Author Contributions
Conceptualization, A.N., T.S., D.I., K.O., H.M., and M.N.; methodology, A.N., T.S., D.I., K.O., H.M., and M.N.; software, A.N.; validation, A.N.; formal analysis, A.N., T.S., D.I., K.O., H.M., and M.N.; investigation, A.N.; resources, A.N. and M.N.; data curation, A.N.; writing—original draft preparation, A.N.; writing—review and editing, A.N.; visualization, A.N.; supervision, T.S., D.I., K.O., H.M., and M.N.; project administration, M.N.; funding acquisition, M.N. All authors have read and agreed to the published version of the manuscript.
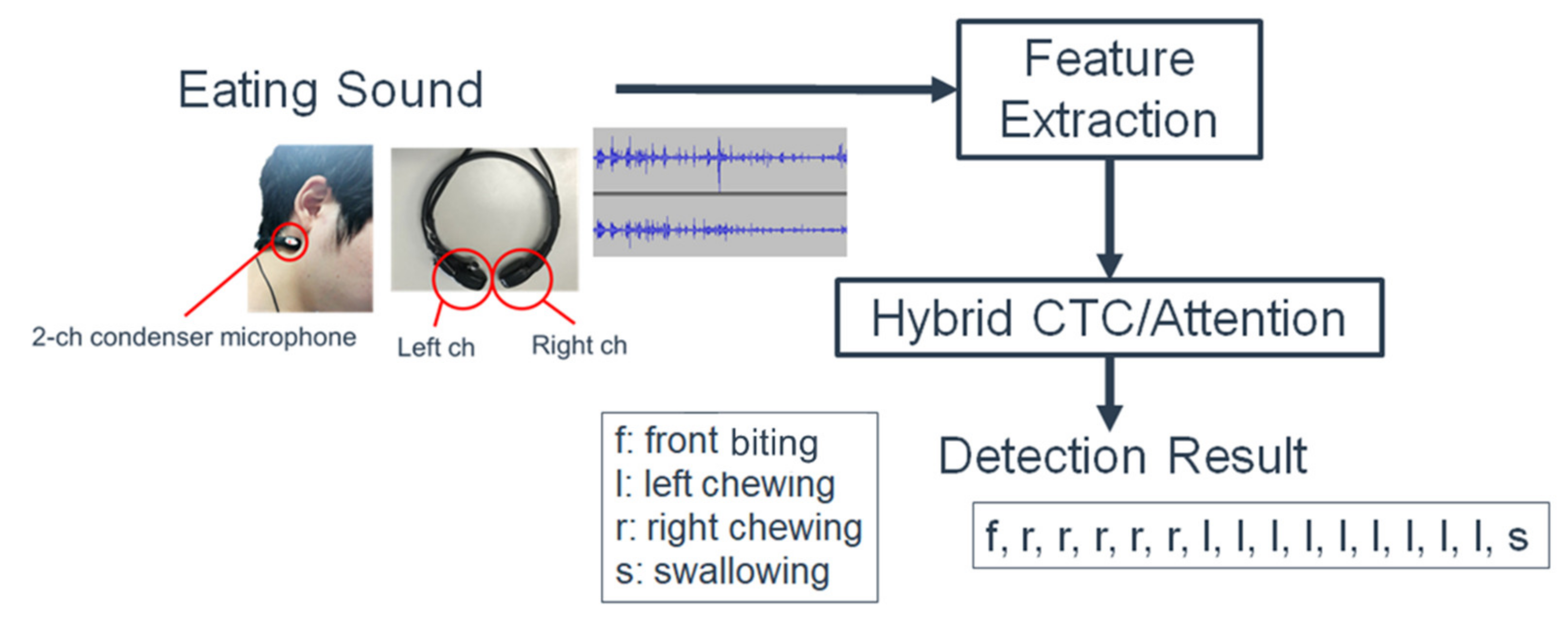
Figure 1.
The automatic detection system of left chewing, right chewing, front biting, and swallowing.
Figure 1.
