Exploration and Research of Human Identification Scheme Based on Inertial Data




Abstract
1. Introduction
2. Problem Statement and Data Preprocessing
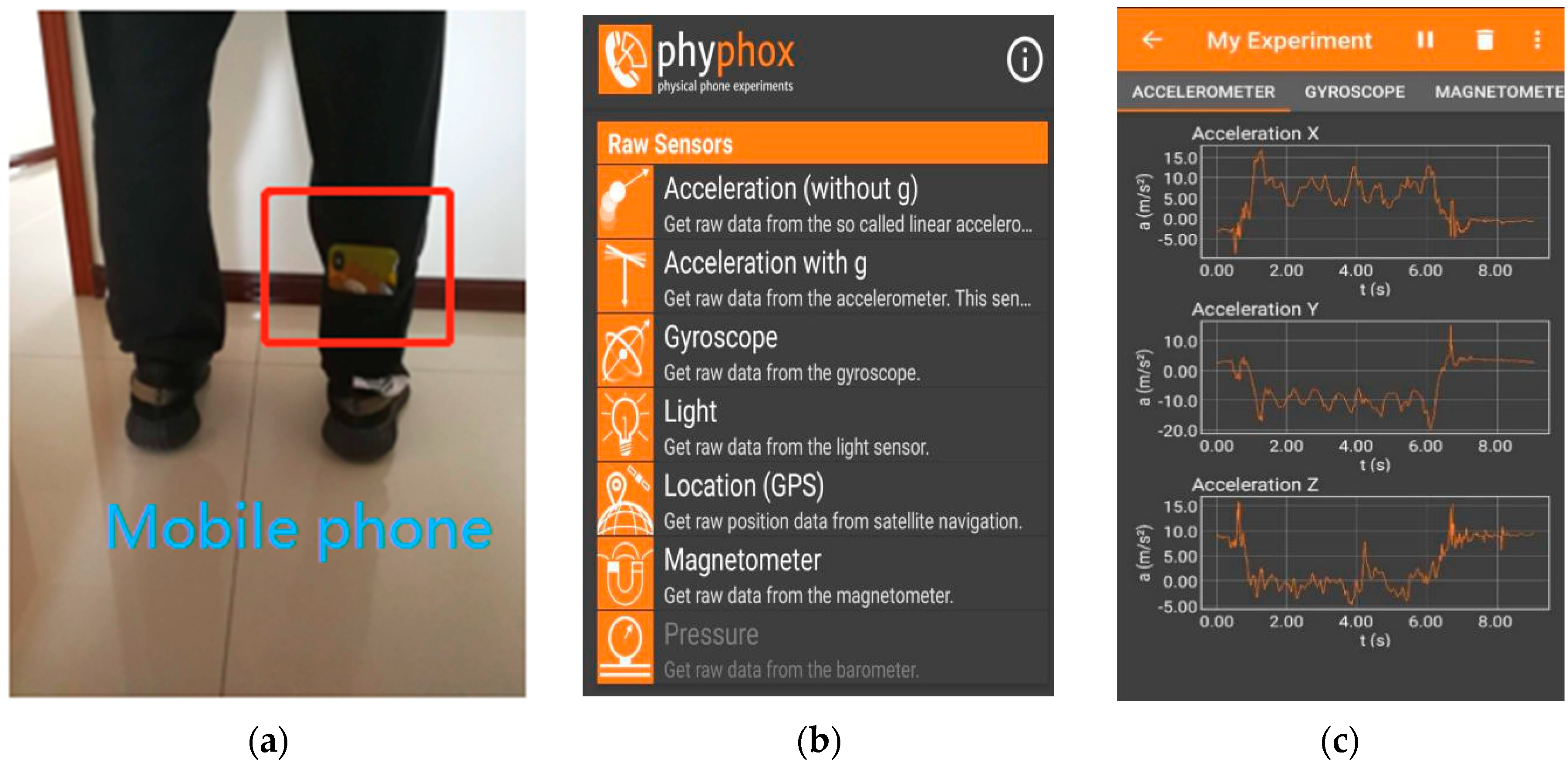
2.1. Description of Research Content and Dataset
2.2. Data Preprocessing
3. Verification of Inertial Data Separability
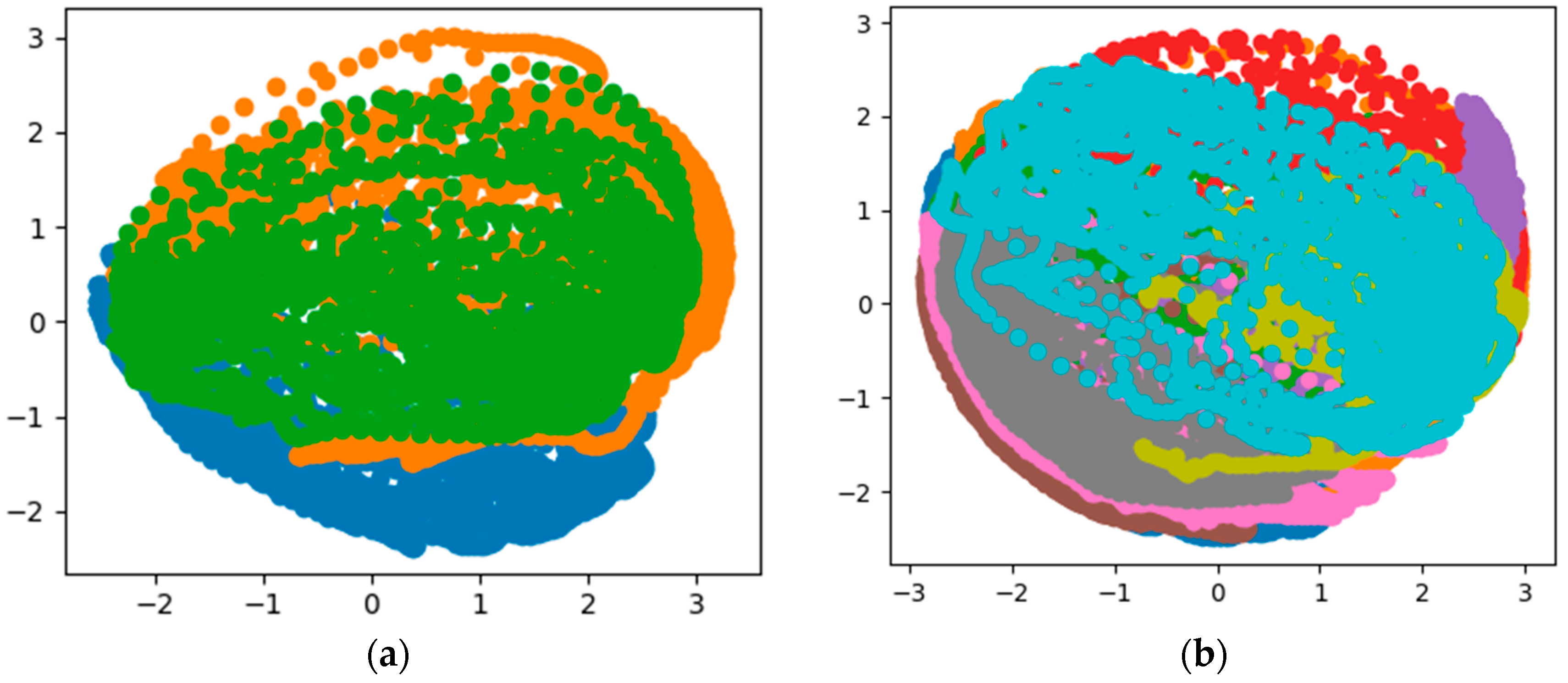
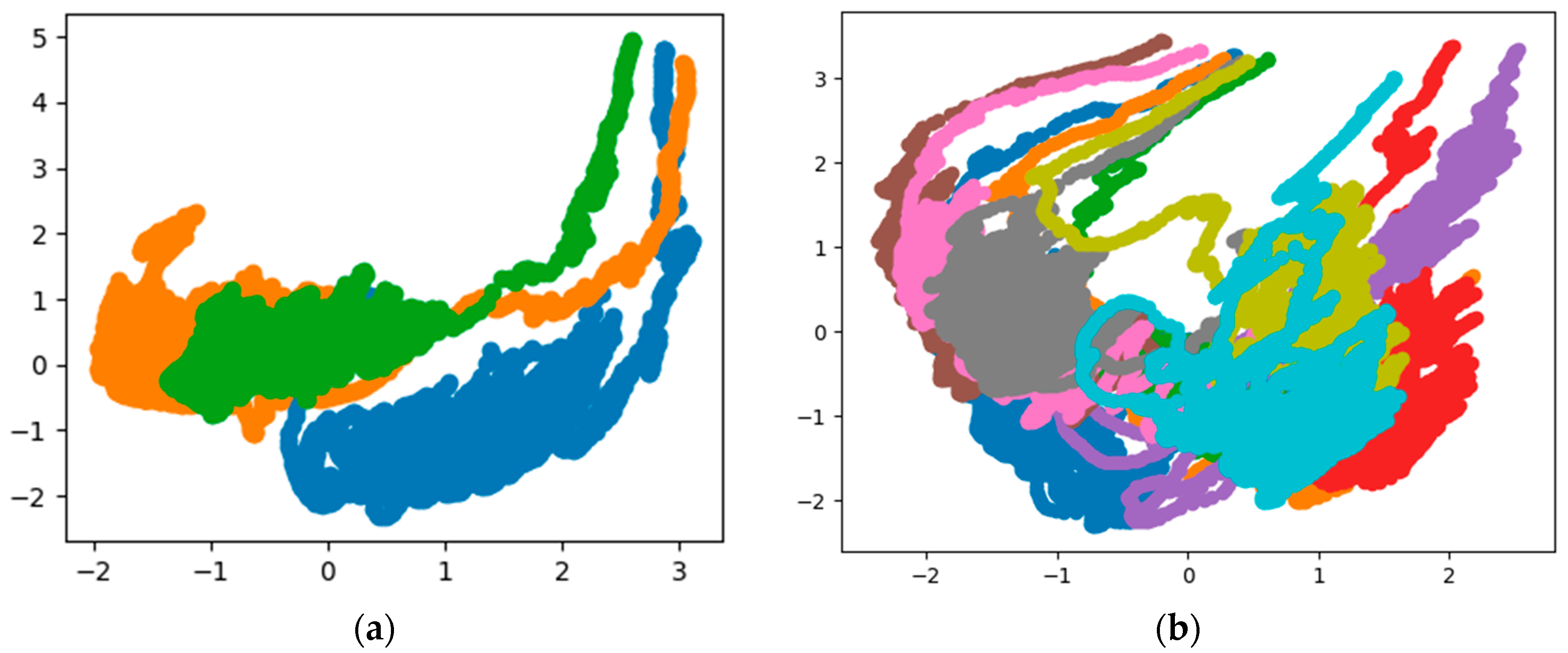
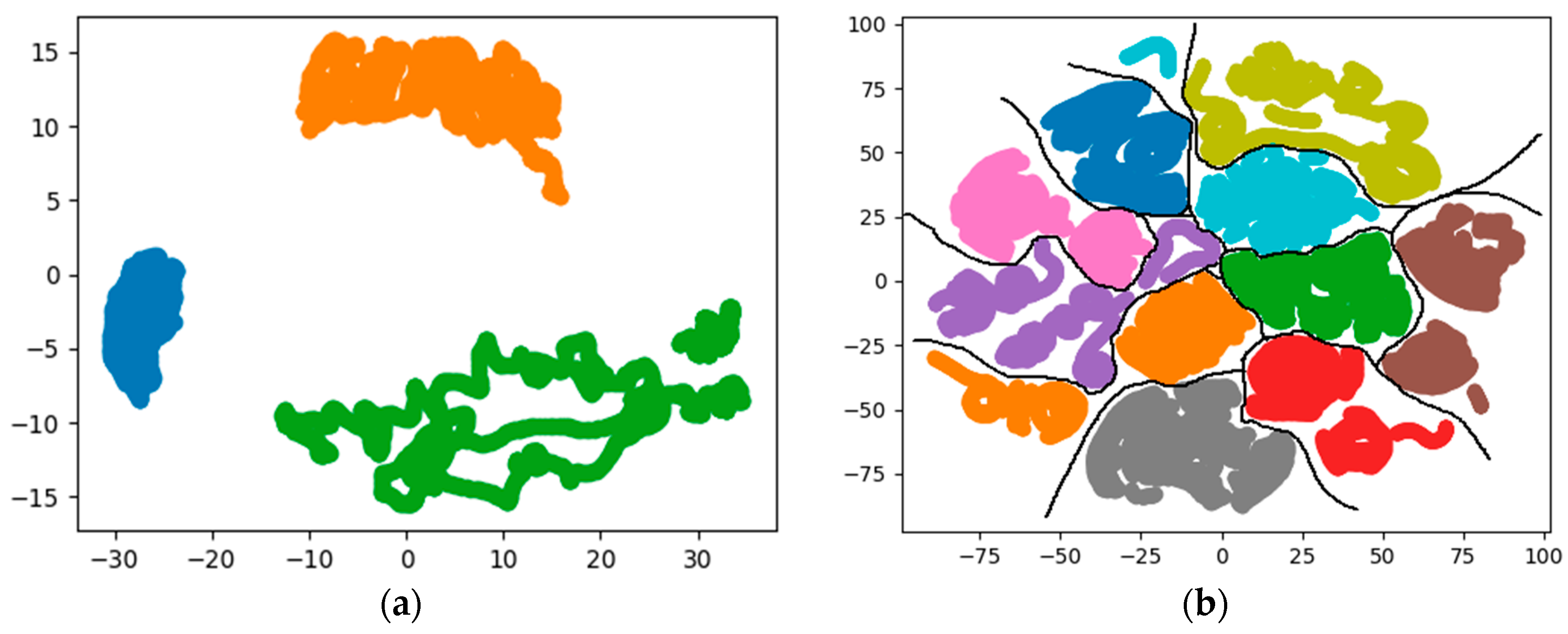
3.1. PCA-Based Data Separability Verification
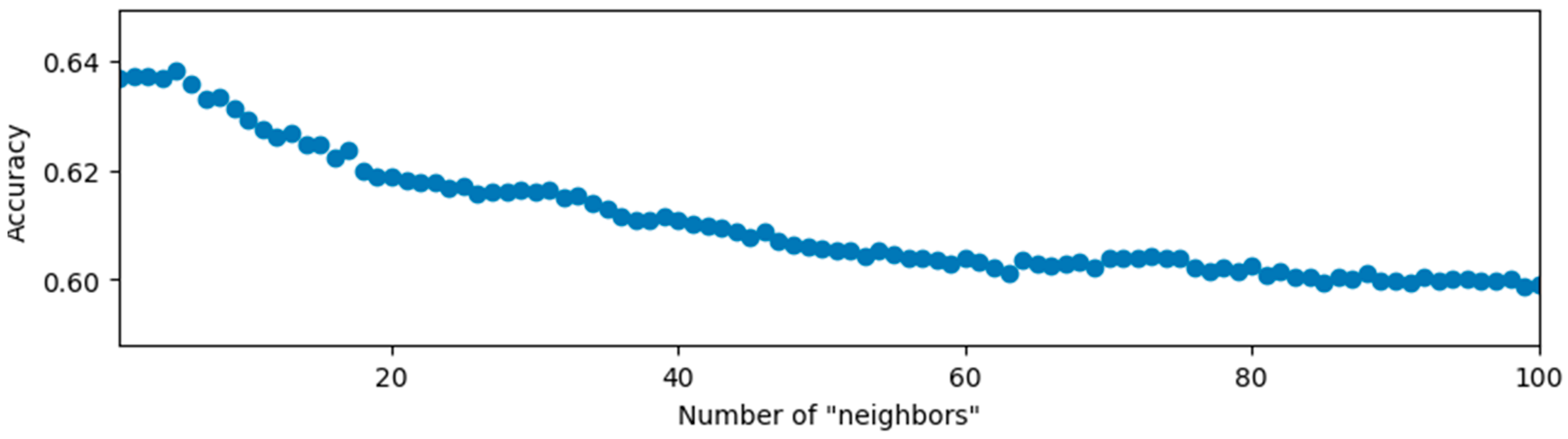
3.2. KNN-Based Data Separability Verification
4. Classification Experiments Based on Feature Extraction
4.1. Feature Extraction Based on Statistical Data and Identity Identification Based on SVM Algorithm
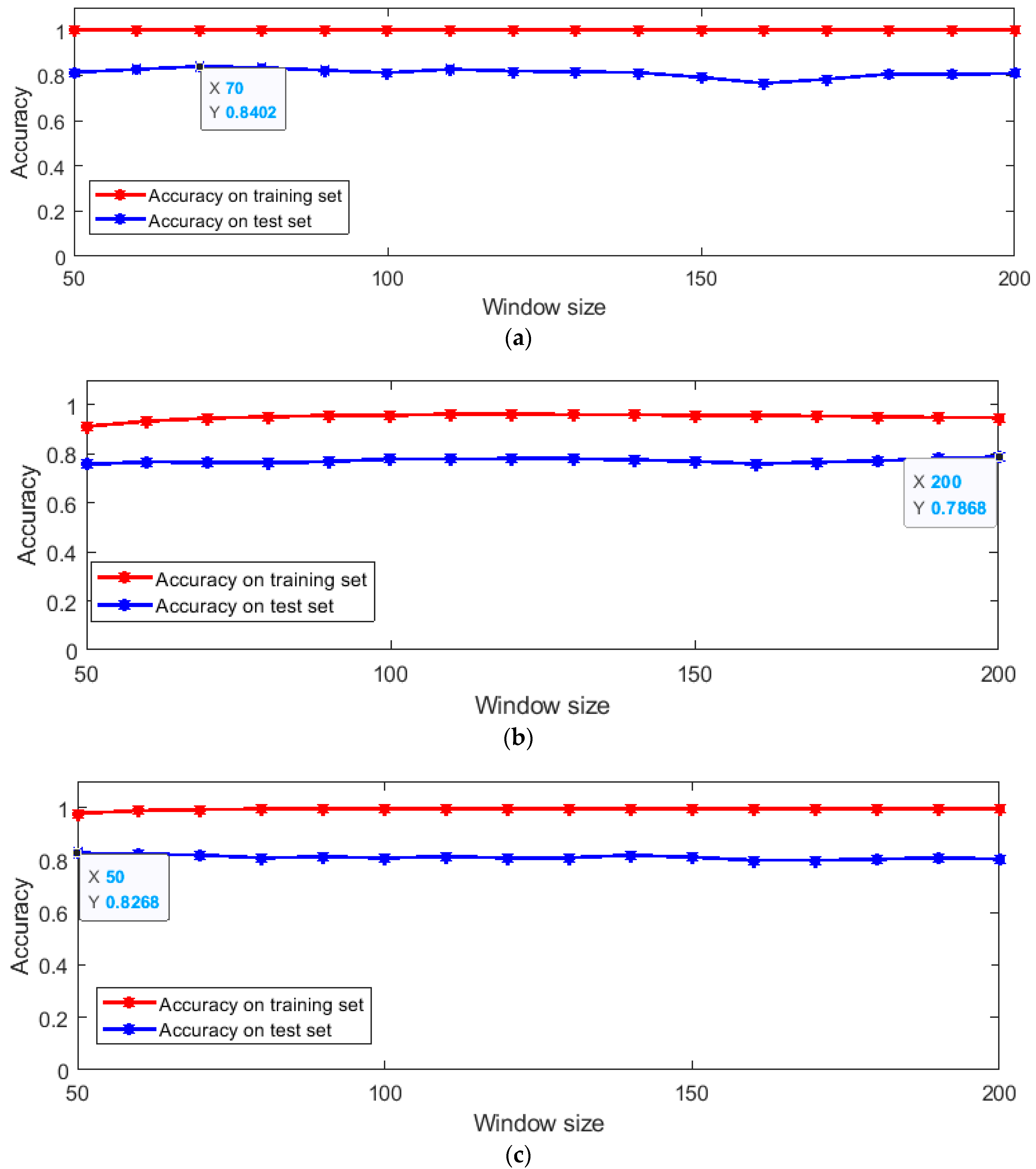
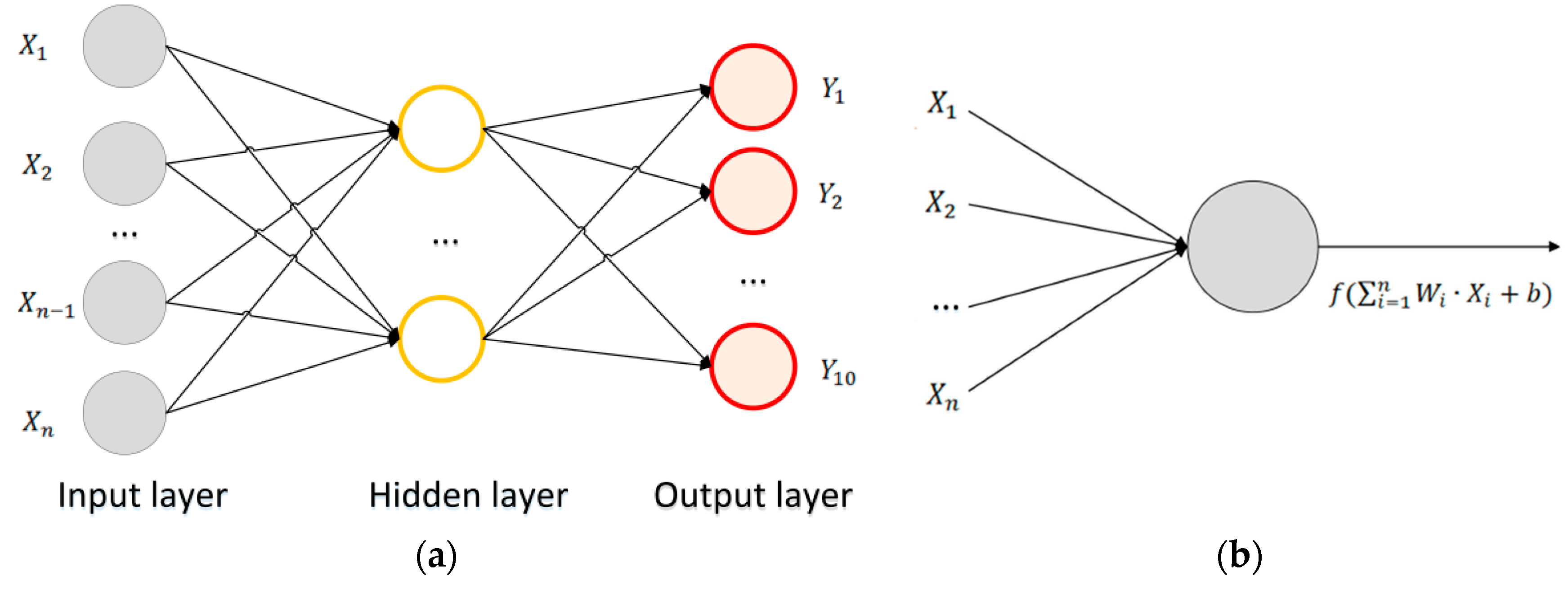
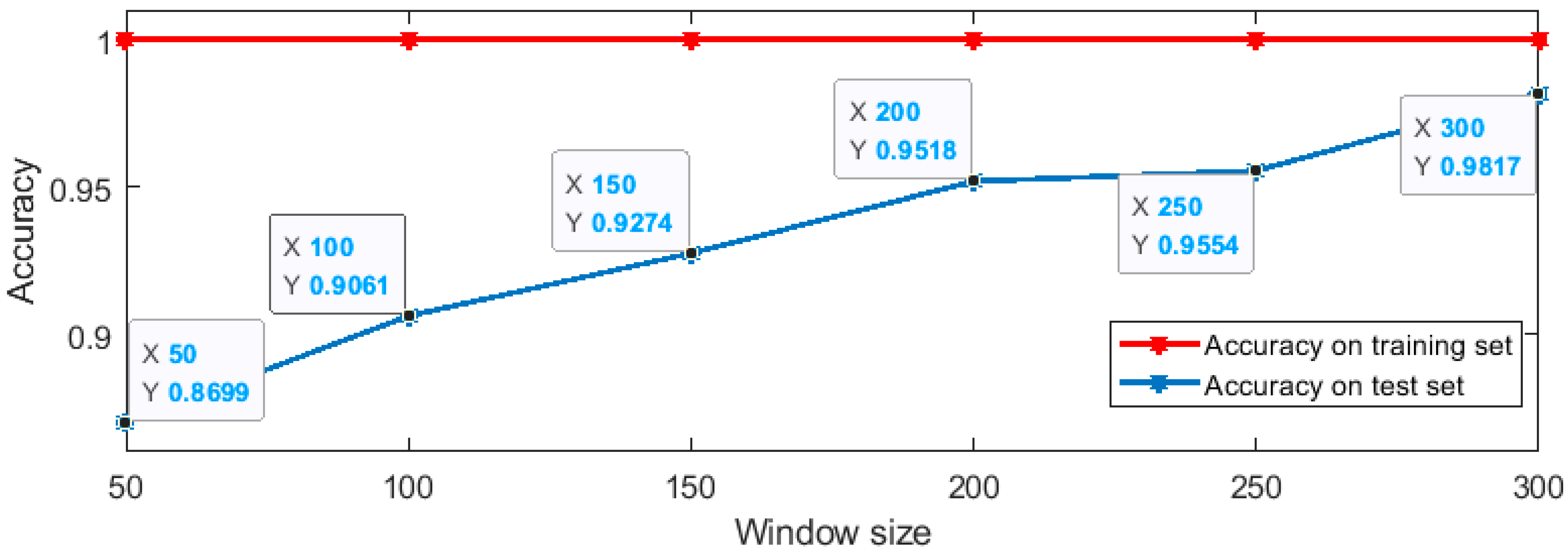
4.2. Machine Learning-Based Identity Recognition
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hong, Y.-J.; Kim, I.; Ahn, S.C.; Kim, H. Mobile health monitoring system based on activity recognition using accelerometer. Simul. Model. Pract. Theory 2010, 18, 446–455. [Google Scholar] [CrossRef]
- Yang, J.-Y.; Wang, J.; Chen, Y. Using acceleration measurements for activity recognition: An effective learning algorithm for constructing neural classifiers. Pattern Recognit. Lett. 2008, 29, 2213–2220. [Google Scholar] [CrossRef]
