An Unsupervised Framework for Online Spatiotemporal Detection of Activities of Daily Living by Hierarchical Activity Models



Abstract
:1. Introduction
- an unsupervised framework for scene modeling and activity discovery;
- dynamic length unsupervised temporal segmentation of videos;
- generating Hierarchical Activity Models using multiple spatial layers of abstraction;
- online detection of activities, as the videos are automatically clipped;
- finally, evaluating daily living activities, particularly in health care and early diagnosis of cognitive impairments.
2. Related Work
2.1. Activity Recognition
2.2. Temporal and Spatiotemporal Activity Detection
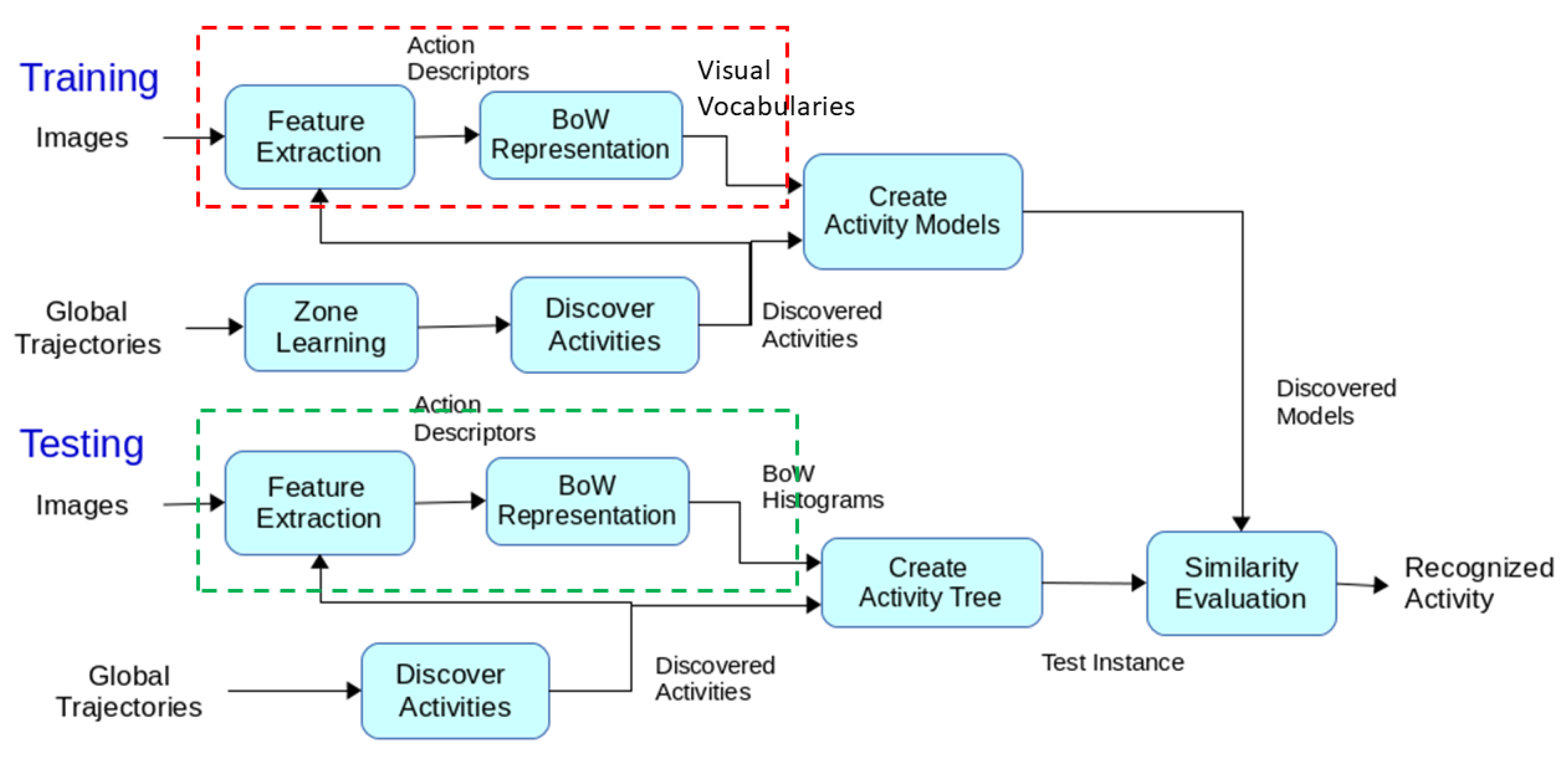
