Automated White Blood Cell Counting in Nailfold Capillary Using Deep Learning Segmentation and Video Stabilization



Abstract
1. Introduction
2. Related Work
2.1. Semantic Segmentation
2.2. Video Stabilization
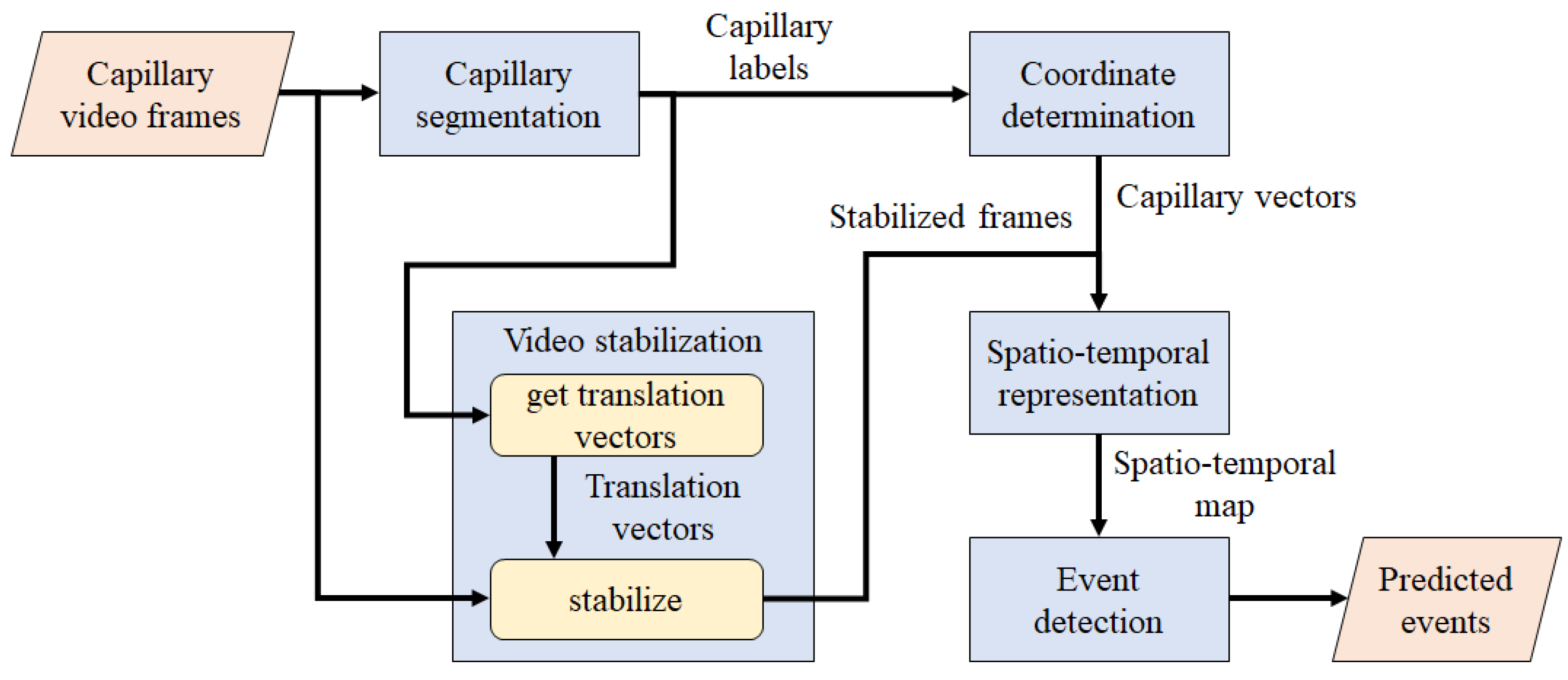
3. Proposed WBC Counting Method
3.1. Frame Extraction
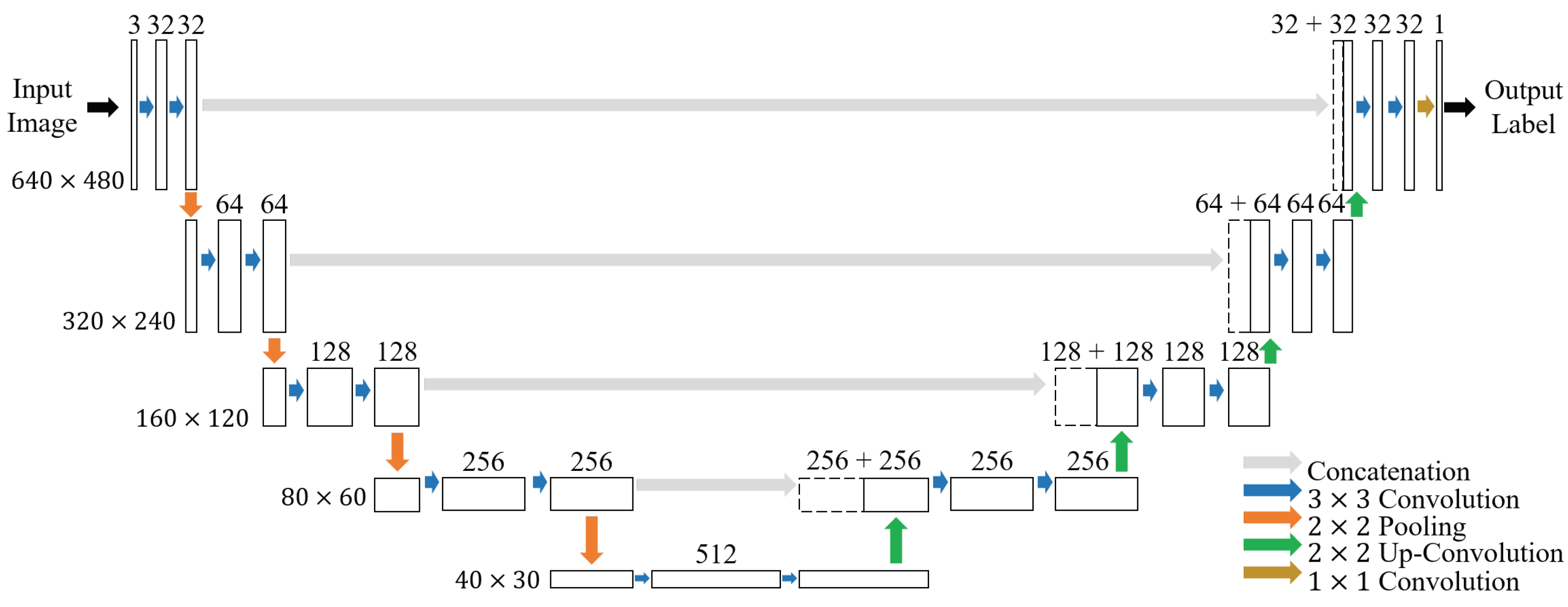
3.2. Capillary Segmentation
3.2.1. Deep Learning-Based Segmentation
3.2.2. Conventional Segmentation
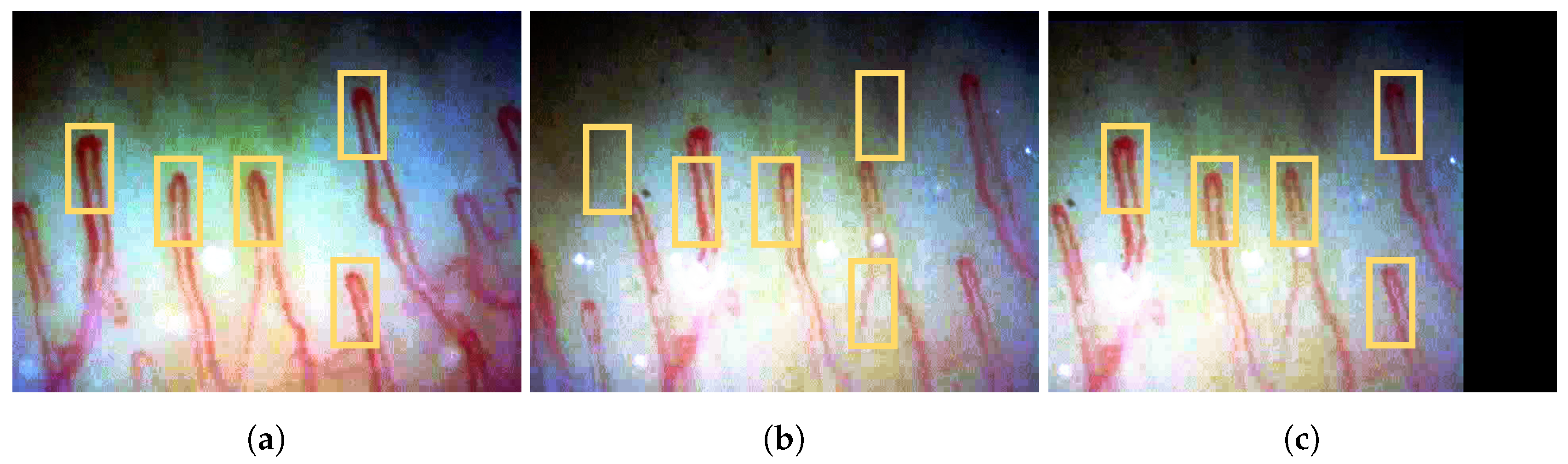
3.3. Video Stabilization
| Algorithm 1: Pseudo code for video stabilization. |
 |
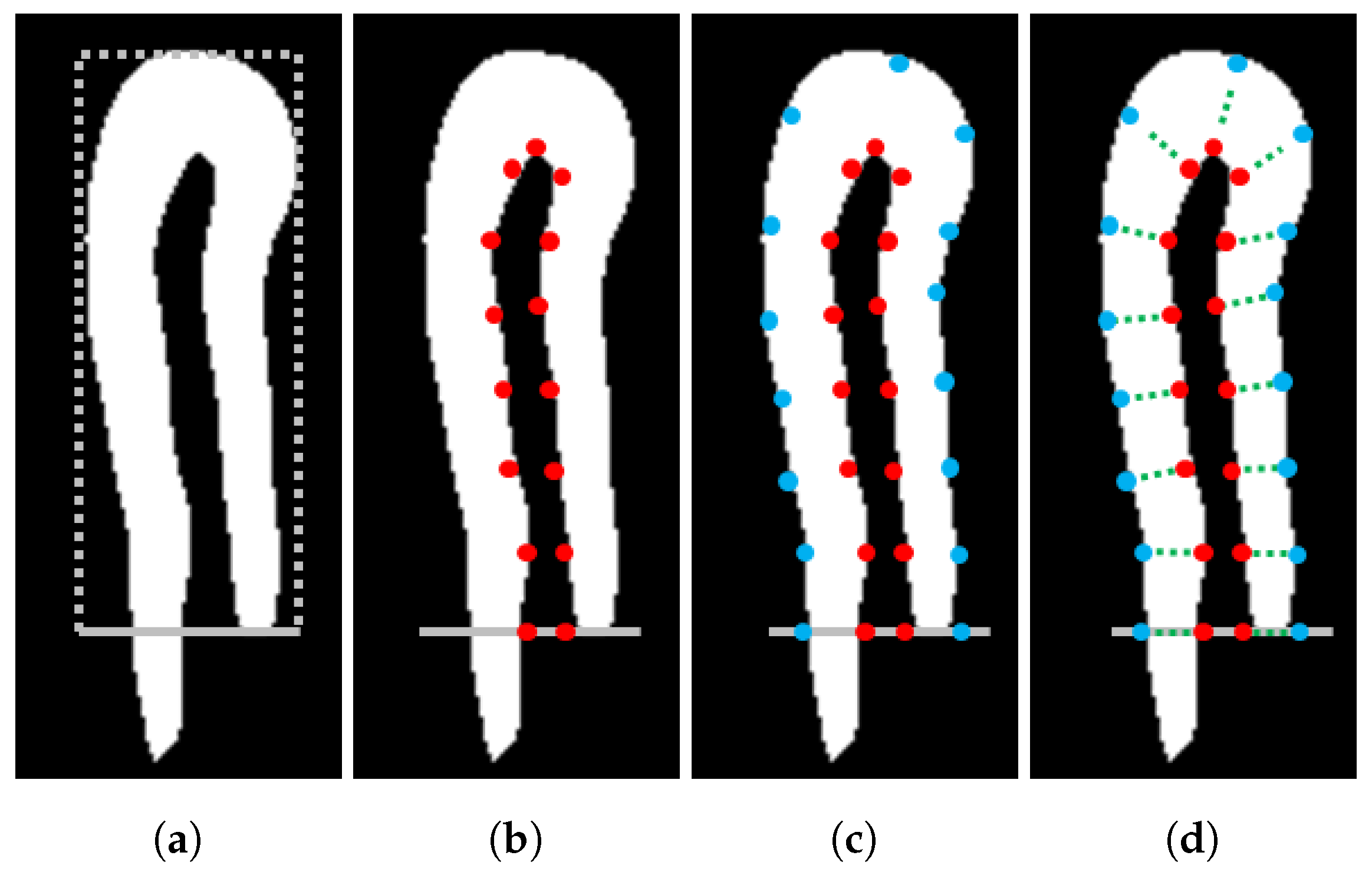
3.4. Capillary Coordinate Determination
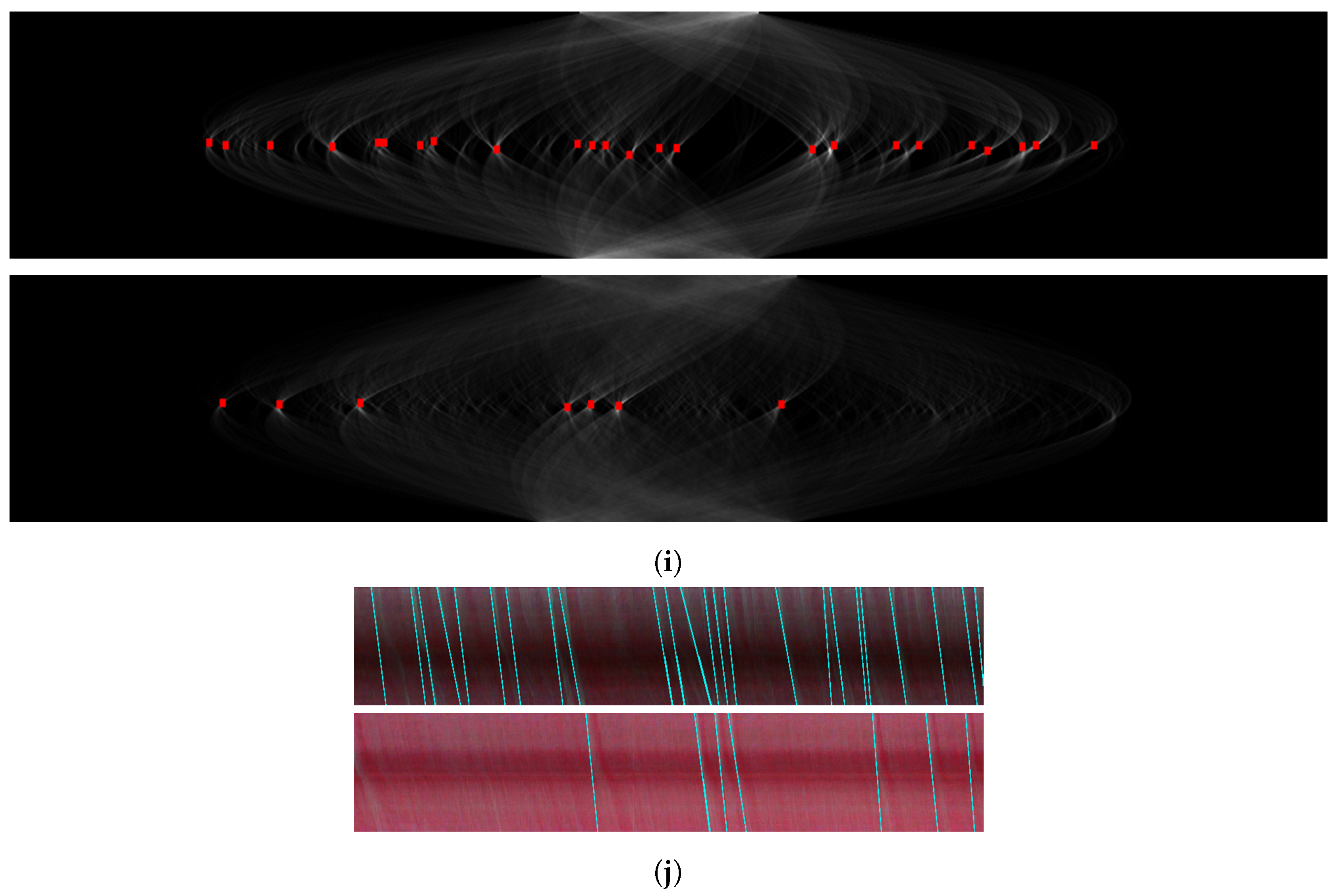
3.5. Spatiotemporal Representation
3.6. WBC Event Detection
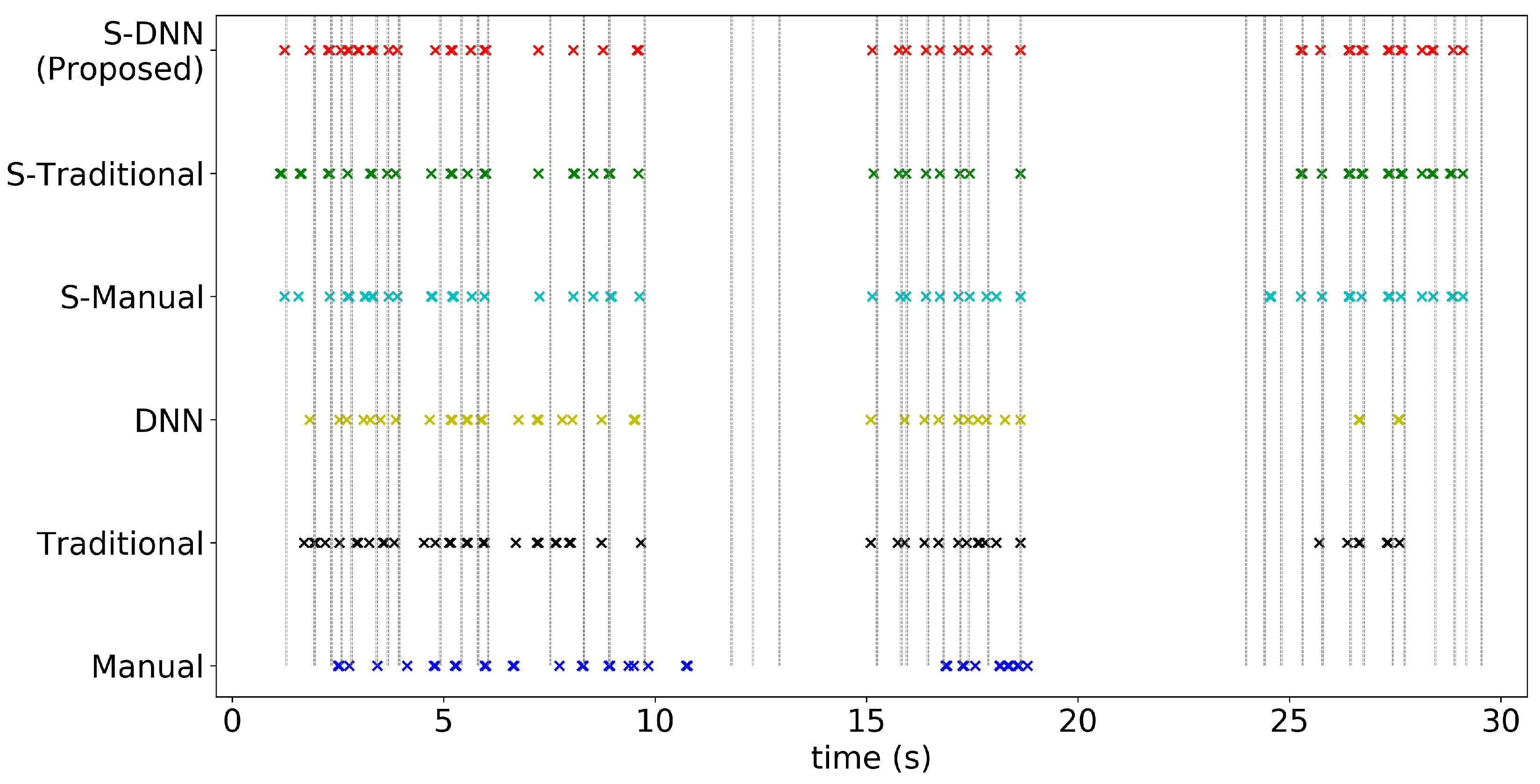
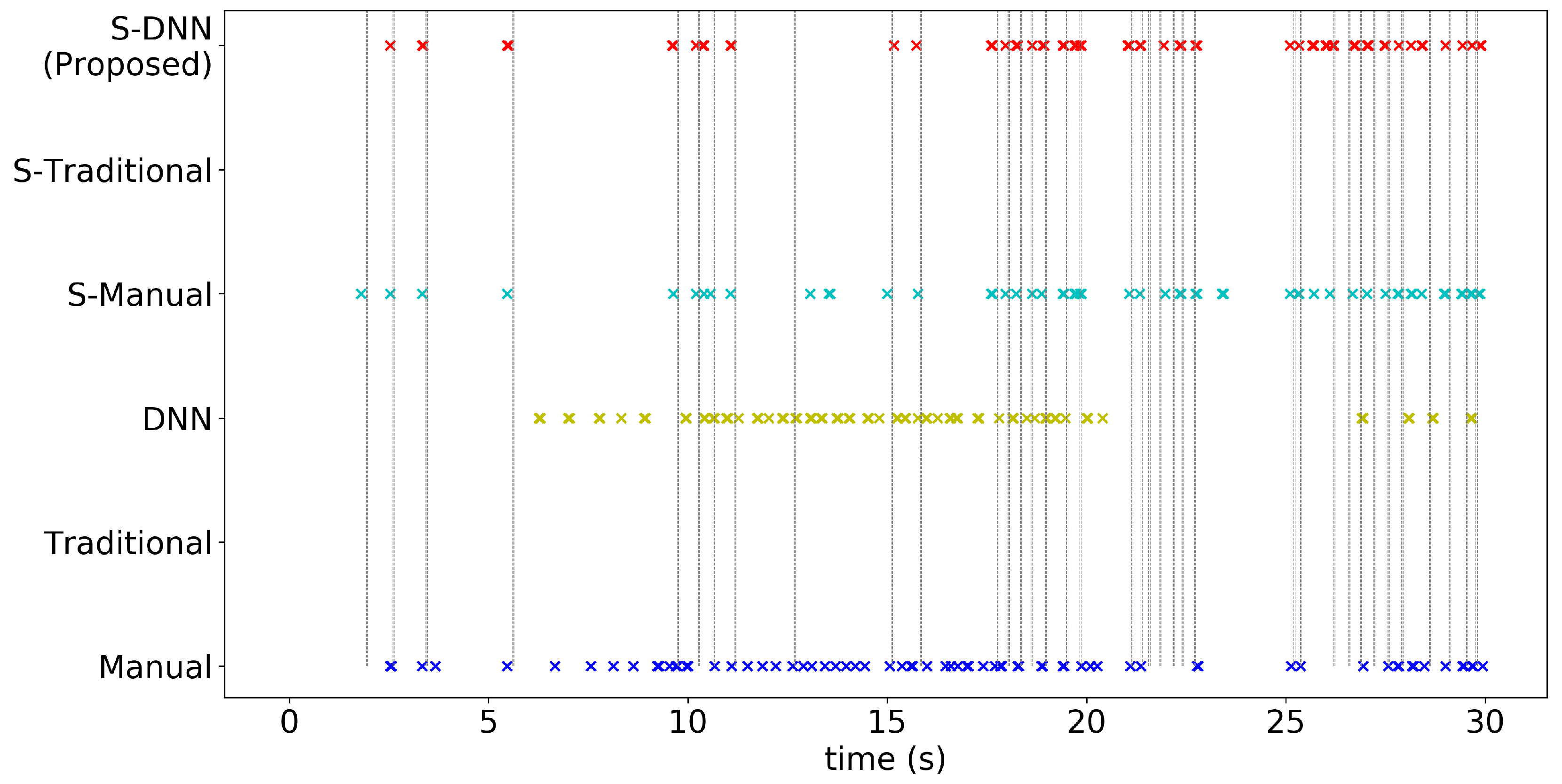
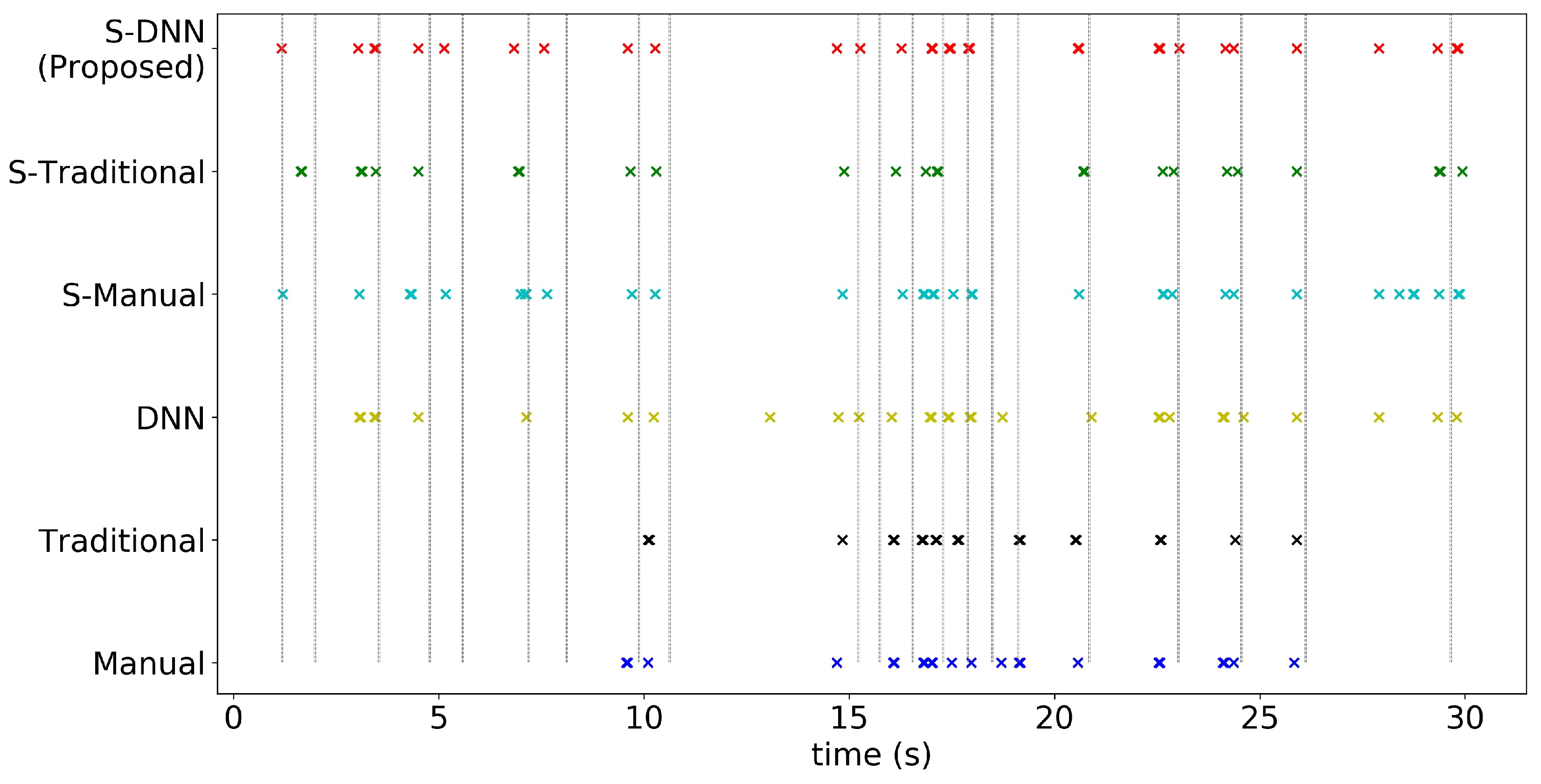
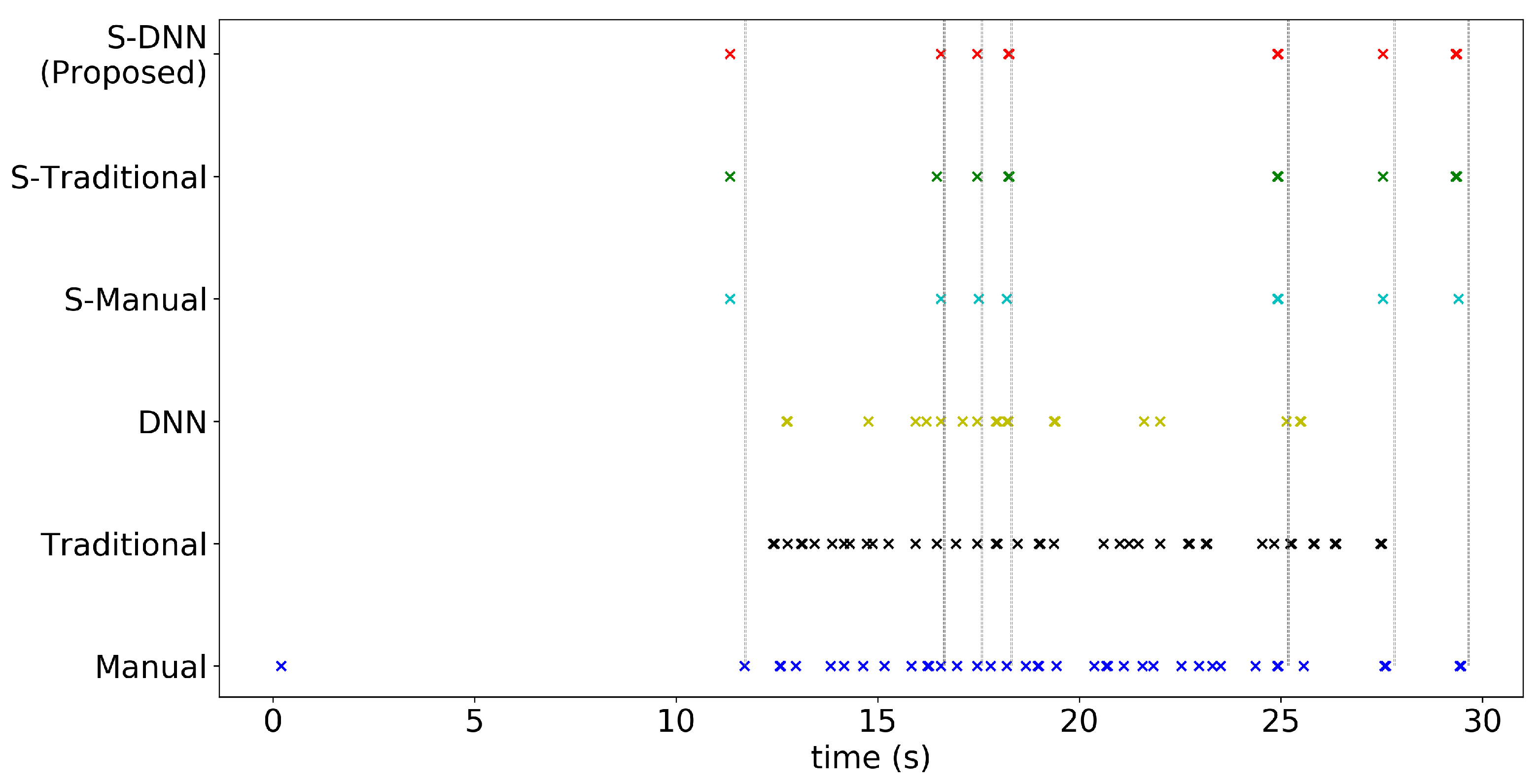
4. Experiments and Results
