1. Introduction
In many practical engineering applications, the actual values of the required state variables are often not directly available. For example, when radar detects an air target, it can calculate the target distance based on information such as reflected waves. Still, there is random interference in the radar detection process, resulting in random noise in the observation signal. In this case, it is impossible to obtain the required state variables accurately, and these state variables can only be estimated or predicted based on the observed signal. In linear systems, the Kalman filter is the optimal filter [
1]. With the development of computer technology, the calculation requirements and complexity of Kalman filtering no longer become obstacles to its application [
2]. At present, the Kalman filtering theory has been widely used in tracking, navigation, guidance, and other areas [
3,
4,
5,
6,
7,
8,
9].
The application of the Kalman filter requires prior knowledge of the mathematical model of the system and the statistical characteristics of noise. Still, in many practical application problems, these are unknown or only partially known [
10,
11,
12]. If inaccurate mathematical models or statistical noise characteristics are used to design the Kalman filter, the performance of the filter will be degraded, resulting in larger estimation errors, and even filter divergence. To solve this problem, various adaptive Kalman filters (AKF) have been produced [
13,
14].
The Sage–Husa filter (SH-KF) is widely used because of its simple algorithm, which can estimate the first and second moments of noise online [
15]. However, the Sage–Husa adaptive noise estimator has problems such as a large amount of calculation and easy divergence of state estimation [
16]. In addition, some literature has pointed out that the covariance matrices of process noise and observation noise cannot be estimated dynamically in real-time by the Sage–Husa adaptive estimator at the same time, which can only estimate the other noise covariance matrix when one noise covariance matrix is known [
17,
18]. The maximum-likelihood-based adaptive filtering method (ML-KF) can evaluate and correct the second-order moments of the noise statistics online, but it needs to rely on accurate innovation covariance estimation, and ML-KF requires a large sliding window to obtain a precise estimate of the noise covariance matrix, which theoretically makes it only for time-varying noise covariance matrix estimation [
19,
20]. Strong tracking Kalman filter (ST-KF) is an adaptive filtering algorithm based on the principle of residual orthogonality. It adjusts the weight of new measurement data by adding an estimate of the one-step predictive covariance matrix. It has strong robustness regarding model parameter mismatch, lower sensitivity to the statistical characteristics of noise and initial values, and a strong ability to track sudden changes. But its adjustment ability for each filtering channel is the same, and state predicted error covariance matrix (PECM) and measurement noise covariance matrix (MNCM) are not estimated [
21,
22]
In recent years, many scholars have introduced the variational Bayesian machine-learning method into the KF algorithm and proposed AKF algorithm based on the variational Bayesian approach (VB-KF), which is an approximation of the Bayesian method. By choosing a suitable conjugate prior distribution, the slow time-varying measurement noise covariance can be estimated [
23,
24,
25]. Literature [
26] proposed a variational adaptive Kalman filter (R-VBKF) but only estimated the system state vector and the measurement noise covariance matrix (MNCM); the accuracy is not satisfactory enough. In the algorithm presented in the literature [
27], the state predicted error covariance matrix (PECM) and the measurement noise covariance matrix (MNCM) are estimated, but the process noise covariance matrix (PNCM) is not directly assessed. The specific estimated value of the PNCM cannot be obtained, and the estimation accuracy needs to be further improved.
Aiming at the linear Gaussian state–space model with slow time-varying covariance of process and measurement noise, taking into account the estimation accuracy, convergence performance, robustness, and the realization of simultaneous estimation of noise covariance matrices, the multi-fading factor and updated monitoring strategy, AKF-based variational Bayesian (MFMS-VBAKF) is proposed. Its feasibility is proved by simulation experiments.
The main contributions of the algorithm proposed in this paper are as follows: compared with the inverse-Gamma distribution applied by the R-VBKF algorithm in [
25], the algorithm proposed in this paper selects the distribution of the measurement noise model as a more reasonable inverse-Wishart distribution in variational Bayesian approach, which improves the estimation accuracy of system state vector and MNCM; compared with SH-KF in [
15], the algorithm proposed in this paper guarantees the positive semi-definiteness of the PNCM under the maximum posterior estimation by designing an updated monitoring strategy, and achieves the simultaneous estimation of the PNCM and MNCM.; and compared with ST-KF [
21], the proposed algorithm has different adjustment abilities for each channel by introducing multi-fading factors and the PECM estimation accuracy is also improved.
The main structure is as follows:
Section 2 illustrates the mathematical modeling of the problem. In
Section 3, the multi-fading factor and updated monitoring strategy AKF-based variational Bayesian is derived. In
Section 4, the proposed algorithm is compared with the existing algorithm through the simulation of the target tracking application, and the excellent performance of the proposed algorithm is proved.
Section 5 summarizes the conclusions. Finally,
Section 6 plans the future work.
2. Problem Modeling
Consider the following discrete linear stochastic system of the state–space model
where (1) and (2) are process and measurement equations, respectively.
is discrete-time,
is the state vector of the system at time
,
is the measurement signal vector of the corresponding state.
is the state-transition matrix,
is the measurement matrix.
and
are uncorrelated white Gaussian noise with zero mean vectors and covariance matrices
and
respectively. The initial state
is assumed to be a Gaussian distribution with mean vector
and the covariance matrix
.
is uncorrelated to
and
at any time [
1].
For linear Gaussian state–space models, the Kalman filter (KF) algorithm is an optimal estimation filter algorithm. If the noise covariance matrices and are fully known, KF estimates the state vector through the measurement information of , and the estimation accuracy is satisfactory. However, the performance of the KF algorithm overly depends on the prior knowledge of the noise statistics. If the time-varying noise covariance matrices and are unknown or inaccurate, the accuracy of the KF algorithm will decrease, and even cause the estimation to diverge. Besides, when most existing AKF algorithms estimate the PNCM and MNCM at the same time, the filtering will diverge. Therefore, a multi-fading factor and updated monitoring strategy AKF-based variational Bayesian with inaccurate time-varying PNCM and MNCM is proposed.
3. The Proposed Multi-Fading Factor and Updates Monitoring Strategy AKF-Based Variational Bayesian
In the VBAKF algorithm, the independent state vector and the measurement noise covariance matrix are regarded as the parameters to be estimated.
3.1. AKF-Based Variational Bayesian (VBAKF)
3.1.1. Prediction Process and Distribution Selection
In the traditional Kalman filter framework, the Gaussian distributions are selected as the distributions of one-step predicted probability density function (PDF)
and likelihood PDF
:
where
is the Gaussian distribution and
and
represent the mean and variance of the distribution, respectively. The PDF of the Gaussian distribution is:
According to Equation (1), the predicted state vector
and the corresponding one-step predicted error covariance matrix (PECM)
can be described as:
where
and
represent the state estimation at time
and the corresponding estimation error covariance matrix, respectively.
represents the transpose of the matrix. Among them, it is assumed that the real PNCM
is unknown due to the complex environmental factors in real applications, which will lead to an inaccurate
in Equation (7). The estimation methods for
and
will be given in the next two sections.
In this section, the aim is to infer with . For the purpose, the conjugate prior distributions need to be first selected for inaccurate MNCM since the conjugacy can ensure that the posterior distribution and the prior distribution maintain the same functional form.
According to Bayesian statistical theory, if the Gaussian distribution has a known mean, the conjugate prior distribution of the covariance matrix can be regarded as the inverse Wishart (IW) distribution [
28].
is the inverse matrix of a positive definite matrix
. If
follows the Wishart-distribution
, the matrix
follows the IW distribution:
In Equation (8),
is a symmetric positive definite random matrix, distribution parameter
is a dof parameter,
is a symmetric positive definite matrix, d is the dimension of
,
represents a multivariate gamma function,
is the matrix trace calculation. Additionally, if
and
, then
.
stands for mathematical expectation calculation [
29]. Since
is the covariance matrix of the Gaussian PDF, the prior distribution of
can be written as IW distribution:
where
and
denote the degrees of freedom (dof) parameter and scale matrix of
, respectively. Next, the values of
and
need to be assigned.