3. Unsupervised Activity Detection Framework
3.1. Feature Extraction
3.2. Global Tracker
3.3. Scene Model
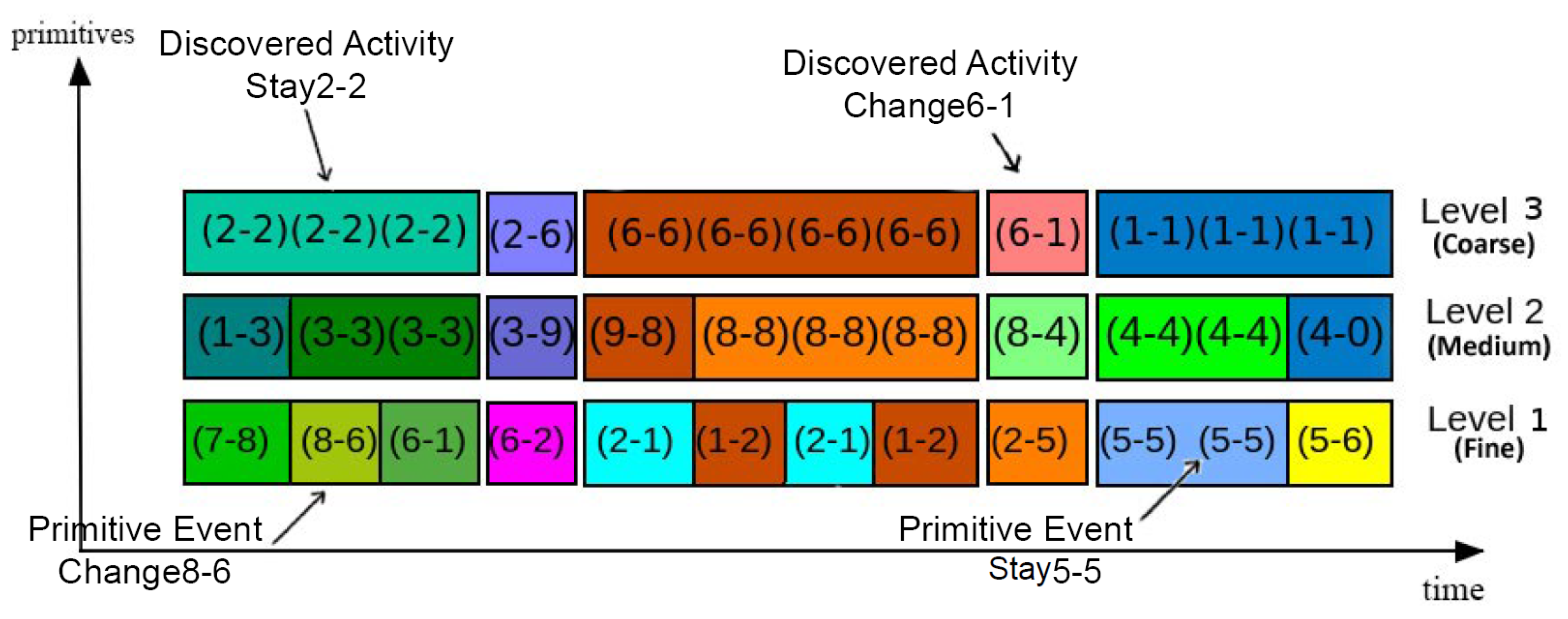
3.4. Primitive Events
3.5. Activity Discovery (Detection)
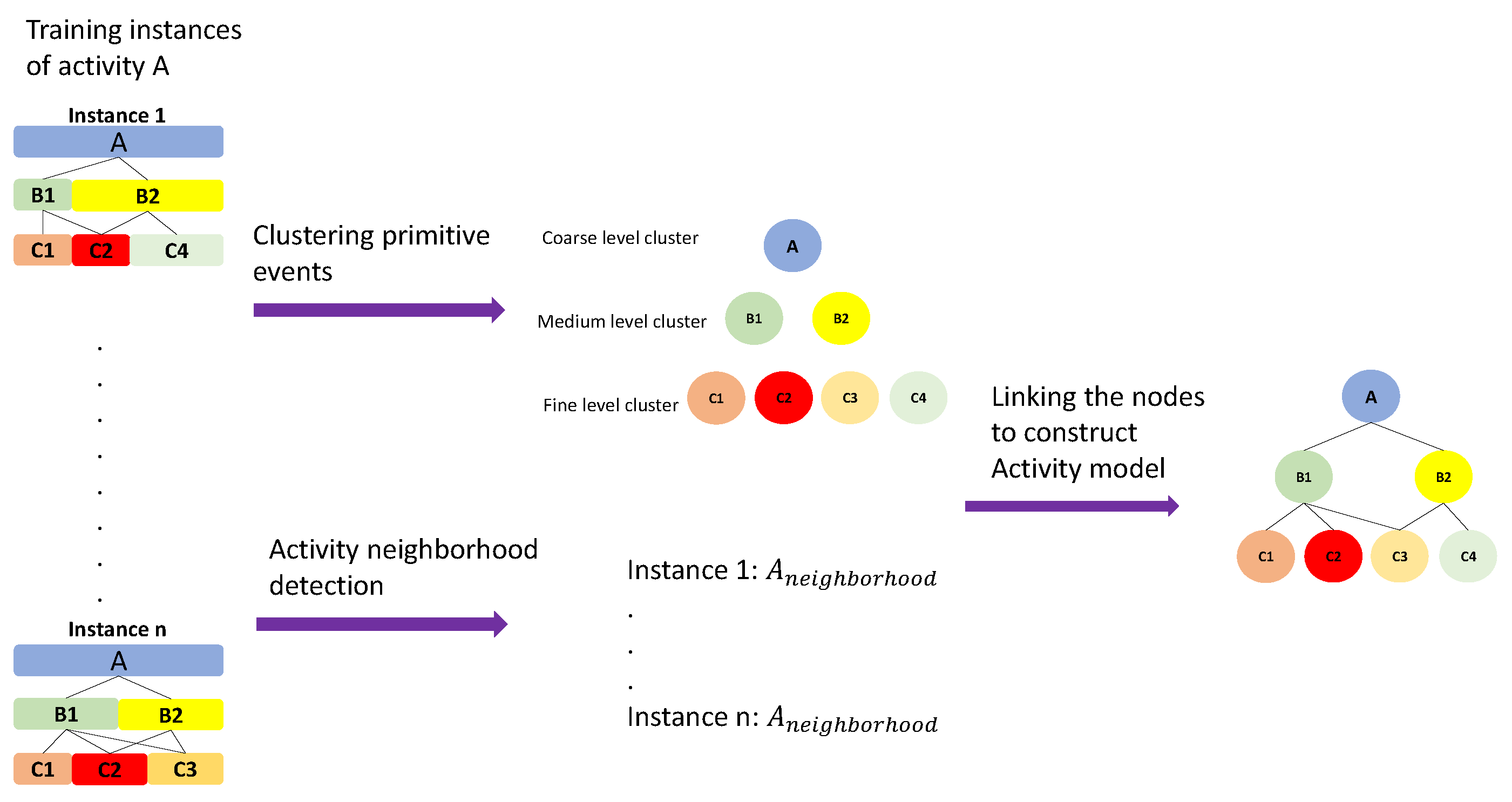
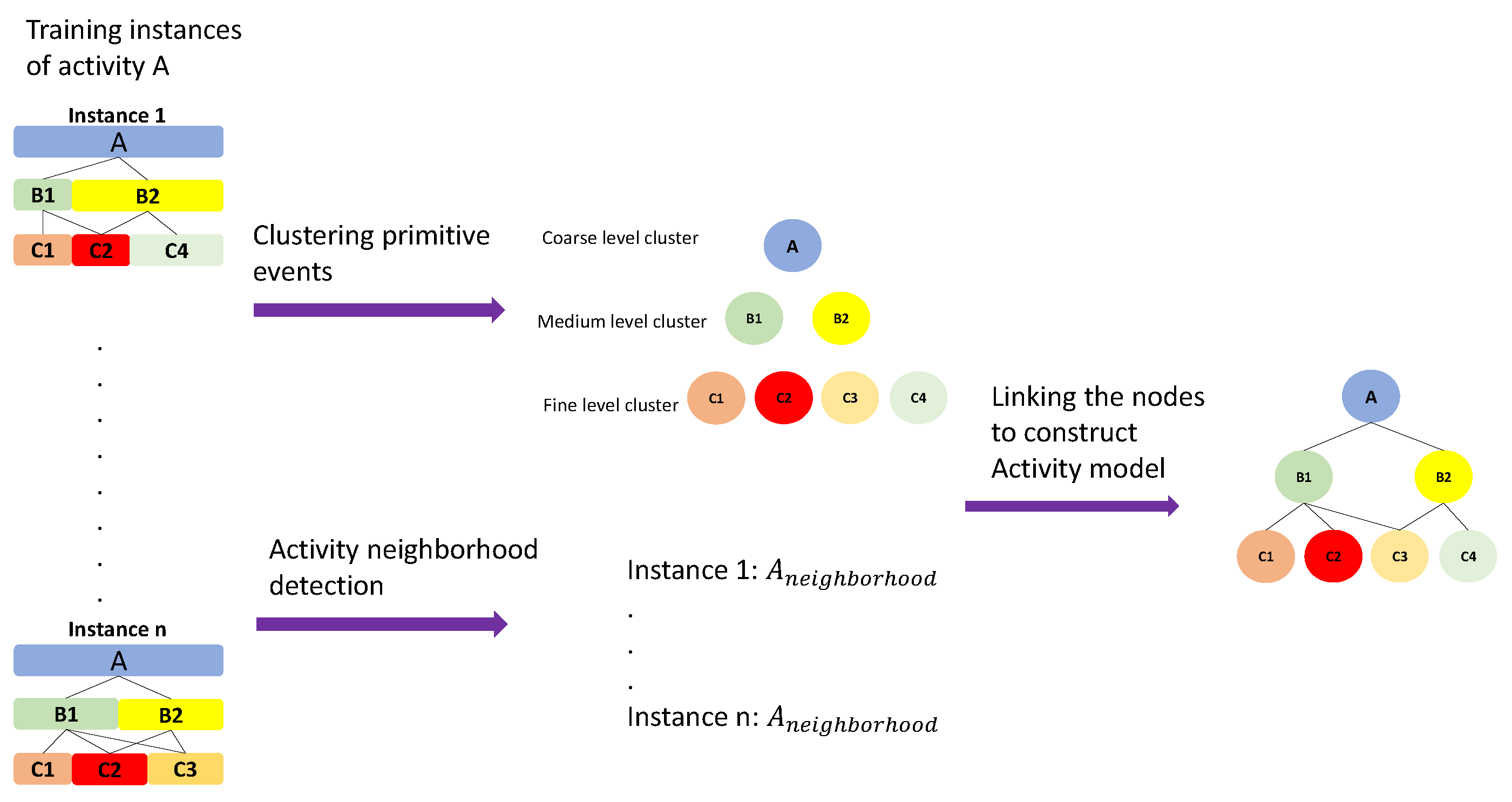
3.6. Activity Modeling
3.6.1. Hierarchical Neighborhood
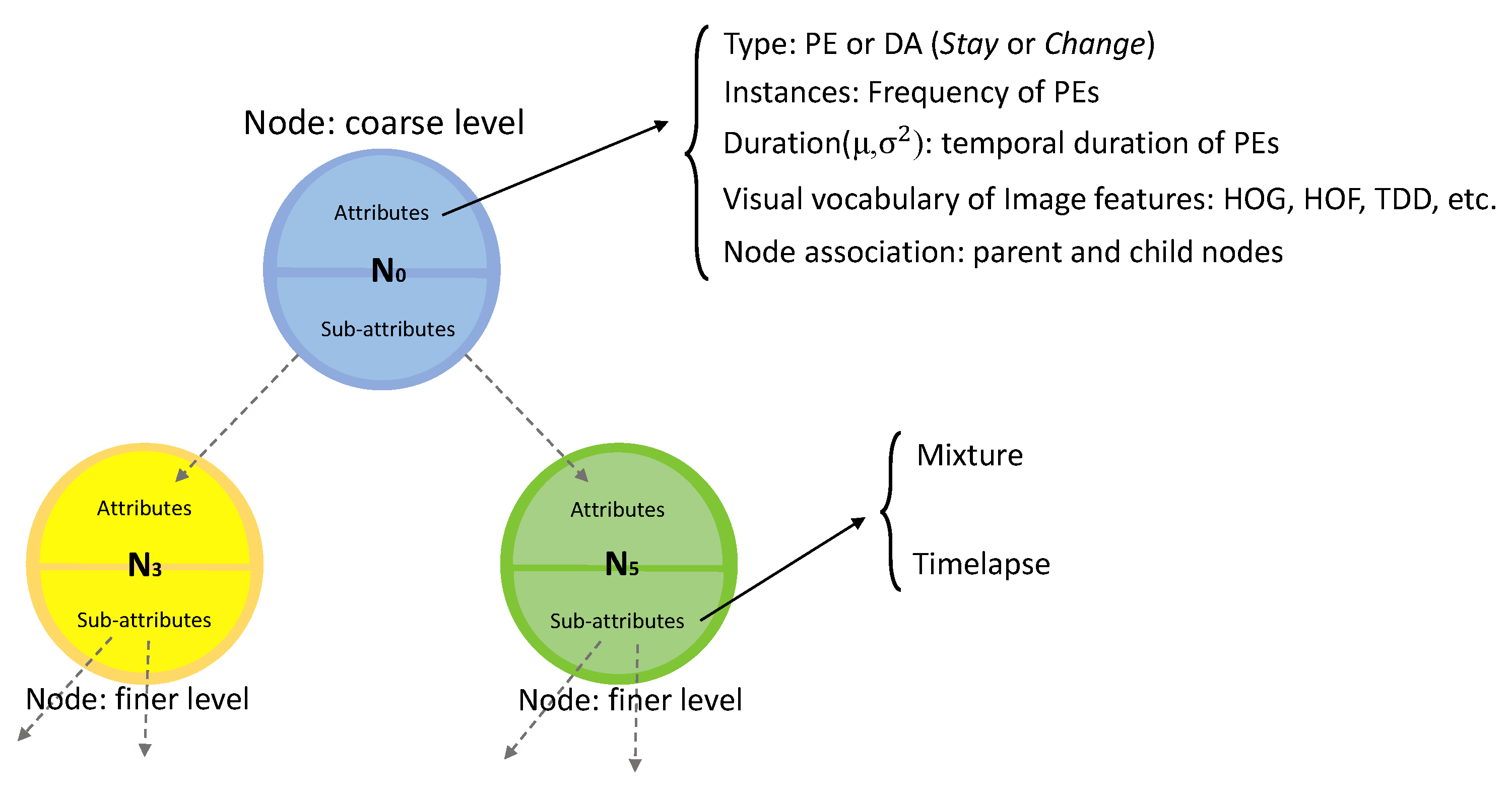
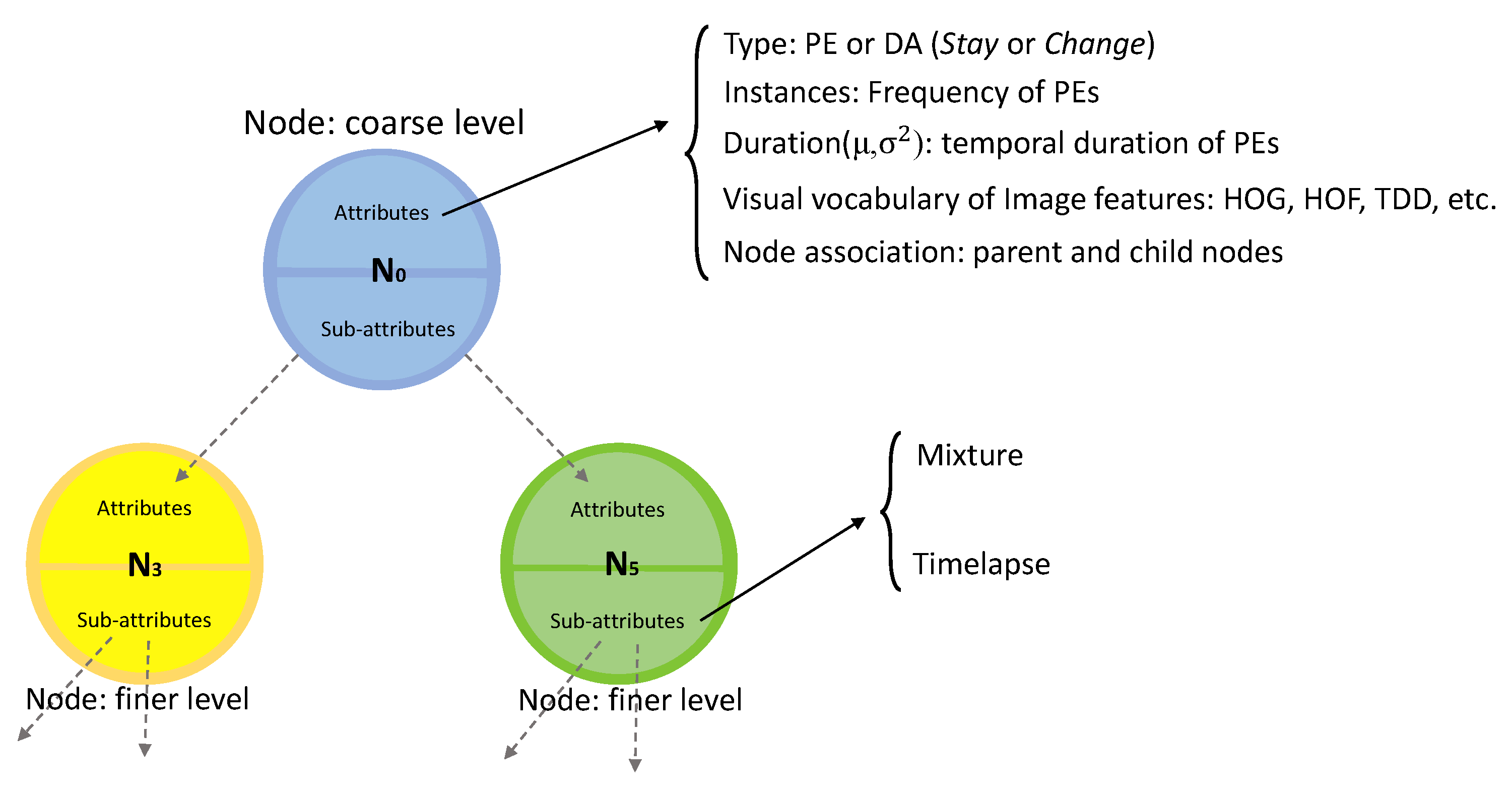
3.6.2. Hierarchical Activity Models
- Type attribute is extracted from the underlying primitive or discovered activity (in case of the root node). For node N, , where of PEs and DAs are either Stay or Change states.
- Instances list PEs of training instances indicating the frequency of each PE included in the node.
- Duration is a Gaussian distribution describing the temporal duration of the PEs () or discovered activities () of the node. It is frame length of the primitives or discovered activities calculated as:where n is the number of PEs or DAs.
- Image Features store different features extracted from the discovered activities. There is no limitation on the type of feature. It can be extracted hand-crafted features, geometrical or deep features (Section 3.1). It is calculated as the histogram of the features of the instances in the training set.
- Node association indicates the parent node of the current node (if it is not the root node) and the list of neighborhood nodes in the lower levels.
