Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration


Abstract
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- Horizontal Pod Autoscaler (HPA) supports high availability by adjusting the number of execution and resource units, known as pods [11], based on various requirements. When triggered, HPA creates new pods to share the workloads without affecting the existing ones currently running inside the cluster.
- Vertical Pod Autoscaler (VPA) [11] directly changes the specifications, such as requested resources, of pods and maintains the number of working pods. Therefore, it requires restarting these pods and thus disrupts the continuity of applications and services.
- Firstly, we evaluate HPA on diverse aspects such as scaling tendency, metric collection, request processing, cluster size, scraping time, and latency with various experiments on our testbed. Our comprehensive analysis of the results provides knowledge and insights that are not available on the official website and other sources.
- Secondly, besides Kubernetes’s default Resource Metrics, we also evaluate HPA using Prometheus Custom Metrics. By understanding the difference between two types of metrics, readers can have a much firmer grasp on HPA’s operational behaviors.
- Lastly, we provide practical lessons obtained from the experiments and analysis. They could serve as fundamental knowledge so that researchers, developers, and system administrators can make informed decisions to optimize the performance of HPA as well as the quality of services in Kubernetes clusters.
2. Related Work
3. Architecture of Kubernetes
3.1. Kubernetes Cluster
3.1.1. Master Node
- kube-controller-manager watches over and ensures that the cluster is running in the desired state. For instance, an application is running with 4 pods; however, one of which is evicted or missing, kube-controller-manager has to ensure that a new replica is created.
