4.1. Neural Network Architecture
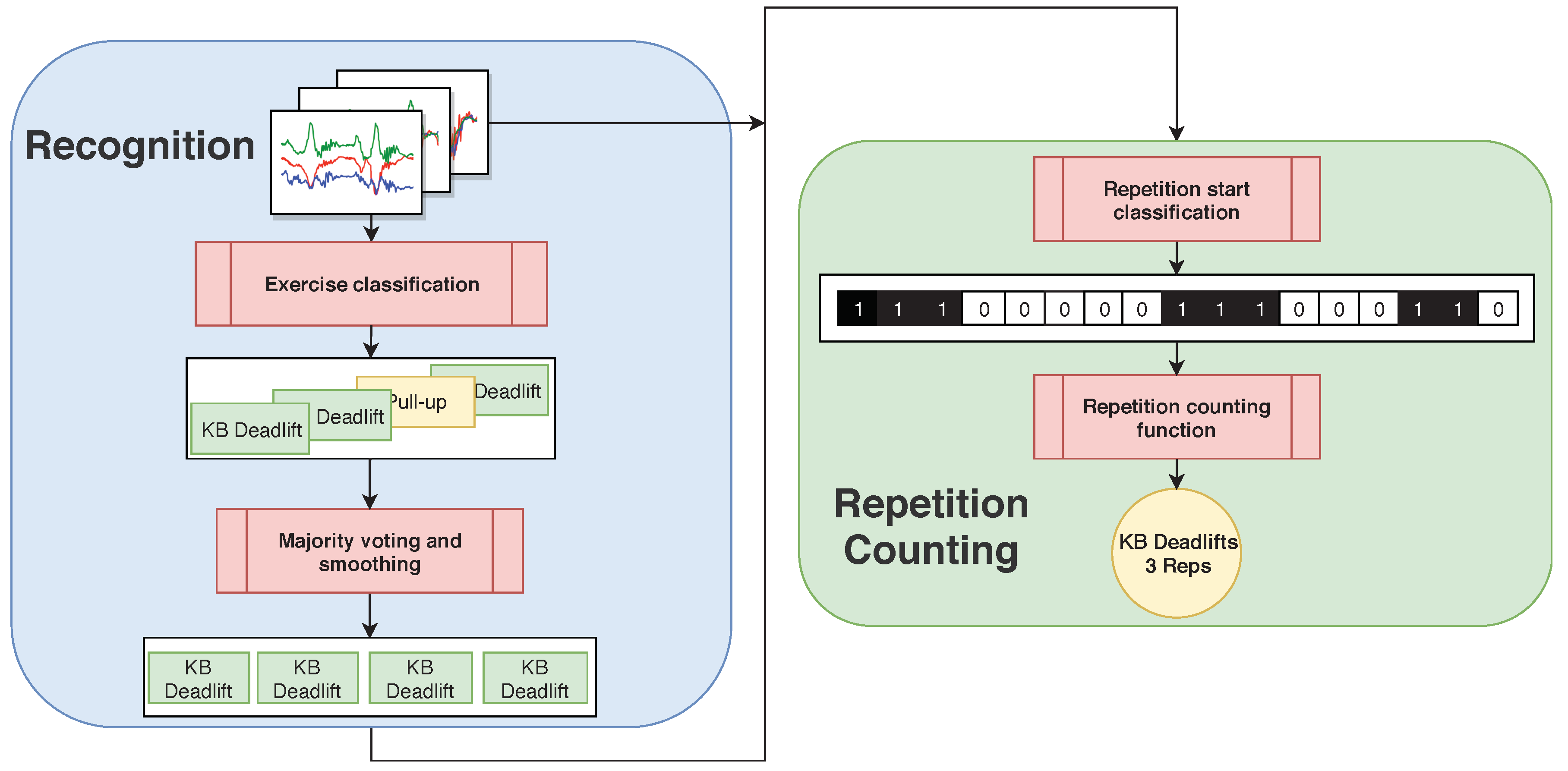
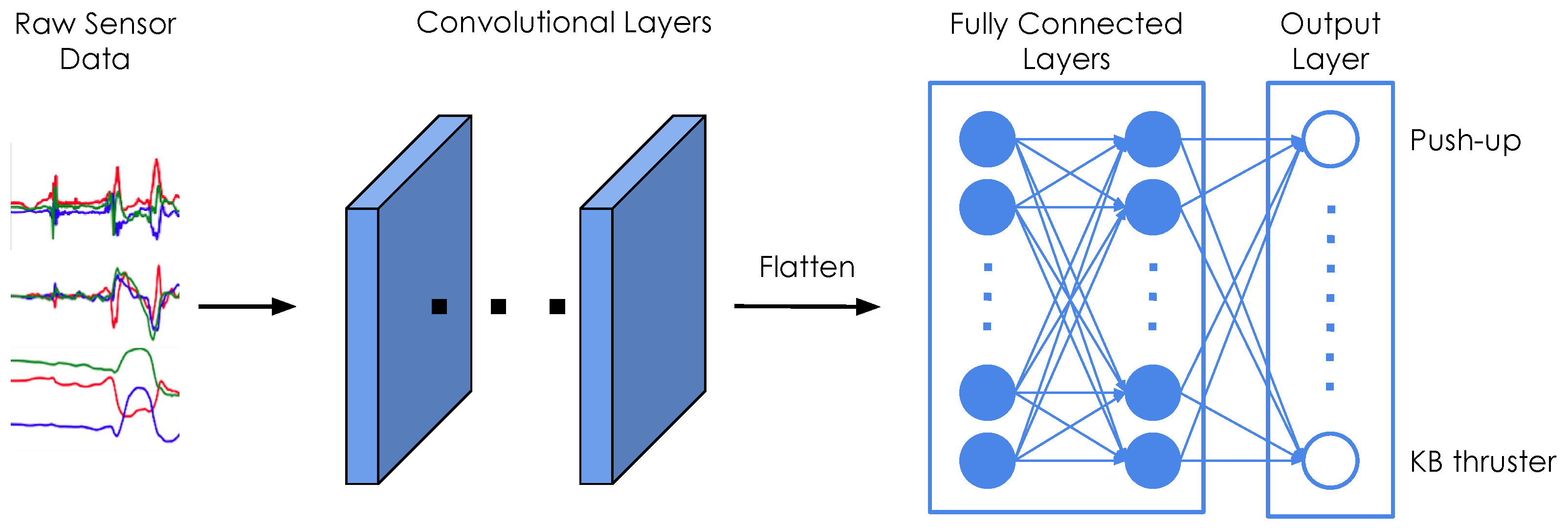
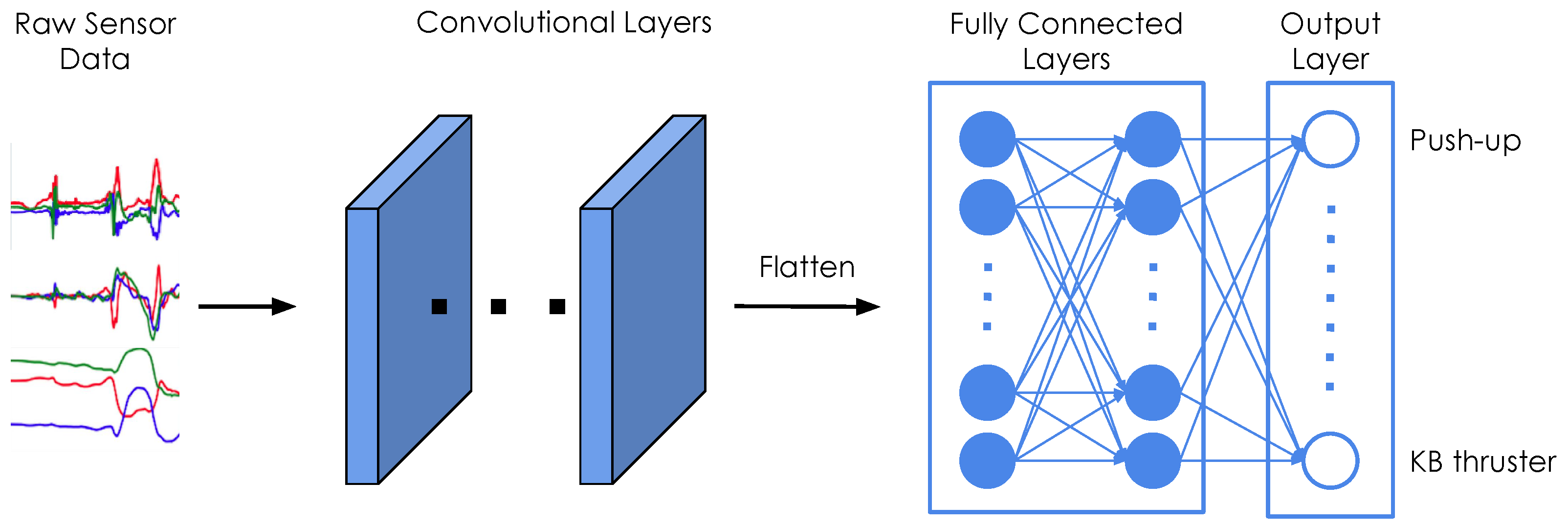
We use the same base architecture for both exercise recognition and repetition counting, as shown in
Figure 5. All our classifiers consist of a series of 2D convolutions and two fully connected layers. We fine-tune our models through hyper-parameter grid searches.
Table 3 summarizes the hyper-parameter search for the recognition model, and indicates the best values that were found. We note that the results are, overall, robust to these hyper-parameter choices and we thus refrained from further tuning. A complete list of the architecture parameters can be found in
Table A1 in
Appendix A. We further tuned the models for each exercise type individually, according to the values in
Table 4. The final hyper-parameters of the repetition counting models for each of the exercises can be found in
Table A2 in
Appendix B.
