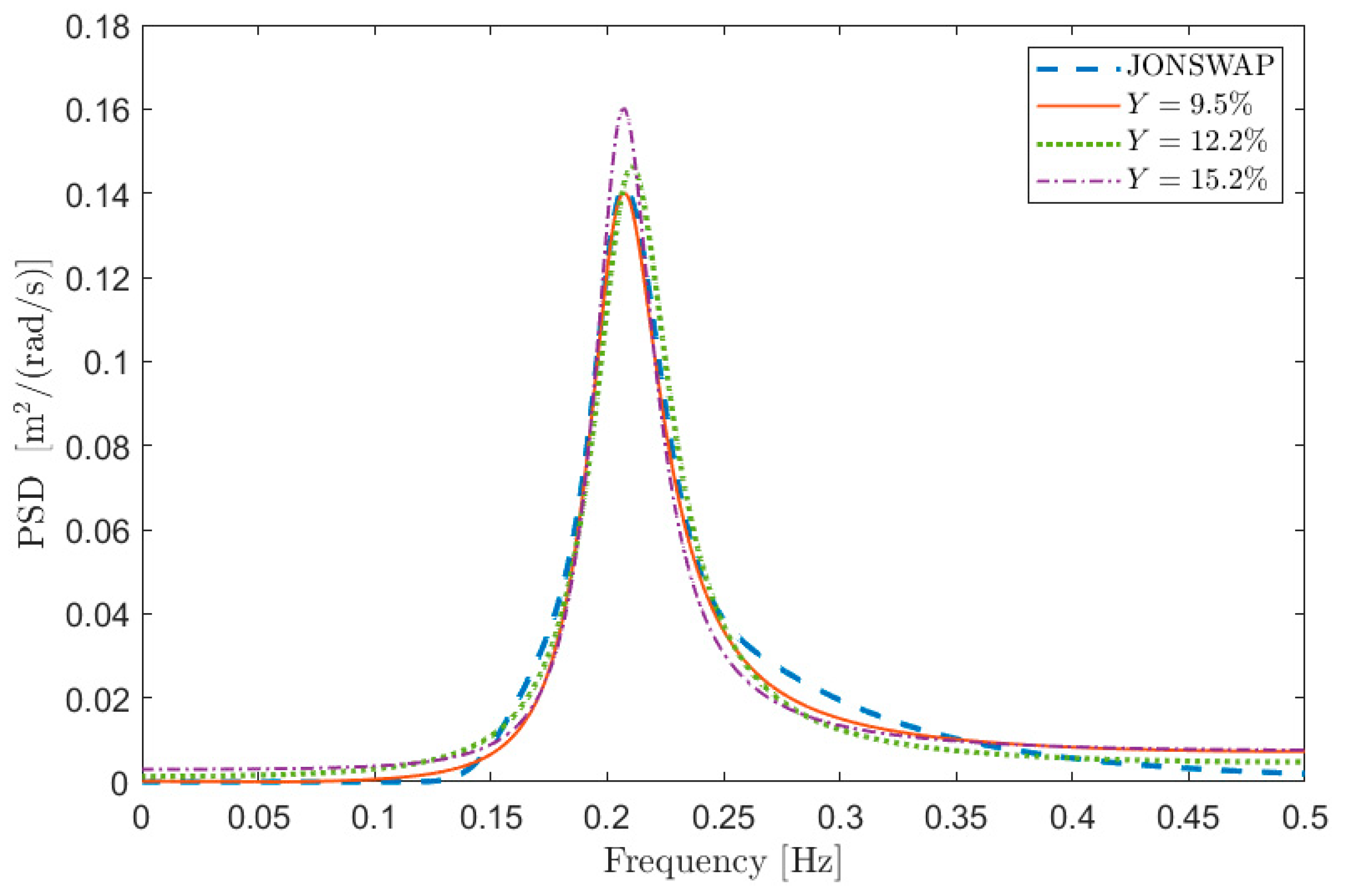
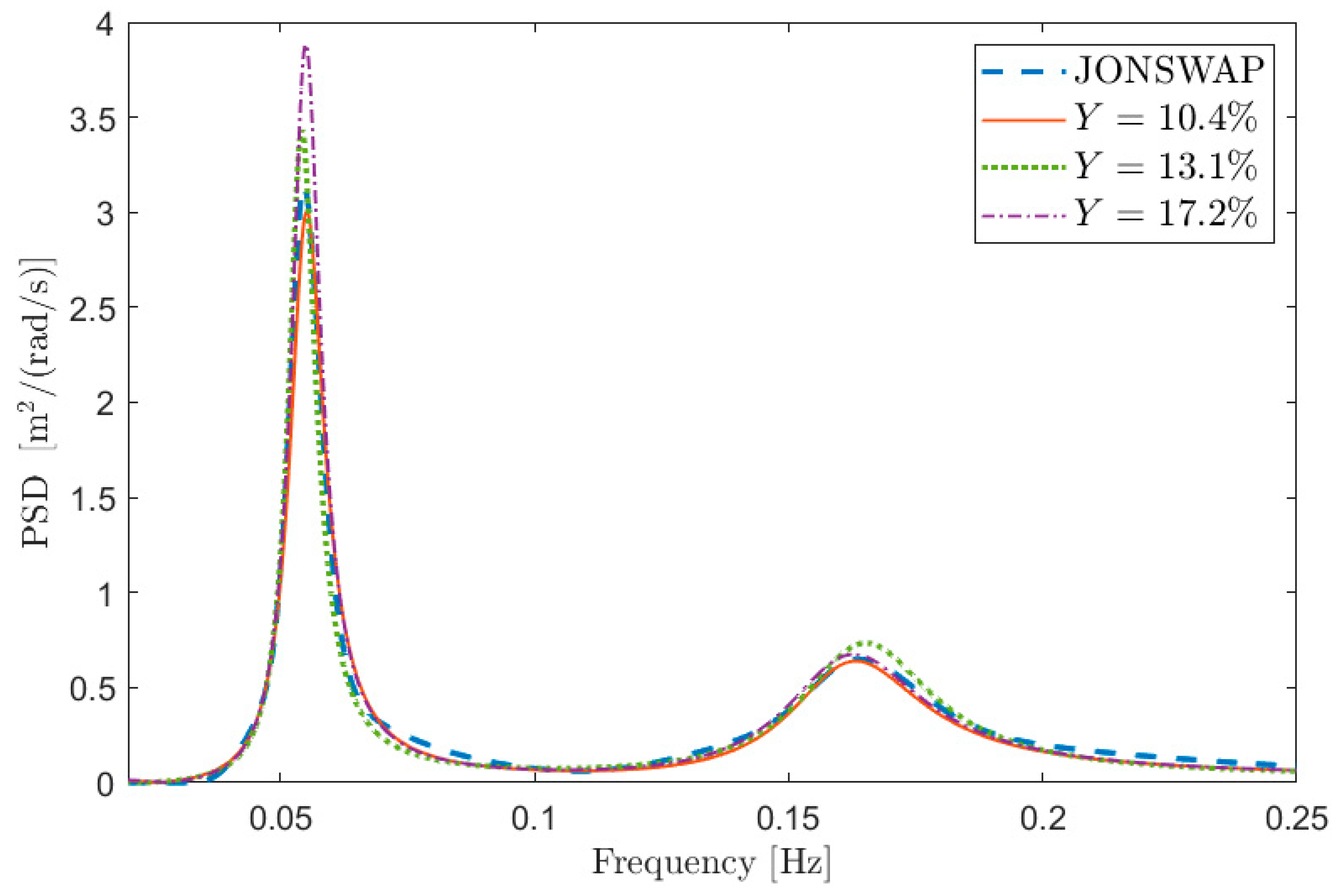
To this purpose,
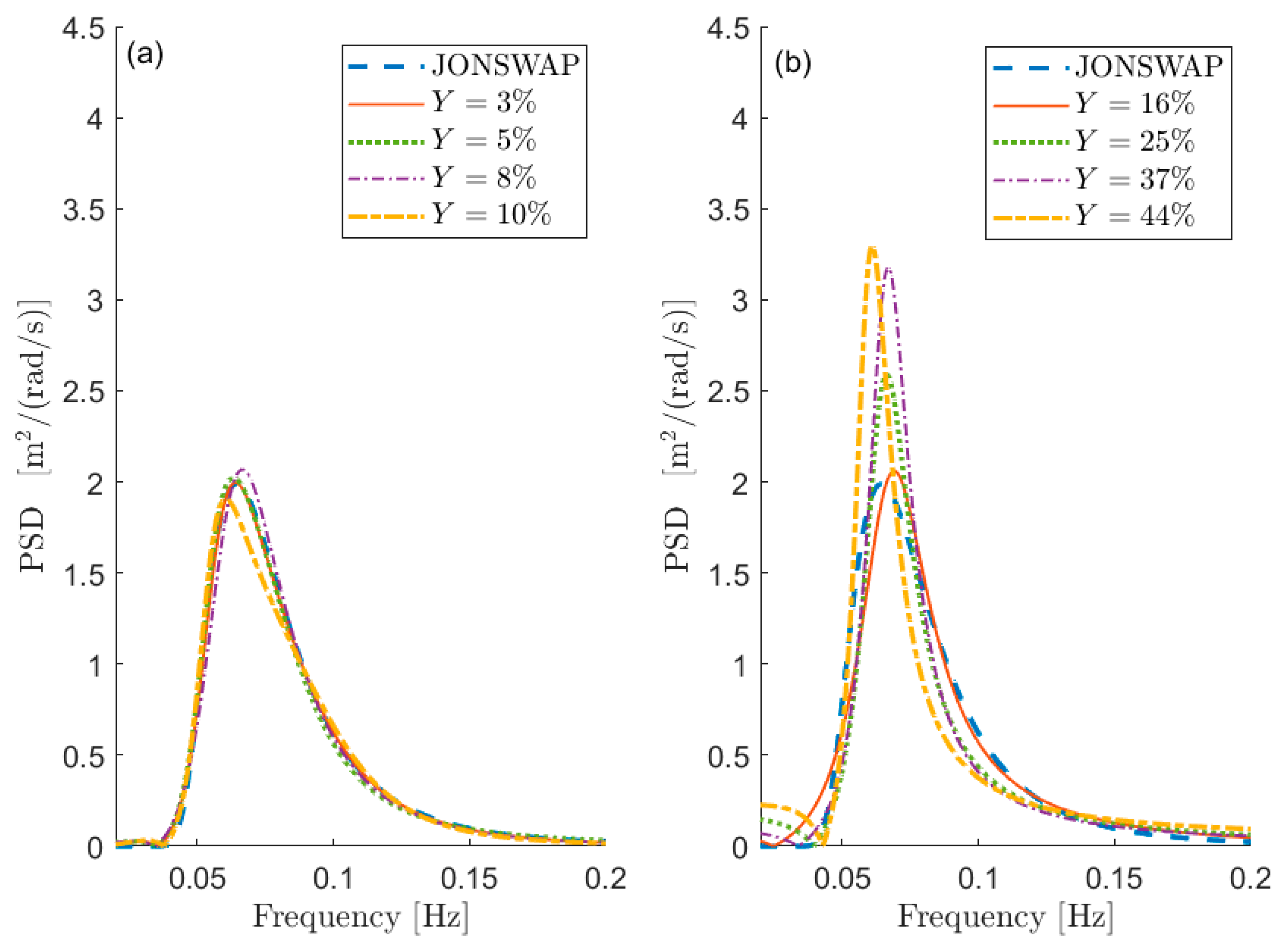
Figure 1 depicts some examples of comparisons in terms of PSD between
and
in the case of test signal 1 in
Table 1. The curves are aimed at showing the meaning of a given percentage
error, and thus the information about the value of the free parameters is not relevant at this stage (i.e., the same
can be obtained with different combinations of the free parameters).
Figure 1a shows the PSD reconstruction associated with low values of
expressed in percentage (i.e.,
) while
Figure 1b shows the PSDs associated with larger values of
(i.e.,
). Obviously, the lower the value of
, the better the PSD reconstruction. However, the maximum admissible error on the spectral reconstruction depends on the specific application.
Finally, it is worth mentioning that the proposed estimation procedure does not imply a high computational cost, and that the processing time is of the same order of magnitude of other competing approaches such as Welch’s and Thomson’s methods.
6.1. Effect of the Number of the Auto-Covariance Samples Used
The first parameter that has to be defined is the number of equations that can be used to solve the least-square problems involved in the ARMA parameter estimation procedure. Despite the increased AR order may seem the first and most important point to be addressed, it strongly depends on the maximum number of useful information available, given a certain time series . To understand this point, some considerations about the auto-covariance series have to be discussed.
As mentioned previously, the auto-covariance of the signal is modelled as a sum of damped exponential components, each corresponding to one pole of the ARMA model (see Equation (13)). Therefore, after some lags, the value of the estimated auto-covariance becomes low. Considering this aspect and recalling that the auto-covariance is estimated on a limited number of samples (see Equation (12)), two factors must be taken into consideration to judge the reliability of the estimated values: the unavoidable variance of the estimated auto-covariance and, in real cases, the presence of electrical noise superimposed to the physical signal provided by the transducer. Both these factors cause a scatter on the auto-covariance values, which becomes more and more significant as increases, when the oscillations of the auto-covariance become low. Therefore, from the mentioned -th auto-covariance sample on, the reliability of the auto-covariance curve becomes low and this makes its use for estimating the ARMA model improper. Thus, it is not enough to avoid the use of very large lag values, as suggested in the literature, but it is fundamental to estimate the length of the reliable part of the auto-covariance curve to the aim of estimating the ARMA model. This in turn has consequences on the number of equations that can be written to solve the Prony’s and Shanks’ problems and thus on the maximum order of the AR model.
