1. Introduction
Surface electromyography (sEMG)-based hand-gesture classification is widely used in clinical applications, such as controlling powered upper-limb prostheses [
1] and electric-powered wheelchairs [
2]. However, sEMG is different from subject to subject, and even sEMG of the same subject can differ substantially due to the displacement of sensors, sweat, fatigue, and many other factors [
3]. To capture the complexity and variability of sEMG, conventional pattern-recognition methods have been used to try to extract representative features of sEMG. Time-domain and frequency-domain features of sEMG, such as root mean square, zero crossing, and power spectra, have been widely used for hand-gesture classification [
4]. However, these features are neither adequately generalizable to different subjects nor sufficiently robust for long-time applications [
5]. To address these limitations, conventional approaches usually propose an easy-to-train model for each individual subject, and the model is frequently retrained once the performance of the model downgrades [
6]. To avoid tedious retraining, more generalizable and robust sEMG features are needed to solve the problem of sEMG-based hand-gesture classification.
Prominent deep learning has improved the performance of solutions for many practical problems. The performance of deep learning lies in the ability to learn high-level abstraction of data and discover important information hidden in the data that is otherwise hard to discover using conventional algorithms [
7]. Convolutional neural network(s) (CNN) are the most popular deep learning models used for sEMG-based hand-gesture classification [
8,
9,
10], and state-of-the-art classification accuracy has been achieved using CNN. Other deep neural networks, such as Recurrent Neural Network(s) (RNN), have also been used for hand-gesture classification [
11,
12]. Most of the deep learning models used for sEMG-based hand-gesture classification are deep discriminative models that model the decision boundary between classes. Despite the high accuracy achieved with these deep discriminative models, the high-level features used in the deep discriminative models are incomprehensible. However, under some clinical conditions, model comprehension is crucial. For controlling prostheses, knowing the reason an algorithm that is performing well for one person with an amputation does not work for another person with an amputation is important for tuning the algorithm to fit different persons. Currently, comprehending the discriminative model is one of the research focuses of deep learning [
13,
14].
The deep generative model, which is a type of deep learning model other than the deep discriminative model, models the actual distribution of the data. A deep generative model can generate input examples from the feature learned by the model, which provides a way to understand the behavior of the model. However, deep generative model is usually used for applications such as fake image generation [
15] or speech synthesis [
16], and the model has no ability to discriminate input examples.
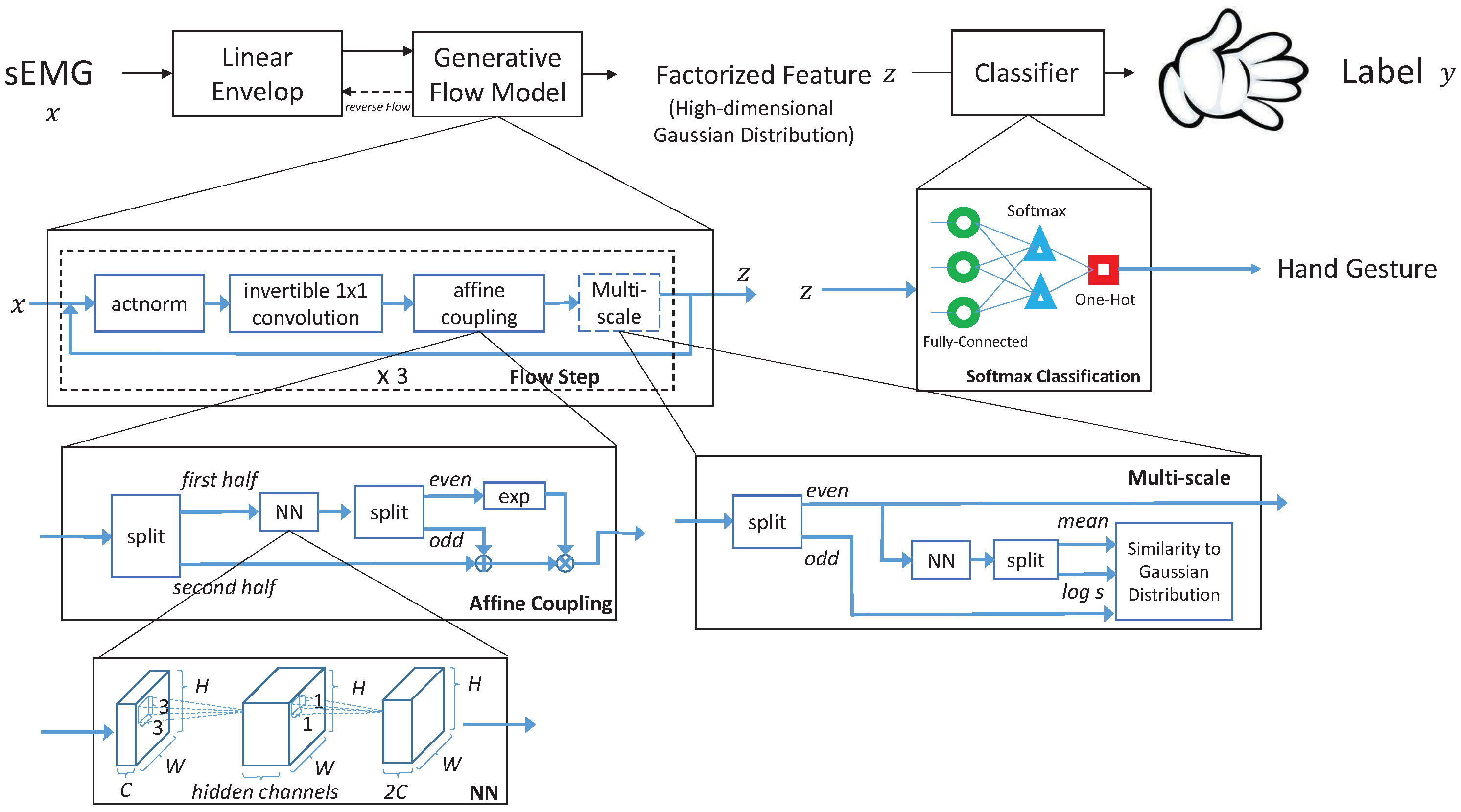
In this paper, a generative flow model (GFM) is used with a simple SoftMax classifier for hand-gesture classification. GFM is an unsupervised model commonly used for generating images [
17] and synthesizing speeches [
18]. In these cases, attention has been paid to the performance of the GFM in generating realistic samples, such as images and speeches. However, we focused on understanding the factorized features learned by the GFM and applying the learned features for supervised tasks. The combination of the GFM with a linear SoftMax classifier has achieved high accuracy in sEMG-based hand-gesture classification. In addition, the features learned by the GFM under the regulation of the SoftMax classifier have physiological relevance to the muscle synergy, which is important for comprehending the classification. The proposed approach achieved
accuracy in classifying 53 different hand gestures from the NinaPro database 5 [
19]. Since the high-level feature learned by the GFM is factorized, each dimension of the feature was analyzed individually using the reverse flow of the GFM. Interestingly, each dimension of the learned feature was found to correspond to a basic sEMG pattern that may reflect human muscle synergy in the sEMG.
