InstanceEasyTL: An Improved Transfer-Learning Method for EEG-Based Cross-Subject Fatigue Detection


 ,
,  ,
,  , and
, and 
Abstract
1. Introduction
2. Materials
2.1. Subjects
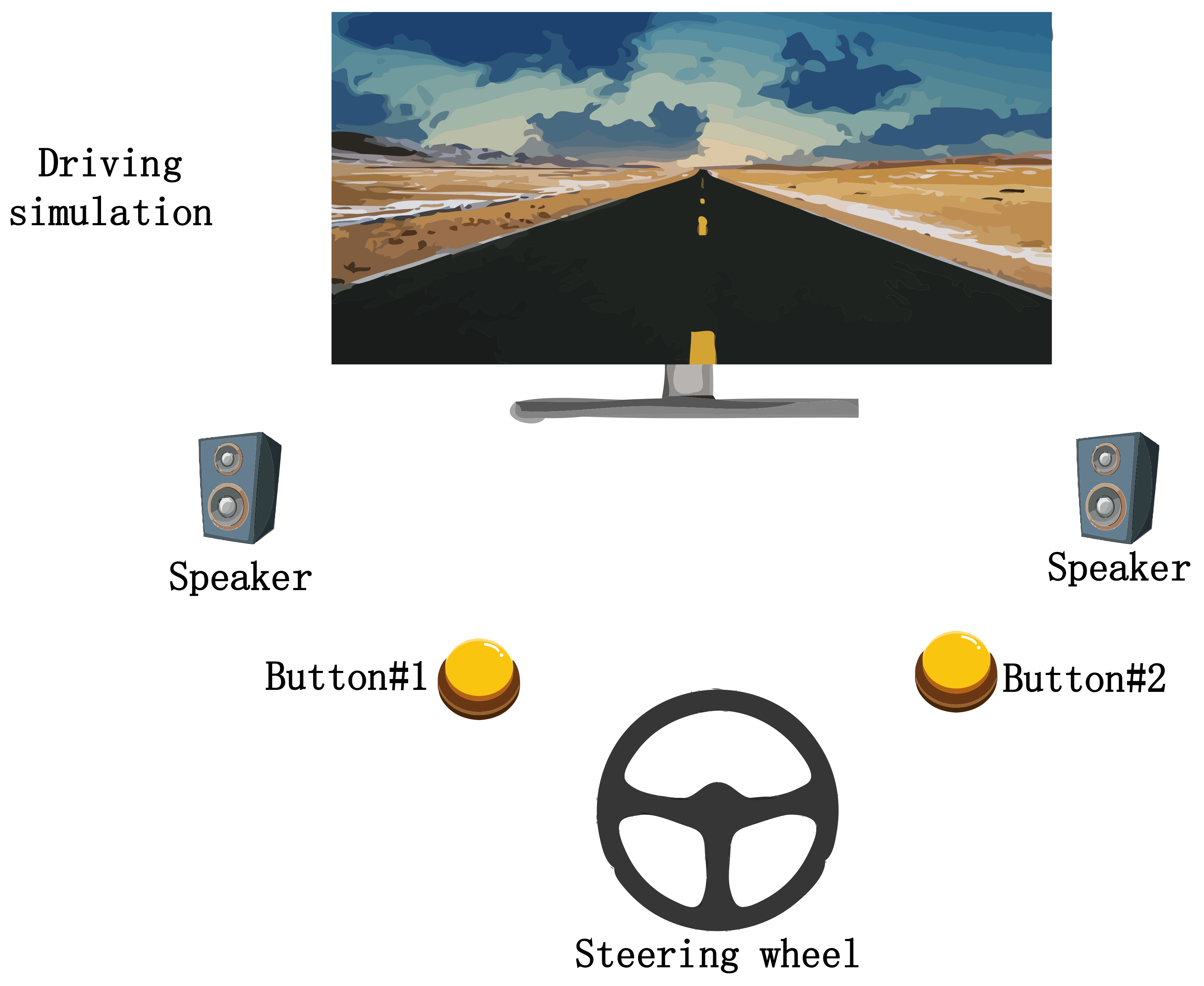
2.2. Experimental Protocol
2.3. EEG Recording and Preprocessing
2.4. EEG Feature Extraction
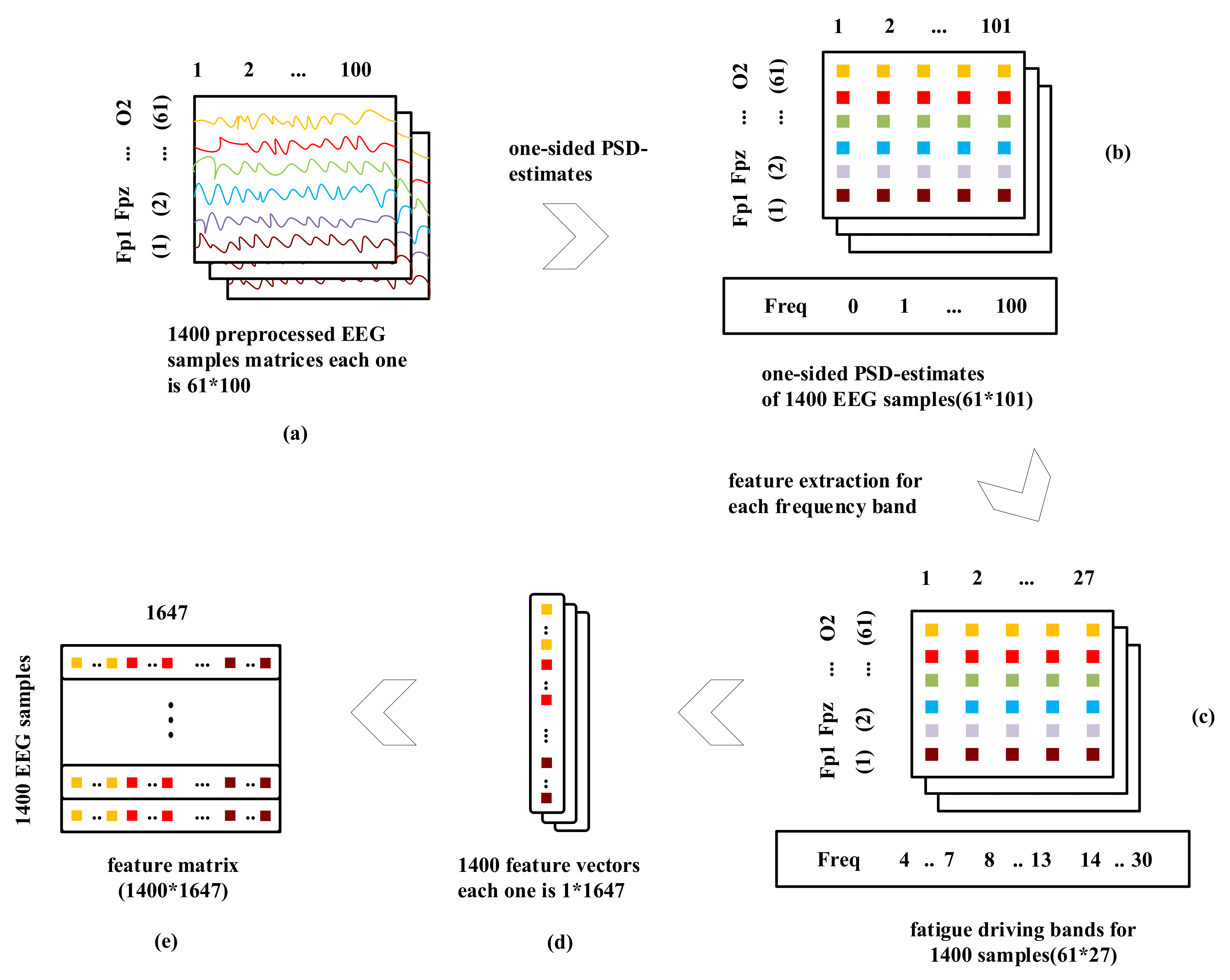
- For the recorded EEG of each channel, a 0.5 s hamming window without overlapping between two successive windows is used for dividing EEG into multiple samples. We extract 1400 hamming windows of sample points and each window have 0.5 s × F_s = 0.5 × 200 = 100 sample points (as shown in Figure 5a). Thus, the number of hamming windows (HW) is 1400 and the sample points in each hamming window are 100 × 61 channels = 6100.
- For each channel in each window, we apply the one-sided PSD-estimate of EEG signals with the frequency of 200 Hz that represent the strength in terms of the logarithm of power content of the signal at integral frequencies between 0 and 100 Hz. This produces 101 feature-length vectors. Therefore, 100 sample points in each channel become 101 features as well (as shown in Figure 5b).
- Then, the extracted features will be appended together to form D = (61 × 27) = 1647 dimension of feature vectors (as shown in Figure 5d).
- Consequently, for those HW =1400 windows/samples, we now have a feature space FS with HW × D =1400 × 1647 of order that will be fed into our proposed model for training (as shown in Figure 5e).
