Automatic Indoor as-Built Building Information Models Generation by Using Low-Cost RGB-D Sensors


Abstract
1. Introduction
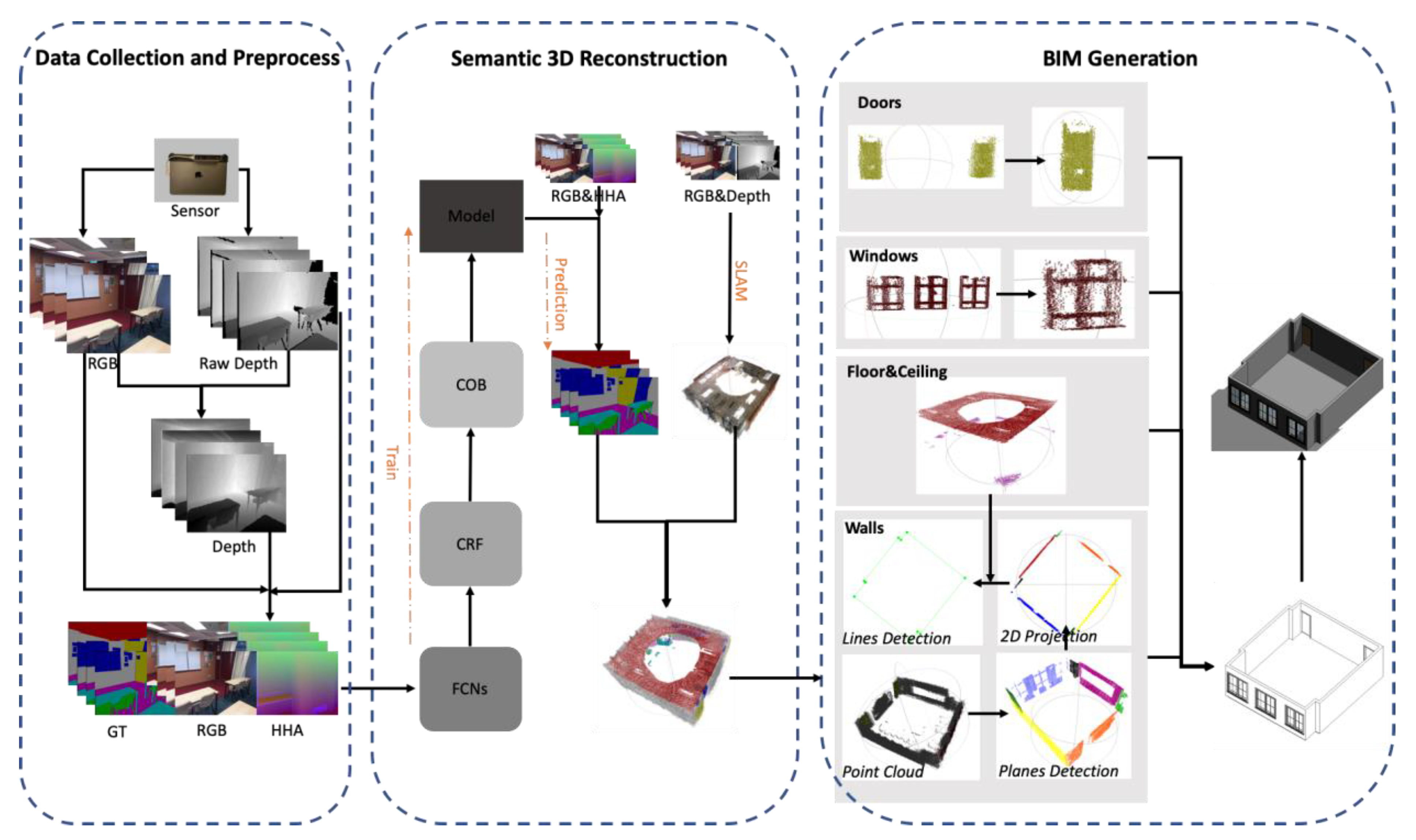
2. Automatic BIM Generation Framework
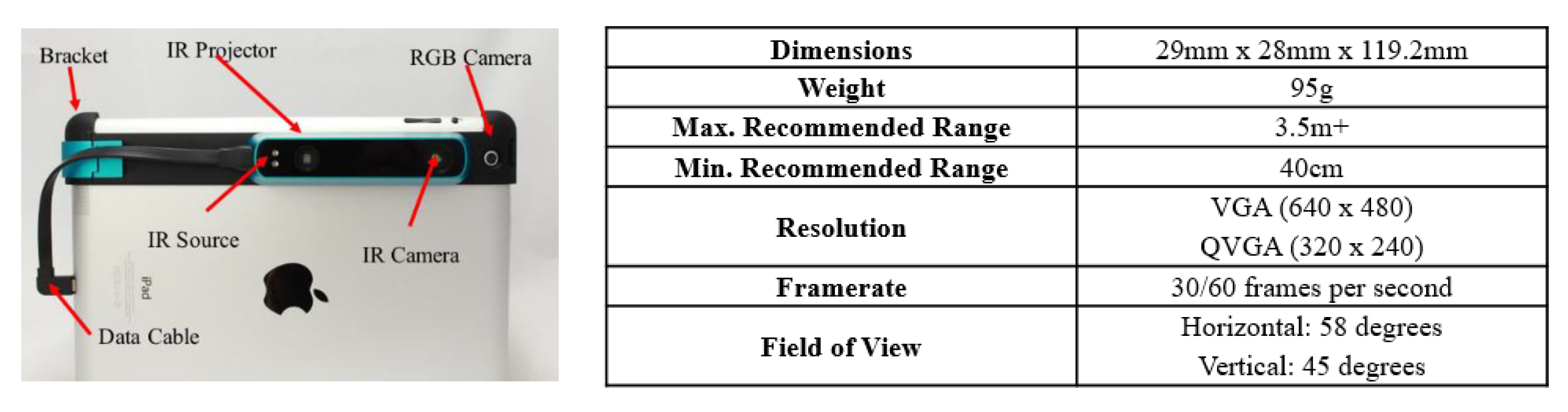
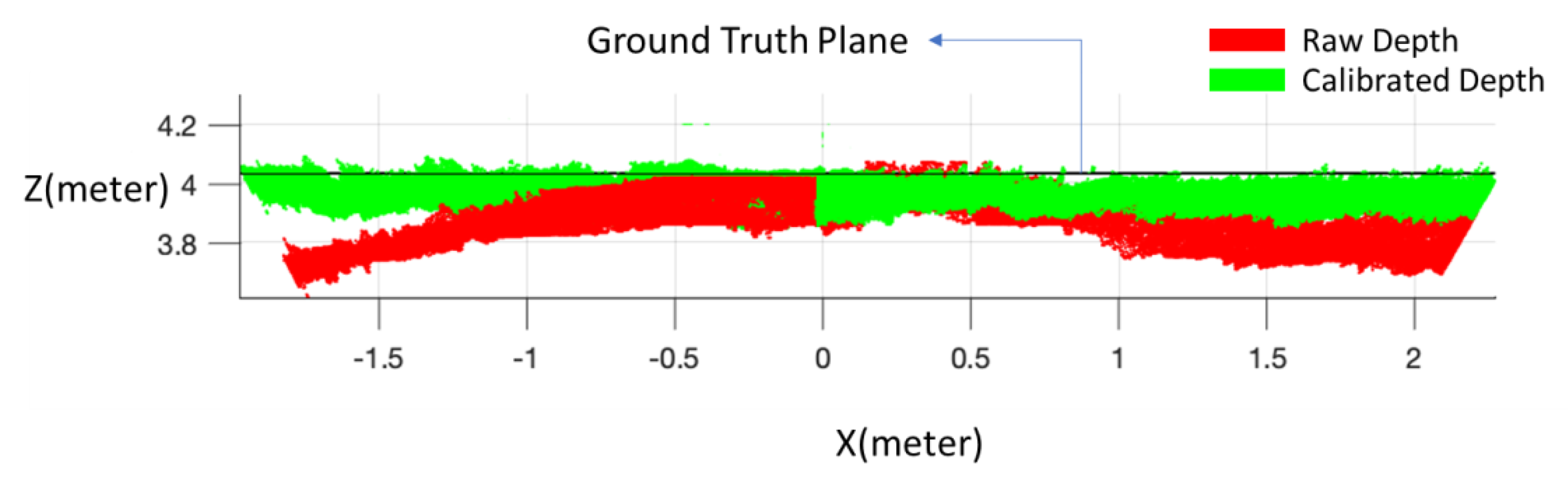
2.1. Data Collection and Preprocessing
2.2. Semantic 3D Reconstruction
2.3. The Transformation from Semantic 3D Reconstruction to BIM Format 3D Model
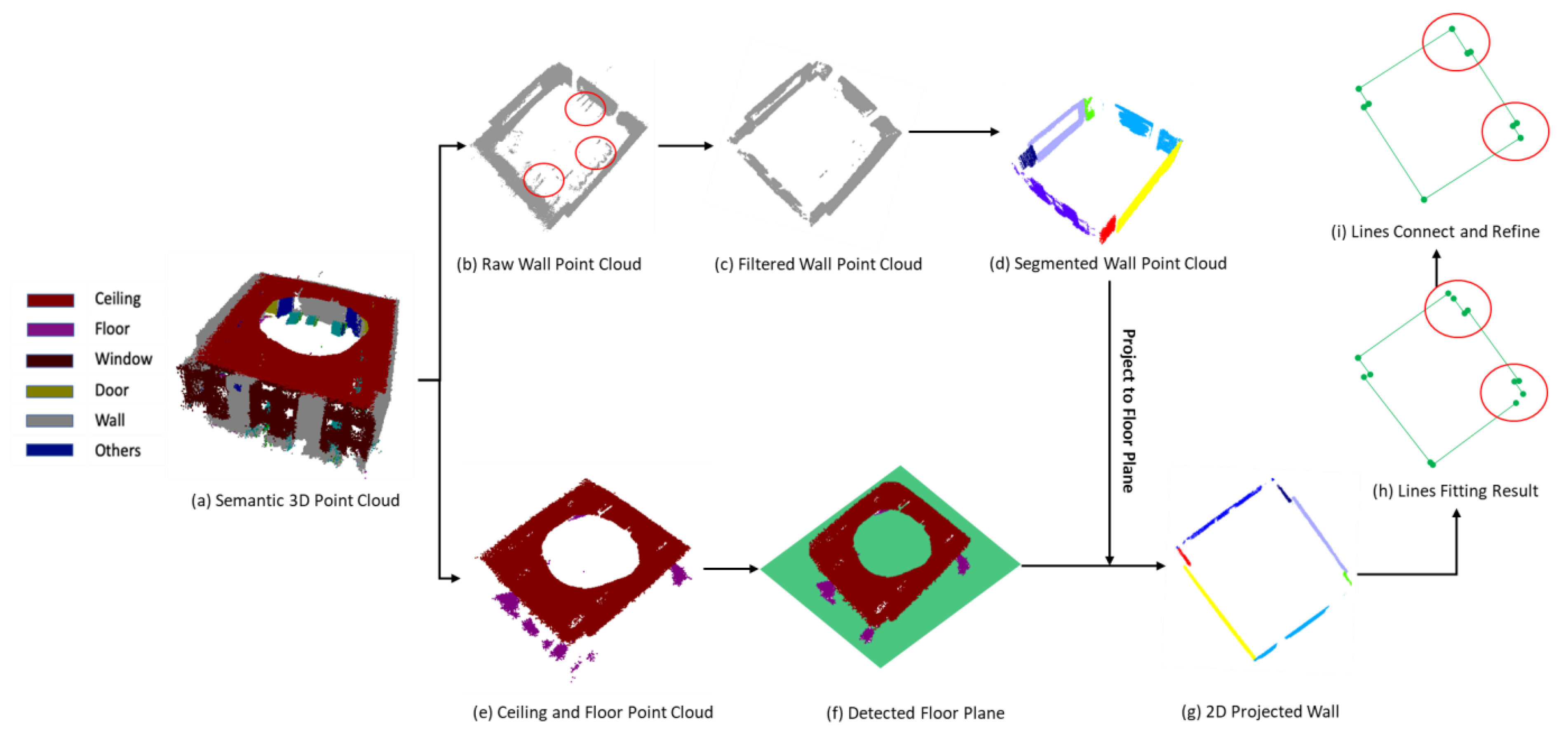
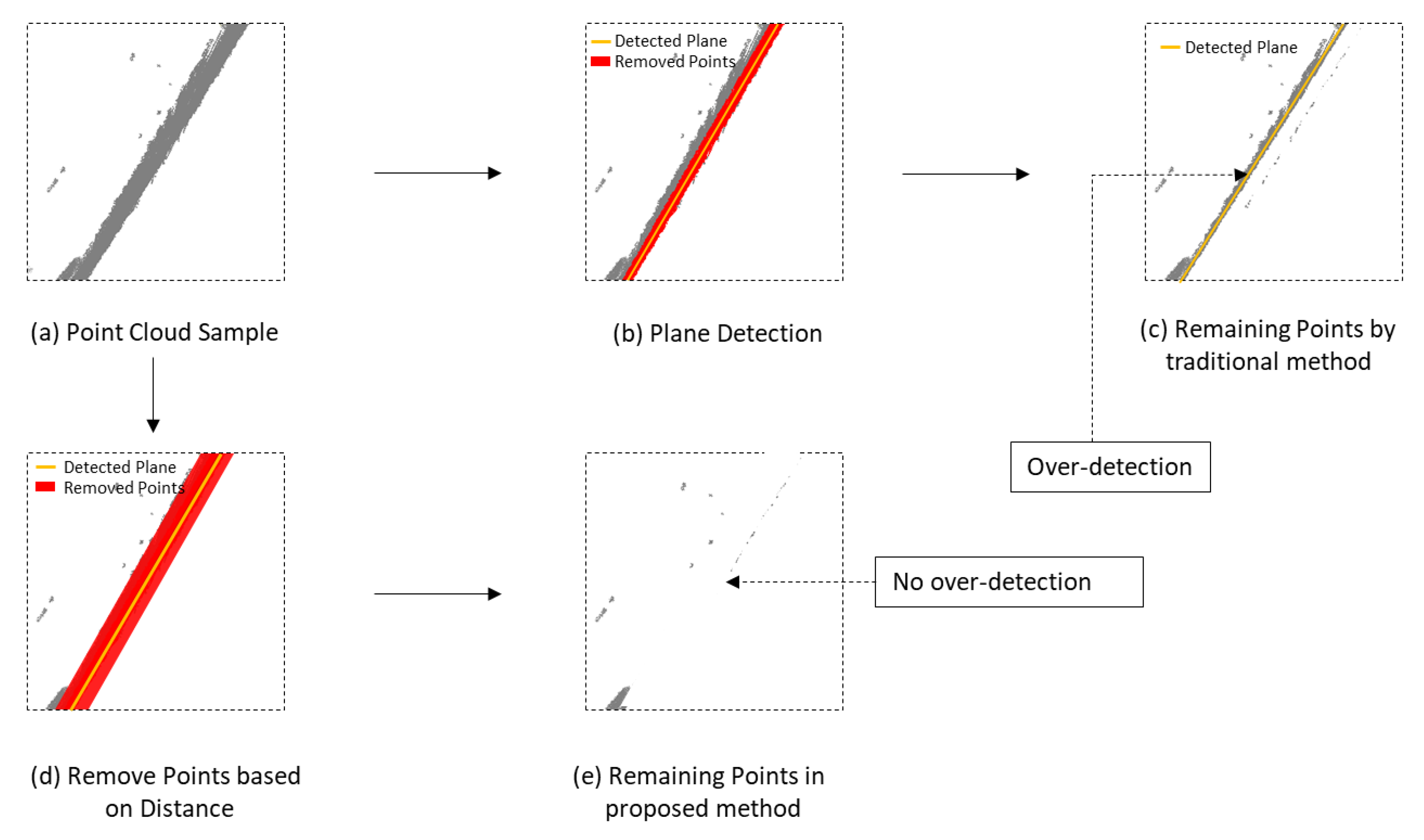
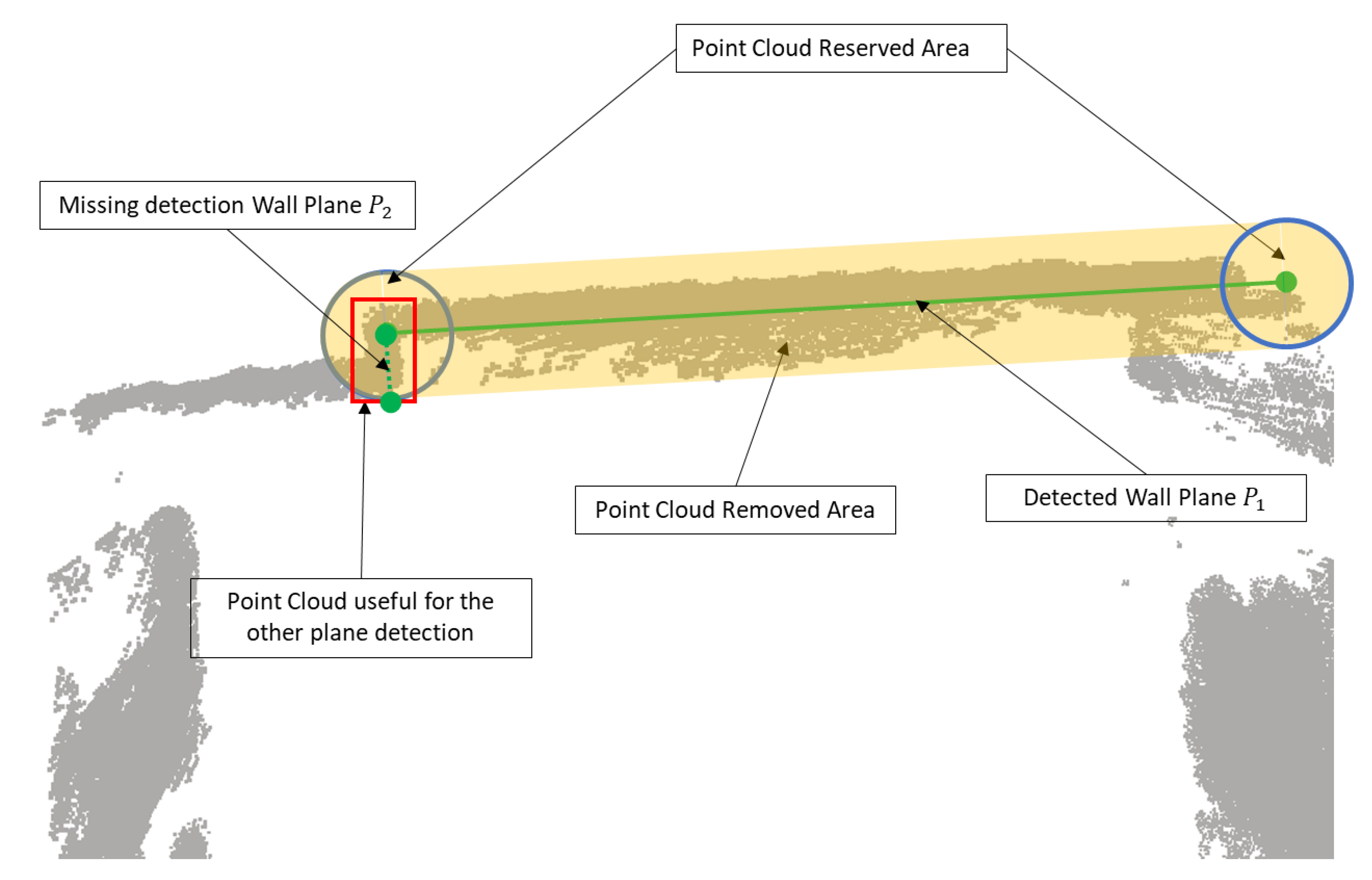
2.3.1. Wall Boundary Extraction
| Algorithm 1 Wall Boundary extraction |
| Input: Lebeled wall point cloud:{} Distance threshold to remove the point cloud: Distance threshold to filter the plane: Angle threshold to filter the plane: Distance threshold to reserve the point cloud: Percentage threshold to end the loop: |
| Output: 2D Wall Lines in floor plane: |
| 1: initialize: remaining point cloud:{} = {} 2: while do 3: Plane candidate: 4: if is empty then 5: add to 6: Distance between points and plane: 7: Distance between points and line in floor plane: 8: for do 9: if < and < then 10: add to ready to