Semantic Extraction of Permanent Structures for the Reconstruction of Building Interiors from Point Clouds




Abstract
1. Introduction
- An optimization of the baseline architecture to reduce inference and training time. To achieve this, we removed some unnecessary operations and performed loop unrolling.
- An adaptation of the baseline architecture such that no information about the scanning trajectory is required. Instead of a truncated signed distance field data representation, we proposed a Manhattan distance based data representation.
- A more realistic synthetic dataset based on scans of building interiors from real-life houses.
- An ablation study on several design choices. In one of the experiments, we show that using previous voxel group predictions instead of ground truth values for training improves the overall results.
- A case study in which we use our adapted and optimized architecture to improve the extraction of planar permanent structures in challenging cluttered indoor environments.
2. Related Work
2.1. Semantic Segmentation
2.2. Shape Completion
2.3. Semantic Scene Completion
3. The Proposed Approach
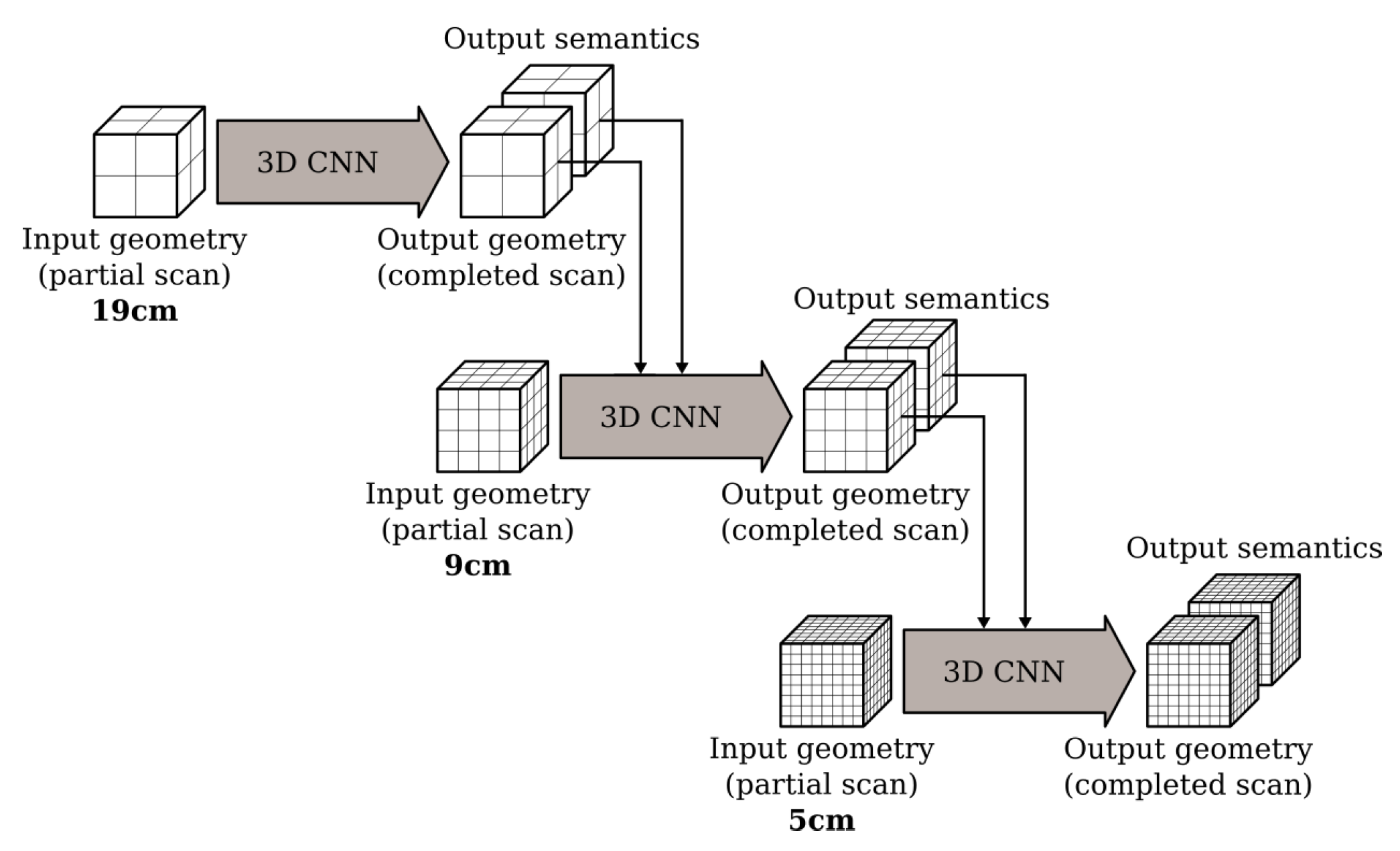
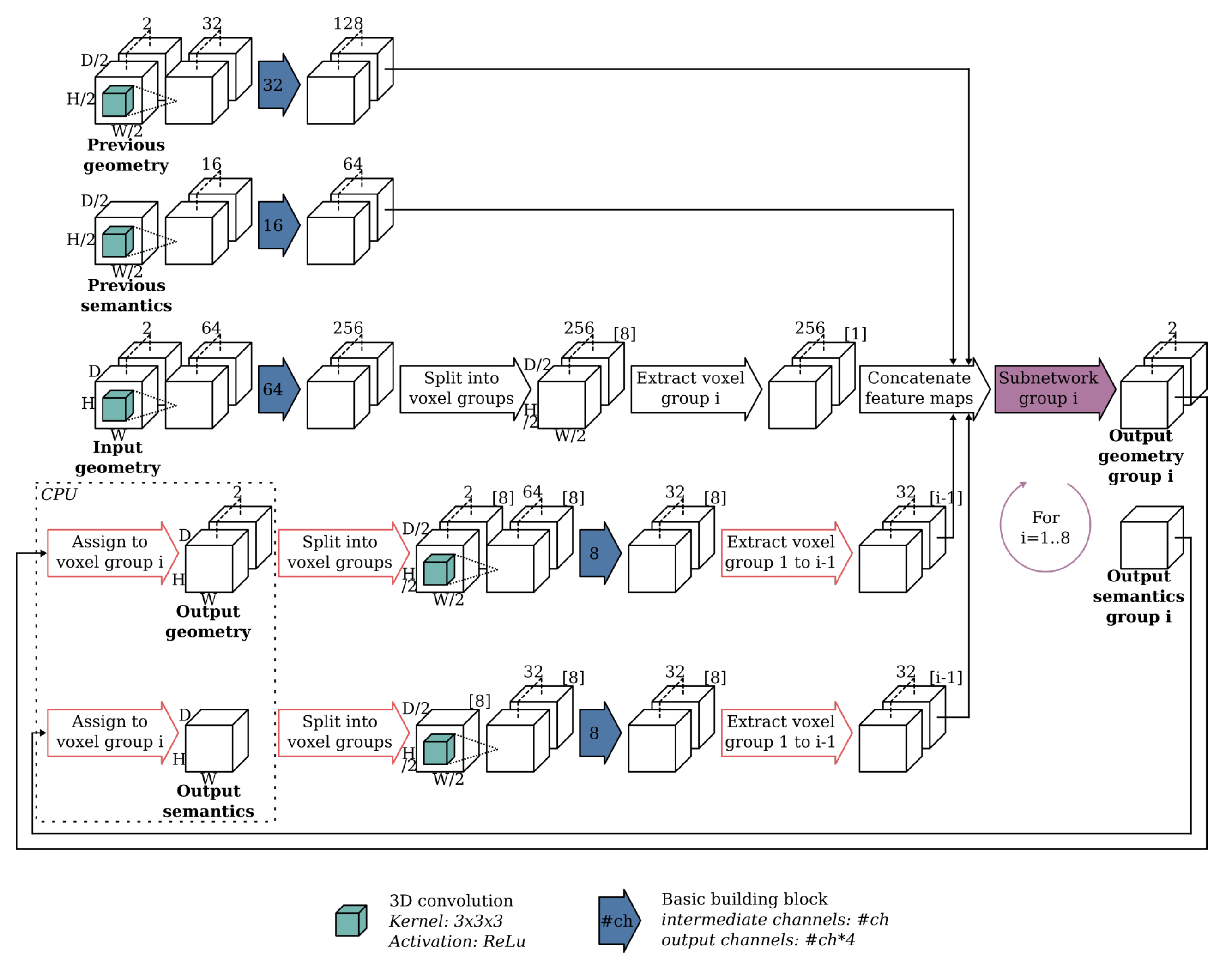