3. Methods
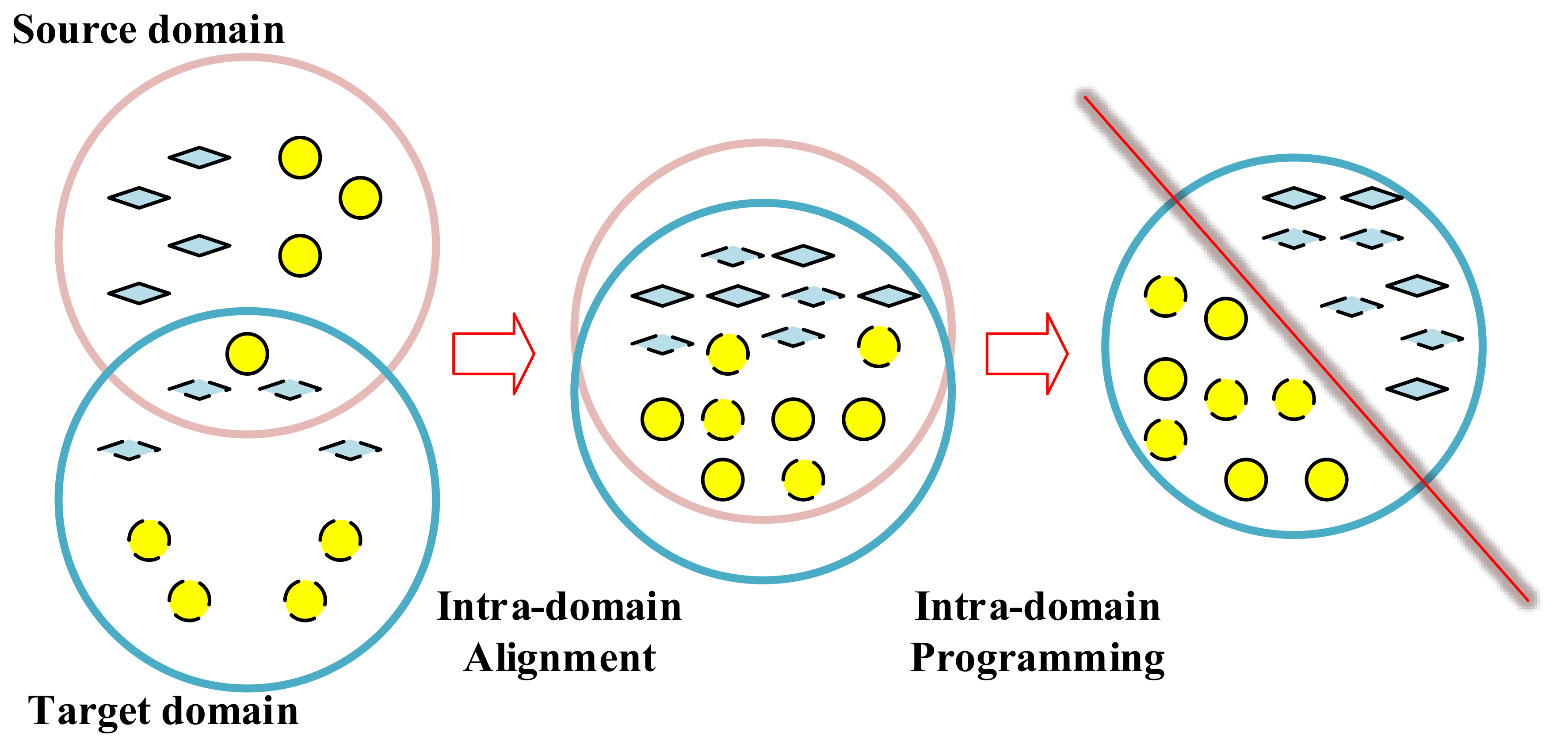
3.1. The Existing EasyTL Method
3.2. InstanceEasyTL
| Algorithm 1. InstanceEasyTL |
|
4. Results
4.1. Selection of Experimental Conditions
4.2. Parameter Configurations of Models
4.3. Classification Accuracy of InstanceEasyTL
4.4. Statistical Analysis Results
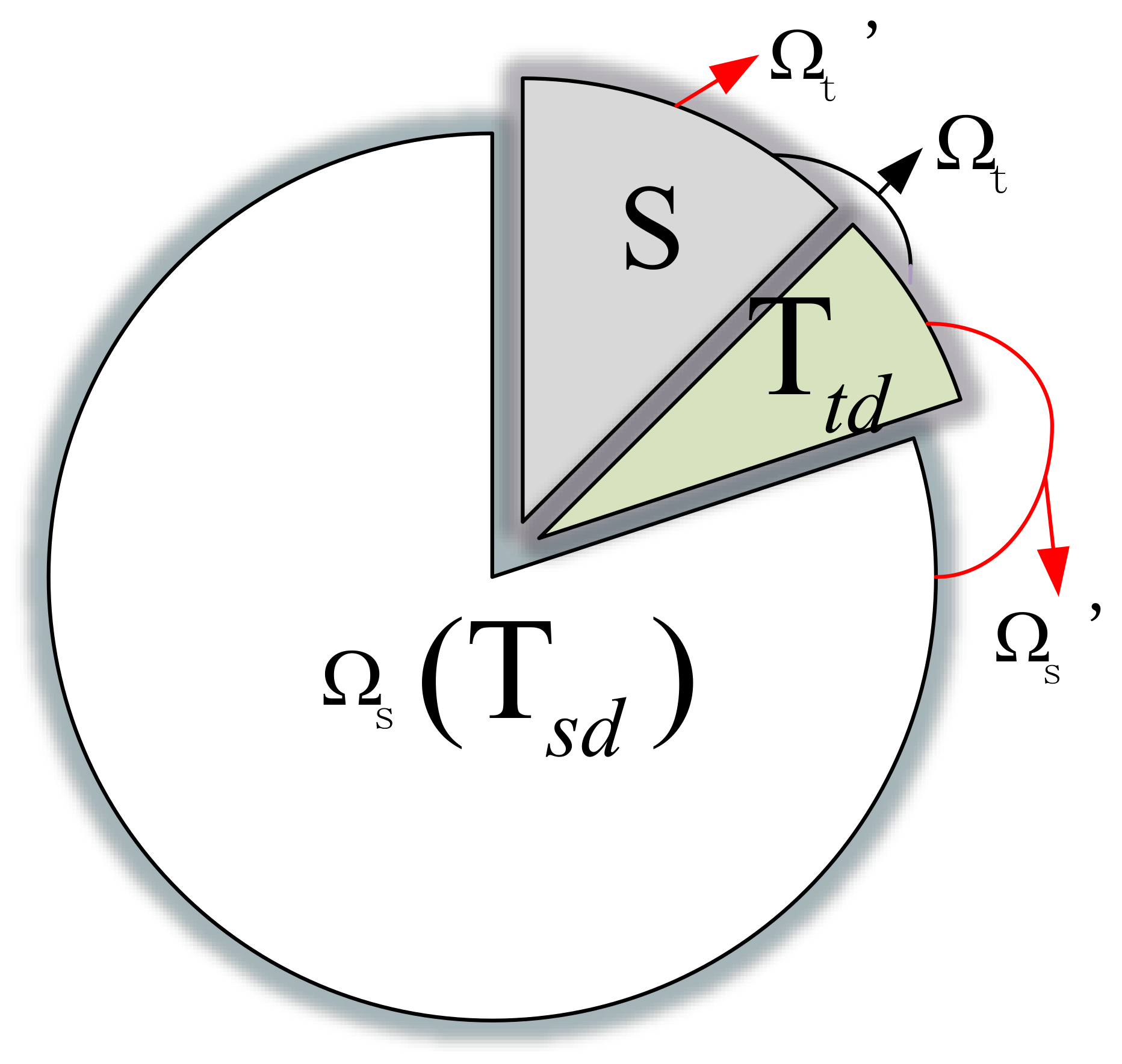
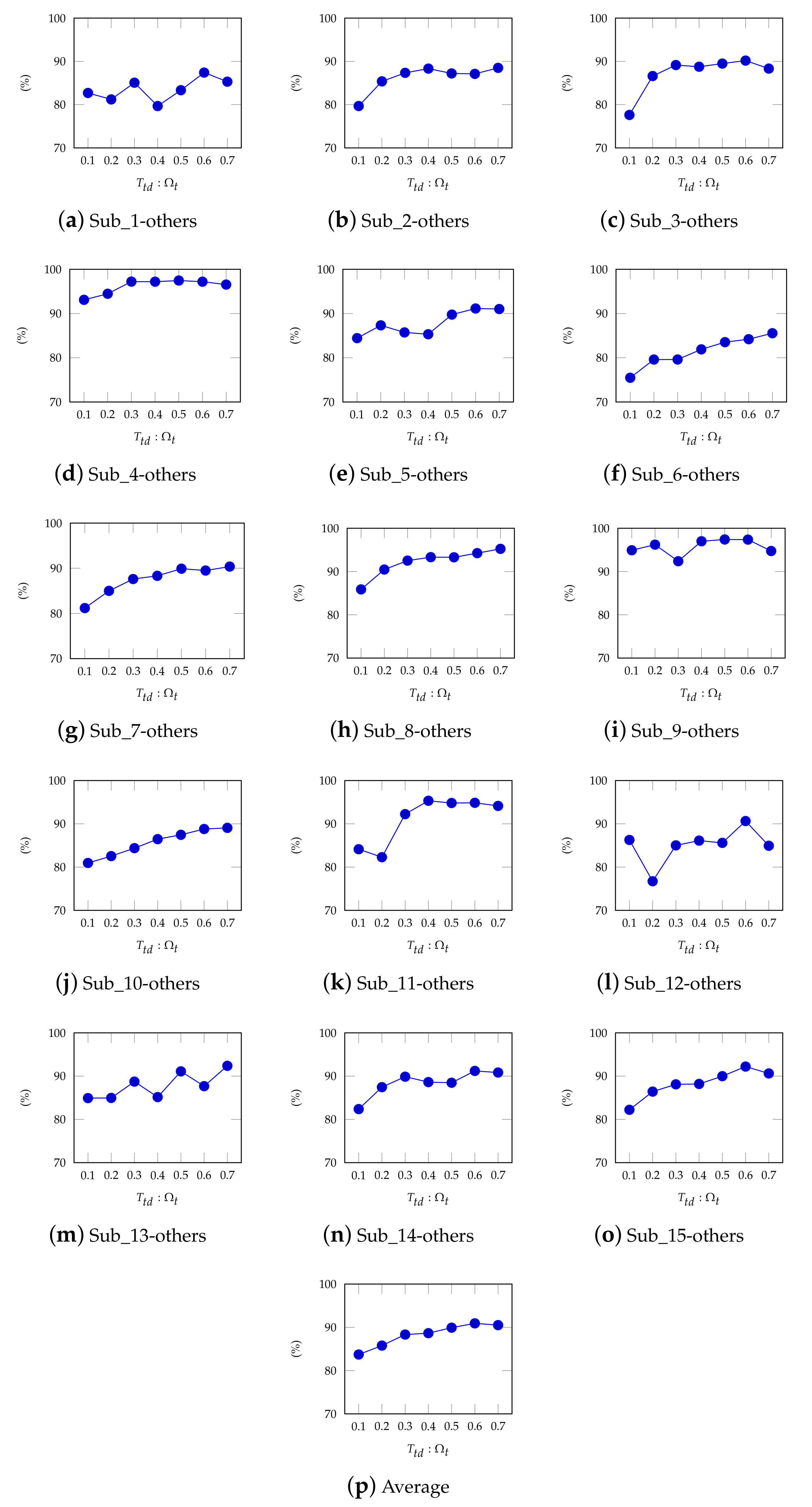
4.5. The Impact of Different on InstanceEasyTL
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Connor, J.L. The role of driver sleepiness in car crashes: A review of the epidemiological evidence. In Drugs, Driving and Traffic Safety; Springer: Basel, Switzerland, 2009; pp. 187–205. [Google Scholar]
- Khushaba, R.N.; Kodagoda, S.; Lal, S.; Dissanayake, G. Driver drowsiness classification using fuzzy wavelet-packet-based feature-extraction algorithm. IEEE Trans. Biomed. Eng. 2010, 58, 121–131. [Google Scholar] [PubMed]
- Hartley, L.; Horberry, T.; Mabbott, N.; Krueger, G.P. Review of Fatigue Detection and Prediction Technologies; National Road Transport Commission: Melbourne, Australia, 2000. [Google Scholar]
- Rau, P.S. Drowsy driver detection and warning system for commercial vehicle drivers: Field operational test design, data analyses, and progress. In Proceedings of the 19th International Conference on Enhanced Safety of Vehicles, Washington, DC, USA, 6–9 June 2005; pp. 6–9. [Google Scholar]
- Zhang, Y.; Hua, C. Driver fatigue recognition based on facial expression analysis using local binary patterns. Optik 2015, 126, 4501–4505. [Google Scholar] [CrossRef]
- Michielsen, H.J.; De Vries, J.; Van Heck, G.L.; Van de Vijver, F.J.; Sijtsma, K. Examination of the dimensionality of fatigue. Eur. J. Psychol. Assess. 2004, 20, 39–48. [Google Scholar] [CrossRef]
- Lai, J.S.; Cella, D.; Choi, S.; Junghaenel, D.U.; Christodoulou, C.; Gershon, R.; Stone, A. How item banks and their application can influence measurement practice in rehabilitation medicine: A PROMIS fatigue item bank example. Arch. Phys. Med. Rehabil. 2011, 92, S20–S27. [Google Scholar] [CrossRef]
- Meng, F.; Li, S.; Cao, L.; Li, M.; Peng, Q.; Wang, C.; Zhang, W. Driving fatigue in professional drivers: A survey of truck and taxi drivers. Traffic Inj. Prev. 2015, 16, 474–483. [Google Scholar] [CrossRef]
