Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network



Abstract
1. Introduction
2. Materials and Methods
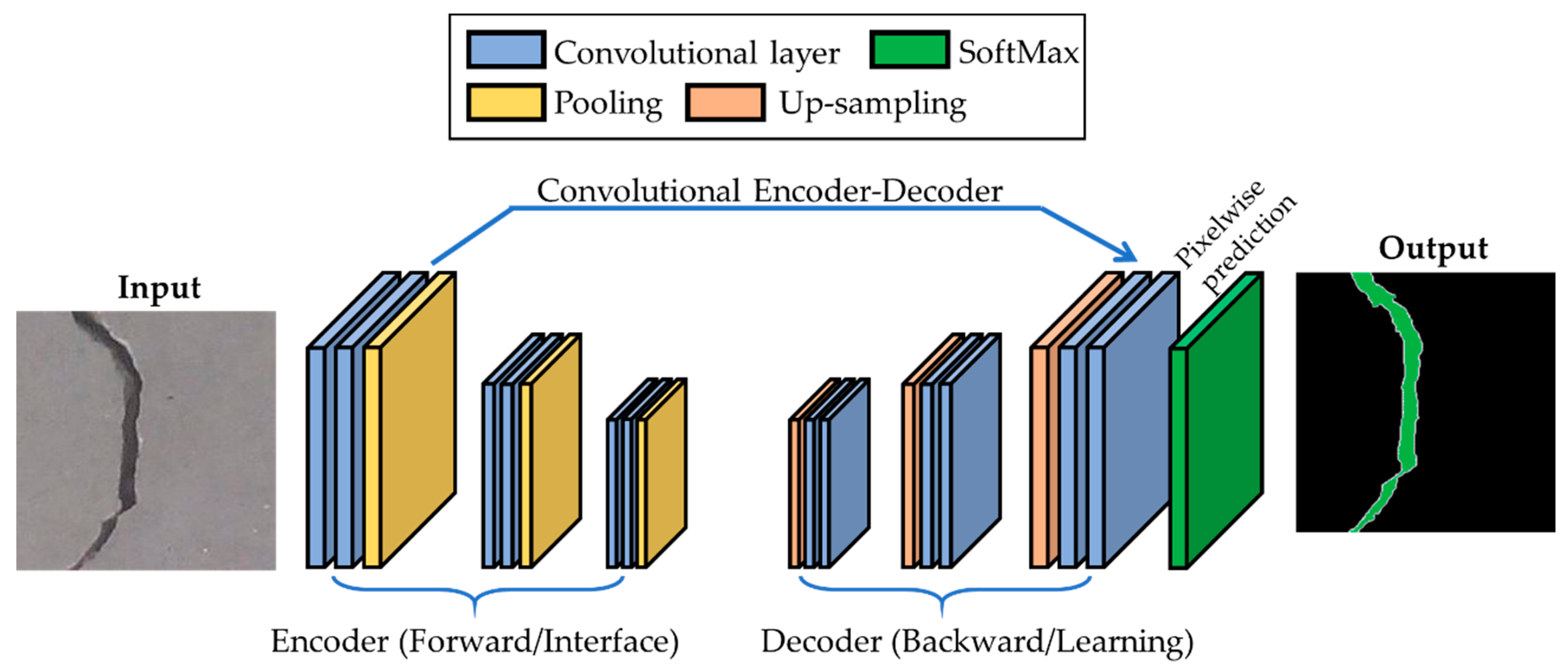