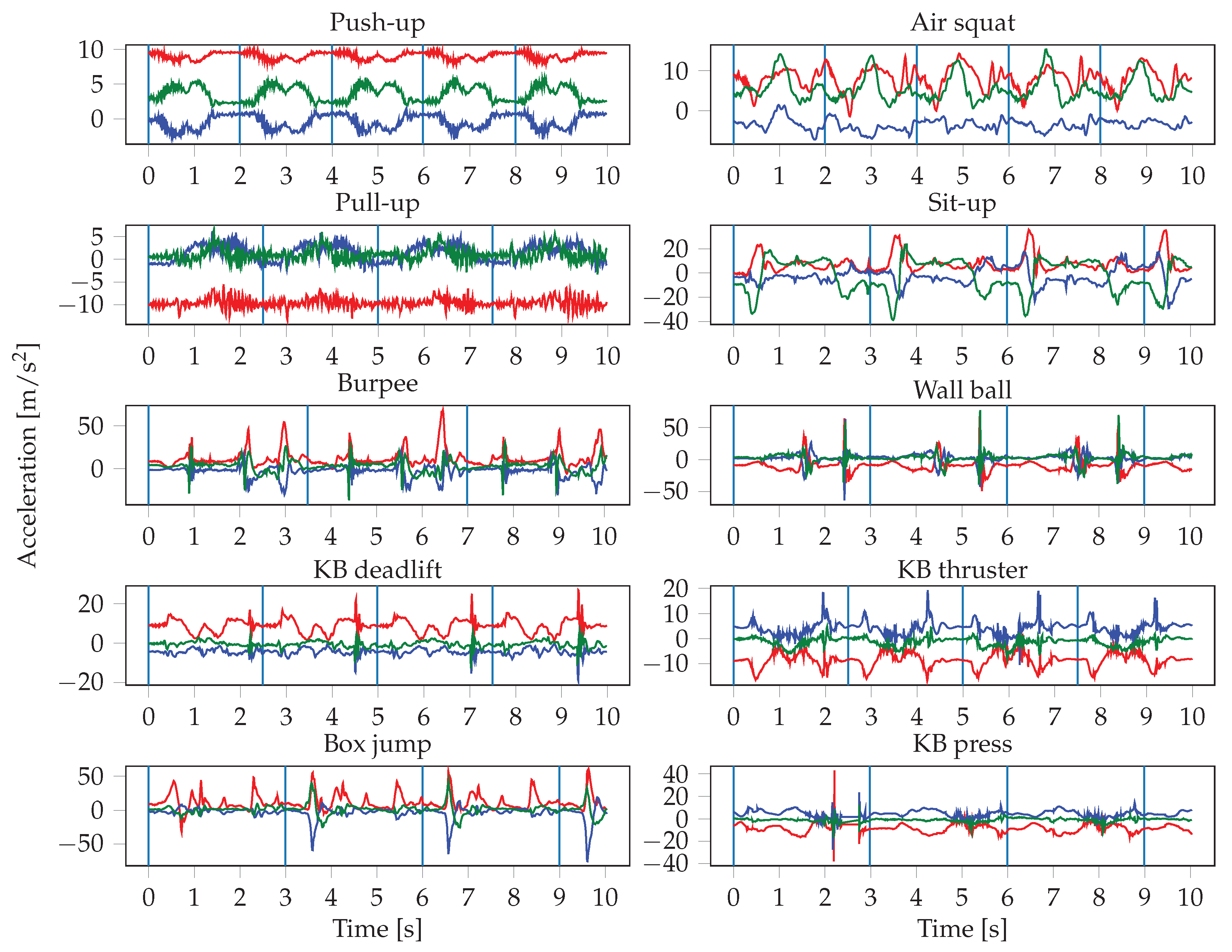
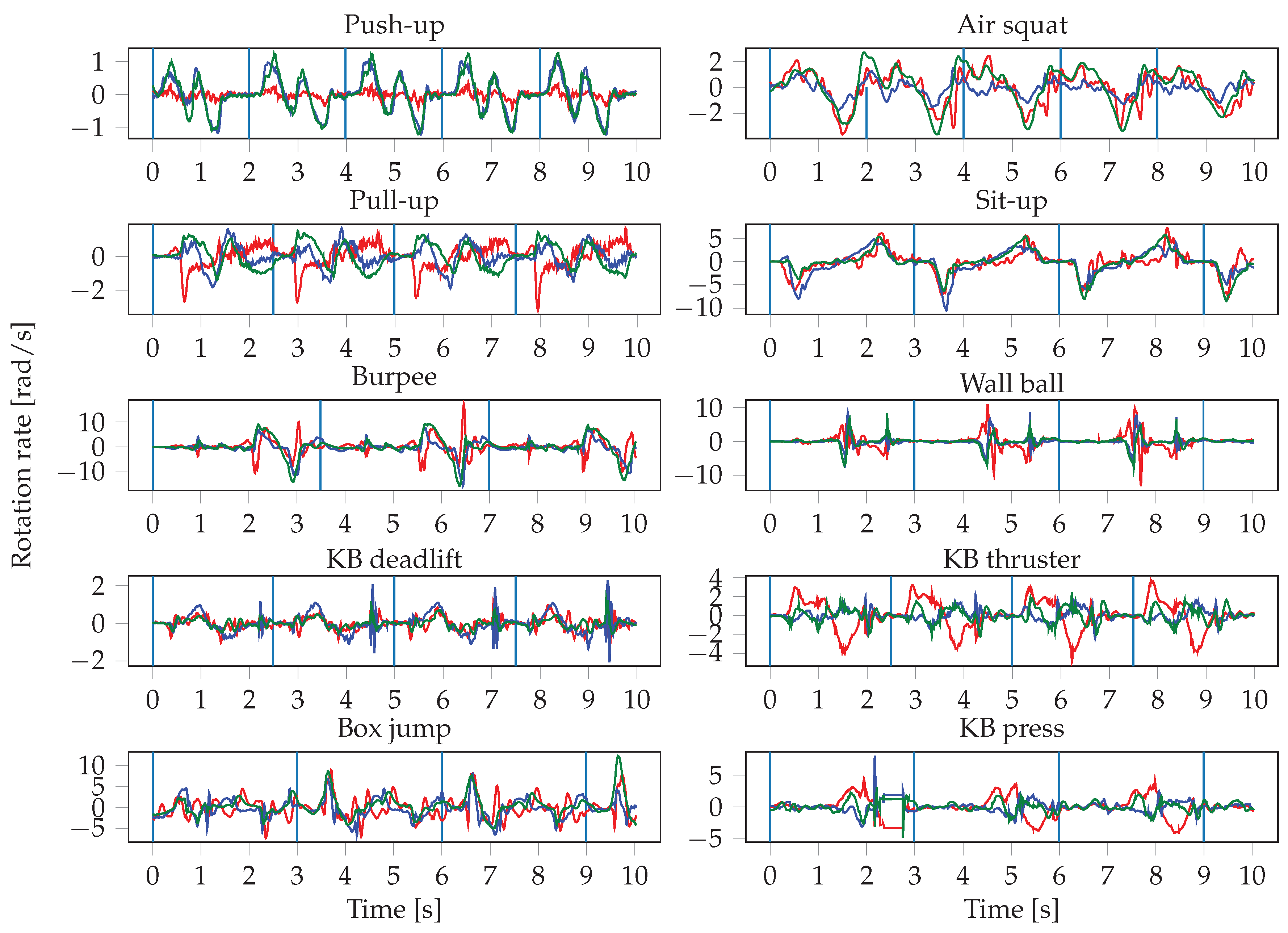
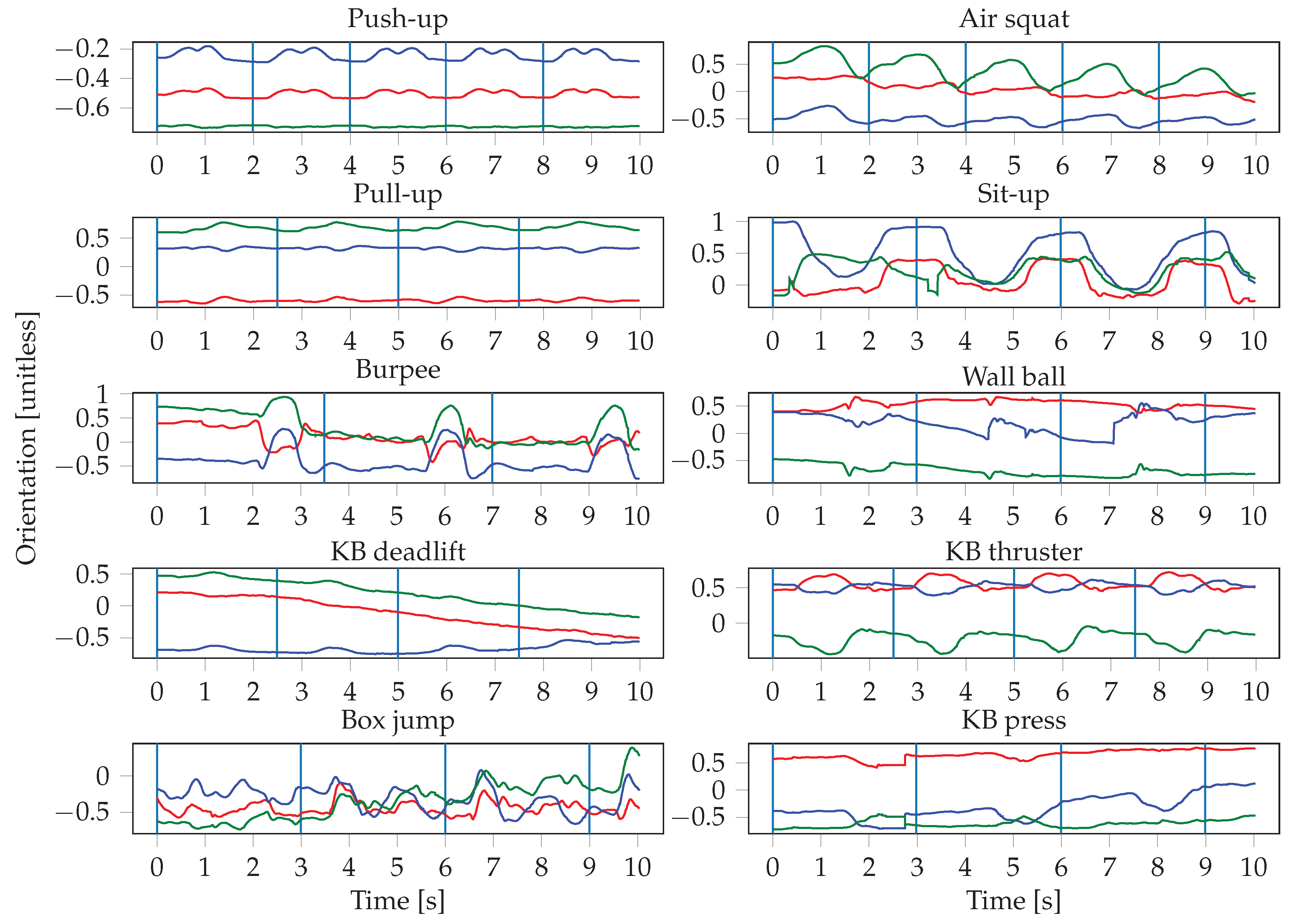
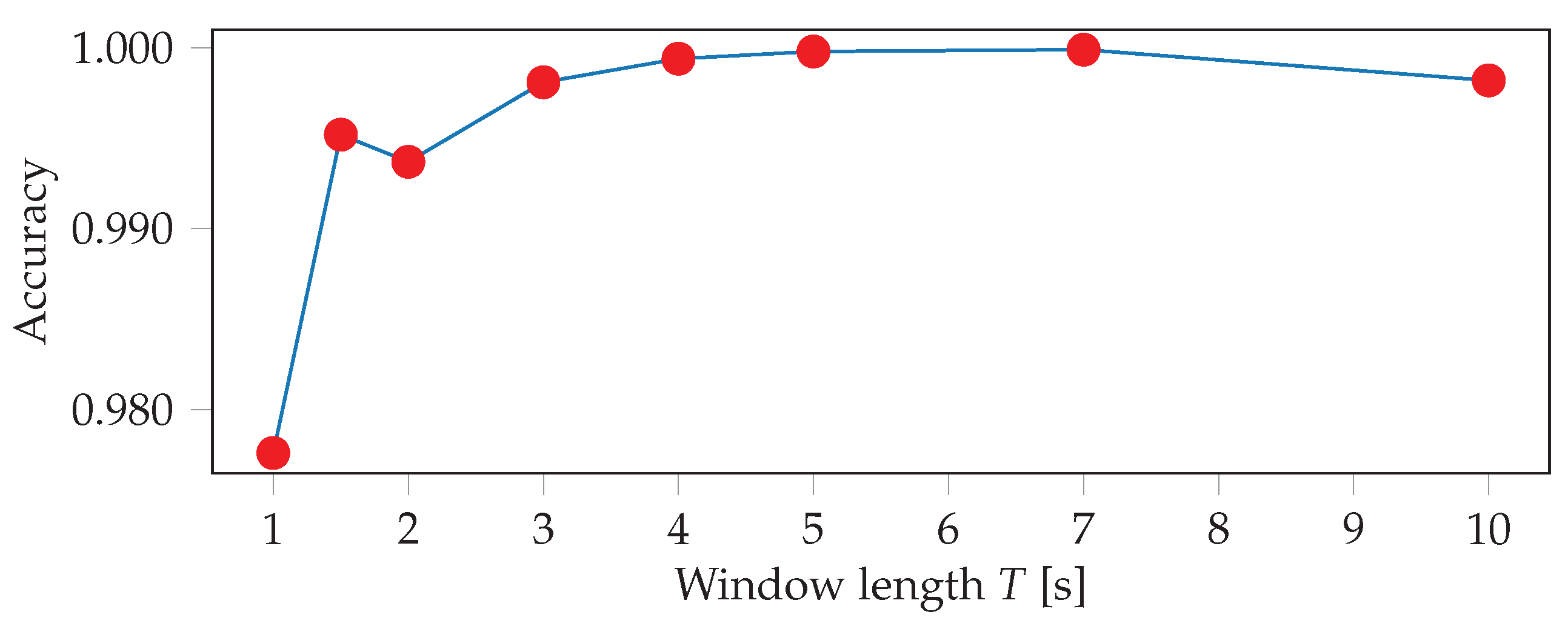
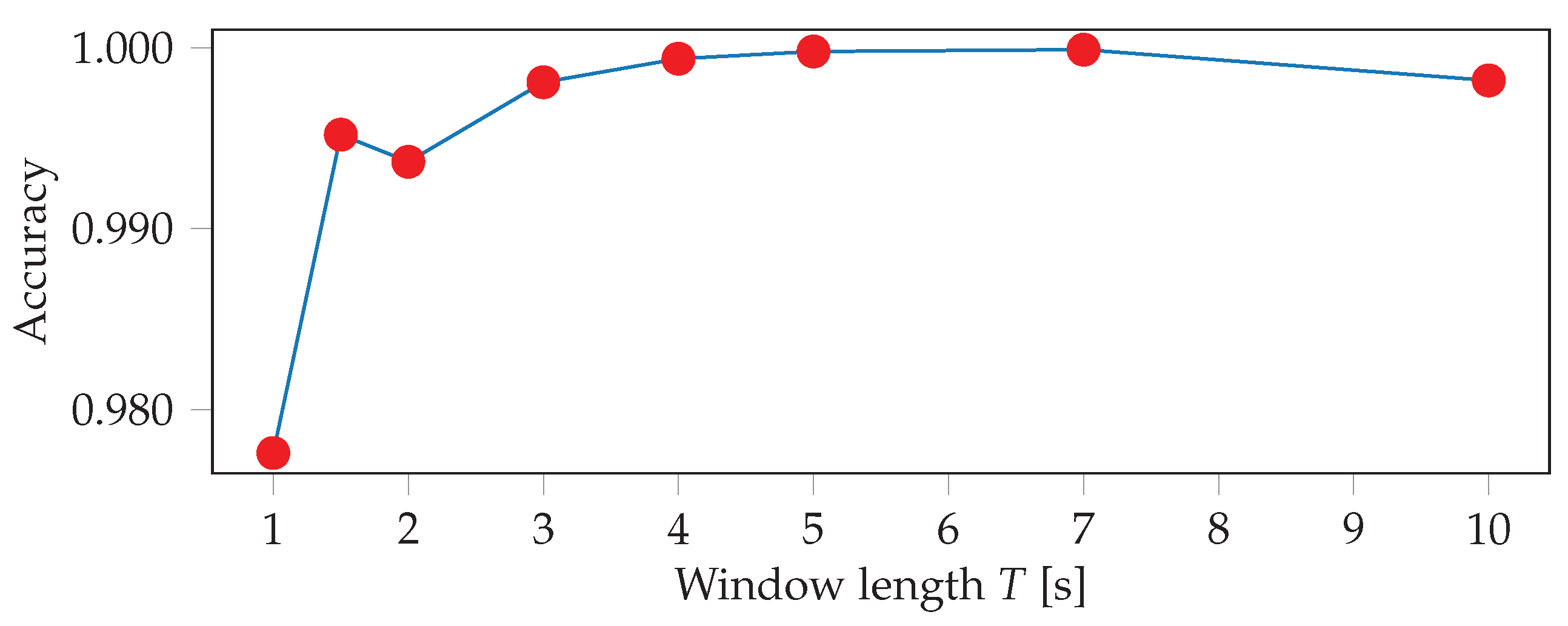
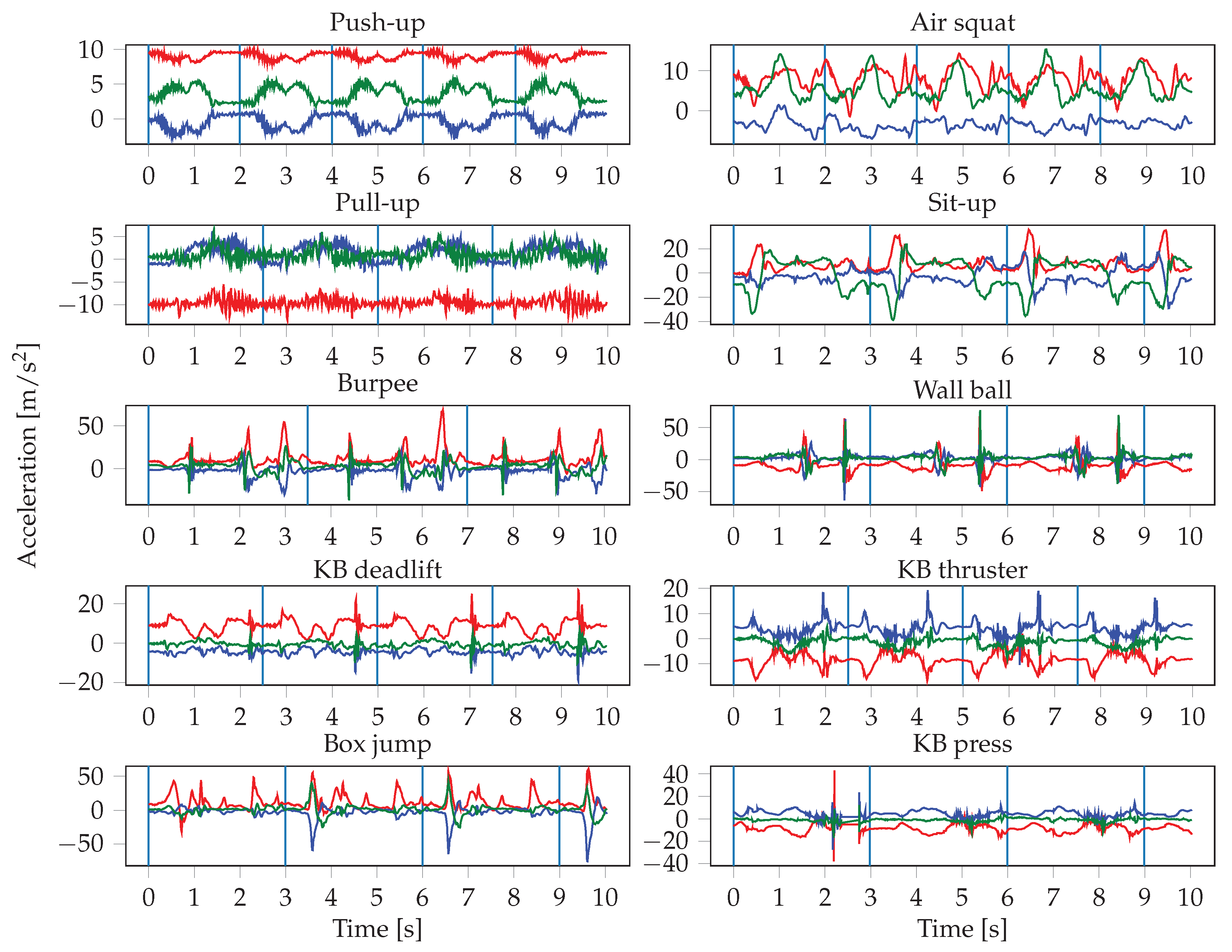
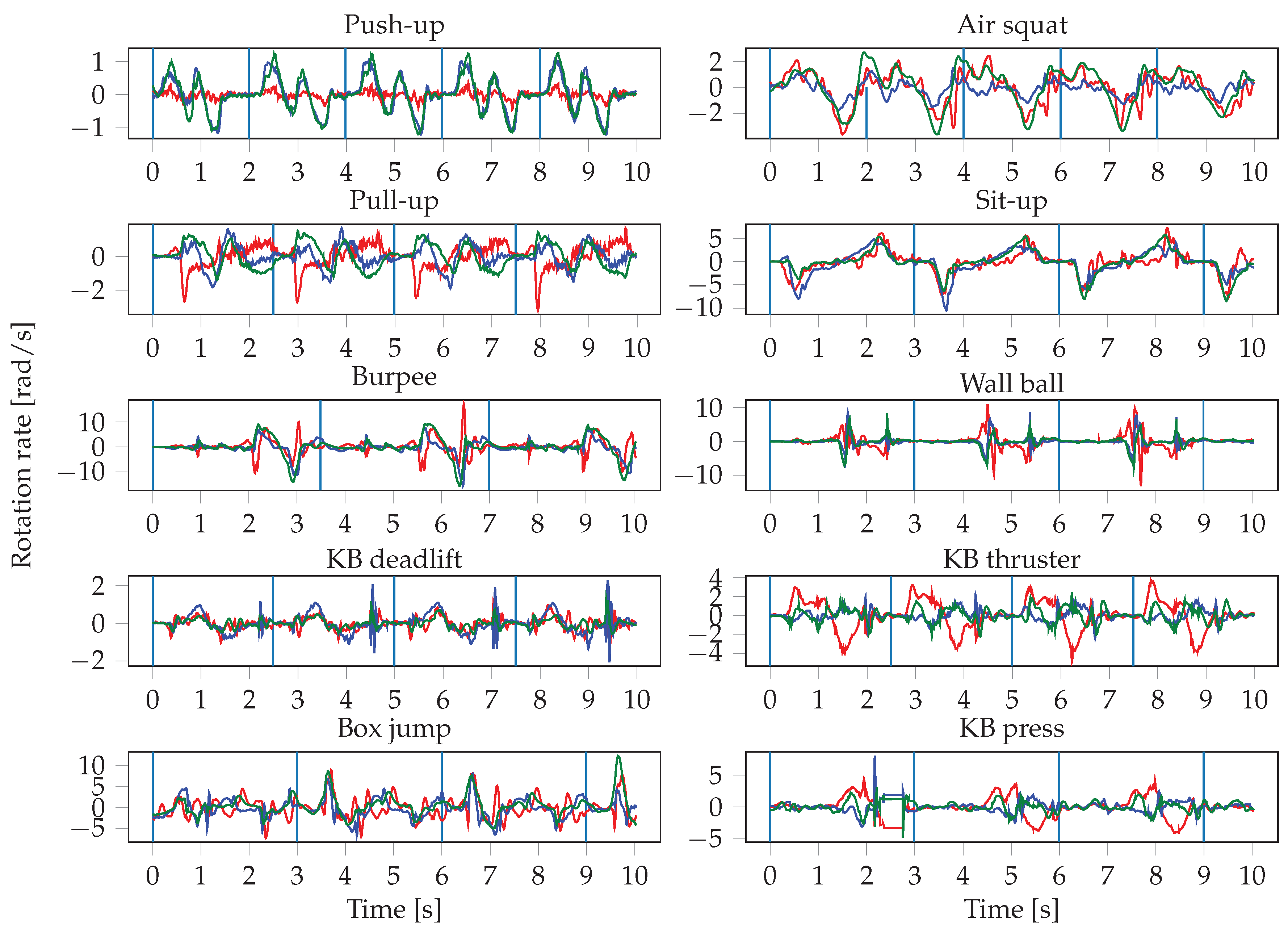
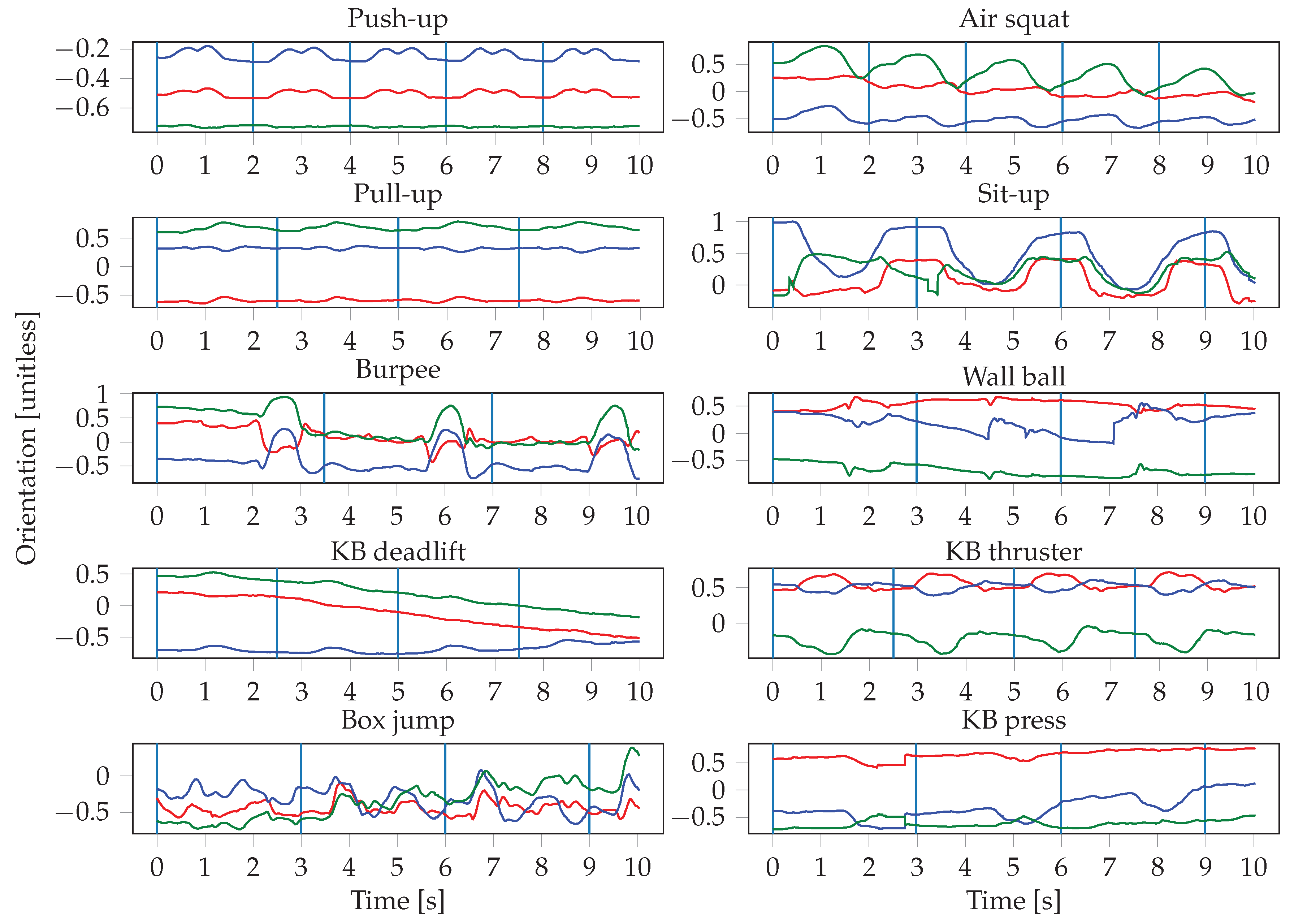
The sensor readings were obtained at irregular intervals, therefore the signals are first interpolated and resampled. The resampling is performed with a frequency of 100 Hz, which represents the average frequency of the watch sensors. The input to the neural networks consists of the resampled sensor data from multiple sensors, where each sensor has three axes. Since we record the signals of the accelerometer, gyroscope, and orientation sensor of two smartwatches, this results in a total of 18 inputs. One input window is a matrix of dimensions , where S denotes the number of sensors that were used, and T is the length of the input window in seconds. This means that we stack the sensors on top of each other in a single channel. In the first convolutional layer, we therefore use a stride of 3 along the vertical