- Bener, A.; Yildirim, E.; Özkan, T.; Lajunen, T. Driver sleepiness, fatigue, careless behavior and risk of motor vehicle crash and injury: Population based case and control study. J. Traffic Transp. Eng. (Engl. Ed.) 2017, 4, 496–502. [Google Scholar] [CrossRef]
- Chai, R.; Ling, S.H.; San, P.P.; Naik, G.R.; Nguyen, T.N.; Tran, Y.; Craig, A.; Nguyen, H.T. Improving EEG-based driver fatigue classification using sparse-deep belief networks. Front. Neurosci. 2017, 11, 103. [Google Scholar]
- Huo, X.Q.; Zheng, W.L.; Lu, B.L. Driving fatigue detection with fusion of EEG and forehead EOG. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 897–904. [Google Scholar]
- Wang, F.; Wang, H.; Fu, R. Real-Time ECG-based detection of fatigue driving using sample entropy. Entropy 2018, 20, 196. [Google Scholar] [CrossRef]
- Aricò, P.; Borghini, G.; Di Flumeri, G.; Sciaraffa, N.; Colosimo, A.; Babiloni, F. Passive BCI in operational environments: Insights, recent advances, and future trends. IEEE Trans. Biomed. Eng. 2017, 64, 1431–1436. [Google Scholar]
- Aricò, P.; Borghini, G.; Di Flumeri, G.; Sciaraffa, N.; Babiloni, F. Passive BCI beyond the lab: Current trends and future directions. Physiol. Meas. 2018, 39, 08TR02. [Google Scholar]
- Akin, M.; Kurt, M.B.; Sezgin, N.; Bayram, M. Estimating vigilance level by using EEG and EMG signals. Neural Comput. Appl. 2008, 17, 227–236. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, W. LMD based features for the automatic seizure detection of EEG signals using SVM. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 1100–1108. [Google Scholar] [CrossRef] [PubMed]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Yuan, S.; Liu, J.; Shang, J.; Kong, X.; Yuan, Q.; Ma, Z. The earth mover’s distance and Bayesian linear discriminant analysis for epileptic seizure detection in scalp EEG. Biomed. Eng. Lett. 2018, 8, 373–382. [Google Scholar] [CrossRef] [PubMed]
- Mehmood, R.M.; Lee, H.J. Emotion classification of EEG brain signal using SVM and KNN. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015; pp. 1–5. [Google Scholar]
