1. Introduction
Human language is divided into natural language and body language. Facial expression is part of body language. As a non-linguistic signal of human beings [
1], facial expressions contain rich personal information, social interaction information, and also convey some information about people’s cognitive behavior, temperament, personality, authenticity, psychology, and almost all of that information cannot be replaced by other means of information expression. Therefore, accurately identifying the expression of others is critical to successful human–computer interaction. When people see different people’s faces, they can easily recognize the same expression, which is called facial expression recognition.
The study of facial expression began in the 19th century. In 1872, Darwin elaborated on the connection and difference between human facial expression and animal facial expression in his famous work [
2]. In 1971, Ekman and Friesen did pioneering work on modern facial expression recognition [
3]. They studied six basic human expressions (i.e., happy, sad, surprised, fearful, angry, disgusted), determining the category of objects to be identified, systematically established a facial expression database with thousands of different samples, and described the corresponding facial changes of each expression in detail, including how eyebrows, eyes, eyelids, lips change, and so on. In 1978, Suwa et al. [
4] carried out the first attempt of facial expression recognition on a video animation of faces, and proposed automatic facial expression analysis on the image sequences. Since the 1990s, K. mase [
5] have used optical flow to determine the main direction of muscle movement. After using the proposed optical flow method for facial expression recognition, automatic facial expression recognition has entered a new era.
With the development of expression researches, scholars focus on a more subtle expression research, that is, the micro expression research. It is a kind of short-lived facial expression made unconsciously by human beings when they try to hide some emotions. They correspond to seven universal emotions: disgusted, angry, fearful, sad, happy, surprised and contempt. The duration of micro expression is only 1/25 to 1/5 s, which expresses the real emotion that a person tries to suppress and hide. Although a subconscious expression may last only a moment, and sometimes it expresses the opposite emotion.
The main application fields of facial expression recognition technology include human–computer interaction, intelligent control, security, medical, communication, education, fatigue detection, political election and other fields. For distance education, teachers can judge the current learning situation of students by analyzing the expression status of students during class. For smart medical care, doctors can understand the degree of patients’ cure by capturing the expression on the patients’ faces. In short, with the progress of science and technology and the continuous development of psychology, the researches on facial expression will be more and more deep, the content will be more and more rich, and the application will be more and more extensive.
