Abstract
Positioning systems are used to determine position coordinates in navigation (air, land and marine). The accuracy of an object’s position is described by the position error and a statistical analysis can determine its measures, which usually include: Root Mean Square (RMS), twice the Distance Root Mean Square (2DRMS), Circular Error Probable (CEP) and Spherical Probable Error (SEP). It is commonly assumed in navigation that position errors are random and that their distribution are consistent with the normal distribution. This assumption is based on the popularity of the Gauss distribution in science, the simplicity of calculating RMS values for 68% and 95% probabilities, as well as the intuitive perception of randomness in the statistics which this distribution reflects. It should be noted, however, that the necessary conditions for a random variable to be normally distributed include the independence of measurements and identical conditions of their realisation, which is not the case in the iterative method of determining successive positions, the filtration of coordinates or the dependence of the position error on meteorological conditions. In the preface to this publication, examples are provided which indicate that position errors in some navigation systems may not be consistent with the normal distribution. The subsequent section describes basic statistical tests for assessing the fit between the empirical and theoretical distributions (Anderson-Darling, chi-square and Kolmogorov-Smirnov). Next, statistical tests of the position error distributions of very long Differential Global Positioning System (DGPS) and European Geostationary Navigation Overlay Service (EGNOS) campaigns from different years (2006 and 2014) were performed with the number of measurements per session being 900’000 fixes. In addition, the paper discusses selected statistical distributions that fit the empirical measurement results better than the normal distribution. Research has shown that normal distribution is not the optimal statistical distribution to describe position errors of navigation systems. The distributions that describe navigation positioning system errors more accurately include: beta, gamma, logistic and lognormal distributions.
1. Introduction
The assumption that a position line error in navigation has a normal distribution is commonplace for book authors [1,2,3], as well as in monographs, regulations and standards directly related to the statistical analysis of position errors [4,5]. It should be noted, however, that several scientific publications draw attention to existing differences between the empirical and theoretical distributions. Global Positioning System (GPS) is the basic positioning system used in navigation. Its operational characteristics are periodically described in several technical standards, of which Global Positioning System Standard Positioning Service Signal Specification versions have already been issued five times; in 1993, 1995, 2001, 2008, and 2020. The first version of this document [6] states expressly that the empirical error distributions are overlaid with Gauss distributions, as a basis for comparison with theoretical expectations (Figure 1). The theoretical distributions were generated using the means and standard deviations of the empirical datasets. The error distributions are based upon measured data from the GPS Control Segment monitor stations recorded for three months.
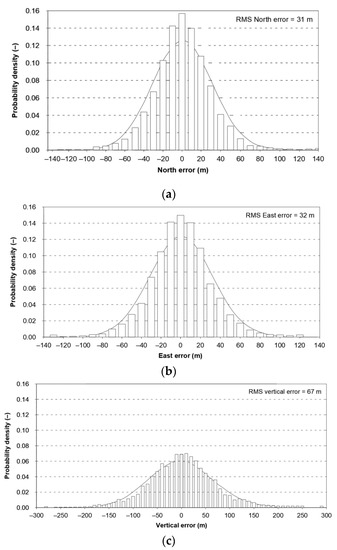
Figure 1.
Comparison of empirical data of the GPS position error in North (a), East (b) and vertical (c) axes with the theoretical normal distribution. Own study based on: [6].
The presented differences in local axes must result in significant differences in the fit of 2D position error with the chi-square distribution. Therefore, in the same document, Figure 2 presents the empirical (64 m) and theoretical (83 m) values of twice the Distance Root Mean Square (2DRMS) measure. It should be stressed that since the estimation error was as high as 19 m, 95% of the measurements will be smaller than this. In this situation, it is difficult to support the use of normal distribution for the calculation of the basic quantity describing the system positioning accuracy (2DRMS). Similar conclusions concerning the inconsistency of the statistical distributions of Differential Global Positioning System (DGPS) and GPS position errors are raised by the Frank van Diggelen, but with much smaller discrepancies [5].
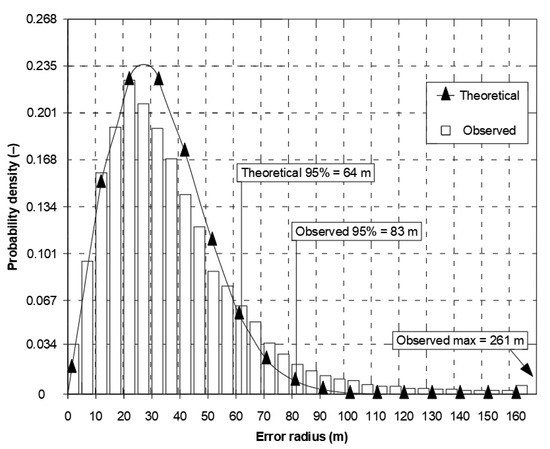
Figure 2.
