A Review of Data Analytic Applications in Road Traffic Safety. Part 1: Descriptive and Predictive Modeling

 , , , , and
, , , , and
Abstract
1. Introduction
2. Data Acquisition Protocols: An Overview of the Types of Collected Data and Their Associated Sensing Systems
2.1. Background: Study Designs
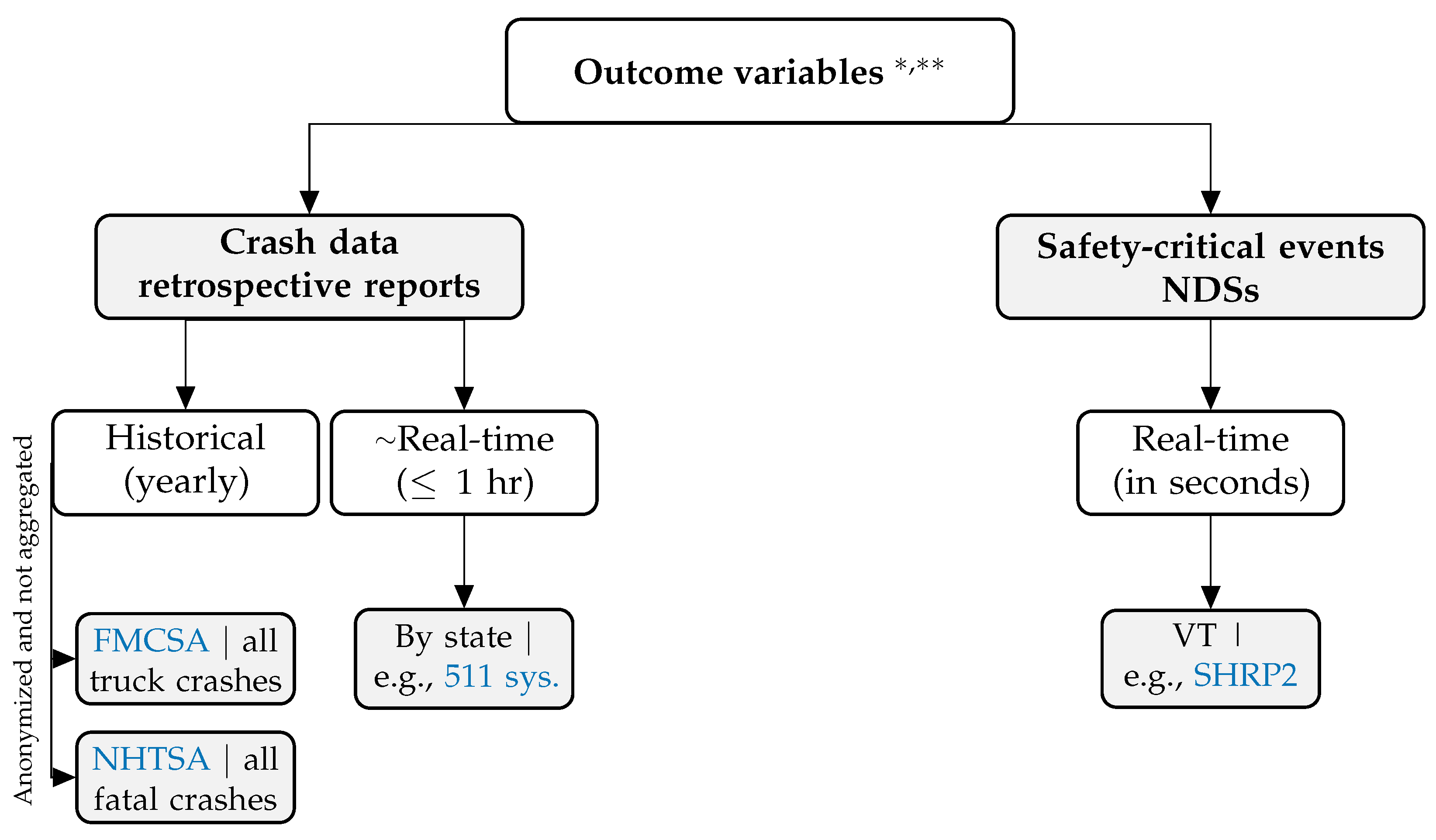
2.2. Outcome Variables Used in Crash Risk Modeling
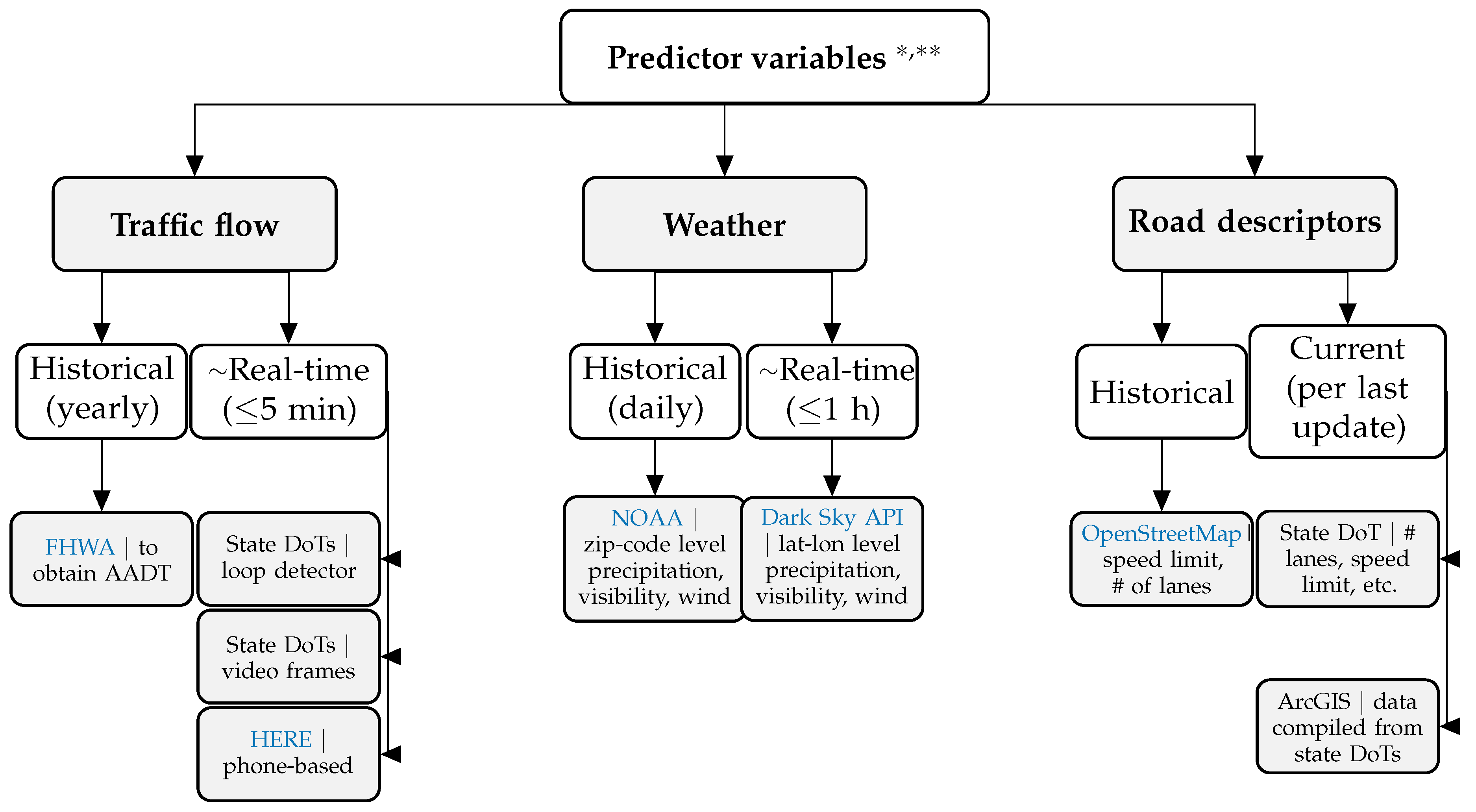
2.3. Predictor Variables Used in Crash Risk Modeling
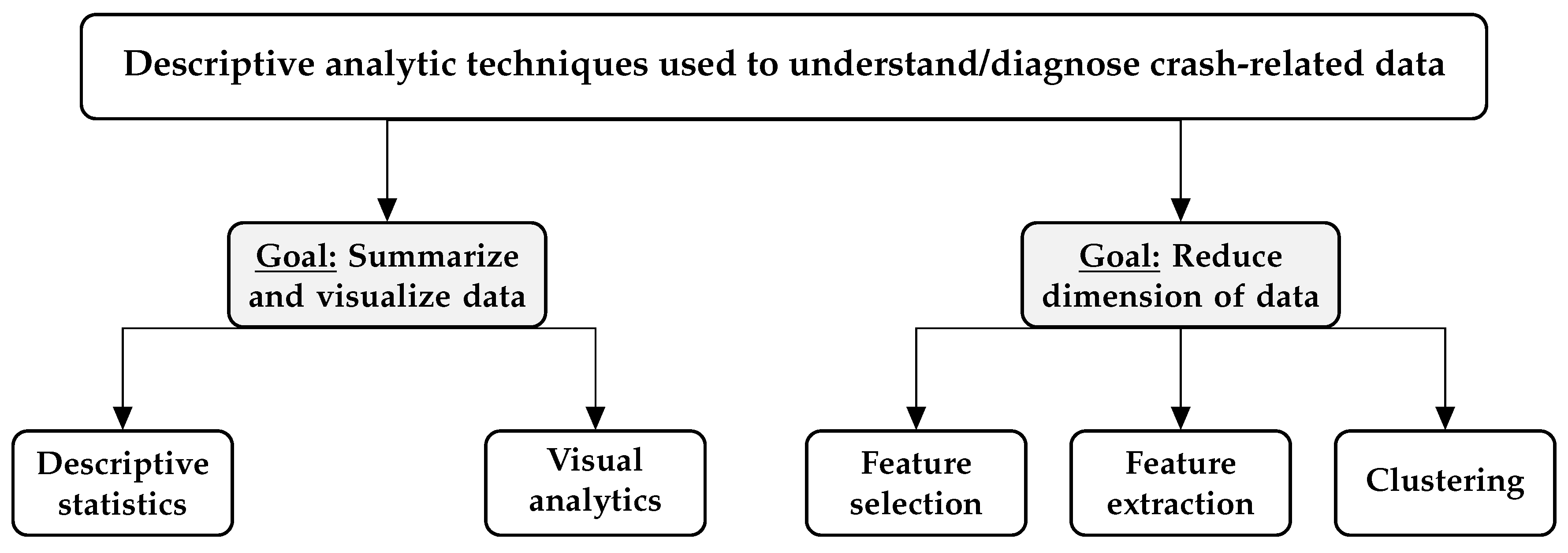
3. Descriptive Analytic Tools Used for Understanding Crash Data
3.1. Data Summarization and Visualization
3.1.1. Visualization of Time-Oriented Data
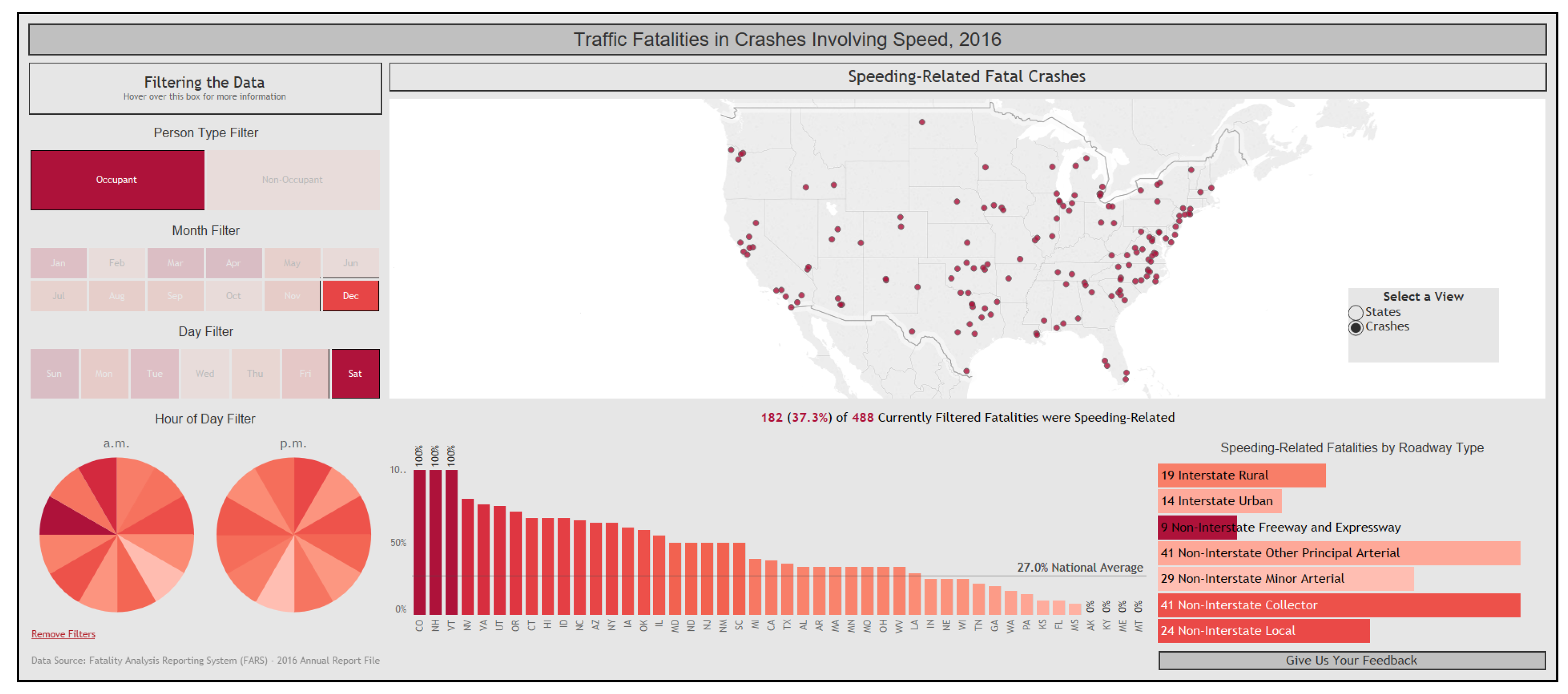
3.1.2. Visualization of Spatial and Spatiotemporal Data
3.1.3. Visualization of High-Dimensional Datasets
3.2. Dimension Reduction
3.2.1. Feature Selection
3.2.2. Feature Extraction
3.2.3. Clustering
4. Explanatory/Predictive Models for Crash Risk
4.1. Risk Factors for Traffic Safety
4.1.1. Sleep and Fatigue
4.1.2. Distracted Driving
4.1.3. Weather, Traffic Conditions, and Road Geometry
4.2. Statistical Modeling
5. Conclusions
- (A)
- The availability of historical, real-time and forecasted weather and traffic data, as well as the potential to collect driver performance data, means that the accessibility of data is no longer a major factor preventing progress in this area. However, a lack of a unified repository and the reluctance of sharing code/models by our research community leads to a fairly high overhead cost of developing such models (since every researcher has to develop many data collection techniques from scratch);