However, no matter the macro basic expressions or micro expressions, in the real interaction, a single expression can not fully express the complex emotional display of human beings. A major recent development in this issue is an article published on PNAS in 2014 [
6]. This study proposes the concept of a compound expression and points out that multiple discrete basic expressions can be combined to form compound expressions. For example, when people encounter unexpected gifts, they should be happy and surprised. Therefore, in addition to the six common expressions of happy, surprised, sad, angry, disgusted and fearful, there are 21 distinguishable compound expressions, such as surprise and joy, sadness and anger. At present, most researchers focus on the researches of basic expression recognition, but few on compound expression recognition. The research of compound expression is a more powerful impetus for us to understand people’s inner feelings more accurately and truly. Therefore, in this paper, we pay our attention to the study on compound expression recognition.
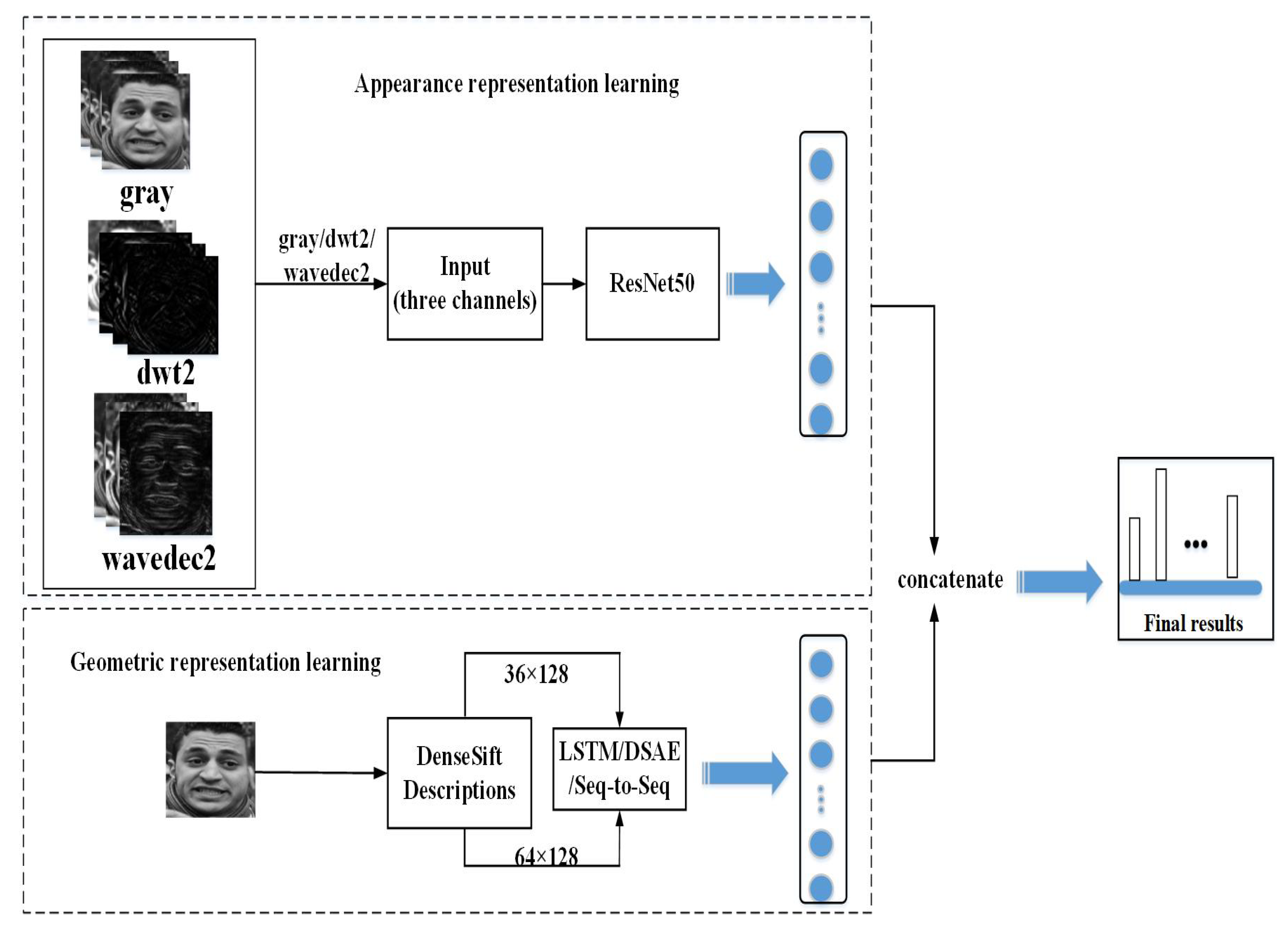
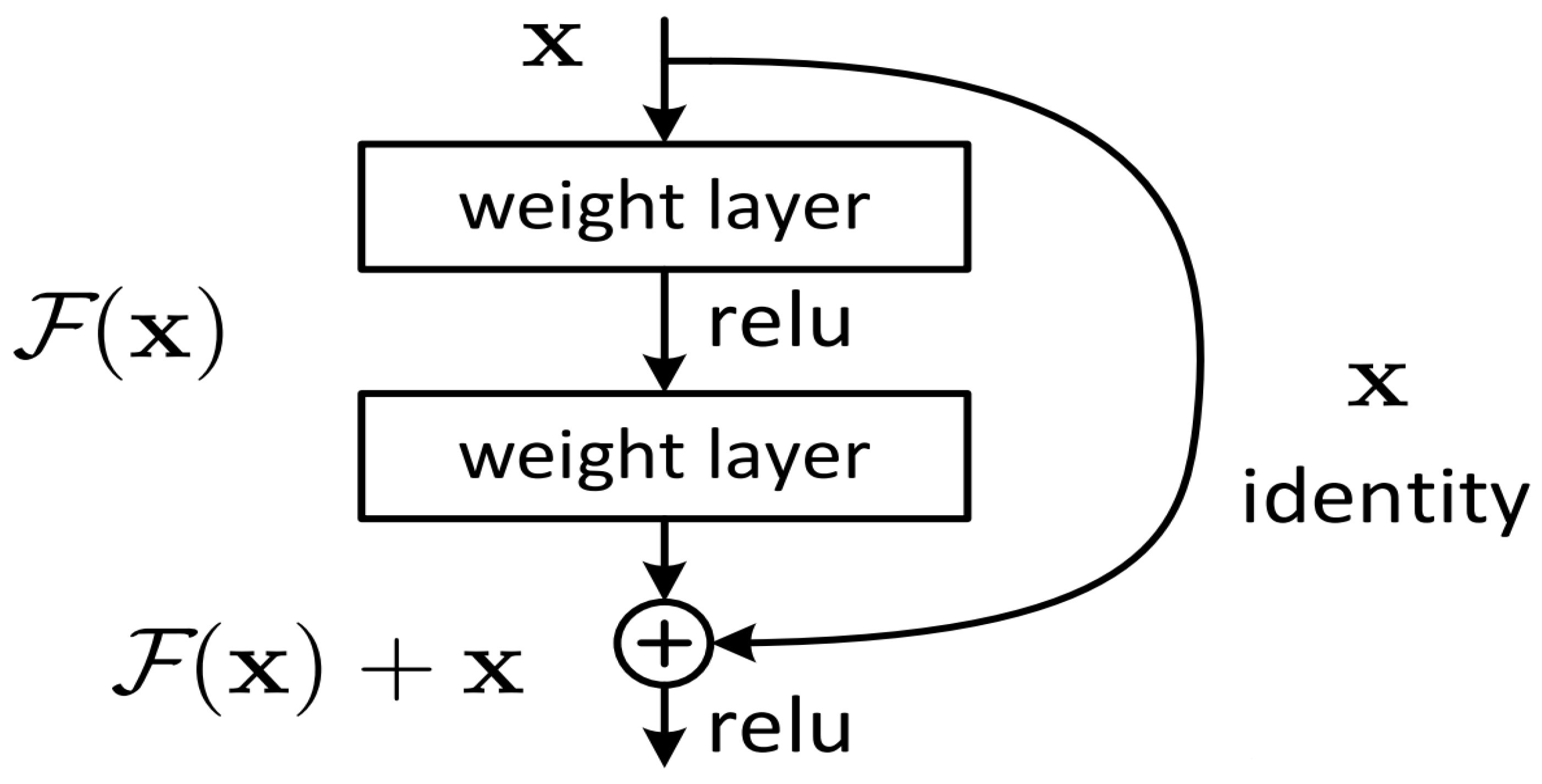
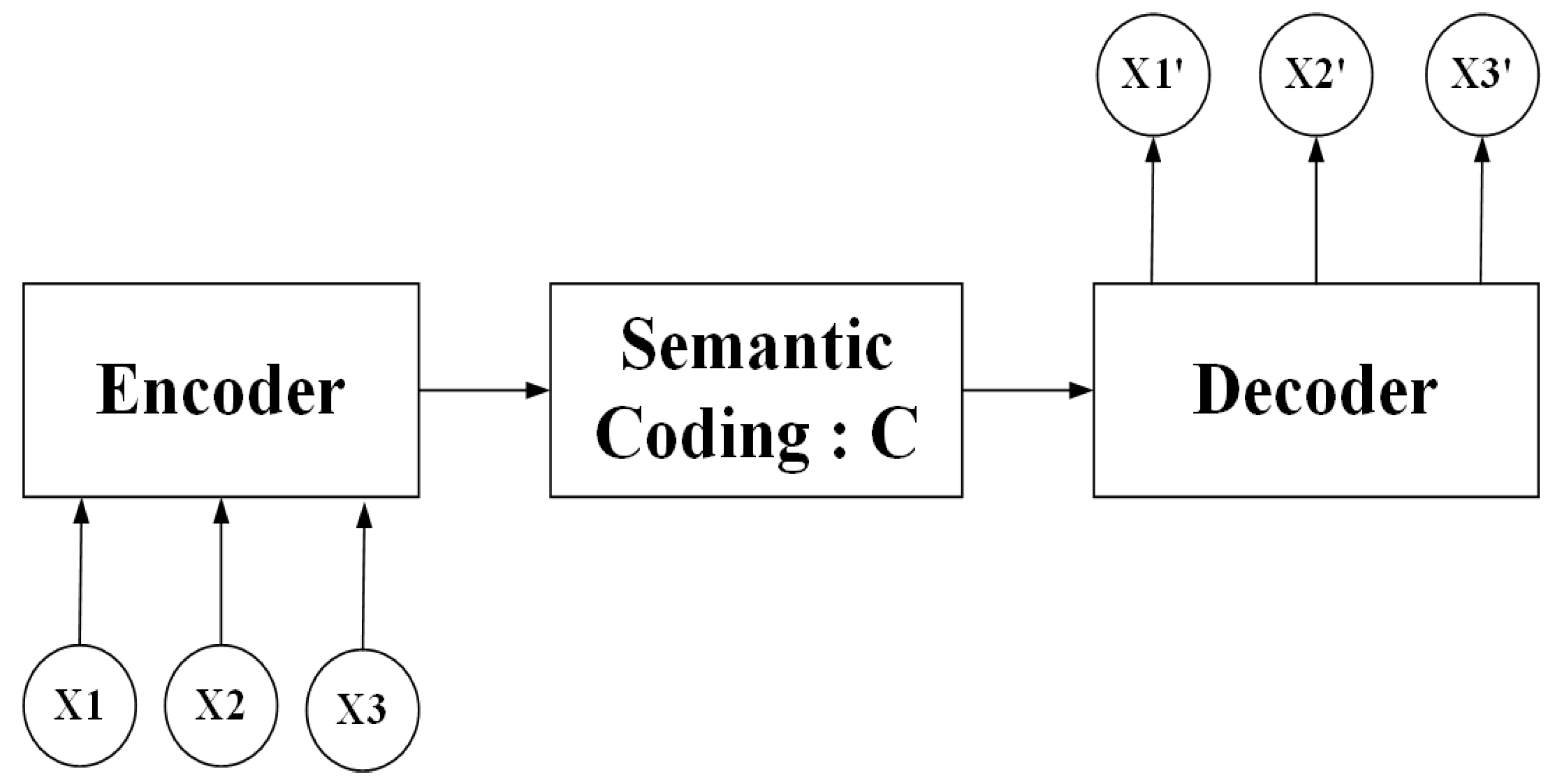
In real life, we can recognize facial expressions by facial information. Generally speaking, facial expression features can be divided into texture and geometry based according to the expression content of facial images. In this work, we mainly start from those two aspects, proposing a scheme of combining spatial and frequency domains to implement end-to-end joint training based on model ensembling between models for appearance and geometric representations learning for the recognition of compound expressions in the wild. For appearance feature acquisition, we adopt the idea of transfer learning, introducing the ResNet50 model [
7] pretrained on VGGFace2 [
8] for face recognition to implement the fine-tuning process. Here, we try and compare two minds, one is that we utilize two static expression databases FER2013 [
9] and RAF Basic [
10,
11] for basic emotion recognition to fine tune, the other is that we fine tune the model on the three channels composed of images generated by DWT2 and WAVEDEC2 wavelet transform based on rbio3.1 [
12] and sym1 [
13] wavelet bases respectively. For geometric feature acquisition, we firstly introduce the densesift [
14] operator to extract facial key points and their histogram descriptions. After that, we introduce deep Stack AutoEncoder (deep SAE) [
15], stacked Long Short Term Memory (LSTM) [
16] and Sequence-to-Sequence with LSTM [
17] and define their structures by ourselves. Then, we feed the key points and their descriptions into the input three models to train respectively and compare their performances. When the model training for appearance and geometric features learning is completed, we combine the two models with category labels to achieve further end-to-end joint training considering that ensembling the models which describe different information can further improve recognition results. Finally, we validate the performance of our proposed framework on the RAF Compound database.
