
Privacy-Enhancing k-Nearest Neighbors Search over Mobile Social Networks †


Abstract
1. Motivation
2. Related Works
2.1. MSNs Privacy
2.2. Location Privacy
3. The Proposed Scheme
3.1. Overview
- -
- Aiming at the limited computation power of resource-constrained mobile devices, we design a lightweight end-to-end location encryption algorithm and a server-aid location re-encryption protocol based on Paillier homomorphic encryption to achieve further location sharing. The protocol allows the service provider to transfer friends’ location ciphertexts into the query user’s homomorphic ciphertexts without requiring them to be online to participate in the calculation.
- -
- We build a secure dual-server architecture and design a secure k-nearest neighbors search protocol by secure multi-party computation and a homomorphic encryption mechanism under this architecture. The server can effectively compute and sort the distance between users and their friends without any decryption operation. Compared with the cloud-center model, where a single server holds complete knowledge, the dual-server architecture minimizes the leakage to the servers and reduces the cost of communication between the mobile user and the server.
- -
- To achieve fine-grained access control, we design a dynamic friends management mechanism based on public-key broadcast encryption. It enables users to grant/revoke their friends’ search rights without updating others’ keys, achieving lightweight friend authentication and authority management. Moreover, this mechanism satisfies revocation secure that the adversary cannot obtain the user’s location information through collusion with the server and the revoked friends, thus further improving the scheme’s overall security.
3.2. Architecture and Syntax

3.3. Security Definition
3.3.1. Adaptive -Semantic Secure

3.3.2. Revocation Security

- -
- : can send grant friend request to this oracle. If , then the oracle runs Grant by the input provides by . If , then the oracle outputs ⊥.
- -
- : can send revoke friend request to this oracle. If , then the oracle runs by the input provides by . If , then the oracle outputs ⊥.
- -
- : can send a search request in to this oracle. generates a search token and sends it to . Then, the oracle runs by the input provides by , and outputs the search result to .
3.4. The Detailed Construction
3.4.1. Initialization
3.4.2. Key Generation
3.4.3. Join
3.4.4. Location Update
3.4.5. Grant
3.4.6. K-Nearest Neighbors Search

3.4.7. Revoke

4. Security Analysis
4.1. Adaptive -Semantic Secure
- -
- Randomly choose , compute as ;
- -
- Randomly choose ;
- -
- Encrypt : ;
- -
- Output .
- -
- Choose ;
- -
- Choose two random values , computes ;
- -
- Output .
4.2. Revocation Secure
- runs to generate keys . initializes , randomly chooses a k-bit string , and sends to . runs to generate , and sends it to . runs to generate , runs to generate , where does not include .
- issues a query to for the secret key of . runs to generate , sends to . To fully enroll as a valid friend, the state ciphertext also needs to be updated by . send and a newly generated to , runs to generate new . runs to generate the key of .
- runs Initial to generate graph , and sends and to . can access to oracles and .
- revokes by running , runs Revoke a second time in order to produce two values and for , and sends and to as the challenge value for , along with a set of no revoked friends of .
- selects a bit , uses to encrypt and generates , sends to as the challenge ciphertext for the CPA secure of . sends to as the challenge ciphertext of .
- generates token , and sends to . Since the advantage for to win is non-negligible, the probability of validity of is non-negligible.
- If , then Search stops. According to the following situations, outputs its guess for b:
- -
- If , this tells that was used to generate the token, outputs its guess for b as ;
- -
- Of , this tells that was used to generate the token, outputs its guess for b as .
