
Skeleton Driven Action Recognition Using an Image-Based Spatial-Temporal Representation and Convolution Neural Network

 ,
,  ,
,  , and
, and
Abstract
:1. Introduction
2. Related Work
3. Methodology
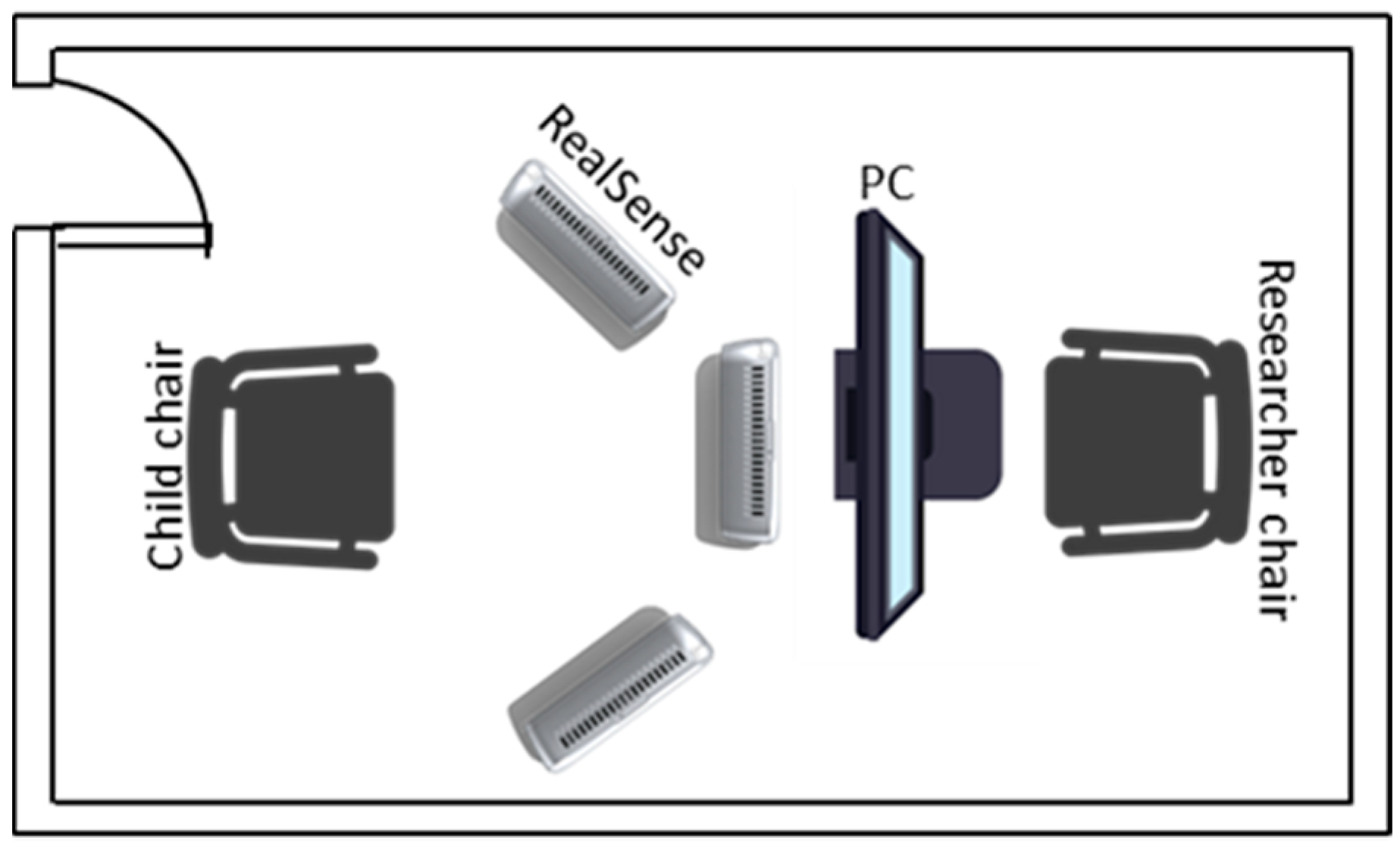
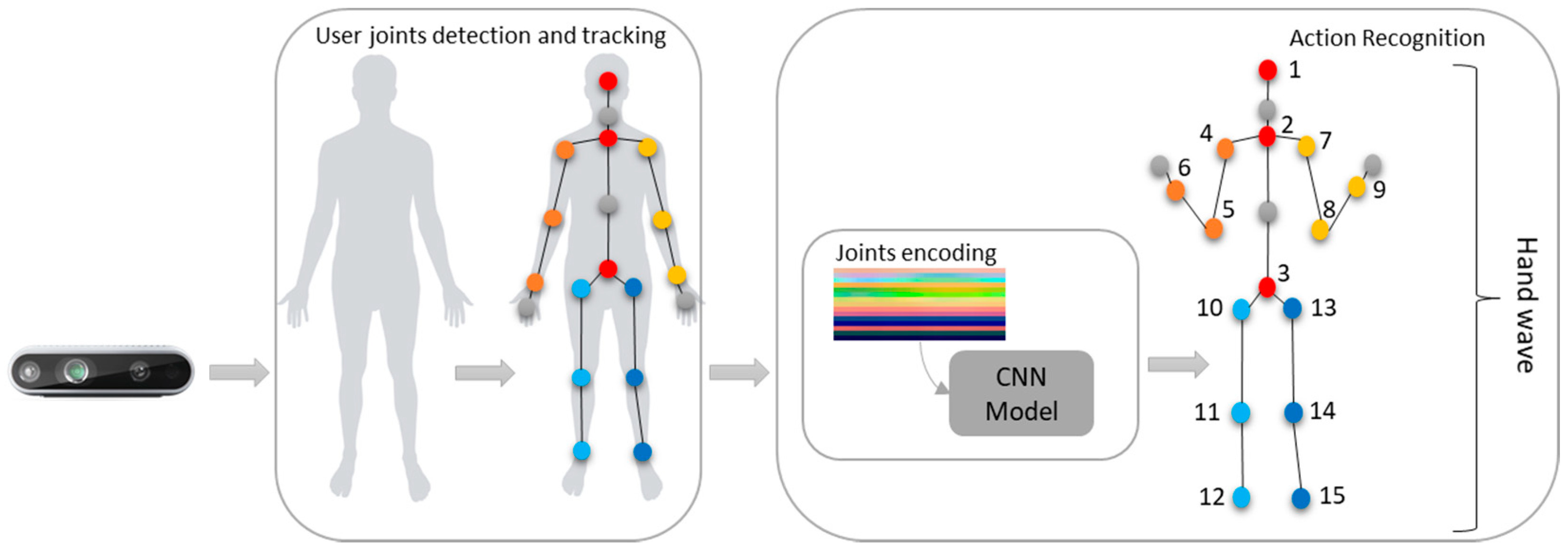
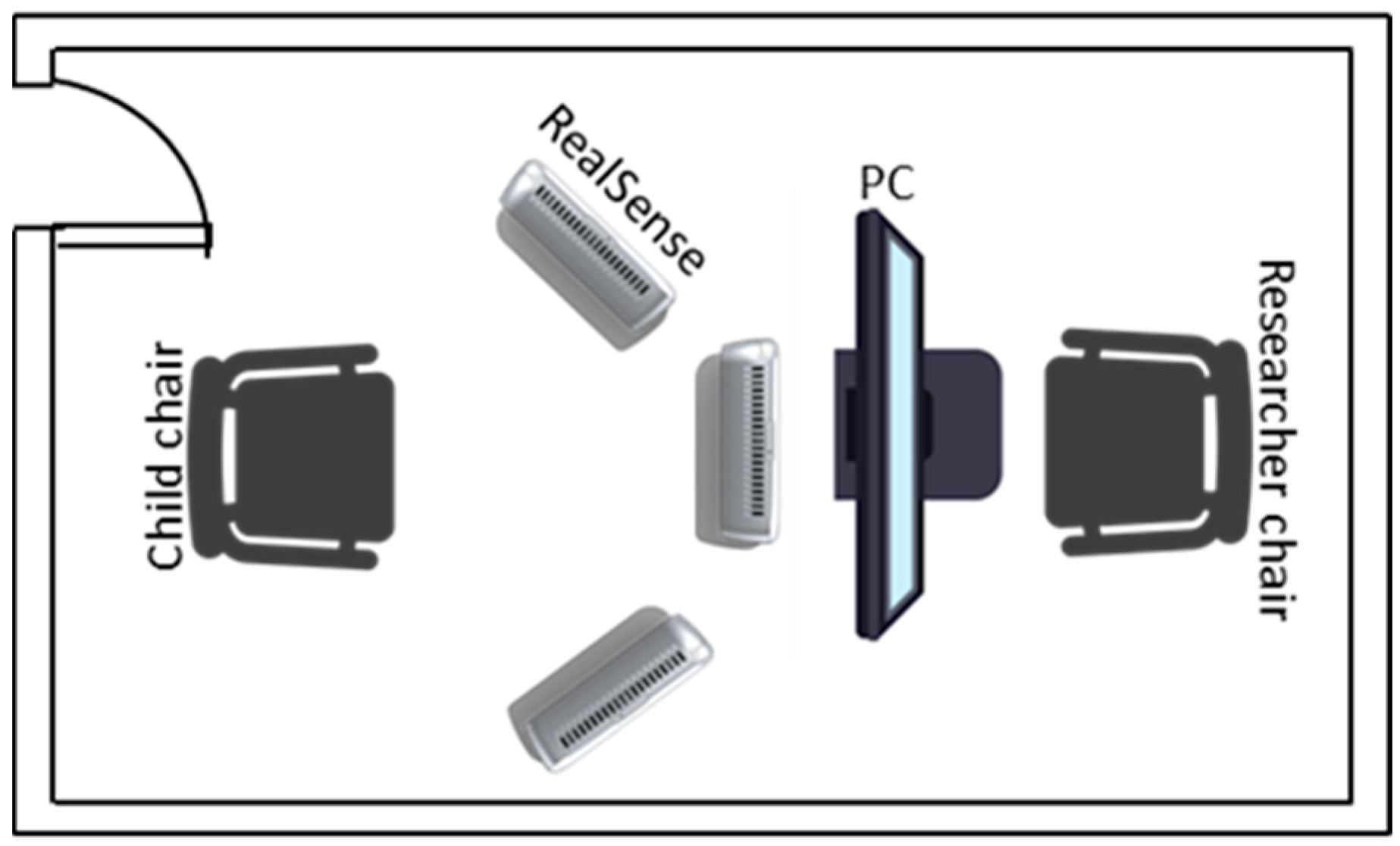
3.1. Proposed System
