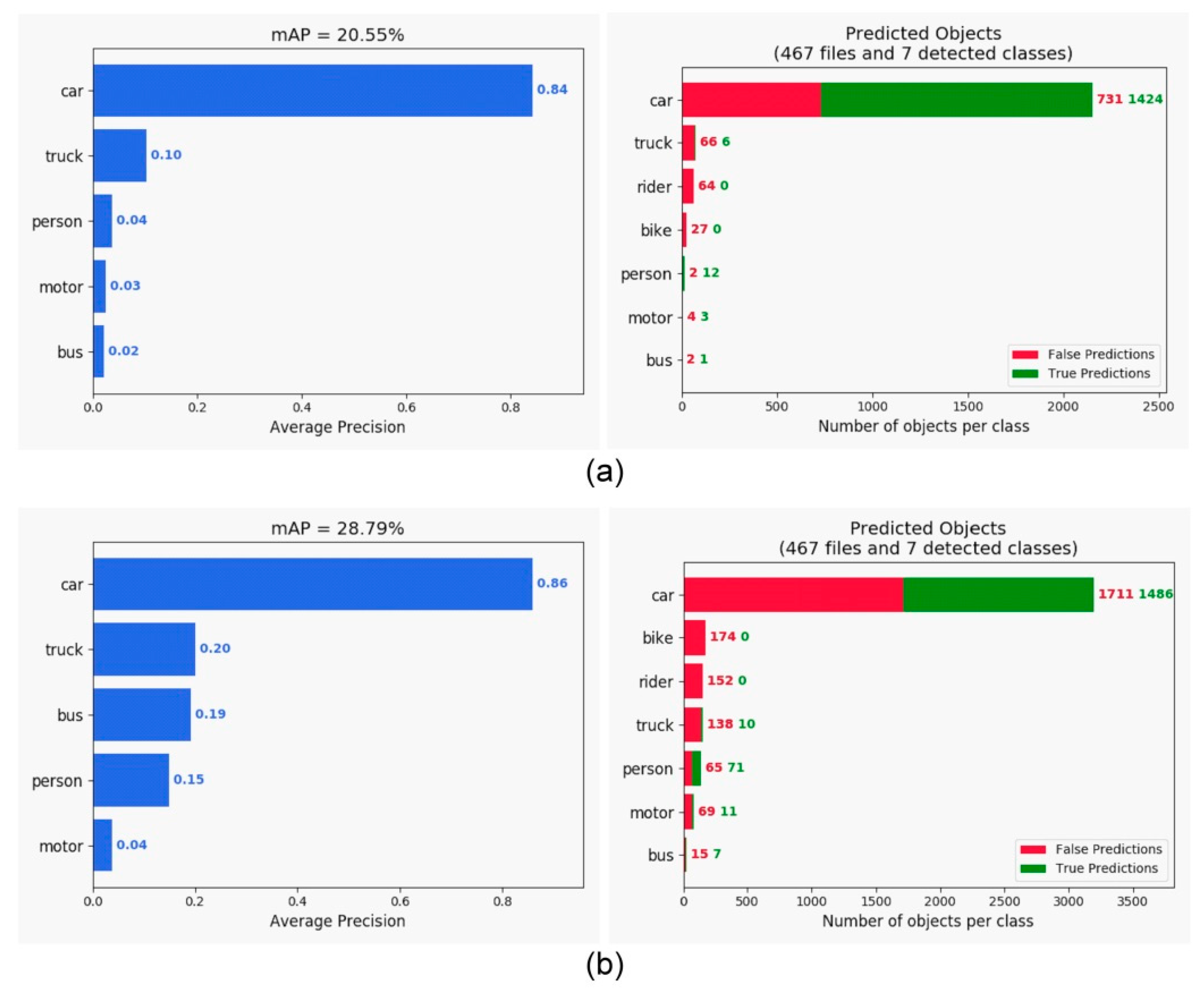
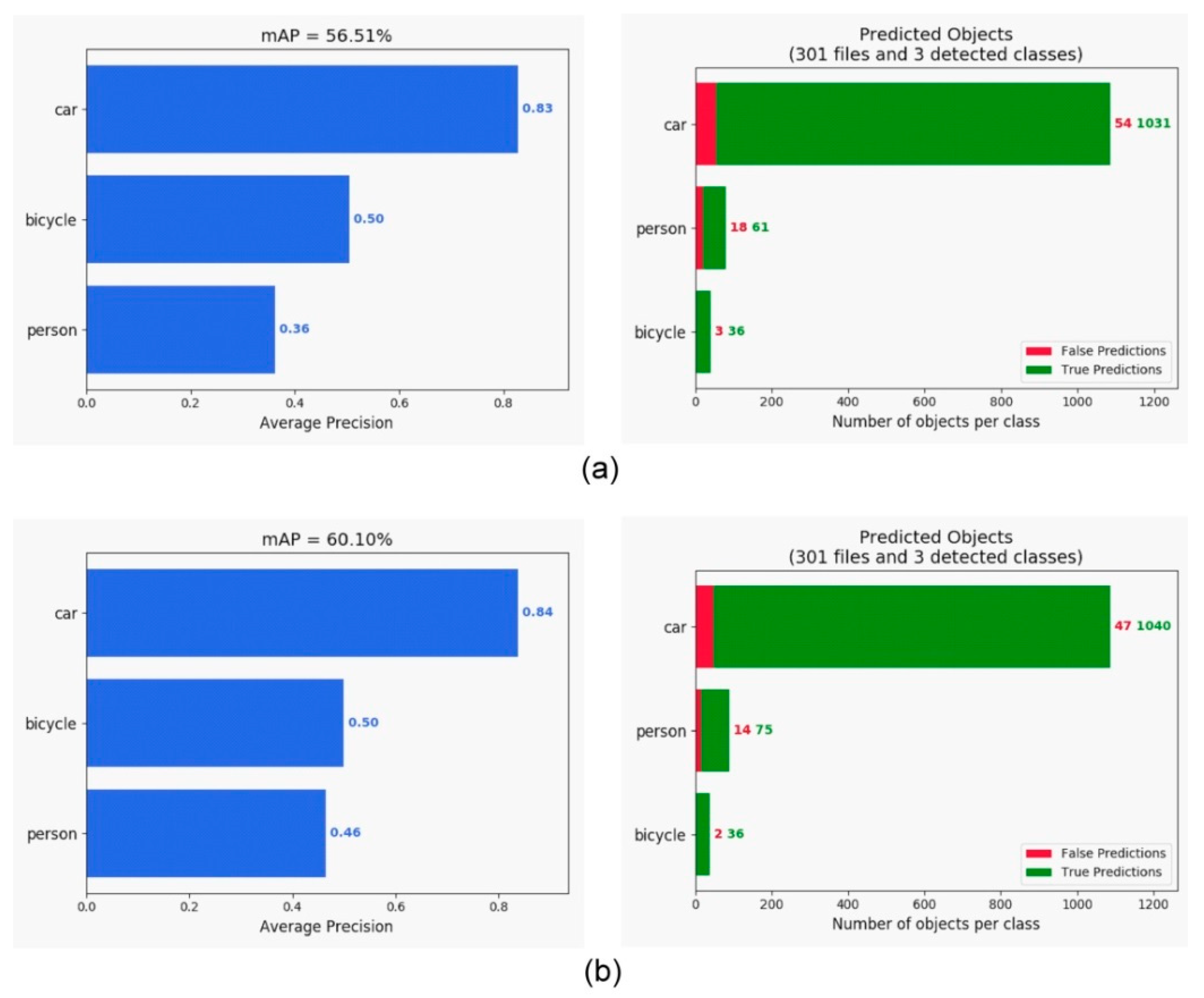
4.2. Evaluation on Object Detection
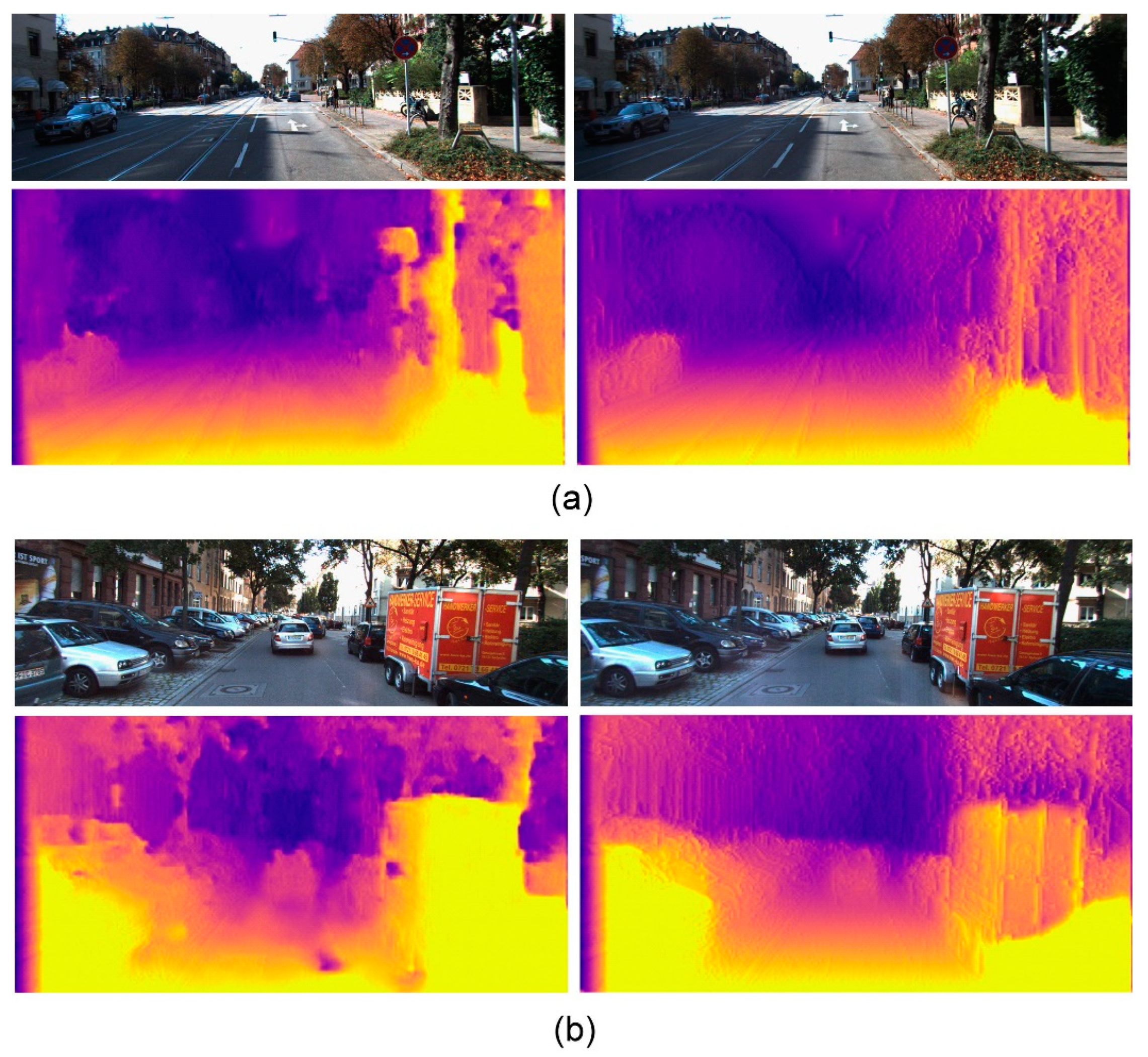
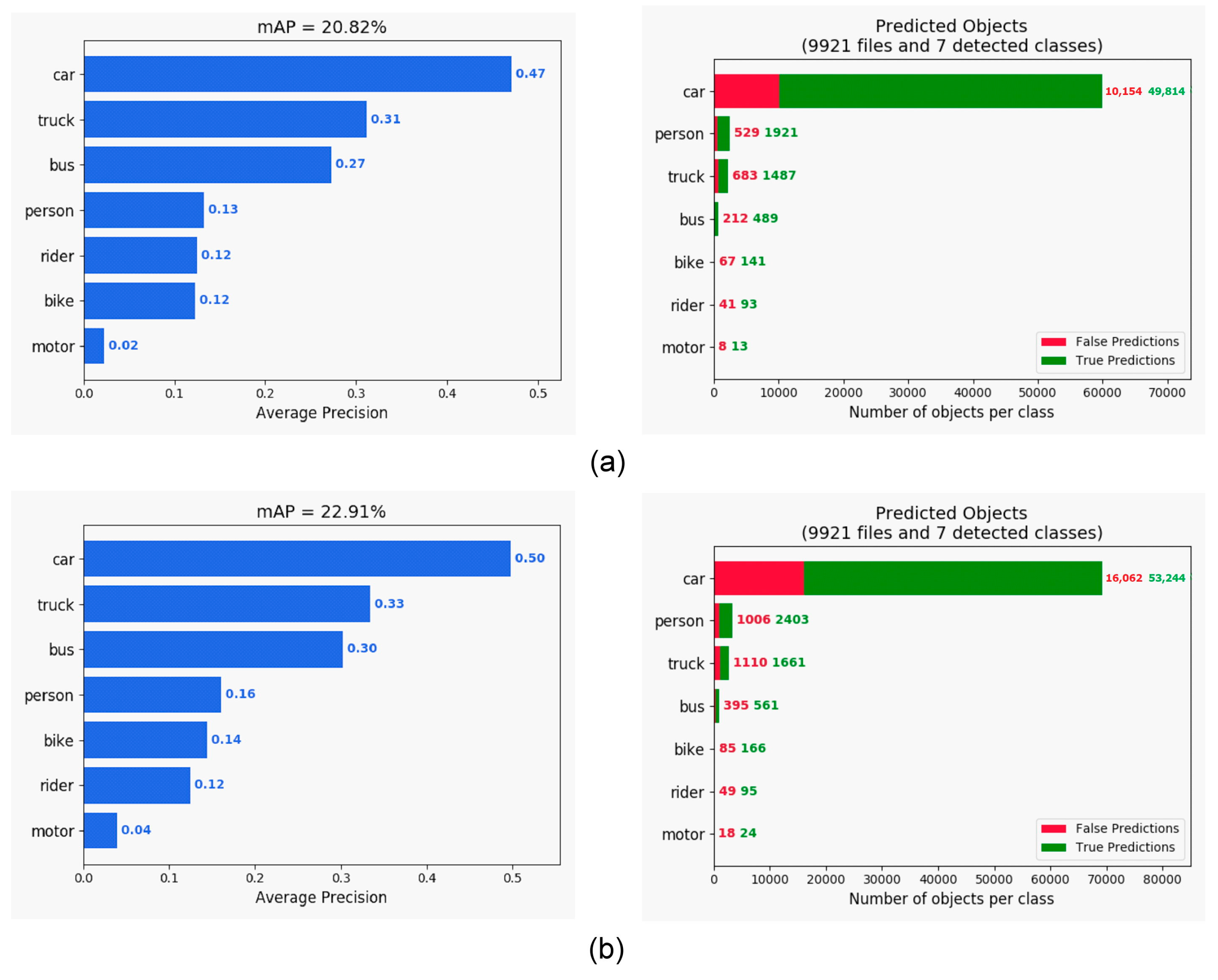
4.3. Evaluation of Depth Estimation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Q.; Sheng, T.; Wang, Y.; Ni, F.; Cai, L. Cfenet: An accurate and efficient single-shot object detector for autonomous driving. arXiv 2018, arXiv:1806.09790. [Google Scholar]
- Li, Y.F.; Tsai, C.C.; Lai, Y.T.; Guo, J.I. A multiple-lane vehicle tracking method for forward collision warning system applications. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPAASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1061–1064. [Google Scholar]
- Naghavi, S.H.; Avaznia, C.; Talebi, H. Integrated real-time object detection for self-driving vehicles. In Proceedings of the 2017 10th Iranian Conference on Machine Vision and Image Processing (MVIP), Isfahan, Iran, 22–23 November 2017; pp. 154–158. [Google Scholar]
- Felzenszwalb, P.F.; McAllester, D.A.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008), Anchorage, AK, USA, 24–26 June 2008. [Google Scholar]
- Lai, C.; Lin, H.; Tai, W. Vision based ADAS for forward vehicle detection using convolutional neural networks and motion tracking. In Proceedings of the 5th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS 2019), Heraklion, Crete, Greece, 3–5 May 2019; pp. 297–304. [Google Scholar]
