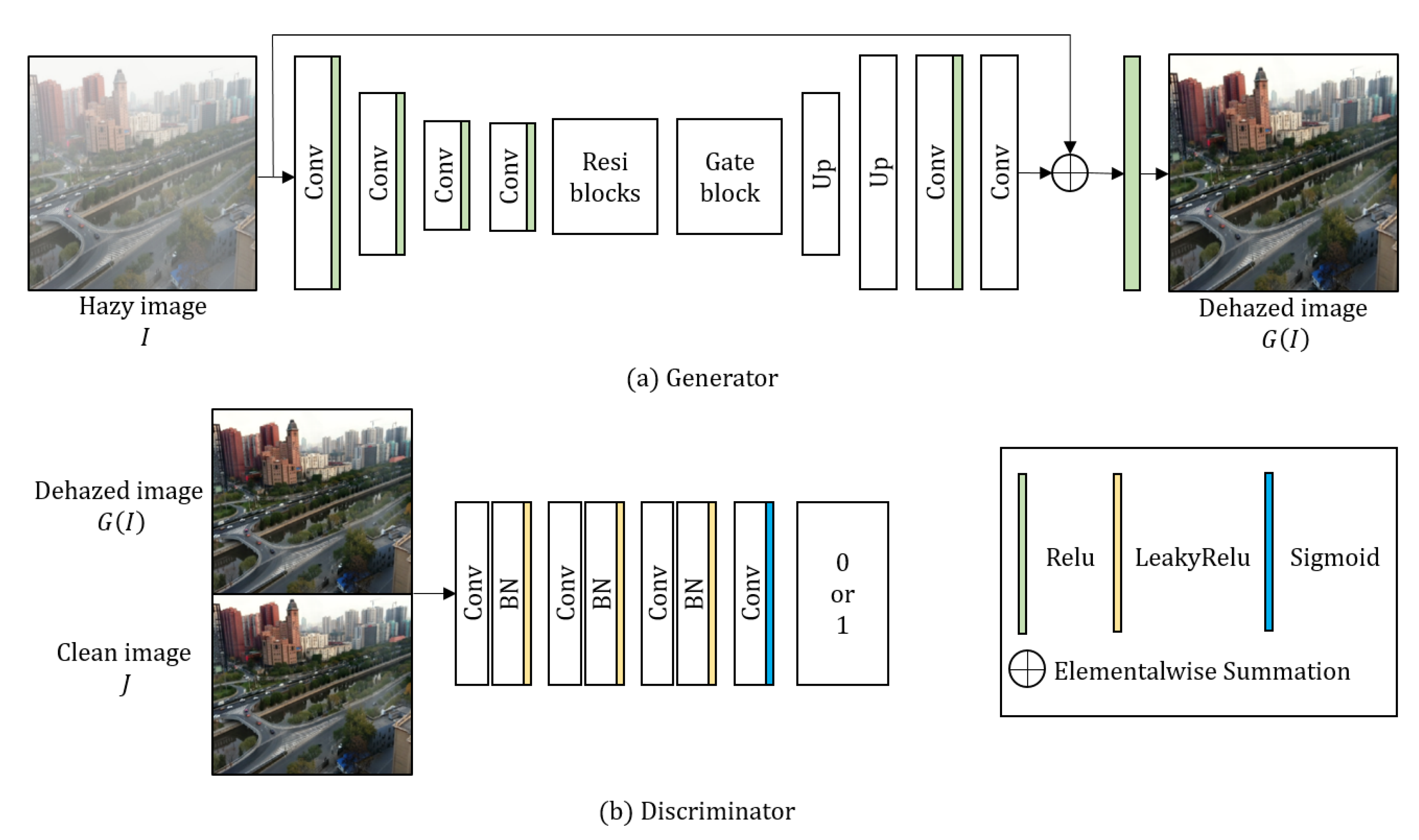
3.1. The Gated Dehazing Network
To remove the haze, the proposed generator takes a single haze image as an input as shown in
Figure 3a. The generator goes through the processes of encoder, residual blocks, gate block, decoder, and global residual operation. In the encoding process, the resolution of the input image is reduced twice through convolution layers, while the number of output channels accordingly increases. The encoding process of proposed method can be expressed as
where
, and
respectively represent the weight, bias, and Relu activation function [
26] of the
k-th convolutional layer, and * the convolution operator. The hazy image
I was used as an input in the encoding process to have 3 input channels. The following convolutional layers have 64 output channels with
kernel. To extract feature maps, the input image is reduced by 4 times using stride 2 twice. In addition, 128 output channels and
layers are used in the encoding block. Since the encoded features have low-scale and large channels, the proposed network has large receptive fields. In other words, the proposed network computes more wider context information [
27]. However, the bottleneck effect decreases the performance of the proposed network because too many parameters are required to restore the features with large receptive fields [
28]. If a network is constructed without residual blocks, the bottleneck problem is as shown in
Figure 2b.
To solve this problem, the proposed network also uses the hierarchical information from low-level to high-level features using five residual blocks as
where
, and
respectively represent the weight, feature map, bias, and Relu activation function for the last layer of the previous encoding block.
represents the first residual feature map through element-wise summation with the last feature map of the encoding block.
