
Gaze Behavior Effect on Gaze Data Visualization at Different Abstraction Levels



Abstract
:1. Introduction
- We compare and analyze how gaze bahavior affects gaze data visualizations at different levels of abstraction.
- We propose a behavior-based gaze data processing with machine learning models.
- We improve an abstract gaze movement visualization and gaze-parsing method by extending the visualization technique presented by Yoo et al. [6].
2. Related Work
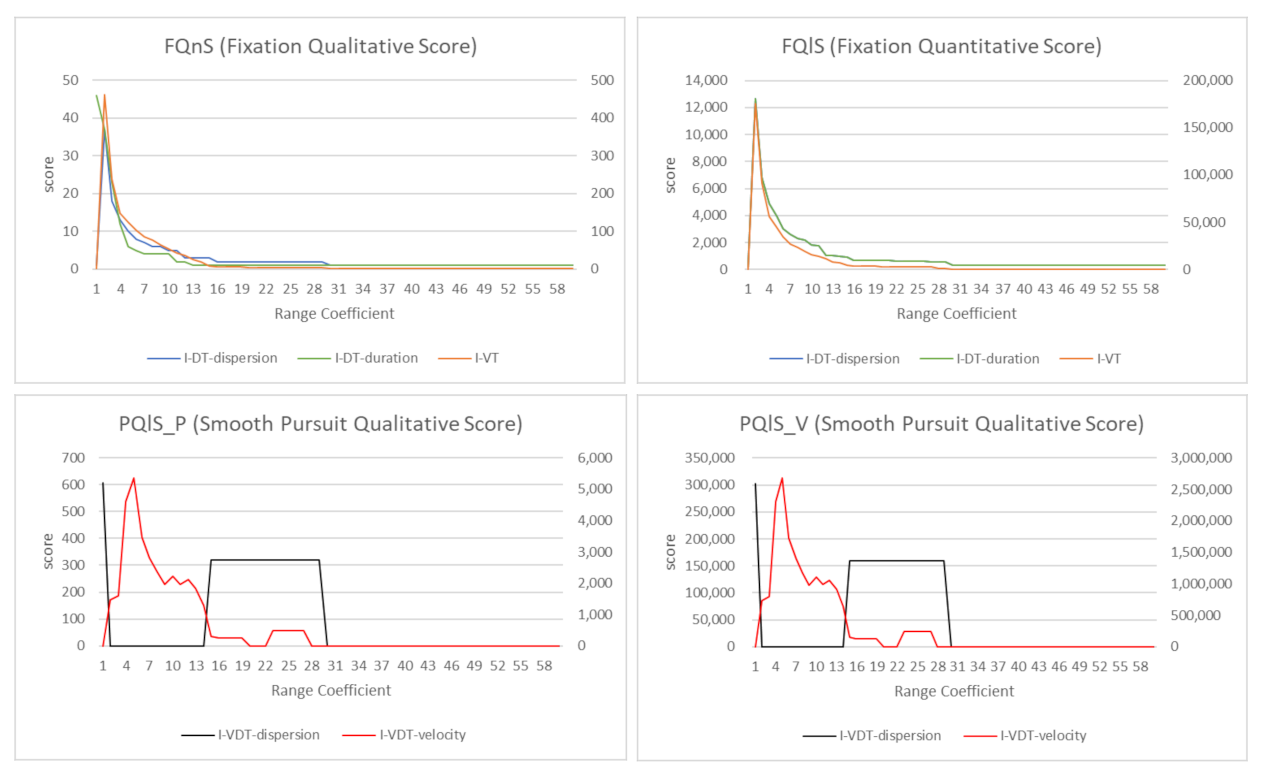
3. Method
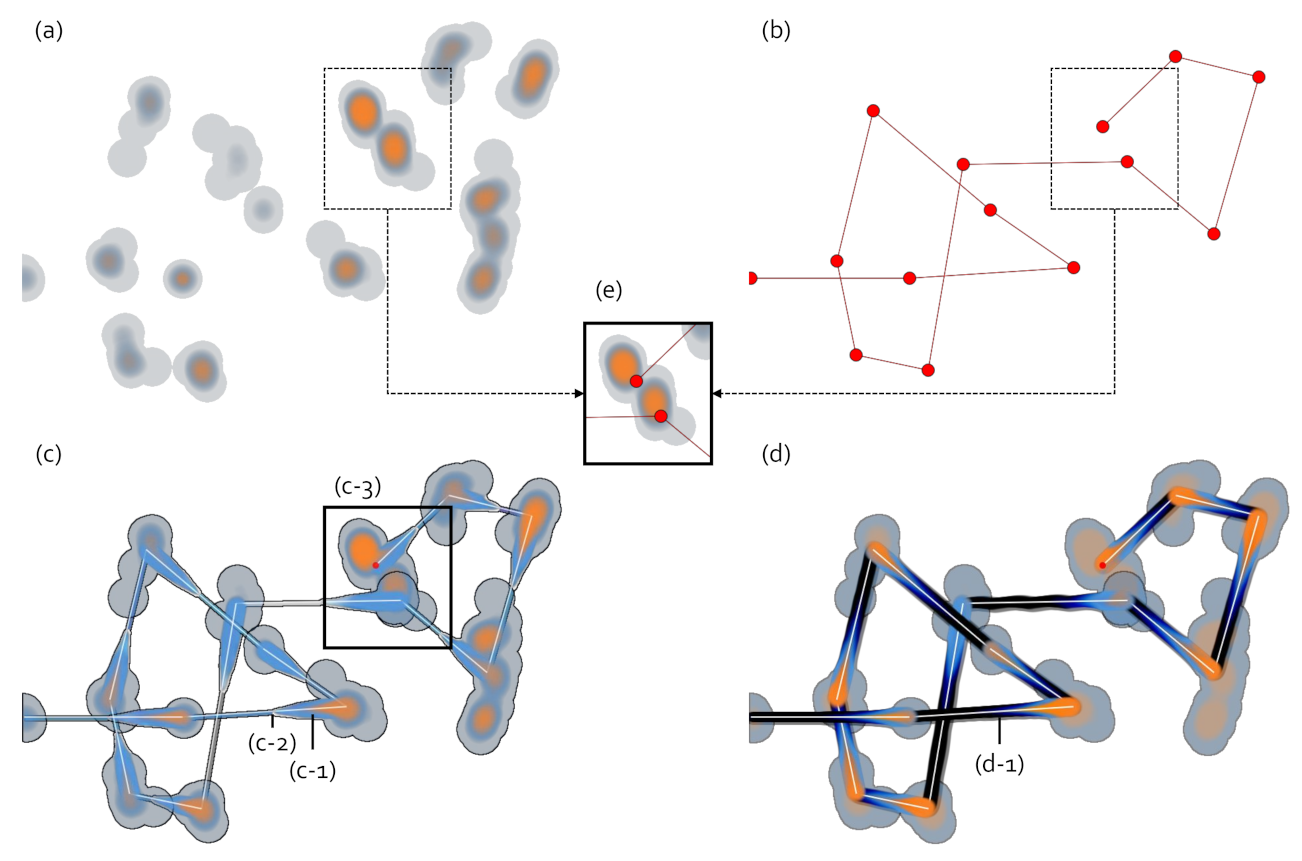
3.1. Different Abstraction Level Gaze Data Visualizations
3.2. Eye-Gaze Tracker
3.3. Recruitment of Observers
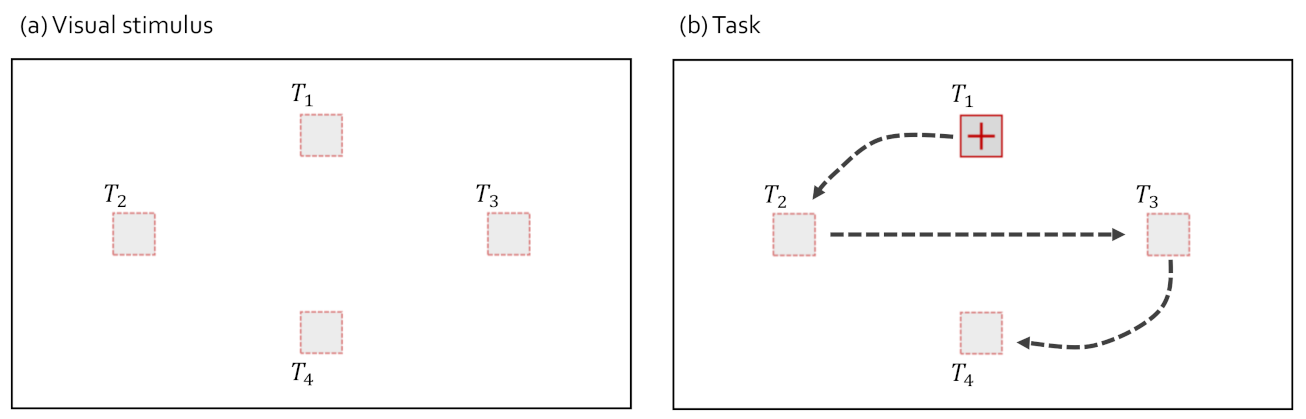
3.4. Visual Stimulus and Task
3.5. Ground-Truth Data
4. Gaze-Parsing Algorithms
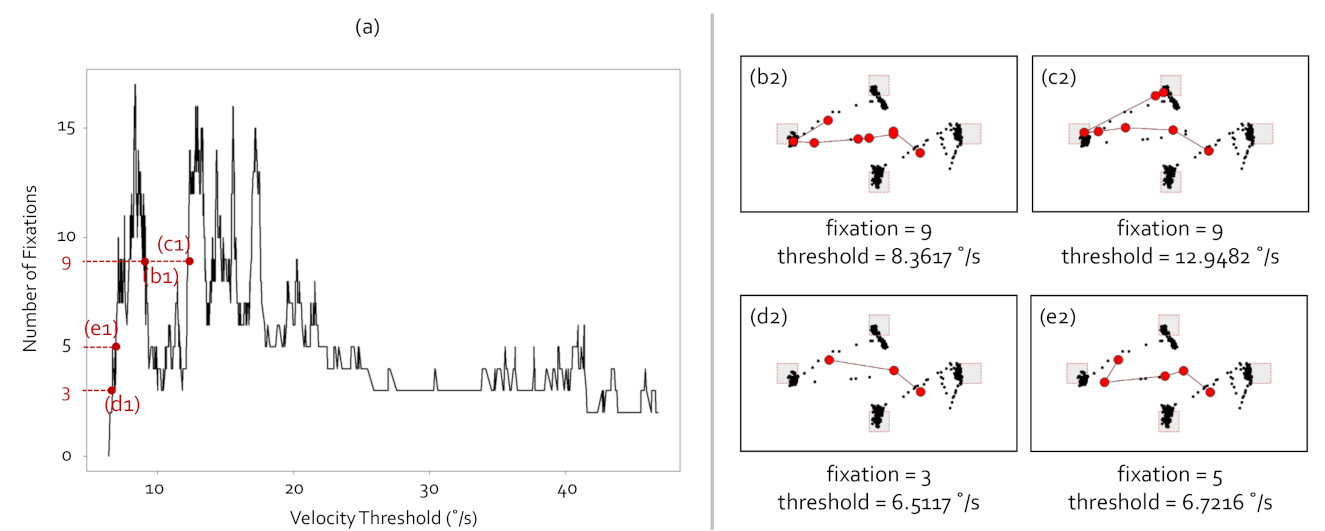
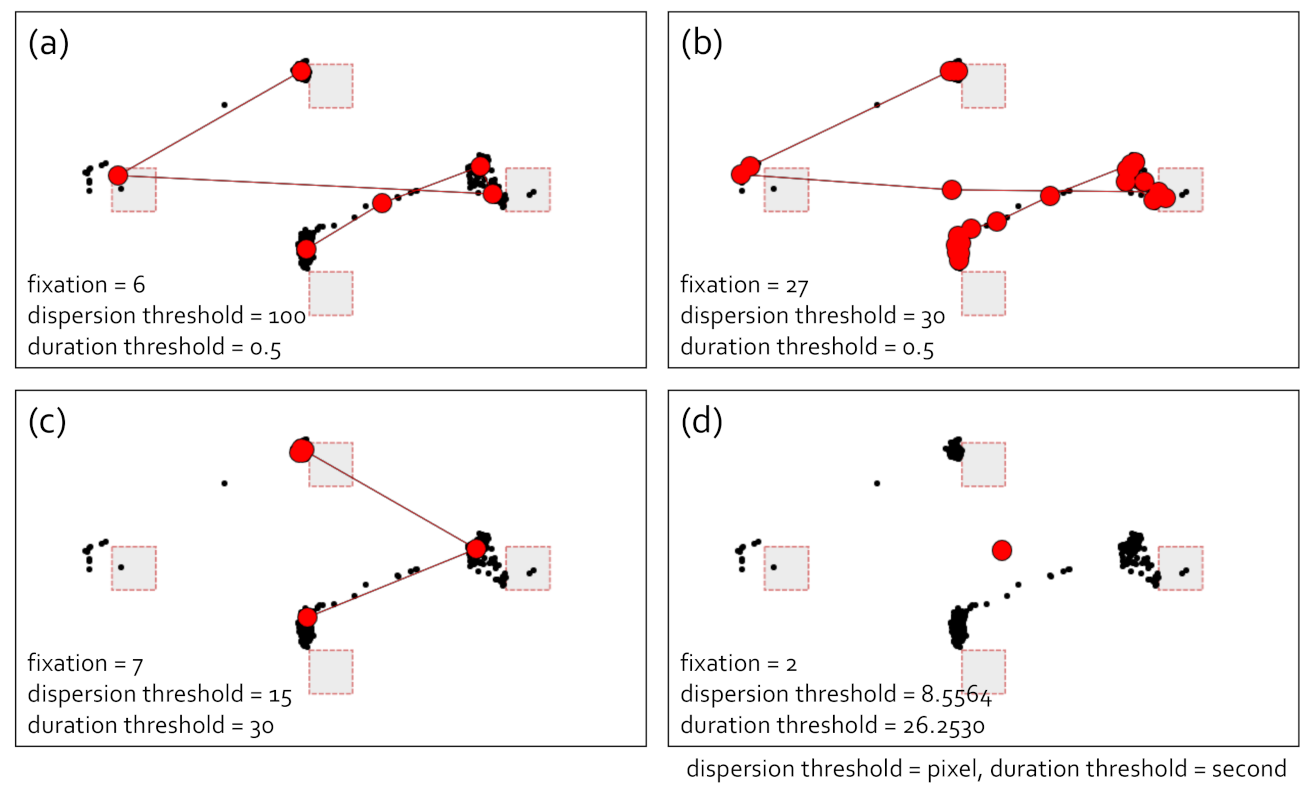
4.1. Problems with Manual Parameter Settings
4.1.1. I-VT Fixation Identification Algorithm
4.1.2. I-DT Fixation Identification Algorithm
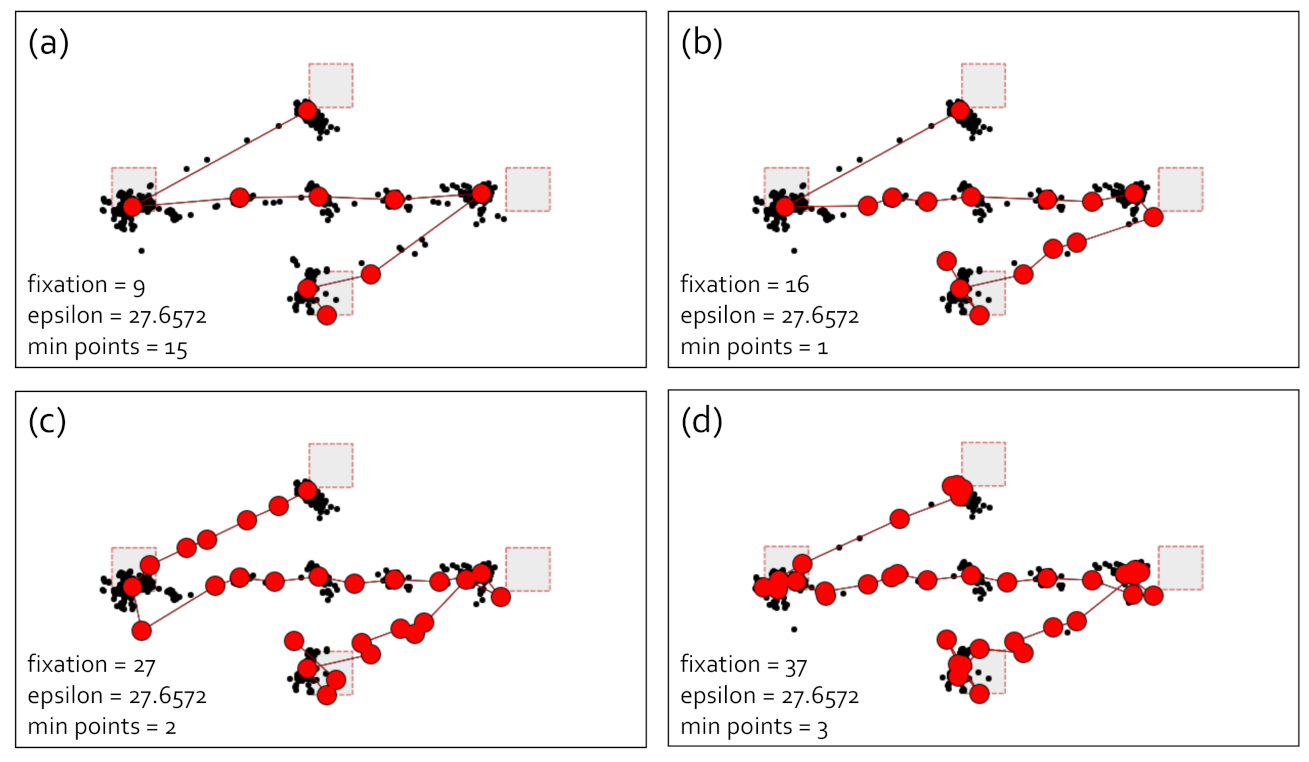
4.1.3. DBSCAN with IQR
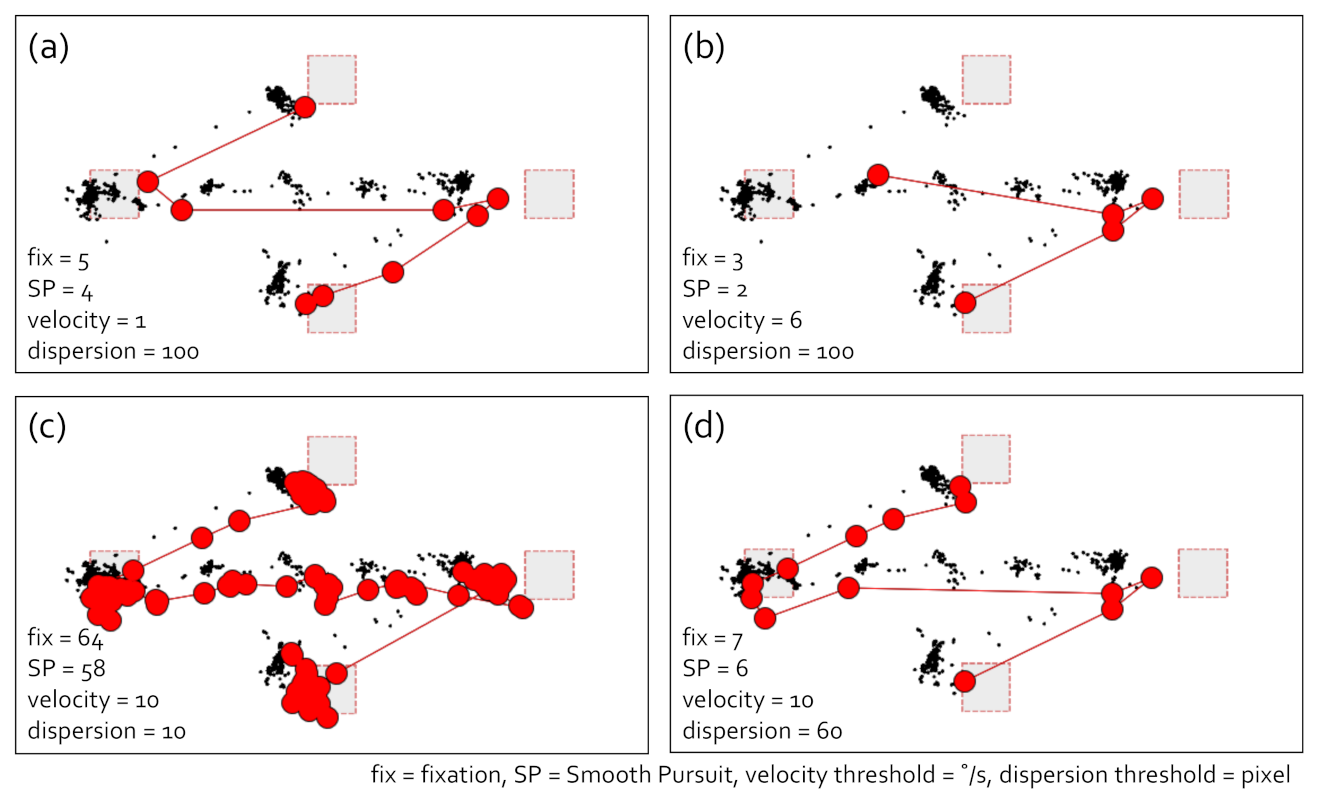
4.1.4. I-VDT Smooth Pursuit Identification Algorithm
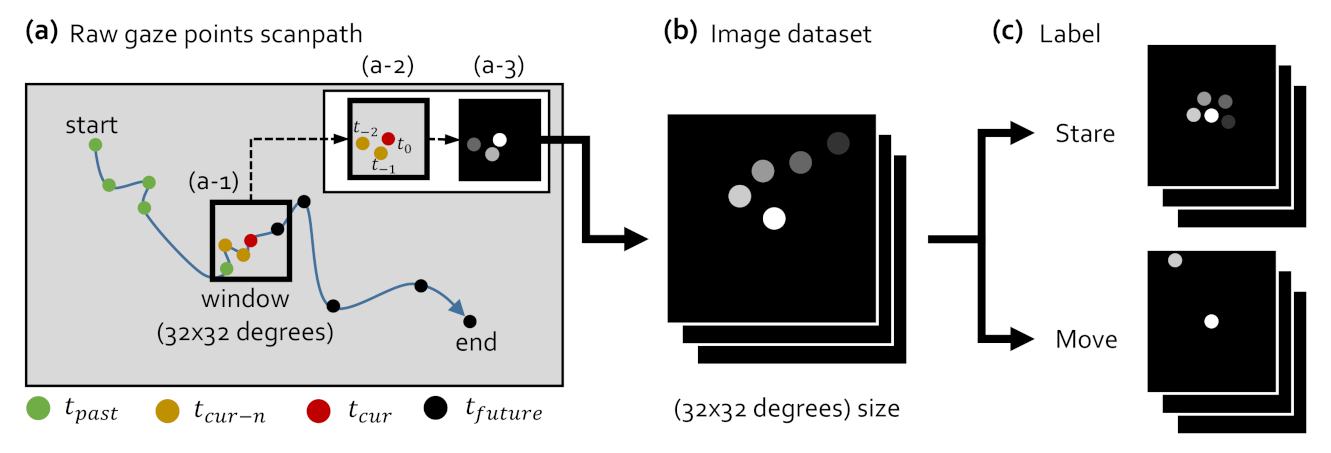
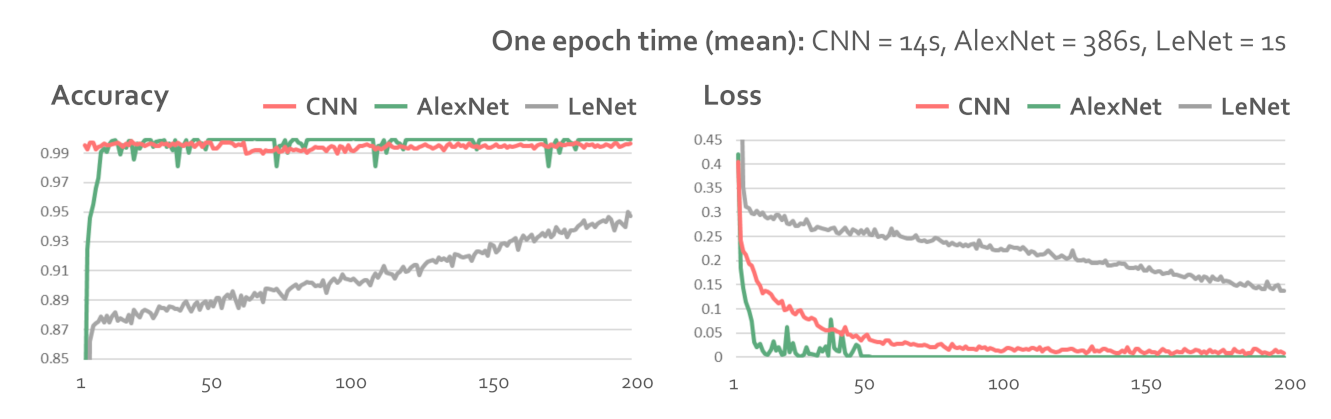
4.2. Behavior-Based Gaze Data Processing
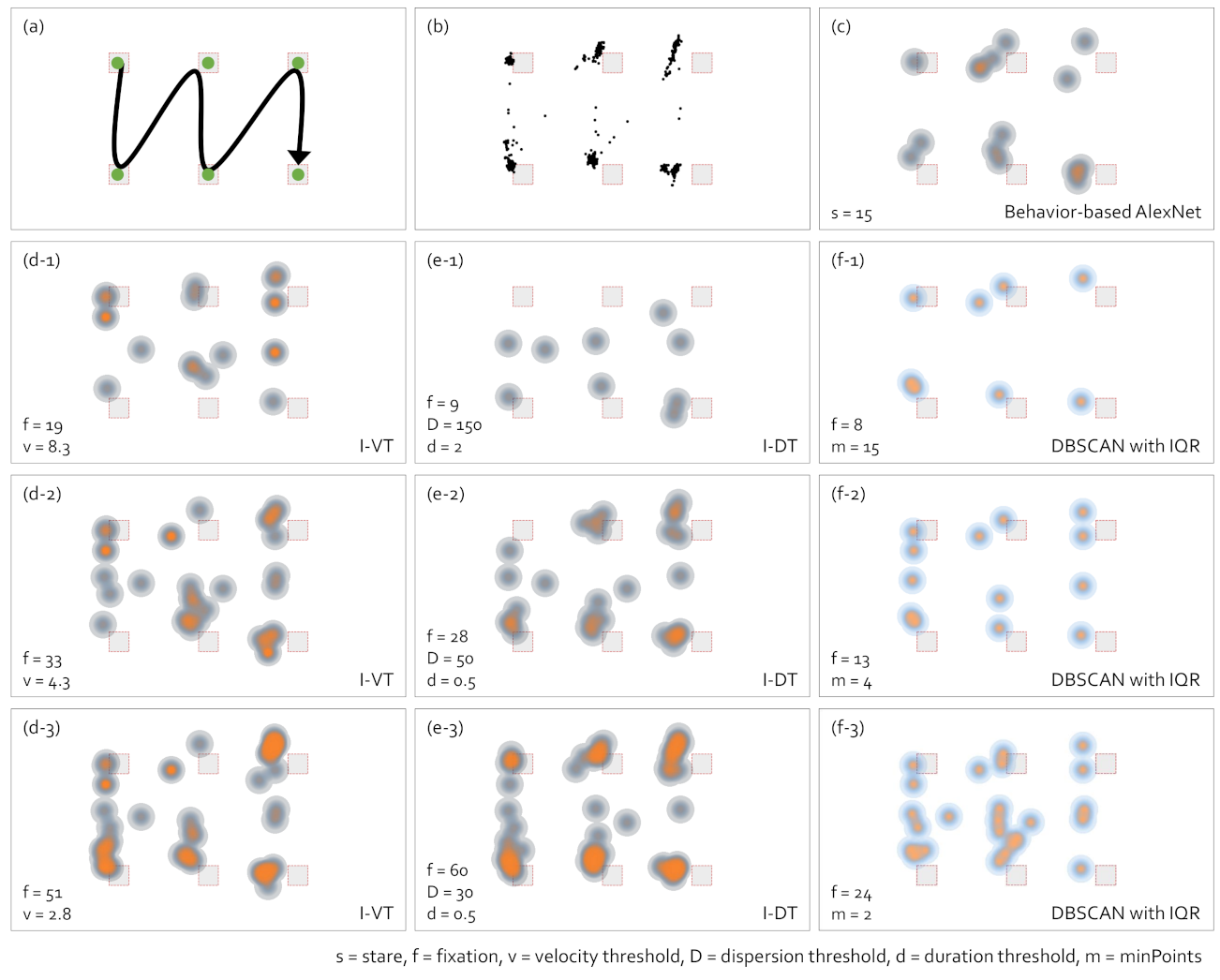
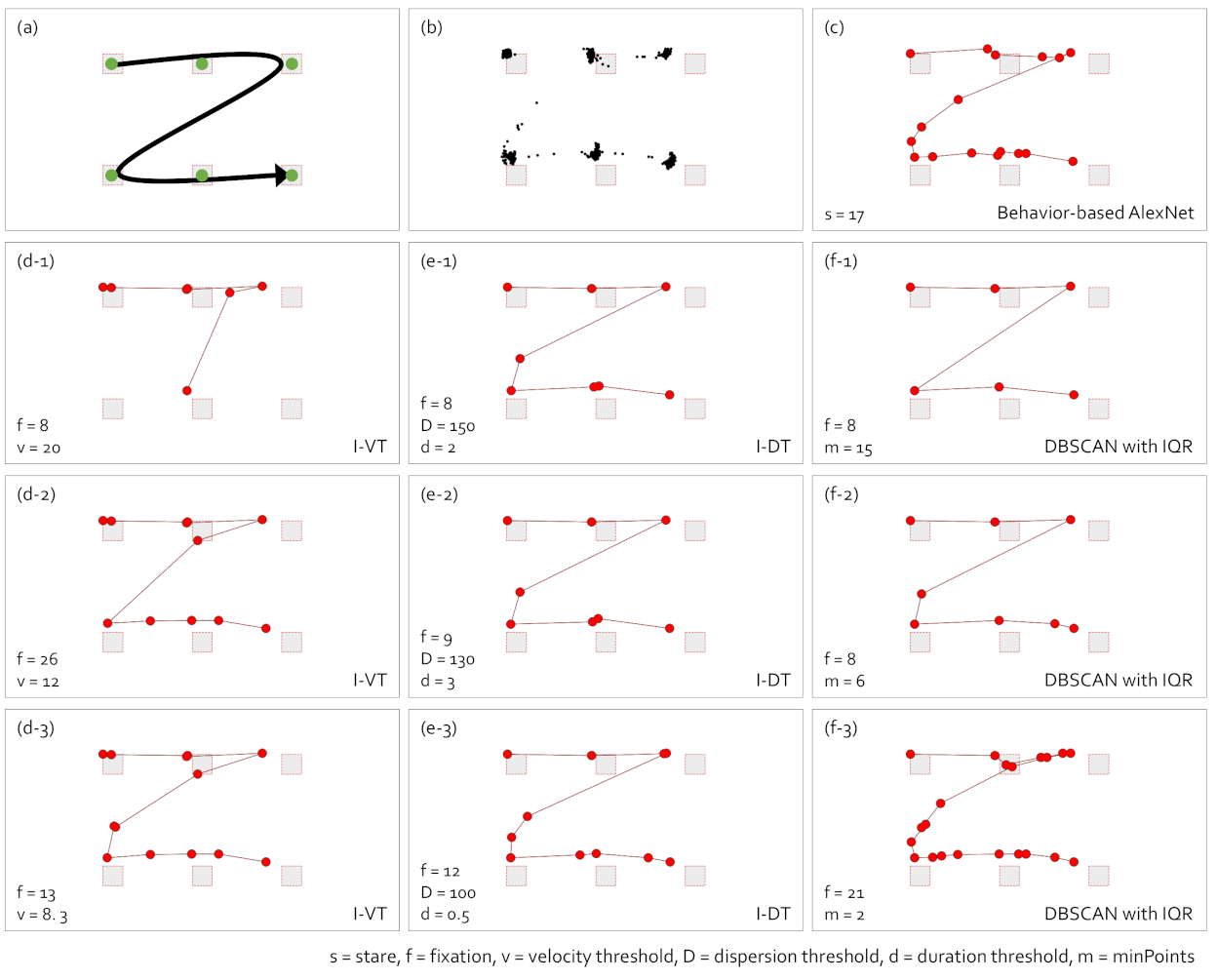
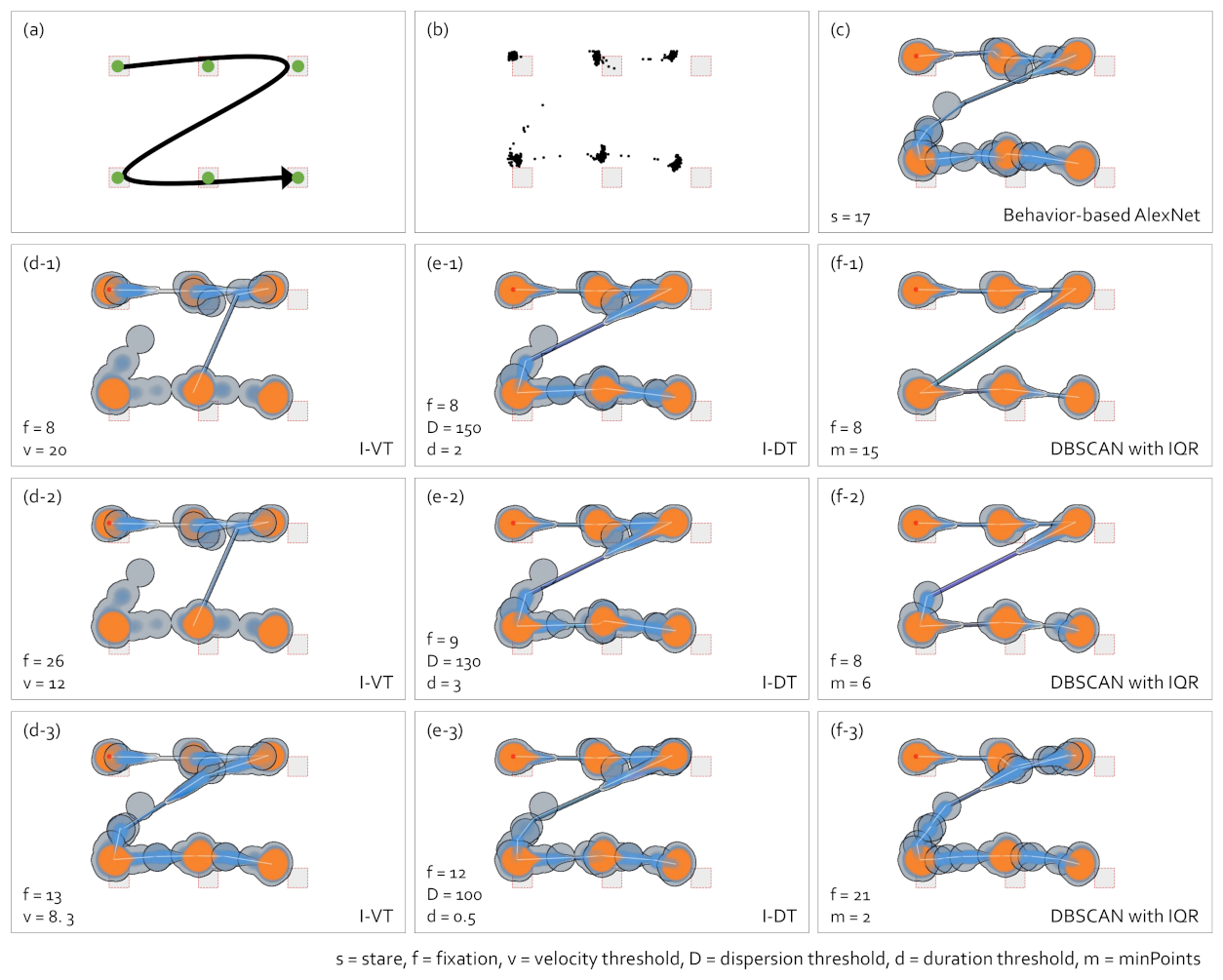
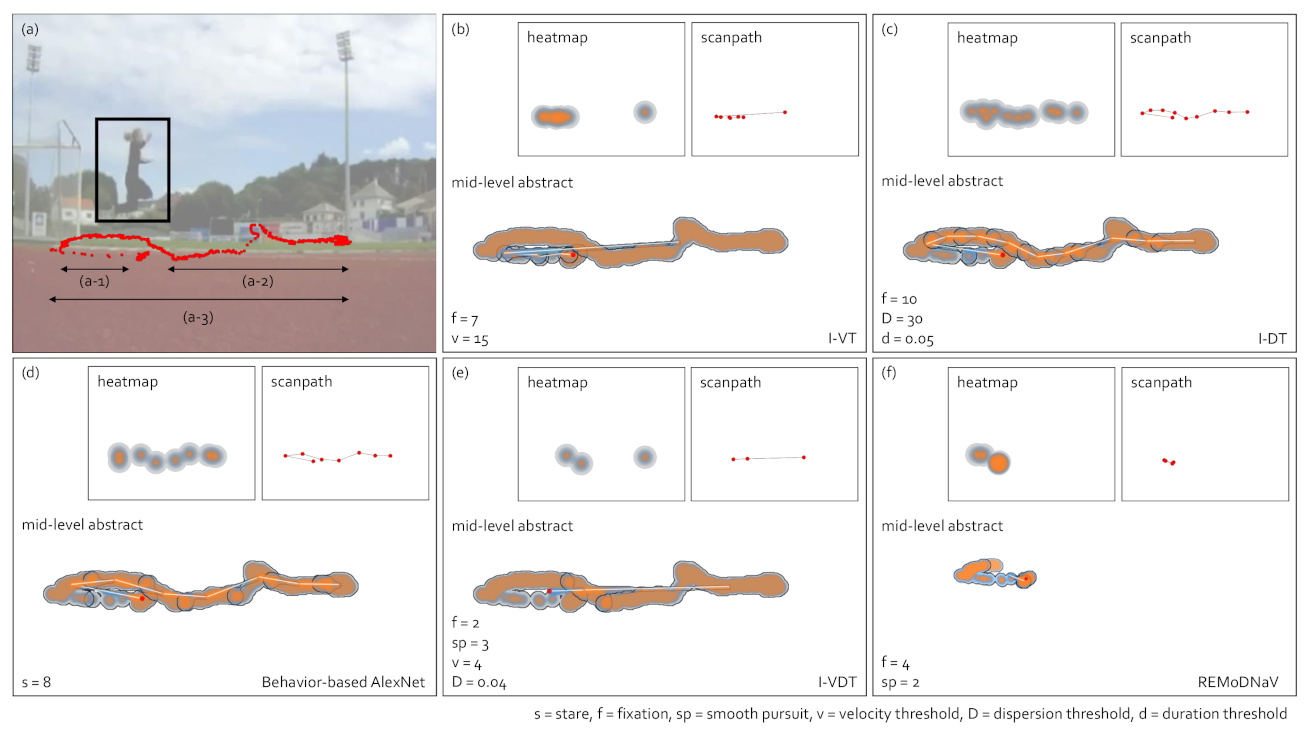
5. Comparison of Gaze-Parsing Algorithms and Gaze Data Visualizations
5.1. Heatmap Visualization
5.2. Scanpath Visualization