2. Physiology Background of Surface Electromyography
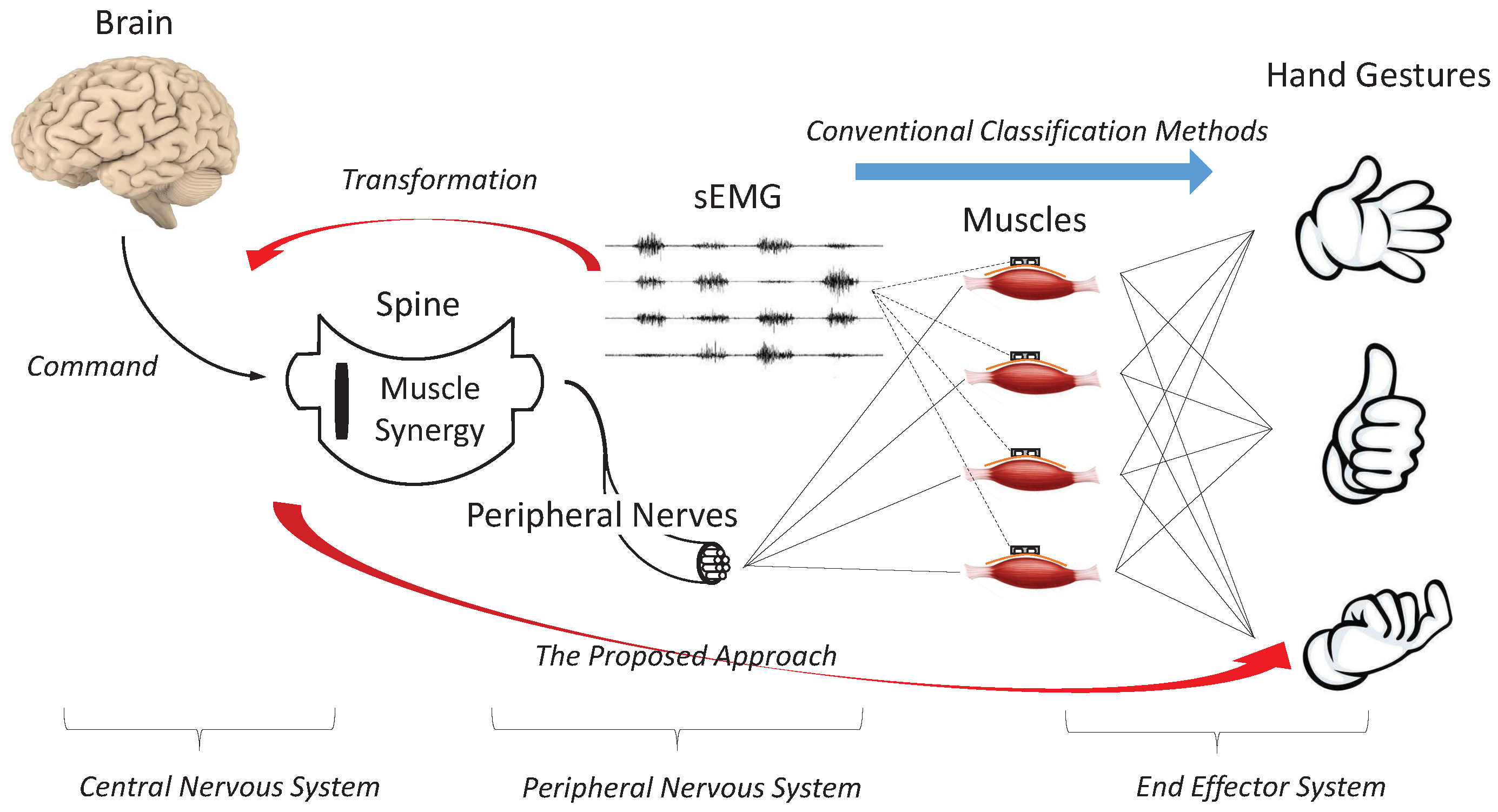
Human hands are controlled by a hierarchical structure, as shown in
Figure 1. This hierarchical structure can be divided into three systems according to their physiological properties. In the central nervous system, the movement command is generated from the brain to the spine. In the peripheral nervous system, the spine activates the corresponding muscles based on the command. Please note that the spine does not activate each muscle individually; instead, several muscles are activated simultaneously as a group to drive the hand to the target gesture. This mechanism of activating several muscles as a group is referred to as muscle synergy, a physiological process used by the human to control high-dimensional systems through low-dimension commands [
20]. In the end effector system, the muscles drive the hand joints to the targeted position.
