1. Introduction
Numerous applications are built using location provided by Global Positioning System (GPS) receivers. While centimetre precision has been demonstrated for dual-frequency [
1] and differential GPS systems, a very large number of systems rely on single-frequency non-differential units, which report positions with typical precision of many metres [
2]. We use the term “noise” to refer to the errors in a sequence of reported positions. The sources of the noise in the positions include atmospheric and ionospheric phenomena [
3], multipath effects [
4,
5], canopy trees [
6], and a wide variety of physical phenomena that may be impractical to model. However, other types of errors are also inadvertently added to the signal, e.g., errors present in the modelling of satellite orbits [
7], finite precision of the digital components of receivers, variations in the built-in phased-locked loop [
8], or the signal processing techniques [
9], etc. The common structure and frequent formulations of GPS algorithms are discussed in Xu and Xu [
10], including some aspects of the mathematical formulation that carry non-trivial correlation in readings between epochs. In summary, however, it is sufficient for this work to realise that there are noise sources that can be adequately modelled by uncorrelated processes, e.g., white noise, and there are sources that inherently carry temporal correlations.
All GPS signals are encumbered with noise, whose sources are hard to distinguish [
11,
12]. The noise could be attributed to satellite clock and orbit errors, to the propagation of the GPS signal through media (ionosphere, troposphere, etc.), and to the receiver units. Many of these noise components are time-correlated and caused by stochastic processes external to the useful signal. It would be ambitious to model and distinguish between all these processes; alternatively, one can consider their cumulative effect on the time series [
13,
14]. Irrespective of the source, a robust signal-processing algorithm needs some model of noise processes. Such a model unavoidably contains assumptions on the nature of the noise, e.g., amplitude and correlation in the time domain, which must be experimentally validated. Often, the measurement errors are modelled by independent, identically distributed random Gaussian variables (Gaussian white noise). While this model is sufficient for many applications, it is generally accepted that a linear combination of coloured noise (whose power spectrum follows a
law with a characteristic exponent
) is a more suitable approximation [
15]. With the assumption of white noise, the time correlation in GPS datastreams leads to biased and inconsistent parameter estimates [
16], especially for sampling rates above 5 Hz. Moreover, it is unrealistic that measurements from different satellites would have the same accuracy; therefore, stochastic models assuming independent and constant variance result in unreliable statistics, and stochastic modelling is needed. Directly estimating statistical parameters of the GPS time series by explicitly taking into account the heteroscedastic space- and time-correlated error structure of the observations could result in improved accuracy at minimal computational cost.
Noise in long GPS time series has been analysed for geodetic purposes by [
17,
18], who found
in the relevant frequency band. Their results are, however, not conclusive, as many spectra would fit this range, e.g., white noise (
) or flicker noise (
). Many processes that these GPS observations are expected to capture, e.g., earthquakes or the wobble of the Earth around its axis, have similar spectra [
19]. Consequently, the physical process being observed by GPS and the inherent noise of a GPS signal are present simultaneously. The noise amplitude changes with time and, for older data, can be a considerable fraction of the signal [
20].
In this study, we analyse time series of GPS measurements with duration between a day and a week at 1 Hz sampling frequency. Observations were made in the Southern Hemisphere with stationary units. The recordings show significant autocorrelation incompatible with a Gaussian white noise model. The observed presence of correlations implies that there are some stochastic equations governing the dynamics of the signal. There are two major sources that plausibly introduce correlations: (a) the movement of GPS satellites and, thus, their constellation, and (b) the algorithms coded in the GPS emitters and receivers. Both sources are, to a high degree, deterministic; thus, in a perfect environment, they would produce a strongly correlated signal. However, there are many other phenomena, e.g., weather and surface reflectance, that introduce effects into the signal that can be most effectively modelled by noise, rather than searching for their respective governing equations. We develop mathematical models for the observed noise and suggest how these models can be used for improved positioning and uncertainty quantification in future devices.
