Consensus-Based Track Association with Multistatic Sensors under a Nested Probabilistic-Numerical Linguistic Environment



Abstract
1. Introduction
2. Assumptions and Abbreviations
2.1. Assumptioins
- The earth is a sphere with a radius of 6371 km.
- The gravitational acceleration is .
- The interference factors obey Gaussian white noise.
- Ignore the time of transmitting and receiving light waves of the sensor.
- The speed of light is infinite.
- The maneuvering target and the sensor are particles.
2.2. Abbreviations
| Variables | Descriptions |
| -th sensor, | |
| -th track point, | |
| -th attribute, | |
| -th maneuvering target, | |
| Distance between target and the sensor | |
| Azimuth angle | |
| Pitch angle | |
| The consensus threshold | |
| The adjustment coefficient | |
| -th weight with respect to the sensor , | |
| -th weight with respect to the attribute , | |
| Acronyms | Full name |
| MAGDM | Multi-attribute group decision making |
| NPNLTSs | Nested probabilistic-numerical linguistic term sets |
| GMM | Gaussian mixture model |
| MHT | Multiple hypothesis tracking |
| JPDA | Joint probabilistic data association |
| HFLTSs | Hesitant fuzzy linguistic term sets |
| PLTSs | Probabilistic linguistic term sets |
| DHHFLTSs | Double hierarchy hesitant fuzzy linguistic term sets |
3. Methodology
3.1. MAGDM with NPNLTSs
3.1.1. NPNLTSs
3.1.2. MAGDM Problem
3.2. Consensus Model in NPNLTSs
3.2.1. Consensus Checking Process
- (1)
- indicates extremely strong consensus;
- (2)
- indicates strong consensus;
- (3)
