1. Introduction
Disasters caused by severe earthquakes, such as collapsed buildings, road damage, dammed lakes, and secondary geological disasters, pose a threat to people’s lives and property safety worldwide. In recent years, major earthquakes that occurred in China, such as the Wenchuan earthquake on 12 May 2018, and the Yushu earthquake on 14 April 2010, attracted considerable attention from the government and society. Obtaining exact disaster information immediately after severe earthquakes is important for disaster rescue and relief and can effectively reduce the damage caused by severe earthquakes [
1,
2]. With the advantages of wide-ranging, multiscale, dynamic comprehensive observation and being free from ground conditions, remote sensing (RS) technology for earth observation provides a rapid, safe, and economical method for earthquake disaster assessment and emergency rescue [
3]. Since the occurrence of the Wenchuan earthquake on May 12, 2018, satellite and airborne RS technologies have played an important role in the rapid acquisition and dynamic monitoring of earthquake disaster information and post-earthquake reconstruction.
The data processing for extracting earthquake disaster information from RS images includes image preprocessing, disaster information extraction, and disaster assessment [
4]. The accuracy and efficiency of image preprocessing, mainly referring to geometric rectification of RS images and the coregistration of multisource RS images, are crucial for the accuracy and efficiency of disaster information extraction. In order to obtain disaster information quickly and support disaster responses, it is particularly important to have geometrically accurate RS images available shortly after the acquirement of post-earthquake RS images. Using the images to extract the disaster information, including the location, distribution, and extension, is very crucial for disaster relief and rescue. For instance, in transportation planning processes after an earthquake, a fast and accurate assessment of the destruction degree of traffic facilities (such as roads and bridges) is essential to have an updated configuration of infrastructures to facilitate disaster relief work [
5]. The accuracy of coregistration of the post-earthquake and pre-earthquake RS images is particularly important when change detection methods are used for disaster information extraction.
With the development of RS technology, different satellite sensors can provide multispectral, multitemporal, and multiplatform RS images. Additionally, the spectral resolution of RS images is also continually improving, and image registration research has gradually shifted from medium-low resolution to high resolution [
6]. The registration of high-resolution RS images is significantly more challenging than that of medium-low-resolution RS images, since high-resolution RS images contain more intricate details and texture information [
7]. Therefore, the coregistration of multisource high-resolution RS images has been a research focus in RS image processing.
Image registration is the process of the geometric registration of two or more images covering the same area and acquired at different times, from different viewpoints, or by different sensors [
8]. The majority of the automatic registration methods for RS images can be classified into two categories, including gray-based (or intensity-based) methods and feature-based methods [
9,
10]. To extract tie points from the two images, the gray-based methods establish a similarity measure between the two images through the mutual information (MI) method [
11,
12] or normalized cross-correlation method (NCC) [
13]. As gray values of pixels within the neighborhood of each pixel need to be considered, this kind of method suffers from a large number of calculations and relatively low efficiency. The feature-based methods locally extract points, lines, and regional features for image registration [
14]. Due to the advantages of easy acquisition, short running time, and high robustness, point features are widely used in image registration. Currently, many feature-based methods have been successfully used for RS image registration, such as the Moravec corner detection algorithm [
15], the Harris corner detection algorithm [
16], the Shi_Tomasi corner detection algorithm [
17], the scale-invariant feature transform (SIFT) [
18], speeded up robust features (SURF) [
19], and the features from accelerated segment test (FAST) [
20].