2. Description of the Data Collection Process
Data were collected from civilian L1-band GPS units at multiple locations. At each location, data were collect from four units with a Telit Jupiter-F2 integrated GPS module, as well as a single standard USB-connected GPS receiver—GlobalSat BU-353S4. The first- and second-order statistics of the location data showed no significant difference between the two devices. For brevity, we present our findings using the data obtained only with the GlobalSat BU-353S4.
The location of satellites is a major factor of GPS accuracy degradation. Devices function well when the satellites are widely distributed [
21]; hence, the altitude errors in measurements are typically much larger than those in latitude or longitude. The GPS satellites operate at an inclination of around 55
; consequently, for devices at higher latitudes, the GPS satellite positions are biased strongly towards the equator.
To ensure that our analysis was not biased due to specifics of the GPS satellite constellation geometry, we carried out measurements at four locations with latitudes between 45
and 10
South (see
Table 1). Data were recorded at each site for approximately 48 h. The decimated latitude and longitude errors (deviations from time average) are shown in
Figure 1. Disregarding the initialisation period (typically ∼1 min), the data resemble a random walk.
While this cursory look seems suggestive, calculating the residuals defined as
(here,
denotes the long-time average, or the ‘true’ position) and creating a QQ-plot [
22] reveals the non-Gaussian nature of
(for technical details see
Appendix A).
In
Figure 2 the QQ-plot of the latitude data collected in Dunedin is depicted. In order to support the graphical findings, we have also calculated two more normality tests [
23], one based on d’Agostino and Pearson’s work [
24,
25], and another one suggested by Lilliefors [
26]. The latter is the most suitable for our use, as it does not assume the knowledge of mean and standard deviation of the normal distribution, but estimates these from the sample. The null hypothesis of both tests is that the data come from a normal distribution. Since both tests return
p-values much smaller than 0.01, we can thus conclude at a 99% confidence level that latitude data do not support the assumption of normal distribution. Similar conclusions can be drawn for longitude and altitude data at all locations.
3. Analysis of Observations
One may think of the collection of positions—emitted by the GPS chip—as a stochastic process, a sequence of random variables, labelled by time In our study, may represent the latitude, longitude, or altitude returned by a GPS unit. We denote random variables with capital letters, e.g., , and its particular realisation with lower case letter, e.g., . Any estimator of a statistic, e.g., the expectation value , is denoted by the same letter but decorated with a symbol, e.g., .
Stochastic Processes
The simplest non-trivial stochastic process can be formulated as the sum of the true position,
, and an additive noise term:
The measurement error,
, is often considered to be a Gaussian white noise with zero mean and variance
. The problems of fitting Gaussian noise models to GPS measurements have been recognised by [
27,
28], and two models were proposed to describe the measurements more accurately: a moving average process (MA) and an autoregressive model (AR).
We check whether adjacent recordings can be considered independent random variables using the empirical autocorrelation function [
29,
30,
31,
32,
33], defined as
where
and
are the expectation value and variance of the random process at step
r, respectively. The process
is stationary if
and
are both time-independent; in such a case, the autocorrelation function depends only on the time difference
(
lag) between its arguments and not explicitly on the arguments themselves. Henceforth, we assume stationarity; thus,
while
and
both become constants, which are calculated by time-averaging. Furthermore, we consider the empirical partial autocorrelation function calculated using the Yule–Walker method [
32,
34] and defined as
which provides the amount of correlation between a variable and a lag of itself that is not explained by correlations at all lower-order lags.