- Alhagry, S.; Fahmy, A.A.; El-Khoribi, R.A. Emotion recognition based on EEG using LSTM recurrent neural network. Emotion 2017, 8, 355–358. [Google Scholar] [CrossRef]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 2018, 100, 270–278. [Google Scholar] [CrossRef]
- Zeng, H.; Yang, C.; Zhang, H.; Wu, Z.; Zhang, J.; Dai, G.; Babiloni, F.; Kong, W. A lightGBM-based EEG analysis method for driver mental states classification. Comput. Intell. Neurosci. 2019, 2019. [Google Scholar] [CrossRef]
- Deng, Z.; Xu, P.; Xie, L.; Choi, K.S.; Wang, S. Transductive joint-knowledge-transfer TSK FS for recognition of epileptic EEG signals. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1481–1494. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Yu, H.; Huang, M.; Yang, Q. Easy Transfer Learning By Exploiting Intra-domain Structures. In Proceedings of the IEEE International Conference on Multimedia & Expo (ICME), Shanghai, China, 8–12 July 2019. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef]
- Gong, B.; Yuan, S.; Fei, S.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Zeng, H.; Yang, C.; Dai, G.; Qin, F.; Zhang, J.; Kong, W. EEG classification of driver mental states by deep learning. Cogn. Neurodynamics 2018, 12, 597–606. [Google Scholar] [CrossRef] [PubMed]
- Kong, W.; Zhou, Z.; Jiang, B.; Babiloni, F.; Borghini, G. Assessment of driving fatigue based on intra/inter-region phase synchronization. Neurocomputing 2017, 219, 474–482. [Google Scholar] [CrossRef]
- Vecchiato, G.; Borghini, G.; Aricò, P.; Graziani, I.; Maglione, A.G.; Cherubino, P.; Babiloni, F. Investigation of the effect of EEG-BCI on the simultaneous execution of flight simulation and attentional tasks. Med. Biol. Eng. Comput. 2016, 54, 1503–1513. [Google Scholar] [CrossRef]
- Jahankhani, P.; Kodogiannis, V.; Revett, K. EEG signal classification using wavelet feature extraction and neural networks. In Proceedings of the IEEE John Vincent Atanasoff 2006 International Symposium on Modern Computing (JVA’06), Sofia, Bulgaria, 3–6 October 2006; pp. 120–124. [Google Scholar]
- Borghini, G.; Astolfi, L.; Vecchiato, G.; Mattia, D.; Babiloni, F. Measuring neurophysiological signals in aircraft pilots and car drivers for the assessment of mental workload, fatigue and drowsiness. Neurosci. Biobehav. Rev. 2014, 44, 58–75. [Google Scholar] [CrossRef]