The performances of several different algorithms, including SIFT, shape context [
21], steerable filters [
22], principal components analysis-SIFT (PCA-SIFT) [
23], differential invariants [
24], and other methods, were compared by Mikolajczyk and Schmid [
25]. The experimental results show that the SIFT algorithm yielded the best performance. However, it was apt to be affected by image noise and texture changes and was computationally intensive and time-consuming during feature point extraction [
26]. To solve these problems, several improved versions of the SIFT algorithm were proposed. For instance, the independent component analysis-SIFT (ICA-SIFT) algorithm, which uses independent component analysis to remove redundant information in the SIFT feature vectors, was proposed [
27]. It improved the efficiency but decreased the accuracy. The affine-SIFT (ASIFT) algorithm proposed by Yu and Morel [
28] achieved complete affine invariance by simulating longitude and latitude, but its efficiency was much lower than that of the SIFT algorithm. The uniform robust SIFT (UR-SIFT) algorithm [
29] is suitable for multisource optical RS images with different illumination conditions, rotations, and five-fold scales. However, the crossmatching approach employed by the UR-SIFT algorithm eliminated a number of correctly matched tie points, which reduced the accuracy. Inspired by the SIFT algorithm, an enhanced feature matching method by combining the position, scale, and orientation of each keypoint, which is called PSO-SIFT, was proposed [
30]. The PSO-SIFT method effectively increased the number of correctly matched tie points, but it also increased the running time. However, for images with complex terrain and surface deformations caused by disasters, these algorithms can hardly meet the requirements of accuracy and efficiency simultaneously. Through the improvement of the corner response function of Harris, the Shi_Tomasi corner detection algorithm is not susceptible to image rotations, lighting conditions, angle changes, and noise. Additionally, it avoids the phenomenon of feature point clustering, which makes the distribution of extracted feature points more even [
31]. Additionally, the Shi_Tomasi algorithm needed less running time than the SIFT algorithm and thus effectively improved the efficiency of feature extraction.
Due to surface deformations caused by severe earthquakes, post-earthquake RS images usually show surface damage such as building collapse, ground displacements, road damage, and landslides, making it more challenging for the coregistration of pre- and post-earthquake RS images. Many algorithms work well for RS image registration, but when used for the registration of pre-earthquake and post-earthquake RS images, especially for mountain areas with complex terrain, two problems arise, including the lack of tie points and the uneven distribution of matched tie points. To solve these two problems, a fast automatic registration method for multisource high-resolution RS image registration in earthquake damage assessment was proposed in this study. In this method, the Shi_Tomasi and SIFT algorithms were combined to obtain tie points using an image partition matching strategy considering geographic information. The proposed method was compared with the classic SIFT method and the SIFT method using the same image partitioning strategy using three pairs of post- and pre-earthquake images that have complex terrain and significant differences in color tone.