The rest of this paper is arranged as follows:
Section 2 discusses the recent development on facial expression recognition and gives an explanation to our proposed framework;
Section 3 reports the experiments and results;
Section 4 and
Section 5 concludes our proposed framework and proposes the challenges on compound expression.
3. Results and Discussion
3.1. Introduction for FER2013, Raf Basic and Raf Compound
FER2013: the FER2013 facial expression database consists of 35,886 facial expression images, including 28,708 training pictures, 3589 public test pictures (PublicTest) and private test pictures (PrivateTest). Each gray image is fixed by size
, there are seven kinds of expressions, corresponding to the digital label 0-6, the specific expression corresponding to the label is as follows: 0 angry; 1 disgusted; 2 fearful; 3 happy; 4 sad; 5 surprised; 6 neutral. Since FER2013 is only used for pretraining of models, in order to involve as many samples as possible in training, we merge the train and the private test set as a large training set, and use the public test set as the validation set to fine tune or pretrain. The distribution of each category sample in FER2013 is described in
Table 1. (download link:
https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data).
RAF: Real-world Affective Faces database (RAF) was built by downloading more than 30,000 images in batches on Flickr image social networks using expression-related keywords, and use crowdsourcing technology to annotate these images. Those annotation results and the annotators’ reliability are evaluated based on the expectation maximization algorithm, which further filters out those noise labels for more accurate annotation results. The entire database contains nearly 30,000 images with a seven-dimensional expression distribution. According to the seven-dimensional expression probability distribution vector corresponding to each picture, we divide the database into seven basic expressions and eleven types of compound expressions (download link:
http://www.whdeng.cn/raf/model1.html#dataset).
There is a big difference between the facial expression naturally revealed in people’s daily life and the facial expression uniformly regulated in the laboratory environment. In real life, different people express their expressions in various ways. Each expression will contain many different forms due to the different identities of the characters, which undoubtedly challenges the expression recognition in the real face world. In our research, we mainly focus on the compound expression recognition in the wild.
Table 2 and
Table 3 shows distribution of various samples in RAF Basic and RAF Compound separately.
3.2. Experiment Setups
We implement our experiments on the 64-bit ubuntu18.04 system with the TITAN RTX 2080TI GPU and pytorch framework.
For data settings, before model training for appearance information mining, we resize the inputs into pixels. Furthermore, we extract the densesift descriptions of and , respectively, for geometric feature extraction considering that different numbers of key points may have different effects on the training of the model.