Owing to the Bayesian theorem, the prior distribution
can be written as:
where
) is the posterior probability density function (PDF) of the MNCM
.
Utilizing (9), the distribution of posterior PDF
can be replaced as inverse Wishart distribution, due to the prior distribution
of MNCM
is selected as inverse Wishart distribution, and
can be written as:
To guarantee
also obeys the inverse Wishart distribution, a changing factor
is introduced to modify the one-step predicted values of the distribution parameters
and
. The formulas are as follows:
among them,
m is the dimension of
,
, the time-varying measurement noise covariance matrix can be changed with a certain probability distribution, and control the posterior and prior probability density functions to have the same distribution.
In addition, the initial PDF distribution of MNCM
is also assumed as inverse Wishart distribution.
. At the initial moment, to formulate the prior information of the measurement noise covariance matrix, the mean value of
is considered as the initial fixed measurement noise covariance matrix
, i.e.,
Assuming that the prior distribution of the joint probability density function of the state variable and the MNCM is the product of the Gaussian distribution and the inverse Wishart distribution, the prediction process can be defined as:
3.1.2. Variational Update Process
Aiming at estimating the state
and the MNCM
, their joint posterior PDF
needs to be calculated. However, the analytical solution of this joint posterior PDF cannot be obtained directly. The variational Bayesian method is utilized to find an approximate PDF of a free form as follows [
30]:
where
means the approximate posterior PDF of
.
In the standard VB method, Kullback–Leibler divergence (KLD) is used to measure the degree of approximation between the approximation posterior PDF and the true posterior PDF, and the optimal solution is obtained by minimizing KLD. The VB method can provide a closed form solution for the approximate posterior PDF. Minimizing the KLD between the approximation posterior PDF
,
and the true joint posterior
is used to form the VB-approximation [
30]:
The divergence function KLD(.) is defined as:
Combined with Equations (17) and (18), the optimal solution of Equation (16) is derived as:
where
stands for natural logarithm calculation,
denotes the expectation calculation of the approximate posterior PDF of the variable
,
and
represent the constants of variable
and MNCM
, respectively. The solutions of Equations (19) and (20) cannot be solved directly since
and
are coupled. Therefore, the fixed-point iteration method is introduced to calculate the solution to these parameters.
The further form of Equation (20) can be derived as (See
Appendix A for details):
where:
represents the approximate probability distribution of
at the
-th iteration,
is the calculation of the matrix trace,
is a constant related to
which independent of the distribution form, and
is the dimension of the real observation matrix. The expectation part of Equation (21) is defined as
, and expanded as:
it can be seen that
obeys a new inverse Wishart distribution form as follows,
and the distribution parameters
and
are, respectively, as follows:
Similarly, the logarithmic expression of the approximate distribution of the system state
is as follows:
where
is given by:
The likelihood PDF
in Equation (4) after updating the (
)-th iteration can be derived as follows:
The corrected measurement noise covariance matrix (MNCM)
can be written as:
Since
obeys the Gaussian distribution as
. Combining with the standard Kalman filter framework, the gain matrix
, system state
, and state covariance
in the variational measurement update are corrected as follows, respectively:
Analyzing the above derivation, it can be seen that the implicit solution of the variational update formula is constituted by the Equations (22), (24), (25), and (29)–(32). The expected maximum approach is used to iteratively calculate
and
to update the parameters
and
to be estimated continuously. When
and
are closer to
, the KLD value of Equation (17) is smaller, and the estimation results of the parameter to be estimated adaptively approach to the true value until the iteration of the variational update process is finished. At this time, the optimal estimation results of parameters
and
to be estimated at time
can be calculated as follows (
is the number of fixed-point iterations):
3.2. Updated Monitoring Strategy Based on Maximum a Posterior (MAP) for Estimating the PNCM
Some existing adaptive filtering methods estimate the process noise covariance matrix (PNCM)
and measurement noise covariance matrix (MNCM)
at the same time, it is easy to cause the accuracy of the estimated value of the state
to decrease or even diverge. This is caused by the value of
becoming negative definite matrix during the estimation process [
17].
Aiming at realizing the simultaneous estimation of the PNCM , MNCM and improving the estimation accuracy of the state vector . An updated monitoring strategy based on maximum a posterior (MAP) for estimating the PNCM is proposed.
According to the state–space model as Equations (1) and (2), in paper [
15], the maximum a posteriori suboptimal unbiased estimation method based on the noise statistics of measurement
for estimating the PNCM
is given as:
combining Equation (35) with the conclusion of
Section 3.1, where
=
is the optimal gain calculated by VBAKF through
th variational iterations at time
,
is the state covariance calculated after
th variational iterations at time
is the residual.
From a statistical point of view, Equation (35) is an arithmetic average, and the weight coefficient in the formula is
. However, when estimating the time-varying process noise covariance matrix, the role of the latest information should be highlighted, which can be achieved by multiplying each item in
by a different weighting coefficient. Owing to the exponential weighting method, we can assign different weights to each item in
, and increase the weight of the latest information, thereby improving the accuracy of
estimation. The exponential weighting method is introduced, and the weighting coefficient
is selected to satisfy:
further deduced as follows:
where
is the attenuation factor. In
of Equation (35), each item is multiplied by the weight coefficient
, instead of the original weight coefficient. The time-varying process noise covariance matrix (PNCM)
estimation method is obtained, and the recursive algorithm is derived as:
Equations (7), (30)–(32), and (38) constitutes the VBAKF algorithm that simultaneously estimates the PNCM , MNCM , state vector and one-step predicted state error covariance matrix (PECM) .
However, through simulation experiments, the estimation of the PNCM by the above algorithm is prone to abnormality; that is, it loses positive semi-definiteness, which leads to filtering divergence.