5.3. Abstract Gaze Movement Visualization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the 2000 symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar]
- Olsen, A. The Tobii I-VT Fixation Filter; Tobii Technology: Stockholm, Sweden, 2012. [Google Scholar]
- Katsini, C.; Fidas, C.; Raptis, G.E.; Belk, M.; Samaras, G.; Avouris, N. Eye gaze-driven prediction of cognitive differences during graphical password composition. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; pp. 147–152. [Google Scholar]
- de Urabain, I.R.S.; Johnson, M.H.; Smith, T.J. GraFIX: A semiautomatic approach for parsing low-and high-quality eye-tracking data. Behav. Res. Methods 2015, 47, 53–72. [Google Scholar] [CrossRef] [Green Version]
- Yu, M.; Lin, Y.; Breugelmans, J.; Wang, X.; Wang, Y.; Gao, G.; Tang, X. A spatial-temporal trajectory clustering algorithm for eye fixations identification. Intell. Data Anal. 2016, 20, 377–393. [Google Scholar] [CrossRef]
- Yoo, S.; Jeong, S.; Kim, S.; Jang, Y. Gaze Attention and Flow Visualization Using the Smudge Effect. In Pacific Graphics (Short Papers); The Eurographics Association: Geneve, Switzerland, 2019; pp. 21–26. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-based Algorithm for Discovering Clusters a Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Wooding, D.S. Fixation maps: Quantifying eye-movement traces. In Proceedings of the 2002 Symposium on Eye Tracking Research & Applications, Denver, CO, USA, 25–28 June 2002; pp. 31–36. [Google Scholar]
- Noton, D.; Stark, L. Scanpaths in eye movements during pattern perception. Science 1971, 171, 308–311. [Google Scholar] [CrossRef]
