A Multitiered Solution for Anomaly Detection in Edge Computing for Smart Meters



Abstract
1. Introduction
2. Related Works
2.1. Model Reduction
2.2. Imbalanced Dataset
2.3. Data Samples
2.4. Comparison of Anomaly Detection in Smart Grid
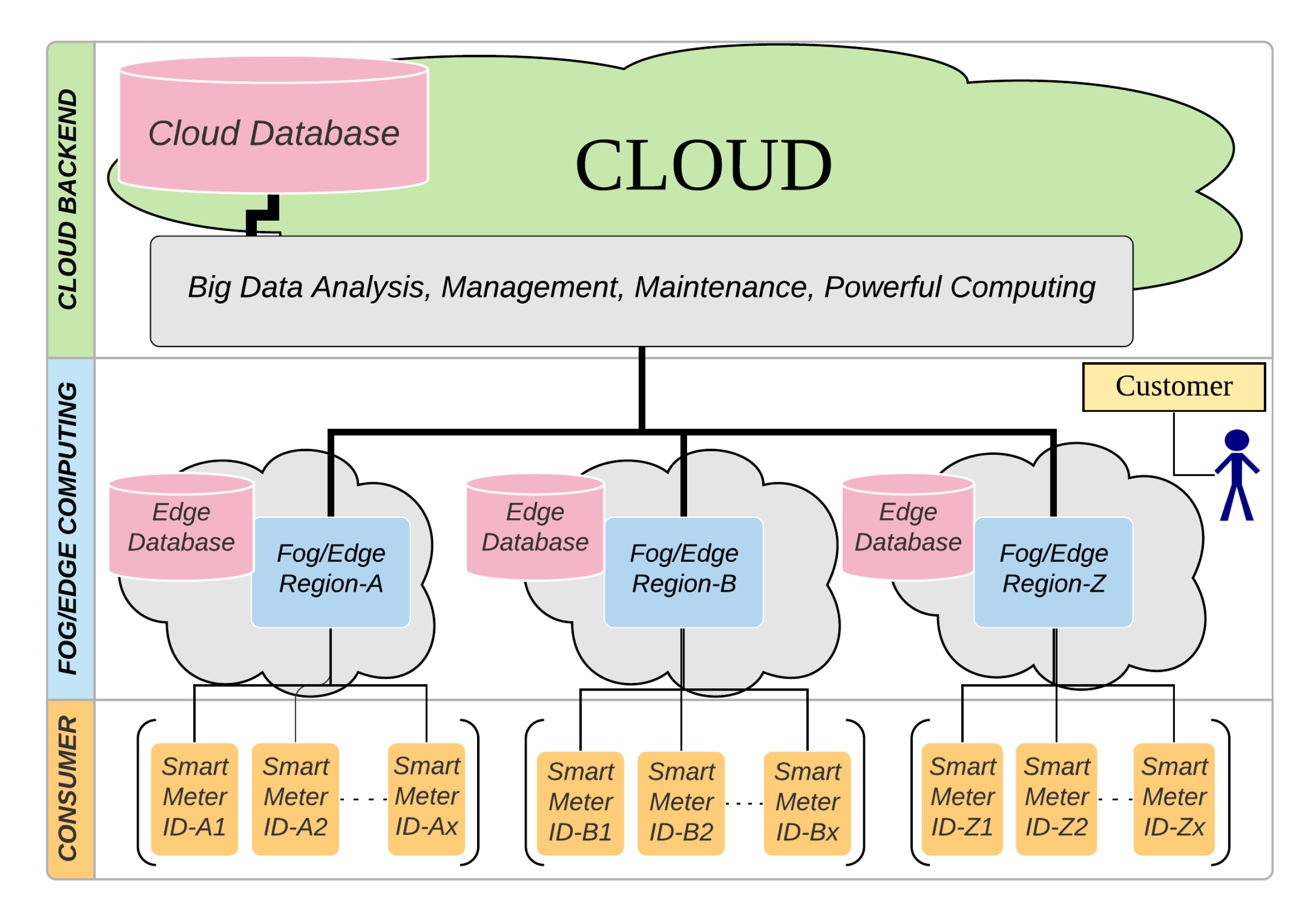
3. Anomaly Detection System
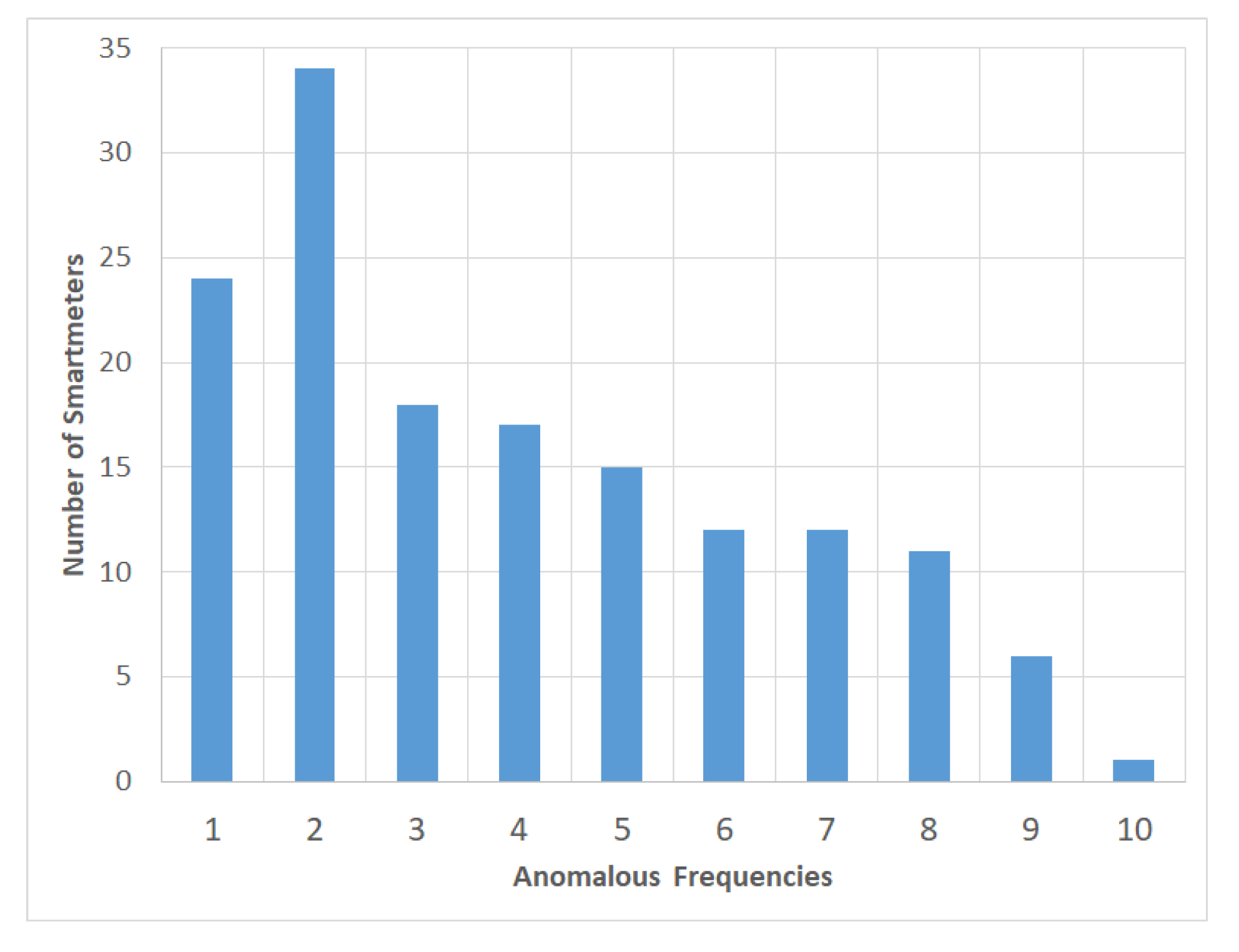
3.1. Dataset
3.1.1. Without Clustering
3.1.2. Kmeans Clustering
| Algorithm 1 Best_K_Cluster: Finding the best k of Kmeans’s clusters. |
 |
| Algorithm 2 Kmeans: Choosing members, data, and labels of Kmeans Clustering. |
 |
3.1.3. Kmeans*HDBSCAN Clustering
| Algorithm 3 Kmeans ∩ HDBSCAN. |
 |
3.2. Platform
