eXnet: An Efficient Approach for Emotion Recognition in the Wild


Abstract
1. Introduction
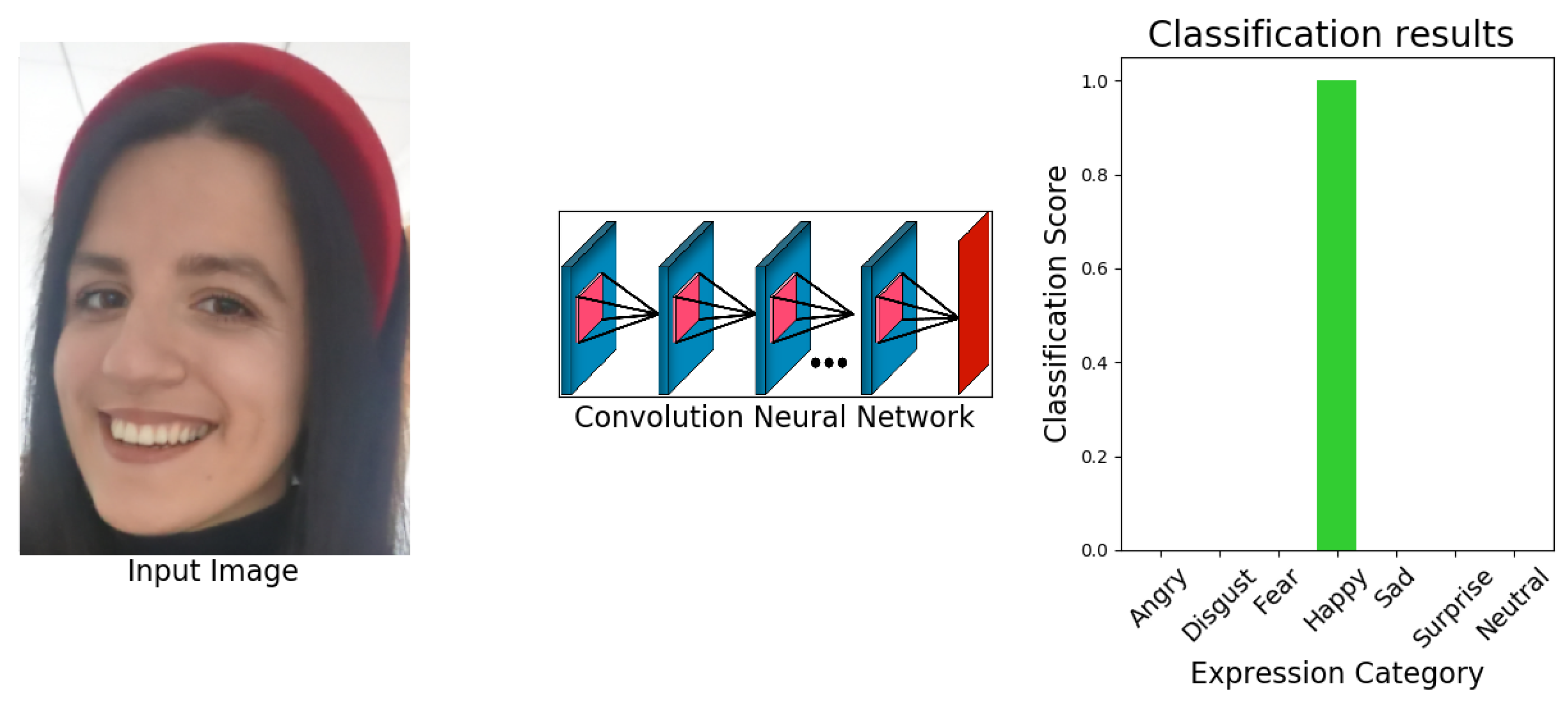
- We propose a novel, lightweight, and efficient CNN-based method “eXnet” for facial expression recognition in the wild.
- In order to enhance the data and to stabilize the training process, we also utilize modern data augmentation/regularization techniques:
- For quantitative analysis, we provide three types of evaluations:
- Ablation evaluation: variations among the structure, optimization methods, and loss functions have been made to fine-tune the method. All variants of eXnet have been thoroughly explained in Section 5.
- Benchmark evaluation: comparison of our method with the benchmark methods prove the efficiency of our work as our approach acquires higher accuracy with much less number of parameters.
- Real-time evaluation: installation of pretrained weights of eXnet on Raspberry Pi 4B bespeaks that eXnet can recognize emotions in the wild more quickly in comparison with existing approaches.