4.1. Experiment Settings
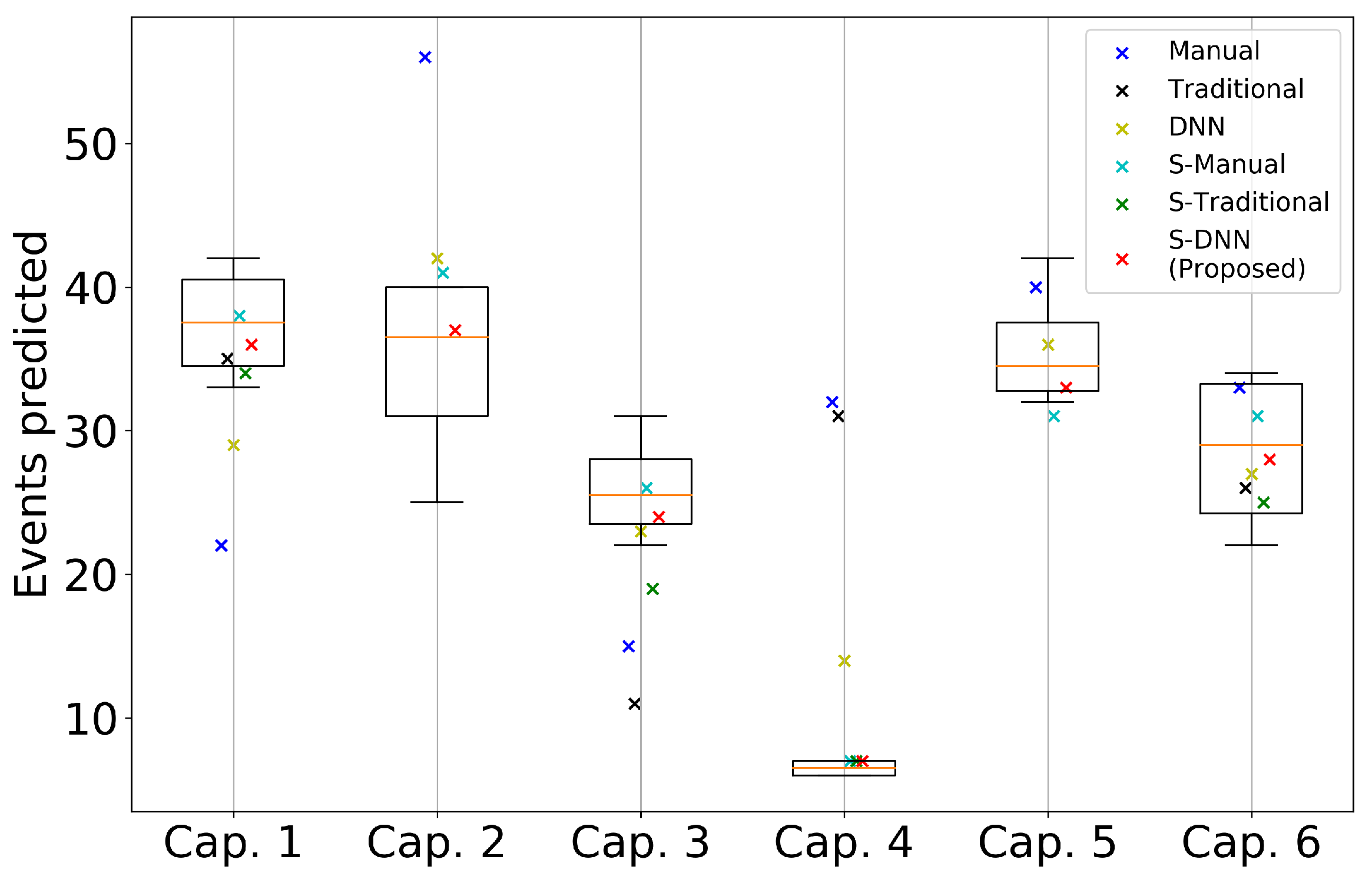
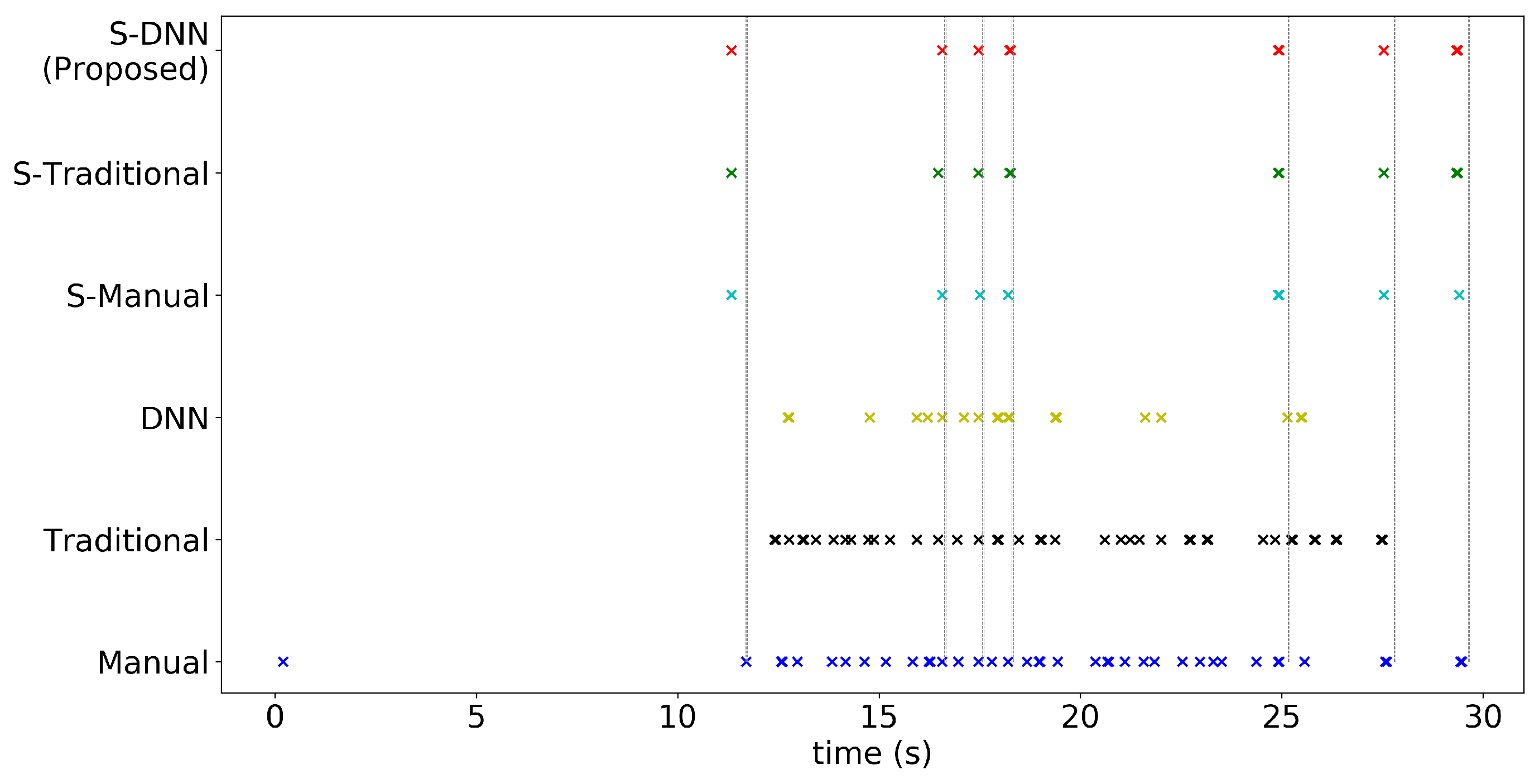
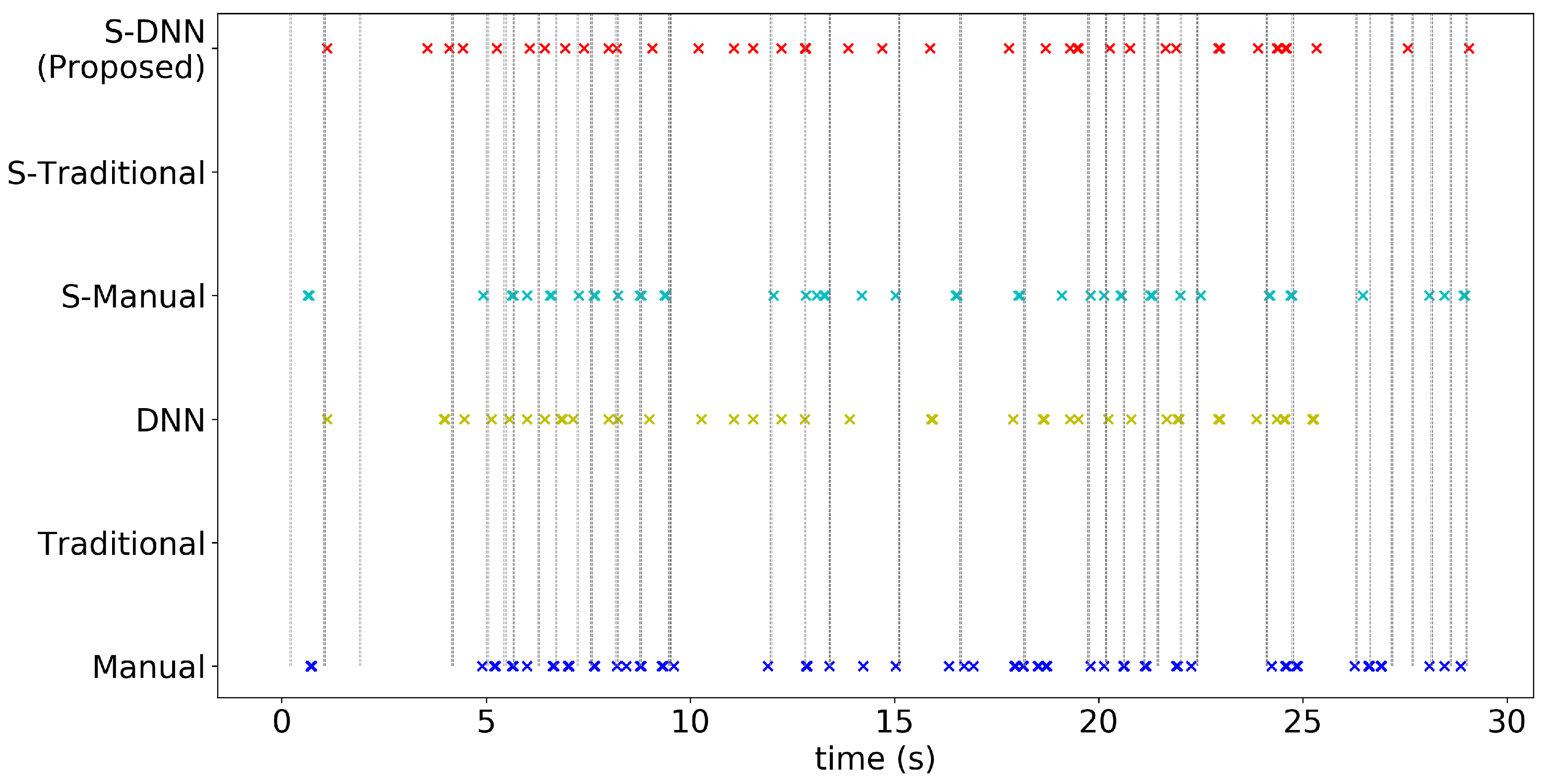
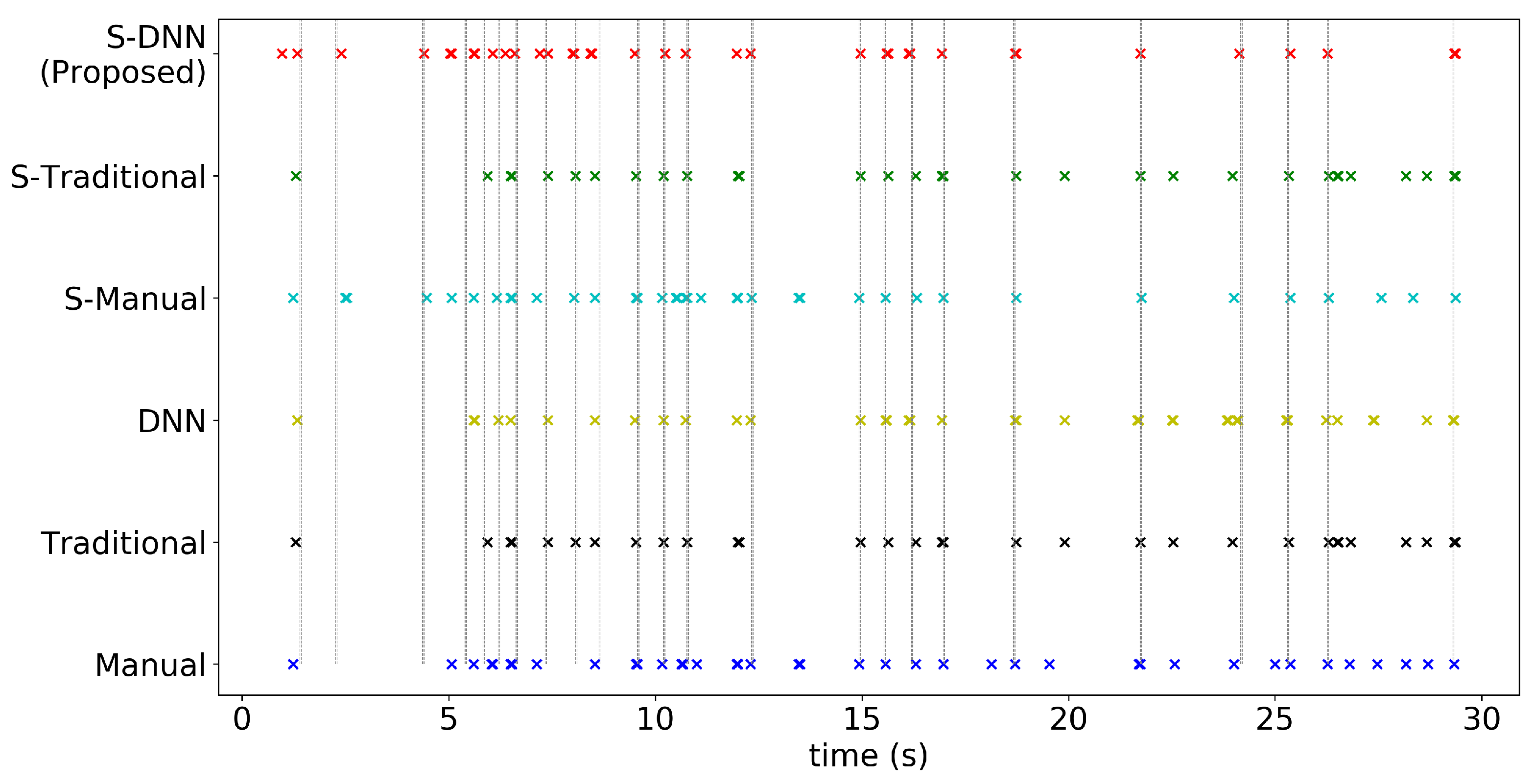
4.2. Results
5. Discussion
5.1. Main Contributions
5.2. Segmentation Method
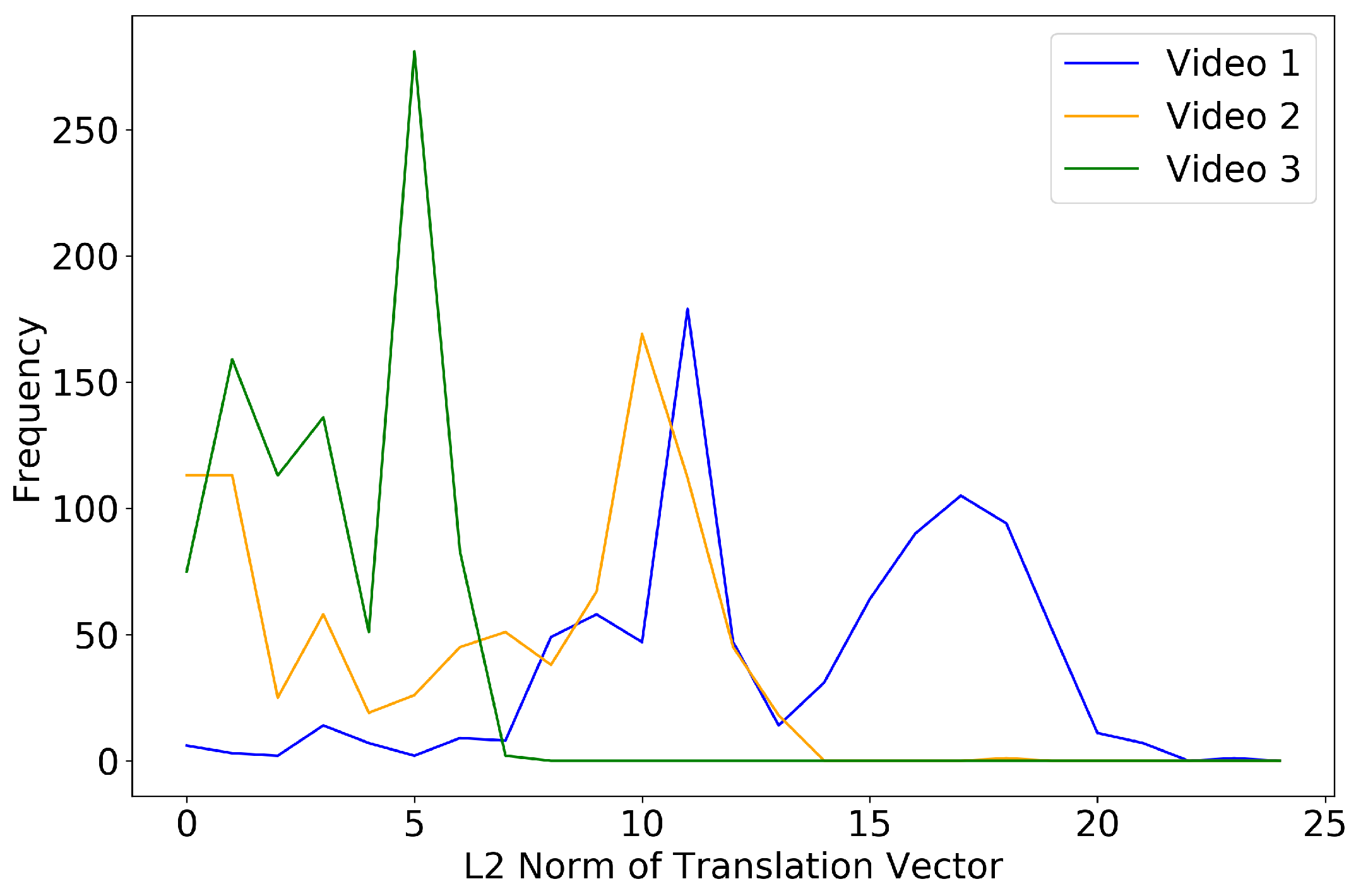
5.3. Video Stabilization
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
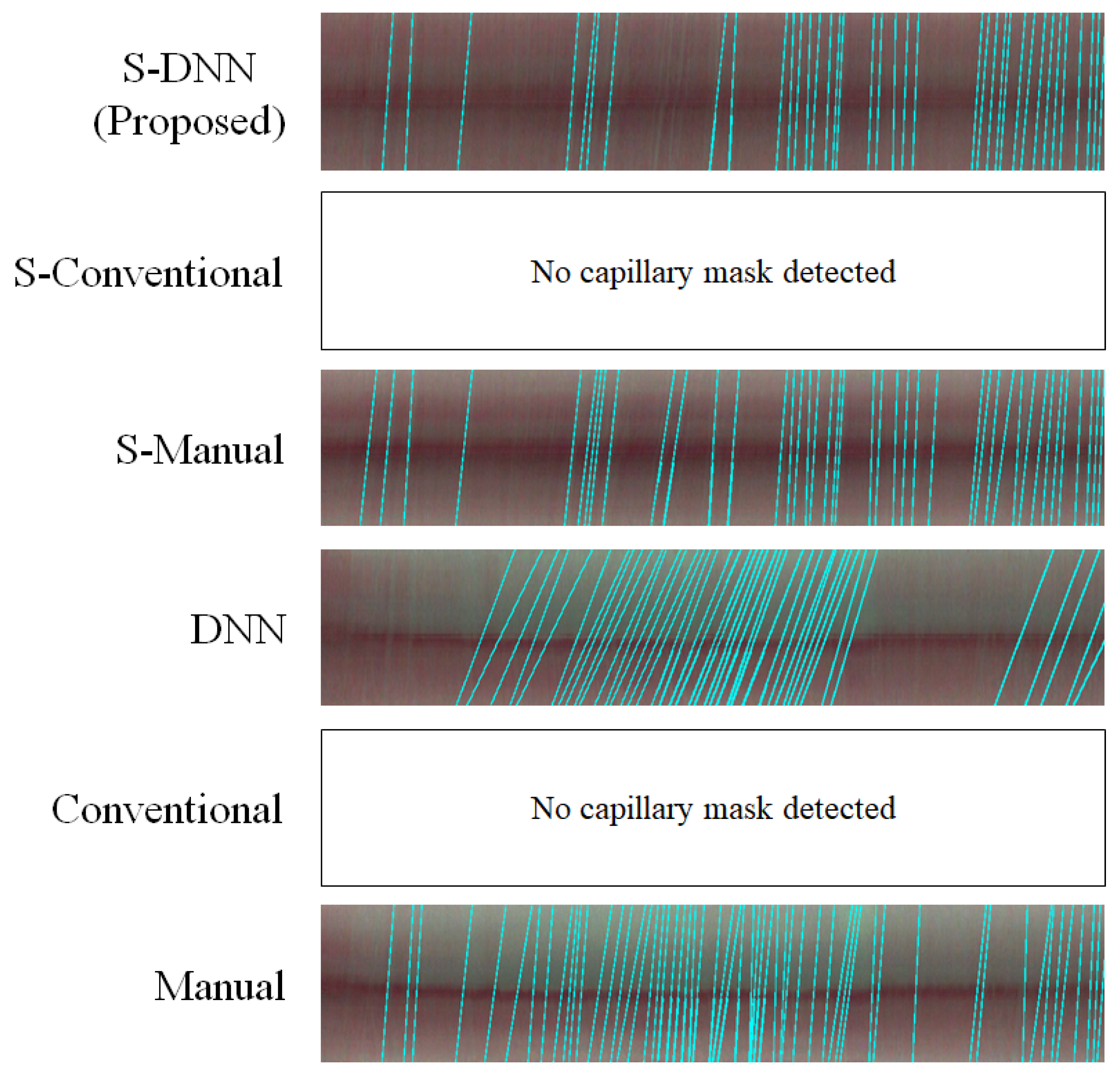
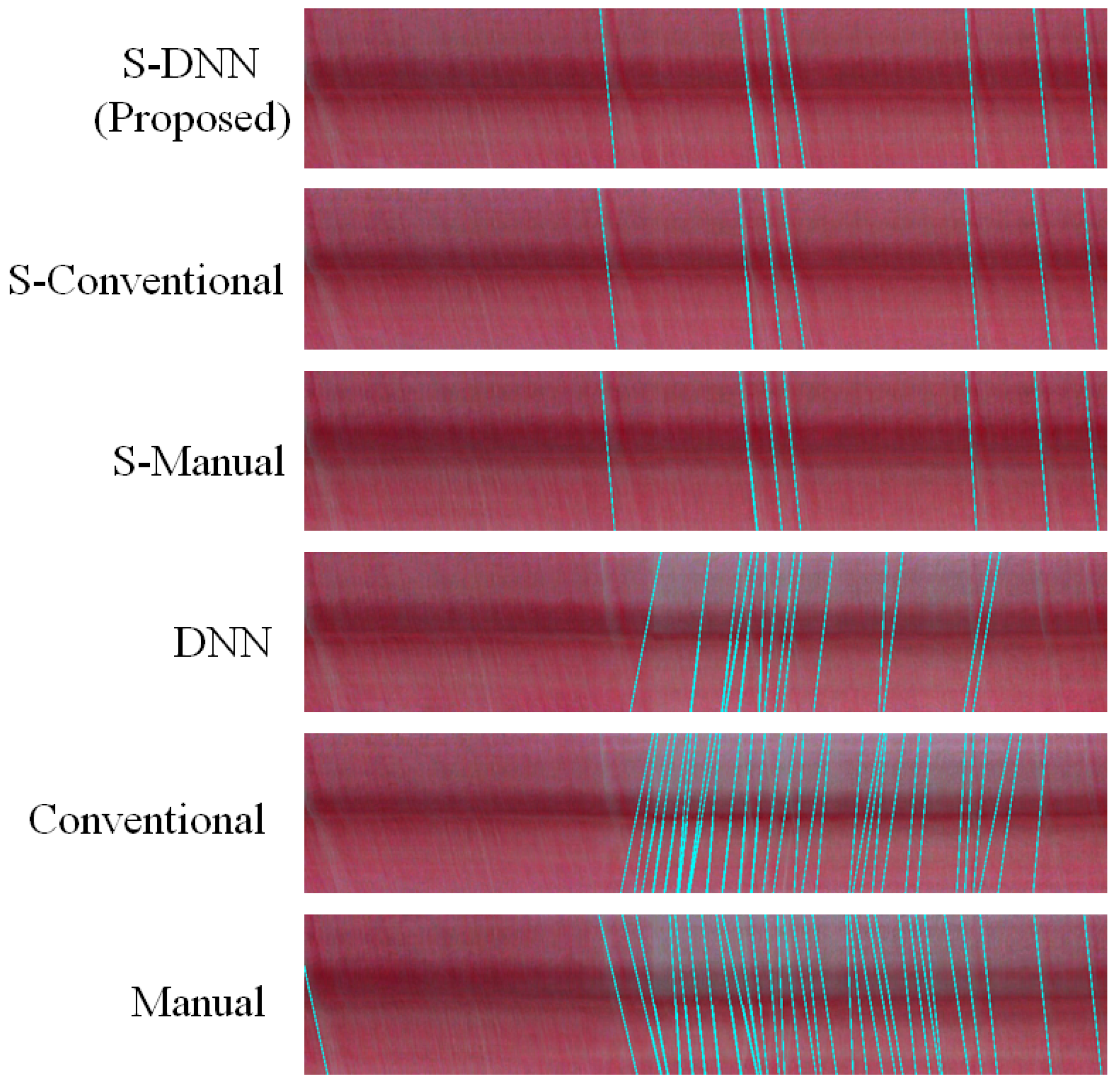
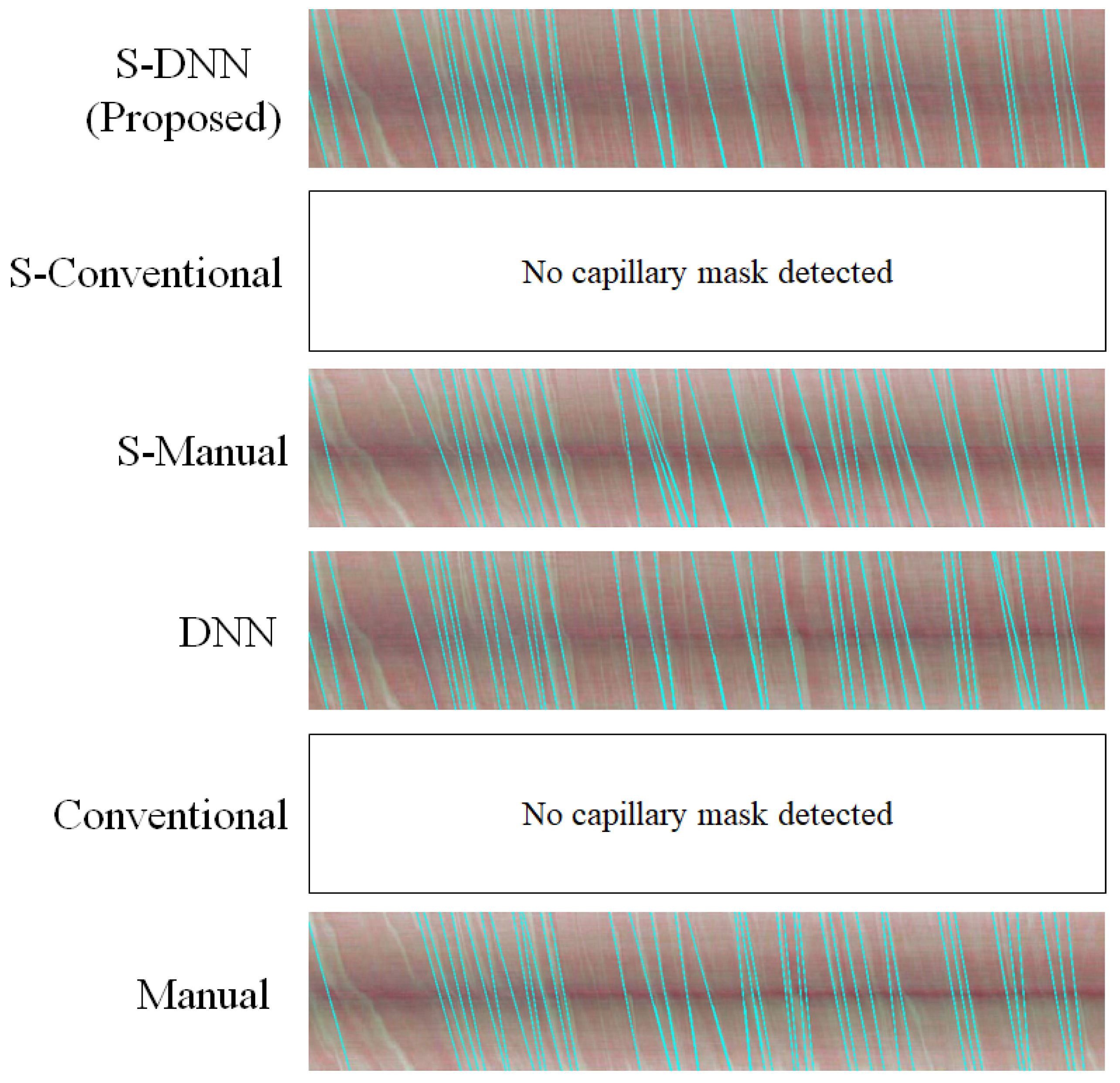
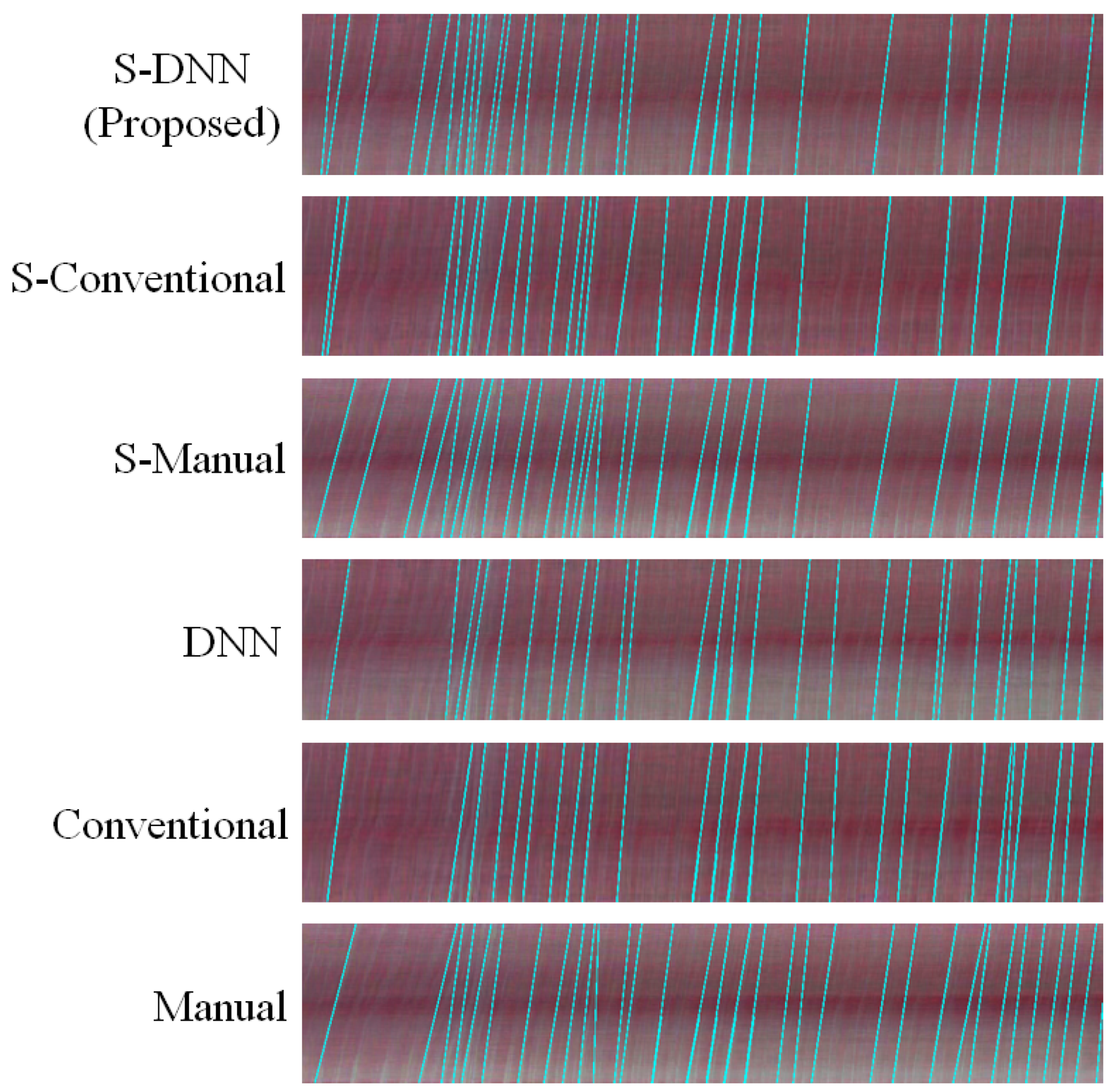
Appendix A. Consistency of WBC Event Counting for Various Methods






Appendix B. Spatiotemporal Maps of Capillaries for Various Methods






References
- Newman, T.B.; Draper, D.; Puopolo, K.M.; Wi, S.; Escobar, G.J. Combining immature and total neutrophil counts to predict early onset sepsis in term and late preterm newborns: Use of the I/T2. Pediatr. Infect. Dis. J. 2014, 33, 798. [Google Scholar] [CrossRef] [PubMed]