- Sprager, S.; Juric, M.B. Inertial sensor-based gait recognition: A review. Sensors 2015, 15, 22089–22127. [Google Scholar] [CrossRef] [PubMed]
- Gyllensten, I.C.; Bonomi, A.G. Identifying types of physical activity with a single accelerometer: Evaluating laboratory-trained algorithms in daily life. IEEE Trans. Biomed. Eng. 2011, 58, 2656–2663. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Wang, J.; Xu, L.; Liu, P. Fall detection by wearable sensor and one-class SVM algorithm. In Intelligent Computing in Signal Processing and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2006; pp. 858–863. [Google Scholar]
- Zappi, P.; Stiefmeier, T.; Farella, E.; Roggen, D.; Benini, D.; Troster, G. Activity recognition from on-body sensors by classifier fusion: Sensor scalability and robustness. In Proceedings of the 2007 3rd International Conference on Intelligent Sensors, Sensor Networks and Information, Melbourne, Australia, 3–6 December 2007; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Cell phone-based biometric identification. In Proceedings of the 2010 Fourth IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS), Washington, DC, USA, 27–29 September 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Gupta, P.; Tim, D. Feature selection and activity recognition system using a single triaxial accelerometer. IEEE Trans. Biomed. Eng. 2014, 61, 1780–1786. [Google Scholar] [CrossRef] [PubMed]
