High Level 3D Structure Extraction from a Single Image Using a CNN-Based Approach



Abstract
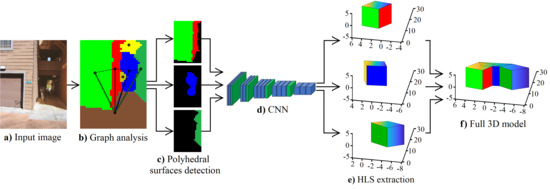
1. Introduction
2. Related Work
2.1. HLS Extraction without Depth Estimation
2.2. HLS Extraction with Depth Estimation
3. The Proposed Method
3.1. Depth Analysis
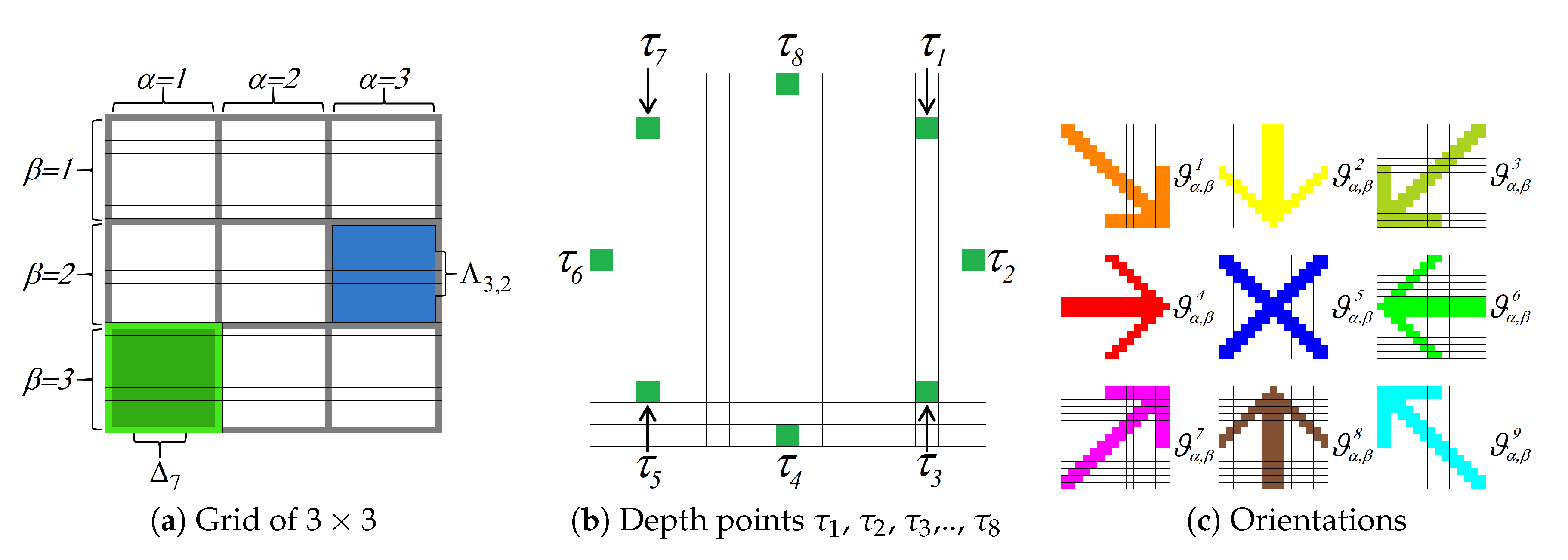
3.1.1. Depth Sections
3.1.2. Semantic Orientation
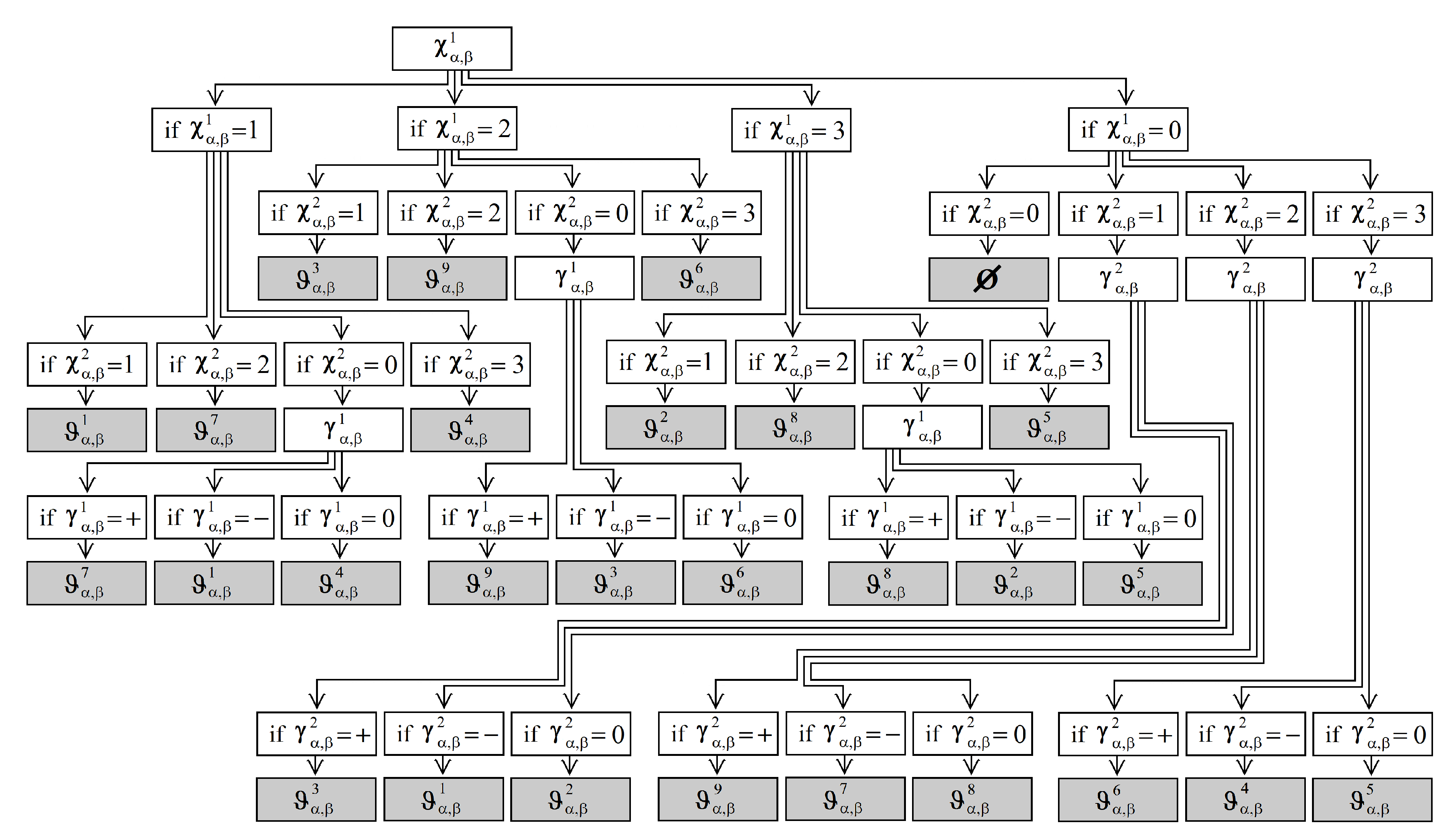
3.2. Orientation Segmentation
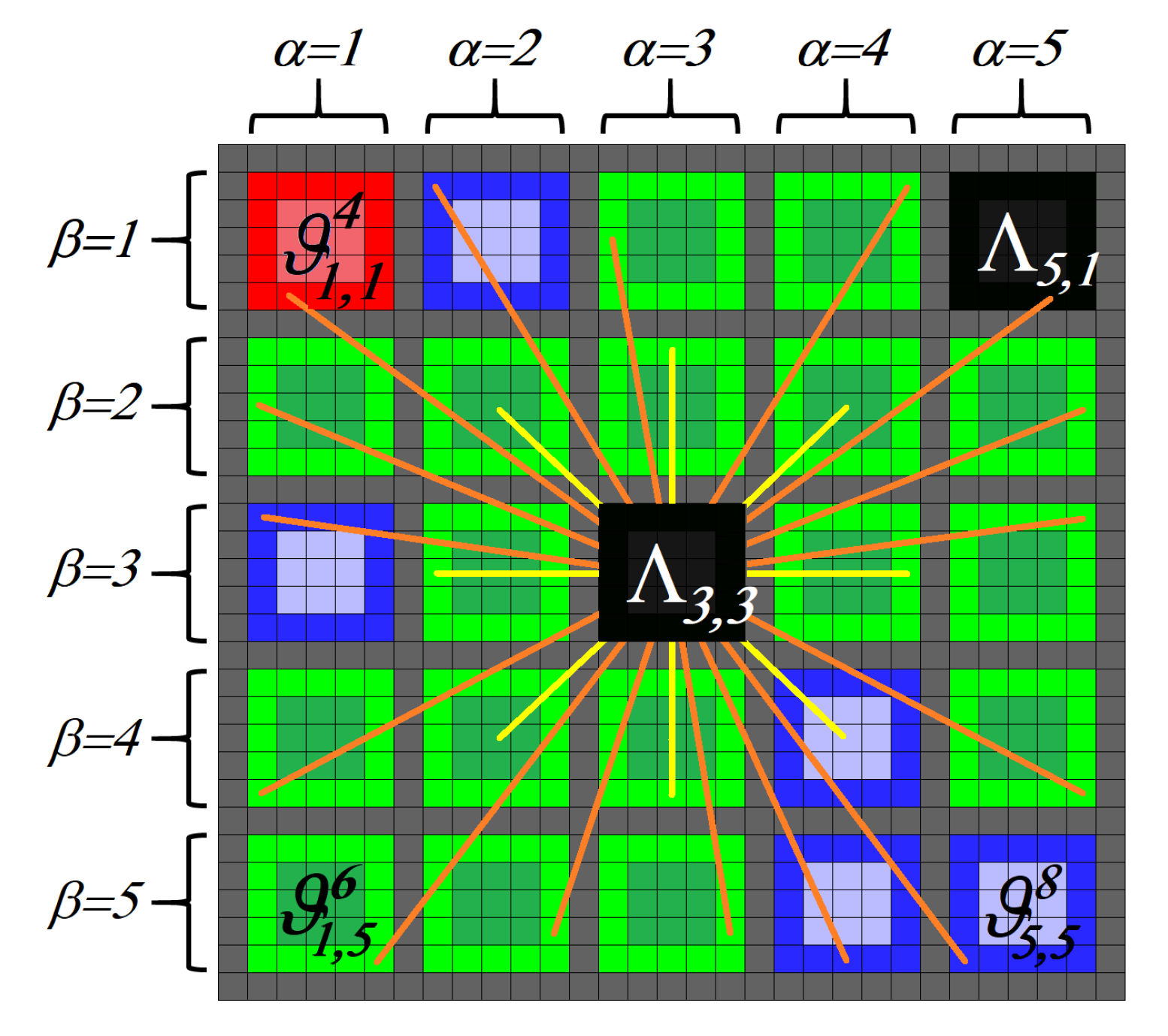
3.3. Graph Analysis
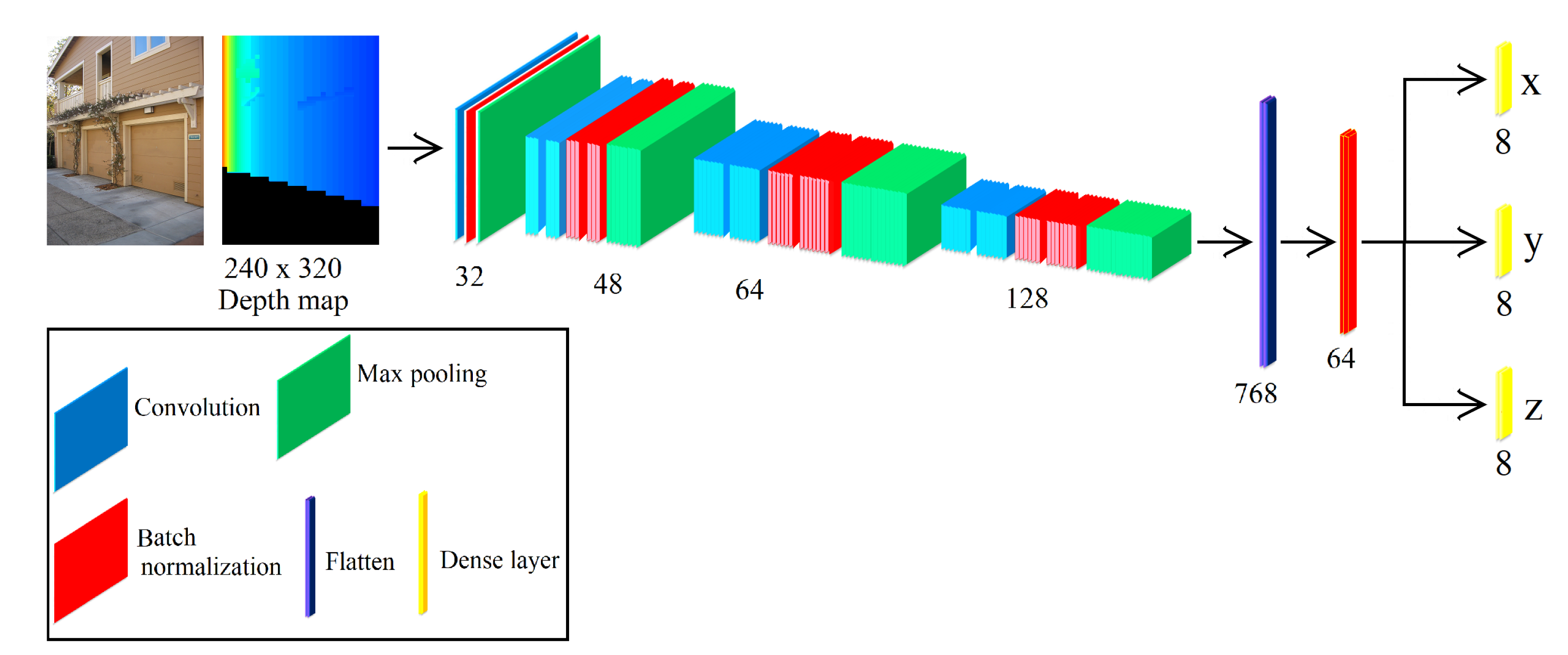
3.4. CNN for HLS Extraction
4. Discussion and Results
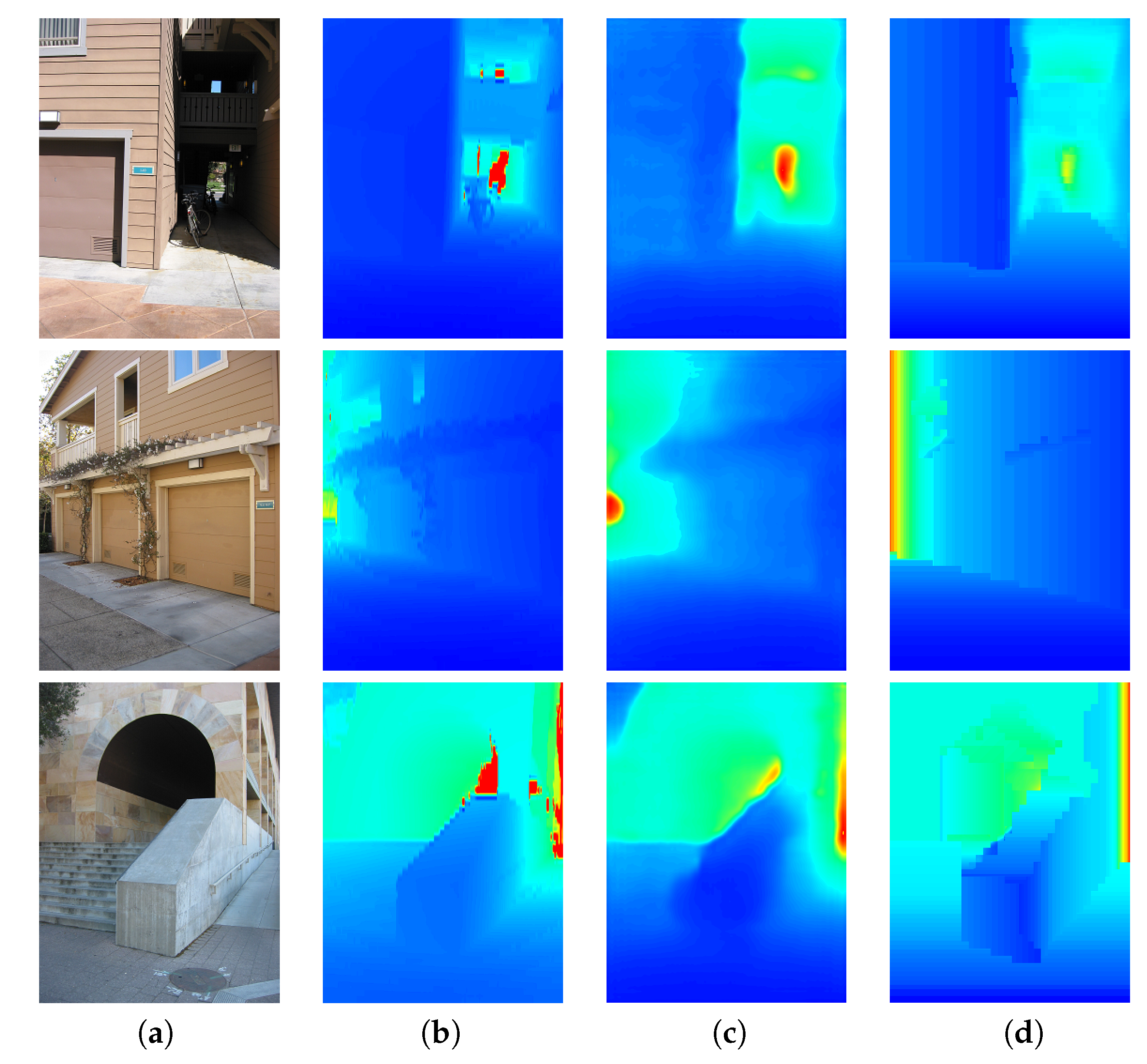
4.1. Depth Evaluation
4.2. Segmented Orientations Evaluation
4.3. HLS Extraction Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dani, A.; Panahandeh, G.; Chung, S.J.; Hutchinson, S. Image moments for higher-level feature based navigation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 602–609. [Google Scholar] [CrossRef]
- Osuna-Coutiño, J.A.D.J.; Cruz-Martínez, C.; Martinez-Carranza, J.; Arias-Estrada, M.; Mayol-Cuevas, W. I Want to Change My Floor: Dominant Plane Recognition from a Single Image to Augment the Scene. In Proceedings of the 2016 IEEE International Symposium on Mixed and Augmented Reality (ISMAR-Adjunct), Merida, Mexico, 19–23 September 2016; pp. 135–140. [Google Scholar] [CrossRef]
- Li, W.; Song, D. Toward featureless visual navigation: Simultaneous localization and planar surface extraction using motion vectors in video streams. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 9–14. [Google Scholar] [CrossRef]
