1. Introduction
The use of error correcting codes (ECCs) is essential for designing reliable digital communication systems. However, while ECCs helps to accurately transmit and receive information for random errors, it has relatively low probabilities to to correct burst errors. To improve the error correction performance for burst type errors, an interleaving technique is used to convert burst errors occurring in the channel into random errors [
1].
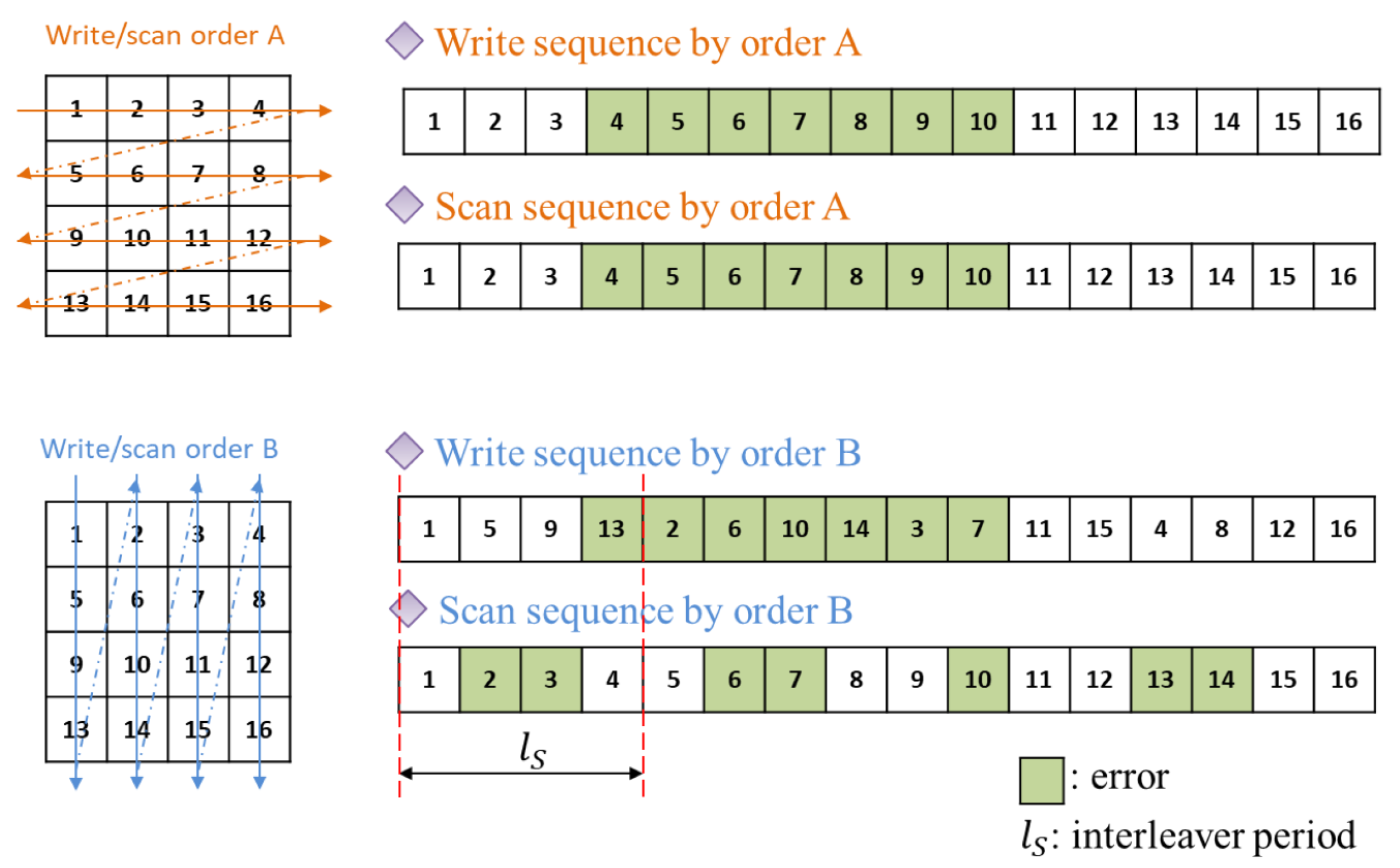
For reconstructing the real bitstreams, the receiver has to find the structure and parameters of the channel code. A blind interleaver parameters estimation must be performed first, following which the other parameters can be easily deduced.