Nominal GPS SPS horizontal error distribution. Own study based on: [6].
In the authors’ research on the accuracy of various navigation positioning systems, two measures of accuracy were also often compared: 2DRMS and R95. The latter is an empirical quantity calculated by sorting errors from the smallest to the largest. This value is higher than 95% of the measurements made. Please note that if the empirical 2DRMS statistics fit the chi-square distribution, these values should be almost identical. The author’s research into the accuracy of various Global Navigation Satellite Systems (GNSS), such as DGPS and European Geostationary Navigation Overlay Service (EGNOS) [7], GNSS geodetic networks, as well as multi-GNSS solutions [8,9], has repeatedly shown significant discrepancies between 2DRMS and R95 measures.
In order to quantify the discrepancy between the 2DRMS and R95 measures, let us analyse the results of the position accuracy tests of six different mobile phones working in parallel, which were conducted in 2017. The same smartphones were tested during both dynamic [8] and stationary [9] measurement campaigns. To compare the fit of both values, the concept of Relative Percent Error (RPE) has been introduced, according to the relationship:

Table 1.
Statistics of position errors of Samsung Galaxy phones during the dynamic measurement campaign. Own study based on: [8].
Table 2.
Statistics of position errors of Samsung Galaxy phones during the 24 h stationary measurement campaign. Own study based on: [9].
The research results indicated that the differences between the values of 2DRMS and R95 may reach a dozen percent or so. Therefore, it can be assumed that there may be significant differences between empirical distributions of latitude (φ) and longitude (λ) errors and the normal distribution. This problem may concern various navigation positioning systems, so it is justified to undertake more research into testing the actual results obtained by positioning systems.
This article examines the statistical fit between empirical distributions with theoretical position errors of two Differential Global Navigation Satellite Systems (DGNSS): marine DGPS and EGNOS. Two measurement campaigns of both systems were used for research purposes, during which more than 1–2 million fixes were recorded. Since there numerous measurements, the conclusions drawn from them can be considered representative. The research were carried out in the years 2006 and 2014.
The aim of the publication is:
- Determining the consistency of empirical distributions with the theoretical (normal and chi-square) for DGPS and EGNOS position errors. Latitude and longitude errors were referred to as the normal distribution and 2D position errors were referred to as the chi-square distribution.
- Finding statistical distributions other than normal and chi-square distributions that present a better fit with DGPS and EGNOS empirical data.
- Comparison of the statistical distributions of DGPS and EGNOS position errors from 2006 and 2014 will make it possible to answer the following question: do the statistical distributions of 1D and 2D position errors also change together with the evolution of the system and increases in its accuracy?
The introduction of the article describes the premises for starting the discussion. The author refers to the works of selected authors and their own research which discuss the discrepancies between empirical statistics of errors in the navigation positioning systems and their theoretical values. The materials and methods section presents selected statistical distribution measures together with the interpretation of the histogram, probability-probability (P-P) plots, as well as differences between the empirical and theoretical cumulative distribution functions. In addition, the three types of statistical tests used in the research were described (Anderson-Darling, chi-square and Kolmogorov-Smirnov). The main research results are shown in the results section and discussed in the discussion section. The publication ends with conclusions and suggestions for further research.
This is the second article in a series of monothematic publications, the aim of which will be statistical distribution analysis of navigation positioning system errors.
2. Materials and Methods
2.1. Statistical Distribution Measures
Statistical testing to assess the consistency of empirical with theoretical distributions should be preceded by the calculation of specific distribution measures to determine their asymmetry, central tendency, concentration and dispersion. It should be noted that there is no specific set of distribution measures for specific analyses or processes in navigation or statistics. This selection should result from the statistical nature of the variable under investigation and the research aim. For example, for normal distributions of φ and λ errors using GPS, it makes sense to determine both the mean and the median. If these values are similar, this may indicate the empirical distribution fitting the normal distribution. However, for a 2D position error distribution (which exhibits an asymmetric chi-square distribution), it is not justified to determine both of these values as this distribution is asymmetric by its nature.
With this in mind, it is proposed to divide the assessment of the fit between error distributions in the navigation positioning systems and the theoretical distributions into two stages:
- Stage I: Calculation of selected statistical distribution measures: asymmetry (skewness), central tendency (arithmetic mean and median), concentration (kurtosis) and dispersion (range, standard deviation and variance).
- Stage II: Statistical testing using Anderson-Darling, chi-square and Kolmogorov-Smirnov tests.
Table 3 presents selected statistical distribution measures that will be used for empirical testing of 1D and 2D position errors. Their definitions, estimators, interpretations and properties are also given.
Table 3.
Selected statistical distribution measures, their definitions, estimators, interpretations and properties, used to study φ and λ error distributions (separately) of navigation positioning systems.
