A Novel Algorithm for Detecting Pedestrians on Rainy Image




Abstract
1. Introduction
2. Related work
2.1. Single Image De-Raining Based Methods
2.2. Pedestrian Detection Methods
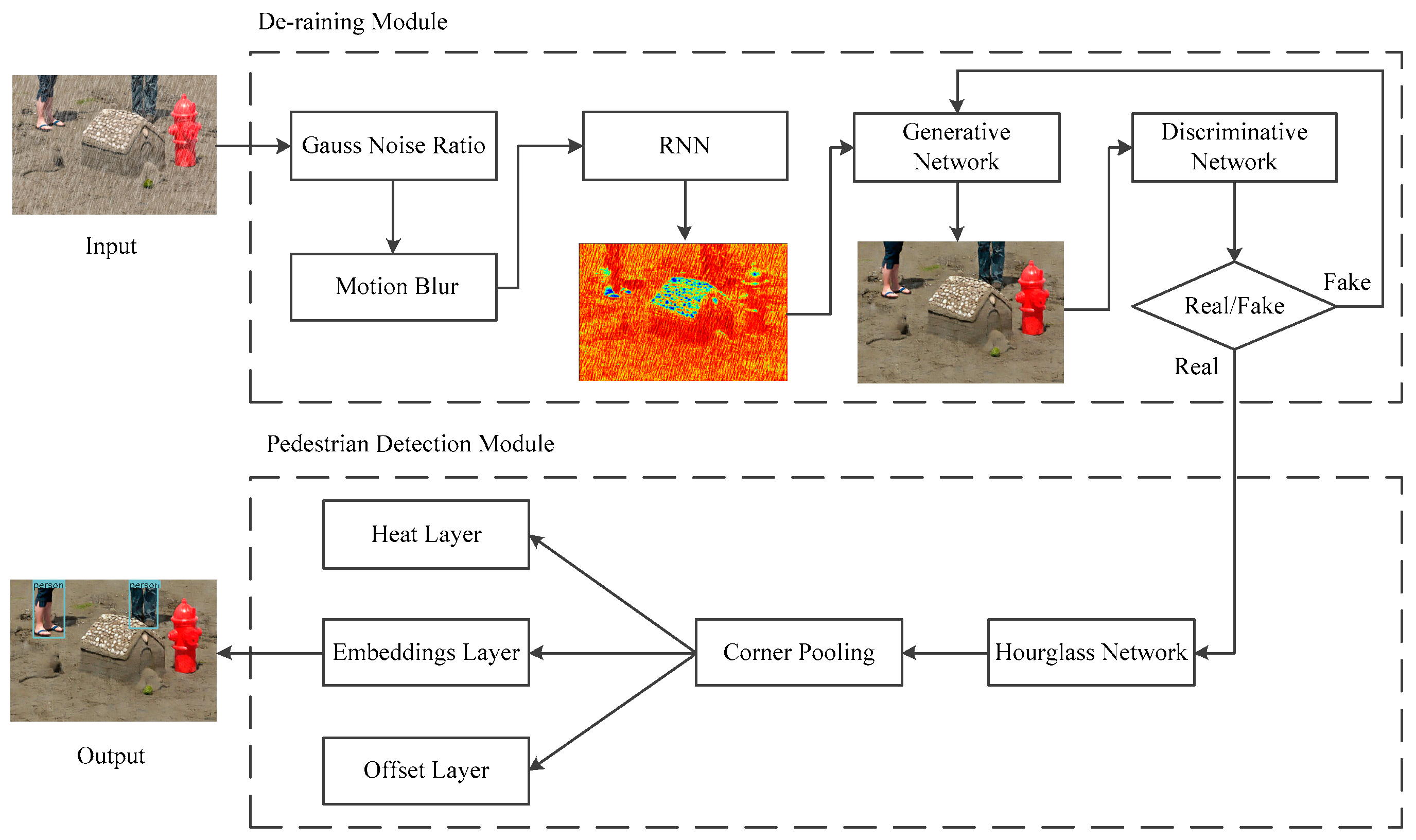
3. The Proposed Algorithm
3.1. De-Raining Module
3.1.1. Recurrent Neural Network
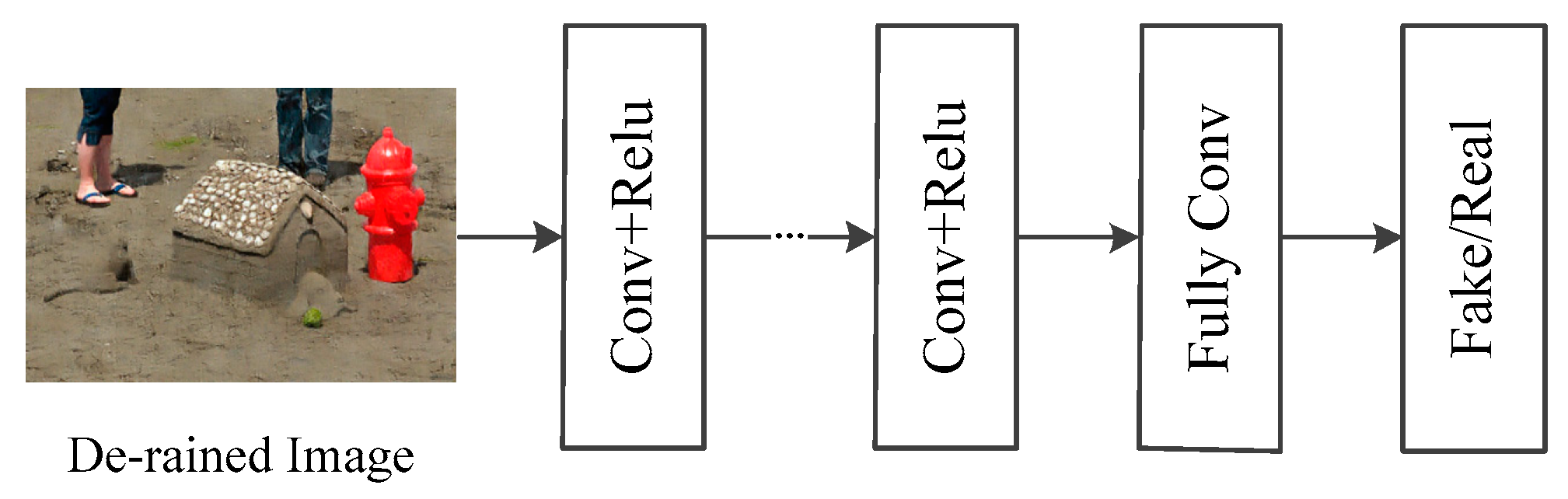
3.1.2. Generative and Discriminative Network
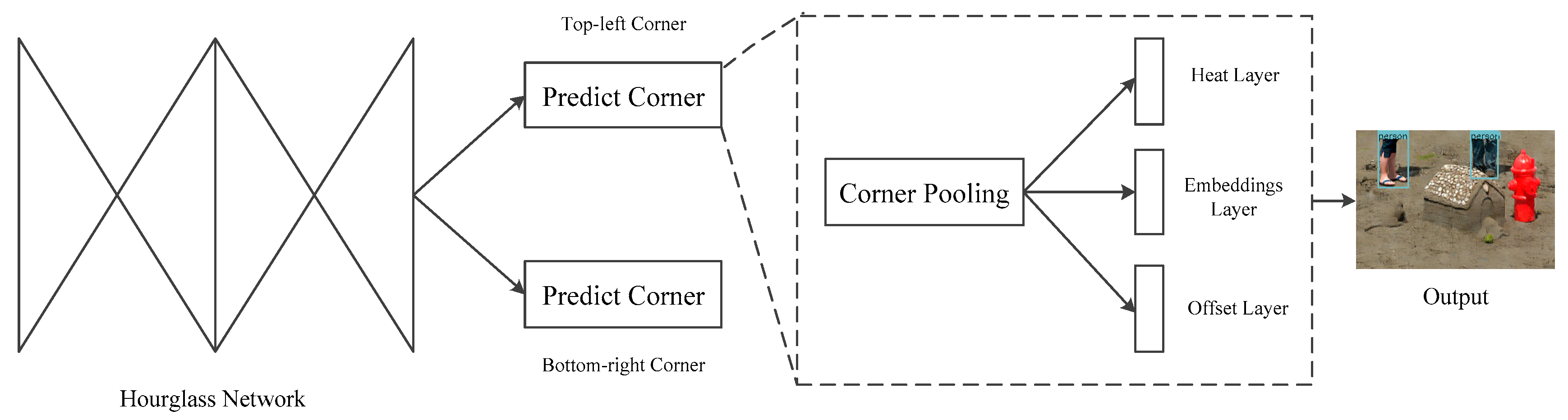
3.2. Pedestrian Detection Module
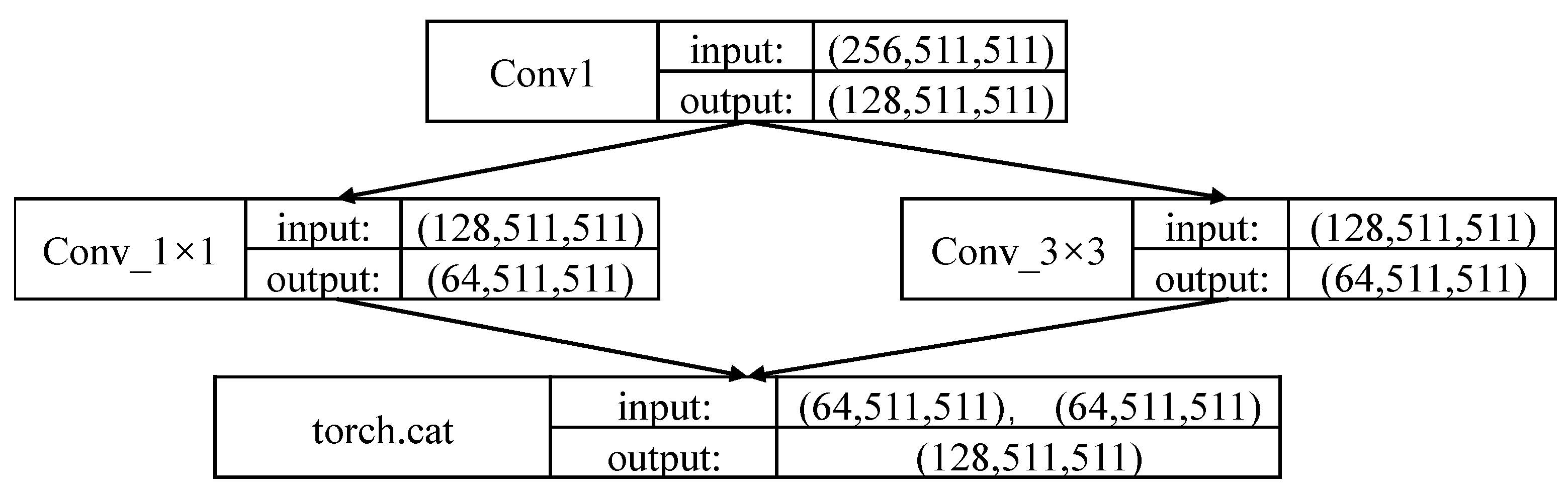
3.2.1. Hourglass Network
3.2.2. Corner Pooling
3.2.3. Loss Function
4. Experimental Result
4.1. Synthetic Dataset
4.2. Training Details
4.3. Results on the Synthetic Datasets
4.4. Results on the Real-World Images
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, W.Y.; Levinson, D.M. Deviation between Actual and Shortest Travel Time Paths for Commuters. J. Transp. Eng. Pt. A-Syst. 2018, 144, 13. [Google Scholar] [CrossRef]
- Chen, X.-Z.; Chang, C.-M.; Yu, C.-W.; Chen, Y.-L. A Real-Time Vehicle Detection System under Various Bad Weather Conditions Based on a Deep Learning Model without Retraining. Sensors 2020, 20, 5731. [Google Scholar] [CrossRef] [PubMed]
- Kallioras, N.A.; Lagaros, N.D. DL-SCALE: A novel deep learning-based model order upscaling scheme for solving topology optimization problems. Neural Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Li, X.; Wu, J.; Lin, Z.; Liu, H.; Zha, H. Recurrent squeeze-and-excitation context aggregation net for single image deraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 254–269. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Fu, X.Y.; Huang, J.B.; Zeng, D.L.; Huang, Y.; Ding, X.H.; Paisley, J.; IEEE. Removing rain from single images via a deep detail network. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; IEEE: New York, NY, USA, 2017; pp. 1715–1723. [Google Scholar] [CrossRef]
- Yang, W.H.; Tan, R.T.; Feng, J.S.; Liu, J.Y.; Guo, Z.M.; Yan, S.C.; IEEE. Deep Joint Rain Detection and Removal from a Single Image. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; IEEE: New York, NY, USA, 2017; pp. 1685–1694. [Google Scholar] [CrossRef]