- (B)
- Descriptive analytics tools are widely used in the preprocessing of driving-related data. Since the applicability of a particular preprocessing technique (e.g., visualization and clustering) often depends on the specific problem, the challenge here is to determine which method is the most suitable. Sharing best practices by creating reproducible documents (e.g., R Markdown and Jupyter notebook) represents one avenue for making the process more efficient for researchers and practitioners alike.
- (C)
- Statistical methods for risk evaluation are well-researched and consider a wide range of factors. At the same time, it must be noted that (in some cases) these studies follow a similar pattern of a case-controlled study based on a single road segment data. In our view, there is an opportunity for a statistical analysis of a larger scale since:
- (i)
- real-time or near-real-time data are more widely available now;
- (ii)
- the computational advancements in the recent years can allow for parallelizing/ computing risk across the entire road network or at the very least for all major highways and interstates;
- (iii)
- the insights from these relatively small road segments may not be generalizable to the entire road network; and
- (iv)
- it is unclear how drivers (regular commuters or commercial) can utilize these insights to make more informed decisions about their time-of-travel, path and/or route selection.
Supplementary Materials
Funding
Conflicts of Interest
Abbreviations
| AADT | Annual Average Daily Traffic |
| DoT | Department of Transportation |
| FHWA | Federal Highway Administration |
| FMCSA | Federal Motor Carrier Safety Administration |
| NDS | Naturalistic Driving Study |
| NHTSA | National Highway Traffic Safety Administration |
| NOAA | National Oceanic & Atmospheric Administration |
| VT | Virginia Tech |
References
- World Health Organization. WHO | The Top 10 Causes of Death. Available online: http://www.who.int/en/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 24 February 2019).
- National Highway Traffic Safety Administration, NHTSA. U.S. DOT Announces 2017 Roadway Fatalities Down. Available online: https://www.nhtsa.gov/press-releases/us-dot-announces-2017-roadway-fatalities-down (accessed on 23 February 2019).
- Insurance Institute for Highway Safety. Fatality Facts—IIHS. The Insurance Institute for Highway Safety and the Highway Loss Data Institute. Available online: http://www.iihs.org/iihs/topics/t/general-statistics/fatalityfacts/overview-of-fatality-facts (accessed on 24 February 2019).
- World Health Organization. WHO | Road Traffic Injuries. Available online: http://www.who.int/mediacentre/factsheets/fs358/en/ (accessed on 22 April 2018).
- Blincoe, L.; Miller, T.R.; Zaloshnja, E.; Lawrence, B.A. The Economic and Societal Impact of Motor Cehicle Crashes, 2010 (Revised). U.S. Department of Transportation, National Highway Safety Administration, Report No.: DOT HS 812 013. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/812013 (accessed on 28 April 2018).
