1. Introduction
In the past decade years, automatic driving has gained much attention with the development of deep learning. As an essential perception task in computer vision, lane detection has long been the core of automatic driving [
1]. Despite the long-term research, lane detection still has the following difficulties: (1) Lanes are slender curves, the local features of them are more difficult to extract than ordinary detection tasks, e.g., pedestrians and vehicles. (2) Occlusion is serious in lane detection so that there are few traceable visual clues, which requires global features with long-distance perception capabilities. (3) The road scenes are complex and changeable, which puts forward high requirements for the real-time and generalization abilities of lane detection.
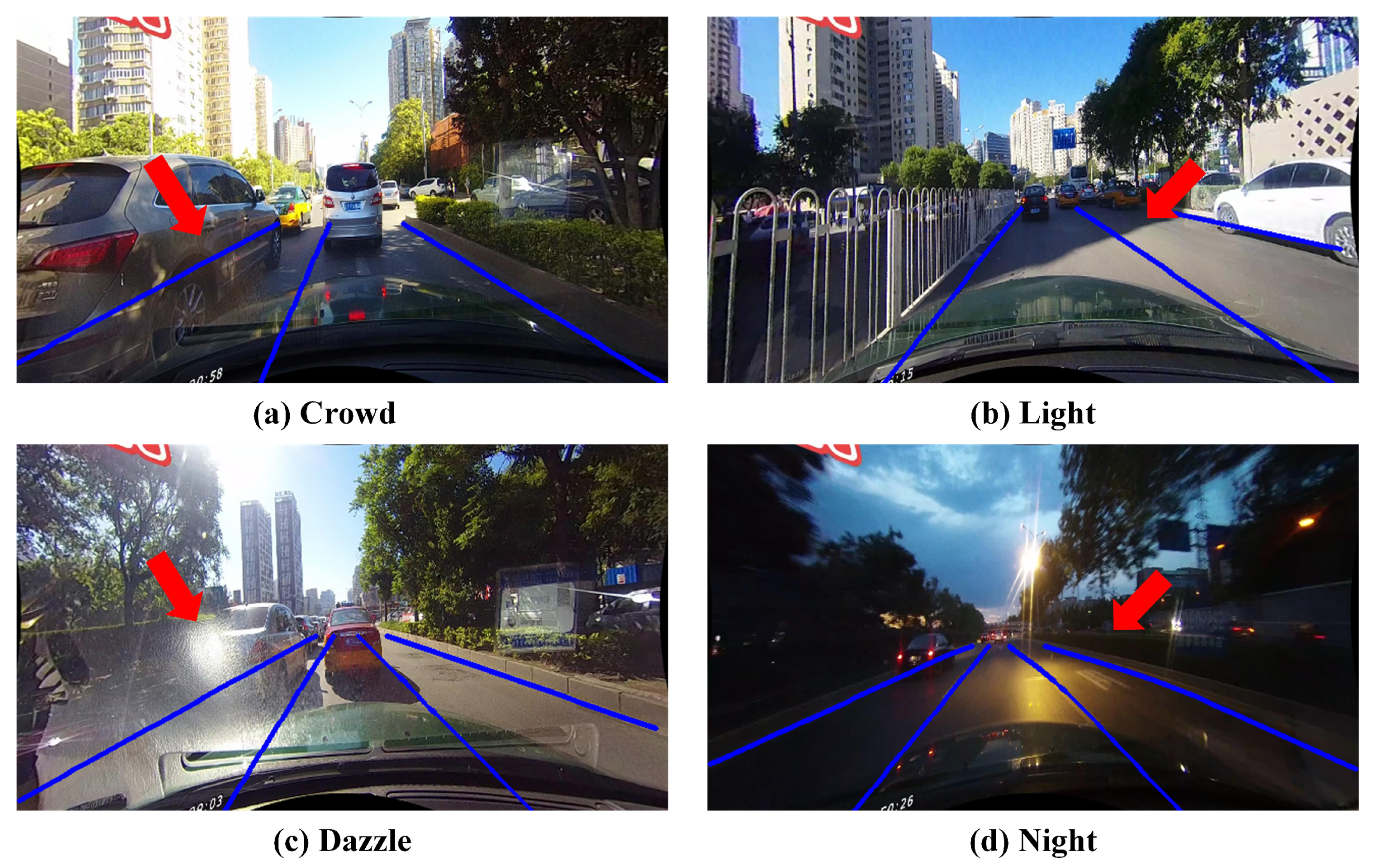
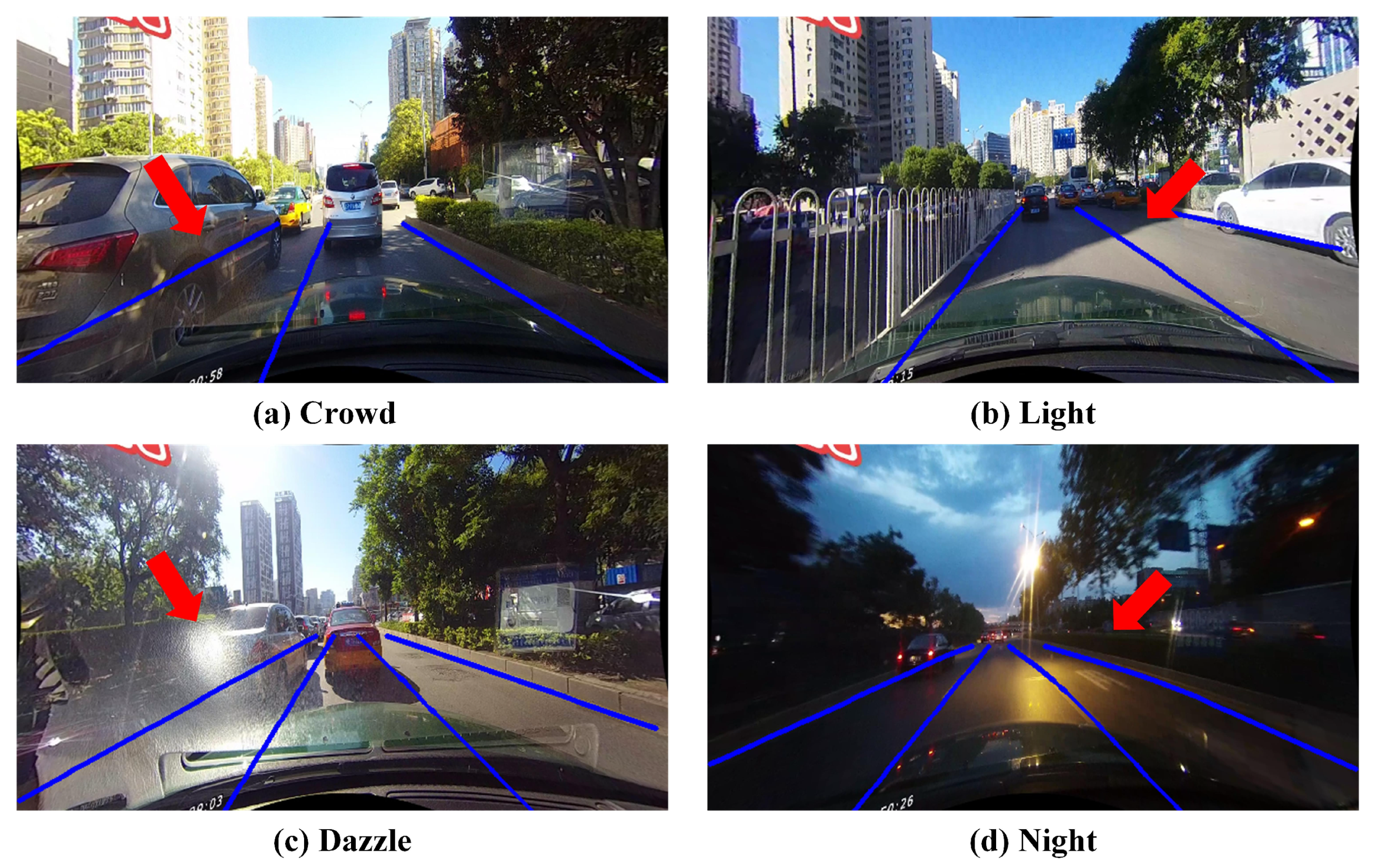
Figure 1 shows the realistic lane detection scenes under occlusion, illumination change, strong exposure, and night conditions.
