Development of Real-Time Hand Gesture Recognition for Tabletop Holographic Display Interaction Using Azure Kinect



Abstract
1. Introduction
2. Background Theory
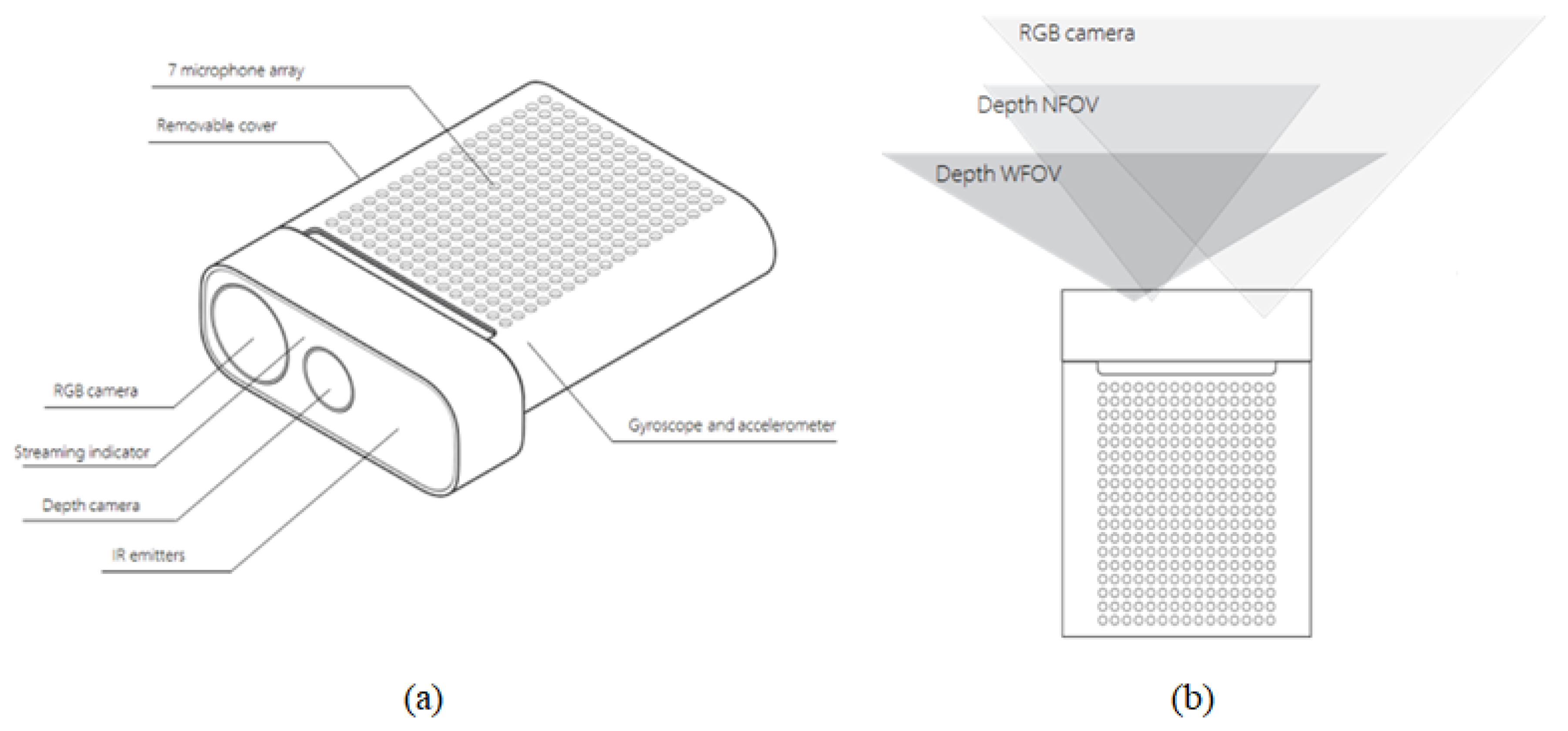
2.1. Azure Kinect
2.2. Gesture Interaction
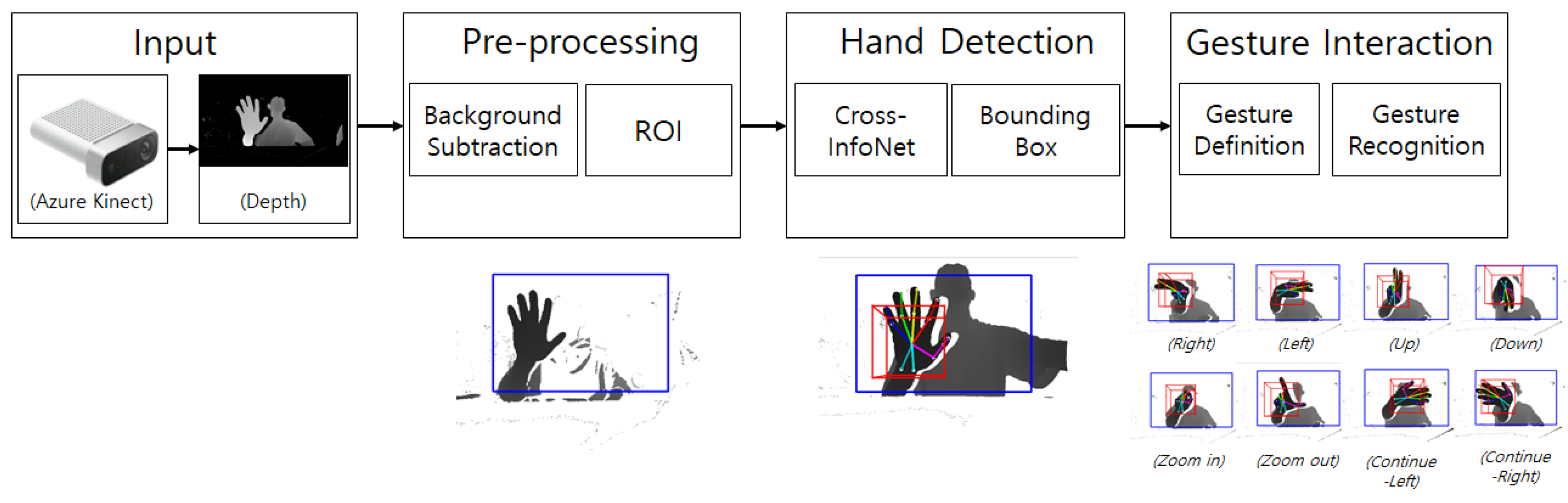
3. Proposed Method
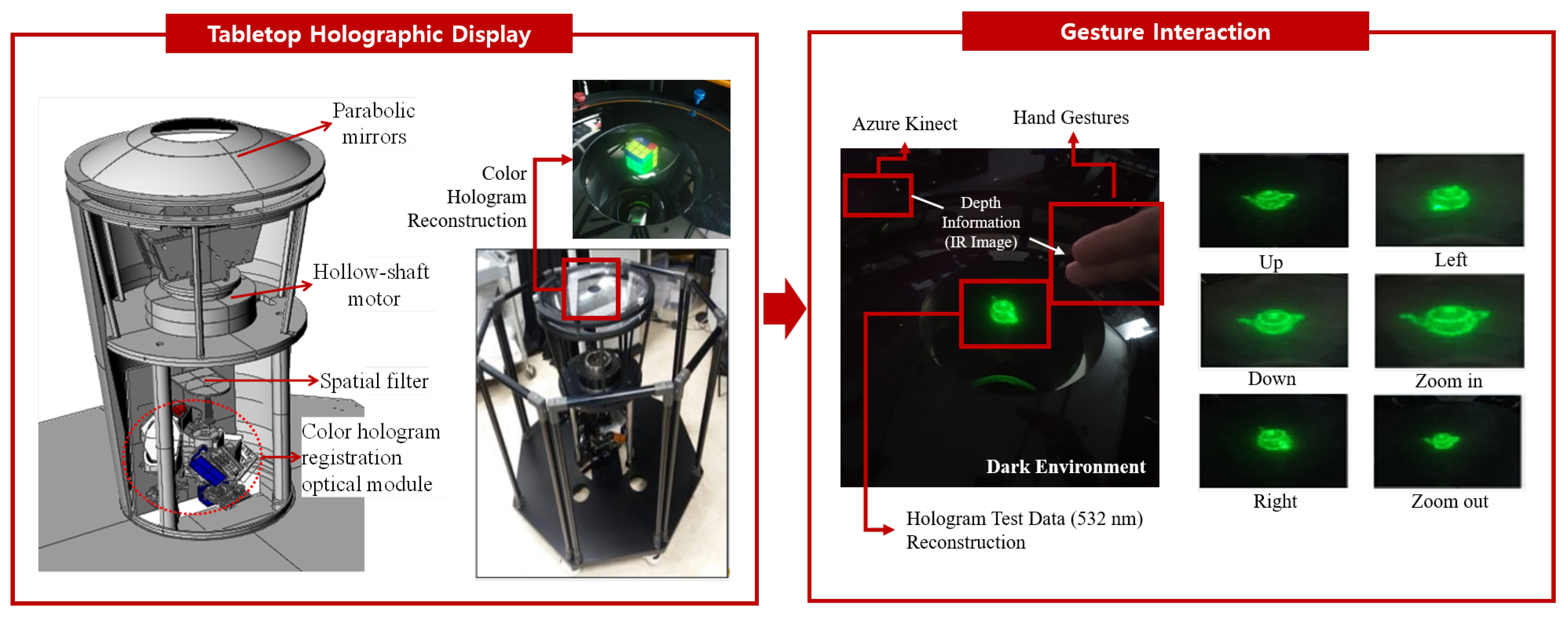
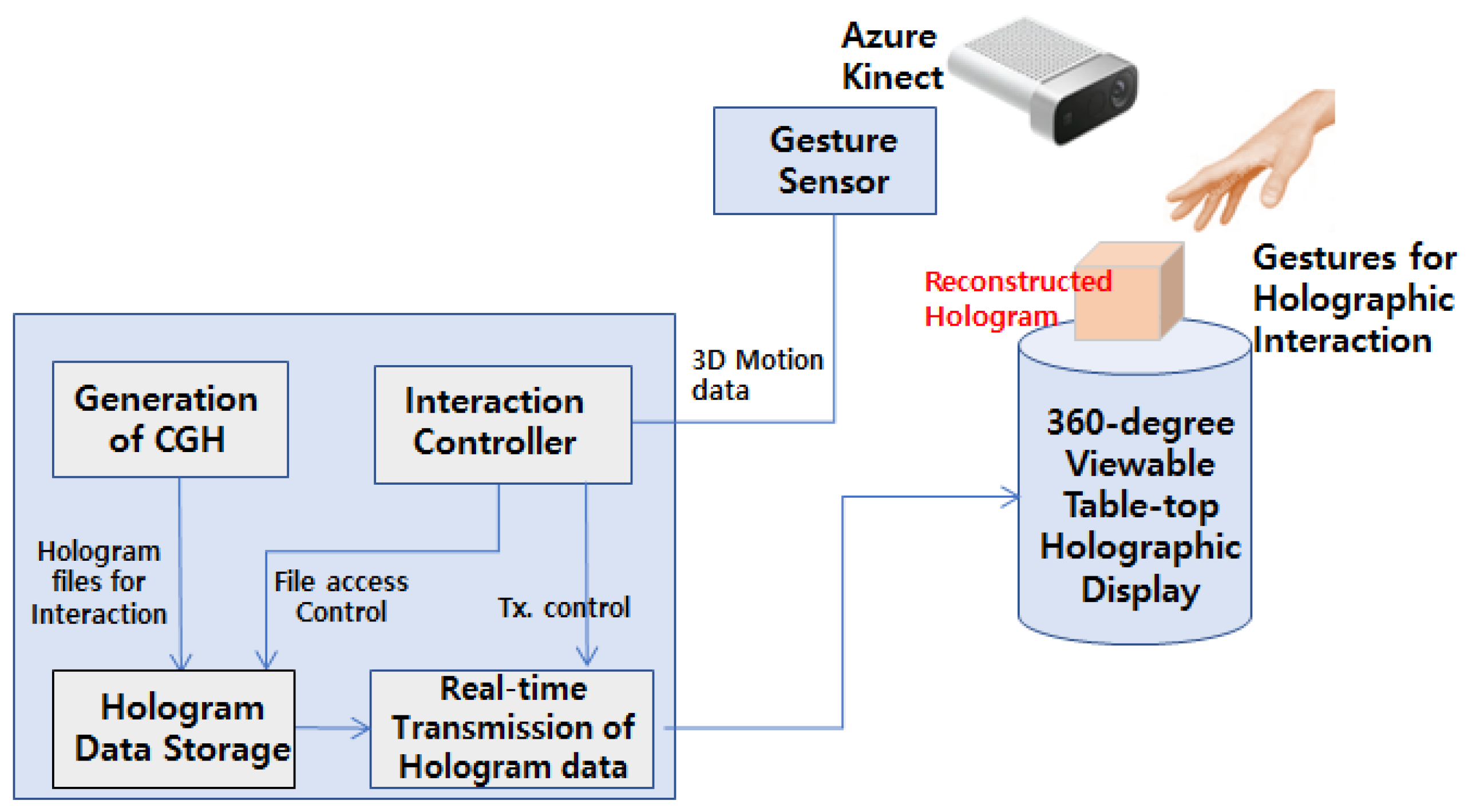
3.1. System Configuration
3.2. Proposed Gesture Interaction
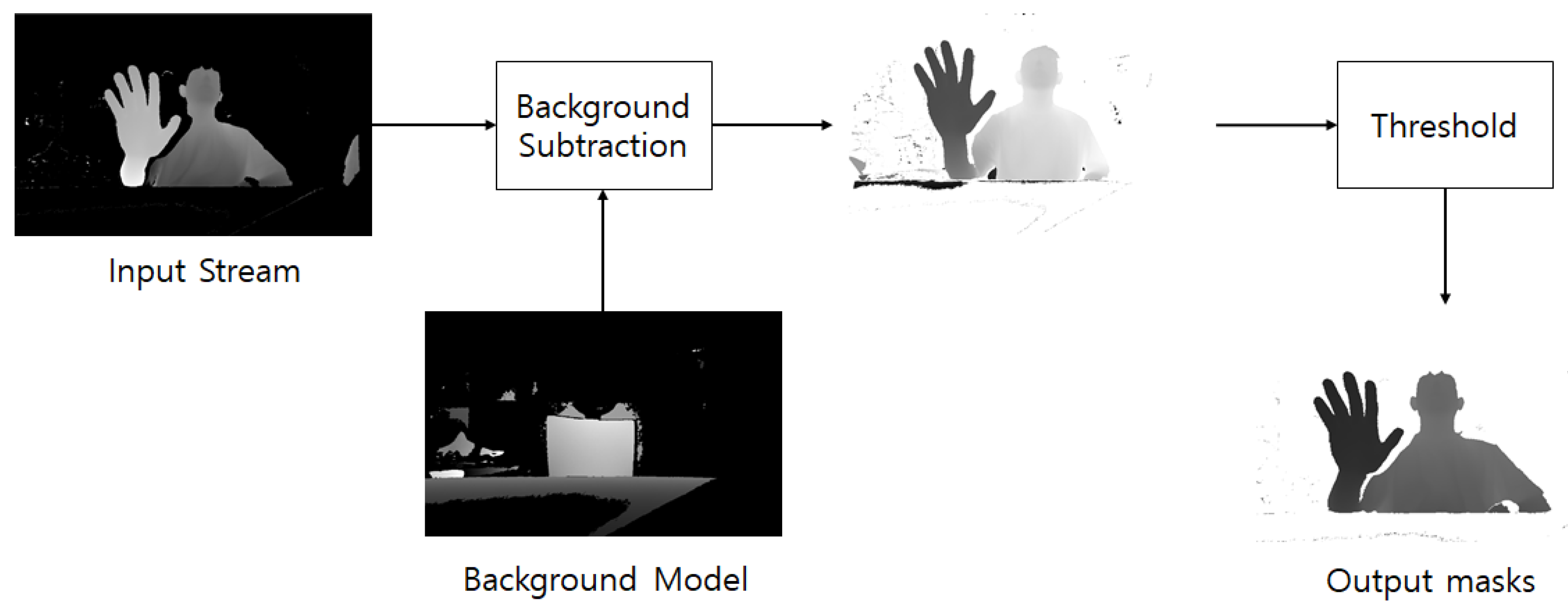
3.2.1. Background Subtraction
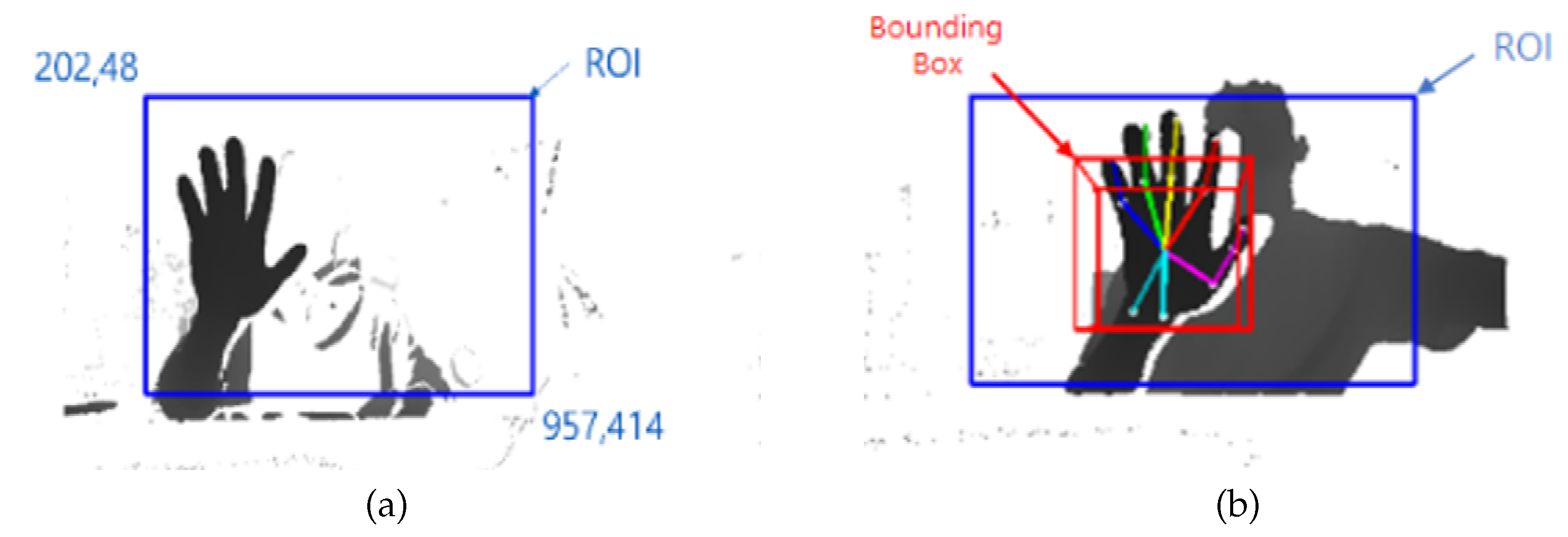
3.2.2. Set ROI
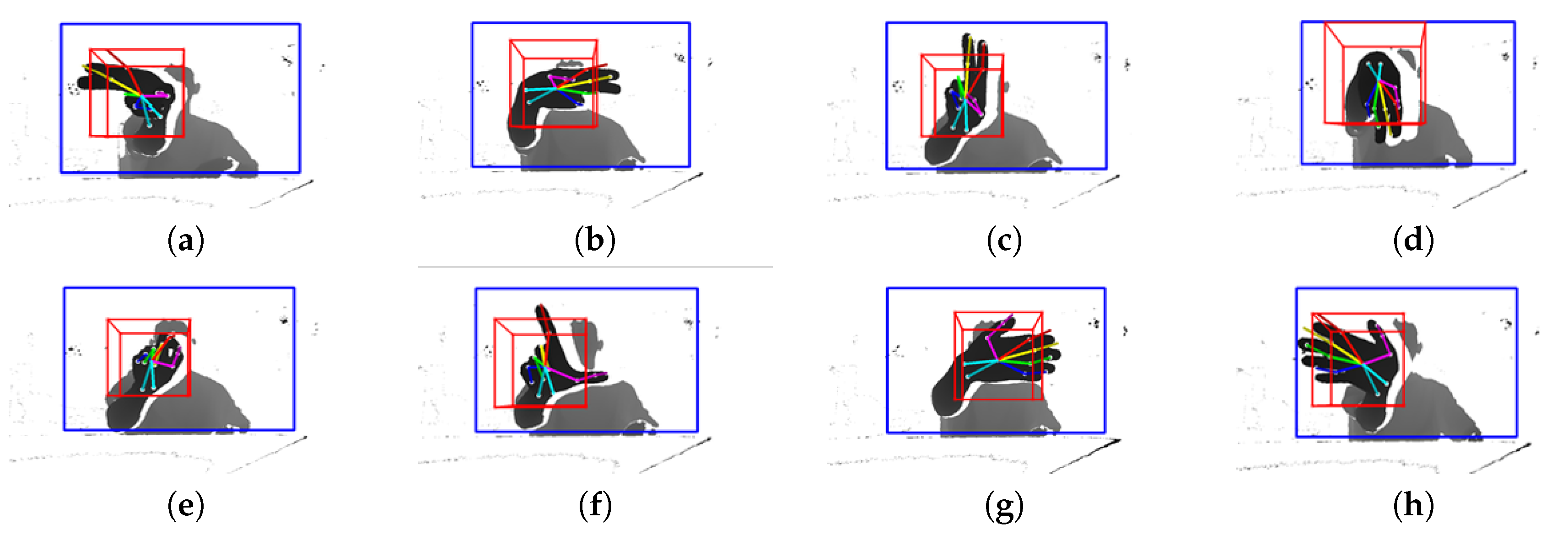
3.2.3. Hand Detection and Bounding Box
3.2.4. Gesture Definition and Gesture Recognition
4. Experiment Method
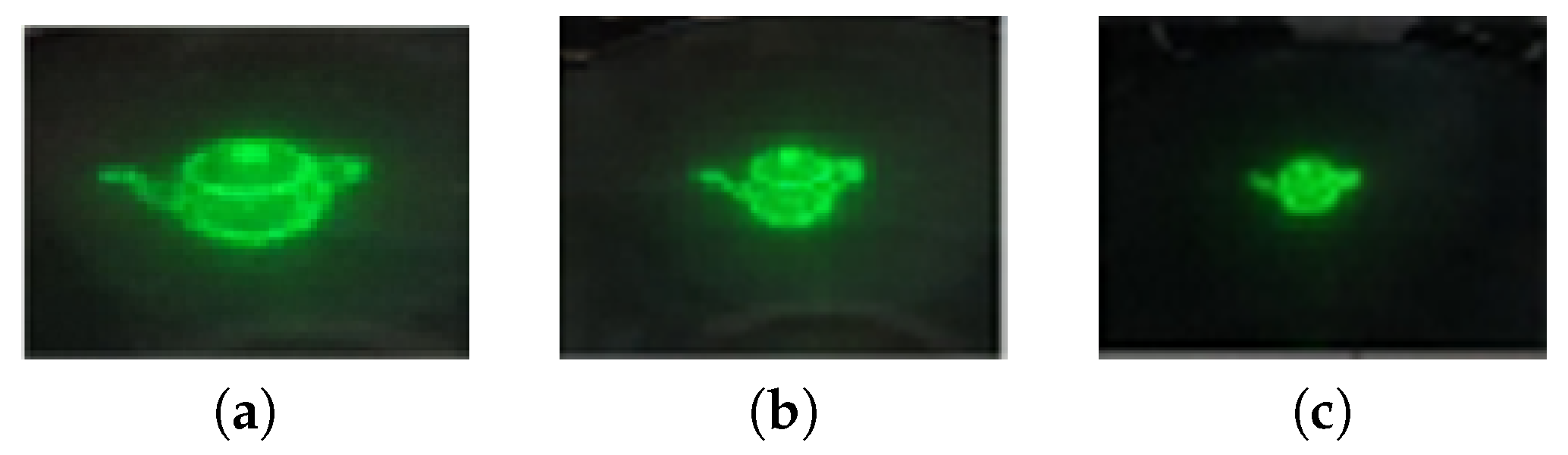
5. Results and Discussions
5.1. Results
5.2. Discussions
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust part-based hand gesture recognition using kinect sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Biswas, K.K.; Basu, S.K. Gesture recognition using microsoft kinect. In Proceeding of the 5th International Conference on Automation, Robotics and Applications, James Cook Hotel, Wellington, New Zealand, 6–8 December 2011; pp. 100–103. [Google Scholar]