- kube-scheduler looks for newly created and unscheduled pods to assign them to nodes. It has to consider several factors including nodes’ resource availability and affinity specifications. In the previous example, when the new pod has been created and currently unscheduled, kube-scheduler searches for a node inside the cluster that satisfies the requirements and assigns the pod to run on that node.
- etcd is the back storage that has all the configuration data of the cluster.
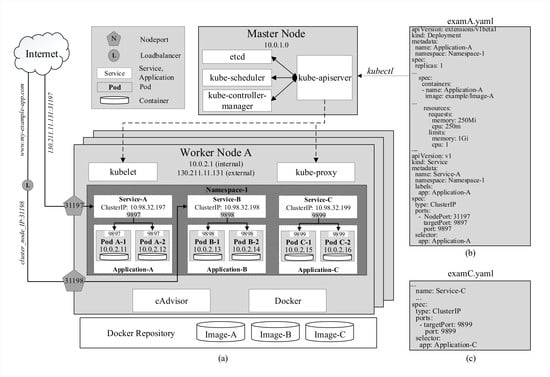
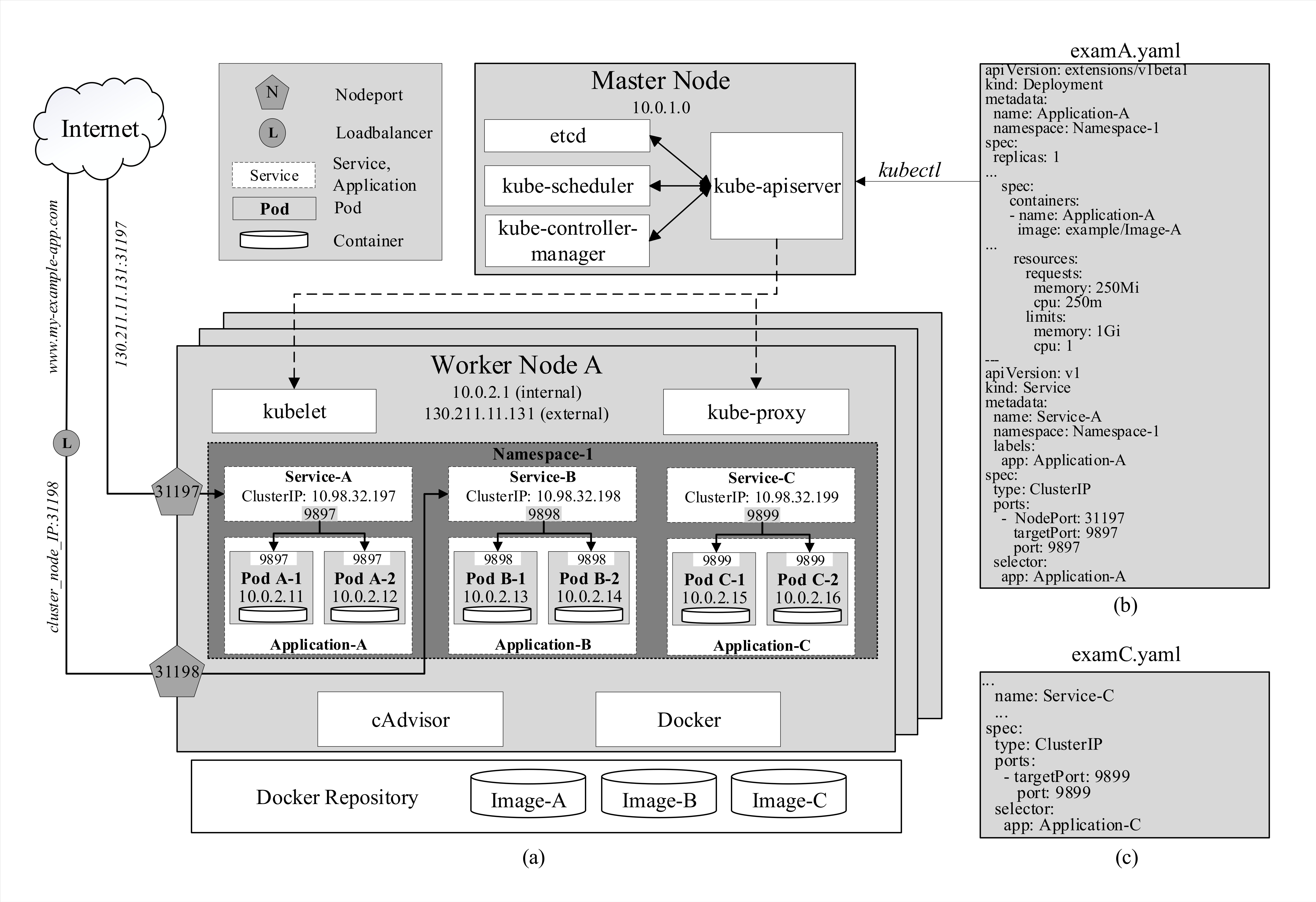
- kube-apiserver is the foundational management component that can communicate with all other components and every change to the cluster’s state has to go through it. kube-apiserver is also able to interact with worker nodes through kubelet, which will be discussed subsequently. Moreover, users can manage the cluster through the master by passing kubectl commands to kube-apiserver. In Figure 1, after running the command kubectl apply -f examA.yaml, the specifications in this file are passed through kube-apiserver to kube-controller-manager for replica-controlling and to kube-scheduler for scheduling pods on specific nodes. They will reply to kube-apiserver who will then signal to these nodes to create and run the pods. These configurations are stored in etcd as well.
3.1.2. Worker Node
- kubelet is a local agent that operates the pods as instructed by the master node’s kube-apiserver and keeps them healthy and alive.
- kube-proxy (KP) allows external and internal communication to pods of the cluster. As mentioned earlier, each pod is assigned a unique IP address upon creation. This IP addresses are used by KP to forward traffic from within and outside of the cluster to pods.
- Container Run-time: Kubernetes can be thought of as a specialized orchestration platform for containerized applications and thus requires container runtimes in all nodes including the master to actually run the containers. It can run on various runtimes including Docker, CRI-O and Containerd. Amongst those, Docker [8] is considered the most common one for Kubernetes. By packaging containers into lightweight images, Docker allows users to automate the deployment of containerized applications.
