Counting Crowds with Perspective Distortion Correction via Adaptive Learning


Abstract
1. Introduction
- We propose a novel adaptive framework with perspective distortion correction for crowd counting and localization. Different from the former proposed multiple columns frameworks, we use a branch to dynamically characterize the degree of perspective change of the images. We further verify the effect of our CAL network and compare with the No-CAL methods in order to explain the improvement of our architecture.
- We design a novel size characterization branch to realize both the crowd counting and the localization task.
- We use VGG [6] for the feature extraction structure and the network constructed by four branches (including the main path), which select output features of different sizes. The perspective change in the image is considered to be a linear combination of our four branches and discrete weights, while the adaptation branch aims to portray a continuous perspective change trend and make corresponding corrections.
- We apply our framework to four congested multi-scene crowd counting datasets (i.e., ShanghaiTech Part A, ShanghaiTech Part B, UCF_CC_50, and UCF-QNRF) and prove that our method outperforms the state-of-the-art methods.
2. Related Work
2.1. Traditional Crowd Counting Methods
2.2. CNNs for Crowd Counting
2.3. CNNs for Localization
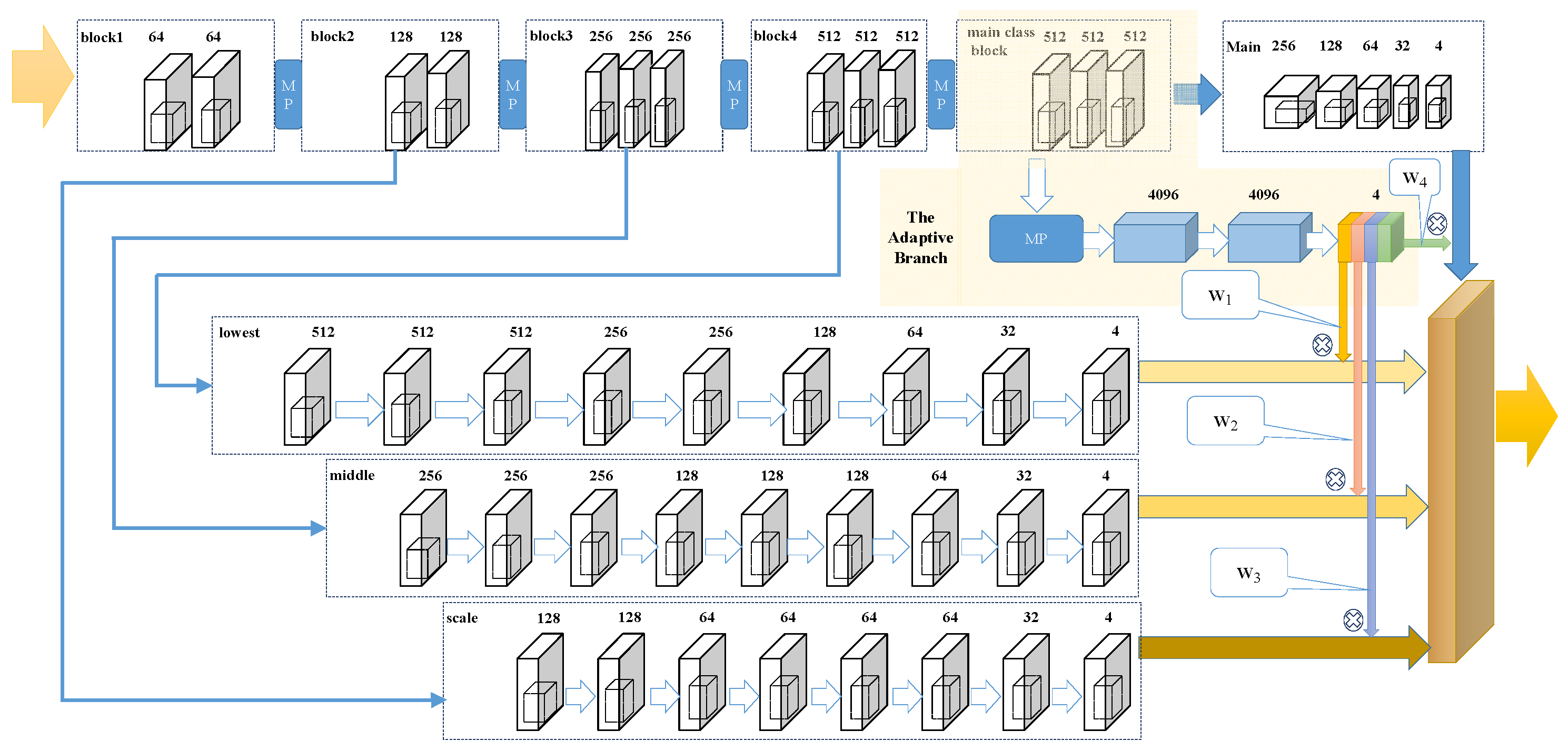
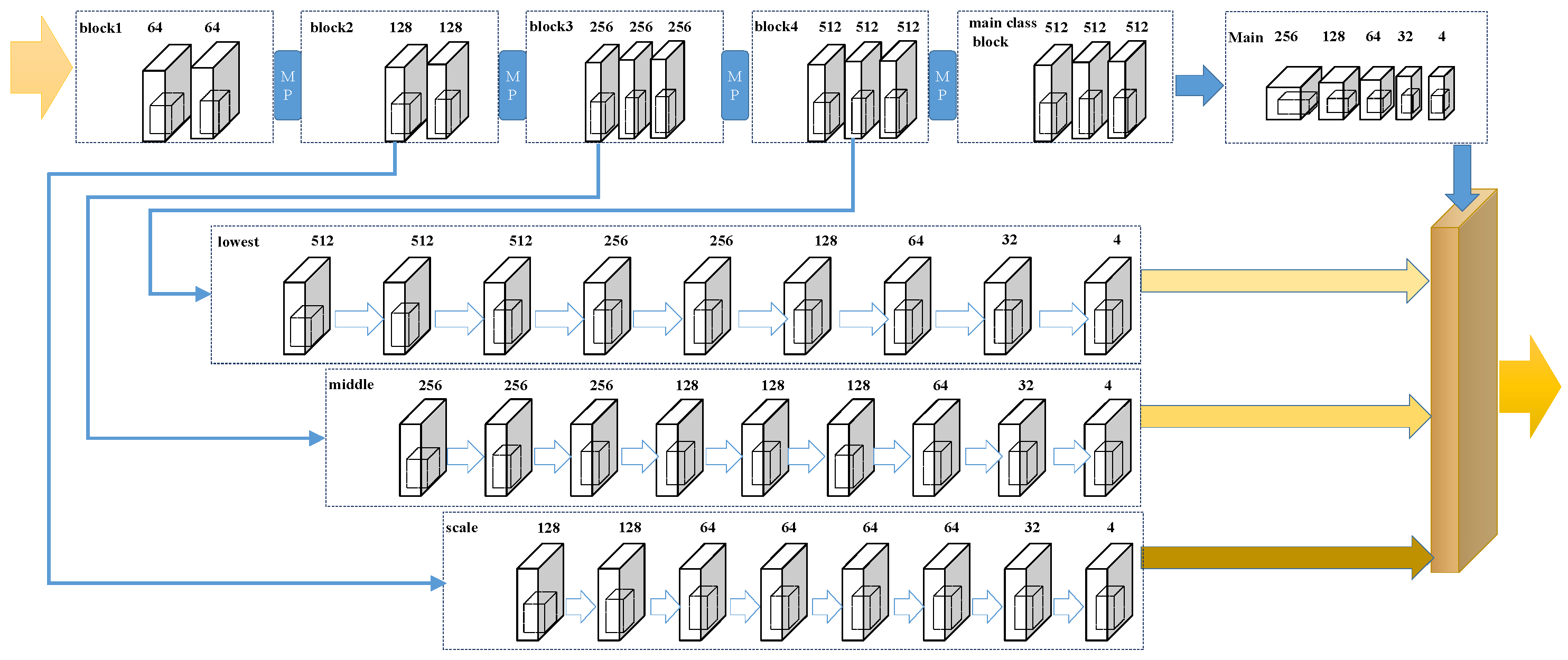
3. Framework
3.1. Backbone
3.2. The Pathways
3.3. The Adaptive Branch
3.4. Implementation Details
3.4.1. Loss Function
3.4.2. Density Map Generation
| Algorithm 1: Ground-truth generation |
 |
4. Experiments
4.1. Evaluation Metrics
4.2. Datasets
- Challenging images Some challenging images are necessary to evaluate the performance of the model in extreme conditions. As the development of the crowd counting methods, most of them perform stably in the sparse scenes. As a result, our model focus on improving the performance in congestion crowds and achieve localization tasks. For the crowd counting and localization task, images of some exceeding congestion crowds are the ideal material to evaluate the robustness and the accuracy of our model.