- Li, Y. Hand gesture recognition using Kinect. In Proceeding of the 2012 IEEE International Conference on Computer Science and Automation Engineering, Zhangjiajie, China, 25–27 May 2012; pp. 196–199. [Google Scholar]
- Marin, G.; Dominio, F.; Zanuttigh, P. Hand gesture recognition with leap motion and kinect devices. In Proceeding of the 2014 IEEE International Conference on Image Processing, La Defense, Paris, France, 27–30 October 2014; pp. 1565–1569. [Google Scholar]
- Patsadu, O.; Nukoolkit, C.; Watanapa, B. Human gesture recognition using Kinect camera. In Proceeding of the 2012 Ninth International Conference on Computer Science and Software Engineering, Bangkok, Thailand, 30 May–1 June 2012; pp. 28–32. [Google Scholar]
- Guzsvinecz, T.; Szucs, V.; Sik-Lanyi, C. Suitability of the Kinect sensor and Leap Motion controller—A literature review. Sensors 2019, 19, 1072. [Google Scholar] [CrossRef] [PubMed]
- He, G.F.; Kang, S.K.; Song, W.C.; Jung, S.T. Real-time gesture recognition using 3D depth camera. In Proceeding of the 2011 IEEE 2nd International Conference on Software Engineering and Service Science, Beijing, China, 15 July 2011; pp. 187–190. [Google Scholar]
- Ito, A.; Nakada, K. UI Design based on Traditional Japanese Gesture. In Proceeding of the 2019 10th IEEE International Conference on Cognitive Infocommunications, Naples, Italy, 23–25 October 2019; pp. 85–90. [Google Scholar]