2.2. Analysis of the Histogram, P-P Plot, as Well as Differences Between the Empirical and Theoretical Cumulative Distribution Functions
A histogram is a very important element in assessing the distribution of the studied population. It is one of the graphic methods of representing the empirical distribution of a characteristic. It is made up of a series of rectangles placed on the axis of coordinates. These rectangles are, on the one hand, determined by the class interval values of the characteristic, while their height is determined by the number (or frequency, or possibly also probability density) of elements included in a given class interval. If the histogram shows the number of elements and not the probability density, then the interval widths should be equal.
In P-P plots, the empirical probability distribution function is plotted against the theoretical distribution. The observations are first sorted in descending order. The i-th observation is then plotted on one axis as (i.e., the value of the observed cumulative distribution) and the other axis as F(xi), where F(xi) is the value of the theoretical probability distribution function for respective observation xi. If the theoretical cumulative distribution is a good approximation of the empirical distribution, then the points on the diagram should be close to the diagonal.
Regarding the idea behind them, the Fn(x), F(x) and Fn(x)–F(x) graphs are based on a comparison of empirical and theoretical distributions, similarly to P-P plots. They present both functions simultaneously or their differences.
2.3. Testing Statistical Distributions of Navigation Positioning System Errors
Testing statistical distributions of navigation positioning system errors is a key issue for assessing their distributions. This study tested the fit between 1D position errors (φ and λ) with the family of normal distributions. To this end, statistical hypotheses were verified, which means that any judgment on the population issued without detailed examination and verification was now tested. These allow determining whether the results obtained for the sample can be applied to the whole population [10].
In the literature review, it was noted that in statistical studies a large sample is considered to be a set consisting of at least 30 or 40 elements. Other samples are considered small. Furthermore, the sample size affects the choice of the type of statistical test. For example, the Shapiro-Wilk test, as confirmed by the experience of other authors, should be used for samples of less than 20 or 30 elements [11]. Another popular test, the Lilliefors test, is used to test the normality of distribution for samples of similar size to the Shapiro-Wilk test [12]. Tests such as the Cramér-von Mises test or the D’Agostino-Pearson test are used for statistical studies with large samples [13,14,15,16]. With this multitude of statistical tests, it was decided to choose the three most frequently used tests for large samples: Anderson-Darling, chi-square and Kolmogorov-Smirnov [17,18,19].
As in the statistical analysis, since it was planned to use records from a navigation positioning system ranging from several hundred thousand to over two million measurements, it became necessary to determine the appropriate sample size [20,21,22]. Based on the literature [23,24,25], to obtain the desired test power (0.8) at a significance level of 5% for the most popular statistical distributions, such as log-normal, normal, Weibull, etc., the statistical hypotheses should be tested for a sample size of about 1000 elements.
The approach to statistical testing presented above is based on a well-known statistical research theory. However, navigation positioning systems have a specific feature that distinguishes them from other measurement systems. This feature is the Position Random Walk (PRW). Its essence lies in the position coordinates “walking” around the reference coordinates. This issue has been described in detail in [26]. In this publication, a detailed analysis of this phenomenon was presented with the need to ensure a representative sample size highlighted based on empirical research. In addition, it shows that it is only selecting a representative sample size and 1000 measurements should be randomly drawn from this sample for statistical testing.
2.4. Statistical Tests Used in Research
The following statistical tests were used in the research:
- Anderson-Darling test: This test is based on the Cramér-von Mises weighted distance between the empirical Fn(x) and theoretical F(x) distributions with weights corresponding to the inverse of the empirical distribution variance (note that Fn(x) has a binomial distribution) [27]:
Test statistics based on the above distance for a simple random sample xi may be written as:
where:
- Chi-square test: This test is based on the χ2 statistic [28]:which, for a true zero hypothesis, has an asymptotic distribution χ2. The Ei symbol indicates the expected number of observations in the i class and Oi stands for the actual number of observations in the i class.
- Kolmogorov-Smirnov test: The test is based on the supremum distance between the empirical Fn(x) and theoretical F(x) distribution functions [29,30]:
Test statistics based on the above distance consist of counting the maximum module of probability distribution difference at the empirical distribution function step points:
2.5. Description of DGPS and EGNOS Measurement Campaigns
Studies of the position determination accuracy of the DGPS and EGNOS systems have been conducted in Poland for many years [31,32,33]. Due to the changing values of GPS position errors, which resulted in the increasing accuracy of DGPS and EGNOS augmentation systems, such research were conducted regularly in the years 2006 and 2014. The paper analyses two long-term measurement campaigns:
- The first measurement campaign took place in March 2006, in Gdynia (Poland). During this campaign, 2’187’842 fixes for DGPS and 1’774’705 fixes for EGNOS were recorded respectively with a recording frequency of 1 Hz.