- Vosselman, G.; Dijkman, S. 3D building model reconstruction from point clouds and ground plans. In Proceedings of the International Society for Photogrammetry and Remote Sensing (ISPRS), Annapolis, MD, USA, 22–24 October 2001; pp. 37–43. [Google Scholar]
- Gee, A.; Chekhlov, A.; Calway, A.; Mayol-Cuevas, W. Discovering Higher Level Structure in Visual SLAM. IEEE Trans. Robot. 2008, 24, 980–990. [Google Scholar] [CrossRef]
- Bartoli, A.; Sturm, P. Constrained Structure and Motion From Multiple Uncalibrated Views of a Piecewise Planar Scene. Int. J. Comput. Vis. (IJCV) 2003, 52, 45–64. [Google Scholar] [CrossRef]
- Silveira, G.F.; Malis, E.; Rives, P. Real-time robust detection of planar regions in a pair of images. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 49–54. [Google Scholar] [CrossRef]
- Gee, A.; Chekhlov, D.; Mayol, W.; Calway, A. Discovering planes and collapsing the state space in visual SLAM. Br. Mach. Vis. Conf. (BMVC) 2007, 6–12. [Google Scholar] [CrossRef]
- Aguilar-González, A.; Arias-Estrada, M.; Berry, F. Depth from a Motion Algorithm and a Hardware Architecture for Smart Cameras. Sensors 2019, 19, 53. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Fang, Z. Direct Depth SLAM: Sparse Geometric Feature Enhanced Direct Depth SLAM System for Low-Texture Environments. Sensors 2018, 18, 3339. [Google Scholar] [CrossRef] [PubMed]