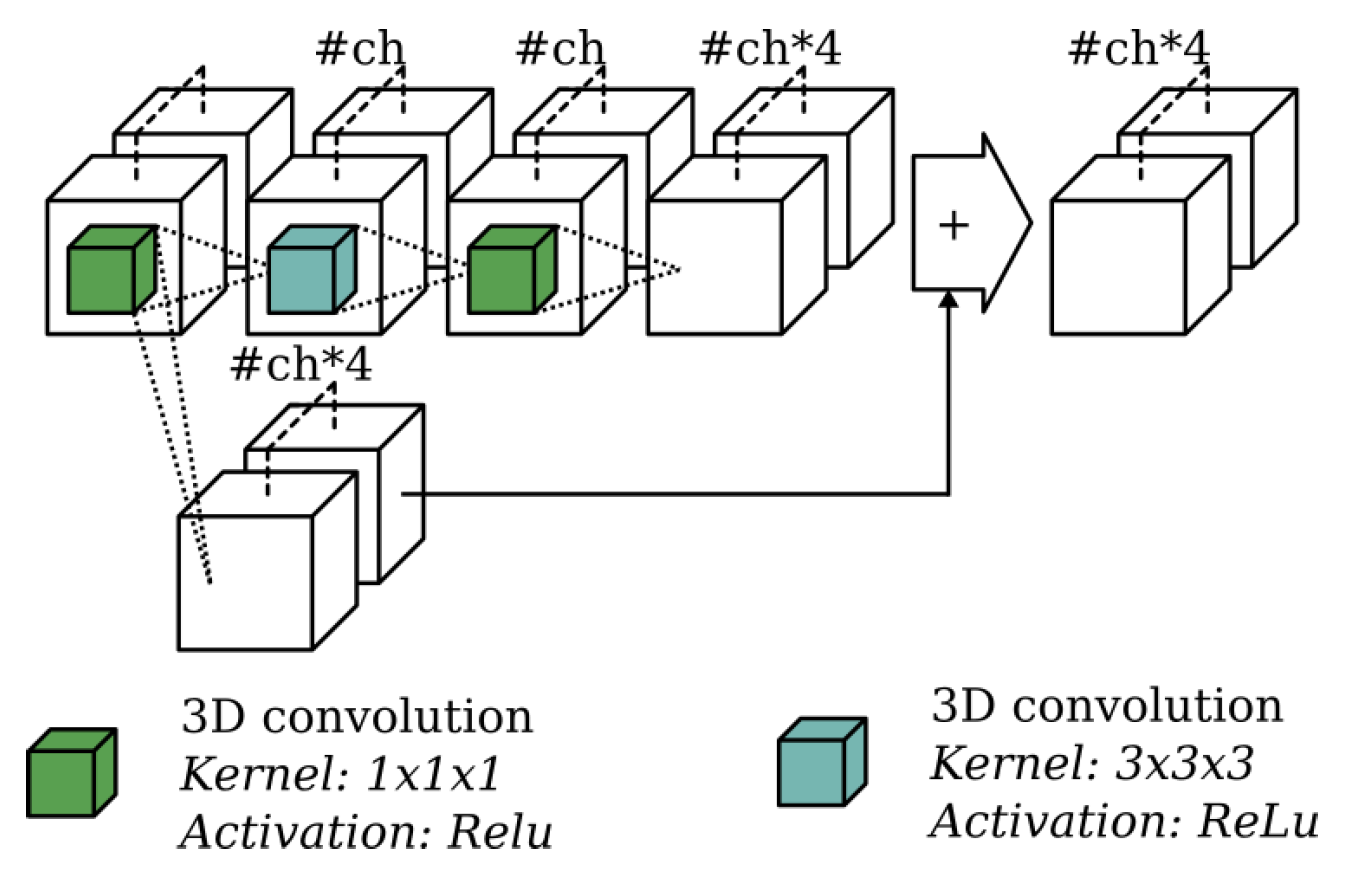
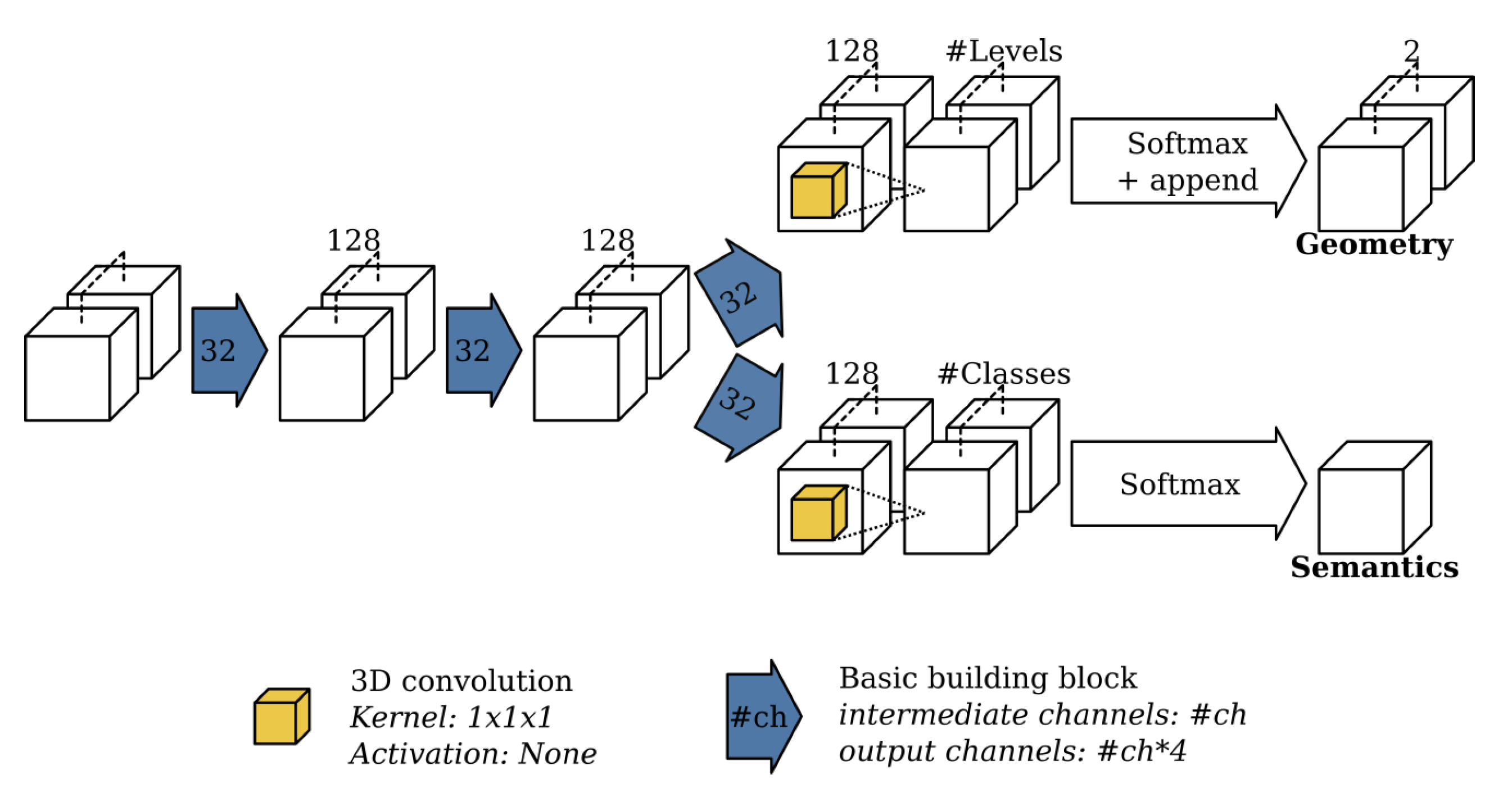
3.1. Baseline: ScanComplete Network
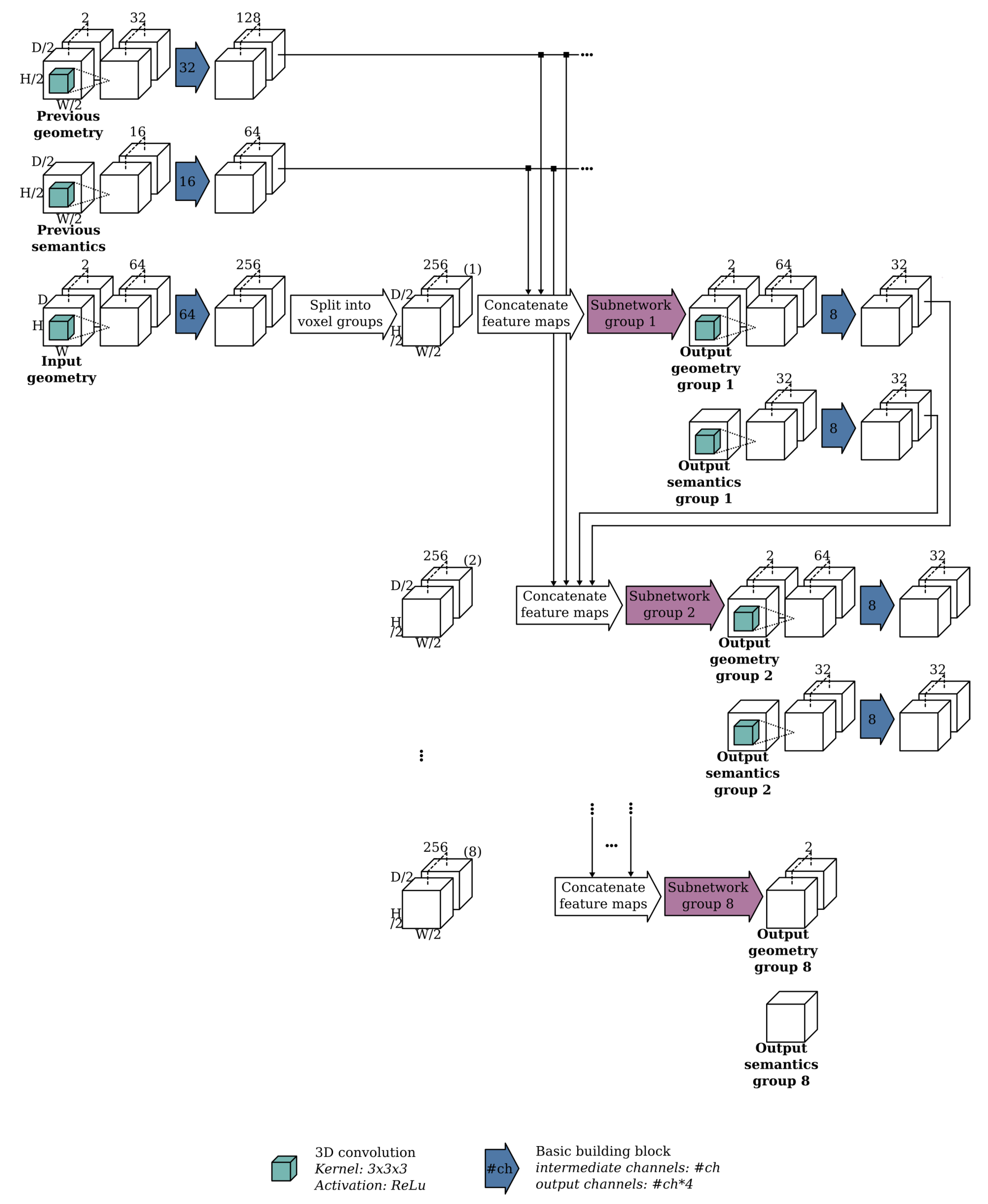
3.2. Overview of the Optimized Architecture
3.3. Overview of the Proposed Input Data Representation
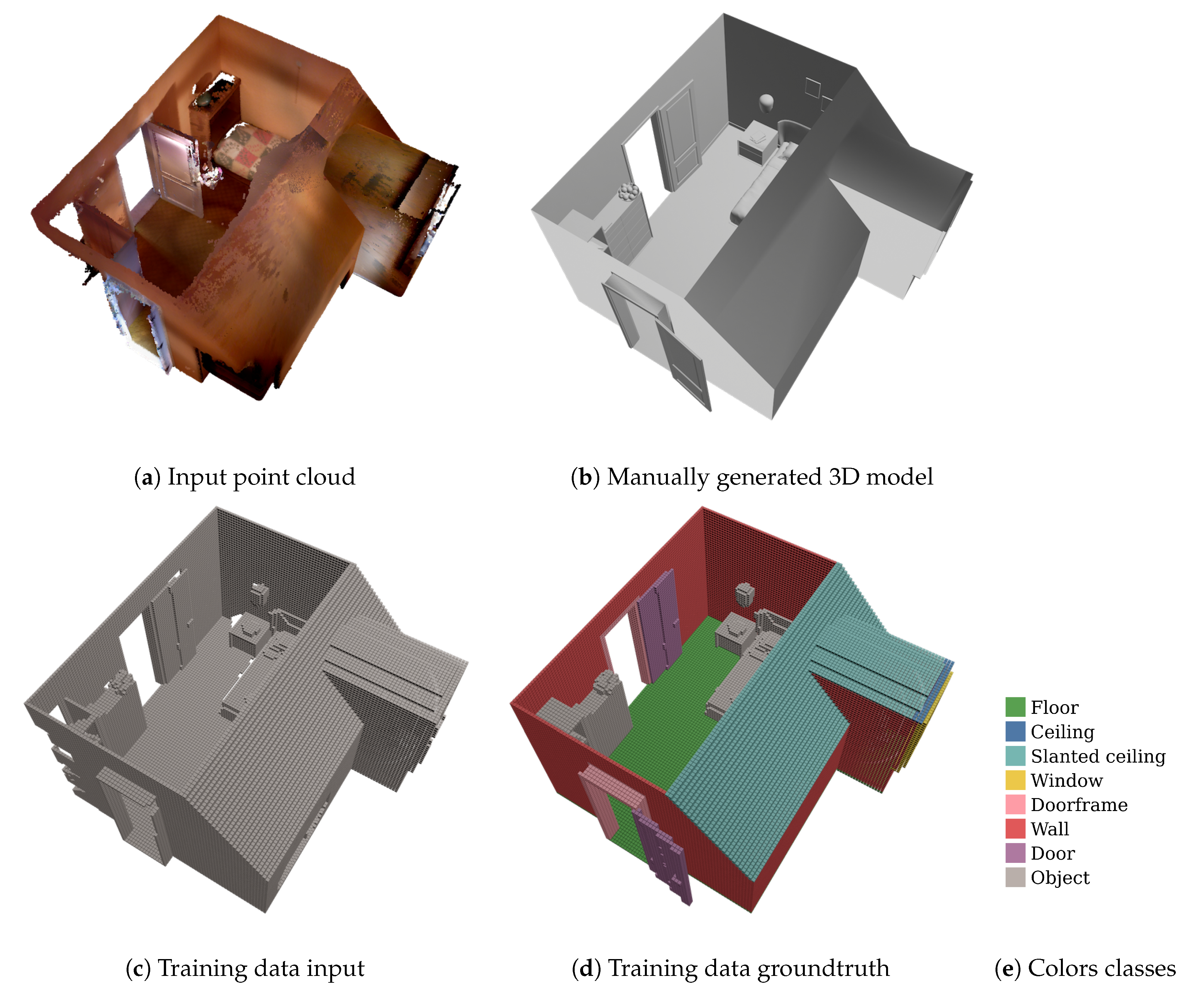
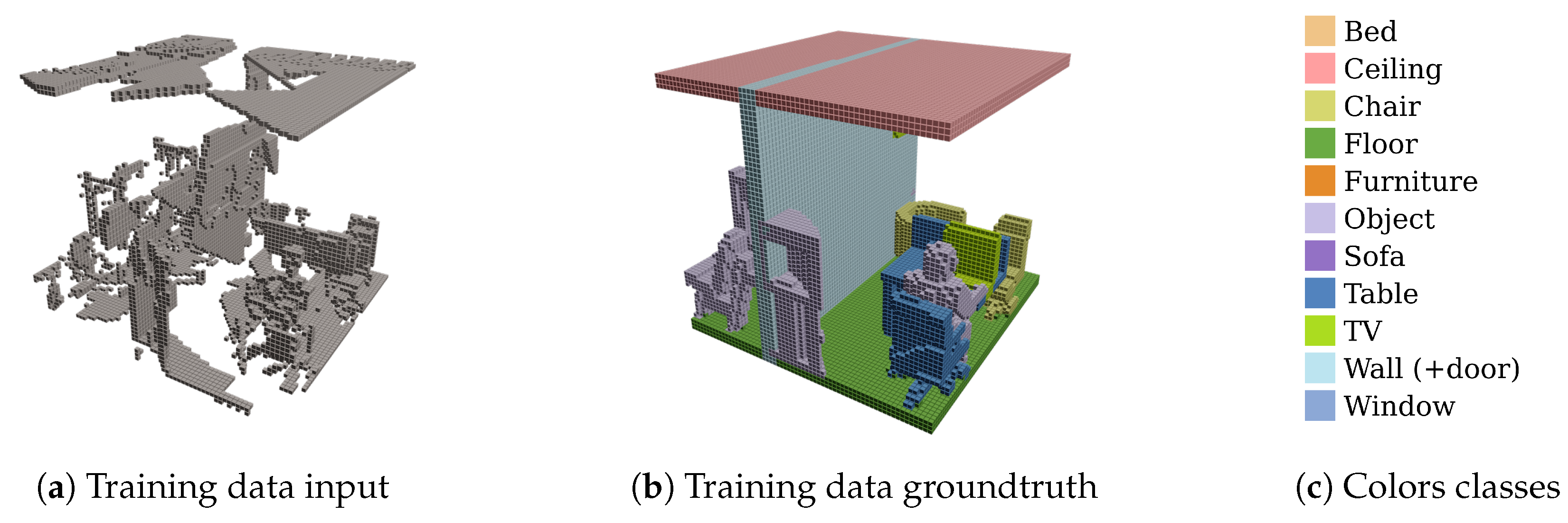
3.4. Training Data Generation
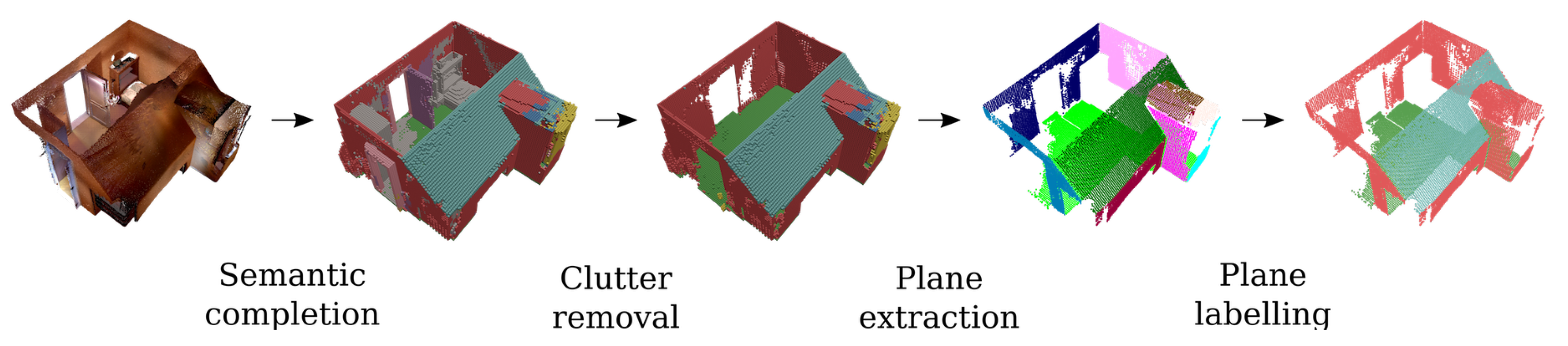