One possible approach to select the proper length
of
to use in the estimation procedure, is to refer to the estimate of the auto-covariance of a white noise random process with unitary standard deviation (i.e.,
), acquired for
samples. The expected value of its normalised auto-covariance
(i.e., the auto-covariance divided by its value at the null lag) is null for
> 0 and its standard deviation can be estimated as
. Therefore, the auto-covariance samples of a white random process, for
, are assumed to be included in a range of
with a confidence level of approximately 99%. Considering now the normalised auto-covariance of
(i.e.,
), the correlation between the signal and its shifted version can be thus considered as not significant if the
curve falls continuously within a range defined as
. Thus, in that region, the low oscillations of
are considered as not useful for the estimation process. This implies that only the first
samples of the auto-covariance
will be used for the estimation of the ARMA model because larger
values show a non-significant correlation level. Thus,
indicates the number of auto-covariance lags
(see
Section 3.1) estimated using the
range, that has to be used to write Equations (14) and (20).
An example of the application of the proposed
selection procedure is shown in
Figure 2 for signals of type 1 in
Table 1, sampled at 1 Hz for 3600 s (i.e., 1 h). In order to give a reference of the theoretical shape of the signal auto-covariance, a sea-state of type 1 has been simulated also considering a time length of 24 h with sampling frequency equal to 1 Hz. Being this auto-covariance computed on a very large number of samples, it can be considered as the reference since, for the amount of lags depicted in the figure, the ratio
between the lag order and the total number of samples is considerably low.
Figure 2 compares the auto-covariance sequence of three different time-series with the reference curve and with the corresponding
range. It is possible to notice that the auto-covariance sequences obtained for the three different simulations become significantly different form each other when they are almost contained in the
range, highlighting the low reliability associated with these data. Instead, except for small differences, the three curves follow the reference auto-covariance in the region of small lags when the
values are not contained in the
allowing us to identify the reliable part of the auto-covariance sequence. In this way it is possible to identify, for each time series, the
number of samples that can be used in the spectral estimation procedure. Obviously, the
-th sample slightly changes simulation by simulation because of its associated scatter (for the three time series of
Figure 1 it is between 34 and 36). Nevertheless, this difference has negligible effects on the quality of the ARMA model identification, because the first and significant oscillations of
are properly described.
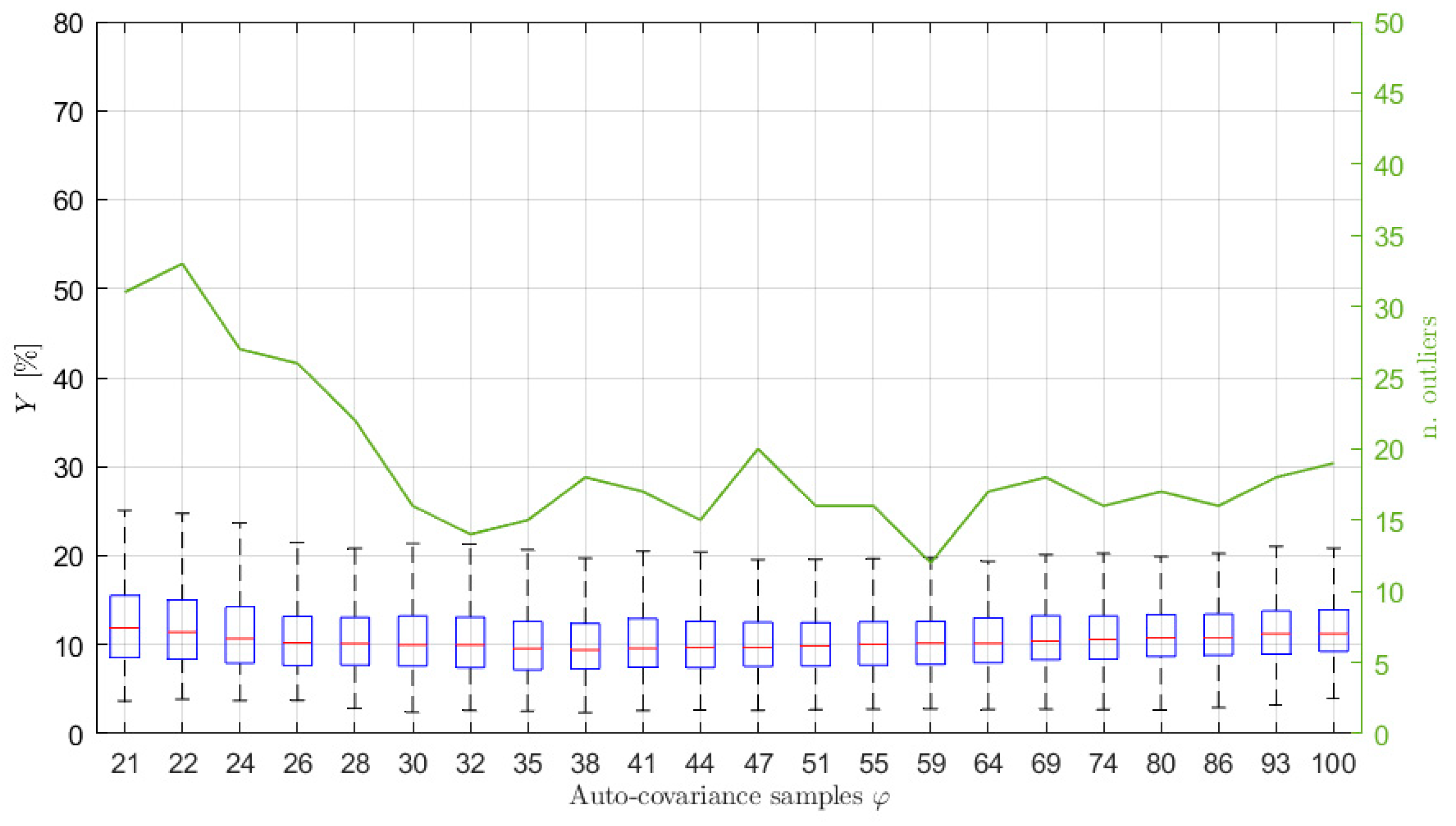
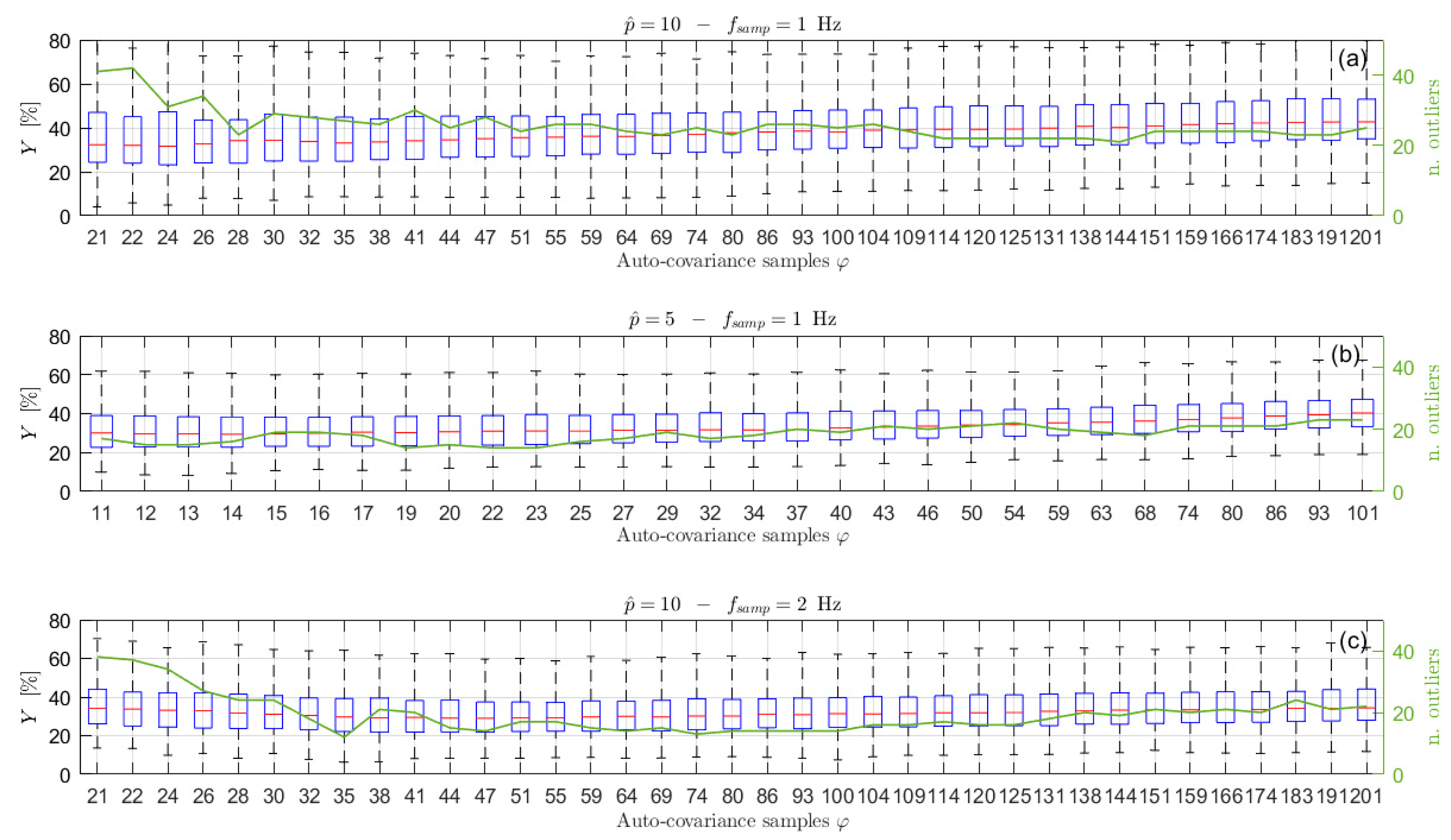
