
Deep Reinforcement Learning for Attacking Wireless Sensor Networks


Abstract
1. Introduction
2. Background
2.1. Deep Reinforcement Learning
- S is a finite set of states s.
- A is a finite set of actions a.
- is the probability that action a in state and time step n will lead to state in time step .
- is the reward received after transitioning from state to state due to action a.
- γ is a discount factor.
2.2. Partially Observable Markov Decision Processes
- S, A, , and γ are defined as in the MDP case.
- Ω is a finite set of observations o.
- is the probability of observing given that the actual state is and the agent takes action a.
- Using Recurrent Neural Networks (RNNs), which are able to store past information. This solution is proposed to learn POMDPs in [6].
2.3. The Swarm Model
- S is the set of local states.
- A is the set of local actions.
- Ω is the set of local observations.
- π is the local policy.
- I is the index set of the agents, where indexes the agent.
- is the agent prototype defined before.
- is the transition probability function defined as in the POMDP. P depends on a, the joint action vector and s is the global state.
- is the reward function defined as in the POMDP case. R depends on the joint action vector a. In addition, all agents i share the same reward function.
- is the observation model, defined as in the POMDP case. O depends on the joint action and observation vectors a and o, respectively.
- is a discount factor as in the POMDP case.
- Neural Networks Mean Embedding (NNME): In this approach, each is used as input to a DNN, which outputs , where denotes the transformation done by the DNN. The total observation vector of agent i, is built by concatenating to the mean of the set of all .
- Mean-based Mean Embeddings (MME): Under this approach, we average and concatenate it to . This vector is the input to the policy network.
3. Defense Systems
3.1. Spectrum Sensing Data Falsification Attack
3.2. Backoff Attack
4. Deep Reinforcement Learning Attacker Architecture
- A continuous set of actions in the range , where the action indicates the normalized energy that the sensor reports to the FC.
- We consider that the reward to each AS is if the FC decides that there is a primary transmitting, whereas the reward to each AS is 0 if the FC decides that there is no primary transmitting. We use a maximum number of timesteps for each episode and if all ASs are discovered we terminate the episode. The DLA must therefore learn to maximize the number of timesteps without being discovered in order to maximize its reward. The punishment for being detected consists of being banned from the network, which means that the agent stops receiving rewards. Furthermore, the reward also tries to increase the probability of misdetection of the WSN; that is, it makes the FC believe that the primary is transmitting more often than it really does.
- In order to build the observations vector, each agent stores its last five actions (i.e., energy reported) and a binary flag indicating whether the agent has been already discovered by the defense mechanism (and hence, banned from the network) or not. We assume that agent i can also access the observations of other sensors , i.e., ASs can communicate their local observations to other sensors (which can be implemented either by direct communication among nodes or by observing the behavior of other sensors).
- The action space is composed by two discrete actions that indicate whether the sensor starts transmitting or not. That is, the actions start transmitting in the current time slot or not. Hence, two consecutive actions may be separated by several physical time slots if no sensor starts transmitting.
- The reward is in case that a GS starts transmitting and 0 otherwise. Our choice of the rewards is different as the attacks have different targets: in case of the SSDF attack, we want to detect the primary as often as possible. However, in the backoff attack, we want GSs to transmit as little as possible. We set a fixed simulation time, which is completed regardless of whether the ASs are discovered. Thus, the DLA needs to learn not to be discovered while preventing GSs from transmitting.
- In order to build the observations vector, we use the time difference between the current timestep and the last K transmissions (i.e., this indicates the frequency of attempted transmission of the sensor). This difference is normalized by the maximum number of timesteps. We also add a binary flag indicating whether the agent has been discovered by the defense mechanism or not, as in the SSDF case.