- Song, S.-k.; Jang, J.; Park, S. A phone for human activity recognition using triaxial acceleration sensor. In Proceedings of the 2008 Digest of Technical Papers-International Conference on Consumer Electronics, Las Vegas, NV, USA, 9–13 January 2008; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar]
- Gafurov, D.; Snekkenes, E.; Bours, P. Gait authentication and identification using wearable accelerometer sensor. In Proceedings of the 2007 IEEE Workshop on Automatic Identification Advanced Technologies, Alghero, Italy, 7–8 June 2007; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Seel, T.; Raisch, J.; Schauer, T. IMU-based joint angle measurement for gait analysis. Sensors 2014, 14, 6891–6909. [Google Scholar] [CrossRef]
- Long, X.; Yin, B.; Aarts, R.M. Single-accelerometer-based daily physical activity classification. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Venture, G.; Ayusawa, K.; Nakamura, Y. Motion capture based identification of the human body inertial parameters. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar]
- Kim, J.-H.; Hong, G.-S.; Kim, B.-G.; Dogra, D.P. deepGesture: Deep learning-based gesture recognition scheme using motion sensors. Displays 2018, 55, 38–45. [Google Scholar] [CrossRef]
- Ghasemzadeh, H.; Jafari, R. Coordination analysis of human movements with body sensor networks: A signal processing model to evaluate baseball swings. IEEE Sens. J. 2010, 11, 603–610. [Google Scholar] [CrossRef]
- Cutting, J.E.; Kozlowski, L.T. Recognizing friends by their walk: Gait perception without familiarity cues. Bull. Psychon. Soc. 1977, 9, 353–356. [Google Scholar] [CrossRef]
- Su, H.; Huang, F.G.; Hong, W. Automatic human identification method based on gait analysis. J. Syst. Simul. 2006, 18, 1292–1296. [Google Scholar]
- Foster, J.P.; Nixon, M.S.; Prügel-Bennett, A. Automatic gait recognition using area-based metrics. Pattern Recognit. Lett. 2003, 24, 2489–2497. [Google Scholar] [CrossRef]
- Lu, J.; Zhang, E. Gait recognition for human identification based on ICA and fuzzy SVM through multiple views fusion. Pattern Recognit. Lett. 2007, 28, 2401–2411. [Google Scholar] [CrossRef]
- Kuhlen, S.; Stampfer, C.; Wilhelm, T.; Kuhn, J. Phyphox bringt das Smartphone ins Rollen: Smarte Physik. Phys. Unserer Zeit 2017, 48, 148–149. [Google Scholar] [CrossRef]