- CAdvisor (or Container Advisor) [35] is a tool that provides statistical running data of the local host or the containers such as resource usage. This data can be exported to kubelet or managing tools such as Prometheus for monitoring purposes. CAdvisor has native support for Docker and is installed in all nodes along with Docker to be able to monitor all nodes inside the cluster.
3.2. Kubernetes Service
- ClusterIP is assigned to a service upon creation and stays constant throughout the lifetime of this service. ClusterIP can only be accessed internally. In Figure 1a, services A, B, and C are assigned with three different internal IP addresses and expose three service ports 9897, 9898, and 9899, respectively. For example, when the address 10.98.32.199:9899, which consists of the cluster IP and exposed port of Service-C, is hit within the cluster, traffic is automatically redirected to targetPort 9899 on containers of pods of Application-C as specified in the YAML file by the keyword selector in Figure 1c. The exact destination pod is chosen according to the selected strategy.
- NodePort is a reserved port by the service on each node that is running pods belonging to that service. In the example in Figure 1b, NodePort 31197 and service port 9897 are virtually coupled together. When traffic arrives at NodePort 31197 on node A, it is routed to Service A on port 9897. Then, similarly to the previous example, the traffic is, in turn, routed to pods A-1 and A-2 on targetPort 9897. This enables pods to be accessed from even outside the cluster. For instance, if node A’s external IP address 130.211.11.131 is accessible from the internet, by hitting the address 130.211.11.131:31197, users are actually sending requests to pods A-1 and A-2. However, it is obvious that directly accessing nodes’ IP addresses is not an efficient strategy.
