Research on Airplane and Ship Detection of Aerial Remote Sensing Images Based on Convolutional Neural Network


 ,
,
Abstract
1. Introduction
2. Related Work
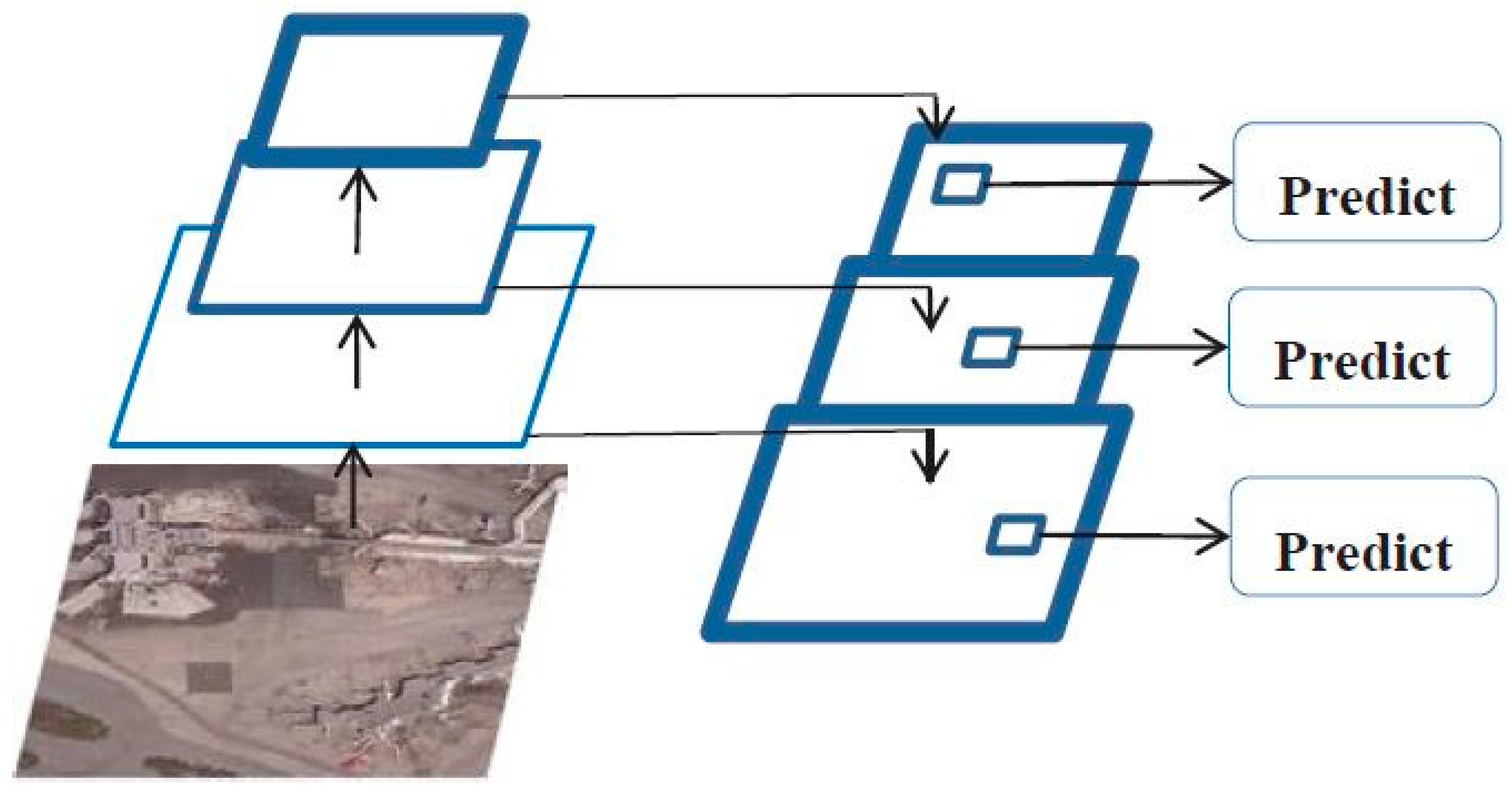
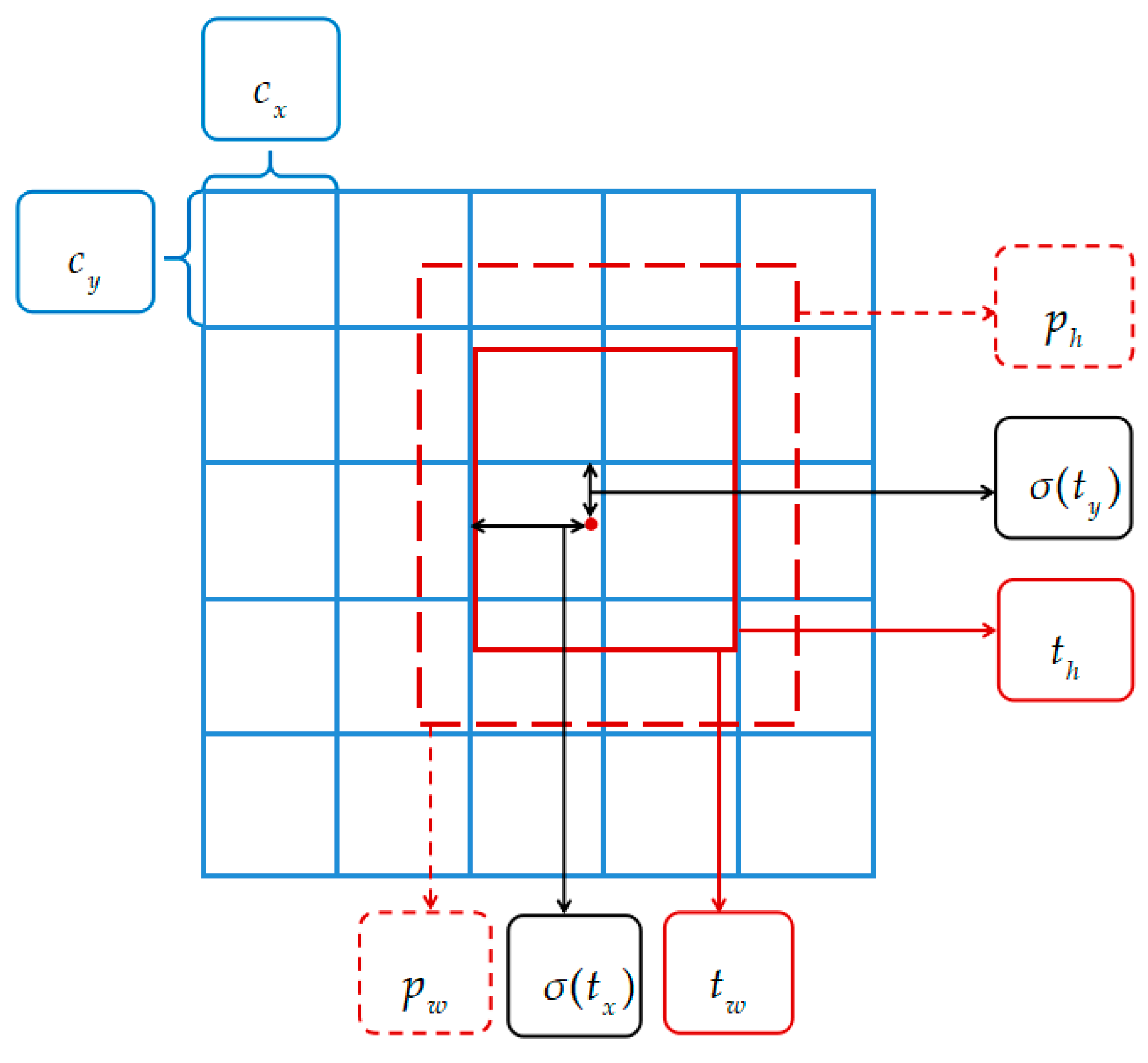
2.1. YOLOv3 Network Analysis
2.1.1. Network Structure
2.1.2. Testing Process
2.2. Improvement of YOLOv3
2.2.1. Detection Scale
2.2.2. Loss Function
3. Experiments
3.1. Network Training
3.1.1. Dataset Creation
- We used the code to automatically traverse all sample images in the DOTA dataset (containing two or more airplane targets) and filtered out the .txt annotation files.
