
An Explainable AI-Based Fault Diagnosis Model for Bearings




Abstract
1. Introduction
- (1)
- In practice, bearing signals are prone to inconsistencies due to several factors which make them difficult to analyze. Therefore, if there is a little variation in the given CM-FD scenario, the adopted signal processing techniques are unable to extract fault characteristics properly.
- (2)
- Wavelets transform-based signal analysis usually experiences the dilemma of appropriate Mother Wavelet (MW) selection and suffer from the drawbacks of poor noise immunity.
- (1)
- It has better immunity to ample noise.
- (2)
- It is free from the MW selection.
- (3)
- It can obtain good resolutions from the signals both at low and high frequencies. Thus, it has a built-in adaptive ability to tackle inconsistencies in the observed data.
- (1)
- The feature selectors available in the literature of bearing fault diagnosis are either the evolutionary algorithm-based approach [33,34] or the filter-based approach [35]. The evolutionary algorithms (i.e., genetic algorithms) select features based on the grid search and knap-snack mechanism [36] with gene cross-over and mutation. Thus, the reason for selecting an individual feature attribute can never be explained or tracked down. In addition, both approaches rely on the technique of removing the redundant feature attributes from the original feature set. Moreover, several data compression techniques, i.e., principal component analysis [37], and different manifold