5. Theoretical Analysis
6. Implementation
6.1. Storage Analysis
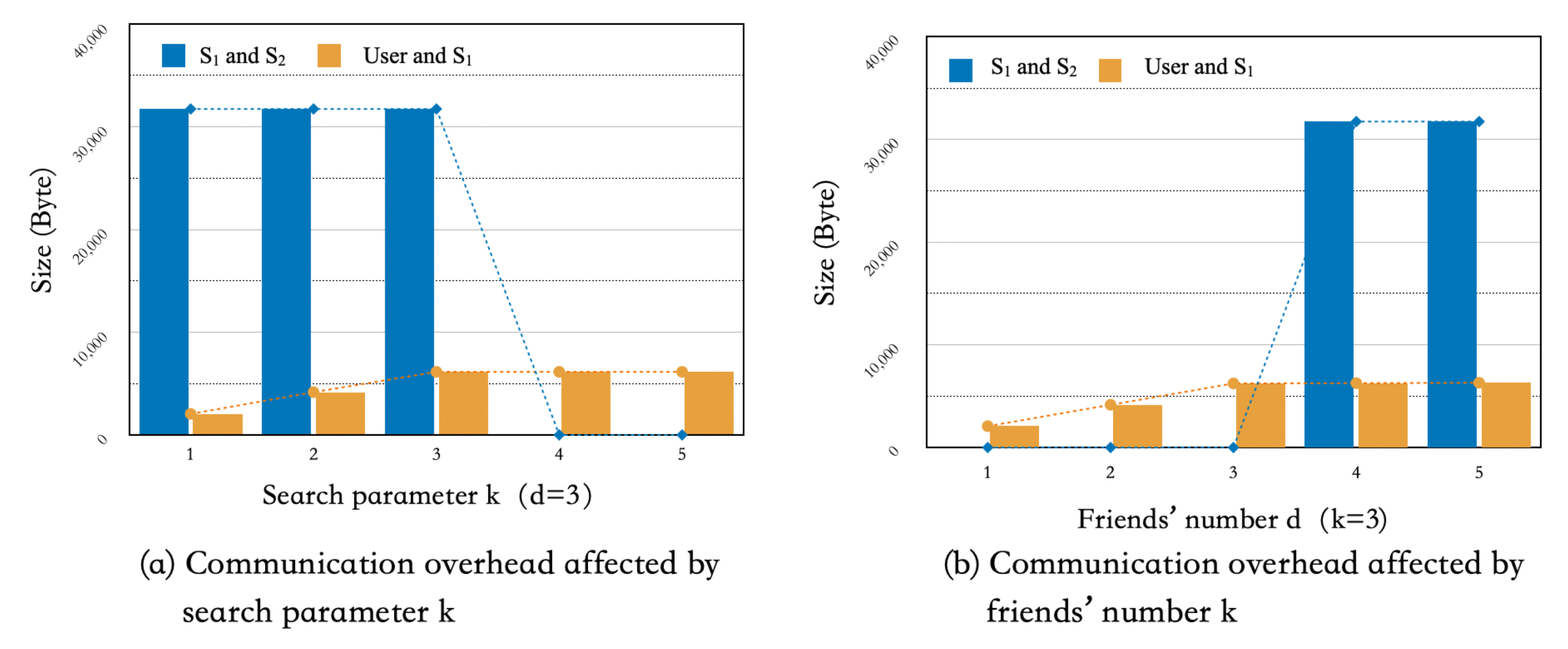
6.2. Communication
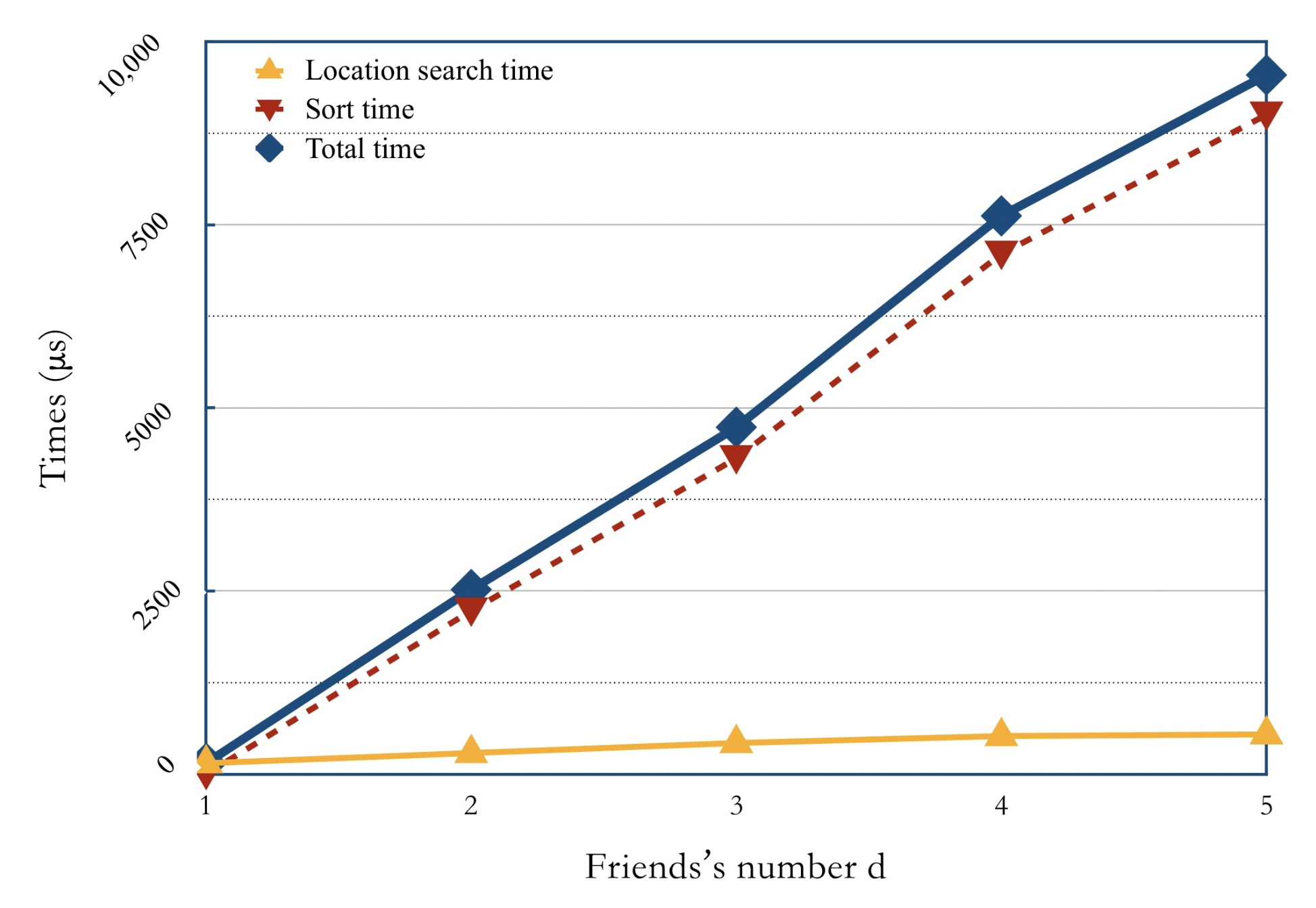
6.3. Search Time
6.4. Scalability
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Global Social Media Stats. Available online: https://datareportal.com/social-media-users (accessed on 10 April 2021).
- Weichbroth, P.; Łysik, Ł. Mobile Security: Threats and Best Practices. Mob. Inf. Syst. 2020. [Google Scholar] [CrossRef]
- Anastasios, N.; Salvatore, S.; Mascolo, C.; Pontil, M. An empirical study of geographic user activity patterns in foursquare. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Cheng, Z.; Caverlee, J.; Lee, K.; Sui, D. Exploring millions of footprints in location sharing services. In Proceedings of the International Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 81–88. [Google Scholar]
- Preotiuc, P.D.; Cohn, T. Mining user behaviors: A study of check-in patterns in location based social network. In Proceedings of the Conference on ACM Web Science, Paris, France, 2–4 May 2013; pp. 306–315. [Google Scholar]
- Chor, B.; Goldreich, O.; Kushilevitz, E.; Sudan, M. Private information retrieval. In Proceedings of the IEEE 36th Annual Foundations of Computer Science, Milwaukee, Wisconsin, 23–25 October 1995; pp. 41–50. [Google Scholar]
- Curtmola, R.; Garay, J.; Kamara, S.; Ostrovsky, R. Searchable symmetric encryption: Improved definitions and efficient constructions. J. Comput. Secur. 2016, 19, 895–934. [Google Scholar] [CrossRef]
- Lucas, M.M.; Nikita, B. Flybynight: Mitigating the privacy risks of social networking. In Proceedings of the 7th ACM Workshop on Privacy in the Electronic Society, Alexandria, VA, USA, 27 October 2008; pp. 1–8. [Google Scholar]
- Guha, S.; Kevin, T.; Paul, F. NOYB: Privacy in online social networks. In Proceedings of the First Workshop on Online Social Networks, Seattle, WA, USA, 18 August 2008; pp. 49–54. [Google Scholar]
- Niu, B.; Li, X.; Zhu, X.; Li, X.; Li, H. Are you really my friend? Exactly spatiotemporal matching scheme in Privacy-Preserving mobile social networks. In Proceedings of the International Conference on Security and Privacy in Communication Systems, Beijing, China, 24–26 September 2014; pp. 33–40. [Google Scholar]
