Spatial–Semantic and Temporal Attention Mechanism-Based Online Multi-Object Tracking


Abstract
1. Introduction
- A tracking system is required to deal with occlusion and insertion. The digital image sensor has a limited receptive field, which means that occlusion and insertion are common. In a receptive field, targets entering and leaving result in boundary insertions, and the close spatial positions of targets in the field result in the occlusion of targets.
- The ability to track small targets is highly important. Small targets are very common in real-life situations, and the ability to recognize small targets gives tracking system a longer response time. This is quite a significant challenge for conventional tracking-by-detection strategies.
- The tracking system is required to be robust. Some scenes, including jungle, desert, and grassland, are more complicated than general scenarios. Dust caused by movement adds complexity to a background.
- There is no ready-made MOT dataset available for armored targets. Compared with general multi-object tracking, the tracking of multi-armored targets is more challenging after adopting camouflage or smoke shielding to avoid exposure.
2. Related Work
2.1. Single-Object Tracking
2.2. Multi-Object Tracking
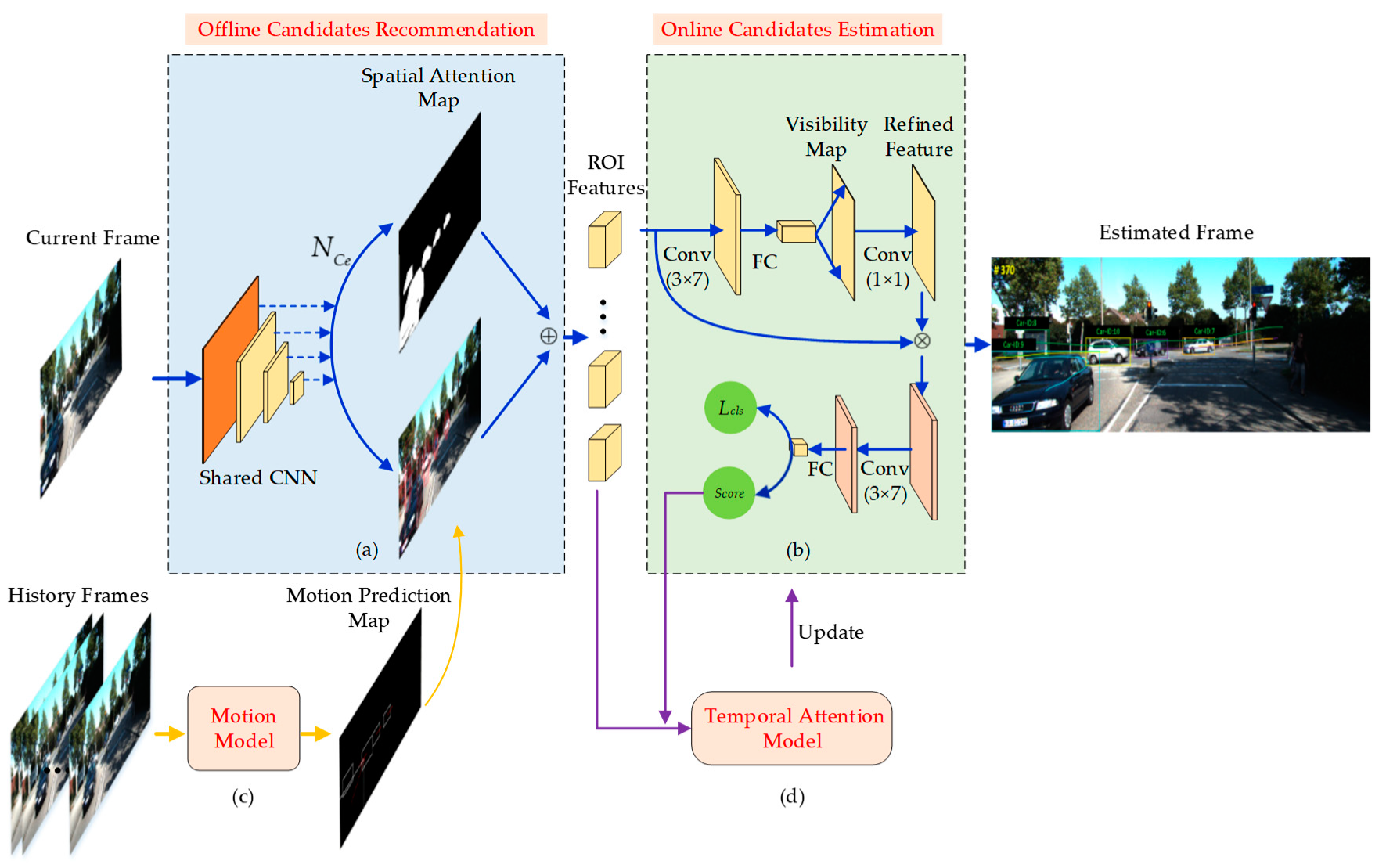
3. Proposed Method
3.1. Overview of Our Method
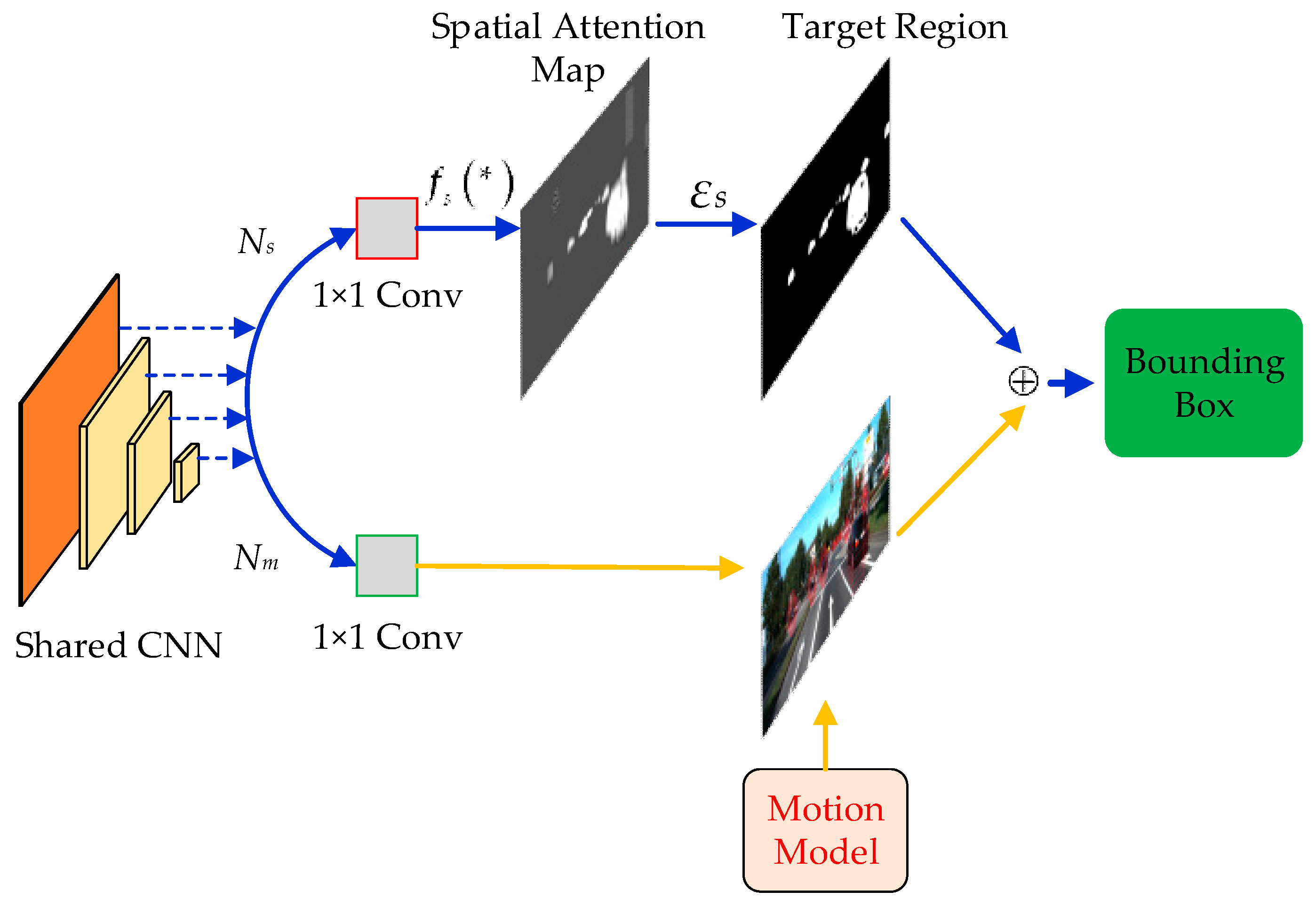
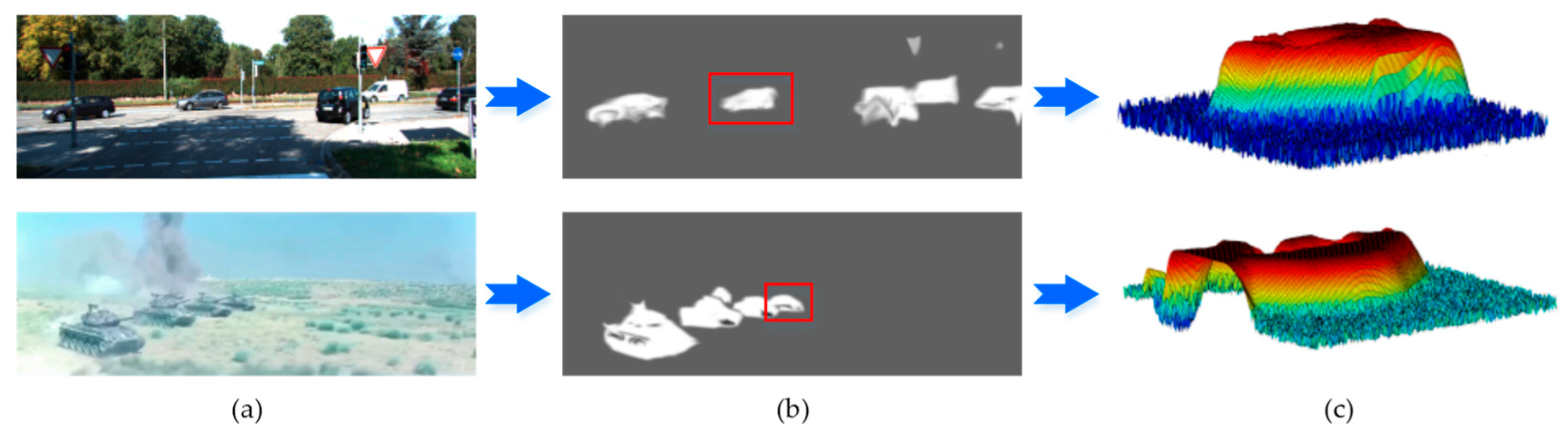