| Algorithm 4 Latency (ms) measurement in edge and cloud. |
|
Input: ; ; ; ___; Output: : = Latency per sample (ms); Variable: T_: Starting time; T_: New time; _: Total Elapsed Time; // Close other programs 1 T_ ← ; // DNN/SVR/KNN model 2 Do ; 3 T_ ← ; 4 _ ← T_ – T_; 5 ← (1000*_/___); 6 ; |
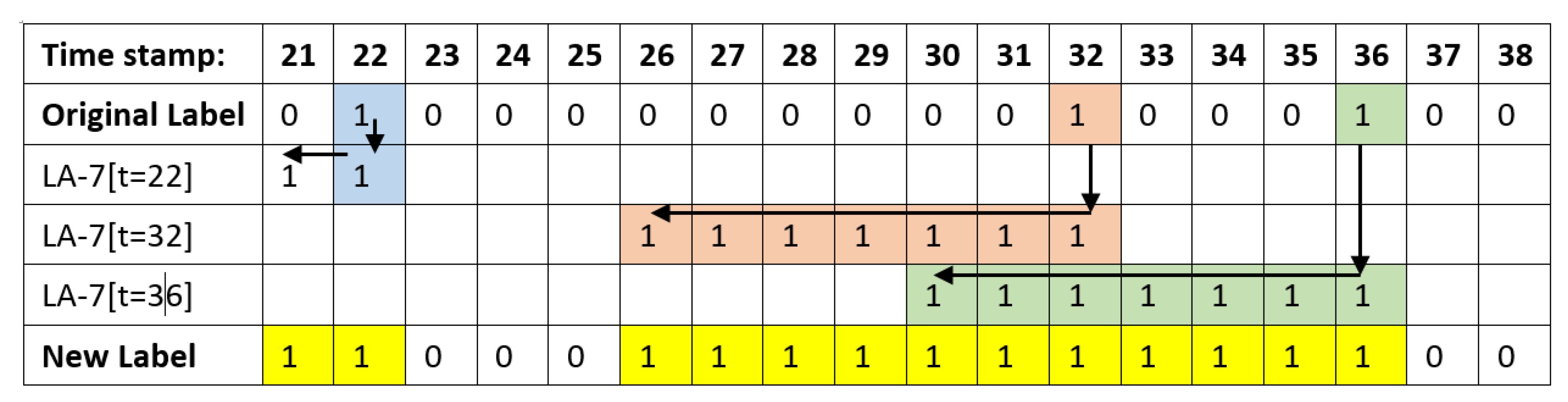
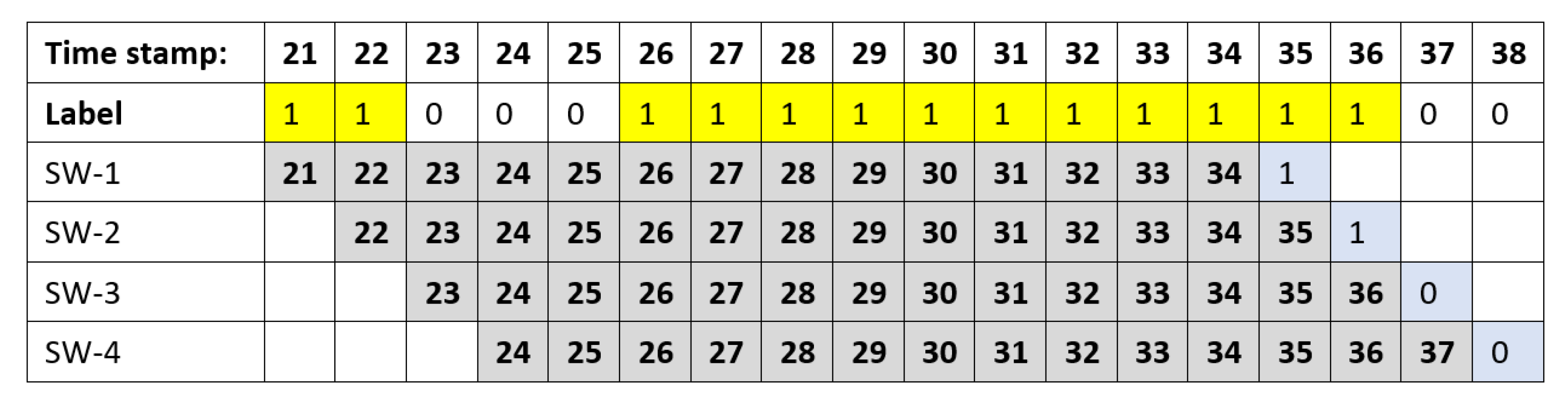
3.3. Methods
| Algorithm 5 To_Serialization: Generating Labels and Sliding Windows. |
 |
| Algorithm 6 Finding the best parameter for DNN. |
 |
4. Evaluation
4.1. Experimental Environment
4.2. Results
4.2.1. Without Clustering Experiment
4.2.2. Kmeans Experiment