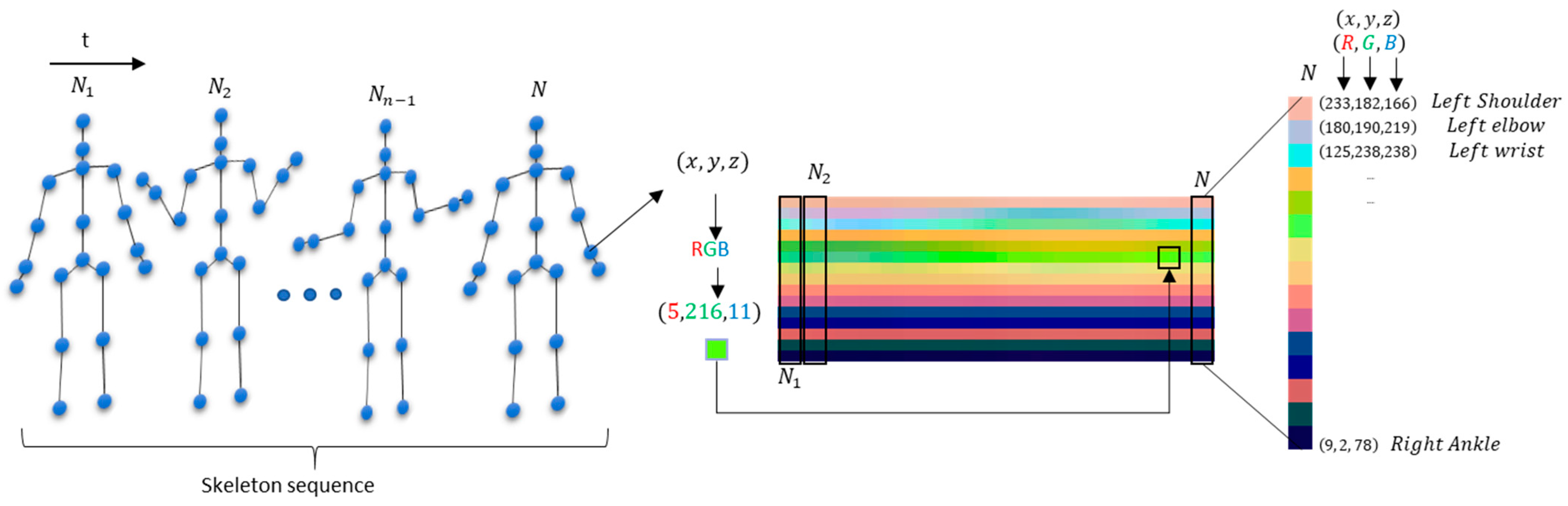
3.2. Pipeline and Processing
3.3. Datasets
3.3.1. KARD Dataset
3.3.2. TSBD Dataset
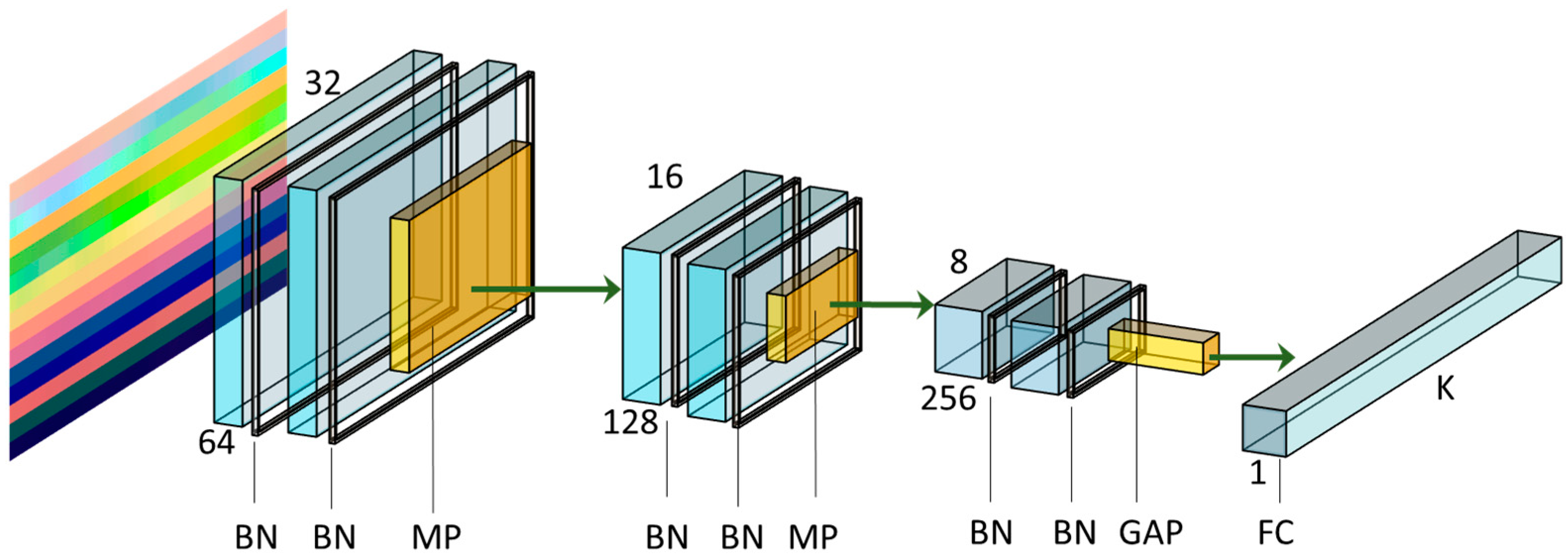
3.4. Deep Learning Network Architecture
4. Experimental Results and Discussion
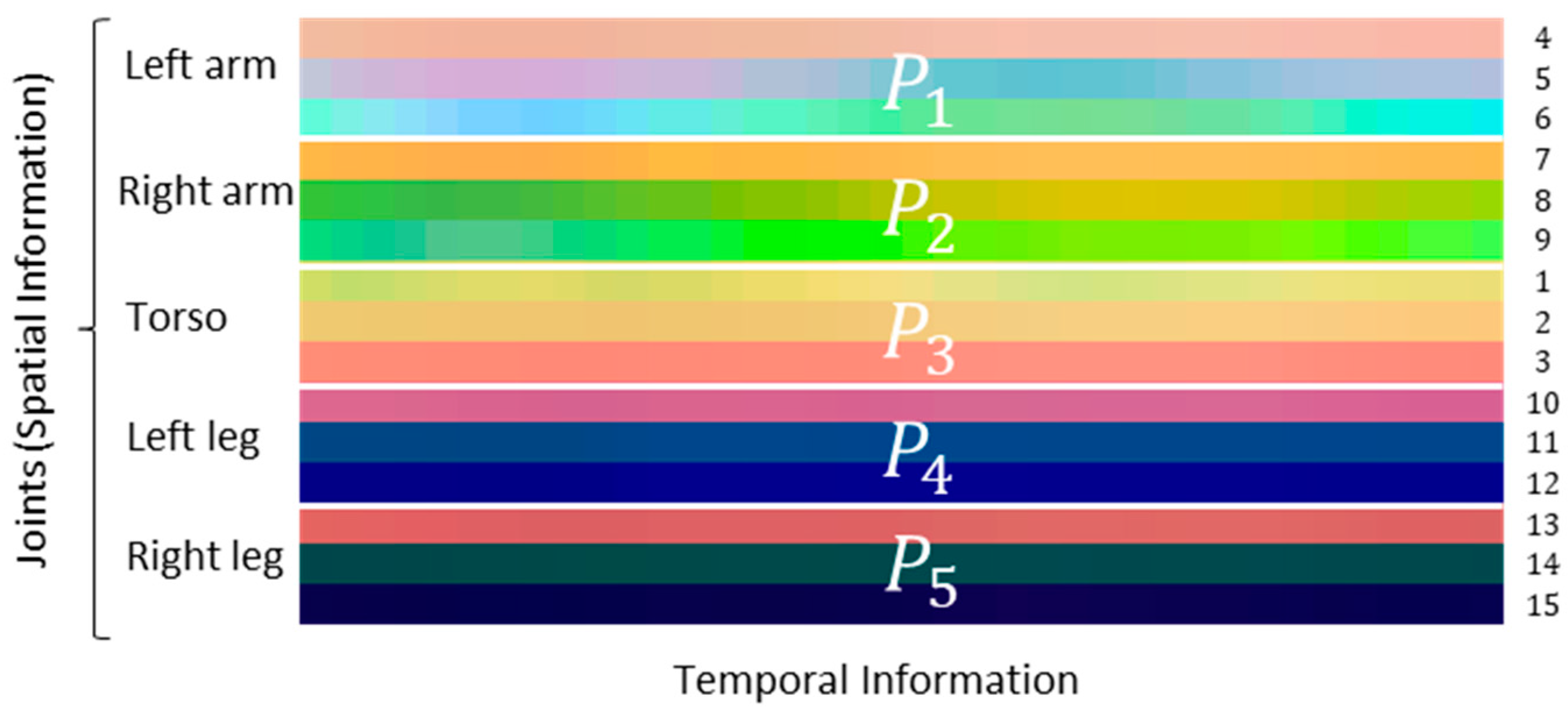
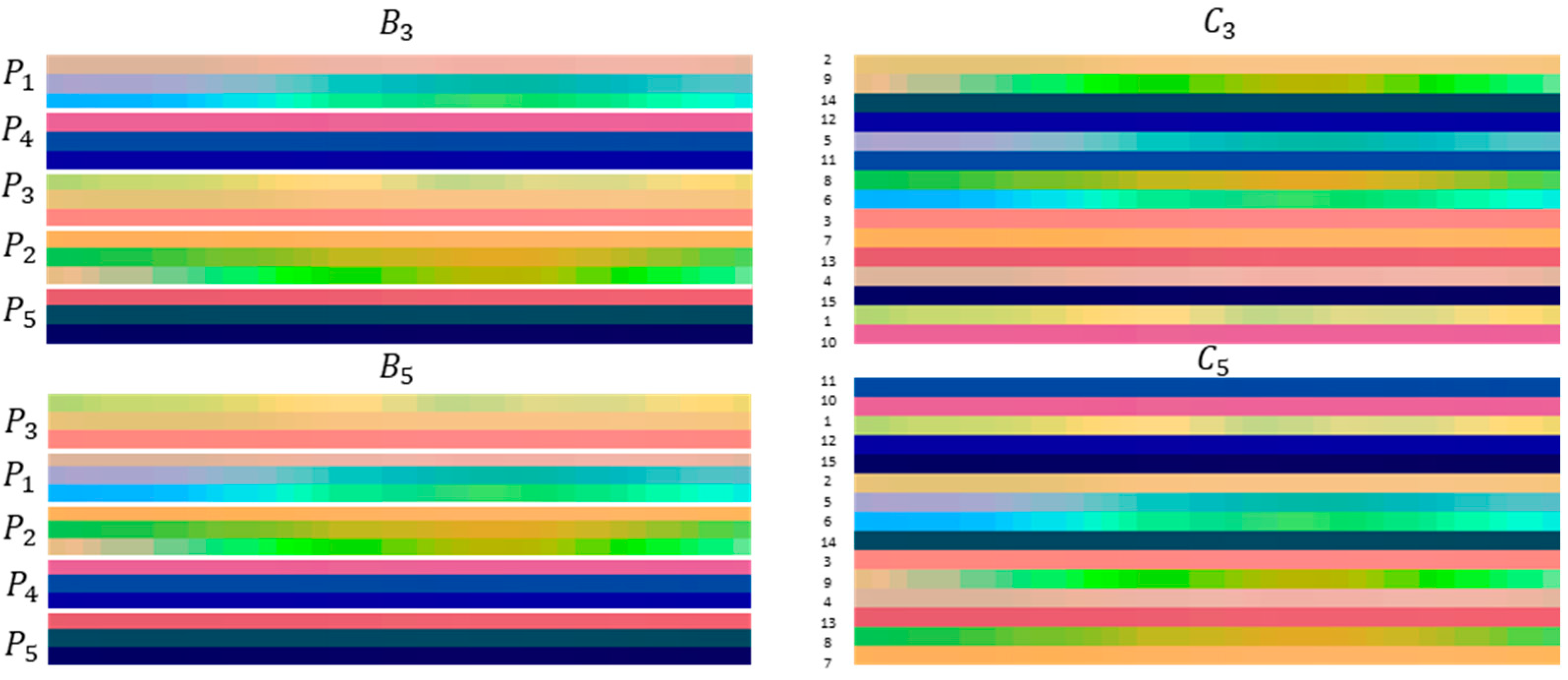