axis, in order not to arbitrarily mix together neighbouring axes of different sensors. In our experiments, we evaluate the importance of sensor types and locations, thus S ranges from 1 (when only using one sensor of one smartwatch) to 6 (when using all sensors from both smartwatches). The choice of the input window length W, defined as , was crucial, especially when dealing with activities of different lengths. In general HAR, one might want to recognize long-running activities such as reading, but also detect short actions, such as taking a sip of water, which might require operating at different time scales (i.e., using multiple different window lengths). In our case, the differences in duration between the shortest (push-up) and longest exercise (burpee) are relatively small, which should allow for use of a single window size. We evaluated different choices for W, ranging from 100 to 1000 sensor samples (1 to 10 s).
Our neural network models are implemented with Keras [
36] using the Tensorflow [
37] backend. We use a batch size of 30, and train for a maximum of 100 epochs. For each batch, the input windows
are sampled independently and uniformly at random from the training data set. We use early stopping, where training is finished early if the test error does not decrease for a number of epochs. For training, we use stochastic gradient descent with a learning rate of 0.0001 to minimize the cross-entropy loss. We experimented with different optimizers, but did not find a significant difference in performance.
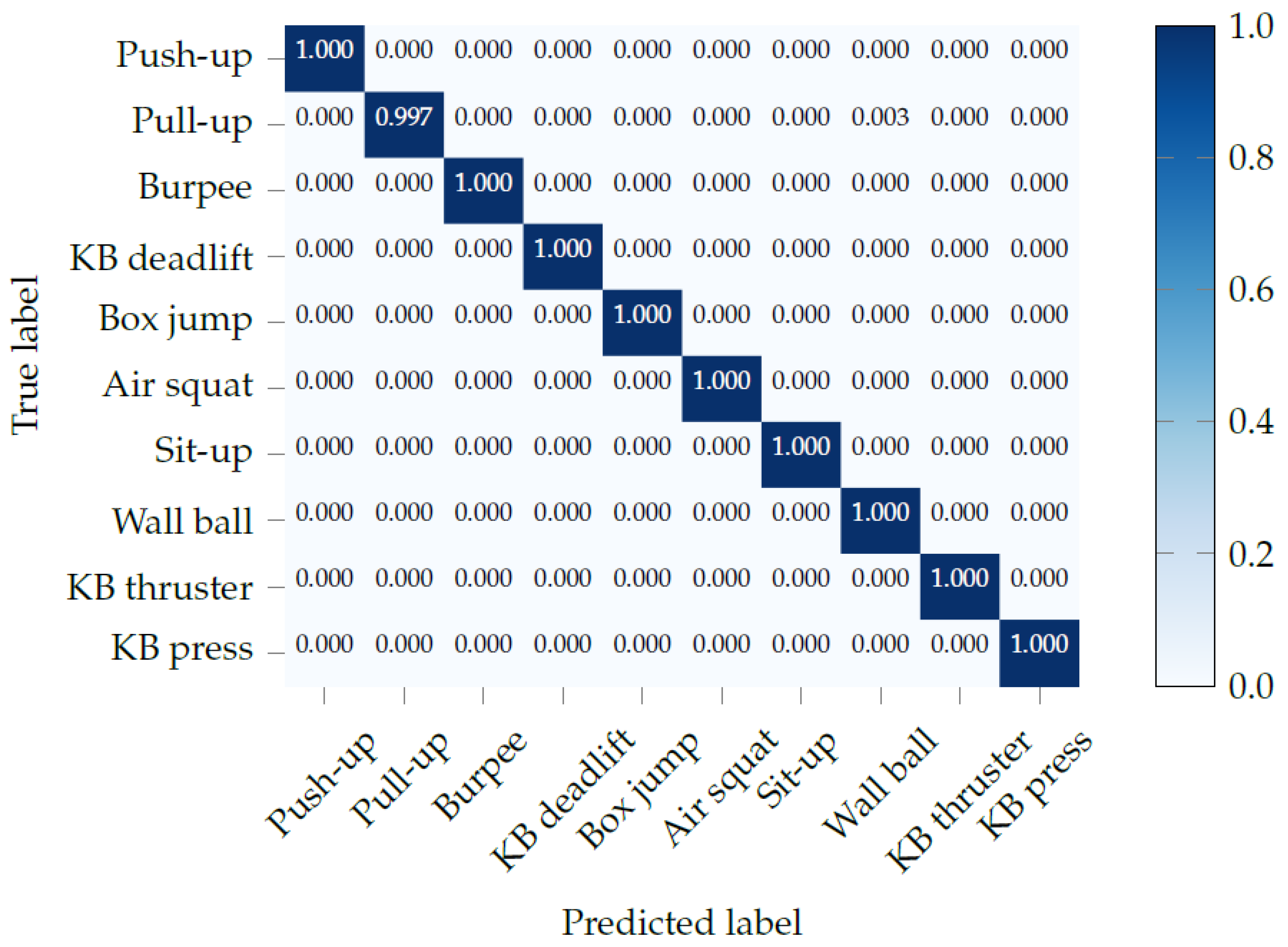
To evaluate the performance of our models we either use 5-fold cross validation with a 80/20 split for each fold, or leave-one-subject-out (LOSO) training. In both cases, we make sure that all exercises of each participant either end up in the training or the test set. In the case of 5-fold cross validation, only 5 models are trained, whereas, for LOSO, the number of trained models equals the number of participants, which was 51 in our case. Therefore, we only use LOSO for the repetition counting, where each model is effectively trained on only 1/10 of the training data, and we thus use LOSO to get a more robust estimate of the model performance and maximize the amount of available training data.