2. Related Work
3. Proposed Model
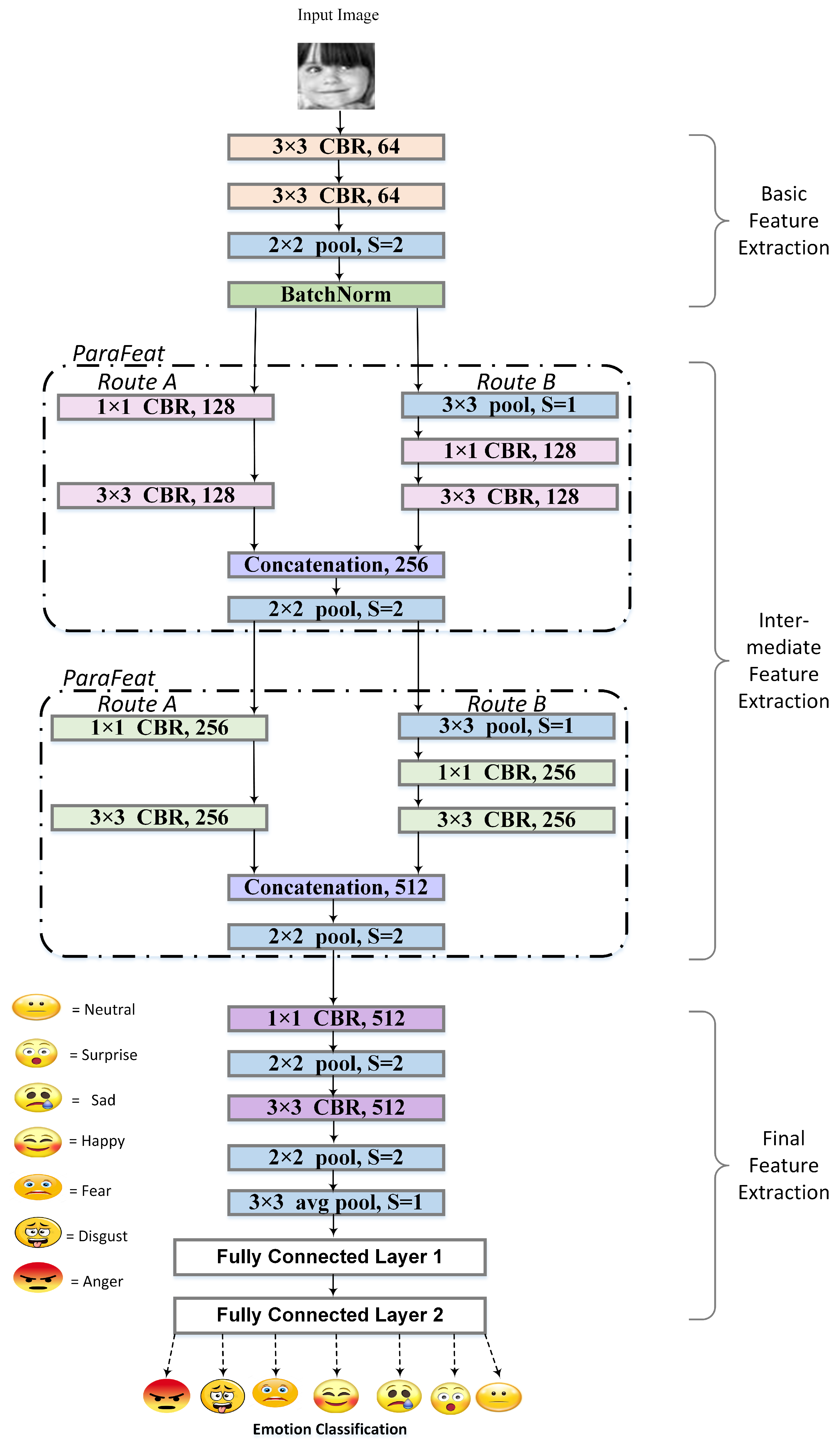
3.1. eXnet: Expression Network
3.1.1. Basic Feature Extraction
3.1.2. Intermediate Feature Extraction
3.1.3. Final Feature Extraction
3.2. eXnet
3.3. eXnet
3.4. eXnet(Cutout+Mixup)
4. Experiments
4.1. Datasets
4.1.1. FER-2013
4.1.2. CK+
4.1.3. RAF-DB
4.1.4. Embedded Device
4.2. Data Augmentation
4.3. Implementation Details
5. Results
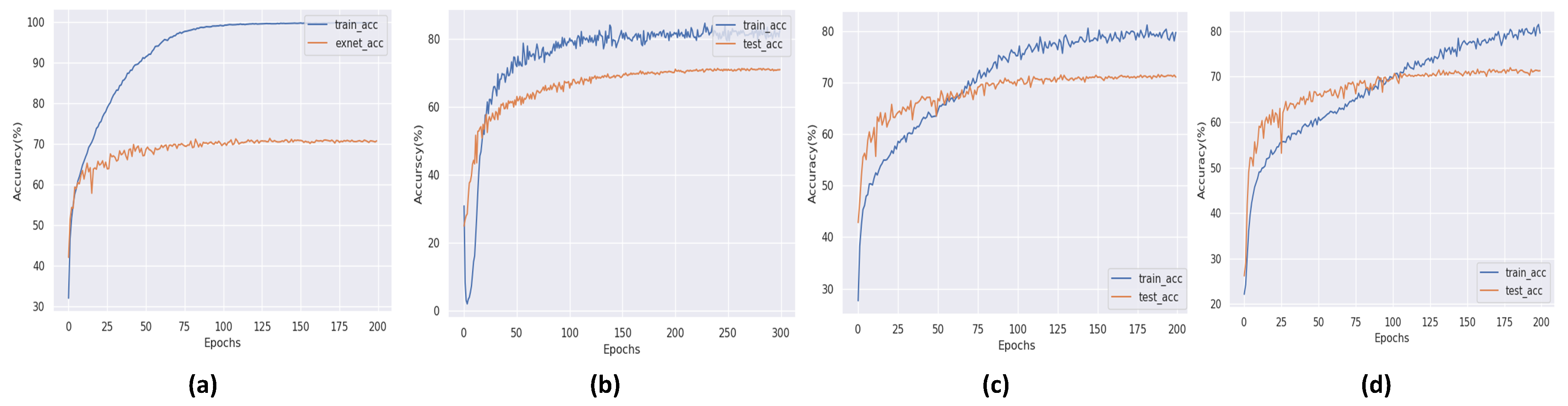
5.1. Ablation Evaluation
5.1.1. Effect of Depth Reduction on the Accuracy of the eXnet
5.1.2. Effect of Pooling Layers on the Accuracy of the eXnet
5.1.3. Effect of Dropout on the Accuracy of the eXnet
5.1.4. Effect of Kernel Size on the Accuracy of the eXnet
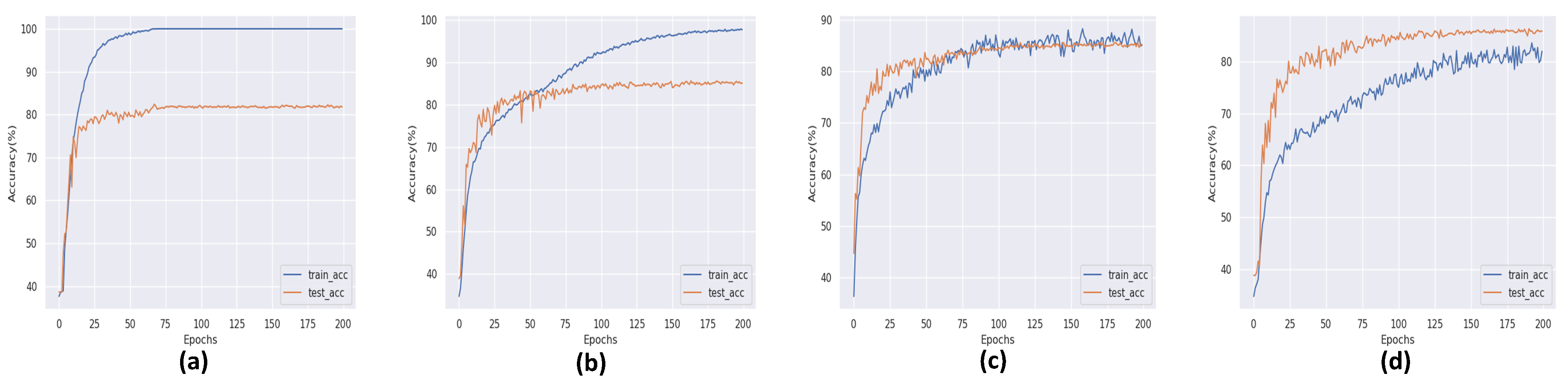
5.1.5. Effect of Blocks on the Accuracy of the eXnet
5.1.6. Effect of Fully Connected Layers on the Accuracy of the eXnet
5.1.7. Effect of Changing Optimizer on the the Accuracy of the eXnet
5.1.8. Effect of Learning Rate on the Accuracy of the eXnet
5.1.9. Effect of , , and Convolutions on the Accuracy of the eXnet
5.2. Benchmark Evaluation
5.3. Real-Time Evaluation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fabiano, D.; Canavan, S.J. Deformable Synthesis Model for Emotion Recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Fujii, K.; Sugimura, D.; Hamamoto, T. Hierarchical Group-level Emotion Recognition in the Wild. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Ionescu, R.T.; Grozea, C. Local Learning to Improve Bag of Visual Words Model for Facial Expression Recognition. 2013. Available online: http://deeplearning.net/wp-content/uploads/2013/03/VV-NN-LL-WREPL.pdf (accessed on 23 December 2019).