- E1 compares the accuracy of the skeleton configuration (control group) with other five skeleton combinations (, , , , and B6), where the sequence of the group (P1 to P5) was changed;
- E2 considered the joints of four skeleton combinations (, , , and ), each with 15 joints randomly sequenced and again compared with the skeleton configuration .
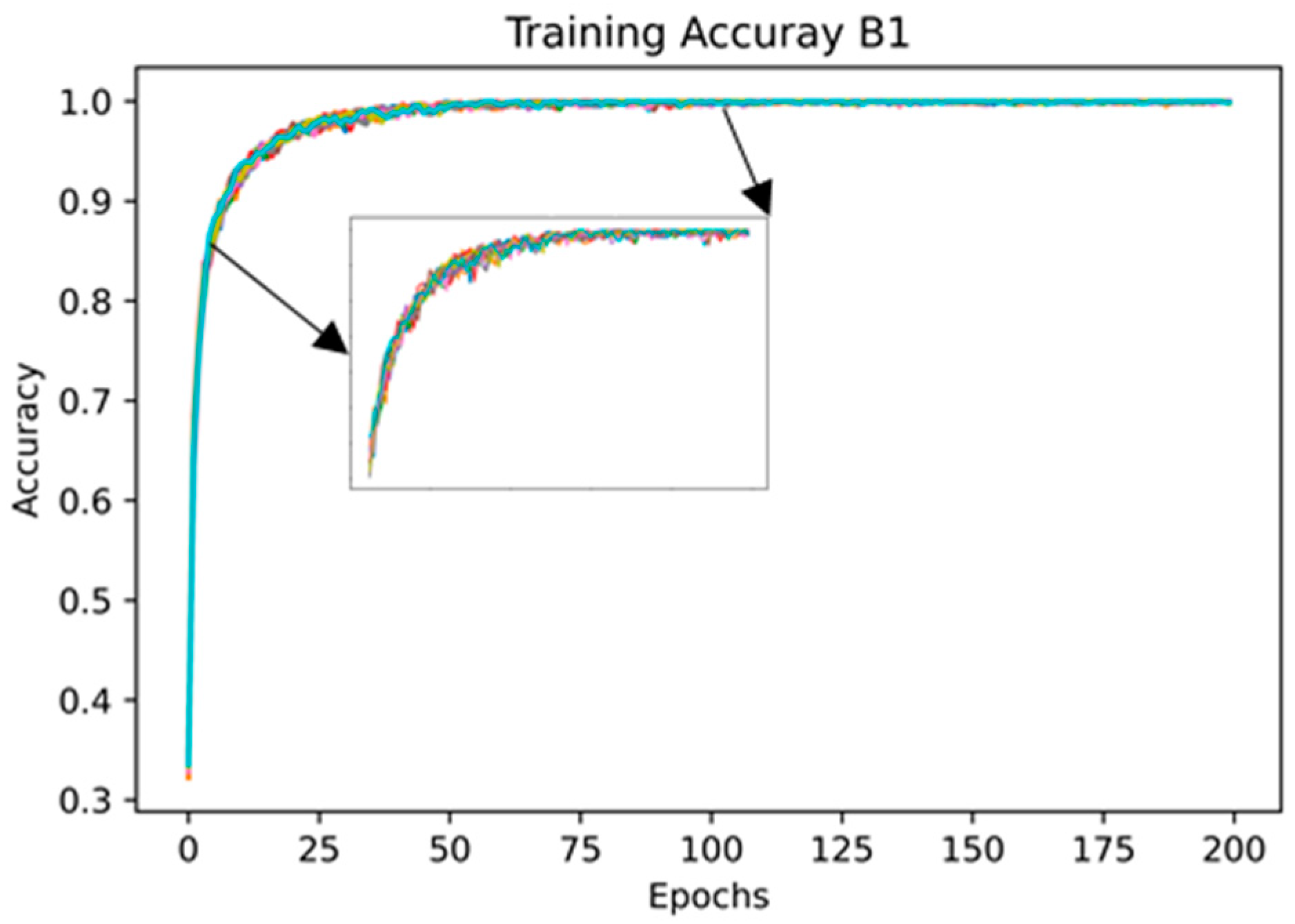
4.1. KARD Results