A deinterleaving problem is usually considered in a non-cooperative context. Considering that receivers only know the intercepted sequences, blind interleaver parameters estimation algorithms exploit the fact that the codewords generated by ECCs have linear dependence [
2,
3,
4,
5,
6].
In [
2], Gaussian elimination is used to find the interleaver parameters. However, because this method does not consider channel noise, the performance of estimation deteriorates steeply as the number of errors increases. A blind interleaver parameters estimation algorithm that uses Gauss-Jordan elimination through pivoting and considers channel noises is described in [
3]. This method finds almost dependent columns which have the minimum Hamming weight and uses it as a measure for predicting interleaver period.
Some algorithms use the rank distribution of random square matrices,
, as a criterion for blind interleaver parameters estimation [
4,
5,
6]. In [
7,
8], they estimate interleaver parameters using the variation of rank ratio depending on the column length of the matrix. These algorithms are based on the fact that the rank distribution of square matrices consisting of codewords,
, is far different from
. Because
follows a specific distribution, the interleaver period of the intercepted bitstreams can be estimated by comparing this distribution with
.
In [
4], when
s represents rank deficiency factor, which is the difference in ranks between the rank of the
l ×
l random binary square matrix,
, and
l, they defined success events as the rank deficiency
s is greater than 2,
. The number of success events is used as a measure to estimate the interleaver periods by modeling
as a Bernoulli trial that classifies events into success and failure based on the rank values.
In addition, the Kullback–Leibler divergence (KLD) was used as a measure for estimating the interleaver parameters [
5]. KLD calculates the degree of rank distribution difference between random square matrices and square matrices of the intercepted stream. Further, KLD was also partially applied for false alarm control. In [
9], maximum difference selection (MDS) is proposed by selecting vectors having fewer errors and they adopted KLD to control false alarm rates.
As an extension to [
4], more events are considered using Multinomial distributions [
6]. Because multinomial distributions can calculate the probability that each event will occur, it predicts interleaver periods by finding the event that has the lowest probability. According to the methodology of the analytical and histogram approach, zero mean ratio values are used to estimate an interleaver period in [
7]. Recently, normalized non-zero-mean-ratio values are introduced as a measure for estimation of interleaver period [
8]. Also, blind interleaver parameters estimation algorithms have been proposed focused on the case of a short length of received data [
10,
11]. In order to overcome degrading estimation performance caused by the lack of available data, they generated additional data by combining received data [
10]. Then, the collected and generated data were used to construct matrices. The rank deficiency of the matrices can be utilized to estimate interleaver periods. In addition, the new approach estimating interleaver periods without generating additional data has been proposed when the length of the received data is short [
11]. They focused on the case that the data collected was so short that matrices could not be sufficiently constructed to calculate rank deficiencies. To solve this problem, the matrix created once from the received data is split into multiple submatrices to calculate the rank deficiency.
In this paper, we do not consider the case of short received data and propose an improved approach that utilizes the difference between the random binomial distribution and the rank distribution of matrices composed of codewords. For a blind interleaver parameters estimation, we used the Kolmogorov–Smirnov (K–S) test. K–S statistics has been used in the automatic modulation classification (AMC) algorithm to measure the fitness whether two groups are extracted from the same distribution [
12,
13]. We utilized the K–S test as a metric to find the final candidate of interleaver peroids with the most different rank distribution from the rank distribution of the random signals. We utilize the K–S test as a metric to make decision whether two groups are extracted from the same distribution. The K–S test value is used to find the most different rank distribution. The K–S test does not include any logarithmic calculation and instead needs only the cumulative distribution function (CDF) of two distributions. Therefore, differences between the two distributions can be easily computed without requiring the complex logarithmic operation that is part of the KLD.
Experimental results validated that our proposed algorithm has relatively low computational complexity and outperforms existing algorithms. Furthermore, we can finer control false alarm rates compared to other algorithms by using multinomial distribution. In a noisy channel environment, simulation results demonstrate that the K–S test estimates the interleaver parameter with high estimation accuracy.