remove set 11: end if 12: end for 13: else 14: for do 15: Distance between planes: 16: Angle between planes: 17: if and then 18: Continue 19: end if 20: end for 21: if then 22: add to 23: Distance between points and plane: 24: Distance between points and line in floor plane: 25: for do 26: if < and < then 27: add to ready to remove set 28: end if 29: end for 30: end if 31: end if 32: remove point from : 33: end while 34: Return: |
| Algorithm 2: 2D Wall Lines Connection and Refining |
| Input: 2D Wall Lines in floor plane: Angle threshold: |
| Output: Connection vectors of 2D wall lines: |
| 1: initialize: Random Select one line from 2: Remove from , and add to 3: while is not empty do 4: for do 5: For distance set 6: end for 7: Find line candidate referring to the minimum value in 8: Remove from , and add to 9: end while 10: for do 11: Calculate the angle between adjacent lines: 12: if then 13: Extend lines to obtain intersection point 14: Update the vertexes of 15: else 16: Add one new line between 17: end if 18: end for 19: Return: |
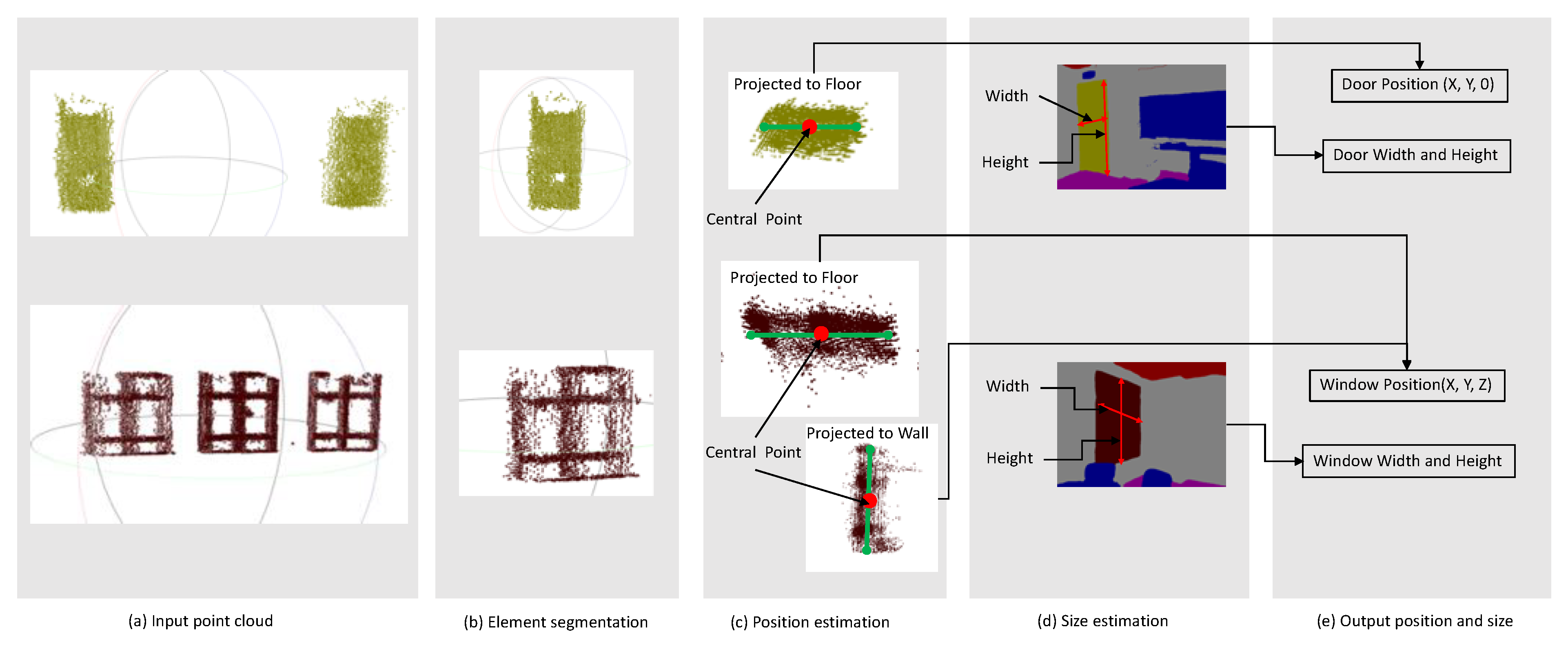
2.3.2. Door and Window Extraction
2.3.3. BIM Format 3D Model Generation Based on Geometry Information
