Learning Soft Mask Based Feature Fusion with Channel and Spatial Attention for Robust Visual Object Tracking



Abstract
1. Introduction
- We propose a soft mask feature fusion mechanism to highlight the full target region compared to the background region. It helps the network to efficiently learn the target representation.
- A channel attentional mechanism is proposed to give the discriminative channels more importance.
- A spatial attention mechanism is proposed to emphasize the discriminative spatial locations within the target.
- Soft mask feature fusion with dual attention is integrated within a Siamese tracking framework using a skip connection to enhance the tracker ability to better discriminate target from the background.
- The proposed SCS-Siam tracker has shown excellent performance compared to 39 existing trackers over five benchmark datasets.
2. Related Work
2.1. Deep Feature-Based Trackers
2.2. Siamese Network-Based Trackers
2.3. Attention Mechanism-Based Trackers
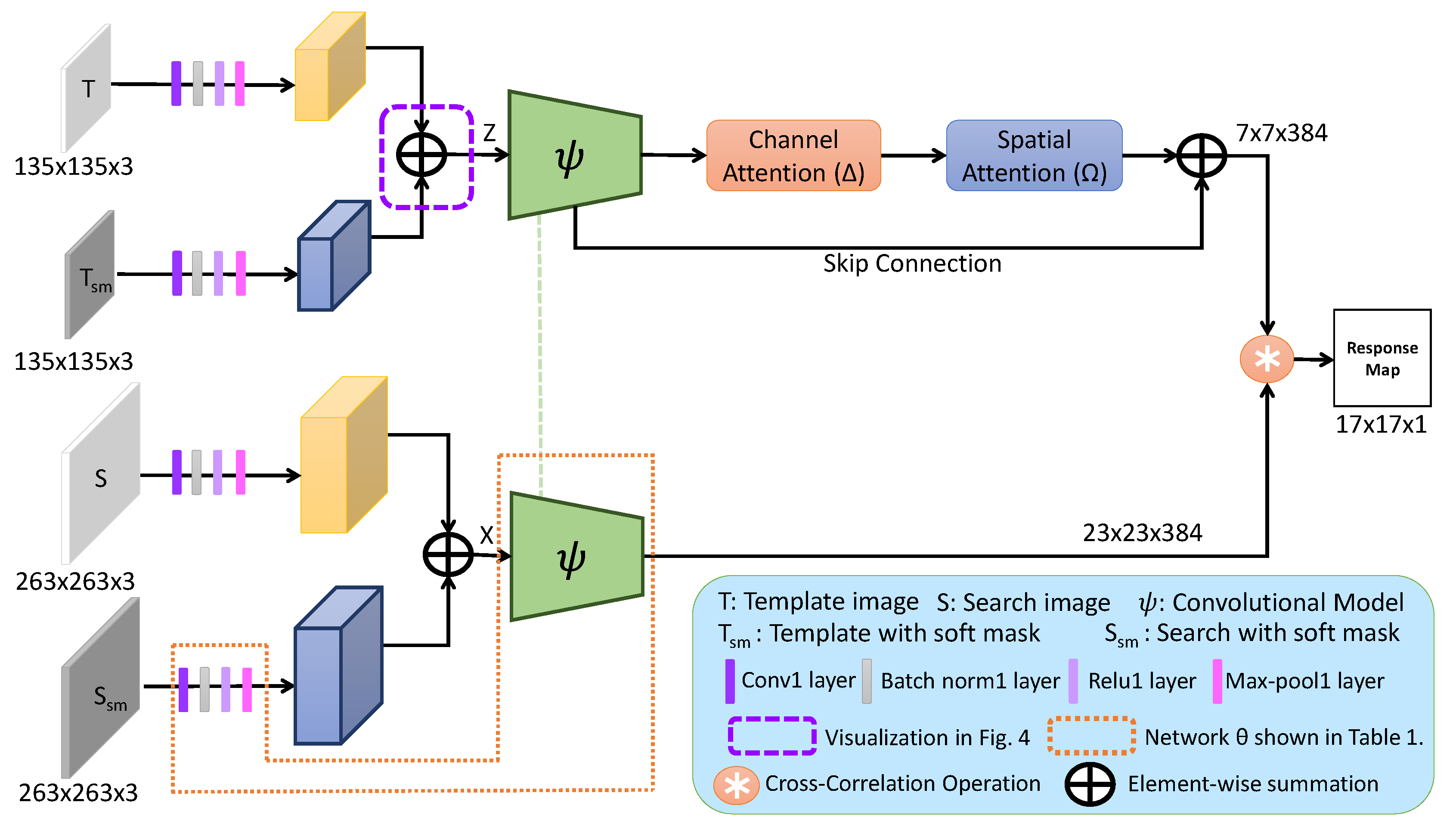
3. Proposed SCS-Siam Network
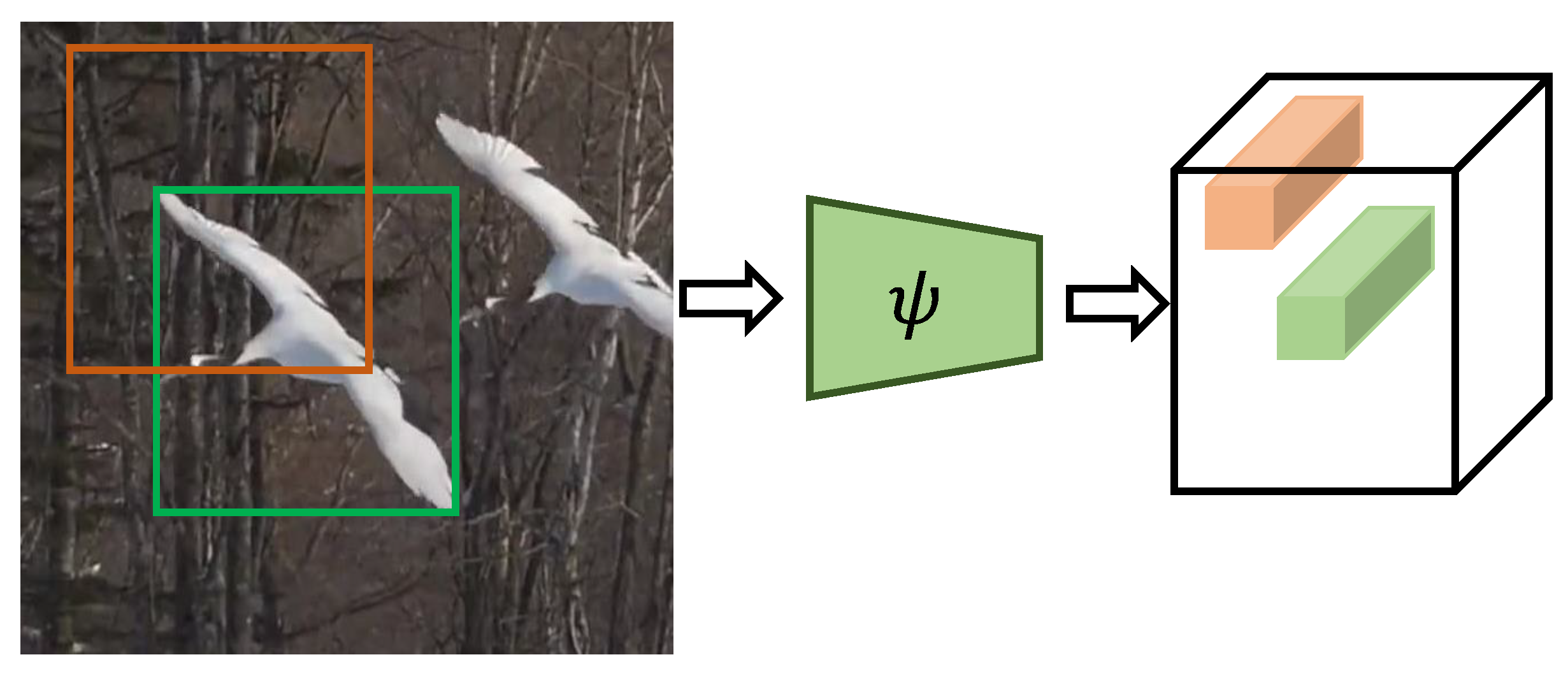
3.1. Baseline SiameseFC Tracker
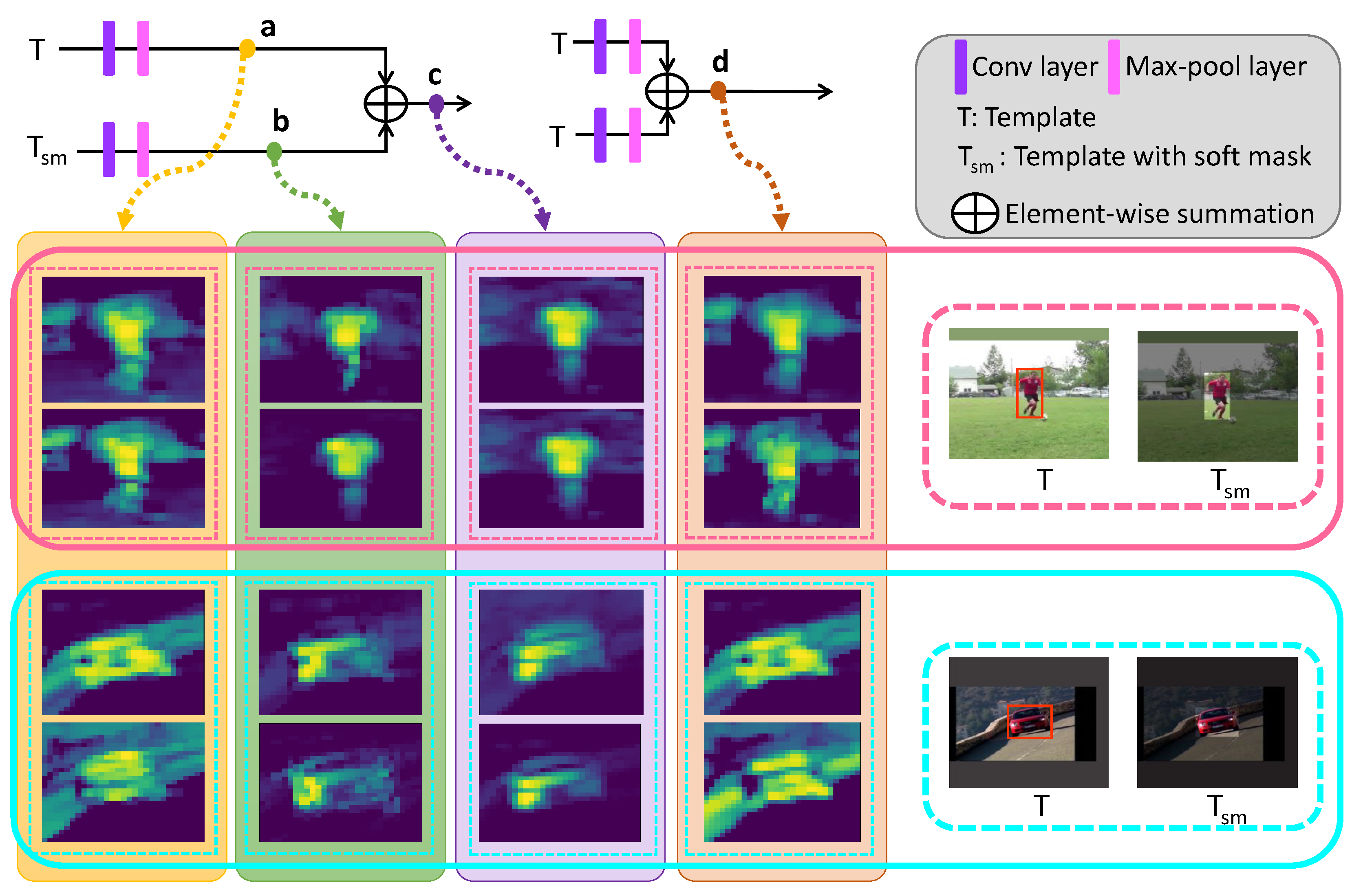
3.2. Soft-Mask Feature Fusion
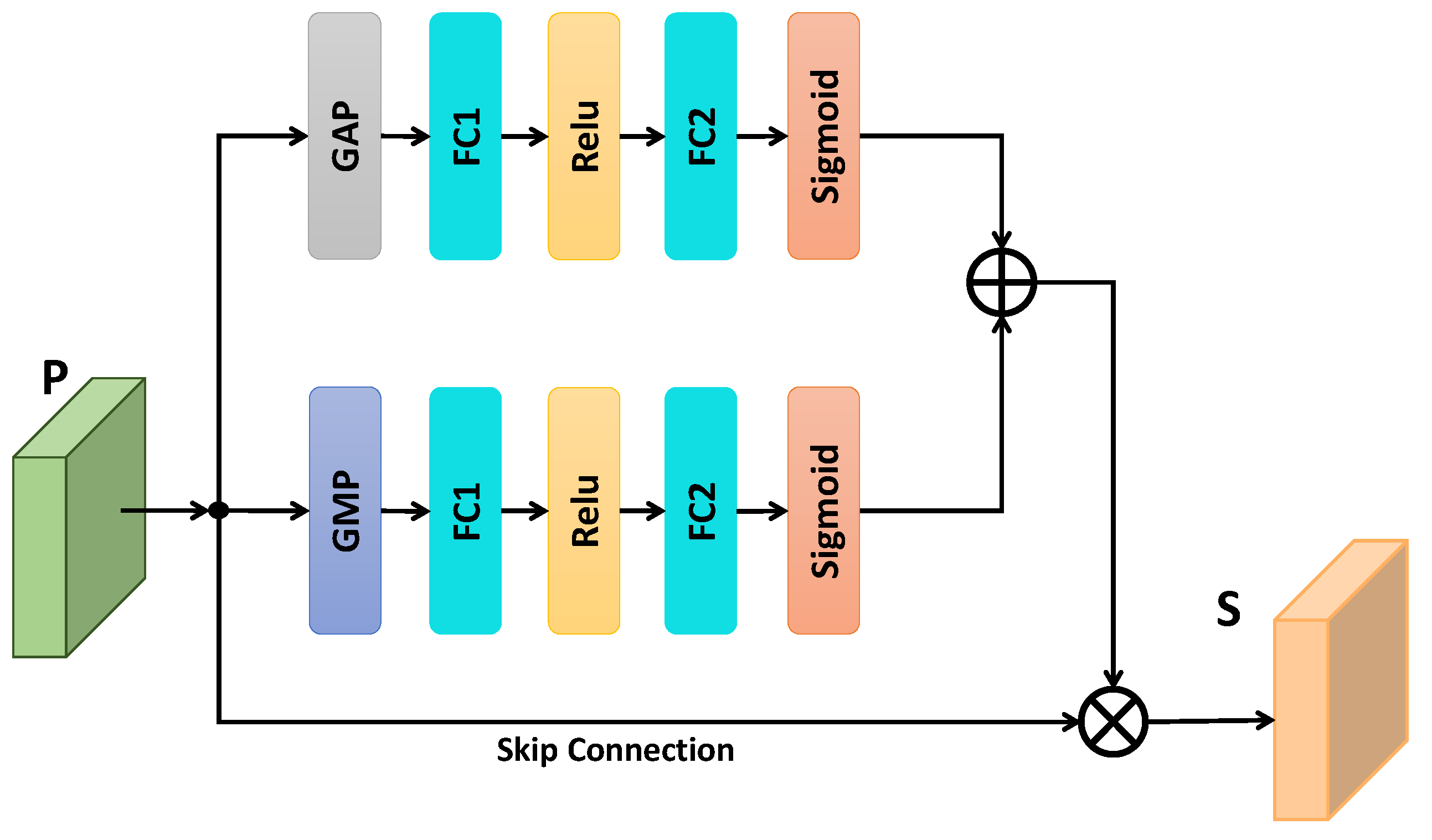
3.3. Channel Attention Module
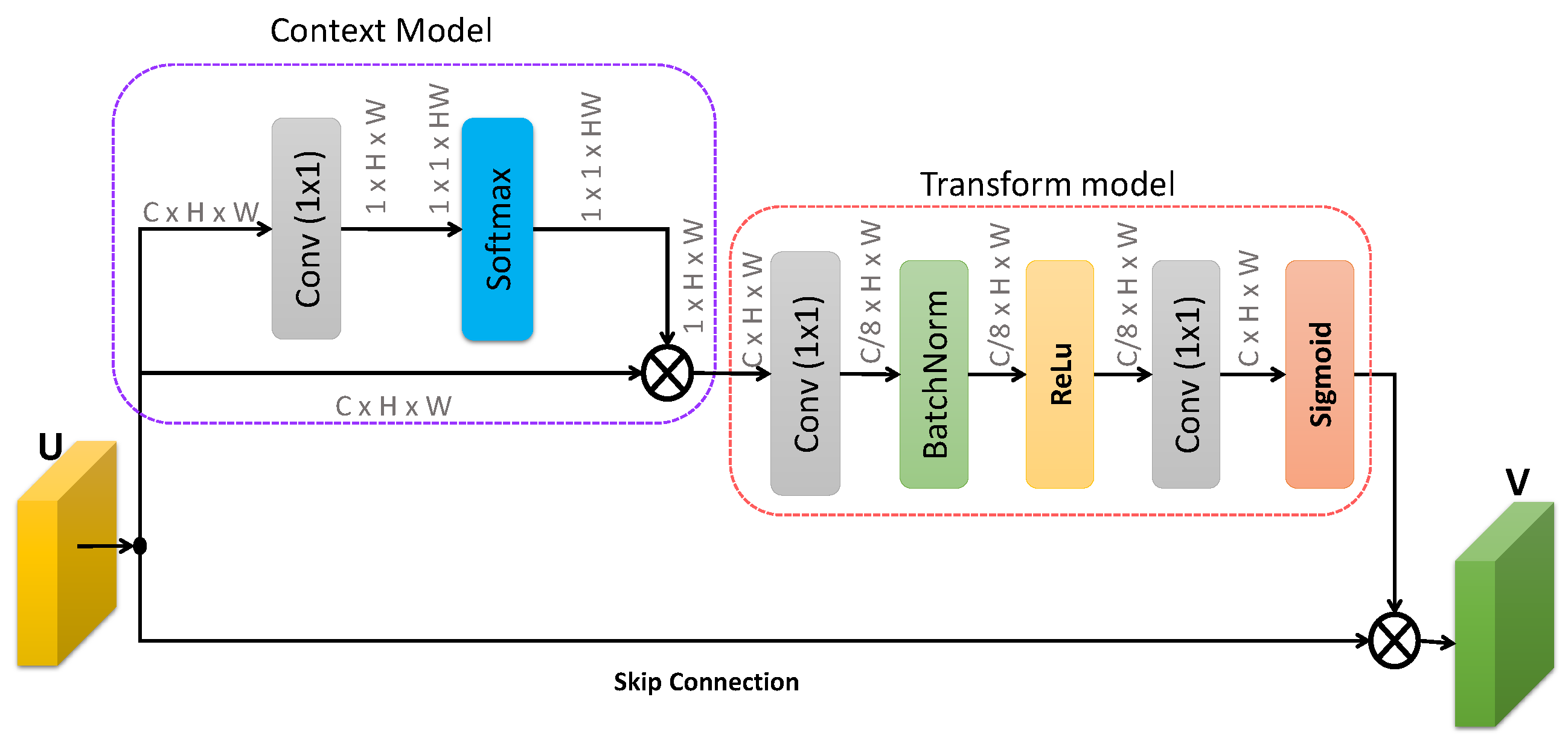
3.4. Spatial Attention Module
3.5. Network Training
| Algorithm 1: Offline Training of the proposed framework |
 |
| Algorithm 2: Tracking of the proposed method |
 |
4. Experiments and Results
4.1. Implementation Details
4.2. Datasets and Evaluation Metrics
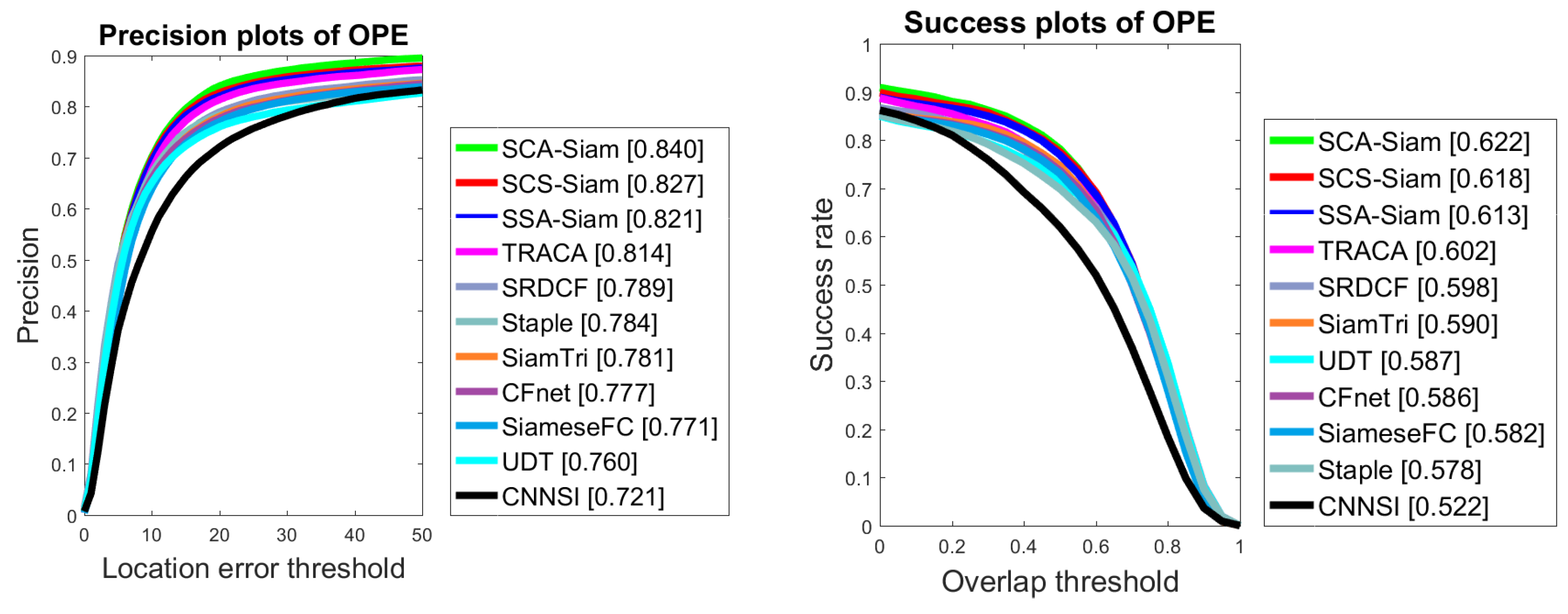
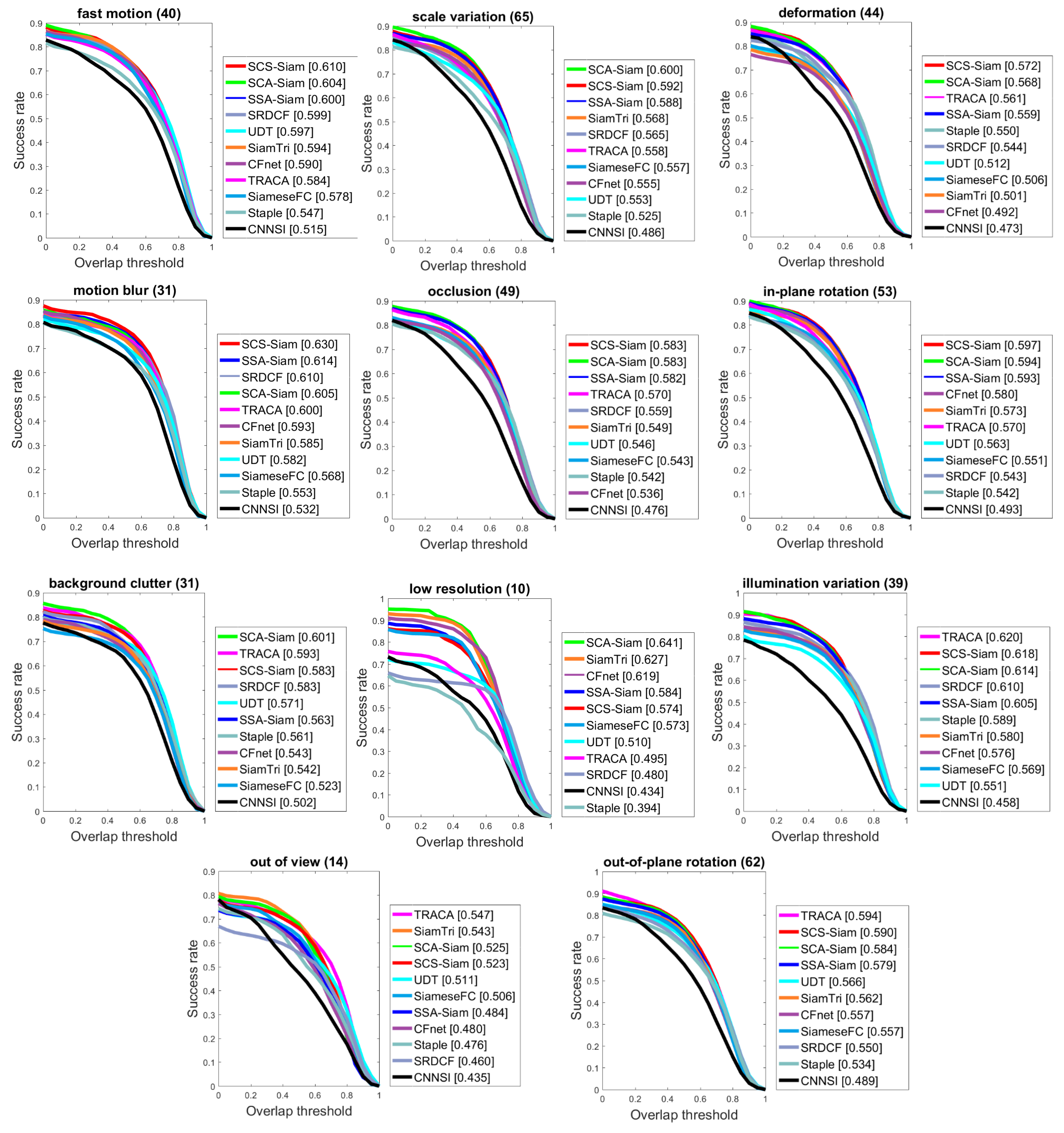
4.3. Experiments on OTB2015
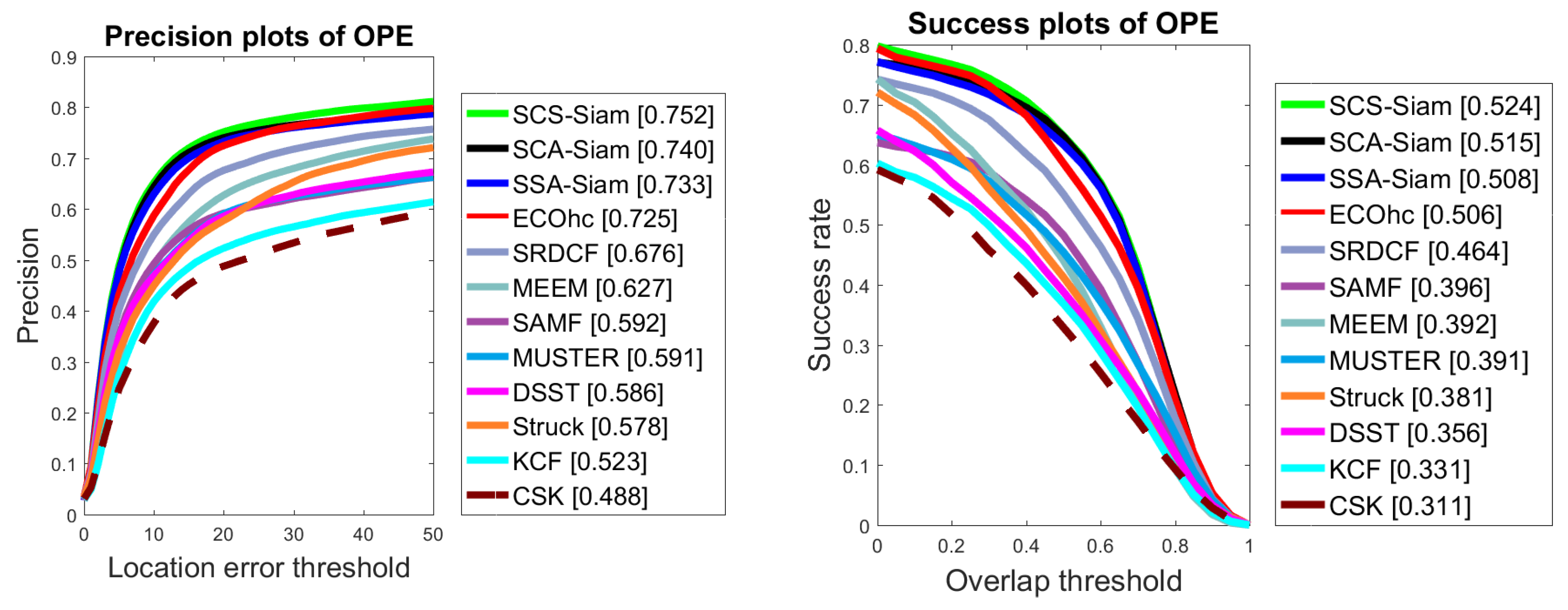
4.4. Experiments on TC128 and UAV123
4.5. Experiments on VOT2016 and VOT2017
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gupta, M.; Kumar, S.; Behera, L.; Subramanian, V.K. A novel vision-based tracking algorithm for a human-following mobile robot. IEEE Trans. Syst. Man, Cybern. Syst. 2016, 47, 1415–1427. [Google Scholar] [CrossRef]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Renoust, B.; Le, D.D.; Satoh, S. Visual analytics of political networks from face-tracking of news video. IEEE Trans. Multimed. 2016, 18, 2184–2195. [Google Scholar] [CrossRef]
- Yao, H.; Cavallaro, A.; Bouwmans, T.; Zhang, Z. Guest editorial introduction to the special issue on group and crowd behavior analysis for intelligent multicamera video surveillance. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 405–408. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning background-aware correlation filters for visual tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1135–1143. [Google Scholar]