The rest of this paper is organized as follows. Related work is described in
Section 2 In
Section 3, the proposed algorithm is explained. The proposed algorithm is compared with conventional algorithms and analyzed based on experimental results in
Section 4. Finally,
Section 5 conclude the paper.
3. Proposed Algorithm
In this section, we explain the proposed blind interleaver parameters estimation algorithm. The proposed algorithm adopts the K–S test to measure the difference between the two distributions and multinomial distribution is used for controlling the false alarm rates. After introducing the K–S test briefly, the proposed algorithm is described in detail.
The K–S test measures the fitness whether data are extracted from the same distribution [
13]. In this scenario, we use this test as a measure to find the most different rank distribution. The degree of difference between the two distributions as calculated by this test is given by
where
P and
Q are CDFs and
sup is the supremum that denotes to the least upper bound of a set. This metric measures the maximum difference between the two cumulative distributions.
3.1. Kolmogorov–Smirnov Test
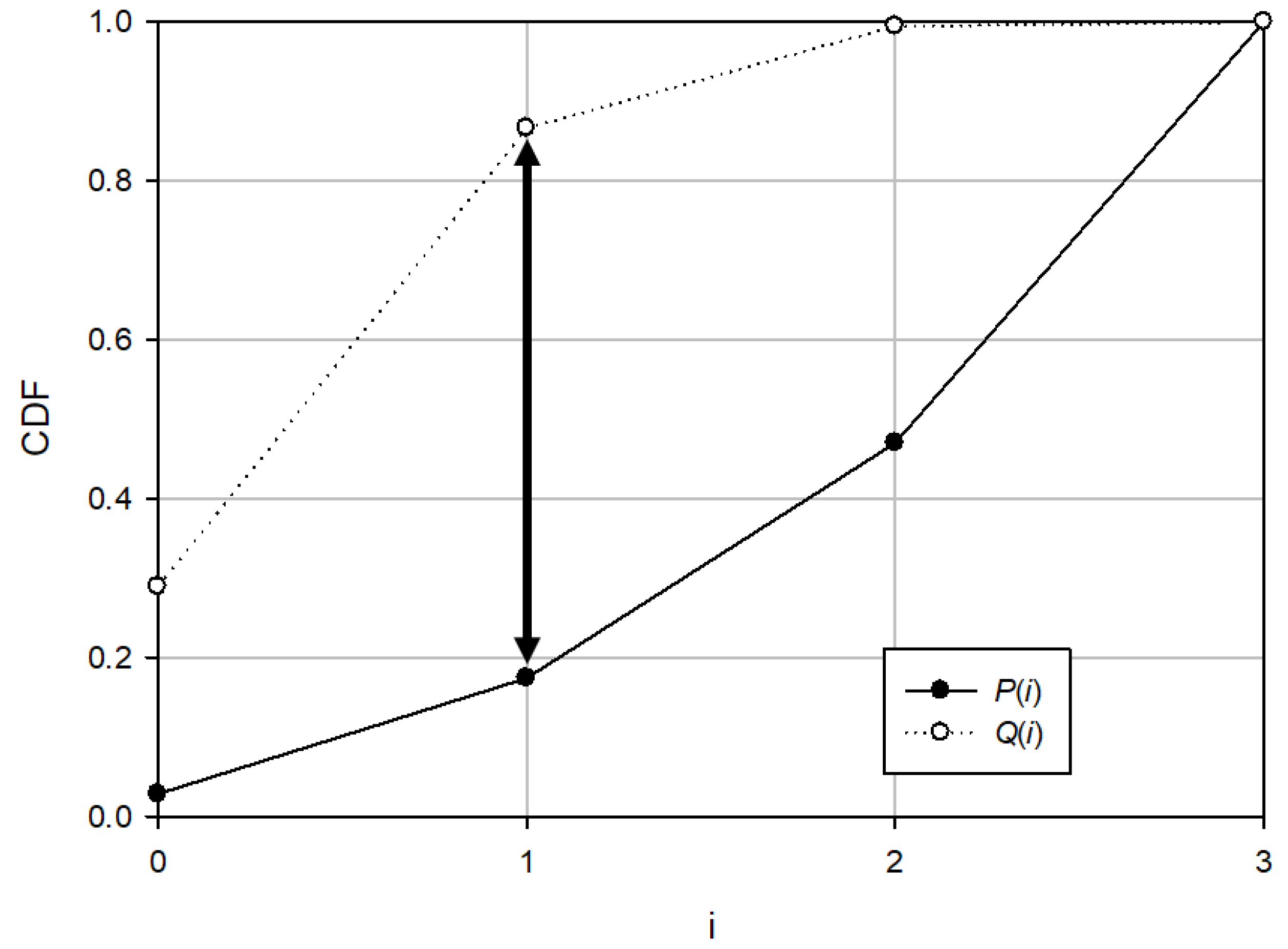
Figure 3 shows an example of the K–S statistics. The larger the K–S value, the greater is the difference between the two distributions. This motivated us to consider the K–S test as a measure for estimating interleaver parameters in our proposed algorithm. Compared to KLD, the K–S test has a relatively lower complexity. Because it does not require a logarithmic operation and needs only the CDFs of the two distributions, it can calculate the degree of difference between two distributions with low complexity.