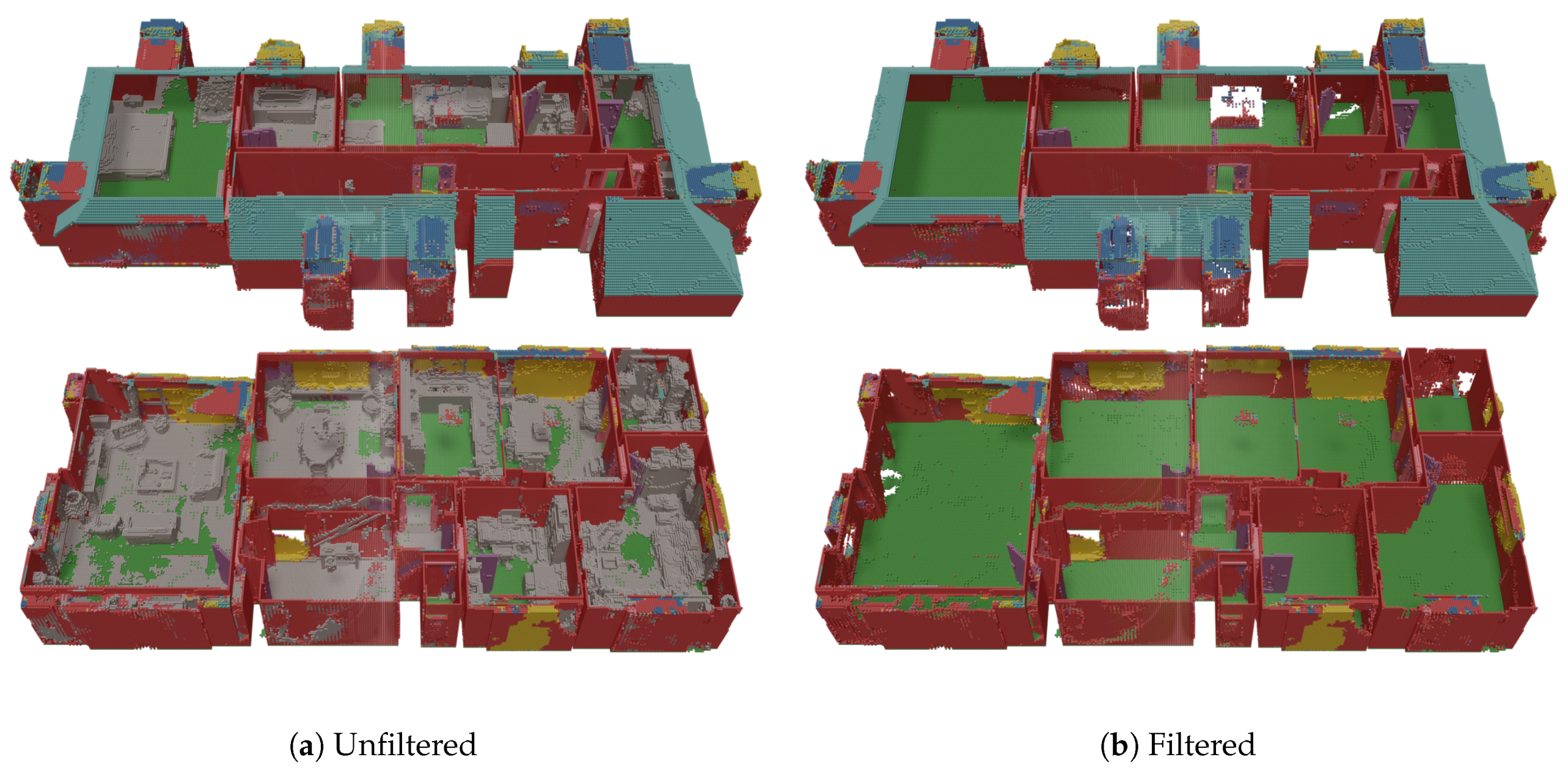
3.5. Application: Semantic Extraction of Permanent Structures
4. Experimental Results
4.1. Ablation Study
4.1.1. Does Training on Previous Voxel Group Predictions Help?
4.1.2. Can We Combine Multiple Object Classes?
4.1.3. How Much Data Do We Need?
4.1.4. To Crop or to Pad?
4.1.5. Can We Remove the View Dependency by Changing the Input Encoding?