- The second measurement campaign took place in May 2014, in Gdynia (Poland). During this campaign, 951’698 fixes for DGPS and 927’553 fixes for EGNOS were recorded respectively with a recording frequency of 1 Hz.
Studies of both measurement campaigns included the installation of the DGPS and EGNOS receivers always in the same place-on the radio beacon in the port of Gdynia (Figure 3). It was a reference point with ellipsoidal coordinates amounting to: φ = 54°31.756087′ N, λ = 18°33.574138′ E and h = 68.070 m. During the measurement campaigns, typical DGPS (Leica MX9212 + MX51R) and EGNOS (Septentrio PolaRx2e) receivers with the possibility of saving data in the form of National Marine Electronics Association (NMEA) GGA messages were used. These measurements yielded text files with position coordinates which were compliant with the data transmission protocol described above. They contain geographic coordinates of designated points presented in angular (curvilinear) measure. To determine individual measurement errors, they were projected from the surface of the World Geodetic System 1984 (WGS 84) ellipsoid to a flat surface using Gauss-Krüger projection.
Figure 3.
Measurement site-the radio beacon in the port of Gdynia.
2.6. Research Assumptions
Basic assumptions for research and numerical analyses were as follows:
- Preliminary analyses carried out in [26] showed that a representative sample for DGPS and EGNOS systems should consist of about 900’000 measurements. Only with this sample size, 1D and 2D position errors are representative. Therefore, each of the analysed campaigns was shortened so that all sessions consist of the same number of measurements (900’000 fixes).
- Analysis of the campaigns (DGPS 2006, DGPS 2014, EGNOS 2006 and EGNOS 2014) with the same number of measurements makes it possible to compare their results and draw generalised conclusions.
- Selected statistical distribution measures (asymmetry, central tendency, concentration and dispersion) were determined for the same sample size (900’000 fixes).
- For statistical testing of fit between empirical distributions of 1D position errors (φ and λ) with the normal distribution, 1000 measurements were randomly selected and subjected to Anderson-Darling, chi-square and Kolmogorov-Smirnov tests.
- In comparative analyses of empirical distributions (1D and 2D position errors), the most frequently used theoretical distributions were used: Beta, Cauchy, chi-square, exponential, gamma, Laplace, logistic, lognormal, normal, Pareto, Rayleigh, Student’s and Weibull.
- Two values were used to assess position accuracy: the 2DRMS(2D) value, which was determined for the entire population (900’000 fixes) based on the relationship:
- sφ—standard deviation of geodetic (geographic) latitude,
- sλ—standard deviation of geodetic (geographic) longitude,
and the R95 value, which was determined by sorting the data from the lowest to the highest value.
- Easy Fit software was used for the analyses. To evaluate the fit of empirical with theoretical distributions, a significance level of 5% was assumed. The rankings of the best fit distributions were created based on the Kolmogorov-Smirnov statistic (D).
- Mathcad software was used to calculate the values of 2DRMS(2D) and R95(2D) and plot graphs of the position error distribution.
3. Results
3.1. DGPS 2006 Results
The study started with analyses of φ and λ error distributions assessed individually. Table 4 presents the results of statistical analysis and tests of φ and λ errors determined using the DGPS system in 2006. These include the evaluation of selected distribution measures and the results of testing the statistical fit of φ and λ errors with the normal distribution.
Table 4.
Statistical analysis of distribution measures and statistical tests of φ and λ errors using the DGPS system in 2006.
Next, in Table 5 the fit between empirical data of φ and λ errors and distributions other than the normal distribution for the DGPS system in 2006 was assessed.
Table 5.
Analysis of fit between empirical data of φ and λ errors and distributions other than the normal distribution for the DGPS system in 2006.
Statistical analysis of φ and λ errors presented in Table 4 and Table 5 allows for the following conclusions:
- Central tendency measures: The mean values of φ and λ errors are very close to zero, which is indicative of a symmetrical distribution of 1D position errors in the N-S and E-W directions.
- Dispersion measures: The dispersion of φ and λ errors (s) is similar, with a similar range value, which indicates that the use of circular measures (2DRMS) of 2D position error is justified.
- Skewness: The latitude and longitude errors exhibit a weak asymmetry, thus both distributions can be considered to be symmetrical.
- Kurtosis: The latitude and longitude errors are leptokurtic (Kurt > 0), which means that they are more concentrated around the mean value than the normal distribution would suggest.
- Statistical testing: All tests have shown that λ error fits the normal distribution. The inverse relationship can be observed for φ error.
- Fit: Statistical distributions that fit empirical data best are beta (φ error) and lognormal (λ error) distributions. These distributions exhibit a much better fit to empirical data than the normal distribution.
