
Computational Offloading in Mobile Edge with Comprehensive and Energy Efficient Cost Function: A Deep Learning Approach

 , ,
, ,  ,
,  ,
,  ,
, 
Abstract
1. Introduction
1.1. Related Work
1.2. Novelty and Contributions
- We propose the partitioning process, for the first time, in fine-grained computational offloading in MEC. The proposed work considers the cost of partitioning a task into multiple components and selects the possible partitioning option with minimum cost in all possible partitioning options;
- We combine the selection of task partitioning from possible options and partial offloading policy from possible options and model as a multi-label classification problem. The computational overhead of finding minimum cost in terms of energy consumption and execution delay while considering the offloading policy and partitioning simultaneously becomes . Therefore, to avoid this huge computation complexity, we propose a supervised deep learning approach to solve both problems simultaneously with a complexity of trained DNN of . We formulate a comprehensive cost function, which considers multiple parameters, namely, network fluctuations and computing resources of MESs, propagation delay, the time delays, and energy consumptions due to partitioning, transmission, execution, and reception;
- Through extensive simulation results we demonstrate the superiority of the proposed technique, compared with total offloading technique (TOT), random offloading technique (ROT), deep learning-based offloading technique (DOT), and energy efficient deep learning-based offloading technique (EEDOT), in terms of energy consumption and execution delay of UEs;
- The UEs can use the trained DNN to find the offloading policy and partitioning for n number of components with minimum cost. Since the cost function depends on both energy consumption and time delay, therefore, the end-user will consume minimum energy with faster decisions on selecting the best partitioning and offloading policy for n number of components per task.
2. System Model
2.1. Local Execution Model ()
2.2. Remote Execution Model ()
2.3. Cost Function
3. The Proposed Deep Learning Approach
| Algorithm 1 Partial Offloading with Partitioning |
Input: {} Output: {}
|
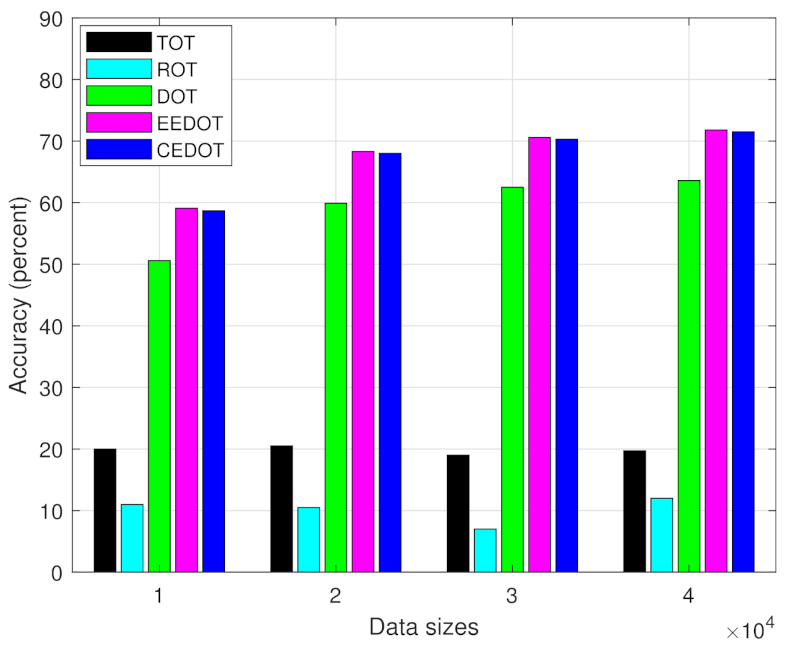
4. Simulation Results and Discussion
Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Piran, M.J.; Pham, Q.V.; Islam, S.R.; Cho, S.; Bae, B.; Suh, D.Y.; Han, Z. Multimedia communication over cognitive radio networks from QoS/QoE perspective: A comprehensive survey. J. Netw. Comput. Appl. 2020, 172, 102759. [Google Scholar] [CrossRef]
- Pereira, R.S.; Lieira, D.D.; da Silva, M.A.; Pimenta, A.H.; da Costa, J.B.; Rosário, D.; Villas, L.; Meneguette, R.I. RELIABLE: Resource allocation mechanism for 5G network using mobile edge computing. Sensors 2020, 20, 5449. [Google Scholar] [CrossRef] [PubMed]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile edge computing: A survey. IEEE Internet Things J. 2017, 5, 450–465. [Google Scholar] [CrossRef]
- Pham, Q.V.; Fang, F.; Ha, V.N.; Le, M.; Le, L.B.; Hwang, W.J.; Ding, Z. A survey of multi-access edge computing in 5G and beyond: Fundamentals, technology integration, and state-of-the-art. IEEE Access 2020, 8, 116974–117017. [Google Scholar] [CrossRef]