- The excessively large size of sample images from the DOTA dataset leads to excessive compression and a large amount of information will be lost when they are sent directly to the network. Therefore, each sample image obtained was cropped into several 1024 × 1024 size images, and the corresponding .txt annotation file was updated. If the intersection ratio between the divided target and the original target was greater than 0.7, the current target was retained; otherwise it was discarded.
- We repeated the above steps to reduce the dataset until the required sample set was obtained and the preliminary preprocessing operation was completed.
3.1.2. Reset Anchor Box Parameters
3.1.3. Model Training
3.2. Experiments and Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mittal, M.; Verma, A.; Kaur, I.; Kaur, B.; Sharma, M.; Goyal, L.M.; Roy, S.; Kim, T.-H. An Efficient Edge Detection Approach to Provide Better Edge Connectivity for Image Analysis. IEEE Access. 2019, 7, 33240–33255. [Google Scholar] [CrossRef]
- Rosenfeld, A. The Max Roberts Operator is a Hueckel-Type Edge Detector. IEEE Trans. Pattern Anal. Mach. Intell. 1981, 3, 101–103. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.J.; Wu, S.H.; Liu, Y.P. Detecting Wood Surface Defects with fusion algorithm of Visual Saliency and Local Threshold Segmentation. In Proceedings of the 9th International Conference on Graphic and Image Processing, Qingdao, Shandong, China, 14–16 October 2017. [Google Scholar]
- Huang, M.; Yu, W.; Zhu, D. An improved image segmentation algorithm based on the Otsu method. In Proceedings of the 13th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Kyoto, Japan, 8–10 August 2012. [Google Scholar]
- Han, J.W.; Zhou, P.C.; Zhang, D.W.; Cheng, G.; Guo, L.; Liu, Z.; Bu, S.; Wu, J. Efficient, simultaneous detection of multi-class geospatial targets based on visual saliency modeling and discriminative learning of sparse coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 47–58. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 20–23 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Ren, S.Q.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/abs/1804.02767 (accessed on 30 June 2020).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y. SSD: Single Shot multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Deng, Z.P.; Lei, L.; Sun, H.; Zou, H.X.; Zhou, S.L.; Zhao, J.P. An enhanced deep convolutional neural network for densely packed objects detection in remote sensing images. In Proceedings of the 2017 Workshop on Remote Sensing with Intelligent Processing, Shanghai, China, 18–21 May 2017. [Google Scholar]
- Long, Y.; Gong, Y.P.; Xiao, Z.F.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Romote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Yu, D.H.; Xu, Q.; Guo, H.T.; Zhao, C.; Lin, Y.Z.; Li, D.J. An Efficient and Lightweight Convolutional Neural Network for Remote Sensing Image Scene Classification. Sensors 2020, 20, 1999. [Google Scholar] [CrossRef] [PubMed]
- Yao, Y.; Jiang, Z.G.; Zhang, H.P.; Cai, B.W.; Meng, G.; Zuo, D.S. Chimney and condensing tower detection based on faster R-CNN in high resolution remote sensing images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Tang, T.Y.; Zhou, S.L.; Deng, Z.P.; Zou, H.X.; Lei, L. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Du, B.; Zhang, L.P.; Xu, M.Z. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Romote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Xu, Y.L.; Zhu, M.M.; Xin, P.; Li, S.; Qi, M.; Ma, S.P. Rapid Airplane Detection in Remote Sensing Images Based on Multilayer Feature Fusion in Fully Convolutional Neural Networks. Sensors 2018, 18, 2335. [Google Scholar] [CrossRef] [PubMed]