Note that we do not use a separate validation set for tuning the hyper-parameters, as is standard in machine learning for most supervised learning tasks. One of the biggest challenges we are facing is that, even though our data set contains a relatively large amount of data (13,800 s, 5461 repetition), the data of any given participant is highly correlated. Therefore, data from one participant must entirely be either in the train or in the test set. This is different to most supervised learning settings, where the train and test sets are uniformly sampled from the entire data set. Assume we were to use a standard 80/20 train/test split (and then split the train set again into train/validation). This would mean assigning all the data from 40 participants to the train set, and the data from the remaining 10 participants to the test set. If we, now, train a single model and test it on this particular test set, the resulting performance estimate would be highly dependent on which 10 individuals were assigned to the test set. For example, let us assume we have two groups of participants that are quite different from one another (e.g., 40 beginners and 10 advanced athletes). If, by chance, the 10 advanced participants end up in the test set, the performance on the test set will likely be low, because the model never saw advanced athletes during training. This is, of course, a simplified example, but it shows that, in order to get a robust estimate of performance, it is necessary to average over many possible choices of train/test splits. This is why we perform 5-fold cross validation, and even LOSO training for the case of repetition counting, in order to get a performance estimate that is independent of the particular choice for the train/test split. If we, now, wanted to use a validation set for hyper-parameter tuning in order to avoid overfitting the hyper-parameters on the test set, we would additionally need to split every train set into separate train and validation sets. The same reasoning as above applies (i.e., we need to consider many such train/validation splits in order to get robust performance estimates for each hyper-parameter setting). Therefore, we would need to perform nested k-fold cross-validation, which, for a choice of , would result in having to train 25 models for a single hyper-parameter setting. Clearly, this becomes prohibitive even for small search grids, especially since we would need to perform this process a total of 11 times (once for the recognition model, 10 times for the repetition counting models).
In order to reduce the risk of overfitting hyper-parameters on the test set, we only perform minimal hyper parameter tuning. We start with a sensible architecture, based on which we perform a limited grid search. We want to emphasize that many hyper-parameter combinations perform almost equally well across the data from all participants. Therefore, we conclude that it is unlikely that we significantly over-estimate the generalization performance.
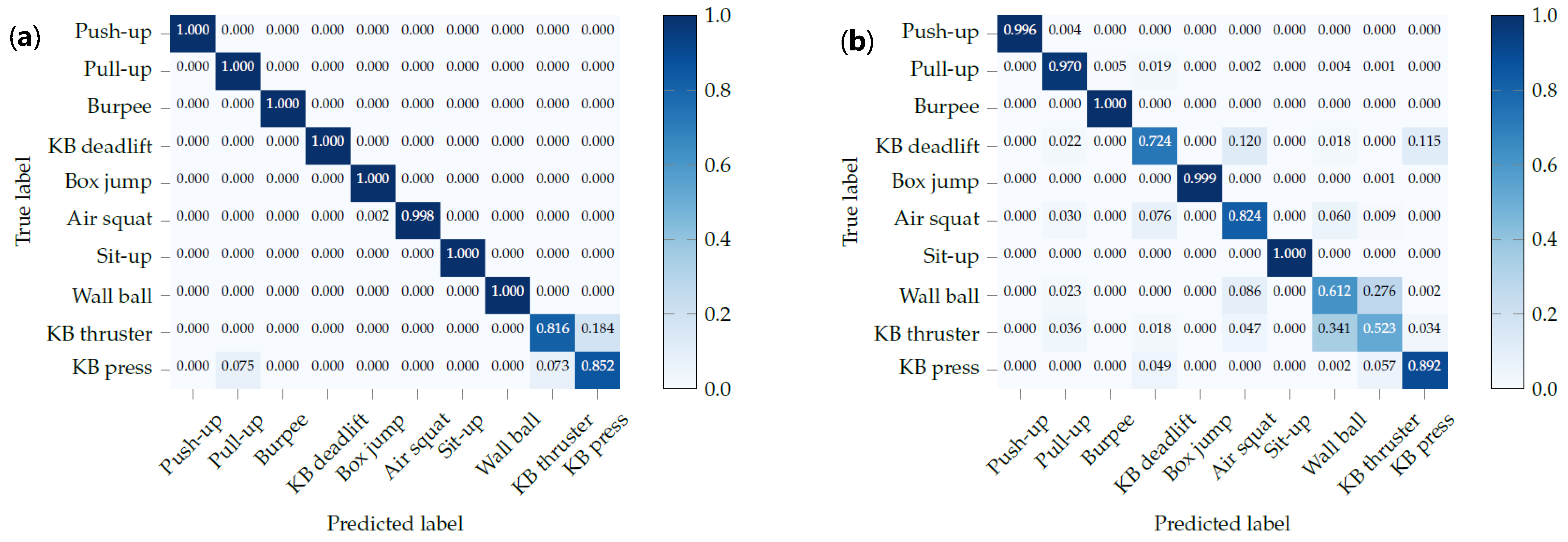
4.2. Exercise Recognition
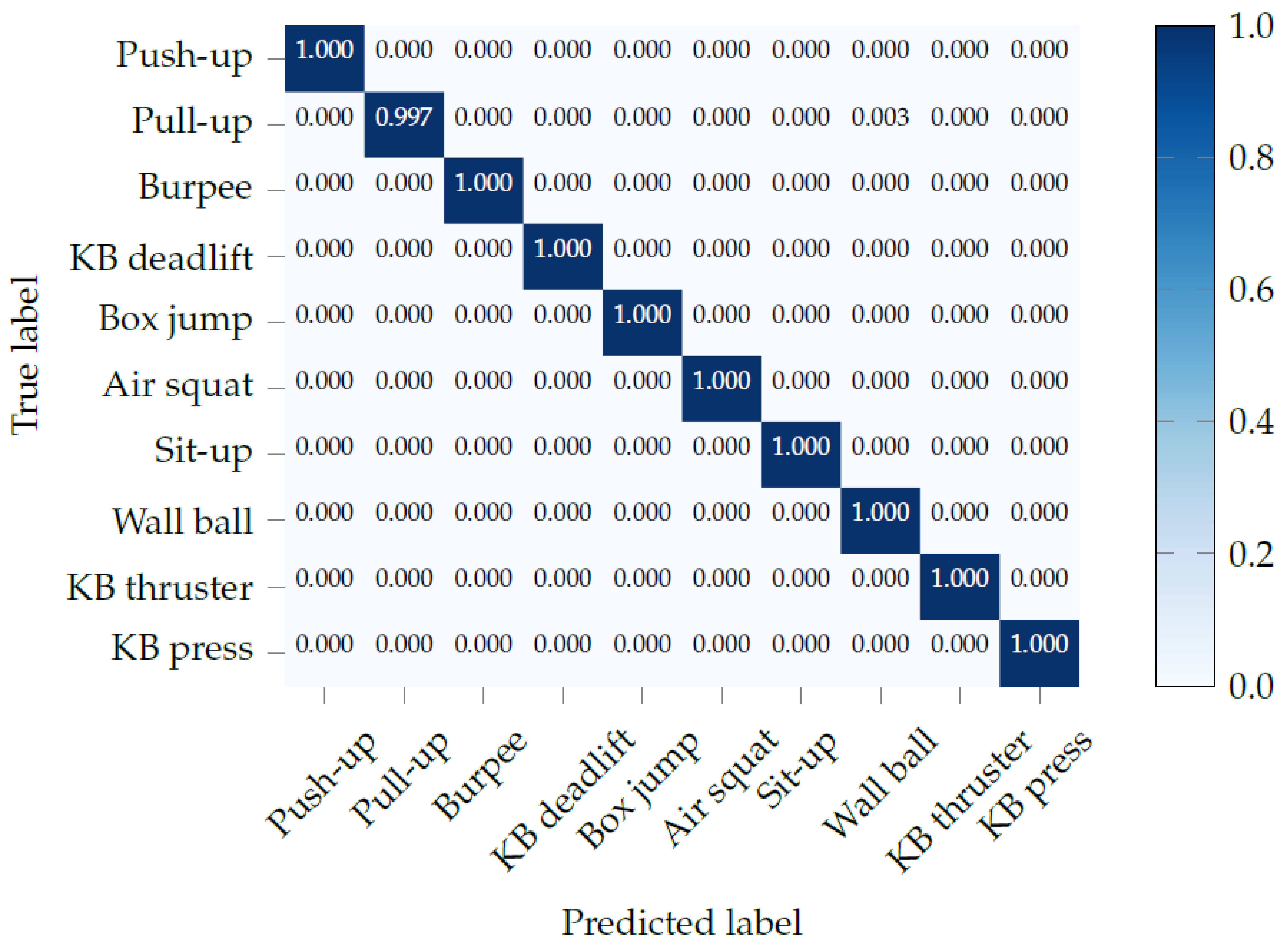
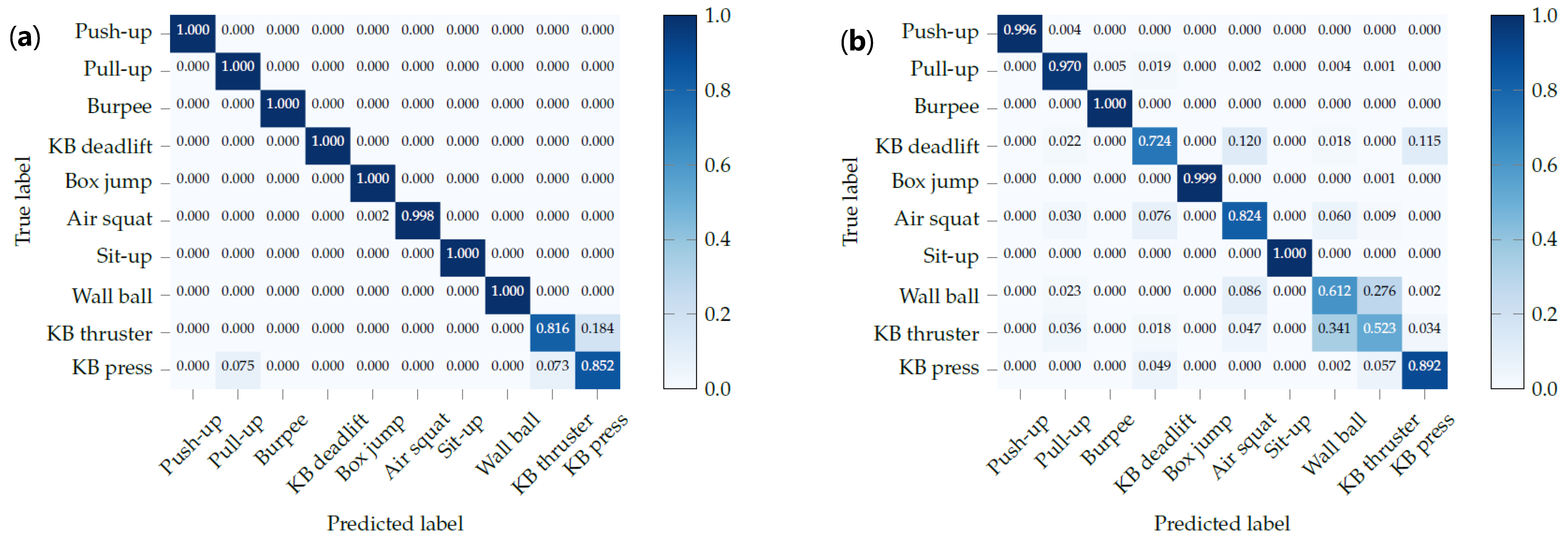
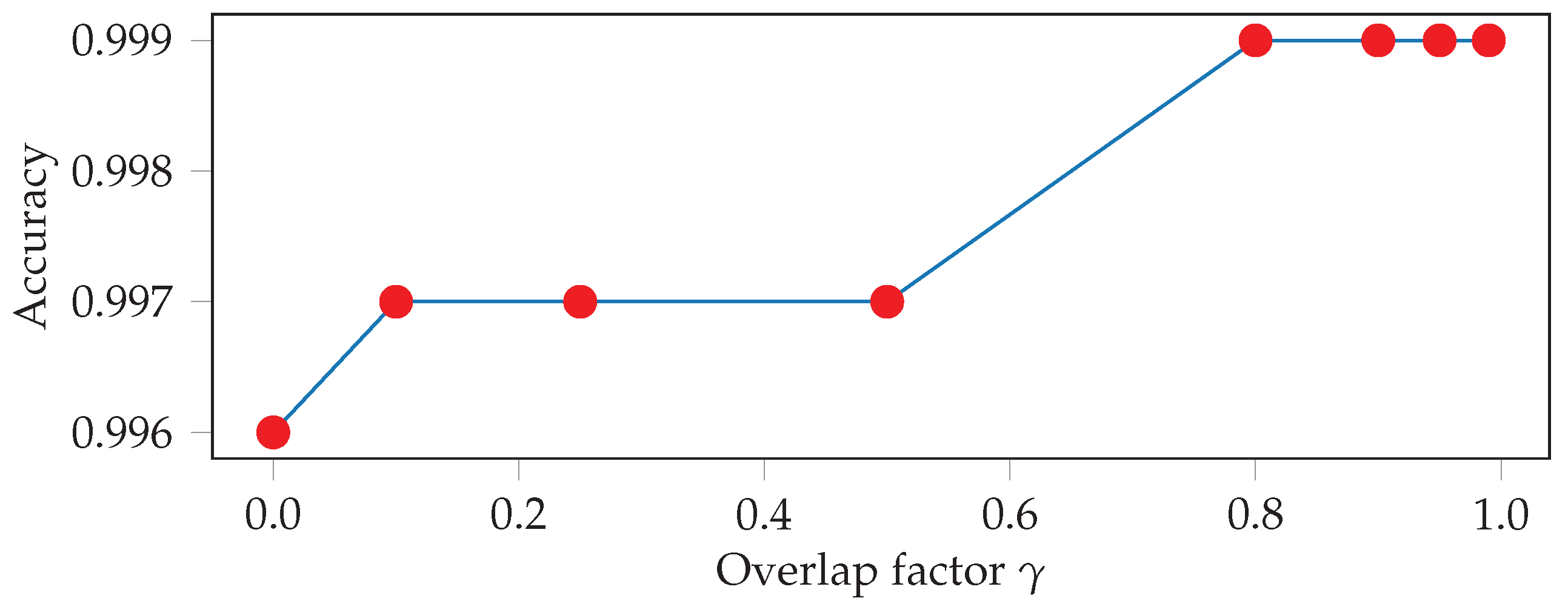
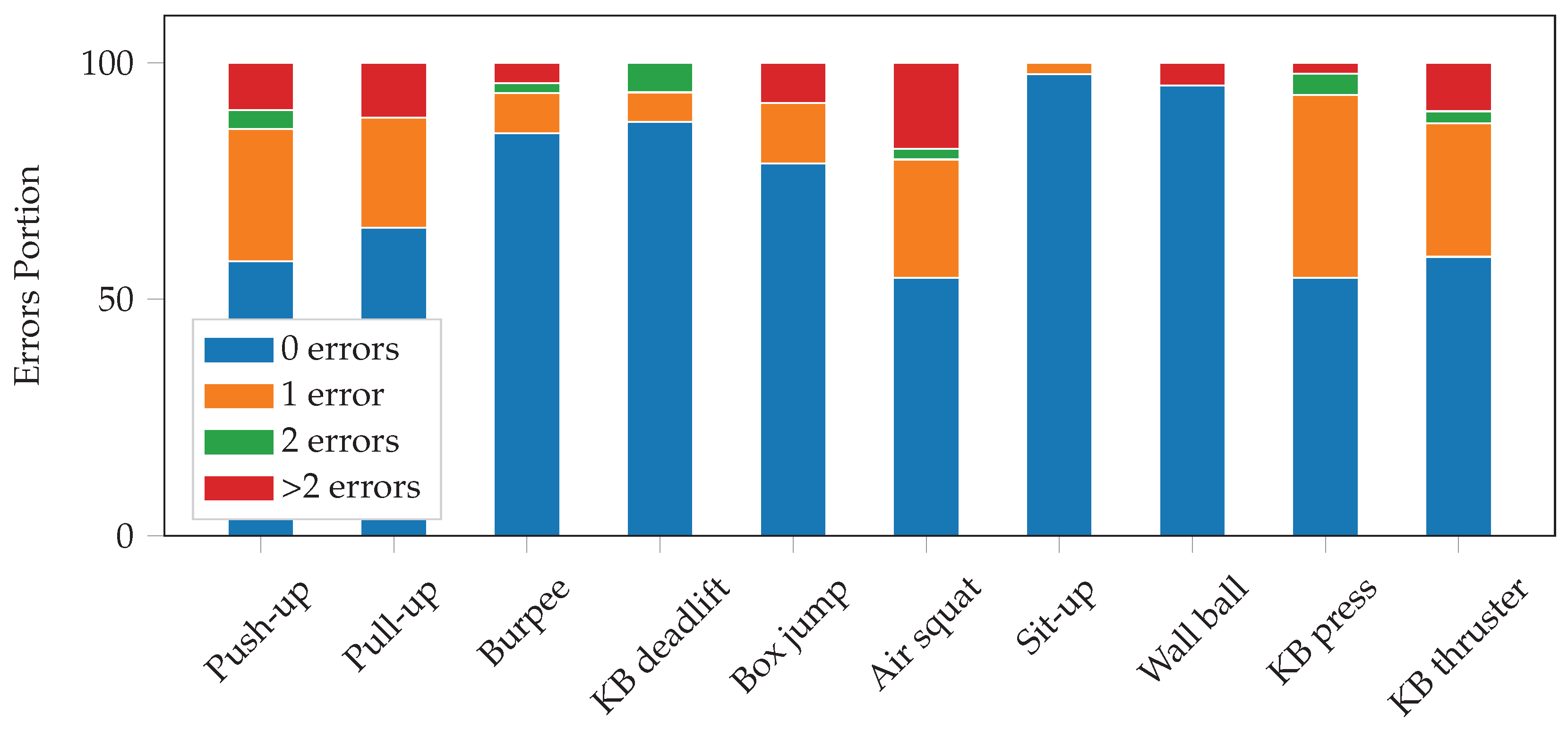
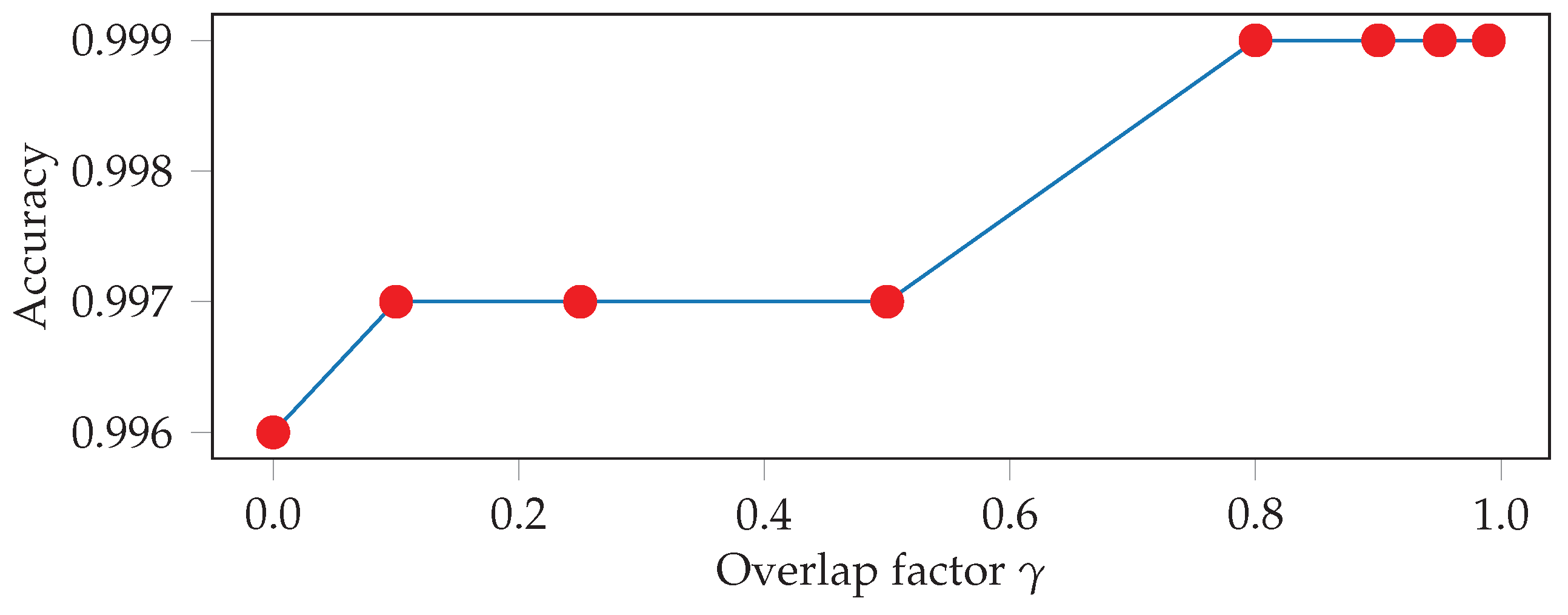
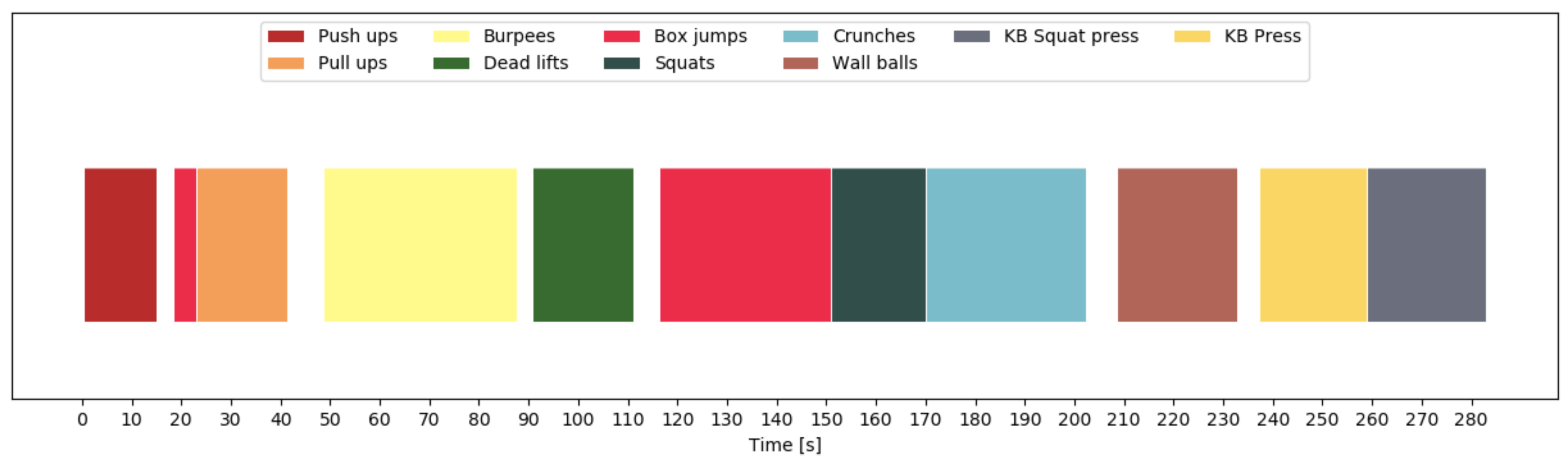