- Hu, S.; Ge, Y.; Han, J.; Zhang, X. Object Tracking Algorithm Based on Dual Color Feature Fusion with Dimension Reduction. Sensors 2019, 19, 73. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 20–36. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Video Object Segmentation using Guided Feature and Directional Deep Appearance Learning. In Proceedings of the 2020 DAVIS Challenge on Video Object Segmentation—CVPR, Workshops, Seattle, WA, USA, 19 June 2020. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–499. [Google Scholar]
- Ranjan, R.; Patel, V.M.; Chellappa, R. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 121–135. [Google Scholar] [CrossRef]
- Fiaz, M.; Mahmood, A.; Javed, S.; Jung, S.K. Handcrafted and Deep Trackers: Recent Visual Object Tracking Approaches and Trends. Acm Comput. Surv. (CSUR) 2019, 52, 43. [Google Scholar] [CrossRef]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Convolutional features for correlation filter based visual tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 58–66. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 472–488. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical convolutional features for visual tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. Context-aware correlation filter tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1396–1404. [Google Scholar]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, Q.; Lim, J.; Yang, M.H. Hedged deep tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4303–4311. [Google Scholar]
- Song, Y.; Ma, C.; Gong, L.; Zhang, J.; Lau, R.W.; Yang, M.H. Crest: Convolutional residual learning for visual tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2555–2564. [Google Scholar]
- Fan, H.; Ling, H. Sanet: Structure-aware network for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 42–49. [Google Scholar]
- Han, B.; Sim, J.; Adam, H. Branchout: Regularization for online ensemble tracking with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3356–3365. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Yun, S.; Choi, J.; Yoo, Y.; Yun, K.; Young Choi, J. Action-decision networks for visual tracking with deep reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2711–2720. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Dong, X.; Shen, J. Triplet loss in siamese network for object tracking. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 459–474. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Deep Siamese Networks toward Robust Visual Tracking. In Visual Object Tracking with Deep Neural Networks; IntechOpen: London, UK, 2019. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 749–765. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T object tracking: Benchmark and baseline. Pattern Recognit. 2019, 96, 106977. [Google Scholar] [CrossRef]