3.2. Offline Candidates Recommendation Module
3.3. Motion Model
3.4. Online Candidates Estimation
3.5. Temporal Attention Model
3.6. Training of Module
3.6.1. Training of the Offline Candidate Recommendation Module
3.6.2. Training of the Online Candidate Estimation Module
4. Experiment
4.1. Dataset and Implementation
4.2. Evaluation Metrics
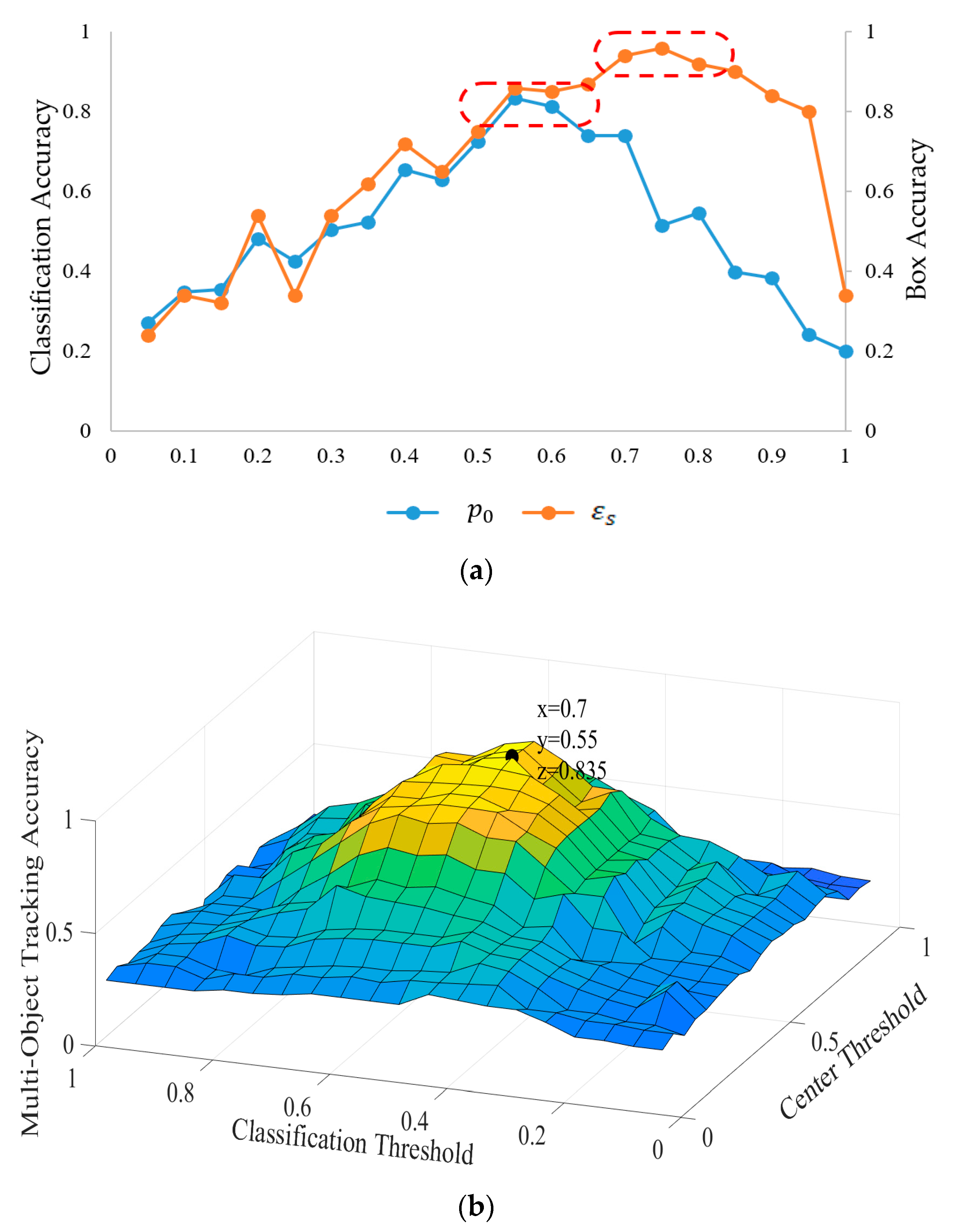
4.3. The Setting of Parameters
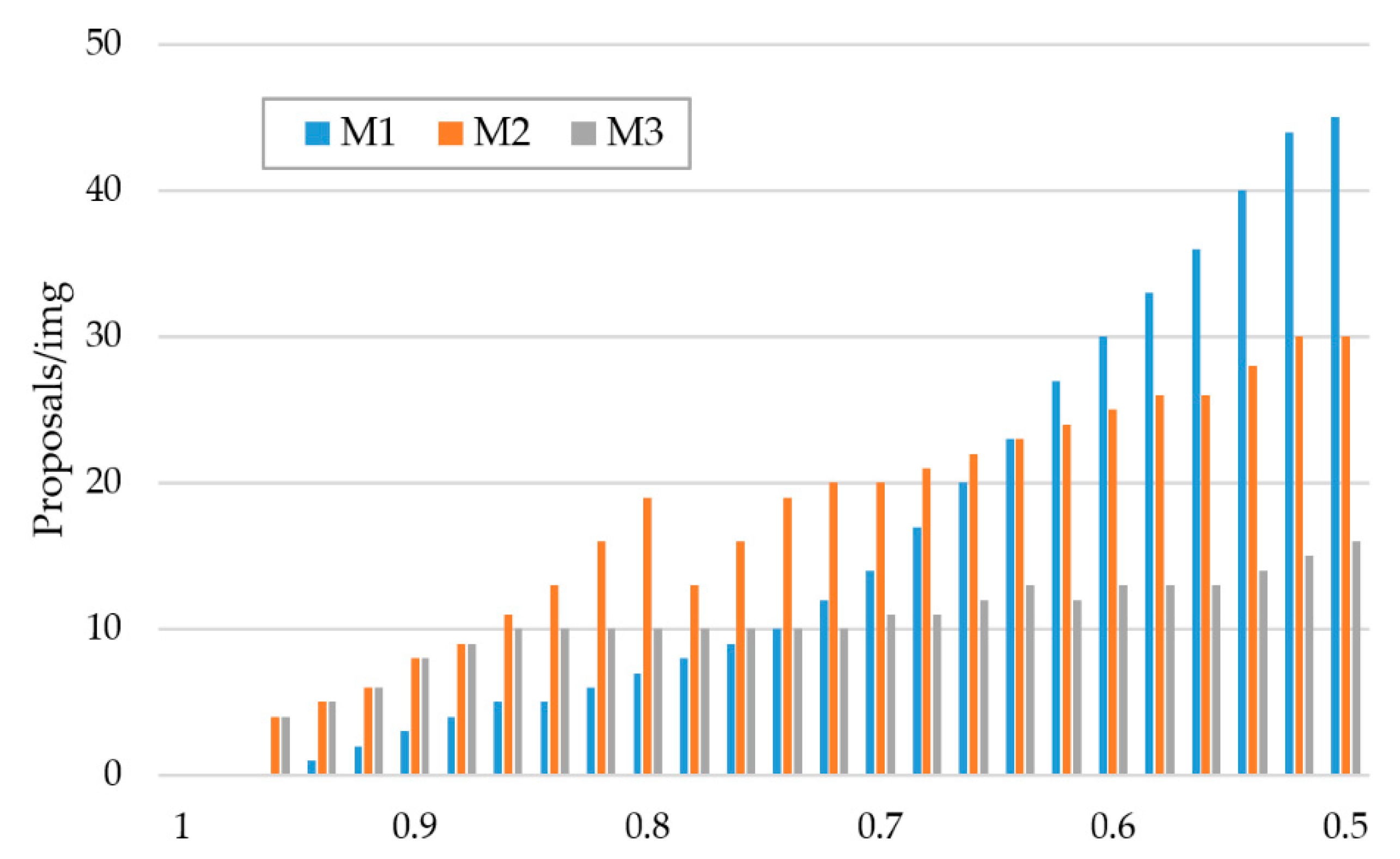
4.4. Analysis of Candidates Recommendation