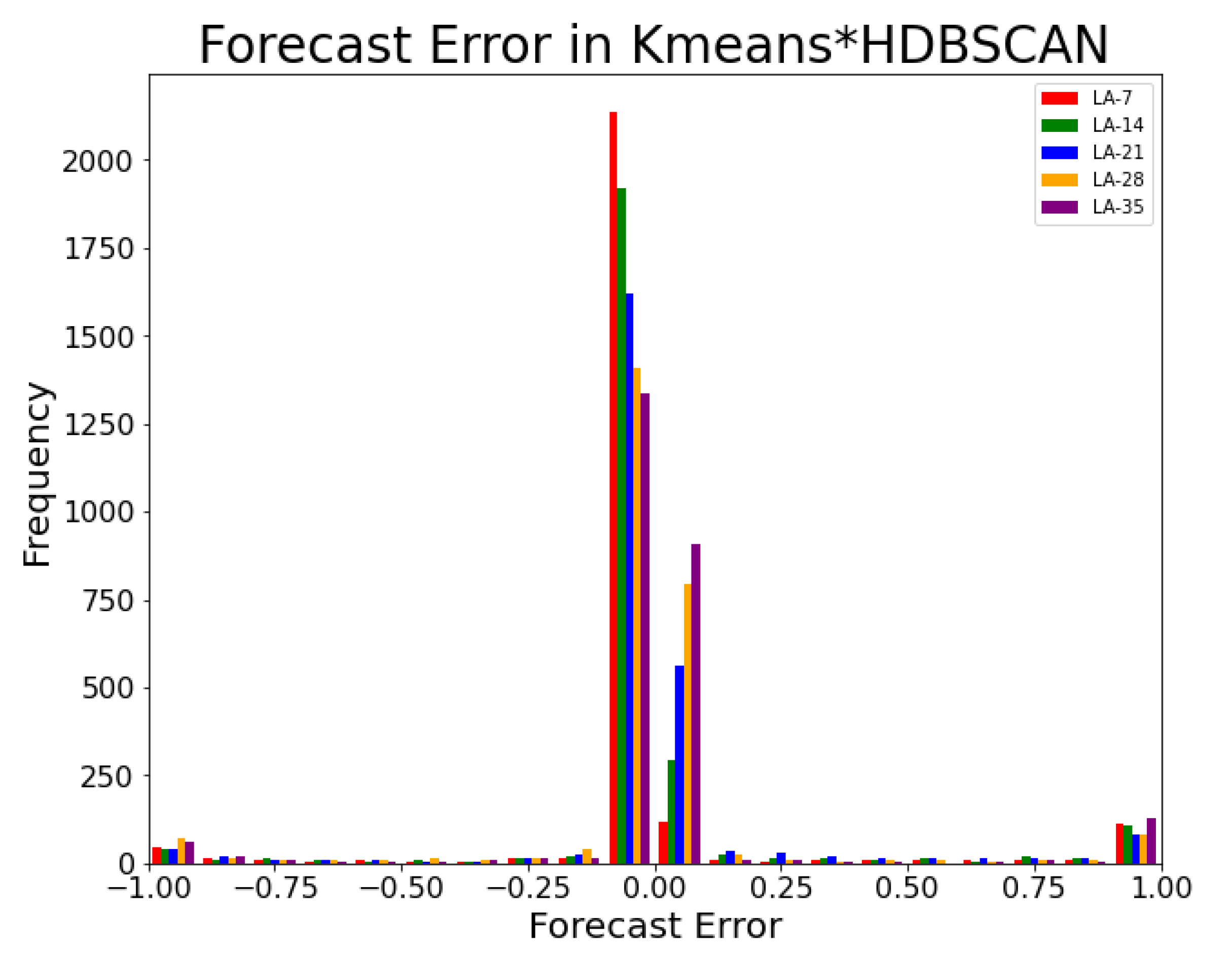
4.2.3. Kmeans*HDBSCAN Experiment
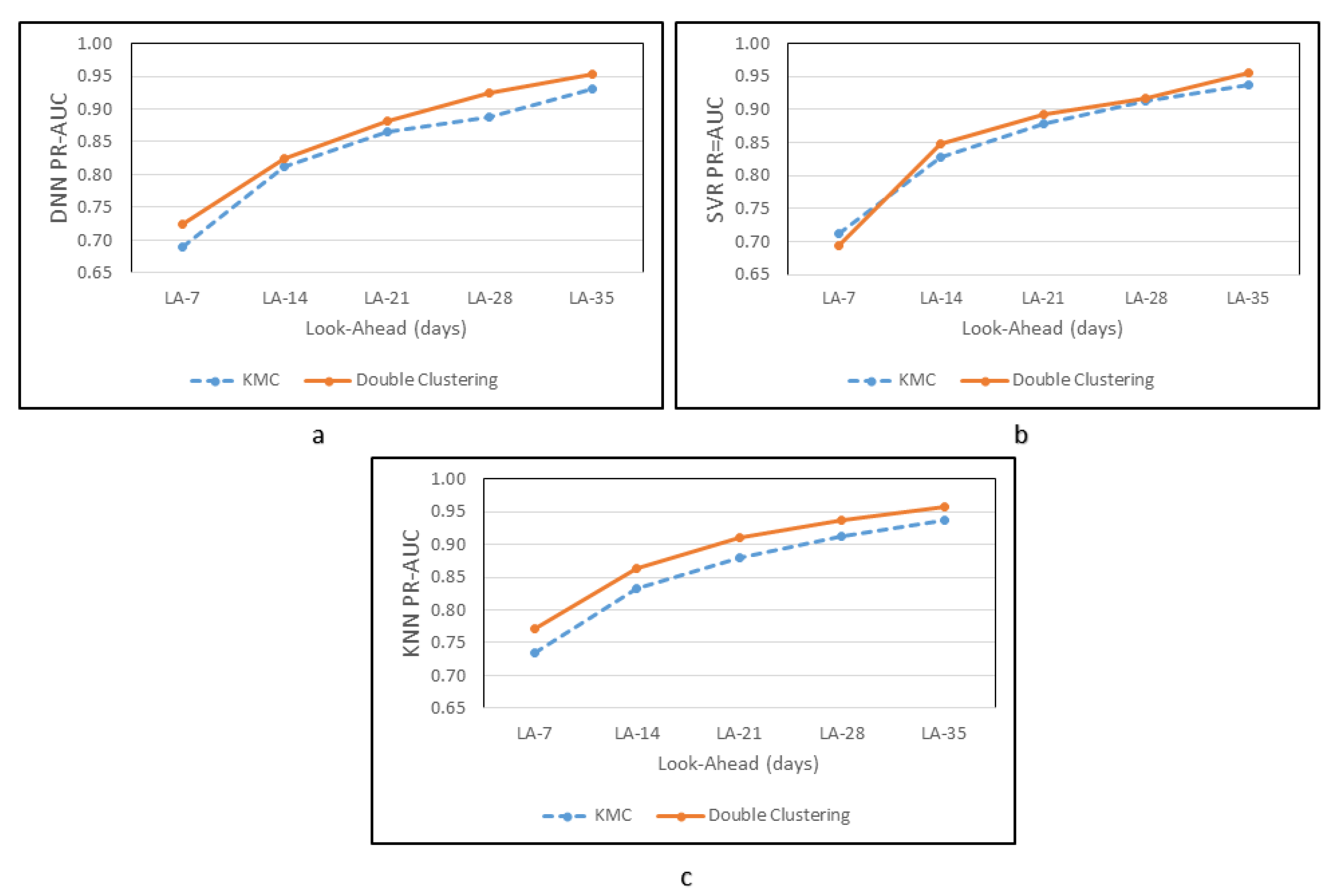
4.2.4. Performance Evaluation for All Clusters and Dominant Cluster
4.2.5. Running on Edge Machine
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AMI | Advanced Metering Infrastructure |
| MDMS | Meter Data Management Systems |
| LF | Load Forecasting |
| LSTM | Long Short Term Memory |
| DNN | Deep Neural Network |
| KNN | k-Nearest Neighbors |
| SVR | Support Vector Regression |
| SVM | Support Vector Machine |
| Conv1D | Convolution one Dimension |
| SMOTE | Synthetic Minority Oversampling Technique |
| ADASYN | Adaptive Synthetic sampling |
| Kmeans | k-means clustering |
| HDBSCAN | Hierarchical Density-Based Spatial Clustering of Applications with Noise |
| SC | Silhouette Coefficient |
| ROC | Receiver Operating Characteristics |
| AUC | Area Under the Curve |
| PR | Precision Recall |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| ACC | Accuracy |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
References
- Menonna, F.; Holden, C. WoodMac: Smart Meter Installations to Surge Globally Over Next 5 Years. 2019. Available online: https://www.greentechmedia.com/articles/read/advanced-metering-infrastructure-to-double-by-2024 (accessed on 25 August 2020).