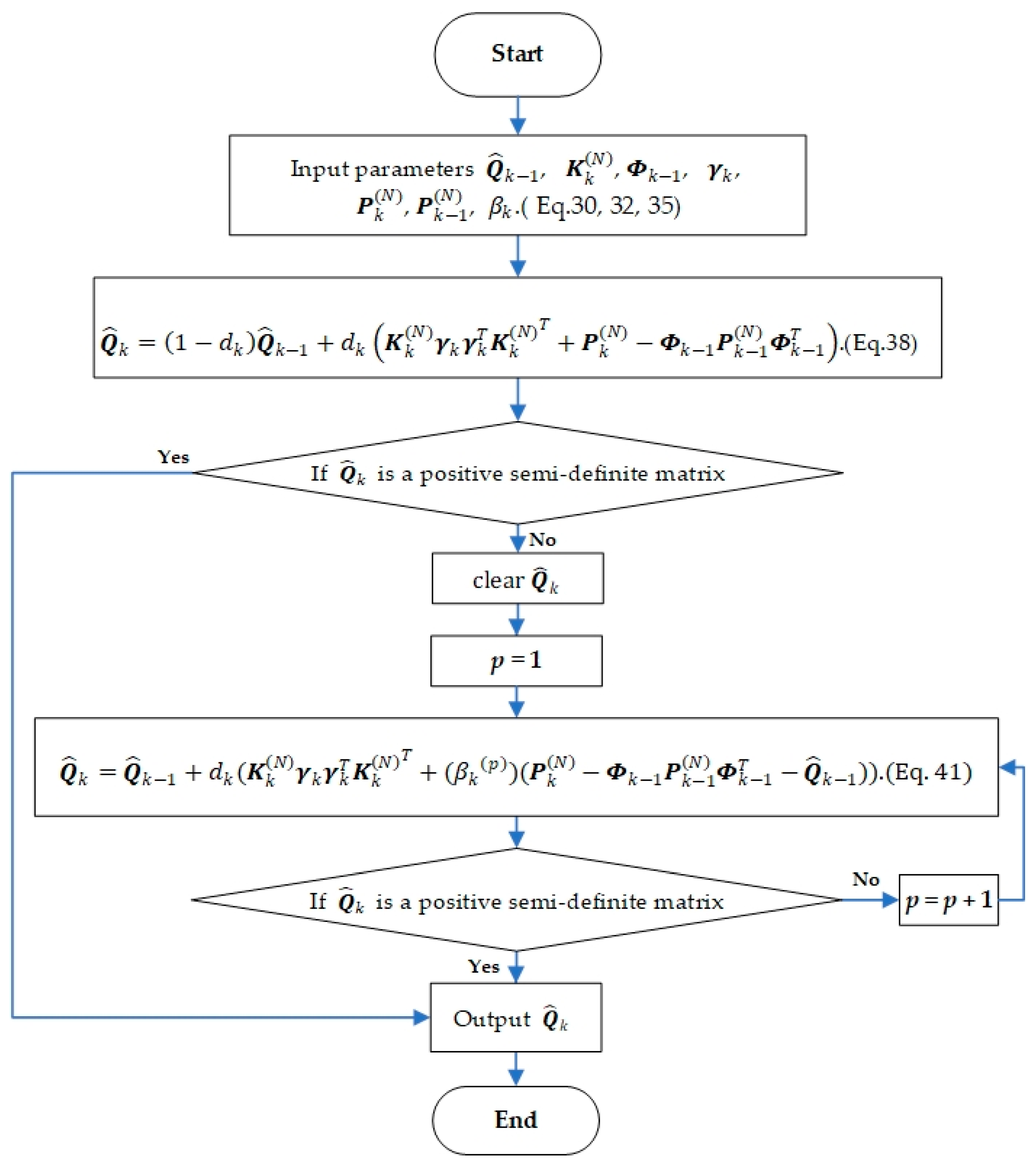
To solve this problem, based on not losing the information of the original process noise estimation algorithm (38), an updated monitoring strategy of process noise parameters is designed. Firstly, it is judged whether calculated by Equation (38) is a positive semi-definite matrix. Then the adjustment factor is introduced to update the process noise estimation parameters to ensure that the corrected PNCM meets the requirements.
The right side of the Equation (38) is shifted as follows:
Generally speaking, the selection of the initial value of the state error covariance matrix
is imprecise, and the deviation from the ideal value is large in the initial stage of filtering, resulting in the absolute value of the theoretical process noise covariance matrix
determined by Equation (39) being much larger than
. It is easy to cause
to lose the positive semi-definiteness, and then the filtering will diverge. Therefore, it is necessary to introduce an adjustment factor to attenuate the effect of the state error covariance matrix at the initial moment, to avoid the indefiniteness of the estimated value of the PNCM, to prevent the filter from diverging. The updated monitoring strategy of the PNCM is as follows:
where
is a positive integer (the initial value is 1),
is the adjustment factor, and the value of
is related to the state error variance matrix as follows:
The specific process for the updated monitoring strategy is as follows: monitor the process noise covariance matrix calculated by Equation (38), and judge whether
is a positive semi-definite matrix to determine whether
needs to be updated. If not, output
. Otherwise, turn to Equation (41) and set
Equation (41) is used to update the process noise parameters. Continue the monitoring of the updated estimated process noise covariance matrix to determine whether it is necessary to continue to update. If it is necessary, take
Equation (41) is used to recalculate
. The loop is executed until
is a positive semi-definite matrix. End the update of the process noise covariance matrix at the current moment. The flowchart of one time-step of the updated monitoring strategy is shown in
Figure 1.
So far, combined with the traditional Kalman filter framework, the VBAKF algorithm with updated monitoring strategy is derived to estimate system state vector , the process noise covariance matrix (PNCM) , measurement noise covariance matrix (MNCM) , one-step predicted state error covariance matrix (PECM) , and state error covariance matrix at the same time.
3.3. Improved by Introducing Multiple Fading Factors
If the statistical characteristics of the process and measurement noise are time-varying, the convergence speed of VBAKF will slow down, and there will be a particular error in the estimation result, which will be reflected by the residual sequence
[
31].
In view of this, to improve the accuracy of estimation, the multiple fading factor
is introduced to realize the correction of the one-step predicted error covariance matrix (PECM)
. Equation (7) can be rewritten as:
adjusting the gain
in real-time to keep
orthogonal, forcing the filter to keep track of the actual state of the system. The tracking ability is thereby improved [
31]. The calculation method of multiple fading factors
is as follows:
where
is the dimension of the state vector
,
, the value of
is determined by the system prior information. The formula of
is as follows:
where
is the
-th element of the main diagonal of
, the calculation formulas of
and
are as follows:
In Equation (48),
is the weakening factor and
is unknown and can be estimated by the following formula:
where
is the forgetting factor.
Since
is used to correct the one-step predicted error covariance matrix (PECM) in the prediction step of the filtering algorithm, the initial value
of the MNCM
must be set in advance, assuming that
also obeys the inverse Wishart distribution. The estimated value of measurement noise covariance matrix
in the time-update step is defined as:
In Equation (51), the variation range of the slowly time-varying measurement noise covariance matrix is small, and the estimated value at the previous time still has a great reference value for the current time estimation. Therefore, estimated by the variational update recursively of the previous time is used as at time . is used as the time-varying parameter of to modify the one-step predicted error covariance matrix (PECM) more accurately, and the accurate can affect the accuracy of the estimation result of the variational iteration recursion directly.
The multi-fading factor and updated monitoring strategy AKF-based variational Bayesian in this paper is composed of Equations (6), (12)–(14), (22)–(25), (27), (29)–(34), (41)–(51). The pseudo-code implementation of the proposed MFMS-VBAKF algorithm is listed in Algorithm 1.
| Algorithm 1 One time-step of the proposed multi-fading factor and updated monitoring strategy AKF-based variational Bayesian |
| Inputs:,,,,,,,,,,,,,, |
| Time update: |
| 1., |
| 2. ifthen |
| 3. , |
| 4. , |
| 5. else |
| 6. |
| 7. |
| 8.,
|
| 9., |
| 10., |
| 11. if |
| 12.
|
| 13. else |
| 14.
|
| 15. |
| 16. |
| 17., |
| 18., |
| 19. |
| 20. |
| 21. whiledo |
| 22. |
| 23. , |
| 24. |
| Iterated measurement update |
| 25. Initialization |
| 26. |
| 27., |
| for |
| Updategivenand: |
| 28. |
| 29. |
| 30. |
| 31. |
| 32. |
| End for |
| 33., , , , |
| Outputs:,,,,, |
4. Simulations and Results
The application of the proposed algorithm in target tracking is simulated. The target moves according to the continuous white noise accelerated motion model in the two-dimensional Cartesian coordinate system. Sensors are used to collect the target location. The system state is defined as
, where
and
represent the Cartesian coordinates of the target at time
,
and
represent the velocity of the target at the corresponding position [
24,
25]. The state transition matrix
and the measurement matrix
are respectively set as:
where the parameter
represent the sampling interval, and
represent the n-dimensional unit matrix. Similar to [
25], the true process noise covariance matrix (PNCM) and the measurement noise covariance matrix (MNCM) are set to slow time-varying models, which are:
The simulation environment is set as follows: is the total simulation time, is a parameter related to process noise, and is a parameter related to measurement noise. The fixed PNCM and MNCM are set as and , respectively, where and are the prior confidence parameters used to adjust the initial fixed noise covariance matrix.
The parameters in the MFMS-VBAKF algorithm proposed in this paper are set as follows:,, changing factor , the number of variational iterations , the initial value of the variational parameter ,, forgetting factor , the weakening factor , the parameter , and the attenuation factor .
This paper compares MFMS-VBAKF and true noise covariance matrix Kalman filter (TCMKF) [
1], fixed noise covariance matrix Kalman filter (FCMKF) [
1], SH-KF [
15], ML-KF [
20], ST-KF [
21], and R-VBKF [
26] algorithms.