sEMG is the bio-electrical signal generated by the muscle when activated by the spine. Conventional classification methods map the sEMG to hand gestures directly, which tries to approximate the low-level end effector system. The proposed GFM transforms sEMG into factorized features, which are, ideally, an approximation of the movement command to the spine activating the mechanism of muscle synergy. Transforming sEMG into high-level abstractions can, to some extent, increase the generalizability and robustness of the following hand-gesture classification because high-level abstractions are believed to be more easily shared among different subjects than low-level information.
4. Experiment
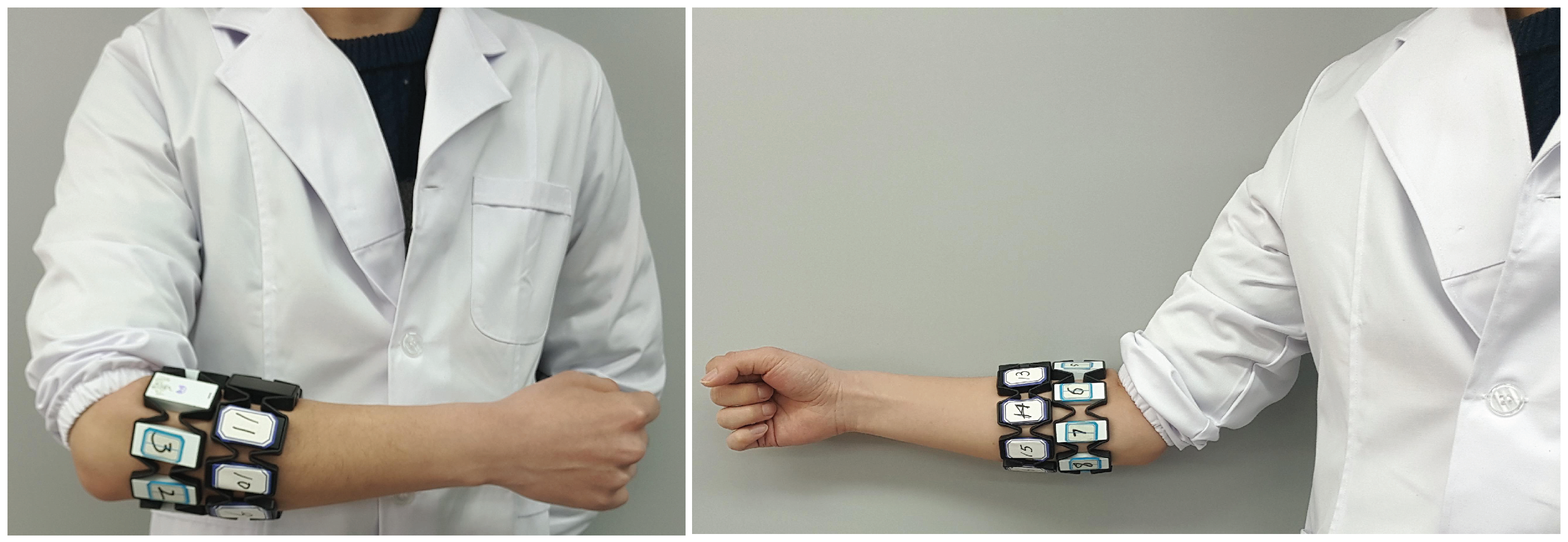
To test the performance of the proposed approach in hand-gesture classification, the proposed model is trained with the NinaPro database 5, which contains sEMG recorded with two Myo armbands. sEMG from the Myo armbands are sampled at a rate of 200 Hz. The two Myo armbands, each including 8 active single differential wireless electrodes, are placed next to each other, as shown in
Figure 4. The top Myo armband is placed close to the elbow with the first sensor placed on the radio humeral joint; the second Myo armband is placed just after the first, near the hand, and is tilted by 22.5 degrees with respect to the first Myo armband. Database 5 includes 6 repetitions of 53 different movements (shown in the