- Li, C.; Lin, L.; Zuo, W.; Tang, J.; Yang, M.H. Visual tracking via dynamic graph learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2770–2782. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Fiaz, M.; Rahman, M.M.; Mahmood, A.; Farooq, S.S.; Baek, K.Y.; Jung, S.K. Adaptive Feature Selection Siamese Networks for Visual Tracking. In Proceedings of the International Workshop on Frontiers of Computer Vision, Ibusuki, Japan, 20–22 February 2020; pp. 167–179. [Google Scholar]
- Rahman, M.M.; Fiaz, M.; Jung, S.K. Efficient Visual Tracking with Stacked Channel-Spatial Attention Learning. IEEE Access 2020, 8. [Google Scholar] [CrossRef]
- Wang, Q.; Teng, Z.; Xing, J.; Gao, J.; Hu, W.; Maybank, S. Learning attentions: Residual attentional Siamese network for high performance online visual tracking. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4854–4863. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Liang, P.; Blasch, E.; Ling, H. Encoding color information for visual tracking: Algorithms and benchmark. IEEE Trans. Image Process. 2015, 24, 5630–5644. [Google Scholar] [CrossRef] [PubMed]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 445–461. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Cehovin, L.; Vojir, T.; Hager, G.; Lukezic, A.; Fernandez, G.; et al. The Visual Object Tracking VOT2016 challenge results. In Proceedings of the European Conference on Computer Vision Workshop, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Cehovin, L.; Vojir, T.; Hager, G.; Lukezic, A.; Eldesokey, A.; et al. The visual object tracking vot2017 challenge results. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1949–1972. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Tracking Noisy Targets: A Review of Recent Object Tracking Approaches. arXiv 2018, arXiv:1802.03098. [Google Scholar]
- Li, P.; Wang, D.; Wang, L.; Lu, H. Deep visual tracking: Review and experimental comparison. Pattern Recognit. 2018, 76, 323–338. [Google Scholar] [CrossRef]
- Bhat, G.; Johnander, J.; Danelljan, M.; Shahbaz Khan, F.; Felsberg, M. Unveiling the power of deep tracking. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 483–498. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.; Yang, M.H. Vital: Visual tracking via adversarial learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8990–8999. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 597–606. [Google Scholar]