- Shakarami, A.; Ghobaei-Arani, M.; Shahidinejad, A. A survey on the computation offloading approaches in mobile edge computing: A machine learning-based perspective. Comput. Netw. 2020, 182, 107496. [Google Scholar] [CrossRef]
- Gu, X.; Ji, C.; Zhang, G. Energy-optimal latency-constrained application offloading in mobile-edge computing. Sensors 2020, 20, 3064. [Google Scholar] [CrossRef]
- Jo, B.; Piran, M.J.; Lee, D.; Suh, D.Y. Efficient computation offloading in mobile cloud computing for video streaming over 5G. Comput. Mater. Contin. 2019, 61, 439–463. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Wang, X.; Hu, X.; Liu, J.; Guo, L.; Hu, B.; Kwok, R.; Leung, V.C. Partial computation offloading and adaptive task scheduling for 5G-enabled vehicular networks. IEEE Trans. Mob. Comput. 2020. Early Access. [Google Scholar] [CrossRef]
- Ding, Y.; Liu, C.; Zhou, X.; Liu, Z.; Tang, Z. A code-oriented partitioning computation offloading strategy for multiple users and multiple mobile edge computing servers. IEEE Trans. Industr. Inform. 2019, 16, 4800–4810. [Google Scholar] [CrossRef]
- Nauman, A.; Qadri, Y.A.; Amjad, M.; Zikria, Y.B.; Afzal, M.K.; Kim, S.W. Multimedia internet of things: A comprehensive survey. IEEE Access 2020, 8, 8202–8250. [Google Scholar] [CrossRef]
- Cui, M.; Fei, Y.; Liu, Y. A survey on secure deployment of mobile services in edge computing. Secur. Commun. Netw. 2021, 2021, 8846239. [Google Scholar] [CrossRef]
- Eom, H.; Juste, P.S.; Figueiredo, R.; Tickoo, O.; Illikkal, R.; Iyer, R. Machine learning-based runtime scheduler for mobile offloading framework. In Proceedings of the 2013 IEEE/ACM 6th International Conference on Utility and Cloud Computing, Dresden, Germany, 9–12 December 2013; pp. 17–25. [Google Scholar]
- Eom, H.; Figueiredo, R.; Cai, H.; Zhang, Y.; Huang, G. Malmos: Machine learning-based mobile offloading scheduler with online training. In Proceedings of the 3rd IEEE International Conference on Mobile Cloud Computing, Services, and Engineering, San Francisco, CA, USA, 30 March–3 April 2015; pp. 51–60. [Google Scholar]
- Kuang, Z.; Li, L.; Gao, J.; Zhao, L.; Liu, A. Partial offloading scheduling and power allocation for mobile edge computing systems. IEEE Internet Things J. 2019, 6, 6774–6785. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Kong, X.; Xia, F. A cooperative partial computation offloading scheme for mobile edge computing enabled Internet of Things. IEEE Internet Things J. 2018, 6, 4804–4814. [Google Scholar] [CrossRef]
- Yang, G.; Hou, L.; He, X.; He, D.; Chan, S.; Guizani, M. Offloading time optimization via Markov decision process in mobile edge computing. IEEE Internet Things J. 2020, 8, 2483–2493. [Google Scholar] [CrossRef]
- Dong, L.; Wu, W.; Guo, Q.; Satpute, M.N.; Znati, T.; Du, D.Z. Reliability-aware offloading and allocation in multilevel edge computing system. IEEE Trans. Reliab. 2019, 70, 200–211. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient multi-user computation offloading for mobile-edge cloud computing. IEEE/ACM Trans. Netw. 2015, 24, 2795–2808. [Google Scholar] [CrossRef]
- Psomas, C.; Krikidis, I. Wireless powered mobile edge computing: Offloading or local computation? IEEE Commun. Lett. 2020, 24, 2642–2646. [Google Scholar] [CrossRef]