- Firman, M.; Mac Aodha, O.; Julier, S.; Brostow, G.J. Structured prediction of unobserved voxels from a single depth image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5431–5440. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. 3D Convolutional Neural Networks for Landing Zone Detection from LiDAR. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 3471–3478. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, W.T.; Tenenbaum, J.B. Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Recovering surface layout from an image. Int. J. Comput. Vis. 2007, 75, 151–172. [Google Scholar] [CrossRef]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3D: Learning 3D Scene Structure from a Single Still Image. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 824–840. [Google Scholar] [CrossRef] [PubMed]
- Haines, O.; Calway, A. Recognising planes in a single image. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1849–1861. [Google Scholar] [CrossRef] [PubMed]
- Hoiem, D.; Efros, A.A.; Hebert, M. Geometric context from a single image. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; pp. 654–661. [Google Scholar] [CrossRef]
- Kosecká, J.; Zhang, W. Extraction, matching, and pose recovery based on dominant rectangular structures. Comput. Vis. Image Understand. 2005, 100, 274–293. [Google Scholar] [CrossRef]
- Micusik, B.; Wildenauer, H.; Kosecka, J. Detection and matching of rectilinear structures. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1063–6919. [Google Scholar] [CrossRef]
- McClean, E.; Cao, Y.; McDonald, J. Single Image Augmented Reality Using Planar Structures in Urban Environments. In Proceedings of the 2011 Irish Machine Vision and Image Processing Conference, Dublin, Ireland, 7–9 September 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Haines, O.; Calway, A. Estimating Planar Structure in Single Images by Learning from Examples. In Proceedings of the International Conference on Pattern Recognition Applications and Methods (ICPRAM), Algarve, Portugal, 6–8 February; pp. 289–294.
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. Proc. Robot. Sci. Syst. 2018, 1–10. [Google Scholar] [CrossRef]
- Fan, H.; Su, H.; Guibas, L. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 1–12. [Google Scholar]
- Liu, M.; Salzmann, M.; He, X. Discrete-Continuous Depth Estimation from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 716–723. [Google Scholar] [CrossRef]
- Zhuo, W.; Salzmann, M.; He, X.; Liu, M. Indoor Scene Structure Analysis for Single Image Depth Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 614–622. [Google Scholar] [CrossRef]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Liu, X.; Wu, Y. Depth Reconstruction from Single Images Using a Convolutional Neural Network and a Condition Random Field Model. Sensors 2018, 18, 1318. [Google Scholar] [CrossRef] [PubMed]
- Cherian, A.; Morellas, V.; Papanikolopoulos, N. Accurate 3D ground plane estimation from a single image. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 2243–2249. [Google Scholar] [CrossRef]