5. Results
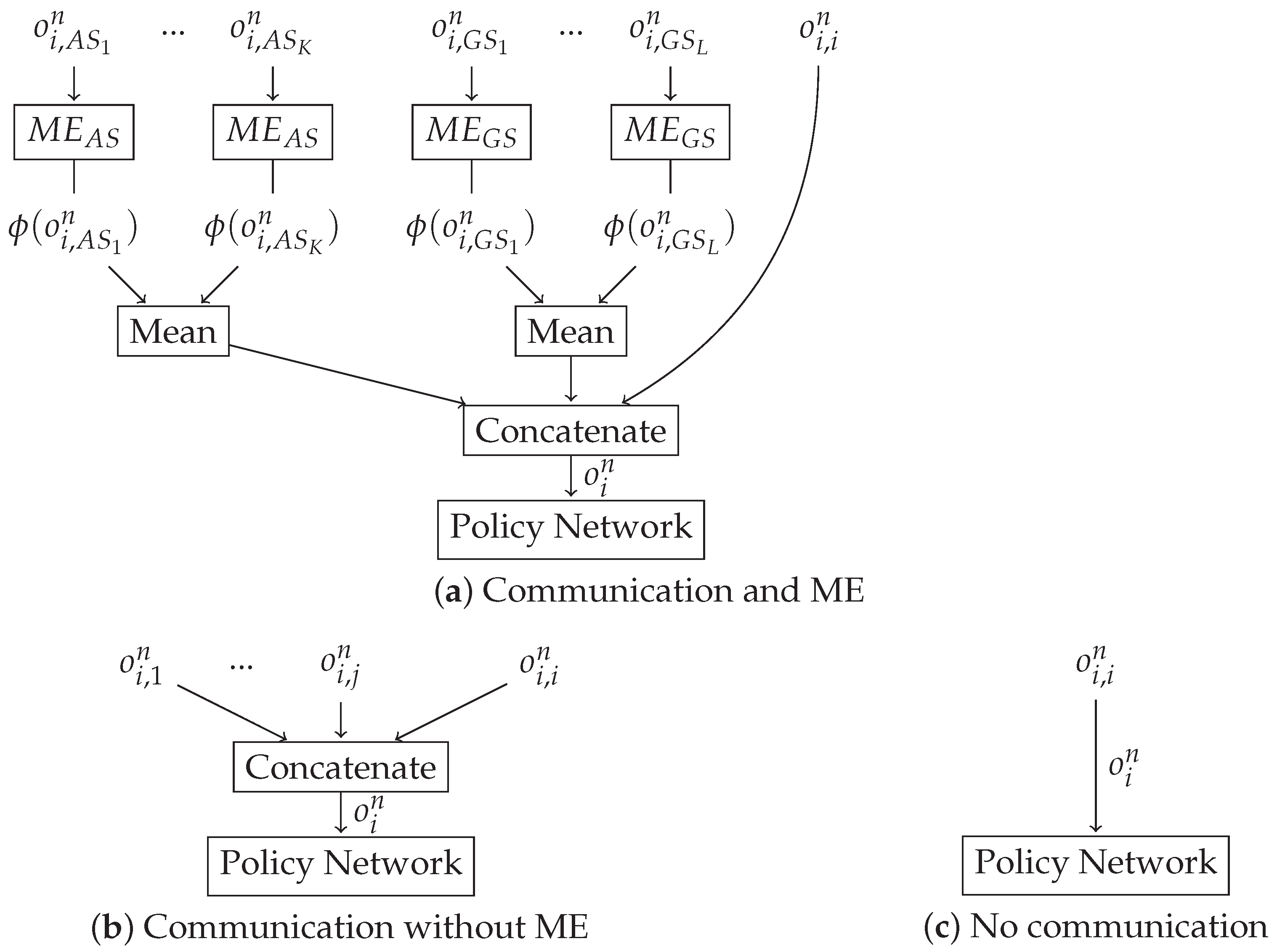
- Communication and Neural Networks Mean Embedding (CNNME) setting: in this case, ASs communicate among them and use MEs to aggregate information (situation (a) in Figure 4). Concretely, we use NNME, which is based on using a DNN as ME where the weights of the DNN are trained together with the TRPO policy.
- Communication and Mean-based Mean Embedding (CMME) setting: in this case, ASs communicate among them and use MEs to aggregate information (situation (a) in Figure 4). Concretely, we use MME, which consists of using the mean operation as ME.