The rest of this paper is organized as follows. The proposed method is introduced in
Section 2, and the experiments are demonstrated in
Section 3. The discussions are provided in
Section 4, and the conclusions are presented in
Section 5.
2. Methodology
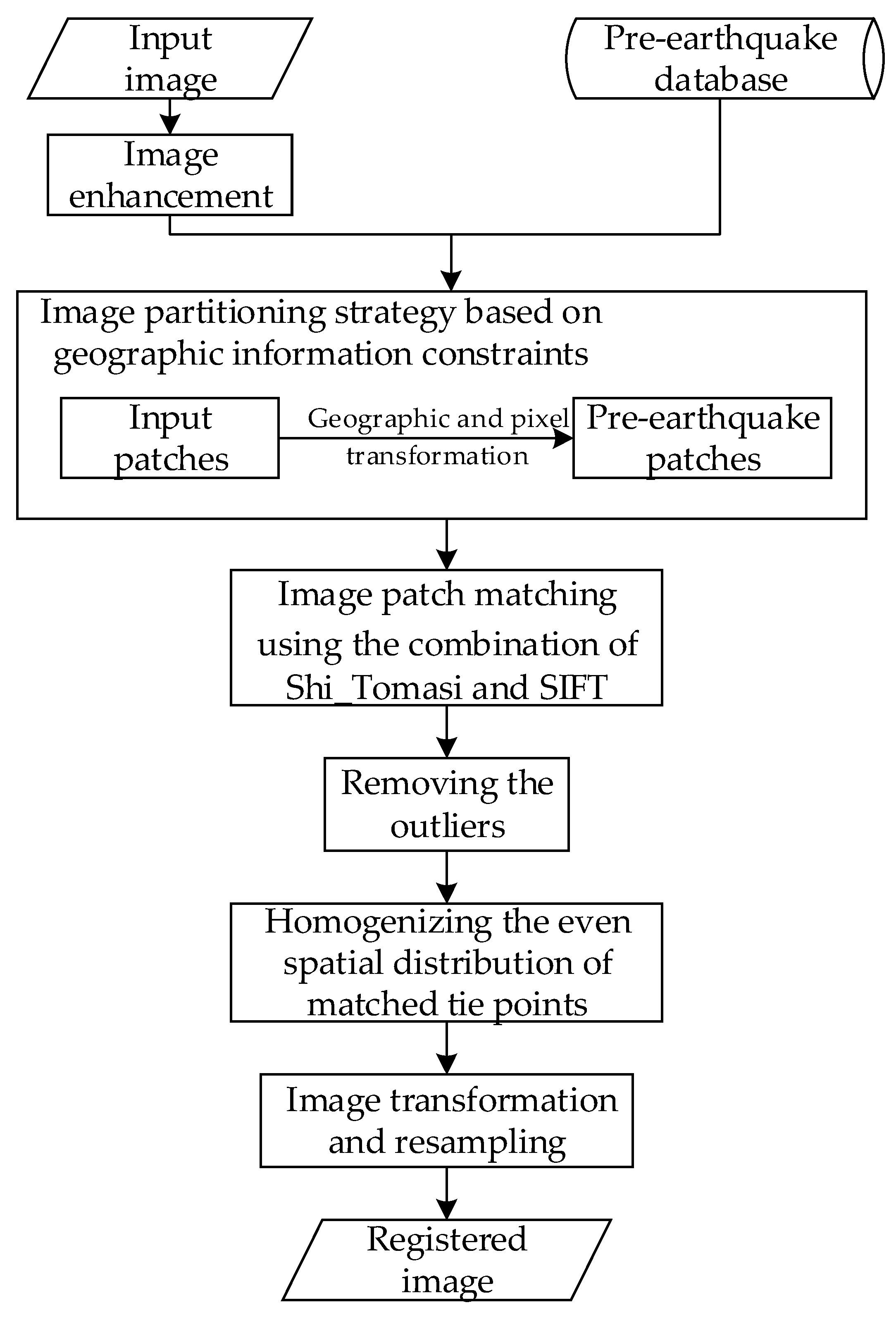
The proposed method employs an improved SIFT algorithm using the Shi_Tomasi approach to detect feature points on enhanced images and a partition matching strategy considering geographic information to search for tie points. Seven steps are involved in the method (
Figure 1), as follows:
- (1)
Constructing a pre-earthquake image database;
- (2)
Image enhancement;
- (3)
Image partitioning strategy based on geographic information constraints;
- (4)
Image patch matching using the combination of Shi_Tomasi and SIFT;
- (5)
Removing the outliers;
- (6)
Homogenizing the even spatial distribution of matched tie points;
- (7)
Image transformation and resampling.
2.1. Constructing a Pre-Earthquake Satellite Image Database
To improve the efficiency and the degree of automation of image processing, a pre-earthquake image database can be first constructed using high-resolution optical remote sensing images covering the study area. The construction of the database mainly consists of three steps. First, radiometric calibration, atmospheric correction, and projection coordinate conversion are used to preprocess the pre-earthquake high-resolution satellite images. Then, the preprocessed images are geometrically corrected according to ground control points (GCPs) if GCPs are available. If no GCPs are available in the case of emergency, high-resolution pre-earthquake RS images with high quality and strict orthorectification can be used without geometric correction. Finally, the identity number (ID) and the coordinates of the corresponding high-resolution satellite image are recorded in a coordinate file, as shown in
Table 1. The pre-earthquake RS images and the corresponding coordinate files were stored in the same directory to construct the pre-earthquake satellite image database.
2.2. Image Enhancement
Usually, image denoising is employed to reduce image noise before image matching. However, the denoised images may suffer from relatively low image contrast when the image has only a single channel or the color change is not obvious [
32]. This makes it difficult to extract feature points. To enhance the details of the denoised images and increase the number of extracted feature points, the proposed method adopted a 2% linear stretch method to enhance both the input and the reference images.
The 2% linear stretch method is usually performed by defining a transfer function in the following form:
where
g (
x, y) is the value of pixel (
x, y) after image stretching,
f (
x, y) is the original value of pixel (
x, y), and
a and
b are the values at 2% and 98%, respectively, of the cumulative frequency of the original image.
c and
d are the minimum and the maximum of the stretched image, respectively. In this work,
c = 0, and
d = 255.
To test the advantage of the 2% linear stretch method, an experiment was performed using the GaoFen-1 (GF-1) multispectral image (with an 8-m resolution) and the SIFT algorithm. The original image yielded 16 matched tie points, as shown in
Figure 2a. In contrast, the enhanced image obtained 119 matched tie points (
Figure 2b). The experimental results show that applying the 2% linear stretching method on the images can facilitate the extraction of feature points and increase the number of matched tie points.