- Honda, T.; Uehara, T.; Matsumoto, G.; Arai, S.; Sugano, M. Neutrophil left shift and white blood cell count as markers of bacterial infection. Clin. Chim. Acta 2016, 457, 46–53. [Google Scholar] [CrossRef]
- van Wolfswinkel, M.E.; Vliegenthart-Jongbloed, K.; de Mendonça Melo, M.; Wever, P.C.; McCall, M.B.; Koelewijn, R.; van Hellemond, J.J.; van Genderen, P.J. Predictive value of lymphocytopenia and the neutrophil-lymphocyte count ratio for severe imported malaria. Malar. J. 2013, 12, 101. [Google Scholar] [CrossRef] [PubMed]
- Crawford, J.; Dale, D.C.; Lyman, G.H. Chemotherapy-induced neutropenia: Risks, consequences, and new directions for its management. Cancer 2004, 100, 228–237. [Google Scholar] [CrossRef] [PubMed]
- Golan, L.; Yeheskely-Hayon, D.; Minai, L.; Dann, E.J.; Yelin, D. Noninvasive imaging of flowing blood cells using label-free spectrally encoded flow cytometry. Biomed. Opt. Express 2012, 3, 1455–1464. [Google Scholar] [CrossRef]
- Uji, A.; Hangai, M.; Ooto, S.; Takayama, K.; Arakawa, N.; Imamura, H.; Nozato, K.; Yoshimura, N. The source of moving particles in parafoveal capillaries detected by adaptive optics scanning laser ophthalmoscopy. Investig. Ophthalmol. Vis. Sci. 2012, 53, 171–178. [Google Scholar] [CrossRef]
- Bourquard, A.; Butterworth, I.; Sánchez-Ferro, A.; Giancardo, L.; Soenksen, L.; Cerrato, C.; Flores, R.; Castro-González, C. Analysis of white blood cell dynamics in nailfold capillaries. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milano, Italy, 25–29 August 2015; pp. 7470–7473. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heisenberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed]
- Hariyani, Y.S.; Eom, H.; Park, C. DA-Capnet: Dual Attention Deep Learning Based on U-Net for Nailfold Capillary Segmentation. IEEE Access 2020, 8, 10543–10553. [Google Scholar] [CrossRef]