- Maglione, A.; Borghini, G.; Aricò, P.; Borgia, F.; Graziani, I.; Colosimo, A.; Kong, W.; Vecchiato, G.; Babiloni, F. Evaluation of the workload and drowsiness during car driving by using high resolution EEG activity and neurophysiologic indices. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 6238–6241. [Google Scholar]
- Lal, S.K.; Craig, A. Driver fatigue: Electroencephalography and psychological assessment. Psychophysiology 2002, 39, 313–321. [Google Scholar] [CrossRef]
- Bach, K.M.; Jæger, M.G.; Skov, M.B.; Thomassen, N.G. Interacting with in-vehicle systems: Understanding, measuring, and evaluating attention. In Proceedings of the People and Computers XXIII Celebrating People and Technology (HCI), Cambridge, UK, 1–5 September 2009; pp. 453–462. [Google Scholar]
- Lay-Ekuakille, A.; Vergallo, P.; Caratelli, D.; Conversano, F.; Casciaro, S.; Trabacca, A. Multispectrum approach in quantitative EEG: Accuracy and physical effort. IEEE Sens. J. 2013, 13, 3331–3340. [Google Scholar] [CrossRef]
- Zeng, H.; Wu, Z.; Zhang, J.; Yang, C.; Zhang, H.; Dai, G.; Kong, W. EEG Emotion Classification Using an Improved SincNet-Based Deep Learning Model. Brain Sci. 2019, 9, 326. [Google Scholar] [CrossRef]
- Bhattacharyya, S.; Sengupta, A.; Chakraborti, T.; Konar, A.; Tibarewala, D.N. Automatic feature selection of motor imagery EEG signals using differential evolution and learning automata. Med. Biol. Eng. Comput. 2014, 52, 131–139. [Google Scholar] [CrossRef]
- Zeng, H.; Dai, G.; Kong, W.; Chen, F.; Wang, L. A novel nonlinear dynamic method for stroke rehabilitation effect evaluation using eeg. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 2488–2497. [Google Scholar] [CrossRef]
- Li, L. The differences among eyes-closed, eyes-open and attention states: An EEG study. In Proceedings of the 2010 6th International Conference on Wireless Communications Networking and Mobile Computing (WiCOM), Chengdu, China, 23–25 September 2010; pp. 1–4. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Dai, W.; Yang, Q.; Xue, G.R.; Yu, Y. Boosting for transfer learning. In Proceedings of the 24th international conference on Machine learning, Madison, Corvallis, OR, USA, 20–24 June 2007; ACM: New York, NY, USA, 2007; pp. 193–200. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