- Proper density distribution The distribution of the images can directly affect the performance of the model in the scenes with different levels of congestion. The proper amount of sparse, middle and congested images can improve training accuracy and make verification more effective.
- Multiple scenes The dataset contains multiple scenes, such as the street view, the market view, the live show view, etc., can improve the robustness of our model. The multiple scenes is not only the images take from a different location but also the different condition of weather (such as rainy and foggy), light intensity etc., which can affect the performance of our model, especially in the localization task.
4.3. Results and Discussion
4.4. Ablation Studies
4.4.1. The Effectiveness of the Multi-Branch Structure
4.4.2. The Effectiveness of the Adaptive Branch
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gao, G.; Gao, J.; Liu, Q.; Wang, Q.; Wang, Y. CNN-based Density Estimation and Crowd Counting: A Survey. arXiv 2020, arXiv:2003.12783. [Google Scholar]
- Kang, D.; Ma, Z.; Chan, A.B. Beyond Counting: Comparisons of Density Maps for Crowd Analysis Tasks Counting, Detection, and Tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1408–1422. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef]
- Tong, M.; Fan, L.; Nan, H.; Zhao, Y. Smart Camera Aware Crowd Counting via Multiple Task Fractional Stride Deep Learning. Sensors 2019, 19, 1346. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Huang, J.; Du, W.; Xiong, N. Design and analysis of a lightweight context fusion CNN scheme for crowd counting. Sensors 2019, 19, 2013. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wu, X.; Zheng, Y.; Ye, H.; Hu, W.; Ma, T.; Yang, J.; He, L. Counting crowds with varying densities via adaptive scenario discovery framework. Neurocomputing 2020, 397, 127–138. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Leibe, B.; Seemann, E.; Schiele, B. Pedestrian detection in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 878–885. [Google Scholar]
- Tuzel, O.; Porikli, F.; Meer, P. Pedestrian detection via classification on riemannian manifolds. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1713–1727. [Google Scholar] [CrossRef]
- Enzweiler, M.; Gavrila, D.M. Monocular pedestrian detection: Survey and experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 2179–2195. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In Proceedings of the International Conference on Pattern Recognition (ICPR), Tampa, FL, USA, 8–11 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–4. [Google Scholar]
- Chan, A.B.; Vasconcelos, N. Bayesian poisson regression for crowd counting. In Proceedings of the International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 545–551. [Google Scholar]
- Ryan, D.; Denman, S.; Fookes, C.; Sridharan, S. Crowd counting using multiple local features. In Proceedings of the Digital Image Computing: Techniques and Applications, Melbourne, Australia, 1–3 December 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 81–88. [Google Scholar]
- Kong, D.; Gray, D.; Tao, H. A viewpoint invariant approach for crowd counting. In Proceedings of the International Conference on Pattern Recognition (ICPR), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 3, pp. 1187–1190. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. In Proceedings of the British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012; Volume 1, p. 3. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]
- Chen, K.; Gong, S.; Xiang, T.; Change Loy, C. Cumulative attribute space for age and crowd density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2467–2474. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Walach, E.; Wolf, L. Learning to count with cnn boosting. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2016; pp. 660–676. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching convolutional neural network for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4031–4039. [Google Scholar]