- Shi, W.; Dustdar, S. The Promise of Edge Computing. Computer 2016, 49, 78–81. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Hong, T.; Kang, C. Review of Smart Meter Data Analytics: Applications, Methodologies, and Challenges. IEEE Trans. Smart Grid 2019, 10, 3125–3148. [Google Scholar] [CrossRef]
- Schofield, J.; Carmichael, R.; Schofield, J.; Tindemans, S.; Bilton, M.; Woolf, M.; Strbac, G. Low carbon london project: Data from the dynamic time-of-use electricity pricing trial. UK Data Serv. Colch. UK 2013, 7857, 7857-1. [Google Scholar]
- Dai, Y.; Xu, D.; Maharjan, S.; Chen, Z.; He, Q.; Zhang, Y. Blockchain and Deep Reinforcement Learning Empowered Intelligent 5G Beyond. IEEE Netw. 2019, 33, 10–17. [Google Scholar] [CrossRef]
- Asghar, M.R.; Dán, G.; Miorandi, D.; Chlamtac, I. Smart Meter Data Privacy: A Survey. IEEE Commun. Surv. Tutor. 2017, 19, 2820–2835. [Google Scholar] [CrossRef]
- Sollacher, R.; Jacob, T.; Derbel, F. Smart wireless Sub-Metering. In Proceedings of the International Multi-Conference on Systems, Signals Devices, Chemnitz, Germany, 20–23 March 2012; pp. 1–6. [Google Scholar]
- Barai, G.R.; Krishnan, S.; Venkatesh, B. Smart metering and functionalities of smart meters in smart grid—A review. In Proceedings of the 2015 IEEE Electrical Power and Energy Conference (EPEC), London, ON, Canada, 26–28 October 2015; pp. 138–145. [Google Scholar]
- Authority-SG, E.M. Metering Options. 2020. Available online: https://www.ema.gov.sg/Metering_Options.aspx (accessed on 25 August 2020).
- Haes Alhelou, H.; Hamedani-Golshan, M.; Njenda, T.; Siano, P. A Survey on Power System Blackout and Cascading Events: Research Motivations and Challenges. Energies 2019, 12, 682. [Google Scholar] [CrossRef]
- Saddler, H. Explainer: Power Station Trips are Normal, But Blackouts Are Not. 2018. Available online: https://theconversation.com/explainer-power-station-trips-are-normal-but-blackouts-are-not-90682 (accessed on 25 August 2020).
- Yen, S.W.; Morris, S.; Ezra, M.A.; Huat, T.J. Effect of smart meter data collection frequency in an early detection of shorter-duration voltage anomalies in smart grids. Int. J. Electr. Power Energy Syst. 2019, 109, 1–8. [Google Scholar] [CrossRef]
- Energy, U. Advanced Metering Infrastructure and Customer Systems. 2016. Available online: https://www.energy.gov/sites/prod/files/2016/12/f34/AMI%20Summary%20Report_09-26-16.pdf (accessed on 25 August 2020).
- Teeraratkul, T.; O’Neill, D.; Lall, S. Shape-Based Approach to Household Electric Load Curve Clustering and Prediction. IEEE Trans. Smart Grid 2018, 9, 5196–5206. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A Survey of Predictive Modeling on Imbalanced Domains. ACM Comput. Surv. 2016, 49. [Google Scholar] [CrossRef]
- Zanetti, M.; Jamhour, E.; Pellenz, M.; Penna, M.; Zambenedetti, V.; Chueiri, I. A Tunable Fraud Detection System for Advanced Metering Infrastructure Using Short-Lived Patterns. IEEE Trans. Smart Grid 2019, 10, 830–840. [Google Scholar] [CrossRef]
- Jeyaranjani, J.; Devaraj, D. Machine Learning Algorithm for Efficient Power Theft Detection using Smart Meter Data. Int. J. Eng. Technol. 2018, 7, 900–904. [Google Scholar]
- Badrinath Krishna, V.; Weaver, G.A.; Sanders, W.H. PCA-Based Method for Detecting Integrity Attacks on Advanced Metering Infrastructure. In Proceedings of the 12th International Conference on Quantitative Evaluation of Systems—Volume 9259; QEST 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 70–85. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A Review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Kröger, P.; Zimek, A. Outlier Detection Techniques. 2010. Available online: https://www.dbs.ifi.lmu.de/~zimek/publications/KDD2010/kdd10-outlier-tutorial.pdf (accessed on 25 August 2020).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Bilogur, A. Oversampling with SMOTE and ADASYN. 2018. Available online: https://www.kaggle.com/residentmario/oversampling-with-smote-and-adasyn (accessed on 25 August 2020).
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J.; Massana, J. A Survey on Electric Power Demand Forecasting: Future Trends in Smart Grids, Microgrids and Smart Buildings. IEEE Commun. Surv. Tutor. 2014, 16, 1460–1495. [Google Scholar] [CrossRef]
- Muratori, M. Impact of uncoordinated plug-in electric vehicle charging on residential power demand. Nat. Energy 2018, 3, 193–201. [Google Scholar] [CrossRef]
- Parvez, I.; Sarwat, A.I.; Wei, L.; Sundararajan, A. Securing Metering Infrastructure of Smart Grid: A Machine Learning and Localization Based Key Management Approach. Energies 2016, 9, 691. [Google Scholar] [CrossRef]
- Nagi, J.; Yap, K.S.; Tiong, S.K.; Ahmed, S.K.; Mohammad, A.M. Detection of Abnormalities and Electricity Theft using Genetic Support Vector Machines. In Proceedings of the IEEE Region Ten Confernce, Hyderabad, India, 19–21 November 2008; pp. 1–6. [Google Scholar]
- Niu, X.; Sun, J. Dynamic Detection of False Data Injection Attack in Smart Grid using Deep Learning. Comput. Res. Repos. 2018, 1808, 1–6. [Google Scholar]
- Murshed, M.G.S.; Murphy, C.; Hou, D.; Khan, N.; Ananthanarayanan, G.; Hussain, F. Machine Learning at the Network Edge: A Survey. arXiv 2019, arXiv:1908.00080. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 25 August 2020).