- Holmqvist, K.; Nyström, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; Van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; OUP Oxford: Oxford, UK, 2011. [Google Scholar]
- Kurzhals, K.; Fisher, B.; Burch, M.; Weiskopf, D. Evaluating visual analytics with eye tracking. In Proceedings of the Fifth Workshop on Beyond Time and Errors: Novel Evaluation Methods for Visualization, Paris, France, 10 November 2014; pp. 61–69. [Google Scholar]
- Blascheck, T.; Kurzhals, K.; Raschke, M.; Burch, M.; Weiskopf, D.; Ertl, T. Visualization of Eye Tracking Data: A Taxonomy and Survey. Comput. Graph. Forum 2017, 36, 260–284. [Google Scholar] [CrossRef]
- Mital, P.K.; Smith, T.J.; Hill, R.L.; Henderson, J.M. Clustering of gaze during dynamic scene viewing is predicted by motion. Cogn. Comput. 2011, 3, 5–24. [Google Scholar] [CrossRef]
- Van Opstal, A.; Van Gisbergen, J. Skewness of saccadic velocity profiles: A unifying parameter for normal and slow saccades. Vis. Res. 1987, 27, 731–745. [Google Scholar] [CrossRef]
- Larsson, L.; Nyström, M.; Stridh, M. Detection of saccades and postsaccadic oscillations in the presence of smooth pursuit. IEEE Trans. Biomed. Eng. 2013, 60, 2484–2493. [Google Scholar] [CrossRef]
- Startsev, M.; Agtzidis, I.; Dorr, M. 1D CNN with BLSTM for automated classification of fixations, saccades, and smooth pursuits. Behav. Res. Methods 2019, 51, 556–572. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Agtzidis, I.; Startsev, M.; Dorr, M. Smooth pursuit detection based on multiple observers. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; pp. 303–306. [Google Scholar]