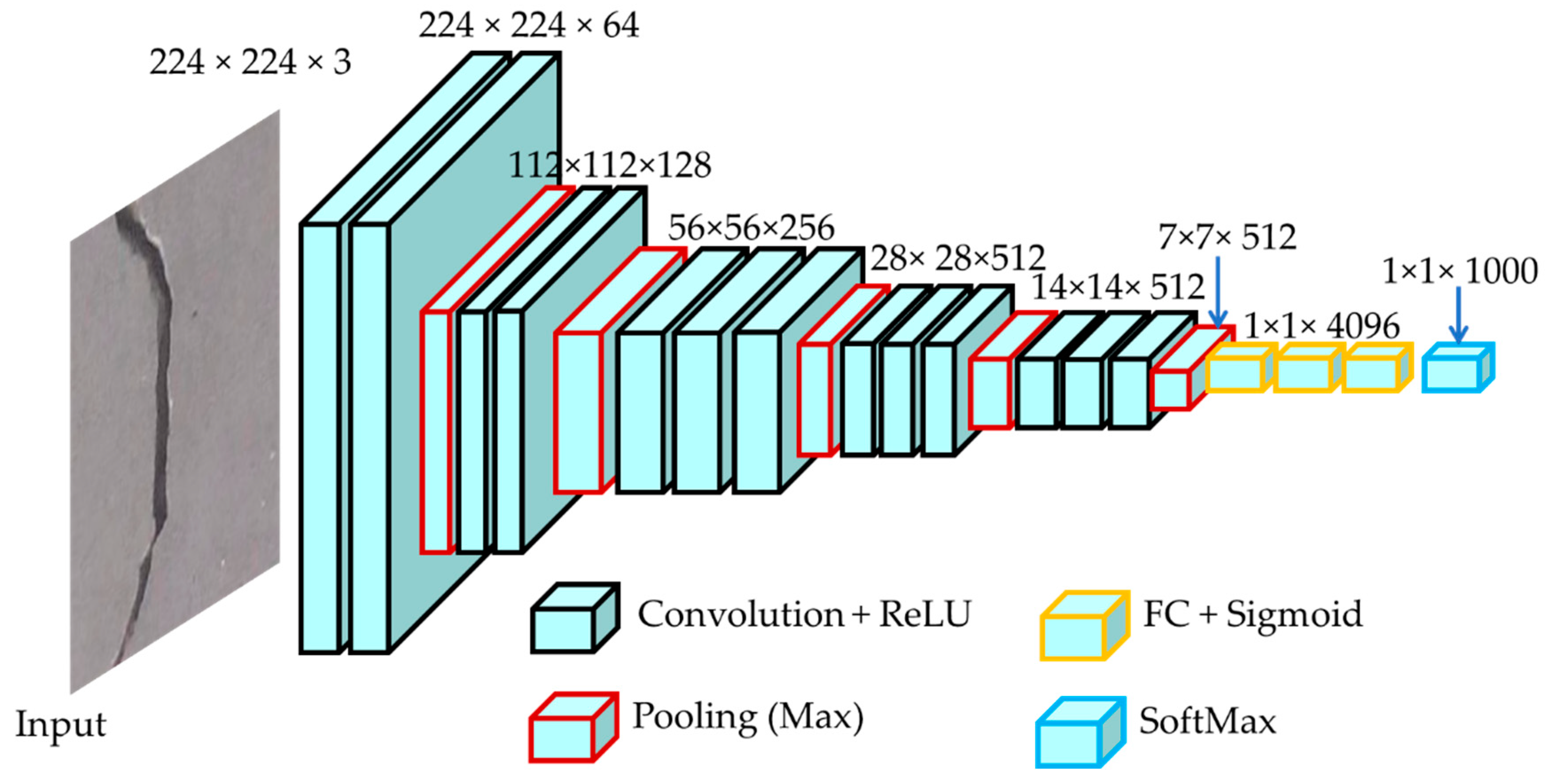
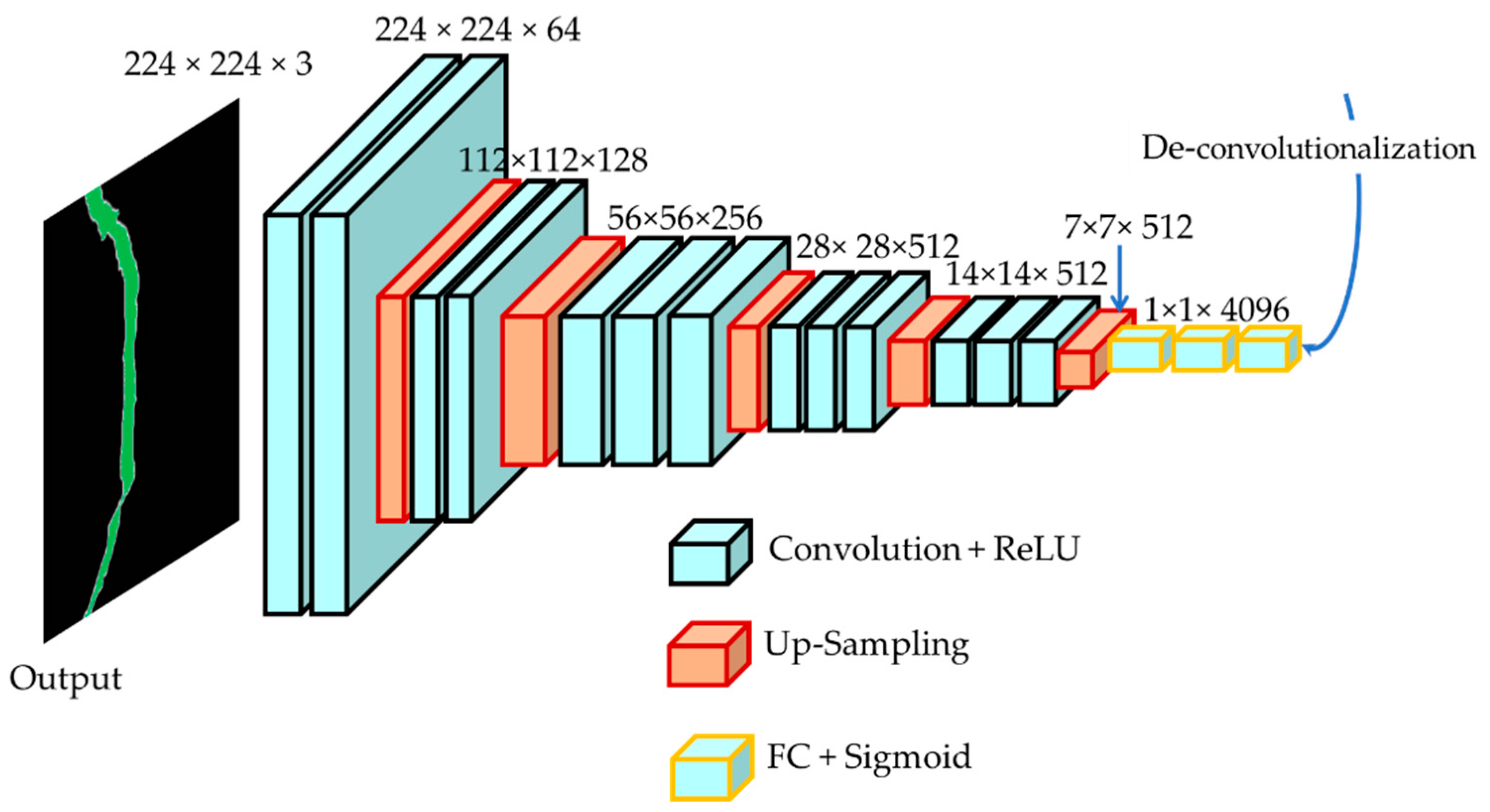
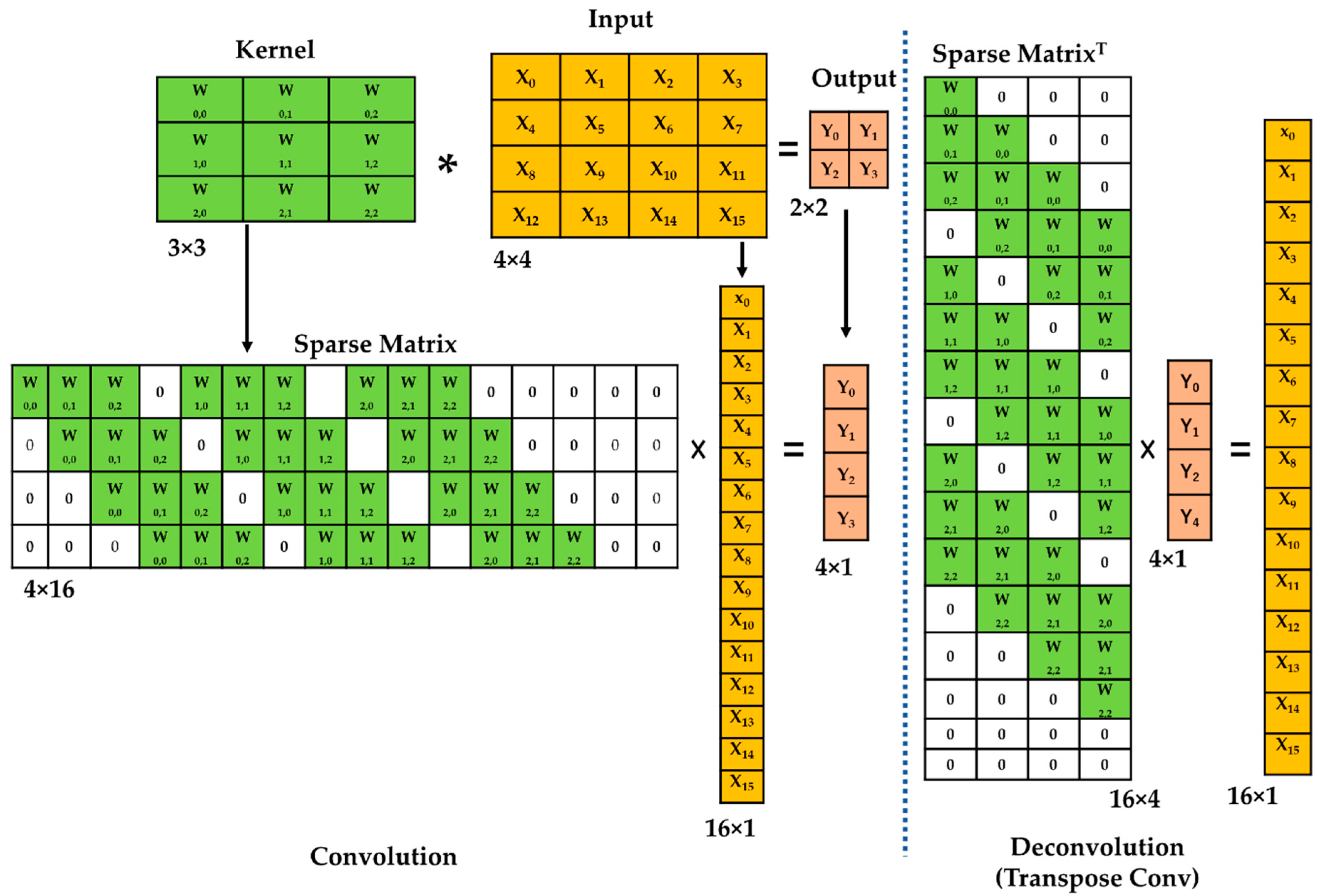
2.1. Proposed FCN Architecture for Crack Classification