4.1.6. Does Data Augmentation Help?
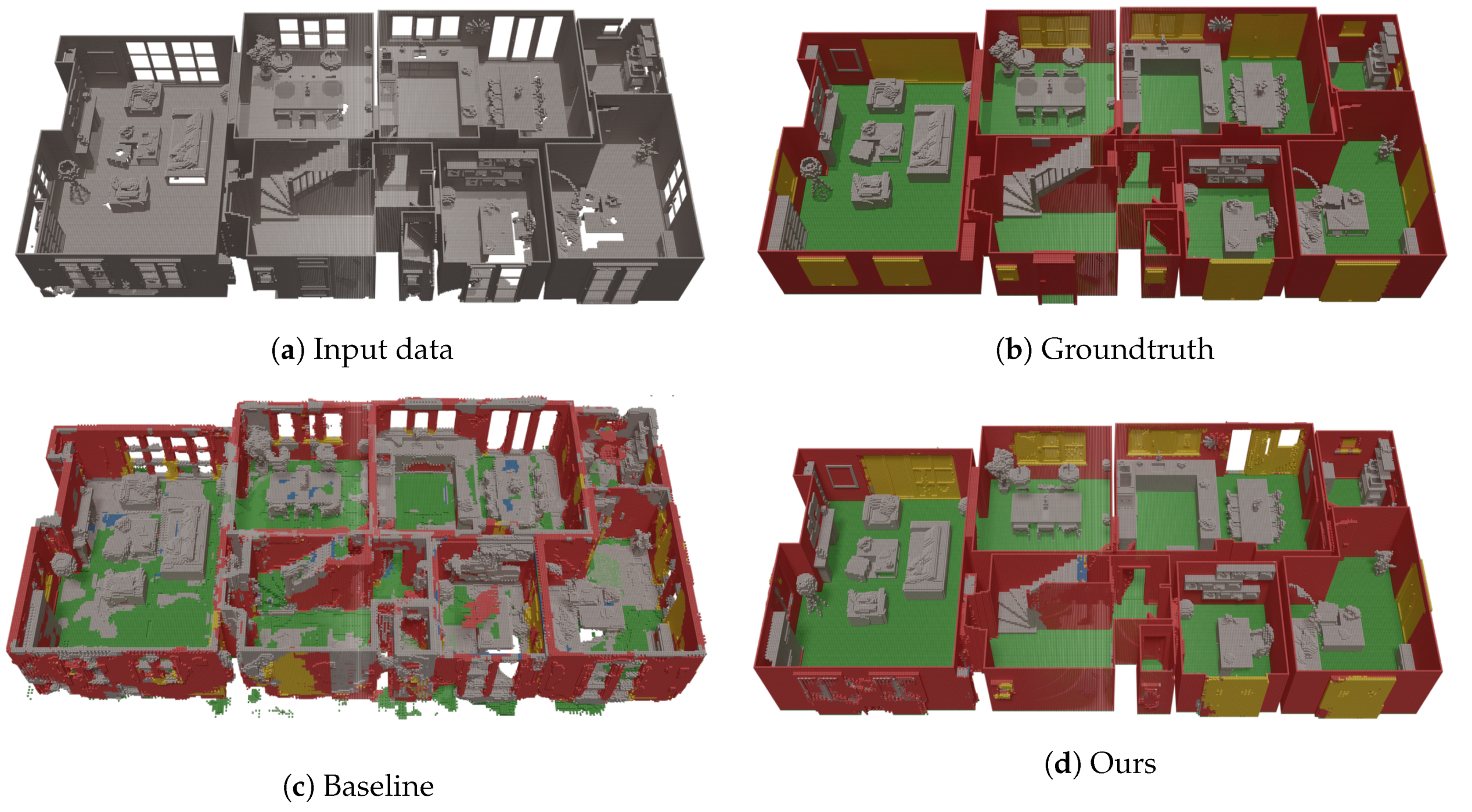
4.2. Qualitative Evaluation of the ScanComplete Network
4.3. Semantic Extraction of Permanent Structures
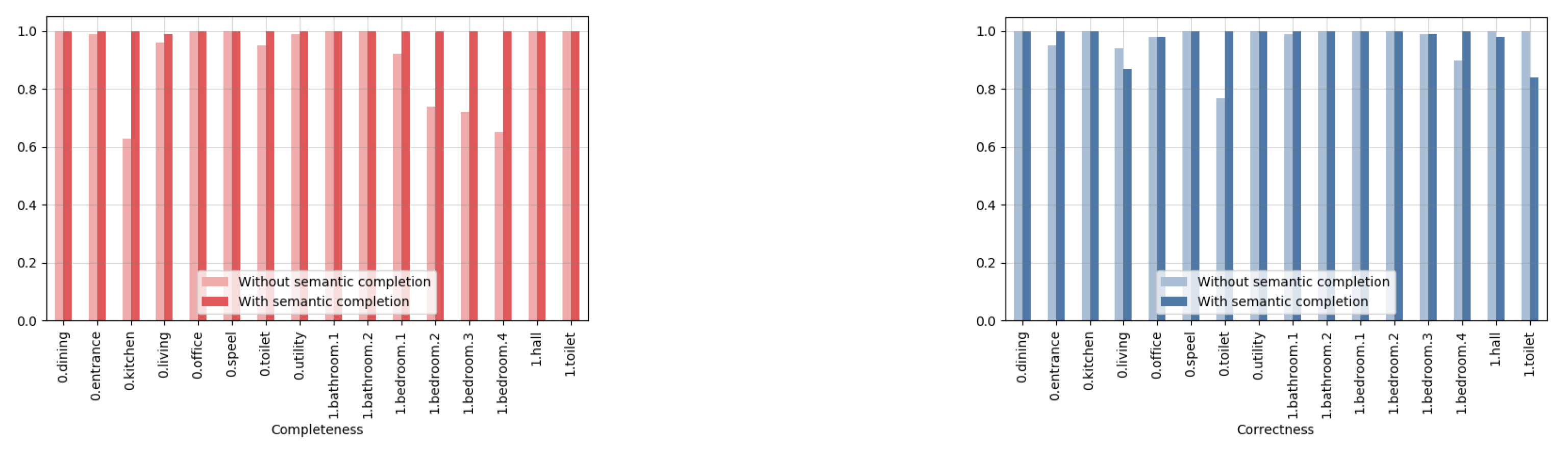
- Completeness (red):The completeness metric ranges from 0.01 to 1, with a higher value indicating that a larger proportion of the groundtruth voxelized model is present in the reconstructed model.