The automatic detection system of left chewing, right chewing, front biting, and swallowing.
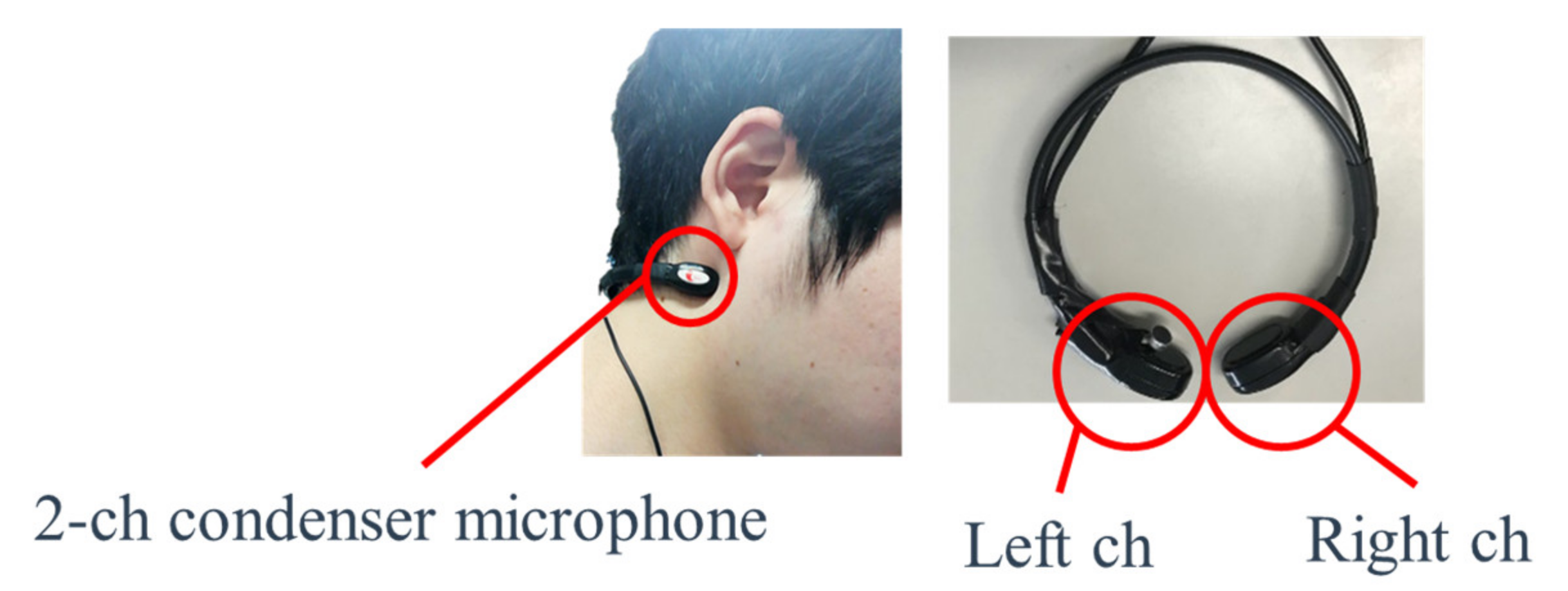
Figure 2.
The installation of the microphone and the microphone unit.
Figure 2.
The installation of the microphone and the microphone unit.