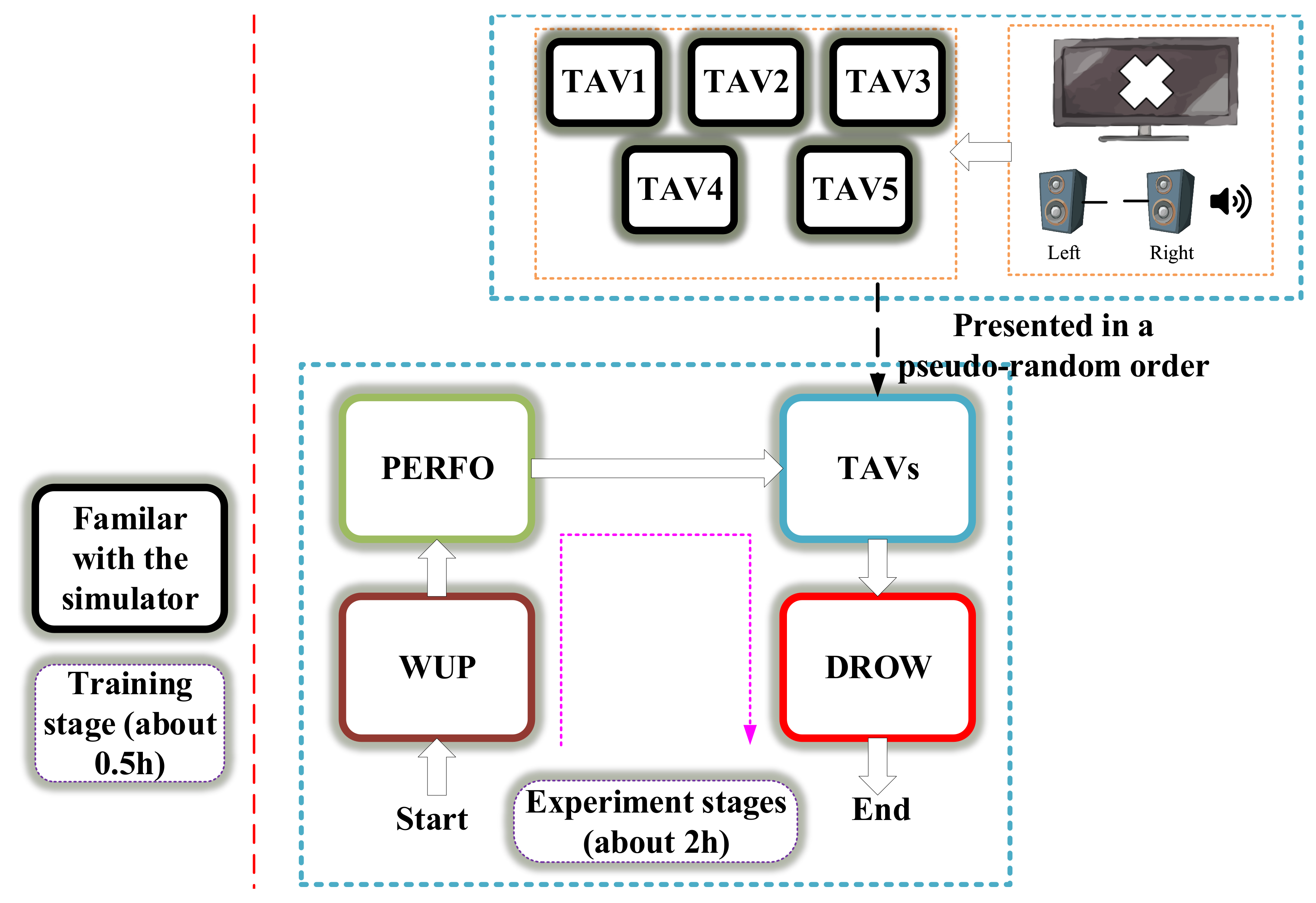
| WUP | WUP is as a baseline, which requires the driver to drive the car throughout the whole track without any speed requirements and any extra stimuli, but always kept the car in the path. |
| PERFO | In PERFO, the subject is asked to improve his previous performance of 2%. (total time = baseline − 2%) |
| TAVs | Five TAVs (TAV1 to TAV5) are presented in a pseudo-random order, TAV3,TAV5,TAV1,TAV2,TAV4, |
| where TAV1 is in the situation with the longest stimulus interval, TAV5 is in the situation with the | |
| shortest stimulus interval. | |
| DROW | DROW is the stage that the subject is required to drive slowly without any requirements on the speed. |
| Target Domain (Source Domain) | SVM | TCA | DANN | EasyTL | InstanceEasyTL | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | Precision | F1score | Recall | Precision | F1score | Recall | Precision | F1score | Recall | Precision | F1score | Recall | Precision | F1score | |
| S1 (S2–S15) | 50.85 | 50.79 | 48.85 | 61.14 | 53.77 | 57.22 | 57.97 | 61.86 | 59.85 | 54.43 | 62.87 | 58.35 | 83.34 | 86.37 | 84.77 |
| S2 (S1,S3–S15) | 53.25 | 52.86 | 49.85 | 66.00 | 59.54 | 62.60 | 67.44 | 74.29 | 70.70 | 73.71 | 83.09 | 78.12 | 90.71 | 84.80 | 87.64 |
| S3 (S1,S2,S4–S15) | 59.22 | 58.07 | 55.29 | 48.43 | 48.57 | 48.50 | 53.65 | 56.71 | 55.14 | 53.57 | 54.51 | 54.03 | 88.86 | 89.45 | 89.14 |
| S4 (S1–S3,S5–S15) | 71.26 | 70.93 | 70.70 | 69.14 | 66.94 | 68.03 | 84.81 | 90.14 | 87.40 | 85.86 | 92.04 | 88.84 | 96.61 | 97.82 | 97.20 |
| S5 (S1–S4,S6–S15) | 62.23 | 62.07 | 61.83 | 60.43 | 58.83 | 59.62 | 79.28 | 78.71 | 79.00 | 80.71 | 83.83 | 82.24 | 86.97 | 84.77 | 85.84 |
| S6 (S1–S5,S7–S15) | 51.11 | 51.00 | 48.34 | 54.43 | 52.84 | 53.62 | 55.47 | 59.43 | 57.38 | 55.86 | 60.71 | 58.18 | 78.67 | 80.33 | 79.46 |
| S7 (S1–S6,S8–S15) | 76.83 | 75.64 | 75.09 | 60.86 | 56.65 | 58.68 | 88.42 | 87.29 | 87.85 | 63.29 | 65.05 | 64.16 | 86.55 | 88.26 | 87.37 |
| S8 (S1–S7,S9–S15) | 47.24 | 47.00 | 49.25 | 66.00 | 63.64 | 64.80 | 60.00 | 61.29 | 60.64 | 84.86 | 85.84 | 85.34 | 93.53 | 91.73 | 92.61 |