Traditional lane detection methods usually rely on hand-crafted features [
2,
3,
4,
5,
6,
7,
8], and fit the lanes by post-processing, e.g., Hough transforms [
2,
3]. However, traditional methods require a sophisticated feature engineering process, and cannot maintain robustness in real scene, hindering their applications.
With the development of deep learning, a large number of lane detection methods based on convolutional neural networks (CNN) have been proposed [
9,
10,
11,
12,
13], which greatly improves the performance. The mainstream lane detection methods are based on segmentation which predict the locations of lanes by pixel-wise classification with an encoder-decoder framework. They first utilize a specific backbone (composed with CNN) as the encoder to generate feature maps from the original image, then use an up-sampling module as the decoder to enlarge the size of feature maps, performing a pixel-wise prediction. However, the lanes are represented as segmented binary features in segmentation methods, which makes it difficult to aggregate the overall information of lanes. Although some works [
10,
12,
14] utilize specially-designedspatial feature aggregation modules to effectively enhance the long-distance perception ability. However, they also increase the computational complexity and make the running speed slower. Moreover, most segmentation-based methods need to use post-processing operations (e.g., clustering) to group the pixel-wise predictions, which is also time-consuming.
In order to avoid the above-mentioned shortcomings of segmentation-based methods, a great number of works [
15,
16,
17,
18] began to focus on using different modeling methods to deal with the lane detection problem. Polynomial-based methods [
16,
18] propose to localize lanes by learnable polynomials. They project the real 3D space into 2D image space and fit a series of point sets to determine the specific coefficients. Row-based classification methods [
15,
19] detect lanes by row-wise classification based on a grid division of the input image. Anchor-based approaches [
17,
20] generate a great number of anchor points [
20] or anchor lines [
17] in images and detect lanes by classifying and regressing them. The above methods consider the strong shape prior of lanes and can extract the local features of lanes more efficiently. Besides, these works discard the heavy decoding network and directly process the high-dimensional features generated by the encoding network, so the real-time ability of them is stronger than segmentation-based methods. However, for fewer calculation and training parameters, most methods above directly use 1 × 1 convolution to compress high-dimensional features to complete downstream tasks (i.e., classification and regression tasks). Because the dimension difference between input features and compressed features is too large, the information loss problem is serious in the feature compression, which affects the upper bound of accuracy.
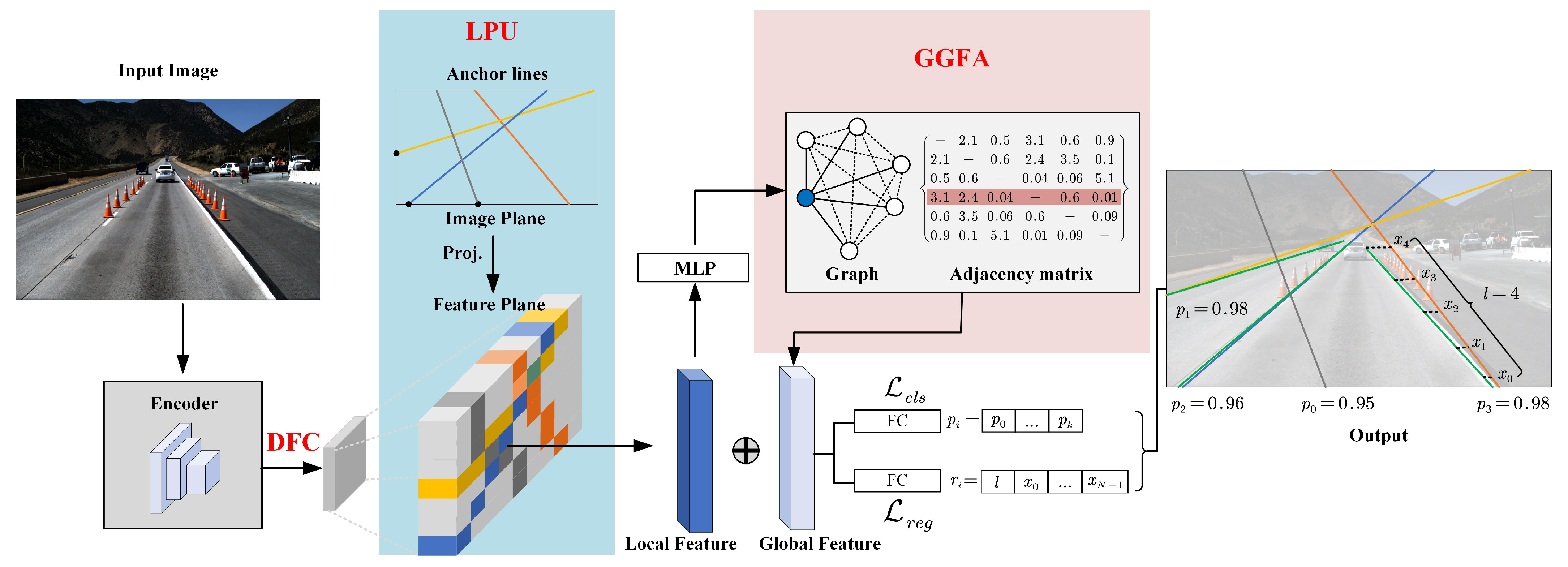
Consider the existing difficulties and the recent development of lane detection, we propose a fast and accurate method to detect lanes, namely FANet, aiming to resolve the three difficulties mentioned in the first paragraph. For the first issue, we utilize a line proposal unit (LPU) to effectively extract the local lane feature with strong discrimination. LPU generates a series of anchor lines over the image space and extracts the thin and long lane features by the locations of anchor lines. For the second problem, we propose a graph-based global feature aggregation module (GGFA) to aggregate global lane features with strong perception. GGFA treats local lane features as nodes of the graph, and adaptively learn the distances between nodes, then utilizes weighted sums to generate global feature. This graph is fully connected, its edges represent the relations between nodes. GGFA can effectively capture visual cues and generate global features with strong perception ability. For the third difficulty, to pursue higher running speed, we also drop the decoder network and compress the high-dimensional feature map as above works. However, unlike they directly use 1 × 1 convolution to compress features, we utilize the idea of disentangled representation learning [
21,
22] to restain more information in compressed features and name this module as Disentangled Feature Compressor (DFC). Specifically, DFC divides the high-dimensional feature map into three groups and integrates features respectively through low-dimensional 1 × 1 convolution. Then, inspired by batch normalization (BN) operation [
23], DFC follows the “normalize and denormalize” steps to learn the statistical information in the spatial dimension, so that the representation of the compressed feature will be richer. Moreover, sufficient experimental results in different scenarios also prove the strong generalization ability of our method.