Similar analyses were carried out with respect to the 2D position error. Their results are presented in Table 6 and Table 7.
Table 6.
Statistical analysis of distribution measures of 2D position error using the DGPS system in 2006.
Table 7.
Analysis of fit between empirical data of 2D position error and distributions other than the normal distribution for the DGPS system in 2006.
- Please note that there are no outliers in the measurements under analysis, which indicates the high quality of the positioning services provided by the DGPS system.
- The 2DRMS and R95 values are similar, which confirms that the φ and λ error distributions have similar distributions.
- The distribution of 2D position error is, by its nature, asymmetrical, hence the best fit distributions include: beta, gamma, lognormal, Rayleigh and Weibull distributions.
3.2. DGPS 2014 Results
Similarly to the 2006 measurements, the results of the 2014 campaign analysis are presented in an identical tabular form in Table 8, Table 9, Table 10 and Table 11 below.
Table 8.
Statistical analysis of distribution measures and statistical tests of φ and λ errors using the DGPS system in 2014.
Table 9.
Analysis of fit between empirical data of φ and λ errors and distributions other than the normal distribution for the DGPS system in 2014.
Table 10.
Statistical analysis of distribution measures of 2D position error using the DGPS system in 2014.
Table 11.
Analysis of fit between empirical data of 2D position error and distributions other than the normal distribution for the DGPS system in 2014.
Statistical analysis of φ and λ errors presented in Table 8 and Table 9 allows for the following conclusions:
- Central tendency measures: The mean values of φ and λ errors are very close to zero, which is indicative of a symmetrical distribution of 1D position errors in the N-S and E-W directions.
- Dispersion measures: The latitude error has a dispersion (s) of about one and a half times higher than longitude error with a similar range value.
- Skewness: The latitude and longitude errors exhibit a very weak asymmetry, thus both distributions can be considered to be symmetrical.
- Kurtosis: The latitude and longitude errors are leptokurtic (Kurt > 0), which means that they are more concentrated around the mean value than the normal distribution would suggest. The very high concentration of 1D position errors represented by the kurtosis value [Kurt(φ) = 6.204 and Kurt(λ) = 12.956] needs emphasis. Compared to the 2006 measurement campaign, the system has significantly increased this parameter, which results in an increase in 2D position accuracy.
- Statistical testing: The Anderson-Darling and Kolmogorov-Smirnov tests have shown that φ error fits the normal distribution. However, all tests were rejected for λ error.
- Fit: The statistical distribution that fits empirical data best is the logistic distribution (φ and λ errors).
Similar analyses were carried out with respect to the 2D position error. Their results are presented in Table 10 and Table 11.
- Please note that there are no outliers in the measurements under analysis, which indicates the high quality of the positioning services provided by the DGPS system.
- The values of 2DRMS and R95 are similar. Moreover, the values of 2DRMS and R95 are below 1 m, which proves the very good accuracy of the system.
- The figure of the 2D position error distribution may suggest that the empirical distribution has a “linear trend”. However, this is not the case, because less than 0.17% (1496 fixes) of the studied population have an error greater than or equal to 2 m. Therefore, they can be considered as outliers.
- The distribution of 2D position error is, by its nature, asymmetrical, hence the best fit distributions include: beta, gamma, lognormal, Rayleigh and Weibull distributions.
3.3. EGNOS 2006 Results
Two EGNOS measurement campaigns were tested from two different implementation phases. The 2006 campaign dates from the period when the system was not fully operational [it was then in the initial operational capability (IOC) phase]. This can be interpreted as a period in which the system was not fully stable and there may have been some position errors classified as gross. However, the 2014 campaign was made in the Full Operational Capability (FOC). Table 12 presents the results of statistical analysis and tests of φ and λ errors determined using the EGNOS system in 2006. These include the evaluation of selected distribution measures and the results of testing the statistical fit of φ and λ errors with the normal distribution.
Table 12.
Statistical analysis of distribution measures and statistical tests of φ and λ errors using the EGNOS system in 2006.
Studies have shown a very wide range of both φ (321.739 m) and λ (161.565 m) errors. Therefore, data represented by the kurtosis for φ and λ errors were very concentrated, although the average values of both variables are close to zero. Skewness calculated for λ error also reached a high value (1.410).
In order to determine the numerical scale of outlier measurements that caused this anomaly, Figure 4 presents histograms of φ and λ errors to make the number of outliers visible.
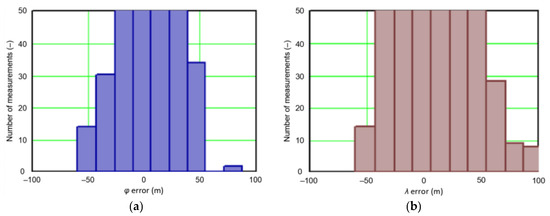
Figure 4.