As an example,
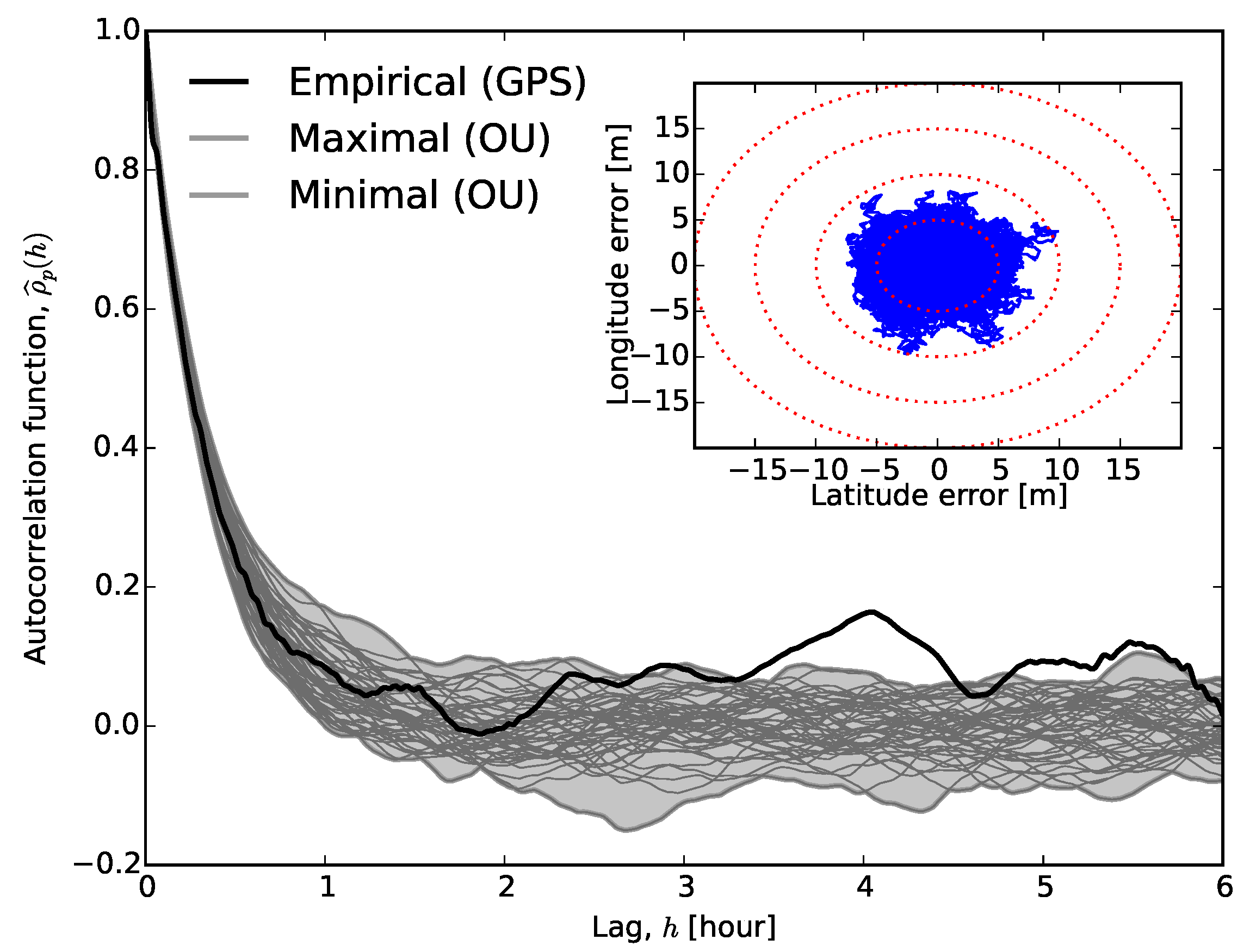
Figure 3 shows the autocorrelation of a typical time series. The autocorrelation function decays slowly. Fitting an exponential decay to the first half-hour dataset provides a characteristic time estimate of
minutes, i.e., it takes approximately an hour (
) to reach statistical independence. Using the reported position for periods much shorter than
would lead to a biased estimate. We wish to draw the reader’s attention to the fact that long-term correlations usually imply a power-law decay of correlation, while our fit assumes an exponential correlation. While exponential decay of correlation is relatively fast, compared to power-law decay, it seems to have an observable effect on location time series, and its inclusion in modelling may provide better positioning algorithms in the future.