- LoadBalanceris provided by specific cloud service providers. When the cluster is deployed on a cloud platform such as GCP [2], Azure [3] or AWS [1], it is provided with a load balancer that can be easily accessed externally with a URL (www.my-example-app.com). All traffic to this URL will be forwarded to nodes of the cluster on NodePort 31198 in a similar manner to the previous example as illustrated in Figure 1a.
4. Horizontal Pod Autoscaling
4.1. Kubernetes Resource Metrics
4.2. Prometheus Custom Metrics
4.3. Readiness Probe
5. Performance Evaluations
5.1. Experimental Setups
5.2. Experimental Results
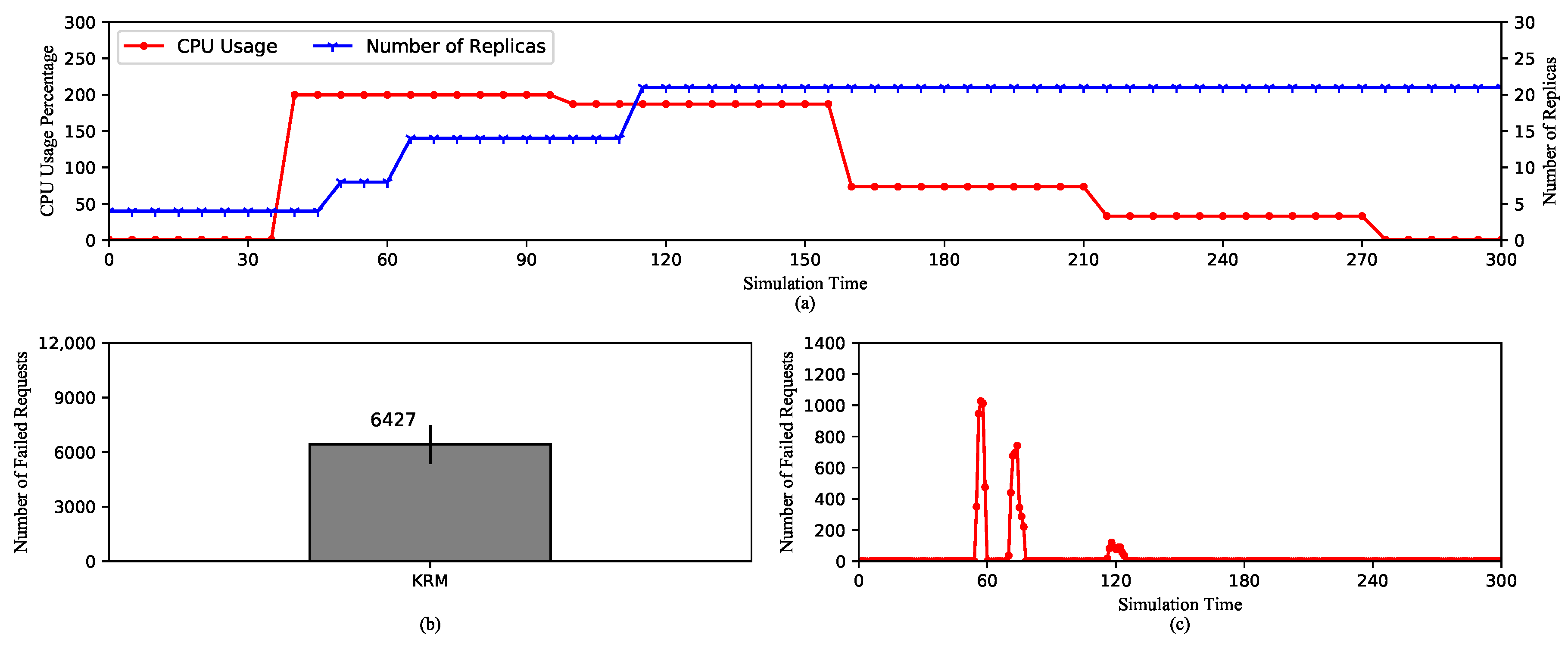
5.2.1. HPA Performances with Default Kubernetes Resource Metrics
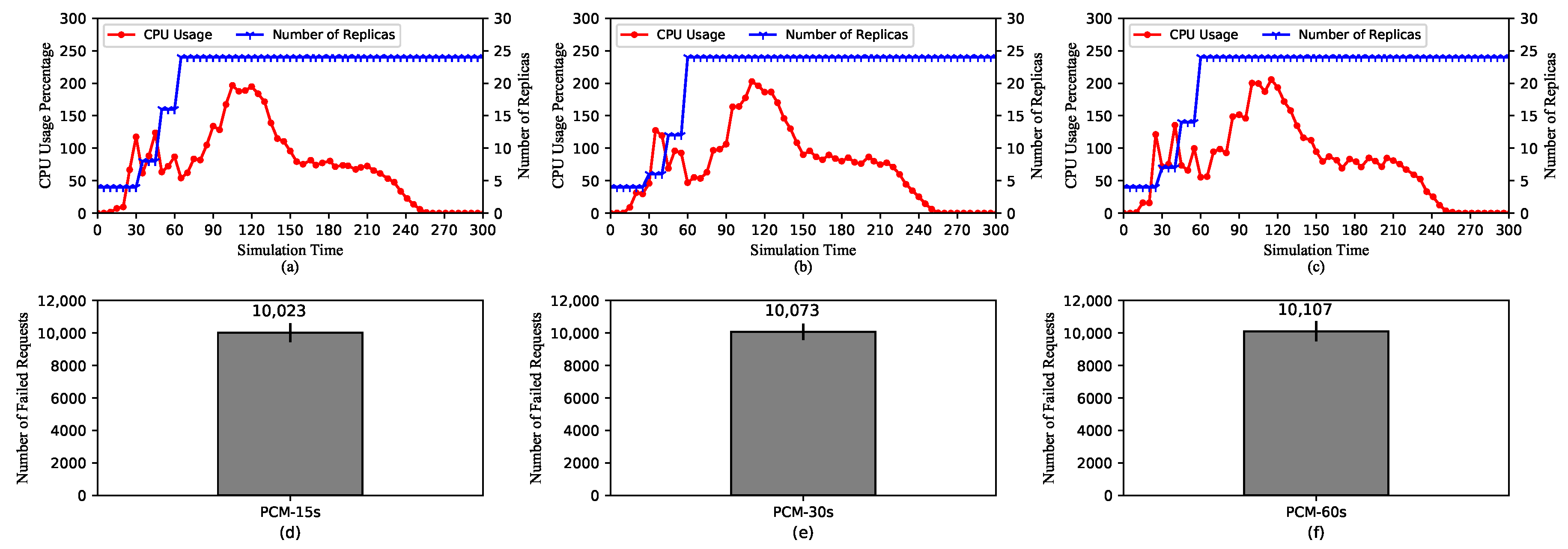
5.2.2. HPA Performances with Default Kubernetes Resource Metrics and Different Scraping Periods
5.2.3. HPA Performances with Prometheus Custom Metrics
5.2.4. HPA Performances with Prometheus Custom Metrics and Different Scraping Periods
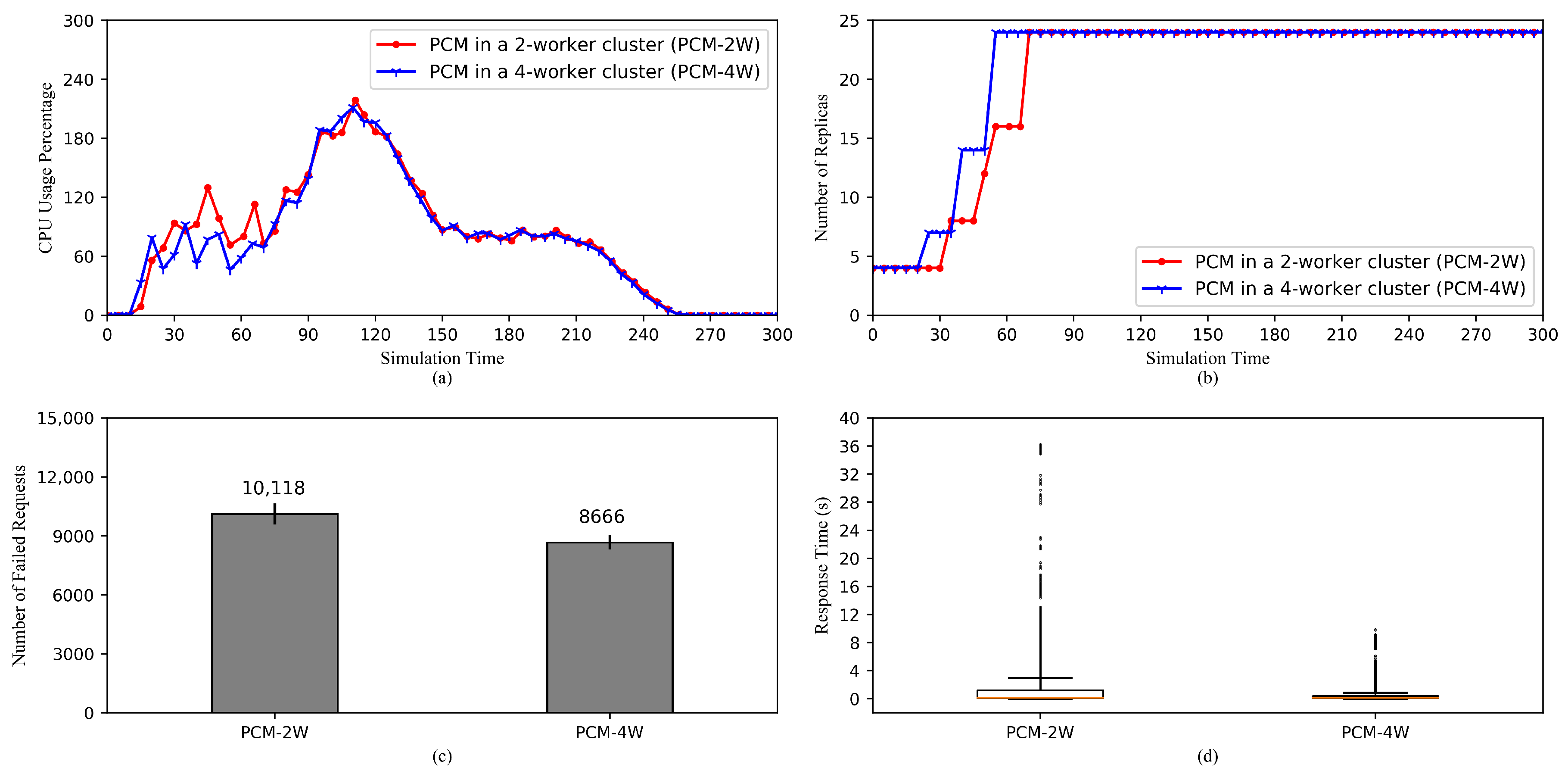
5.2.5. Comparison of HPA Performances in a 2-Worker Cluster and a 4-Worker Cluster
5.2.6. Comparison of HPA Performances with Different Custom Metrics
5.2.7. Comparison of HPA Performances with and without Readiness Probe
5.3. Discussion
- On KRM and PCM: KRM only reports values of metrics and is able to change only once every scraping cycle as opposed to PCM, which are able to maintain the trend of metrics’ values even during the middle of a scraping cycle or if there are missing data points. As a direct consequence, KRM expands the replica set slower and mostly to a smaller number of replicas compared to PCM. The advantage of this behavior is obviously less resource consumption. On the other hand, when under high load pods could be crashing