2.3. Image Partitioning Strategy Based on Geographic Information Constraints
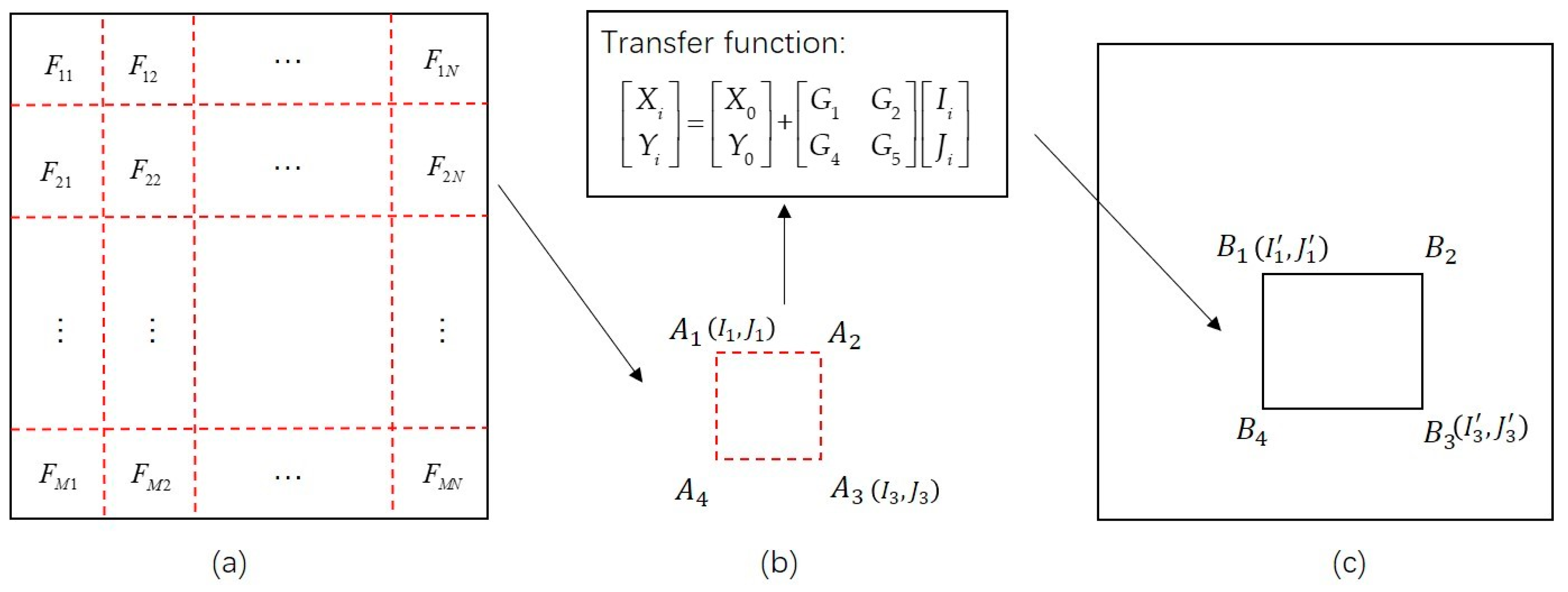
For large high-resolution remote sensing images, the extraction and matching of feature points usually have high computational complexity, which requires considerable memory and is time-consuming. In addition, it yields a low accuracy of registration when enough feature points are extracted from only some of the regions of the image. To solve this problem, an image partitioning strategy based on geographic information constraints was adopted to divide remote sensing images into several image patches. For each image patch, the corresponding reference image can be obtained according to the projected coordinates of the image patch. The extraction and matching of feature points were applied to each image patch pair.
With respect to the geometric information of RS images, the mapping relationship [
33] between the image coordinates and geographic coordinates can be expressed using Equation (2).
where (
Ii, Ji) are the image coordinates of the
ith pixel, and (
Xi, Yi) are the corresponding projected coordinates of (
Ii, Ji); (
X0, Y0) are the projected coordinates of the top left corner in the original whole scene input image, and
G1,
G2,
G4, and
G5, are the parameters of the transformation model.