- Khan, A.M.; Lee, Y.-K.; Lee, S.Y.; Kim, T.-S. Human activity recognition via an accelerometer-enabled-smartphone using kernel discriminant analysis. In Proceedings of the 2010 5th International Conference on Future Information Technology, Busan, Korea, 21–23 May 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Zhu, Y.; Yu, J.; Hu, F.; Li, Z.; Ling, Z. Human activity recognition via smart-belt in wireless body area networks. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719849357. [Google Scholar] [CrossRef]
- Yang, J.; Bang, W.-C.; Choi, E.; Cho, S.-J.; Ki, E.-K.; Kim, D.-Y.; Kim, S.R. A 3D hand-drawn gesture input device using fuzzy ARTMAP-based recognizer. J. Syst. Cybern. Inform. 2006, 4, 1–7. [Google Scholar]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Tsymbal, A.; Puuronen, S.; Penchenizkiy, M.; Baumgarten, M.; Patterson, D.W. Eigenvector-Based Feature Extraction for Classification. In Proceedings of the Fifteenth International Florida Artificial Intelligence Research Society Conference (FLAIRS Conference), Pensacola Beach, FL, USA, 14–16 May 2002. [Google Scholar]
- Hotelling, H.H. Analysis of Complex Statistical Variables into Principal Components. Br. J. Educ. Psychol. 1932, 24, 417–520. [Google Scholar] [CrossRef]
- Wang, Z.L.; Jiang, M.; Hu, Y.; Li, H. An Incremental Learning Method Based on Probabilistic Neural Networks and Adjustable Fuzzy Clustering for Human Activity Recognition by Using Wearable Sensors. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 691–699. [Google Scholar] [CrossRef]