4.2. TSBD Dataset Results
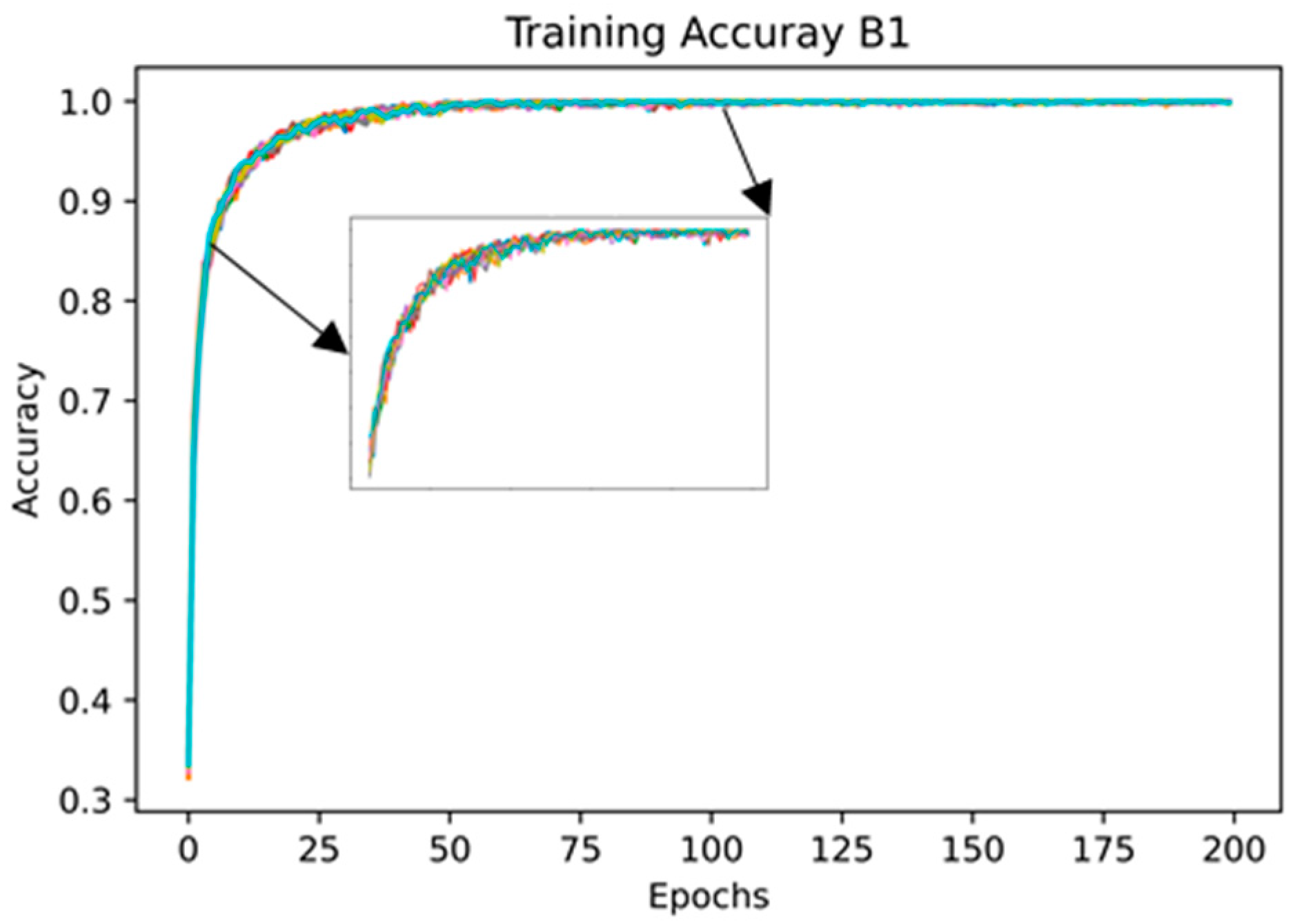
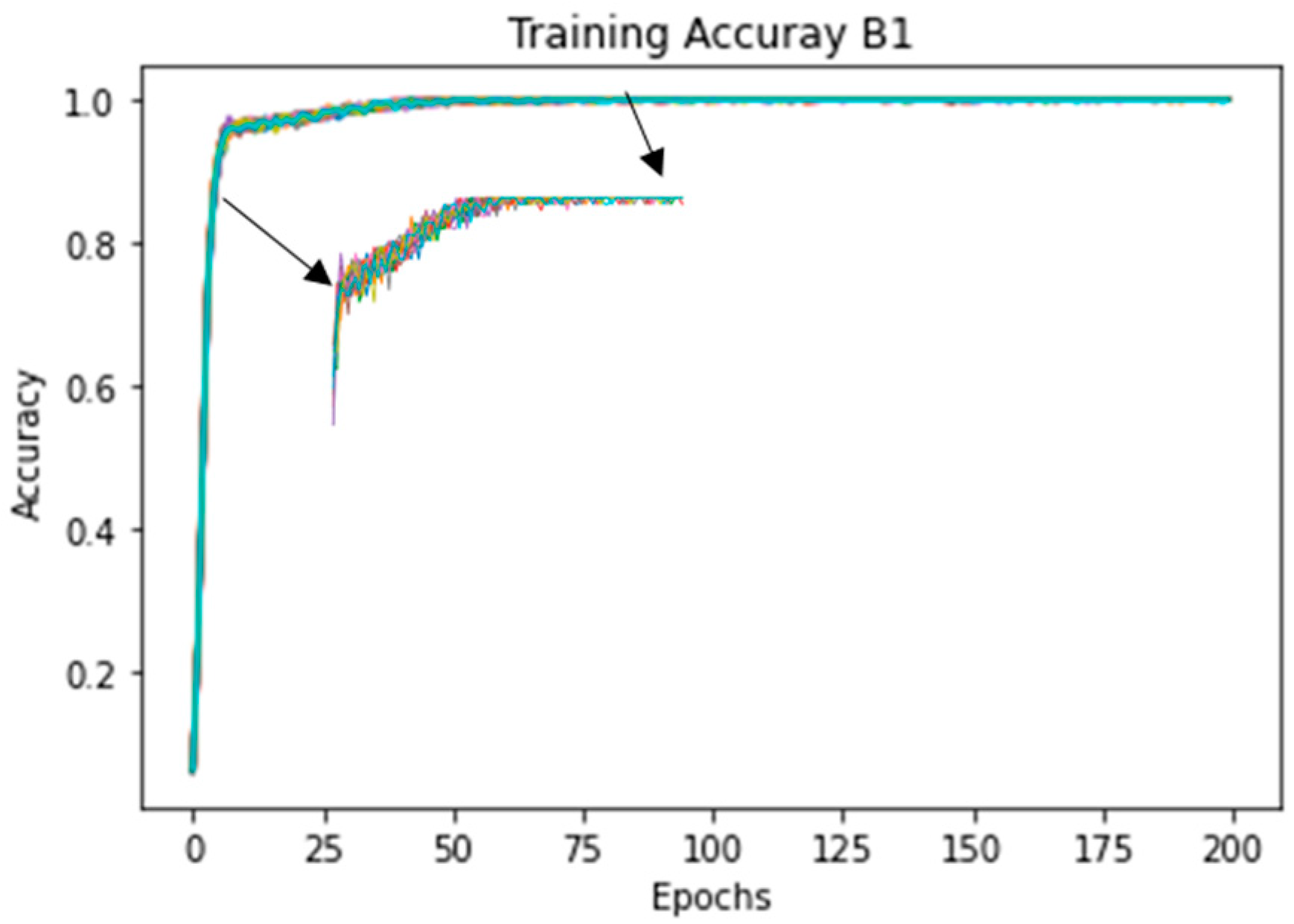
4.2.1. Statistical Analysis
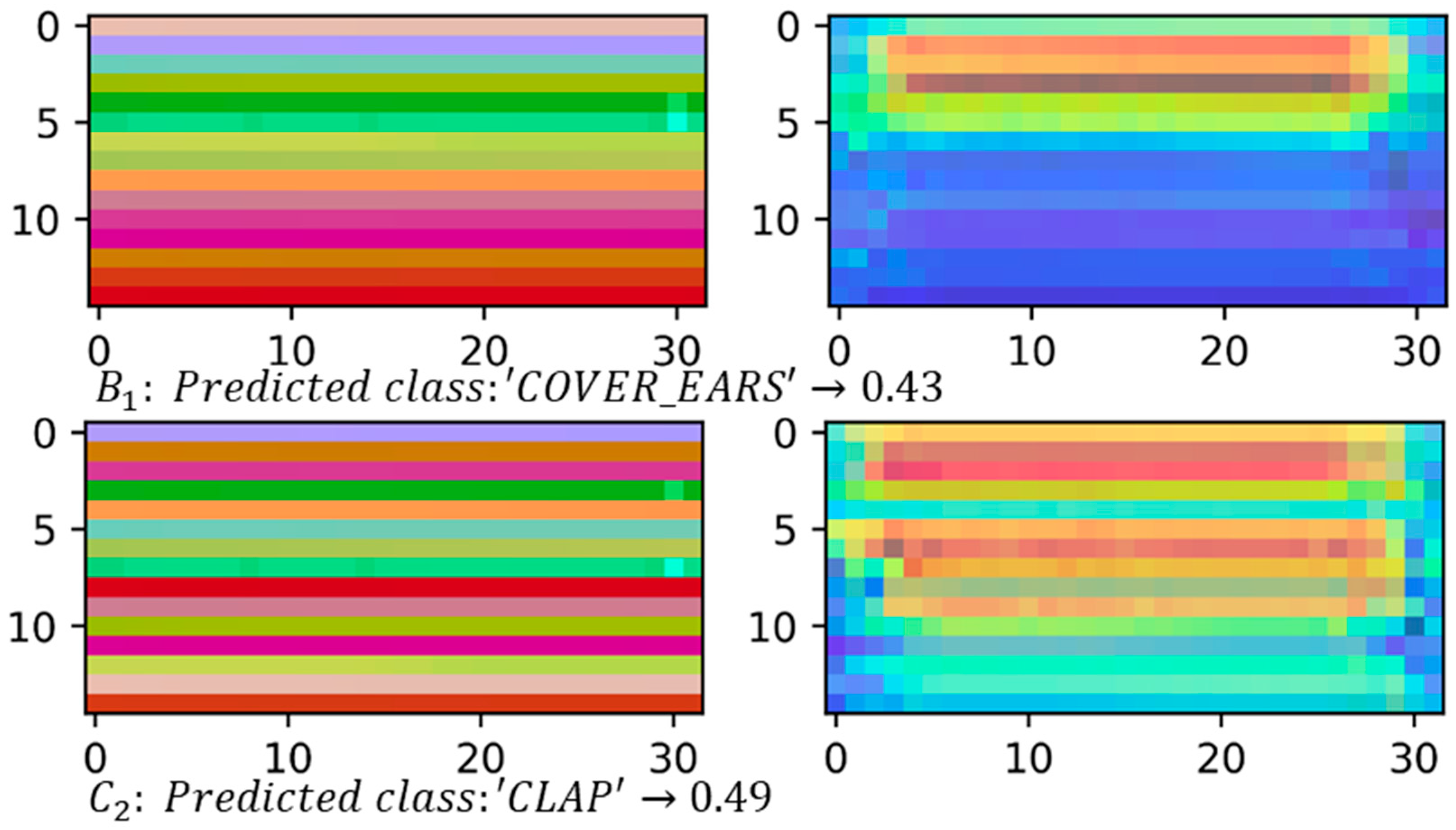
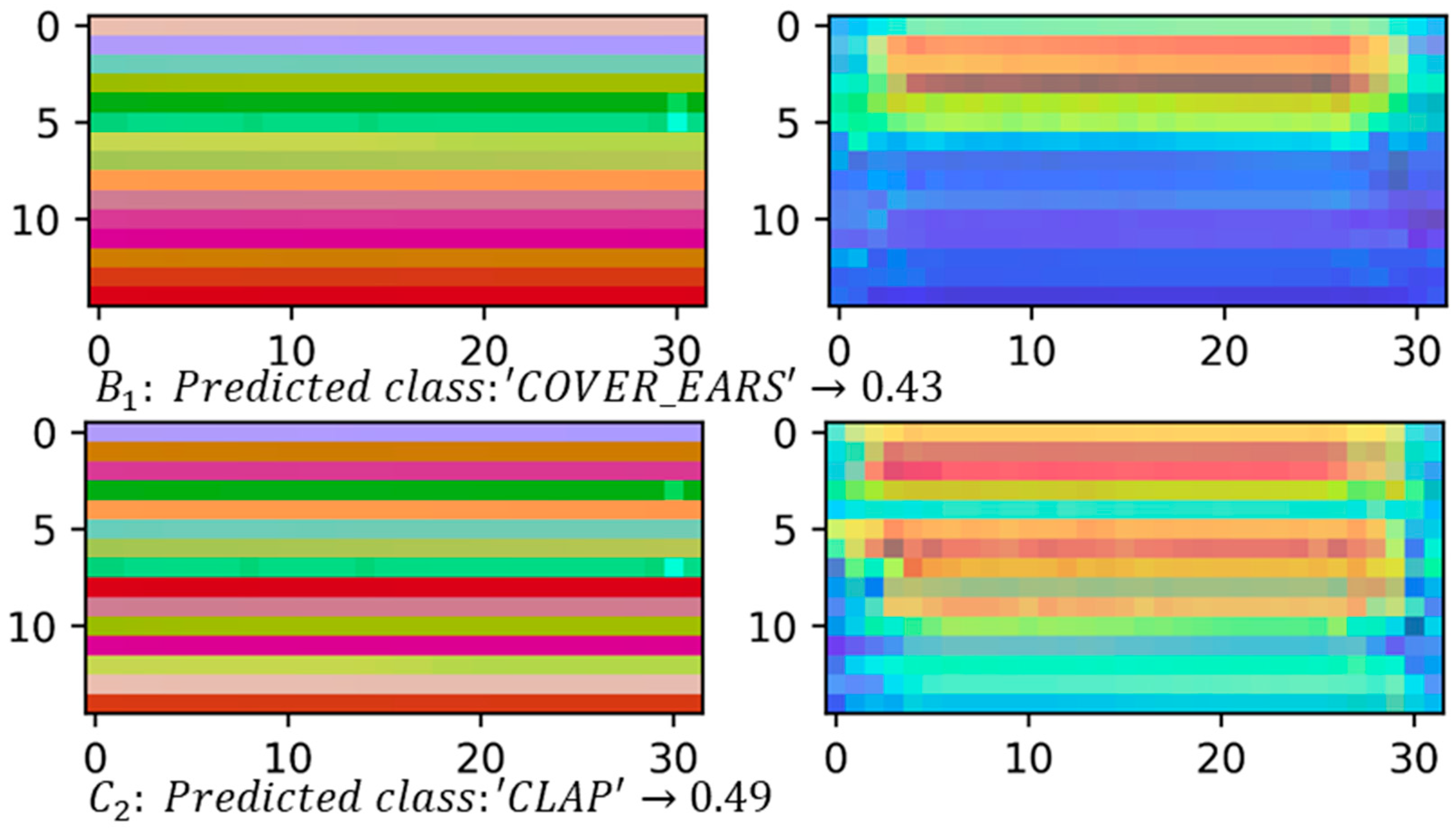
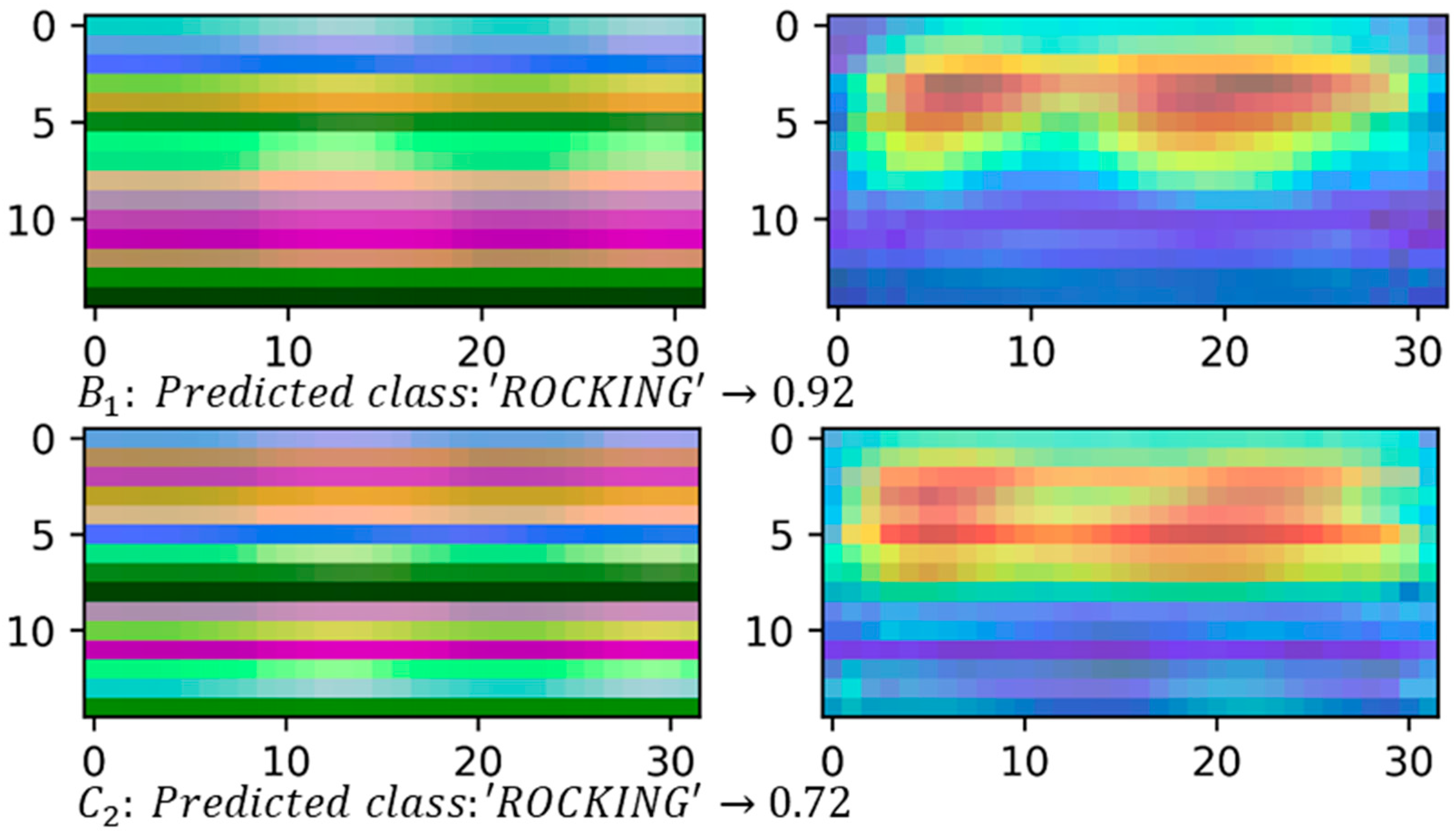
4.2.2. Class Activation Maps
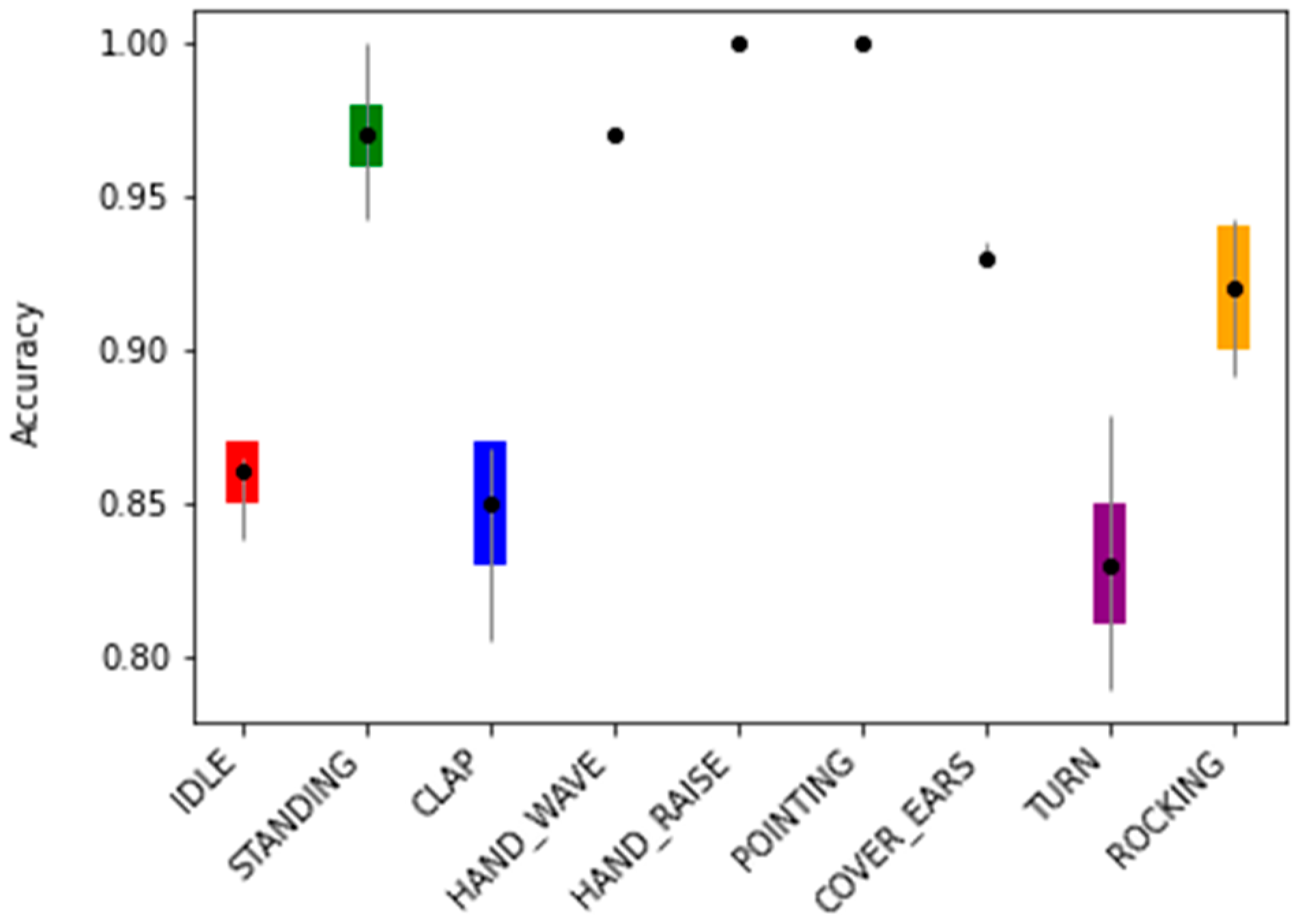
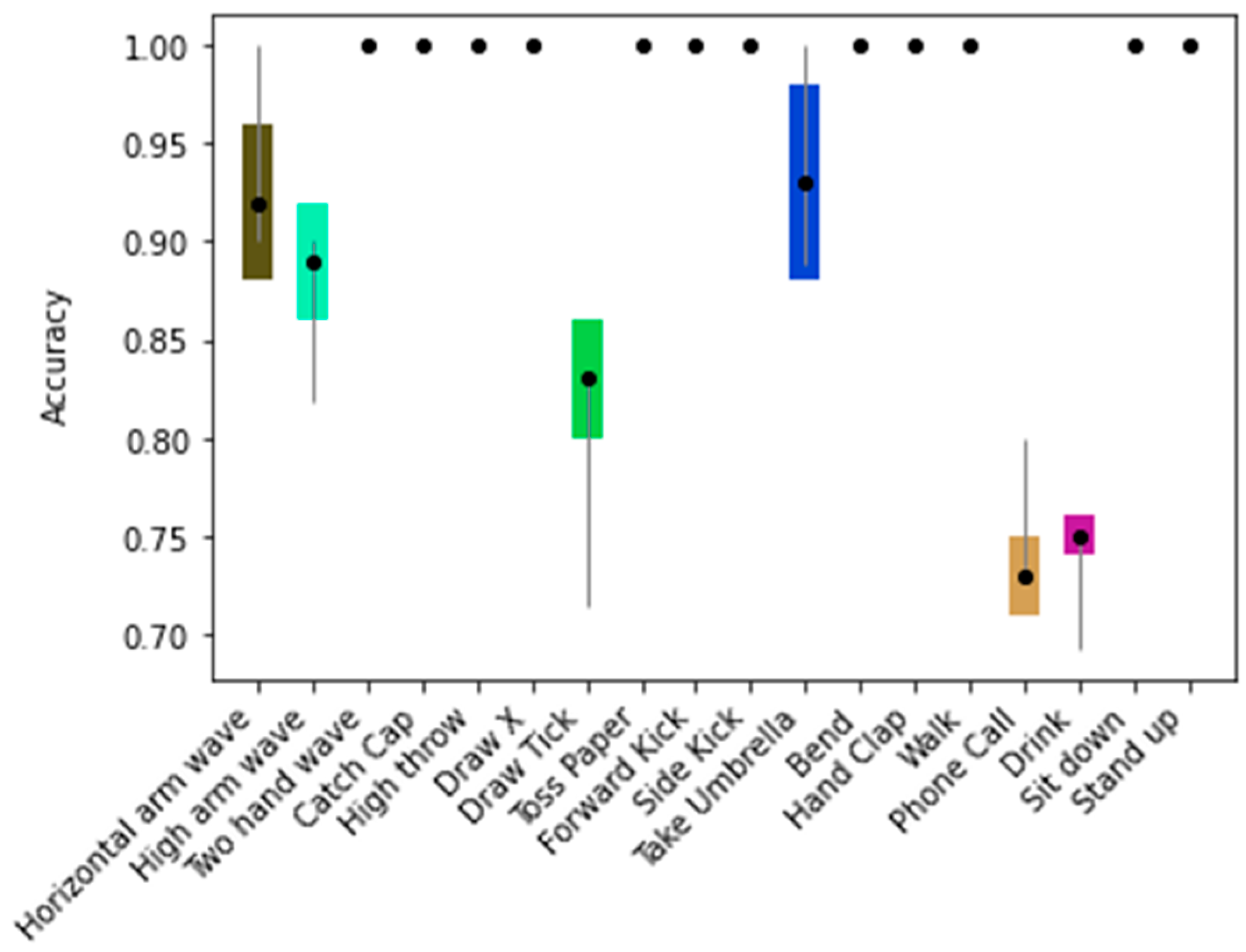
4.2.3. Per Class Performance and Real-Time Tests
4.3. Computational Efficiency
4.4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Christensen, D.L.; Bilder, D.A.; Zahorodny, W.; Pettygrove, S.; Durkin, M.S.; Fitzgerald, R.T.; Rice, C.; Kurzius-Spencer, M.; Baio, J.; Yeargin-Allsopp, M. Prevalence and Characteristics of Autism Spectrum Disorder Among Children Aged 8 Years—Autism and Developmental Disabilities Monitoring Network, 11 Sites, United States, 2012. MMWR. Surveill. Summ. 2016, 65, 1–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- CDC. Signs and Symptoms of Autism Spectrum Disorders|CDC, 202AD. Available online: https://www.cdc.gov/ncbddd/autism/signs.html (accessed on 9 March 2020).