Figure 3 shows a schematic of the image partitioning strategy. The image partition of the input RS image and the corresponding reference image can be conducted using the following steps:
First, the input image is divided into n×n patches, each of which has a size of M×N pixels. Each patch is numbered, and the coordinates of the four corners of the patch are recorded. For example, the corners of patch F2N are recorded as A1, A2, A3, and A4. The image coordinates of corners A1 and A3 are then calculated and recorded as (I1, J1) and (I3, J3), respectively.
Second, the image coordinates are transformed using Equation (2) into the projected coordinates according to the geometric information of the input image. Specifically, (X0, Y0) are the projected coordinates of the top left corner in the original whole scene input image; (Ii, Ji), i = 1 or 3 are the image coordinates of corners A1 and A3 of the image patch F2N; (Xi, Yi), i = 1 or 3 are the projected coordinates of A1 and A3; G1 is the pixel size of the input image; G5 is the negative value of pixel size of the input image; and the values of G2 and G4 are equal to 0.
Third, according to the projected coordinates
(Xi, Yi) of an input image patch, the pre-earthquake satellite image covering this patch is found through the pre-earthquake high-resolution image database. If there is more than one image covering the patch, the reference image is the one whose spatial resolution is closest to the input image. Additionally, the extension of the corresponding reference patch can be determined according to
(Xi, Yi). The image coordinates (
(I1’, J1’),
(I3’, J3’)), which correspond to the two corners (
B1 and
B3) of the reference image patch shown in
Figure 3c, are calculated using Equation (2).
Finally, the image coordinates of the other two corners (B2 and B4) of the reference image patch can be obtained according to those of corners B1 and B3. The image coordinates of the four corners B1, B2, B3, and B4 are then used to obtain the corresponding reference image patch from the pre-earthquake satellite image.
2.4. Partition Matching Using Shi_Tomasi and SIFT
The Shi_Tomasi and SIFT algorithms were combined to extract feature points from each of the image patch pairs obtained according to the introduction in
Section 2.3. The Shi_Tomasi algorithm was used to detect feature points from the image pairs. The SIFT descriptor, which is invariant of scale and rotation, was used to describe the features of detected feature points. The Best Bin First (BBF) algorithm [
34] was employed to match the feature points.
2.4.1. Feature Detection Using the Shi_Tomasi Algorithm
The Shi_Tomasi corner detection algorithm is an improved version of the Harris corner detector. Considering a local window in the image, Harris corner points are detected based on the determination of the average changes in image intensity that result from shifting the local window by a small amount in various directions.
Denoting the image intensity of the image as
I, the intensity difference (
E) produced by a shift (
u, v) of the local window is provided by Equation (3):
where
w (
x, y) is a window function at position (
x, y).
To search for the windows that produce a large
E (
u, v),
I (
x + u, y + v) can be expanded using the Taylor series:
where
Ix and
Iy are image derivatives in the
x and
y directions, respectively. Combining Equations (3) and (4), we obtain Equation (5) as:
where
M is defined using Equation (6),
Finally, a score
R is calculated using Equation (7) and used to justify whether the window contains a corner:
where
detM = λ1λ2;
trace(M) = λ1 +
λ2; and
λ1 and
λ2 are the eigenvalues of
M.
K is an empirical value, and the general value of
K is 0.04 [
35]. If the value of
R is greater than a threshold value (
T), the window in which
R is treated as a corner point is a good tracking point.
Different from the Harris algorithm, the score
R for the Shi_Tomasi algorithm is calculated using Equation (8).
If
R is greater than
T, the point can be marked as a Shi_Tomasi corner. The schematic of the Shi_Tomasi algorithm is shown in
Figure 4. In this work, the maximum number of corner points (
Nmax) for each image patch should be set in advance, usually to 1500.
2.4.2. Feature Description Using the SIFT Descriptor
The SIFT descriptor was employed for feature description of the feature points detected in this work. The SIFT descriptor proposed by Lowe in 2004 is a local feature descriptor based on the gradient distribution in the detected regions. By assigning one or more consistent orientations to each feature point based on the gradient directions of a local image, the feature descriptor of the feature point can be represented relative to the orientations and therefore achieve invariance to image rotation. For each feature point (x, y) of the scale image
L, the gradient magnitude
m (x, y) and orientation
θ (x, y) can be calculated using Equations (9) and (10), respectively.