- Rahimi, A.; Moradi, H.; Zoroofi, R.A. Single image ground plane estimation. IEEE Int. Conf. Image Process. (ICIP) 2013, 2149–2153. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar] [CrossRef]
- Sharma, A.; Grau, O.; Fritz, M. VConv-DAE: Deep Volumetric Shape Learning Without Object Labels. Eur. Conf. Comput. Vis. 2016, 9915, 236–250. [Google Scholar] [CrossRef]
- Ren, M.; Niu, L.; Fang, Y. 3D-A-Nets: 3D Deep Dense Descriptor for Volumetric Shapes with Adversarial Networks. arXiv, 2017; arXiv:1711.10108. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Comput. Vis. Pattern Recognit. 2015, 802–810. [Google Scholar]
- Chen, J.; Luo, D.-L.; Mu, F.-X. An improved ID3 decision tree algorithm. In Proceedings of the International Conference on Computer Science & Education, Nanning, China, 25–28 July 2009. [Google Scholar] [CrossRef]
- Norris, J.R. Markov Chains; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Bazarra, M.S.; Jarvis, J.; Sherali, H. Linear Programming and Networks Flow; John Wiley & Sons: New York, NY, USA, 1990. [Google Scholar]
- Saxena, A.; Chung, S.H.; Ng, A.Y. Learning Depth from Single Monocular Images. In Proceedings of the Advances in Neural Information Processing Systems 19 (NIPS 2006), Vancouver, BC, Canada, 4–9 December 2006. [Google Scholar]
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity Invariant CNNs. In Proceedings of the International Conference on 3D Vision 2017, Qingdao, China, 10–12 October 2017. [Google Scholar]