2.1.1. Encoder Network
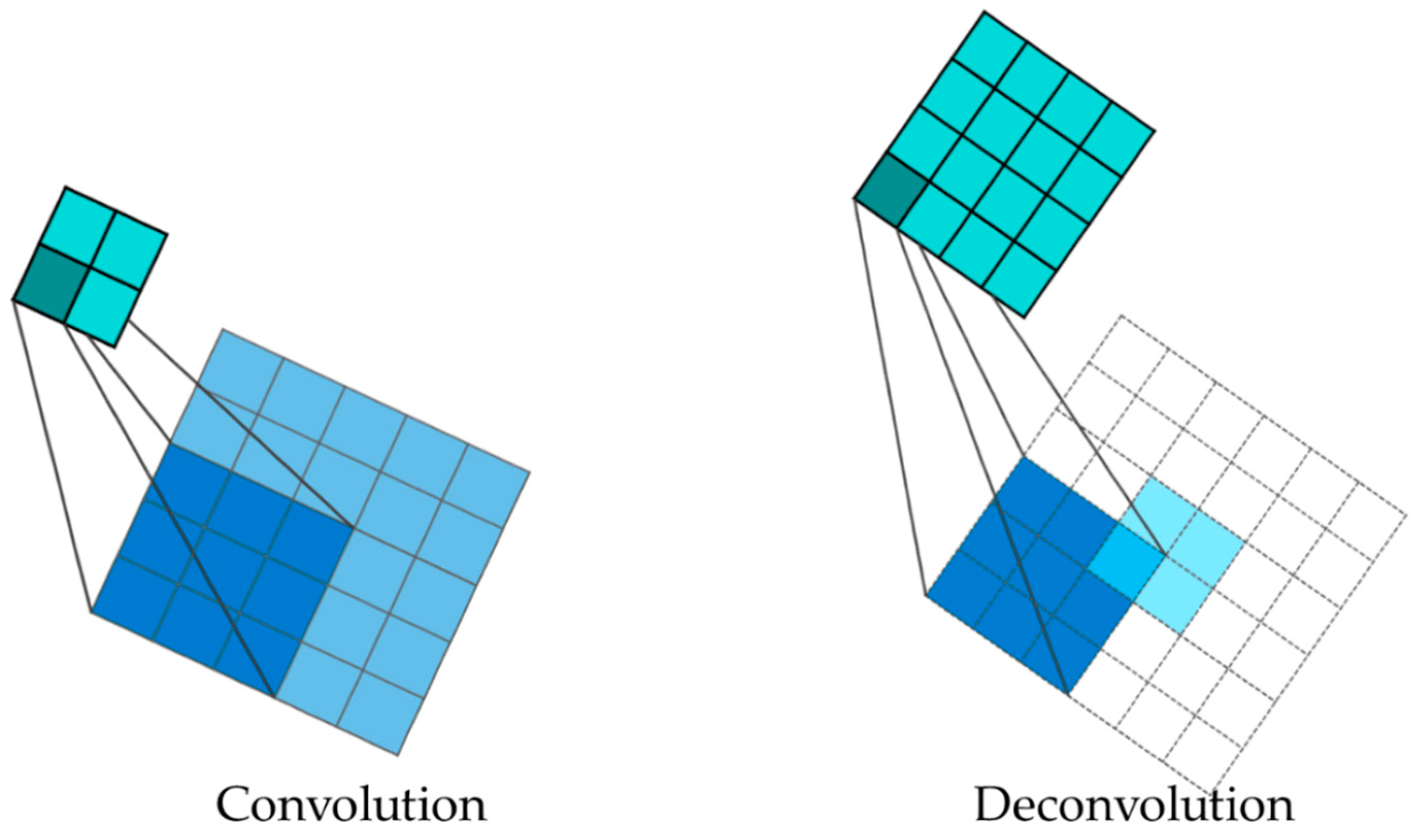
2.1.2. Decoder Network
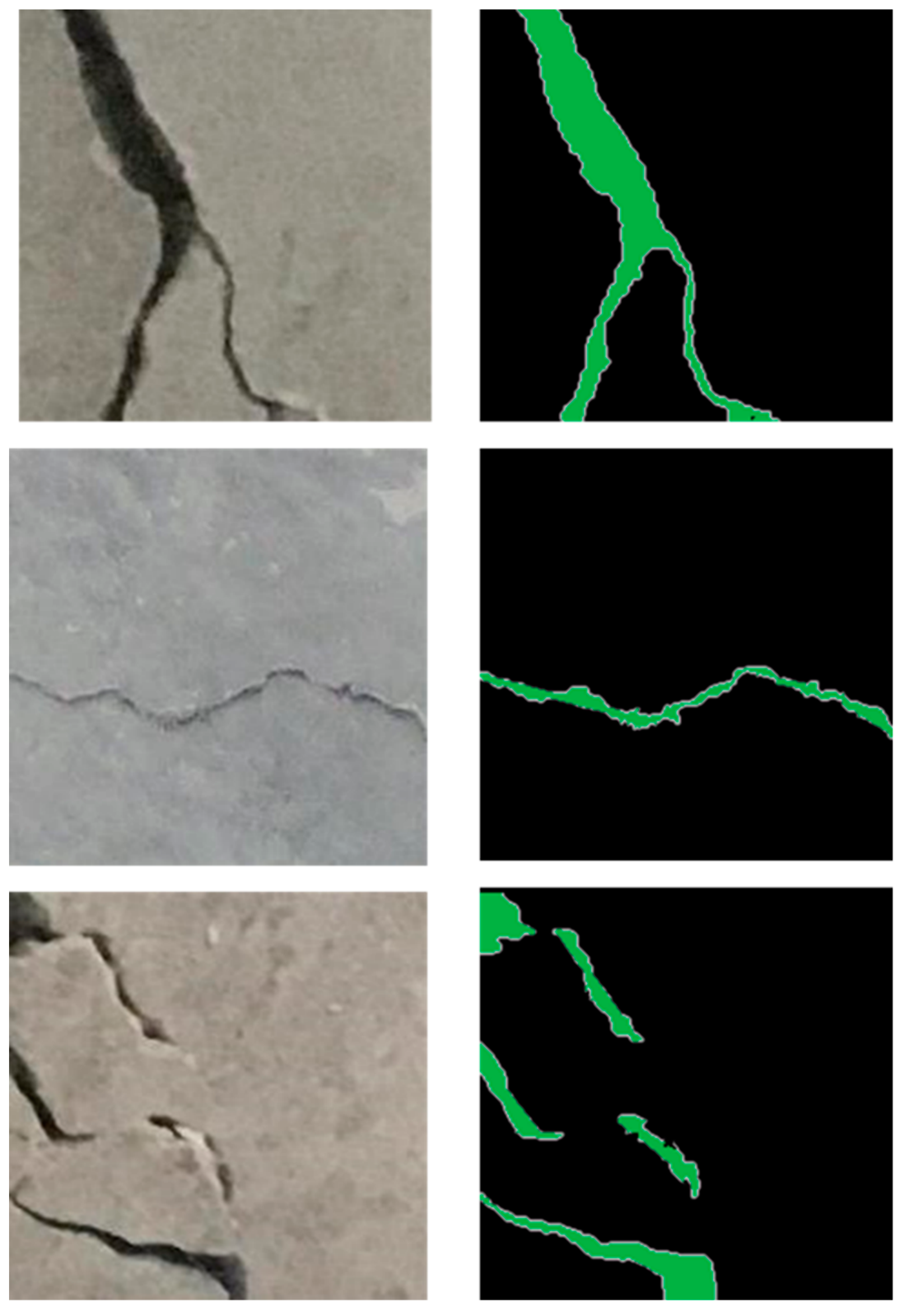