- M1:
- The shared features extraction CNN + “RPN + 9 anchors”;
- M2:
- The shared features extraction CNN + + + “RPN + 9 anchors”;
- M3:
- The shared features extraction CNN + + + Motion Model.
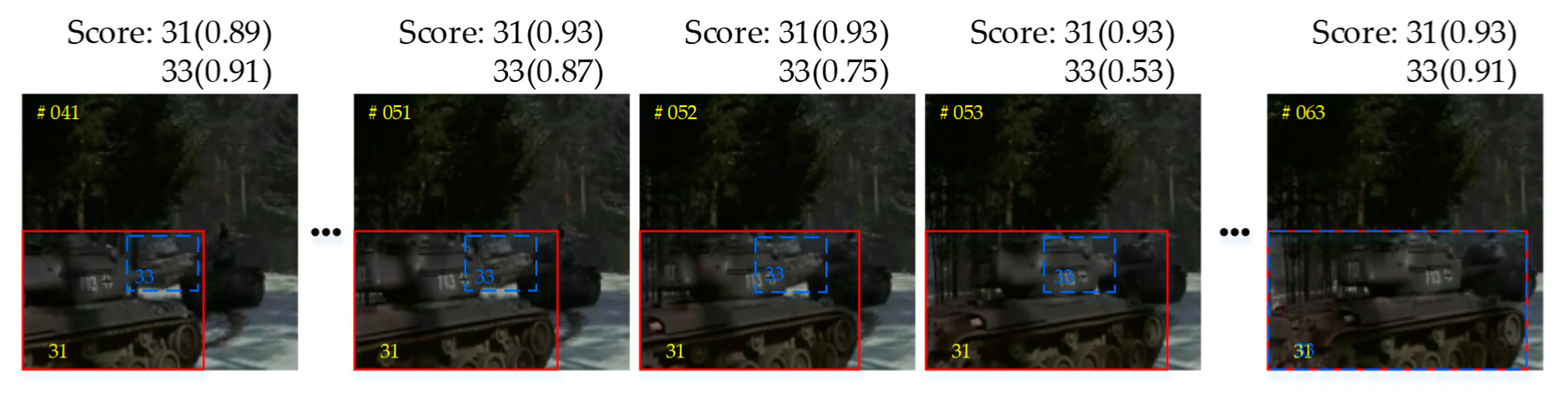
4.5. Analysis of Candidates Estimation
- M3:
- The shared features extraction CNN + + + Motion Model;
- M4:
- M3 + Online Candidates Estimation Module;
- M5:
- M3 + Online Candidates Estimation Module + Temporal Attention Model.