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Steinwart, I. Sparseness of Support Vector Machines. J. Mach. Learn. Res. 2003, 4, 1071–1105. [Google Scholar]
- Menon, A.K. Large-Scale Support Vector Machines: Algorithms and Theory; University of California: San Diego, CA, USA, 2009. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kshetri, N.; Voas, J. Hacking Power Grids: A Current Problem. Computer 2017, 50, 91–95. [Google Scholar] [CrossRef]
- Shewhart, W. Economic Control of Quality of Manufactured Product; Bell Telephone Laboratories Series; D. Van Nostrand Company, Incorporated: New York City, NY, USA, 1931. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. AI 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Campello, R.J.G.B.; Moulavi, D.; Zimek, A.; Sander, J. Hierarchical Density Estimates for Data Clustering, Visualization, and Outlier Detection. ACM Trans. Knowl. Discov. Data 2015, 10. [Google Scholar] [CrossRef]
- Aburukba, R.O.; AliKarrar, M.; Landolsi, T.; El-Fakih, K. Scheduling Internet of Things requests to minimize latency in hybrid Fog–Cloud computing. Future Gener. Comput. Syst. 2019. [Google Scholar] [CrossRef]
- Brownlee, J. How to Develop Multi-Step LSTM Time Series Forecasting Models for Power Usage. 2018. Available online: https://machinelearningmastery.com/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/ (accessed on 25 August 2020).
- Goldstein, M.; Uchida, S. A comparative evaluation of unsupervised anomaly detection algorithms for multivariate data. PLoS ONE 2016, 11. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | DNN | SVR | KNN |
|---|---|---|---|
| Model Determination | Desainer layout (i.e., model.summary [30]) | Linear Function, Kernel trick, and Optimization Problem [31] | k value |
| Training Goal | Update node weights | Find the support vectors [32,33] | Remember all training data [34] |
| Persistence Size | Fixed predetermined model | Size of support vectors | Fixed based on training data |
| Training Time | Slow | Medium | Fast |
| Inference Time | Fast | Medium | Slow |
| Name | PC-Server | Raspberry Pi 3B+ |
|---|---|---|
| CPU | Intel (R) i7-7700 | Arm Cortex-A53 |
| GPU | NVIDIA GTX 1060 | - |
| RAM | 16 GB | 1 GB |
| Operating System | Windows 10 | Raspbian Stretch |
| Python | 3.6.6 | 3.5.3 |
| Tensorflow | 1.10.0 | 1.8 |
| Keras | 2.2.2 | 2.2.4 |
| Scikit-learn | 0.22.2 | 0.22.2 |
| Experiments | ROC-AUC | PR-AUC | TOTAL-AUC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| LSTM-1L | Tanh | Sigmoid | ReLU | Tanh | Sigmoid | ReLU | Tanh | Sigmoid | ReLU |
| N32-Cv16 | 0.829 | 0.821 | 0.836 | 0.498 | 0.485 | 0.517 | 1.327 | 1.306 | 1.353 |
| N32-Cv32 | 0.838 | 0.845 | 0.866 | 0.527 | 0.532 | 0.563 | 1.365 | 1.378 | 1.429 |
| N32-Cv64 | 0.852 | 0.882 | 0.859 | 0.548 | 0.583 | 0.563 | 1.400 | 1.465 | 1.423 |
| N64-Cv16 | 0.844 | 0.804 | 0.839 | 0.532 | 0.462 | 0.489 | 1.376 | 1.266 | 1.328 |
| N64-Cv32 | 0.873 | 0.814 | 0.852 | 0.575 | 0.481 | 0.541 | 1.448 | 1.295 | 1.393 |
| N64-Cv64 | 0.847 | 0.885 | 0.858 | 0.541 | 0.554 | 0.595 | 1.387 | 1.439 | 1.453 |
| N256-Cv16 | 0.836 | 0.852 | 0.855 | 0.504 | 0.485 | 0.551 | 1.339 | 1.337 | 1.405 |
| N256-Cv32 | 0.838 | 0.846 | 0.844 | 0.550 | 0.523 | 0.545 | 1.388 | 1.368 | 1.389 |
| N256-Cv64 | 0.824 | 0.842 | 0.866 | 0.538 | 0.466 | 0.550 | 1.362 | 1.308 | 1.417 |
| Experiments | ROC-AUC | PR-AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1L32N64 | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 |
| D200-032 | 0.780 | 0.780 | 0.783 | 0.779 | 0.783 | 0.394 | 0.475 | 0.522 | 0.549 | 0.577 |