For exercise recognition, each input window is labeled with one of the 10 exercises, and the neural network tries to predict the correct label. For the unconstrained workout data, there is an additional label for the null class. During test time, we overlap consecutive windows by a factor of , with 0 ≤ γ < 1. If is greater than zero, we use majority voting to get a single prediction for each point in time. Intuitively, the larger the overlap, the more accurate and robust the final predictions should be. The output of the neural network is a sequence of predicted exercise labels with , and where denotes that exercise is predicted at time t. In order to further improve the final results, we smooth the predicted sequence. We, first, look up the minimum repetition duration for each exercise in our data set, which is equal to the shortest vibration-interval for that exercise used during data collection. We, then, go through the output of the neural network and find all sequences of the form , where . For each of these sequences, we then replace with if the duration of is shorter than .
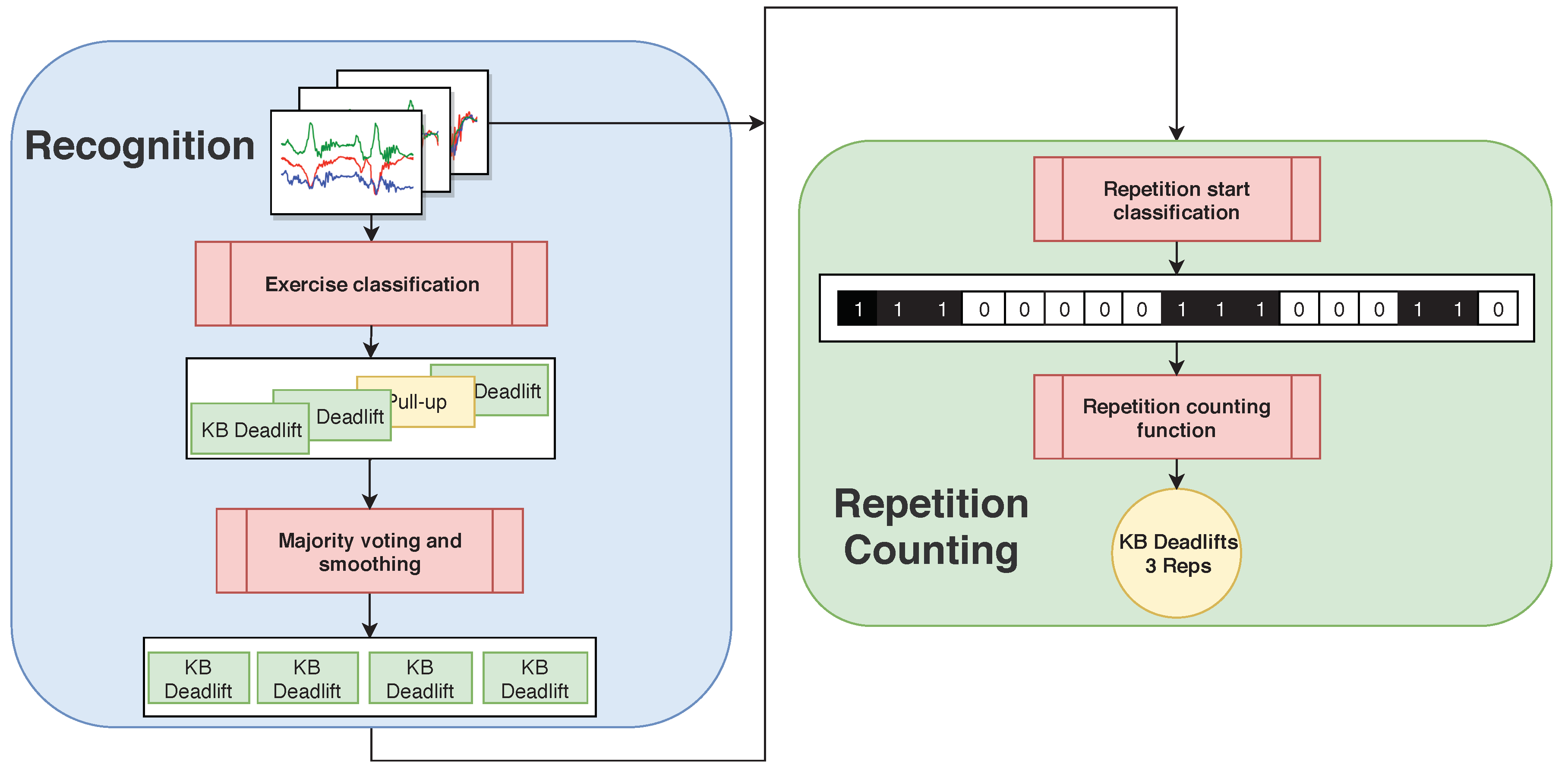
4.3. Repetition Counting
Since we have used a vibration signal during data collection that signals the start of each repetition, we obtain labels for the beginnings of repetitions. We then train a neural network to recognize whether an input window contains a repetition start. As explained in
Section 4.1, we use the same basic architecture as for exercise recognition. In contrast to exercise recognition, where we use a single window size, we use a separate window size for each exercise. The length of the window for exercise
is set to the shortest vibration-interval