- Communication without using mean embeddings (C) setting: in this case, ASs communicate among them without using any ME to aggregate information (situation (b) in Figure 4). In this case, the input size of the policy network is equal to the dimension of and thus increases with the number of ASs, while it remains invariant for all other cases.
- Without any communication among ASs (NC) setting (situation (c) in Figure 4). In this case, each AS only uses its local observations in order to obtain their local policy.
5.1. Baselines
- Random policy (RP), which samples the actions uniformly from the action space; i.e., in the SSDF attack, it means that ASs report a random energy level, and in the backoff attack, ASs transmit randomly.
- Always High (AH), which selects the highest action possible; i.e., in the SSDF attack, it means that ASs always report the maximum energy level, and in the backoff attack, ASs always transmit.
- Always Low (AL), which selects the lowest action possible; i.e., in the SSDF attack, it means that ASs always report the minimum energy level, and in the backoff attack, ASs never transmit.
5.2. Spectrum Sensing Data Falsification Attack
5.3. Backoff Attack
5.4. Results
6. Conclusions
- We do not need to know the state of the system (i.e., the reputations), as DLA relies only on partial observations (i.e., information about how the sensors have interacted in the past that can be observed by other sensors). Even though we have only partial observations, they provide very good results, especially when the ASs are able to communicate their observations—in Table 2, the results using communication and ME consistently are the best. However, even when this communication is not considered—i.e., the NC setup—the results are still better than the baselines. Even though the underlying model of the attack is a POMDP, DLA learns to attack having only a limited amount of past observations. Thus, when attacking a network, if communication among ASs is possible, our results point towards using ME to aggregate the local information in a meaningful way. We test using two different ME types: NNME, which may extract better features at the cost of extra training complexity, and MMEs, which provide a lower training computational cost but obtain more limited features for the policy. The results shown in Table 2 show that both MEs provide good results, and hence, choosing between them may depend on the concrete problem to solve and the training restrictions we may have.
- Since DLA does not need to know a priori which defense mechanism it is facing, it is a very flexible approach. Thus, DLA could be the base for a universal attacker, successful in exploiting many defense mechanisms. Indeed, DRL methods have been used to provide human-like performance in many Atari games [5], so DRL could also be applied to exploit defense mechanisms in a universal fashion.
- It is a method with balanced computational requirements. The training process is the most computationally expensive part of the system. However, most of this cost was used in generating samples from the defense mechanisms: training the DNNs using gradient techniques was fast. This low training cost appears because we use simple DNNs, which, however, are enough to exploit the defense mechanisms. Once the DNN is trained, the policy is quick to execute and can be deployed in devices with low computational capabilities.
- We remark that we have used the same set of hyper-parameters for all of our simulations. We have done no fine-tuning of these hyper-parameters, and thus, our approach may suit very different attack situations with minimal tuning. Equivalently, the results obtained could be improved by doing a fine-tuning for each situation.
- The reward scheme has a strong influence on the attack that is learned. There is a tradeoff between attacking and not being discovered, and hence, modifying the reward scheme will cause the DLA to learn a different attack strategy. In other words, we must carefully design the reward depending on the attack result desired. Note that this is not something specific to our problem but a general problem that arises in the RL field.
- Our approach relies on the DLA being able to interact with a network continuously, episode after episode. As we considered that ASs could be banned during episodes, this means that the banning must be temporal. If it is permanent, then the DLA could not learn. Note, however, that if ASs had access to a simulator of the defense mechanism, this problem would be overcome.
- Our DLA is not sample-efficient, as it requires many samples to learn; in addition, the results are dependent on the initial parameters of the policy DNN. These are known problems of DRL methods, which are subject to current research [62]. A very promising research field that could address these problems is few-shot learning, focused on learning from a few samples. There are several works in this area that may be used to improve the sample efficiency of DRL methods, such as [64,65], and hence could further improve the results of attacks to WSN.
- A related challenge comes from the fact that we have assumed a static defense mechanism, but it could be dynamic and change after a series of attack attempts have been detected. DLA may be currently vulnerable to this defense strategy due to its low sample efficiency, and hence, we expect that the research on increasing the DRL sample efficiency would also be useful to prevent and/or adapt quickly to changes in the defense mechanism. Another alternative could consist in replacing a banned AS with a new one that is initialized based on the experience of the banned AS (i.e., by having the same policy as the banned one).