learning techniques are also used to represent the data into lower dimension for diagnosis purpose [38]. However, these techniques are based on algebraic calculation and geometric projection to create the separability into the feature space. Therefore, explainability remains the problem for these linear and non-linear dimensionality reduction-based techniques.
- (2)
- Without a proper understanding of the feature selection process, all the ML-based classifiers only focus on the classification accuracy, like a black box approach. This creates an adaptability issue for the model when the working environment changes.
- (1)
- This interpretation of the Shapley value is inspired from a collaborative game theory scenario where contributions of each feature attribute on the model performance are unequal but in cooperation with each other [45]. The Shapley value guarantees each feature attribute profits as much or more as they would have from performing independently.
- (2)
- The SHAP kernel can provide a unique solution by satisfying local accuracy, missingness, and consistency on the basis of the original model, hence allows explainability of a model [44]. The proof of these properties will be discussed later in Section 2.5 of this manuscript.
- (1)
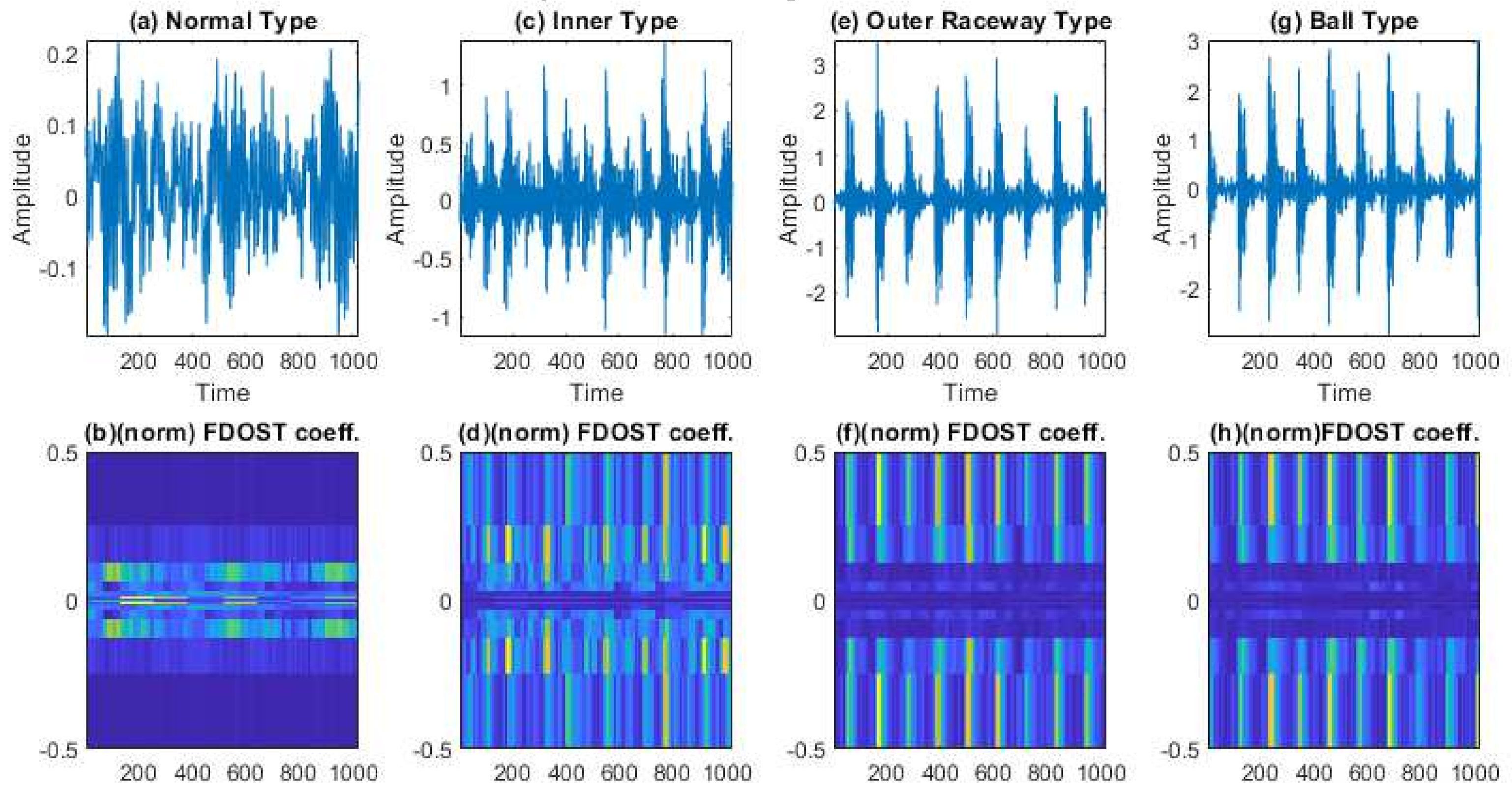
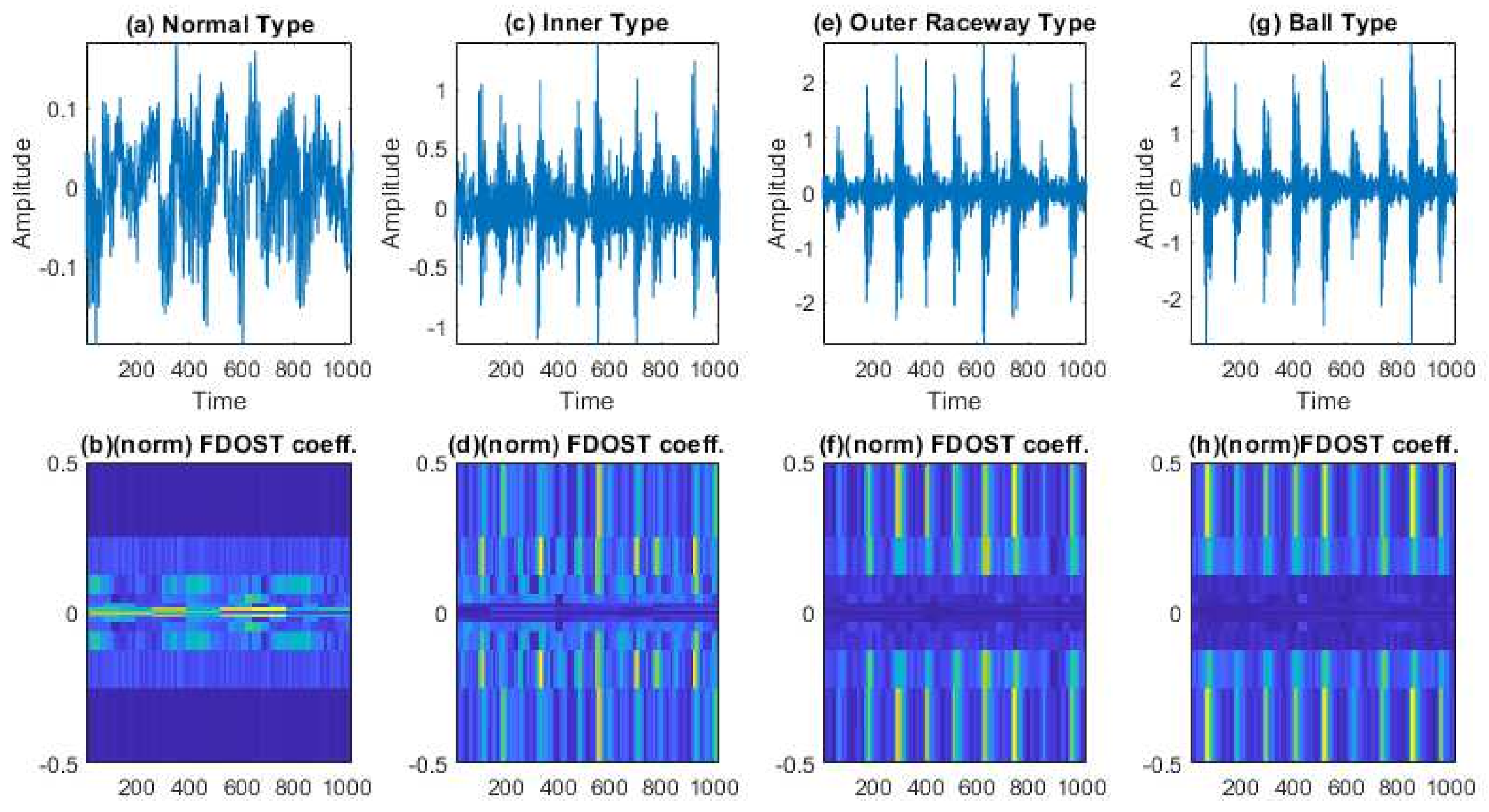
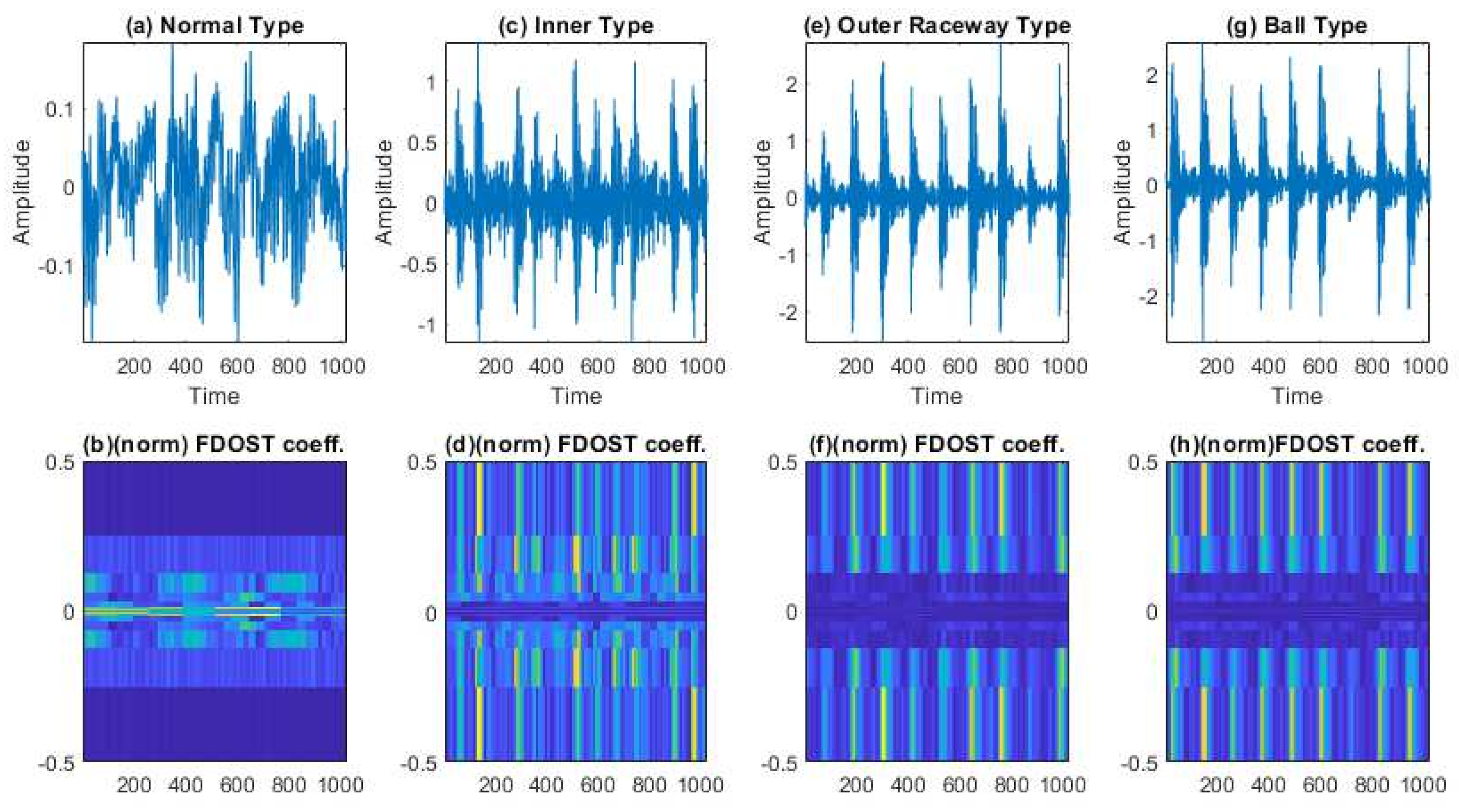
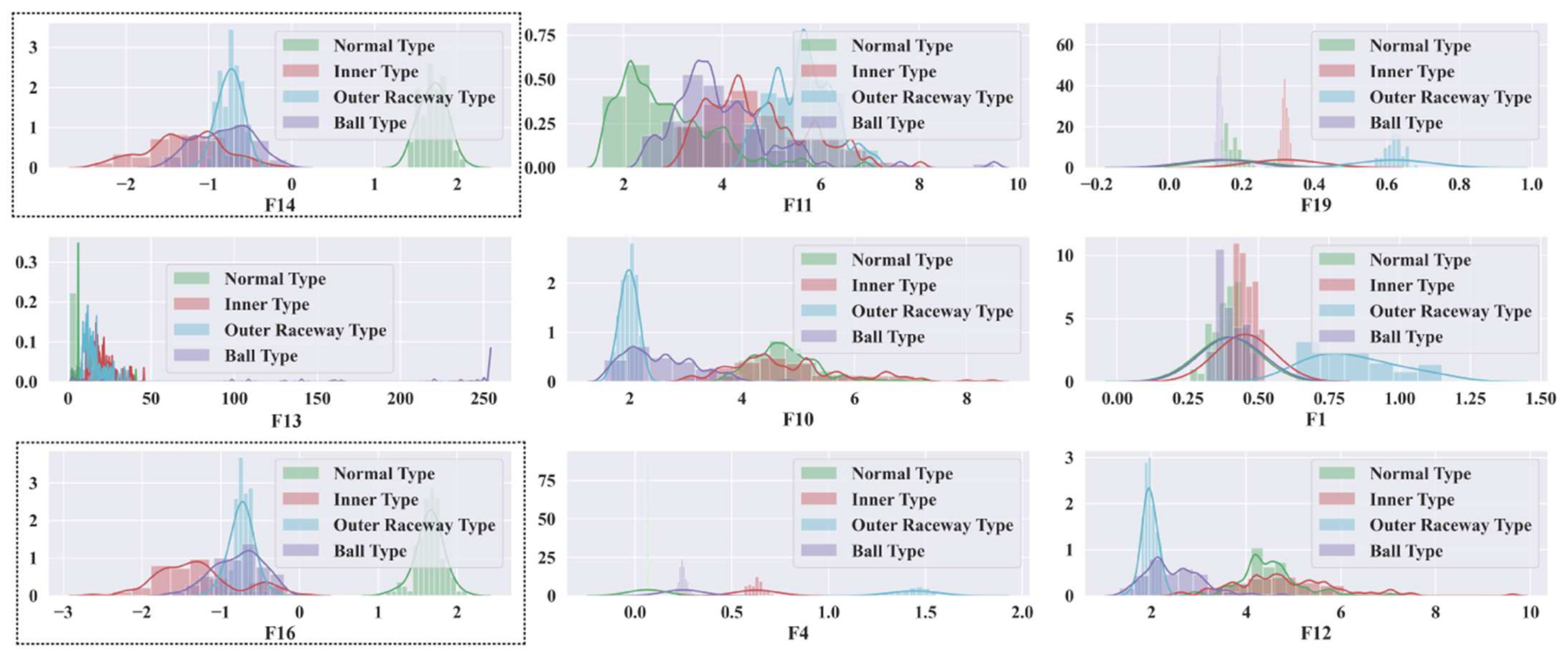
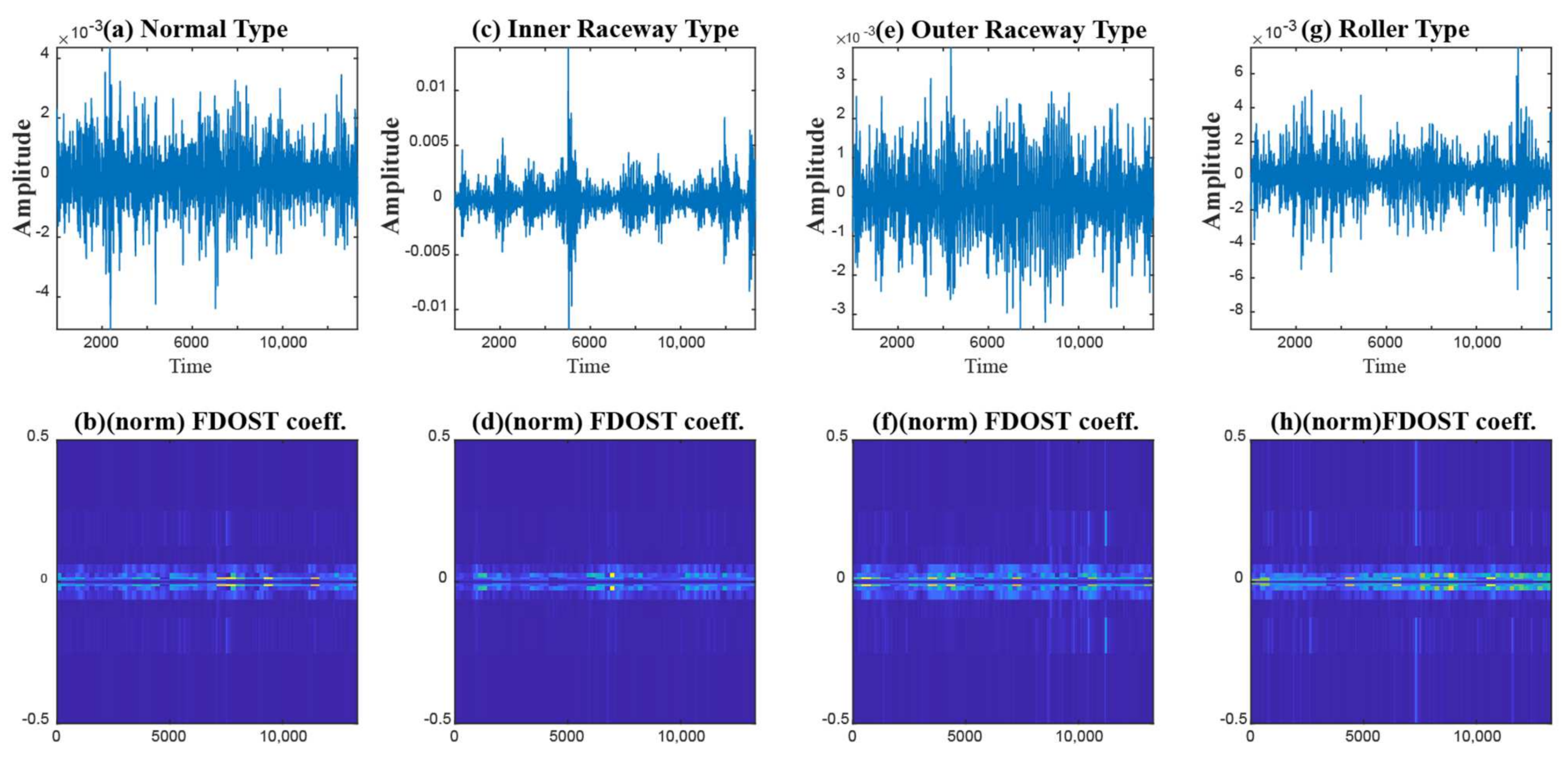
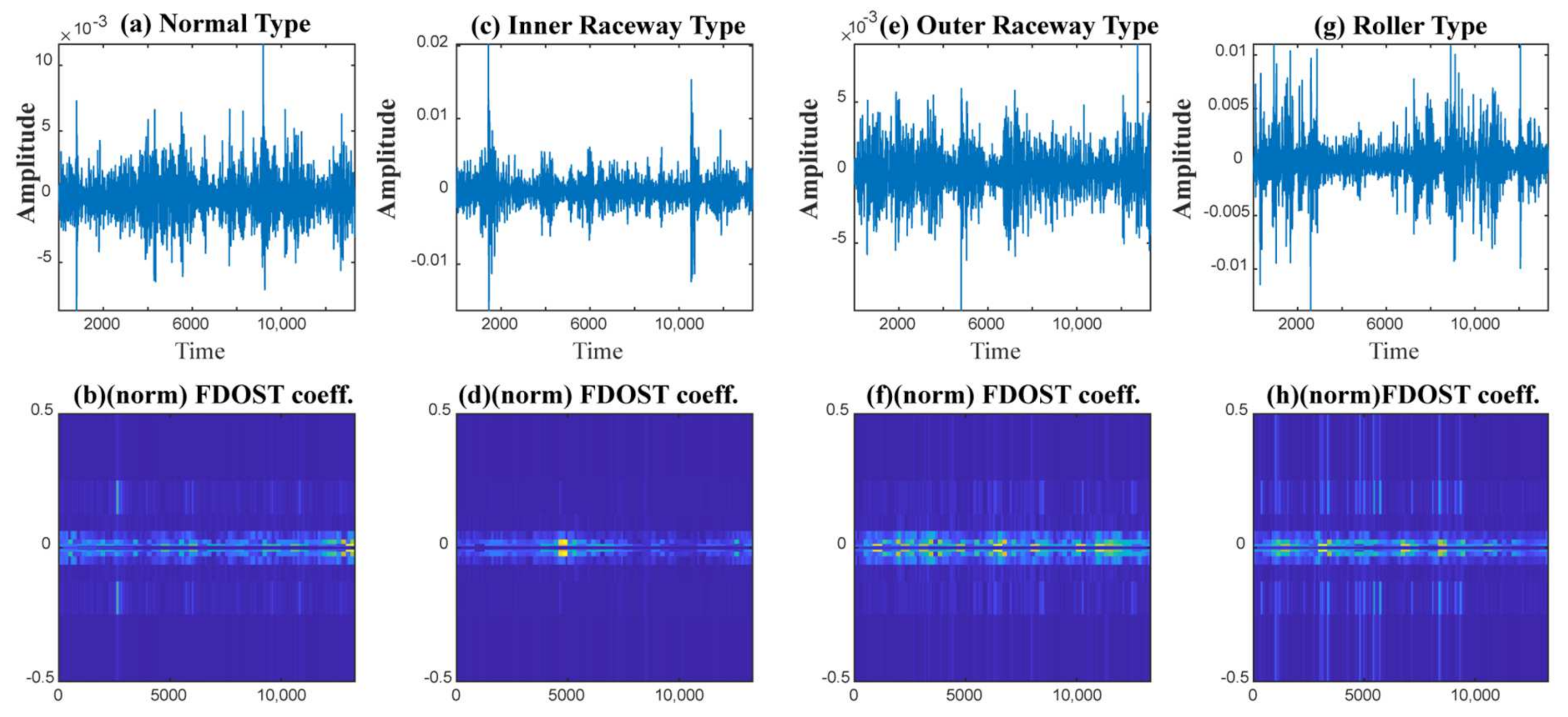