- indicates moderate degree consensus;
- (4)
- indicates weak consensus;
- (5)
- indicates extremely weak consensus or no consensus.
3.2.2. Consensus Modifying Process
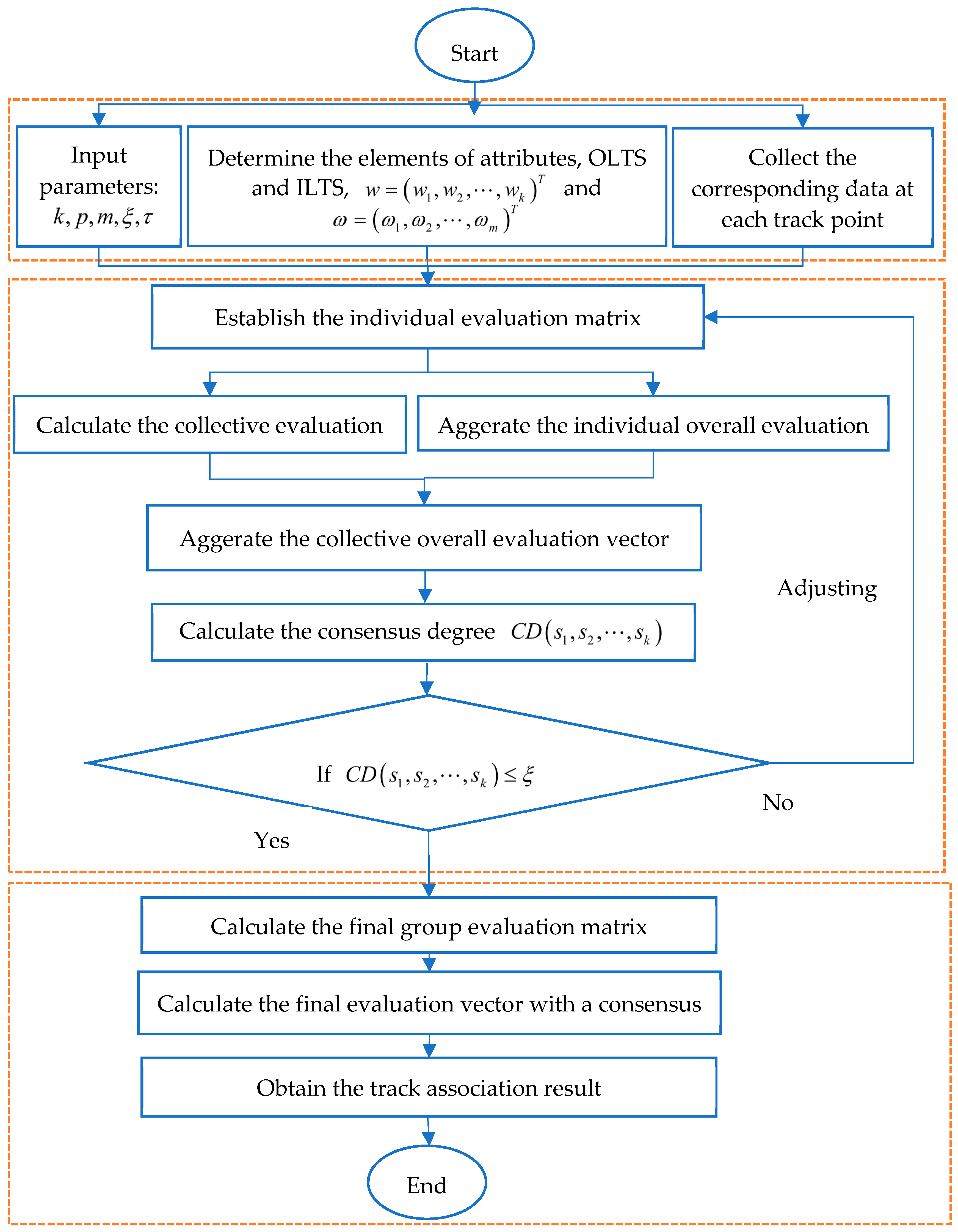
3.3. Track Association Algoritm
| Algorithm 1. The track association algorithm based on consensus model with NPNLTSs. | |
| Step 1. | (1) Input the parameters: . (2) Determine the attributes, OLTS, ILTS and the weight vectors and . (3) Collect the corresponding data at each track point measured by a set of sensors . Go to the next step. |
| Step 2. | Based on the OLTS and the ILTS, establish the individual evaluation matrix with the sensor for the track point with respect to the attribute . Go to the next step. |
| Step 3. | (1) Calculate the collective evaluation matrix using Equation (5). using Equation (6), with the associated weight vector over sensors . Go to the next step. |
| Step 4. | Aggregate the collective overall evaluation vector using Equation (6), with the associated weight vector over attributes . Go to the next step. |
| Step 5. | Determine the consensus threshold , which is in the range of [0.4, 0.8] generally, and the adjustment coefficient , in this paper, we let . Go to the next step. |
| Step 6. | Calculate the consensus degree by Equation (7). If , then go to the next step; Otherwise, go to Step 8. |
| Step 7. | Adjust the individual evaluation matrix by Equation (8) until . Go to the next step. |
| Step 8. | Aggregate all the individual evaluation matrices into a final group evaluation matrix by Equation (5). Go to the next step. |