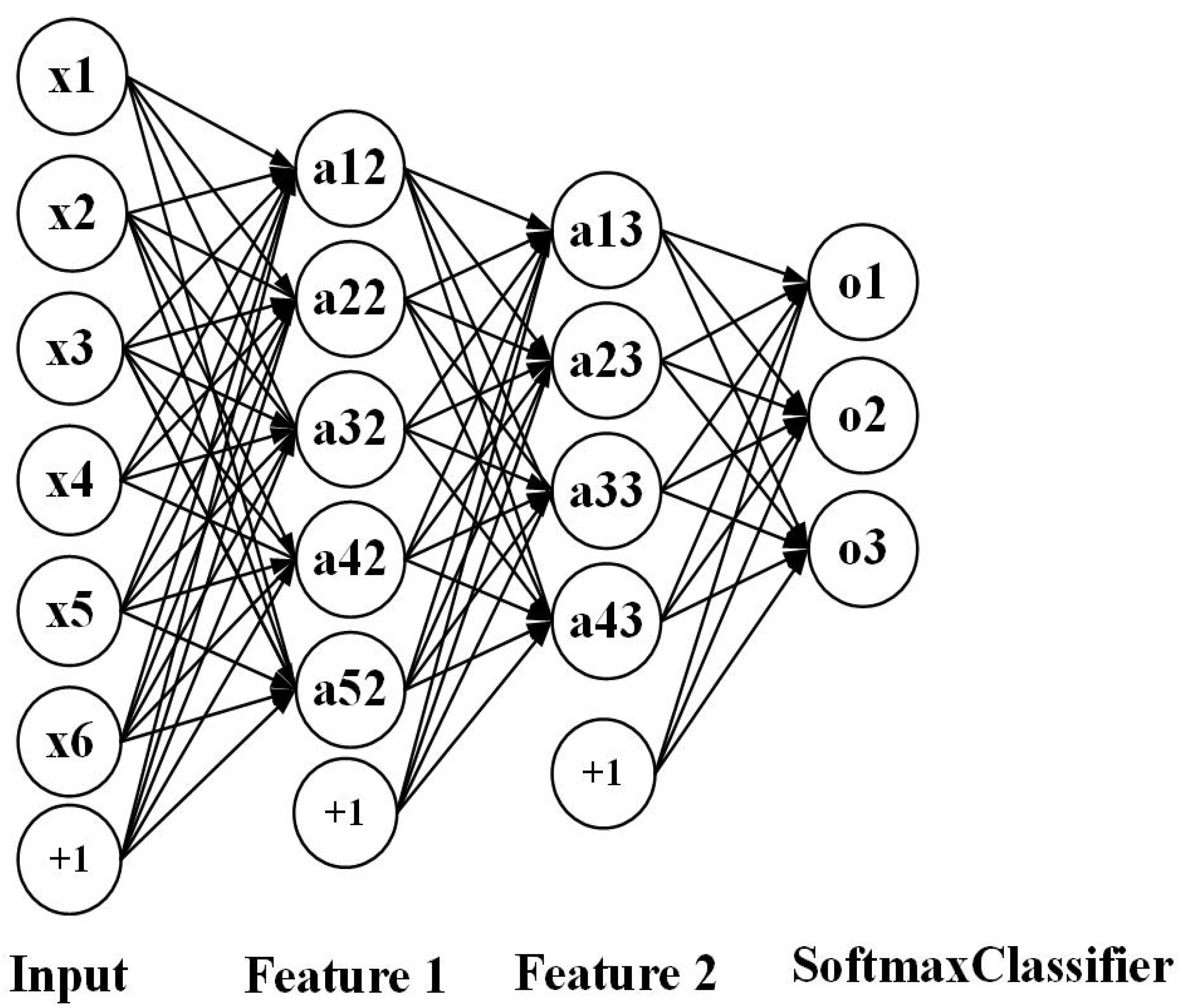
For model settings, we only replace the output layer of ResNet50 with the number of category tags for the current training set. In addition, we define the structures of deep SAE, stacked LSTM, BLSTM and Sequence-to-Sequence with stacked LSTM and BLSTM from scratch. We stack several LSTMs and a softmax layer to generate a stacked LSTM model, and we set the number of categories of the current training set to the number of nodes in the softmax layer. The stacked BLSTM model is built similar to the stacked LSTM model. In addition, the stacked LSTM and BLSTM are also embedded in the Sequence-to-Sequence model, which is concentrated on Sequence-to-Sequence mapping to generate compressed coding representations. The encoder and decoder for the deep SAE are built with several dense layers respectively. It is worth mentioning that the input for stacked LSTM and BLSTM and Sequence-to-Sequence is a three-dimensional vector, which contains batchsize, timesteps and input_features. However, the deep SAE’s input is a one-dimensional vector.
3.3. Experimental Results
We implement two training mechanisms for the extraction of appearance representations. One is based on gray images, the other is based on the input of the three channels composed of images of the frequency domain. There are four forms of frequency domain images based on different wavelet bases and illumination normalization methods: dwt2_firstthree (rbio3.1), which denotes CA, CH, CV of DWT2 transform based on wavelet basis rbio3.1; dwt2_latterthree (rbio3.1), which represents CH, CV, CD of DWT2 transform based on wavelet basis rbio3.1; wavedec2_rbiosharpen, which describes WAVEDEC2 transform based on wavelet basis rbio3.1 and the linear sharpening method is employed on a high frequency component; and wavedec2_symsharpen, which depicts WAVEDEC2 transform based on wavelet basis sym1 and the linear sharpening method is employed on a high frequency component, respectively. For the training process, we first fine tune the ResNet50 model on FER2013, then the RAF Basic is utilized to further train the fine-tuned model based on FER2013 for two learning mechanisms. Finally, three-fold cross-validation and grid search is introduced to utilize RAF Compound to train the ResNet50, which is fine tuned on FER2013 and RAF Basic.
The model parameters for appearance feature learning are set as follows: we set the epoch to 20; 0.001, 0.0001, and 0.00001 are selected to find the best learning rate, the size of batch is set to 64 or 128; and Adam, RMSprop, SGD are tried separately. It should be noted that fine tuning ResNet50 on dwt2_latterthree (rbio3.1) performs worse than other three frequency domain transforms, thus, dwt2_latterthree (rbio3.1) was not considered to continue subsequent learning on RAF Compound. The results of the RAF Compound test set based on different input channels of ResNet50 fine tuned on FER2013 are shown in
Table 4; the results of the RAF Compound test set based on ResNet 50 pretrained on FER2013 and RAF Basic are displayed in
Table 5.
By comparing
Table 4 and
Table 5, we find that the model just fine tuned on FER2013 performs worse on the test set of RAF Compound than the model fine tuned on FER2013 and RAF Basic although there are some slight differences in data presentation between the two databases. It can be concluded that databases with similar contents can be beneficial to train the model and achieve good results in the final task.
Table 4 and
Table 5 also confirm that for small databases that want to achieve better results on deeper and more complex models, transfer learning is a very good choice.
In addition, in our research, we fine-tune the ResNet50 with spatial and several different forms of frequency-domain images, respectively. We argue that the spatial and frequency domains provide us with different perspectives. The shape of the signal can be directly observed in the space-time domain, but the signal cannot be accurately described with limited parameters. However, in the frequency domain, some features are more prominent and easy to process. For example, it is difficult to find the noise pattern in the spatial images. If it is transformed into the frequency domain, it is better to find the noise pattern and it can be more easily processed.