- Ferri, J.; Llinares Llopis, R.; Moreno, J.; Ibañez Civera, J.; Garcia-Breijo, E. A wearable textile 3D gesture recognition sensor based on screen-printing technology. Sensors 2019, 19, 5068. [Google Scholar] [CrossRef] [PubMed]
- Zsolczay, R.; Brown, R.; Maire, F.; Turkay, S. Vague gesture control: Implications for burns patients. In Proceeding of the 31st Australian Conference on Human-Computer-Interaction, Fremantle, Australia, 3–5 December 2019; pp. 524–528. [Google Scholar]
- Jiang, L.; Xia, M.; Liu, X.; Bai, F. Givs: Fine-Grained Gesture Control for Mobile Devices in Driving Environments. IEEE Access 2020, 8, 49229–49243. [Google Scholar] [CrossRef]
- Streeter, L.; Gauch, J. Detecting Gestures Through a Gesture-Based Interface to Teach Introductory Programming Concepts. In Proceeding of the International Conference on Human-Computer Interaction, Vienna, Austria, 29–30 July 2020; pp. 137–153. [Google Scholar]
- Bakken, J.P.; Varidireddy, N.; Uskov, V.L. Smart Universities: Gesture Recognition Systems for College Students with Disabilities. In Proceeding of the 7th International KES Conference on Smart Education and e-Learning, Split, Croatia, 17–19 June 2020; pp. 393–411. [Google Scholar]