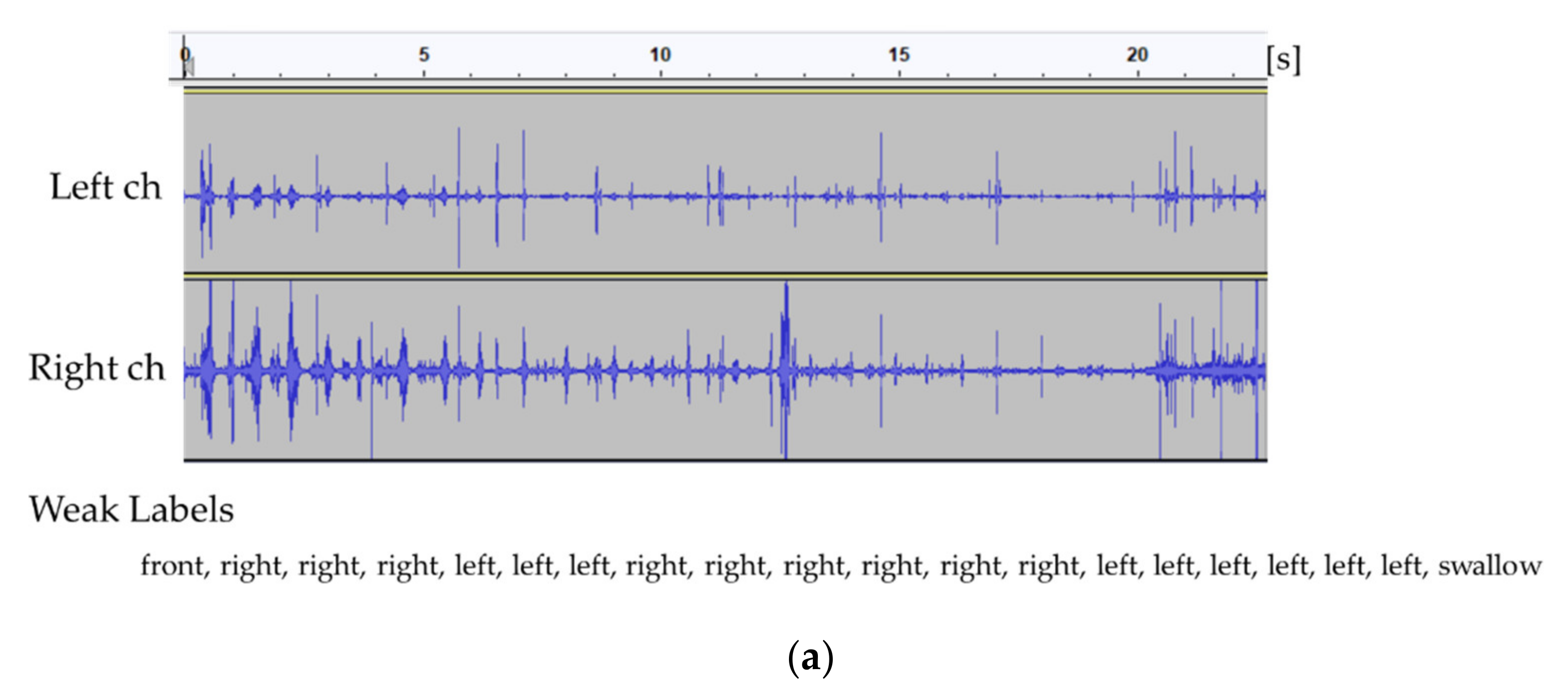
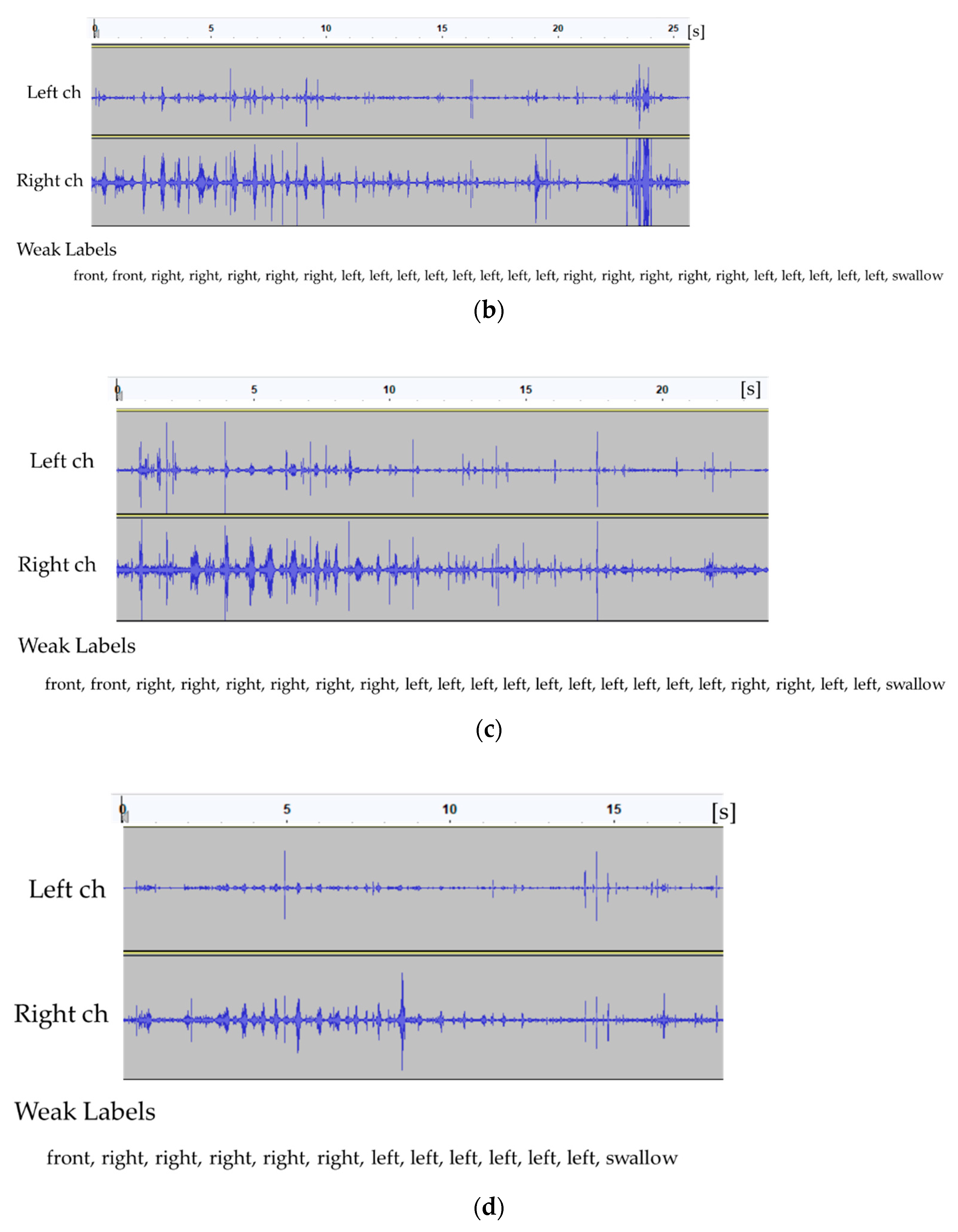
Figure 3.
Recorded eating sounds (one cracker) and their corresponding logs for each subject (a–d).
Figure 3.
Recorded eating sounds (one cracker) and their corresponding logs for each subject (a–d).