- Zafer, A.; Nawaz, R.; Iqbal, J. Face recognition with expression variation via robust NCC. In Proceedings of the 2013 IEEE 9th International Conference on Emerging Technologies (ICET), Islamabad, Pakistan, 9–10 December 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Zhong, L.; Liu, Q.; Yang, P.; Liu, B.; Huang, J.; Metaxas, D.N. Learning active facial patches for expression analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2562–2569. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems 2012, Lake Tahoe, CA, USA, 3–8 December 2012; pp. 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Khan, F. Facial Expression Recognition using Facial Landmark Detection and Feature Extraction via Neural Networks. arXiv 2014, arXiv:1812.04510. [Google Scholar]
- Sang, D.V.; Van Dat, N.; Thuan, D.P. Facial expression recognition using deep convolutional neural networks. In Proceedings of the 2017 9th International Conference on Knowledge and Systems Engineering (KSE), Hue, Vietnam, 19–21 October 2017; pp. 130–135. [Google Scholar] [CrossRef]
- Tautkute, I.; Trzcinski, T. Classifying and Visualizing Emotions with Emotional DAN. arXiv 2018, arXiv:1810.10529. [Google Scholar] [CrossRef]
- Tang, Y. Deep Learning using Support Vector Machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- Shah, J.H.; Sharif, M.; Yasmin, M.; Fernandes, S.L. Facial expressions classification and false label reduction using LDA and threefold SVM. Pattern Recognit. Lett. 2017. [Google Scholar] [CrossRef]
- Burkert, P.; Trier, F.; Afzal, M.Z.; Dengel, A.; Liwicki, M. DeXpression: Deep Convolutional Neural Network for Expression Recognition. arXiv 2015, arXiv:1509.05371. [Google Scholar]
- Agrawal, A.; Mittal, N. Using CNN for facial expression recognition: A study of the effects of kernel size and number of filters on accuracy. Visual Comput. 2019, 2, 405–412. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.-H.; et al. Challenges in Representation Learning: A report on three machine learning contests. In Proceedings of the ICONIP: International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; pp. 84–90. [Google Scholar]
- Lopes, A.T.; de Aguiar, E.; Souza, A.F.D.; Oliveira-Santos, T. Facial expression recognition with Convolutional Neural Networks: Coping with few data and the training sample order. Pattern Recognit. 2017, 61, 610–628. [Google Scholar] [CrossRef]
- Jain, D.K.; Shamsolmoali, P.; Sehdev, P. Extended deep neural network for facial emotion recognition. Pattern Recognit. Lett. 2019, 120, 69–74. [Google Scholar] [CrossRef]
- Shao, J.; Qian, Y. Three convolutional neural network models for facial expression recognition in the wild. Neurocomputing 2019, 355, 82–92. [Google Scholar] [CrossRef]
- Breuer, R.; Kimmel, R. A Deep Learning Perspective on the Origin of Facial Expressions. arXiv 2017, arXiv:1705.01842. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Verma, V.; Lamb, A.; Beckham, C.; Najafi, A.; Courville, A.; Mitliagkas, I.; Bengio, Y. Manifold Mixup: Learning Better Representations by Interpolating Hidden States. 2019. Available online: https://arxiv.org/pdf/1806.05236.pdf (accessed on 2 December 2019).