- GDP (Current US$) | Data: United States. World Bank National Accounts Data, and OECD National Accounts Data Files. 2018. Available online: https://data.worldbank.org/indicator/NY.GDP.MKTP.CD?locations=US (accessed on 28 April 2018).
- Erkut, E.; Tjandra, S.A.; Verter, V. Hazardous materials transportation. Handb. Oper. Res. Manag. Sci. 2007, 14, 539–621. [Google Scholar]
- Androutsopoulos, K.N.; Zografos, K.G. A bi-objective time-dependent vehicle routing and scheduling problem for hazardous materials distribution. EURO J. Trans. Logist. 2012, 1, 157–183. [Google Scholar] [CrossRef]
- Abkowitz, M.; Cheng, P.D.M. Developing a risk/cost framework for routing truck movements of hazardous materials. Accid. Anal. Prev. 1988, 20, 39–51. [Google Scholar] [CrossRef]
- Theofilatos, A.; Yannis, G. A review of the effect of traffic and weather characteristics on road safety. Accid. Anal. Prev. 2014, 72, 244–256. [Google Scholar] [CrossRef]
- Roshandel, S.; Zheng, Z.; Washington, S. Impact of real-time traffic characteristics on freeway crash occurrence: Systematic review and meta-analysis. Accid. Anal. Prev. 2015, 79, 198–211. [Google Scholar] [CrossRef] [PubMed]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informet. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Garfield, E.; Sher, I.H. KeyWords Plus™—Algorithmic derivative indexing. J. Am. Soc. Inf. Sci. 1993, 44, 298–299. [Google Scholar] [CrossRef]
- Thiese, M.S.; Hanowski, R.J.; Kales, S.N.; Porter, R.J.; Moffitt, G.; Hu, N.; Hegmann, K.T. Multiple conditions increase preventable crash risks among truck drivers in a cohort study. J. Occup. Environ. Med. 2017, 59, 205. [Google Scholar] [CrossRef]
- Newnam, S.; Xia, T.; Koppel, S.; Collie, A. Work-related injury and illness among older truck drivers in Australia: A population based, retrospective cohort study. Saf. Sci. 2019, 112, 189–195. [Google Scholar] [CrossRef]
- Dingus, T.A.; Hanowski, R.J.; Klauer, S.G. Estimating crash risk. Ergon. Des. 2011, 19, 8–12. [Google Scholar] [CrossRef]
- Guo, F. Statistical methods for naturalistic driving studies. Annu. Rev. Stat. Appl. 2019, 6, 309–328. [Google Scholar] [CrossRef]
- Federal Highway Administration. Real-Time System Management. Department of Transportation, 2016. Available online: https://ops.fhwa.dot.gov/511/index.htm (accessed on 3 August 2018).
- Guo, F.; Klauer, S.G.; Hankey, J.M.; Dingus, T.A. Near crashes as crash surrogate for naturalistic driving studies. Transp. Res. Rec. 2010, 2147, 66–74. [Google Scholar] [CrossRef]
- Jansen, R.J.; Simone Wesseling, S. Harsh Braking by Truck Drivers: A Comparison of Thresholds and Driving Contexts Using Naturalistic Driving Data. In Proceedings of the 6th Humanist Conference, The Hague, The Netherlands, 13–14 June 2018. [Google Scholar]
- Mollicone, D.; Kan, K.; Mott, C.; Bartels, R.; Bruneau, S.; van Wollen, M.; Sparrow, A.R.; Van Dongen, H.P. Predicting performance and safety based on driver fatigue. Accid. Anal. Prev. 2019, 126, 142–145. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Ismail, K.; Meng, X. Traffic conflict techniques for road safety analysis: Open questions and some insights. Can. J. Civ. Eng. 2014, 41, 633–641. [Google Scholar] [CrossRef]
- Johnsson, C.; Laureshyn, A.; De Ceunynck, T. In search of surrogate safety indicators for vulnerable road users: a review of surrogate safety indicators. Transp. Rev. 2018, 38, 765–785. [Google Scholar] [CrossRef]
- Mahmud, S.S.; Ferreira, L.; Hoque, M.S.; Tavassoli, A. Application of proximal surrogate indicators for safety evaluation: A review of recent developments and research needs. IATSS Res. 2017, 41, 153–163. [Google Scholar] [CrossRef]
- Knipling, R.R. Naturalistic Driving Events: No Harm, No Foul, No Validity. In Proceedings of the Eighth International Driving Symposium on Human Factors in Driver Assessment, Training and Vehicle Design, Salt Lake City, UT, USA, 22–25 June 2015. [Google Scholar]
- Knipling, R.R. Threats to Scientific Validity in Truck Driver Hours-of-Service Studies. In Proceedings of the Ninth International Driving Symposium on Human Factors in Driver Assessment, Training and Vehicle Design, Manchester Village, VT, USA, 26–29 June 2017. [Google Scholar]
- Guerrero-Ibáñez, J.; Zeadally, S.; Contreras-Castillo, J. Sensor technologies for intelligent transportation systems. Sensors 2018, 18, 1212. [Google Scholar] [CrossRef]
- Abdelhamid, S.; Hassanein, H.S.; Takahara, G. Vehicle as a mobile sensor. Proc. Comput. Sci. 2014, 34, 286–295. [Google Scholar] [CrossRef]
- Wikipedia Contributors. OpenStreetMap—Wikipedia, The Free Encyclopedia. 2019. Available online: https://en.wikipedia.org/w/index.php?title=OpenStreetMap&oldid=900226891 (accessed on 5 June 2019).