Extensive experiments are conducted on two popular benchmarks, i.e., Tusimple [
24] and CULane [
10], our proposed FANet achieves higher efficacy and efficiency compared with current state-of-the-art methods. In summary, our main contributions are:
We propose a fast and accurate lane detection method, which aims to alleviate the main difficulties among lane detection problems. Our method achieves state-of-the-art performance on Tusimple and CULane benchmarks. Besides, the generalization of it is also outstanding in different driving scenarios.
We propose an efficient and effective global feature aggregator, namely GGFA, which can generate the global lane feature with strong perception. This module is a general module that can apply to other methods whose local features are available.
We propose a general feature compressor based on disentangled representation learning, namely DFC, which can restrain more information in the compressed feature without speed delay. This module is suitable to feature compression with huge dimensional differences, which can greatly improve the upper bound of accuracy.
3. Methods
We first introduce the overall architecture of our proposed FANet in
Section 3.1. Then, the DFC module, a feature compressor that is based on disentangled representation learning, will be introduced in
Section 3.2. Subsequently, Line Proposal Unit (LPU), an anchor lines generator will be introduced in
Section 3.3. The proposed GGFA module, an effective and efficient global lane feature aggregator, will be introduced in
Section 3.4. Finally, we elaborate on the details of the model training process in
Section 3.5.
3.1. Architecture
FANet is a single-stage anchor-based detection model (like YOLOv3 [
31] or SSD [
32]) for lane detection. The overview of our method is as shown in
Figure 2.
It receives an RGB image
as input, which is taken from the camera mounted in a vehicle. Then, an encoder (such as ResNet [
33]) extracts the features of
I, outputting a high-dimensional feature map
with deep semantic information, where
,
, and
C are the height, the width, and the channel dimension of
. For fast running, the DFC module we proposed is then applied into
and generates compressed feature
with a low dimension, where
is the channel dimension of
. After that, LPU generates predefined anchor lines which are throughout the image and extracts local lane features by their locations from
. To enhance the perception of the features, GGFA builds a graph structure and aggregates global lane features with the input of local lane features. Then, we concatenate the local lane features and the global features, then predict the lanes by two fully connected layers (FC). The first one is to classify the proposal lanes are background or targets. The second one is to regress relative coordinates. Since the lane is represented by 2D-points with fixed equally-spaced
y-coordinates, the corresponding
x-coordinates and the length of the lane are the targets in the regression branch.
3.2. Disentangled Feature Compressor
Our proposed DFC aims to preserve more information of compressed features, thereby improving the representation of features. The core of it is to exploit the idea of disentangled representation learning to reduce the correlation of feature components. Besides, the module design is inspired by the classic batch normalization (BN) operation, which follows the “normalize and denormalize” steps to learn the feature distribution. Next, we will detail the structure design, the theory, and the computational complexity of our module.
3.2.1. Structure Design