- Hegazy, M.A.; Cho, M.H.; Cho, M.H.; Lee, S.Y. U-net based metal segmentation on projection domain for metal artifact reduction in dental ct. Biomed. Eng. Lett. 2019, 9, 375–385. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Guizar-Sicairos, M.; Thurman, S.T.; Fienup, J.R. Efficient subpixel image registration algorithms. Opt. Lett. 2008, 33, 156–158. [Google Scholar] [CrossRef] [PubMed]
- Huynh, L.; Choi, J.; Medioni, G. Aerial implicit 3D video stabilization using epipolar geometry constraint. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3487–3492. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- dos Anjos, A.; Shahbazkia, H.R. Bi-level image thresholding. Biosignals 2008, 2, 70–76. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965 and 27 December 1965–7 January 1966; Volume 1, pp. 281–297. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Ibrokhimov, B.; Hur, C.; Kim, H.; Kang, S. An Optimized Deep Belief Network Model for Accurate Breast Cancer Classification. IEIE Trans. Smart Process. Comput. 2020, 9, 266–273. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Munirathinam, R.; M, S. Hybrid LSM-based Image Segmentation and Analysis of Morphological Variations of the Brainstem in Alzheimer MR Images. Trans. Smart Process. Comput. 2018, 7, 124–131. [Google Scholar] [CrossRef]
- Comelli, A.; Dahiya, N.; Stefano, A.; Benfante, V.; Gentile, G.; Agnese, V.; Raffa, G.M.; Pilato, M.; Yezzi, A.; Petrucci, G.; et al. Deep learning approach for the segmentation of aneurysmal ascending aorta. Biomed. Eng. Lett. 2020, 1–10. [Google Scholar] [CrossRef]
- Bourquard, A.; Pablo-Trinidad, A.; Butterworth, I.; Sánchez-Ferro, Á.; Cerrato, C.; Humala, K.; Urdiola, M.F.; Del Rio, C.; Valles, B.; Tucker-Schwartz, J.M.; et al. Non-invasive detection of severe neutropenia in chemotherapy patients by optical imaging of nailfold microcirculation. Sci. Rep. 2018, 8, 5301. [Google Scholar] [CrossRef] [PubMed]