or becoming unavailable. Therefore, we suggest KRM for applications with more stable loads such as video processing services. In this case, the number of requests from viewers is usually small as it takes at least a few minutes to a few hours for a video. On the contrary, PCM is more suitable for applications with frequent changes in metrics. For instance, e-commerce websites may experience continuous surges in a few hours during a sale event, thus require fast system reactions.
- On the scraping period: Adjustments to the scraping period of PCM do not strongly affect the performance of HPA. Therefore, a longer period can be set to reduce the amount of resource used for pulling the metrics. However, it is worth noting that a overly long period can cause imprecision in calculating the metrics. Regarding KRM, the scraping period has a significant influence on the performance of HPA. A longer period can reduce the amount of resource allocated for new pods, but it can cause decreased quality of service. Therefore, the scraping period should be carefully chosen having considered the type of service and the capability of the cluster.
- On the cluster size: It is obvious that a 4-worker cluster has more computational power, which allows it to perform HPA operations faster, than a 2-worker cluster, assuming workers of the two clusters are identical in terms of computational capabilities. In addition, the communicational capability of the 4-worker cluster is superior to the 2-worker cluster. This results in the difference in request response time of the two clusters. However, even if the 2-worker cluster has equal computational and communicational power, it is safer to spread pods to a wider cluster as half of the pods can become unavailable when a node crashes, compared to a forth of the pods in the case of the 4-worker cluster.