| S9 (S1–S8,S10–S15) | 77.25 | 73.79 | 72.01 | 67.14 | 65.83 | 66.48 | 88.43 | 83.00 | 85.63 | 92.14 | 92.94 | 92.54 | 97.58 | 92.21 | 94.05 |
| S10 (S1–S9,S11–S15) | 63.23 | 61.00 | 57.41 | 58.14 | 52.31 | 55.07 | 66.18 | 64.29 | 65.22 | 58.86 | 61.04 | 59.93 | 85.52 | 83.24 | 84.30 |
| S11 (S1–S10,S12–S15) | 63.42 | 61.43 | 58.33 | 66.57 | 63.84 | 65.17 | 84.60 | 80.86 | 82.69 | 79.57 | 85.30 | 82.34 | 94.20 | 90.76 | 92.40 |
| S12 (S1–S11,S13–S15) | 64.45 | 63.64 | 62.60 | 66.57 | 58.84 | 62.47 | 68.22 | 71.14 | 69.65 | 62.57 | 68.98 | 65.62 | 85.39 | 85.22 | 85.20 |
| S13 (S1–S12,S14–S15) | 76.78 | 74.21 | 72.92 | 63.86 | 64.41 | 64.13 | 80.45 | 76.43 | 78.39 | 68.14 | 76.44 | 72.05 | 89.99 | 87.81 | 88.80 |
| S14 (S1–S13,S15) | 67.54 | 66.21 | 64.88 | 51.57 | 50.92 | 51.24 | 75.87 | 77.71 | 76.78 | 67.71 | 63.88 | 65.74 | 90.20 | 89.62 | 89.90 |
| S15 (S1–S14) | 56.43 | 56.07 | 54.81 | 48.71 | 47.63 | 48.16 | 50.37 | 48.43 | 49.38 | 44.00 | 45.29 | 44.64 | 88.15 | 87.94 | 88.00 |
| Average | 62.74 | 61.65 | 60.14 | 60.60 | 57.64 | 59.05 | 70.74 | 71.44 | 71.05 | 68.35 | 72.12 | 70.14 | 89.08 | 88.02 | 88.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, H.; Zhang, J.; Zakaria, W.; Babiloni, F.; Gianluca, B.; Li, X.; Kong, W. InstanceEasyTL: An Improved Transfer-Learning Method for EEG-Based Cross-Subject Fatigue Detection. Sensors 2020, 20, 7251. https://doi.org/10.3390/s20247251
Zeng H, Zhang J, Zakaria W, Babiloni F, Gianluca B, Li X, Kong W. InstanceEasyTL: An Improved Transfer-Learning Method for EEG-Based Cross-Subject Fatigue Detection. Sensors. 2020; 20(24):7251. https://doi.org/10.3390/s20247251
Chicago/Turabian StyleZeng, Hong, Jiaming Zhang, Wael Zakaria, Fabio Babiloni, Borghini Gianluca, Xiufeng Li, and Wanzeng Kong. 2020. "InstanceEasyTL: An Improved Transfer-Learning Method for EEG-Based Cross-Subject Fatigue Detection" Sensors 20, no. 24: 7251. https://doi.org/10.3390/s20247251
APA StyleZeng, H., Zhang, J., Zakaria, W., Babiloni, F., Gianluca, B., Li, X., & Kong, W. (2020). InstanceEasyTL: An Improved Transfer-Learning Method for EEG-Based Cross-Subject Fatigue Detection. Sensors, 20(24), 7251. https://doi.org/10.3390/s20247251