Depth Map Upsampling via Multi-Modal Generative Adversarial Network


Abstract
1. Introduction
2. Related Work
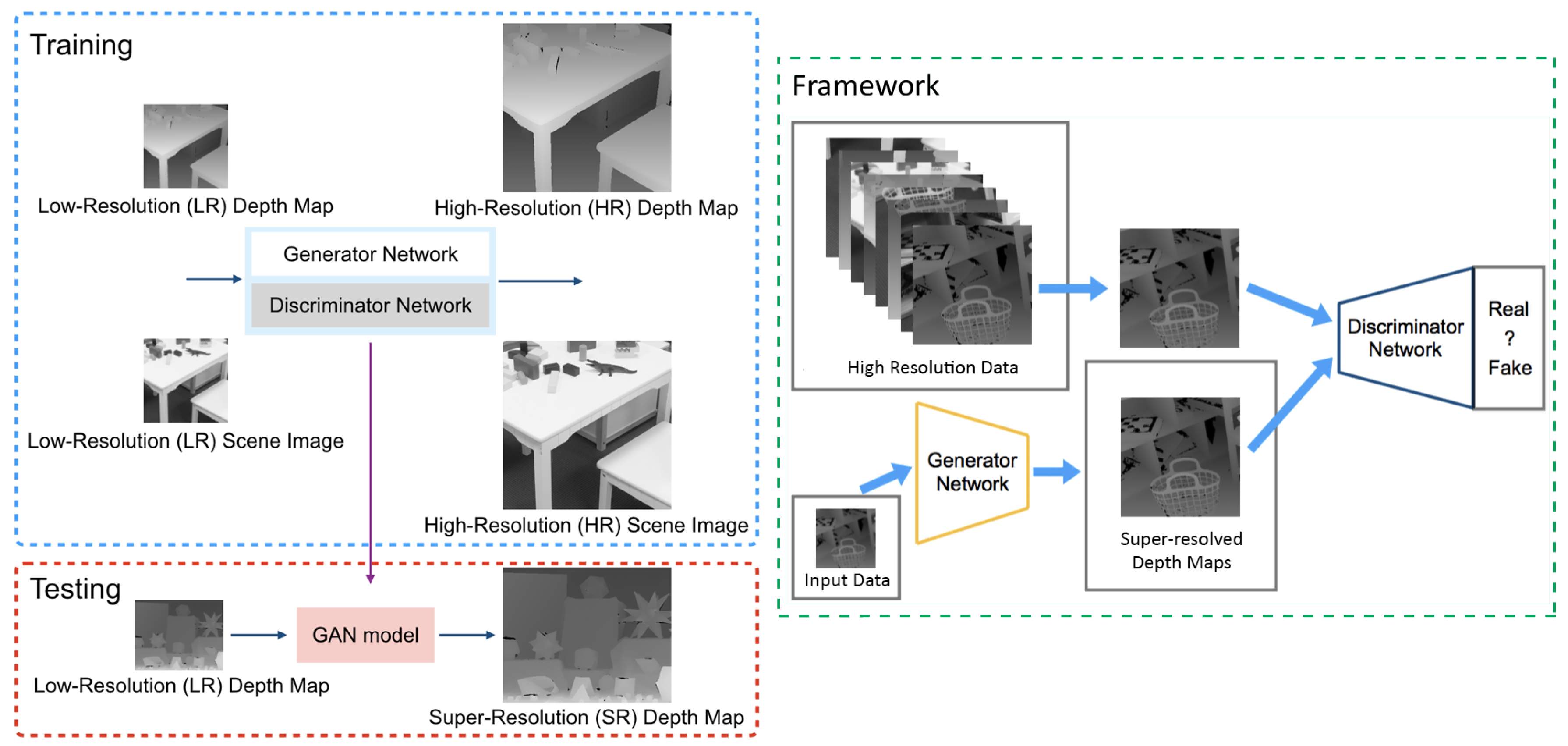
3. Proposed Framework
3.1. Problem Formulation
3.2. Generative Adversarial Network
3.3. Loss Function
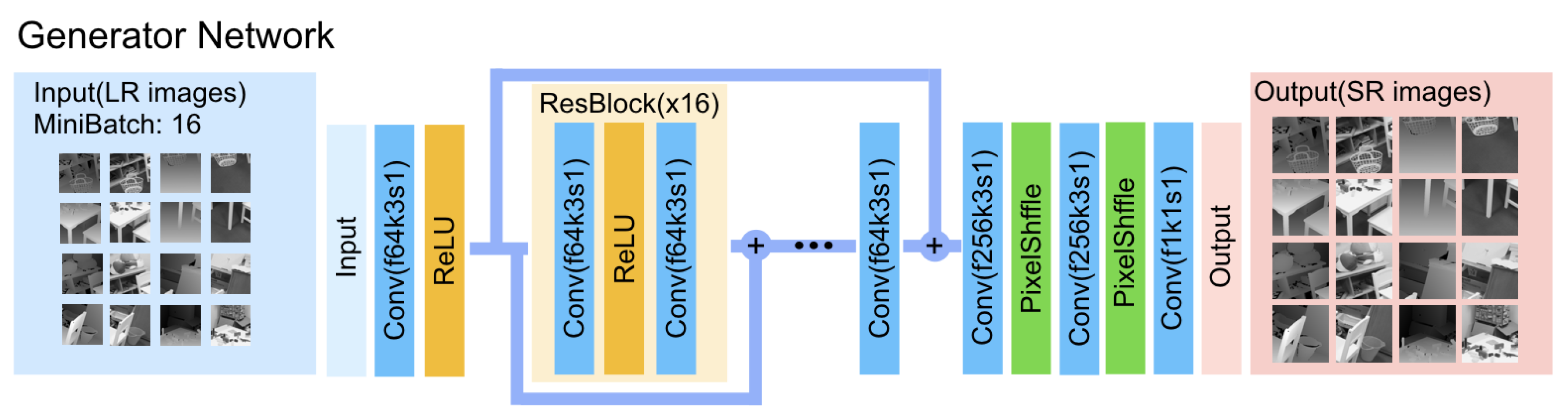
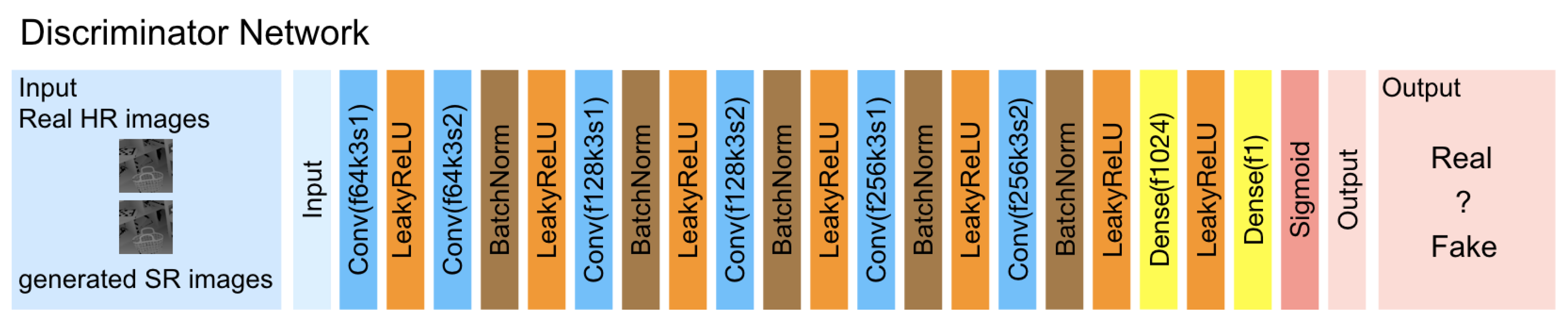
3.4. Network Architecture
3.5. Multi-Modal Mini-Batch
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Performance Evaluations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RGB | Red, Green, and Blue |
| GAN | Generative Adversarial Network |
| LR | Low-Resolution |
| HR | High-Resolution |
| SR | Super-Resolution |
| BF | Bilateral Filter |
| JBU | Joint Bilateral Upsampling |
| JBF | Joint Bilateral Filtering |
| WMF | Weighted Mode Filter |
| MRF | Markov Random Field |
| NLM | Non-Local Means |
| BP | Bad Pixel |
| MSE | Mean Squared Error |
References
- Schuon, S.; Theobalt, C.; Davis, J.; Thrun, S. High-quality scanning using time-of-flight depth superresolution. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW’08), Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Guomundsson, S.A.; Aanaes, H.; Larsen, R. Environmental effects on measurement uncertainties of Time-of-Flight cameras. In Proceedings of the International Symposium on Signals, Circuits and Systems (ISSCS), Iasi, Romania, 12–13 July 2007; Volume 1, pp. 1–4. [Google Scholar]
- Lo, K.H.; Hua, K.L.; Wang, Y.C.F. Depth map super-resolution via Markov random fields without texture-copying artifacts. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 1414–1418. [Google Scholar]