Table 1 lists the estimated parameters and parameter settings of the existing algorithms. All algorithms are programmed using MATLAB R2018a, and the simulation program runs on a computer with Intel
® Core™ i5-6300HQ CPU at 2.30 GHz and 8GB of RAM.
With the aim of evaluating the accuracy of system state estimation, the root mean square error and average root mean square error of position and velocity are regarded as performance indicators, which are defined as follows:
where
and
respectively, represent the true value and estimated value of the position in the
-th Monte Carlo experiment and
represents the total number of Monte Carlo experiment runs. Similarly, the calculation formulas of RMSE and ARMSE for the corresponding velocity can be obtained.
True and estimated trajectories of the target are shown in
Figure 2. It can be seen that, compared to the existing adaptive filtering algorithm, the proposed filter maintains excellent target tracking performance throughout the entire process.
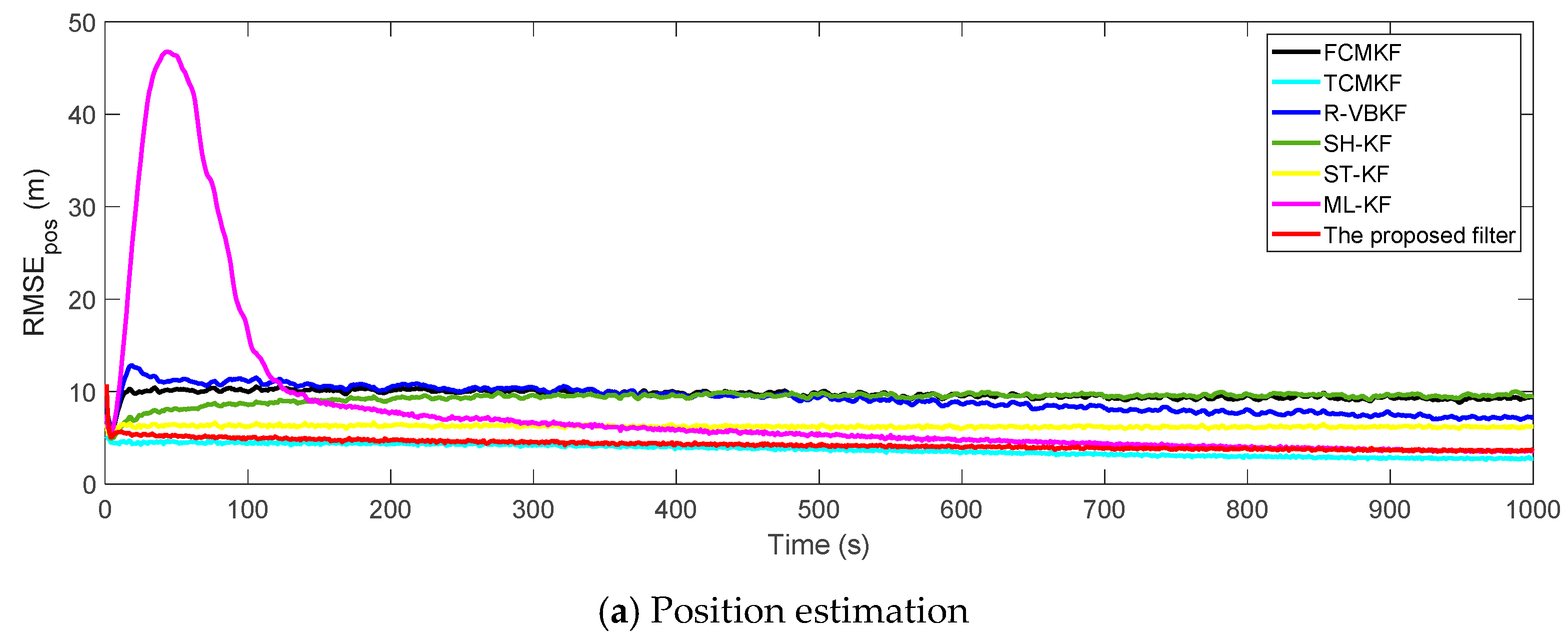
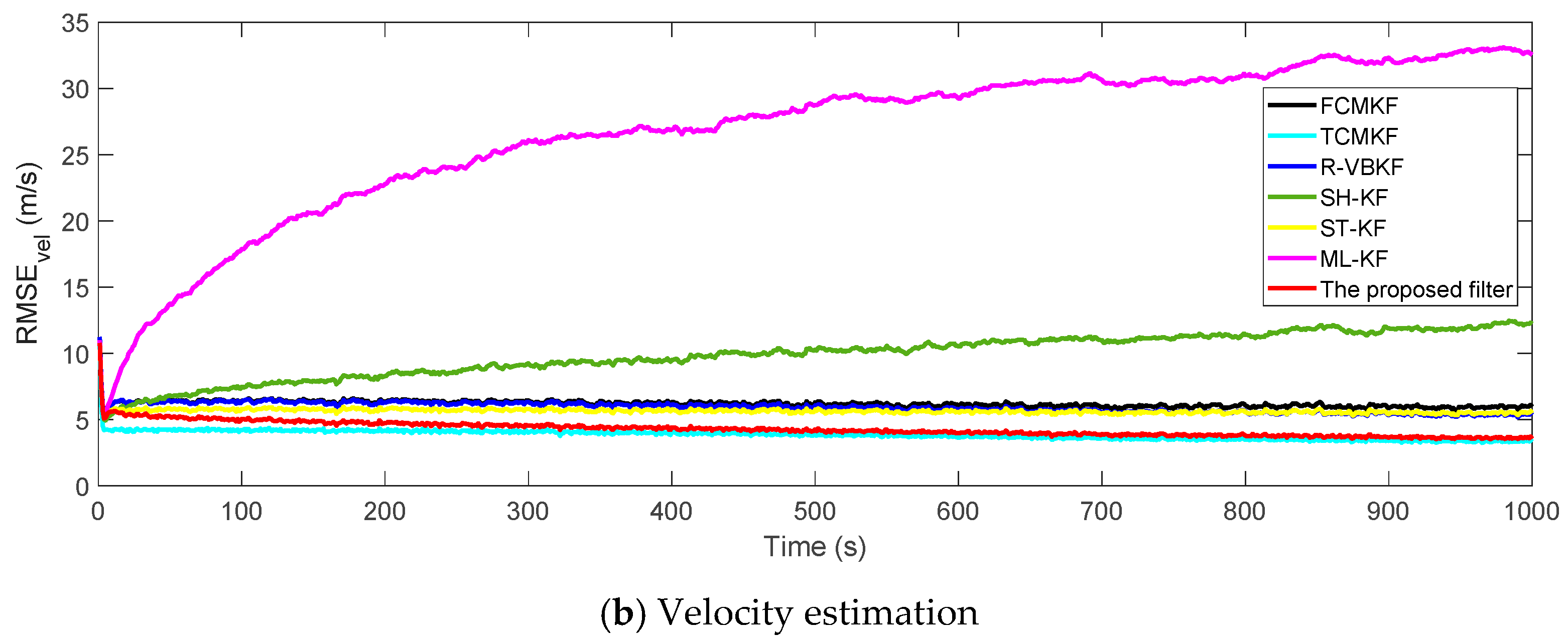
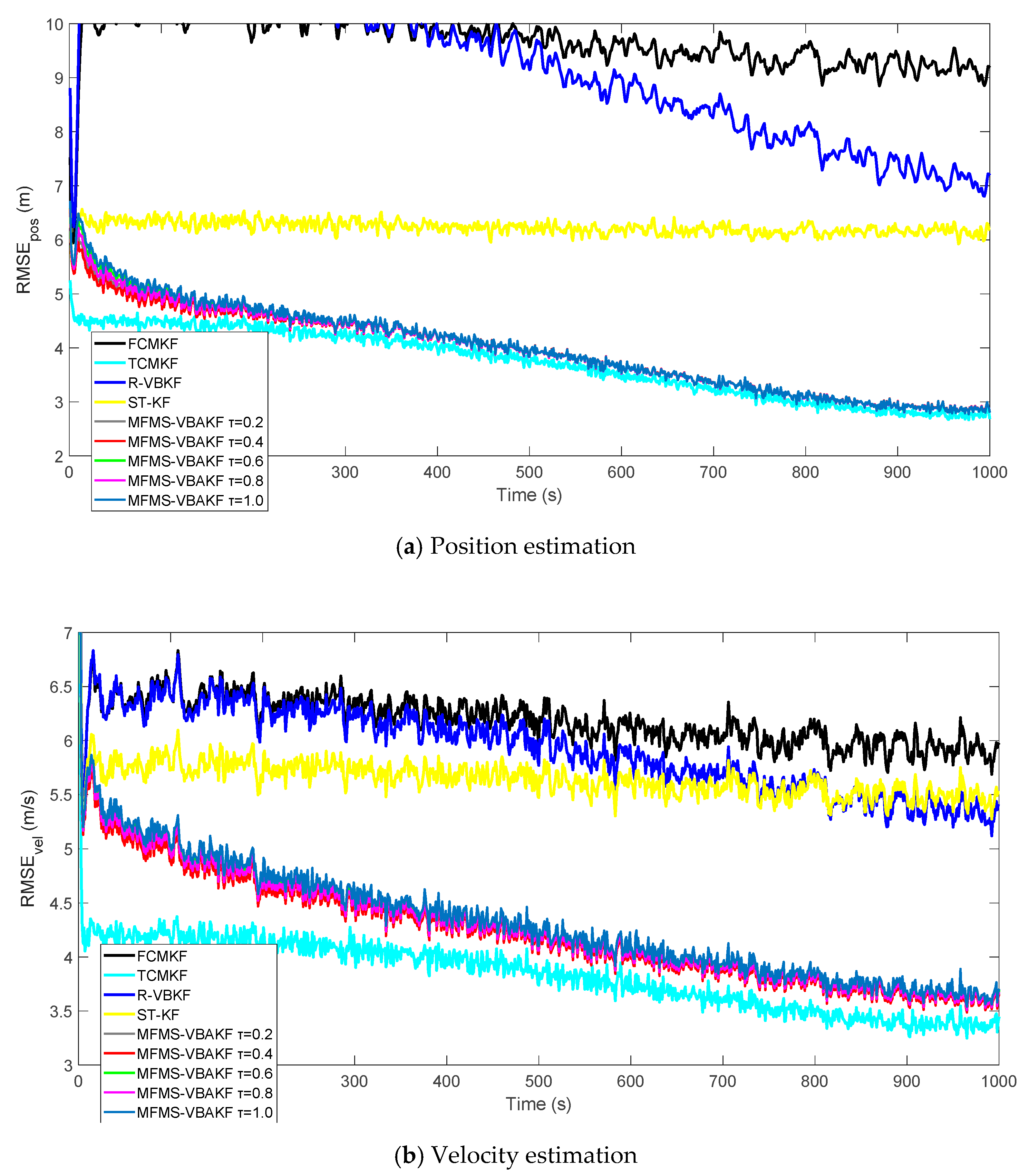
Figure 3a,b plot the RMSE variation curves of the position and velocity of the existing filter and the proposed MFMS-VBAKF, respectively. The RMSE of the estimation result of TCMKF algorithm is regarded as the benchmark. It can be seen from
Figure 2 that compared with existing algorithms, the proposed algorithm has a faster convergence speed and higher accuracy. To further elaborate on the advantages of the proposed algorithm,