- On HPA with different custom metrics: Prometheus enables the use of custom metrics such as HTTP request rate to meet specific demands. Especially combining multiple metrics together can also increase the effectiveness of HPA as changes in any individual metric will cause scaling reactions. However, as a downside, this may result in waste of resource. Therefore, metrics, or combinations of metrics, should be chosen according to the type of the application. For instance, a gaming application may have various request sizes. Requests to move a character around the map are small in size but their number can be numerous. Thus, the request rate should be considered, so that each request can be quickly served, which reduces the “lagging” effect and improves the overall gaming experience. On the other hand, requests to load new locations’ maps are heavy but small in number. Here, computational requirements grow significantly higher, which indicates HPA should scale based on CPU and memory usage. In short, Custom Metrics enable applications to consider various factors such as the number of requests, latency, and bandwidth for efficient horizontal autoscaling.
- On Readiness Probe: It is a powerful feature from Kubernetes to prevent requests from being routed to unready pods, which will reject the requests. However, routing a number of requests to existing pods can cause the rest of the requests to have significantly longer response time. Therefore, between keeping the incoming requests alive or letting them fail and expecting re-requests, one should be chosen carefully based on balancing between system resources and QoS requirements.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Amazon Web Services. Available online: https://aws.amazon.com (accessed on 23 June 2020).