2.2. Concrete Crack Image Dataset
3. Results and Discussion
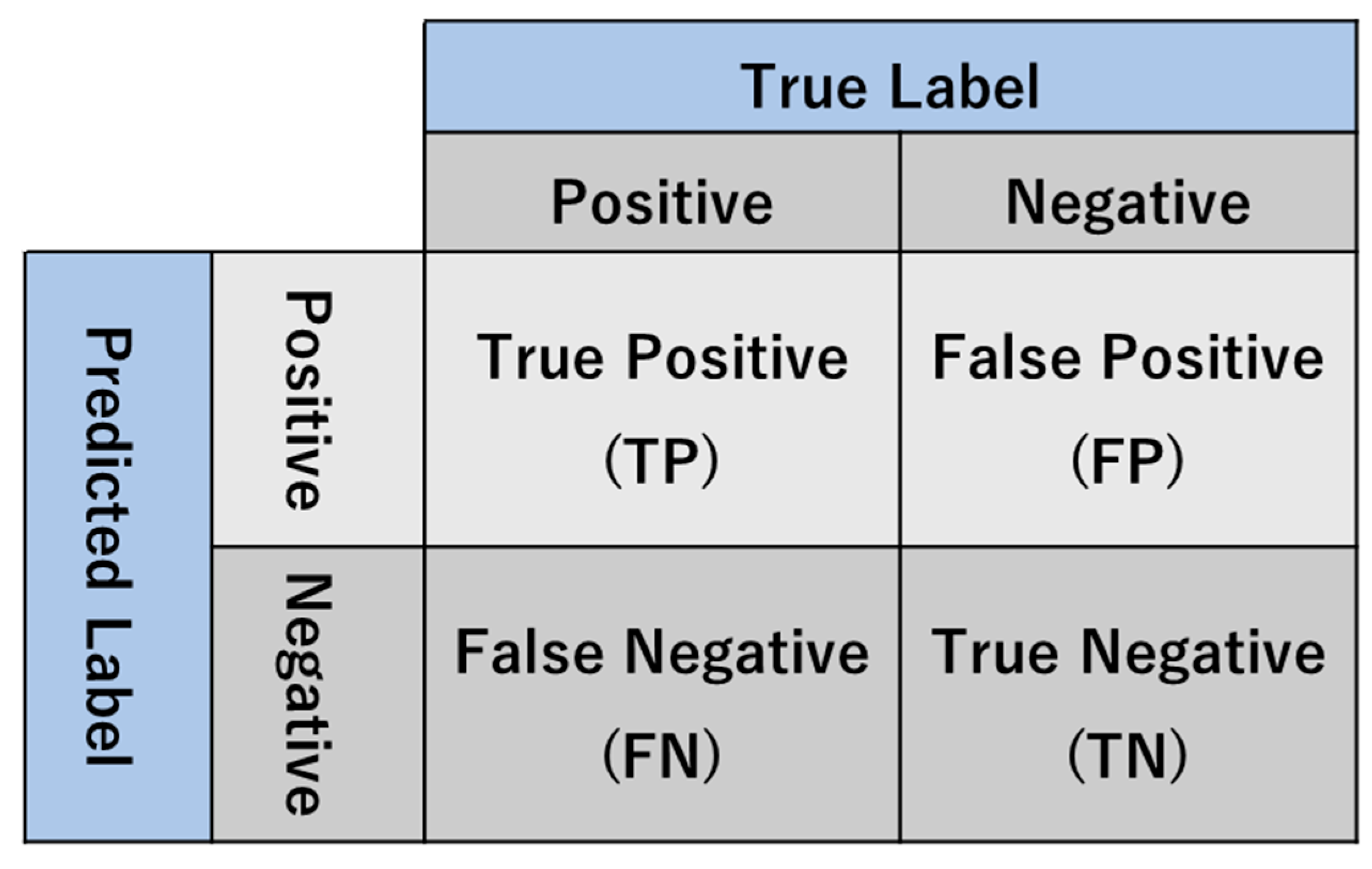
3.1. Performance Metrics
3.1.1. Structural Accuracy
- (1)
- TP defines the number of positive observations predicted to be positive. In our model, TP represents the number of cracks that are correctly classified as a crack.