- Teng, Z.; Xing, J.; Wang, Q.; Lang, C.; Feng, S.; Jin, Y. Robust object tracking based on temporal and spatial deep networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1144–1153. [Google Scholar]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3119–3127. [Google Scholar]
- Gordon, D.; Farhadi, A.; Fox, D. Re 3: Re al-Time Recurrent Regression Networks for Visual Tracking of Generic Objects. IEEE Robot. Autom. Lett. 2018, 3, 788–795. [Google Scholar] [CrossRef]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- Yang, T.Y.; Antoni, B.C. Learning Dynamic Memory Networks for Object Tracking. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 152–167. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Improving Object Tracking by Added Noise and Channel Attention. Sensors 2020, 20, 3780. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, Z.; Yang, L.; Cheng, H. Combing rgb and depth map features for human activity recognition. In Proceedings of the 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference, Hollywood, CA, USA, 3–6 December 2012; pp. 1–4. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Du, W.; Wang, Y.; Qiao, Y. Rpan: An end-to-end recurrent pose-attention network for action recognition in videos. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3725–3734. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Cui, Z.; Xiao, S.; Feng, J.; Yan, S. Recurrently target-attending tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1449–1458. [Google Scholar]
- Fan, J.; Wu, Y.; Dai, S. Discriminative spatial attention for robust tracking. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 480–493. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 4834–4843. [Google Scholar]
- Abdelpakey, M.H.; Shehata, M.S.; Mohamed, M.M. Denssiam: End-to-end densely-siamese network with self-attention model for object tracking. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 19–21 November 2018; pp. 463–473. [Google Scholar]
- Lukezic, A.; Vojir, T.; Cehovin Z, L.; Matas, J.; Kristan, M. Discriminative correlation filter with channel and spatial reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6309–6318. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Choi, J.; Jin Chang, H.; Fischer, T.; Yun, S.; Lee, K.; Jeong, J.; Demiris, Y.; Young Choi, J. Context-aware deep feature compression for high-speed visual tracking. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 479–488. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Wang, N.; Song, Y.; Ma, C.; Zhou, W.; Liu, W.; Li, H. Unsupervised Deep Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NY, USA, 26 June–1 July 2016; pp. 1401–1409. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Convolutional neural network with structural input for visual object tracking. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Long Beach, CA, USA, 16–20 June 2019; pp. 1345–1352. [Google Scholar]