- Correctness (blue):The correctness metric ranges from 0, implying an incorrect reconstruction of the entire reconstructed model, to 1, indicating that the reconstructed model contains no redundant voxels. compared to the groundtruth voxelized model.
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mura, C.; Mattausch, O.; Pajarola, R. Piecewise-planar Reconstruction of Multi-room Interiors with Arbitrary Wall Arrangements. Comput. Graph. Forum 2016, 35, 179–188. [Google Scholar] [CrossRef]
- Ochmann, S.; Vock, R.; Klein, R. Automatic reconstruction of fully volumetric 3D building models from oriented point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 151, 251–262. [Google Scholar] [CrossRef]
- Xiong, X.; Adan, A.; Akinci, B.; Huber, D. Automatic creation of semantically rich 3D building models from laser scanner data. Autom. Constr. 2013, 31, 325–337. [Google Scholar] [CrossRef]
- Adan, A.; Huber, D. 3D reconstruction of interior wall surfaces under occlusion and clutter. In Proceedings of the 2011 International Conference on 3D Imaging, Modeling, Processing, Visualization and Transmission, Hangzhou, China, 16–19 May 2011; pp. 275–281. [Google Scholar]
- Macher, H.; Landes, T.; Grussenmeyer, P. From point clouds to building information models: 3D semi-automatic reconstruction of indoors of existing buildings. Appl. Sci. 2017, 7, 1030. [Google Scholar] [CrossRef]
- Tran, H.; Khoshelham, K. A Stochastic Approach to Automated Reconstruction of 3D Models of Interior Spaces from Point Clouds. In Proceedings of the ISPRS Geospatial Week, Enschede, The Netherlands, 10–14 June 2019; pp. 299–306. [Google Scholar]
- Hong, S.; Jung, J.; Kim, S.; Cho, H.; Lee, J.; Heo, J. Semi-automated approach to indoor mapping for 3D as-built building information modeling. Comput. Environ. Urban Syst. 2015, 51, 34–46. [Google Scholar] [CrossRef]
- Jung, J.; Stachniss, C.; Ju, S.; Heo, J. Automated 3D volumetric reconstruction of multiple-room building interiors for as-built BIM. Adv. Eng. Inform. 2018, 38, 811–825. [Google Scholar] [CrossRef]
- Bassier, M.; Vergauwen, M.; Poux, F. Point Cloud vs. Mesh Features for Building Interior Classification. Remote Sens. 2020, 12, 2224. [Google Scholar] [CrossRef]
- Ma, J.W.; Czerniawski, T.; Leite, F. Semantic segmentation of point clouds of building interiors with deep learning: Augmenting training datasets with synthetic BIM-based point clouds. Autom. Constr. 2020, 113. [Google Scholar] [CrossRef]
- Dai, A.; Ritchie, D.; Bokeloh, M.; Reed, S.; Sturm, J.; Nießner, M. Scancomplete: Large-scale scene completion and semantic segmentation for 3d scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4578–4587. [Google Scholar]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T. Semantic scene completion from a single depth image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1746–1754. [Google Scholar]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Huang, J.; You, S. Point cloud labeling using 3d convolutional neural network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep projective 3D semantic segmentation. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 95–107. [Google Scholar]
- Garcia-Garcia, A.; Gomez-Donoso, F.; Garcia-Rodriguez, J.; Orts-Escolano, S.; Cazorla, M.; Azorin-Lopez, J. Pointnet: A 3d convolutional neural network for real-time object class recognition. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1578–1584. [Google Scholar]
- Dai, A.; Nießner, M. 3dmv: Joint 3d-multi-view prediction for 3d semantic scene segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 452–468. [Google Scholar]
- Sorkine, O.; Cohen-Or, D. Least-squares meshes. In Proceedings of the Shape Modeling Applications, Genova, Italy, 7–9 June 2004; pp. 191–199. [Google Scholar]
- Nealen, A.; Igarashi, T.; Sorkine, O.; Alexa, M. Laplacian mesh optimization. In Proceedings of the 4th International Conference on Computer Graphics and Interactive Techniques in Australasia and Southeast Asia, Kuala Lumpur, Malaysia, 1 November 2006; pp. 381–389. [Google Scholar]
- Zhao, W.; Gao, S.; Lin, H. A robust hole-filling algorithm for triangular mesh. Vis. Comput. 2007, 23, 987–997. [Google Scholar] [CrossRef]
- Thrun, S.; Wegbreit, B. Shape from symmetry. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 2, pp. 1824–1831. [Google Scholar]
- Pauly, M.; Mitra, N.J.; Wallner, J.; Pottmann, H.; Guibas, L.J. Discovering structural regularity in 3D geometry. In Proceedings of the ACM transactions on graphics (TOG), Los Angeles, CA, USA, August 2008; Volume 27, p. 43. [Google Scholar]
- Sipiran, I.; Gregor, R.; Schreck, T. Approximate symmetry detection in partial 3d meshes. Comput. Graph. Forum 2014, 33, 131–140. [Google Scholar] [CrossRef]
- Speciale, P.; Oswald, M.R.; Cohen, A.; Pollefeys, M. A symmetry prior for convex variational 3d reconstruction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 313–328. [Google Scholar]
- Firman, M.; Mac Aodha, O.; Julier, S.; Brostow, G.J. Structured prediction of unobserved voxels from a single depth image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5431–5440. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Han, X.; Li, Z.; Huang, H.; Kalogerakis, E.; Yu, Y. High-resolution shape completion using deep neural networks for global structure and local geometry inference. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 85–93. [Google Scholar]
- Häne, C.; Tulsiani, S.; Malik, J. Hierarchical surface prediction for 3d object reconstruction. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 412–420. [Google Scholar]
- Dai, A.; Ruizhongtai Qi, C.; Nießner, M. Shape completion using 3d-encoder-predictor cnns and shape synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5868–5877. [Google Scholar]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. Pcn: Point completion network. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 728–737. [Google Scholar]
- Guedes, A.B.S.; de Campos, T.E.; Hilton, A. Semantic scene completion combining colour and depth: Preliminary experiments. arXiv 2018, arXiv:1802.04735. [Google Scholar]
- Garbade, M.; Chen, Y.T.; Sawatzky, J.; Gall, J. Two stream 3d semantic scene completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Liu, S.; Hu, Y.; Zeng, Y.; Tang, Q.; Jin, B.; Han, Y.; Li, X. See and think: Disentangling semantic scene completion. Adv. Neural Inf. Process. Syst. 2018, 31, 263–274. [Google Scholar]
- Hoppe, H.; DeRose, T.; Duchamp, T.; McDonald, J.; Stuetzle, W. Surface Reconstruction from Unorganized Points. In Proceedings of the ACM SIGGRAPH, Chicago, IL, USA, 27–31 July 1992. [Google Scholar]
- Reed, S.; van den Oord, A.; Kalchbrenner, N.; Colmenarejo, S.G.; Wang, Z.; Chen, Y.; Belov, D.; de Freitas, N. Parallel multiscale autoregressive density estimation. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2912–2921. [Google Scholar]
- Salimans, T.; Karpathy, A.; Chen, X.; Kingma, D.P. Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv 2017, arXiv:1701.05517. [Google Scholar]
- Google. AI & Machine Learning Products: Performance Guide. Available online: https://cloud.google.com/tpu/docs/performance-guide (accessed on 10 December 2019).