Table 2 lists the average root mean square error (ARMSE) of different KF filtering algorithms:
According to the data in
Table 2, it can be found that in comparison with other AKF algorithms, the MFMS-VBAKF algorithm has the smallest ARMSE and the highest accuracy in estimating target position and velocity.
To compare the computational complexity with existing algorithms,
Table 3 lists the single-step running time of each algorithm. It can be seen that, compared with the R-VBAKF using the variational Bayesian method, the proposed MFMS-VBAKF increases the single-step running time by 0.21 μs. The design of multi-fading factors and updated monitoring strategy has ensured a substantial increase in estimation accuracy while bringing higher computational complexity.
To evaluate the accuracy of the estimation of one-step predicted state error covariance matrix PECM and the noise covariance matrices PNCM, MNCM, the square root of the normalized Frobenius norm (SRNFN) and the averaged SRNFN (ASRNFN) are used as the measure of error, which are defined as:
where
and
represent the true value and estimated value of the noise covariance matrix or one-step predicted state error covariance matrix in the
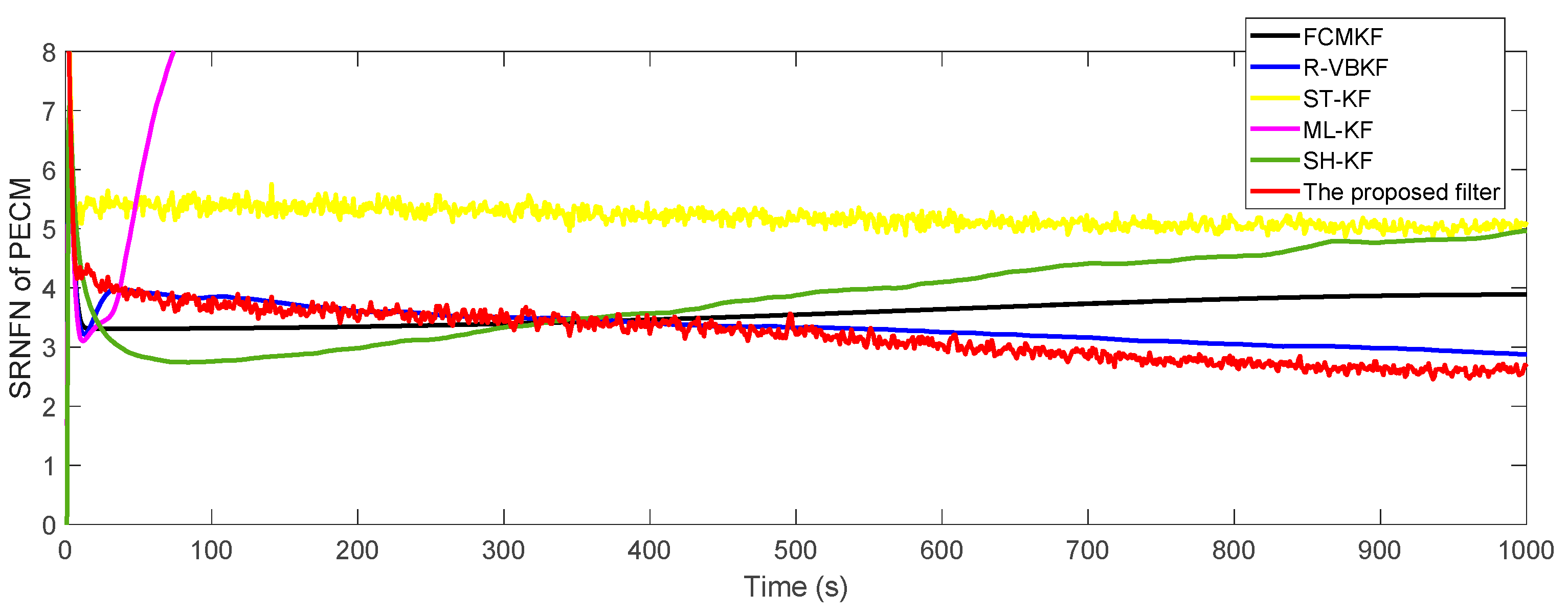
-th Monte Carlo experiment, respectively. The SRNFN and ASRNFN of the estimation result of PECM are shown in
Figure 4 and
Table 4, respectively.