- Eugster, M.J.; Schlesinger, T. osmar: OpenStreetMap and R. R J. 2013, 5, 53–63. [Google Scholar] [CrossRef]
- Washington, S.P.; Karlaftis, M.G.; Mannering, F. Statistical and Econometric Methods for Transportation Data Analysis; Chapman and Hall/CRC: London, UK, 2010. [Google Scholar]
- Chen, W.; Guo, F.; Wang, F.Y. A survey of traffic data visualization. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2970–2984. [Google Scholar] [CrossRef]
- Han, W.; Wang, J.; Shaw, S.L. Visual Exploratory Data Analysis of Traffic Volume. In MICAI 2006: Advances in Artificial Intelligence; Gelbukh, A., Reyes-Garcia, C.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 695–703. [Google Scholar]
- Alam, I.; Ahmed, M.F.; Alam, M.; Ulisses, J.; Farid, D.M.; Shatabda, S.; Rossetti, R.J. Pattern mining from historical traffic big data. In Proceedings of the IEEE Region 10 Symposium (TENSYMP), Cochin, India, 14–16 July 2017; pp. 1–5. [Google Scholar]
- Nookala, L.S. Weather Impact on Traffic Conditions and Travel Time Prediction. Master’s Thesis, Department of Computer Science, University of Minnesota Duluth, Duluth, MN, USA, 2006. Available online: https://www.semanticscholar.org/paper/Weather-Impact-on-Traffic-Conditions-and-Travel-Nookala/cc2d6345ee24c5383d5b25560f19856d862edd5e (accessed on 4 September 2018).
- Ferreira, N.; Poco, J.; Vo, H.T.; Freire, J.; Silva, C.T. Visual exploration of big spatio-temporal urban data: A study of new york city taxi trips. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2149–2158. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Wang, Z.; Yu, B.; Zhao, H.; Yuan, X. Tripvista: Triple perspective visual trajectory analytics and its application on microscopic traffic data at a road intersection. In Proceedings of the 2011 IEEE Pacific Visualization Symposium (PacificVis), Hong Kong, China, 1–4 March 2011; pp. 163–170. [Google Scholar]
- Tsai, Y.T.; Alhwiti, T.; Swartz, S.M.; Megahed, F.M. Using visual data mining in highway traffic safety analysis and decision making. J. Trans. Manag. 2015, 26, 43–60. [Google Scholar] [CrossRef]
- Pu, J.; Liu, S.; Ding, Y.; Qu, H.; Ni, L. T-Watcher: A new visual analytic system for effective traffic surveillance. In Proceedings of the 2013 IEEE 14th International Conference on Mobile Data Management (MDM), Milan, Italy, 3–6 June 2013; Volume 1, pp. 127–136. [Google Scholar]
- NHTSA. FARS Speeding Data Visualization. United States Department of Transportation. Available online: https://www.nhtsa.gov/press-releases/usdot-releases-2016-fatal-traffic-crash-data (accessed on 7 September 2018).
- Xie, Z.; Yan, J. Kernel density estimation of traffic accidents in a network space. Comput. Environ. Urban Syst. 2008, 32, 396–406. [Google Scholar] [CrossRef]
- Lovelace, R.; Nowosad, J.; Muenchow, J. Geocomputation with R; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Kraak, M.J. Visualising spatial distributions. Chapter 1999, 11, 157–173. [Google Scholar]
- Erdogan, S. Explorative spatial analysis of traffic accident statistics and road mortality among the provinces of Turkey. J. Saf. Res. 2009, 40, 341–351. [Google Scholar] [CrossRef]
- Wongsuphasawat, K.; Pack, M.; Filippova, D.; VanDaniker, M.; Olea, A. Visual analytics for transportation incident data sets. Transp. Res. Rec. J. Transp. Res. Board 2009, 2138, 135–145. [Google Scholar] [CrossRef]
- Liu, S.; Pu, J.; Luo, Q.; Qu, H.; Ni, L.M.; Krishnan, R. VAIT: A visual analytics system for metropolitan transportation. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1586–1596. [Google Scholar] [CrossRef]
- Zeng, W.; Fu, C.W.; Arisona, S.M.; Qu, H. Visualizing Interchange Patterns in Massive Movement Data. In Proceedings of the 15th Eurographics Conference on Visualization (EuroVis ’13); The Eurographs Association & John Wiley & Sons, Ltd.: Chichester, UK, 2013; pp. 271–280. [Google Scholar] [CrossRef]
- Kraak, M.J. The space-time cube revisited from a geovisualization perspective. In Proceedings of the 21st International Cartographic Conference, Durban, South Africa, 10–16 August 2003; pp. 1988–1996. [Google Scholar]
- Kapler, T.; Wright, W. GeoTime information visualization. Inf. Vis. 2005, 4, 136–146. [Google Scholar] [CrossRef]
- Romero, B. Traffic Accidents. 2015. Available online: http://brettromero.com/traffic-accidents-cyclists/ (accessed on 9 September 2018).
- Galka, M. Traffic Accidents. 2016. Available online: http://metrocosm.com/map-us-traffic/ (accessed on 9 September 2018).