From
Table 4 we can see that test accuracy on the input data composed of a combination of frequency and spatial domain images is the best, while the model trained on spatial images achieves slightly higher results in
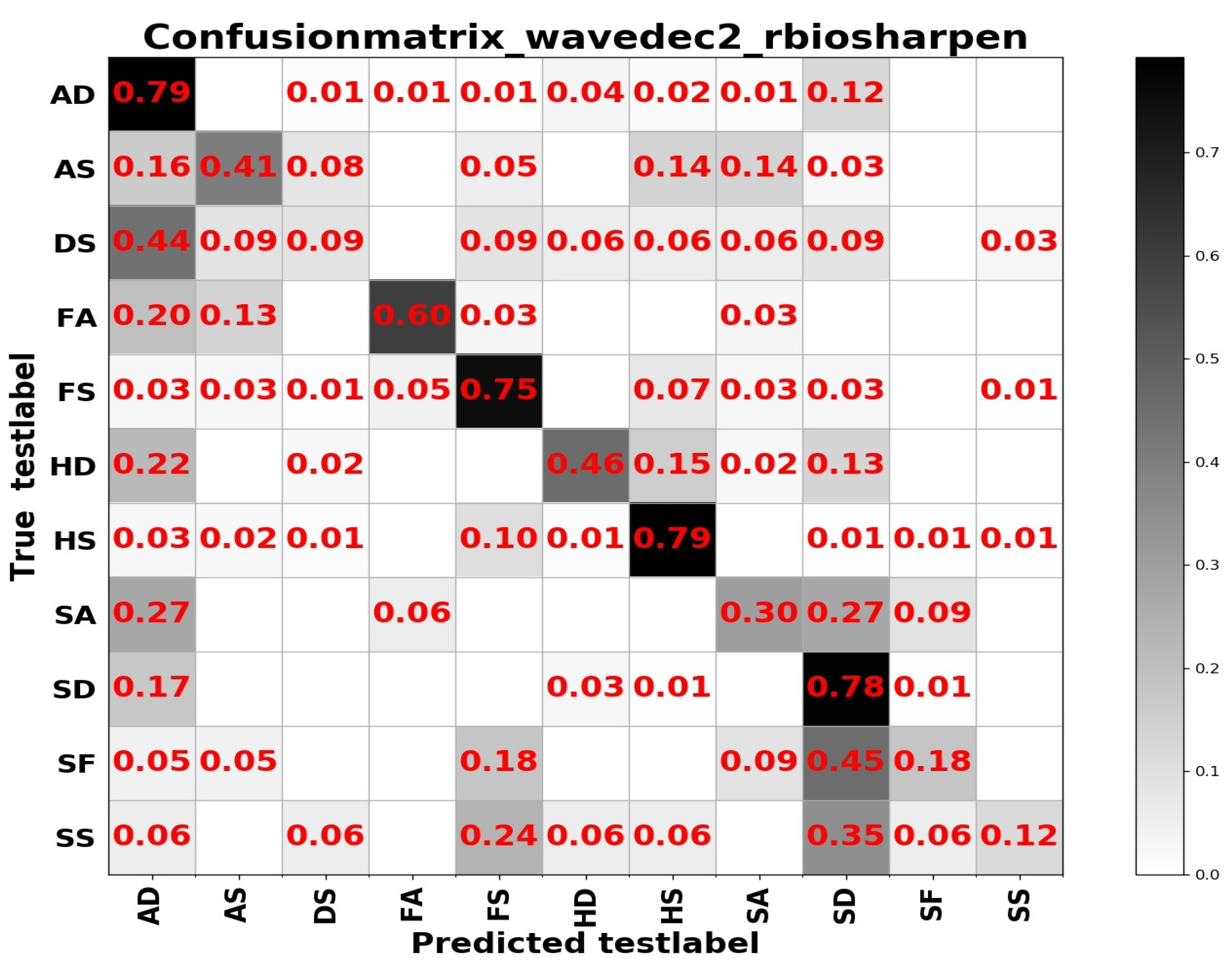
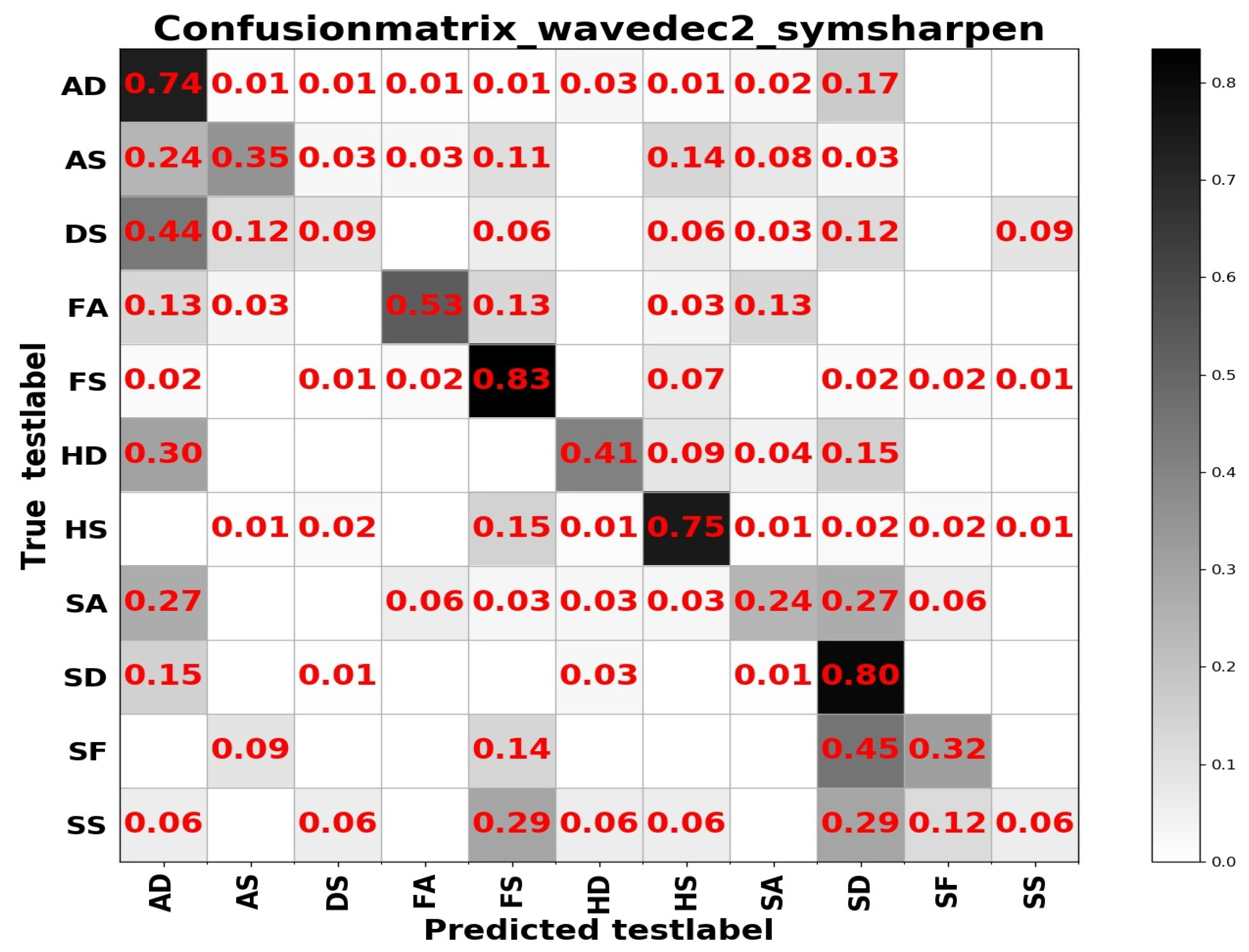
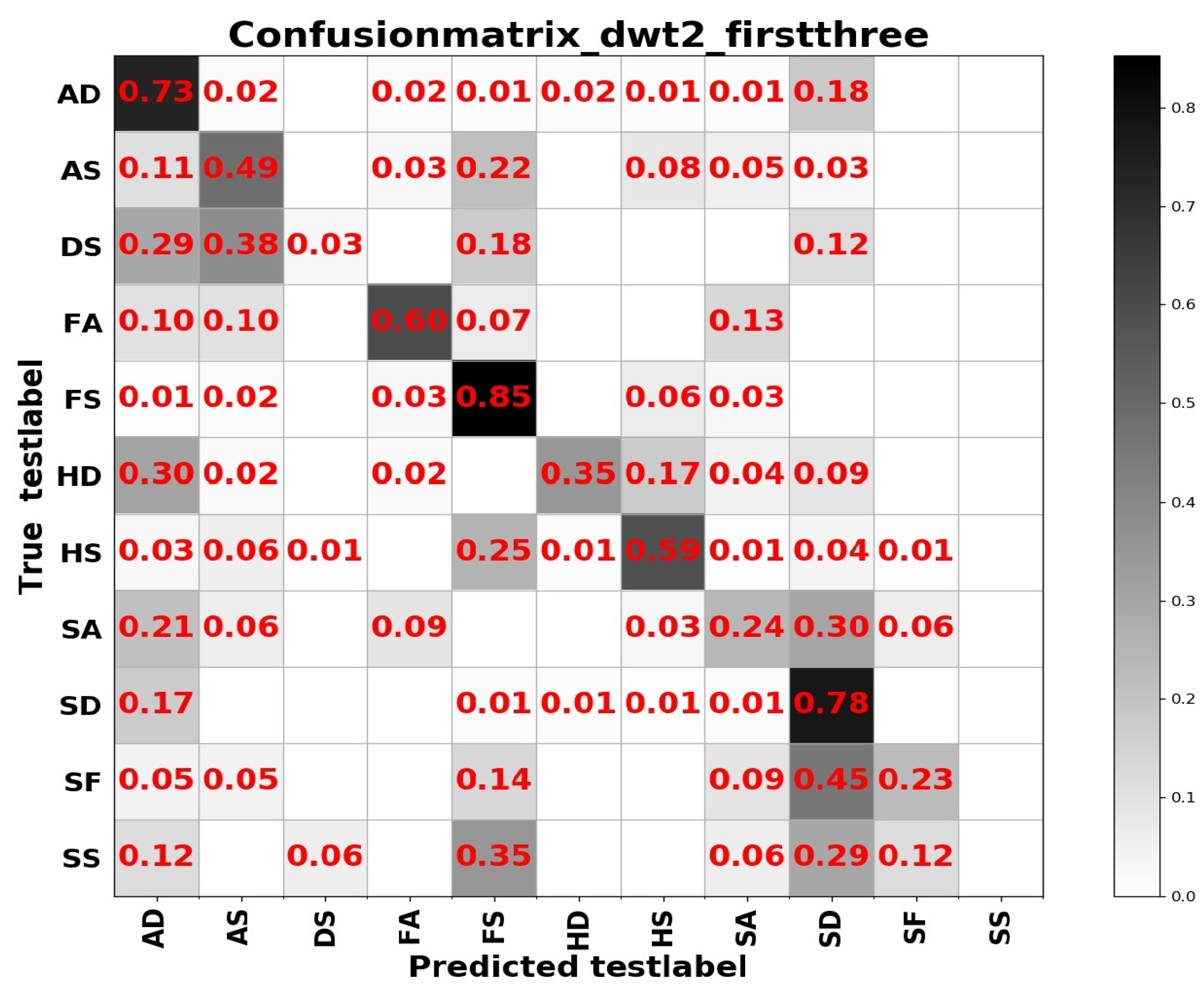
Table 5. Investigating the reason, we think that the difference between the expressions of the two sample sets has a lot to do with it. In summary, from the results of the two tables above, the learning based entirely on the frequency domain is the worst, while the learning combining the spatial and frequency domains shows more outstanding performance. The confusion matrices on the RAF Compound test set based on different input channels for ResNet50 pretrained on two databases for the recognition of basic emotions are presented in
Figure 10,
Figure 11,
Figure 12 and
Figure 13.