- Kim, J.; Lim, Y.; Hong, K.; Kim, H.; Kim, H.E.; Nam, J.; Park, J.; Hahn, J.; Kim, Y.J. Electronic tabletop holographic display: Design, implementation, and evaluation. Appl. Sci. 2019, 9, 705. [Google Scholar] [CrossRef]
- Lim, Y.; Hong, K.; Kim, H.E.; Chang, E.Y.; Lee, S.; Kim, T.; Nam, J.; Choo, H.G.; Kim, J.; Hahn, J. 360-degree tabletop electronic holographic display. Opt. Express 2016, 24, 24999–25009. [Google Scholar] [CrossRef] [PubMed]
- Chang, E.Y.; Choi, J.; Lee, S.; Kwon, S.; Yoo, J.; Park, M.; Kim, J. 360-degree color hologram generation for real 3D objects. Appl. Opt. 2018, 57, A91–A100. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, X.S.; Brun, L.; Lézoray, O.; Bougleux, S. A neural network based on SPD manifold learning for skeleton-based hand gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12036–12045. [Google Scholar]
- Wan, C.; Probst, T.; Gool, L.V.; Yao, A. Self-supervised 3d hand pose estimation through training by fitting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10853–10862. [Google Scholar]
- Du, K.; Lin, X.; Sun, Y.; Ma, X. Crossinfonet: Multi-task information sharing based hand pose estimation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9896–9905. [Google Scholar]