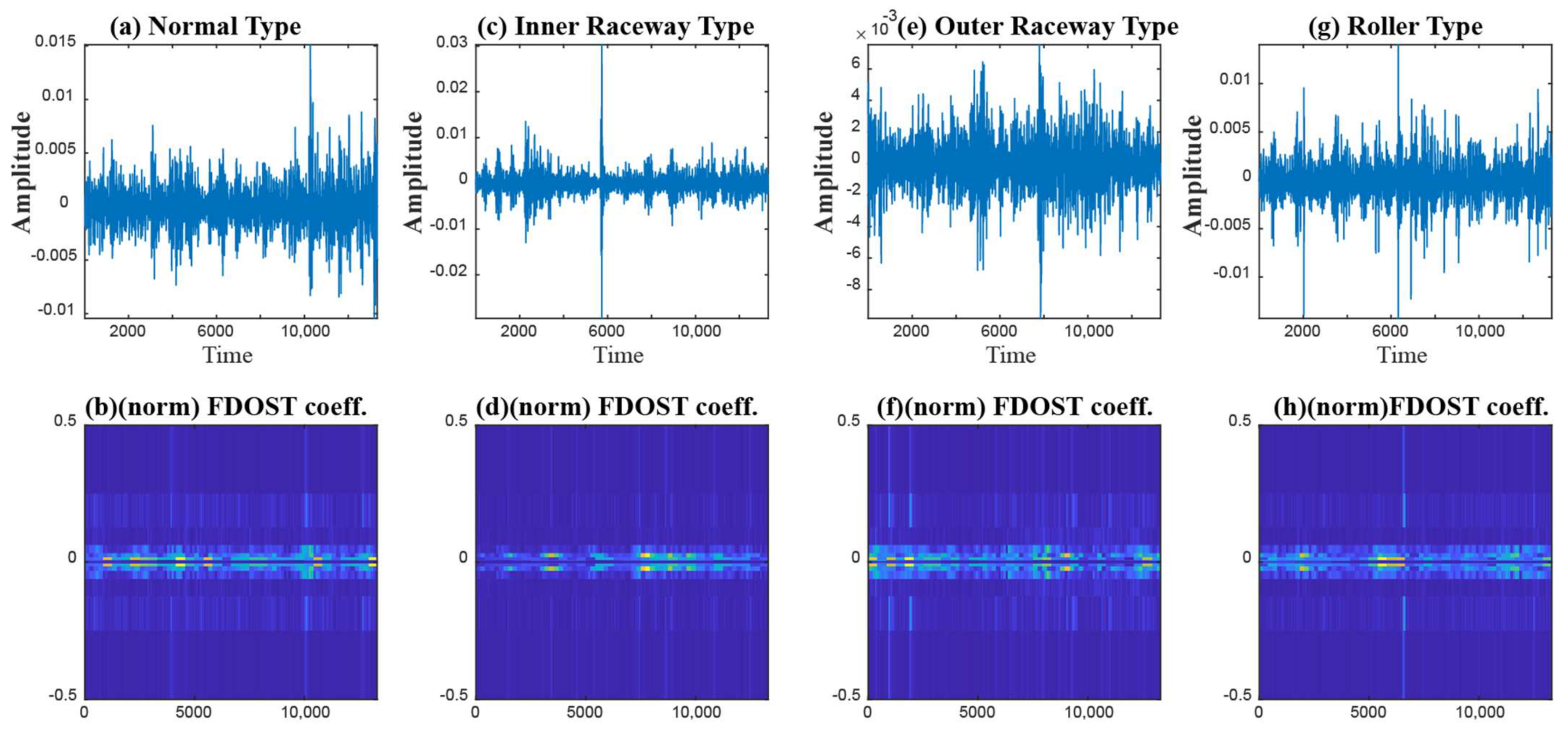
- To capture the information of variable working conditions from the vibration signals both at low and high frequencies, a computationally advanced version of ST called FDOST is proposed as the signal preprocessing step. First, statistical parameters are extracted as features from the time-frequency magnitudes and their corresponding phase angles of the FDOST coefficients. The extracted statistical features are then arranged as a feature matrix which can be regarded as input in the proceedings step. Thus, a carefully curated statistical feature pool extracted from unique FDOST patterns for different types of bearing faults is proposed in this study, which is helpful for boosting up the classification performance of the subsequent classifier.
- (2)
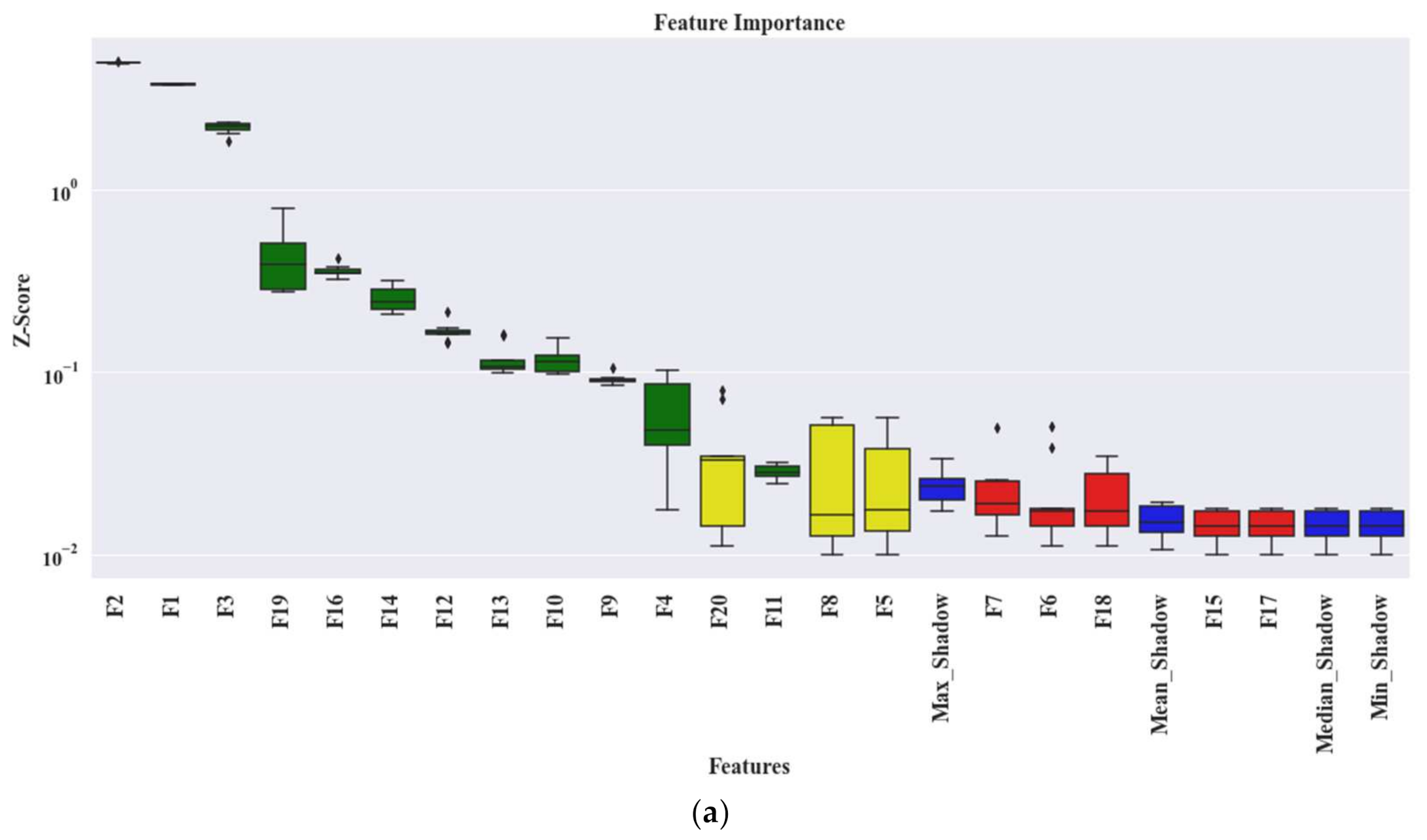
- A wrapper-based feature selector named Boruta is utilized to find the best features from the extracted statistical feature pool. This algorithm can justify the selection of each feature attribute with the help of an embedded RF classifier. Thus, the feature selection process is easily interpretable in the proposed bearing fault diagnosis model.
- (3)
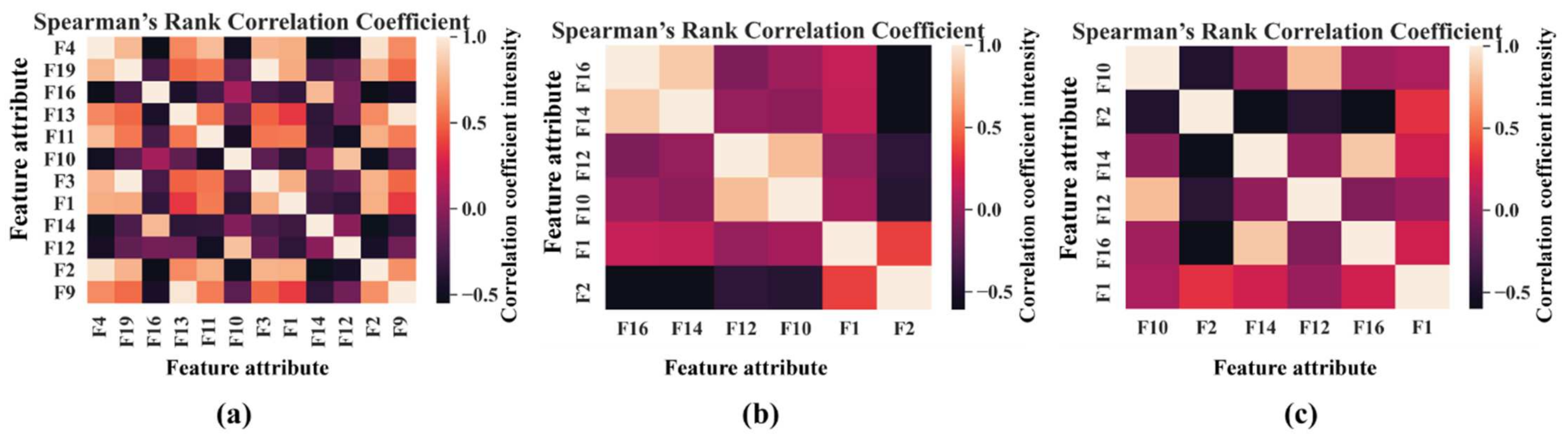
- In addition to interpretable feature selection process, a feature filtration technique is proposed by using SRCC to create a reduced feature set for the classifier which can produce bias free results. Thus, it helps the classifier to avoid the multicollinearity trap.