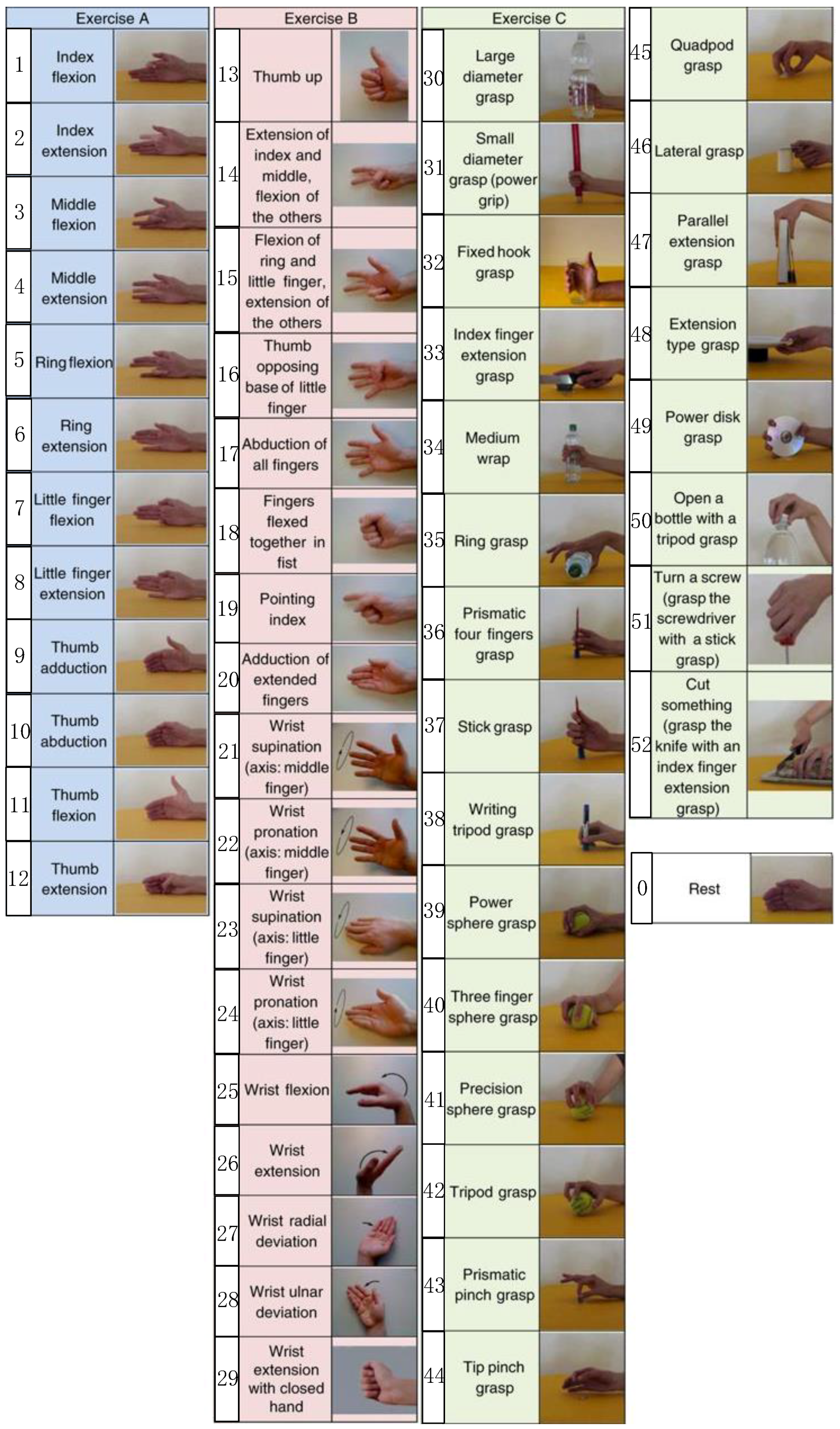
Appendix A) performed by 10 intact subjects. Please note that the number of sEMG examples for hand rest is much larger compared to the other movements, and we randomly sampled some of the rest sEMG examples to guarantee a balance in the sEMG examples for different hand gestures.
Two methods are used to divide the NinaPro database 5 into a train set and test set. In the first approach, the database is divided in a machine-learning way: 70% of the sEMG examples are randomly selected from the database and used to train the model, while the remaining 30% of the sEMG examples are used to test the accuracy of the proposed approach in classifying hand gestures. In the second approach, the database is divided according to subjects: sEMG examples of 7 randomly selected subjects are used to train the model, while sEMG examples of the remaining 3 subjects are used as a test set. The main difference between these two methods of division is whether the model can see sEMG examples from a subject in both the training and test sets. Obviously, the second division approach better matches the real-world applications for sEMG. In both cases, the proposed model was trained for 15 epochs at a batch size of 24. The average accuracy of the proposed approach was achieved by repeating the training and testing procedures 5 times.