Histograms of φ (a) and λ (b) errors using the EGNOS system in 2006. The chart was cut to show the number of outliers.
Figure 4 shows that both for φ and λ errors outliers even by −60–60 m were quite frequent (more than 10 fixes). There is no doubt that the assessment of the statistical distribution of position errors from the EGNOS 2006 measurement campaign cannot be considered representative and no general conclusions can be drawn from it. Predictably, statistical testing of the fit between empirical data of φ and λ errors with the normal distribution showed a lack of fit.
Despite the anomalies identified in this campaign resulting from the status of the system (IOC), the EGNOS system was tested in the same way as the DGPS system. The results are presented in Table 13, Table 14 and Table 15.
Table 13.
Analysis of fit between empirical data of φ and λ errors and distributions other than the normal distribution for the EGNOS system in 2006.
Table 14.
Statistical analysis of distribution measures of 2D position error using the EGNOS system in 2006.
Table 15.
Analysis of fit between empirical data of 2D position error and distributions other than the normal distribution for the EGNOS system in 2006.
Results presented in Table 13 indicate that the Cauchy distribution is the best fit for φ and λ errors.
Similar to the DGPS system, the analysis was carried out in relation to the 2D position error. The results are presented in Table 14 and Table 15.
From Table 14 and Table 15, it follows that a considerable number of outliers and the lack of fit between the errors and the normal distribution caused the values of 2DRMS and R95 to differ significantly. The distributions being the best fit for the EGNOS 2006 2D position error are: beta, exponential, gamma, lognormal and Weibull distributions.
3.4. EGNOS 2014 Results
The measurements of the EGNOS system carried out in 2014, which are analysed in this subsection, should be considered fully representative, since in 2014 the system operated in FOC mode. Table 16, Table 17, Table 18 and Table 19 present the results of statistical analyses. The method used was identical as for the DGPS 2006 and 2014 studies.
Table 16.
Statistical analysis of distribution measures and statistical tests of φ and λ errors using the EGNOS system in 2014.
Table 17.
Analysis of fit between empirical data of φ and λ errors and distributions other than the normal distribution for the EGNOS system in 2014.
Table 18.
Statistical analysis of distribution measures of 2D position error using the EGNOS system in 2014.
Table 19.
Analysis of fit between empirical data of 2D position error and distributions other than the normal distribution for the EGNOS system in 2014.
Statistical analysis of φ and λ errors presented in Table 16 and Table 17 allows for the following conclusions:
- Central tendency measures: The mean values of φ and λ errors are very close to zero, which is indicative of a symmetrical distribution of 1D position errors in the N-S and E-W directions.
- Dispersion measures: The dispersion of φ error (s) and the range value are almost twice the value for λ error.
- Skewness: The latitude error exhibits significant skewness to the right, whereas the longitude error exhibits slight skewness to the left.
- Kurtosis: The latitude and longitude errors are leptokurtic (Kurt > 0), which means that they are more concentrated around the mean value than the normal distribution would suggest.
- Statistical testing: The Anderson-Darling and Kolmogorov-Smirnov tests have shown that λ error fits the normal distribution. However, all tests were rejected for φ error.
- Fit: Statistical distributions that fit empirical data best are lognormal (φ error) and logistic (λ error) distributions. These distributions exhibit a much better fit to empirical data than the normal distribution.
Similar to the DGPS system, the analysis was carried out in relation to the 2D position error. The results are presented in Table 18 and Table 19.
- Please note that there are no outliers in the measurements under analysis, which indicates the high quality of the positioning services provided by the EGNOS system.
- The values of 2DRMS and R95 are similar. Moreover, the values of 2DRMS and R95 are below 1 m, which proves the very good accuracy of the system.
- The distribution of 2D position error is, by its nature, asymmetrical, hence the best fit distributions include: beta, gamma, lognormal, Rayleigh and Weibull distributions.
4. Discussion
In order to assess which of the statistical distributions are the best fit for empirical data of DGPS and EGNOS systems, Table 20 and Table 21 summarise the analyses and studies carried out. Points (1–10) were assigned to individual distributions to allow the selection of the best fit. The distributions being the best fit were assigned 10 points.
Table 20.
Statistical distributions being the best fit for empirical data from DGPS 2006 and 2014 measurement campaigns.
Table 21.
Statistical distributions being the best fit for empirical data from EGNOS 2006 and 2014 measurement campaigns.
The use of distribution gradations (from the best to the worst fit) and assigning points to them made it possible to determine those distributions which present the best fit in three categories:
- (1)
- (2)
- Best fit 1D position error distribution where the fit results for 1D errors were analysed from the following measurement campaign: DGPS 2006, DGPS 2014 and EGNOS 2014.