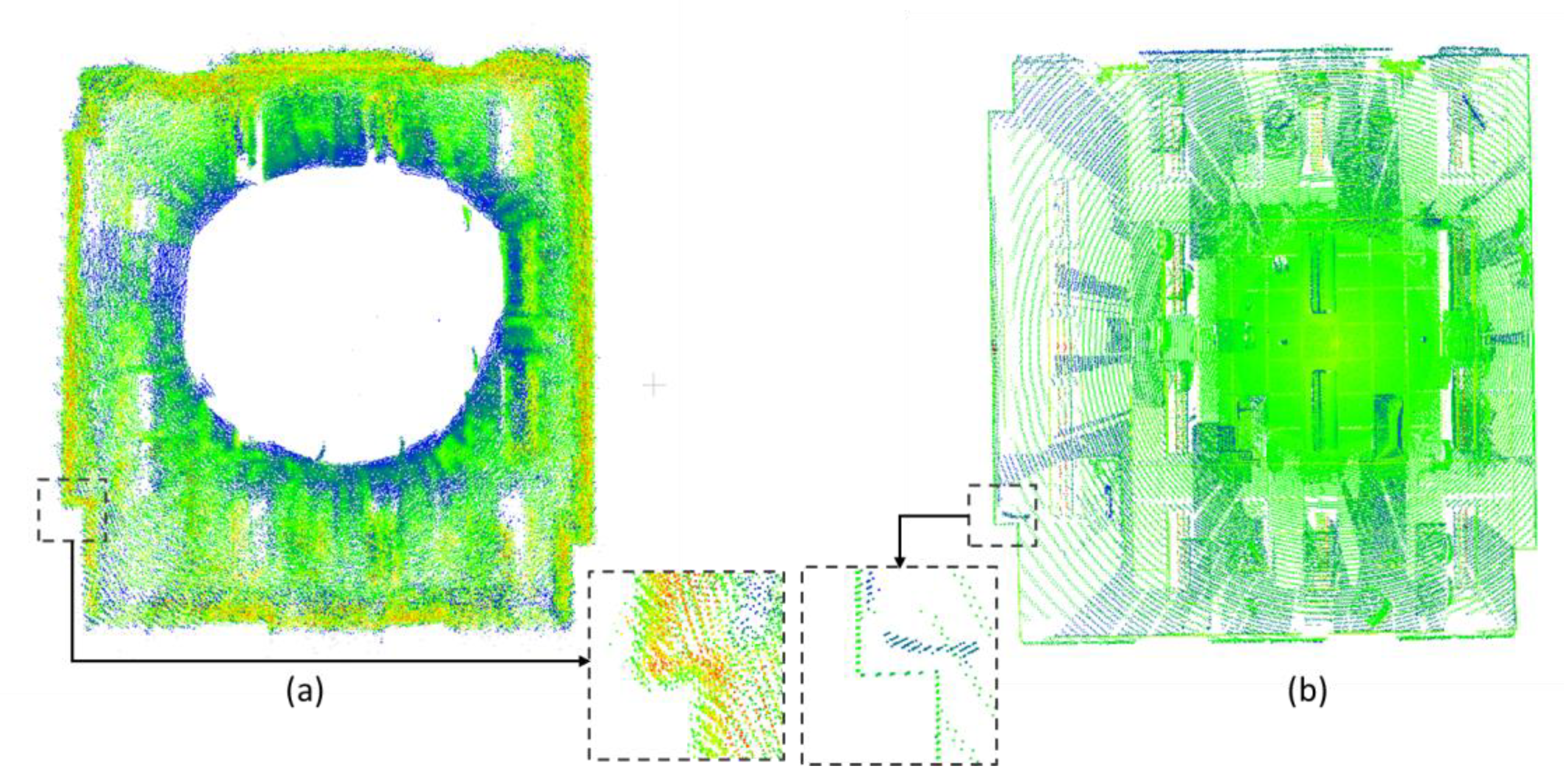
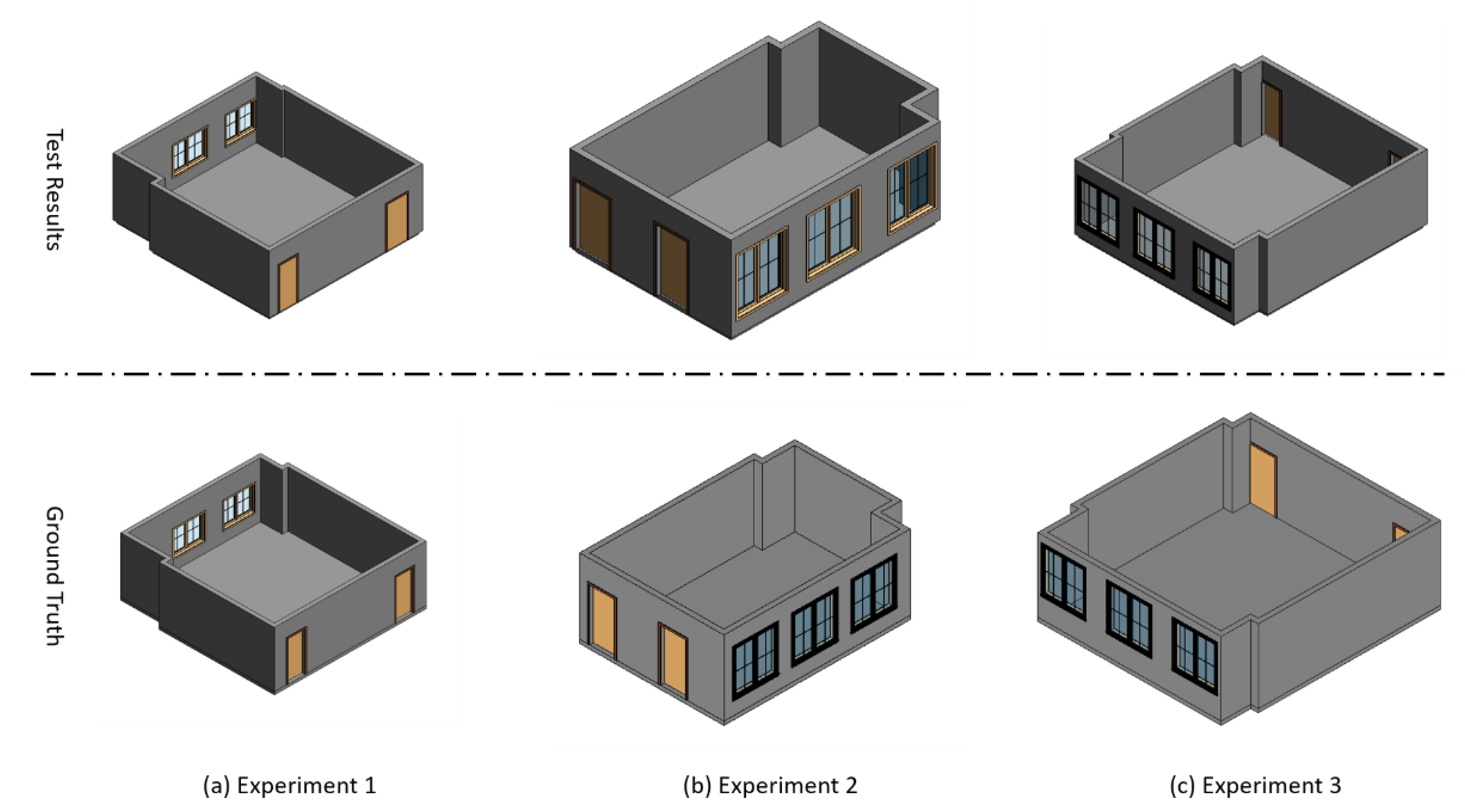
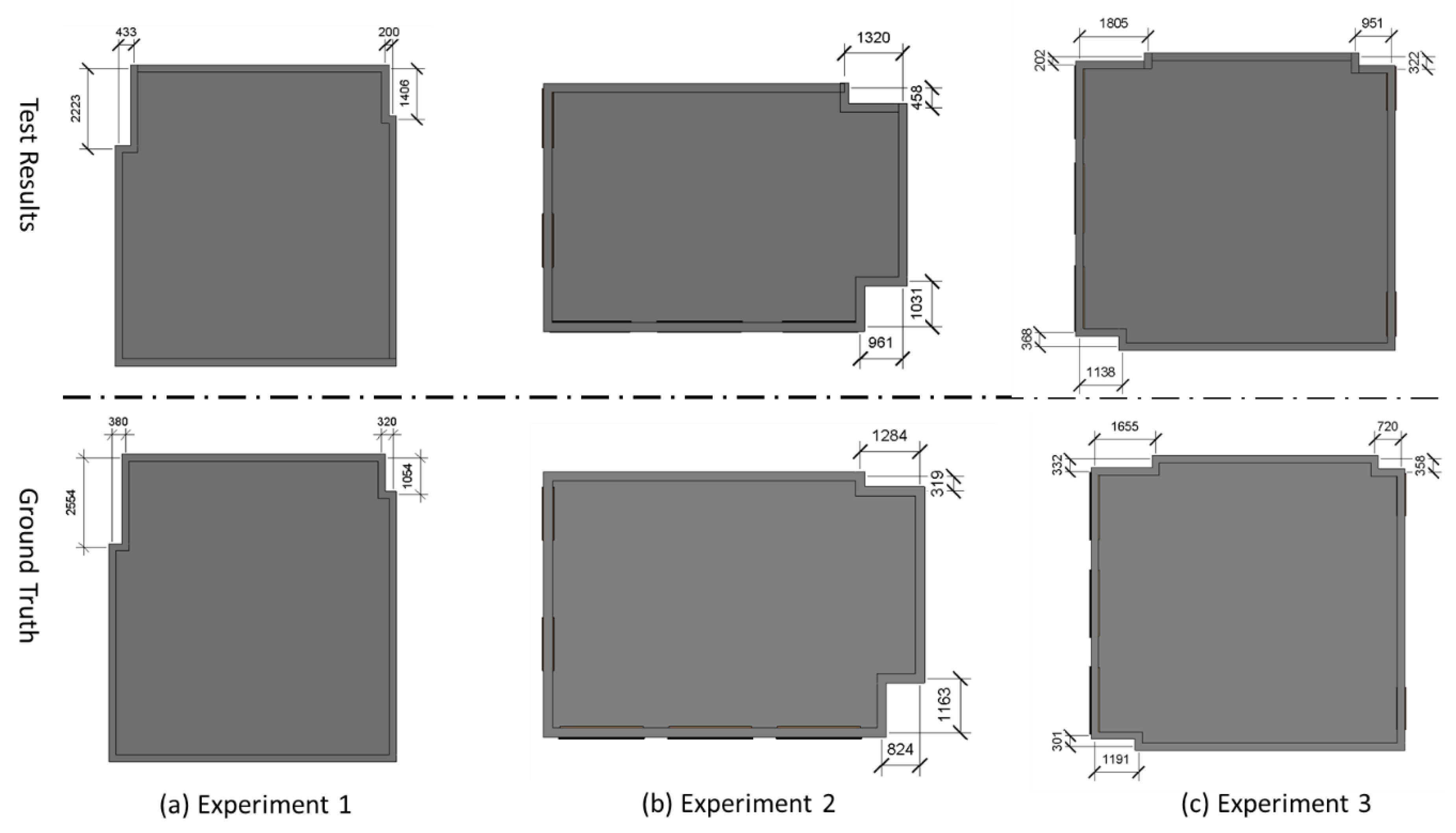
3. Experimental Tests and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Volk, R.; Stengel, J.; Schultmann, F. Building Information Modeling (BIM) for existing buildings—Literature review and future needs. Autom. Constr. 2014, 38, 109–127. [Google Scholar] [CrossRef]
- Hartmann, T.; Van Meerveld, H.; Vossebeld, N.; Adriaanse, A. Aligning building information model tools and construction management methods. Autom. Constr. 2012, 22, 605–613. [Google Scholar] [CrossRef]
- Yan, W.; Culp, C.; Graf, R. Integrating BIM and gaming for real-time interactive architectural visualization. Autom. Constr. 2011, 20, 446–458. [Google Scholar] [CrossRef]
- Becker, T.; Nagel, C.; Kolbe, T.H. A multilayered space-event model for navigation in indoor spaces. In 3D Geo-information Sciences; Springer: Berlin/Heidelberg, Germany, 2009; pp. 61–77. [Google Scholar]
- Li, N.; Becerik-Gerber, B.; Krishnamachari, B.; Soibelman, L. A BIM centered indoor localization algorithm to support building fire emergency response operations. Autom. Constr. 2014, 42, 78–89. [Google Scholar] [CrossRef]