- Zhang, R.; Zhang, Y.; Sun, J.; Yan, G. Fine-grained private matching for proximity-based mobile social networking. In Proceedings of the IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 1969–1977. [Google Scholar]
- Fu, Y.; Wang, Y. BCE: A privacy-preserving common-friend estimation method for distributed online social networks without cryptography. In Proceedings of the 7th International Conference on Communications and Networking, Kunming, China, 8–10 August 2012; pp. 212–217. [Google Scholar]
- Sun, J.; Zhang, R.; Zhang, Y. Privacy-preserving spatiotemporal matching. In Proceedings of the IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 800–808. [Google Scholar]
- Bamba, B.; Liu, L.; Pesti, P.; Wang, T. Supporting anonymous location queries in mobile environments with PrivacyGrid. In Proceedings of the 17th international conference on World Wide Web, New York, NY, USA, 21–25 April 2008; pp. 237–246. [Google Scholar]
- Bordenabe, N.E.; Chatzikokolakis, K.; Palamidessi, C. Optimal Geo-Indistinguishable Mechanisms for Location Privacy. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security (CCS ’14), Scottsdale, AZ, USA, 3–7 November 2014; pp. 251–262. [Google Scholar]
- Elaine, S.; Richard, C.; Hubert, C. Privacy-preserving aggregation of time-series data. In Proceedings of the Network and Distributed System Security Symposium (NDSS 2011), San Diego, CA, USA, 6–9 February 2011; pp. 1–17. [Google Scholar]
- Jorgensen, Z.; Yu, T.; Cormode, G. Publishing attributed social graphs with formal privacy guarantees. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 107–122. [Google Scholar]
- Zhou, C.L.; Chen, Y.H.; Tian, H.; Cai, S.B. Location Privacy and Query Privacy Preserving Method for K-nearest Neighbor Query in Road Networks. J. Softw. 2020, 31, 471–492. [Google Scholar] [CrossRef]
- Li, Z.; Wang, C.; Yang, S.; Jiang, C.; Li, X. Lass: Local-activity and social-similarity based data forwarding in mobile social networks. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 174–184. [Google Scholar] [CrossRef][Green Version]
- Schlegel, R.; Chow, C.; Huang, Q.; Wong, D. User-defined privacy grid system for continuous location-based services. IEEE Trans. Mob. Comput. 2015, 14, 2158–2172. [Google Scholar] [CrossRef]