3.2. Proposed Algorithm
Motivated by the foregoing observations, this subsection describes how to exploit rank distributions to estimate interleaver periods in detail. First, to exploit rank distributions for interleaver period estimation, the rank distribution must be obtained.
We describe the process of getting rank distribution as shown in
Figure 4. Given the received bitstream,
l vectors of length
l are randomly selected to construct
and the rank distribution is calculated by counting the rank of the matrices
N times.
Sufficiently large N shall be considered to guarantee reliable rank distributions. For example, if N is set to 10,000, we must receive a captured sequence of length at least 280,000 when the interleaver period is 28. To resolve this excessive requirement, we exploited the linearity of linear codes; i.e., the sum of two codewords is also a codeword.
Then, we use the K–S test as a measure of the probability matching problem. In other words, we find
l which has the most different distribution from that of random square matrices. Equation (
5) represents how we can predict interleaver period exploiting K–S test.
where
represents the CDF of the rank distribution from the random square matrices and
represents the CDF of the rank distribution from constructed square matrices, respectively.
If
l is not equal to the interleaver period,
S, there is no linear dependence in the rows of the constructed matrix. Therefore, the distribution may follow that shown in
Table 1 with high probability. This results in the K–S test value,
, converging to near zero.
On the contrary, if
l equals
S, the rows of
consist of codewords. The distribution is totally different from that given in
Table 1 owing to the linear dependence of the codewords. Therefore,
can reach the maximum value and
l can be predicted as the interleaver period.
Finally, multinomial distribution is used for false alarm control. It ensures that the probability of the rank distribution at that time is lower than a threshold, which is sufficient to judge that it does not happen by chance. The proposed algorithm is summarized in Algorithm 1.
| Algorithm 1: Proposed Algorithm |
Input: received sequence r, translate parameter d = 0, predicted interleaver period l = 7 Output: estimated interleaver period - 1:
Translate the received sequence by the length d. - 2:
Divide the translated sequence by the length l. - 3:
Randomly select l vectors and construct an l ×l square matrix . - 4:
Calculate the rank of the matrix. - 5:
Repeat the third and the fourth steps N times. - 6:
Construct rank distribution - 7:
ifthen Go to the first step with increment d as d+1. - 8:
ifthen Set d to 0. - 9:
Go to the first step with increment l as l+1. - 10:
Compute ( 5) and declare to be an interleaver period.
|
4. Results
In this section, we present experimental results and compare the performance of the proposed algorithm to that of previous algorithms. To generate bitstreams, a (7, 4) binary Hamming code and two BCH codes, (15, 5), (15, 7), and (15, 11) were used [
1]. The generated bit length was 50,000 and a random block interleaver was used.
Instead of the signal-to-noise ratio(SNR), we compare the performance of each algorithm based on the probability of errors occurring in the channel. We assumed that the interleaved bitstream passed through a binary symmetric channel with different bit error rates (BER), and even considered the possibility that the data collected by the receiver would have been translated. The number of trials for constructing rank distributions was 500 for each searching process.