| Step 9. | Obtain the most likely maneuvering target at each track point based on Equation (6). Go to the next step. |
| Step 10. | End. |
| Pseudo-code. The pseudo-code of the track association algorithm. |
| Input parameters: k—the number of sensors; p—the number of track points; m—the number of attributes; —the consensus threshold; —the adjustment coefficient; —the weight of the sensors; —the weight of the attributes. 1. // Calculate the collective evaluation matrix 2. for i: = 1 to p 3. for j: = 1 to k 4. collective. element (i, j): = sum (sensor (i, j) * (j)) 5. // Calculate the consensus degree 6. for i: = 1 to p 7. for j: = 1 to m 8. individual. element (i, j): = sum (attribute (i, j) * (j)) 9. overall. element (i): = sum (individual. element (i, j) * (j)) 10. consensus = sum (abs (individual. element (i)—overall. element (i)))/p 11. // Calculate the final result with a consensus 12. while (consensus < ) 13. ad_individual. element (i, j): = (individual. element (i, j) + collective. element (i, j))/ 14. group. element (i, j): = ad_individual. element (i, j) * (j)) 15. final. element (i): = group. element (i, j) *(j) |
| 16. return max_final. element (i) |
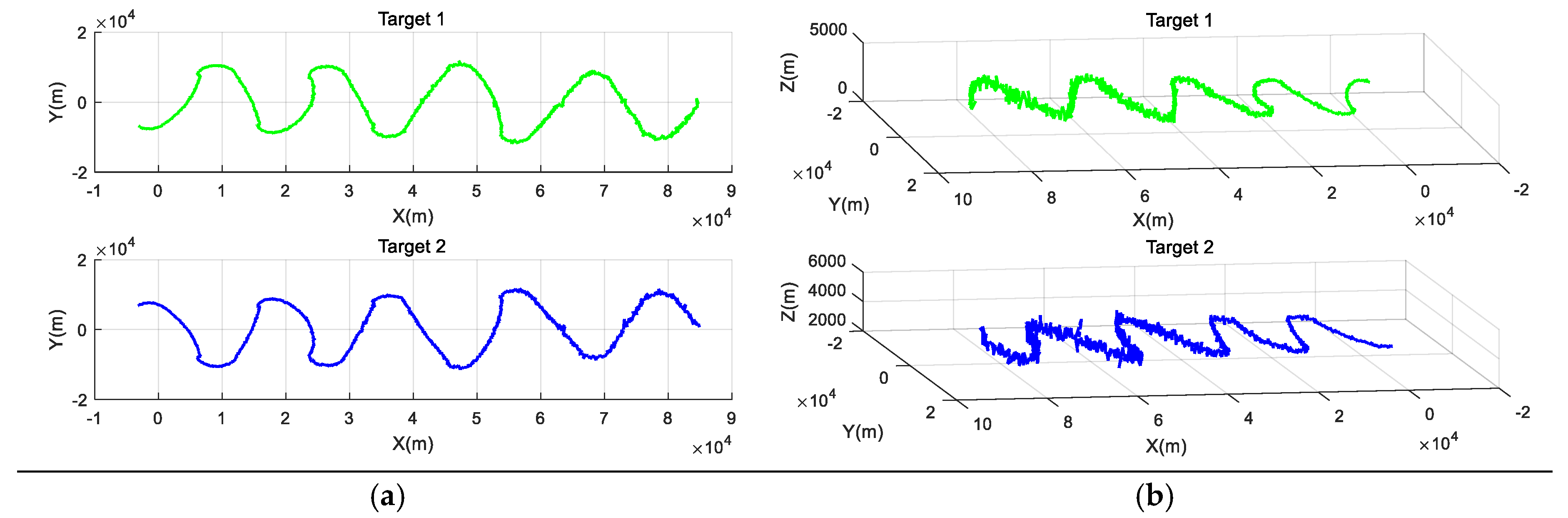
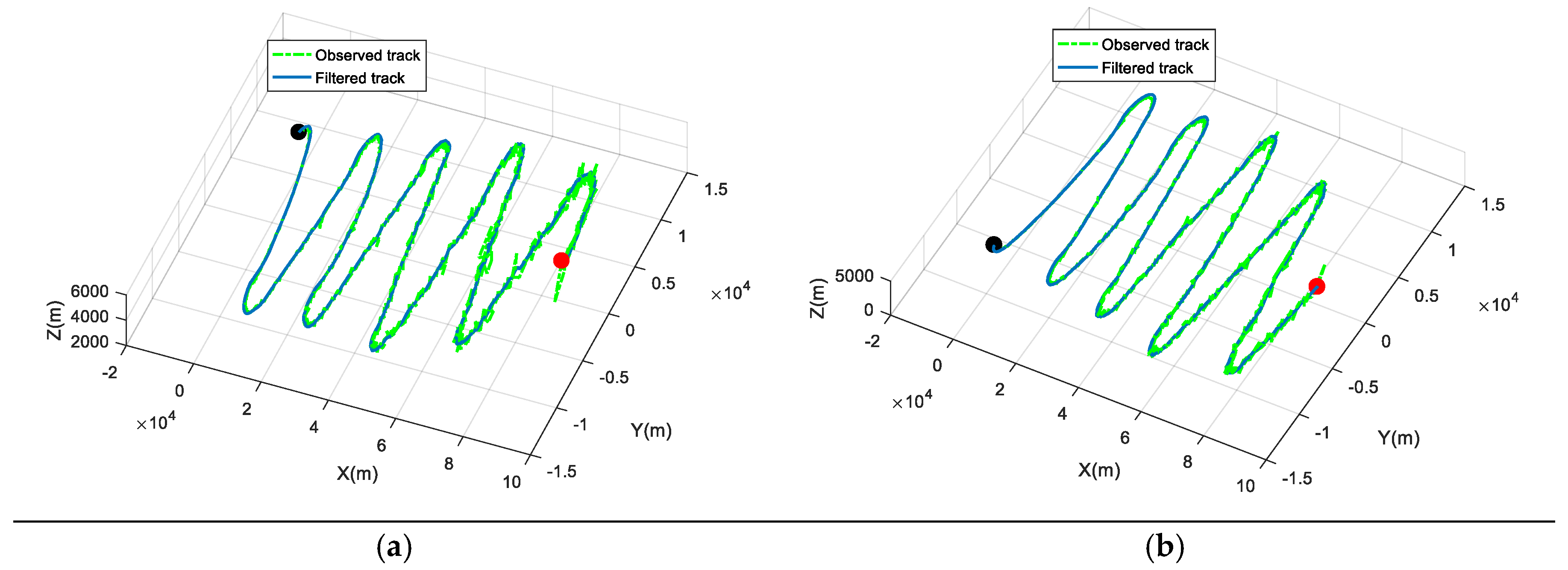
4. A Case Study
4.1. Problem Description
4.2. Establishing the Proposed Model
4.3. Solving the Problem
5. Comparison and Discussion
5.1. Comparative Analysis
- (1)
- The average root-mean-square error (RMSE) of the key parameters.