The theoretical autocorrelation function of Gaussian white noise is the Dirac-delta,
. Assuming this model, one may test for statistical independence of
and
by checking whether the autocorrelation function is different from zero, i.e., whether it falls within the confidence interval around
[
35,
36].
where
is the cumulative distribution function of the standard normal probability distribution,
is the required level of significance,
denotes the sample standard deviation, and
n is the number of measurements. This confidence interval at the
level is plotted with dashed lines in
Figure 3. The majority of
falls outside this interval; therefore, our observations and the assumption of Gaussian white noise are inconsistent with each other. One may take into account that the empirical autocorrelation function estimated from a finite-length time series also carries error [
37] and could derive a modified confidence interval. At significance level
, this is given by the Box–Jenkins standard error [
38,
39,
40]:
where
.
Figure 3 also depicts the Box–Jenkins standard error with dash-dotted lines, and it is apparent that the two confidence intervals differ from each other substantially, thus confirming the statistical dependence in the measured location readings. It is worth noting here that the exponential fit and the first crossing of
with the Box–Jenkins confidence interval agree with each other. The inset in
Figure 3 shows
for
s with its standard error at a 0.95 significance level. This graph may suggest the application of a high-order autoregressive noise model (see next section), since
vanishes only for lags larger than approximately 30 s.
However, we find that other datasets exhibit much shorter ‘memory’, so lower-order processes might also be sufficient.
Datasets from other locations exhibited different behaviour (see
Figure 4). The autocorrelation still takes less than an hour to reach the Box–Jenkins standard error, but the initial drop is much sharper. This drop may explain the different behaviour of the partial autocorrelation function, which vanishes for lags larger than unity.
Figure 3 and
Figure 4 illustrate the extreme cases.
The autocorrelation of the Thursday Island dataset, see
Figure 5, displays persistent oscillations not observed at other locations. This could be because of a temporary loss of power experienced on Thursday Island, which forced the data to be split into two sets, each approximately 24 h long, or an artefact of the local geography contributing to long-term multipath effects.
4. Modelling the Noise
In this section, we develop some statistical models for the observed noise. A model is a relationship between random variables,
, in the following form:
where
and
are sets of integers,
h and
g are fixed functions, and
. Here, the quartet (
h,
g,
,
) constitutes the model to be inferred. To simplify the task, we presume that
h and
g are linear in all their variables (so-called linear models). The stochastic model is then
where
and
are all constants with
(convenience), and causality restricts summations to the current or past values of
or
[
41]. This model requires an infinite number of coefficients, which cannot be estimated using a finite number of observations. Therefore, we focus on finite-parameter linear models and estimate the unknowns via the maximum likelihood method, in which the likelihood function below is constructed for Gaussian processes.
The likelihood function,
L, is the joint probability density of obtaining the actually observed data
,
, …,
, according to the model. It is a function of the unknown parameters
,
, …,
,
,
, and
. Under general assumptions, the log-likelihood function of a finite parameter linear model is:
where the
-th component of the covariance matrix
is calculated from
Although the likelihood function,
L, is derived under Gaussian processes, if the time series is causal and invertible, then maximising this likelihood leads to asymptotically consistent estimators [
42,
43]. This approximation is convenient, as the asymptotic likelihood function has a unique stationary point, the global maximum [
44].
Below, we introduce and analyse finite-parameter linear noise models and compare their performance, including the Gaussian white noise model for a benchmark.
4.1. Gaussian White Noise Model
The simplest noise model treats measurements as statistically independent, normally distributed random variables:
for fixed
. Thus,
, with yet unknown parameter values
and
. Using the maximum likelihood approach, these parameters are estimated from the observations as
4.2. Autoregressive Models
An autoregressive process of order
p, abbreviated as AR(
p), is a stochastic process where
h is a linear combination of
p terms:
where
are constants. The process has
parameters:
and
. The estimators
and
are found by linear algebra [
37]. Alternatively, the estimators can be found by least squares regression [
45]. The parameter estimation procedure costs, at most,
operations, where
n is the number of observations.