- Zhang, H.; Patel, V.M.; IEEE. Density-aware Single Image De-raining using a Multi-stream Dense Network. In Proceedings of the 2018 IEEE/Cvf Conference on Computer Vision and Pattern Recognition, Salk Lake City, UT, USA, 18–22 June 2018; pp. 695–704. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online dictionary learning for sparse coding. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 689–696. [Google Scholar]
- Reynolds, D.A.; Quatieri, T.F.; Dunn, R.B. Speaker verification using adapted Gaussian mixture models. Digit. Signal Process. 2000, 10, 19–41. [Google Scholar] [CrossRef]
- Liu, G.C.; Lin, Z.C.; Yan, S.C.; Sun, J.; Yu, Y.; Ma, Y. Robust Recovery of Subspace Structures by Low-Rank Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef] [PubMed]
- Kang, L.W.; Lin, C.W.; Fu, Y.H. Automatic Single-Image-Based Rain Streaks Removal via Image Decomposition. IEEE Trans. Image Process. 2012, 21, 1742–1755. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Xu, Y.; Ji, H.; IEEE. Removing rain from a single image via discriminative sparse coding. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; IEEE: New York, NY, USA, 2015; pp. 3397–3405. [Google Scholar] [CrossRef]
- Gu, S.; Meng, D.; Zuo, W.; Zhang, L.; IEEE. Joint Convolutional Analysis and Synthesis Sparse Representation for Single Image Layer Separation. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; pp. 1717–1725. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.X.; Zhong, S.; IEEE. Transformed Low-rank Model for Line Pattern Noise Removal. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; IEEE: New York, NY, USA, 2017; pp. 1735–1743. [Google Scholar] [CrossRef]
