Optimal Energy Aware Clustering in Sensor Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Problem Description
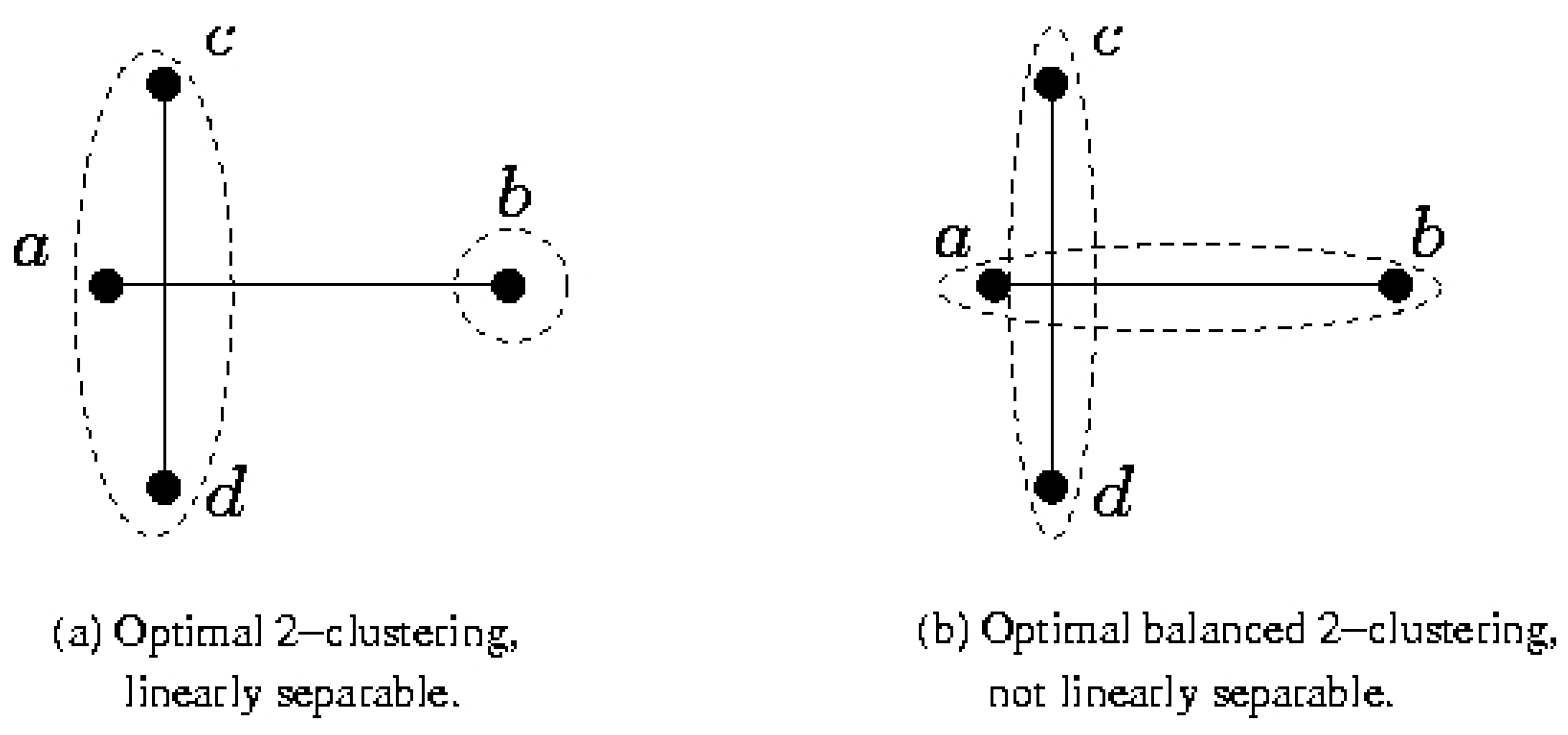
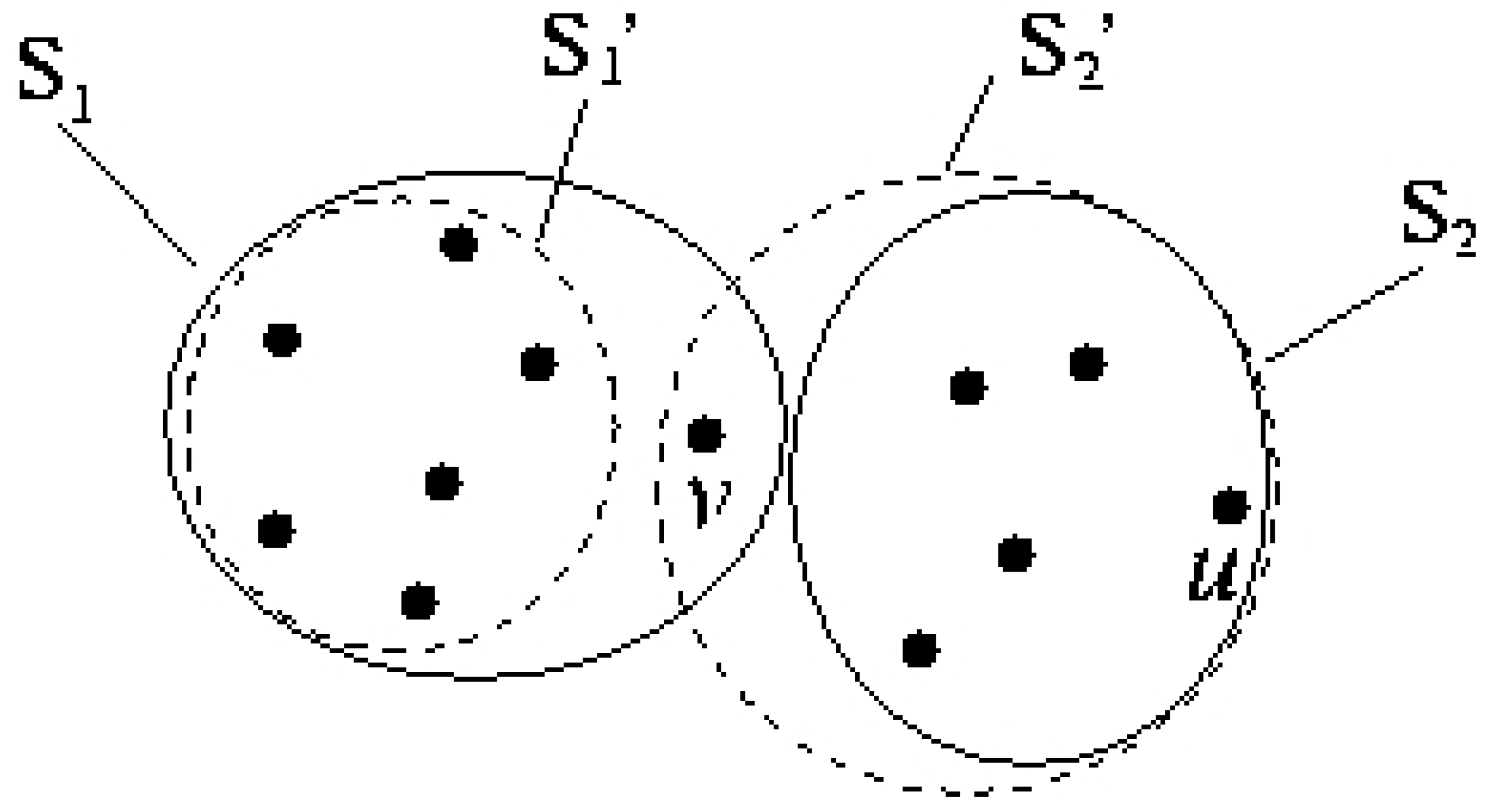
- Each point belongs to exactly one of clusters.