As the Laplace transformation of
suggests the autocorrelation function of an AR(
p) process is formally the sum of
p exponentially decaying terms, thus,
exhibits exponential decay or oscillatory behaviour [
32], while
vanishes for lags
.
4.3. Moving Average Model
Rather than using the past values of the random variable, a moving average model of order
q, abbreviated as MA(
q), regresses on past errors,
for
, and is defined as
The process has parameters. One may cast any stationary AR(p) process as an MA(∞) model and an invertible MA(q) model as an AR(∞) process. Nevertheless, MA(q) models are useful, as one cannot fit an AR(∞) model on a finite number of observations.
Unlike autoregressive processes, for MA processes, any estimator based on a finite amount of observations inherently carries some loss of information. Resultantly, parameter estimation is harder than for AR processes of comparable order.
The qualitative behaviours of the autocorrelation and partial autocorrelation functions,
and
, are similar to those in autoregressive processes, but with roles interchanged. The autocorrelation function vanishes for
, while the partial autocorrelation function is dominated by damped exponential and/or periodic functions. In the examples shown in
Figure 3 and
Figure 4, the autocorrelation function vanishes too slowly to be described by a low-order MA process.
4.4. Autoregressive Moving Average Model
The combination of AR(
p) and MA(
q) processes can be formulated as
The combination inherits most of its properties from these simpler processes. Neither the autocorrelation nor the partial autocorrelation function vanishes after a threshold lag. The autocorrelation function exhibits damped exponential and/or oscillatory behaviour for lags
, while
is dominated by exponential and periodic terms for lag values
. The variance of the sample autocorrelation function can exceed the Box–Jenkins error (see
Figure 3). As a result, it is often difficult to determine the model orders; model verification and iterative parameter estimation are needed.
For normally and independently distributed
with zero mean and constant variance, and for stationary
, Melard [
46] provided an efficient algorithm for calculating the exact likelihood function of an ARMA(
p,
q) model. This algorithm requires
operations for
n observations, which—in practice—can be reduced by considering the observations in a finite window.
4.5. Ornstein–Uhlenbeck Model
In this section, we consider a stochastic differential equation (SDE) rather than a discrete stochastic process. Stochastic partial differential equations are a natural choice to model dynamical systems subject to random fluctuation. For an introduction to SDEs, we point to Evans’ [
47] and Øksendal’s [
48] excellent monographs.
The scatter-plots in
Figure 1 resemble a random walk on a phenomenological level. However, in a Brownian motion, the variance of the position increases with time, which we do not observe here. On the contrary, we observe (and expect) that the GPS reading will return to the true location even if it deviates from it momentarily, i.e., it is mean-reverting. Furthermore,
Figure 3 shows that the correlation function decreases exponentially. These properties suggest an Ornstein–Uhlenbeck (OU) process [
49], defined by the SDE
where
,
, and
are real parameters, with
. For historical and physical reasons, the parameters
and
are called the drift and diffusion coefficients, respectively. The fluctuation part,
, is a Wiener process. The same process can also be represented as
The first term corresponds to the long-term but diminishing influence of the initial observation. The second reaches the steady value exponentially fast, while the third describes a scaled and time-transformed random fluctuation. The expectation value at time t is .
One may simplify (
6) by eliminating
with the
transformation, but we keep
explicit, as it is the ‘true’ position of the GPS device. The parameter
sets the scale of the autocorrelation function
, while
determines the noise between measurements. The OU process is the continuous-time generalisation of an AR(1) process. It has several desirable properties: (a) It is mean-reverting for
, (b) it has finite variance for all
contrary to Brownian motion, (c) its analytic covariance
permits a long autocorrelation time, (d) the autocorrelation function is insensitive to the sampling rate, and (e) it approaches Gaussian white noise as
. More precisely, the OU process is the only non-trivial, mean-reverting, Gauss–Markov process, i.e., whose transitions are memory-less, and it thus allows predictions of the future state based on the current state [
50]. This does not prohibit more sophisticated models for GPS time series, but these models will lack at least one of the properties listed above.