- Wang, C.; Liu, Z.; Chan, S.C. Superpixel-based hand gesture recognition with kinect depth camera. IEEE Trans. Multimed. 2014, 17, 29–39. [Google Scholar] [CrossRef]
- Supancic, J.S.; Rogez, G.; Yang, Y.; Shotton, J.; Ramanan, D. Depth-based hand pose estimation: Data, methods, and challenges. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1868–1876. [Google Scholar]
- Joo, S.I.; Weon, S.H.; Choi, H.I. Real-time depth-based hand detection and tracking. Sci. World J. 2014, 2014, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Fujimura, K. Hand gesture recognition using depth data. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004; pp. 529–534. [Google Scholar]
- Poularakis, S.; Katsavounidis, I. Finger detection and hand posture recognition based on depth information. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, 4–9 May 2014; pp. 4329–4333. [Google Scholar]
- Ren, Z.; Meng, J.; Yuan, J. Depth camera based hand gesture recognition and its applications in human-computer-interaction. In Proceedings of the 2011 8th International Conference on Information, Communications Signal Processing, Singapore, 13–16 December 2011; pp. 1–5. [Google Scholar]
- Yu, M.; Kim, N.; Jung, Y.; Lee, S. A Frame Detection Method for Real-Time Hand Gesture Recognition Systems Using CW-Radar. Sensors 2020, 20, 2321. [Google Scholar] [CrossRef] [PubMed]