- Clusters are balanced, i.e.:where 0 ≤ δ ≤ 1 / k is the unbalance factor. δ depends on n/k and the master nodes' actual capacity. In this paper, our focus is on strictly balanced clusters and we assume δ = 0. Therefore, we assume that n is a multiple of k.
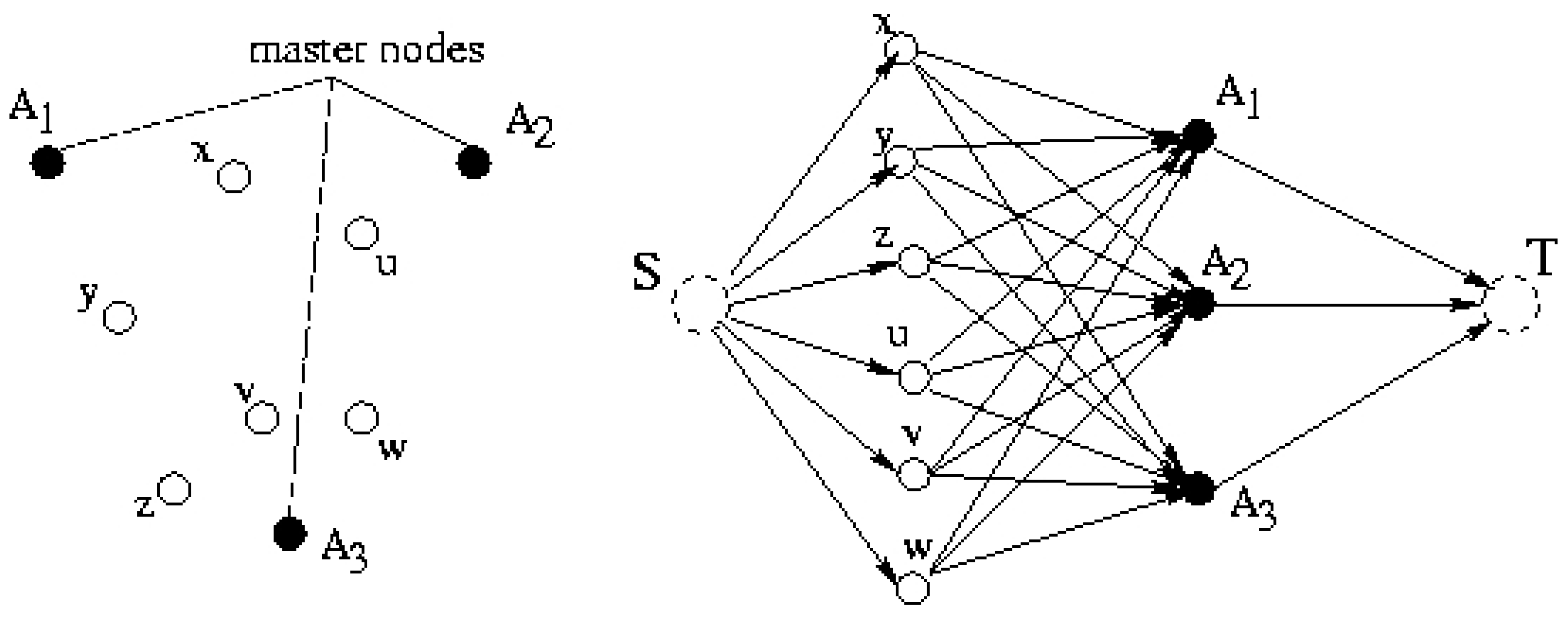
- The total cost over all clusters is minimized. Specifically, the cost for each cluster Si is:where x and ai are the locations (x and y coordinates) of a sensor and the master node in cluster i. f(x, ai) is the message transmission energy dissipation between a sensor and a master node. Function f can be as simple as the square of the distance between these two points. The balanced clustering feature makes the k-clustering problem in our work distinct from previous works [19,8,18]. In the next section, We solve this problem optimally by transforming it to matching on bipartite graphs.