4.6. Benchmark Evaluation Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Haoze, S.; Tianqing, C.; Lei, Z.; Guozhen, Y.; Bin, H.; Junwei, C. Armored target detection in battlefield environment based on top-down aggregation network and hierarchical scale optimization. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 312–370. [Google Scholar] [CrossRef]
- Haoze, S.; Tianqing, C.; Quandong, W.; Depeng, K.; Wenjun, D. Image detection method for tank and armored targets based on hierarchical multi-scale convolution feature extraction. Acta Armamentarii 2017, 38, 1681–1691. [Google Scholar] [CrossRef]
- Qi, C.; Wanli, O.; Hongsheng, L.; Xiaogang, W.; Liu, B.; Yu, N. Online multi-object tracking using CNN-based single object tracker with spatial-temporal attention mechanism. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Gundogdu, E.; Alatan, A.A. Good features to correlate for visual tracking. IEEE Trans. Image Process. 2018, 27, 2526–2540. [Google Scholar] [CrossRef] [PubMed]
- Fantacci, C.; Vo, B.N.; Vo, B.T.; Battistelli, G.; Chisci, L. Robust fusion for multisensor multiobject tracking. IEEE Signal Process. Lett. 2018, 25, 640–644. [Google Scholar] [CrossRef]
- Jia, B.; Lv, J.; Liu, D. Deep learning-based automatic downbeat tracking: A brief review. Multimedia Systems 2019, 1–22. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of siamese visual tracking with very deep networks. arXiv 2018, arXiv:1812.11703. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H.S. Fast online object tracking and segmentation: A unifying approach. arXiv 2018, arXiv:1812.05050. [Google Scholar]
- Melekhov, I.; Kannala, J.; Rahtu, E. Siamese network features for image matching. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar] [CrossRef]
- Yicong, T.; Afshin, D.; Mubarak, S. On detection, data association and segmentation for multi-target tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2146–2160. [Google Scholar] [CrossRef]
- Dawei, Z.; Hao, F.; Liang, X.; Tao, W.; Bin, D. Multi-object tracking with correlation filter for autonomous vehicle. Sensors 2018, 18, 2004. [Google Scholar] [CrossRef]
- Yang, M.; Wu, Y.; Jia, Y. A hybrid data association framework for robust online multi-object tracking. IEEE Trans. Image Process. 2017, 26, 5667–5679. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef]
- Min, J.; Jianyu, S.; Jun, K.; Hongtao, H. Regularisation learning of correlation filters for robust visual tracking. IET Image Process. 2018, 12, 1586–1594. [Google Scholar] [CrossRef]
- Kuai, Y.; Wen, G.; Li, D. Learning adaptively windowed correlation filters for robust tracking. J. Visual Comm. Image Represent. 2018, 51, 104–111. [Google Scholar] [CrossRef]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.H. Learning spatial-temporal regularized correlation filters for visual tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS’12 Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012. [Google Scholar] [CrossRef]
- Tom, Y.; Devamanyu, H.; Soujanya, P.; Erik, C. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced deep-learning techniques for salient and category-specific object detection: A survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Chin, T.W.; Yu, C.L.; Halpern, M.; Genc, H.; Tsao, S.L.; Reddi, V.J. Domain-Specific Approximation for Object Detection. IEEE Micro 2018, 38, 31–40. [Google Scholar] [CrossRef]
- Ranjan, R.; Sankaranarayanan, S.; Bansal, A.; Bodla, N.; Chen, J.C.; Patel, V.M.; Castillo, C.D.; Chellappa, R. Deep learning for understanding faces: Machines may be just as good, or better, than humans. IEEE Signal Process. Mag. 2018, 35, 66–83. [Google Scholar] [CrossRef]
- Voigtlaender, P.; Krause, M.; Osep, A.; Luiten, J.; Sekar, B.B.G.; Geiger, A. Mots: Multi-object tracking and segmentation. arXiv 2018, arXiv:1902.03604. [Google Scholar]