- Wang, L.; Liu, T.; Wang, B.; Lin, J.; Yang, X.; Wang, G. Learning Hierarchical Features for Visual Object Tracking With Recursive Neural Networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipai, Taiwan, 22–25 September 2019; pp. 3088–3092. [Google Scholar]
- Choi, J.; Kwon, J.; Lee, K.M. Deep meta learning for real-time target-aware visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 911–920. [Google Scholar]
- Baik, S.; Kwon, J.; Lee, K.M. Learning to Remember Past to Predict Future for Visual Tracking. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipai, Taiwan, 22–25 September 2019; pp. 3068–3072. [Google Scholar]
- Li, B.; Xie, W.; Zeng, W.; Liu, W. Learning to Update for Object Tracking With Recurrent Meta-Learner. IEEE Trans. Image Process. 2019, 28, 3624–3635. [Google Scholar] [CrossRef]
- Li, G.; Peng, M.; Nai, K.; Li, Z.; Li, K. Multi-view correlation tracking with adaptive memory-improved update model. Neural Comput. Appl. 2019. [Google Scholar] [CrossRef]
- Kuai, Y.; Wen, G.; Li, D. Masked and dynamic siamese network for robust visual tracking. Inf. Sci. 2019, 503, 169–182. [Google Scholar] [CrossRef]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2016; pp. 1420–1429. [Google Scholar]
- Shen, J.; Tang, X.; Dong, X.; Shao, L. Visual object tracking by hierarchical attention siamese network. IEEE Trans. Cybern. 2019. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: Robust tracking via multiple experts using entropy minimization. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 188–203. [Google Scholar]
- Li, Y.; Zhu, J. A scale adaptive kernel correlation filter tracker with feature integration. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 254–265. [Google Scholar]
- Hong, Z.; Chen, Z.; Wang, C.; Mei, X.; Prokhorov, D.; Tao, D. Multi-store tracker (muster): A cognitive psychology inspired approach to object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 749–758. [Google Scholar]
- Huang, B.; Xu, T.; Jiang, S.; Chen, Y.; Bai, Y. Robust Visual Tracking via Constrained Multi-Kernel Correlation Filters. IEEE Trans. Multimed. 2020. [Google Scholar] [CrossRef]
- Gao, P.; Yuan, R.; Wang, F.; Xiao, L.; Fujita, H.; Zhang, Y. Siamese attentional keypoint network for high performance visual tracking. Knowl. Based Syst. 2019. [Google Scholar] [CrossRef]
- Chen, B.; Wang, D.; Li, P.; Wang, S.; Lu, H. Real-time’Actor-Critic’Tracking. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 318–334. [Google Scholar]