From the confusion matrices, we can derive that imbalance of various samples leads to huge differences in recognition results. The imbalance of various types of samples leads to huge differences in recognition results. The recognition accuracy of categories with a larger number of samples is relatively high, and vice versa. Some expressions with similar facial muscle movements are easy to misrecognize. For example, it is easy to mistake ‘sadly fearful’ as ‘sadly disgusted’, especially for complex expressions, which are composed of multiple emotions, it is easier to be misclassified.
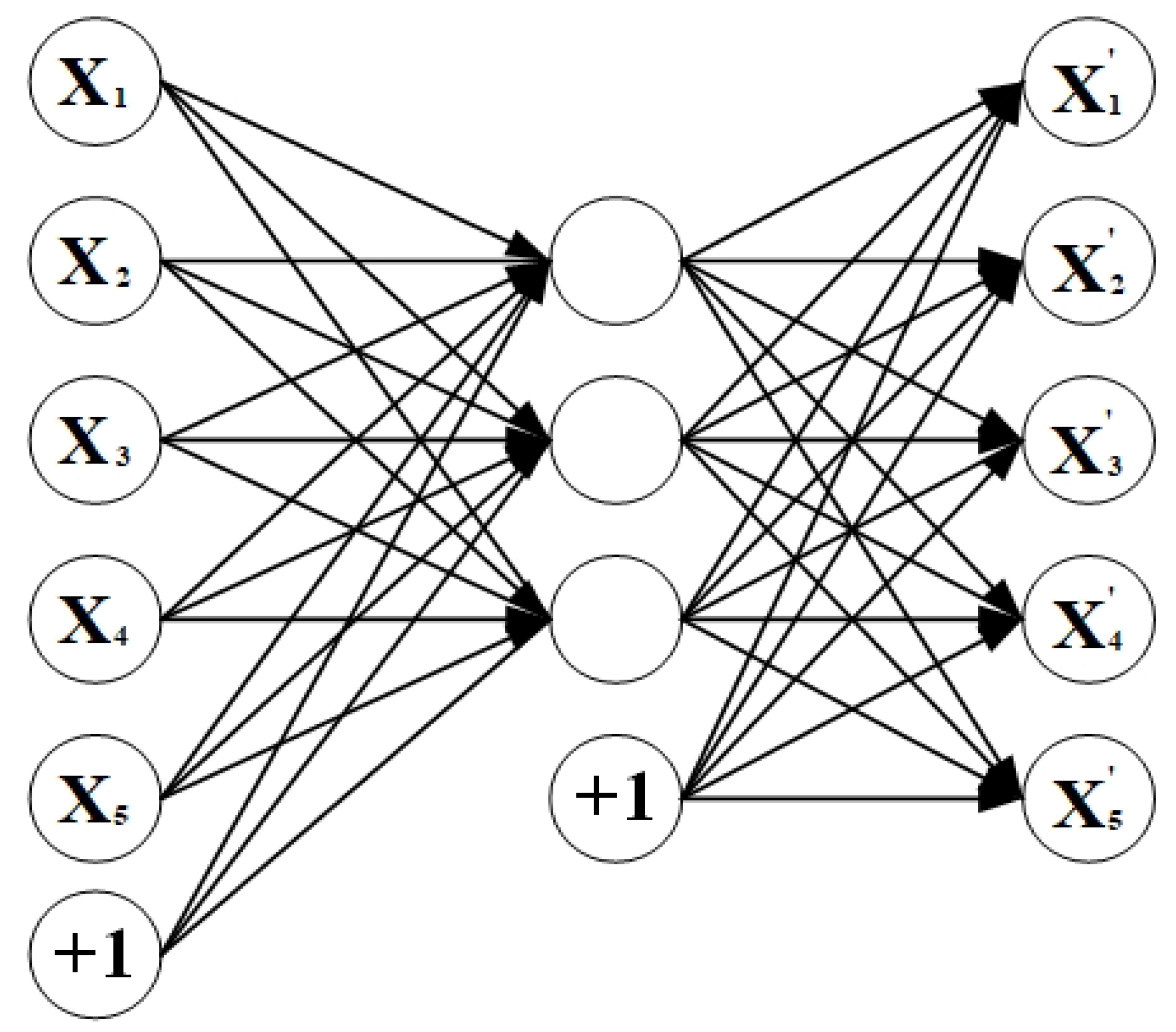
In addition to extracting the appearance information to express the texture features, we also extract the key points of the faces and the histogram descriptions based on the key points to achieve the exploration of geometric features. In this regard, we have introduced a total of two types of models, one is an unsupervised AutoEncoder and the other is a sequence model. We defined a stacked AutoeEncoder from scratch and two sequence models which includes LSTM and Sequence-to-Sequence.