- Macher, H.; Landes, T.; Grussenmeyer, P.J.A.S. From point clouds to building information models: 3D semi-automatic reconstruction of indoors of existing buildings. Appl. Sci. 2017, 7, 1030. [Google Scholar] [CrossRef]
- Xue, F.; Lu, W.; Chen, K.; Zetkulic, A. From Semantic Segmentation to Semantic Registration: Derivative-Free Optimization–Based Approach for Automatic Generation of Semantically Rich As-Built Building Information Models from 3D Point Clouds. J. Comput. Civil Eng. 2019, 33, 04019024. [Google Scholar] [CrossRef]
- Hong, S.; Jung, J.; Kim, S.; Cho, H.; Lee, J.; Heo, J. Semi-automated approach to indoor mapping for 3D as-built building information modeling. Comput. Environ. Urban. Syst. 2015, 51, 34–46. [Google Scholar] [CrossRef]
- Thomson, C.; Apostolopoulos, G.; Backes, D.; Boehm, J. Mobile laser scanning for indoor modelling. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2013, 5, W2. [Google Scholar] [CrossRef]
- Mill, T.; Alt, A.; Liias, R. Combined 3D building surveying techniques–terrestrial laser scanning (TLS) and total station surveying for BIM data management purposes. J. Civ. Manag. 2013, 19, S23–S32. [Google Scholar] [CrossRef]