- (3)
- Best fit 2D position error distribution where the fit results for 2D error were analysed from the following measurement campaign: DGPS 2006, DGPS 2014 and EGNOS 2014.
In the analyses in points 2 and 3, the results of the EGNOS 2006 measurement campaign were omitted due to its low representativeness. Cumulative results are presented in Table 22.
Table 22.
Statistical distributions which were the best fit for the measurement campaigns analysed depending on the position dimension (1D, 2D or 1D and 2D).
The results presented in Table 22 indicate that:
- The universality of the lognormal distribution which approximates both 1D and 2D position errors.
- Beta, gamma, logistic and Weibull distributions fit almost as well as the lognormal distribution.
- The normal distribution, commonly used for analysing navigation positioning system errors, is only suitable for 1D applications.
- The chi-square distribution, which is often recommended for position error analysis (especially 2D), shows no significant similarity to empirical data obtained from navigation positioning systems.
5. Conclusions
The Gauss distribution is commonly used to present results of accuracy analyses for the position determination by navigation systems. Due to the simplicity of calculations, the special features of standard deviation, as well as the intuitive perception of randomness in statistics to which this distribution corresponds, it is commonly used in science. It should be noted however that the necessary conditions for a random variable to be normally distributed include the independence of measurements and identical conditions of their realisation, which is not the case in the iterative method of determining successive positions, the filtration of coordinates or the dependence of the position error on meteorological conditions. The consistency of φ and λ errors was tested on DGPS and EGNOS systems. For each of the systems, the analyses used two measurement campaigns from 2006 and 2014.
Studies of DGPS (2006 and 2014) and EGNOS (2014) systems confirmed that φ and λ errors alternately fit the normal distribution, but also showed that the normal distribution is not an optimal statistical distribution to describe the navigation positioning system errors. The distributions that describe positioning system errors more accurately include: beta, gamma, logistic, lognormal and Weibull distributions. The results of the EGNOS 2006 measurement campaign cannot be considered representative and no general conclusions can be drawn from it. This is due to the fact that the EGNOS system was then in the IOC phase, hence numerous position errors classified as gross have appeared during the measurements (Figure 4). The research proved that in order to reliably determine navigation positioning system errors, statistical analyses should be performed using various distributions (by selecting the best one) for a representative sample size.
This is the second article in a series of monothematic publications [26], the aim of which will be statistical distribution analysis of navigation positioning system errors. One of the next research issues that has not been studied in this article will be to determine the impact of GNSS errors (ionospheric and tropospheric effects, multipath, noise, etc.) that influence the consistency of the empirical distributions of navigation positioning system errors with theoretical distributions.
Funding
This research was funded from the statutory activities of Gdynia Maritime University, grant number WN/2020/PZ/05.
Conflicts of Interest
The author declares no conflict of interest.
References
- Bowditch, N. American Practical Navigator; Paradise Cay Publications: Blue Lake, CA, USA, 2019; Volume 1 & 2. [Google Scholar]
- Cutler, T.J. Dutton’s Nautical Navigation, 15th ed.; Naval Institute Press: Annapolis, MD, USA, 2003. [Google Scholar]
- Hofmann-Wellenhof, B.; Legat, K.; Wieser, M. Navigation—Principles of Positioning and Guidance; Springer: Wien, Austria, 2003. [Google Scholar]
- Langley, R.B. The Mathematics of GPS. GPS World 1991, 2, 45–50. [Google Scholar]
- van Diggelen, F. GPS Accuracy: Lies, Damn Lies, and Statistics. GPS World 1998, 9, 1–6. [Google Scholar]
- U.S. DoD. Global Positioning System Standard Positioning Service Signal Specification, 1st ed.; U.S. DoD: Arlington County, VA, USA, 1993.