- (2)
- The impact of the number of the track points on the average RMSE.
- (3)
- The average operation time (AOT).
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Attari, M.; Habibi, S.; Gadsden, S.A. Target tracking formulation of the SVSF with data association techniques. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 12–25. [Google Scholar] [CrossRef]
- Zhu, S.H.; Shi, Z.; Sun, C.J. Tracklet association based multi-target tracking. Multimedia Tools Appl. 2016, 75, 9489–9506. [Google Scholar] [CrossRef]
- Hu, X.Q.; Bao, M.; Zhang, X.P.; Wen, S.; Li, X.D.; Hu, Y.H. Quantized kalman filter tracking in directional sensor networks. IEEE Trans. Mob. Comput. 2018, 17, 871–883. [Google Scholar] [CrossRef]
- Fortino, G.; Galzarano, S.; Gravina, R.; Li, W.F. A framework for collaborative computing and multisensor data fusion in body sensor networks. Inf. Fusion 2015, 22, 50–70. [Google Scholar] [CrossRef]
- Gravina, R.; Alinia, P.; Ghassemzadeh, H.; Fortino, G. Multisensor fusion in body sensor networks: State-of-the-art and research challenges. Inf. Fusion 2017, 35, 68–80. [Google Scholar] [CrossRef]
- Kazimierski, W. Proposal of neural approach to maritime radar and automatic identification system tracks association. IET Radar Sonar Navig. 2017, 11, 729–735. [Google Scholar] [CrossRef]
- Yoon, J.H.; Lee, C.R.; Yang, M.H.; Yoon, K.J. Structural constraint data association for online multi-object tracking. Int. J. Comput. Vis. 2019, 127, 1–21. [Google Scholar] [CrossRef]
- Yang, M.; Wu, Y.W.; Jia, Y.D. A hybrid data association framework for robust online multi-object tracking. IEEE Trans. Image Process. 2017, 26, 5667–5679. [Google Scholar] [CrossRef]
- Ma, J.Y.; Jiang, J.J.; Liu, C.Y.; Li, Y.S. Feature guided Gaussian mixture model with semi-supervised EM and local geometric constraint for retinal image registration. Inf. Sci. 2017, 417, 128–142. [Google Scholar] [CrossRef]
- Coraluppi, S.P.; Carthel, C.A. Multiple-hypothesis tracking for targets producing multiple measurements. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1485–1498. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.A.; Li, Y.X.; Yu, J.; Li, X.H. A novel probabilistic data association for target tracking in a cluttered environment. Sensors 2016, 16, 2180. [Google Scholar] [CrossRef] [PubMed]
- Vivone, G.; Braca, P. Joint probabilistic data association tracker for extended target tracking applied to X-band marine radar data. IEEE J. Ocean. Eng. 2016, 41, 1007–1019. [Google Scholar] [CrossRef]
- Fan, L.X.; Fan, E.; Yuan, C.H.; Hu, K.L. Weighted fuzzy track association method based on Dempster-Shafer theory in distributed sensor networks. Int. J. Distrib. Sens. Netw. 2016, 12. [Google Scholar] [CrossRef]
- Li, J.; Xie, W.X.; Li, L.Q. Online visual multiple target tracking by intuitionistic fuzzy data association. Int. J. Fuzzy Syst. 2017, 19, 355–366. [Google Scholar]
- Yang, D.; Ji, H.B.; Gao, Y.C. A robust D-S fusion algorithm for multi-target multisensor with higher reliability. Inf. Fusion 2019, 47, 32–44. [Google Scholar]
- Yoon, K.; Kim, D.Y.; Yoon, Y.C.; Jeon, M. Data association for multi-object tracking via deep neural networks. Sensors 2019, 19, 559. [Google Scholar] [CrossRef] [PubMed]