- Abavisani, M.; Joze, H.R.V.; Patel, V.M. Improving the performance of unimodal dynamic hand-gesture recognition with multimodal training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1165–1174. [Google Scholar]
- Lee, S.H.; Lee, G.C.; Yoo, J.; Kwon, S. Wisenetmd: Motion detection using dynamic background region analysis. Symmetry 2019, 11, 621. [Google Scholar] [CrossRef]
- Yin, Y.; Randall, D. Gesture spotting and recognition using salience detection and concatenated hidden markov models. In Proceedings of the 15th ACM on International conference on multimodal interaction, Coogee Bay Hotel, Sydney, Australia, 9–12 December 2013; pp. 489–494. [Google Scholar]
- Kim, J.H.; Hong, G.S.; Kim, B.G.; Dogra, D.P. deepGesture: Deep learning-based gesture recognition scheme using motion sensors. Displays 2018, 55, 38–45. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gesture | Left | Right | Up | Down | Zoom-In | Zoom-Out | Continue Left | Continue Right |
|---|---|---|---|---|---|---|---|---|
| Total Attempts | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| True Positive | 100 | 100 | 98 | 100 | 99 | 99 | 100 | 93 |
| False Positive | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| False Negative | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 7 |
| Precision | 100 | 100 | 100 | 100 | 99 | 99 | 100 | 100 |
| Recall | 100 | 100 | 98 | 100 | 100 | 100 | 100 | 93 |
| F1 score | 100 | 100 | 98.98 | 100 | 99.49 | 99.49 | 100 | 96.37 |
| Gesture | Left | Right | Up | Down | Zoom-in | Zoom-out | Continue Left | Continue Right |
|---|---|---|---|---|---|---|---|---|
| Total Attempts | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| True Positive | 94 | 91 | 100 | 98 | 99 | 99 | 93 | 88 |
| False Positive | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| False Negative | 6 | 9 | 0 | 2 | 0 | 0 | 7 | 12 |
| Precision | 100 | 100 | 100 | 100 | 99 | 99 | 100 | 100 |
| Recall | 94 | 91 | 100 | 98 | 100 | 100 | 93 | 88 |
| F1 score | 96.90 | 95.28 | 100 | 98.98 | 99.49 | 99.49 | 96.37 | 93.61 |
| Gesture | Left | Right | Up | Down | Zoom-In | Zoom-Out | Continue Left | Continue Right |
|---|---|---|---|---|---|---|---|---|
| Total Attempts | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| True Positive | 90 | 90 | 91 | 94 | 99 | 99 | 83 | 79 |
| False Positive | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| False Negative | 10 | 10 | 9 | 6 | 0 | 0 | 17 | 21 |
| Precision | 100 | 100 | 100 | 100 | 99 | 99 | 100 | 100 |
| Recall | 90 | 90 | 91 | 94 | 100 | 100 | 83 | 79 |