An orientation histogram is formed from the gradient orientations of the sample points within a region around the feature point. It has 36 bins covering the 360° range of orientations. Each bin covers 10 degrees. As shown in
Figure 5, the peak in the histogram, indicating the dominant orientation of the local gradient image, is assigned as the orientation of the feature point.
After determining the orientation of a feature point, the SIFT descriptor of the feature point is calculated using three steps, as illustrated in
Figure 6.
First, the coordinates of the descriptor and the gradient orientations are rotated relative to the orientation of the feature point to achieve orientation invariance. Then, the orientation histograms over 4×4 sample regions centered with the feature point are created. There are eight directions for each orientation histogram, in which the length of each arrow represents the size of that histogram entry. Therefore, Lowe suggested using a 4 × 4 × 8 = 128 element feature vector for each feature point. Finally, the feature vector is normalized to unit length to reduce the effects of illumination change.
2.4.3. Feature Matching
The BBF algorithm, based on a multidimensional space segmentation tree (K-D tree) [
36], was adopted for feature matching in this work. The BBF algorithm can quickly find the nearest neighbor point and the second-closest neighbor point of a feature point to be matched. However, due to image noise or other reasons, the distance of the second nearest neighbor (
DSN) may be very close to that of the nearest neighbor (
DN). To reduce the impact of noise, the proposed method calculates the distance ratio, denoted as
R, of
DN to
DSN (R = DN/DSN). The nearest neighbor point is accepted as the match point of the feature point if
R is higher than a default value of 0.8.
It is worth noting that the image coordinates of the matched points within each image patch need to be converted to the coordinates of the entire image scene.
2.5. Removing the Outliers
The random sample consensus (RANSAC) algorithm is commonly used to remove incorrect matches obtained using the SIFT algorithm [
37]. The RANSAC algorithm was proposed by Fischler and Bolles in 1981 [
38]. It is an outlier detection method [
39] that iteratively derives the parameters of a mathematical model from a set of observed data that contains outliers. However, because of the randomness of RANSAC, the effect of removing incorrect matches depends on the selection of sample points. To achieve robust performances, the RANSAC algorithm was combined with the homography matrix to remove outliers in this work. The homography matrix is a transformation matrix that maps the points in one image to the corresponding points in the other image. It can be represented using Equation (11).
The matched tie points are denoted as {(xw, yw), (x, y)}, where (xw, yw) are the coordinates of the feature point in the input image to be registered, and (x, y) are the coordinates of the corresponding feature point in the reference image. The incorrectly matched tie points were excluded using the following steps.
First, a homography matrix H between the input image and the reference image was initially estimated by the RANSAC algorithm using all the matched tie points.
Then, the transformed coordinates of each feature point to be registered were estimated using the initial homography matrix
H, according to Equation (12).
where
(xw, yw) is the coordinates of the feature points of the input image and
(X, Y) is the transformed coordinates of
(xw, yw).
After that, the residual error and root-mean-square error
(RMSE) of the
ith tie point were obtained using Equations (13) and (14), respectively,
where Δ
xi and Δ
yi are the residual errors of the
ith feature point and
xi and
yi are the coordinates of the
ith feature point in the reference image. Tie point pairs that have
(Δ
xi, Δ
yi) and
RMSEi values higher than an initial threshold, which is denoted as
TR, are considered outliers and removed.
Finally, H and RMSEi were estimated iteratively based on the remaining tie points and the outliers were removed until either the Δxi, Δyi and RMSEi values were lower than the threshold TR or the number of iterations was higher than a set value denoted as Niter.
2.6. Even Spatial Distribution of Matched Tie Points
The uneven spatial distribution of the matched tie points may lead to local geometric distortions of the rectified images. In addition, redundant tie points covering some local regions may increase the number of computations and therefore reduce the efficiency of image processing. To solve this problem, a greedy algorithm [
40] was used in this work to remove matched tie points with high density.
Given that a number of Ntp tie point pairs were obtained after the elimination of the outliers, the following steps were performed to achieve the even distribution of the tie points.
Step 1: The perspective transform model between the input image and the reference image was estimated using all the matched tie points. The RMSE value of each tie point pair was calculated, and all the tie point pairs were then sorted in ascending order according to the RMSE values.