- Gastaldi, X. Shake-Shake regularization. arXiv 2017, arXiv:1705.07485. [Google Scholar]
- Yamada, Y.; Iwamura, M.; Kise, K. ShakeDrop regularization. arXiv 2018, arXiv:1802.02375. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. DropBlock: A regularization method for convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems 31, Montreal, QC, Canada, 2–8 December 2018; pp. 10727–10737. [Google Scholar]
- Bettadapura, V. Face Expression Recognition and Analysis: The State of the Art. arXiv 2012, arXiv:1203.6722. [Google Scholar]
- Roychowdhury, S.; Emmons, M. A Survey of the Trends in Facial and Expression Recognition Databases and Methods. Int. J. Comput. Sci. Eng. Surv. 2015, 6. [Google Scholar] [CrossRef]
- Canedo, D.; Neves, A.J.R. Facial Expression Recognition Using Computer Vision: A Systematic Review. Appl. Sci. 2019, 9, 4678. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial Expression Recognition: A Survey. Symmetry 2019, 11, 1189. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Liu, C.; Tang, T.; Lv, K.; Wang, M. Multi-Feature Based Emotion Recognition for Video Clips. In Proceedings of the International Conference on Multimodal Interaction (ICMI ’18), Boulder, CO, USA, 16–20 October 2018; pp. 630–634. [Google Scholar]
- Arriaga, O.; Valdenegro-Toro, M.; Plöger, P. Real-time Convolutional Neural Networks for Emotion and Gender Classification. arXiv 2017, arXiv:1710.07557. [Google Scholar]
- Liu, K.; Zhang, M.; Pan, Z. Facial Expression Recognition with CNN Ensemble. In Proceedings of the 2016 International Conference on Cyberworlds (CW), Chongqing, China, 28–30 September 2016; pp. 163–166. [Google Scholar]
- Mehta, D.; Siddiqui, M.F.H.; Javaid, A.Y. Recognition of Emotion Intensities Using Machine Learning Algorithms: A Comparative Study. Sensors 2019, 19, 1897. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. arXiv 2018, arXiv:1804.08348. [Google Scholar]
- Yang, H.; Han, J.; Min, K. A Multi-Column CNN Model for Emotion Recognition from EEG Signals. Sensors 2019, 19, 4736. [Google Scholar] [CrossRef] [PubMed]
- Santamaria-Granados, L.; Munoz-Organero, M.; Ramirez-Gonzalez, G.; Abdulhay, E.; Arunkumar, N. Using Deep Convolutional Neural Network for Emotion Detection on a Physiological Signals Dataset (AMIGOS). IEEE Access 2019, 7, 57–67. [Google Scholar] [CrossRef]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chrzanowski, M.; et al. Deep Speech 2: End-to-end Speech Recognition in English and Mandarin. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Zhu, X.; Liu, Y.; Qin, Z.; Li, J. Data Augmentation in Emotion Classification Using Generative Adversarial Networks. arXiv 2017, arXiv:1711.00648. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- EEG-Based Emotion Recognition using 3D Convolutional Neural Networks. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 329–337.
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. NIPS Autodiff Workshop. 2017. Available online: https://openreview.net/pdf?id=BJJsrmfCZ (accessed on 12 December 2019).