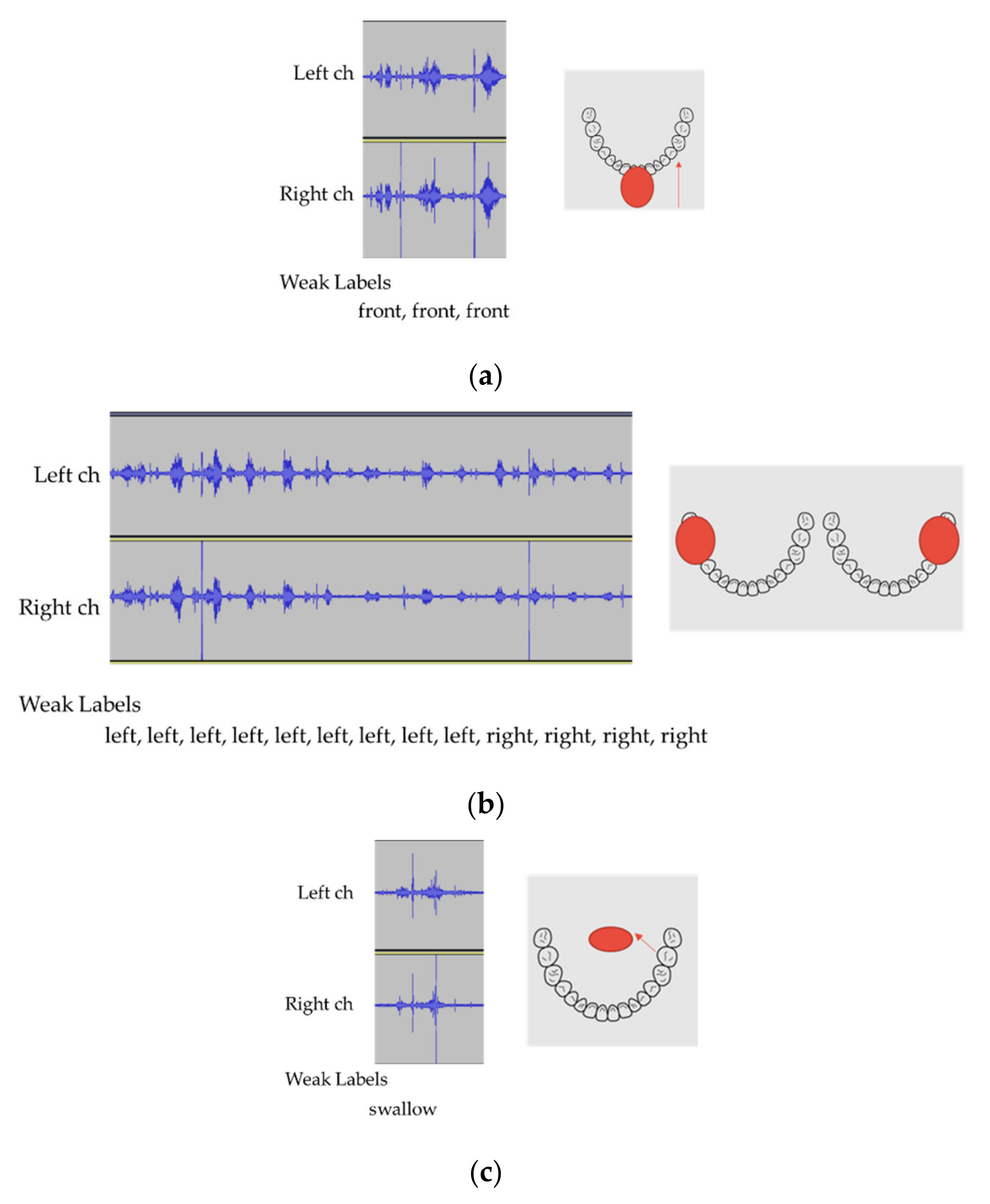
Figure 4.
Sample recorded eating sound (two-channel) and event sequence (weak labels) for one cracker.
Figure 4.
Sample recorded eating sound (two-channel) and event sequence (weak labels) for one cracker.
Figure 5.
Motion for eating one cracker (a) front biting, (b) left and right chewing, and (c) swallowing.
Figure 5.
Motion for eating one cracker (a) front biting, (b) left and right chewing, and (c) swallowing.
Figure 6.
Division of event sound data using weak labeled data.
Figure 6.
Division of event sound data using weak labeled data.