- Wang, H.M.; Lin, H.Y. A real-time forward collision warning technique incorporating detection and depth estimation networks. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC 2020), Toronto, ON, Canada, 11–14 October 2020. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 379–387. [Google Scholar]
- Lin, T.Y.; Dollaŕ, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollaŕ, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; Volume 1, pp. 2999–3007. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollaŕ, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 12th European Conference on Computer Vision (ECCV2014), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (ICPR 2018), Beijing, China, 20–24 August 2018; pp. 4203–4212. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (ICPR2016), Cancún, Mexico, 4–8 December 2016; pp. 4040–4048. [Google Scholar]
- Teed, Z.; Deng, J. Deepv2d: Video to depth with differentiable structure from motion. arXiv 2018, arXiv:1812.04605. [Google Scholar]
- Perez-Cham, O.E.; Puente, C.; Soubervielle-Montalvo, C.; Olague, G.; Castillo-Barrera, F.E.; Nunez-Varela, J.; Limon-Romero, J. Automata design for honeybee search algorithm and its applications to 3D scene reconstruction and video tracking. Swarm Evol. Comput. 2021, 61, 100817. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, H.; Dong, C.; Chen, Q. A car-following data collecting method based on binocular stereo vision. IEEE Access 2020, 8, 25350–25363. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 3354–3361. [Google Scholar]
- Pilzer, A.; Xu, D.; Puscas, M.; Ricci, E.; Sebe, N. Unsupervised adversarial depth estimation using cycled generative networks. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 587–595. [Google Scholar]
- Tonioni, A.; Tosi, F.; Poggi, M.; Mattoccia, S.; Stefano, L.D. Real- time self-adaptive deep stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR2019), Long Beach, CA, USA, 16–20 June 2019; pp. 195–204. [Google Scholar]
- Yang, G.; Zhao, H.; Shi, J.; Deng, Z.; Jia, J. Segstereo: Exploiting semantic information for disparity estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 636–651. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 842–857. [Google Scholar]
- Tian, W.; Wang, Z.; Shen, H.; Deng, W.; Chen, B.; Zhang, X. Learning better features for face detection with feature fusion and segmentation supervision. arXiv 2018, arXiv:1811.08557. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV2015), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (ICPR2018), Beijing, China, 20–24 August 2018; pp. 7132–7141. [Google Scholar]