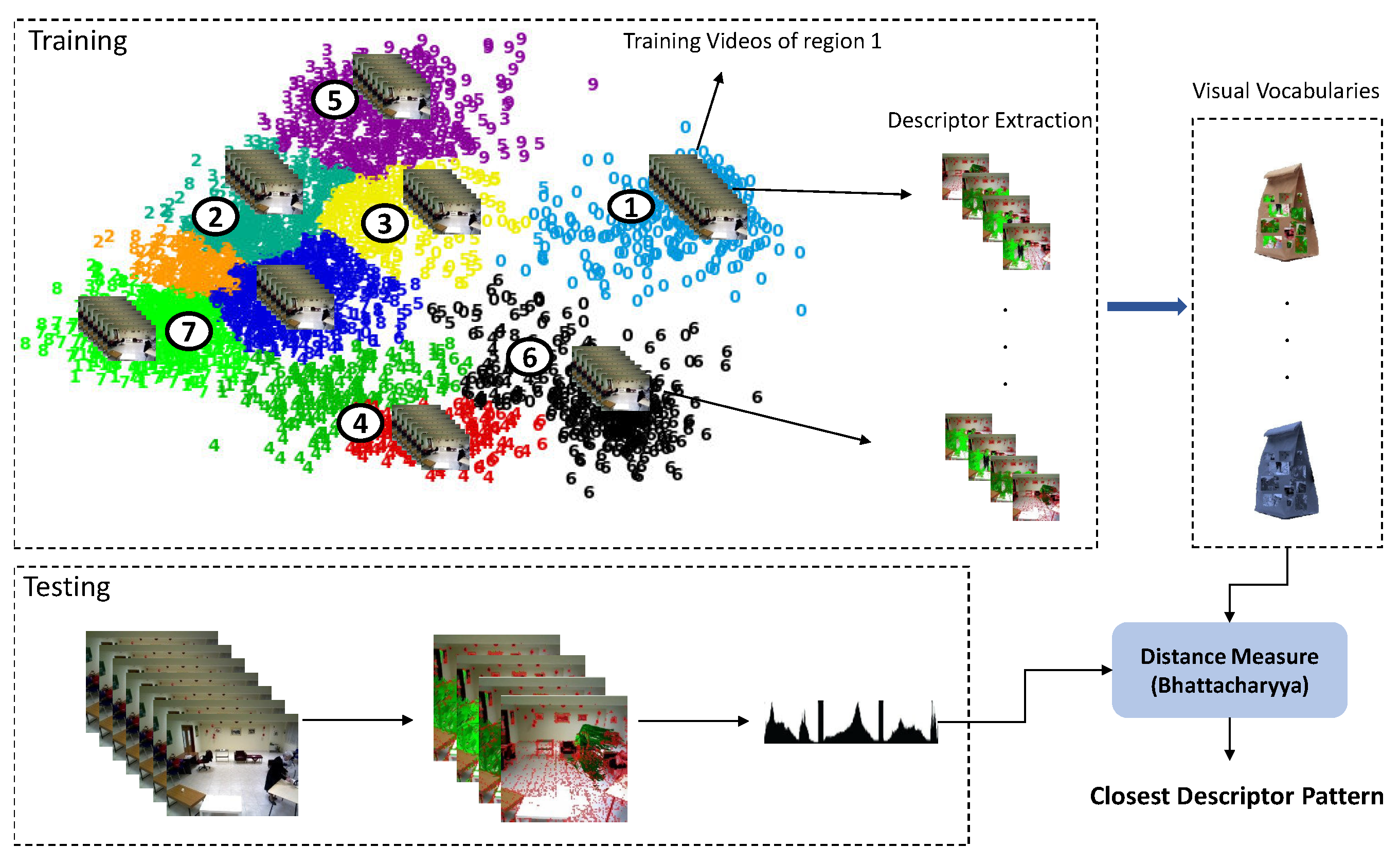
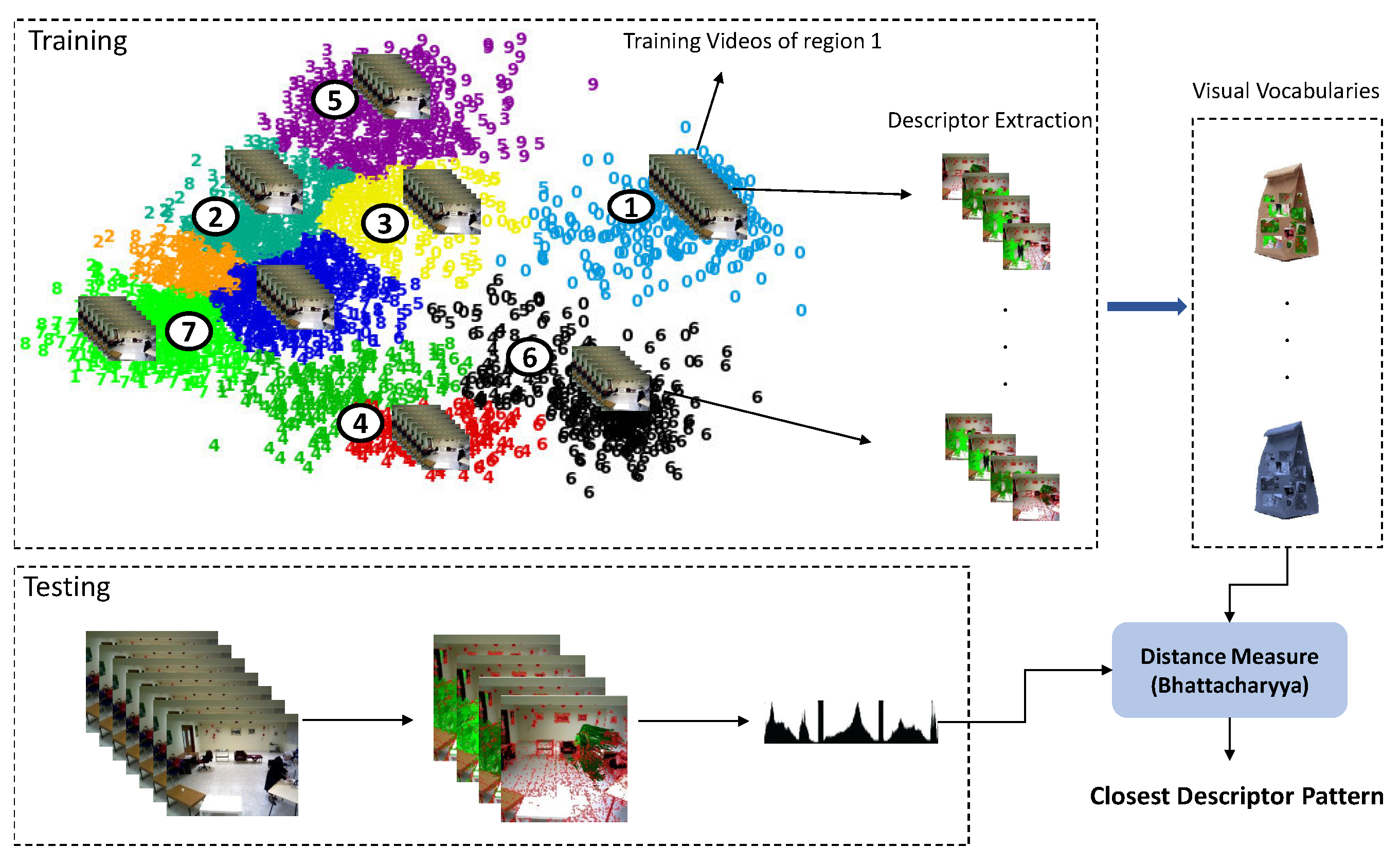
3.7. Descriptor Matching of Tree Nodes
3.8. Model Matching for Recognition
- Perceptual information, such as trajectories of a new subject, is retrieved.
- Using the previously learned scene model, the primitive events for the new video are calculated.
- By means of retrieved primitive events, the discovered activities are calculated.
- Using the collected attribute information, a test instance HAM () is created.
- The similarity score of the created HAM and trained HAM models are calculated and the activity with the highest score is selected as the target activity.