- Larsson, L.; Nyström, M.; Andersson, R.; Stridh, M. Detection of fixations and smooth pursuit movements in high-speed eye-tracking data. Biomed. Signal Process. Control. 2015, 18, 145–152. [Google Scholar] [CrossRef]
- Ke, S.R.; Lam, J.; Pai, D.K.; Spering, M. Directional asymmetries in human smooth pursuit eye movements. Investig. Ophthalmol. Vis. Sci. 2013, 54, 4409–4421. [Google Scholar] [CrossRef] [Green Version]
- Robinson, D.A.; Gordon, J.; Gordon, S. A model of the smooth pursuit eye movement system. Biol. Cybern. 1986, 55, 43–57. [Google Scholar] [CrossRef]
- Bergstrom, J.R.; Schall, A. Eye Tracking in User Experience Design; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Stuart, S.; Hickey, A.; Vitorio, R.; Welman, K.; Foo, S.; Keen, D.; Godfrey, A. Eye-tracker algorithms to detect saccades during static and dynamic tasks: A structured review. Physiol. Meas. 2019, 40, 02TR01. [Google Scholar] [CrossRef]
- Andersson, R.; Larsson, L.; Holmqvist, K.; Stridh, M.; Nyström, M. One algorithm to rule them all? An evaluation and discussion of ten eye movement event-detection algorithms. Behav. Res. Methods 2017, 49, 616–637. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Komogortsev, O.V.; Jayarathna, S.; Koh, D.H.; Gowda, S.M. Qualitative and quantitative scoring and evaluation of the eye movement classification algorithms. In Proceedings of the 2010 Symposium on Eye-Tracking Research & Applications, Austin, TX, USA, 22–24 March 2010; pp. 65–68. [Google Scholar]