5. Results
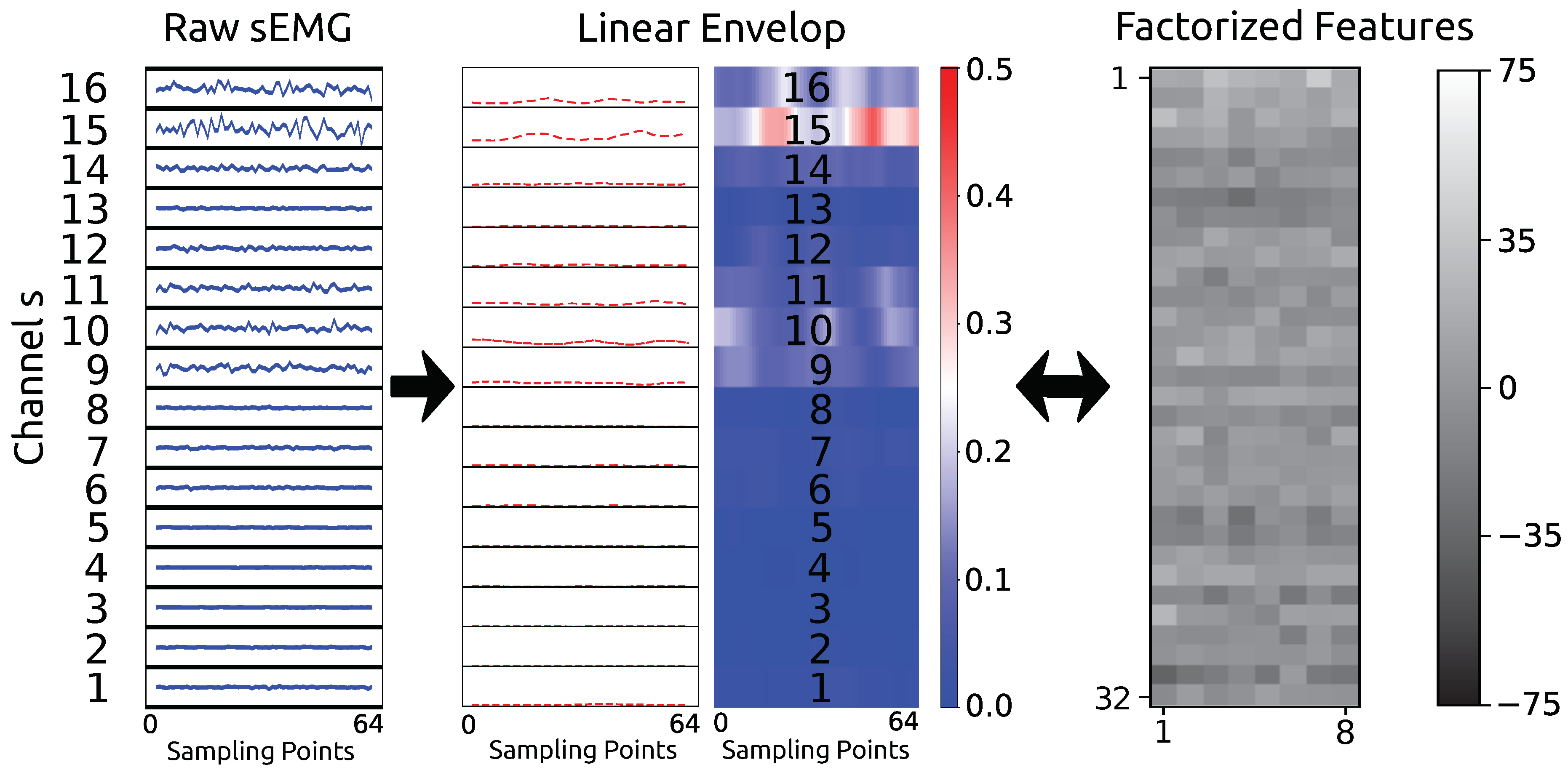
The raw sEMG data were transformed into factorized features, as shown in
Figure 5, using the linear envelope pipeline and GFM. Please note that the transformation between the linear envelope and the factorized feature is invertible.
As shown in
Figure 6, the classification accuracy of the proposed approach on the test set divided according to subjects is
. In addition, the classification accuracy of the proposed approach on the test set divided in the machine-way, where sEMG examples of the test set are randomly selected from the NinaPro database 5, is
. The proposed approach, as expected, performs worse on the test set divided according to subjects than the test set divided in the machine-learning way. This performance reduction is caused by the approach lacking enough knowledge about the sEMG examples of a specific subject. However, the reduction is only
, which means that the proposed approach has learned some common features across subjects.
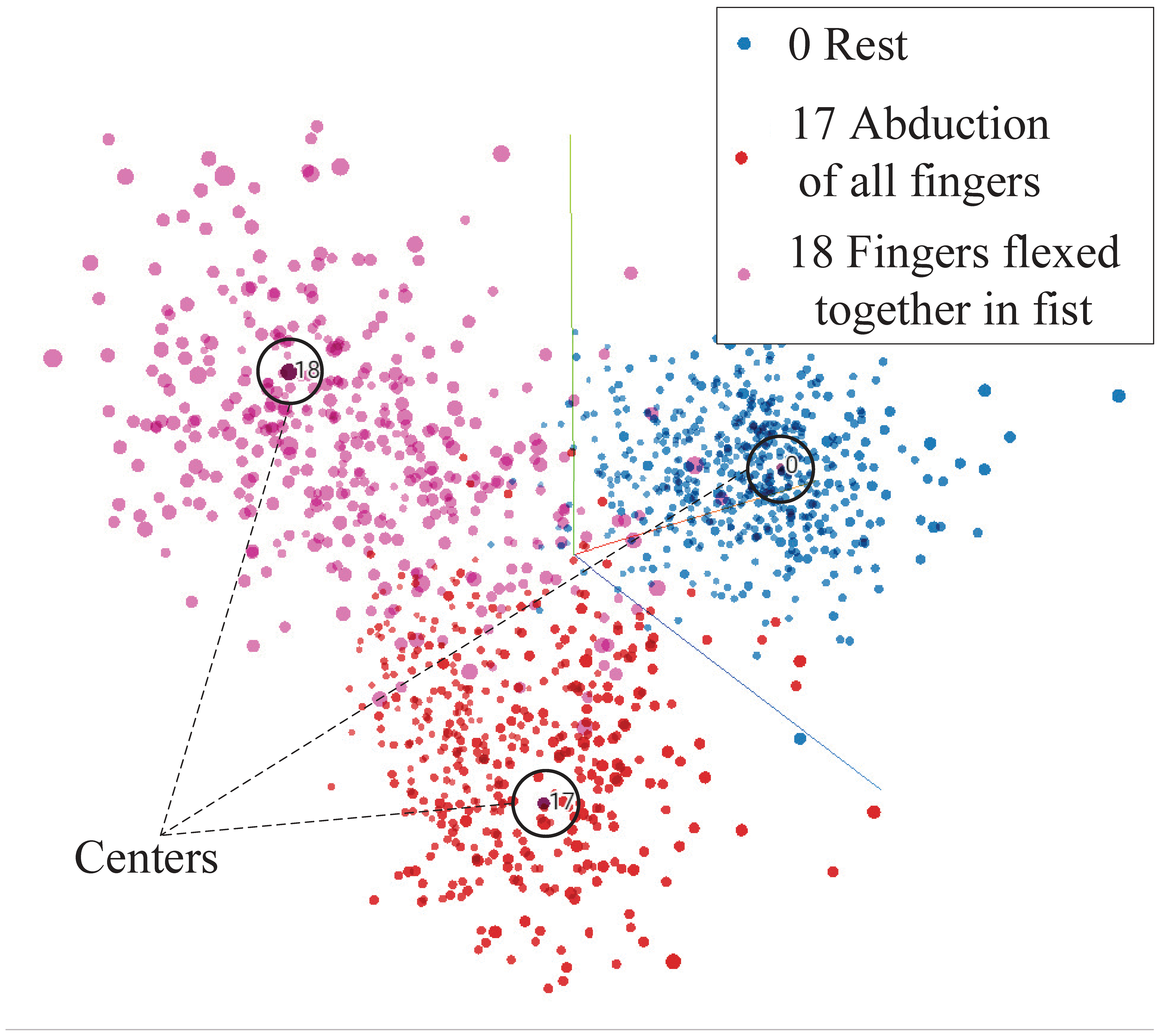
GFM, as a generative model, models the actual distribution of the data based on the distribution of the factorized feature. To see the distribution of the factorized feature and its association with different hand gestures, three commonly used hand gestures for prosthetic hand control are selected, and the distribution of their factorized features is shown in