Step 2: The sorted tie point pairs were numbered according to the RMSE values. The first item of the sorted tie point pairs, which is numbered as 1 (i.e., i = 1), was selected as the first node.
Step 3: The distances between tie point i and the other tie points j (j = i+1, …, Ntp) were calculated using the Euclidean distance. If the distance of a tie point j was less than a threshold (TL), this tie point was considered to be too close to the tie point i. Then, this tie point was removed, and let i = i+1.
Step 4: Step 3 was repeated until i = Ntp.
To test the employed approach for the even distribution of tie points, an experiment was performed using an 800 × 800 RS image (experimental results are shown in
Figure 7). As shown in
Figure 7a, 181 matched tie points (dots in red) with a model error of 0.93 pixels were obtained after removing outliers using the combination of RANSAC and the homography matrix. After removing high-density tie point pairs using a threshold (
TL) of 30 pixels, 108 tie points with a model error of 0.75 pixels remained, as shown in
Figure 7b. The remaining tie points were more evenly distributed and offered higher accuracy than the initial tie points.
2.7. Image Transformation and Resampling
In this paper, the polynomial rectification model was used to warp the input image. The coefficients of the polynomial model were solved using the matched tie points. The number of matched tie points should meet the requirement in Equation (15),
where
Ncp is the number of tie point pairs and
Nd is the degree of the polynomial model. The value of
Nd is determined according to
Ncp and the terrain relief of the images. When
Nd is 2 or 3, the polynomial model is applicable for topographic relief areas, such as mountain areas. After the coefficients were obtained, the input image was transformed and resampled to align it with the reference image.
4. Discussions
The experimental results demonstrate the advantages of the proposed method over the SIFT and Patch-SIFT methods in terms of accuracy, running time, and the number and distribution of matched tie points for the three sets of pre- and post-earthquake images. All three image pairs covered mountainous areas affected by disasters (such as landslides and river expansion, triggered by severe earthquakes). Topographic relief in the images increased the difficulty of image registration. However, in this case, the proposed method still achieved better registration results.
Both the quadratic (Nd = 2) and cubic (Nd = 3) polynomial models were used in the experiments to generate registered images. The proposed method yielded very similar performances when using the two models. Using the quadratic polynomial model (Nd = 2), the proposed method also provided shorter running times and lower RMSET values than the Patch-SIFT and SIFT methods using the same model. The proposed method using the cubic polynomial model yielded slightly longer running times and lower RMSET values than the proposed method using the quadratic polynomial model. Consequently, we think that both the quadratic and cubic polynomial models can be selected for the images used in the experiments.
The proposed method can be also used for satellite images (such as GF-1 and GF-2 images) covering plains, according to the results of the other experiments. For example, a GF-1 multispectral image covering Chengdu City, Sichuan province, China, was also tested. The image was recorded on March 9, 2018 and had a relatively large size (5354 × 5354 pixels) and a spatial resolution of 8 m. A total of 175 matched tie points were extracted by the proposed method, with an RMSET of 0.38 pixels. The Patch-SIFT method obtained 116 matched tie points with an RMSET of 0.55 pixels, whereas the SIFT method provided 80 tie points with an RMSET of 0.66 pixels. The proposed method obtained the registered image within 17.17 s, which is only 26.5% of the SIFT (64.77 s) and 36.7% of the Patch-SIFT (46.76 s). The experimental results also show that the registration results of the proposed method are better than those of the other two methods. This demonstrates that the proposed method also works for RS images covering urban areas and shows advantages in running time on larger RS images.
The GE images were used in this work to construct the pre-earthquake image database and then used as the reference for the co-registration of post-earthquake RS images. If higher quality high-resolution satellite remote sensing images were available in the study area, the images could be used as the reference for image registration. In this case, the proposed method is also applicable and is expected to yield better performance than the other two methods.
In general, the proposed method can provide geometrically accurate images for disaster information extraction, and is helpful for the assessment of disasters, such as collapsed buildings, damaged roads, and landslides. The proposed method also has potential applications. For instance, the registered images obtained by the proposed method can be integrated with big data, such as the Floating Car Data [
41], which is used to observe historical traffic patterns, traffic facilities, and services, to the phenomenon after the earthquakes.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}