| F1 score | 94.73 | 94.73 | 95.28 | 96.90 | 99.49 | 99.49 | 90.71 | 88.26 |
| Distance | 35–50 cm | 50–60 cm | 60–70 cm |
|---|---|---|---|
| Precision | 0.99747 | 0.99747 | 0.99747 |
| Recall | 0.98872 | 0.95500 | 0.90875 |
| F1 score | 0.99307 | 0.97577 | 0.95104 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.; Kim, J.; Cho, S.; Kim, J.; Yoo, J.; Kwon, S. Development of Real-Time Hand Gesture Recognition for Tabletop Holographic Display Interaction Using Azure Kinect. Sensors 2020, 20, 4566. https://doi.org/10.3390/s20164566
Lee C, Kim J, Cho S, Kim J, Yoo J, Kwon S. Development of Real-Time Hand Gesture Recognition for Tabletop Holographic Display Interaction Using Azure Kinect. Sensors. 2020; 20(16):4566. https://doi.org/10.3390/s20164566
Chicago/Turabian StyleLee, Chanhwi, Jaehan Kim, Seoungbae Cho, Jinwoong Kim, Jisang Yoo, and Soonchul Kwon. 2020. "Development of Real-Time Hand Gesture Recognition for Tabletop Holographic Display Interaction Using Azure Kinect" Sensors 20, no. 16: 4566. https://doi.org/10.3390/s20164566
APA StyleLee, C., Kim, J., Cho, S., Kim, J., Yoo, J., & Kwon, S. (2020). Development of Real-Time Hand Gesture Recognition for Tabletop Holographic Display Interaction Using Azure Kinect. Sensors, 20(16), 4566. https://doi.org/10.3390/s20164566