- Yang, T.; Chan, A.B. Visual Tracking via Dynamic Memory Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Chen, B.; Ouyang, W.; Wang, D.; Yang, X.; Lu, H. Gradnet: Gradient-guided network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6162–6171. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Choi, J.; Jin Chang, H.; Yun, S.; Fischer, T.; Demiris, Y.; Young Choi, J. Attentional correlation filter network for adaptive visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4807–4816. [Google Scholar]
- Choi, J.; Jin Chang, H.; Jeong, J.; Demiris, Y.; Young Choi, J. Visual tracking using attention-modulated disintegration and integration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NY, USA, 26 June–1 July 2016; pp. 4321–4330. [Google Scholar]
- Lukežič, A.; Zajc, L.Č.; Kristan, M. Deformable parts correlation filters for robust visual tracking. IEEE Trans. Cybern. 2017, 48, 1849–1861. [Google Scholar] [CrossRef]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative scale space tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1561–1575. [Google Scholar] [CrossRef]
- Chen, S.; Qiu, D.; Huo, Q. Siamese Networks with Discriminant Correlation Filters and Channel Attention. In Proceedings of the 2018 14th International Conference on Computational Intelligence and Security (CIS), Hangzhou, China, 16–19 November 2018; pp. 110–114. [Google Scholar]
- Zhu, Z.; Huang, G.; Zou, W.; Du, D.; Huang, C. Uct: Learning unified convolutional networks for real-time visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1973–1982. [Google Scholar]
- Song, K.; Zhang, W.; Lu, W.; Zha, Z.J.; Ji, X.; Li, Y. Visual Object Tracking via Guessing and Matching. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Filter Size | Stride | In and Out Channel | Template and Template with Soft-Mask | Search and Search with Soft-Mask |
|---|---|---|---|---|---|
| Input | 3 | ||||
| Conv1 | 2 | ||||
| Max-Pool1 | 2 | - | |||
| Feature Fusion | - | - | - | ||
| Conv2 | 1 | ||||
| Conv3 | 1 | ||||
| Max-Pool2 | 2 | - | |||
| Conv4 | 1 | ||||
| Conv5 | 1 | ||||
| Conv6 | 1 |
| Benchmarks | OTB2015 | TC-128 | UAV123 | VOT2016 | VOT2017 |
|---|---|---|---|---|---|
| Sequences | 100 | 128 | 123 | 60 | 60 |
| Minimum frames | 71 | 71 | 109 | 48 | 41 |
| Mean frames | 590 | 429 | 915 | 357 | 356 |
| Max frames | 3872 | 3872 | 3085 | 1500 | 1500 |
| Total frames | 59,040 | 55,346 | 1,12,578 | 21,455 | 21,356 |
| Trackers | Precision | Success | FPS | Real-Time |
|---|---|---|---|---|
| RNN [76] | 79.8 | 60.6 | - | - |
| MLT [77] | - | 61.1 | 48 | Yes |
| P2FNet [78] | 79.8 | 59.5 | 52 | Yes |