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| A3C | Asynchronous Advantage Actor Critic |
| ACER | Actor Critic with Experience Replay |
| ACK | Acknowledgement |
| AH | Always High |
| AL | Always Low |
| AS | Attacking Sensor |
| CDF | Cumulative Distribution Function |
| CM | Cramer-von Mises |
| CNNME | Communication and Neural Networks Mean Embedding |
| CMME | Communication and Mean-based Mean Embedding |
| DLA | Deep Learning Attacker |
| DNN | Deep Neural Network |
| DoS | Denial of Service |
| DRL | Deep Reinforcement Learning |
| DRQN | Deep Recurrent Q-Networks |
| DQN | Deep Q-Networks |
| FC | Fusion Center |
| GS | Good Sensor |
| MAC | Medium Access Control |
| MDP | Markov Decision Process |
| ME | Mean Embedding |
| MME | Mean-based Mean Embedding |
| NNME | Neural Networks Mean Embedding |
| PHY | Physical |
| POMDP | Partially Observable Markov Decision Process |
| PPO | Proximal Policy Optimization |
| QoS | Quality of Service |
| RL | Reinforcement Learning |
| RNN | Recurrent Neural Network |
| RP | Random Policy |
| SNR | Signal-to-Noise Ratio |
| SSDF | Spectrum Sensing Data Falsification |
| TRPO | Trust Region Policy Optimization |
| WSN | Wireless Sensor Network |
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; Volume 1. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. arXiv 2015, arXiv:1507.06527. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Wang, Z.; Bapst, V.; Heess, N.; Mnih, V.; Munos, R.; Kavukcuoglu, K.; de Freitas, N. Sample efficient actor-critic with experience replay. arXiv 2016, arXiv:1611.01224. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Alsheikh, M.A.; Lin, S.; Niyato, D.; Tan, H.P. Machine learning in wireless sensor networks: Algorithms, strategies, and applications. IEEE Commun. Surv. Tutor. 2014, 16, 1996–2018. [Google Scholar] [CrossRef]
- Curiac, D.; Volosencu, C.; Doboli, A.; Dranga, O.; Bednarz, T. Neural network based approach for malicious node detection in wireless sensor networks. In Proceedings of the WSEAS International Conference on Circuits, Systems, Signal and Telecommunications, Gold Coast, QLD, Australia, 17–19 January 2007; pp. 17–19. [Google Scholar]
- Curiac, D.I.; Plastoi, M.; Banias, O.; Volosencu, C.; Tudoroiu, R.; Doboli, A. Combined malicious node discovery and self-destruction technique for wireless sensor networks. In Proceedings of the 2009 Third International Conference on Sensor Technologies and Applications, Athens, Greece, 18–23 June 2009; pp. 436–441. [Google Scholar]
- Yang, K. Wireless Sensor Networks; Springer: Berlin, Germany, 2014. [Google Scholar]
- Rawat, P.; Singh, K.D.; Chaouchi, H.; Bonnin, J.M. Wireless sensor networks: A survey on recent developments and potential synergies. J. Supercomput. 2014, 68, 1–48. [Google Scholar] [CrossRef]
- Ndiaye, M.; Hancke, G.P.; Abu-Mahfouz, A.M. Software defined networking for improved wireless sensor network management: A survey. Sensors 2017, 17, 1031. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Sagduyu, Y.E.; Erpek, T.; Davaslioglu, K.; Lu, Z.; Li, J.H. Adversarial deep learning for cognitive radio security: Jamming attack and defense strategies. In Proceedings of the 2018 IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Xiao, L.; Wan, X.; Lu, X.; Zhang, Y.; Wu, D. IoT Security Techniques Based on Machine Learning. arXiv 2018, arXiv:1801.06275. [Google Scholar]