- Gojcic, Z.; Zhou, C.; Wegner, J.D.; Wieser, A. The perfect match: 3d point cloud matching with smoothed densities. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5545–5554. [Google Scholar]
- Blender Online Community. Blender—A 3D Modelling and Rendering Package; Blender Foundation, Stichting Blender Foundation: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Li, W.; Saeedi, S.; McCormac, J.; Clark, R.; Tzoumanikas, D.; Ye, Q.; Huang, Y.; Tang, R.; Leutenegger, S. InteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Girardeau-Montaut, D. CloudCompare. Available online: https://cloudcompare.org (accessed on 10 December 2019).
- Oesau, S.; Verdie, Y.; Jamin, C.; Alliez, P.; Lafarge, F.; Giraudot, S. Point Set Shape Detection. CGAL User and Reference Manual, 4.14 ed. 2019. Available online: https://doc.cgal.org/latest/Manual/packages.html (accessed on 2 December 2020).
- Nguyen, A.; Le, B. 3D point cloud segmentation: A survey. In Proceedings of the 2013 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; pp. 225–230. [Google Scholar]
- Coudron, I.; Puttemans, S.; Goedemé, T. Polygonal reconstruction of building interiors from cluttered pointclouds. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 459–472. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene Completion | Semantic Scene Completion | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Prec. | Recall | IoU | Bed | Ceil. | Chair | Floor | Furn. | Obj. | Sofa | Desk | Tv | Wall | Wind. | Avg. |
| Baseline network [11] | 85.69 | 65.99 | 59.56 | 22.95 | 58.46 | 14.91 | 71.99 | 16.95 | 27.63 | 28.17 | 22.32 | 6.29 | 63.77 | 6.41 | 30.90 |
| Previous groups | 85.10 | 66.04 | 59.20 | 13.47 | 55.82 | 24.53 | 71.92 | 34.13 | 36.17 | 43.17 | 43.61 | 15.78 | 69.23 | 6.08 | 37.63 |
| Limited dataset | 82.52 | 66.34 | 58.17 | 20.38 | 58.19 | 10.42 | 69.43 | 15.57 | 15.74 | 20.43 | 18.04 | 0.25 | 58.78 | 5.47 | 26.61 |
| Combined classes | 88.41 | 94.03 | 83.71 | - | 84.07 | - | 85.07 | - | 44.97 | - | - | - | 68.94 | 11.13 | 58.84 |
| Method | Scene Completion | Semantic Scene Completion | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prep. | Augm. | Enc. | Prec. | Recall | IoU | Floor | Ceil. | Sl. Ceil. | Wind. | Dr. Fr. | Wall | Door | Obj. | Avg. |
| crop | no | ftdf [ours] | 98.04 | 98.82 | 96.91 | 97.84 | 83.55 | 42.07 | 0.00 | 0.00 | 42.09 | 3.47 | 32.06 | 37.63 |
| pad | no | ftdf [ours] | 99.55 | 99.38 | 98.93 | 98.77 | 93.32 | 69.44 | 45.38 | 47.70 | 77.62 | 26.73 | 57.32 | 64.54 |
| pad | no | tsdf [11] | 98.51 | 98.33 | 96.89 | 96.68 | 71.25 | 41.90 | 41.85 | 54.11 | 11.68 | 13.43 | 31.25 | 45.27 |
| pad | yes | ftdf [ours] | 99.61 | 99.53 | 99.14 | 98.84 | 92.99 | 68.57 | 53.90 | 48.82 | 84.55 | 45.63 | 62.85 | 69.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coudron, I.; Puttemans, S.; Goedemé, T.; Vandewalle, P. Semantic Extraction of Permanent Structures for the Reconstruction of Building Interiors from Point Clouds. Sensors 2020, 20, 6916. https://doi.org/10.3390/s20236916
Coudron I, Puttemans S, Goedemé T, Vandewalle P. Semantic Extraction of Permanent Structures for the Reconstruction of Building Interiors from Point Clouds. Sensors. 2020; 20(23):6916. https://doi.org/10.3390/s20236916
Chicago/Turabian StyleCoudron, Inge, Steven Puttemans, Toon Goedemé, and Patrick Vandewalle. 2020. "Semantic Extraction of Permanent Structures for the Reconstruction of Building Interiors from Point Clouds" Sensors 20, no. 23: 6916. https://doi.org/10.3390/s20236916
APA StyleCoudron, I., Puttemans, S., Goedemé, T., & Vandewalle, P. (2020). Semantic Extraction of Permanent Structures for the Reconstruction of Building Interiors from Point Clouds. Sensors, 20(23), 6916. https://doi.org/10.3390/s20236916