. This ensures that one window will never fully contain two repetition beginnings. We, then, define the start of a repetition as the first
samples after the vibration signal. We label the input windows
with 1 if and only if the entire start of the repetition is contained in
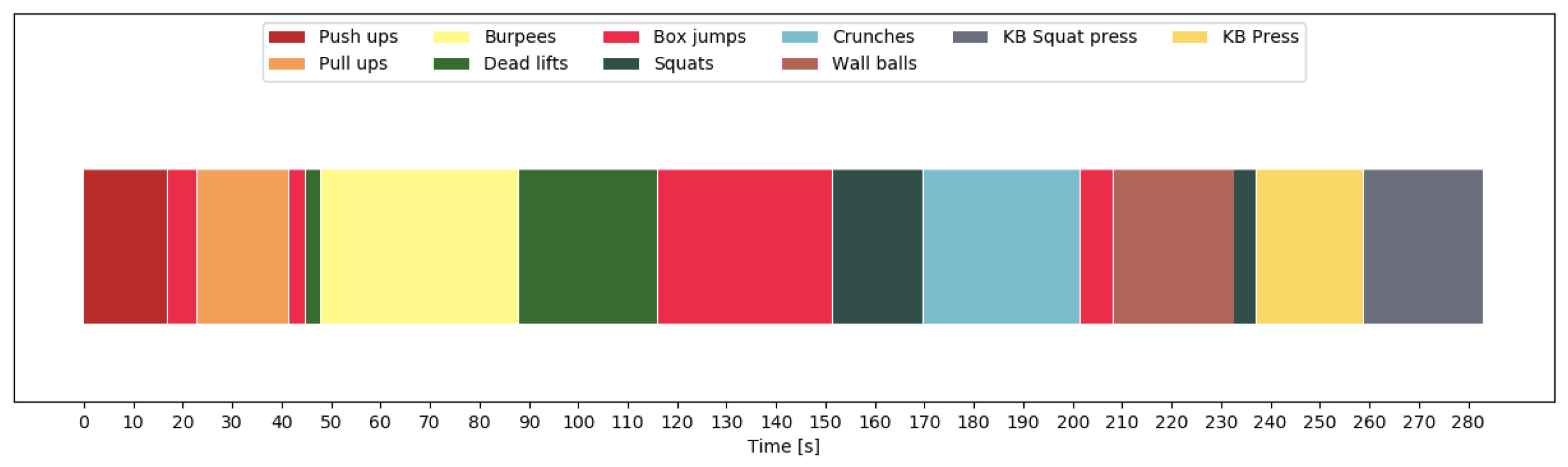
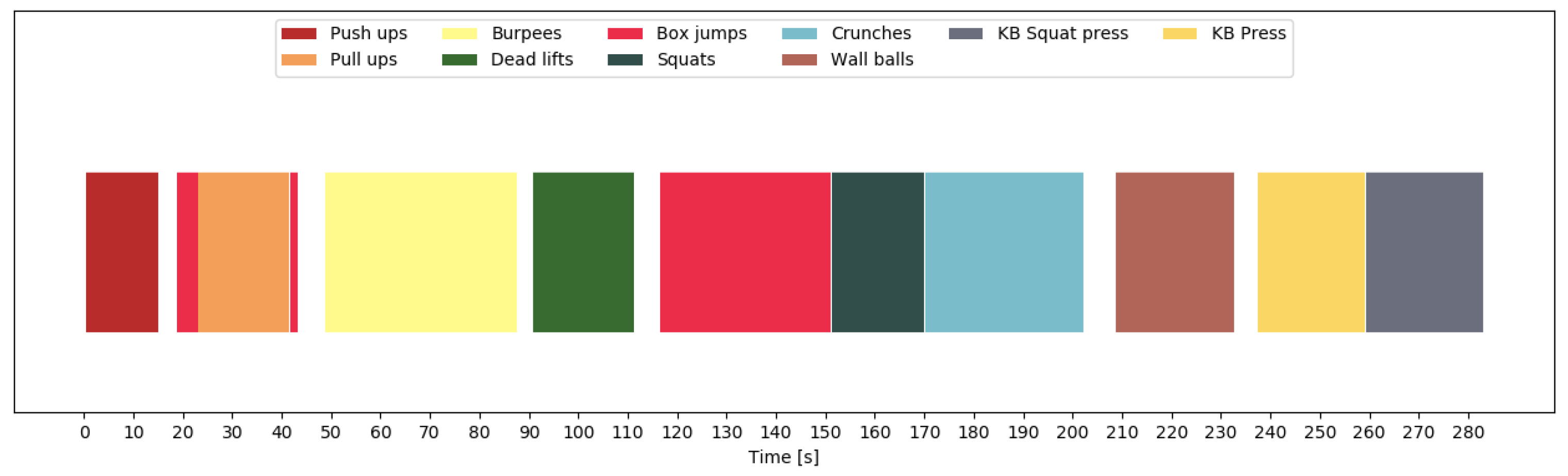
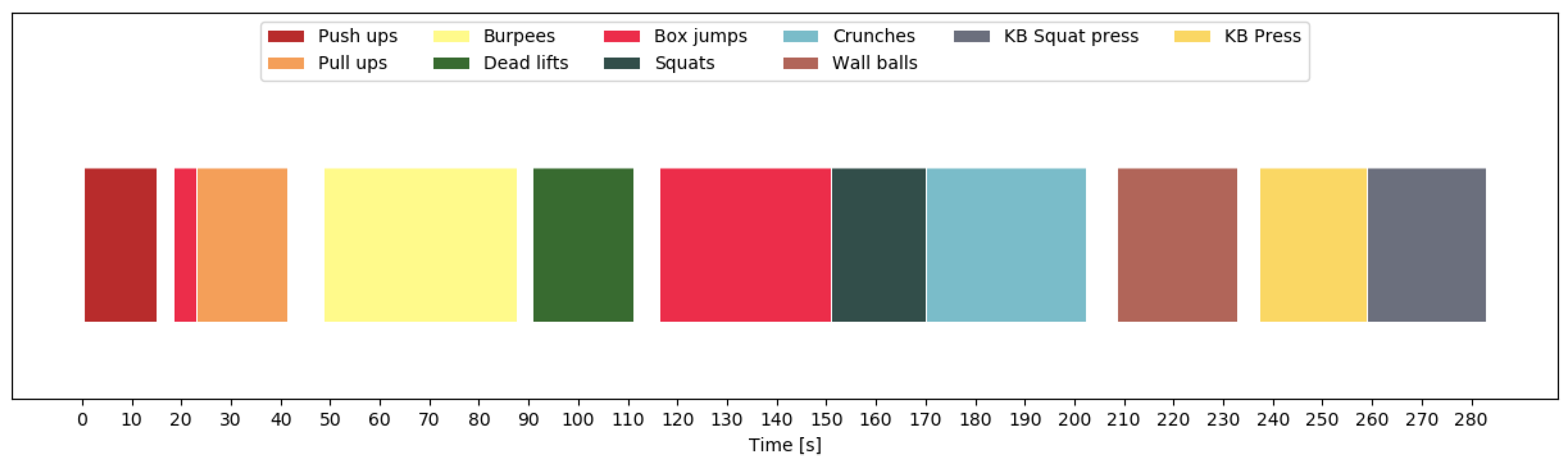
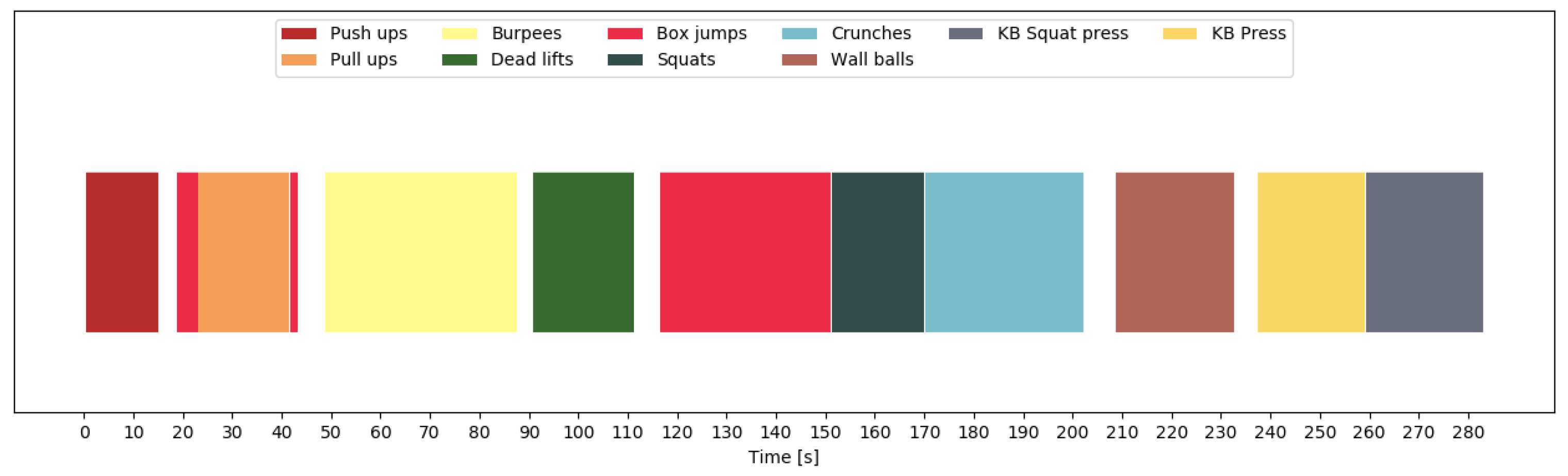
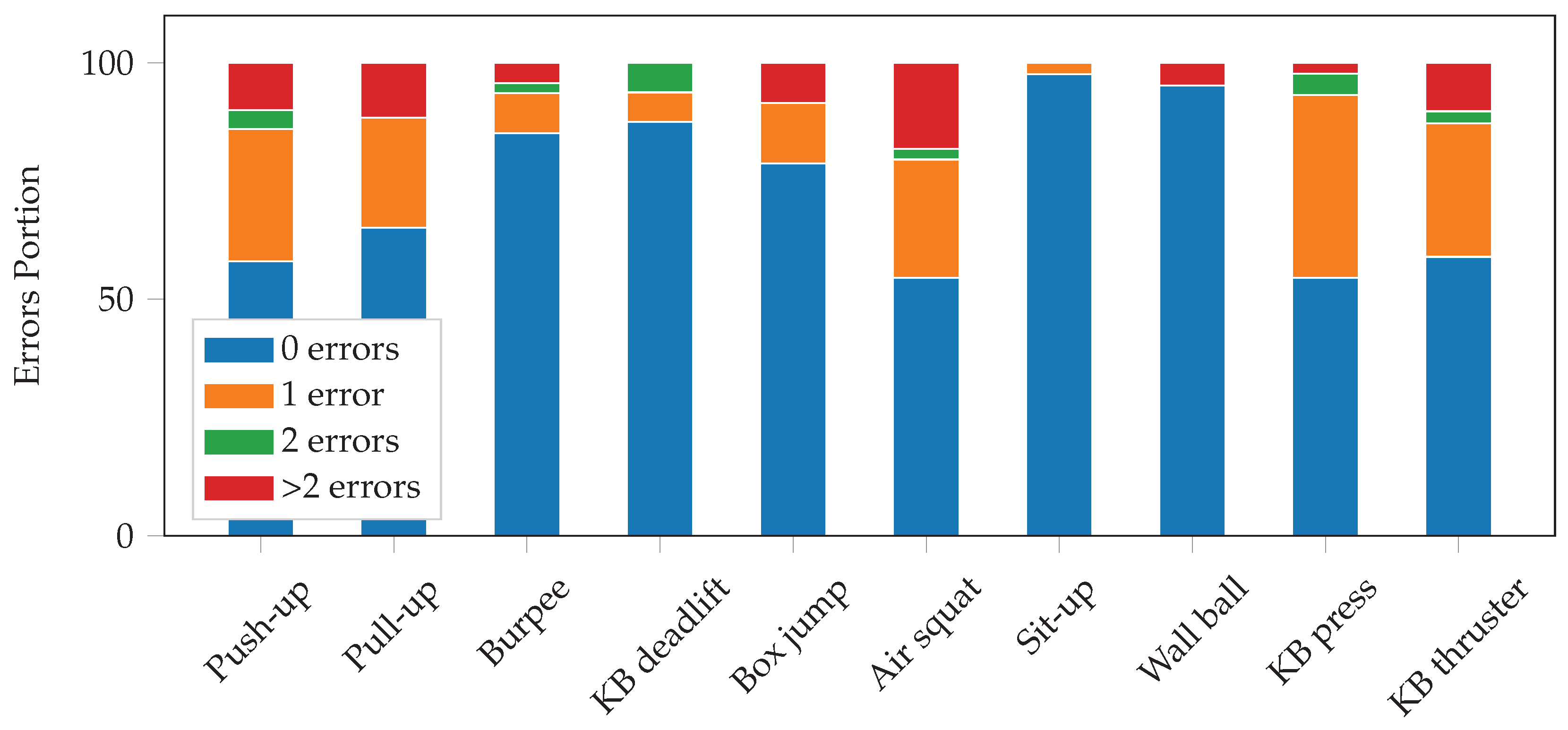
, and with 0 otherwise. Thus, the problem of counting repetitions is reduced to a binary classification problem. The output of the repetition counting network is a binary sequence (e.g., as in
Figure 4). If the network output was perfect, counting the number of 1-sequences would yield the repetition count. However, as this is not always the case and many errors can be easily recognized by inspection, we further smooth the binary sequence to improve the results. Thus, we first determine the repetition mode
by finding the most frequent 1-sequence length. This gives us a good estimate of how many consecutive 1’s constitute an actual repetition. We, then, find all 1-sequences that are shorter than
and mark them as candidates for removal. All 1-sequences of length at least
are considered as confirmed repetition starts. We, then, determine the repetition mode
of the 0-sequences in the same manner. For each of the candidates, we check if they are at realistic distances from a confirmed repetition start and, if not, we set that candidate to 0. We define a candidate as realistic if there is no confirmed repetition starting
before and after it. Finally, we count the remaining 1-sequences, which yields the repetition count.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}