In order to show the importance of choosing the right number of auto-covariance samples to be considered, and to show the reliability of the proposed selection procedure, several simulations have been carried out, varying the number of the auto-covariance samples used in the estimation process,
. Particularly, 500 simulations for each selected
value have been performed. For each of them, the
index has been evaluated to quantify the accuracy of the estimation procedure. The results are presented in terms of box-plots (showing the
percentage values of the median, the minimum, the maximum and the 25-th and 75-th percentiles) and of the number of outliers obtained for different
values, starting from the minimum needed to solve Equation (14) (i.e.,
).
Figure 3 shows the results obtained considering signals of type 1 of
Table 1, acquired at a sampling frequency of
Hz for 1 h. In this case, the increased number of poles
has been set equal to 10 (details about the order selection procedure are given in
Section 6.2) and
has been set equal to
, without any loss of generality (the same will apply for all the examples further in the paper). As mentioned previously, for this kind of sea wave elevation signal, the typical
values are between 34 and 36 (see
Figure 2).
Looking at
Figure 3 it is interesting to notice that, when
increases over approximately
, the value of
slightly increases (a larger increase occurs for larger
values, not shown in the figure) because of the use of non-significant values of the auto-covariance sequence. Further details and evidence of this aspect are also given in
Section 6.2. In the same way, the use of a number of samples that is too low (i.e., few samples more than those strictly necessary for solving Equation (14)) leads to poor results. Indeed, the left part of
Figure 3, if compared to the area close to
, shows higher values of the median error
, a wider range between the maximum and the minimum and between the 25-th and 75-th percentiles, as well as a higher number of outliers, evidencing a higher dispersion of the estimation results and a greater variability of the spectral estimates. Therefore, the proposed approach to find
shows to be effective since the range of the best
values in the graph (i.e., the lowest
values) is found to be close to the
values. Moreover, it is noticed that slight changes of
, such as those deriving from the use of different time series (e.g.,
) does not imply considerable changes in the estimation performance, but rather a slight increase (i.e., few lags) with respect to
slightly improves the estimates. Thus, a slight increased value of
is suggested in most of the cases (see also
Section 6.3 for further details).
Therefore, this analysis evidences that it is essential to properly estimate the value of to be used in the estimation procedure in order to improve the identification of the ARMA model.
Other examples of the effect on the estimation accuracy of the choice of the number of auto-covariance samples used for the estimation are given in the following sections, where also the effect of the choice of the AR order and the length of the time series are considered.