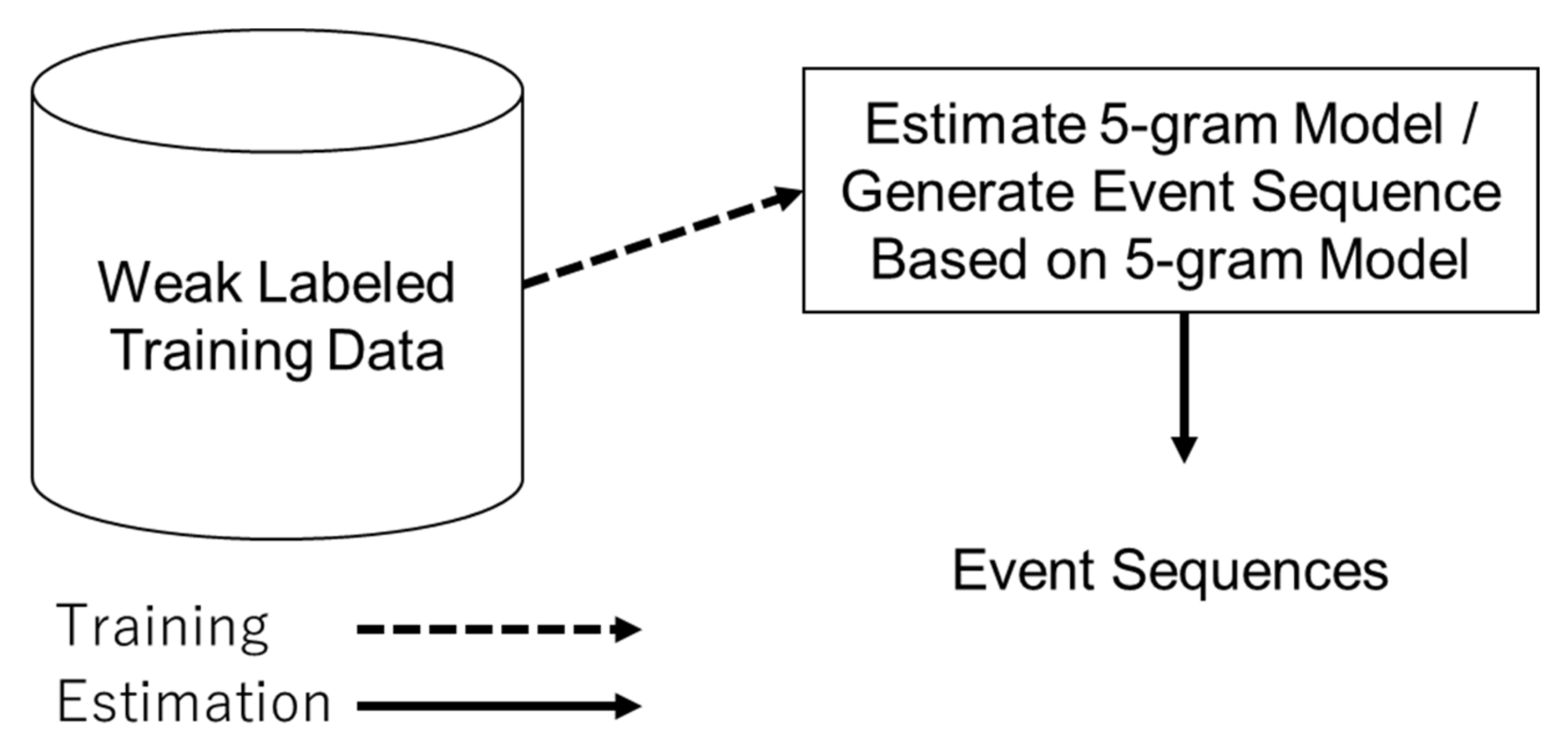
Figure 7.
The 5-gram based event sequence augmentation.
Figure 7.
The 5-gram based event sequence augmentation.
Figure 8.
Data augmentation by concatenating eating event sound data.
Figure 8.
Data augmentation by concatenating eating event sound data.
Figure 9.
The relationship between the amount of data augmentation and overall detection performance (closed food and hybrid CTC/attention model): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
Figure 9.