For each BER, we tested the process for calculating the probability of estimating interleaver parameters 1000 times. Given the interleaver period, S, the search range of the predicted interleaver period, l, was set from 7 to . The search range of the randomly chosen translation value, d, was set from 0 to .
We compared the performance of the proposed algorithm with that of algorithms based on Bernoulli trials [
4], KLD [
5], Multinomial [
6], and MDS [
9]. In the case of Bernoulli [
4], the interleaver period was predicted when the number of success events is maximum. In KLD [
5], the interleaver period is predicted when (
2) is maximum. Likewise, Multinomial [
6] predicts interleaver periods by finding the minimum value of (
1), and MDS finds the predicted length
l with the maximum value of (
3).
To show objective performance comparison, we denote detection probability as below:
where
is the total number of times the interleaver period is estimated, and
is the number of times among
predicted correctly.
Figure 5,
Figure 6 and
Figure 7 show the experimental results in terms of code rates, interleaver periods, and the lengths of the intercepted bitstream, respectively. Since the value of (5) varies depending on the linearity of the codewords in the received data, so the higher the probability that the linearity of the codeword is not maintained, the faster the performance deteriorates according to the increase of BER.
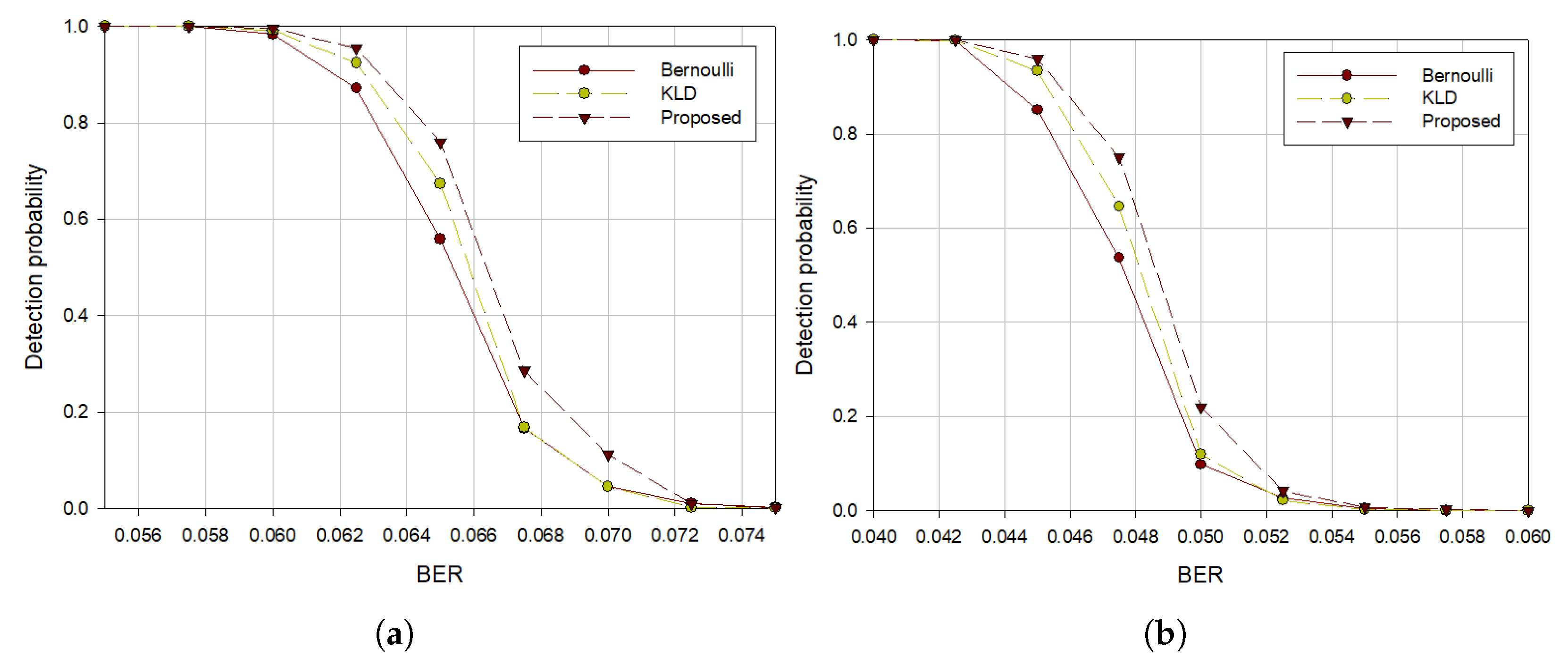
To compare performances based on the code rates, two BCH codes were used with 50,000 intercepted symbols. As shown in
Figure 5, we can see that the proposed algorithm had the highest detection probability of blind estimating interleaver parameters regardless of the code rate change. It can be seen that when the code rate is high, performance degradation begins at the lower BER than when the code rate is low. Further,
Figure 5a,b show that the higher the code rates, the lower the detection probability for the same BER.