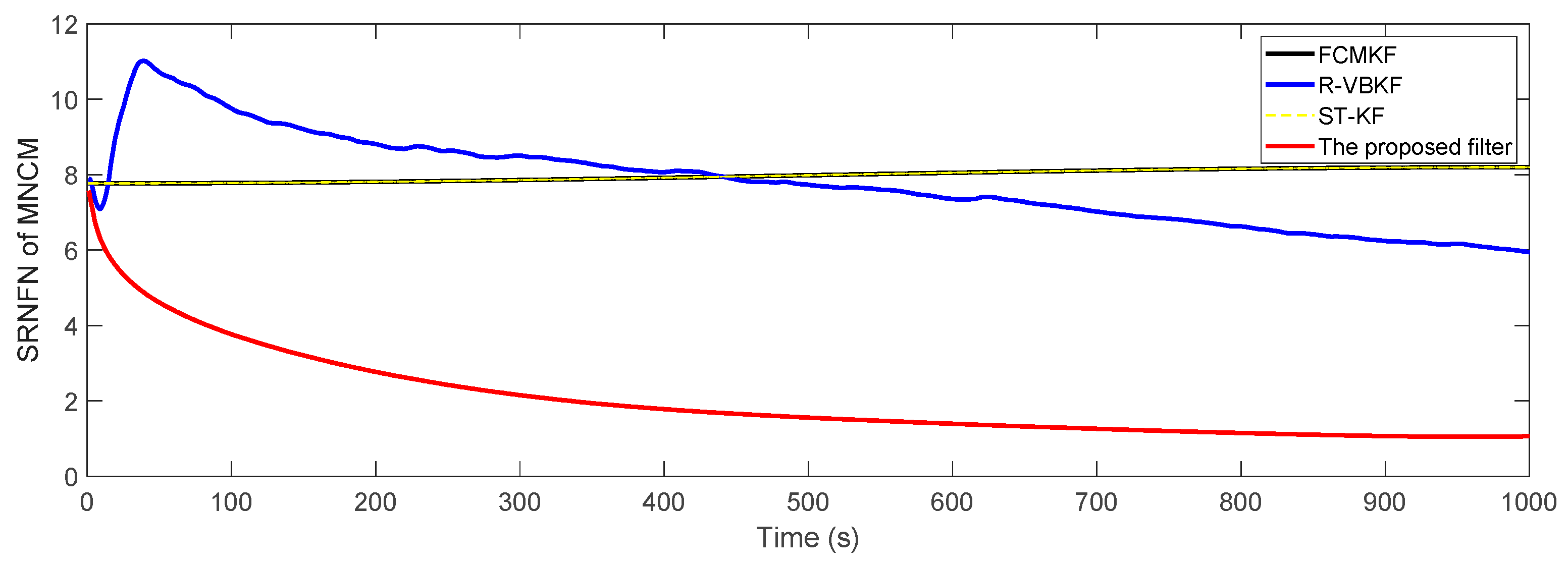
It can be clearly seen that, compared with the existing adaptive KF algorithm, if the noise covariance matrices are slowly time-varying, the SRNFN of the MFMS-VBAKF algorithm is smaller than the SRNFN of the current algorithm. Compared with R-VBKF with similar performance, the ASRNFN of MFMS-VBAKF is reduced by 5.45%.
Figure 5 shows the SRNFN of the measurement noise covariance matrix (MNCM) estimation. Obviously, the MFMS-VBAKF algorithm has the strongest tracking ability, the highest estimation accuracy and the fastest convergence speed of the slowly time-varying measurement noise covariance matrix estimation.
Figure 6 and
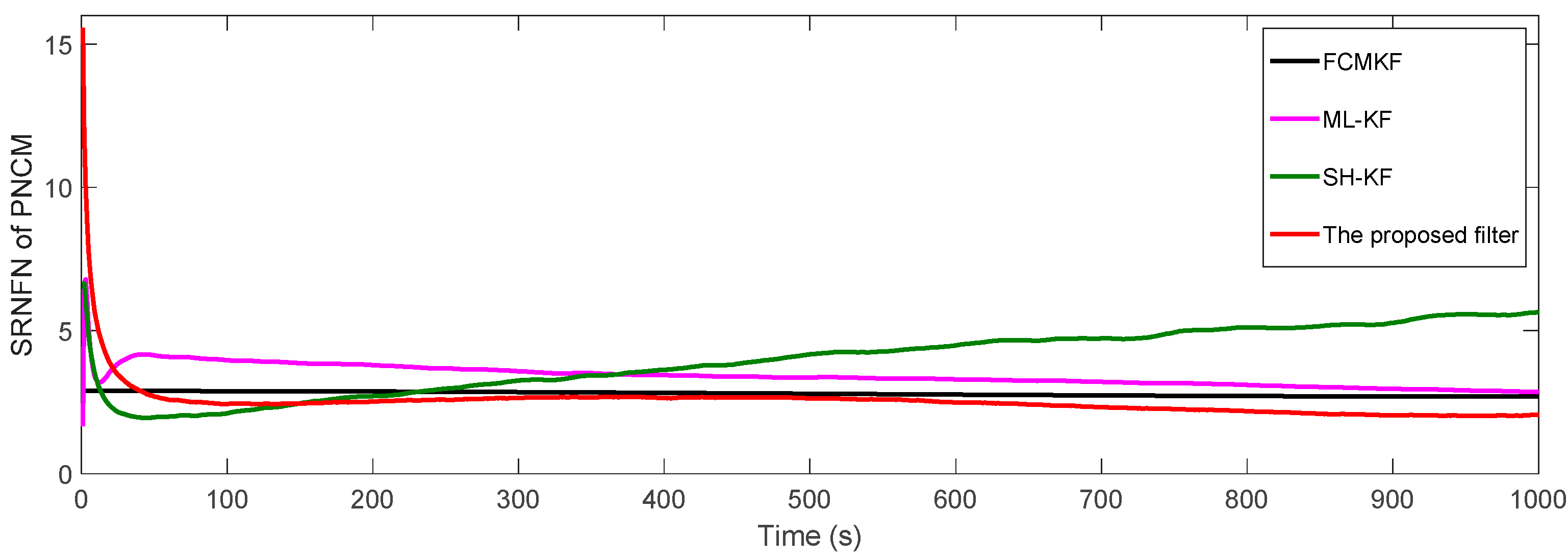
Table 5 show respectively the SRNFNs and the ASRNFNs of the PNCM from the existing filters and MFMS-VBAKF algorithm. It can be seen that the SRNFN and ASRNFN of the proposed MFMS-VBAKF are both smaller than the current filters. Thus, the MFMS-VBAKF has better estimation accuracy and satisfactory convergence speed in PNCM estimation.