4. Experiments and Discussion
4.1. Datasets
4.1.1. GAADRD Dataset
4.1.2. CHU Dataset
4.1.3. DAHLIA Dataset
4.2. Evaluation Metrics
4.3. Results and Discussion
4.4. Comparisons
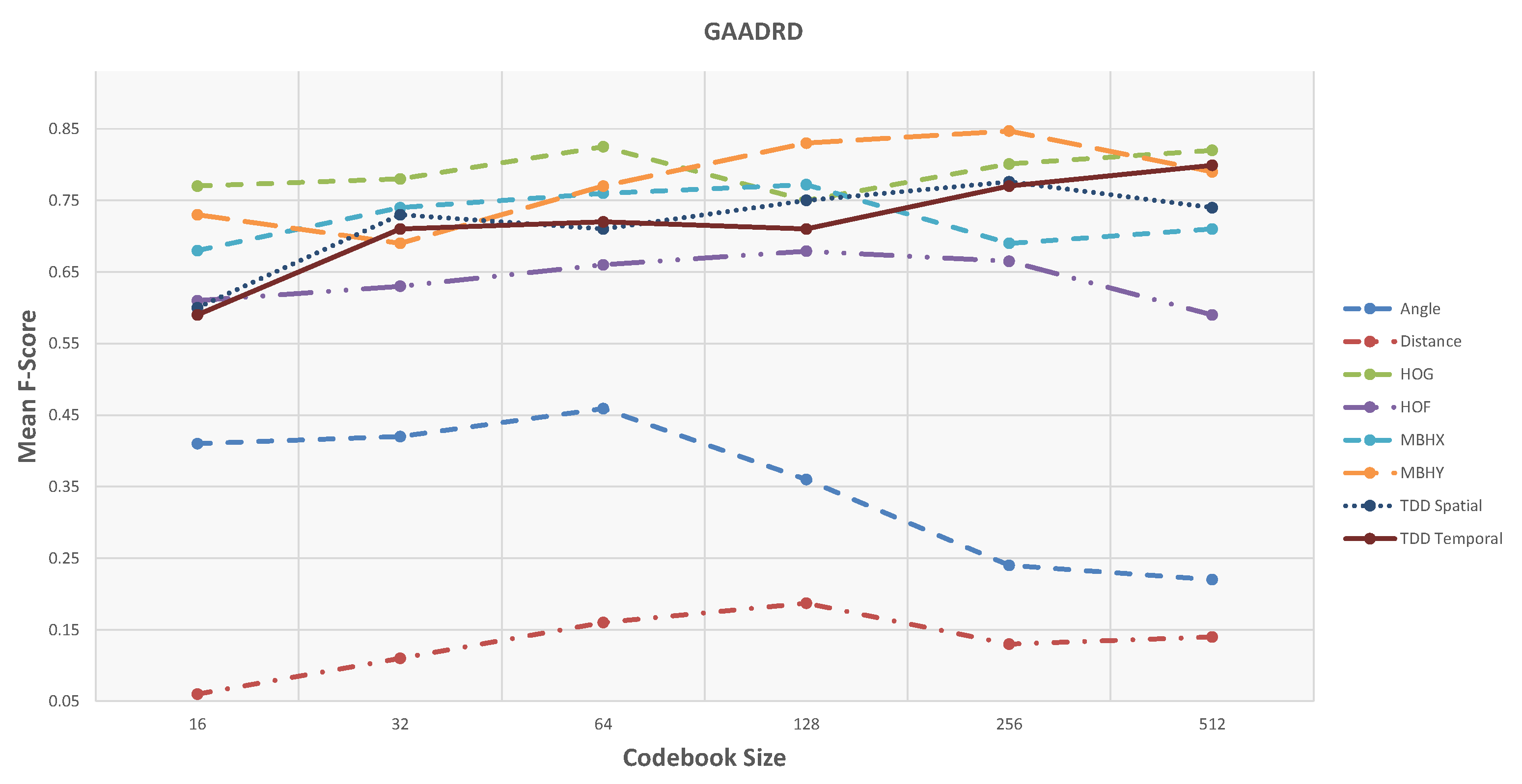
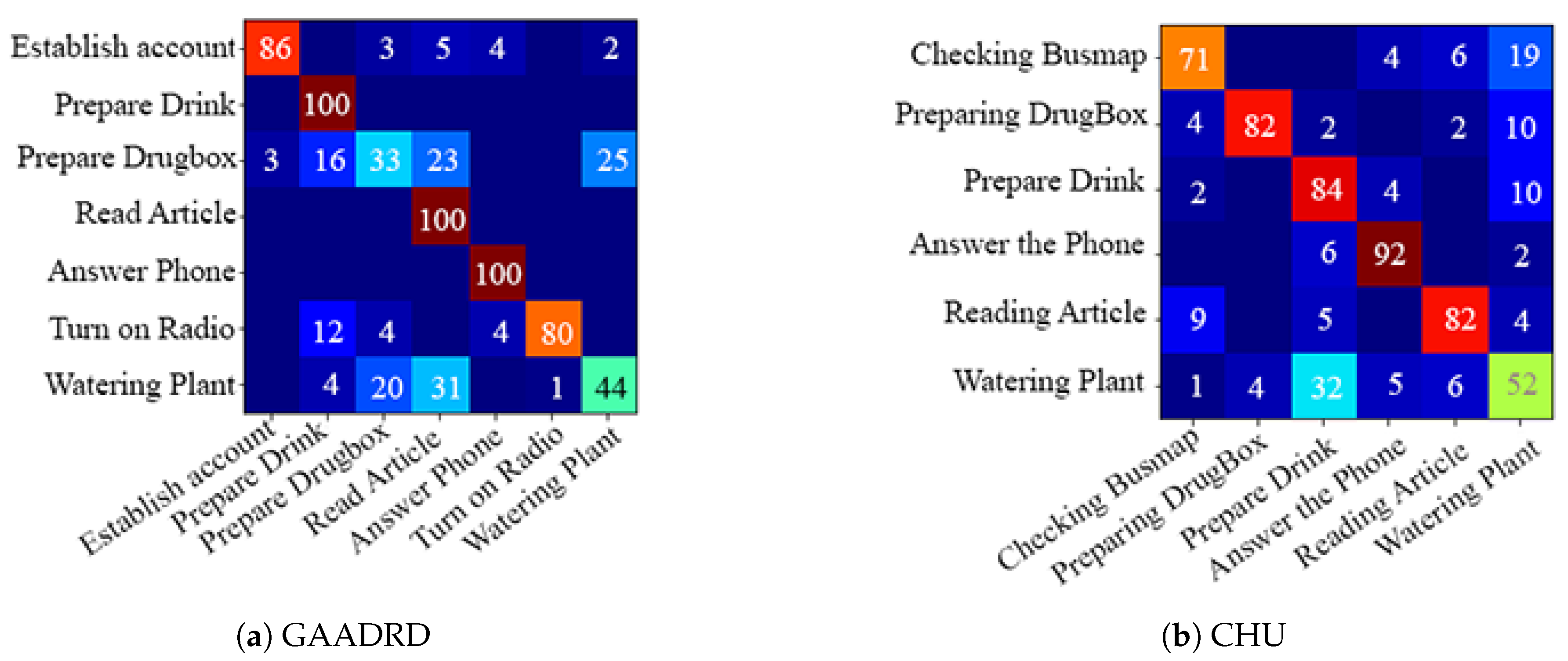
4.5. GAADRD Dataset
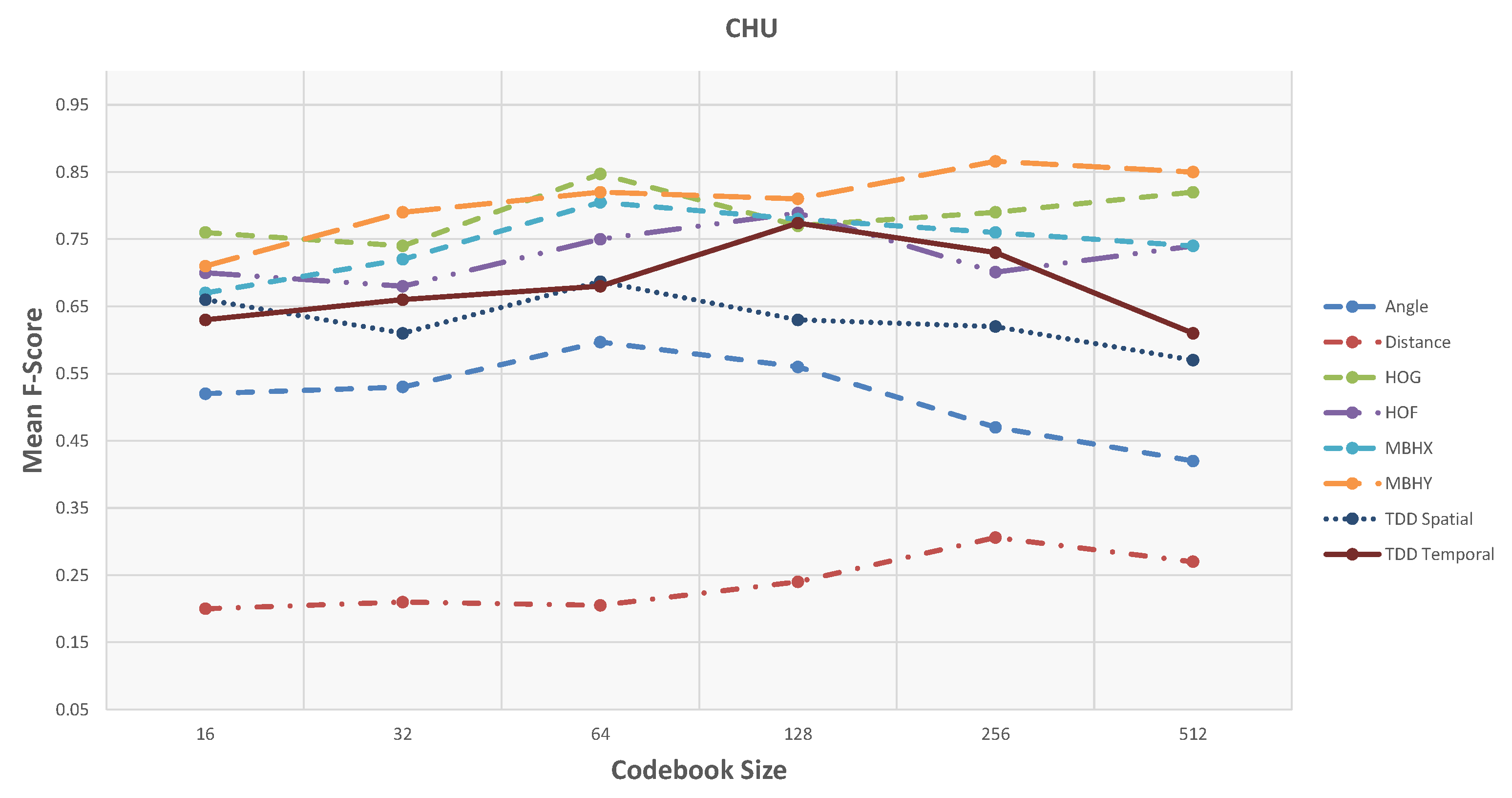
4.6. CHU Dataset
4.7. DAHLIA Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ADL | Activities of Daily Living |
| CNN | Convolutional Neural Networks |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| C3D | Convolution3D |
| TCN | Temporal Convolutional Network |
| HDP | Hierarchical Dirichlet Process |
| HOG | Histogram of Oriented Gradients |
| HOF | Histogram of Optical Flow |
| MBH | Motion Boundaries Histogram |
| MBHX | Motion Boundaries Histogram in X axis |
| MBHY | Motion Boundaries Histogram in Y axis |
| TSD | Trajectory Shape Descriptor |
| TDD | Trajectory-Pooled Deep-Convolutional Descriptors |
| BIC | Bayesian Information Criterion |
| SR | Scene Region |
| PE | Primitive Event |
| DA | Discovered Activity |
| FV | Fisher Vector |
| HAM | Hierarchical Activity Model |
| MAP | Maximum A Posteriori |
| TP | True Positive |
| FP | False Positive |
| TN | True Negative |
| FN | False Negative |
| TPR | True Positive Rate |
| PPV | Positive Predictive Value |
| IoU | Intersection over Union |
| SSBD | Sequential statistical boundary detection |
| ELS | Efficient Linear Search |
| PC-CNN | Person-Centered CNN |
| SVM | Support Vector Machine |
References
- Heilbron, F.C.; Barrios, W.; Escorcia, V.; Ghanem, B. Scc: Semantic context cascade for efficient action detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3175–3184. [Google Scholar]
- Zhao, Y.; Xiong, Y.; Wang, L.; Wu, Z.; Tang, X.; Lin, D. Temporal action detection with structured segment networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2914–2923. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. R-c3d: Region convolutional 3d network for temporal activity detection. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 5783–5792. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S.F. Temporal action localization in untrimmed videos via multi-stage cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1049–1058. [Google Scholar]
- Oneata, D.; Verbeek, J.; Schmid, C. The lear submission at thumos 2014. In Proceedings of the IEEE Euro. Conf. Computer Vision (ECCV) THUMOS Workshop, Zürich, Switzerland, 6–7 September 2014. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition and detection by combining motion and appearance features. THUMOS14 Action Recognit. Chall. 2014, 1, 2. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X.; Van Gool, L. Actionness estimation using hybrid fully convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2708–2717. [Google Scholar]
- Caba Heilbron, F.; Carlos Niebles, J.; Ghanem, B. Fast temporal activity proposals for efficient detection of human actions in untrimmed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1914–1923. [Google Scholar]
- Escorcia, V.; Heilbron, F.C.; Niebles, J.C.; Ghanem, B. Daps: Deep action proposals for action understanding. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germnay, 2016; pp. 768–784. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Hosang, J.; Benenson, R.; Dollár, P.; Schiele, B. What makes for effective detection proposals? IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 814–830. [Google Scholar] [CrossRef] [PubMed]
- Marszałek, M.; Laptev, I.; Schmid, C. Actions in context. In Proceedings of the CVPR 2009-IEEE Conference on Computer Vision & Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 2929–2936. [Google Scholar]
- Wu, Z.; Fu, Y.; Jiang, Y.G.; Sigal, L. Harnessing object and scene semantics for large-scale video understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3112–3121. [Google Scholar]
- Jain, M.; Van Gemert, J.C.; Snoek, C.G. What do 15,000 object categories tell us about classifying and localizing actions? In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 46–55. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (IClR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sadanand, S.; Corso, J.J. Action bank: A high-level representation of activity in video. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1234–1241. [Google Scholar]
- Liu, J.; Kuipers, B.; Savarese, S. Recognizing human actions by attributes. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3337–3344. [Google Scholar]
- Bojanowski, P.; Lajugie, R.; Bach, F.; Laptev, I.; Ponce, J.; Schmid, C.; Sivic, J. Weakly supervised action labeling in videos under ordering constraints. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 628–643. [Google Scholar]
- Duchenne, O.; Laptev, I.; Sivic, J.; Bach, F.R.; Ponce, J. Automatic annotation of human actions in video. In Proceedings of the IEEE 12th International Conference on Computer Vision, ICCV 2009, Kyoto, Japan, 27 September–4 October 2009; Volume 1. [Google Scholar]
- Tian, Y.; Sukthankar, R.; Shah, M. Spatiotemporal deformable part models for action detection. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2642–2649. [Google Scholar]
- Ni, B.; Paramathayalan, V.R.; Moulin, P. Multiple granularity analysis for fine-grained action detection. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 756–763. [Google Scholar]
- Bhattacharya, S.; Kalayeh, M.M.; Sukthankar, R.; Shah, M. Recognition of complex events: Exploiting temporal dynamics between underlying concepts. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2235–2242. [Google Scholar]
- Tang, K.; Fei-Fei, L.; Koller, D. Learning latent temporal structure for complex event detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1250–1257. [Google Scholar]
- Vo, N.N.; Bobick, A.F. From stochastic grammar to bayes network: Probabilistic parsing of complex activity. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2641–2648. [Google Scholar]