- Lo, K.H.; Wang, Y.C.F.; Hua, K.L. Joint trilateral filtering for depth map super-resolution. In Proceedings of the Visual Communications and Image Processing (VCIP), Kuching, Malaysia, 17–20 November 2013; pp. 1–6. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Aodha, O.M.; Campbell, N.D.; Nair, A.; Brostow, G.J. Patch based synthesis for single depth image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 71–84. [Google Scholar]
- Hornacek, M.; Rhemann, C.; Gelautz, M.; Rother, C. Depth super-resolution by rigid body self-similarity in 3d. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 1123–1130. [Google Scholar]
- Li, J.; Lu, Z.; Zeng, G.; Gan, R.; Zha, H. Similarity-aware patchwork assembly for depth image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 3374–3381. [Google Scholar]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Bombay, India, 4–7 January 1998; pp. 839–846. [Google Scholar]
- Kopf, J.; Cohen, M.; Lischinski, D.; Uyttendaele, M. Joint bilateral upsampling. ACM Trans. Graph. 2007, 26, 96–101. [Google Scholar] [CrossRef]
- Chan, D.; Buisman, H.; Theobalt, C.; Thrun, S. A noise-aware filter for real-time depth upsampling. In Proceedings of the ECCV Workshop on Multi-camera and Multi-modal Sensor Fusion Algorithms and Applications, Marseille, France, 18 October 2008. [Google Scholar]
- Li, Y.; Zhang, L.; Zhang, Y.; Xuan, H.; Dai, Q. Depth map super-resolution via iterative joint-trilateral-upsampling. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), Valletta, Malta, 7–10 December 2014; pp. 386–389. [Google Scholar]