- Specht, C.; Pawelski, J.; Smolarek, L.; Specht, M.; Dabrowski, P. Assessment of the Positioning Accuracy of DGPS and EGNOS Systems in the Bay of Gdansk using Maritime Dynamic Measurements. J. Navig. 2019, 72, 575–587. [Google Scholar] [CrossRef]
- Specht, C.; Dabrowski, P.; Pawelski, J.; Specht, M.; Szot, T. Comparative Analysis of Positioning Accuracy of GNSS Receivers of Samsung Galaxy Smartphones in Marine Dynamic Measurements. Adv. Space Res. 2019, 63, 3018–3028. [Google Scholar] [CrossRef]
- Szot, T.; Specht, C.; Specht, M.; Dabrowski, P.S. Comparative Analysis of Positioning Accuracy of Samsung Galaxy Smartphones in Stationary Measurements. PLoS ONE 2019, 14, e0215562. [Google Scholar] [CrossRef]
- Masereka, E.M.; Otieno, F.A.O.; Ochieng, G.M.; Snyman, J. Best Fit and Selection of Probability Distribution Models for Frequency Analysis of Extreme Mean Annual Rainfall Events. Int. J. Eng. Res. Dev. 2015, 11, 34–53. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An Analysis of Variance Test for Normality (Complete Samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Lilliefors, H.W. On the Kolmogorov-Smirnov Test for Normality with Mean and Variance Unknown. J. Am. Stat. Assoc. 1967, 62, 399–402. [Google Scholar] [CrossRef]
- Anscombe, F.J.; Glynn, W.J. Distribution of the Kurtosis Statistic b2 for Normal Samples. Biometrika 1983, 70, 227–234. [Google Scholar] [CrossRef]
- Cramér, H. On the Composition of Elementary Errors. Scand. Actuar. J. 1928, 1928, 13–74. [Google Scholar] [CrossRef]
- D’Agostino, R.B. Transformation to Normality of the Null Distribution of g1. Biometrika 1970, 57, 679–681. [Google Scholar] [CrossRef]
- D’Agostino, R.; Pearson, E.S. Tests for Departure from Normality. Empirical Results for the Distributions of b2 and √b1. Biometrika 1973, 60, 613–622. [Google Scholar] [CrossRef]
- Ahad, N.A.; Yin, T.S.; Othman, A.R.; Yaacob, C.R. Sensitivity of Normality Tests to Non-normal Data. Sains Malays. 2011, 40, 637–641. [Google Scholar]
- Lehmann, R. Observation Error Model Selection by Information Criteria vs. Normality Testing. Stud. Geophys. Geod. 2015, 59, 489–504. [Google Scholar] [CrossRef][Green Version]
- Ramljak, I.; Bago, D. Statistical Approach in Analyzing of Advanced Metering Data in Power Distribution Grid. J. Commun. Softw. Syst. 2019, 15, 159–165. [Google Scholar] [CrossRef]
- Binu, V.S.; Mayya, S.S.; Dhar, M. Some Basic Aspects of Statistical Methods and Sample Size Determination in Health Science Research. Int. Q. J. Res. Ayurveda 2014, 35, 119–123. [Google Scholar]
- Das, S.; Mitra, K.; Mandal, M. Sample Size Calculation: Basic Principles. Indian J. Anaesth. 2016, 60, 652–656. [Google Scholar] [CrossRef]
- Jones, S.R.; Carley, S.; Harrison, M. An Introduction to Power and Sample Size Estimation. Emerg. Med. J. 2003, 20, 453–458. [Google Scholar] [CrossRef]
- Ogunleye, L.I.; Oyejola, B.A.; Obisesan, K.O. Comparison of Some Common Tests for Normality. Int. J. Probab. Stat. 2018, 7, 130–137. [Google Scholar]
- Razali, N.M.; Wah, Y.B. Power Comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling Tests. J. Stat. Model. Anal. 2011, 2, 21–33. [Google Scholar]
- Yap, B.W.; Sim, C.H. Comparisons of Various Types of Normality Tests. J. Stat. Comput. Simul. 2011, 81, 2141–2155. [Google Scholar] [CrossRef]
- Specht, M. Statistical Distribution Analysis of Navigation Positioning System Errors—Issue of the Empirical Sample Size. Sensors 2020, 20, 7144. [Google Scholar] [CrossRef] [PubMed]
- Anderson, T.W.; Darling, D.A. A Test of Goodness of Fit. J. Am. Stat. Assoc. 1954, 49, 765–769. [Google Scholar] [CrossRef]
- Pearson, K. On the Criterion that a Given System of Deviations from the Probable in the Case of a Correlated System of Variables is Such that it Can be Reasonably Supposed to have Arisen from Random Sampling. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1900, 50, 157–175. [Google Scholar] [CrossRef]
- Kolmogorov, A. Sulla Determinazione Empirica di una Legge di Distribuzione. G. Ist. Ital. Attuari 1933, 4, 83–91. (In Italian) [Google Scholar]
- Smirnov, N. Table for Estimating the Goodness of Fit of Empirical Distributions. Ann. Math. Stat. 2007, 19, 279–281. [Google Scholar] [CrossRef]
- Dziewicki, M.; Specht, C. Position Accuracy Evaluation of the Modernized Polish DGPS. Pol. Marit. Res. 2009, 16, 57–61. [Google Scholar] [CrossRef]
- Mięsikowski, M.; Nowak, A.; Specht, C.; Oszczak, B. EGNOS—Accuracy Performance in Poland. Ann. Navig. 2006, 11, 63–72. [Google Scholar]
- Specht, C. Accuracy and Coverage of the Modernized Polish Maritime Differential GPS System. Adv. Space Res. 2011, 47, 221–228. [Google Scholar] [CrossRef]












































Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).