- Wang, X.; Ji, Q. A hierarchical context model for event recognition in surveillance video. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2641–2648. [Google Scholar]
- Modiri Assari, S.; Roshan Zamir, A.; Shah, M. Video classification using semantic concept co-occurrences. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2641–2648. [Google Scholar]
- Niebles, J.C.; Chen, C.W.; Fei-Fei, L. Modeling temporal structure of decomposable motion segments for activity classification. In Proceedings of the European Conference on Computer Vision 2010, Heraklion, Greece, 5–11 September 2010; pp. 392–405. [Google Scholar]
- Koppula, H.; Saxena, A. Learning spatio-temporal structure from rgb-d videos for human activity detection and anticipation. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 792–800. [Google Scholar]
- Jones, S.; Shao, L. Unsupervised spectral dual assignment clustering of human actions in context. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 604–611. [Google Scholar]
- Yang, Y.; Saleemi, I.; Shah, M. Discovering motion primitives for unsupervised grouping and one-shot learning of human actions, gestures, and expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1635–1648. [Google Scholar] [CrossRef] [PubMed]
- Morris, B.; Trivedi, M. Trajectory Learning for Activity Understanding: Unsupervised, Multilevel, and Long-Term Adaptive Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2287–2301. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, Q.; Sun, S. Trajectory-based human activity recognition with hierarchical Dirichlet process hidden Markov models. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; pp. 456–460. [Google Scholar]
- Hu, W.; Xiao, X.; Fu, Z.; Xie, D.; Tan, T.; Maybank, S. A system for learning statistical motion patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1450–1464. [Google Scholar] [Green Version]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Mathe, S.; Sminchisescu, C. Actions in the eye: Dynamic gaze datasets and learnt saliency models for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1408–1424. [Google Scholar] [CrossRef]
- Hoai, M.; Lan, Z.Z.; De la Torre, F. Joint segmentation and classification of human actions in video. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3265–3272. [Google Scholar]
- Shi, Q.; Cheng, L.; Wang, L.; Smola, A. Human action segmentation and recognition using discriminative semi-markov models. Int. J. Comput. Vis. 2011, 93, 22–32. [Google Scholar] [CrossRef]
- Kuehne, H.; Arslan, A.; Serre, T. The language of actions: Recovering the syntax and semantics of goal-directed human activities. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 780–787. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Neural Information Processing Systems, Motreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Yue-Hei Ng, J.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Karaman, S.; Seidenari, L.; Del Bimbo, A. Fast saliency based pooling of fisher encoded dense trajectories. In Proceedings of the Computer Vision—ECCV 2014 Workshops, Zurich, Switzerland, 6–7 September 2014. [Google Scholar]
- Gaidon, A.; Harchaoui, Z.; Schmid, C. Temporal localization of actions with actoms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2782–2795. [Google Scholar] [CrossRef]
- Tang, K.; Yao, B.; Fei-Fei, L.; Koller, D. Combining the right features for complex event recognition. In Proceedings of the IEEE International Conference on Computer Vision, Portland, OR, USA, 23–28 June 2013; pp. 2696–2703. [Google Scholar]
- De Geest, R.; Gavves, E.; Ghodrati, A.; Li, Z.; Snoek, C.; Tuytelaars, T. Online action detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 269–284. [Google Scholar]
- Yeung, S.; Russakovsky, O.; Mori, G.; Fei-Fei, L. End-to-end learning of action detection from frame glimpses in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2678–2687. [Google Scholar]
- Montes, A.; Salvador, A.; Pascual, S.; Giro-i Nieto, X. Temporal activity detection in untrimmed videos with recurrent neural networks. arXiv 2016, arXiv:1608.08128. [Google Scholar]
- Ma, S.; Sigal, L.; Sclaroff, S. Learning activity progression in lstms for activity detection and early detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1942–1950. [Google Scholar]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 156–165. [Google Scholar]
- Chen, W.; Xiong, C.; Xu, R.; Corso, J.J. Actionness ranking with lattice conditional ordinal random fields. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 748–755. [Google Scholar]
- Qiu, H.; Zheng, Y.; Ye, H.; Lu, Y.; Wang, F.; He, L. Precise temporal action localization by evolving temporal proposals. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 388–396. [Google Scholar]
- Gkioxari, G.; Malik, J. Finding action tubes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 759–768. [Google Scholar]
- Mettes, P.; Van Gemert, J.C.; Snoek, C.G. Spot on: Action localization from pointly-supervised proposals. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 437–453. [Google Scholar]
- Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. Learning to track for spatio-temporal action localization. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 3164–3172. [Google Scholar]
- Jiang, Z.; Lin, Z.; Davis, L.S. A unified tree-based framework for joint action localization, recognition and segmentation. Comput. Vis. Image Underst. 2013, 117, 1345–1355. [Google Scholar] [CrossRef]
- Soomro, K.; Idrees, H.; Shah, M. Action localization in videos through context walk. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 3280–3288. [Google Scholar]
- Jain, M.; Van Gemert, J.; Jégou, H.; Bouthemy, P.; Snoek, C.G. Action localization with tubelets from motion. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 740–747. [Google Scholar]