The relationship between the amount of data augmentation and overall detection performance (closed food and hybrid CTC/attention model): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
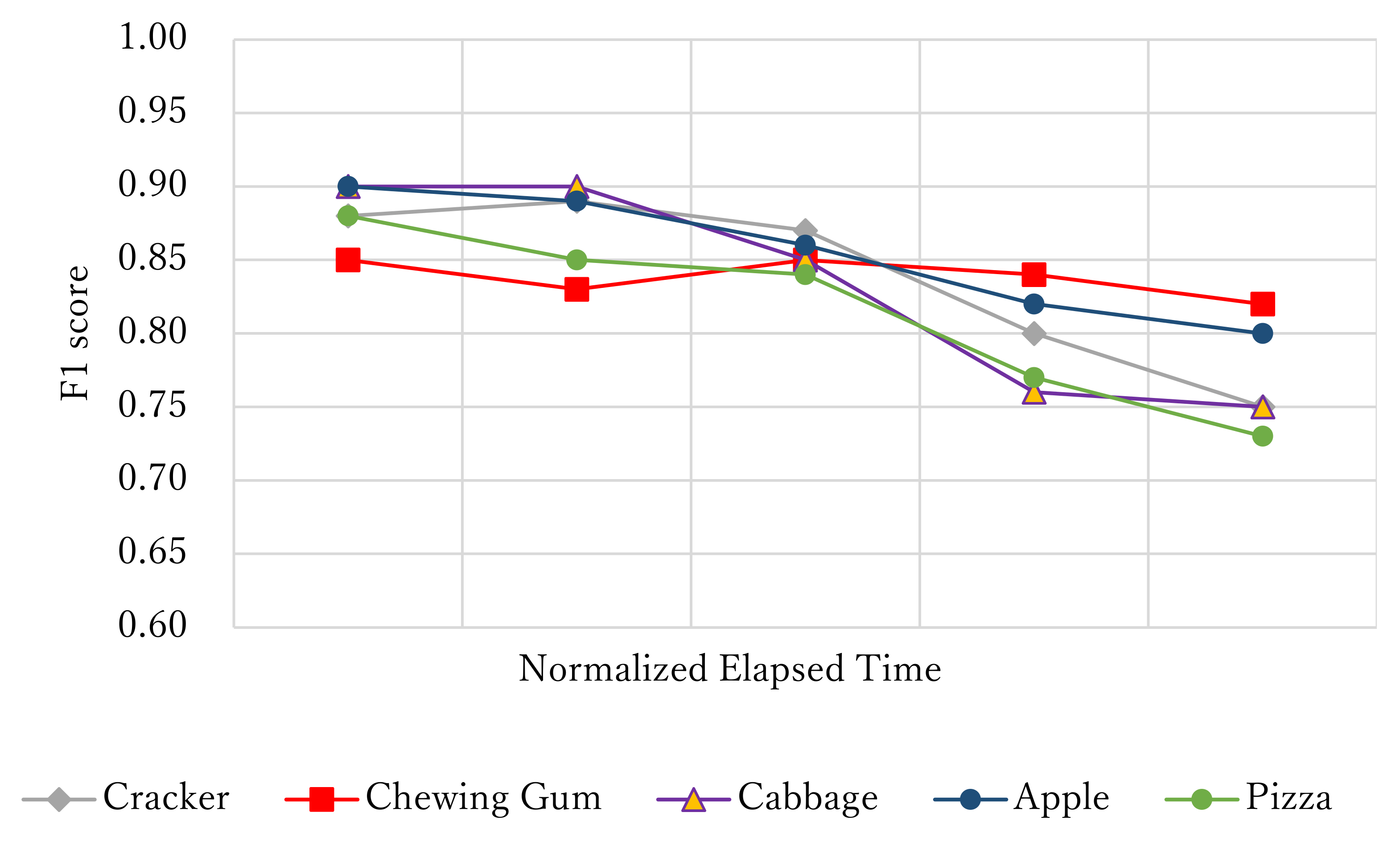
Figure 10.
Relationship between normalized elapsed time and F1 score (open food, hybrid CTC/attention model, and 10× data augmentation): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
Figure 10.
Relationship between normalized elapsed time and F1 score (open food, hybrid CTC/attention model, and 10× data augmentation): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
Table 1.
The overall detection performance of the model (closed food): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
Table 1.