- Cunningham, A.B.; Schreibman, L. Stereotypy in autism: The importance of function. Res. Autism Spectr. Disord. 2008, 2, 469–479. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tapus, A.; Peca, A.; Amir, A.; Pop, C.A.; Jisa, L.; Pintea, S.; Rusu, A.S.; David, D. Children with autism social engagement in interaction with Nao, an imitative robot. Interact. Stud. 2012, 13, 315–347. [Google Scholar] [CrossRef]
- Chevalier, P.; Li, J.; Ainger, E.; Alcorn, A.M.; Babovic, S.; Charisi, V.; Petrovic, S.; Pellicano, E. Dialogue Design for a Robot-Based Face-Mirroring Game to Engage Autistic Children with Emotional Expressions. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Tsukuba, Japan, 2017; Volume 10652, pp. 546–555. [Google Scholar]
- Wainer, J.; Dautenhahn, K.; Robins, B.; Amirabdollahian, F. Collaborating with Kaspar: Using an autonomous humanoid robot to foster cooperative dyadic play among children with autism. In Proceedings of the 2010 10th IEEE-RAS International Conference on Humanoid Robots, Humanoids 2010, Nashville, TN, USA, 6–8 December 2010. [Google Scholar]
- Costa, S.; Lehmann, H.; Robins, B.; Dautenhahn, K.; Soares, F. “Where is your nose?”: Developing body awareness skills among children with autism using a humanoid robot. In Proceedings of the ACHI 2013, Sixth International Conference on Advances in Computer-Human Interactions, Nice, France, 24 February–1 March 2013; Volume 7, pp. 117–122. [Google Scholar]
- Costa, S.; Lehmann, H.; Dautenhahn, K.; Robins, B.; Soares, F. Using a Humanoid Robot to Elicit Body Awareness and Appropriate Physical Interaction in Children with Autism. Int. J. Soc. Robot. 2015, 7, 265–278. [Google Scholar] [CrossRef] [Green Version]
- Soares, F.O.; Costa, S.C.; Santos, C.P.; Pereira, A.P.S.; Hiolle, A.R.; Silva, V. Socio-emotional development in high functioning children with Autism Spectrum Disorders using a humanoid robot. Interact. Stud. Stud. Soc. Behav. Commun. Biol. Artif. Syst. 2019, 20, 205–233. [Google Scholar] [CrossRef]
- Dautenhahn, K.; Nehaniv, C.L.; Walters, M.L.; Robins, B.; Kose, H.; Mirza, N.A.; Blow, M. KASPAR-A minimally expressive humanoid robot for human-robot interaction research. Appl. Bionics Biomech. 2009, 6, 369–397. [Google Scholar] [CrossRef] [Green Version]
- D’Mello, S.; Calvo, R. Beyond the basic emotions: What should affective computing compute? Abstr. Hum. Factors Comput. 2013, 13, 2287–2294. [Google Scholar]
- Robinson, P.; el Kaliouby, R. Computation of emotions in man and machines. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 3441–3447. [Google Scholar] [CrossRef]
- Messinger, D.S. Affective Computing, Emotional Development, and Autism; Oxford Press: Oxford, UK, 2014; pp. 516–536. [Google Scholar]
- Rudovic, O.; Lee, J.; Dai, M.; Schuller, B.; Picard, R.W. Personalized machine learning for robot perception of affect and engagement in autism therapy. Sci. Robot. 2018, 3, 19. [Google Scholar] [CrossRef] [Green Version]
- Silva, V.; Queirós, S.; Soares, F.; Esteves, J.S.; Matos, D. A supervised autonomous approach for robot intervention with children with autism spectrum disorder. In Proceedings of the ICINCO 2019—16th International Conference on Informatics in Control, Automation and Robotics, Prague, Czech Republic, 29–31 July 2019; pp. 497–503. [Google Scholar]
- Pham, H.H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Exploiting deep residual networks for human action recognition from skeletal data. Comput. Vis. Image Underst. 2018. [Google Scholar] [CrossRef] [Green Version]
- Ludl, D.; Gulde, T.; Curio, C. Simple yet efficient real-time pose-based action recognition. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference, ITSC 2019, Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Laraba, S.; Tilmanne, J.; Dutoit, T. Leveraging Pre-Trained CNN Models for Skeleton-Based Action Recognition, Vol. 11754 LNCS, No. November; Springer International Publishing: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Lee, J.; Ahn, B. Real-Time Human Action Recognition with a Low-Cost RGB Camera and Mobile Robot Platform. Sensors 2020, 20, 2886. [Google Scholar] [CrossRef]
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior recognition via sparse spatio-temporal features. In Proceedings of the 2nd Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, VS-PETS, Beijing, China, 15–16 October 2005. [Google Scholar]
- Laptev, I.; Marszałek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Afsar, P.; Cortez, P.; Santos, H. Automatic human action recognition from video using Hidden Markov Model. In Proceedings of the 2015 IEEE 18th International Conference on Computational Science and Engineering, Porto, Portugal, 21–23 October 2015; pp. 105–109. [Google Scholar]
- Ahmad, M.; Lee, S.W. HMM-based human action recognition using multiview image sequences. Proc. Int. Conf. Pattern Recognit. 2006, 1, 263–266. [Google Scholar]
- Abdul-Azim, H.A.; Hemayed, E.E. Human action recognition using trajectory-based representation. Egypt. Inform. J. 2015, 16, 187–198. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, M.D.; Ahmed, J.; Shah, M. Action MACH: A spatio-temporal maximum average correlation height filter for action recognition. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Aggarwal, J.K.; Xia, L. Human activity recognition from 3D data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Microsoft, Developing with Kinect. 2017. Available online: https://developer.microsoft.com/en-us/windows/kinect/develop (accessed on 13 March 2017).
- ORBBEC, Astra Series–Orbbec. 2019. Available online: https://orbbec3d.com/product-astra-pro/ (accessed on 8 March 2020).
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Liu, B.; Yu, H.; Zhou, X.; Tang, D.; Liu, H. Combining 3D joints Moving Trend and Geometry property for human action recognition. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2016-Conference, Budapest, Hungary, 9–12 October 2017. [Google Scholar]
- Goncalves, N.; Rodrigues, J.L.; Costa, S.; Soares, F. Automatic detection of stereotyped hand flapping movements: Two different approaches. In Proceedings of the IEEE International Workshop on Robot and Human Interactive Communication, Paris, France, 9–12 September 2012. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A large scale dataset for 3D human activity analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal LSTM with trust gates for 3D human action recognition. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9907, pp. 816–833. [Google Scholar]
- Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Spatio–temporal image representation of 3D skeletal movements for view-invariant action recognition with deep convolutional neural networks. Sensors 2019, 19, 1932. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Bengio, C.L.; Courville, A. Towards end-to-end speech recognition with deep convolutional neural networks. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016; Volume 8, pp. 410–414. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Dauphin, Y.N. A convolutional encoder model for neural machine translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 123–135. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Hou, Y.; Wang, P.; Li, W. Joint Distance Maps Based Action Recognition with Convolutional Neural Networks. IEEE Signal Process. Lett. 2017, 7, 19. [Google Scholar] [CrossRef] [Green Version]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, AAAI 2017, San Francisco, CA, USA, 7 February 2017. [Google Scholar]
- Tasnim, N.; Islam, M.K.; Baek, J.H. Deep learning based human activity recognition using spatio-temporal image formation of skeleton joints. Appl. Sci. 2021, 11, 2675. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement; University of Washington: Seattle, WA, USA, 2018. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, CVPRW 2010, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Gaglio, S.; Lo Re, G.; Morana, M. Human Activity Recognition Process Using 3-D Posture Data. IEEE Trans. Hum. Mach. Syst. 2015. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3D action recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4570–4579. [Google Scholar]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Supplementary Material for Two-person Interaction Detection Using Body-Pose Features and Multiple Instance Learning Additional Real-time Interaction Detection Results. Most 2012, 28–35. [Google Scholar] [CrossRef]
- Zhu, W.; Lan, C.; Li, Y.; Xing, J. Co-Occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In Proceedings of the 30th AAAI Conference Artification Intelligence AAAI 2016, Phoenix, AR, USA, 12–17 February 2016; pp. 3697–3703. [Google Scholar]
- Jazouli, M.; Majda, A.; Merad, D.; Aalouane, R.; Zarghili, A. Automatic detection of stereotyped movements in autistic children using the Kinect sensor. Int. J. Biomed. Eng. Technol. 2019, 29, 201. [Google Scholar] [CrossRef]
- Intel. Intel® RealSense™ Technology. 2019. Available online: https://www.intel.com/content/www/us/en/architecture-and-technology/realsense-overview.html (accessed on 8 April 2019).