- Google Cloud Platform. Available online: https://cloud.google.com (accessed on 23 June 2020).
- Microsoft Azure. Available online: https://azure.microsoft.com (accessed on 23 June 2020).
- Pahl, C.; Brogi, A.; Soldani, J.; Jamshidi, P. Cloud Container Technologies: A State-of-the-Art Review. IEEE Trans. Cloud Comput. 2017, 7, 677–692. [Google Scholar] [CrossRef]
- He, S.; Guo, L.; Guo, Y.; Wu, C.; Ghanem, M.; Han, R. Elastic application container: A lightweight approach for cloud resource provisioning. In Proceedings of the 2012 IEEE 26th International Conference on Advanced Information Networking and Applications, Fukuoka, Japan, 26–29 March 2012; pp. 15–22. [Google Scholar] [CrossRef]
- Dua, R.; Raja, A.R.; Kakadia, D. Virtualization vs containerization to support PaaS. In Proceedings of the 2014 IEEE International Conference on Cloud Engineering, Boston, MA, USA, 11–14 March 2014; pp. 610–614. [Google Scholar] [CrossRef]
- Pahl, C. Containerization and the PaaS Cloud. IEEE Cloud Comput. 2015, 2, 24–31. [Google Scholar] [CrossRef]
- Docker. Available online: https://www.docker.com (accessed on 23 June 2020).
- Amazon Elastic Container Service. Available online: https://aws.amazon.com/ecs (accessed on 23 June 2020).
- Red Hat OpenShift Container Platform. Available online: https://www.openshift.com/products/container-platform (accessed on 23 June 2020).
- Kubernetes. Available online: www.kubernetes.io (accessed on 23 June 2020).
- Chang, C.C.; Yang, S.R.; Yeh, E.H.; Lin, P.; Jeng, J.Y. A Kubernetes-based monitoring platform for dynamic cloud resource provisioning. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Prometheus. Available online: https://prometheus.io (accessed on 23 June 2020).
- Cloud Native Computing Foundation. Available online: https://www.cncf.io (accessed on 23 June 2020).
- Thurgood, B.; Lennon, R.G. Cloud computing with Kubernetes cluster elastic scaling. ICPS Proc. 2019, 1–7. [Google Scholar] [CrossRef]
- Rattihalli, G.; Govindaraju, M.; Lu, H.; Tiwari, D. Exploring potential for non-disruptive vertical auto scaling and resource estimation in kubernetes. In Proceedings of the IEEE International Conference on Cloud Computing (CLOUD), Milan, Italy, 8–13 July 2019; pp. 33–40. [Google Scholar] [CrossRef]
- Song, M.; Zhang, C.; Haihong, E. An auto scaling system for API gateway based on Kubernetes. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 109–112. [Google Scholar] [CrossRef]
- Jin-Gang, Y.; Ya-Rong, Z.; Bo, Y.; Shu, L. Research and application of auto-scaling unified communication server based on Docker. In Proceedings of the 2017 10th International Conference on Intelligent Computation Technology and Automation (ICICTA), Changsha, China, 9–10 October 2017; pp. 152–156. [Google Scholar] [CrossRef]
- Townend, P.; Clement, S.; Burdett, D.; Yang, R.; Shaw, J.; Slater, B.; Xu, J. Improving data center efficiency through holistic scheduling in kubernetes. In Proceedings of the 2019 IEEE International Conference on Service-Oriented System Engineering (SOSE), Newark, CA, USA, 4–9 April 2019; pp. 156–166. [Google Scholar] [CrossRef]
- Rossi, F. Auto-scaling policies to adapt the application deployment in Kubernetes. CEUR Workshop Proc. 2020, 2575, 30–38. [Google Scholar]
- Balla, D.; Simon, C.; Maliosz, M. Adaptive scaling of Kubernetes pods. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium 2020: Management in the Age of Softwarization and Artificial Intelligence, NOMS 2020, Budapest, Hungary, 20–24 April 2020; pp. 8–12. [Google Scholar] [CrossRef]