To model our observations as an Ornstein–Uhlenbeck process, we must estimate
,
, and
using maximum likelihood estimation [
51]. Tang and Chen [
52] provided a detailed derivation of estimators for these parameters, and Dacunha-Castelle and Florens-Zmirou [
53] showed that for time-equidistant observations, the maximum likelihood estimators are consistent and asymptotically normal, irrespective of the sampling time-step,
.
The estimators for
,
, and
require
operations each. Therefore, the overall parameter estimation takes
operations. However, Tang also gives explicit estimates for the asymptotic form of these estimators, e.g.,
Thus, one needs only a moderate number of observations, n, or short sampling time to estimate the parameter, especially compared with the estimator of the mean for an uncorrelated process, which would have (much slower) convergence to the true mean.
Parameter estimation for SDEs is a rapidly developing field, especially the sub-field of online estimators that update the parameter estimates as newer observations become available. Such estimators are usually associated with constant computational cost, as their performance is independent of n. A method of online estimators for a sampled, continuous-time Ornstein–Uhlenbeck is the subject of future publication.
After estimating
,
, and
, we simulated an ensemble of Ornstein–Uhlenbeck processes using the Euler–Maruyama method [
54]. We calculated and plotted the autocorrelation function for each run (see
Figure 6) as well as the range covered by these functions. Clearly, the OU noise model represents the autocorrelation in the data up to at least two hours. However, it is unable to capture the undulation of
. Therefore, an Ornstein–Uhlenbeck process should be complemented with some other process for longer-term predictability. We believe that a more complicated noise model is unwarranted unless the sampling period exceeds an hour.
5. Quantitative Analysis of Noise Models
In this section, we present and discuss the quantitative performance of the previously described noise models. For each model, the parameters were chosen to best fit the location data. The process of selecting which of these models best describes the data, called model selection, is a large and complex field in statistics; thus, we leave detailed explanation to the technical literature, e.g., [
55] and references therein.
There are three properties of model selection criteria: consistency, efficiency, and parsimony. Consistency means that the criterion selects the true model with probability approaching unity with increasing sample size provided the true model is among those considered. However, nothing guarantees that the true model is simple and tractable; thus, it is also necessary to measure how much error one might make by accepting a model knowing that it is not the true model. Efficiency is a measure of this property; as the sample size becomes large, the error in predictions using the selected model becomes indistinguishable from the error obtained using the best model among the candidates. Parsimony dictates that if all measures are equal for two competing statistical models, the preferred one should be the simpler model.
The most common model selection criteria use the likelihood function,
L, and introduce some penalty proportional to the model complexity. Akaike’s Information Criterion (AIC) is defined as
, where
k is the number of fit parameters in the model [
56,
57]. The best model has the smallest AIC value—it encodes the most information using the least number of fitted parameters. The AIC has a definite minimum value with respect to
k, and the appropriate order of the model is determined by the value of
k at this minimum. The AIC is biased for small samples, and a bias-corrected version (AICc) is gaining popularity [
43]. Here, we analyse time series with
and
, so we can ignore this correction. Other criteria have been developed, e.g., Bayesian Information Criterion (BIC), which more severely penalises the introduction of extra model parameters by replacing the
term with
.
Regarding the model selection criteria, AIC and AICc are both inconsistent, while BIC is only asymptotically consistent. Meanwhile, AIC is efficient, while BIC is not. Therefore there is no clear choice between AIC and BIC. The latter is asymptotically consistent as the sample size approaches infinity, while the former selects models that have acceptable predictive power [
58].
We use AIC, as it is almost universally accepted. While it does not validate a statistical model, it determines relative probabilities between alternative models. We compare AIC values for a selection of models.
Table 2 shows AIC scores for model fits of latitude, longitude, and altitude at four geographic locations. For each location, we individually fitted different noise models using the same observation datasets. For the AR(
p), MA(
q), and the ARMA(
p,
q), we increased the number of parameters involved. Occasionally the statistics routine was unable to converge for the MA(
q) processes. In these cases, the corresponding entry in
Table 2 is left empty.