- Yu, G.; Yuan, J. Fast action proposals for human action detection and search. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1302–1311. [Google Scholar]
- Guerra Filho, G.; Aloimonos, Y. A language for human action. Computer 2007, 40, 42–51. [Google Scholar] [CrossRef]
- Fox, E.B.; Hughes, M.C.; Sudderth, E.B.; Jordan, M.I. Joint modeling of multiple time series via the beta process with application to motion capture segmentation. Ann. Appl. Stat. 2014, 8, 1281–1313. [Google Scholar] [CrossRef] [Green Version]
- Emonet, R.; Varadarajan, J.; Odobez, J.M. Temporal analysis of motif mixtures using dirichlet processes. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 140–156. [Google Scholar] [CrossRef] [PubMed]
- Brattoli, B.; Buchler, U.; Wahl, A.S.; Schwab, M.E.; Ommer, B. Lstm self-supervision for detailed behavior analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6466–6475. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised learning of visual representations using videos. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 2794–2802. [Google Scholar]
- Cherian, A.; Fernando, B.; Harandi, M.; Gould, S. Generalized rank pooling for activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3222–3231. [Google Scholar]
- Fernando, B.; Gavves, E.; Oramas, J.M.; Ghodrati, A.; Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5378–5387. [Google Scholar]
- Lee, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Unsupervised representation learning by sorting sequences. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 667–676. [Google Scholar]
- Ramanathan, V.; Tang, K.; Mori, G.; Fei-Fei, L. Learning temporal embeddings for complex video analysis. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 4471–4479. [Google Scholar]
- Milbich, T.; Bautista, M.; Sutter, E.; Ommer, B. Unsupervised video understanding by reconciliation of posture similarities. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4394–4404. [Google Scholar]
- Crispim-Junior, C.; Gómez Uría, A.; Strumia, C.; Koperski, M.; König, A.; Negin, F.; Cosar, S.; Nghiem, A.; Chau, D.; Charpiat, G.; et al. Online recognition of daily activities by color-depth sensing and knowledge models. Sensors 2017, 17, 1528. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Action Recognition by Dense Trajectories. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3169–3176. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Agahian, S.; Negin, F.; Köse, C. Improving bag-of-poses with semi-temporal pose descriptors for skeleton-based action recognition. Vis. Comput. 2019, 35, 591–607. [Google Scholar] [CrossRef]
- Nghiem, A.T.; Auvinet, E.; Meunier, J. Head detection using Kinect camera and its application to fall detection. In Proceedings of the 11th International Conference on Information Science, Signal Processing and their Applications (ISSPA), Montreal, QC, Canada, 2–5 July 2012; pp. 164–169. [Google Scholar]
- Anh, N.T.L.; Khan, F.M.; Negin, F.; Bremond, F. Multi-object tracking using multi-channel part appearance representation. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Chau, D.P.; Thonnat, M.; Bremond, F. Automatic parameter adaptation for multi-object tracking. In Proceedings of the International Conference on Computer Vision Systems, St. Petersburg, Russia, 16–18 July 2013; pp. 244–253. [Google Scholar]
- Pelleg, D.; Moore, A.W. X-means: Extending k-means with efficient estimation of the number of clusters. In Proceedings of the Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; Volume 1, pp. 727–734. [Google Scholar]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Karakostas, A.; Briassouli, A.; Avgerinakis, K.; Kompatsiaris, I.; Tsolaki, M. The Dem@Care Experiments and Datasets: A Technical Report; Technical Report; Centre for Research and Technology Hellas: Thessaloniki, Greece, 2014. [Google Scholar]
- Vaquette, G.; Orcesi, A.; Lucat, L.; Achard, C. The DAily Home LIfe Activity Dataset: A High Semantic Activity Dataset for Online Recognition. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017. [Google Scholar] [CrossRef]
- Negin, F.; Cogar, S.; Bremond, F.; Koperski, M. Generating unsupervised models for online long-term daily living activity recognition. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 186–190. [Google Scholar]
- Negin, F.; Koperski, M.; Crispim, C.F.; Bremond, F.; Coşar, S.; Avgerinakis, K. A hybrid framework for online recognition of activities of daily living in real-world settings. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 37–43. [Google Scholar]
- Avgerinakis, K.; Briassouli, A.; Kompatsiaris, I. Activity detection using sequential statistical boundary detection (ssbd). Comput. Vis. Image Underst. 2016, 144, 46–61. [Google Scholar] [CrossRef]
- Meshry, M.; Hussein, M.E.; Torki, M. Linear-time online action detection from 3D skeletal data using bags of gesturelets. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016. [Google Scholar]
- Chen, C.; Grauman, K. Efficient Activity Detection in Untrimmed Video with Max-Subgraph Search. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 908–921. [Google Scholar] [CrossRef] [PubMed]
- Chan-Hon-Tong, A.; Achard, C.; Lucat, L. Deeply Optimized Hough Transform: Application to Action Segmentation. In Proceedings of the International Conference on Image Analysis and Processing, Naples, Italy, 9–13 September 2013. [Google Scholar]
- Negin, F.; Goel, A.; Abubakr, A.G.; Bremond, F.; Francesca, G. Online detection of long-term daily living activities by weakly supervised recognition of sub-activities. In Proceedings of the 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 32 | 64 | 128 | 256 | 512 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | |
| Angle | 57.6 | 33.2 | 0.42 | 61.2 | 36.1 | 0.45 | 46.9 | 30.2 | 0.36 | 28.1 | 22.4 | 0.24 | 26.7 | 19.8 | 0.22 |