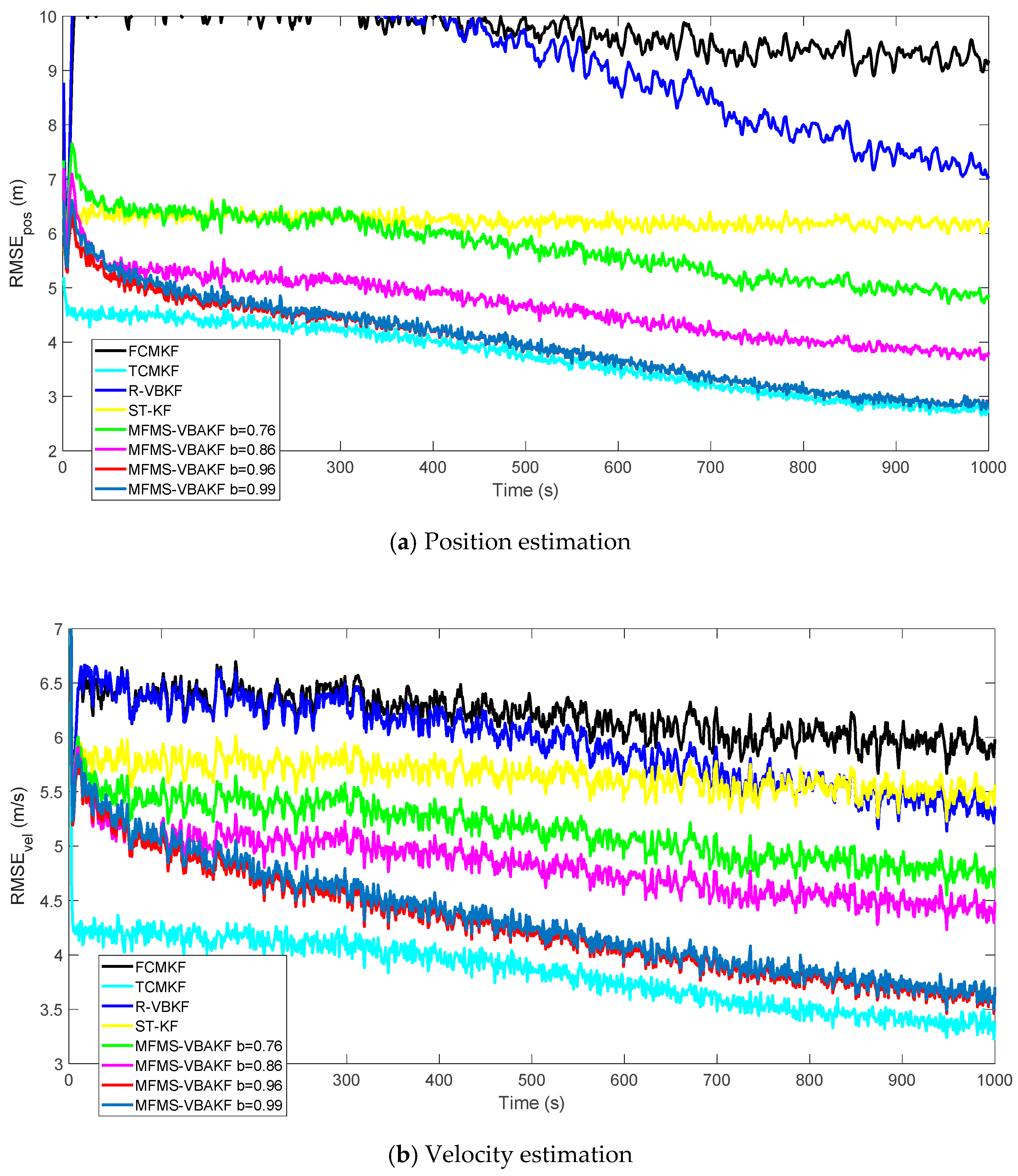
Next, we compare and analyze the influence of the values of four critical parameters (changing factor , forgetting factor , weakening factor and attenuation factor ) in the MFMS-VBAKF algorithm on the estimated effect.
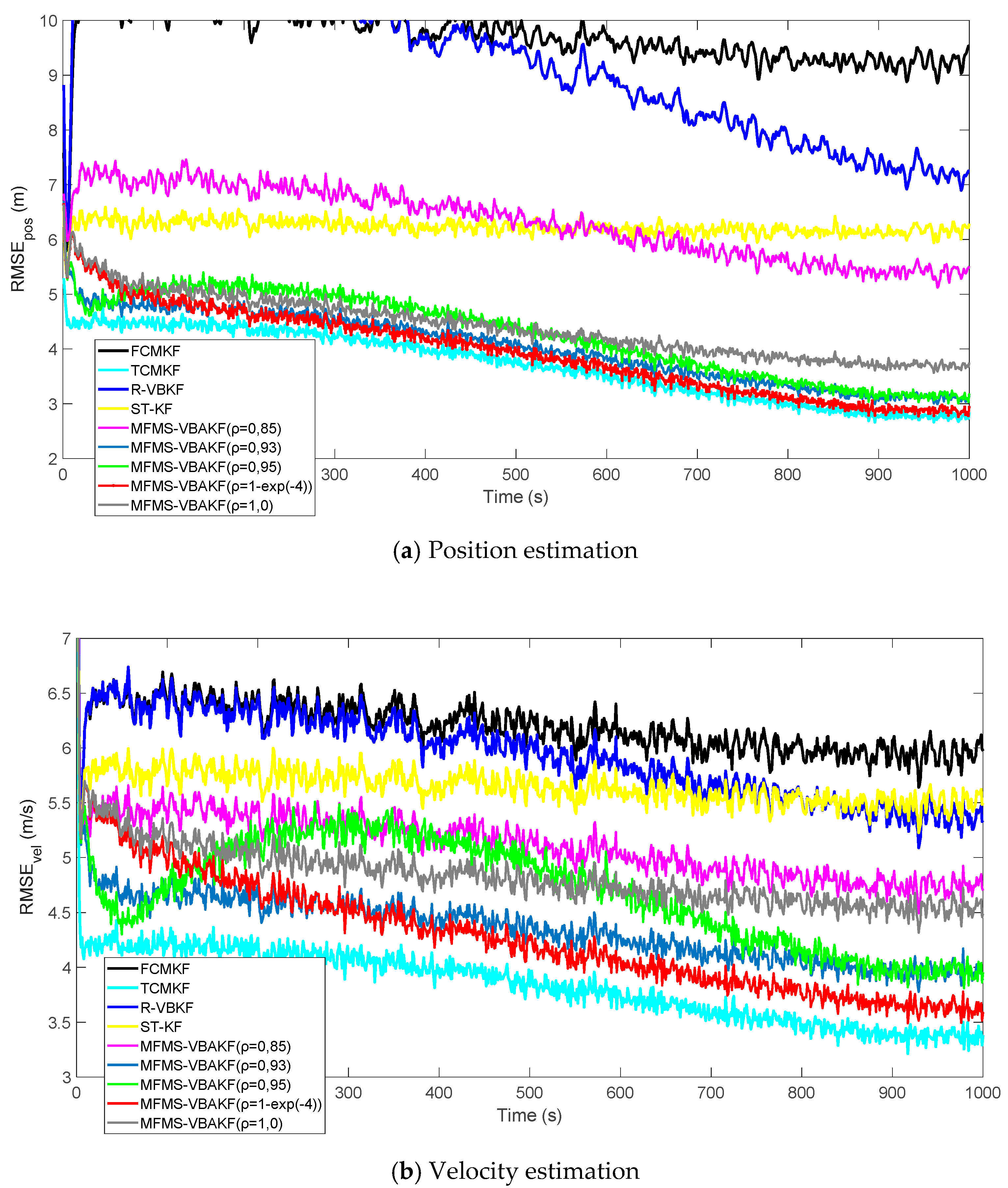
Figure 7 shows the RMSEs of position and velocity from the existing filters and MFMS-VBAKF in the case of
. The MFMS-VBAKF with
has better estimation accuracy than existing adaptive KF filters. And when
, the MFMS-VBAKF algorithm has the best estimation accuracy and convergence performance.