- Stewart, R.; Andriluka, M.; Ng, A.Y. End-to-end people detection in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2325–2333. [Google Scholar]
- Liu, L.; Qiu, Z.; Li, G.; Liu, S.; Ouyang, W.; Lin, L. Crowd counting with deep structured scale integration network. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 1774–1783. [Google Scholar]
- Guo, D.; Li, K.; Zha, Z.J.; Wang, M. Dadnet: Dilated-attention-deformable convnet for crowd counting. In Proceedings of the ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1823–1832. [Google Scholar]
- Zhang, L.; Shi, Z.; Cheng, M.M.; Liu, Y.; Bian, J.W.; Zhou, J.T.; Zheng, G.; Zeng, Z. Nonlinear regression via deep negative correlation learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Lian, D.; Li, J.; Zheng, J.; Luo, W.; Gao, S. Density map regression guided detection network for rgb-d crowd counting and localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1821–1830. [Google Scholar]
- Basalamah, S.; Khan, S.D.; Ullah, H. Scale driven convolutional neural network model for people counting and localization in crowd scenes. IEEE Access 2019, 7, 71576–71584. [Google Scholar] [CrossRef]
- Liu, C.; Weng, X.; Mu, Y. Recurrent attentive zooming for joint crowd counting and precise localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1217–1226. [Google Scholar]
- Wen, L.; Du, D.; Zhu, P.; Hu, Q.; Wang, Q.; Bo, L.; Lyu, S. Drone-based Joint Density Map Estimation, Localization and Tracking with Space-Time Multi-Scale Attention Network. arXiv 2019, arXiv:1912.01811. [Google Scholar]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly detection and localization in crowded scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 18–32. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–21 June 2018; pp. 1091–1100. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition loss for counting, density map estimation and localization in dense crowds. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 532–546. [Google Scholar]
- Onoro-Rubio, D.; López-Sastre, R.J. Towards perspective-free object counting with deep learning. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2016; pp. 615–629. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8198–8207. [Google Scholar]
- Sam, D.B.; Sajjan, N.N.; Maurya, H.; Babu, R.V. Almost unsupervised learning for dense crowd counting. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8868–8875. [Google Scholar]
- Liu, X.; van de Weijer, J.; Bagdanov, A.D. Exploiting unlabeled data in cnns by self-supervised learning to rank. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1862–1878. [Google Scholar] [CrossRef] [PubMed]
- Chaker, R.; Al Aghbari, Z.; Junejo, I.N. Social network model for crowd anomaly detection and localization. Pattern Recognit. 2017, 61, 266–281. [Google Scholar] [CrossRef]
- Chen, S.; Fern, A.; Todorovic, S. Person count localization in videos from noisy foreground and detections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1364–1372. [Google Scholar]
- Matan, O.; Burges, C.J.; LeCun, Y.; Denker, J.S. Multi-digit recognition using a space displacement neural network. In Advances in Neural Information Processing Systems; MIT: Cambridge, MA, USA, 1992; pp. 488–495. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Ning, F.; Delhomme, D.; LeCun, Y.; Piano, F.; Bottou, L.; Barbano, P.E. Toward automatic phenotyping of developing embryos from videos. IEEE Trans. Image Process. 2005, 14, 1360–1371. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Eigen, D.; Krishnan, D.; Fergus, R. Restoring an image taken through a window covered with dirt or rain. In Proceedings of the International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 633–640. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Laradji, I.H.; Rostamzadeh, N.; Pinheiro, P.O.; Vazquez, D.; Schmidt, M. Where are the blobs: Counting by localization with point supervision. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 547–562. [Google Scholar]