- De Boor, C. Applied Mathematical Sciences. In A Practical Guide to Splines; Springer: Berlin/Heisenberg, Germany, 1978; Volume 27. [Google Scholar]
- Pablo-Trinidad, A.; Butterworth, I.; Ledesma-Carbayo, M.J.; Vettenburg, T.; Sánchez-Ferro, A.; Soenksen, L.; Durr, N.J.; Muñoz-Barrutia, A.; Cerrato, C.; Humala, K.; et al. Automated detection of neutropenia using noninvasive video microscopy of superficial capillaries. Am. J. Hematol. 2019, 94, E219–E222. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Method | Segmentation Method | Video Stabilization |
|---|---|---|---|
| 1 | Manual | Manual | No |
| 2 | Conventional | Conventional | No |
| 3 | DNN | DNN | No |
| 4 | S-Manual | Manual | Yes |
| 5 | S-Conventional | Conventional | Yes |
| 6 | S-DNN | DNN | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Hariyani, Y.-S.; Cho, Y.-H.; Park, C. Automated White Blood Cell Counting in Nailfold Capillary Using Deep Learning Segmentation and Video Stabilization. Sensors 2020, 20, 7101. https://doi.org/10.3390/s20247101
Kim B, Hariyani Y-S, Cho Y-H, Park C. Automated White Blood Cell Counting in Nailfold Capillary Using Deep Learning Segmentation and Video Stabilization. Sensors. 2020; 20(24):7101. https://doi.org/10.3390/s20247101
Chicago/Turabian StyleKim, Byeonghwi, Yuli-Sun Hariyani, Young-Ho Cho, and Cheolsoo Park. 2020. "Automated White Blood Cell Counting in Nailfold Capillary Using Deep Learning Segmentation and Video Stabilization" Sensors 20, no. 24: 7101. https://doi.org/10.3390/s20247101
APA StyleKim, B., Hariyani, Y.-S., Cho, Y.-H., & Park, C. (2020). Automated White Blood Cell Counting in Nailfold Capillary Using Deep Learning Segmentation and Video Stabilization. Sensors, 20(24), 7101. https://doi.org/10.3390/s20247101