6.2. Choice of the Increased AR Order
Once the
value is defined, the other parameter that has to be defined is the AR order of the model,
. As explained in
Section 4.1, it is convenient to set the pole number to
and then, once the
poles are identified, only the most significant ones in terms of energy are selected. Here, in the most part of the simulations the energy threshold
was set in order to discard the poles associated with systems whose energy was lower than 10% of the value associated with the system with the highest energy (see
Section 4.1 and
Section 8 for further details). In
Section 4.1, the use of the AIC index is suggested to properly choose the
value. Nevertheless, there are cases in which the AIC index (as well as other indexes such as, for example, the Bayesian Information Criterion [
41]) does not provide clear indications about how to set the value of
(e.g., [
31]). In these cases, such as the one considered here (see
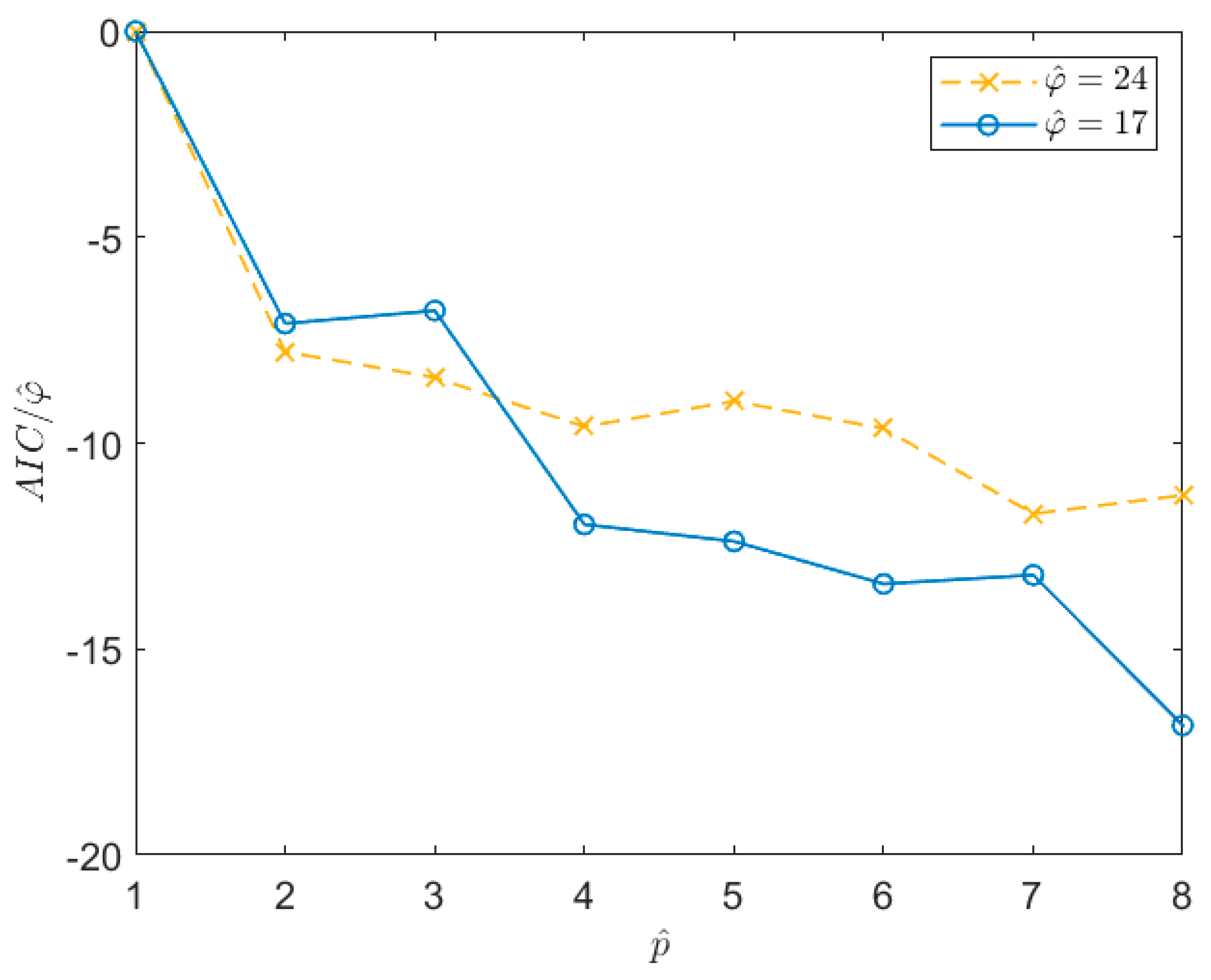
Figure 4), the value of
can be chosen as that allowing us to obtain a first stabilization in the AIC value, even if the AIC is not at its minimum (e.g., it is still slightly decreasing). As an example,
Figure 4 shows the trend of the AIC index, normalized with respect to the number of auto-covariance samples used in the estimation procedure,
. In this case, the signal is of type 1 in
Table 1, acquired for 1 h at a sampling frequency of 1 Hz. The two curves are related to two different time series for which a different
value was estimated. Looking at the curves, it is evident that the AIC does not provide a clear indication of the optimal
value to be used. However, it is possible to see that, after a first drop in correspondence of
almost equal to 4, the curves stabilize. One possibility to set
would be to choose a value close to the maximum allowed for the considered time series (i.e., that allowing to write a determined system in Equation (14) for the given
). However, this reduces the number of equations that can be written to solve the Equations (14) and (20), thus worsening the results of the least square minimisation. Therefore, even if
needs to be larger than
, its value must be not too high and a balance between the number of equations that can be used and the increase of the pole number has to be reached. One possible solution is to choose the
value inside the stabilized region which guarantees a good number of equations to solve the least square problems and that is, at the same time, far from the first drop of the normalized AIC. Therefore,
is set to a value lower than the mentioned maximum, taking care not to move too close to the stabilisation point. In this case, a good balance is a
value of about 10. Of course, this choice is subjective (e.g., the value could be 8 or 12 as well); however, this does not modify the obtained results significantly.
To show the effect of the number of poles on the accuracy of the spectral estimates as a function of the number of the auto-covariance samples
, many simulations were carried out on different wave elevation signals where both the sea state conditions and the length of the time histories were changed. For sake of clarity, and coherently with the test case study of the previous section (so that a straight comparison can be carried out), the results related to 1 h signals of type 1, sampled at 1 Hz, are shown. The considered
range in this case was between 10 and 40 poles. The value of the maximum number of poles was set equal to 40 in the simulations to also test values very far from the maximum achievable with the usual
in order to see its effect on the accuracy of the PSD estimates. The results are summarized in
Figure 5, which shows a comparison in terms of accuracy of the spectral estimates, measured by the index
, when the increased order of the poles is
= 10, 20 and 40. In the figure, the trends of the median and the 75-th percentile values of
associated to each
value are shown as functions of the value of
. Comparing the curves in the figure, it is evident that, at a given value of
, the value of
is lower for the lowest value of
and increasing
makes the identification worse (higher values of
), with the only exception of the right part of the plot where the curves related to
= 10 and 20 merge. Nevertheless, this part of the plot is related to
values providing results that are not satisfactory.
The use of a lower level of overestimation of proves to provide better results because of two main reasons: (i) the use of high values of obliges to employ auto-covariance samples in the lag range where the auto-covariance is low and (ii) for a given value of , the number of equations used to solve the least square problems of Equations (14) and (20) is larger for lower values of .
Finally, it is worth highlighting that, as already shown in
Section 6.1, the use of a number of auto-covariance samples higher than
can significantly worsen the achievable performance. Indeed, the curves in
Figure 5 show an increase of the
index for high
values.
6.3. Effect of the Length of the Time Series
So far, all the examples used to support the presented analyses were related to long time histories, in particular 1 h time series were considered. Despite the proposed procedure and all the results are valid whichever signal is taken into account, it is worth paying attention to the problems that can arise when short-time signals are considered and showing the results that can be achieved in terms of accuracy of the estimated sea PSD. Indeed, in these cases, problems can arise, making the use of the proposed procedure more cumbersome. To this purpose, sea wave elevation signals of 30 and 10 min are analysed, using a sea state of type 1 of
Table 1, also to allow for a comparison with the already presented results. The first point that has to be analysed is the auto-covariance behaviour of the time series.