- Seguin, G.; Bojanowski, P.; Lajugie, R.; Laptev, I. Instance-Level Video Segmentation from Object Tracks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Sadeghian, A.; Alahi, A.; Savarese, S. Tracking the untrackable: Learning to track multiple cues with long-term dependencies. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual tracking with online Multiple Instance Learning. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [CrossRef]
- Yang, W.; Liu, Y.; Zhang, Q.; Zheng, Y. Comparative object similarity learning-based robust visual tracking. IEEE Access 2019, 7, 50466–50475. [Google Scholar] [CrossRef]
- Son, J.; Baek, M.; Cho, M.; Han, B. Multi-object Tracking with Quadruplet Convolutional Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Sarikaya, D.; Corso, J.; Guru, K. Detection and localization of robotic tools in robot-assisted surgery videos using deep neural networks for region proposal and detection. IEEE Trans. Med. Imaging 2017, 36, 1542–1549. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Z.; Sun, L.; Huo, Q. An anchor-free region proposal network for faster r-cnn based text detection approaches. Int. J. Doc. Anal. Recognit. 2019, 22, 315. [Google Scholar] [CrossRef]
- Sun, X.; Wu, P.; Hoi, S.C.H. Face detection using deep learning:an improved faster rcnn approach. Neurocomputing 2018, 299, 42–50. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Giuseppe, S.; Massimiliano, G.; Antonio, M.; Raffaele, G. A cnn-based fusion method for feature extraction from sentinel data. Remote Sens. 2018, 10, 236. [Google Scholar] [CrossRef]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.; Lin, D. Region proposal by guided anchoring. arXiv 2019, arXiv:1901.03278. [Google Scholar]
- Yeung, F.; Levinson, S.F.; Parker, K.J. Multilevel and motion model-based ultrasonic speckle tracking algorithms. Ultrasound Med. Biol. 1998, 24, 427–441. [Google Scholar] [CrossRef]
- Park, J.D.; Doherty, J.F. Track detection of low observable targets using a motion model. IEEE Access 2015, 3, 1408–1415. [Google Scholar] [CrossRef]
- Bae, S.H.; Yoon, K.J. Confidence-based data association and discriminative deep appearance learning for robust online multi-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 595–610. [Google Scholar] [CrossRef]
- Henschel, R.; Leal-Taixé, L.; Cremers, D.; Rosenhahn, B. Fusion of head and full-body detectors for multi-object tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Long, L.; Xinchao, W.; Shiliang, Z.; Dacheng, T.; Wen, G.; Huang, T.S. Interacting tracklets for multi-object tracking. IEEE Trans. Image Process. 2018, 27, 4585–4597. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Leal-Taixe, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge 2015: Towards a benchmark for multi-target tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. Mot16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Keni, B.; Rainer, S. Evaluating multiple object tracking performance: The clear mot metrics’, eurasip. EURASIP J. Image Video Proc. 2008, 1, 246309. [Google Scholar] [CrossRef]
- Leal-Taixé, L.; Ferrer, C.C.; Schindler, K. Learning by tracking: Siamese cnn for robust target association. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Wang, B.; Wang, L.; Shuai, B.; Zuo, Z.; Wang, G. Joint Learning of Convolutional Neural Networks and Temporally Constrained Metrics for Tracklet Association. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Milan, A.; Schindler, K.; Roth, S. Multi-target tracking by discrete-continuous energy minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2054–2068. [Google Scholar] [CrossRef]
- Wang, S.; Fowlkes, C.C. Learning optimal parameters for multi-target tracking with contextual interactions. Int. J. Comput. Vis. 2016, 122, 1–18. [Google Scholar] [CrossRef]