Figure 7. The figure is a snapshot from TensorBoard [
31]. The distribution of the features of all 53 hand gestures is available in the
Appendix A. From
Figure 7, we can see that features belonging to the same hand gesture are gathered, and the features of the three gestures are perfectly distinguishable. Since each dimension of the feature is continuous and independent, features corresponding to a hand gesture are summed and averaged to determine the center of the hand gesture. The center of a hand gesture is also considered the typical feature of the hand gesture.
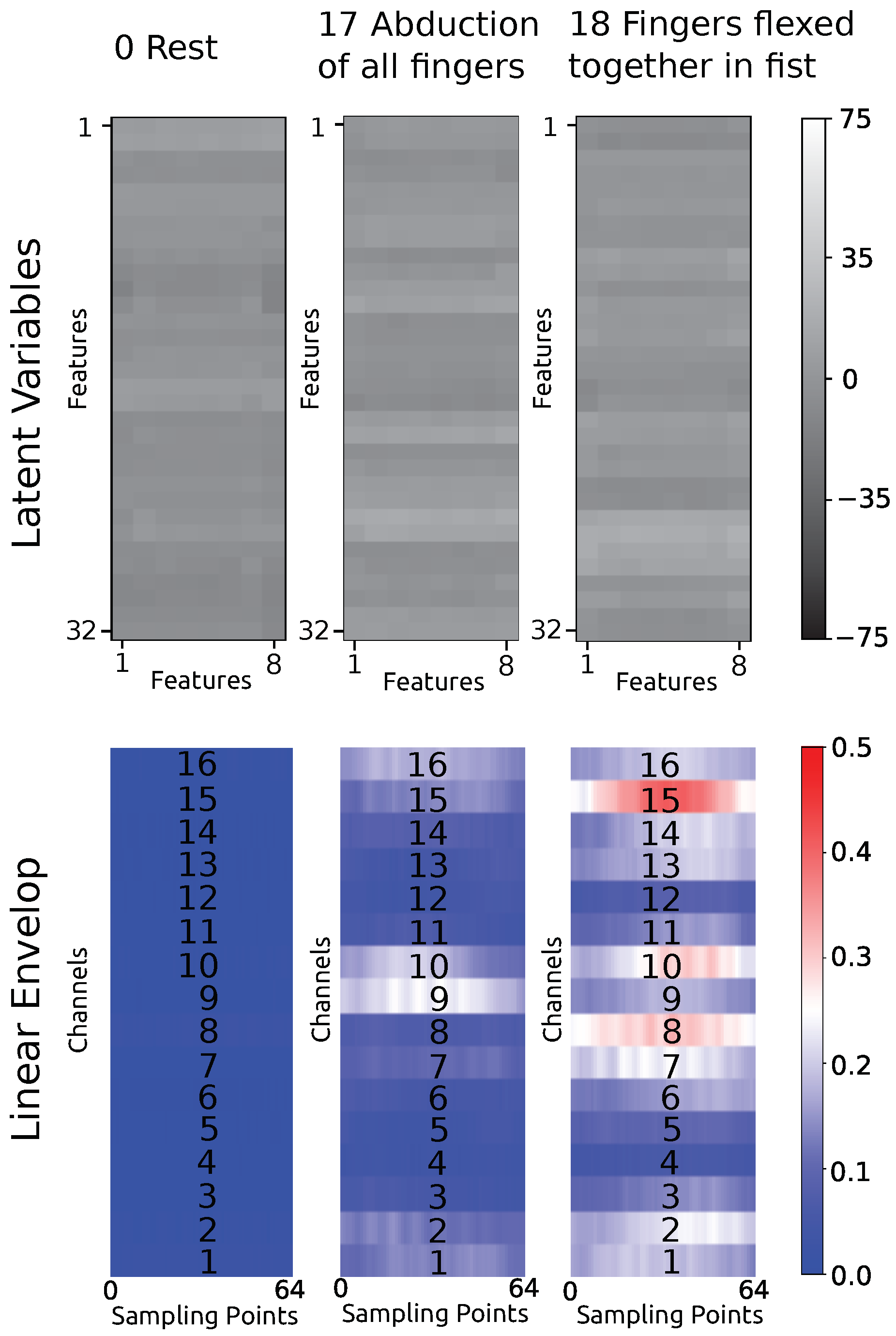
The typical features of the three hand gestures are transformed by the reverse flow of the GFM to the corresponding sEMG linear envelope. Features and the transformed sEMG linear envelope corresponding to hand gesture 0 (rest), 17 (abduction of all fingers), and 18 (fingers flexed together in fist) are shown in
Figure 8. We can see that the typical feature of rest is transformed to a zero sEMG linear envelope, which correlates with the rest movement. Furthermore, hand gesture 17 and 18 differ mainly in the activation of channel 8 and 15. Channel 8 and 15 cover the activity of the flexor carpi ulnaris muscle of the forearm, which acts to flex and adduct the hand. Physiologically, the activity of the flexor carpi ulnaris muscle is useful for distinguishing hand opening and hand closing.