- Han, M.; Li, L.; Xie, Y.; Wang, J.; Duan, Z.; Li, J.; Yan, M. Cognitive approach for location privacy protection. IEEE Access 2018, 6, 13466–13477. [Google Scholar] [CrossRef]
- Siddula, M.; Li, Y.; Cheng, X.; Tian, Z.; Cai, Z. Privacy-enhancing preferential lbs query for mobile social network users. Wirel. Commun. Mob. Comput. 2020. [Google Scholar] [CrossRef]
- Yang, X.; Yang, M.; Yang, P.; Leng, Q. A multi-authority attribute-based encryption access control for social network. In Proceedings of the 2017 3rd IEEE International Conference on Control Science and Systems Engineering (ICCSSE), Beijing, China, 17–19 August 2017; pp. 671–674. [Google Scholar]
- Luo, E.; Liu, Q.; Wang, G. Hierarchical multi-authority and attribute-based encryption friend discovery scheme in mobile social networks. IEEE Commun. Lett. 2016, 20, 1772–1775. [Google Scholar] [CrossRef]
- Alanwar, A.; Shoukry, Y.; Chakraborty, S.; Martin, P.; Tabuada, P.; Srivastava, M. PrOLoc: Resilient localization with private observers using partial homomorphic encryption. In Proceedings of the 2017 16th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Pittsburgh, PA, USA, 18–21 April 2017; pp. 41–52. [Google Scholar]
- Boneh, D.; Craig, G.; Brent, W. Collusion resistant broadcast encryption with short ciphertexts and private keys. In Proceedings of the Advances in Cryptology—CRYPTO 2005, Santa Barbara, CA, USA, 14–18 August 2005; pp. 258–275. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Goldwasser, S.; Micali, S. Probabilistic Encryption. J. Comput. Syst. Sci. 1984, 28, 270–299. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, F.; Xu, Z. PPFQ: Privacy-Preserving Friends Query over Online Social Networks. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December–1 January 2021; pp. 1348–1353. [Google Scholar]
- Batcher, K.E. Sorting networks and their applications. In Proceedings of the spring joint computer conference, New York, NY, USA, 30 April–2 May 1968; pp. 307–314. [Google Scholar]
- Veugen, T. Improving the DGK comparison protocol. In Proceedings of the International Workshop on Information Forensics and Security, Tenerife, Spain, 2 December 2012; pp. 49–54. [Google Scholar]