- Howard, A.; Koenig, N. gazebosim.org; University of Southern California: Los Angeles, CA, USA, 2018. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Make3D | KITTI | |||
|---|---|---|---|---|
| Method | log10 | rms | log10 | rms |
| Saxena et al. [15] | 0.187 | - | - | 8.734 |
| DCCRF [24] | 0.134 | 12.60 | - | - |
| DCNF-FCSP [26] | 0.122 | 14.09 | 0.092 | 7.046 |
| ours | 0.119 | 13.20 | 0.086 | 6.805 |
| Orientation | Recall | Precision | F-Score |
|---|---|---|---|
| Down view | 0.865789 | 0.850642 | 0.858148 |
| Right view | 0.831157 | 0.929074 | 0.877392 |
| Front view | 0.933024 | 0.878332 | 0.904852 |
| Left view | 0.837613 | 0.962360 | 0.895663 |
| Upward view | 0.931210 | 0.920342 | 0.925744 |
| Average | 0.879758 | 0.908150 | 0.892359 |
| 3D Shape | Training | rms (x) | rms (y) | rms (z) | Average rms |
|---|---|---|---|---|---|
| Cube | 500 | 0.307791 | 0.974300 | 2.344010 | 1.208700 |
| 5000 | 0.168358 | 0.858216 | 1.155927 | 0.727500 | |
| 10,000 | 0.170676 | 0.492700 | 0.848051 | 0.503809 | |
| 17,500 | 0.176459 | 0.329077 | 0.667617 | 0.391051 | |
| 25,000 | 0.139411 | 0.332585 | 0.655419 | 0.375805 | |
| 33,000 | 0.135793 | 0.333141 | 0.589185 | 0.352706 | |
| Half cube | 500 | 0.293828 | 0.987950 | 2.265533 | 1.182437 |
| 5000 | 0.172247 | 0.799870 | 1.161913 | 0.711343 | |
| 10,000 | 0.171351 | 0.510368 | 0.835438 | 0.505719 | |
| 17,500 | 0.166451 | 0.315625 | 0.656397 | 0.379491 | |
| 25,000 | 0.145339 | 0.316189 | 0.663797 | 0.375108 | |
| 33,000 | 0.136711 | 0.305686 | 0.619623 | 0.354006 | |
| Horizontal rectangle | 500 | 0.331915 | 1.012385 | 2.452832 | 1.265710 |