| SiamFc-lu [79] | - | 62.0 | 82 | Yes |
| DSiamM [57] | - | 60.5 | 18 | No |
| SiamTri [31] | 78.1 | 59.0 | 85 | Yes |
| Li’s [80] | 77.1 | 58.2 | 30 | Yes |
| CNNSI [75] | 72.1 | 52.2 | 1< | No |
| Kuai et al. [81] | 82.2 | 62.2 | 25 | No |
| TRACA [71] | 81.4 | 60.2 | 101 | Yes |
| SINT [82] | - | 59.2 | 4 | No |
| ACFN [93] | 80.2 | 57.5 | 15 | No |
| CSRDCF [68] | 73.3 | 58.7 | 13 | No |
| Staple [74] | 78.4 | 57.8 | 80 | Yes |
| SRDCF [72] | 78.9 | 59.8 | 6 | No |
| HASiam [83] | 81.0 | 61.1 | 30 | Yes |
| UDT [73] | 76.0 | 59.4 | 70 | Yes |
| SiameseFC-G&M [99] | 81.0 | 61.3 | 68 | Yes |
| CMKCF [87] | 82.2 | 61.0 | 74.4 | Yes |
| CFNet [34] | 77.7 | 58.6 | 43 | Yes |
| SiameseFC [30] | 77.1 | 58.2 | 86 | Yes |
| SCA-Siam (Ours) | 84.0 | 62.2 | 76 | Yes |
| SSA-Siam (Ours) | 82.1 | 61.3 | 75 | Yes |
| SCS-Siam (Ours) | 82.7 | 61.8 | 73 | Yes |
| Trackers | SiamTri | CFNet | SRDCF | TRACA | SiameseFC | UDT | Staple | CNNSI | SCA-Siam | SCA-Siam | SCS-Siam |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FM | 77.6 | 77.4 | 77.3 | 76.2 | 75.8 | 75.3 | 72.9 | 67.5 | 80.2 | 78.3 | 79.2 |
| BC | 71.5 | 73.1 | 77.5 | 79.9 | 69.0 | 74.9 | 74.9 | 68.7 | 80.2 | 74.6 | 77.5 |
| MB | 74.4 | 76.1 | 78.2 | 77.1 | 72.4 | 71.4 | 71.9 | 69.6 | 78.2 | 77.9 | 79.2 |
| Def | 68.0 | 66.9 | 73.4 | 76.9 | 69.0 | 67.0 | 75.1 | 68.7 | 80.0 | 77.6 | 79.3 |
| IV | 75.1 | 76.3 | 78.7 | 83.3 | 74.0 | 70.0 | 78.2 | 60.0 | 83.6 | 81.2 | 83.3 |
| IPR | 75.9 | 78.5 | 73.7 | 79.4 | 72.8 | 74.1 | 75.1 | 68.8 | 81.1 | 80.5 | 80.5 |
| LR | 88.4 | 86.1 | 63.1 | 73.1 | 81.5 | 68.8 | 59.1 | 66.0 | 91.9 | 83.0 | 82.5 |
| OCC | 72.6 | 71.3 | 73.5 | 77.5 | 72.2 | 70.6 | 72.8 | 64.4 | 78.5 | 77.1 | 77.3 |
| OPR | 76.1 | 75.8 | 74.4 | 82.8 | 75.4 | 74.7 | 73.7 | 68.9 | 80.6 | 79.8 | 80.3 |
| OV | 72.3 | 65.0 | 59.7 | 70.0 | 66.9 | 65.1 | 66.8 | 59.4 | 73.0 | 65.6 | 70.3 |
| SV | 75.2 | 74.8 | 74.9 | 76.9 | 73.9 | 71.4 | 73.1 | 68.7 | 81.6 | 79.2 | 79.6 |
| Trackers | Precision | Success | FPS |
|---|---|---|---|
| SCT [94] | 62.7 | 46.6 | 40 |
| KCF [7] | 54.9 | 38.7 | 160 |
| CNNSI [75] | 63.8 | 45.6 | <1 |
| UDT [73] | 65.8 | 50.7 | 70 |
| CFNet [34] | 60.7 | 45.6 | 43 |
| ACT [89] | 73.8 | 53.2 | 30 |
| SiameseFC [30] | 68.8 | 50.3 | 86 |
| SCA-Siam (Ours) | 73.1 | 53.2 | 76 |
| SSA-Siam (Ours) | 73.8 | 54.2 | 75 |
| SCS-Siam (Ours) | 74.2 | 53.8 | 73 |
| Trackers | Overlap (↑) | Robustness (↓) | EAO (↑) |
|---|---|---|---|
| MemTrack [58] | 0.53 | 1.44 | 0.27 |
| MemDTC [90] | 0.51 | 1.82 | 0.27 |
| ECO [21] | 0.54 | - | 0.37 |
| Staple [74] | 0.53 | 0.38 | 0.29 |
| SRDCF [72] | 0.54 | 0.42 | 0.25 |
| DSiam [57] | 0.49 | 2.93 | 0.18 |