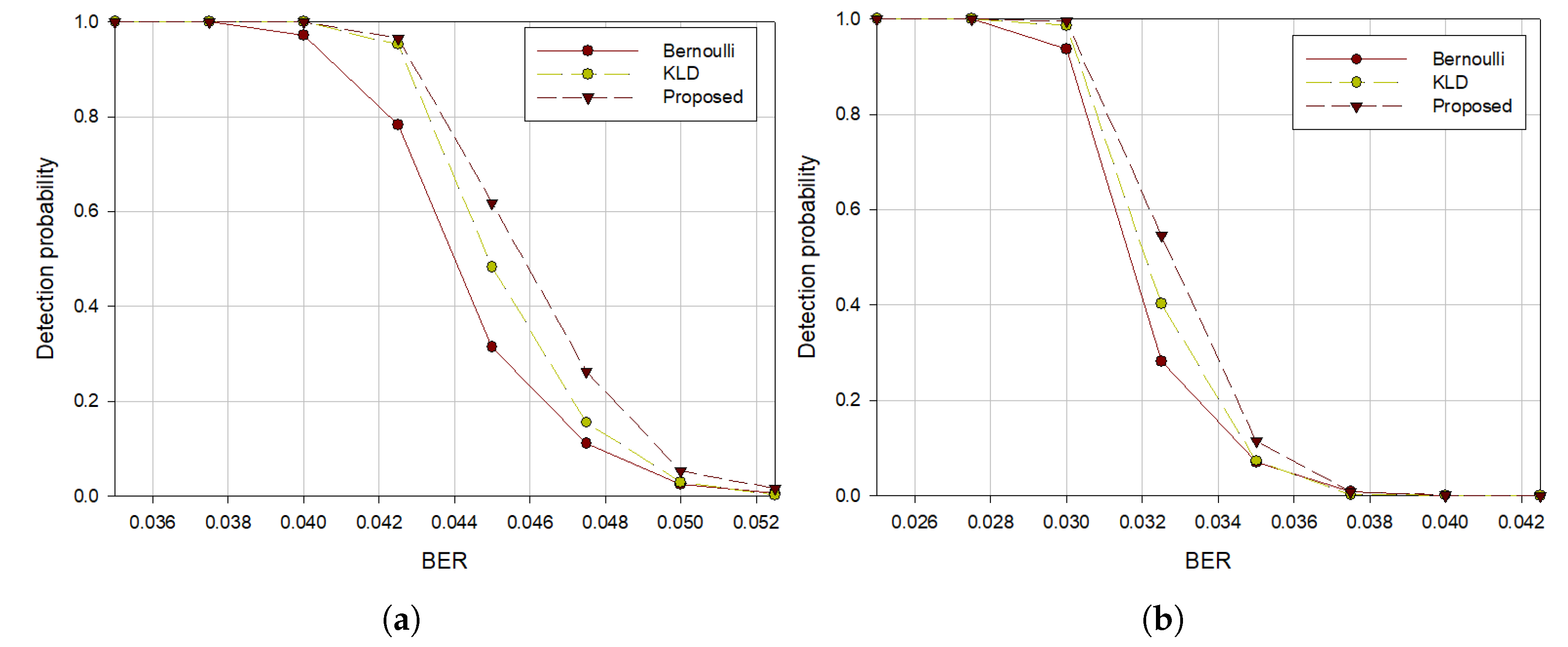
In terms of interleaver periods, we compared the performances of the proposed algorithm with the previous algorithms. Two interleaver periods, 28 and 42, were used and bitstreams of length 50,000 were generated using Hamming (7, 4) code.