- Cannady, J. Next generation intrusion detection: Autonomous reinforcement learning of network attacks. In Proceedings of the 23rd National Information Systems Security Conference, Baltimore, MD, USA, 16–19 October 2000; pp. 1–12. [Google Scholar]
- Gwon, Y.; Dastangoo, S.; Fossa, C.; Kung, H. Competing mobile network game: Embracing antijamming and jamming strategies with reinforcement learning. In Proceedings of the 2013 IEEE Conference on Communications and Network Security (CNS), National Harbor, MD, USA, 14–16 October 2013; pp. 28–36. [Google Scholar]
- Xiao, L.; Li, Y.; Liu, G.; Li, Q.; Zhuang, W. Spoofing detection with reinforcement learning in wireless networks. In Proceedings of the Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–5. [Google Scholar]
- Xiao, L.; Xie, C.; Chen, T.; Dai, H.; Poor, H.V. A mobile offloading game against smart attacks. IEEE Access 2016, 4, 2281–2291. [Google Scholar] [CrossRef]
- Xiao, L.; Li, Y.; Huang, X.; Du, X. Cloud-based malware detection game for mobile devices with offloading. IEEE Trans. Mob. Comput. 2017, 16, 2742–2750. [Google Scholar] [CrossRef]
- Aref, M.A.; Jayaweera, S.K.; Machuzak, S. Multi-agent reinforcement learning based cognitive anti-jamming. In Proceedings of the Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Han, G.; Xiao, L.; Poor, H.V. Two-dimensional anti-jamming communication based on deep reinforcement learning. In Proceedings of the 42nd IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Li, Y.; Quevedo, D.E.; Dey, S.; Shi, L. SINR-based DoS attack on remote state estimation: A game-theoretic approach. IEEE Trans. Control Netw. Syst. 2017, 4, 632–642. [Google Scholar] [CrossRef]
- Li, M.; Sun, Y.; Lu, H.; Maharjan, S.; Tian, Z. Deep reinforcement learning for partially observable data poisoning attack in crowdsensing systems. IEEE Internet Things J. 2019, 7, 6266–6278. [Google Scholar] [CrossRef]
- Fragkiadakis, A.G.; Tragos, E.Z.; Askoxylakis, I.G. A survey on security threats and detection techniques in cognitive radio networks. IEEE Commun. Surv. Tutor. 2013, 15, 428–445. [Google Scholar] [CrossRef]
- Sokullu, R.; Dagdeviren, O.; Korkmaz, I. On the IEEE 802.15. 4 MAC layer attacks: GTS attack. In Proceedings of the 2008 Second International Conference on Sensor Technologies and Applications (sensorcomm 2008), Cap Esterel, France, 25–31 August 2008; pp. 673–678. [Google Scholar]
- Wang, W.; Sun, Y.; Li, H.; Han, Z. Cross-layer attack and defense in cognitive radio networks. In Proceedings of the 2010 IEEE Global Telecommunications Conference (GLOBECOM 2010), Miami, FL, USA, 6–10 December 2010; pp. 1–6. [Google Scholar]
- Parras, J.; Zazo, S. Learning attack mechanisms in Wireless Sensor Networks using Markov Decision Processes. Expert Syst. Appl. 2019, 122, 376–387. [Google Scholar] [CrossRef]
- Šošić, A.; KhudaBukhsh, W.R.; Zoubir, A.M.; Koeppl, H. Inverse reinforcement learning in swarm systems. In Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems (AAMAS 17), São Paulo, Brazil, 8–12 May 2017; pp. 1413–1421. [Google Scholar]
- Wang, G.G.; Gandomi, A.H.; Alavi, A.H.; Gong, D. A comprehensive review of krill herd algorithm: Variants, hybrids and applications. Artif. Intell. Rev. 2019, 51, 119–148. [Google Scholar] [CrossRef]
- Li, J.; Lei, H.; Alavi, A.H.; Wang, G.G. Elephant herding optimization: Variants, hybrids, and applications. Mathematics 2020, 8, 1415. [Google Scholar] [CrossRef]
- Feng, Y.; Deb, S.; Wang, G.G.; Alavi, A.H. Monarch butterfly optimization: A comprehensive review. Expert Syst. Appl. 2020, 168, 114418. [Google Scholar] [CrossRef]