| Distance | 12.9 | 9.7 | 0.11 | 18.2 | 14.9 | 0.16 | 20.7 | 16.1 | 0.18 | 14.7 | 12.1 | 0.13 | 14.7 | 15.2 | 0.14 |
| HOG | 81.4 | 75.2 | 0.78 | 84.7 | 79.6 | 0.825 | 77.5 | 74.3 | 0.75 | 82.7 | 77.6 | 0.80 | 84.7 | 79.8 | 0.82 |
| HOF | 64.6 | 61.9 | 0.63 | 64.9 | 67.7 | 0.66 | 66.1 | 68.1 | 0.67 | 65.4 | 67.9 | 0.66 | 57.4 | 62.1 | 0.59 |
| MBHX | 71.3 | 77.2 | 0.74 | 74.8 | 78.2 | 0.76 | 79.8 | 76.1 | 0.77 | 67.6 | 72.1 | 0.69 | 69.4 | 72.8 | 0.71 |
| MBHY | 71.5 | 68.4 | 0.69 | 78.8 | 76.1 | 0.77 | 82.7 | 84.9 | 0.83 | 83.1 | 85.7 | 0.84 | 80.2 | 79.4 | 0.79 |
| TDD Spatial | 74.5 | 72.9 | 0.73 | 72.8 | 71.2 | 0.71 | 77.5 | 74.3 | 0.75 | 77.5 | 76.9 | 0.77 | 76.4 | 73.5 | 0.74 |
| TDD Temporal | 73.4 | 69.1 | 0.71 | 73.9 | 70.6 | 0.72 | 72.5 | 69.9 | 0.71 | 79.4 | 76.2 | 0.77 | 81.9 | 76.9 | 0.79 |
| 32 | 64 | 128 | 256 | 512 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | |
| Angle | 58.4 | 49.7 | 0.53 | 60.7 | 57.8 | 0.59 | 58.6 | 55.2 | 0.56 | 50.3 | 45.9 | 0.47 | 41.7 | 44.1 | 0.42 |
| Distance | 23.9 | 19.2 | 0.21 | 22.7 | 19.5 | 0.20 | 27.8 | 21.7 | 0.24 | 29.2 | 31.9 | 0.30 | 28.8 | 27.1 | 0.27 |
| HOG | 77.7 | 71.9 | 0.74 | 85.7 | 82.9 | 0.84 | 80.8 | 74.9 | 0.77 | 81.9 | 76.3 | 0.79 | 84.9 | 79.8 | 0.82 |
| HOF | 68.2 | 69.8 | 0.68 | 73.9 | 76.4 | 0.75 | 77.1 | 79.1 | 0.78 | 68.4 | 71.9 | 0.70 | 73.4 | 74.9 | 0.74 |
| MBHX | 73.4 | 72.1 | 0.72 | 81.3 | 80.4 | 0.80 | 78.6 | 79.2 | 0.78 | 75.2 | 78.3 | 0.76 | 73.4 | 76.2 | 0.74 |
| MBHY | 80.5 | 77.9 | 0.79 | 84.3 | 79.9 | 0.82 | 83.9 | 79.3 | 0.81 | 88.6 | 83.6 | 0.866 | 87.4 | 83.1 | 0.85 |
| TDD Spatial | 65.8 | 58.4 | 0.61 | 71.9 | 64.7 | 0.68 | 67.2 | 60.9 | 0.63 | 65.9 | 60.1 | 0.62 | 60.0 | 55.9 | 0.57 |
| TDD Temporal | 67.7 | 65.7 | 0.66 | 69.7 | 66.1 | 0.68 | 79.2 | 76.1 | 0.77 | 74.4 | 73.5 | 0.73 | 61.8 | 62.1 | 0.61 |
| Supervised (Manual Clipping) with HOG, Dict sz = 512 [75] | Online Version of [75] | Classification by Detection SSBD [88] | Unsupervised Using Only Global Motion [86] | Hybrid [87] | Unsupervised (Proposed Method) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | |
| Establish Account | 92.2 | 84.3 | 0.88 | 29.1 | 100 | 0.45 | 41.67 | 41.67 | 0.41 | 86.2 | 100 | 0.92 | 92.3 | 100 | 0.95 | 86.2 | 100 | 0.92 |
| Prepare Drink | 92.1 | 100 | 0.95 | 69.4 | 100 | 0.81 | 80.0 | 96.2 | 0.87 | 100 | 78.1 | 0.87 | 100 | 92.1 | 0.95 | 100 | 100 | 1.0 |
| Prepare DrugBox | 94.9 | 85.5 | 0.89 | 20.2 | 11.7 | 0.14 | 51.28 | 86.96 | 0.64 | 100 | 33.34 | 0.50 | 78.5 | 91.3 | 0.84 | 100 | 33.1 | 0.49 |
| Reading Article | 96.2 | 96.2 | 0.96 | 37.8 | 88.6 | 0.52 | 31.88 | 100 | 0.48 | 100 | 100 | 1.0 | 100 | 100 | 1.0 | 100 | 100 | 1.0 |
| Answer the Phone | 88.5 | 100 | 0.93 | 70.1 | 100 | 0.82 | 34.29 | 96.0 | 0.50 | 100 | 100 | 1.0 | 100 | 91.2 | 0.95 | 100 | 100 | 1.0 |
| Turn On Radio | 89.4 | 86.7 | 0.88 | 75.1 | 100 | 0.85 | 19.86 | 96.55 | 0.32 | 89.0 | 89.0 | 0.89 | 89.1 | 93.4 | 0.91 | 89.1 | 89.3 | 0.89 |
| Watering Plant | 84.8 | 72.6 | 0.78 | 0 | 0 | 0 | 44.45 | 86.36 | 0.58 | 57.1 | 44.45 | 0.49 | 79.9 | 86.1 | 0.82 | 100 | 44.2 | 0.61 |
| Average | 91.16 | 89.33 | 0.90 | 43.1 | 71.4 | 0.51 | 43.34 | 86.24 | 0.54 | 90.32 | 77.84 | 0.81 | 91.4 | 93.44 | 0.92 | 96.47 | 80.94 | 0.84 |
| Supervised (Manual Clipping) with HOG, Dict sz = 256 [75] | Online Version of [75] | Unsupervised Using Only Global Motion [86] | Hybrid | Unsupervised (Proposed Method) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | Prec. (%) | Rec. (%) | F-Score | |
| Checking BusMap | 100 | 97.1 | 0.98 | 50.1 | 100 | 0.66 | 54.54 | 100 | 0.70 | 96.1 | 100 | 0.98 | 80.5 | 86.2 | 0.83 |
| Prepare DrugBox | 100 | 92.3 | 0.95 | 43.2 | 100 | 0.60 | 100 | 90.1 | 0.94 | 100 | 100 | 1.0 | 88.2 | 92.7 | 0.90 |
| Prepare Drink | 93.1 | 97.4 | 0.95 | 38.1 | 76.1 | 0.50 | 80.0 | 84.21 | 0.82 | 88.9 | 96.3 | 0.92 | 94.2 | 88.5 | 0.91 |
| Answer the Phone | 92.2 | 100 | 0.95 | 86.7 | 100 | 0.92 | 60.1 | 100 | 0.75 | 100 | 100 | 1.0 | 92.4 | 100 | 0.96 |
| Reading Article | 97.5 | 94.1 | 0.95 | 36.4 | 92.0 | 0.52 | 100 | 81.82 | 0.90 | 100 | 100 | 1.0 | 93.2 | 87.4 | 0.90 |
| Watering Plant | 100 | 88.3 | 0.93 | 33.9 | 76.9 | 0.47 | 53.9 | 68.9 | 0.60 | 77.0 | 96.3 | 0.85 | 77.4 | 61.2 | 0.68 |
| Average | 97.13 | 94.87 | 0.95 | 48.06 | 90.83 | 0.61 | 74.75 | 87.50 | 0.78 | 93.66 | 98.76 | 0.96 | 87.65 | 86.00 | 0.86 |
| ELS [89] | Max Subgraph Search [90] | DOHT (HOG) [91] | Sub Activity [92] | Unsupervised (proposed method) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FA_1 | F_score | IoU | FA_1 | F_score | IoU | FA_1 | F_score | IoU | FA_1 | F_score | IoU | FA_1 | F_score | IoU | |
| View 1 | 0.18 | 0.18 | 0.11 | - | 0.25 | 0.15 | 0.80 | 0.77 | 0.64 | 0.85 | 0.81 | 0.73 | 0.84 | 0.79 | 0.70 |
| View 2 | 0.27 | 0.26 | 0.16 | - | 0.18 | 0.10 | 0.81 | 0.79 | 0.66 | 0.87 | 0.82 | 0.75 | 0.88 | 0.83 | 0.77 |
| View 3 | 0.52 | 0.55 | 0.39 | - | 0.44 | 0.31 | 0.80 | 0.77 | 0.65 | 0.82 | 0.76 | 0.69 | 0.79 | 0.73 | 0.69 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Negin, F.; Brémond, F. An Unsupervised Framework for Online Spatiotemporal Detection of Activities of Daily Living by Hierarchical Activity Models. Sensors 2019, 19, 4237. https://doi.org/10.3390/s19194237
Negin F, Brémond F. An Unsupervised Framework for Online Spatiotemporal Detection of Activities of Daily Living by Hierarchical Activity Models. Sensors. 2019; 19(19):4237. https://doi.org/10.3390/s19194237
Chicago/Turabian StyleNegin, Farhood, and François Brémond. 2019. "An Unsupervised Framework for Online Spatiotemporal Detection of Activities of Daily Living by Hierarchical Activity Models" Sensors 19, no. 19: 4237. https://doi.org/10.3390/s19194237
APA StyleNegin, F., & Brémond, F. (2019). An Unsupervised Framework for Online Spatiotemporal Detection of Activities of Daily Living by Hierarchical Activity Models. Sensors, 19(19), 4237. https://doi.org/10.3390/s19194237