| 5000 | 0.186942 | 0.766469 | 1.115302 | 0.689571 | |
| 10,000 | 0.199112 | 0.663864 | 0.765380 | 0.542785 | |
| 17,500 | 0.165131 | 0.677991 | 0.704600 | 0.515907 | |
| 25,000 | 0.164179 | 0.337327 | 0.645978 | 0.382494 | |
| 33,000 | 0.154344 | 0.299278 | 0.631273 | 0.361631 | |
| Vertical rectangle | 500 | 0.261852 | 0.963921 | 2.263405 | 1.163059 |
| 5000 | 0.176730 | 0.813496 | 1.190372 | 0.726866 | |
| 10,000 | 0.180218 | 0.743857 | 0.637044 | 0.520373 | |
| 17,500 | 0.156088 | 0.701990 | 0.693192 | 0.517090 | |
| 25,000 | 0.158378 | 0.321481 | 0.721955 | 0.400604 | |
| 33,000 | 0.168115 | 0.303499 | 0.613946 | 0.361853 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Osuna-Coutiño, J.A.d.J.; Martinez-Carranza, J. High Level 3D Structure Extraction from a Single Image Using a CNN-Based Approach. Sensors 2019, 19, 563. https://doi.org/10.3390/s19030563
Osuna-Coutiño JAdJ, Martinez-Carranza J. High Level 3D Structure Extraction from a Single Image Using a CNN-Based Approach. Sensors. 2019; 19(3):563. https://doi.org/10.3390/s19030563
Chicago/Turabian StyleOsuna-Coutiño, J. A. de Jesús, and Jose Martinez-Carranza. 2019. "High Level 3D Structure Extraction from a Single Image Using a CNN-Based Approach" Sensors 19, no. 3: 563. https://doi.org/10.3390/s19030563
APA StyleOsuna-Coutiño, J. A. d. J., & Martinez-Carranza, J. (2019). High Level 3D Structure Extraction from a Single Image Using a CNN-Based Approach. Sensors, 19(3), 563. https://doi.org/10.3390/s19030563