- Li, W.; Wang, G.G.; Gandomi, A.H. A survey of learning-based intelligent optimization algorithms. Arch. Comput. Methods Eng. 2021, 1–19. [Google Scholar] [CrossRef]
- Hüttenrauch, M.; Šošić, A.; Neumann, G. Deep Reinforcement Learning for Swarm Systems. J. Mach. Learn. Res. 2019, 20, 1–31. [Google Scholar]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Bertsekas, D.P. Dynamic Programming and Optimal Control; Athena Scientific: Belmont, MA, USA, 1995; Volume 1. [Google Scholar]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1329–1338. [Google Scholar]
- Littman, M.L.; Sutton, R.S.; Singh, S.P. Predictive representations of state. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2001; Volume 14, p. 30. [Google Scholar]
- Singh, S.P.; Littman, M.L.; Jong, N.K.; Pardoe, D.; Stone, P. Learning predictive state representations. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 712–719. [Google Scholar]
- Wang, G.G.; Deb, S.; Gandomi, A.H.; Alavi, A.H. Opposition-based krill herd algorithm with Cauchy mutation and position clamping. Neurocomputing 2016, 177, 147–157. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.x.; Tian, S.s.; Xia, J.l. An improved cuckoo search algorithm with self-adaptive knowledge learning. Neural Comput. Appl. 2019, 32, 11967–11997. [Google Scholar] [CrossRef]
- Li, J.; Yang, Y.H.; Lei, H.; Wang, G.G. Solving Logistics Distribution Center Location with Improved Cuckoo Search Algorithm. Int. J. Comput. Intell. Syst. 2020, 14, 676–692. [Google Scholar] [CrossRef]
- Feng, Y.; Wang, G.G.; Dong, J.; Wang, L. Opposition-based learning monarch butterfly optimization with Gaussian perturbation for large-scale 0-1 knapsack problem. Comput. Electr. Eng. 2018, 67, 454–468. [Google Scholar] [CrossRef]
- Li, W.; Wang, G.G. Elephant herding optimization using dynamic topology and biogeography-based optimization based on learning for numerical optimization. Eng. Comput. 2021, 1–29. [Google Scholar] [CrossRef]
- Wiering, M.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 51. [Google Scholar]
- Oliehoek, F.A.; Spaan, M.T.; Vlassis, N. Optimal and approximate Q-value functions for decentralized POMDPs. J. Artif. Intell. Res. 2008, 32, 289–353. [Google Scholar] [CrossRef]
- Bernstein, D.S.; Givan, R.; Immerman, N.; Zilberstein, S. The complexity of decentralized control of Markov decision processes. Math. Oper. Res. 2002, 27, 819–840. [Google Scholar] [CrossRef]
- Dibangoye, J.S.; Amato, C.; Buffet, O.; Charpillet, F. Optimally solving Dec-POMDPs as continuous-state MDPs. J. Artif. Intell. Res. 2016, 55, 443–497. [Google Scholar] [CrossRef]
- Smola, A.; Gretton, A.; Song, L.; Schölkopf, B. A Hilbert space embedding for distributions. In Proceedings of the International Conference on Algorithmic Learning Theory, Sendai, Japan, 1–4 October 2007; pp. 13–31. [Google Scholar]
- Zhang, L.; Ding, G.; Wu, Q.; Zou, Y.; Han, Z.; Wang, J. Byzantine attack and defense in cognitive radio networks: A survey. IEEE Commun. Surv. Tutor. 2015, 17, 1342–1363. [Google Scholar] [CrossRef]
- Urkowitz, H. Energy detection of unknown deterministic signals. Proc. IEEE 1967, 55, 523–531. [Google Scholar] [CrossRef]
- IEEE Standard for Information Technology—Telecommunications and Information Exchange between Systems Local and Metropolitan Area Networks—Specific Requirements—Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications; IEEE Computer Society: 2016; pp. 1–3534. Available online: https://standards.ieee.org/standard/802_11-2016.html (accessed on 20 April 2021).