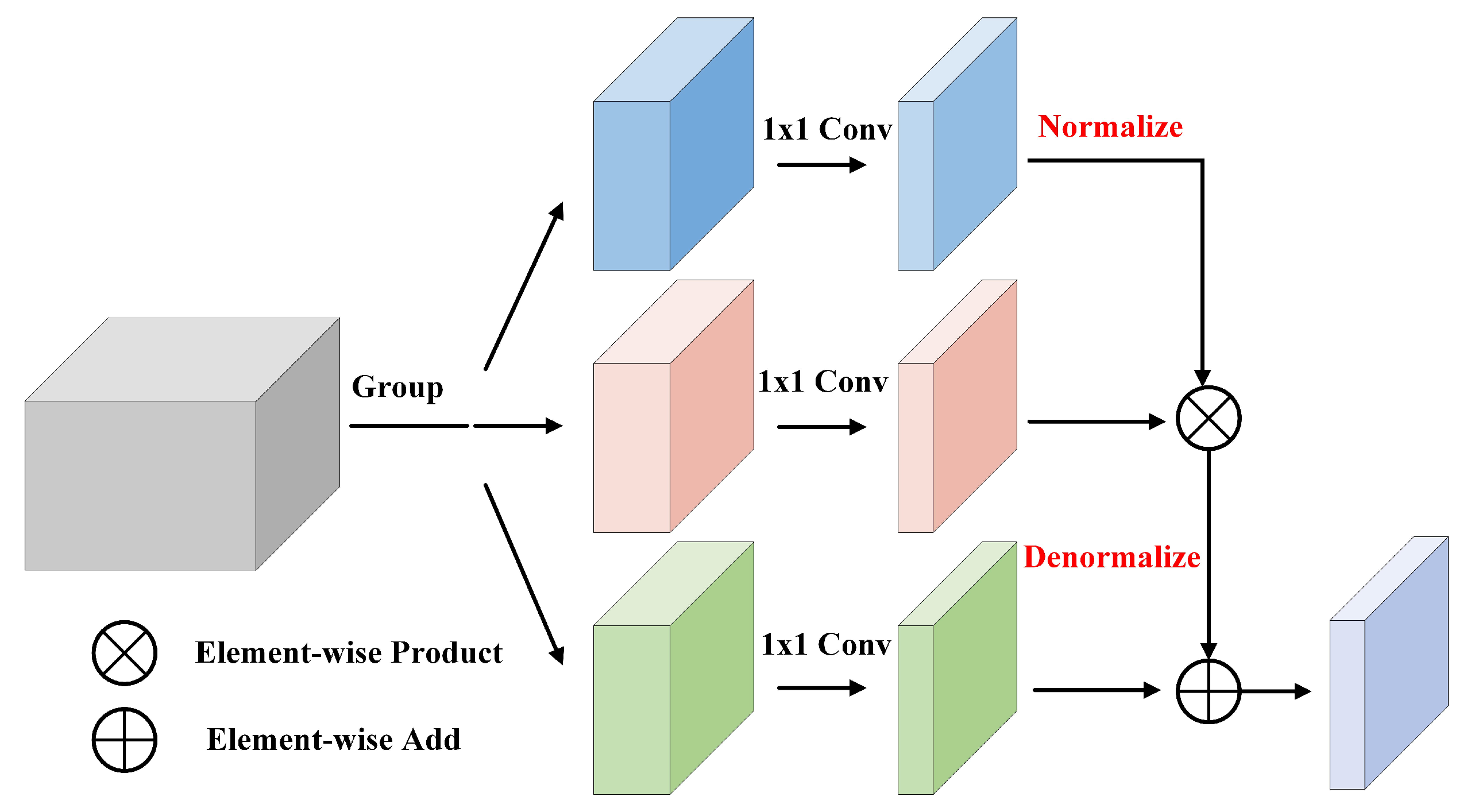
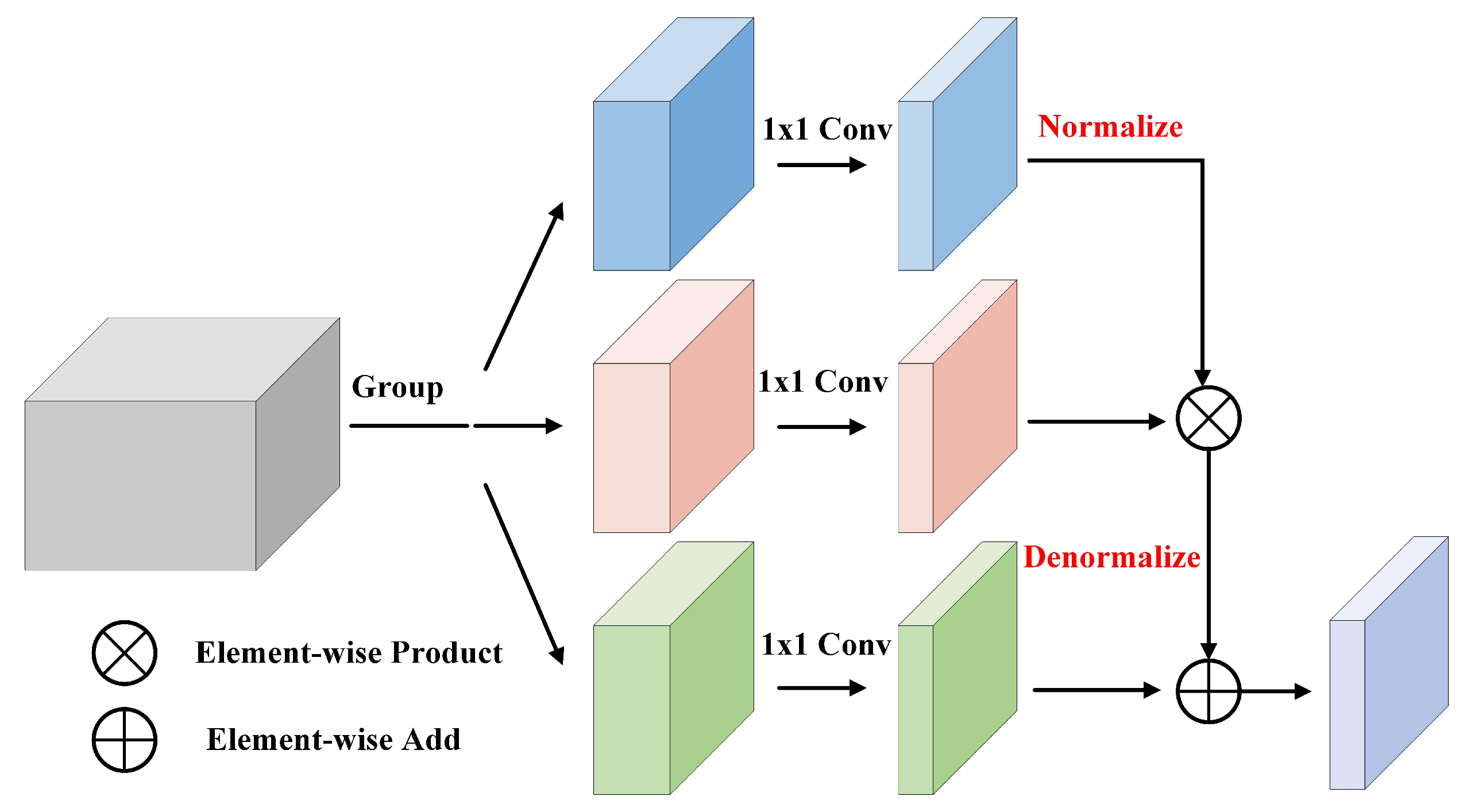
As shown in
Figure 3, DFC module receives a high-dimensional feature
as input, the size of it is
. Then, DFC divides
into three groups and generates three low-dimensional feature maps
through three 1 × 1 convolutions that do not share weights. The size of the low-dimensional feature map is
. After that, normalization operation in the spatial dimension is performed onto
, making the features more compact. Finally, with the input of
,
, and
, denormalization operation consisting of element-wise product and element-wise add is then used to learn the spatial statistical information, thus enhancing the diversity of the compressed feature.
3.2.2. Theory Analysis
As mentioned above, the core of DFC is based on decoupling representation learning, which can reduce the coupling between features, thereby enhancing feature diversity. Different from common decoupling representation learning tasks [
34,
35,
36] that branches have different supervision goals respectively. In our module, the three branches are all supervised by the final targets, i.e., classification and regression tasks. Nevertheless, the “divide and conquer” strategy of decoupling representation learning is exploited in our module. After deciding the main idea of our module, we make an assumption for the feature compression problem, i.e., the high-dimensional feature has a great amount of redundant information, and suitable division does not have much impact on its representation ability. Therefore, we divide the high-dimensional feature map into three components, each of which has a different effect on the target.
Inspired by the classic batch normalization algorithm, we apply the “normalize and denormalize” steps to learn the statistical information in the feature plane. The formulation of BN is as follows:
where
and
are the learnable parameters to perform the “denormalize” operation.
denotes the
l-th sample in a mini-batch.
and
are the mean and standard deviation of
Z,
is a small number, preventing the denominator from being zero.
Instead of learning the mini-batch sample distribution in BN, we propose to learn the spatial feature distribution. The computation is as follows:
where
and
are the mean and standard deviation of
in the spatial feature dimension.
and
are analogous to the
and
in Equation (
1), which are also learnable. Therefore, the three independent components, i.e.,
.
, and
all have the different functions towards the target.
is the component to control the specific value, somewhat like the “value” component of transformer [
30].
controls the deviation of the main distribution, and also decides the preservation degree of
.
controls the bias of the distribution.
3.2.3. Computational Complexity
We compare the computational complexity of the 1 × 1 convolution and the DFC module we designed in this section. The computational complexity of 1 × 1 convolution is as follows:
While the computational complexity of DFC is written as:
where the convolution part of two operations is the same, while DFC adds normalization operation, element-wise product, and element-wise add. The extra computational complexity is far less than
. Taking
and
as an example, calculation increment is only 1%, which can almost be ignorable.
3.3. Line Proposal Unit
The structure of LPU is as shown in
Figure 2, which generates a series of anchor lines and extracts local lane features by their locations. In this way, these local features have a strong shape prior, i.e., thin and long, thereby having a stronger discrimination ability.