The correlation matrix is important for evaluating the ability of a generative model in distinguishing different classes. Each element of the correlation matrix is calculated as the cosine of the angle between two hand-gesture centers. A hand-gesture center can be treated as a vector connecting the origin of coordinates to the center. The cosine of the angle between two vectors evaluates their correlations. The correlation matrix of the proposed approach is shown in
Figure 9. If the correlation between two hand-gesture centers is close to 1, then the two hand gestures are hard to distinguish from each other.
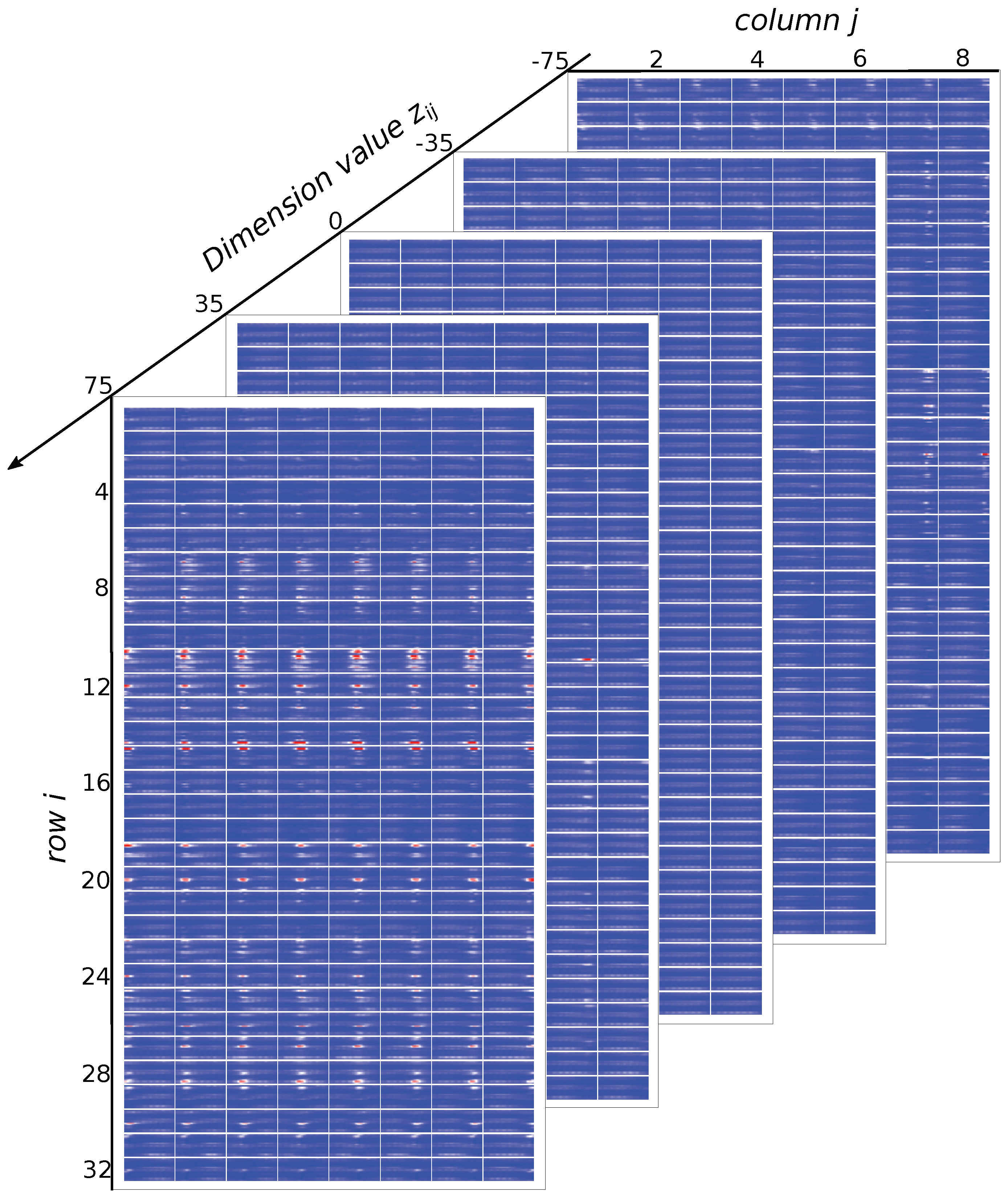
Since the feature learned by the GFM is factorized, each dimension of the feature is analyzed individually to evaluate its relation to the sEMG linear envelope.