- (2)
- TN defines the number of negative observations predicted to be negative. In our model, TN represents the number of backgrounds that are correctly classified as background.
- (3)
- FP defines the number of negative observations predicted to be positive. In our model, FP represents the number of backgrounds that are incorrectly identified as a crack.
- (4)
- FN defines the number of positive observations predicted to be negative. In our model, FN represents the number of cracks that are incorrectly identified as background.
3.1.2. F1-Score
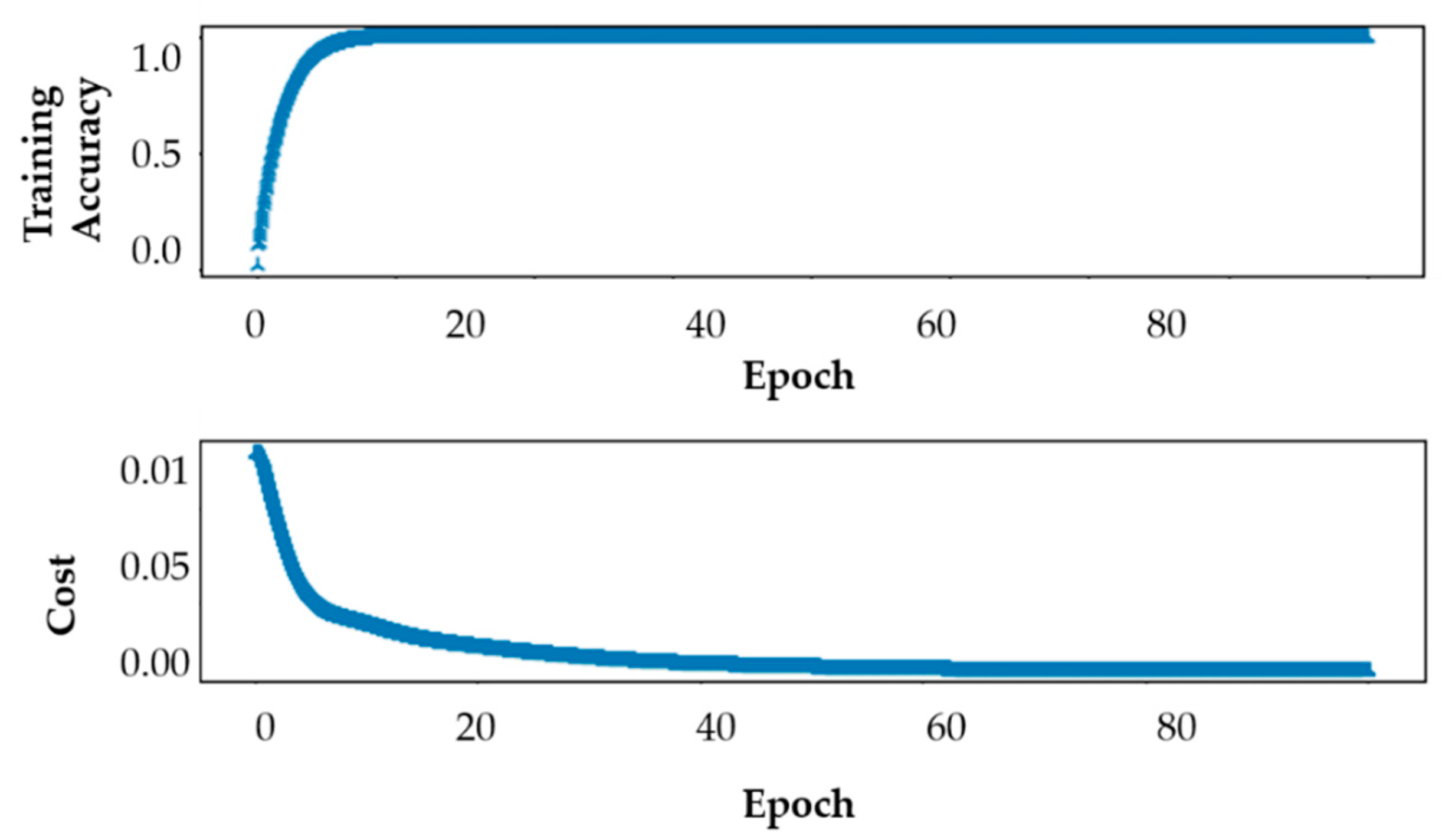
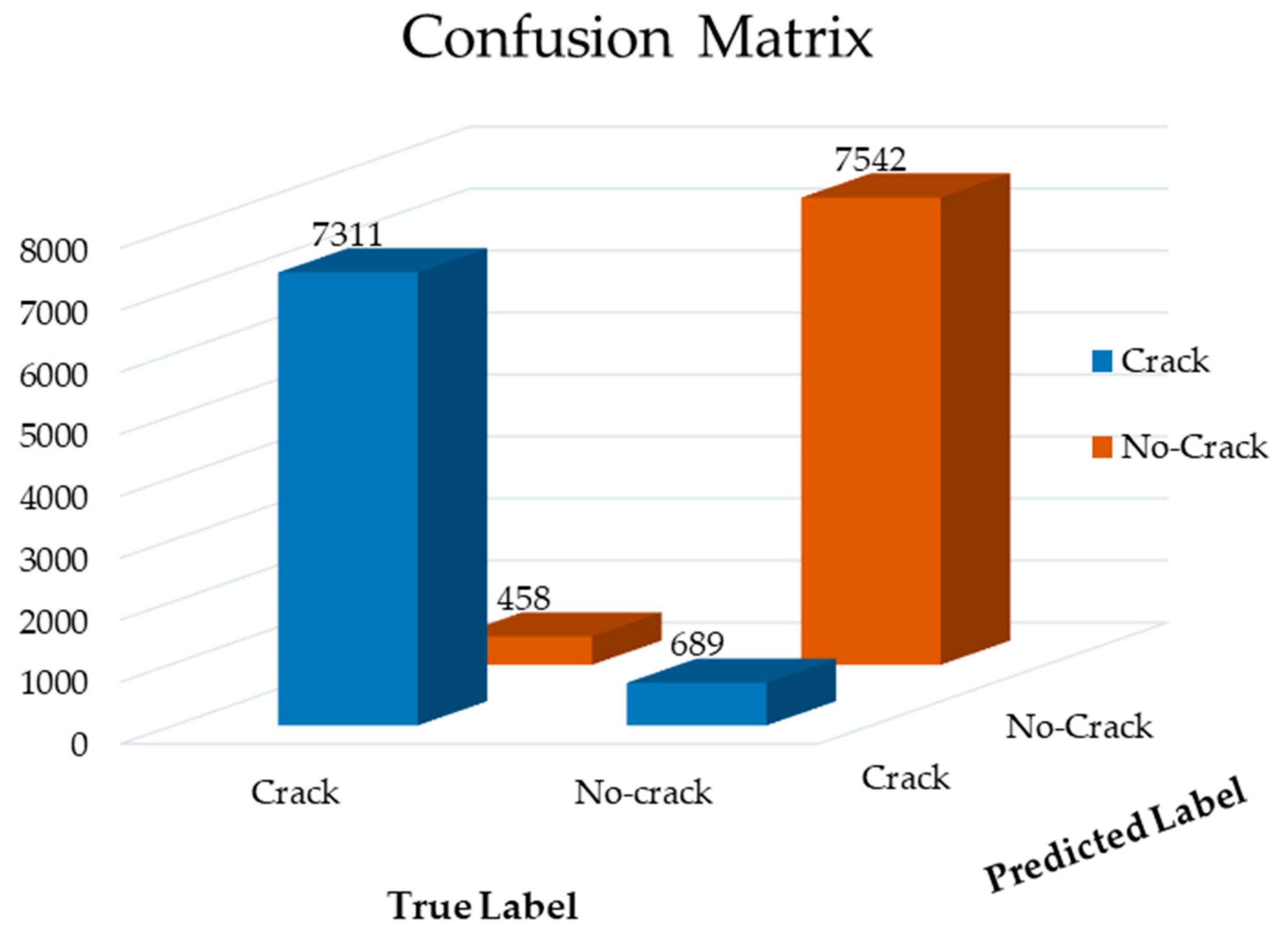
3.2. Performance Analysis of Proposed FCN Model
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef]
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Yan, J.; Downey, A.; Cancelli, A.; Laflamme, S.; Chen, A.; Li, J.; Ubertini, F. Concrete Crack Detection and Monitoring Using a Capacitive Dense Sensor Array. Sensors 2019, 19, 1843. [Google Scholar] [CrossRef] [PubMed]
- Ye, X.W.; Su, Y.H.; Han, J.P. Structural Health Monitoring of Civil Infrastructure Using Optical Fiber Sensing Technology: A Comprehensive Review. Sci. World J. 2014, 2014, 11. [Google Scholar] [CrossRef]
- Ko, J.M.; Ni, Y.Q. Technology developments in structural health monitoring of large-scale bridges. Eng. Struct. 2005, 27, 1715–1725. [Google Scholar] [CrossRef]
- Zhao, X.; Gong, P.; Qiao, G.; Lu, J.; Lv, X.; Ou, J. Brillouin Corrosion Expansion Sensors for Steel Reinforced Concrete Structures Using a Fiber Optic Coil Winding Method. Sensors 2011, 11. [Google Scholar] [CrossRef] [PubMed]
- Adhikari, R.S.; Moselhi, O.; Bagchi, A. Image-based retrieval of concrete crack properties for bridge inspection. Autom. Constr. 2014, 39, 180–194. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Noh, Y.; Koo, D.; Kang, Y.; Park, D.; Lee, D. Automatic crack detection on concrete images using segmentation via fuzzy C-means clustering. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 877–880. [Google Scholar]
- Nishikawa, T.; Yoshida, J.; Sugiyama, T.; Fujino, Y. Concrete Crack Detection by Multiple Sequential Image Filtering. Comput. Aided Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar] [CrossRef]