- (4)
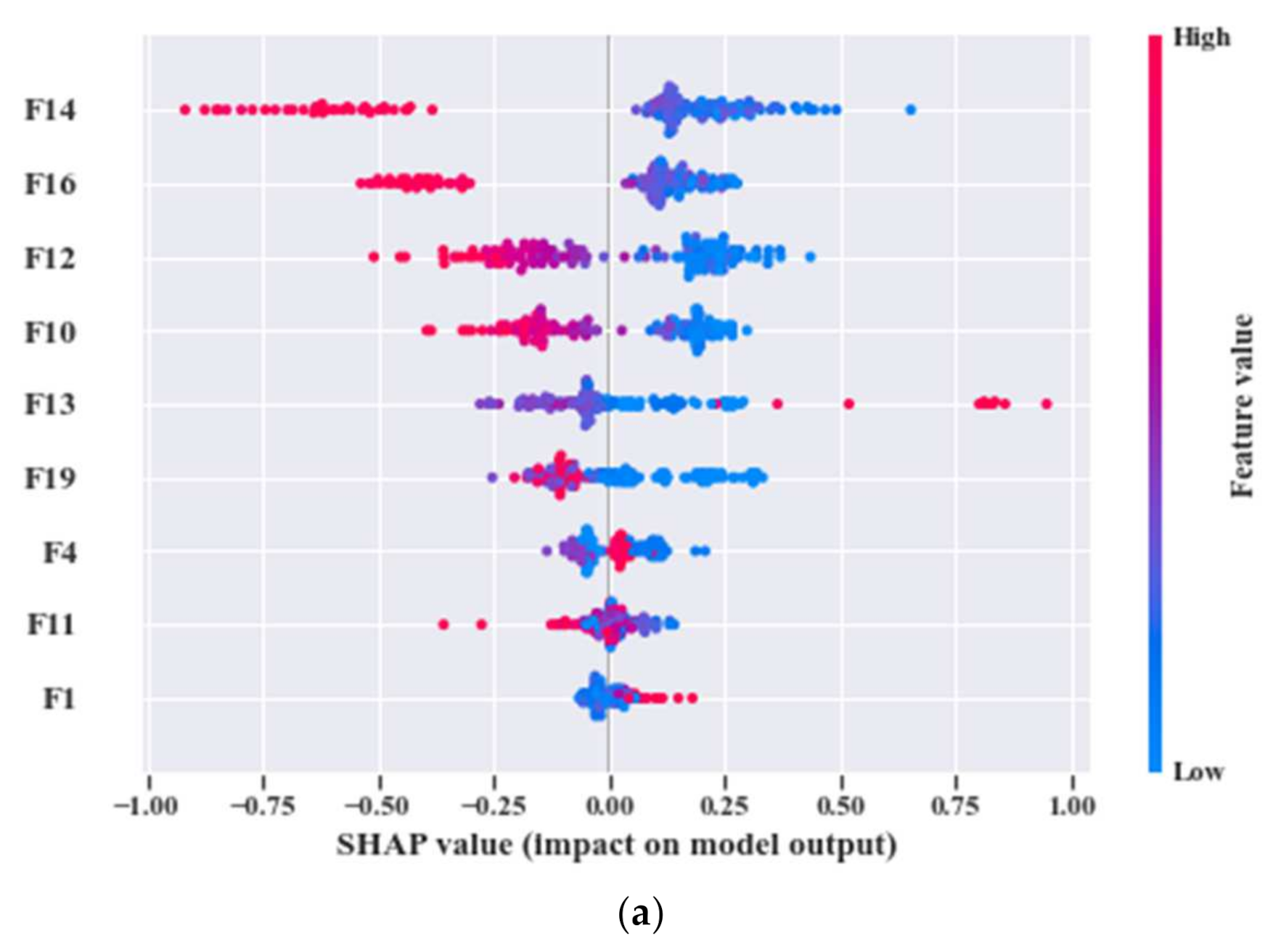
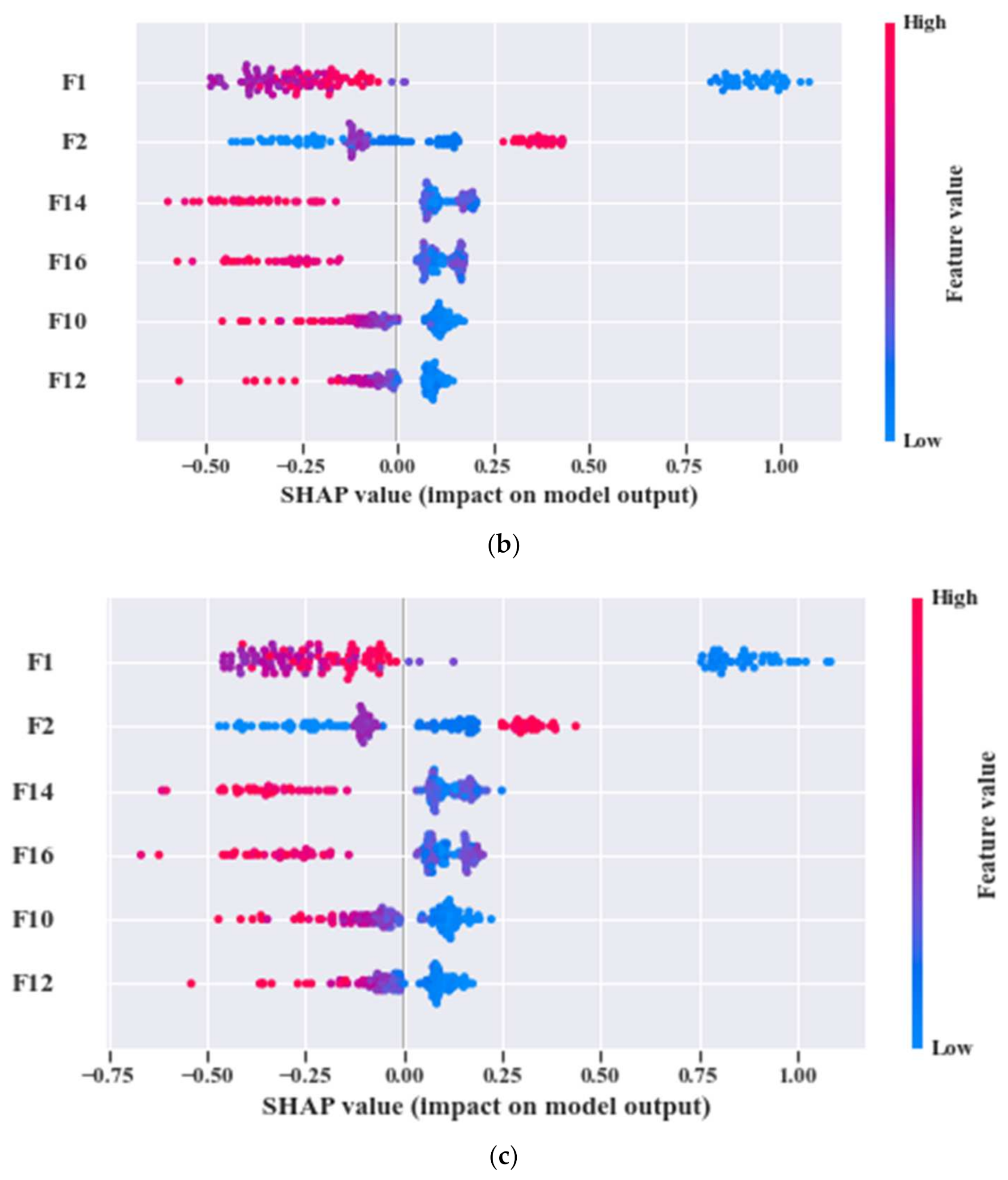
- A correlation between the filtered feature pool and results of a non-parametric k-NN classifier is presented in this work, i.e., the predictions of k-NN are explained in context of SHAP values.
2. Technical Background
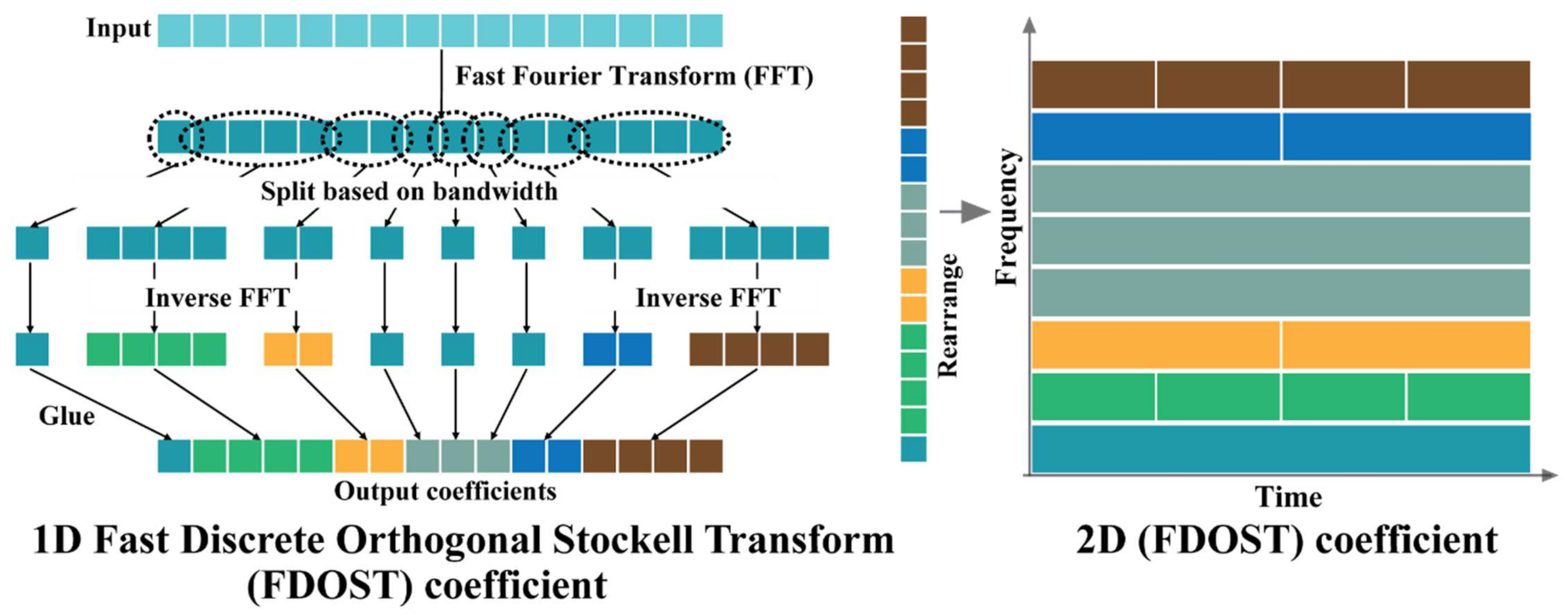
2.1. Fast Discrete Orthogonal Stockwell Transformation
2.2. Wrapper-Based Feature Selector—Boruta
- (1)
- By shuffling and permuting all the original feature attributes, it first creates a randomized copy of the original feature set. These replicated feature sets are known as Shadow Attributes (SAs). Then, these SAs are merged with the original feature attributes to form the Extended Information System (EIS) [40]. At least five SAs are required to form the EIS.
- (2)
- Then, the values of these SAs are randomly permuted and shuffled. Thus, pure randomness is present in all the replicated variables and the decision attributes.
- (3)
- Afterwards, an RF classifier is fitted to the EIS several times, and the SAs are randomized before each run. Therefore, for each run, the randomly updated part of the EIS is distinct.
- (4)
- For each run, the importance of all feature attributes ( score) is computed. To compute this importance, the following steps are considered:
- (a)
- The EIS is divided into several Bootstrapped Sets of Samples (BSSs) (in another word, the training samples) equivalent to the considered number of Decision Trees (DTs) used for the RF. Therefore, the samples for testing, which are commonly known as the Out of the Bag Samples (OOBSs), are equivalent to the number of BSSs.
- (b)
- Then, each BSS is used for training individual DTs, whereas the corresponding OOB is used for testing the performance of that DT. Thus, for each feature attributes from the EIS, the number of votes for the correct class are recorded.
- (c)
- Later, the values of the feature attributes of the OOBs are randomly permuted to record the votes for the correct class once more, like the previous step.