- Demirkol, I.; Ersoy, C.; Alagoz, F. MAC protocols for wireless sensor networks: A survey. IEEE Commun. Mag. 2006, 44, 115–121. [Google Scholar] [CrossRef]
- Yadav, R.; Varma, S.; Malaviya, N. A survey of MAC protocols for wireless sensor networks. UbiCC J. 2009, 4, 827–833. [Google Scholar]
- Parras, J.; Zazo, S. Wireless Networks under a Backoff Attack: A Game Theoretical Perspective. Sensors 2018, 18, 404. [Google Scholar] [CrossRef]
- Anderson, T.W. On the distribution of the two-sample Cramer-von Mises criterion. Ann. Math. Stat. 1962, 33, 1148–1159. [Google Scholar] [CrossRef]
- Bianchi, G. Performance analysis of the IEEE 802.11 distributed coordination function. IEEE J. Sel. Areas Commun. 2000, 18, 535–547. [Google Scholar] [CrossRef]
- Parras, J.; Zazo, S. Using one class SVM to counter intelligent attacks against an SPRT defense mechanism. Ad. Hoc. Netw. 2019, 94, 101946. [Google Scholar] [CrossRef]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3207–3214. [Google Scholar]
- Zhu, F.; Seo, S.W. Enhanced robust cooperative spectrum sensing in cognitive radio. J. Commun. Netw. 2009, 11, 122–133. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Jamal, M.A.; Qi, G.J. Task agnostic meta-learning for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11719–11727. [Google Scholar]
- Payal, A.; Rai, C.S.; Reddy, B.R. Analysis of some feedforward artificial neural network training algorithms for developing localization framework in wireless sensor networks. Wirel. Pers. Commun. 2015, 82, 2519–2536. [Google Scholar] [CrossRef]
- Hernandez-Leal, P.; Kaisers, M.; Baarslag, T.; de Cote, E.M. A Survey of Learning in Multiagent Environments: Dealing with Non-Stationarity. arXiv 2017, arXiv:1707.09183. [Google Scholar]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| MAC header | 272 bits | PHY header | 128 bits |
| ACK | 112 bits + PHY header | Bit rate | 1 Mbps |
| SIFS | 28 s | DIFS | 128 s |
| 1 s | 4096 s |
| ASs | CNNME | CMME | C | NC | RP | AH | AL | |
|---|---|---|---|---|---|---|---|---|
| SSDF | 1 | |||||||
| 3 | ||||||||
| 10 | ||||||||
| Backoff | 1 | |||||||
| 3 | ||||||||
| 10 |
| ASs | CNNME | CMME | C | NC | RP | AH | AL | |
|---|---|---|---|---|---|---|---|---|
| SSDF | 1 | |||||||
| 3 | ||||||||
| 10 | ||||||||
| Backoff | 1 | |||||||
| 3 | ||||||||
| 10 |
| ASs | CNNME | CMME | C | NC | RP | AH | AL | No ASs | |
|---|---|---|---|---|---|---|---|---|---|
| SSDF | 1 | ||||||||
| 3 | |||||||||
| 10 | |||||||||
| Backoff | 1 | ||||||||
| 3 | |||||||||
| 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parras, J.; Hüttenrauch, M.; Zazo, S.; Neumann, G. Deep Reinforcement Learning for Attacking Wireless Sensor Networks. Sensors 2021, 21, 4060. https://doi.org/10.3390/s21124060
Parras J, Hüttenrauch M, Zazo S, Neumann G. Deep Reinforcement Learning for Attacking Wireless Sensor Networks. Sensors. 2021; 21(12):4060. https://doi.org/10.3390/s21124060
Chicago/Turabian StyleParras, Juan, Maximilian Hüttenrauch, Santiago Zazo, and Gerhard Neumann. 2021. "Deep Reinforcement Learning for Attacking Wireless Sensor Networks" Sensors 21, no. 12: 4060. https://doi.org/10.3390/s21124060
APA StyleParras, J., Hüttenrauch, M., Zazo, S., & Neumann, G. (2021). Deep Reinforcement Learning for Attacking Wireless Sensor Networks. Sensors, 21(12), 4060. https://doi.org/10.3390/s21124060