- Dinh, T.H.; Ha, Q.; La, H.M. Computer vision-based method for concrete crack detection. In Proceedings of the 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), Phuket, Thailand, 13–15 November 2016; pp. 1–6. [Google Scholar]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Oh, J.-K.; Jang, G.; Oh, S.; Lee, J.H.; Yi, B.-J.; Moon, Y.S.; Lee, J.S.; Choi, Y. Bridge inspection robot system with machine vision. Autom. Constr. 2009, 18, 929–941. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Shin, M.; Sim, S.-H. Crack and Noncrack Classification from Concrete Surface Images Using Machine Learning. Struct. Health Monit. 2018, 18, 725–738. [Google Scholar] [CrossRef]
- Dai, B.; Gu, C.; Zhao, E.; Zhu, K.; Cao, W.; Qin, X. Improved online sequential extreme learning machine for identifying crack behavior in concrete dam. Adv. Struct. Eng. 2019, 22, 402–412. [Google Scholar] [CrossRef]
- Li, G.; Zhao, X.; Du, K.; Ru, F.; Zhang, Y. Recognition and evaluation of bridge cracks with modified active contour model and greedy search-based support vector machine. Autom. Constr. 2017, 78, 51–61. [Google Scholar] [CrossRef]
- Na, W.; Tao, W. Proximal support vector machine based pavement image classification. In Proceedings of the 2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI), Nanjing, China, 18–20 October 2012; pp. 686–688. [Google Scholar]
- Abdel-Qader, I.; Pashaie-Rad, S.; Abudayyeh, O.; Yehia, S. PCA-based algorithm for unsupervised bridge crack detection. Adv. Eng. Softw. 2006, 37, 771–778. [Google Scholar] [CrossRef]
- Choudhary, G.K.; Dey, S. Crack detection in concrete surfaces using image processing, fuzzy logic, and neural networks. In Proceedings of the 2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI), Nanjing, China, 18–20 October 2012; pp. 404–411. [Google Scholar]
- Zhang, H.; Tan, J.; Liu, L.; Wu, Q.M.J.; Wang, Y.; Jie, L. Automatic crack inspection for concrete bridge bottom surfaces based on machine vision. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 4938–4943. [Google Scholar]
- Zhang, K.; Cheng, H.D.; Zhang, B. Unified Approach to Pavement Crack and Sealed Crack Detection Using Preclassification Based on Transfer Learning. J. Comput. Civ. Eng. 2018, 32, 04018001. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Tao, X.; Zhang, D.; Ma, W.; Liu, X.; Xu, D. Automatic Metallic Surface Defect Detection and Recognition with Convolutional Neural Networks. Appl. Sci. 2018, 8, 1575. [Google Scholar] [CrossRef]