- Ullman, S. The interpretation of structure from motion. Proceedings of the Royal Society of London. Ser. B Biol. Sci. 1979, 203, 405–426. [Google Scholar]
- Turner, D.; Lucieer, A.; Watson, C. An automated technique for generating georectified mosaics from ultra-high resolution unmanned aerial vehicle (UAV) imagery, based on structure from motion (SfM) point clouds. Remote. Sens. 2012, 4, 1392–1410. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Alexiadis, D.S.; Kordelas, G.; Apostolakis, K.C.; Agapito, J.D.; Vegas, J.; Izquierdo, E.; Daras, P. Reconstruction for 3D immersive virtual environments. In Proceedings of the 13th International Workshop on Image Analysis for Multimedia Interactive Services, Dublin, Ireland, 23–25 May 2012; pp. 1–4. [Google Scholar]
- Choi, S.; Zhou, Q.-Y.; Koltun, V. Robust reconstruction of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5556–5565. [Google Scholar]
- Wang, J.; Zhang, C.; Zhu, W.; Zhang, Z.; Xiong, Z.; Chou, P.A. 3D scene reconstruction by multiple structured-light based commodity depth cameras. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5429–5432. [Google Scholar]
- Okorn, B.; Xiong, X.; Akinci, B.; Huber, D. Toward automated modeling of floor plans. In Proceedings of the symposium on 3D data processing, visualization and transmission, Thessaloniki, Greece, 9 September 2004. [Google Scholar]
- Wang, C.; Cho, Y.K.; Kim, C.J.A.i.C. Automatic BIM component extraction from point clouds of existing buildings for sustainability applications. Autom. Constr. 2015, 56, 1–13. [Google Scholar] [CrossRef]
- Previtali, M.; Barazzetti, L.; Brumana, R.; Scaioni, M. Towards automatic indoor reconstruction of cluttered building rooms from point clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 281–288. [Google Scholar] [CrossRef]
- Valero, E.; Adán, A.; Cerrada, C. Automatic method for building indoor boundary models from dense point clouds collected by laser scanners. Sensors 2012, 12, 16099–16115. [Google Scholar] [CrossRef]
- Ikehata, S.; Yang, H.; Furukawa, Y. Structured indoor modeling. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 1323–1331. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Izadinia, H.; Shan, Q.; Seitz, S.M. Im2cad. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5134–5143. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Darwish, W.; Tang, S.; Li, W.; Chen, W.J.S. A new calibration method for commercial RGB-D sensors. Sensors 2017, 17, 1204. [Google Scholar] [CrossRef]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 345–360. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Rusu, R.B. Semantic 3d object maps for everyday manipulation in human living environments. KI-Künstliche Intell. 2010, 24, 345–348. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the 12th European Conference on Computer Version, Florence, Italy, 7–13 Ocotober 2012; pp. 746–760. [Google Scholar]
- Xiao, J.; Owens, A.; Torralba, A. Sun3d: A database of big spaces reconstructed using sfm and object labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 3 January 2016; pp. 1625–1632. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Levin, A.; Lischinski, D.; Weiss, Y. Colorization using optimization. ACM Trans. Graph. (tog) 2004, 23, 689–694. [Google Scholar] [CrossRef]
- Occipital. Structure Sensor. Available online: https://structure.io/structure-sensor (accessed on 5 December 2019).