- Komogortsev, O.V.; Gobert, D.V.; Jayarathna, S.; Koh, D.H.; Gowda, S.M. Standardization of automated analyses of oculomotor fixation and saccadic behaviors. IEEE Trans. Biomed. Eng. 2010, 57, 2635–2645. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Smith, T.J.; Mital, P.K. Attentional synchrony and the influence of viewing task on gaze behavior in static and dynamic scenes. J. Vis. 2013, 13, 16. [Google Scholar] [CrossRef] [PubMed]
- Löwe, T.; Stengel, M.; Förster, E.C.; Grogorick, S.; Magnor, M. Visualization and analysis of head movement and gaze data for immersive video in head-mounted displays. In Proceedings of the Workshop on Eye Tracking and Visualization (ETVIS), Chicago, IL, USA, 25 October 2015; Volume 1. [Google Scholar]
- Wang, X.; Koch, S.; Holmqvist, K.; Alexa, M. Tracking the gaze on objects in 3D: How do people really look at the bunny? In Proceedings of the SIGGRAPH Asia 2018 Technical Papers, Tokyo, Japan, 4–7 December 2018; p. 188. [Google Scholar]
- Blignaut, P.; van Rensburg, E.J.; Oberholzer, M. Visualization and quantification of eye tracking data for the evaluation of oculomotor function. Heliyon 2019, 5, e01127. [Google Scholar] [CrossRef] [Green Version]
- Fujii, K.; Rekimoto, J. SubMe: An Interactive Subtitle System with English Skill Estimation Using Eye Tracking. In Proceedings of the 10th Augmented Human International Conference 2019, Reims, France, 11–12 March 2019; p. 23. [Google Scholar]
- Otero-Millan, J.; Troncoso, X.G.; Macknik, S.L.; Serrano-Pedraza, I.; Martinez-Conde, S. Saccades and microsaccades during visual fixation, exploration, and search: Foundations for a common saccadic generator. J. Vis. 2008, 8, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martinez-Conde, S.; Otero-Millan, J.; Macknik, S.L. The impact of microsaccades on vision: Towards a unified theory of saccadic function. Nat. Rev. Neurosci. 2013, 14, 83. [Google Scholar] [CrossRef] [PubMed]