- Li, C.; Chen, W.; Tang, H.; Xin, Y.; Luo, Y. Stochastic computation resource allocation for mobile edge computing powered by wireless energy transfer. Ad Hoc Netw. 2019, 93, 101897. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, Y.J. Computation rate maximization for wireless powered mobile-edge computing with binary computation offloading. IEEE Trans. Wirel. Commun. 2018, 17, 4177–4190. [Google Scholar] [CrossRef]
- Zhou, F.; Wu, Y.; Hu, R.Q.; Qian, Y. Computation rate maximization in UAV-enabled wireless-powered mobile-edge computing systems. IEEE J. Sel. Areas Commun. 2018, 36, 1927–1941. [Google Scholar] [CrossRef]
- Wu, D.; Wang, F.; Cao, X.; Xu, J. Wireless powered user cooperative computation in mobile edge computing systems. In Proceedings of the IEEE GLOBECOM Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Mao, S.; Leng, S.; Yang, K.; Huang, X.; Zhao, Q. Fair energy-efficient scheduling in wireless powered full-duplex mobile-edge computing systems. In Proceedings of the IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Mahmood, A.; Ahmed, A.; Naeem, M.; Hong, Y. Partial offloading in energy harvested mobile edge computing: A direct search approach. IEEE Access 2020, 8, 36757–36763. [Google Scholar] [CrossRef]
- Li, C.; Song, M.; Zhang, L.; Chen, W.; Luo, Y. Offloading optimization and time allocation for multiuser wireless energy transfer based mobile edge computing system. Mobile Netw. Appl. 2020, 25, 1–9. [Google Scholar] [CrossRef]
- Zhang, D.; Chen, Z.; Awad, M.K.; Zhang, N.; Zhou, H.; Shen, X.S. Utility-optimal resource management and allocation algorithm for energy harvesting cognitive radio sensor networks. IEEE J. Sel. Areas Commun. 2016, 34, 3552–3565. [Google Scholar] [CrossRef]
- Mao, S.; Leng, S.; Maharjan, S.; Zhang, Y. Energy efficiency and delay tradeoff for wireless powered mobile-edge computing systems with multi-access schemes. IEEE Trans. Wirel. Commun. 2019, 19, 1855–1867. [Google Scholar] [CrossRef]
- Liao, Z.; Peng, J.; Xiong, B.; Huang, J. Adaptive offloading in mobile-edge computing for ultra-dense cellular networks based on genetic algorithm. J. Cloud Comput. 2021, 10, 1–16. [Google Scholar] [CrossRef]
- Xu, Z.; Zhao, L.; Liang, W.; Rana, O.F.; Zhou, P.; Xia, Q.; Xu, W.; Wu, G. Energy-aware inference offloading for DNN-driven applications in mobile edge clouds. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 799–814. [Google Scholar] [CrossRef]
- Li, B.; He, M.; Wu, W.; Sangaiah, A.K.; Jeon, G. Computation offloading algorithm for arbitrarily divisible applications in mobile edge computing environments: An OCR case. Sustainability 2018, 10, 1611. [Google Scholar] [CrossRef]
- Tao, X.; Ota, K.; Dong, M.; Qi, H.; Li, K. Performance guaranteed computation offloading for mobile-edge cloud computing. IEEE Wirel. Commun. Lett. 2017, 6, 774–777. [Google Scholar] [CrossRef]
- Dinh, T.Q.; La, Q.D.; Quek, T.Q.; Shin, H. Learning for computation offloading in mobile edge computing. IEEE Trans. Commun. 2018, 66, 6353–6367. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, Y.; Huang, X.; Fang, C.; Zhang, P. Ultra-low latency multi-task offloading in mobile edge computing. IEEE Access 2021, 9, 32569–32581. [Google Scholar] [CrossRef]
- Ale, L.; Zhang, N.; Fang, X.; Chen, X.; Wu, S.; Li, L. Delay-aware and energy-efficient computation offloading in mobile edge computing using deep reinforcement learning. IEEE Trans. Cogn. Commun. Netw. 2021. Early Access. [Google Scholar] [CrossRef]