- Tominski, C.; Schumann, H.; Andrienko, G.; Andrienko, N. Stacking-based visualization of trajectory attribute data. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2565–2574. [Google Scholar] [CrossRef]
- Pack, M.L.; Wongsuphasawat, K.; VanDaniker, M.; Filippova, D. ICE–visual analytics for transportation incident datasets. In Proceedings of the IEEE International Conference on Information Reuse & Integration (IRI’09), Las Vegas, NV, USA, 10–12 August 2009; pp. 200–205. [Google Scholar]
- Cottrill, C.D.; Thakuriah, P.V. Evaluating pedestrian crashes in areas with high low-income or minority populations. Accid. Anal. Prev. 2010, 42, 1718–1728. [Google Scholar] [CrossRef]
- Pack, M.L. Visualization in transportation: Challenges and opportunities for everyone. IEEE Comput. Graph. Appl. 2010, 30, 90–96. [Google Scholar] [CrossRef] [PubMed]
- Chu, D.; Sheets, D.A.; Zhao, Y.; Wu, Y.; Yang, J.; Zheng, M.; Chen, G. Visualizing hidden themes of taxi movement with semantic transformation. In Proceedings of the 2014 IEEE Pacific Visualization Symposium (PacificVis), Yokohama, Japa, 4–7 March 2014; pp. 137–144. [Google Scholar]
- van Huysduynen, H.H.; Terken, J.; Martens, J.B.; Eggen, B. Measuring driving styles: A validation of the multidimensional driving style inventory. In Proceedings of the 7th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Nottingham, UK, 22 September 2015; pp. 257–264. [Google Scholar]
- Liu, H.; Taniguchi, T.; Tanaka, Y.; Takenaka, K.; Bando, T. Visualization of driving behavior based on hidden feature extraction by using deep learning. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2477–2489. [Google Scholar] [CrossRef]
- Das, S.; Avelar, R.; Dixon, K.; Sun, X. Investigation on the wrong way driving crash patterns using multiple correspondence analysis. Accid. Anal. Prev. 2018, 111, 43–55. [Google Scholar] [CrossRef] [PubMed]
- Croxford, B.; Penn, A.; Hillier, B. Spatial distribution of urban pollution: Civilizing urban traffic. Sci. Total Environ. 1996, 189, 3–9. [Google Scholar] [CrossRef]
- Havre, S.; Hetzler, B.; Nowell, L. ThemeRiver: Visualizing theme changes over time. In Proceedings of the IEEE Symposium on Information Visualization 2000, Salt Lake City, UT, USA, 9–10 October 2000; pp. 115–123. [Google Scholar]
- Van Wijk, J.J.; Van Selow, E.R. Cluster and calendar based visualization of time series data. In Proceedings of the 1999 IEEE Symposium on Information Visualization (InfoVis’99), San Francisco, CA, USA, 24–29 Octber 1999; pp. 4–9. [Google Scholar]
- Gudes, O.; Varhol, R.; Sun, Q.C.; Meuleners, L. Investigating articulated heavy-vehicle crashes in western Australia using a spatial approach. Accid. Anal. Prev. 2017, 106, 243–253. [Google Scholar] [CrossRef] [PubMed]
- Sawalha, Z.; Sayed, T. Traffic accident modeling: Some statistical issues. Can. J. Civ. Eng. 2006, 33, 1115–1124. [Google Scholar] [CrossRef]
- Shi, Q.; Abdel-Aty, M. Big data applications in real-time traffic operation and safety monitoring and improvement on urban expressways. Transp. Res. Part C Emerg. Technol. 2015, 58, 380–394. [Google Scholar] [CrossRef]
- Hassan, H.M.; Abdel-Aty, M.A. Predicting reduced visibility related crashes on freeways using real-time traffic flow data. J. Saf. Res. 2013, 45, 29–36. [Google Scholar] [CrossRef]
- Hossain, M.; Muromachi, Y. A real-time crash prediction model for the ramp vicinities of urban expressways. IATSS Res. 2013, 37, 68–79. [Google Scholar] [CrossRef]
- Yu, R.; Abdel-Aty, M. Utilizing support vector machine in real-time crash risk evaluation. Accid. Anal. Prev. 2013, 51, 252–259. [Google Scholar] [CrossRef]
- You, J.; Wang, J.; Guo, J. Real-time crash prediction on freeways using data mining and emerging techniques. J. Mod. Transp. 2017, 25, 116–123. [Google Scholar] [CrossRef]
- Basso, F.; Basso, L.J.; Bravo, F.; Pezoa, R. Real-time crash prediction in an urban expressway using disaggregated data. Transp. Res. Part C Emerg. Technol. 2018, 86, 202–219. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef]
- Goldberg, D.E.; Holland, J.H. Genetic algorithms and Machion Learning. Mach. Learn. 1988, 3, 95–99. [Google Scholar] [CrossRef]
- Kennedy, R.; Eberhart, J. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks IV, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Xu, C.; Wang, W.; Liu, P. A Genetic Programming Model for Real-Time Crash Prediction on Freeways. IEEE Trans. Intell. Transp. Syst. 2013, 14, 574–586. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in Machine Learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Nagendra, S.S.; Khare, M. Principal component analysis of urban traffic characteristics and meteorological data. Transp. Res. Part D Transp. Environ. 2003, 8, 285–297. [Google Scholar] [CrossRef]
- Lee, H.C.; Cameron, D.; Lee, A.H. Assessing the driving performance of older adult drivers: On-road versus simulated driving. Accid. Anal. Prev. 2003, 35, 797–803. [Google Scholar] [CrossRef]
- Li, Q.; Jianming, H.; Yi, Z. A flow volumes data compression approach for traffic network based on principal component analysis. In Proceedings of the 2007 IEEE Intelligent Transportation Systems Conference, Seattle, WA, USA, 30 September–3 October 2007. [Google Scholar]
- Caliendo, C.; Guida, M.; Parisi, A. A crash-prediction model for multilane roads. Accid. Anal. Prev. 2007, 39, 657–670. [Google Scholar] [CrossRef]
- Guo, F.; Fang, Y. Individual driver risk assessment using naturalistic driving data. Accid. Anal. Prev. 2013, 61, 3–9. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Abdel-Aty, M.; Shah, I. Evaluation of surrogate measures for pedestrian trips at intersections and crash modeling. Accid. Anal. Prev. 2018. [Google Scholar] [CrossRef] [PubMed]
- Cook, R.D. Principal components, sufficient dimension reduction, and envelopes. Annu. Rev. Stat. Appl. 2018, 5, 533–559. [Google Scholar] [CrossRef]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. Royal Stat. Soc. Ser. B Stat. Methods 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 1997; pp. 583–588. [Google Scholar]
- Berkhin, P. A survey of clustering data mining techniques. In Grouping Multidimensional Data; Springer: Berlin/Heidelberg, Germany, 2006; pp. 25–71. [Google Scholar]
- Rai, P.; Singh, S. A survey of clustering techniques. Int. J. Comput. Appl. 2010, 7, 1–5. [Google Scholar] [CrossRef]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Hall, F.L.; Hurdle, V.; Banks, J.H. Synthesis of Recent Work on the Nature of Speed-Flow and Flow-Occupancy (Or Density) Relationships on Freeways. 1993. Available online: https://trid.trb.org/view/1172887 (accessed on 10 August 2019).