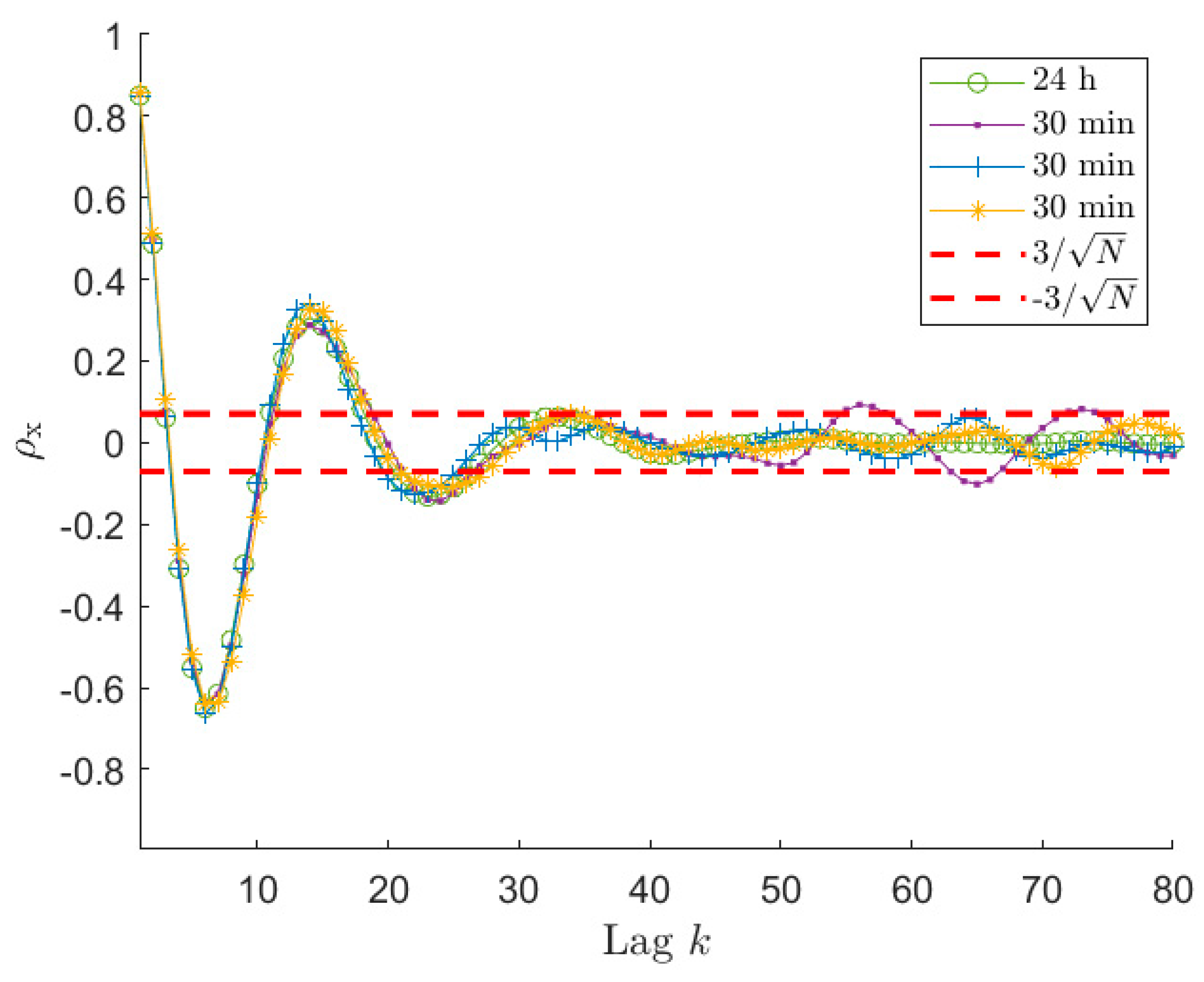
Figure 6 and
Figure 7 present normalised auto-covariances
achieved using
signals of 30 min and 10 min length, respectively. As mentioned in
Section 6.1, the auto-covariance plot allows us to select the reliable portion of the samples that have to be used in the estimation procedure, since this allows for more accurate PSD estimates. However, the identification of the
value using the
can be not so straightforward if the length of the time series decreases too much. Indeed, looking at
Figure 6, it is possible to notice that
for the 30 min signal, after entering the
band, starts oscillating and the amplitude of these oscillations increases as the lag increases. It can be also seen that one of the curves in
Figure 6 overcomes the upper threshold due to the large scatter. Comparing
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6, it appears that this behaviour is instead not evident for the 1 h time series. Actually, also in the case of long time series (e.g., 1 h long) the behaviour is similar; however, it is related to higher lag values. This happens because, decreasing the time length (e.g., from 1 h to 30 min), even if the
bounds become larger, at the same lag value the scatter associated with the auto-covariance of the short signal, is larger compared to the case of long signals since the considered lag is closer to the tail of the auto-covariance (i.e., higher
value).
Therefore, it is evident that, lowering the total number of samples, the auto-covariance shows a larger scatter for a fixed lag value. This can become a problem in identifying the significant portion of
. However, the important point for the application of the method proposed to choose
is to have the auto-covariance series within the
for a significant number of lags in order to recognize when the auto-covariance becomes non-significant for the purpose of the ARMA identification. Looking at
Figure 2 and
Figure 6, it is easy to notice that this is verified for time signals of 1 h and 30 min. Therefore, the procedure of
Section 6.1 allows us to identify
values related to portions of the auto-covariance series that are close to the reference auto-covariance curve, implying employing a part of
that is significant (i.e.,
for 30 min signals, see
Figure 6). However, in the two cases, the identified value of
is different and in particular decreases from 1 h to 30 min signals (i.e., from
to
) because of the larger value of
. This helps in avoiding using portions of the
that are too affected by its scatter, but in turn it limits the number of available points, and this has an effect on the achievable identification performance, as described in
Section 6.1. To show this effect and the accuracy of the PSD estimates achievable with time histories of 30 min and 10 min,
Figure 8 presents the results in terms of box plots and number of outliers, as those of
Figure 3 for series 1 h long. Considering signals 30 min long, from
Figure 8b it can be noticed that, as in the previous case, the best results are achieved for a
value close to
. Moreover, even if the quality of the reconstruction is lower reducing the time length (see
Figure 3 and
Figure 8b), as expected, it is still satisfactory, which in turn means that 30 min is an acceptable time length for a proper ARMA identification.