- Burch, M.; Andrienko, G.; Andrienko, N.; Höferlin, M.; Raschke, M.; Weiskopf, D. Visual task solution strategies in tree diagrams. In Proceedings of the 2013 IEEE Pacific Visualization Symposium (PacificVis), Sydney, NSW, Australia, 27 Febuary–1 March 2013; pp. 169–176. [Google Scholar]
- Eraslan, S.; Yesilada, Y.; Harper, S. Eye tracking scanpath analysis techniques on web pages: A survey, evaluation and comparison. J. Eye Mov. Res. 2016, 9, 1–19. [Google Scholar]
- Peysakhovich, V.; Hurter, C.; Telea, A. Attribute-driven edge bundling for general graphs with applications in trail analysis. In Proceedings of the 2015 IEEE Pacific Visualization Symposium (PacificVis), Hangzhou, China, 14–17 April 2015; pp. 39–46. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Burch, M.; Weiskopf, D. Visual analytics methodology for eye movement studies. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2889–2898. [Google Scholar] [CrossRef] [Green Version]
- Kurzhals, K.; Weiskopf, D. Visualizing eye tracking data with gaze-guided slit-scans. In Proceedings of the 2016 IEEE Second Workshop on Eye Tracking and Visualization (ETVIS), Baltimore, MD, USA, 23 October 2016; pp. 45–49. [Google Scholar]
- Peysakhovich, V.; Hurter, C. Scanpath visualization and comparison using visual aggregation techniques. J. Eye Mov. Res. 2018, 10, 1–14. [Google Scholar]
- Ramdane-Cherif, Z.; NaÏt-AliNait-Ali, A. An adaptive algorithm for eye-gaze-tracking-device calibration. IEEE Trans. Instrum. Meas. 2008, 57, 716–723. [Google Scholar] [CrossRef]