- Li, S.; Deng, W. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Unconstrained Facial Expression Recognition. IEEE Trans. Image Process. 2019, 28, 356–370. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Lam, J.C.K.; Li, V.O.K. Multi-region Ensemble Convolutional Neural Network for Facial Expression Recognition. In Proceedings of the 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 84–94. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Parameters | Values |
|---|---|---|
| FER-2013 | Size of images used | 48 × 48 |
| Optimizer | Stochastic Gradient Descent (SGD) | |
| Number of epochs | 200–250 | |
| Batch size | 64 | |
| Learning rate | 0.01 | |
| Momentum | 0.9 | |
| Learning decay | 4e-5 | |
| Cyclical learning rate | Yes | |
| CK+ | Size of images used | 48 × 48 |
| Optimizer | SGD | |
| Number of epochs | 60–100 | |
| Batch size | 64 | |
| Learning rate | 0.01 | |
| Momentum | 0.9 | |
| Learning decay | 4e-5 | |
| Cyclical learning rate | No | |
| RAF-DB | Size of images used | 48 × 48 |
| Optimizer | SGD | |
| Number of epochs | 150–200 | |
| Batch size | 64 | |
| Learning rate | 0.01 | |
| Momentum | 0.9 | |
| Learning decay | 1e-4 | |
| Cyclical learning rate | Yes |
| Model Parameter | Accuracy |
|---|---|
| Effect of depth reduction on the accuracy of the eXnet | |
| eXnet after removal of initial two CBR blocks | 67 |
| eXnet after removal of last two CBR blocks | 69 |
| Effect of pooling layers on the accuracy of the eXnet | |
| eXnet having convolutions with larger strides | 58 |
| eXnet having convolutions with smaller strides | 65 |
| eXnet having pooling layers | >71 |
| Effect of dropout layer on the accuracy of the eXnet | |
| eXnet without dropout layer | 69 |
| eXnet with dropout between fully-connected layers | 71 |
| Effect of kernel size on the accuracy of the eXnet | |
| eXnet with kernel size 32 | 48 |
| eXnet with kernel size 16 | 57 |
| eXnet with kernel size 8 | 68 |
| Effect ofblocks on the accuracy of the eXnet | |
| eXnet after skipping first | 68 |
| eXnet after skipping second | 67 |
| eXnet without using both | 62 |
| Effect of fully connected layer on the accuracy of the eXnet | |
| eXnet without any fully connected layer | 60 |
| eXnet without fully connected layer 1 | 65 |
| eXnet without fully connected layer 2 | 68 |
| Effect of changing optimizer on the accuracy of the eXnet | |
| eXnet with Adaptive moment estimation (Adam) optimizer | 70 |
| eXnet with SGD optimizer | 71.67 |
| Effect of learning rate on the accuracy of the eXnet | |
| eXnet with fix learning rate | 69 |
| eXnet cyclical learning rate | 71.67 |
| Model | Param |
|---|---|
| eXnet with 5 × 5 and 3 × 3 conv | 20 M |
| eXnet with only 3 × 3 conv | 12 M |
| eXnet with 1 × 1 and 3 × 3 | 4.57 M |
| Model | Accuracy (%) | Params | Size (MB) |
|---|---|---|---|
| VGG [7] | 71.29 | 14.72M | 70.94 |
| ResNet [20] | 71.12 | 11.17M | 61.18 |
| DenseNet [47] | 67.54 | 3.0M | 59.69 |
| DeXpression [13] | 68 | 3.54M | 57.14 |
| Liu et al. [36] | 61.74 | 84M | - |
| CNN + Support Vector Machine. [9] | 71 | 4.92M | - |
| Tang [11] | 69.4 | 7.17M | - |
| Shao at el. [18] | 71.14 | 7.12M | - |
| eXnet (ours) | 71.67 | 4.57M | 36.49 |
| eXnet (ours) | 71.92 | 4.57M | 36.49 |
| eXnet (ours) | 72.67 | 4.57M | 36.49 |
| eXnet (ours) | 73.54 | 4.57M | 36.49 |
| Model | Accuracy (%) 10-Cross |
|---|---|
| VGG [7] | 94.6 |
| ResNet [20] | 94 |
| DenseNet [47] | 92 |
| DeXpression [13] | 96 |
| Tautkute et al. [10] | 92 |
| Lopes et al. [16] | 92.73 |
| Jain et al. [17] | 93.24 |
| Shao et al. [18] light-CNN | 92.86 (without 10-cross ) |
| Shao et al. [18] pretrained-CNN | 95.29 (without 10-cross) |
| eXnet (ours) | 95.63 |
| eXnet (ours) | 95.81 |
| eXnet(ours) | 96.17 |
| eXnet (ours) | 96.75 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riaz, M.N.; Shen, Y.; Sohail, M.; Guo, M. eXnet: An Efficient Approach for Emotion Recognition in the Wild. Sensors 2020, 20, 1087. https://doi.org/10.3390/s20041087
Riaz MN, Shen Y, Sohail M, Guo M. eXnet: An Efficient Approach for Emotion Recognition in the Wild. Sensors. 2020; 20(4):1087. https://doi.org/10.3390/s20041087
Chicago/Turabian StyleRiaz, Muhammad Naveed, Yao Shen, Muhammad Sohail, and Minyi Guo. 2020. "eXnet: An Efficient Approach for Emotion Recognition in the Wild" Sensors 20, no. 4: 1087. https://doi.org/10.3390/s20041087
APA StyleRiaz, M. N., Shen, Y., Sohail, M., & Guo, M. (2020). eXnet: An Efficient Approach for Emotion Recognition in the Wild. Sensors, 20(4), 1087. https://doi.org/10.3390/s20041087