- Sam, D.B.; Peri, S.V.; Kamath, A.; Babu, R.V. Locate, Size and Count: Accurately Resolving People in Dense Crowds via Detection. arXiv 2019, arXiv:1906.07538. [Google Scholar]
- Wu, X.; Zheng, Y.; Ye, H.; Hu, W.; Yang, J.; He, L. Adaptive scenario discovery for crowd counting. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2382–2386. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems; MIT: Cambridge, MA, USA, 2019; pp. 8024–8035. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–7. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Sam, D.B.; Babu, R.V. Top-down feedback for crowd counting convolutional neural network. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhang, L.; Shi, M.; Chen, Q. Crowd counting via scale-adaptive convolutional neural network. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1113–1121. [Google Scholar]
- Zeng, L.; Xu, X.; Cai, B.; Qiu, S.; Zhang, T. Multi-scale convolutional neural networks for crowd counting. In Proceedings of the International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 465–469. [Google Scholar]
- Shen, Z.; Xu, Y.; Ni, B.; Wang, M.; Hu, J.; Yang, X. Crowd counting via adversarial cross-scale consistency pursuit. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5245–5254. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Generating high-quality crowd density maps using contextual pyramid cnns. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1861–1870. [Google Scholar]
- Liu, L.; Wang, H.; Li, G.; Ouyang, W.; Lin, L. Crowd counting using deep recurrent spatial-aware network. arXiv 2018, arXiv:1807.00601. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale aggregation network for accurate and efficient crowd counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Shi, M.; Yang, Z.; Xu, C.; Chen, Q. Revisiting perspective information for efficient crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7279–7288. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Chen, X.; Bin, Y.; Sang, N.; Gao, C. Scale pyramid network for crowd counting. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1941–1950. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Ha-ccn: Hierarchical attention-based crowd counting network. IEEE Trans. Image Process. 2019, 29, 323–335. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Xiao, Z.; Zhang, B.; Zhen, X.; Cao, X.; Doermann, D.; Shao, L. Crowd counting and density estimation by trellis encoder-decoder networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6133–6142. [Google Scholar]
- Zhang, A.; Shen, J.; Xiao, Z.; Zhu, F.; Zhen, X.; Cao, X.; Shao, L. Relational attention network for crowd counting. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6788–6797. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input (224 × 224 RGB Image) | ||||
|---|---|---|---|---|
| Channels Number | Kernel_Size | Stride | Size | |
| Conv1_1 | 64 | 3 | 1 | 224 × 224 |
| Conv1_2 | 64 | 3 | 1 | 224 × 224 |
| Max Pooling | - | 2 | 2 | 112 × 112 |
| Conv2_1 | 128 | 3 | 1 | 112 × 112 |
| Conv2_2 | 128 | 3 | 1 | 112 × 112 |
| Max Pooling | - | 2 | 2 | 56 × 56 |
| Conv3_1 | 256 | 3 | 1 | 56 × 56 |
| Conv3_2 | 256 | 3 | 1 | 56 × 56 |
| Conv3_3 | 256 | 3 | 1 | 56 × 56 |
| Max Pooling | - | 2 | 2 | 28 × 28 |
| Conv4_1 | 512 | 3 | 1 | 28 × 28 |
| Conv4_2 | 512 | 3 | 1 | 28 × 28 |
| Conv4_3 | 512 | 3 | 1 | 28 × 28 |
| Max Pooling | - | 2 | 2 | 14 × 14 |
| Conv5_1 | 512 | 3 | 1 | 14 × 14 |
| Conv5_2 | 512 | 3 | 1 | 14 × 14 |
| Conv5_3 | 512 | 3 | 1 | 14 × 14 |
| Orgin Image Size: 224 × 224 | ||||
|---|---|---|---|---|
| Input Size | 14 × 14 | 112 × 112 | 56 × 56 | 28 × 28 |
| Main | Scale | Middle | Lowest | |