- (d)
- Then, the importance of the values of the attribute for a single DT can be calculated as follows:
This importance measure is known as the Mean Decrease in Accuracy (MDA).- (e)
- Finally, the importance of the values of the feature attribute () throughout the forest is computed as follows:
- (f)
- Therefore, the final importance score is calculated as:
- (5)
- Find the Maximum Value of among the Shadow Attributes (MVSA). After that, assign a hit to every attribute that scored higher than the MVSA. To determine the best attributes, the following steps are considered:
- (a)
- Consider an attribute as important if it performs significantly higher than the MVSA.
- (b)
- Remove an attribute from the EIS as non-important if it performs significantly lower than the MVSA.
- (c)
- For an attribute with undetermined importance, a two-sided test of equality is conducted with the MVSA.
- (6)
- Remove all the SAs from the EIS.
- (7)
- Repeat the whole process till any of the following two cases are satisfied:
- (a)
- The importance is assigned to all the attributes.
- (b)
- The algorithm reaches the limit of defined number of RF runs.
2.3. Spearman’s Rank Correlation Coefficient
- (1)
- Due to the non-parametric test approach, it carries no assumptions of the distribution of the data [42].
- (2)
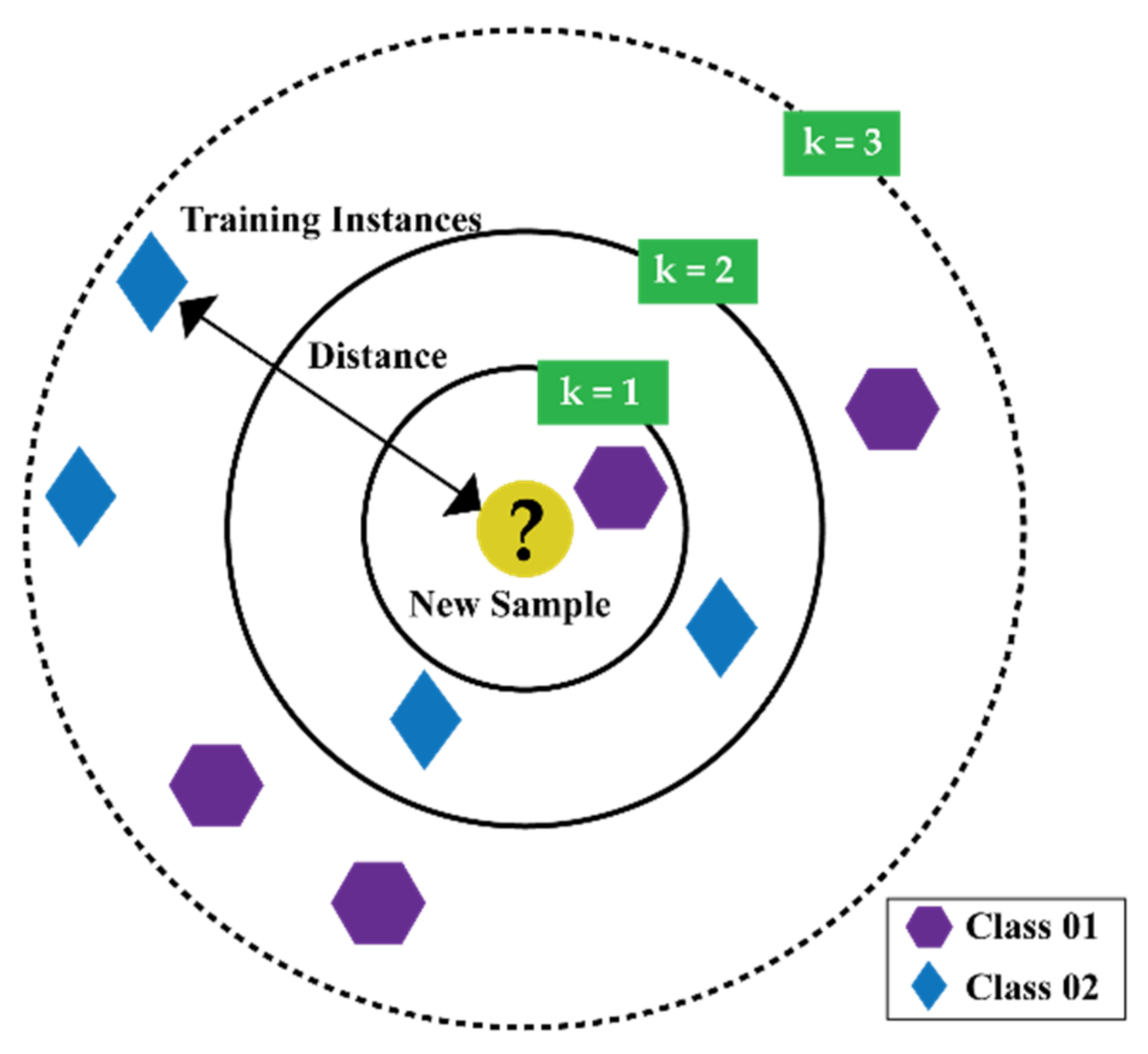
2.4. k-Nearest Neighbor Algorithm
- (1)
- If the value of k is set to 1, the prediction turns out to be less stable.
- (2)
- Inversely, if the value of k is increased, the prediction becomes stable due to the majority voting/averaging. However, after a certain value for the target dataset, the number of errors will start to increase.
- (3)
- The optimal k value can be determined by considering the square root of , where is the total number of samples. Then, by using a grid search approach, from 1 to the optimal value of k, an error plot or accuracy plot is calculated to determine the most favorable k value.
- (4)
- Usually, when considering the values for the range of k for the grid search, each value for k is set as an odd number, i.e., . Thus, for the scenario while majority voting is necessary to determine the prediction, the tiebreaker becomes easy.
2.5. Shapley Additive Explanation for Model Interpretation
- (1)
- Local accuracy: If is the specific input to the original model , then for approximating , local accuracy requires the explanation model to match its output with the output of for any simplified given input to model .
- (2)
- Missingness: If any feature is missing in the original input , that feature has no attributed impact.
- (3)
- Consistency: If a model is changed in a way such that a feature brings greater impact on the model, the attribution assigned to that feature will never decrease. Let and imply the setting for where . For any two models , and , if
- (1)
- It can estimate the SHAP values without considering the model type.
- (2)
- Feature importance is calculated in the presence of multicollinearity in the data.
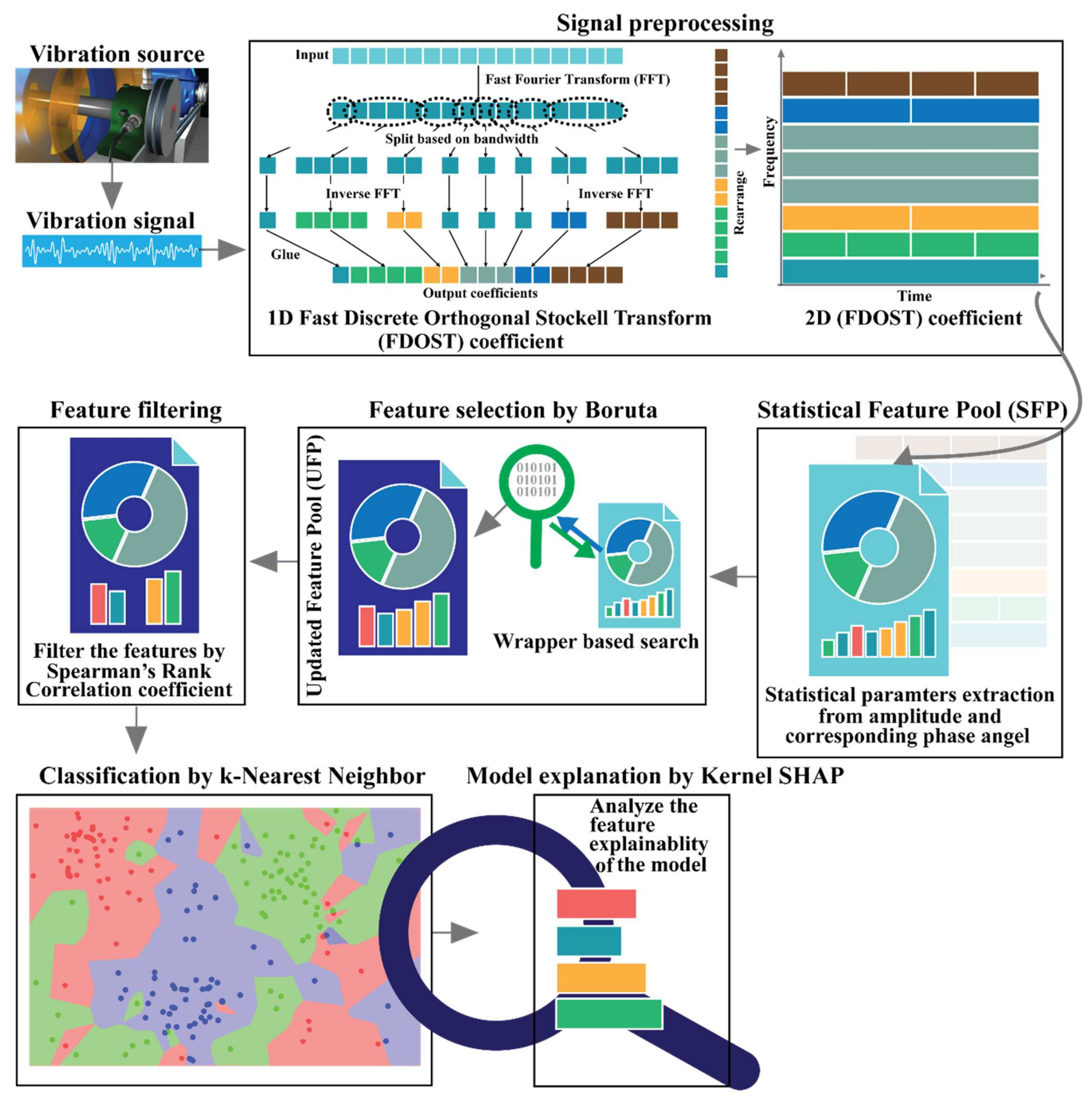
3. Proposed Method
3.1. Data Preprocessing by the Fast Discrete Orthogonal Stockwell Transformation (FDOST)
3.2. Statistical Feature Pool Configuration
3.3. Feature Filtering by the Spearman’s Rank Correlation Coefficient (SRCC)
3.4. Classification by k-Nearest Neighbor (k-NN))
- (1)
- It is a non-parametric clustering analysis-based model.
- (2)
- Parameter’s tuning is not a concern for k-NN as it is a non-parametric algorithm. Therefore, assumptions about the input data are not a concern while dealing with k-NN.