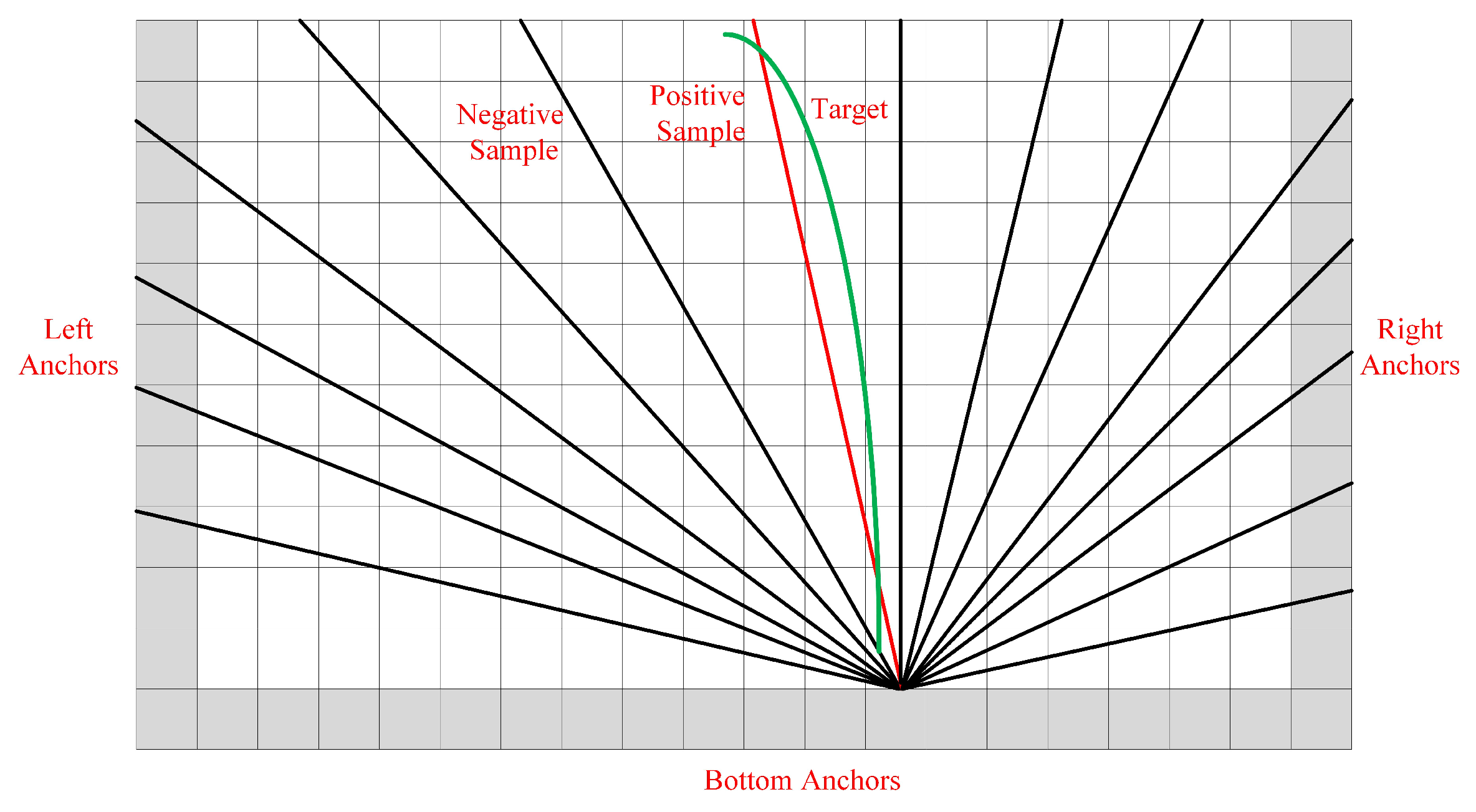
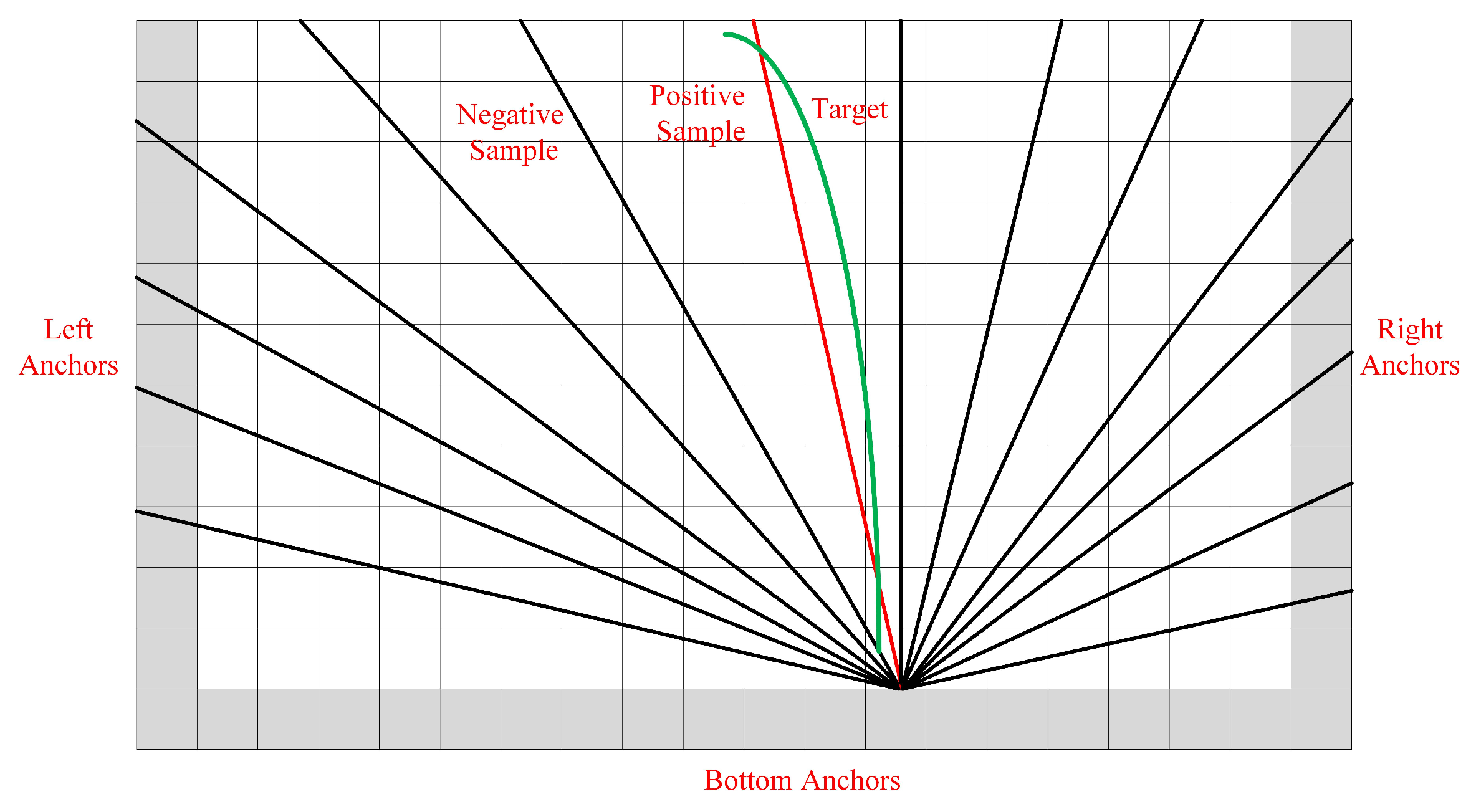
As shown in
Figure 4, we define the anchor line as a straight ray. LPU generates lines from the left, bottom, and right boundaries. A straight ray is set with a certain orientation
and each starting point
is associated with a group of rays. However, the number of anchor lines greatly influences the efficiency of the method. Therefore, we exploit the statistical method to find the most common locations of lanes, thereby reducing the number of anchor lines. Specifically, we first approximate the curve lanes as straight lines in the training samples and record the angles and the start coordinates of them. Then, we utilize K-means clustering algorithm to find the most commonly used clusters, thereby getting the set of anchor lines.