| D200-064 | 0.829 | 0.819 | 0.823 | 0.821 | 0.820 | 0.456 | 0.529 | 0.567 | 0.591 | 0.616 |
| D200-128 | 0.860 | 0.856 | 0.853 | 0.846 | 0.837 | 0.472 | 0.549 | 0.575 | 0.596 | 0.629 |
| Experiments | ROC-AUC | PR-AUC | ||||||
|---|---|---|---|---|---|---|---|---|
| C, | 0.1 | 0.2 | 0.3 | 0.4 | 0.1 | 0.2 | 0.3 | 0.4 |
| 1 | 0.850 | 0.855 | 0.859 | 0.864 | 0.582 | 0.588 | 0.600 | 0.612 |
| 2 | 0.854 | 0.859 | 0.864 | 0.871 | 0.602 | 0.606 | 0.612 | 0.617 |
| 3 | 0.854 | 0.862 | 0.868 | 0.874 | 0.608 | 0.611 | 0.616 | 0.619 |
| 4 | 0.853 | 0.865 | 0.871 | 0.876 | 0.610 | 0.615 | 0.617 | 0.618 |
| Experiments | ROC-AUC | PR-AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Tanh-Sig | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 |
| C0-032 | 0.889 | 0.878 | 0.900 | 0.870 | 0.899 | 0.589 | 0.710 | 0.782 | 0.775 | 0.842 |
| C0-064 | 0.929 | 0.929 | 0.924 | 0.931 | 0.930 | 0.700 | 0.794 | 0.831 | 0.878 | 0.895 |
| C0-128 | 0.922 | 0.936 | 0.939 | 0.938 | 0.953 | 0.689 | 0.813 | 0.865 | 0.887 | 0.931 |
| C1-032 | 0.667 | 0.669 | 0.665 | 0.683 | 0.709 | 0.049 | 0.076 | 0.101 | 0.142 | 0.181 |
| C1-064 | 0.705 | 0.723 | 0.738 | 0.727 | 0.745 | 0.062 | 0.132 | 0.165 | 0.183 | 0.255 |
| C1-128 | 0.739 | 0.722 | 0.744 | 0.759 | 0.751 | 0.080 | 0.115 | 0.171 | 0.227 | 0.261 |
| Experiments | ROC-AUC | PR-AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| C = 1, = 0.2 | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 |
| C0-032 | 0.901 | 0.914 | 0.919 | 0.920 | 0.923 | 0.674 | 0.782 | 0.829 | 0.854 | 0.879 |
| C0-064 | 0.899 | 0.921 | 0.929 | 0.932 | 0.934 | 0.695 | 0.808 | 0.857 | 0.880 | 0.900 |
| C0-128 | 0.915 | 0.930 | 0.938 | 0.948 | 0.956 | 0.711 | 0.827 | 0.879 | 0.912 | 0.937 |
| C1-032 | 0.667 | 0.684 | 0.697 | 0.703 | 0.703 | 0.052 | 0.099 | 0.135 | 0.174 | 0.203 |
| C1-064 | 0.713 | 0.738 | 0.743 | 0.745 | 0.751 | 0.075 | 0.152 | 0.206 | 0.254 | 0.301 |
| C1-128 | 0.748 | 0.764 | 0.774 | 0.782 | 0.796 | 0.113 | 0.181 | 0.235 | 0.301 | 0.351 |
| Experiments | ROC-AUC | PR-AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| K = 37 | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 |
| C0-032 | 0.933 | 0.928 | 0.925 | 0.922 | 0.925 | 0.693 | 0.784 | 0.829 | 0.854 | 0.885 |
| C0-064 | 0.935 | 0.930 | 0.931 | 0.933 | 0.937 | 0.725 | 0.814 | 0.858 | 0.883 | 0.907 |
| C0-128 | 0.940 | 0.942 | 0.947 | 0.952 | 0.957 | 0.734 | 0.833 | 0.880 | 0.912 | 0.937 |
| C1-032 | 0.667 | 0.690 | 0.698 | 0.704 | 0.711 | 0.039 | 0.084 | 0.123 | 0.150 | 0.180 |
| C1-064 | 0.676 | 0.719 | 0.725 | 0.730 | 0.738 | 0.063 | 0.118 | 0.147 | 0.177 | 0.214 |
| C1-128 | 0.696 | 0.730 | 0.757 | 0.772 | 0.788 | 0.084 | 0.150 | 0.203 | 0.260 | 0.321 |
| Kmeans | HDBSCAN | Kmeans ∩ HDBSCAN |
|---|---|---|
| C0 = 77 | H0 = 80 | 74 |
| C0 = 77 | H1 = 57 | 0 |
| C1 = 123 | H0 = 80 | 6 |
| C1 = 123 | H1 = 57 | 57 |
| Noise = 63 | 63 |
| Experiments | ROC-AUC | PR-AUC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| LA-7 | LA-14 | LA-21 | LA-28 | LA-35 | LA-7 | LA-14 | LA-21 | LA-28 | LA-35 | |
| DNN | ||||||||||
| C-032 | 0.906 | 0.925 | 0.925 | 0.923 | 0.921 | 0.655 | 0.747 | 0.807 | 0.845 | 0.876 |
| C-064 | 0.924 | 0.934 | 0.938 | 0.941 | 0.943 | 0.716 | 0.812 | 0.861 | 0.895 | 0.922 |
| C-128 | 0.913 | 0.934 | 0.945 | 0.957 | 0.967 | 0.724 | 0.824 | 0.881 | 0.924 | 0.954 |
| C-128-SM | - | 0.932 | - | - | - | - | 0.816 | - | - | - |
| SVR | ||||||||||
| C-032 | 0.911 | 0.916 | 0.907 | 0.913 | 0.910 | 0.642 | 0.764 | 0.807 | 0.847 | 0.869 |
| C-064 | 0.906 | 0.937 | 0.938 | 0.931 | 0.938 | 0.668 | 0.822 | 0.877 | 0.885 | 0.900 |
| C-128 | 0.927 | 0.945 | 0.950 | 0.954 | 0.966 | 0.694 | 0.847 | 0.893 | 0.917 | 0.955 |