Figure 6 shows that the performance of our algorithm is better than that of other algorithms in both interleaver periods. From
Figure 6a,b, we observe that the performance deteriorated when the interleaver periods increased because the probability that the constructed matrices for rank calculation contain errors increases.
When comparing the performances based on the lengths of the intercepted bitstreams, we ran the test 10,000 times for each BER to achieve more accurate results.
Figure 7 visualizes the detection and false alarm probability when the lengths of the bitstreams are 50,000 and 5000. When the BER is lower than 0.04, we can see that the longer the length of the intercepted bitstreams, the higher is the performance for each method.
However, when the BER is higher than 0.04, we observed that the performance with shorter intercepted symbols was the better in terms of detection probability. Further, the proposed algorithm had the lowest false alarm rates as shown in
Figure 7b.
Figure 7 also shows that the proposed algorithm outperformed the previous algorithms for each bitstream length.
In addition, for a fair performance comparison with Multinomial [
6] and MDS [
9], additional experiments were conducted with the number of attempts to construct the rank distribution at 1000. BCH (15, 7) and BCH (15, 11) was used to show superiority of the proposed algorithm even at high code rates.
Figure 8 shows that our method improved even more with increasing number of trials compared to other methods. As the code rate increases, the difference in performance from other algorithms has decreased, but it can be seen that it still outperforms the other algorithms in terms of detection probability.
Lastly, we calculated the run time for complexity comparison.
Table 2 represents the time it takes to estimate the interleaver period once when
with BCH (15, 11) code. The false alarm control process was omitted, and the average time was obtained by measuring the time taken to estimate the interleaver period 100 times for each algorithm.
Except for MDS [
9] and Multinomial [
6], Bernoulli [
4], KLD [
5], and proposed method have the similar execution speed as represented in
Table 2. It can be seen that Bernoulli, KLD, and the proposed algorithm have a high proportion of the computational complexity of Gauss elimination process in exploiting the rank distributions. Since Multinomial [
6] calculates the probability that each event will occur and finds the lowest probable event, it takes more times to estimate the interleaver periods. We can see that MDS has a relatively high computational complexity because MDS adopted the method of using vectors with a high probability of low errors before comparing two distributions.
5. Discussion and Conclusions
In this paper, we proposed a blind interleaver parameters estimation algorithm based on a combination of the K–S test and multinomial distribution in noisy channels. To compare the performance from various perspectives, we compared the false alarm rates according to the length of the available bitstream, the detection probability according to code rates, and execution time. The performance of the proposed estimation algorithm was superior to that of Bernoulli, KLD, Multinomial, and MDS.
We exploited the fact that rank distributions of linear codes differ significantly from those of random sequences owing to the linear dependence of linear codes. To estimate interleaver periods using that property, we adopted the K–S test as a measure of the probability matching problem between the two rank distributions of the random binary signal and the received signal. After finding the final candidate of the interleaver period, we adopted Multinomial [
6] to control false alarm rates. The value of (
1) is lower than a threshold, it is enough to judge that it does not happen by chance.
In terms of probability matching metric, KLD includes logarithmic operations and considers all values between two PDFs, but the our method does not involve logarithmic calculations and finds the largest difference between the two CDFs. Despite the absence of logarithmic operations, our approach took 0.14 s longer than KLD, but with shorter execution times than Multinomial and MDS.
Through the experimental results, the proposed algorithm is verified by comparing false alarm rates, the estimated performance, and execution time. In terms of false alarm rates, the probability of false alarm appears as low as KLD. We can see that our algorithm outperforms Bernoulli, KLD, Multinomial, and MDS in terms of detection probability. Also, we calculate execution time for Bernoulli, KLD, Multinomial, MDS, and our method. Although our method was the third fastest among the compared algorithm, we can see that the computational complexity of the proposed method was about 48% lower than that of MDS. Experimental results verified that our method outperformed the previous algorithms with a relatively low computational complexity.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}