Table 1 shows the results after clustering representative angles. After getting the set of anchor lines, LPU can extract the feature of each anchor line by its location, which is composed of many pixel-level feature vectors. To ensure that the feature dimension of each anchor line is the same, we uniformly sample pixels in the height dimension of the feature map
. The corresponding
x-coordinates can be obtained by a projection function:
where
S is the global stride of the backbone. Then, we can extract the local feature
for each anchor line based on projected coordinates. In cases where
is outside the boundaries of
,
is zero-padded. Finally, the local lane features
of anchor lines with the same dimension can be obtained.
3.4. Graph-Based Global Feature Aggregator
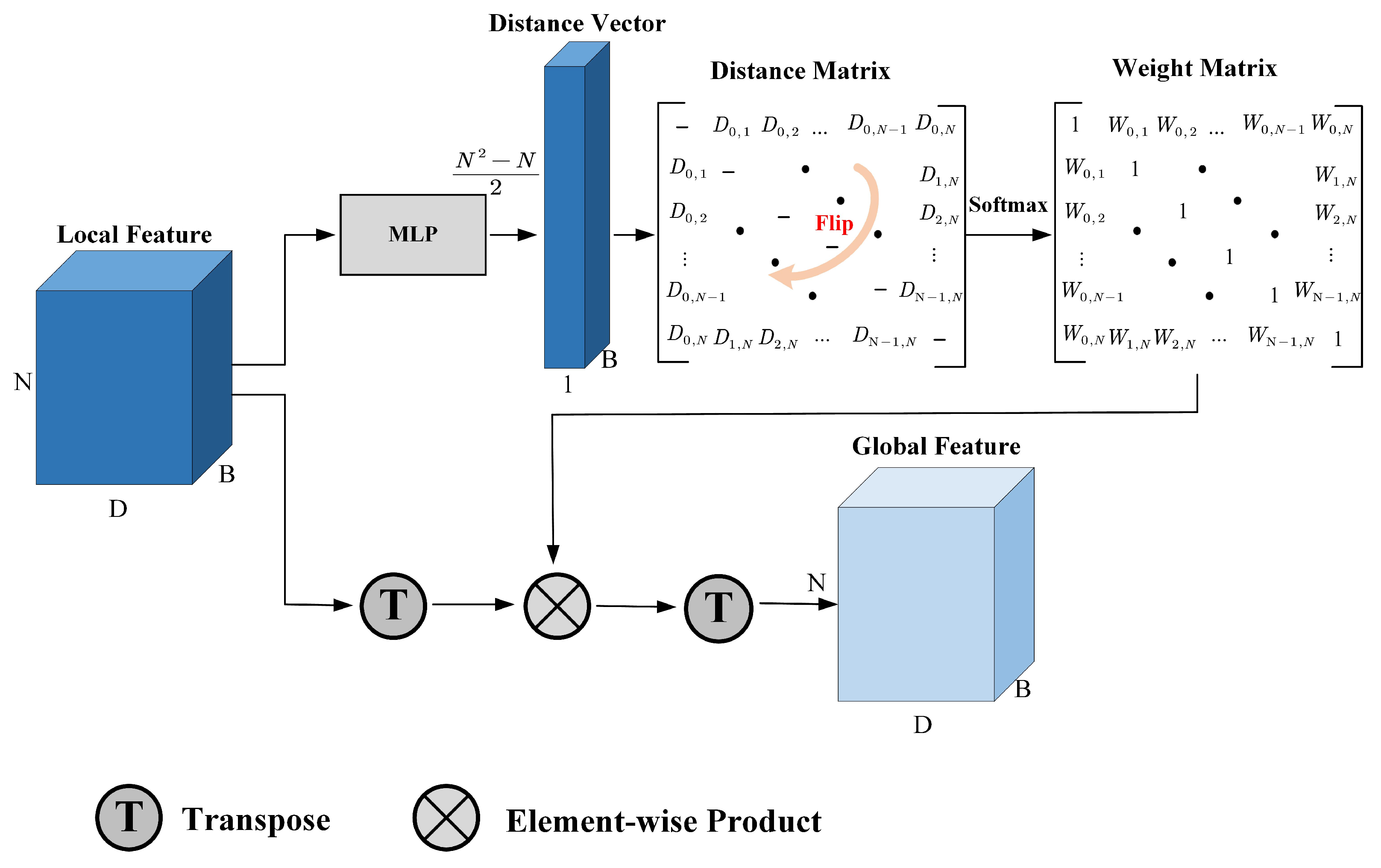
Lane detection requires a strong perception to locate the positions of lanes, but the local features cannot effectively perceive the global structure of the image, thus we propose GGFA to extract global lane features based on graph structure.
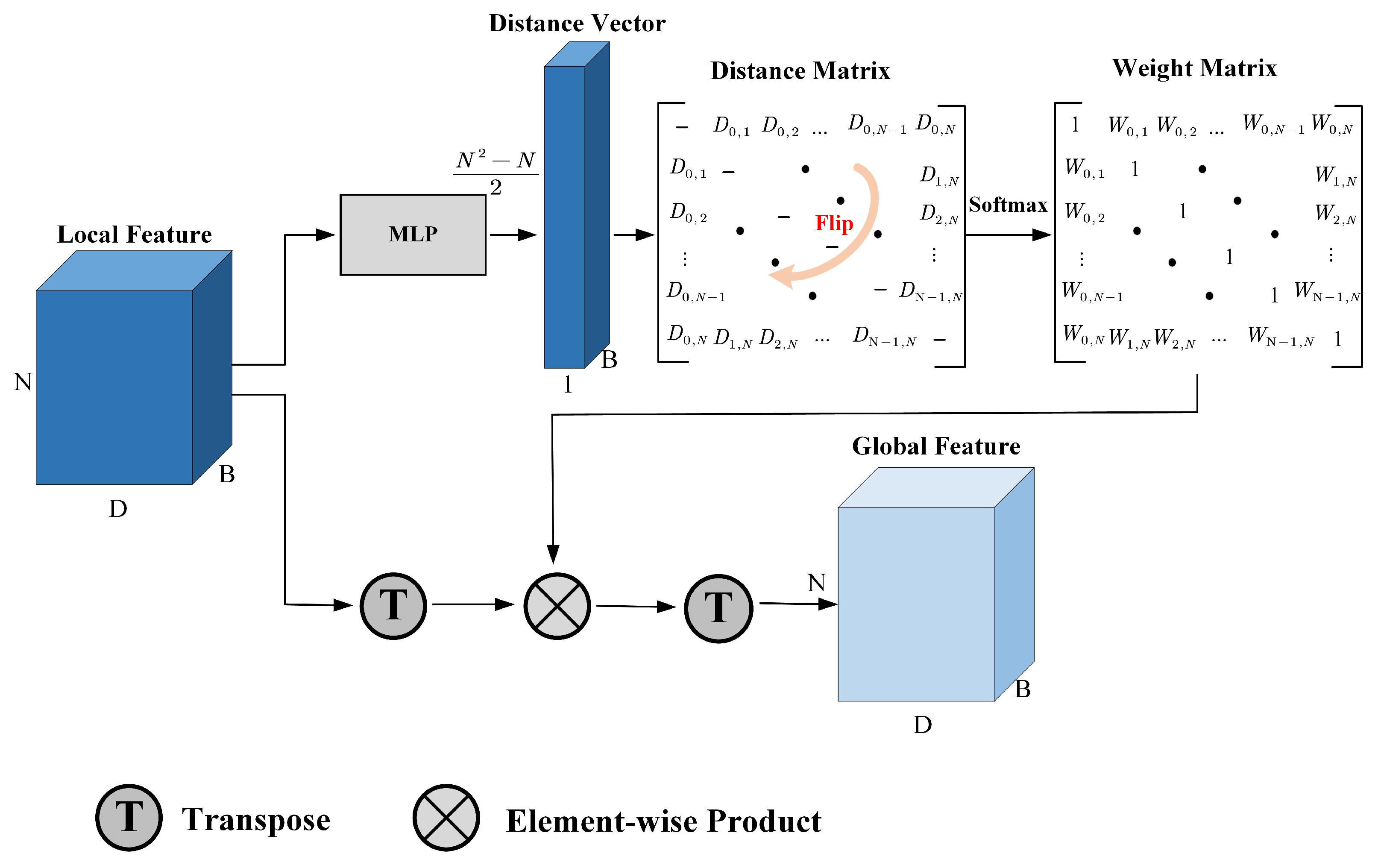
The structure of GGFA is as shown in
Figure 5. It receives the local lane features
as input and outputs the global lane features
, which have the same dimension as
. Specifically, with the input of
, Multi-Layer Perceptron (MLP) generates a distance vector with
dimensions. Then, the distance vector is filled in the upper half part of an all-zero matrix. Flipping operation is applied to this matrix, making it perform as an axisymmetric matrix. In this way, the graph constructed by local features is a fully connected undirected graph. The distance between two nodes is the same for each one. After that, the weight matrix can be got as follows:
where
is the distance between
i-th and
j-th nodes. Softmax operation transforms the distances to a soft value, then 1 reduces this soft value, which represents the similarity of two nodes. The distance between the two nodes is closer, the similarity weight will be bigger. After performing matrix transpose and element-wise product operation, the global feature
can be obtained finally.
This module learns the relationship between the local features by constructing the graph structure. Because the anchor lines are all over the whole image, the learned global features also fully consider the spatial relationship and visual cues. Therefore, the local features with long-distance can also be effectively communicated, thus enhancing the perception of features. At the same time, using adaptive weighted summation, the importance of each local feature can also be distinguished, making the learned global features informative.
3.5. Module Training
Similar to object detection, anchor-based lane detection methods also need to define a function to measure the distance between two lanes. For two lanes with common valid indices (i.e., equal-distance
y-coordinates), the
x-coordinates are
and
, respectively, where
is the number of common points. The lane distance metric proposed in [
17] is adopted to compute the distance between two lanes:
where
and
are the start valid indices of two lanes,
and
are the end valid indices of two lanes, and
and
define the range of those common indices.
Based on the distance metric in Equation (
7), the process of training sample assignment can be defined. We compute the distance between anchor lines and targets, the anchor lines with a distance lower than a threshold
are considered as positive samples, while those with a distance larger than a threshold
are considered as negative samples.
The final loss function consists of two components, i.e., classification loss and regression loss, which are implemented by Focal loss [
37] and L1 loss, respectively. The total loss can be defined as:
where