- Yang, Q.; Yang, R.; Davis, J.; Nister, D. Spatial-depth super-resolution for range images. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Kim, J.; Lee, J.; Han, S.; Kim, D.; Min, J.; Kim, C. Trilateral filter construction for depth map upsampling. In Proceedings of the IEEE IVMSP Workshop, Seoul, Korea, 10–12 June 2013; pp. 1–4. [Google Scholar]
- Liu, M.Y.; Tuzel, O.; Taguchi, Y. Joint geodesic upsampling of depth images. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 169–176. [Google Scholar]
- Jung, S.W. Enhancement of Image and Depth Map Using Adaptive Joint Trilateral Filter. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 258–269. [Google Scholar] [CrossRef]
- Choi, O.; Jung, S.W. A Consensus-Driven Approach for Structure and Texture Aware Depth Map Upsampling. IEEE Trans. Image Process. 2014, 23, 3321–3335. [Google Scholar] [CrossRef] [PubMed]
- Min, D.; Lu, J.; Do, M.N. Depth Video Enhancement Based on Weighted Mode Filtering. IEEE Trans. Image Process. 2012, 21, 1176–1190. [Google Scholar] [PubMed]
- Hua, K.L.; Lo, K.H.; Wang, Y.C.F. Extended Guided Filtering for Depth Map Upsampling. IEEE MultiMedia Mag. 2016, 23, 72–83. [Google Scholar] [CrossRef]
- Lo, K.H.; Wang, Y.C.F.; Hua, K.L. Edge-preserving depth map upsampling by joint trilateral filter. IEEE Trans. Cybern. 2018, 48, 371–384. [Google Scholar] [CrossRef] [PubMed]
- Diebel, J.; Thrun, S. An application of Markov random fields to range sensing. In Proceedings of the MIT Press Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 5–8 December 2005; pp. 291–298.