- Huang, P.; Lin, H. Rear obstacle warning for reverse driving using stereo vision techniques. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC 2019), Bari, Italy, 6–9 October 2019; pp. 921–926. [Google Scholar]
- Poggi, M.; Aleotti, F.; Tosi, F.; Mattoccia, S. Towards real-time unsupervised monocular depth estimation on cpu. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2018), Madrid, Spain, 1–5 October 2018; pp. 5848–5854. [Google Scholar]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Ketkar, N. Introduction to pytorch. In Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; pp. 195–208. [Google Scholar]
- Lai, H.Y.; Tsai, Y.H.; Chiu, W.C. Bridging stereo matching and optical flow via spatiotemporal correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Zhang et al. [17] | Liu et al. [10] | Redmon et al. [11] | Ren et al. [7] | Dai et al. [8] | Our Approach |
|---|---|---|---|---|---|---|
| Backbone | VGG-16 | VGG-16 | VGG-16 | ResNet-50 | ResNet-50 | VGG-16 |
| Training Data | PASCAL VOC | PASCAL VOC | PASCAL VOC | PASCAL VOC | PASCAL VOC | PASCAL VOC |
| Input Size | 320 × 320 | 300 × 300 | 416 × 416 | 320 × 320 | 320 × 320 | 320 × 320 |
| Boxes | 6375 | 6200 | Unknown | Unknown | Unknown | 6500 |
| FPS | 25 | 35 | 67 | 2.4 | 5.9 | 25 |
| mAP | 79.49 | 75.3 | 76.8 | 73.8 | 77.6 | 79.75 |
| Approach | Abs-rel | Sq-rel | RMS | Log-rms | D1-all | Er < 1.25 | Er < 1.253 |