- Kerner, B.S.; Rehborn, H. Experimental properties of complexity in traffic flow. Phys. Rev. E 1996, 53, R4275. [Google Scholar] [CrossRef]
- Wu, N. A new approach for modeling of Fundamental Diagrams. Transp. Res. Part A Pol. Pract. 2002, 36, 867–884. [Google Scholar] [CrossRef]
- Golob, T.F.; Recker, W.W. A method for relating type of crash to traffic flow characteristics on urban freeways. Transp. Res. Part A Pol. Pract. 2004, 38, 53–80. [Google Scholar] [CrossRef]
- Xu, C.; Liu, P.; Wang, W.; Li, Z. Evaluation of the impacts of traffic states on crash risks on freeways. Accid. Anal. Prev. 2012, 47, 162–171. [Google Scholar] [CrossRef]
- Steenberghen, T.; Dufays, T.; Thomas, I.; Flahaut, B. Intra-urban location and clustering of road accidents using GIS: A Belgian example. Inter. J. Geog. Inf. Sci. 2004, 18, 169–181. [Google Scholar] [CrossRef]
- Xie, Z.; Yan, J. Detecting traffic accident clusters with network kernel density estimation and local spatial statistics: an integrated approach. J. Transp. Geog. 2013, 31, 64–71. [Google Scholar] [CrossRef]
- Shen, L.; Lu, J.; Long, M.; Chen, T. Identification of Accident Blackspots on Rural Roads Using Grid Clustering and Principal Component Clustering. Math. Prob. Eng. 2019, 2019. [Google Scholar] [CrossRef]
- Kwon, O.H.; Park, S.H. Identification of Influential Weather Factors on Traffic Safety Using K-means Clustering and Random Forest. In Advanced Multimedia and Ubiquitous Engineering; Springer: Singapore, 2016; pp. 593–599. [Google Scholar]
- Crum, M.R.; Morrow, P.C.; Olsgard, P.; Roke, P.J. Truck driving environments and their influence on driver fatigue and crash rates. Transp. Res. Rec. 2001, 1779, 125–133. [Google Scholar] [CrossRef]
- Crum, M.R.; Morrow, P.C. The influence of carrier scheduling practices on truck driver fatigue. Transp. J. 2002, 20–41. [Google Scholar]
- Garbarino, S.; Durando, P.; Guglielmi, O.; Dini, G.; Bersi, F.; Fornarino, S.; Toletone, A.; Chiorri, C.; Magnavita, N. Sleep apnea, sleep debt and daytime sleepiness are independently associated with road accidents. A cross-sectional study on truck drivers. PLoS ONE 2016, 11, e0166262. [Google Scholar] [CrossRef]
- Dingus, T.A.; Klauer, S.G.; Neale, V.L.; Petersen, A.; Lee, S.E.; Sudweeks, J.; Perez, M.A.; Hankey, J.; Ramsey, D.; Gupta, S.; et al. The 100-Car Naturalistic Driving Study. Phase 2: Results of the 100-Car Field Experiment; Technical Report; United States Department of Transportation, National Highway Traffic Safety: Washington, DC, USA, 2006.
- McCauley, P.; Kalachev, L.V.; Smith, A.D.; Belenky, G.; Dinges, D.F.; Van Dongen, H.P. A new mathematical model for the homeostatic effects of sleep loss on neurobehavioral performance. J. Theor. Biol. 2009, 256, 227–239. [Google Scholar] [CrossRef]
- McCauley, P.; Kalachev, L.V.; Mollicone, D.J.; Banks, S.; Dinges, D.F.; Van Dongen, H.P. Dynamic circadian modulation in a biomathematical model for the effects of sleep and sleep loss on waking neurobehavioral performance. Sleep 2013, 36, 1987–1997. [Google Scholar] [CrossRef]
- Stern, H.S.; Blower, D.; Cohen, M.L.; Czeisler, C.A.; Dinges, D.F.; Greenhouse, J.B.; Guo, F.; Hanowski, R.J.; Hartenbaum, N.P.; Krueger, G.P.; et al. Data and methods for studying commercial motor vehicle driver fatigue, highway safety and long-term driver health. Accid. Anal. Prev. 2019, 126, 37–42. [Google Scholar] [CrossRef]
- Bowden, Z.E.; Ragsdale, C.T. The truck driver scheduling problem with fatigue monitoring. Decis. Sup. Syst. 2018, 110, 20–31. [Google Scholar] [CrossRef]
- Åkerstedt, T.; Folkard, S. Validation of the S and C components of the three-process model of alertness regulation. Sleep 1995, 18, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Åkerstedt, T.; Folkard, S.; Portin, C. Predictions from the three-process model of alertness. Aviat. Space Environ. Med. 2004, 75, A75–A83. [Google Scholar] [PubMed]
- World Health Organization. Mobile Phone Use: A Growing Problem of Driver Distraction; World Health Organization: Geneva, Switzerland, 2011. [Google Scholar]
- Young, K.; Regan, M.; Hammer, M. Driver distraction: A review of the literature. Dist. Driv. 2007, 2007, 379–405. [Google Scholar]
- Wilson, F.A.; Stimpson, J.P. Trends in fatalities from distracted driving in the United States, 1999 to 2008. Am. J. Publ. Health 2010, 100, 2213–2219. [Google Scholar] [CrossRef] [PubMed]
- Olson, R.L.; Hanowski, R.J.; Hickman, J.S.; Bocanegra, J. Driver Distraction in Commercial Vehicle Operations; Technical Report; United States Federal Motor Carrier Safety Administration: Washington, DC, USA, 2009.