3.5. Model Interpretation by Kernel SHAP
3.6. Overall Evaluation Criteria
4. Dataset Description
4.1. Case Western Reserve University (CWRU) Bearing Dataset
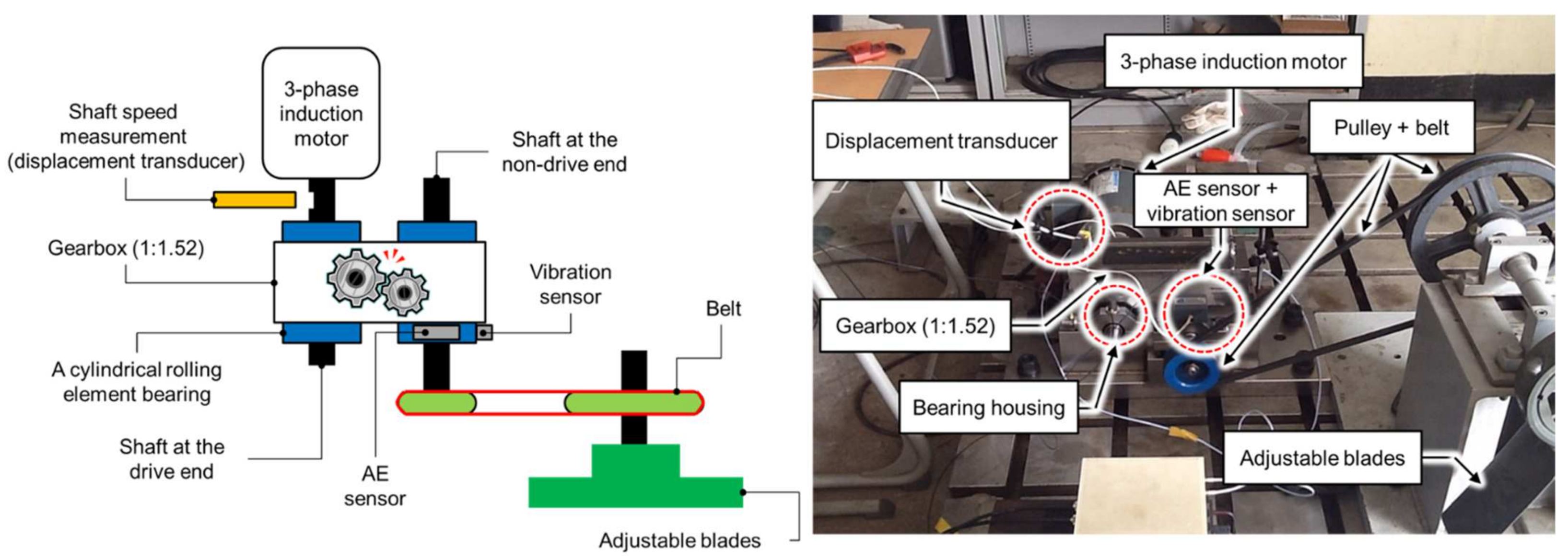
4.2. Dataset from the Self-Designed Testbed
5. Experimental Result Analysis
5.1. Case Study 1—CWRU Dataset
5.2. Case Study 2—Dataset from the Self Designed Testbed
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 2018, 313, 47–64. [Google Scholar] [CrossRef]
- Lei, Y.; He, Z.; Zi, Y. A new approach to intelligent fault diagnosis of rotating machinery. Expert Syst. Appl. 2008, 35, 1593–1600. [Google Scholar] [CrossRef]
- Yan, X.; Liu, Y.; Jia, M.; Zhu, Y. A multi-stage hybrid fault diagnosis approach for rolling element bearing under various working conditions. IEEE Access 2019, 7, 138426–138441. [Google Scholar] [CrossRef]
- Hasan, M.J.; Sohaib, M.; Kim, J.-M. A Multitask-Aided Transfer Learning-Based Diagnostic Framework for Bearings under Inconsistent Working Conditions. Sensors 2020, 20, 7205. [Google Scholar] [CrossRef] [PubMed]
- Cui, L.; Huang, J.; Zhang, F. Quantitative and localization diagnosis of a defective ball bearing based on vertical–horizontal synchronization signal analysis. IEEE Trans. Ind. Electron. 2017, 64, 8695–8706. [Google Scholar] [CrossRef]
- Tian, J.; Ai, Y.; Fei, C.; Zhao, M.; Zhang, F.; Wang, Z. Fault diagnosis of intershaft bearings using fusion information exergy distance method. Shock Vib. 2018, 2018. [Google Scholar] [CrossRef]
- Hoang, D.T.; Kang, H.J. A Motor Current Signal-Based Bearing Fault Diagnosis Using Deep Learning and Information Fusion. IEEE Trans. Instrum. Meas. 2019, 69, 3325–3333. [Google Scholar] [CrossRef]
- Mao, W.; Chen, J.; Liang, X.; Zhang, X. A new online detection approach for rolling bearing incipient fault via self-adaptive deep feature matching. IEEE Trans. Instrum. Meas. 2019, 69, 443–456. [Google Scholar] [CrossRef]
- Rai, A.; Kim, J.-M. A novel health indicator based on the Lyapunov exponent, a probabilistic self-organizing map, and the Gini-Simpson index for calculating the RUL of bearings. Measurement 2020, 164, 108002. [Google Scholar] [CrossRef]
- Hasan, M.J.; Islam, M.M.M.; Kim, J.M. Acoustic spectral imaging and transfer learning for reliable bearing fault diagnosis under variable speed conditions. Meas. J. Int. Meas. Confed. 2019, 138, 620–631. [Google Scholar] [CrossRef]
- Sohaib, M.; Kim, C.-H.; Kim, J.-M. A Hybrid Feature Model and Deep-Learning-Based Bearing Fault Diagnosis. Sensors 2017, 17, 2876. [Google Scholar] [CrossRef] [PubMed]
- Meng, M.; Chua, Y.J.; Wouterson, E.; Ong, C.P.K. Ultrasonic signal classification and imaging system for composite materials via deep convolutional neural networks. Neurocomputing 2017, 257, 128–135. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, R.; Yang, Y.; Li, Y.; Xu, M. Intelligent fault identification based on multisource domain generalization towards actual diagnosis scenario. IEEE Trans. Ind. Electron. 2019, 67, 1293–1304. [Google Scholar] [CrossRef]
- Oh, H.; Jung, J.H.; Jeon, B.C.; Youn, B.D. Scalable and unsupervised feature engineering using vibration-imaging and deep learning for rotor system diagnosis. IEEE Trans. Ind. Electron. 2017, 65, 3539–3549. [Google Scholar] [CrossRef]
- Shao, S.-Y.; Sun, W.-J.; Yan, R.-Q.; Wang, P.; Gao, R.X. A deep learning approach for fault diagnosis of induction motors in manufacturing. Chin. J. Mech. Eng. 2017, 30, 1347–1356. [Google Scholar] [CrossRef]
- Sun, Y.; Li, S.; Wang, X. Bearing fault diagnosis based on EMD and improved Chebyshev distance in SDP image. Measurement 2021, 176, 109100. [Google Scholar] [CrossRef]
- Ali, J.B.; Fnaiech, N.; Saidi, L.; Chebel-Morello, B.; Fnaiech, F. Application of empirical mode decomposition and artificial neural network for automatic bearing fault diagnosis based on vibration signals. Appl. Acoust. 2015, 89, 16–27. [Google Scholar]
- Zhao, L.-Y.; Wang, L.; Yan, R.-Q. Rolling bearing fault diagnosis based on wavelet packet decomposition and multi-scale permutation entropy. Entropy 2015, 17, 6447–6461. [Google Scholar] [CrossRef]
- Qiao, Z.; Liu, Y.; Liao, Y. An improved method of EWT and its application in rolling bearings fault diagnosis. Shock Vib. 2020, 2020. [Google Scholar] [CrossRef]
- Gu, R.; Chen, J.; Hong, R.; Wang, H.; Wu, W. Incipient fault diagnosis of rolling bearings based on adaptive variational mode decomposition and Teager energy operator. Measurement 2020, 149, 106941. [Google Scholar] [CrossRef]
- Cheng, Y.; Lin, M.; Wu, J.; Zhu, H.; Shao, X. Intelligent fault diagnosis of rotating machinery based on continuous wavelet transform-local binary convolutional neural network. Knowl. Based Syst. 2021, 216, 106796. [Google Scholar] [CrossRef]
- Zheng, J.; Cheng, J.; Yang, Y.; Luo, S. A rolling bearing fault diagnosis method based on multi-scale fuzzy entropy and variable predictive model-based class discrimination. Mech. Mach. Theory 2014, 78, 187–200. [Google Scholar] [CrossRef]
- Immovilli, F.; Bellini, A.; Rubini, R.; Tassoni, C. Diagnosis of bearing faults in induction machines by vibration or current signals: A critical comparison. IEEE Trans. Ind. Appl. 2010, 46, 1350–1359. [Google Scholar] [CrossRef]
- Frosini, L.; Harlişca, C.; Szabó, L. Induction machine bearing fault detection by means of statistical processing of the stray flux measurement. IEEE Trans. Ind. Electron. 2014, 62, 1846–1854. [Google Scholar] [CrossRef]
- Frosini, L.; Borin, A.; Girometta, L.; Venchi, G. Development of a leakage flux measurement system for condition monitoring of electrical drives. In Proceedings of the 8th IEEE Symposium on Diagnostics for Electrical Machines, Power Electronics & Drives, Bologna, Italy, 5–8 September 2011; pp. 356–363. [Google Scholar]
- Kang, M.; Kim, J.; Kim, J.M.; Tan, A.C.C.; Kim, E.Y.; Choi, B.K. Reliable fault diagnosis for low-speed bearings using individually trained support vector machines with kernel discriminative feature analysis. IEEE Trans. Power Electron. 2015, 30, 2786–2797. [Google Scholar] [CrossRef]
- Rai, A.; Upadhyay, S.H. A review on signal processing techniques utilized in the fault diagnosis of rolling element bearings. Tribol. Int. 2016, 96, 289–306. [Google Scholar] [CrossRef]
- Khan, S.A.; Kim, J.-M. Rotational speed invariant fault diagnosis in bearings using vibration signal imaging and local binary patterns. J. Acoust. Soc. Am. 2016, 139, EL100–EL104. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.M.M.; Myon, J. Time–frequency envelope analysis-based sub-band selection and probabilistic support vector machines for multi-fault diagnosis of low-speed bearings. J. Ambient Intell. Humaniz. Comput. 2017, 48, 2110–2117. [Google Scholar] [CrossRef]
- Qu, J.; Zhang, Z.; Gong, T. A novel intelligent method for mechanical fault diagnosis based on dual-tree complex wavelet packet transform and multiple classifier fusion. Neurocomputing 2016, 171, 837–853. [Google Scholar] [CrossRef]
- Chen, G.; Liu, F.; Huang, W. Sparse discriminant manifold projections for bearing fault diagnosis. J. Sound Vib. 2017, 399, 330–344. [Google Scholar] [CrossRef]
- Zheng, X.; Wei, Y.; Liu, J.; Jiang, H. Multi-synchrosqueezing S-transform for fault diagnosis in rolling bearings. Meas. Sci. Technol. 2020, 32, 25013. [Google Scholar] [CrossRef]
- Leardi, R. Application of a genetic algorithm to feature selection under full validation conditions and to outlier detection. J. Chemom. 1994, 8, 65–79. [Google Scholar] [CrossRef]
- Oreski, S.; Oreski, G. Genetic algorithm-based heuristic for feature selection in credit risk assessment. Expert Syst. Appl. 2014, 41, 2052–2064. [Google Scholar] [CrossRef]
- Ambusaidi, M.A.; He, X.; Nanda, P.; Tan, Z. Building an intrusion detection system using a filter-based feature selection algorithm. IEEE Trans. Comput. 2016, 65, 2986–2998. [Google Scholar] [CrossRef]
- Chu, P.C.; Beasley, J.E. A genetic algorithm for the multidimensional knapsack problem. J. Heuristics 1998, 4, 63–86. [Google Scholar] [CrossRef]
- Xie, H.; Li, J.; Xue, H. A survey of dimensionality reduction techniques based on random projection. arXiv 2017, arXiv:1706.04371. [Google Scholar]
- Refahi Oskouei, A.; Heidary, H.; Ahmadi, M.; Farajpur, M. Unsupervised acoustic emission data clustering for the analysis of damage mechanisms in glass/polyester composites. Mater. Des. 2012, 37, 416–422. [Google Scholar] [CrossRef]
- Kursa, M.B.; Jankowski, A.; Rudnicki, W.R. Boruta–a system for feature selection. Fundam. Inform. 2010, 101, 271–285. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Zar, J.H. Spearman rank correlation. Encycl. Biostat. 2005, 7. [Google Scholar]
- Zar, J.H. Significance testing of the Spearman rank correlation coefficient. J. Am. Stat. Assoc. 1972, 67, 578–580. [Google Scholar] [CrossRef]
- Breusch, T.S.; Pagan, A.R. A simple test for heteroscedasticity and random coefficient variation. Econom. J. Econom. Soc. 1979, 1287–1294. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.-I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Shapley, L.S. A Value for N-Person Games, Contribution to the Theory of Games; Kuhn, H.W., Tucker, A.W., Eds.; Princeton University Press: Princeton, TX, USA, 1952; Volume II. [Google Scholar]
- Case Western Reserve University Bearing Dataset of Case Western Reserve University. Available online: https://csegroups.case.edu/bearingdatacenter/pages/download-data-file (accessed on 3 June 2021).