| The config of the Pathways | conv(3, 512) relu conv(3, 512) relu conv(3, 512) relu conv(3, 256) relu conv(3, 128) relu conv(3, 64) relu conv(3, 32) relu conv(3, 4) relu | conv(3, 128) relu conv(3, 128) relu conv(3, 64) relu conv(3, 64) relu conv(3, 64) relu conv(3, 64) relu conv(3, 32) relu conv(3, 4) relu | conv(3, 256) relu conv(3, 256) relu conv(3, 256) relu conv(3, 128) relu conv(3, 128) relu conv(3, 128) relu conv(3, 64) relu conv(3, 32) relu conv(3, 4) relu | conv(3, 512) relu conv(3, 512) relu conv(3, 512) relu conv(3, 256) relu conv(3, 256) relu conv(3, 128) relu conv(3, 64) relu conv(3, 32) relu conv(3, 4) relu |
| Methods | Part A | Part B | |||
|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | ||
| Counting | MCNN [19] | 110.2 | 173.2 | 26.4 | 41.3 |
| CMTL [54] | 101.3 | 152.4 | 20 | 31.1 | |
| TDF-CNN [55] | 97.5 | 145.1 | 20.7 | 32.8 | |
| Switching CNN [21] | 90.4 | 135 | 21.6 | 33.4 | |
| SaCNN [56] | 86.8 | 139.2 | 16.2 | 25.8 | |
| MSCNN [57] | 83.8 | 127.4 | 17.7 | 30.2 | |
| ACSCP [58] | 75.7 | 102.7 | 17.2 | 27.4 | |
| CP-CNN [59] | 73.6 | 106.4 | 20.1 | 30.1 | |
| D-ConvNet-v1 [25] | 73.5 | 112.3 | 18.7 | 26 | |
| DRSAN [60] | 69.3 | 96.4 | 11.1 | 18.2 | |
| CSRNet [31] | 68.2 | 115 | 10.6 | 16 | |
| SANet [61] | 67 | 104.5 | 8.4 | 13.6 | |
| PACNN [62] | 66.3 | 106.4 | 8.9 | 13.5 | |
| ASD [49] | 65.6 | 98 | 8.5 | 13.7 | |
| Localization | RAZNet [28] | 65.1 | 106.7 | 8.4 | 14.1 |
| RDNet [26] | - | - | 8.8 | 15.3 | |
| LC-FCN8 [47] | - | - | 13.14 | - | |
| LSC-CNN [48] | 66.4 | 117 | 8.1 | 12.7 | |
| CAL | 63.5 | 99.2 | 8.1 | 11.9 | |
| Methods | MAE | MSE | |
|---|---|---|---|
| Counting | Idrees 2013 [17] | 468.0 | 590.3 |
| Zhang 2015 [63] | 467.0 | 498.5 | |
| MCNN [19] | 377.6 | 509.1 | |
| MSCNN [57] | 363.7 | 468.4 | |
| TDF-CNN [55] | 354.7 | 491.4 | |
| CMTL [54] | 322.8 | 397.9 | |
| Switching CNN [21] | 318.1 | 439.2 | |
| SaCNN [56] | 314.9 | 424.8 | |
| CP-CNN [59] | 298.8 | 320.9 | |
| PACNN [62] | 267.9 | 357.8 | |
| CSRNet [31] | 266.1 | 397.5 | |
| SPN [64] | 259.2 | 335.9 | |
| SANet [61] | 258.4 | 334.9 | |
| HA-CCN [65] | 256.2 | 348.4 | |
| Localization | LSC-CNN [48] | 225.6 | 302.7 |
| CAL | 211.4 | 306.7 |
| Method | MAE | MSE | |
|---|---|---|---|
| Counting | Idrees 2013 [17] | 315 | 508 |
| MCNN [19] | 277 | 426 | |
| CMTL [54] | 252 | 514 | |
| Switching CNN [21] | 228 | 445 | |
| HA-CCN [65] | 118.1 | 180.4 | |
| TEDnet [66] | 113 | 188 | |
| RANet [67] | 111 | 190 | |
| Localization | RAZNet [28] | 116 | 195 |
| CL [32] | 132 | 191 | |
| LSC-CNN [48] | 120.5 | 218.2 | |
| CAL | 110.3 | 178.2 |
| ShanghaiTech Part A | ShanghaiTech Part B | UCF_CC_50 | UCF-QNRF | |||||
|---|---|---|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | |
| MCNN [19] | 110.2 | 173.2 | 26.4 | 41.3 | 377.6 | 509.1 | 277 | 426 |
| CMTL [54] | 101.3 | 152.4 | 20 | 31.1 | 322.8 | 397.9 | 252 | 514 |
| Switching CNN [21] | 90.4 | 135 | 21.6 | 33.4 | 318.1 | 439.2 | 228 | 445 |
| NO-CAL | 70.8 | 119.5 | 14.2 | 18.9 | 258.9 | 369.0 | 163.7 | 200.9 |
| CAL | 63.5 | 99.2 | 8.1 | 11.9 | 211.4 | 306.7 | 110.3 | 178.2 |
| ShanghaiTech Part A | ShanghaiTech Part B | UCF_CC_50 | UCF-QNRF | FPS | |||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | ShanghaiTech Part B | |
| CAL | 63.5 | 99.2 | 8.1 | 11.9 | 211.4 | 306.7 | 110.3 | 178.2 | 12 |
| NO-CAL | 70.8 | 119.5 | 14.2 | 18.9 | 258.9 | 369.0 | 163.7 | 200.9 | 13 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Jin, J.; Wu, X.; Ma, T.; Yang, J. Counting Crowds with Perspective Distortion Correction via Adaptive Learning. Sensors 2020, 20, 3781. https://doi.org/10.3390/s20133781
Sun Y, Jin J, Wu X, Ma T, Yang J. Counting Crowds with Perspective Distortion Correction via Adaptive Learning. Sensors. 2020; 20(13):3781. https://doi.org/10.3390/s20133781
Chicago/Turabian StyleSun, Yixuan, Jian Jin, Xingjiao Wu, Tianlong Ma, and Jing Yang. 2020. "Counting Crowds with Perspective Distortion Correction via Adaptive Learning" Sensors 20, no. 13: 3781. https://doi.org/10.3390/s20133781
APA StyleSun, Y., Jin, J., Wu, X., Ma, T., & Yang, J. (2020). Counting Crowds with Perspective Distortion Correction via Adaptive Learning. Sensors, 20(13), 3781. https://doi.org/10.3390/s20133781