| CCOT [20] | 0.54 | 0.24 | 0.33 |
| UDT [73] | 0.54 | - | 0.22 |
| SiameseFC [30] | 0.53 | 0.46 | 0.23 |
| CMKCF [87] | 0.53 | 0.18 | 0.30 |
| SCA-Siam (Ours) | 0.55 | 0.23 | 0.28 |
| SSA-Siam (Ours) | 0.55 | 0.23 | 0.27 |
| SCS-Siam (Ours) | 0.55 | 0.21 | 0.28 |
| Trackers | Overlap (↑) | Robustness (↓) | EAO (↑) | FPS |
|---|---|---|---|---|
| CSRDCF [68] | 0.49 | 0.49 | 0.25 | 13 |
| MemTrack [58] | 0.49 | 1.77 | 0.24 | 50 |
| MemDTC [90] | 0.49 | 1.77 | 0.25 | 40 |
| SRDCF [72] | 0.49 | 0.97 | 0.12 | 6 |
| DSST [96] | 0.39 | 1.45 | 0.08 | 24 |
| SATIN [88] | 0.49 | 1.34 | 0.28 | 24 |
| SiamDCF [97] | 0.50 | 0.47 | 0.25 | 60 |
| UCT [98] | 0.49 | 0.48 | 0.20 | 41 |
| SiameseFC [30] | 0.50 | 0.59 | 0.19 | 86 |
| GradNet [91] | 0.50 | 0.37 | 0.24 | 80 |
| SiameseRPN [92] | 0.49 | 0.46 | 0.24 | 200 |
| SCA-Siam (Ours) | 0.51 | 0.36 | 0.21 | 76 |
| SSA-Siam (Ours) | 0.52 | 0.38 | 0.20 | 75 |
| SCS-Siam (Ours) | 0.52 | 0.29 | 0.24 | 73 |
| SCS-Siam- | Precision | Success |
|---|---|---|
| SCS-Siam-0.0 | 76.3 | 56.5 |
| SCS-Siam-0.3 | 78.2 | 58.6 |
| SCS-Siam-0.5 | 81.5 | 60.4 |
| SCS-Siam-0.7 | 80.0 | 59.6 |
| SCS-Siam-0.9 | 82.7 | 61.8 |
| SCS-Siam-1.0 | 79.7 | 59.5 |
| SCS-Siam- | 81.7 | 60.5 |
| Tracker | Precision | Success | FPS |
|---|---|---|---|
| SiameseFC | 77.1 | 58.2 | 86 |
| SiameseFC* | 79.2 | 59.7 | 86 |
| Extended-SiamFC | 80.3 | 60.2 | 79 |
| SSA-Siam | 82.1 | 61.3 | 75 |
| SCA-Siam | 84.0 | 62.2 | 76 |
| SSC-Siam | 82.0 | 60.9 | 73 |
| SCS-Siam | 82.7 | 61.8 | 73 |
| B-SCS-Siam | 81.5 | 60.4 | 59 |
| Tracker | Precision | Success |
|---|---|---|
| SCA-GMP | 83.5 | 61.8 |
| SCA-GAP | 83.9 | 62.0 |
| SCA-Siam | 84.0 | 62.2 |
| SSA-Context | 81.5 | 60.8 |
| SSA-Transform | 81.8 | 61.0 |
| SSA-Siam | 82.1 | 61.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fiaz, M.; Mahmood, A.; Jung, S.K. Learning Soft Mask Based Feature Fusion with Channel and Spatial Attention for Robust Visual Object Tracking. Sensors 2020, 20, 4021. https://doi.org/10.3390/s20144021
Fiaz M, Mahmood A, Jung SK. Learning Soft Mask Based Feature Fusion with Channel and Spatial Attention for Robust Visual Object Tracking. Sensors. 2020; 20(14):4021. https://doi.org/10.3390/s20144021
Chicago/Turabian StyleFiaz, Mustansar, Arif Mahmood, and Soon Ki Jung. 2020. "Learning Soft Mask Based Feature Fusion with Channel and Spatial Attention for Robust Visual Object Tracking" Sensors 20, no. 14: 4021. https://doi.org/10.3390/s20144021
APA StyleFiaz, M., Mahmood, A., & Jung, S. K. (2020). Learning Soft Mask Based Feature Fusion with Channel and Spatial Attention for Robust Visual Object Tracking. Sensors, 20(14), 4021. https://doi.org/10.3390/s20144021