- Zou, Z.X.; Shi, Z.W. Ship detection in spaceborne optical image with SVD networks. IEEE Trans. Geosci. Romote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Wang, T.F.; Gu, Y.F. Cnn Based Renormalization Method for Ship Detection in Vhr Remote Sensing Images. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Zhang, W.; Wang, S.H.; Thachan, S.; Chen, J.Z.; Qian, Y.T. Deconv R-CNN for Small Object Detection on Remote Sensing Images. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Model | Real Targets | TP | TN | Test Time/s |
|---|---|---|---|---|
| Faster R-CNN+Resnet101 | 7436 | 6399 | 1133 | 147.2 |
| Faster R-CNN+VGG16 | 7436 | 6383 | 1145 | 105.1 |
| YOLOv3 | 7436 | 6976 | 911 | 25.4 |
| Improved algorithm | 7436 | 7056 | 708 | 28.3 |
| Network Model | Real Targets | TP | TN | Test Time/s |
|---|---|---|---|---|
| Faster R-CNN+Resnet101 | 68,054 | 39,419 | 10,116 | 131.0 |
| Faster R-CNN+VGG16 | 68,054 | 38,494 | 10,523 | 93.6 |
| YOLOv3 | 68,054 | 62,761 | 9413 | 23.4 |
| Improved algorithm | 68,054 | 63,856 | 9261 | 26.2 |
| Network Model | Precision/% | False/% | Miss/% | AP/% | Train Time/h |
|---|---|---|---|---|---|
| Faster R-CNN+Resnet101 | 84.96 | 15.04 | 13.95 | 81.64 | 11 |
| Faster R-CNN+VGG16 | 84.79 | 15.21 | 14.16 | 81.29 | 9 |
| YOLOv3 | 88.45 | 11.55 | 6.19 | 91.60 | 3 |
| Improved algorithm | 90.88 | 9.12 | 5.11 | 94.29 | 5 |
| Network Model | Precision/% | False/% | Miss/% | AP/% | Train Time/h |
|---|---|---|---|---|---|
| Faster R-CNN+Resnet101 | 79.59 | 20.41 | 42.08 | 53.38 | 14 |
| Faster R-CNN+VGG16 | 78.53 | 21.47 | 43.44 | 51.30 | 11 |
| YOLOv3 | 86.96 | 13.04 | 7.78 | 91.32 | 5 |
| Improved algorithm | 87.33 | 12.67 | 6.17 | 93.13 | 7 |
| Network Model | 104 × 104 Scale | LossL2 | Anchor Setting | AP/% | Recall/% |
|---|---|---|---|---|---|
| YOLOv3(1) | √ | 92.17 | 94.01 | ||
| YOLOv3(2) | √ | √ | 93.82 | 94.65 | |
| YOLOv3(3) | √ | √ | √ | 94.29 | 94.89 |
| Network Model | 104 × 104 Scale | LossL2 | Anchor Setting | AP/% | Recall/% |
|---|---|---|---|---|---|
| YOLOv3(1) | √ | 91.70 | 92.54 | ||
| YOLOv3(2) | √ | √ | 92.75 | 93.51 | |
| YOLOv3(3) | √ | √ | √ | 93.13 | 93.83 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, C.; Wu, J.; Zeng, X.; Feng, Z.; Wang, T.; Yan, X.; Wu, Z.; Wu, Q.; Huang, Z. Research on Airplane and Ship Detection of Aerial Remote Sensing Images Based on Convolutional Neural Network. Sensors 2020, 20, 4696. https://doi.org/10.3390/s20174696
Cao C, Wu J, Zeng X, Feng Z, Wang T, Yan X, Wu Z, Wu Q, Huang Z. Research on Airplane and Ship Detection of Aerial Remote Sensing Images Based on Convolutional Neural Network. Sensors. 2020; 20(17):4696. https://doi.org/10.3390/s20174696
Chicago/Turabian StyleCao, Changqing, Jin Wu, Xiaodong Zeng, Zhejun Feng, Ting Wang, Xu Yan, Zengyan Wu, Qifan Wu, and Ziqiang Huang. 2020. "Research on Airplane and Ship Detection of Aerial Remote Sensing Images Based on Convolutional Neural Network" Sensors 20, no. 17: 4696. https://doi.org/10.3390/s20174696
APA StyleCao, C., Wu, J., Zeng, X., Feng, Z., Wang, T., Yan, X., Wu, Z., Wu, Q., & Huang, Z. (2020). Research on Airplane and Ship Detection of Aerial Remote Sensing Images Based on Convolutional Neural Network. Sensors, 20(17), 4696. https://doi.org/10.3390/s20174696