- Lu, J.; Min, D.; Pahwa, R.S.; Do, M.N. A revisit to MRF-based depth map super-resolution and enhancement. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 985–988. [Google Scholar]
- Kim, D.; Yoon, K. High quality depth map up-sampling robust to edge noise of range sensors. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Orlando, FL, USA, 30 September–3 October 2012; pp. 553–556. [Google Scholar]
- Lu, J.; Forsyth, D. Sparse Depth super-resolution. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 2015; pp. 2245–2253. [Google Scholar]
- Park, J.; Kim, H.; Tai, Y.W.; Brown, M.; Kweon, I. High quality depth map upsampling for 3d-tof cameras. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1623–1630. [Google Scholar]
- Ferstl, D.; Reinbacher, C.; Ranftl, R.; Ruether, M.; Bischof, H. Image guided depth upsampling using anisotropic total generalized variation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 993–1000. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; Shi, W. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGBD images. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2001, 47, 7–42. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Middlebury Stereo. Available online: http://vision.middlebury.edu/stereo/ (accessed on 4 January 2019).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BP% of 4× SR | Venus | Teddy | Cones | Dolls | Midd2 | Moebius | Reindeer | Kitchen1 | Kitchen2 | Store1 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| nonocc. | all | disc. | nonocc. | all | disc. | nonocc. | all | disc. | all | |||||||
| Diebel et al. [22] | 0.85 | 1.16 | 3.93 | 7.46 | 8.17 | 18.02 | 6.98 | 8.10 | 19.82 | 6.64 | 2.96 | 9.58 | 3.95 | 3.45 | 6.04 | 3.09 |
| JBU [11] | 0.40 | 0.72 | 5.62 | 5.75 | 6.61 | 20.08 | 6.43 | 7.54 | 19.18 | 5.55 | 1.95 | 6.48 | 3.36 | 2.30 | 3.21 | 3.60 |
| Chan et al. [12] | 0.41 | 0.69 | 5.74 | 5.64 | 6.48 | 19.75 | 6.24 | 7.31 | 18.78 | 4.96 | 1.87 | 5.53 | 3.30 | 1.96 | 2.51 | 2.84 |
| Lu et al. [23] | 0.24 | 0.31 | 3.27 | 5.14 | 5.60 | 14.47 | 3.73 | 4.51 | 10.07 | 6.69 | 3.00 | 6.36 | 3.48 | 2.32 | 3.01 | 2.56 |
| Kim et al. [24] | 0.17 | 0.30 | 2.31 | 5.33 | 6.20 | 16.86 | 4.86 | 5.33 | 14.62 | 4.37 | 2.92 | 5.46 | 2.14 | 2.24 | 3.23 | 2.46 |
| Jung [17] | 0.27 | 0.59 | 3.76 | 4.77 | 5.65 | 15.99 | 4.83 | 5.93 | 14.58 | 5.04 | 2.10 | 6.03 | 2.91 | 2.00 | 2.71 | 2.86 |
| Lo et al. [3] | 0.12 | 0.16 | 1.67 | 3.35 | 3.69 | 9.59 | 3.15 | 3.82 | 9.43 | 3.45 | 1.80 | 4.33 | 1.97 | 1.45 | 2.96 | 2.39 |
| Lo et al. [4] | 0.09 | 0.13 | 1.24 | 3.93 | 4.32 | 12.81 | 3.54 | 3.92 | 10.62 | 2.12 | 0.75 | 3.03 | 1.81 | 1.32 | 1.82 | 2.17 |
| Park et al. [26] | 0.38 | 0.66 | 5.15 | 4.29 | 5.24 | 13.88 | 4.07 | 5.73 | 12.27 | 5.07 | 1.68 | 6.49 | 3.86 | 2.21 | 3.64 | 3.59 |
| Ferstl et al. [27] | 0.27 | 0.41 | 3.77 | 3.75 | 4.32 | 10.03 | 2.47 | 3.44 | 8.17 | 2.80 | 1.40 | 3.53 | 1.93 | 1.76 | 2.78 | 2.24 |
| Choi et al. [18] | 0.28 | 0.49 | 3.89 | 3.23 | 3.88 | 11.41 | 4.83 | 5.52 | 14.65 | 3.17 | 1.75 | 4.97 | 2.42 | 1.86 | 2.86 | 2.78 |
| Lo et al. [21] | 0.08 | 0.16 | 1.10 | 2.73 | 3.20 | 8.52 | 2.67 | 3.19 | 8.09 | 1.78 | 0.72 | 3.04 | 1.42 | 1.16 | 1.73 | 2.15 |