- Mishra, S.; Bhende, C.N.; Panigrahi, B.K. Detection and classification of power quality disturbances using S-transform and probabilistic neural network. IEEE Trans. Power Deliv. 2007, 23, 280–287. [Google Scholar] [CrossRef]
- Stockwell, R.G.; Mansinha, L.; Lowe, R.P. Localization of the complex spectrum: The S transform. IEEE Trans. Signal Process. 1996, 44, 998–1001. [Google Scholar] [CrossRef]
- Stockwell, R.G. A basis for efficient representation of the S-transform. Digit. Signal Process. A Rev. J. 2007, 17, 371–393. [Google Scholar] [CrossRef]
- Patel, B. A new FDOST entropy based intelligent digital relaying for detection, classification and localization of faults on the hybrid transmission line. Electr. Power Syst. Res. 2018, 157, 39–47. [Google Scholar] [CrossRef]
- Kaba, M.D.; Camlibel, M.K.; Wang, Y.; Orchard, J. Fast discrete orthonormal Stockwell transform. SIAM J. Sci. Comput. 2009, 31, 4000–4012. [Google Scholar]
- Battisti, U.; Riba, L. Window-dependent bases for efficient representations of the Stockwell transform. Appl. Comput. Harmon. Anal. 2016, 40, 292–320. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man. Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Chen, P.Y.; Smithson, M.; Popovich, P.M. Correlation: Parametric and Nonparametric Measures; Sage: Newcastle upon Tyne, UK, 2002; ISBN 0761922288. [Google Scholar]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Francis, D.P.; Coats, A.J.S.; Gibson, D.G. How high can a correlation coefficient be? Effects of limited reproducibility of common cardiological measures. Int. J. Cardiol. 1999, 69, 185–189. [Google Scholar] [CrossRef]
- Hasan, M.J.; Kim, J.M. Fault detection of a spherical tank using a genetic algorithm-based hybrid feature pool and k-nearest neighbor algorithm. Energies 2019, 12, 991. [Google Scholar] [CrossRef]
- Hasan, M.J.; Kim, J.; Kim, C.H.; Kim, J.-M. Health State Classification of a Spherical Tank Using a Hybrid Bag of Features and K-Nearest Neighbor. Appl. Sci. 2020, 10, 2525. [Google Scholar] [CrossRef]
- Danielsson, P.-E. Euclidean distance mapping. Comput. Graph. Image Process. 1980, 14, 227–248. [Google Scholar] [CrossRef]
- Greche, L.; Jazouli, M.; Es-Sbai, N.; Majda, A.; Zarghili, A. Comparison between Euclidean and Manhattan distance measure for facial expressions classification. In Proceedings of the 2017 International Conference on Wireless Technologies, Embedded and Intelligent Systems (WITS), Fez, Morocco, 19–20 April 2017; pp. 1–4. [Google Scholar]
- Lipovetsky, S.; Conklin, M. Analysis of regression in game theory approach. Appl. Stoch. Model. Bus. Ind. 2001, 17, 319–330. [Google Scholar] [CrossRef]
- Datta, A.; Sen, S.; Zick, Y. Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 598–617. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Hasan, M.J.; Kim, J.-M. Bearing Fault Diagnosis under Variable Rotational Speeds Using Stockwell Transform-Based Vibration Imaging and Transfer Learning. Appl. Sci. 2018, 8, 2357. [Google Scholar] [CrossRef]
- Bag, S.; Pradhan, A.K.; Das, S.; Dalai, S.; Chatterjee, B. S-transform aided random forest based PD location detection employing signature of optical sensor. IEEE Trans. Power Deliv. 2018, 34, 1261–1268. [Google Scholar] [CrossRef]
- Alin, A. Multicollinearity. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 370–374. [Google Scholar] [CrossRef]
- Yigit, H. A weighting approach for KNN classifier. In Proceedings of the 2013 International Conference on Electronics, Computer and Computation (ICECCO), Ankara, Turkey, 7–9 November 2013; Volume 1, pp. 228–231. [Google Scholar]
- Ahmed, O.S.; Franklin, S.E.; Wulder, M.A.; White, J.C. Extending airborne lidar-derived estimates of forest canopy cover and height over large areas using knn with landsat time series data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 3489–3496. [Google Scholar] [CrossRef]
- Domingos, P. The role of Occam’s razor in knowledge discovery. Data Min. Knowl. Discov. 1999, 3, 409–425. [Google Scholar] [CrossRef]
- Feldman, J. The simplicity principle in perception and cognition. Wiley Interdiscip. Rev. Cogn. Sci. 2016, 7, 330–340. [Google Scholar] [CrossRef]
- Zenil, H.; Kiani, N.A.; Zea, A.A.; Tegnér, J. Causal deconvolution by algorithmic generative models. Nat. Mach. Intell. 2019, 1, 58–66. [Google Scholar] [CrossRef]
- Remodelling Machine Learning: An AI That Thinks Like a Scientist. Nat. Mach. Intell. 2019. Available online: https://www.nature.com/articles/s42256-019-0026-3 (accessed on 3 June 2021).
- García, M.V.; Aznarte, J.L. Shapley additive explanations for NO2 forecasting. Ecol. Inform. 2020, 56, 101039. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-agnostic interpretability of machine learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64, 100–131. [Google Scholar] [CrossRef]
- Kang, M.; Kim, J.; Kim, J. High-Performance and Energy-Efficient Fault Diagnosis Using Effective Envelope Analysis Processing Unit. IEEE Trans. Power Electron. 2015, 30, 2763–2776. [Google Scholar] [CrossRef]
- Sohaib, M.; Kim, J.-M. Fault diagnosis of rotary machine bearings under inconsistent working conditions. IEEE Trans. Instrum. Meas. 2019, 69, 3334–3347. [Google Scholar] [CrossRef]
- Nayana, B.R.; Geethanjali, P. Analysis of statistical time-domain features effectiveness in identification of bearing faults from vibration signal. IEEE Sens. J. 2017, 17, 5618–5625. [Google Scholar] [CrossRef]