- The OpenSSL Project. OpenSSL: The Open Source Toolkit for SSL/TLS. 2015. Available online: http://www.openssl.org/ (accessed on 26 May 2021).
- Relic-Toolkit. Available online: https://github.com/relic-toolkit (accessed on 26 May 2021).
- Cohen, W.W. Enron Email Dataset. 2015. Available online: https://www.cs.cmu.edu/~enron/ (accessed on 26 May 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Register | (1) | (n) | (n) | (1) | – | – | (1) | (1) | (1) |
| Grant | (d) | () | – | (d) | – | – | (d) | () | – |
| Revoke | – | – | – | (1) | (1) | – | (1) | (1) | – |
| LocUpdate | – | (n) | – | (1) | – | – | (1) | (n) | – |
| Search | – | – | – | (d) | ((logd)) | ((logd)) | (k) |
| Accuracy | Evaluation Method | Dynamic | Cryptography tool | SP | LP | AC | Rank Model | |
|---|---|---|---|---|---|---|---|---|
| [16] | ✓ | Euclidean distance/Anchor points | × | PIR/ | ✓ | ✓ | × | – |
| [17] | × | Linear Programming | ✓ | HMAC | ✓ | ✓ | × | – |
| [21] | × | Dynamic Grid | × | HMAC | ✓ | × | × | User |
| Ours | ✓ | Squared Euclidean distance | ✓ | // | ✓ | ✓ | ✓ | 2 servers |
| Unencrypted | Encrypted | ||||
|---|---|---|---|---|---|
| Vertex | Storage (kb) | GenTime (s) | Storage (kb) | GenTime (s) | Inflation Rate |
| 200 | 18.752 | 0.423 | 57.506 | 2.359 | 306.665% |
| 400 | 38.101 | 0.477 | 115.302 | 2.941 | 302.622% |
| 600 | 57.460 | 0.514 | 174.379 | 3.316 | 303.478% |
| 800 | 74.677 | 0.538 | 225.039 | 3.770 | 301.349% |
| 1000 | 95.988 | 0.575 | 289.864 | 4.113 | 301.979% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhou, F.; Ge, Y.; Xu, Z. Privacy-Enhancing k-Nearest Neighbors Search over Mobile Social Networks. Sensors 2021, 21, 3994. https://doi.org/10.3390/s21123994
Li Y, Zhou F, Ge Y, Xu Z. Privacy-Enhancing k-Nearest Neighbors Search over Mobile Social Networks. Sensors. 2021; 21(12):3994. https://doi.org/10.3390/s21123994
Chicago/Turabian StyleLi, Yuxi, Fucai Zhou, Yue Ge, and Zifeng Xu. 2021. "Privacy-Enhancing k-Nearest Neighbors Search over Mobile Social Networks" Sensors 21, no. 12: 3994. https://doi.org/10.3390/s21123994
APA StyleLi, Y., Zhou, F., Ge, Y., & Xu, Z. (2021). Privacy-Enhancing k-Nearest Neighbors Search over Mobile Social Networks. Sensors, 21(12), 3994. https://doi.org/10.3390/s21123994