| Our method | 0.04 (1) | 0.07 (1) | 0.57 (1) | 2.13 (1) | 2.76 (1) | 6.54 (1) | 2.16 (1) | 2.58 (1) | 6.54 (1) | 1.74 (1) | 0.52 (1) | 1.53 (1) | 0.74 (1) | 0.48 (1) | 0.74 (1) | 0.58 (1) |
| MSE of 4× SR | Venus | Teddy | Cones | Dolls | Midd2 | Moebius | Reindeer | Kitchen1 | Kitchen2 | Store1 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| nonocc. | all | disc. | nonocc. | all | disc. | nonocc. | all | disc. | all | |||||||
| Diebel et al. [22] | 9.55 | 12.69 | 49.98 | 40.63 | 51.95 | 135.42 | 60.88 | 66.38 | 180.37 | 14.70 | 42.19 | 27.72 | 40.95 | 23.37 | 44.39 | 28.46 |
| JBU [11] | 2.90 | 5.04 | 36.27 | 61.03 | 72.47 | 224.36 | 80.12 | 84.11 | 241.50 | 17.18 | 25.31 | 23.99 | 51.36 | 7.89 | 20.38 | 10.39 |
| Chan et al. [12] | 2.77 | 4.79 | 36.41 | 60.78 | 72.17 | 223.87 | 79.79 | 83.71 | 241.06 | 16.35 | 24.32 | 22.58 | 50.62 | 7.35 | 18.61 | 9.37 |
| Lu et al. [23] | 6.34 | 25.43 | 39.54 | 16.97 | 20.98 | 44.56 | 56.16 | 60.36 | 161.66 | 14.02 | 35.73 | 21.88 | 54.25 | 13.76 | 36.51 | 15.59 |
| Kim et al. [24] | 2.83 | 3.59 | 19.24 | 40.22 | 51.04 | 141.75 | 61.30 | 63.01 | 182.77 | 13.27 | 31.08 | 14.84 | 29.94 | 11.51 | 38.45 | 15.06 |
| Jung [17] | 2.42 | 4.72 | 30.08 | 49.74 | 60.84 | 179.52 | 69.15 | 75.27 | 208.78 | 14.76 | 27.62 | 21.92 | 51.18 | 7.53 | 20.06 | 8.03 |
| Lo et al. [3] | 2.16 | 2.54 | 18.67 | 26.07 | 32.40 | 80.02 | 67.81 | 70.98 | 198.39 | 11.52 | 24.49 | 17.46 | 39.58 | 8.67 | 31.84 | 11.69 |
| Lo et al. [4] | 1.40 | 1.74 | 17.44 | 18.11 | 22.57 | 63.82 | 59.16 | 59.54 | 178.97 | 7.34 | 15.03 | 10.86 | 80.08 | 10.24 | 17.80 | 19.01 |
| Park et al. [26] | 2.89 | 4.96 | 35.08 | 49.46 | 57.58 | 111.65 | 49.12 | 83.94 | 141.60 | 11.32 | 20.83 | 16.03 | 64.97 | 9.88 | 17.88 | 14.21 |
| Ferstl et al. [27] | 2.01 | 3.21 | 29.49 | 39.88 | 50.98 | 109.60 | 42.62 | 58.15 | 97.52 | 9.02 | 19.67 | 10.34 | 44.87 | 5.95 | 18.18 | 12.94 |
| Choi et al. [18] | 2.38 | 3.44 | 30.65 | 17.34 | 22.56 | 63.24 | 39.17 | 41.94 | 118.48 | 8.72 | 18.06 | 14.03 | 43.75 | 5.55 | 8.42 | 6.64 |
| Lo et al. [21] | 1.33 | 2.13 | 16.53 | 15.19 | 19.16 | 51.56 | 41.24 | 42.84 | 124.63 | 5.84 | 14.00 | 11.25 | 24.01 | 6.57 | 17.72 | 8.95 |
| Our method | 0.30 (1) | 0.43 (1) | 2.82 (1) | 17.03 (3) | 22.47 (3) | 62.75 (3) | 21.30 (1) | 24.98 (1) | 64.19 (1) | 7.97 (3) | 9.66 (1) | 8.93 (1) | 11.50 (1) | 1.27 (1) | 1.60 (1) | 1.40 (1) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, D.S.; Lin, J.-M.; Lai, Y.-C.; Ilao, J.; Hua, K.-L. Depth Map Upsampling via Multi-Modal Generative Adversarial Network. Sensors 2019, 19, 1587. https://doi.org/10.3390/s19071587
Tan DS, Lin J-M, Lai Y-C, Ilao J, Hua K-L. Depth Map Upsampling via Multi-Modal Generative Adversarial Network. Sensors. 2019; 19(7):1587. https://doi.org/10.3390/s19071587
Chicago/Turabian StyleTan, Daniel Stanley, Jun-Ming Lin, Yu-Chi Lai, Joel Ilao, and Kai-Lung Hua. 2019. "Depth Map Upsampling via Multi-Modal Generative Adversarial Network" Sensors 19, no. 7: 1587. https://doi.org/10.3390/s19071587
APA StyleTan, D. S., Lin, J.-M., Lai, Y.-C., Ilao, J., & Hua, K.-L. (2019). Depth Map Upsampling via Multi-Modal Generative Adversarial Network. Sensors, 19(7), 1587. https://doi.org/10.3390/s19071587