- Casalicchio, E.; Perciballi, V. Auto-scaling of containers: The impact of relative and absolute metrics. In Proceedings of the 2017 IEEE 2nd International Workshops on Foundations and Applications of Self* Systems (FAS*W), Tucson, AZ, USA, 18–22 September 2017; pp. 207–214. [Google Scholar] [CrossRef]
- Casalicchio, E. A study on performance measures for auto-scaling CPU-intensive containerized applications. Clust. Comput. 2019, 22, 995–1006. [Google Scholar] [CrossRef]
- Taherizadeh, S.; Grobelnik, M. Key influencing factors of the Kubernetes auto-scaler for computing-intensive microservice-native cloud-based applications. Adv. Eng. Softw. 2020, 140, 102734. [Google Scholar] [CrossRef]
- Santos, J.; Wauters, T.; Volckaert, B.; De Turck, F. Towards network-Aware resource provisioning in kubernetes for fog computing applications. In Proceedings of the 2019 IEEE Conference on Network Softwarization (NetSoft), Paris, France, 24–28 June 2019; pp. 351–359. [Google Scholar] [CrossRef]
- Santos, J.; Wauters, T.; Volckaert, B.; Turck, F.D. Resource provisioning in fog computing: From theory to practice. Sensors 2019, 19, 2238. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.S.; Yen, L.H. Auto-scaling in Kubernetes-based Fog Computing platform. In International Computer Symposium; Springer: Singapore, 2018; pp. 338–345. [Google Scholar] [CrossRef]
- Heapster. Available online: https://github.com/kubernetes-retired/heapster (accessed on 23 June 2020).
- InfluxDB. Available online: https://www.influxdata.com (accessed on 23 June 2020).
- Grafana. Available online: https://grafana.com (accessed on 23 June 2020).
- Apache JMeter. Available online: https://jmeter.apache.org (accessed on 23 June 2020).
- Syu, Y.; Wang, C.M. modeling and forecasting http requests-based Cloud workloads using autoregressive artificial Neural Networks. In Proceedings of the 2018 3rd International Conference on Computer and Communication Systems (ICCCS), Nagoya, Japan, 27–30 April 2018; pp. 21–24. [Google Scholar] [CrossRef]
- Dickel, H.; Podolskiy, V.; Gerndt, M. Evaluation of autoscaling metrics for (stateful) IoT gateways. In Proceedings of the 2019 IEEE 12th Conference on Service-Oriented Computing and Applications (SOCA), Kaohsiung, Taiwan, 18–21 November 2019; pp. 17–24. [Google Scholar] [CrossRef]
- Prometheus Operator. Available online: https://github.com/coreos/prometheus-operator (accessed on 23 June 2020).
- CAdvisor. Available online: https://github.com/google/cadvisor (accessed on 23 June 2020).
- Prometheus Adapter. Available online: https://github.com/DirectXMan12/k8s-prometheus-adapter (accessed on 23 June 2020).
- Gatling. Available online: https://gatling.io/open-source (accessed on 23 June 2020).









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.-T.; Yeom, Y.-J.; Kim, T.; Park, D.-H.; Kim, S. Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration. Sensors 2020, 20, 4621. https://doi.org/10.3390/s20164621
Nguyen T-T, Yeom Y-J, Kim T, Park D-H, Kim S. Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration. Sensors. 2020; 20(16):4621. https://doi.org/10.3390/s20164621
Chicago/Turabian StyleNguyen, Thanh-Tung, Yu-Jin Yeom, Taehong Kim, Dae-Heon Park, and Sehan Kim. 2020. "Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration" Sensors 20, no. 16: 4621. https://doi.org/10.3390/s20164621
APA StyleNguyen, T.-T., Yeom, Y.-J., Kim, T., Park, D.-H., & Kim, S. (2020). Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration. Sensors, 20(16), 4621. https://doi.org/10.3390/s20164621