- Scott, S.L.; Blocker, A.W.; Bonassi, F.V.; Chipman, H.A.; George, E.I.; McCulloch, R.E. Bayes and big data: The consensus Monte Carlo algorithm. Int. J. Eng. Sci. 2016, 11, 78–88. [Google Scholar] [CrossRef]
- Luengo, D.; Martino, L.; Elvira, V.; Bugallo, M.F. Efficient linear fusion of partial estimators. Digit. Signal Process. 2018, 78, 265–283. [Google Scholar] [CrossRef]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and cooperation in networked multi-agent systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef]
- Dimakis, A.G.; Kar, S.; Moura, J.F.; Rabbat, M.G.; Scaglione, A. Gossip algorithms for distributed signal processing. Proc. IEEE 2010, 98, 1847–1864. [Google Scholar] [CrossRef]
- Yu, Y.H. Distributed target tracking in wireless sensor networks with data association uncertainty. IEEE Commun. Lett. 2017, 21, 1281–1284. [Google Scholar] [CrossRef]
- Wang, X.X.; Xu, Z.S.; Gou, X.J. Nested probabilistic-numerical linguistic term sets in two-stage multi-attribute group decision making. Appl. Intell. 2019, 49, 1–21. [Google Scholar] [CrossRef]
- Wang, X.X.; Xu, Z.S.; Gou, X.J.; Trajkovic, L. Tracking a maneuvering target by multiple sensors using extended kalman filter with nested probabilistic-numerical linguistic information. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Liao, H.C.; Xu, Z.S.; Zeng, X.J.; Merigo, J.M. Qualitative decision making with correlation coefficients of hesitant fuzzy linguistic term sets. Knowl.-Based Syst. 2015, 76, 127–138. [Google Scholar] [CrossRef]
- Wei, C.P.; Zhao, N.; Tang, X.J. Operators and comparisons of hesitant fuzzy linguistic term sets. IEEE Trans. Fuzzy Syst. 2014, 22, 575–585. [Google Scholar] [CrossRef]
- Zhang, Y.X.; Xu, Z.S.; Liao, H.C. A consensus process for group decision making with probabilistic linguistic preference relations. Inf. Sci. 2017, 414, 260–275. [Google Scholar] [CrossRef]
- Rodriguez, R.M.; Martinez, L.; Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z.S. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Gou, X.J.; Liao, H.C.; Xu, Z.S.; Herrera, F. Double hierarchy hesitant fuzzy linguistic term set and MULTIMOORA method: A case of study to evaluate the implementation status of haze controlling measures. Inf. Fusion 2017, 38, 22–34. [Google Scholar] [CrossRef]
- Wang, X.X.; Xu, Z.S.; Gou, X.J. Distance and similarity measures for nested probabilistic-numerical linguistic term sets applied to evaluation of medical treatment. Int. J. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Karplus, P.A.; Diederichs, K. Linking crystallographic model and data quality. Science 2012, 336, 1030–1033. [Google Scholar] [CrossRef] [PubMed]
- Chiclana, F.; Tapia Garcia, J.M.; del Moral, M.J.; Herrera-Viedma, E. A statistical comparative study of different similarity measures of consensus in group decision making. Inf. Sci. 2013, 221, 110–123. [Google Scholar] [CrossRef]
- Herrera-Viedma, E.; Herrera, F.; Chiclana, F. A consensus model for multiperson decision making with different preference structures. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2002, 32, 394–402. [Google Scholar] [CrossRef]
- Herrera-Viedma, E.; Martinez, L.; Mata, F.; Chiclana, F. A consensus support system model for group decision-making problems with multigranular linguistic preference relations. IEEE Trans. Fuzzy Syst. 2005, 13, 644–658. [Google Scholar] [CrossRef]