| C-128-SM | - | 0.943 | - | - | - | - | 0.845 | - | - | - |
| KNN | ||||||||||
| C-032 | 0.944 | 0.939 | 0.936 | 0.934 | 0.935 | 0.727 | 0.803 | 0.851 | 0.878 | 0.907 |
| C-064 | 0.945 | 0.942 | 0.942 | 0.944 | 0.945 | 0.745 | 0.828 | 0.872 | 0.903 | 0.924 |
| C-128 | 0.947 | 0.952 | 0.958 | 0.963 | 0.968 | 0.771 | 0.863 | 0.910 | 0.936 | 0.957 |
| C-128-SM | - | 0.946 | - | - | - | - | 0.852 | - | - | - |
| Machine | Type | TP | FP | TN | FN | TPR | FPR | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|---|---|---|
| XGBOOST | Without-Clustering | 555 | 447 | 7460 | 498 | 0.527 | 0.057 | 0.554 | 0.527 | 0.540 |
| DNN | Without-Clustering | 616 | 521 | 7385 | 436 | 0.586 | 0.066 | 0.542 | 0.586 | 0.563 |
| DNN | Kmeans | 616 | 292 | 7614 | 437 | 0.585 | 0.037 | 0.699 | 0.585 | 0.637 |
| DNN | Kmeans*HDBSCAN | 635 | 360 | 7545 | 417 | 0.603 | 0.046 | 0.638 | 0.603 | 0.620 |
| SVR | Without-Clustering | 637 | 250 | 7655 | 416 | 0.605 | 0.032 | 0.718 | 0.605 | 0.657 |
| SVR | Kmeans | 617 | 211 | 7695 | 436 | 0.586 | 0.027 | 0.758 | 0.586 | 0.661 |
| SVR | Kmeans*HDBSCAN | 650 | 266 | 7638 | 400 | 0.619 | 0.034 | 0.710 | 0.619 | 0.661 |
| KNN | Without-Clustering | 629 | 270 | 7635 | 424 | 0.597 | 0.034 | 0.700 | 0.597 | 0.644 |
| KNN | Kmeans | 615 | 198 | 7709 | 438 | 0.584 | 0.025 | 0.765 | 0.584 | 0.662 |
| KNN | Kmeans*HDBSCAN | 645 | 272 | 7632 | 407 | 0.613 | 0.034 | 0.704 | 0.613 | 0.655 |
| Dominant | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Machine | Cluster-Only | TP | FP | TN | FN | TPR | FPR | Precision | Recall | F1 |
| DNN | C0 | 616 | 291 | 2389 | 153 | 0.801 | 0.109 | 0.682 | 0.801 | 0.737 |
| DNN | C0H0 | 596 | 265 | 2300 | 153 | 0.796 | 0.103 | 0.699 | 0.796 | 0.744 |
| SVR | C0 | 617 | 211 | 2469 | 153 | 0.802 | 0.079 | 0.746 | 0.802 | 0.773 |
| SVR | C0H0 | 616 | 196 | 2369 | 133 | 0.822 | 0.076 | 0.758 | 0.822 | 0.789 |
| KNN | C0 | 614 | 197 | 2484 | 155 | 0.799 | 0.073 | 0.761 | 0.799 | 0.780 |
| KNN | C0H0 | 611 | 191 | 2374 | 138 | 0.816 | 0.074 | 0.765 | 0.816 | 0.790 |
| Machine | Inference/Sample (ms) | Inference Frequency (/s) | Size of the Model (KB) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| A. Server+GPU (Latency-1) | DNN | SVR | KNN | DNN | SVR | KNN | DNN | SVR | KNN |
| 1. Without-Clustering | 0.25 | 1.38 | 14.56 | 4,000 | 725 | 69 | 159 | 10,807 | 92,501 |
| 2. Kmeans | 0.22 | 0.65 | 3.59 | 4,525 | 1,550 | 278 | 159 | 4,517 | 28,849 |
| 3. Kmeans*HDBSCAN | 0.23 | 0.47 | 2.90 | 4,425 | 2,123 | 345 | 159 | 3,524 | 23,794 |
| B. Raspberry Pi (Latency-2) | |||||||||
| 1. Without-Clustering | 1.26 | 33.11 | 176.17 | 794 | 30 | 6 | 159 | 10,807 | 92,501 |
| 2. Kmeans | 1.18 | 6.05 | 27.87 | 847 | 165 | 36 | 159 | 4,517 | 28,849 |
| 3. Kmeans*HDBSCAN | 1.24 | 4.76 | 24.34 | 810 | 210 | 41 | 159 | 3,524 | 23,794 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Utomo, D.; Hsiung, P.-A. A Multitiered Solution for Anomaly Detection in Edge Computing for Smart Meters. Sensors 2020, 20, 5159. https://doi.org/10.3390/s20185159
Utomo D, Hsiung P-A. A Multitiered Solution for Anomaly Detection in Edge Computing for Smart Meters. Sensors. 2020; 20(18):5159. https://doi.org/10.3390/s20185159
Chicago/Turabian StyleUtomo, Darmawan, and Pao-Ann Hsiung. 2020. "A Multitiered Solution for Anomaly Detection in Edge Computing for Smart Meters" Sensors 20, no. 18: 5159. https://doi.org/10.3390/s20185159
APA StyleUtomo, D., & Hsiung, P.-A. (2020). A Multitiered Solution for Anomaly Detection in Edge Computing for Smart Meters. Sensors, 20(18), 5159. https://doi.org/10.3390/s20185159