- Yu, S.; Wang, X.; Langar, R. Computation offloading for mobile edge computing: A deep learning approach. In Proceedings of the IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Montreal, QC, Canada, 8–13 October 2017; pp. 1–6. [Google Scholar]
- Ali, Z.; Jiao, L.; Baker, T.; Abbas, G.; Abbas, Z.H.; Khaf, S. A deep learning approach for energy efficient computational offloading in mobile edge computing. IEEE Access 2019, 7, 149623–149633. [Google Scholar] [CrossRef]
- Shakarami, A.; Shahidinejad, A.; Ghobaei-Arani, M. An autonomous computation offloading strategy in Mobile Edge Computing: A deep learning-based hybrid approach. J. Netw. Comput. Appl. 2021, 178, 102974. [Google Scholar] [CrossRef]
- Irshad, A.; Abbas, Z.H.; Ali, Z.; Abbas, G.; Baker, T.; Al-Jumeily, D. Wireless powered mobile edge computing systems: Simultaneous time allocation and offloading policies. Electronics 2021, 10, 965. [Google Scholar] [CrossRef]
- Yu, S.; Chen, X.; Yang, L.; Wu, D.; Bennis, M.; Zhang, J. Intelligent edge: Leveraging deep imitation learning for mobile edge computation offloading. IEEE Wirel. Commun. 2020, 27, 92–99. [Google Scholar] [CrossRef]
- Qin, M.; Cheng, N.; Jing, Z.; Yang, T.; Xu, W.; Yang, Q.; Rao, R.R. Service-oriented energy-latency tradeoff for iot task partial offloading in mec-enhanced multi-rat networks. IEEE Internet Things J. 2020, 8, 1896–1907. [Google Scholar] [CrossRef]
- Butt, U.A.; Mehmood, M.; Shah, S.B.H.; Amin, R.; Shaukat, M.W.; Raza, S.M.; Suh, D.Y.; Piran, M. A Review of Machine Learning Algorithms for Cloud Computing Security. Electronics 2020, 9, 1379. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of deep-learning approaches for remote sensing observation enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I. Multi-label classification: An overview. IJDWM 2007, 3, 1–13. [Google Scholar] [CrossRef]
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for AI-enabled IoT devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques | Considers Service Delays? | Considers Energy Consumption? | Task Partitioning Considered? | Multi-User Multi-Server Considered? | Deep Learning Approach? | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Transmission | Execution , | Reception | Partitioning | Propagation | Transmission , | Reception | Partitioning | ||||
| MDP-based VIA Technique [16] | Yes | Yes | Yes | No | No | No | No | No | No | Yes | No |
| Reliability-aware Offloading [17] | Yes | Yes | Yes | No | No | Yes | Yes | No | No | Yes | No |
| Traditional Optimization Techniques [18,19] | Yes | Yes | No | No | No | Yes | No | No | No | No | No |
| Energy Harvesting Techniques [20,21,22,25,26,27] | Yes | Yes | No | No | No | Yes | No | No | No | No | No |
| Genetic Algorithm -based Offloading [30] | Yes | Yes | No | No | No | Yes | No | No | No | Yes | No |
| Offloading of DNN-driven Applications [31] | Yes | Yes | No | No | Yes | Yes | No | No | No | Yes | No |
| Offloading for OCR Case [32] | Yes | Yes | No | No | Yes | No | No | No | Yes | No | No |
| Game Theoretic Approach [34] | No | No | No | No | No | Yes | Yes | No | No | Yes | No |
| Energy Efficiency-based Offloading [35,37,41] | Yes | Yes | No | No | No | No | No | No | No | Yes | Yes |
| Cost Function-based Offloading [36,38] | Yes | Yes | Yes | No | No | Yes | Yes | No | No | Yes | Yes |