- Fu, X.Y.; Huang, J.B.; Ding, X.H.; Liao, Y.H.; Paisley, J. Clearing the Skies: A Deep Network Architecture for Single-Image Rain Removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Joint rain detection and removal via iterative region dependent multi-task learning. arXiv 2016, arXiv:1609.07769. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3943–3956. [Google Scholar] [CrossRef]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D.; Soc, I.C. Progressive Image Deraining Networks: A Better and Simpler Baseline. In Proceedings of the 2019 IEEE/Cvf Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3932–3941. [Google Scholar] [CrossRef]
- Cai, L.; Li, S.-Y.; Ren, D.; Wang, P.; IEEE. Dual Recursive Network for Fast Image Deraining. In Proceedings of the 2019 IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 2756–2760. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; IEEE. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R.; IEEE. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A.; IEEE. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A.; IEEE. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; IEEE: New York, NY, USA, 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. Cornernet-lite: Efficient keypoint based object detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T.; IEEE. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/Cvf International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Neural Information Processing Systems (Nips): La Jolla, CA, USA, 2014; Volume 27. [Google Scholar]
- Qian, R.; Tan, R.T.; Yang, W.H.; Su, J.J.; Liu, J.Y.; IEEE. Attentive Generative Adversarial Network for Raindrop Removal from A Single Image. In Proceedings of the 2018 IEEE/Cvf Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 2482–2491. [Google Scholar] [CrossRef]
- Zhao, B.; Wu, X.; Feng, J.S.; Peng, Q.; Yan, S.C. Diversified Visual Attention Networks for Fine-Grained Object Classification. IEEE Trans. Multimed. 2017, 19, 1245–1256. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.U.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Computer Vision—Eccv 2016, Pt VIII; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing Ag: Cham, Switzerland, 2016; Volume 9912, pp. 483–499. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Newell, A.; Deng, J. Pixels to Graphs by Associative Embedding. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Neural Information Processing Systems (Nips): La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Pan, Y.Y. Lagrangian Relaxation for the Multiple Constrained Robust Shortest Path Problem. Math. Probl. Eng. 2019, 2019, 13. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—Eccv 2014, Pt V; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing Ag: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conditions | Light | Medium | Heavy | Average | ||||
|---|---|---|---|---|---|---|---|---|
| Measure | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| DID-MDN [8] | 29.86 | 0.899 | 25.9 | 0.713 | 25.3 | 0.755 | 27.02 | 0.789 |
| PReNet [19] | 29.42 | 0.892 | 24.9 | 0.698 | 15.07 | 0.542 | 23.13 | 0.711 |
| DRN [20] | 30.78 | 0.937 | 23.35 | 0.661 | 16.95 | 0.582 | 23.69 | 0.727 |
| De-raining Module | 30.56 | 0.921 | 26.56 | 0.757 | 27.8 | 0.837 | 28.31 | 0.838 |
| Algorithms | AP | APs | APm | APl |
|---|---|---|---|---|
| CornerNet-Lite [30] | 40.4 | 12.3 | 37.6 | 63.1 |
| YOLOv4 [28] | 42.1 | 12.7 | 43.5 | 62.6 |
| Pedestrian Detection Module | 43 | 13.4 | 39.3 | 67.2 |
| Conditions | Without Proposed | With Proposed |
|---|---|---|
| Light | 34.2 | 41.4 |
| Medium | 26.8 | 39.7 |
| Heavy | 23.5 | 37.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Ma, J.; Wang, Y.; Zong, C. A Novel Algorithm for Detecting Pedestrians on Rainy Image. Sensors 2021, 21, 112. https://doi.org/10.3390/s21010112
Liu Y, Ma J, Wang Y, Zong C. A Novel Algorithm for Detecting Pedestrians on Rainy Image. Sensors. 2021; 21(1):112. https://doi.org/10.3390/s21010112
Chicago/Turabian StyleLiu, Yuhang, Jianxiao Ma, Yuchen Wang, and Chenhong Zong. 2021. "A Novel Algorithm for Detecting Pedestrians on Rainy Image" Sensors 21, no. 1: 112. https://doi.org/10.3390/s21010112
APA StyleLiu, Y., Ma, J., Wang, Y., & Zong, C. (2021). A Novel Algorithm for Detecting Pedestrians on Rainy Image. Sensors, 21(1), 112. https://doi.org/10.3390/s21010112