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE winter conference on applications of computer vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 13–16 December 2015; pp. 1529–1537. [Google Scholar]
- Maninis, K.-K.; Pont-Tuset, J.; Arbeláez, P.; Van Gool, L. Convolutional oriented boundaries: From image segmentation to high-level tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 819–833. [Google Scholar] [CrossRef] [PubMed]
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D mapping with an RGB-D camera. IEEE Trans. Robot. 2014, 30, 177–187. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.1 | 0.25 | 0.25 | 0.25 | 5 | 0.05 | 45 |
| Experiment ID | Elements | True Number | Extracted Number | Accuracy (%) |
|---|---|---|---|---|
| 1 | Windows | 2 | 2 | 100 |
| Doors | 2 | 2 | 100 | |
| Walls | 8 | 8 | 100 | |
| Ceiling | 1 | 1 | 100 | |
| Floor | 1 | 1 | 100 | |
| 2 | Windows | 3 | 3 | 100 |
| Doors | 2 | 2 | 100 | |
| Walls | 8 | 8 | 100 | |
| Ceiling | 1 | 1 | 100 | |
| Floor | 1 | 1 | 100 | |
| 3 | Windows | 3 | 3 | 100 |
| Doors | 2 | 2 | 100 | |
| Walls | 10 | 10 | 100 | |
| Ceiling | 1 | 1 | 100 | |
| Floor | 1 | 1 | 100 |
| Experiment ID | Wall ID | True Length (mm) | Detected Length (mm) | Error (mm) | Accuracy (%) | Average Accuracy (%) |
|---|---|---|---|---|---|---|
| 1 | Wall1 | 7240 | 7122 | 118 | 98.4 | 98.6 |
| Wall2 | 5914 | 5934 | −20 | 99.7 | ||
| Wall3 | 7850 | 7636 | 214 | 97.3 | ||
| Wall4 | 8293 | 8206 | 87 | 99.0 | ||
| 2 | Wall1 | 7989 | 8022 | −33 | 99.6 | 98.4 |
| Wall2 | 5505 | 5404 | 101 | 98.2 | ||
| Wall3 | 7165 | 7068 | 97 | 98.6 | ||
| Wall4 | 4023 | 3904 | 119 | 97.0 | ||
| 3 | Wall1 | 8323 | 8220 | 103 | 98.8 | 98.6 |
| Wall2 | 7168 | 7057 | 111 | 98.5 | ||
| Wall3 | 7132 | 7082 | 50 | 99.3 | ||
| Wall4 | 7801 | 7627 | 174 | 97.8 |
| Experiment ID | Elements | True Area (m2) | Detected Area (m2) | Error (m2) | Accuracy (%) | Average Accuracy (%) |
|---|---|---|---|---|---|---|
| 1 | Walls | 88.44 | 86.18 | 2.26 | 97.4 | 92.4 |
| Ceiling | 67.2 | 64.8 | 2.4 | 96.4 | ||
| Floor | 67.2 | 64.8 | 2.4 | 96.4 | ||
| Doors | 4.2 | 4.07 | 0.13 | 96.9 | ||
| Windows | 6.12 | 4.57 | 1.55 | 74.7 | ||
| 2 | Walls | 67.77 | 65.88 | 1.89 | 97.2 | 91.9 |
| Ceiling | 45.35 | 41.79 | 3.56 | 92.2 | ||
| Floor | 45.35 | 41.79 | 3.56 | 92.2 | ||
| Doors | 4.2 | 4.8 | −0.6 | 85.7 | ||
| Windows | 9.18 | 9.87 | −0.69 | 96.8 | ||
| 3 | Walls | 83.55 | 81.65 | 1.9 | 97.7 | 96.5 |
| Ceiling | 67.03 | 64.82 | 2.21 | 96.7 | ||
| Floor | 67.03 | 64.82 | 2.21 | 96.7 | ||
| Doors | 4.2 | 3.97 | 0.23 | 94.5 | ||
| Windows | 9.18 | 9.47 | −0.29 | 96.8 |
| Experiment ID | Narrow Wall ID | True Length (mm) | Detected Length (mm) | Error (mm) | Accuracy (%) | Average Accuracy (%) |
|---|---|---|---|---|---|---|
| 1 | Wall1 | 380 | 433 | −53 | 86.1 | 75.3 |
| Wall2 | 320 | 200 | 120 | 62.5 | ||
| Wall3 | 2554 | 2223 | 331 | 87.0 | ||
| Wall4 | 1054 | 1406 | −352 | 65.5 | ||
| 2 | Wall1 | 319 | 458 | −139 | 56.4 | 81.3 |
| Wall2 | 824 | 961 | −140 | 83.0 | ||
| Wall3 | 1163 | 1031 | 132 | 88.7 | ||
| Wall4 | 1284 | 1320 | −36 | 97.2 | ||
| 3 | Wall1 | 332 | 202 | 130 | 60.8 | 80.5 |
| Wall2 | 1655 | 1805 | −150 | 90.9 | ||
| Wall3 | 720 | 951 | −231 | 67.9 | ||
| Wall4 | 358 | 322 | 36 | 89.9 | ||
| Wall5 | 1191 | 1138 | 53 | 95.5 | ||
| Wall6 | 301 | 368 | −67 | 77.7 |
| TLS | Structure Sensor | ||||
|---|---|---|---|---|---|
| Experiment ID | Point Number | Station Number | Frame Number | Raw Point Number | Sampled Point Number |
| 1 | 576,627 | 1 | 61 | 2,939,060 | 587,812 |
| 2 | 373,510 | 1 | 37 | 1,713,590 | 342,718 |
| 3 | 571,825 | 1 | 66 | 2,892,520 | 578,504 |
| TLS | Range Finder | Our Proposed | ||||
|---|---|---|---|---|---|---|
| Experiment ID | Collection | Processing | Collection | Processing | Collection | Processing |
| 1 | ~3600 s | ~600 s | ~360 s | ~900 s | ~300 s | 34.2 s |
| 2 | ~3000 s | ~480 s | ~300 s | ~600 s | ~240 s | 26.7 s |
| 3 | ~3600 s | ~720 s | ~420 s | ~1020 s | ~360 s | 36.5 s |
| Total | 200 min | 60 min | 16.7 min | |||
| Output Point Cloud | Yes | No | Yes | |||
| Automatically | No | No | Yes | |||
| Manual Load | Much | Median | Little | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, W.; Tang, S.; Darwish, W.; Hu, Y.; Chen, W. Automatic Indoor as-Built Building Information Models Generation by Using Low-Cost RGB-D Sensors. Sensors 2020, 20, 293. https://doi.org/10.3390/s20010293
Li Y, Li W, Tang S, Darwish W, Hu Y, Chen W. Automatic Indoor as-Built Building Information Models Generation by Using Low-Cost RGB-D Sensors. Sensors. 2020; 20(1):293. https://doi.org/10.3390/s20010293
Chicago/Turabian StyleLi, Yaxin, Wenbin Li, Shengjun Tang, Walid Darwish, Yuling Hu, and Wu Chen. 2020. "Automatic Indoor as-Built Building Information Models Generation by Using Low-Cost RGB-D Sensors" Sensors 20, no. 1: 293. https://doi.org/10.3390/s20010293
APA StyleLi, Y., Li, W., Tang, S., Darwish, W., Hu, Y., & Chen, W. (2020). Automatic Indoor as-Built Building Information Models Generation by Using Low-Cost RGB-D Sensors. Sensors, 20(1), 293. https://doi.org/10.3390/s20010293