Figure 10 shows sub-images arranged along the axis of dimension value z in 32 rows and 8 columns in which the sub-image at row
a and column
b is generated by a factorized feature with
. The dimension value
v is constrained in
because
is the minimum/maximum value of the feature obtained in the train set, and a dimension with value >75 or <−75 is the output of the reasonable range of the feature. In
Figure 10, generated sEMG linear envelopes corresponding to some selected
v values
are shown. From the results, we can see that
v determines the strength of the generated sEMG linear envelope, and the strength of the sEMG linear envelope increases with increasing
v. We can also determine that each row of the factorized feature corresponds to a basic pattern of the sEMG linear envelope, which may reflect the muscle synergy taking effect underneath the sEMG recording channels. Each column of the feature corresponds to the spreading of the basic pattern with time. For example, the 11th row corresponds to a pattern of the sEMG linear envelope, where channels 16, 15, 12, 11, 10, and 4 are activated simultaneously, and the columns determine the occurrence time of the pattern. At the first column, the pattern occurs on the left side of the sub-image, while at the
column, the pattern occurs at the right side of the sub-image. The left/right side of the sub-image corresponds to the occurrence of a pattern in the sEMG linear envelope. In summary, the
factorized feature is interpreted as follows: the 32 rows determine 32 different sEMG linear envelope patterns, the 8 columns determine the occurrence of the patterns in the sEMG linear envelope, and the elements of the matrix determine the strength of the sEMG linear envelope.
We made a GUI for the readers to interact with the proposed approach to see the relation between the factorized feature
z and the corresponding sEMG linear envelope. The GUI is available in the
Appendix A.
6. Discussion
A deep learning approach that can extract comprehensible features from sEMG for hand-gesture classification was proposed. The approach allows employing deep learning to clinical applications of sEMG-based hand-gesture classification where model comprehension is required.
As a newly coming approach, GFM has not been widely used in applications other than image generation and speech synthesis. In most cases, the Gaussian-distributed factorized features learned by GFM are uninterpretable. Since images and speeches are intuitive for human, one can manually interpret the meaning of the factorized feature by tuning the factorized feature and check its influences on the generated samples from GFM. However, for biomedical signal, it is difficult to interpret the meaning of the factorized feature without a task-related label/event to check the generated biomedical samples from GFM. In the paper, a well-designed GFM trained under regulation of a linear SoftMax classifier can learn good features for classification, and the task-related features are well-interpretable.
The proposed approach has achieved competitive accuracy for classifying hand gestures of NinaPro database 5 compared with existing methods. Overall, 69.04% ± 5.24% accuracy for 41 selected hand gestures from the database was achieved by the method described in [
19] using the support vector machine (SVM) algorithm and multivariate discrete wavelet technique (mDWT). The sEMG used in the method was segmented at a window of 200 sampling points with an overlap of 100 sampling points. Meanwhile, 82.15% accuracy was achieved by a CNN described in [
32] for 17 selected hand gestures; however, the CNN required pre-training using sEMG from other databases. The sEMG used in this method was segmented at a window of 16 sampling points. In the paper, NinaPro database 5 was chosen for comparing the hand-gesture classification accuracy of the proposed approach with other existing algorithms. In addition, using an open-source database is good for other researchers to verify the results. Since the proposed approach is applicable to most of the EMG databases by designing a proper input/output flow of GFM and a linear classifier, we will be interested in applying the approach to robotic prosthesis control in the future.
In designing the classifier, the linear SoftMax classifier used in the proposed approach finds a good balance between learning a good distribution of the factorized feature and achieving a high classification accuracy. Actually, we had tried to combine GFM with nonlinear classifiers, such as SoftMax classifier with multiple hidden layers and CNNs. Although the nonlinear classifiers can increase the classification accuracy a little bit, the factorized feature learned by the GFM under the regulation of the nonlinear classifiers is incomprehensible. The distribution of the factorized features belonging to a hand gesture is not gathered as shown in
Figure 7, but the features are scattered around. The scattered features have little physiological meaning and are uninterpretable.
The red square at the right bottom of the correlation matrix suggests that it is hard to distinguish hand gestures 30∼52. Hand gestures 30∼52 belong to exercise C, which consists of human grasping and functional movements. The difficulty in distinguishing functional movements is caused by the fact that functional movements activate most of the forearm muscles, while the isometric movements in exercise A and B only activate a small portion of the forearm muscles. With more muscles recruited, the hand can both exert large force and reduce fatigue while performing function movements. Based on the correlation matrix, the remarkable hand gestures out of the 53 hand gestures can be selected to reduce improper classification. Most of the widely used discriminative methods lack a way to calculate their correlation matrix for hand gestures because instead of modelling the actual distribution of the hand gestures as the proposed approach, these methods only model the decision boundary of the hand gestures, which removes the correlation information.
The analysis of each dimension of the factorized feature indicates that its rows correspond to different sEMG linear envelope patterns, its columns correspond to the occurrence of the patterns, and its elements determine the strength of the pattern. The regular pattern of the factorized feature is more comprehensive than we expected. Often, representations of features in deep learning models are hard for humans to understand. Since the proposed approach is trained to distinguish hand gestures of different subjects, muscle synergy, which is a common mechanism shared among subjects, is theoretically an optimal feature for the task. From the results, we can see that the proposed approach learned to represent the sEMG linear envelope as a combination of some basic patterns of the sEMG. We suppose that these basic patterns may be reflections of the muscle synergy in the sEMG. However, the dimension of the factorized feature is much larger than that of muscle synergy, which means that there are some redundancies in the factorized feature. The dimension of the factorized feature can be reduced by adding more multi-scale modules to the GFM. However, with the dimension of the feature reduced, the accuracy of the classifier may decrease.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