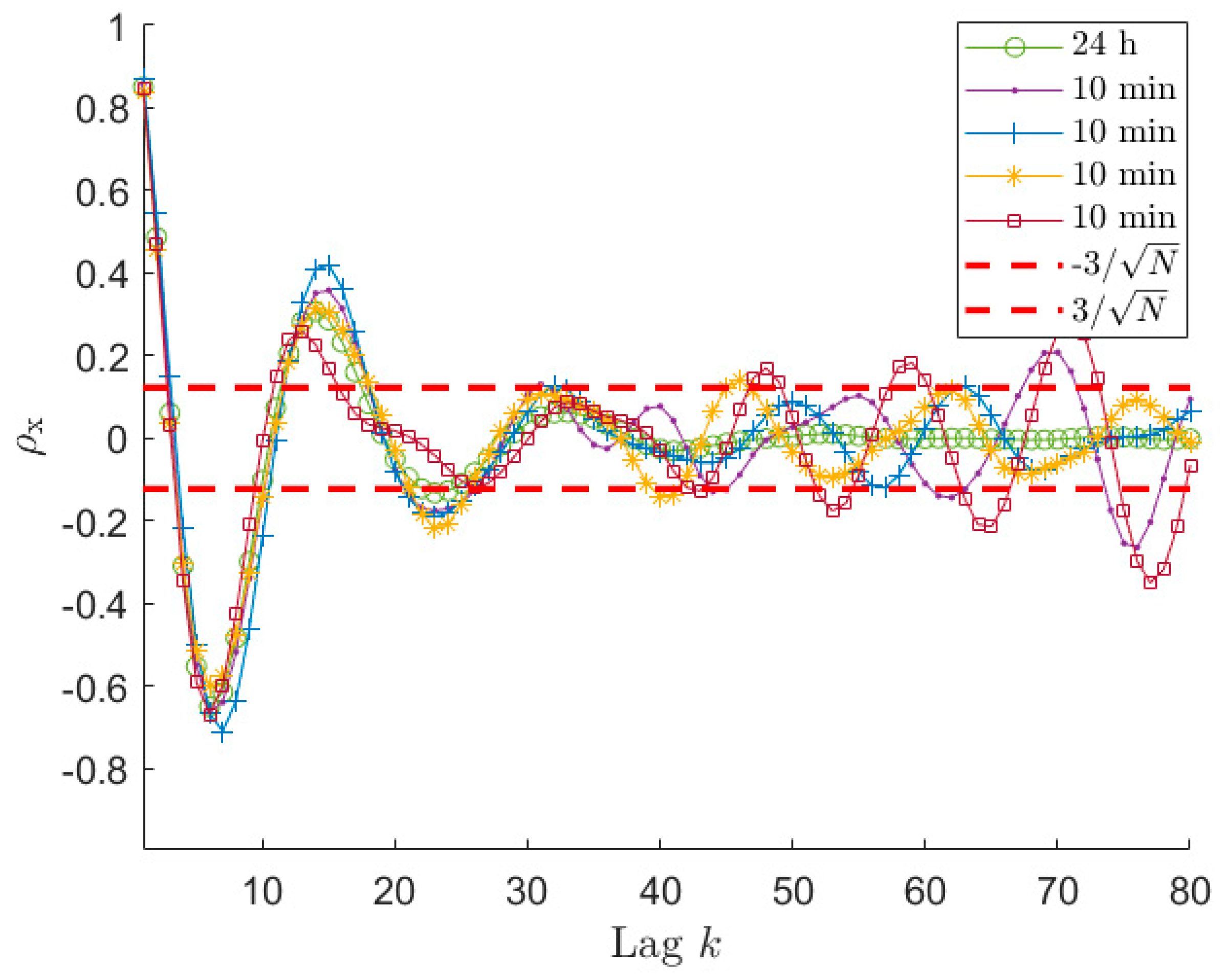
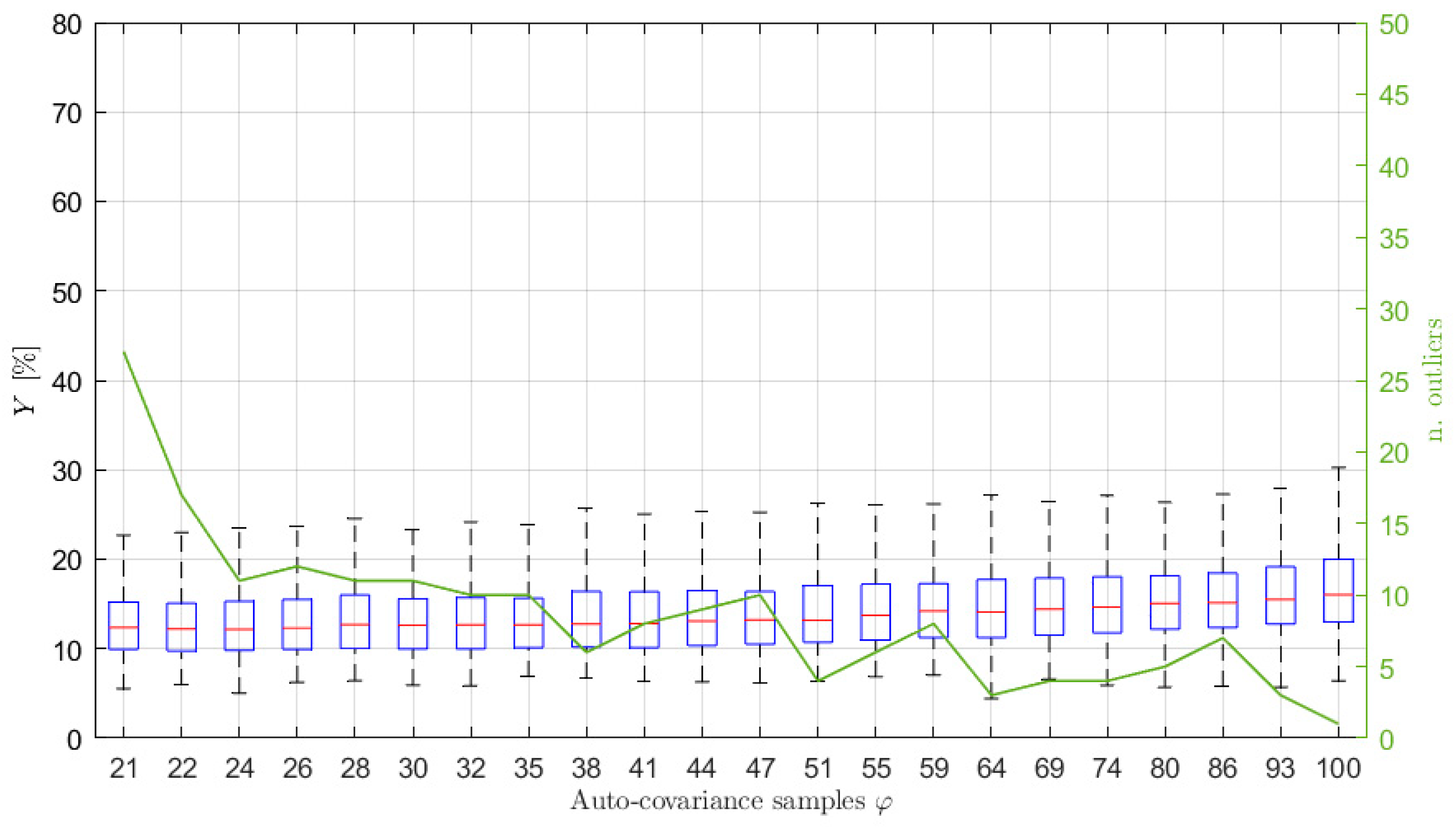
If the length of the time signal is further decreased, for example to 10 min, the problems discussed previously become more and more evident. Considering
Figure 7, which shows the auto-covariance for signals 10 min long, it is clear that it becomes difficult to clearly identify a lag range after the first oscillations where the curve remains within the
range. Moreover, the four auto-covariance series are different even for small lag values (e.g., at lag 15), because of the lower ratio between the lag value and the total amount of samples of the original signal, meaning that the usable portion of the auto-covariance curve is strongly decreased. Therefore, sometimes, it can occur that the criterium proposed to find
leads to a very small number of usable lag values. In these cases, there are various possibilities to manage the situation. One possibility is to use a small value for
. This case is treated in
Section 6.4, as well as the possibility to use an increased sampling frequency for the time series
. The other possibility is to use a
values that is usually fine for longer time series (e.g.,
= 10) and accepting to increase
to a value allowing to write a determined (or slightly overdetermined) system for the solution of the Prony’s problem. This case is treated in this section in order to compare the identification results when the time length of
is changed. For example,
Figure 7 shows that, in the case of 10 min signals in some cases the
lag is around 24 while for some others the value of
can be around the 17-th lag. In these latter cases,
is not enough for writing all the required equations in Equation (14) with
. Therefore, the number of the auto-covariance points that has to be considered must be increased at least up to 21. In order to show the effect of these problems on the accuracy of the estimated PSD,
Figure 8a presents the box plot for the signals 10 min long with
. Since the observed phenomenon is always the same (i.e., sea state of type 1), the choice of maintaining the
value equal to the previous cases is reasonable.