- Wang, A.; Chen, G.; Yang, J.; Zhao, S.; Chang, C. A Comparative Study on Human Activity Recognition Using Inertial Sensors in a Smartphone. IEEE Sens. J. 2016, 16, 4566–4578. [Google Scholar] [CrossRef]
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. In Proceedings of the 17th IAAI, Pittsburgh, PA, USA, 9–13 July 2005; pp. 1541–1546. [Google Scholar]
- Khan, A.M.; Lee, Y.-K.; Lee, S.Y.; Kim, T.-S. A triaxial accelerometer-based physical-activity recognition via augmented-signal features and a hierarchical recognizer. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1166–1172. [Google Scholar] [CrossRef]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 21st ESANN, Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- He, Z.-Y.; Jin, L.-W. Activity recognition from acceleration data using AR model representation and SVM. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 2245–2250. [Google Scholar]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Disc. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Lee, J.H.; Marzelli, M.; Jolesz, F.A.; Yoo, S.-S. Automated classification of fMRI data employing trial-based imagery tasks. Med. Image Anal. 2009, 13, 392–404. [Google Scholar] [CrossRef] [PubMed]
- Fan, R.E.; Chen, P.H.; Lin, C.J. Working set selection using second order information for training support vector machines. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Hinton, G.E. Connectionist learning procedures. Artif. Intell. 1989, 40, 185–234. [Google Scholar] [CrossRef]
- Hara, K.; Saito, D.; Shouno, H. Analysis of function of rectified linear unit used in deep learning. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. Available online: https://arxiv.org/abs/1412.6980 (accessed on 5 April 2018).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Category | Data Sources | Feature Extraction | Advantages | Disadvantages |
|---|---|---|---|---|
| Joint position changes [16] | Position of joints in the image | Statistics of positions | Simple data processing | Complex image acquisition method and low accuracy |
| Extract limb angle information from images [17] | Image sequence | Analyze the change in silhouette width | No human body required, high accuracy | Still background is required |
| Recognition using area-based metrics [18] | Image sequence | Body contour extraction and combination of masks | Simple calculation, high accuracy | Need a fixed camera position for image acquisition |