,
,
and
respectively represent the weight, residual feature map, bias, and Relu activation function of the
th block of the residual process. For the residual blocks of the proposed method, 25 layers were used.
Figure 2c shows that the bottleneck problem is solved by adding residual blocks. However, the enlarged red box does not converge due to the hierarchical information generated from the residual blocks. To solve this problem, we obtain the weights from low to high level through the gating operation inspired by the GFN [
18] for the feature map to contain a hierarchical information generated in the residual blocks. The gating operation to obtain the feature map through the element-wise multiplication of the acquired weights and the value generated in the residual blocks can be defined as
where
and
respectively represent the weight and bias of gate blocks. “
” represents the concatenation operation of residual feature maps with hierarchical information from low to high level, and “∘” the element-wise multiplication of
and hierarchical feature maps
.
The decoding layer reconstructs the restored image based on the generated and computed features [
29]. In the decoding process, the resolution is restored as
where
, and
respectively represent weight, bias, and Relu activation function in the decoding layer, and “
” the up-sampling operation with a scale of 2. The proposed decoding layer repeats the
convolution after up-sampling using bilinear interpolation twice to decode the image to the original resolution.
The global residual operation can effectively restore degraded images, and can improve the robustness of the network [
30,
31]. In this context, we can formulate the relationship between the global residual operation and the input hazy image
I as
where
represents the Relu activation function in the global residual operation. Through summation of decoded
and input hazy image
I, the generator’s dehazed image
is acquired. We designed the network structure to solve the bottleneck problem for clean results shown in
Figure 2d, where the proposed gated network can generate more hierarchical features. A list of parameters of the generator are given in
Table 1 and
Table 2.
Although it was successful to obtain enhanced results of synthetic data using only a generator, adversarial learning was applied to obtain more robust results in real-world images. For the adversarial learning, we also propose the discriminator inspired by [
32], which increases the number of filters while passing through layers and has a wider receptive field. The discriminator takes the dehazed image
or clean image
J as input. To classify the images, the proposed discriminator estimates the features using four convolutional layers as
where
, and
respectively represent the
n-th weight, bias, batch normalization, leaky Relu function [
33], and sigmoid function in the discriminator. As in Equation (
10), the discriminator takes
or
J as input, and the input channel is set to 3. As the number of channels passed through the layer increases, 192 output feature maps were extracted. In the last layer, the discriminator extracts a single output feature map to classify the image, and determines whether it is valid (1) or fake (0) applying to sigmoid function. Detailed parameters of the discriminator are given in
Table 3.
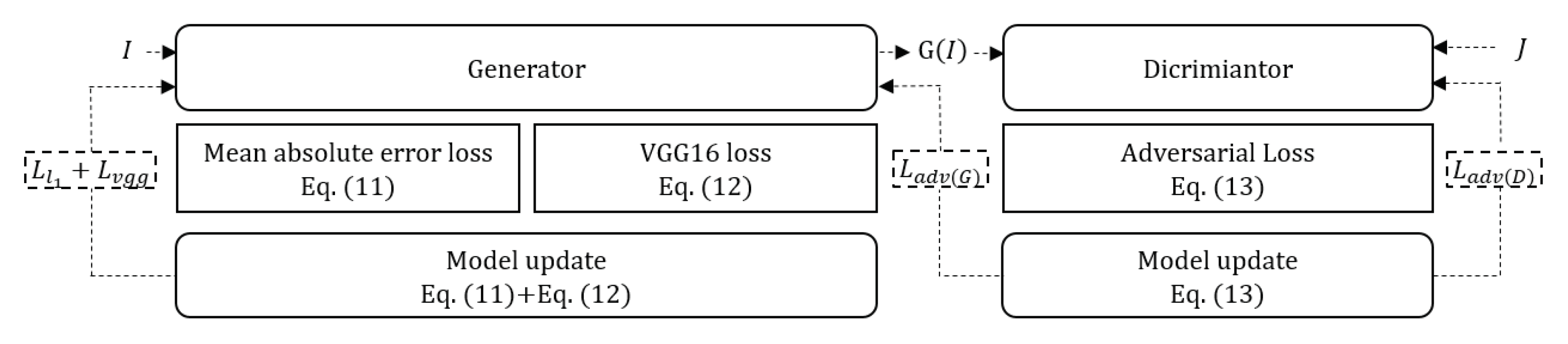
3.2. Overall Loss Function
The loss function of the proposed method consists of
,
,
, and
.
can be obtained by using the mean absolute error between the dehazed image
and the generated clean image
J, which is formulated as
where
represents the size of input image.
used a pre-trained VGG16 network that can extract perceptual information from images and enhance contrast [
21]. The equation for obtaining the VGG16 loss can be formulated as
where
represents the pre-trained VGG16 network, and
the number of layers containing important features.
is the product of the height, width, and channel of the VGG16 layer corresponding to
k.
For stable learning and higher quality outputs, least squares generative adversarial network (LSGAN) [
34], which is an improved version of the original GAN, was applied to our proposed model. The generator creates a dehazed image
, and the discriminator distinguishes whether the dehazed image is real or fake. The resulting adversarial loss is calculated as
where hyper-parameters
were used for the discriminator and generator losses, respectively. As shown in Equation (
13), the proposed adversarial loss goes through an optimization process that minimizes the Euclidean distance between the discriminator and generator.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}