is the number of positive and negative samples,
is used to balance the loss terms,
,
are the classification and regression predictions of the
i-th anchor line, and
,
are the corresponding classification and regression targets.
consists of “0” and “1”, i.e., background and lanes.
is composed with the length
l and the
x-coordinates.
4. Experiments
In this section, we first introduce the datasets of our experiments, i.e., Tusimple [
24] and CULane [
10] benchmarks in
Section 4.1, then present the implementation details of our methods in
Section 4.2. After that, we compare the performance of our proposed FANet with other SOTA methods in
Section 4.3 and conduct sufficient ablation studies to prove the effectiveness of our proposed modules in
Section 4.4.
4.1. Dataset
Tusimple [
24] and CULane [
10] are the most popular benchmarks in lane detection. The TuSimple dataset is collected with stable lighting conditions in highways. The CULane dataset consists of nine different scenarios, including normal, crowd, dazzle, shadow, no line, arrow, curve, cross, and night in urban areas. More details about these datasets can be seen in
Table 2.
4.1.1. TuSimple
TuSimple is a lane detection dataset for highway scenes, which is used for the primary evaluation of lane detection methods. This dataset contains 3626 training images and 2782 test images. The image size in TuSimple is , and each image contains up to 5 lanes.
On TuSimple, the main evaluation metric is accuracy, which is computed as:
where
is the number of lane points that are predicted correctly and
is the total number of evaluation points in each clip. For each evaluation point, if the predicted point and the target point are within 20-pixel values, the prediction is considered to be correct, otherwise wrong. Moreover, we also calculate the false-positive rate (FP), the false-negative rate (FN), and the F1 score on predictions.
4.1.2. CULane
CULane is a large lane detection dataset containing multiple scenarios. CULane has 98,555 training images and 34,680 test images. The image size is , and each image contains up to 4 lanes.
The evaluation metric of CULane benchmark is F1 score, which can be defined as:
where
and
. Different from TuSimple, each lane is considered as a line with a width of 30 pixels. Intersection-over-union (IoU) is calculated between predictions and targets. Those predictions with IoUs larger than a threshold (e.g., 0.5) are considered as correct.
4.2. Implementation Details
For all datasets, the input images are resized to 360 × 640 by bilinear interpolation during training and testing. Then, we utilize a random affine transformation (with translation, rotation, and scaling) along with random horizontal flips for data augmentaion. Adam [
38] is adopted as the optimizer for training, the epoch is 100 in Tusimple dataset and 15 in CULane dataset. Learning rate is set to 0.003 with the
CosineAnnealingLR learning rate schedule. To ensure the consistency of the experimental environment, all experimental results and speed measurements are performed on a single RTX 2080 Ti GPU. The number of anchor lines is set to 1000, the number of evaluation points (
) is 72, the threshold for positive samples (
) is set to 15, and the threshold for negative samples (
) is set to 20.
To ensure the invisibility of the test dataset during the training process, we divide a small part of the two datasets as validation datasets for saving the optimal model. 358 and 9675 images were selected in TuSimple and CULane datasets, respectively.
4.3. Comparisons with State-of-the-Art Methods
In this section, we compare our FANet with other state-of-the-art methods on TuSimple and CULane benchmarks. In addition to the F1 score and accuracy, we also evaluate the running speed (FPS) and calculation amount (MACs) for a fair comparison.