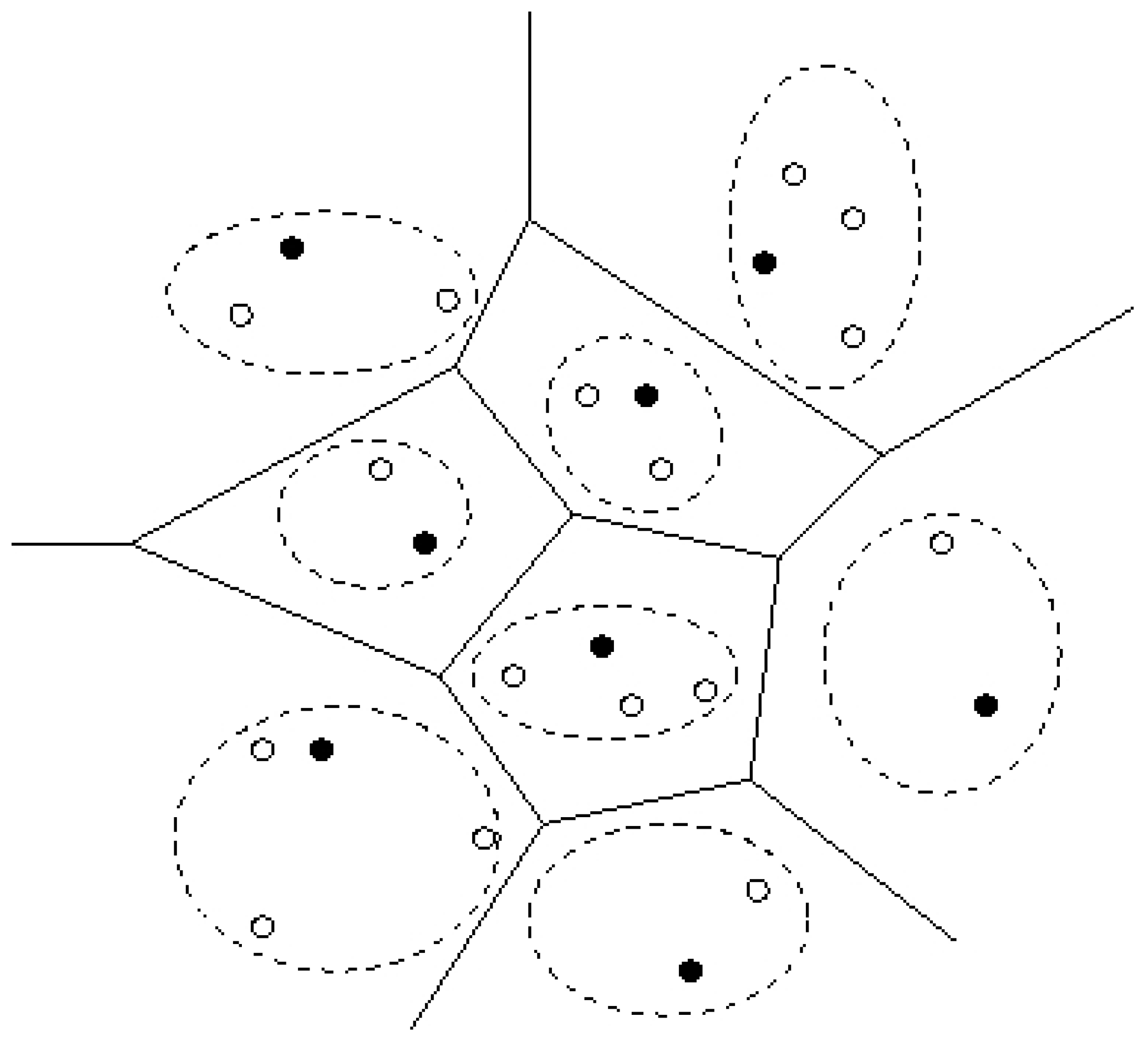
3. Optimal k-Clustering for Energy Optimization
3.1 General Clustering (no balance constraint)
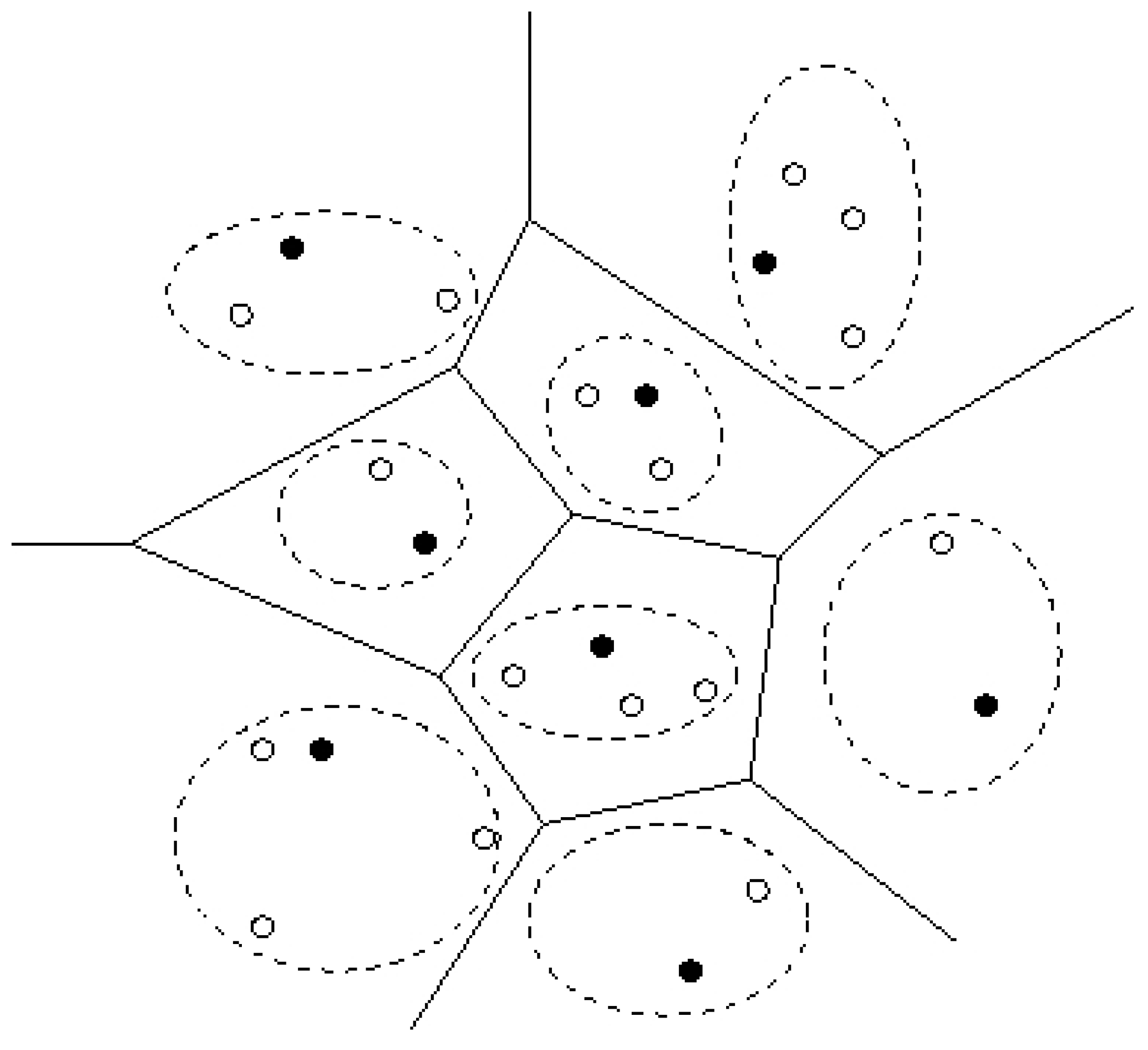
3.2 Balanced k-Clustering
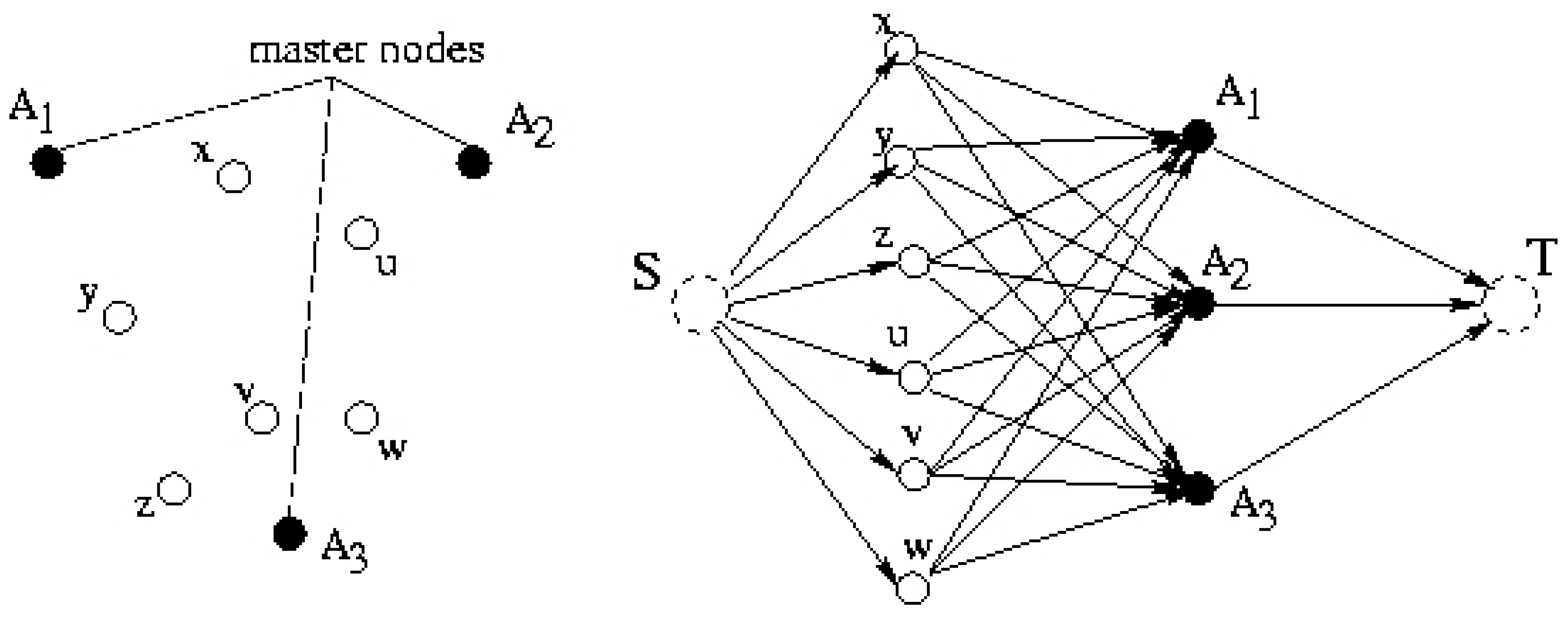
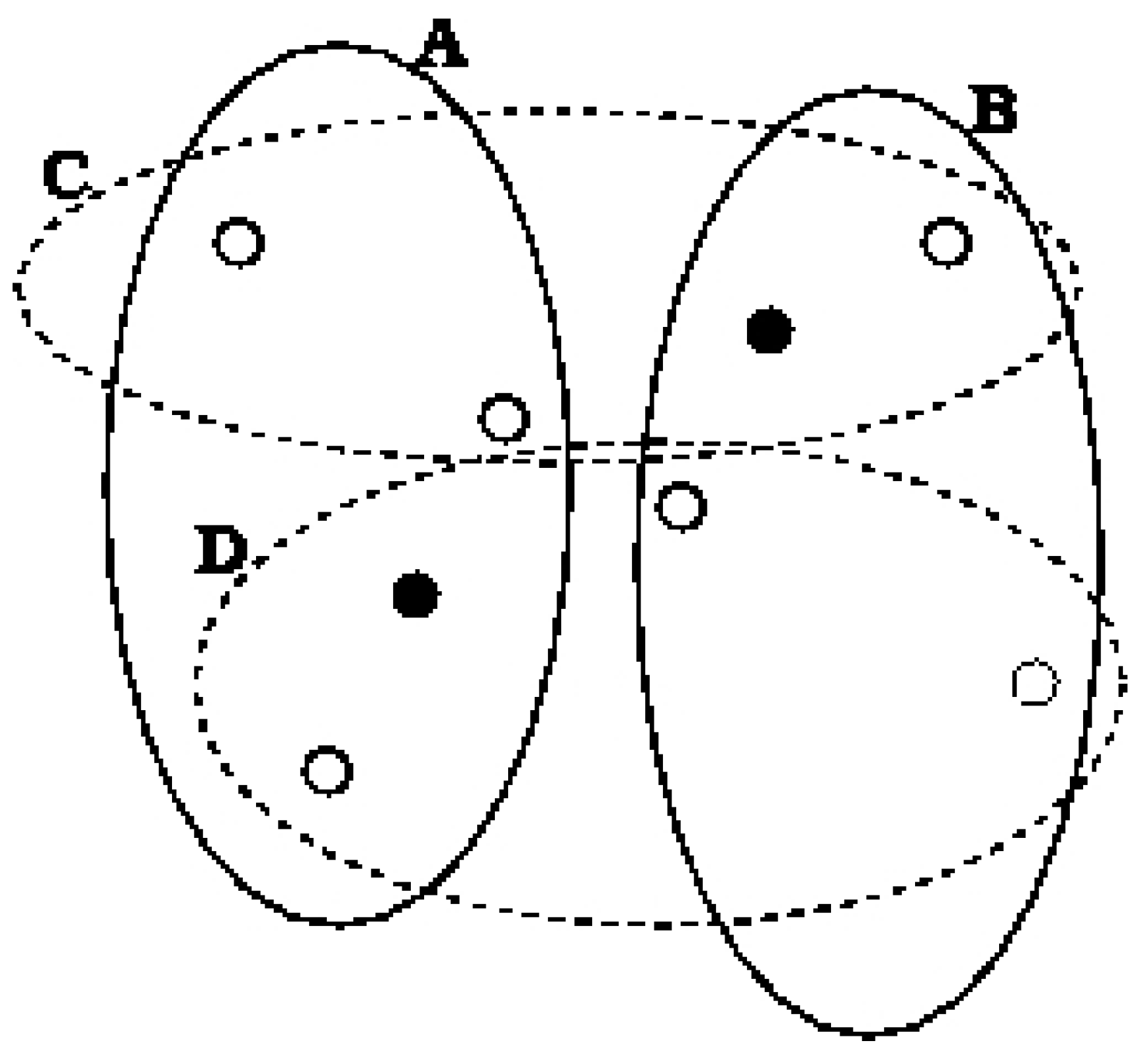
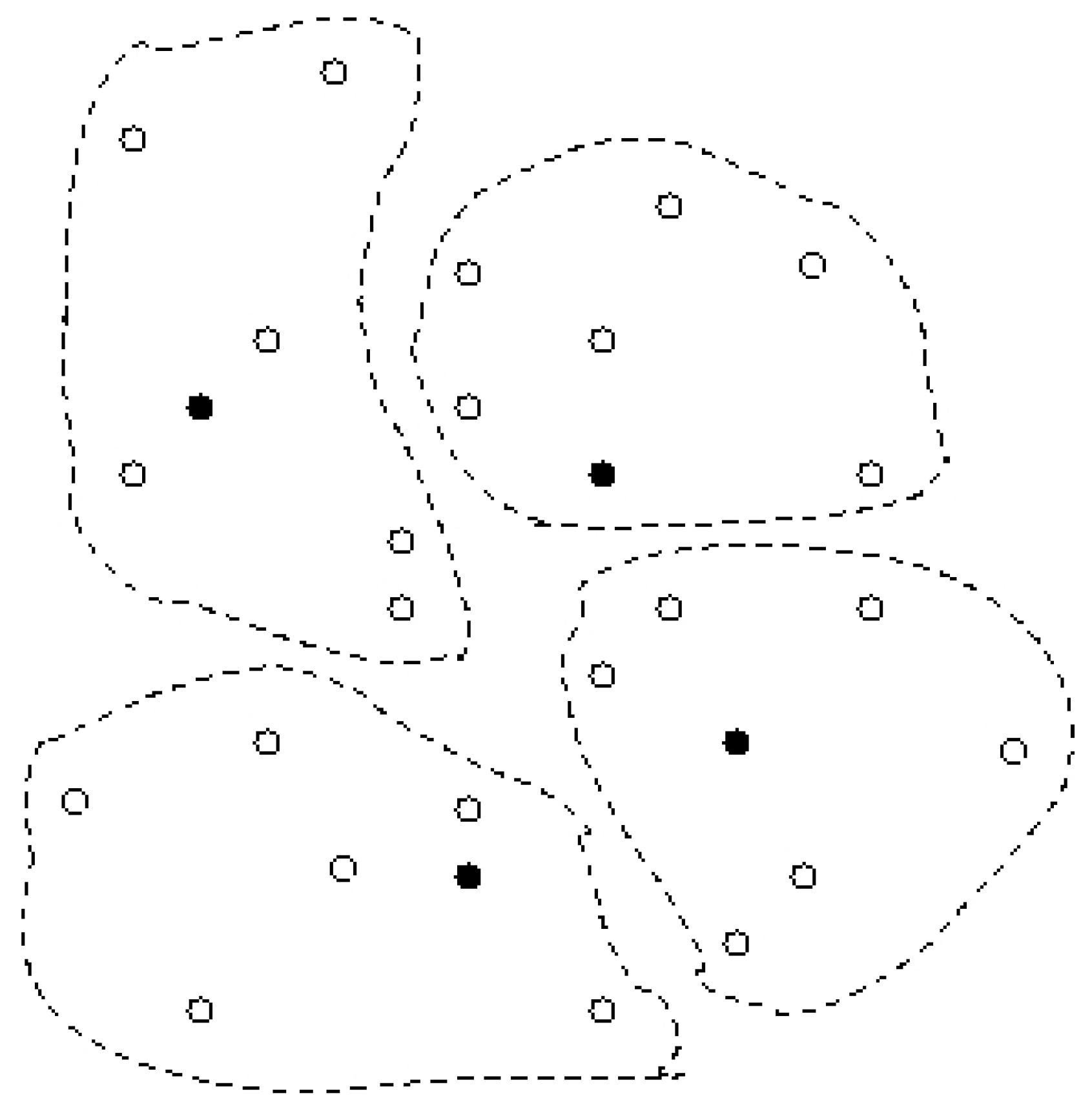
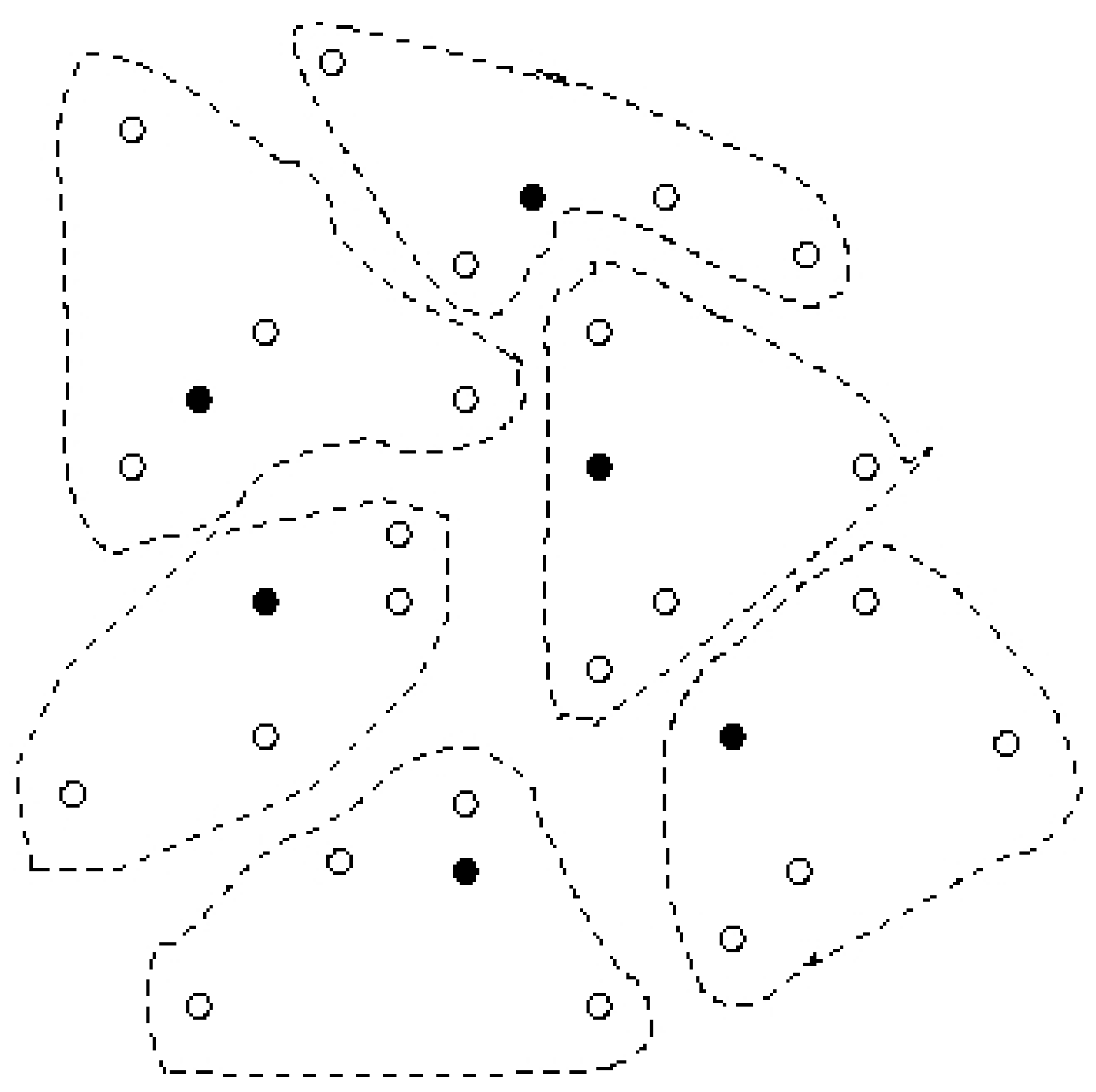
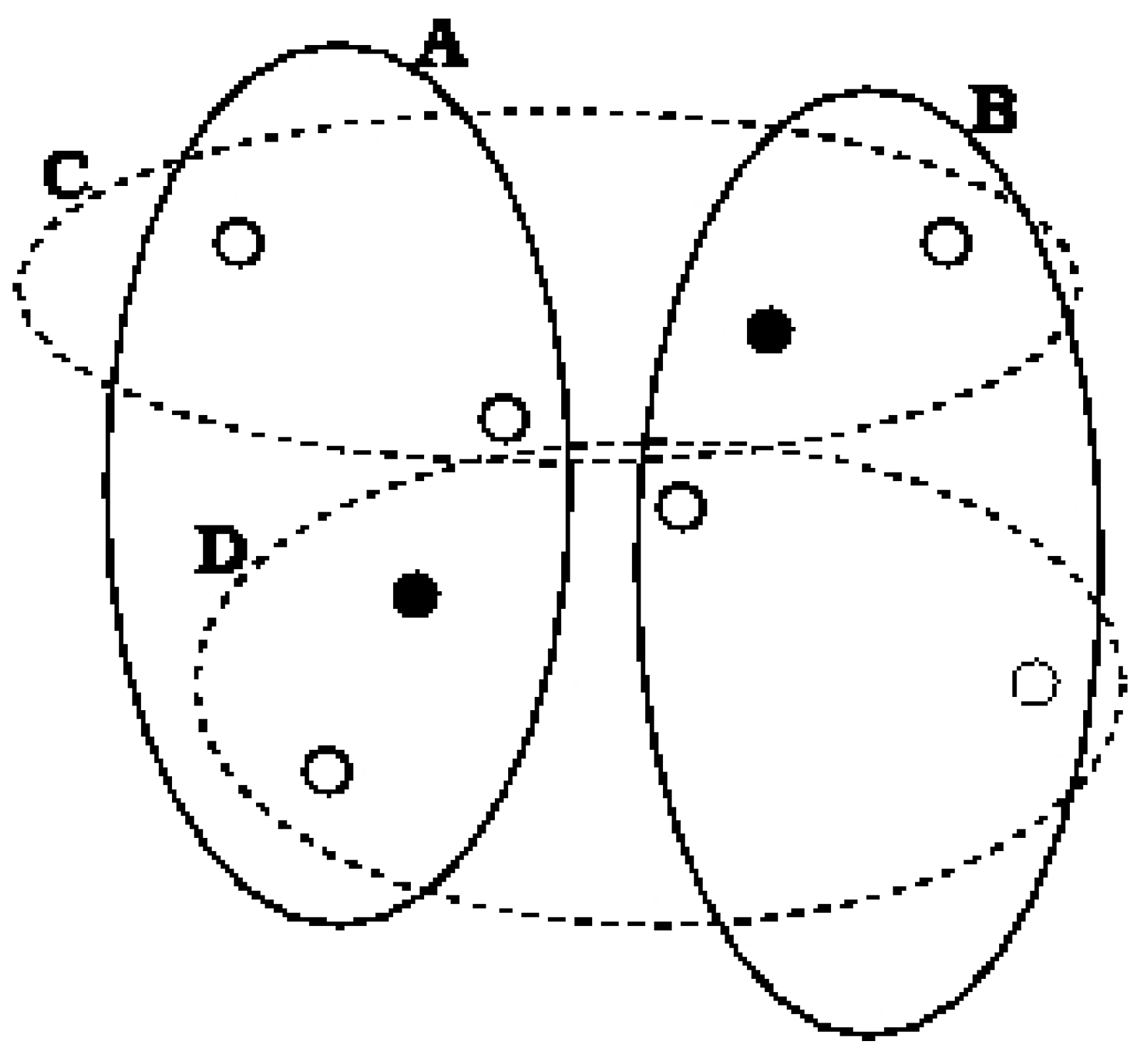
4. 2–Clustering to Minimize the Maximum Diameter
4.1 2–Clustering for Minimizing the Maximum Diameter
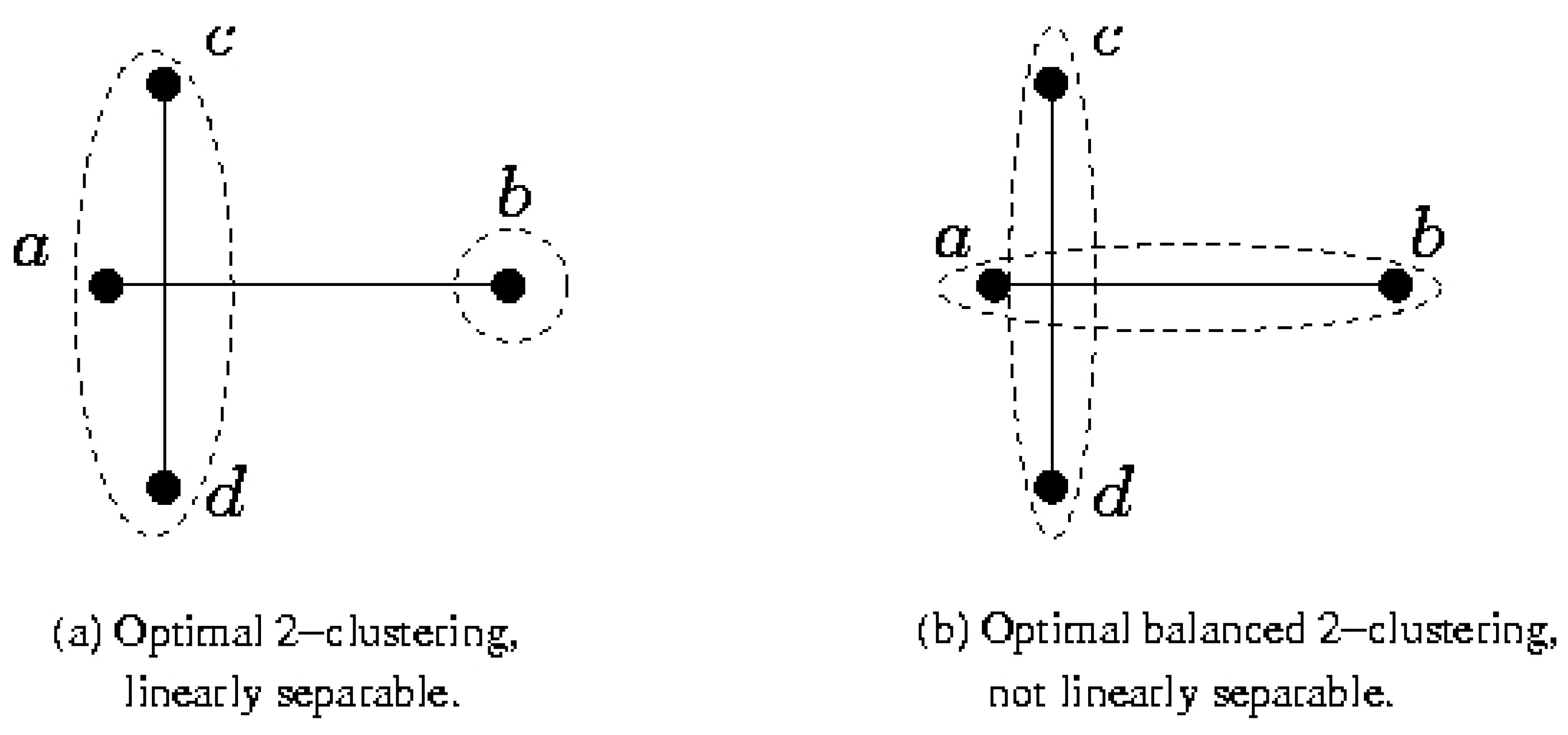

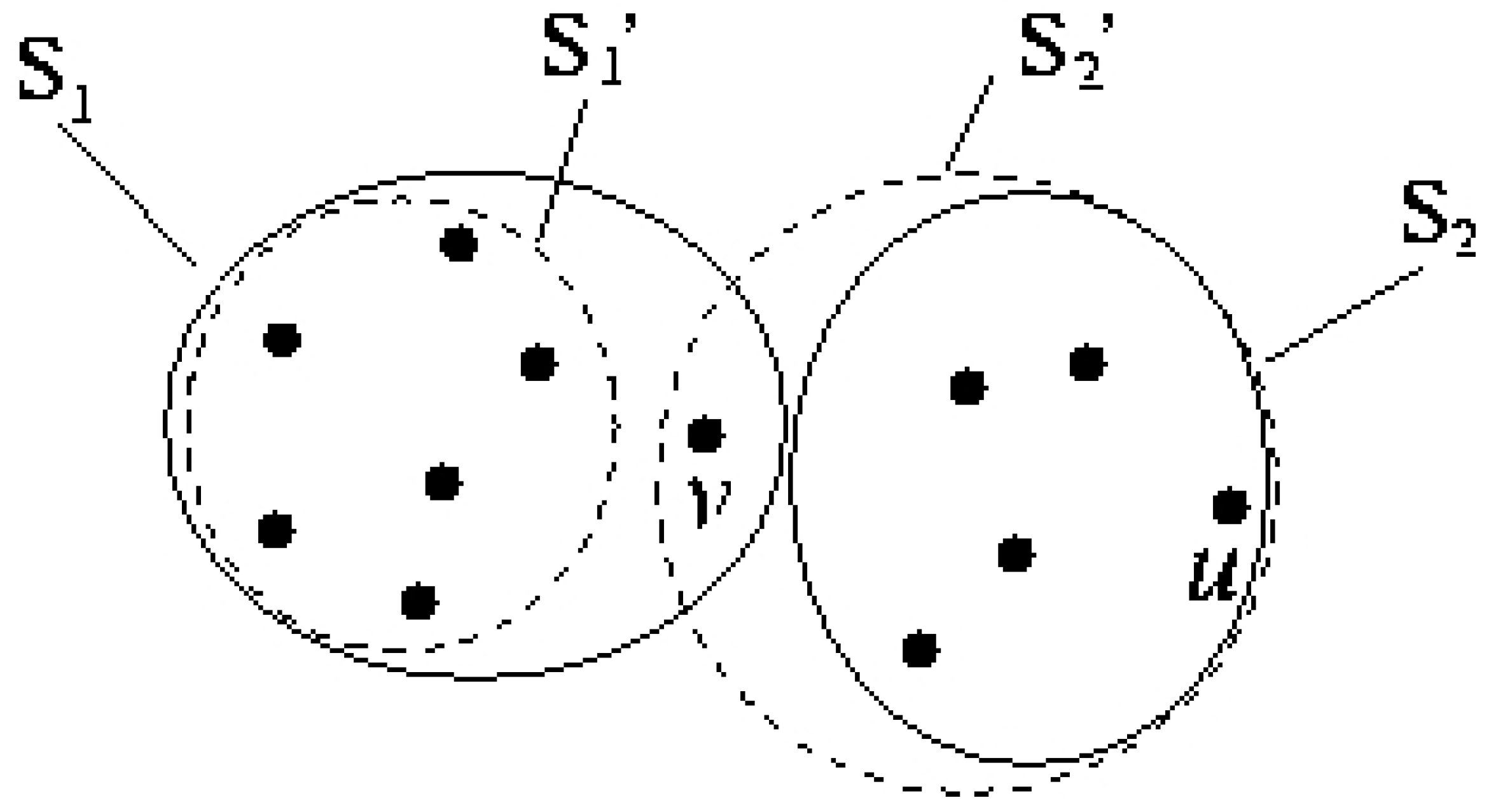
5. Preliminary Experiments
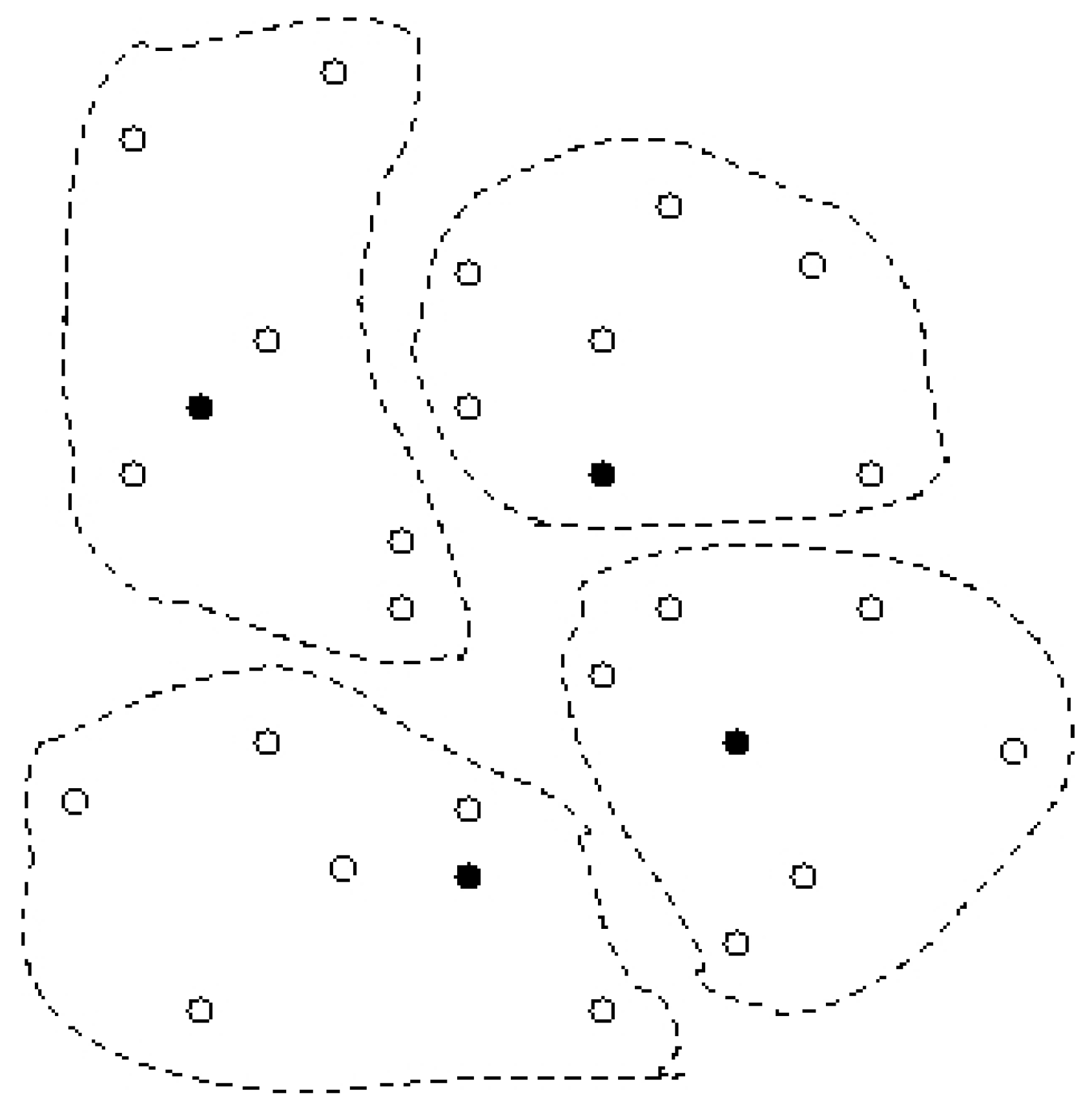
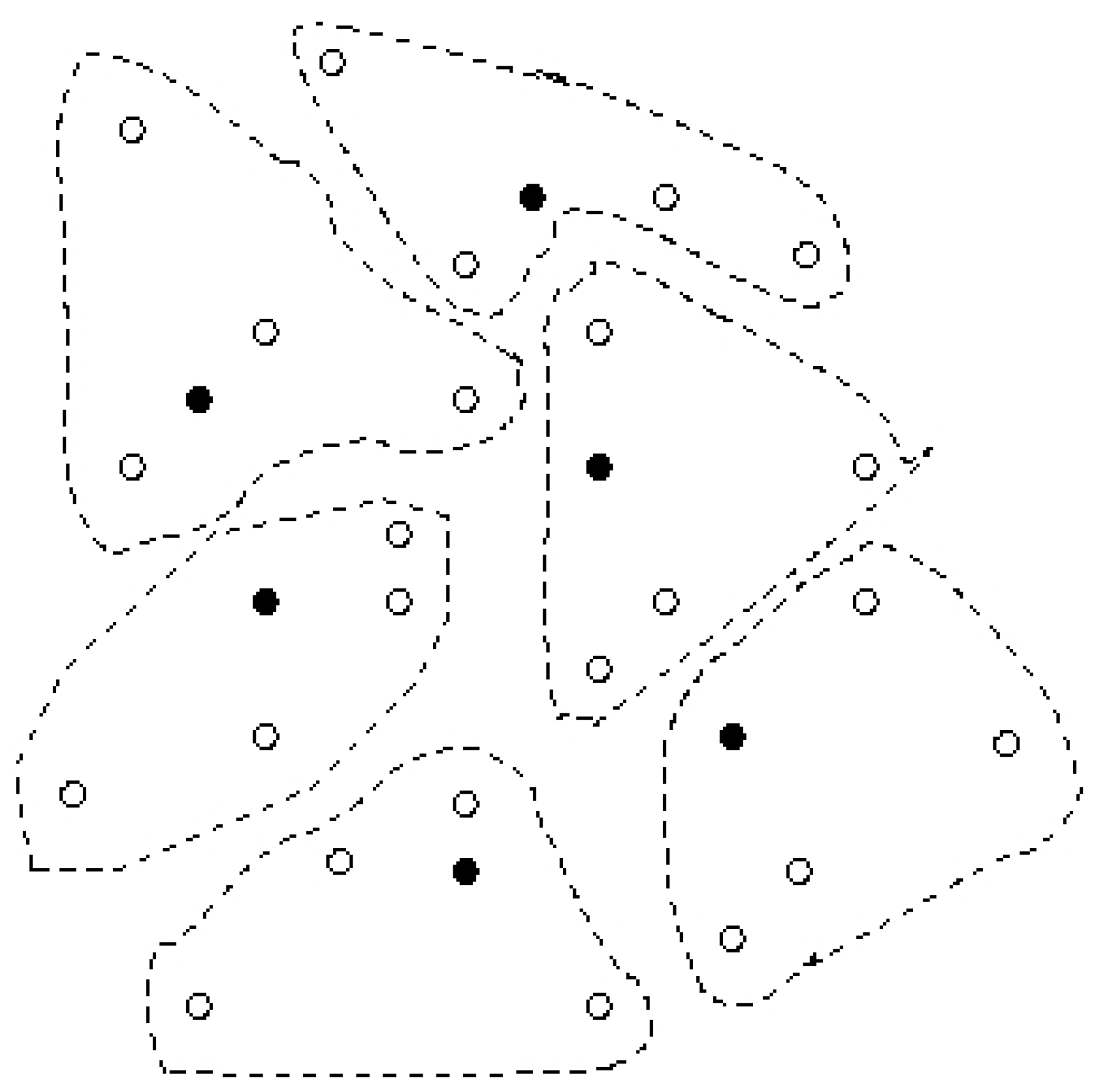
6. Conclusion
References