- Wang, K.; Ji, Q. Real time eye gaze tracking with 3d deformable eye-face model. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1003–1011. [Google Scholar]
- Hennessey, C.A.; Lawrence, P.D. Improving the accuracy and reliability of remote system-calibration-free eye-gaze tracking. IEEE Trans. Biomed. Eng. 2009, 56, 1891–1900. [Google Scholar] [CrossRef]
- Zhu, Z.; Ji, Q. Novel eye gaze tracking techniques under natural head movement. IEEE Trans. Biomed. Eng. 2007, 54, 2246–2260. [Google Scholar]
- Button, C.; Dicks, M.; Haines, R.; Barker, R.; Davids, K. Statistical modelling of gaze behaviour as categorical time series: What you should watch to save soccer penalties. Cogn. Process. 2011, 12, 235–244. [Google Scholar] [CrossRef]
- Mazumdar, D.; Meethal, N.S.K.; George, R.; Pel, J.J. Saccadic reaction time in mirror image sectors across horizontal meridian in eye movement perimetry. Sci. Rep. 2021, 11, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Krejtz, K.; Szmidt, T.; Duchowski, A.T.; Krejtz, I. Entropy-based statistical analysis of eye movement transitions. In Proceedings of the Symposium on Eye Tracking Research and Applications, Safety Harbor, FL, USA, 26–28 March 2014; pp. 159–166. [Google Scholar]
- Caldara, R.; Miellet, S. i Map: A novel method for statistical fixation mapping of eye movement data. Behav. Res. Methods 2011, 43, 864–878. [Google Scholar] [CrossRef] [Green Version]
- Dink, J.W.; Ferguson, B. eyetrackingR: An R Library for Eye-Tracking Data Analysis. 2015. Available online: www.eyetracking-r.com (accessed on 8 July 2021).