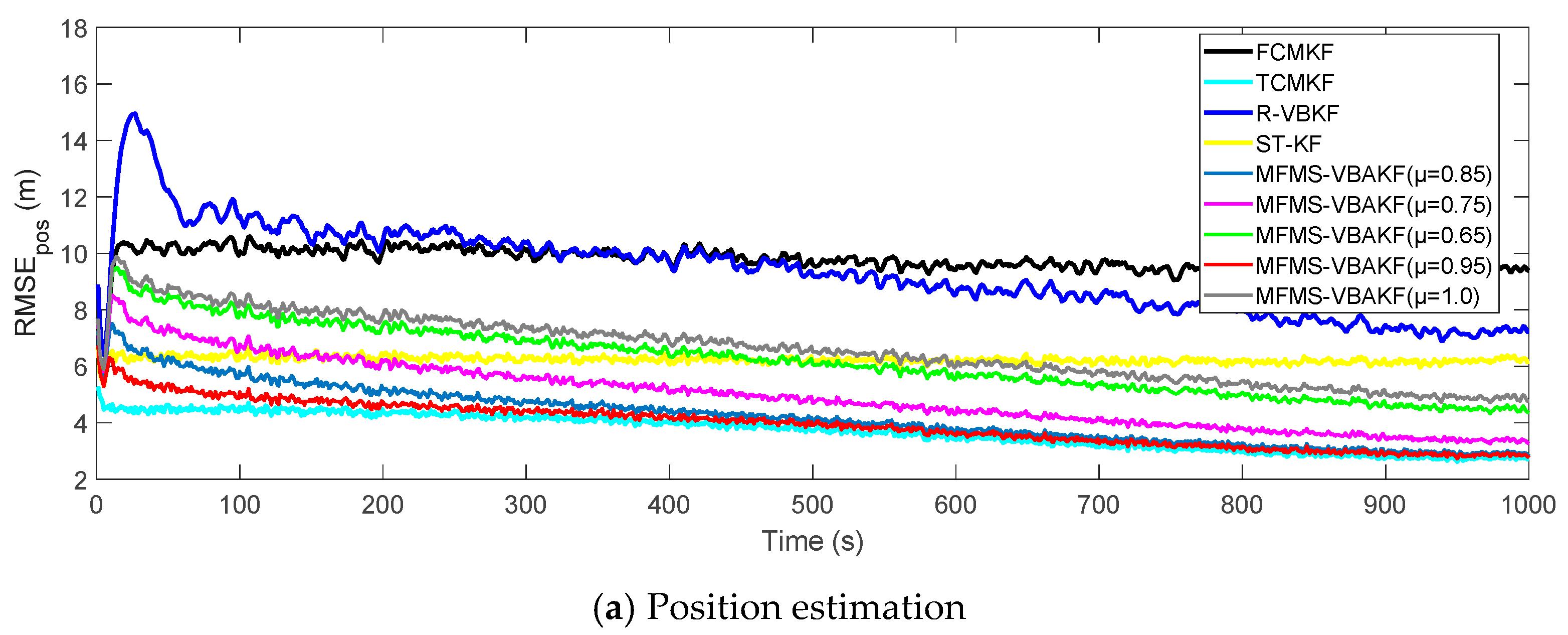
Figure 8 plots the RMSE curves of position and velocity from the existing filters and the MFMS-VBAKF in the case of
The MFMS-VBAKF with
. has better estimation accuracy than existing adaptive KF filters, and when
, the MFMS-VBAKF algorithm has the best estimation accuracy and convergence performance.
Figure 9 plots the RMSE curves of position and velocity from the existing filters and the MFMS-VBAKF in the case of
. The MFMS-VBAKF with
has better estimation accuracy than existing adaptive KF filters, and when
, the MFMS-VBAKF algorithm has the best estimation accuracy and convergence performance.
Figure 10 shows the RMSEs of position and velocity from the existing filters and MFMS-VBAKF in the case of
. The MFMS-VBAKF with
. has better estimation accuracy than existing adaptive KF filters. And when
, MFMS-VBAKF algorithm has the best estimation accuracy and convergence performance.
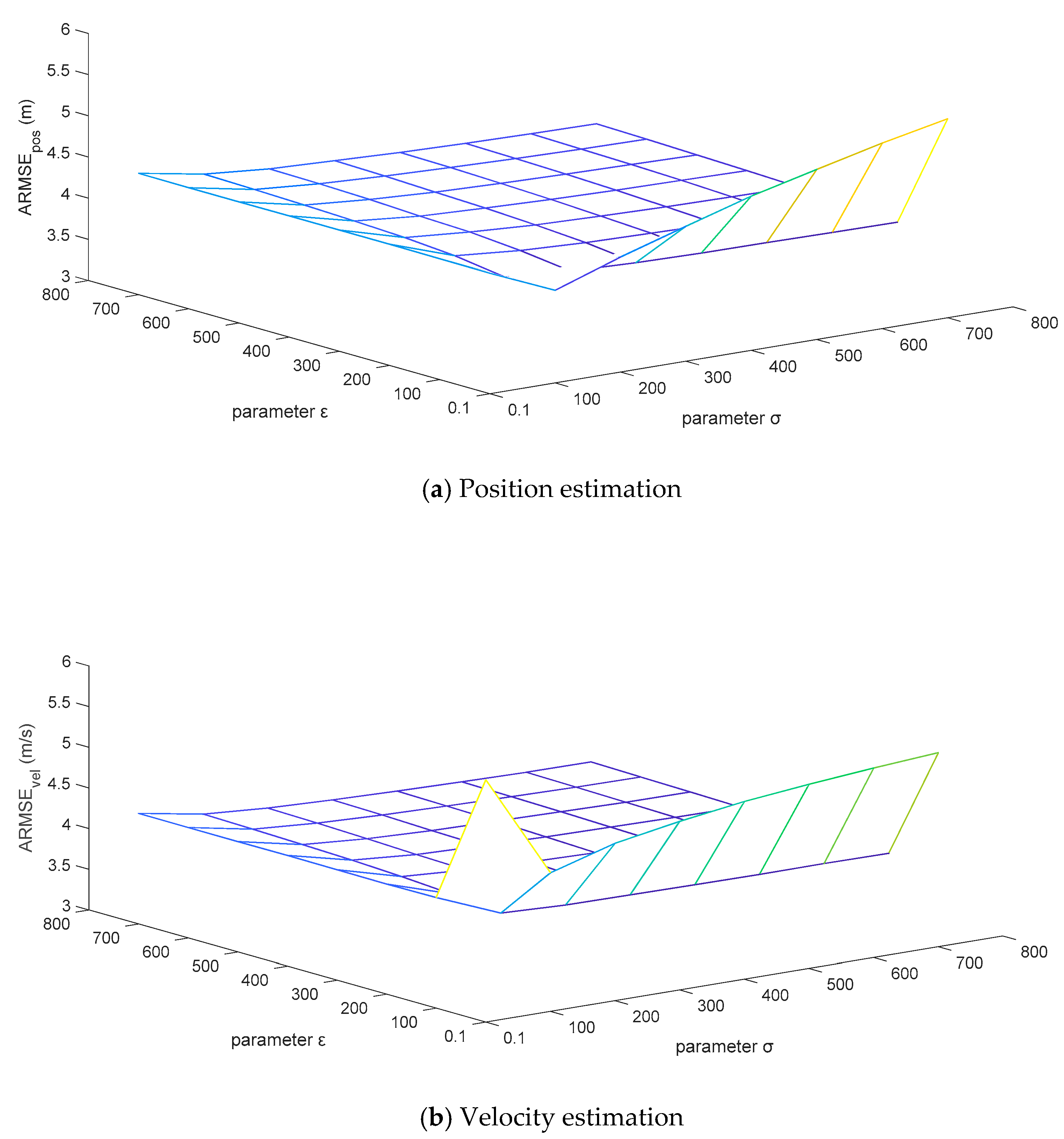
For the sake of testing the robustness of the adaptive correction capability of the MFMS-VBAKF algorithm when the fixed noise covariance matrices are set to different initial values, the priori confidence parameters
and
are set to change in combination within the grid area of
. The ARMSEs estimated by the algorithm for position and velocity are displayed in
Figure 10.
It can be analyzed from
Figure 11 that the ARMSEs of position and velocity estimation are flat in a large area of the set grid, and the estimation results are close to the actual values. However, the initial setting values of the fixed noise covariance matrices in the extremely narrow area on the right edge of the grid are too different from the actual values, which leads to unsatisfactory performance of the estimation results. This is caused by the variational Bayesian method that can only guarantee local convergence. In general, the estimated effects of the MFMS-VBAKF algorithm can converge to near the actual values, with excellent robust performance.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}