- Dong, Q.X.; Cooper, O. A peer-to-peer dynamic adaptive consensus reaching model for the group AHP decision making. Eur. J. Oper. Res. 2016, 250, 521–530. [Google Scholar] [CrossRef]
- Ma, L.C. A new group ranking approach for ordinal preferences based on group maximum consensus sequences. Eur. J. Oper. Res. 2016, 251, 171–181. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distance (m) | Azimuth Angle (degree) | Pitch Angle (degree) | Time (s) | Sensor Label |
|---|---|---|---|---|
| 84,626.83 | 89.99 | 1.74 | 0.10 | 1 |
| 85,016.58 | 89.50 | 3.07 | 0.70 | 1 |
| … | … | … | … | 1 |
| 53,481.28 | 87.24 | 3.93 | 272.50 | 1 |
| 48,556.38 | 233.38 | 3.02 | 272.60 | 2 |
| 48,538.89 | 227.05 | 3.50 | 273.10 | 2 |
| … | … | … | … | 2 |
| 20,360.67 | 248.65 | 7.49 | 542.50 | 2 |
| 25,166.65 | 331.88 | 8.21 | 543.00 | 3 |
| 25,229.30 | −8.92 | 9.50 | 543.10 | 3 |
| … | … | … | … | 3 |
| 32,031.73 | −104.41 | 29.11 | 808.90 | 3 |
| Sensor Label | (degree) | (degree) | (m) | (m) | (degree) | (degree) |
|---|---|---|---|---|---|---|
| 1 | 102.1 | 30.5 | 0 | 50 | 0.4 | 0.4 |
| 2 | 102.4 | 31.5 | 0 | 60 | 0.5 | 0.5 |
| 3 | 102.7 | 31.9 | 0 | 60 | 0.5 | 0.5 |
| Sensor 1 | Location | Height | Speed |
|---|---|---|---|
| … | … | … | … |
| Sensor 2 | Location | Height | Speed |
|---|---|---|---|
| … | … | … | … |
| Sensor 3 | Location | Height | Speed |
|---|---|---|---|
| … | … | … | … |
| Location | Height | Speed | |
|---|---|---|---|
| … | … | … | … |
| Sensor 1 | Sensor 2 | Sensor 3 | |
|---|---|---|---|
| … | … | … | … |
| … | … |
| Location | Height | Speed | |
|---|---|---|---|
| … | … | … | … |
| … | … |
| Average RMSE | Method 1 [12] | Method 2 [27] | Method 3 [28] | Proposed Method |
|---|---|---|---|---|
| Distance (m) | 66.93 | 63.21 | 57.32 | 52.12 |
| Azimuth angle (degree) | 0.60 | 0.55 | 0.52 | 0.42 |
| Pitch angle (degree) | 0.58 | 0.52 | 0.50 | 0.41 |
| Average RMSE | Number | Method 1 [12] | Method 2 [27] | Method 3 [28] | Proposed Method |
|---|---|---|---|---|---|
| Distance (m) | 1000 | 75.73 | 74.25 | 64.72 | 59.13 |
| 2000 | 66.94 | 65.98 | 58.25 | 53.72 | |
| 3000 | 64.78 | 62.56 | 56.29 | 50.44 | |
| Azimuth angle (degree) | 1000 | 0.63 | 0.59 | 0.57 | 0.46 |
| 2000 | 0.60 | 0.55 | 0.52 | 0.42 | |
| 3000 | 0.58 | 0.54 | 0.50 | 0.40 | |
| Pitch angle (degree) | 1000 | 0.63 | 0.55 | 0.53 | 0.45 |
| 2000 | 0.59 | 0.52 | 0.50 | 0.41 | |
| 3000 | 0.58 | 0.50 | 0.48 | 0.40 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Xu, Z.; Gou, X. Consensus-Based Track Association with Multistatic Sensors under a Nested Probabilistic-Numerical Linguistic Environment. Sensors 2019, 19, 1381. https://doi.org/10.3390/s19061381
Wang X, Xu Z, Gou X. Consensus-Based Track Association with Multistatic Sensors under a Nested Probabilistic-Numerical Linguistic Environment. Sensors. 2019; 19(6):1381. https://doi.org/10.3390/s19061381
Chicago/Turabian StyleWang, Xinxin, Zeshui Xu, and Xunjie Gou. 2019. "Consensus-Based Track Association with Multistatic Sensors under a Nested Probabilistic-Numerical Linguistic Environment" Sensors 19, no. 6: 1381. https://doi.org/10.3390/s19061381
APA StyleWang, X., Xu, Z., & Gou, X. (2019). Consensus-Based Track Association with Multistatic Sensors under a Nested Probabilistic-Numerical Linguistic Environment. Sensors, 19(6), 1381. https://doi.org/10.3390/s19061381