For TuSimple benchmark, the results of FANet along with other state-of-the-art methods are shown in
Table 3. Our proposed FANet performs the best in F1 score and also achieves good performance in other metrics. It is clear that the accuracy in TuSimple is relatively saturated, and the accuracy improvement in state-of-the-art methods is also small. Nevertheless, our proposed FANet also performs high accuracy with high efficacy simultaneously. FANet is 33 times faster than SCNN [
10], almost 8 times faster than Line-CNN [
17], about 3 times faster than ENet-SAD [
12], and 2 times faster than PolyLaneNet [
16]. Compared with the UFLD [
19], although it runs faster than ours, the false positive rate of UFLD is too high, reaching 19.05%, making it difficult to be applied to actual scenarios.
For CULane benchmark, the results of FANet along with other state-of-the-art methods are as shown in
Table 4. Our FANet achieves state-of-the-art performance while with high running speed. In crowded, dazzle, no line, cross, and night scenarios, FANet outperforms the other methods. Compared with SIM-CycleGAN [
39], although it is specifically designed for different scenarios, FANet is also close to it in many metrics, or even better. Compared with the knowledge distillation method IntRA-KD [
14] and the network search method CurveLanes-NAS [
40], FANet has a higher F1 score of 3.09% and 4.09% F1 respectively. Compared with UFLD, although it is faster than ours, FANet outperforms it with a 7.09% F1 score.
The visualization results of FANet on TuSimple and CULane are also shown in
Figure 6. Although the anchor lines are all straight in FANet, it does not affect the fitting of curved lane lines, as shown in the second row of
Figure 6. Besides, FANet also has a strong generalization in various scenarios, such as dazzle, crowded, and night scenes, as shown in the fourth row of
Figure 6.
4.4. Ablation Study
4.4.1. The Number Setting of Anchor Lines
Efficiency is crucial for a lane detection model. In some cases, it even needs to trade some accuracy to achieve the application’s requirement. In this section, we compare the performance of different numbers of anchor lines settings. In addition to the F1 score, we also compared the running speed (FPS), calculation complexity (MACs), and training time (TT).
As shown in
Table 5, until the number of anchor lines is equal to 1000, as the number increases, the F1 score also increases. However, if there are too many anchor lines, i.e., 1250, the F1 score will drop slightly. During the inference phase, the predicted proposals are filtered by non-maximum suppression (NMS), and its running time depends directly on the number of proposals, therefore the number of anchor lines directly affects the running speed of the method.
4.4.2. The Effect of Graph-Based Global Feature Aggregator
As shown in
Table 6, under the same backbone network, i.e., ResNet-18, the F1 value is 74.02% when GGFA is not added, and the F1 value is increased to 75.05% after adding GGFA, an increase of 1.03%. The performance improvement shows that our proposed GGFA can effectively capture global information by long-distance weight learning. At the same time, the performance gap also proves the importance of global features with strong perception for lane detection.
GGFA measures the distance between anchor lines by MLP and generates similarity through softmax operation. To better observe the relationship between the various anchor line features, we draw the three most similar anchor lines of the predicted lanes, as shown in
Figure 7. It is clear that the anchor lines with big similarities are always close to the predicted lanes. Besides, these anchor lines always focus on some visual cues, e.g., light changes and occlusion, which makes the method can capture some important information.
4.4.3. Performance Comparison under Different Groupings in DFC
As mentioned in
Section 3.2, DFC divides the high-dimensional feature into three groups. In this part, we further research the effect of different grouping methods, i.e., block, interval, and random methods. The block method directly divides the high-dimensional features into three groups according to the original arrangement order; the interval method internally takes out the high-dimensional features according to the number of channels, and puts them in three groups; the random method divides the high-dimensional features into three groups after shuffling in the channel dimension.
As shown in
Table 7, It is clear that the interval method achieves the best performance, and the random method achieves the second performance, yet the performance of the block method has a large gap. For the feature of each group, the first two methods cover the full range of original channels while the block method only takes the information of 1/3 area. The block method breaks the structure of the original feature, so resulting in an accuracy gap. It also proves the assumption we proposed, i.e., the high-dimensional feature has a great amount of redundant information, the suitable division does not affect its representation ability.
4.4.4. The Effect of Different Channel Dimensions in DFC
To verify the effect of our proposed DFC module, we apply it to high-dimensional feature compression with different dimensions. ResNet-18 and ResNet-50 are used to generate 512 and 2048 dimensions of features, respectively. In ResNet-18, high-dimensional features are compressed from 512 to 64 dimensions while 2048 to 64 in ResNet-50. In terms of task difficulty, it is undoubtedly more difficult to reduce feature dimensions from 2048 to 64.
As shown in
Table 8, compared with 1 × 1 convolution, our proposed DFC achieves 0.44% F1 score improvement in ResNet-18, and 0.78% F1 score improvement in ResNet-50. With the same 64-dimensional compressed features, the accuracy is improved significantly after applying our proposed DFC module. It proves that DFC can indeed preserve more information compared with 1 × 1 convolution. Besides, the performance improvement of DFC is more obvious when the feature dimension is higher. It shows that DFC performs better when the dimensional difference is great. At the same time, the consistent improvement in different dimensions also proves the effectiveness and strong generalization of DFC.
5. Discussion
According to the results in
Table 4, our proposed FANet is not ideal to detect curve lanes. Compared with other scenarios, the results of the curve scene are unsatisfactory. Therefore, we discuss the reason for this phenomenon.
We first make a visualization towards the curve scene in CULane. As shown in
Figure 8, it is clear that the predictions are straight. The predictions only find the locations of target lanes and do not fit the curvature of lanes. However, the predictions of TuSimple are indeed curved as shown in
Figure 6. Therefore, this is not the problem of the model or code implementation.
We further discuss CULane dataset itself. As shown in
Table 9, we count the number of images in various scenarios in CULane. We found that curve lanes are rare in CULane, which are only 1.2% of training images. It means that almost all the lanes in CULane are straight, result in significant bias. It can also explain why the predictions of our model are all straight in CULane.
However, after confirmation, we found that the prediction results in
Figure 8 are all regarded as correct because of the high degree of coincidence. Therefore, it can not explain the accuracy gap compared with other methods in the curve scene. Then, we train the model many times and found the experimental results in the curve scene fluctuate greatly. As shown in
Table 10, the accuracy gap between the best and the worst is huge, i.e., 2.36 % F1 score. It seems that the few training samples of the curve scene make the accuracy unstable.
6. Conclusions
In this paper, we proposed a fast and accurate lane detection method, namely FANet. FANet alleviates three main difficulties of lane detection: (1) how to efficiently extract local lane features with strong discrimination ability; (2) how to effectively capture long-distance visual cues; (3) how to achieve strong real-time ability and generation ability. For the first difficulty, we utilize Line Proposal Unit (LPU) to generate anchor lines over the image with strong shape prior, and efficiently extract local features by their locations. For the second difficulty, we propose a Graph-based Global Feature Aggregator (GGFA), which treats local features as nodes and learns global lane features with strong perception by establishing graph structure. For the third difficulty, our goal is to improve the accuracy of the model without affecting the running speed. Therefore, we propose a Disentangled Feature Compressor (DFC), which is a general and well-designed module for feature compression with a large dimension gap. DFC greatly improves the upper bound of accuracy while without speed delay. We also evaluate the generation of our method in various scenarios, the consistent outstanding performance proves the strong generation ability of FANet.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}