- Chandrakasan, A.; Amirtharajah, R.; Cho, S. H.; Goodman, J.; Konduri, G.; Kulik, J.; Rabiner, W.; Wang, A. Design Considerations for Distributed Microsensor Systems. In Proc. of IEEE Custom Integrated Circuits Conference, 1999; pp. 279–286.
- Estrin, D.; Govindan, R.; Heidemann, J.; Kumar, S. Next Century Challenges Scalable Coordination in Sensor Networks. In Proceedings of the ACM IEEE International Conference on Mobile Computing and Networking, 1999; pp. 263–270.
- Chang, J.; Tassiulas, L. Energy Conserving Routing in Wireless Ad hoc Networks. In Proc. of IEEE INFOCOM, 2000.
- Li, Q.; Aslam, J.; Rus, D. Hierarchical Power aware Routing in Sensor Networks. In Proceedings of the DIMACS Workshop on Pervasive Networking, 2001.
- Singh, S. S.; Woo, M.; Raghavendra, C. S. Power Aware Routing in Mobile Ad Hoc Networks. In Proceedings of the ACM IEEE International Conference on Mobile Computing and Networking, 1998.
- Srivastava, A.; Sobaje, J.; Potkonjak, M.; Sarrafzadeh, M. Optimal Node Scheduling for Effective Energy Usage in Sensor Networks. In IEEE Workshop on Integrated Management of Power Aware Communications Computing and Networking, 2002.
- Wang, A.; Chandrakasan, A. Energy Efficient System Partitioning for Distributed Wireless Sensor Networks. In Proc. of IEEE International Conference on Acoustics Speech and Signal Processing, 2001.
- Avis, D. Diameter Partitioning. Discrete and Computational Geometry 1986, 1, 265–276. [Google Scholar] [CrossRef]
- Shamos, M.; Preparata, F. Computational Geometry; Springer Verlag, 1985. [Google Scholar]