- Llanes-Jurado, J.; Marín-Morales, J.; Guixeres, J.; Alcañiz, M. Development and calibration of an eye-tracking fixation identification algorithm for immersive virtual reality. Sensors 2020, 20, 4956. [Google Scholar] [CrossRef]
- Liu, W.; Trapp, A.C.; Djamasbi, S. Outlier-Aware, density-Based gaze fixation identification. Omega 2021, 102, 102298. [Google Scholar] [CrossRef]
- Akshay, S.; Megha, Y.; Shetty, C.B. Machine Learning Algorithm to Identify Eye Movement Metrics using Raw Eye Tracking Data. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 949–955. [Google Scholar]
- Zemblys, R.; Niehorster, D.C.; Holmqvist, K. gazeNet: End-to-end eye-movement event detection with deep neural networks. Behav. Res. Methods 2019, 51, 840–864. [Google Scholar] [CrossRef] [Green Version]
- Blignaut, P. Fixation identification: The optimum threshold for a dispersion algorithm. Atten. Percept. Psychophys. 2009, 71, 881–895. [Google Scholar] [CrossRef] [PubMed]
- Urruty, T.; Lew, S.; Djeraba, C.; Simovici, D.A. Detecting eye fixations by projection clustering. In Proceedings of the 14th International Conference of Image Analysis and Processing-Workshops (ICIAPW 2007), Modena, Italy, 10–13 September 2007; pp. 45–50. [Google Scholar]
- Sugano, Y.; Matsushita, Y.; Sato, Y. Graph-based joint clustering of fixations and visual entities. Acm Trans. Appl. Percept. (TAP) 2013, 10, 10. [Google Scholar] [CrossRef]
- Soleh, M.B.; Anisa, Y.H.; Absor, N.F.; Edison, R.E. Differences of Visual Attention to Memes: An Eye Tracking Study. In Proceedings of the 1st Annual International Conference on Natural and Social Science Education (ICNSSE 2020), Bantul Yogyakarta, Indonesia, 21–22 October 2021; pp. 146–150. [Google Scholar]
- Srivastava, N.; Nawaz, S.; Newn, J.; Lodge, J.; Velloso, E.; Erfani, S.M.; Gasevic, D.; Bailey, J. Are you with me? Measurement of Learners’ Video-Watching Attention with Eye Tracking. In Proceedings of the LAK21: 11th International Learning Analytics and Knowledge Conference, Irvine, CA, USA, 12–16 April 2021; pp. 88–98. [Google Scholar]
- Garro, V.; Sundstedt, V. Pose and Visual Attention: Exploring the Effects of 3D Shape Near-Isometric Deformations on Gaze. J. WSCG 2020, 28, 153–160. [Google Scholar]
- Jaeger, L.; Eckhardt, A. Eyes wide open: The role of situational information security awareness for security-related behaviour. Inf. Syst. J. 2021, 31, 429–472. [Google Scholar] [CrossRef]
- Nizam, D.N.M.; Law, E.L.C. Derivation of young children’s interaction strategies with digital educational games from gaze sequences analysis. Int. J. Hum.-Comput. Stud. 2021, 146, 102558. [Google Scholar] [CrossRef]
- Tancredi, S.; Abdu, R.; Abrahamson, D.; Balasubramaniam, R. Modeling nonlinear dynamics of fluency development in an embodied-design mathematics learning environment with Recurrence Quantification Analysis. Int. J. Child-Comput. Interact. 2021, 29, 100297. [Google Scholar] [CrossRef]
- Komogortsev, O.V.; Karpov, A. Automated classification and scoring of smooth pursuit eye movements in the presence of fixations and saccades. Behav. Res. Methods 2013, 45, 203–215. [Google Scholar] [CrossRef] [Green Version]
- Dar, A.H.; Wagner, A.S.; Hanke, M. REMoDNaV: Robust eye movement detection for natural viewing. BioRxiv 2020, 53, 619254. [Google Scholar]
Short Biography of Authors
 | Sangbong Yoo received a Bachelor’s degree in computer engineering in 2015 from Sejong University in Seoul, South Korea. He is currently pursuing a Ph.D. at Sejong University. His research interests include gaze analysis, eye tracking technique, mobile security, and data visualization.. |
 | Seongmin Jeong received a BS degree in computer engineering from Sejong University, South Korea, in 2016. He is currently working toward a Ph.D. degree at Sejong University. His research interests include flow map visualization and visual analytics. |
 | Yun Jang received a Bachelor’s degree in electrical engineering from Seoul National University, South Korea in 2000, and a Masters and doctoral degree in electrical and computer engineering from Purdue University in 2002 and 2007, respectively. He is an associate professor of computer engineering at Sejong University, Seoul, South Korea. He was a postdoctoral researcher at CSCS and ETH Zürich, Switzerland from 2007 to 2011. His research interests include interactive visualization, volume rendering, HCI, machine learning, and visual analytics. |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lund2013 Dataset (500 Hz) | Tobii Pro X2-30 Dataset (40 Hz) | |||||
|---|---|---|---|---|---|---|
| Smooth Pursuit F1 | Fixation F1 | Saccade F1 | Smooth Pursuit F1 | Fixation F1 | Saccade F1 | |
| I-VDT | 0.42231 | 0.68683 | 0.52303 | 0.42803 | 0.58926 | 0.50061 |
| REMoDNaV | 0.52516 | 0.68745 | 0.52729 | 0.44115 | 0.68806 | 0.52281 |
| Fixation | Saccade | Smooth Pursuit | Stare | Move | |
|---|---|---|---|---|---|
| Behavior-based | - | - | - | 0.78080 | 0.542831 |
| REMoDNaV | 0.60656 | 0.43529 | 0.33945 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, S.; Jeong, S.; Jang, Y. Gaze Behavior Effect on Gaze Data Visualization at Different Abstraction Levels. Sensors 2021, 21, 4686. https://doi.org/10.3390/s21144686
Yoo S, Jeong S, Jang Y. Gaze Behavior Effect on Gaze Data Visualization at Different Abstraction Levels. Sensors. 2021; 21(14):4686. https://doi.org/10.3390/s21144686
Chicago/Turabian StyleYoo, Sangbong, Seongmin Jeong, and Yun Jang. 2021. "Gaze Behavior Effect on Gaze Data Visualization at Different Abstraction Levels" Sensors 21, no. 14: 4686. https://doi.org/10.3390/s21144686
APA StyleYoo, S., Jeong, S., & Jang, Y. (2021). Gaze Behavior Effect on Gaze Data Visualization at Different Abstraction Levels. Sensors, 21(14), 4686. https://doi.org/10.3390/s21144686