- Kieritz, H.; Becker, S.; Hubner, W.; Arens, M. Online multi-person tracking using Integral Channel Features. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal BasedSurveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016. [Google Scholar] [CrossRef]
- Yoon, J.H.; Lee, C.R.; Yang, M.H.; Yoon, K.J. Online multi-object tracking via structural constraint event aggregation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Lenz, P.; Geiger, A.; Urtasun, R. FollowMe: Efficient Online Min-Cost Flow Tracking with Bounded Memory and Computation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) 2015, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Zhang, W.; Zhou, H.; Sun, S.; Wang, Z.; Shi, J.; Loy, C.C. Robust multi-modality multi-object tracking. Proceedings of The IEEE International Conference on Computer Vision (ICCV) 2019, Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Sharma, S.; Ansari, J.A.; Murthy, J.K.; Krishna, K.M. Beyond pixels: Leveraging geometry and shape cues for online multi-object tracking. In Proceedings of the IEEE Conference on Robotics and Automation (ICRA) 2018, Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MOTA | MOTP | MT | ML |
|---|---|---|---|---|
| M1(Shared CNN + RPN + 9 anchors) | 45.47% | 65.30% | 27.54% | 19.35% |
| M2(M1 + + ) | 56.32% | 66.43% | 35.46% | 18.36% |
| M3(Shared CNN + + + Motion Model) | 69.45% | 80.56% | 46.83% | 17.25% |
| Method | MOTA | MOTP | MT | ML |
|---|---|---|---|---|
| M3(Shared CNN + + + Motion Model) | 69.45% | 80.56% | 46.83% | 17.25% |
| M4(M3 + Online Candidates Estimation) | 85.32% | 81.52% | 75.46% | 15.36% |
| M5(M4 + Temporal Attention Model) | 89.65% | 85.55% | 80.65% | 2.25% |
| Method | Mode | MOTA | MOTP | MT | ML | Tracking Time (s) |
|---|---|---|---|---|---|---|
| Siamese CNN | offline | 46.31% | 71.20% | 15.52% | 27.30% | 0.81 |
| CNNTCM | offline | 49.50% | 71.80% | 19.75% | 22.64% | 0.73 |
| LP-SSVM | offline | 75.65% | 77.80% | 42.54% | 10.25% | 0.95 |
| mmMOT | offline | 84.77% | 85.21% | 73.23% | 2.77% | 0.16 |
| NOMT-HM | online | 69.12% | 78.52% | 38.51% | 15.28% | 0.09 |
| STAM | online | 77.20% | 74.90% | 29.65% | 18.57% | 0.25 |
| SSP | online | 68.00% | 79.52% | 42.05% | 10.64% | 0.61 |
| MOTBeyondPixels | online | 84.24% | 85.73% | 73.23% | 2.77% | 0.30 |
| Ours | online | 89.65% | 85.55% | 80.65% | 2.25% | 0.16 |
| Method | Mode | MOTA | MOTP | MT | ML | Tracking Time (s) |
|---|---|---|---|---|---|---|
| SiameseCNN | offline | 46.31% | 71.20% | 15.52% | 27.30% | 0.81 |
| CNNTCM | offline | 49.50% | 71.80% | 19.75% | 22.64% | 0.73 |
| DCO-X | offline | 65.12% | 73.85% | 31.52% | 14.25% | 0.95 |
| LP-SSVM | offline | 75.65% | 77.80% | 42.54% | 10.25% | 0.16 |
| NOMT-HM | online | 69.12% | 78.52% | 38.51% | 15.28% | 0.09 |
| SCEA | online | 34.35% | 71.10% | 47.35% | 37.50% | 0.18 |
| STAM | online | 77.20% | 74.90% | 29.65% | 18.57% | 0.25 |
| SSP | online | 68.00% | 79.52% | 42.05% | 10.64% | 0.61 |
| Ours | online | 80.65% | 83.55% | 49.52% | 6.27% | 0.26 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, F.; Wang, X.; Wang, D.; Shao, F.; Fu, L. Spatial–Semantic and Temporal Attention Mechanism-Based Online Multi-Object Tracking. Sensors 2020, 20, 1653. https://doi.org/10.3390/s20061653
Meng F, Wang X, Wang D, Shao F, Fu L. Spatial–Semantic and Temporal Attention Mechanism-Based Online Multi-Object Tracking. Sensors. 2020; 20(6):1653. https://doi.org/10.3390/s20061653
Chicago/Turabian StyleMeng, Fanjie, Xinqing Wang, Dong Wang, Faming Shao, and Lei Fu. 2020. "Spatial–Semantic and Temporal Attention Mechanism-Based Online Multi-Object Tracking" Sensors 20, no. 6: 1653. https://doi.org/10.3390/s20061653
APA StyleMeng, F., Wang, X., Wang, D., Shao, F., & Fu, L. (2020). Spatial–Semantic and Temporal Attention Mechanism-Based Online Multi-Object Tracking. Sensors, 20(6), 1653. https://doi.org/10.3390/s20061653