Table 2 clearly shows that the Gaussian white noise model, irrespective of the geographic location or the coordinate, is the worst-performing noise model. All of its AIC values are positive, indicating a very low likelihood that the observations are described by the model. The MA models also seem a poor fit to the data, although one may increase the order of the model,
q, to achieve lower AIC scores. Our standard numerical routine, based on the Yule–Walker method [
37], could not converge. In contrast, an AR model with increasing order fit best among the noise models examined. Although both the ARMA(
p,
q) and Ornstein–Uhlenbeck models could achieve comparable AIC values (with the exception of the North Stradbroke Island dataset), the quantitative comparison of AIC values always favoured the high-order AR model. We note here that slightly lower AIC values could be achieved for autoregressive models by increasing their order, but the gain is becoming negligible around
(see
Figure 7).
Figure 7 also captures two typical phenomena: For low values of
p, the AR(
p) models do improve significantly with increasing values of
p, but there is a ‘kink’ in the AIC curve around approximately
, where some improvement can be still achieved by increasing
p, but these may not be worthwhile considering the increasing computational workload. In many GPS applications, the sampling period is often shorter than a few minutes or an hour, so the aim of developing a noise model is to focus on the short-term behaviour of the time series. For this reason, the choice of
seems a good compromise between modelling performance and computational load (cf.
Table 2).
In summary, the Gaussian white noise model is the worst fit to the observation. The next worst model, according to the AIC, is a low-order MA process, followed by the Ornstein–Uhlenbeck model. A higher-order AR scores better, with the higher-order AR processes scoring best. The AR process has the further advantage of robust parameter estimation.
6. Discussion
The use of Gaussian white noise models is very common in sensor fusion algorithms that incorporate GPS data (Hamilton 1994). We have shown here that the assumption of uncorrelated noise does not capture important features of real-world GPS data. Fitting a Gaussian white noise model results in an artificially large variance and does not account for the observed autocorrelations. Analysis of location data shows that the error between the position measurement and the ‘true’ location shows strong autocorrelation up to approximately an hour. We proposed stochastic noise models that take into account such autocorrelation. Estimating the model parameters for the Ornstein–Uhlenbeck and AR models based on likelihood maximisation is straightforward where either the analytic solution is known or the numerical algorithm is well known and can be performed efficiently. Conversely, estimating the parameters for the MA or ARMA models is more involved and computationally expensive. If the stochastic process is known to be non-stationary, then the MA model is non-invertible, and further measures are required to estimate the model parameters. Here, we mention an alternative approach for supporting the suitability of novel noise models. One can calculate the second moment of the residuals, , using single-path or multipath ensemble averaging for the observed time series and the one generated by the model. However, this approach is left for future analysis.
Autoregressive processes of moderate order provide a sufficient noise model for the signal returned by the commercial GPS device, and the extra computational cost compared to that of a naive Gaussian white noise model is negligible. Increasing the order of the autoregressive process results in lower AIC values, indicating that, from the purely statistical perspective, the likelihood maximisation outweighs the increase in complexity. However, for the less accurate GPS units, the higher-order AR processes are only slightly more likely than the first-order AR(1) process. For an AR(1) process, we would advise a discretised Ornstein–Uhlenbeck process, which brings several advantages. First, the sampling period of the device is explicit in its formulation; thus, variable sampling periods can easily be fit into this description. Second, the other parameters of an Ornstein–Uhlenbeck process give clear insight into the noise characteristics: describes how the rate measurements revert towards the mean , while indicates the amount of noise present between each measurement.
Wendel and Trommer [
59] analysed the effect of time-correlated noise on the applicability of classical Kalman Filtering, and proposed new filter equations. The noise models we proposed here can thus be incorporated into a Kalman Filter or Bayesian inference algorithms and provide both an estimate for the location along with quantified uncertainty. In addition, recent work [
60] has shown that there are practical algorithms for sensor fusion in multi-dimensional systems that allow arbitrary noise distributions and approach the computational efficiency of Kalman Filtering.

 and
and 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}