Same as the pretraining strategy for models used for appearance representations, we pretrain our model continuously on FER2013 and RAF Basic for unsupervised and supervised learning. Based on being able to capture more distinctive features of each image by encoding itself, AutoEncoder is considered given that the occurrence of expressions, the process of performing actions at significant key points on the face also occurs in a certain order, and different expressions have different orders, sequence models are selected.
Table 6 presents the performance of sequence models and AutoEncoder on the RAF Compound test set.
From
Table 6, we can see that DSAE+Softmax achieves the best results compared to other models for geometric representation learning. Introducing AutoEncoder to reconstruct the samples in an unsupervised way and by minimizing the reconstruction error, the model structures and parameters are optimized to extract the most expressive information for the samples firstly. Then, we combine the encoder with the softmax layer and incorporate the category labels to realize supervised learning. Based on that, we can also infer that applying unsupervised and supervised learning to some recognition tasks may achieve better performance than a single learning method.
Furthermore, from
Table 6, we also notice that Sequence-to-Sequence with LSTM or BLSTM is also a self-encoding unsupervised learning mode, which is just a sequence-to-sequence self-encoding mode. In our work, we use its implementation principles to carry out sequence-to-sequence modeling on a series of extracted facial key points and their histogram descriptions. In order to avoid underfitting caused by insufficient sample sizes, we extracted densesift descriptions of two sizes respectively, but the performance is so unsatisfactory. The possible causes of that result are, as a sequence expression, its context information is not closely connected, time information is also not obvious, and the feature size and number of samples are not enough by observing that inputs with
densesift descriptions outperform
.
In addition, for the simply supervised training mode, BLSTM is better than LSTM based on the results presented in
Table 6. We can conclude that in the case of avoiding overfitting, bidirectional sequence learning is helpful for mining more useful information.
After completing the model training for appearance and geometric information, model ensembling technology is utilized to integrate appearance and geometric representations to generate more comprehensive information and achieve better recognition results. The accuracy rates of the RAF Compound test set based on different model ensembling strategies are shown in
Table 7 and
Table 8.
From
Table 7 and
Table 8, it can be observed that model ensembling can effectively improve the recognition effect by observing that most ensembling strategies achieve better results on the final task compared to the previous single model. And the combination of unsupervised and supervised learning is still far ahead of other models based on the recognition results generating from the model ensembling between ResNet50 and DSAE+Softmax. Furthermore, the performance of model ensembling between ResNet50 and Sequence-to-Sequence on spatial and frequency domain images is better than spatial images. It can also be inferred that the sequence model is more suitable for frequency domain images that are more sensitive to timing signals.
An interesting discovery is that model ensembling between ResNet50 trained on spatial and frequency domain images and Seq-to-Seq with LSTM or BLSTM+Softmax achieves the satisfactory recognition rates in
Table 7. Based on that, we can infer that model diversity plays a vital role in model ensembling and it is not how good your best model is.
4. Discussion
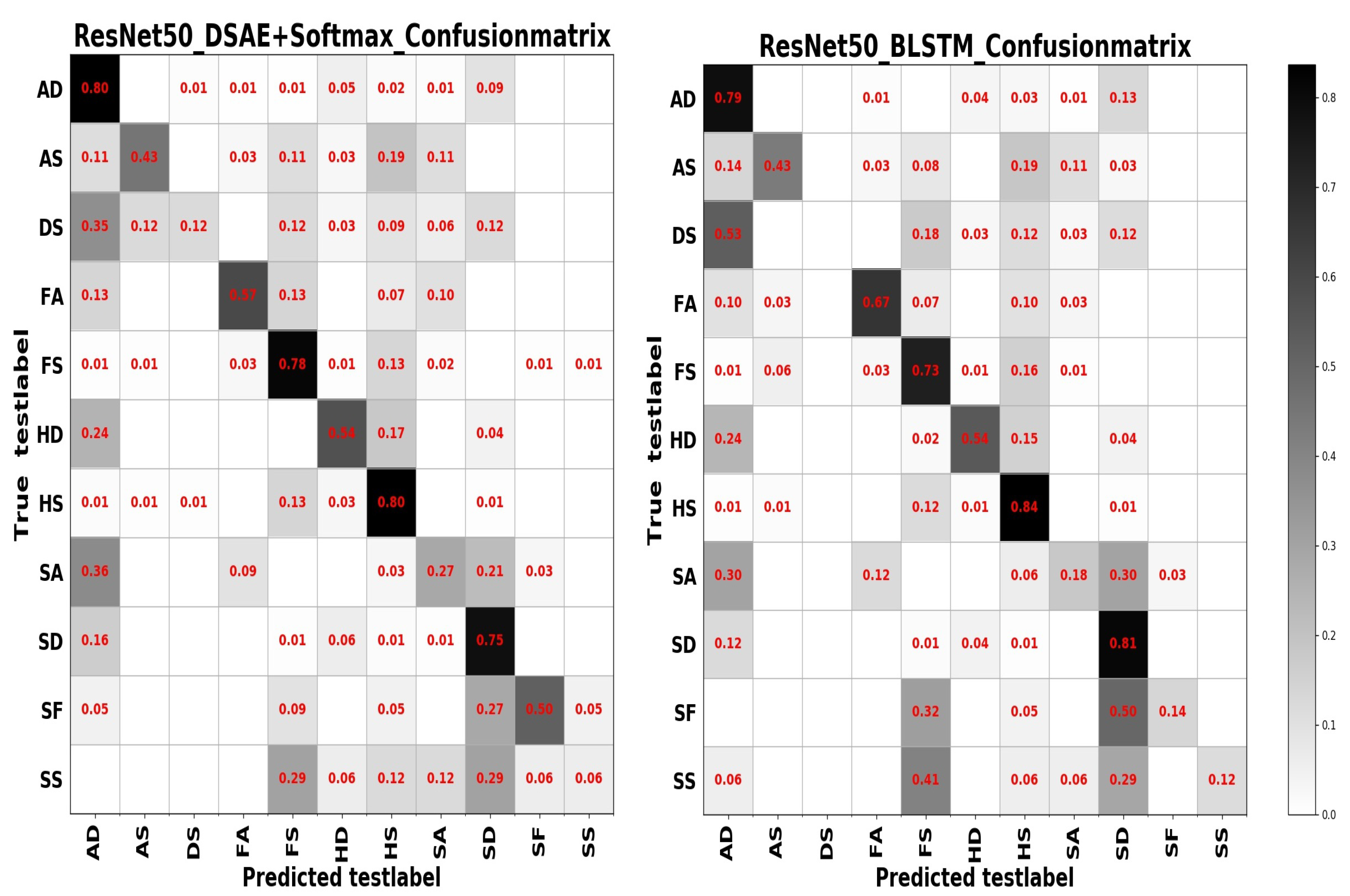
The confusion matrices based on different model ensembling strategies are displayed in
Figure 14 and
Figure 15. Based on different model ensembling strategies, the learned information is also different, and from the confusion matrices, we can observe that for categories with a small number of samples, the recognition results are different for different model ensembling strategies, some can get a small recognition rate, some can get a high recognition rate, but some results are 0. This also precisely shows that although we have introduced the model ensembling technology, we have only ensembled two models, and the diversity of models is insufficient, resulting in the learned information not being comprehensive. There are significant shortcomings in both the number of models and the diversity of models.
All in all, for our final task, the ensembling of different models is still very beneficial. We think the framework we propose is flexible and extensive. First of all, in terms of the form of features, we combine texture and geometric features, which will make the expression of features more comprehensive; second, in terms of the basic properties of the signal, we combine the temporal and spatial images, which allows us to analyze the signal changes in the images from different angles; third, in terms of the model, we introduce the convolutional neural networks to describe the spatial information and the recurrent neural networks to describe the temporal information respectively; fourth, as for the inputs of the model, we consider both the information of the whole images and the information of the local image blocks. As for the learning of geometric features, we define the model structures ourselves, so other researchers can redefine the model related to their tasks according to their own needs, which is more flexible. In addition, the model used for texture feature learning can also be replaced with other models. Based on the combination of the two, when implementing end-to-end training, the training is relatively fast. We believe that the framework we recommend has a certain reference for application in real life.