The overall detection performance of the model (closed food): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
| Model | MAPE (%) |
|---|
| Attention | 46.3 |
| CTC | 33.6 |
| Hybrid CTC/attention | 19.5 |
Table 2.
Per-event detection performance by model (closed food): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
Table 2.
Per-event detection performance by model (closed food): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
| | CTC | Hybrid CTC/Attention |
|---|
| Event | Recall | Precision | F1 Score | Recall | Precision | F1 Score |
|---|
| Left chewing | 0.74 | 0.83 | 0.76 | 0.83 | 0.87 | 0.85 |
| Right chewing | 0.76 | 0.82 | 0.78 | 0.85 | 0.89 | 0.87 |
| Front biting | 0.34 | 0.66 | 0.45 | 0.44 | 0.67 | 0.53 |
| Swallowing | 0.80 | 0.40 | 0.60 | 0.80 | 0.70 | 0.75 |
Table 3.
The overall detection performance by sound feature (closed food and hybrid CTC/attention model): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
Table 3.
The overall detection performance by sound feature (closed food and hybrid CTC/attention model): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
| Sound Feature | MAPE (%) |
| MFCC of left signal | 81.4 |
| MFCC of right signal | 85.3 |
| Concatenation of MFCC of left and right signals | 46.6 |
| MFCC of the sum of left and right signals | 51.1 |
| Proposed * (3-point shift) | 19.8 |
| Proposed * (7-point shift) | 19.5 |
| Proposed * (15-point shift) | 19.9 |
Table 4.
N-gram and overall detection performance (closed food and hybrid CTC/attention model): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
Table 4.
N-gram and overall detection performance (closed food and hybrid CTC/attention model): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
| Model | MAPE (%) |
|---|
| Random | 21.5 |
| 2-gram | 20.0 |
| 5-gram | 18.9 |
| 7-gram | 18.9 |
Table 5.
Per-event detection performance by data augmentation (closed food and hybrid CTC/attention model): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
Table 5.
Per-event detection performance by data augmentation (closed food and hybrid CTC/attention model): Five-class detection (left chewing, right chewing, front biting, swallowing, and others).
| Event | Baseline | Augmented (10×, 5-gram) |
|---|
| Recall | Precision | F1 Score | Recall | Precision | F1 Score |
|---|
| Left Chewing | 0.81 | 0.87 | 0.84 | 0.84 | 0.87 | 0.85 |
| Right Chewing | 0.82 | 0.86 | 0.84 | 0.82 | 0.88 | 0.85 |
| Front Biting | 0.47 | 0.70 | 0.58 | 0.56 | 0.80 | 0.68 |
| Swallowing | 0.80 | 0.63 | 0.77 | 0.86 | 0.74 | 0.80 |
Table 6.
The detection performance of chewing side by food type (closed food, hybrid CTC/attention model, and 10× data augmentation).
Table 6.
The detection performance of chewing side by food type (closed food, hybrid CTC/attention model, and 10× data augmentation).
| Food Type | Three-Class Detection * | Five-Class Detection ** |
|---|
| Recall | Precision | F1 Score | Recall | Precision | F1 Score |
|---|
| Gum | 0.92 | 0.93 | 0.92 | 0.83 | 0.88 | 0.85 |
| Cracker | 0.91 | 0.95 | 0.93 | 0.81 | 0.89 | 0.85 |
| Cabbage | 0.93 | 0.95 | 0.94 | 0.82 | 0.88 | 0.84 |
Table 7.
Detection performance by food type (open food, hybrid CTC/attention model, and 10× data augmentation).
Table 7.
Detection performance by food type (open food, hybrid CTC/attention model, and 10× data augmentation).
| Food Type | Three-Class Selection * | Five-Class Detection ** |
|---|
| Recall | Precision | F1 Score | Recall | Precision | F1 Score |
|---|
| Apple | 0.89 | 0.85 | 0.92 | 0.82 | 0.89 | 0.86 |
| Pizza | 0.86 | 0.90 | 0.88 | 0.79 | 0.85 | 0.82 |


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}