|---|---|---|---|---|---|---|---|
| Godard et al. [12] | 0.124 | 1.40 | 6.137 | 0.217 | 30.350 | 0.841 | 0.975 |
| Pilzer et al. [24] (half-cycle stereo) | 0.228 | 4.277 | 7.646 | 0.318 | Null | 0.748 | 0.945 |
| Pilzer et al. [24] (full-cycle+D+SE) | 0.190 | 2.556 | 6.927 | 0.353 | Null | 0.751 | 0.951 |
| Lai et al. (stereo only) [35] | 0.078 | 0.811 | 4.700 | Null | Null | 0.983 | Null |
| Poggi et al. [32] | 0.153 | 1.363 | 6.030 | 0.252 | Null | 0.789 | 0.630 |
| Godard et al. [12] + Stereo (no correlation) | 0.083 | 0.944 | 4.765 | 0.163 | 13.087 | 0.927 | 0.986 |
| The Proposed Approach | 0.08 | 0.925 | 4.846 | 0.160 | 12.480 | 0.929 | 0.987 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.-M.; Lin, H.-Y.; Chang, C.-C. Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks. Sensors 2021, 21, 4755. https://doi.org/10.3390/s21144755
Wang H-M, Lin H-Y, Chang C-C. Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks. Sensors. 2021; 21(14):4755. https://doi.org/10.3390/s21144755
Chicago/Turabian StyleWang, Huai-Mu, Huei-Yung Lin, and Chin-Chen Chang. 2021. "Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks" Sensors 21, no. 14: 4755. https://doi.org/10.3390/s21144755
APA StyleWang, H.-M., Lin, H.-Y., & Chang, C.-C. (2021). Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks. Sensors, 21(14), 4755. https://doi.org/10.3390/s21144755