The abbreviations of the above expression categories are shown in
Table 9.
However, due to the lack of researches on compound expressions, we cannot directly compare with other researchers’ works on this topic. Therefore, we have taken several traditional classic operators that describe texture and geometric information on our database to extract features and a SVM classifier is introduced to recognize. In addition, we employ four-fold cross-validation and grid search methods to train and select the best parameters for SVM. Results of the comparison are listed in
Table 10. From
Table 10, we found that our proposed combination of texture and geometric representation based on traditional and deep learning methods performs better than the single traditional feature engineering methods.
5. Conclusions
In this study, we propose a framework of combining spatial and frequency domain transform to implement end-to-end joint training based on model ensembling between models for appearance and geometric representations learning for the recognition of compound expressions in the wild. In our scheme, we explore the appearance features based on the spatial and frequency domains respectively. In addition, we dig the more abstract geometric information based on training the models of different structures with densesift descriptions, which are extracted from gray images. When the two models complete the training independently, we conduct model ensembling based on independent models with large structural differences for further training to get more comprehensive information and more accurate results. Finally, the validity of our recommended framework is verified on RAF Compound. At the same time, our work also shows that model learning based on the combination of spatial and frequency domains is better than single-form input. Furthermore, model ensembling is a very effective way to improve the final recognition results and there is much more room to mine. In addition, much more attention should be paid to the model diversity for the learning of complementary information.
Another point is that although there have been many studies on seven basic expressions, theresearches on the compound expressions are far from enough. There are some questions that we need to consider. So far, the defined categories of compound expression cover only a small part. Compound expressions are not just about two basic emotions, they may have more emotions happening at the same time. In addition, an old-fashioned question is one of unbalanced sample distribution across categories, leading to poor recognition performance on the categories with small size. Annotation of samples is also an arduous task due to annotators with different backgrounds, cultures and ages. Furthermore, the features learned only based on visual modality may not be complete. We need to introduce more modalities to achieve comprehensive and complementary feature mining.
In addition, in future work, we will make improvements in the following aspects: for the learning of texture features, in the final feature extraction, add a layer of feature transformation based on a nonlinear injective function, which retains more potential information. For the learning of geometric features, we introduce a recurrent network model that describes time series information based on local image blocks. For this part, considering that when facial expressions occur, facial actions occur in a certain time sequence, and the contribution of each local block is different. Therefore, the attention mechanism in NLP can be introduced into the recurrent neural network, such as self-attention and multi-head attention. What is more, the convolution models currently used are all based on the data with Euclidean structure to achieve feature learning. However, most data in real life exists in non-Euclidean structures, but the convolutional neural network models seem to be invalid in the face of such a data structure, because it has no translation invariance. In order to find a model suitable for this structure, graph neural network (GNN) came into being, and then graph convolutional neural network was also proposed. However, not all data have some kind of adjacency relationship, forming a topological graph, so that poses another challenge for the application of graph convolutional neural networks. In order to solve this problem, dynamic Graph Convolutional Network (GCN) was introduced, based on a certain similarity calculation method to dynamically find the K neighbors of each node, and then realize the aggregation of the features of the neighboring nodes. In terms of feature aggregation for GCN, whether the aggregation function has a nonlinear injective property plays a vital role in the performance of the entire model. We are considering combining the model based on data with Euclidean structure and the model based on the data with non-Euclidean structure to achieve end-to-end training, using the input of the former as the output of the latter for joint training. In addition, in the division of local image blocks, we can try to obtain local image blocks based on 68 facial landmarks as the center. Such local blocks may be more sensitive to changes in facial movements.
All in all, there are many more spaces to explore, especially based on compound expression recognition under natural scenes.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}