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic Bridge Crack Detection Using a Convolutional Neural Network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Roth, H.R.; Lu, L.; Liu, J.; Yao, J.; Seff, A.; Cherry, K.; Summers, R.M. Improving computer-aided detection using convolutional neural networks and random view aggregation. IEEE Trans. Med Imaging 2016, 35, 1170–1181. [Google Scholar] [CrossRef] [PubMed]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Özgenel, Ç.F.; Sorguç, A.G. Performance Comparison of Pretrained Convolutional Neural Networks on Crack Detection in Buildings. In Proceedings of the ISARC International Symposium on Automation and Robotics in Construction, Berlin, Germany, 20–25 July 2008; pp. 693–700. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Varadharajan, S.; Jose, S.; Sharma, K.; Wander, L.; Mertz, C. Vision for road inspection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 115–122. [Google Scholar]
- Cha, Y.-J.; Choi, W. Vision-based concrete crack detection using a convolutional neural network. In Dynamics of Civil Structures; Springer: Berlin/Heidelberg, Germany, 2017; Volume 2, pp. 71–73. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Geometric context from a single image. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV′05), Beijing, China, 17–21 October 2005; Volume 1, pp. 654–661. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 2818–2826. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Images | Size (Pixels) | Crack | No-Crack | Training | Validation | Test |
|---|---|---|---|---|---|---|
| 40,000 | 224 × 224 | 20,000 | 20,000 | 40% | 20% | 40% |
| Methods | Precision | Recall | F1-Score | SA |
|---|---|---|---|---|
| SVM | 68.75 | 73.33 | 70.96 | 71.87 |
| CNN | 88.75 | 78.02 | 83.04 | 81.87 |
| Proposed FCN | 91.3 | 94.1 | 92.7 | 92.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.M.M.; Kim, J.-M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network. Sensors 2019, 19, 4251. https://doi.org/10.3390/s19194251
Islam MMM, Kim J-M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network. Sensors. 2019; 19(19):4251. https://doi.org/10.3390/s19194251
Chicago/Turabian StyleIslam, M. M. Manjurul, and Jong-Myon Kim. 2019. "Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network" Sensors 19, no. 19: 4251. https://doi.org/10.3390/s19194251
APA StyleIslam, M. M. M., & Kim, J.-M. (2019). Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network. Sensors, 19(19), 4251. https://doi.org/10.3390/s19194251