| Method based on machine learning | Image sequence | Body contour extraction and classification based on SVM | Feature fusion, high accuracy | Need a fixed camera position |
| Solutions explored and discussed in this article | Inertial data | Statistical features and network fitting features | Simple data collection, not affected by the environment, high accuracy | The method of feature extraction needs further exploration to meet the use of large-scale data |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Z.; Sun, J.; Yang, H.; Tan, J.; Zhou, B.; Wei, Q.; Zhang, R. Exploration and Research of Human Identification Scheme Based on Inertial Data. Sensors 2020, 20, 3444. https://doi.org/10.3390/s20123444
Gao Z, Sun J, Yang H, Tan J, Zhou B, Wei Q, Zhang R. Exploration and Research of Human Identification Scheme Based on Inertial Data. Sensors. 2020; 20(12):3444. https://doi.org/10.3390/s20123444
Chicago/Turabian StyleGao, Zhenyi, Jiayang Sun, Haotian Yang, Jiarui Tan, Bin Zhou, Qi Wei, and Rong Zhang. 2020. "Exploration and Research of Human Identification Scheme Based on Inertial Data" Sensors 20, no. 12: 3444. https://doi.org/10.3390/s20123444
APA StyleGao, Z., Sun, J., Yang, H., Tan, J., Zhou, B., Wei, Q., & Zhang, R. (2020). Exploration and Research of Human Identification Scheme Based on Inertial Data. Sensors, 20(12), 3444. https://doi.org/10.3390/s20123444