| Cost Function-based Offloading [39,40] | Yes | Yes | No | No | No | Yes | No | No | No | No | Yes |
| Our Proposed Technique (CEDOT) | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Notations | Meaning |
|---|---|
| Number of CPU cycles to process | |
| B | Transmission bandwidth |
| C | Set off components per tasks |
| ith component | |
| Total required delay to execute locally | |
| Required delay for transmission of | |
| Required delay for execution of | |
| Required delay for reception of | |
| Propagation delay for | |
| Total remote execution delay for | |
| Delay due to division process per component | |
| Energy consumption due to division process per component | |
| Total energy consumption to execute locally | |
| Total remote energy consumption for | |
| Transmission energy consumption for | |
| Reception energy consumption for | |
| Average switch capacitance and activity factor | |
| Binary offloading decision variable | |
| Number of CPU cycles per bit | |
| Local cost for component | |
| Remote cost for component | |
| CPU frequency of MES | |
| CPU frequency of UE | |
| , | Weighting coefficients for local cost function |
| , | Weighting coefficients for remote cost function |
| Division resolution in partitioning | |
| , | Channel fading coefficients for downlink, uplink |
| K | Maximum available subcarriers |
| Number of subcarriers assigned to | |
| Distance between UE and MES | |
| m | Task size |
| Input data size of | |
| Noise power | |
| n | Number of components per tasks |
| Matrix of possible offloading policies | |
| Optimal partitioning | |
| Matrix of possible partitions | |
| Transmitting power of MES | |
| Transmitting power of UE | |
| Receiving power of UE | |
| R | Maximum CPU cores of MES |
| Path loss exponent | |
| Required delay to divide a task into two components | |
| Number of CPU cores of MES assigned to | |
| Output data size of | |
| Downlink data rate | |
| Uplink data rate | |
| Optimal offloading policy |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| B | 0.5 MHz | R | 256 |
| 800 J | 1.2 W | ||
| K | 16 | 0.8 W | |
| 300 s | 0.6 | ||
| 200 MB | 0.4 | ||
| 0.5 | |||
| 737.5 cycles/bit | 0.3 | ||
| −174 dBm/Hz | 0.1 | ||
| 3 | 0.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, Z.H.; Ali, Z.; Abbas, G.; Jiao, L.; Bilal, M.; Suh, D.-Y.; Piran, M.J. Computational Offloading in Mobile Edge with Comprehensive and Energy Efficient Cost Function: A Deep Learning Approach. Sensors 2021, 21, 3523. https://doi.org/10.3390/s21103523
Abbas ZH, Ali Z, Abbas G, Jiao L, Bilal M, Suh D-Y, Piran MJ. Computational Offloading in Mobile Edge with Comprehensive and Energy Efficient Cost Function: A Deep Learning Approach. Sensors. 2021; 21(10):3523. https://doi.org/10.3390/s21103523
Chicago/Turabian StyleAbbas, Ziaul Haq, Zaiwar Ali, Ghulam Abbas, Lei Jiao, Muhammad Bilal, Doug-Young Suh, and Md. Jalil Piran. 2021. "Computational Offloading in Mobile Edge with Comprehensive and Energy Efficient Cost Function: A Deep Learning Approach" Sensors 21, no. 10: 3523. https://doi.org/10.3390/s21103523
APA StyleAbbas, Z. H., Ali, Z., Abbas, G., Jiao, L., Bilal, M., Suh, D.-Y., & Piran, M. J. (2021). Computational Offloading in Mobile Edge with Comprehensive and Energy Efficient Cost Function: A Deep Learning Approach. Sensors, 21(10), 3523. https://doi.org/10.3390/s21103523