Figure 8a, shows that increasing
over 21 (i.e., the number of auto-covariance samples to be used for having as many equations as the number of unknowns in Equation (14)), provides a very slight decrease of the value
and the number of outliers. Conversely, if the number of the used auto-covariance samples increases over about 24, the value
starts increasing due to the fact that the added auto-covariance samples are already unreliable. Indeed, even if using 26 lag samples (as an example) means to employ few unreliable auto-covariance samples, their number is not negligible compared to the total number of auto-covariance samples used for the identification, thus turning out in a worsening of the procedure results. Therefore, in the cases of short time series, it is not convenient to slightly increase
value, as instead occurred in the case of long-time signals. Moreover,
Figure 8a shows that the
results for 10 min are far from those achievable with either 30 or 60 min for all the possible
values.
As mentioned, other possible ways to deal with short-time series are: the use of a lower number of poles and the increase the sampling frequency. These methods, explained in the next section, will also allow to slightly improve the estimation accuracy.
6.4. Short-Time Series: Effect of the Number of Poles and the Sampling Frequency
The analyses of the previous section showed the problems that can arise when dealing with short-time series, due to the scatter of the auto-covariance samples that occur even for low lag values. One possibility to try to improve the achievable estimates is to reduce the increased order
of the AR problem. This would allow increasing the overdetermination level of the least square problems of Equations (14) and (20) and thus to improve the accuracy of the estimates. However, the increase of the poles used to solve the first step of the estimation procedure will be lower than in the previous case (i.e., the difference between
and
will be lower). This choice can have consequences in the pole-selection procedure based on the energetic criterion and also implies the risk of choosing a
value too close or even lower than
. In order to evaluate the effect of the order reduction on the estimates, a new lower
value has been selected for the 10 min long time series, following the criterion described in
Section 6.2. The trend of the normalized AIC index is shown in
Figure 9 for two different 10 min long time series. In this case the
value must be close to the first drop of the AIC value in order to be able to solve in the least square sense the minimisation problem of Equation (14). Therefore,
Figure 9 suggests in this case a value of
of about 5, though, as in the previous case, its interpretation is not straightforward. With this value of
, new simulations have been carried out to evaluate the accuracy of the obtained sea PSD estimates, which are shown in
Figure 10b. In this case, in order to allow for a straight comparison with the results related to the case where the sampling frequency is increased (see further in this section), also some noise has been added to the wave elevation signal. The signal-to-noise ratio has been set equal to 30 dB (assuming a noise having flat power spectrum). Before analysing the results, it is worth mentioning that the effect of an increased noise level does not affect significantly the results shown for 30 min and 1 h time series as well as for 10 min, as mentioned further in this section, mainly thanks to the use of auto-covariance series in the estimation process and to the least square solution of the problems involved in the proposed procedure. Comparing
Figure 10a where
to
Figure 10b where
, and the signal-to-noise-ratio is the same, it is evident that the results obtained using
shows an improvement of the accuracy of the spectral reconstruction of few percentage points (i.e., about 5%), though the achieved results do not reach the accuracy values achievable with longer time series (see
Figure 3 and
Figure 8b).
Another possible way to improve the results achievable with short-time series is to slightly increase the sampling frequency of the signal. In order to verify if this could provide benefits, simulations have been carried out increasing the sampling frequency of the original time sequence . When the sampling frequency is increased, different factors must be considered:
in real cases, electrical noise is superimposed to the physical signal in the time sequence x, and an increase of the sampling frequency turns into an increase of the noise power. This implies a larger scatter associated to the auto-covariance sequence, especially when its value is low. Therefore, this worsens the ARMA identification;
on the other hand, a larger number of samples can be used to write Equation (14), thus improving the least square solution, because, for the same lag value in the time domain (i.e., for the same ), a larger number of lag samples is obtained due the smaller value of ;
given the spectral content of the wave elevation signals (i.e., far below 1 Hz) and the values of sampling frequency considered (i.e., 1 Hz), the expected improvement of the auto-covariance estimates provided by an increase of the sampling frequency is low. Indeed, according to [
42], only a slight decrease of the auto-covariance scatter is obtained increasing
from 1 Hz.
According to the above points, no large improvements can be obtained by increasing
. Simulations using
= 2 Hz for the case of 10 min long signals,
and noise added (signal-to-noise ratio equal to 30 dB for
= 1 Hz and to approximately 27 dB for
= 2 Hz, assuming noise with a flat power spectrum) confirmed this expectation. It is noticed that is straightforward to adapt the procedure described in
Section 3 to non-unitary sampling frequency. Comparing
Figure 10a,c, where only the sampling frequency changes, the best performance obtained for the highest sampling frequency is slightly better than that obtained with
. The main benefit provided by employing
= 2 Hz is related to the fact that changes in the number of lags used to write Equation (14) generate less changes of the results (see the right part of plot (c)), compared to the case of 1 Hz. Furthermore, as mentioned, comparing
Figure 8a and
Figure 10a, it is evident that the noise does not cause significant worsening of the ARMA identification because the two figures show similar
results, regardless of the presence of noise. Moreover, comparing
Figure 10b,c, it is clear that both the proposed strategies (i.e., decrease of
and increase of
) provide the same slight performance improvement; thus, neither the use of one nor the other is preferred. Finally, it is worth mentioning that use of the two strategies together leads to further slight improvements (i.e., about 1 percentage point).
Finally, to summarize, this analysis evidenced that a decrease of the time length of (e.g., under 20 min) always implies a worsening of the model identification. Furthermore, for signals with short duration, the variance associated to is significant compared to the range even at low order lag values, thus making difficult the use of the proposed criterion for the choice of . Therefore, the two proposed strategies can be applied to slightly improve the estimation accuracy, that are to choose a low value or to slightly increase the sampling frequency.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}