- Nuitrack. Nuitrack Full Body Skeletal Tracking Software-Kinect replacement for Android, Windows, Linux, iOS, Intel RealSense, Orbbec. 2019. Available online: https://nuitrack.com/ (accessed on 8 April 2019).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014-Conference Track, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- OpenCV. OpenCV: Deep Neural Networks (dnn Module). Available online: https://docs.opencv.org/master/d2/d58/tutorial_table_of_content_dnn.html (accessed on 8 April 2020).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Type of Camera | Hardware | Real-Time | Classification Algorithm | Nº of Actions | Application Area | Recognition Rate |
|---|---|---|---|---|---|---|---|
| Goncalves et al. 2012 [32] | Kinect V1 | ----- | Yes | DTW | 1 stereotyped action | HCI and ASD | 51.0% |
| Li et al. 2017 [41] | Kinect V1 | ---- | ---- | CNN | 60 actions [34] 27 actions [48] | HCI | 76.2% 88.1% |
| Liu et al. 2017 [31] | Kinect V2 | ------- | ------- | Three sets of 8 actions each | Human Computer Interaction (HCI) | 91.3% | |
| Ke et al. 2017 [49] | Kinect | ---- | ----- | CNN + MTLN | 60 actions [34] 8 actions [50] 45 actions [51] | HCI | 79.6% 93.6% 93.2% |
| Pham et al. 2018 [16] | Kinect V2 | NVIDIA GTX 1080 Ti GPU | Yes | ResNet | 20 actions [46] 18 actions [47] 60 actions [34] | HCI | 99.9% 99.8% 78.2% |
| Jazouli et al. 2019 [52] | Kinect V1 | ------ | Yes | $P Point-Cloud Recognizer | 5 stereotyped actions | HCI and ASD | 94.0% |
| Ludl, Gulde and Curio 2019 [17] | RGB Camera | Intel i7-8700 6 core CPU NVIDIA GTX 1080 GPU | Yes | CNN | 3 actions | Autonomous Driving | 97.1% |
| Laraba et al. 2019 [18] | Kinect V2 | Intel i7-7800X 2 × NVIDIA GTX 1080 Ti | ---- | Pre-trained architectures of CNN and RNNs | 49 actions [34] | HCI | 82.1% |
| Junwoo and Bummo 2020 [19] | RGB camera | NVIDEA JETSON XAVIER with dedicated Volta GPU | Yes (14 fps) | CNN | 15 actions [34] | Human Robot Interaction (HRI) | 71.0% |
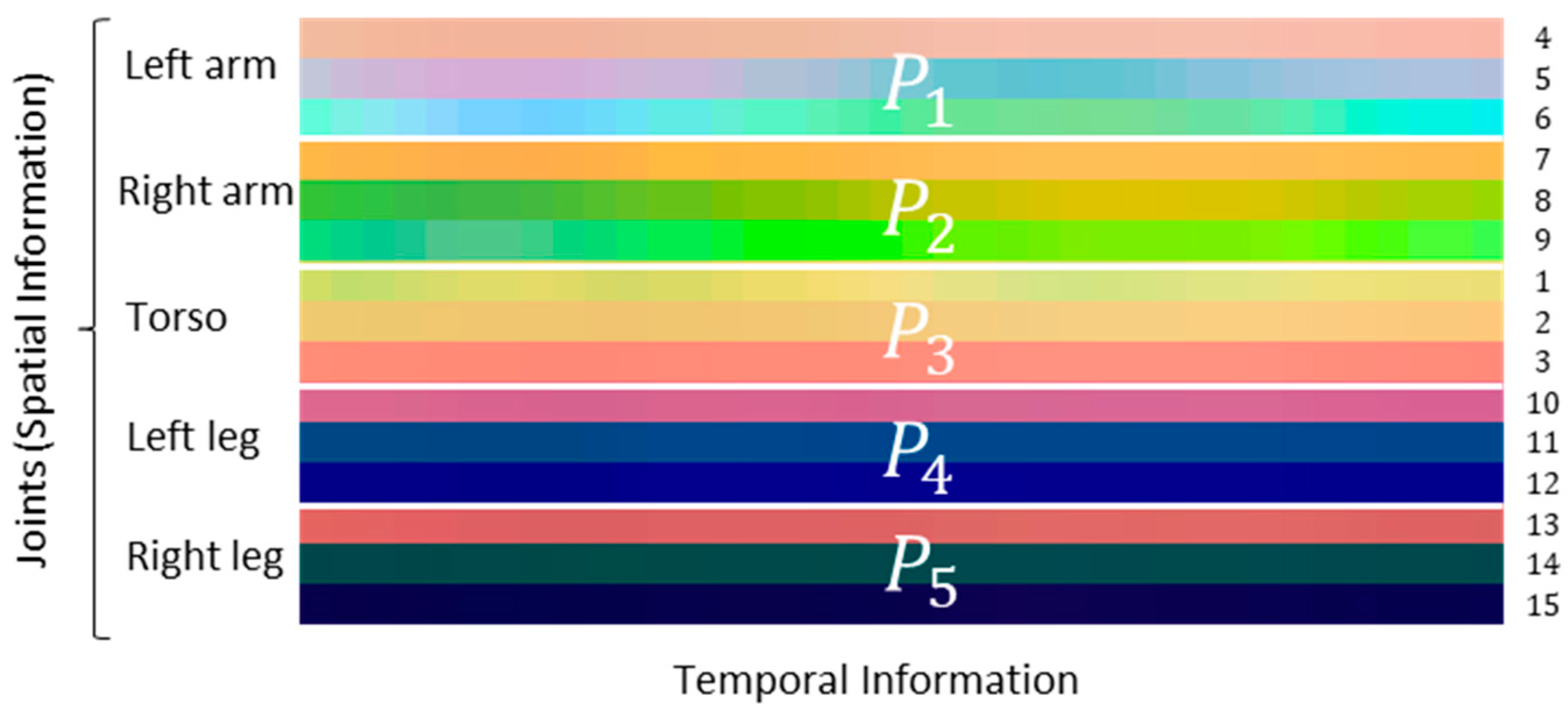
| LA 1 (4, 5, and 6) | RA 2 (7, 8, and 9) | Torso (1, 2, and 3) | LL 3 (10, 11, and 12) | RL 4 (13, 14, and 15) |
| SC 1 | Joint Groups Sequence | ||||
|---|---|---|---|---|---|
| SC 1 | Joint Number | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
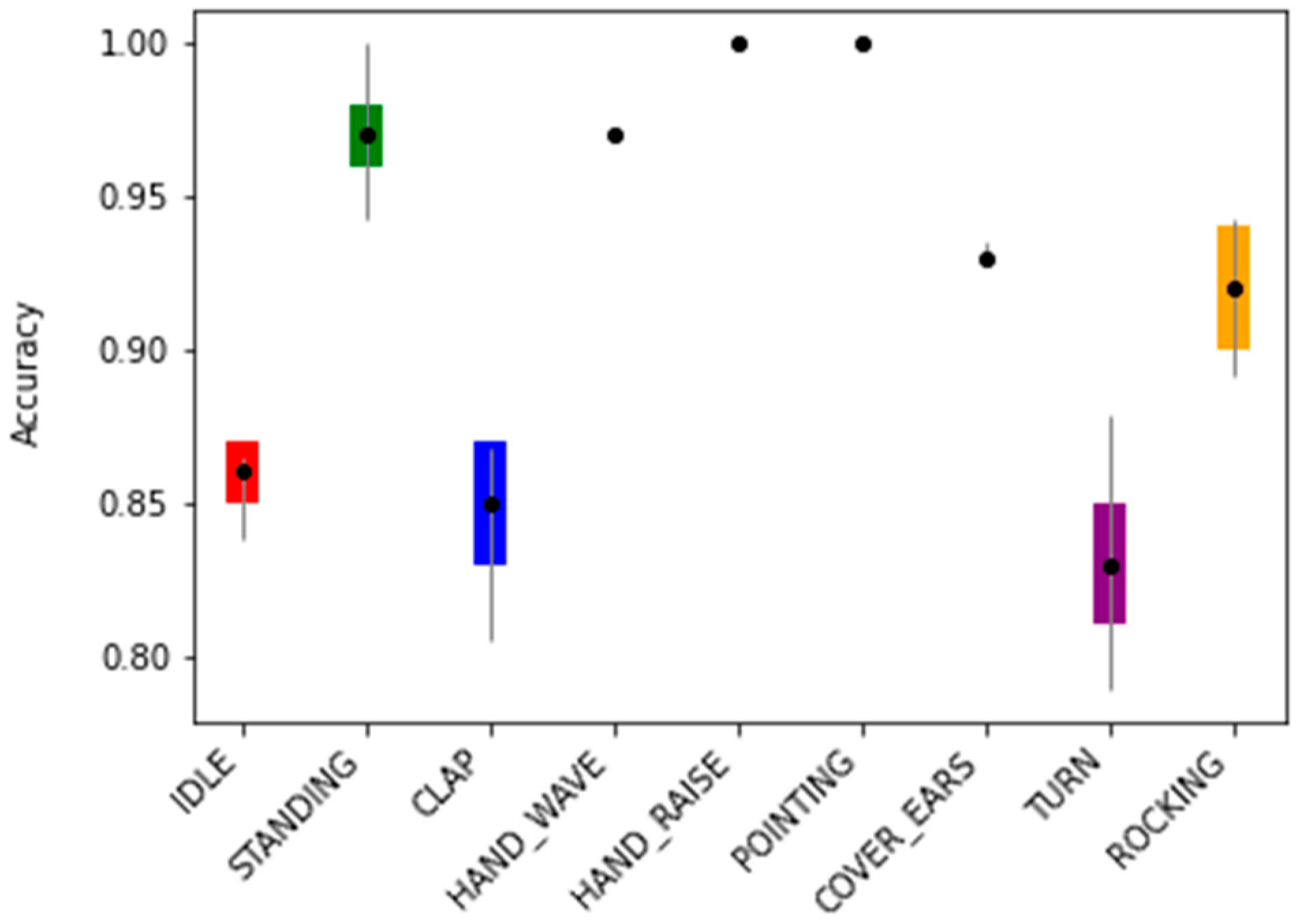
| SC 1 | IDLE | SD 2 | CLAP | HW 3 | HR 4 | PT 5 | CE 6 | TURN | RK 7 |
|---|---|---|---|---|---|---|---|---|---|
| 85.9% ± 1.1% | 97.1% ± 1.1% | 85.1% ± 1.7% | 97.2% ± 0.0% | 100% ± 0.0% | 100% ± 0.0% | 93.2% ± 0.6% | 83.2% ± 2.2% | 92.0% ± 2.3% | |
| 80.5% ± 1.7% | 95.9% ± 1.7% | 84.3% ± 0.2% | 94.6% ± 0.0% | 100% ± 0.0% | 97.4% ± 0.6% | 83.2% ± 2.3% | 86.7% ± 2.2% | 88.8% ± 2.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, V.; Soares, F.; Leão, C.P.; Esteves, J.S.; Vercelli, G. Skeleton Driven Action Recognition Using an Image-Based Spatial-Temporal Representation and Convolution Neural Network. Sensors 2021, 21, 4342. https://doi.org/10.3390/s21134342
Silva V, Soares F, Leão CP, Esteves JS, Vercelli G. Skeleton Driven Action Recognition Using an Image-Based Spatial-Temporal Representation and Convolution Neural Network. Sensors. 2021; 21(13):4342. https://doi.org/10.3390/s21134342
Chicago/Turabian StyleSilva, Vinícius, Filomena Soares, Celina P. Leão, João Sena Esteves, and Gianni Vercelli. 2021. "Skeleton Driven Action Recognition Using an Image-Based Spatial-Temporal Representation and Convolution Neural Network" Sensors 21, no. 13: 4342. https://doi.org/10.3390/s21134342
APA StyleSilva, V., Soares, F., Leão, C. P., Esteves, J. S., & Vercelli, G. (2021). Skeleton Driven Action Recognition Using an Image-Based Spatial-Temporal Representation and Convolution Neural Network. Sensors, 21(13), 4342. https://doi.org/10.3390/s21134342