- Cadez, I. V.; Ganffey, S.; Smyth, P. A General Probabilistic Framework for Clustering Individuals and Objects. In Proceedings of the KDD, 2000; pp. 140–149.
- Edmonds, J.; Karp, R. M. Theoretical Improvements in Algorithmic Efficiency for Network Flow Problems. Journal of the Association for Computation Machine 1972, 19, 248–261. [Google Scholar] [CrossRef]
- Kleinhans, J. M.; Sigl, G.; Johannes, F. M.; Antreich, K. J. GORDIAN: VLSI Placement by Quardratic Programming and Slicing Optimization. IEEE Trans on Computer Aided Design 1991. [Google Scholar] [CrossRef]
- Min, R.; Bhardwaj, M.; Cho, S. H.; Sinha, A.; Shih, E.; Wang, A.; Chandrakasan, A. Low Power Wireless Sensor Networks. Proc. of VLSI Design 2001. [Google Scholar]
- Rabaey, J. M.; et al. PicoRadio supports ad hoc ultra low power wireless networking In Computer. 2000. [Google Scholar]
- Asano, T.; Bhattacharya, B.; Keil, M.; Yao, F. Clustering Algorithms Based on Minimum and Maximum Spanning Trees. In Proceedings of the 4th Annual Symposium on Computational Geometry, 1988; pp. 252–257.
- Rivest, R.; Cormen, T.; Leiserson, C. An introduction to algorithms. In MIT Press; 1990. [Google Scholar]
- Feder, T.; Greene, D. H. Optimal Algorithms for Approximate Clustering. In Proc. 20th Annu. ACM Symp. Theory Computing ACM, 1988; pp. 434–444.
- Capoyleas, V. Geometric Clusterings. Journal of Algorithms 1991, 12, 341–356. [Google Scholar] [CrossRef]
- Heinzelman, W. R.; Chandrakasan, A.; Balakrishnan, H. Energy efficient Communication Protocols for Wireless Microsensor Networks. In Proc. Hawaaian Int’l Conf. on Systems Science, 2000.
- Sample Availability: Available from the authors.
© 2002 by MDPI (http://www.mdpi.net). Reproduction is permitted for noncommercial purposes.
Share and Cite
Ghiasi, S.; Srivastava, A.; Yang, X.; Sarrafzadeh, M. Optimal Energy Aware Clustering in Sensor Networks. Sensors 2002, 2, 258-269. https://doi.org/10.3390/s20700258
Ghiasi S, Srivastava A, Yang X, Sarrafzadeh M. Optimal Energy Aware Clustering in Sensor Networks. Sensors. 2002; 2(7):258-269. https://doi.org/10.3390/s20700258
Chicago/Turabian StyleGhiasi, Soheil, Ankur Srivastava, Xiaojian Yang, and Majid Sarrafzadeh. 2002. "Optimal Energy Aware Clustering in Sensor Networks" Sensors 2, no. 7: 258-269. https://doi.org/10.3390/s20700258
APA StyleGhiasi, S., Srivastava, A., Yang, X., & Sarrafzadeh, M. (2002). Optimal Energy Aware Clustering in Sensor Networks. Sensors, 2(7), 258-269. https://doi.org/10.3390/s20700258