- Klauer, S.G.; Guo, F.; Simons-Morton, B.G.; Ouimet, M.C.; Lee, S.E.; Dingus, T.A. Distracted driving and risk of road crashes among novice and experienced drivers. N. Engl. J. Med. 2014, 370, 54–59. [Google Scholar] [CrossRef]
- Xu, C.; Tarko, A.P.; Wang, W.; Liu, P. Predicting crash likelihood and severity on freeways with real-time loop detector data. Accid. Anal. Prev. 2013, 57, 30–39. [Google Scholar] [CrossRef]
- Ahmed, M.; Abdel-Aty, M.; Yu, R. Assessment of interaction of crash occurrence, mountainous freeway geometry, real-time weather, and traffic data. Transp. Res. Rec. J. Transp. Res. Board 2012, 2280, 51–59. [Google Scholar] [CrossRef]
- Yu, R.; Abdel-Aty, M.; Ahmed, M. Bayesian random effect models incorporating real-time weather and traffic data to investigate mountainous freeway hazardous factors. Accid. Anal. Prev. 2013, 50, 371–376. [Google Scholar] [CrossRef]
- Wang, L.; Abdel-Aty, M.; Lee, J.; Shi, Q. Analysis of real-time crash risk for expressway ramps using traffic, geometric, trip generation, and socio-demographic predictors. Accid. Anal. Prev. 2019, 122, 378–384. [Google Scholar] [CrossRef]
- Pande, A.; Abdel-Aty, M. Comprehensive analysis of the relationship between real-time traffic surveillance data and rear-end crashes on freeways. Transp. Res. Rec. 2006, 1953, 31–40. [Google Scholar] [CrossRef]
- Pande, A.; Das, A.; Abdel-Aty, M.; Hassan, H. Estimation of real-time crash risk: Are all freeways created equal? Transp. Res. Rec. Transp. Res. Rec. J. Transp. Res. Board 2011, 2237, 60–66. [Google Scholar] [CrossRef]
- Theofilatos, A.; Yannis, G.; Kopelias, P.; Papadimitriou, F. Impact of real-time traffic characteristics on crash occurrence: Preliminary results of the case of rare events. Accid. Anal. Prev. 2018, 130, 151–159. [Google Scholar] [CrossRef] [PubMed]
- Lin, L.; Wang, Q.; Sadek, A.W. A novel variable selection method based on frequent pattern tree for real-time traffic accident risk prediction. Transp. Res. Part C Emerg. Technol. 2015, 55, 444–459. [Google Scholar] [CrossRef]
- Sun, J.; Sun, J. A dynamic Bayesian network model for real-time crash prediction using traffic speed conditions data. Transp. Res. Part C Emerg. Technol. 2015, 54, 176–186. [Google Scholar] [CrossRef]
- Wang, L.; Abdel-Aty, M.; Shi, Q.; Park, J. Real-time crash prediction for expressway weaving segments. Transp. Res. Part C Emerg. Technol. 2015, 61, 1–10. [Google Scholar] [CrossRef]
- Wang, L.; Abdel-Aty, M.; Lee, J. Safety analytics for integrating crash frequency and real-time risk modeling for expressways. Accid. Anal. Prev. 2017, 104, 58–64. [Google Scholar] [CrossRef]
- Lord, D.; Mannering, F. The statistical analysis of crash-frequency data: A review and assessment of methodological alternatives. Transp. Res. Part A Pol. Pract. 2010, 44, 291–305. [Google Scholar] [CrossRef]
- Mannering, F.L.; Bhat, C.R. Analytic methods in accident research: Methodological frontier and future directions. Anal. Meth. Accid. Res. 2014, 1, 1–22. [Google Scholar] [CrossRef]
- Abdulhafedh, A. Road crash prediction models: Different statistical modeling approaches. J. Transp. Technol. 2017, 7, 190–205. [Google Scholar] [CrossRef]
- Ambros, J.; Jurewicz, C.; Turner, S.; Kieć, M. An international review of challenges and opportunities in development and use of crash prediction models. Eur. Transp. Res. Rev. 2018, 10, 35. [Google Scholar] [CrossRef]
- Yannis, G.; Dragomanovits, A.; Laiou, A.; Richter, T.; Ruhl, S.; La Torre, F.; Domenichini, L.; Graham, D.; Karathodorou, N.; Li, H. Use of accident prediction models in road safety management–an international inquiry. Transp. Res. Procedia 2016, 14, 4257–4266. [Google Scholar] [CrossRef]
- Xie, Y.; Allaire, J.J.; Grolemund, G. R Markdown: The Definitive Guide; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type(Main Group) | Subgroup | Visualization Techniques | Examples |
|---|---|---|---|
| Time-series data | Linear time | Line and stacked graphs | [33,34,35,36,37,38] |
| Periodic time | Radial layout and cluster-and-calendar based visualization | [38,39] | |
| Spatial | Point-based | Symbol maps | [40] |
| Line-based | Line maps, edge bundling, and kernel density estimation charts (KDE) | [41,42] | |
| Region-based | Radial metaphor charts, choropleth, proportional symbol maps, and heat maps | [43,44,45,46,47] | |
| Spatiotemporal | - | Space-Time-Cube (STC), animated maps, GeoTime, and stacking-based STC | [48,49,50,51,52] |
| Multiple properties | - | Parallel coordinates plot, trellis plot, and multidimensional scaling | [45,53,54,55,56,57,58,59] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehdizadeh, A.; Cai, M.; Hu, Q.; Alamdar Yazdi, M.A.; Mohabbati-Kalejahi, N.; Vinel, A.; Rigdon, S.E.; Davis, K.C.; Megahed, F.M. A Review of Data Analytic Applications in Road Traffic Safety. Part 1: Descriptive and Predictive Modeling. Sensors 2020, 20, 1107. https://doi.org/10.3390/s20041107
Mehdizadeh A, Cai M, Hu Q, Alamdar Yazdi MA, Mohabbati-Kalejahi N, Vinel A, Rigdon SE, Davis KC, Megahed FM. A Review of Data Analytic Applications in Road Traffic Safety. Part 1: Descriptive and Predictive Modeling. Sensors. 2020; 20(4):1107. https://doi.org/10.3390/s20041107
Chicago/Turabian StyleMehdizadeh, Amir, Miao Cai, Qiong Hu, Mohammad Ali Alamdar Yazdi, Nasrin Mohabbati-Kalejahi, Alexander Vinel, Steven E. Rigdon, Karen C. Davis, and Fadel M. Megahed. 2020. "A Review of Data Analytic Applications in Road Traffic Safety. Part 1: Descriptive and Predictive Modeling" Sensors 20, no. 4: 1107. https://doi.org/10.3390/s20041107
APA StyleMehdizadeh, A., Cai, M., Hu, Q., Alamdar Yazdi, M. A., Mohabbati-Kalejahi, N., Vinel, A., Rigdon, S. E., Davis, K. C., & Megahed, F. M. (2020). A Review of Data Analytic Applications in Road Traffic Safety. Part 1: Descriptive and Predictive Modeling. Sensors, 20(4), 1107. https://doi.org/10.3390/s20041107