- Peng, B.; Wan, S.; Bi, Y.; Xue, B.; Zhang, M. Automatic Feature Extraction and Construction Using Genetic Programming for Rotating Machinery Fault Diagnosis. IEEE Trans. Cybern. 2020, 1–15. [Google Scholar]
- Kaplan, K.; Kaya, Y.; Kuncan, M.; Minaz, M.R.; Ertunç, H.M. An improved feature extraction method using texture analysis with LBP for bearing fault diagnosis. Appl. Soft Comput. 2020, 87, 106019. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Definition | Feature Attributes | ||||
|---|---|---|---|---|---|
| Mean | Std | Kurtosis | Skewness | Rms | |
| Health Type | Shaft Speed (r/min) | Load | Crack Size | |
|---|---|---|---|---|
| Length (inches) | ||||
| Dataset 1 | NT | 1797 | 0 | - |
| IRT | 0 | 0.007 | ||
| ORT | 0 | 0.007 | ||
| BT | 0 | 0.007 | ||
| Dataset 2 | NT | 1772 | 1 | - |
| IRT | 1 | 0.007 | ||
| ORT | 1 | 0.007 | ||
| BT | 1 | 0.007 | ||
| Dataset 3 | NT | 1750 | 2 | - |
| IRT | 2 | 0.007 | ||
| ORT | 2 | 0.007 | ||
| BT | 2 | 0.007 |
| Health Type | Shaft Speed (r/min) | Crack Size | |
|---|---|---|---|
| Length (mm) | |||
| Dataset 1 | NT | 300 | - |
| IRT | 6 | ||
| ORT | 6 | ||
| RT | 6 | ||
| Dataset 2 | NT | 400 | - |
| IRT | 6 | ||
| ORT | 6 | ||
| RT | 6 | ||
| Dataset 3 | NT | 500 | - |
| IRT | 6 | ||
| ORT | 6 | ||
| RT | 6 |
| Dataset | Train (70%) | Test (30%) | Total Samples | Sample/Health Type | |
|---|---|---|---|---|---|
| Training (80%) | Validation (20%) | ||||
| 1 | 261 samples | 66 samples | 141 samples | 468 | 117 |
| 2 | 261 samples | 66 samples | 141 samples | 468 | 117 |
| 3 | 261 samples | 66 samples | 141 samples | 468 | 117 |
| Model | Dataset | UFP | FFP | Common Feature Attributes | Best k | Accuracy (%) |
|---|---|---|---|---|---|---|
| 1 | 1 | ‘F13’, ‘F4’, ‘F2’, ‘F14’, ‘F3’, ‘F11’, ‘F10’, ‘F16’, ‘F9’, ‘F12’, ‘F1’, ‘F19’ | ‘F13’, ‘F4’, ‘F14’, ‘F19’, ‘F11’, ‘F10’, ‘F16’, ‘F12’, ‘F1’ | ‘F12’, ‘F16’, ‘F10’, ‘F14’ | 1 | 100 |
| 2 | 2 | ‘F2’, ‘F14’, ‘F10’, ‘F16’, ‘F12’, ‘F1’ | ‘F2’, ‘F14’, ‘F10’, ‘F16’, ‘F12’, ‘F1’ | 1 | 100 | |
| 3 | 3 | ‘F1’, ‘F12’, ‘F16’, ‘F10’, ‘F14’, ‘F2’ | ‘F1’, ‘F12’, ‘F16’, ‘F10’, ‘F14’, ‘F2’ | 1 | 100 |
| Test | Training Dataset | Test Dataset | Performance Measurement (%)—Avg. | ||
|---|---|---|---|---|---|
| TPR | TNR | Accuracy | |||
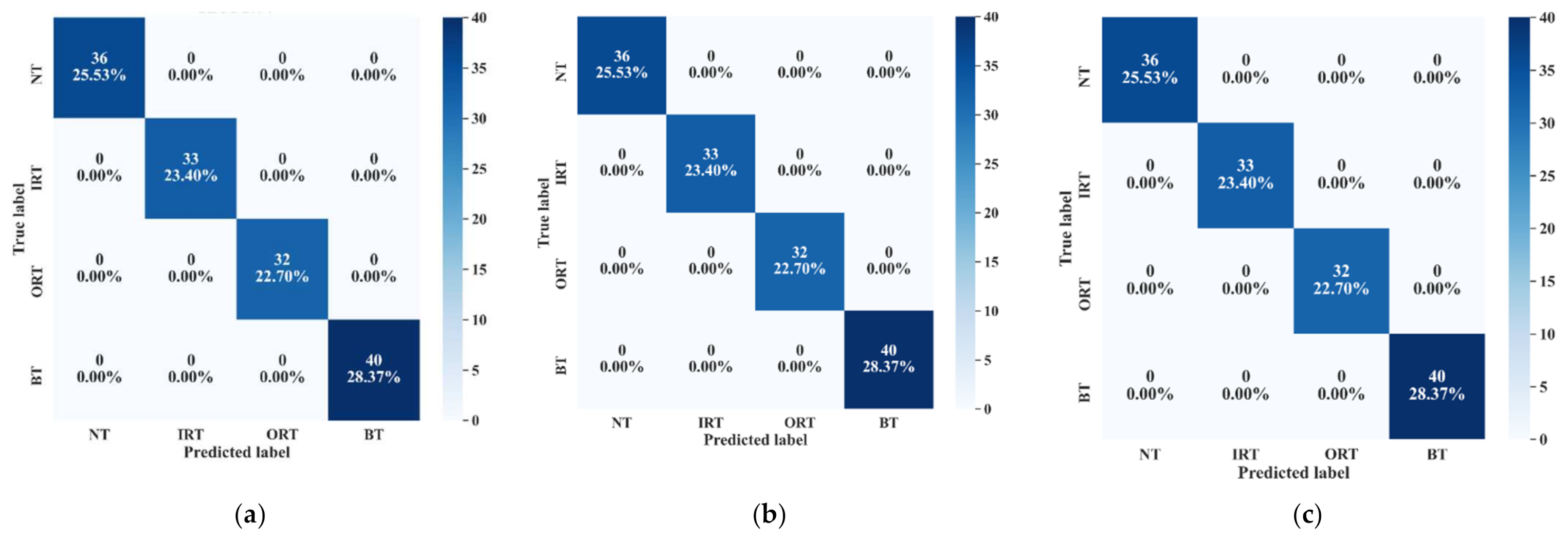
| 1 | 1 | 2, 3 | 100 | 100 | 100 |
| 2 | 2 | 3, 1 | 100 | 100 | 100 |
| 3 | 3 | 1, 2 | 100 | 100 | 100 |
| Method no. | Ref. | Signal Processing | Feature Extraction | Feature Selector | Classifier | Invariance Capability | Explain Ability | Debuggable | Accuracy (%) | Performance Gap |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | [81] | No | Time domain features: waveform length, slope sign changes, simple sign integral and Wilson amplitude inaddition to established mean absolute value and zero crossing | Laplacian Score (LS) | (Linear Discriminant Analysis) LDA, (Naïve Bayes) NB, SVM | No | No | No | 99.6 | 0.4 |
| 2 | [82] | Genetic Programming (GP) | Evolved features by GP stages | GP based filtering | k-NN | Yes | No | No | 100 | 0.0 |
| 3 | [83] | No | Local Binary Pattern (LBP) | No | Artificial Neural Network (ANN) | Yes | No | No | 99.5 | 0.5 |
| 4 | [65] | Stockwell Transform (ST) | ST coefficient imaging | No | CNN + Transfer Learning (TL) | Yes | No | No | 100 | 0.0 |
| Dataset | Train (70%) | Test (30%) | Total Samples | Sample/Health Type | |
|---|---|---|---|---|---|
| Training (80%) | Validation (20%) | ||||
| 1 | 717 samples | 179 samples | 384 samples | 1280 | 320 |
| 2 | 717 samples | 179 samples | 384 samples | 1280 | 320 |
| 3 | 717 samples | 179 samples | 384 samples | 1280 | 320 |
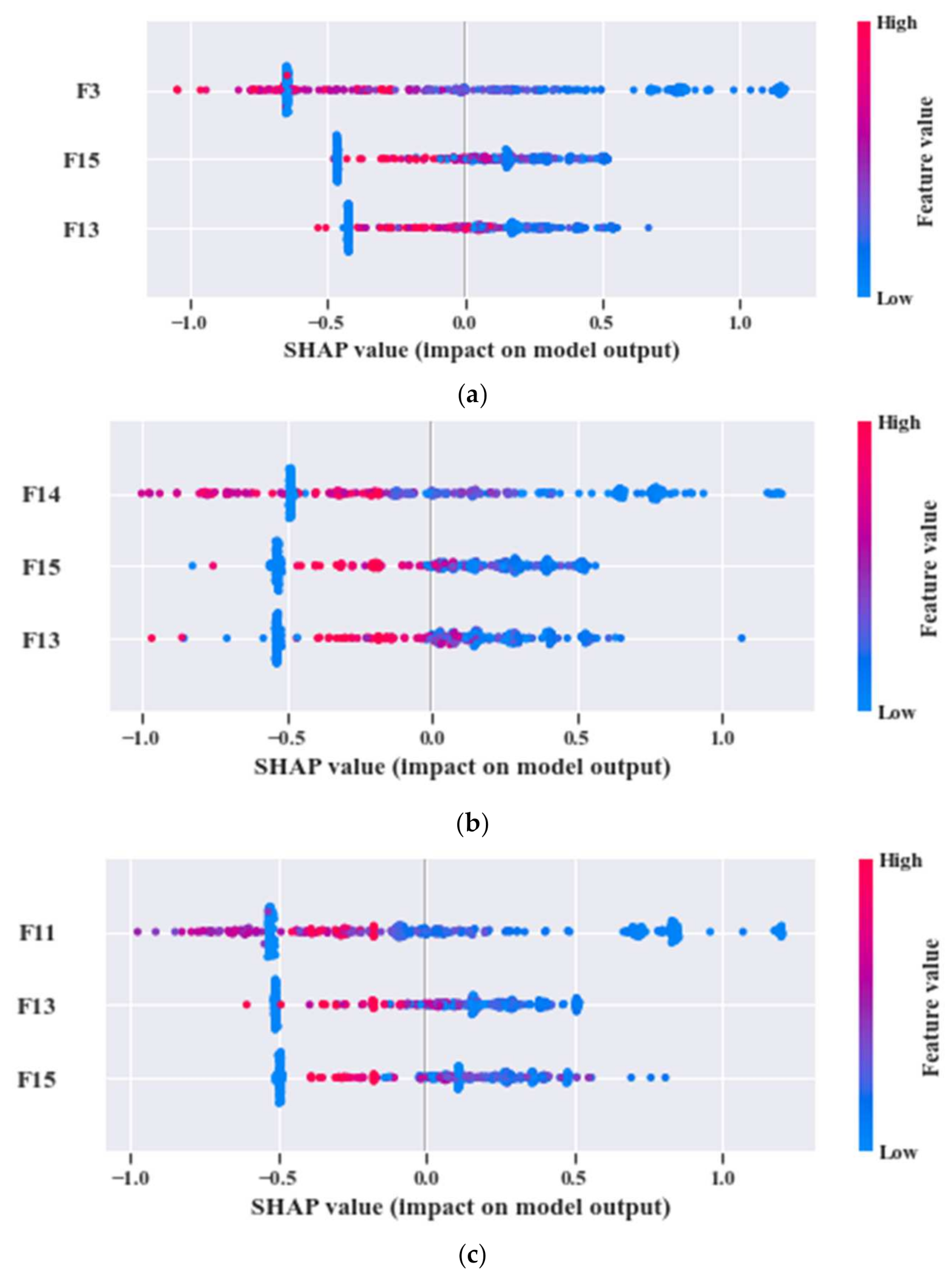
| Model | Dataset | UFP | FFP | Common Feature Attributes | Best k | Accuracy (%) |
|---|---|---|---|---|---|---|
| 1 | 1 | ‘F3’, ‘F13’, ‘F16’, ‘F17’, ‘F20’, ‘F9’, ‘F1’, ‘F11’, ‘F14’, ‘F7’, ‘F15’, ‘F4’, ‘F19’, ‘F12’, ‘F18’ | ‘F3’, ‘F13’, ‘F15’ | ‘F13’, ‘F15’ | 5 | 97.4 |
| 2 | 2 | ‘F15’, ‘F14’, ‘F19’, ‘F11’, ‘F18’, ‘F13’, ‘F9’, ‘F3’, ‘F12’, ‘F16’, ‘F20’, ‘F1’ | ‘F15’, ‘F14’, ‘F13’ | 7 | 97.4 | |
| 3 | 3 | ‘F11’, ‘F19’, ‘F20’, ‘F1’, ‘F13’, ‘F15’, ‘F17’, ‘F14’, ‘F16’, ‘F3’, ‘F9’, ‘F4’ | ‘F11’, ‘F13’, ‘F15’ | 5 | 96.1 |
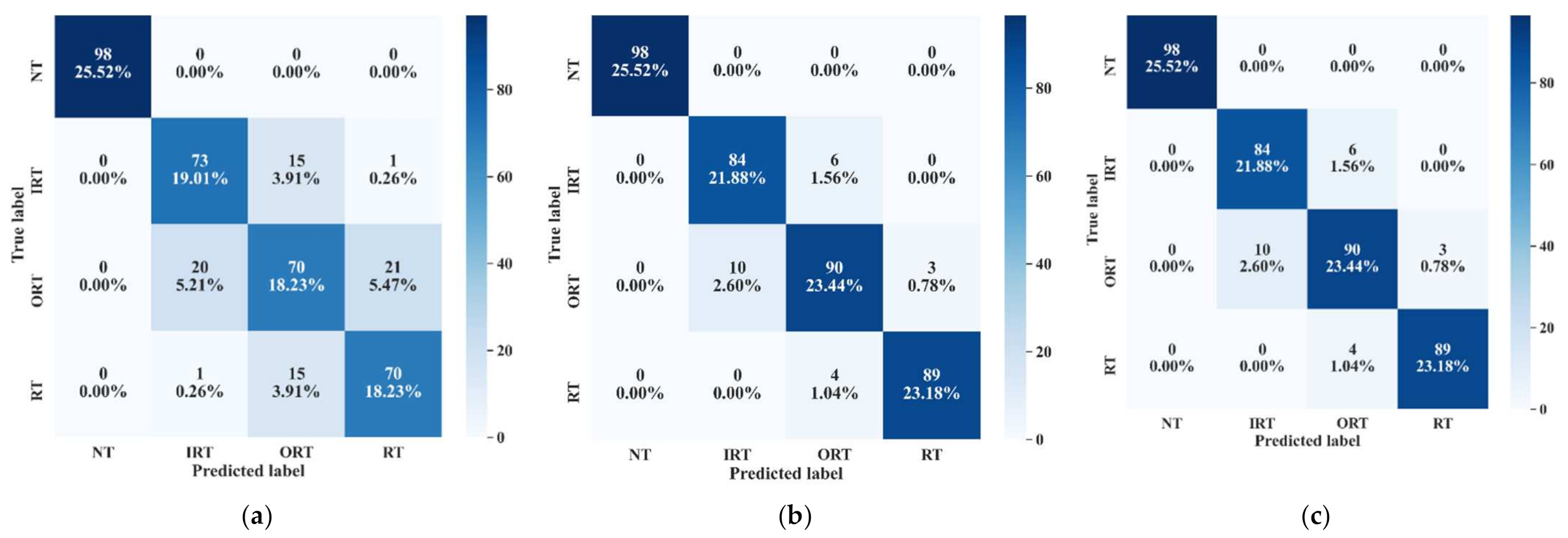
| Test | Training Dataset | Test Dataset | TPR | TNR | Accuracy (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NT | IRT | ORT | RT | NT | IRT | ORT | RT | ||||
| 1 | 1 | 2 | 1.00 | 0.93 | 0.95 | 0.98 | 0.99 | 0.99 | 0.97 | 0.99 | 97.0 |
| 3 | 1.00 | 0.95 | 0.97 | 0.98 | 0.99 | 0.99 | 0.98 | 0.99 | 97.8 | ||
| 2 | 2 | 3 | 1.00 | 0.96 | 0.97 | 0.99 | 0.99 | 0.99 | 0.98 | 0.99 | 98.2 |
| 1 | 1.00 | 0.95 | 0.95 | 0.98 | 0.99 | 0.98 | 0.98 | 0.99 | 97.4 | ||
| 3 | 3 | 1 | 1.00 | 0.95 | 0.95 | 0.98 | 0.99 | 0.98 | 0.98 | 0.99 | 97.1 |
| 2 | 1.00 | 0.95 | 0.94 | 0.97 | 0.99 | 0.99 | 0.98 | 0.99 | 97.0 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, M.J.; Sohaib, M.; Kim, J.-M. An Explainable AI-Based Fault Diagnosis Model for Bearings. Sensors 2021, 21, 4070. https://doi.org/10.3390/s21124070
Hasan MJ, Sohaib M, Kim J-M. An Explainable AI-Based Fault Diagnosis Model for Bearings. Sensors. 2021; 21(12):4070. https://doi.org/10.3390/s21124070
Chicago/Turabian StyleHasan, Md Junayed, Muhammad Sohaib, and Jong-Myon Kim. 2021. "An Explainable AI-Based Fault Diagnosis Model for Bearings" Sensors 21, no. 12: 4070. https://doi.org/10.3390/s21124070
APA StyleHasan, M. J., Sohaib, M., & Kim, J.-M. (2021). An Explainable AI-Based Fault Diagnosis Model for Bearings. Sensors, 21(12), 4070. https://doi.org/10.3390/s21124070